Открываем Google, пишем то, что нужно найти в специальную строку и жмем Enter. «Все просто, чему вы меня учить собрались», — думаете вы. Ага, не тут-то было, друзья.
После сегодняшней статьи большинство из вас поймет, что делали это неправильно. Но этот навык – один из самых важных для продуктивного сотрудника. Потому что в 2021 году дергать руководство по вопросам, которые, как оказалось, легко гуглятся, — моветон.
Ну и на форумах не даст вам упасть лицом в грязь, чего уж там.
Затягивать не будем, ниже вас ждут фишки, которые облегчат вам жизнь.
Кстати, вы замечали, что какую бы ты ни ввёл проблему в Google, это уже с кем-то было? Серьёзно, даже если ввести запрос: «Что делать, если мне кинули в лицо дикобраза?», то на каком-нибудь форуме будет сидеть мужик, который уже написал про это. Типа, у нас с женой в прошлом году была похожая ситуация.
Ваня Усович, Белорусский и российский стендап-комик и юморист
Фишка 1
Если вам нужно найти точную цитату, например, из книги, возьмите ее в кавычки. Ниже мы отыскали гениальную цитату из книги «Мастер и Маргарита».
Фишка 2
Бывает, что вы уже точно знаете, что хотите найти, но гугл цепляет что-то схожее с запросом. Это мешает и раздражает. Чтобы отсеять слова, которые вы не хотите видеть в выдаче, используйте знак «-» (минус).
Вот, например, поисковой запрос ненавистника песочного печенья:
Фишка 3
Подходит для тех, кто привык делать всё и сразу. Уже через несколько долей секунд вы научитесь вводить сразу несколько запросов.
*барабанная дробь*
Для этого нужна палочка-выручалочка «|». Например, вводите в поисковую строку «купить клавиатуру | компьютерную мышь» и получаете страницы, содержащие «купить клавиатуру» или «купить компьютерную мышь».
Совет: если вы тоже долго ищете, где находится эта кнопка, посмотрите над Enter.
Фишка 4
Выручит, если вы помните первое и последнее слово в словосочетании или предложении. А еще может помочь составить клевый заголовок. Короче, знак звездочка «*» как бы говорит гуглу: «Чувак, я не помню, какое слово должно там быть, но я надеюсь, ты справишься с задачей».
Фишка 5
Если вы хотите найти файл в конкретном формате, добавьте к запросу «filetype:» с указанием расширения файла: pdf, docx и т.д., например, нам нужно было отыскать PDF-файлы:
Фишка 6
Чтобы найти источник, в котором упоминаются сразу все ключевые слова, перед каждым словом добавьте знак «&». Слов может быть много, но чем их больше, тем сильнее сужается зона поиска.
Кстати, вы еще не захотели есть от наших примеров?
Фишка 7
Признавайтесь, что вы делаете, когда нужно найти значение слова. «ВВП что такое» или «Шерофобия это». Вот так пишете, да?
Гуглить значения слов теперь вам поможет оператор «define:». Сразу после него вбиваем интересующее нас слово и получаем результат.
— Ты сильный?!
— Я сильный!
— Ты матерый?!
— Я матерый!
— Ты даже не знаешь, что такое сдаваться?!
— Я даже не знаю, что такое «матерый»!
Фишка 8
Допустим, вам нужно найти статью не во всём Интернете, а на конкретном сайте. Для этого введите в поисковую строку «site:» и после двоеточия укажите адрес сайта и запрос. Вот так все просто.
Фишка 9
Часто заголовок полностью отображает суть статьи или материалов, которые вам нужны. Поэтому в некоторых случаях удобно пользоваться поиском по заголовку. Для этого введите «intitle:», а после него свой запрос. Получается примерно так:
Фишка 10
Чтобы расширить количество страниц в выдаче за счёт синонимов, указывайте перед запросом тильду «~». К примеру, загуглив «~cтранные имена», вы найдете сайты, где помимо слова «странные» будут и его синонимы: «необычные, невероятные, уникальные».
Ну и, конечно, не забывайте о расширенных инструментах, которые предлагает Google. Там вы можете установить точный временной промежуток для поиска, выбирать язык и даже регион, в которым был опубликован материал.
В комментариях делитесь, о каких функциях вы знали, а о каких услышали впервые 
Кстати, еще больше интересных фишек в области онлайн-образования, подборки с полезными ресурсами и т.д., вы найдете в нашем Telegram-канале. Присоединяйтесь!
От посещаемости до секретов.
Сегодня мы продолжаем играть в детективов. Началось все с двух статей о сборе досье на человека с помощью общедоступных источников:
- 15 фишек для сбора информации о человеке в интернете
- Как снять девушку в сети
Теперь перед нами стоит задача собрать максимум информации о чужом сайте с минимальными усилиями.
Эта статья не для веб-разработчиков и специалистов по SEO или информационной безопасности. Она для простого человека, которому надо по-быстрому получить представление о ценности и качестве определенного интернет-ресурса.
Критерии отбора сервисов для статьи:
- Искомая информация предоставляется бесплатно;
- Чтобы посмотреть сведения о сайте, не нужно иметь к нему доступа;
- Желаемый результат можно получить немедленно, без регистрации или длительного ожидания.
Посещаемость сайта
Нам поможет старый добрый SimilarWeb. Набираем адрес сайта:
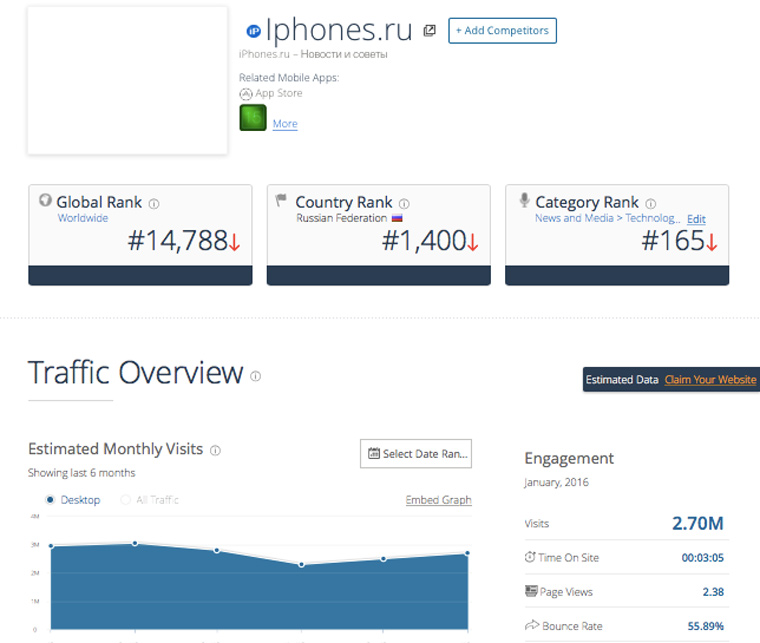
iPhones.ru находится на 165 месте в рейтинге самых посещаемых новостных сайтов мира, посвященных технологиям. Для сравнения, знаменитый на весь мир англоязычный macworld.com находится на 75-м.
У многих людей, когда они впервые сталкиваются с SimilarWeb, возникает вопрос: «Каким образом сервис узнает посещаемость сайта, не устанавливая на него счетчик?». Детальный ответ на него могут дать только работники компании.
Если говорить вкратце, то SimilarWeb собирает данные о трафике пользователей, у которых установлен тулбар от компании + с помощью поискового робота подсчитывает ссылки на сайты, анализирует каким запросам соответствует контент сайта и какую позицию в поисковиках ресурс по ним занимает. Доверять на 100% таким данным нельзя (они очень приблизительные).
Примерно тем же способом рассчитывается сайтов России. На 66 позиций выше, чем cosmo.ru.
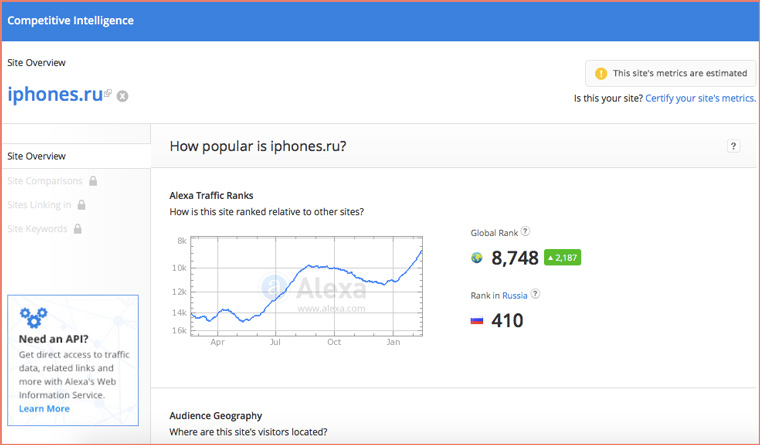
2. Распределение посетителей по странам
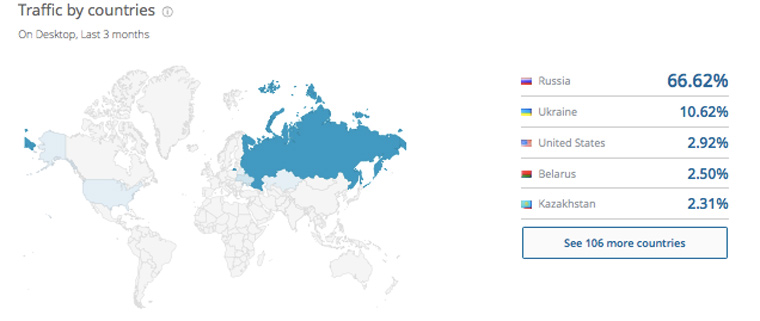
Ниже на странице с отчетом от SimilarWeb наглядно видим распределение посетителей на карте мира:
3. Основные источники трафика
Пролистаем страницу еще ниже и смотрим на диаграмму:
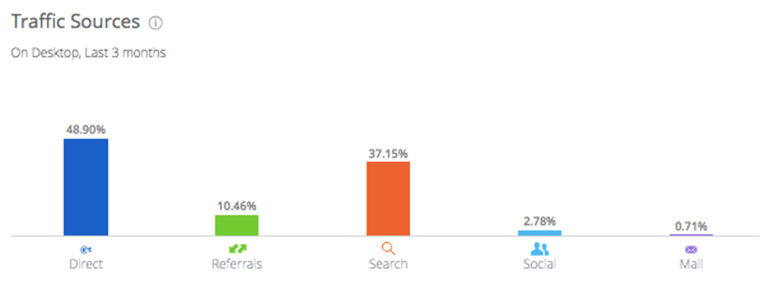
Не зря комментаторы пишут, что заходить на наш сайт, это такая же вредная привычка, как курить или грызть ногти. Доля прямого траффика (когда человек осознанно набирает в адресной строке iPhones.ru) очень велика.
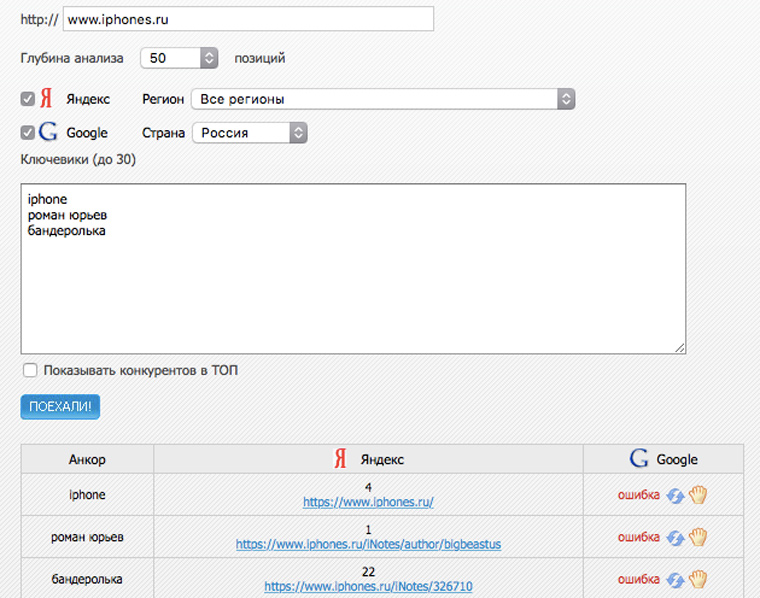
3. Статистика сайта в поисковиках по разным запросам?
На seogadget.ru можно бесплатно проверить позиции сайта по 25 запросам в поисковой выдачи «Яндекса»:
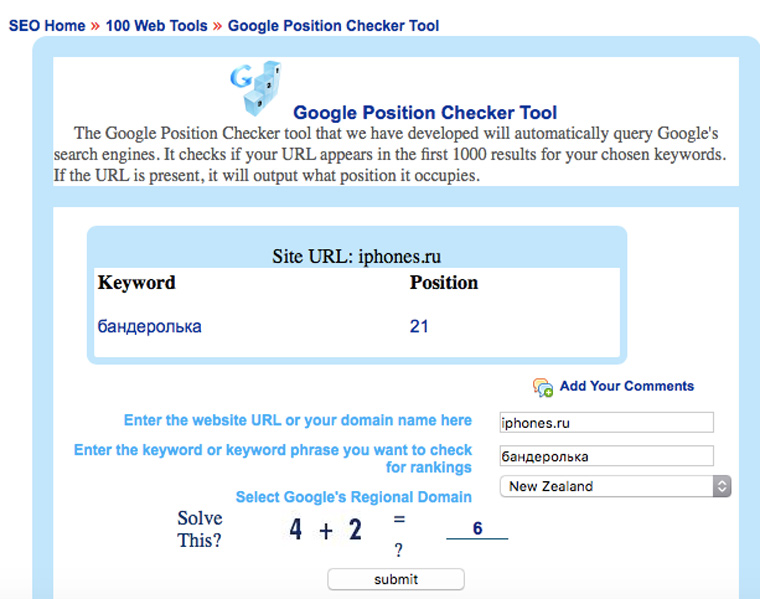
А позиции в Google можно посмотреть на searchengenie.com:
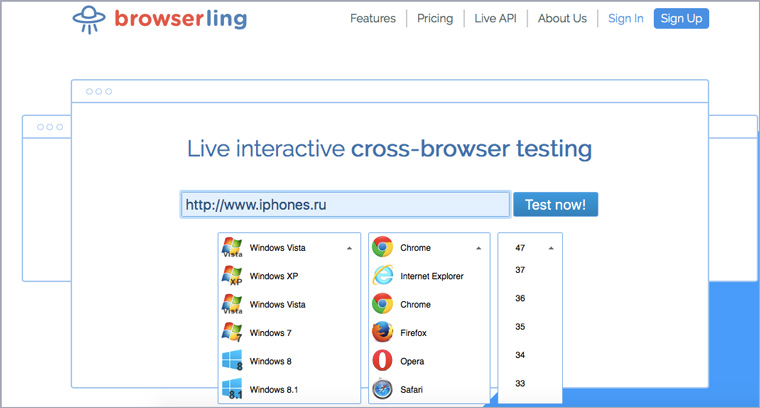
4. Как выглядит сайт в разных браузерах
Идем на Browserling, выбираем операционную систему, название браузера и номер версии:
Любуемся и ищем косяки. Если что-то нашлось, то можно скопировать ссылку на комбинацию сайт-браузер и отправить разработчику:
5. Как смотрится сайт на разных девайсах
Посмотреть, как будет выглядеть сайт на самых распространенных телефонах, планшетах и мониторах можно здесь. Либо выбирайте фиксированные размеры конкретных девайсов:
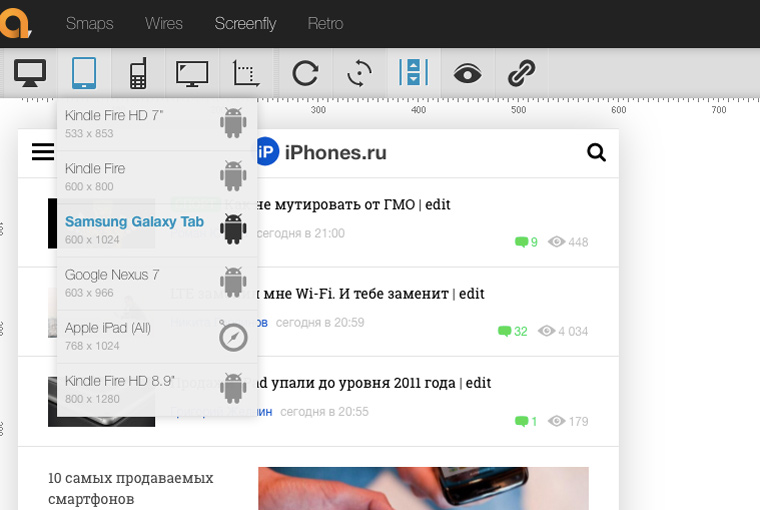
Либо вводите высоту и ширину вручную:
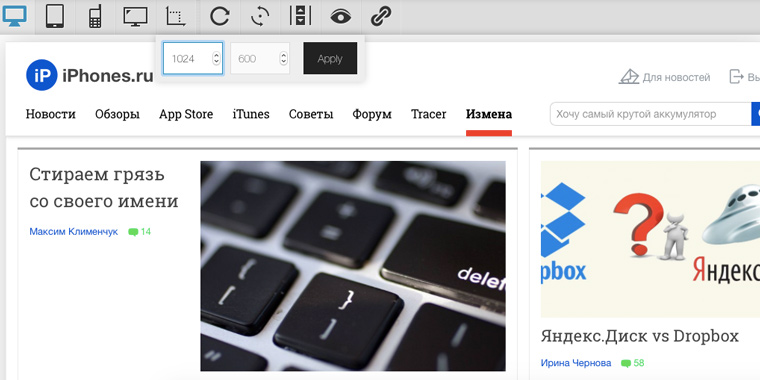
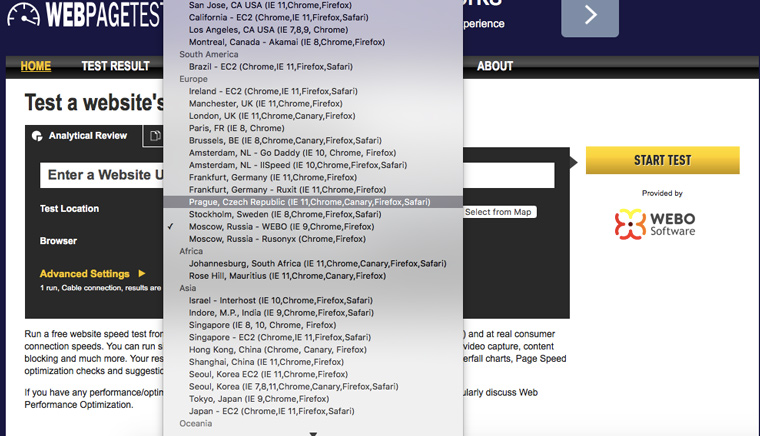
6. С какой скоростью загружается сайт из разных точек планеты
Идем на webpagetest.org и выбираем географическое положение сервера для тестирования:
На выходе получаем подробный отчет о загрузке страницы с указаниями над какими местами надо поработать (где отметки F и D, у нас все плохо):
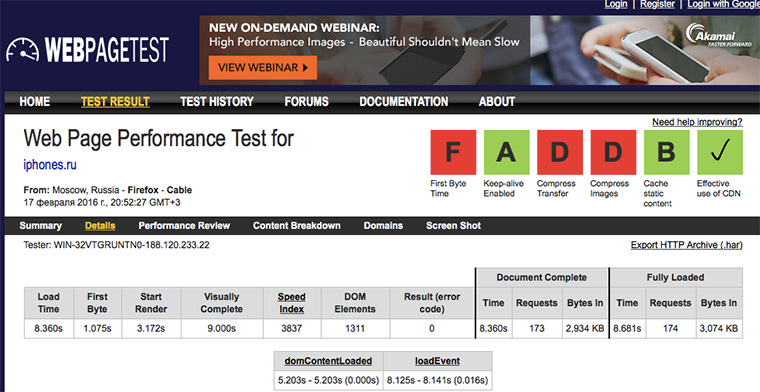
Иногда перед получением результата приходиться минуту другую подождать, но оно того стоит.
7. Что именно тормозит работу сайта
Когда вы открываете iphones.ru, то происходит почти две сотни http-запросов (это абсолютно нормальная цифра). Под общими сведениями в отчете из предыдущего пункта имеется диаграмма в виде водопада, на которой отображаются сведения о загрузке каждого элемента страницы:
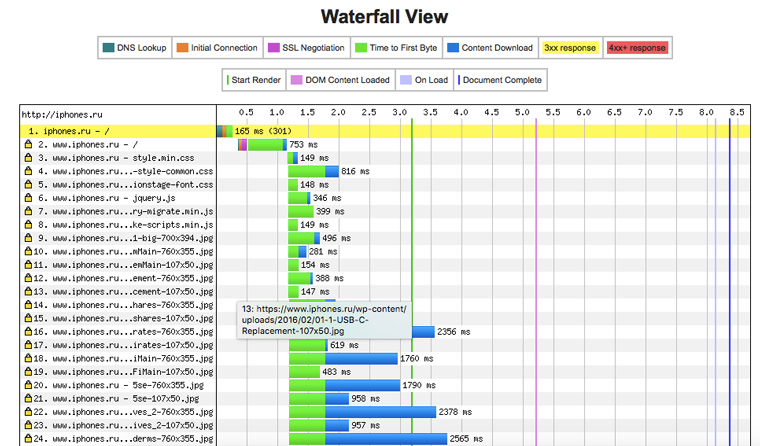
Ясно видно, какие картинки или файлы со скриптами больше всего тормозят сайт.
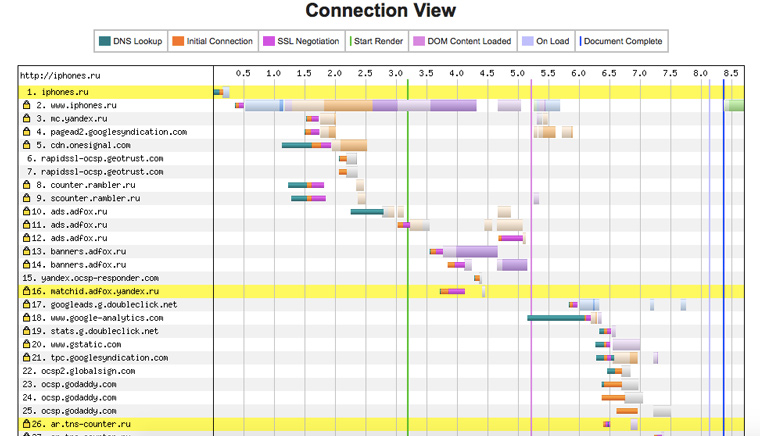
8. К каким доменам сайт посылает запросы при загрузке
Чуть ниже есть еще одна полезная диаграмма. По ней можно определить какими счетчиками посещаемости пользуется сайт и откуда подгружает баннеры. Плюс к этому видно влияние внешних доменов на скорость его работы:
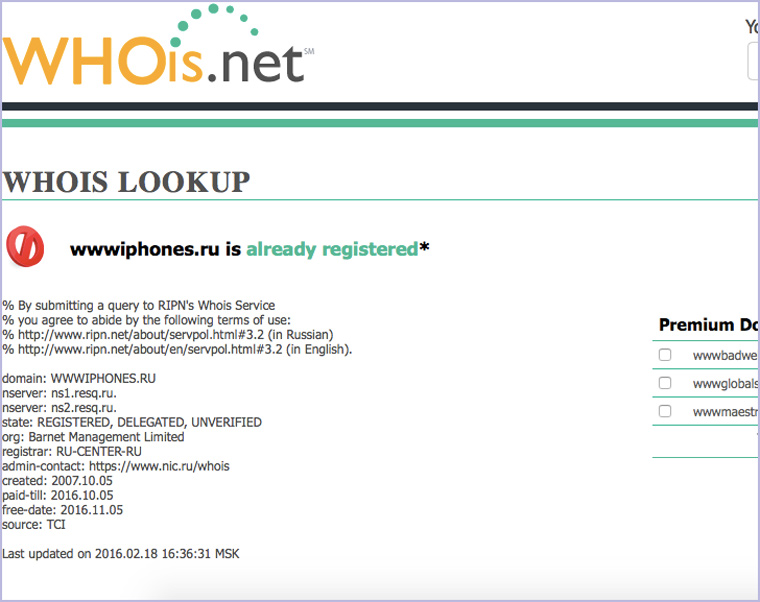
9. Когда зарегистрирован домен для сайта
А вот сервис для просмотра данных о домене: когда создан, какая фирма регистрировала и окончание срока регистрации:
10. Качество html-кода сайта
Чтобы сайт хорошо индексировался поисковыми системам и корректно отображался в разных браузерах, его код должен соответствовать стандартам консорциума W3C. Так написано в валидаторе от консорциума:

Там же проверяется на правильность синтаксис RSS-каналов.
А здесь можно найти ошибки в JS-скриптах.
11. Есть ли на сайте битые ссылки?
Отдельным пунктом стоит отметить проверку на наличие битых ссылок, которые поисковые системы очень не любят. Найти их все можно здесь:

Проверка может занять пару минут, но если вы взялись тестировать собственный сайт, то этот этап лучше не пропускать.
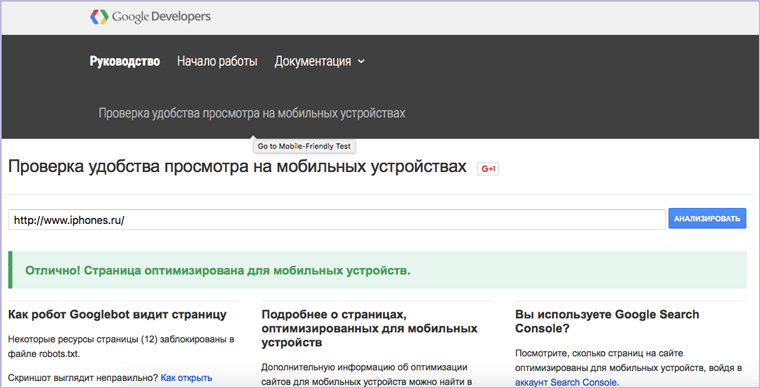
12. Наличие оптимизации под мобильные устройства
А вот сервис от Google, который определяет годен ли сайт для просмотра на мобильных устройствах:
13. Доступность для людей с ограниченными возможностями?
Для Google важно, чтобы сайтом могли пользоваться люди с ограниченными возможностями. Подробнее о том, зачем это нужно и как это осуществить технически можно прочитать на сайте консорциума W3C.
А проверить страницу на доступность для инвалидов можно здесь:
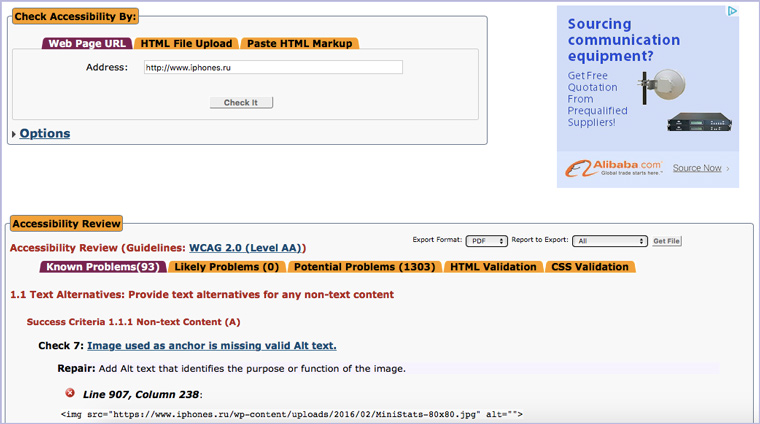
14. Как много людей ссылаются на сайт в соцсетях
На muckruck.com можно узнать, как много людей и в каких соцсетях поделились ссылкой на определенную страницу:
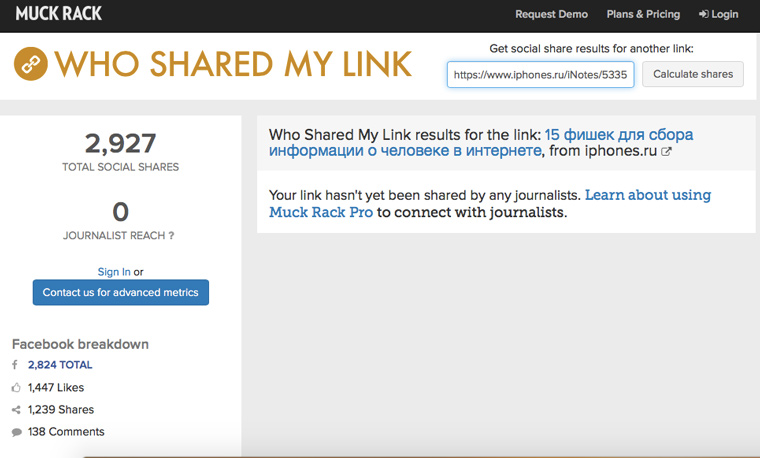
К сожалению, самую интересную и детальную информацию сервис предоставляет за деньги и российские соцсети не учитываются. Но общие масштабы народной любви к сайту с его помощью прикинуть можно.
15. Визуальное восприятие цветов сайта
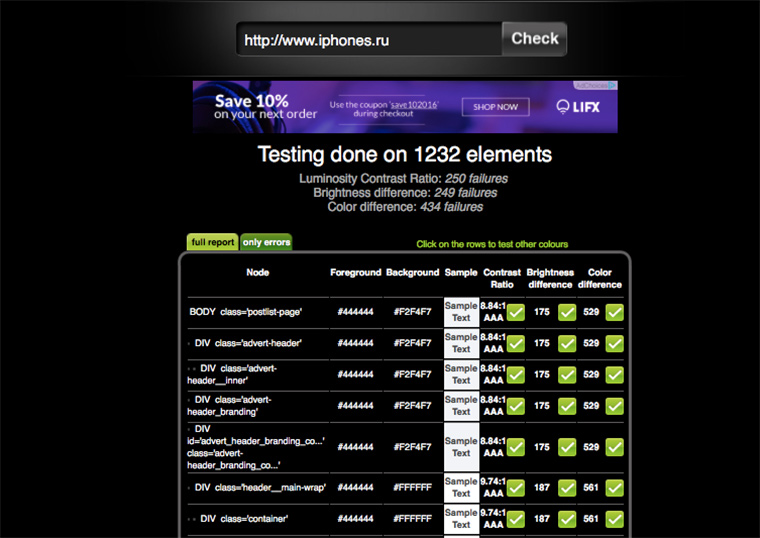
На сайте у Темы Лебедева есть таблица «безопасных цветов», которые рекомендуется использовать в экранном дизайне. Эти 216 оттенков будут правильно отображаться на любом устройстве, независимо от технических характеристик его дисплея.
Проверить все цветные элементы своего сайта на корректность восприятия человеком на экране можно здесь:
16. ТИЦ и PR сайта
ТИЦ (тематический индекс цитирования) – это показатель, который рассчитывается поисковой системой Яндекс для определения авторитетности ресурса (чем он больше, тем выше позиции сайта в поисковиках). PR (Page Rank) – аналогичный показатель у Google. Проверить их можно здесь:
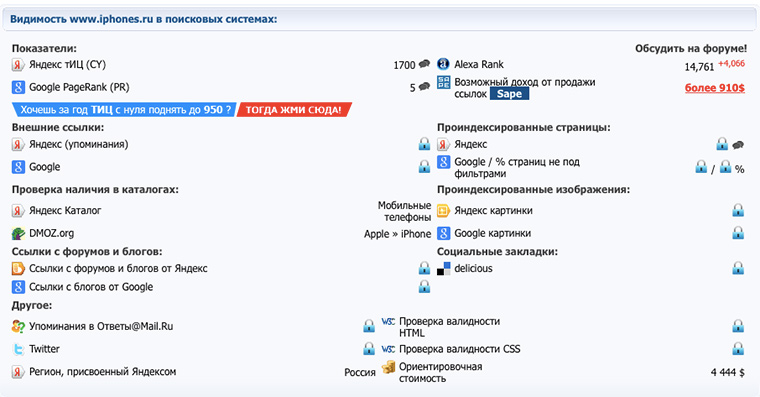
Значения индексов меняются каждые несколько месяцев. Их величина зависит от количества ссылок на сайт на других ресурсах.
17. Работает ли сайт в данный момент
Конечно, веселее написать кому-нибудь посреди рабочего дня и спросить: «Эй, а у тебя контактик открывается или это только у меня так?». Но лучше зайти на сервис для проверки доступности сайта:
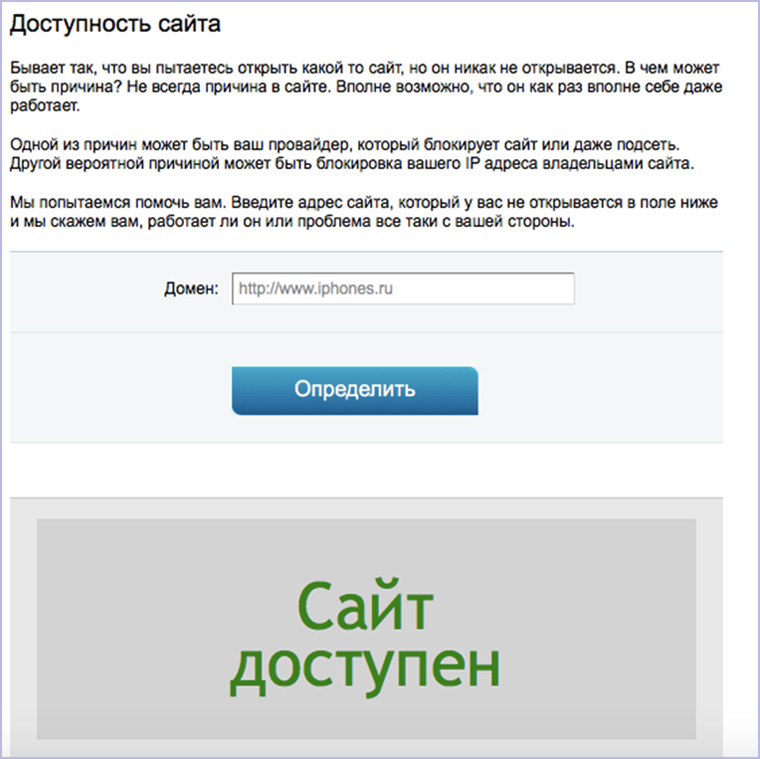
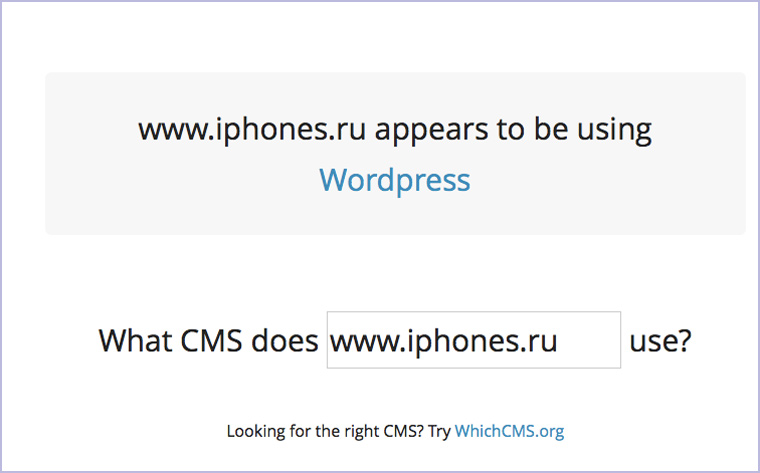
18. Какую CMS использует сайт
Предельно минималистичный сервис, где можно узнать на каком движке работает ресурс:
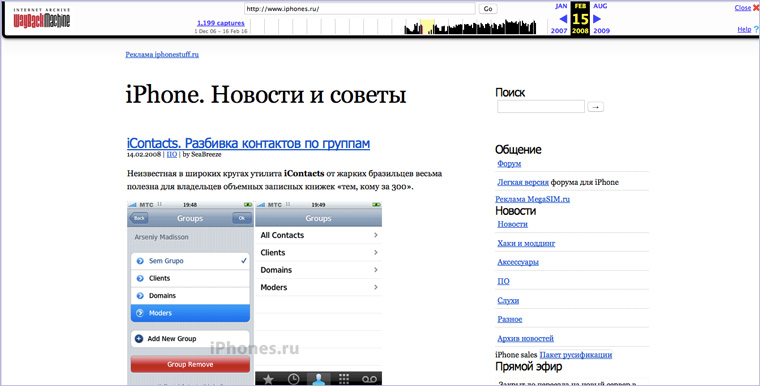
19. Как сайт выглядел в былые времена
Проследить изменение внешнего вида и контента сайта можно в Архиве Интернета. Вбиваем адрес на главной и смотрим доступные версии:
20. Сравнение с конкурентами
Идем на WolframAlpha и набираем через запятую адреса сайтов, которые мы хотим сравнить:

Можно ввести не два адреса, а три, четыре, пять и т.д.
Кстати, об экспертной системе WolframAlpha у нас вышла подробная статья на новогодних каникулах:
- 35 команд, которые наглядно покажут, в чем Wolfram Alpha круче Google
Все! Естественно, это очень малая часть из всех онлайн-сервисов для тестирования и сбора информации о сайтах, которые есть в интернете. Но большинство из них не выполняют заявленных функций, жестоко тормозят, требуют денег, не сказав «Здрасти» или предназначены для узких специалистов.
Рекомендую сохранить эту подборку, чтобы иметь ее всегда под рукой, когда вам или вашим близким нужно будет собрать максимум информации о сайте за 10-15 минут.
Качественный сбор информации о сайте подразумевает также исследование изображений на нем. Об этом можно почитать в статье:
- 10 веб-сервисов для анализа фотографий

 (8 голосов, общий рейтинг: 4.88 из 5)
(8 голосов, общий рейтинг: 4.88 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
От посещаемости до секретов. Сегодня мы продолжаем играть в детективов. Началось все с двух статей о сборе досье на человека с помощью общедоступных источников: 15 фишек для сбора информации о человеке в интернете Как снять девушку в сети Теперь перед нами стоит задача собрать максимум информации о чужом сайте с минимальными усилиями. Эта статья не…
- полезный в быту софт,
- сеть,
- хаки
![]()
Время на прочтение
8 мин
Количество просмотров 348K

Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал Российский сервис парсинга сайтов и последующего мониторинга цен XMLDATAFEED (xmldatafeed.com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени

10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
1. Import.io
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
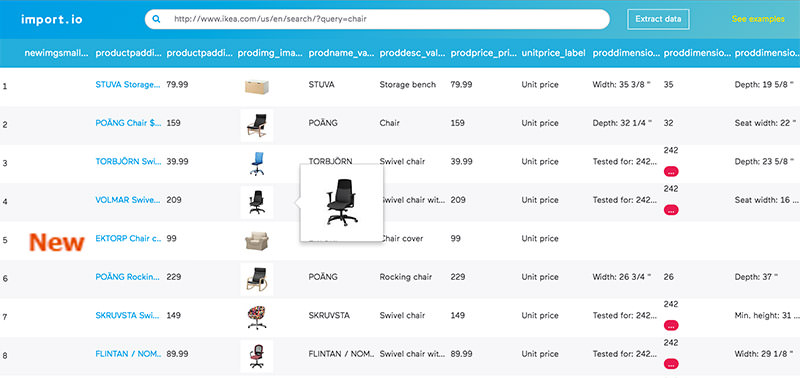
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.

Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
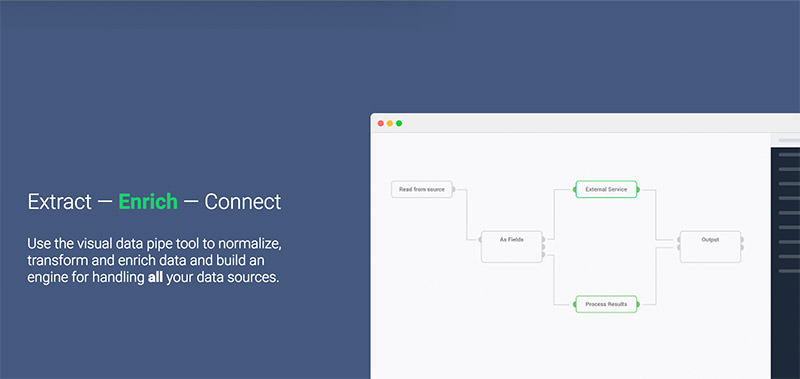
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.

Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
5. ParseHub
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.

ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
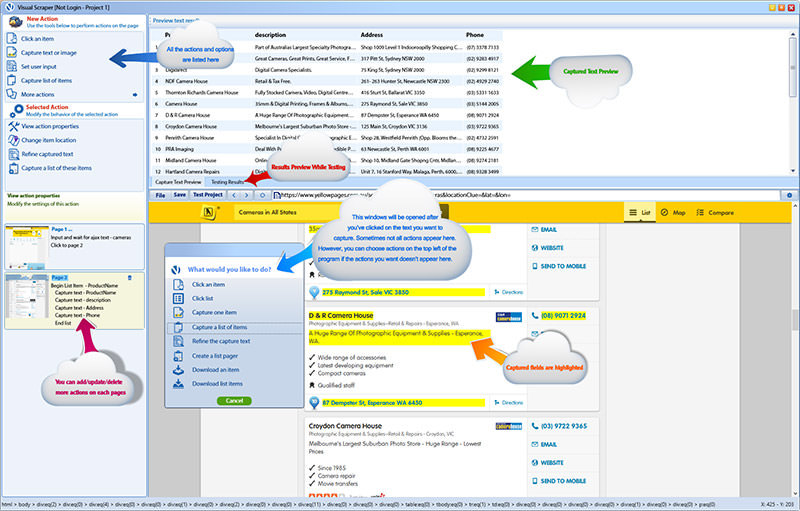
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
7. Spinn3r
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
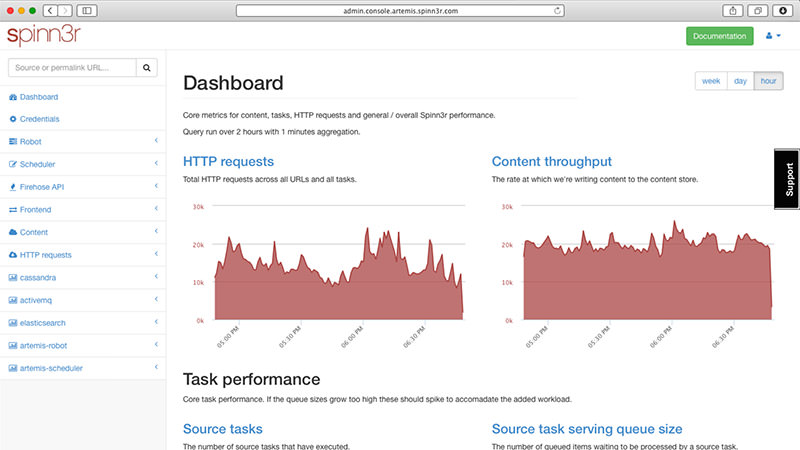
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
8. 80legs
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.

Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
9. Scraper
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
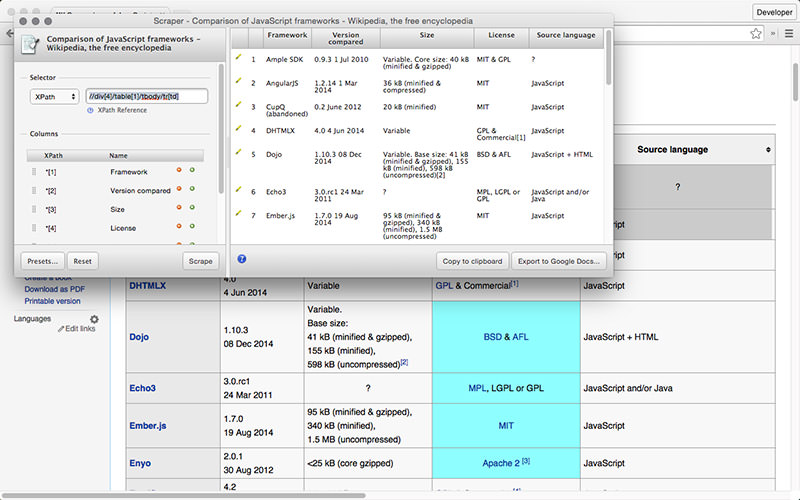
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
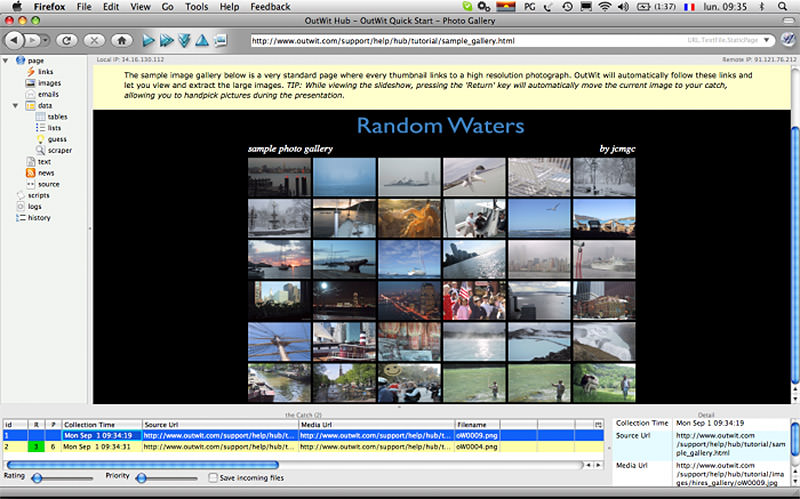
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
Воспользоваться функционалом расширенного поиска, например, Гугла. Задать поисковый запрос в Гугле, затем при получении результата зайти в «Настойки — Расширенный поиск»:

Затем на открывшейся странице в соответствующем поле ввести тот сайт, на котором не удосужились сделать функционал поиска, или даже прикрепить чужой:

Будет выполняться поиск только на указанном сайте. Можно указать просто домен для поиска — иногда это удобно, если вы помните, например, что сайт был в домене .net, но простым поиском не можете его найти на первых страницах.