Время на прочтение
16 мин
Количество просмотров 236K
Добрый день, уважаемые хаброжители!
Время от времени некоторым (а может и более, чем некоторым) из нас приходится сталкиваться с задачами по обработке небольших массивов данных, начиная от составления и анализа домашнего бюджета и заканчивая какими-либо расчетами по работе, учебе и т.д. Пожалуй, наиболее подходящим инструментом для этого является Microsoft Excel (или возможно иные его аналоги, но они менее распространены).
Поиск выдал мне всего одну статью на Хабре по схожей тематике — «Талмуд по формулам в Google SpreadSheet». В ней дано хорошее описание базовых вещей для работы в excel (хотя он и не 100% про сам excel).
Таким образом, накопив определенный пул запросов/задач, появилась идея их типизировать и предложить возможные решения (пусть не все возможные, но быстро дающие результат).
Речь пойдет о решении наиболее распространенных задач, с которыми сталкиваются пользователи.
Описание решений построено следующим образом – дается кейс, содержащий исходное задание, которое постепенно усложняется, к каждому шагу дано развернутое решение с пояснениями. Наименования функций будут даваться на русском языке, но в скобках при первом упоминании будет приводиться оригинальное наименование на английском языке (т.к. по опыту у подавляющего большинства пользователей установлена русскоязычная версия).
Кейс_1: Логические функции и функции поиска совпадений
«У меня есть набор значений в табличке и необходимо что бы при выполнении определенного условия/набора условий выводилось определенное значение» (с) Пользователь
Данные, как правило, представлены в табличной форме:
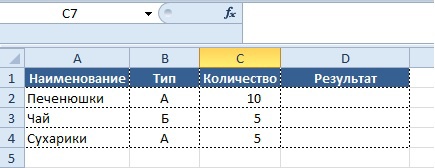
Условие:
- если значение в столбце «Количество» больше 5,
- то нужно вывести в колонке «Результат» значение «Заказ не требуется»,
В этом нам поможет формула «ЕСЛИ» (IF), которая относится к логическим формулам и может выдавать в решении любые значения, которые мы заранее записываем в формуле. Обращаю внимание, что любые текстовые значения записываются, используя кавычки.
Синтаксис формулы следующий:
ЕСЛИ(лог_выражение, [значение_если_истина], [значение_если_ложь])
- Лог_выражение — выражение, дающее в результате значение ИСТИНА или ЛОЖЬ.
- Значение_если_истина — значение, которое выводится, если логическое выражение истинно
- Значение_если_ложь — значение, которое выводится, если логическое выражение ложно
Синтаксис формулы для решения:
Вывод результата в ячейку D2:
=ЕСЛИ(C5>5;«Заказ не требуется»;«Необходим заказ»)
На выходе получаем результат:

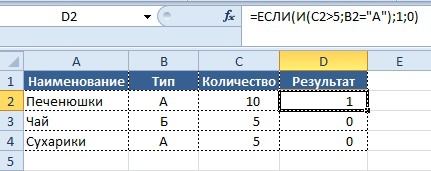
Бывает, что условие носит более сложный характер, например выполнение 2-х и более условий:
- если значение в столбце «Количество» больше 5, а значение в колонке «Тип» равно «А»
- то нужно вывести в колонке «Результат» значение «1», в обратном случае «0».
В данном случае мы уже не можем ограничиться использованием одной только формулы «ЕСЛИ», необходимо добавить в ее синтаксис другую формулу. И это будет еще одна логическая формула «И» (AND).
Синтаксис формулы следующий:
И(логическое_значение1, [логическое_значение2], …)
- Логическое_значение1-2 и т.д. — проверяемое условие, вычисление которого дает значение ИСТИНА или ЛОЖЬ
Синтаксис решения будет следующим:
Вывод результата в ячейку D2:
=ЕСЛИ(И(C2>5;B2=«А»);1;0)
Таким образом, используя сочетание 2-х формул, мы находим решение нашей задачи и получаем результат:
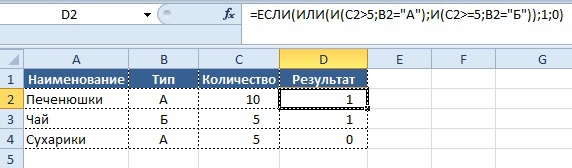
Попробуем усложнить задачу – новое условие:
- если значение в столбце «Количество» равно 10, а значение в колонке «Тип» равно «А»
- или же значение в столбце «Количество» больше или равно 5, а значение «Тип» равен «Б»
- то нужно вывести в колонке «Результат» значение «1», в обратном случае «0».
Синтаксис решения будет следующим:
Вывод результата в ячейку D2:
=ЕСЛИ(ИЛИ(И(C2=10;B2=«А»); И(C2>=5;B2=«Б»));1;0)
Как видно из записи, в формулу «ЕСЛИ» включено одно условие «ИЛИ» (OR) и два условия с использованием формулы «И», включенных в него. Если хотя бы одно из условий 2-го уровня имеет значение «ИСТИНА», то в колонку «Результат» будет выведен результат «1», в противном случае будет «0».
Результат:
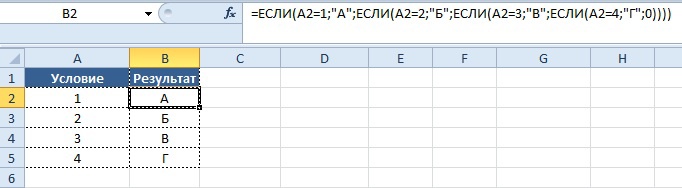
Теперь перейдем к следующей ситуации:
Представим, что в зависимости от значения в столбце «Условие» должно выводиться определенное условие в столбце «Результат», ниже приведено соответствие значений и результата.
Условие:
- 1 = А
- 2 = Б
- 3 = В
- 4 = Г
При решении задачи с помощью функции «ЕСЛИ», синтаксис будет следующим:
Вывод результата в ячейку B2:
=ЕСЛИ(A2=1;«А»; ЕСЛИ(A2=2;«Б»; ЕСЛИ(A2=3;«В»; ЕСЛИ(A2=4;«Г»;0))))
Результат:
Как видно, написание подобной формулы не только не очень удобно и громоздко, но и может занять некоторое время на ее редактирование у неопытного пользователя в случае ошибки.
Минус подобного подхода в том, что он применим для небольшого количества условий, ведь, все их придется набирать вручную и «раздувать» нашу формулу до больших размеров, однако подход отличает полная «всеядность» к значениям и универсальность использования.
Альтернативное решение_1:
Использование формулы «ВЫБОР» (CHOOSE),
Синтаксис функции:
ВЫБОР(номер_индекса, значение1, [значение2], …)
- Номер_индекса — номер выбираемого аргумента-значения. Номер индекса должен быть числом от 1 до 254, формулой или ссылкой на ячейку, содержащую число в диапазоне от 1 до 254.
- Значение1, значение2,… — значение от 1 до 254 аргументов-значений, из которых функция «ВЫБОР», используя номер индекса, выбирает значение или выполняемое действие. Аргументы могут быть числами, ссылками на ячейки, определенными именами, формулами, функциями или текстом.
При ее использовании, мы сразу заносим результаты условий в зависимости от указанных значений.
Условие:
- 1 = А
- 2 = Б
- 3 = В
- 4 = Г
Синтаксис формулы:
=ВЫБОР(A2;«А»;«Б»;«В»;«Г»)
Результат аналогичен решению с цепочкой функций «ЕСЛИ» выше.
При применении этой формулы существуют следующие ограничения:
В ячейку «А2» (номер индекса) могут быть указаны только цифры, а значения результата будут выводиться в порядке возрастания от 1 до 254 значений.
Иными словами, функция будет работать только если в ячейке «А2» указаны цифры от 1 до 254 в порядке возрастания и это накладывает определенные ограничения при использовании этой формулы.
Т.е. если мы захотим, что бы значение «Г» выводилось при указании числа 5,
- 1 = А
- 2 = Б
- 3 = В
- 5 = Г
то формула будет иметь следующий синтаксис:
Вывод результата в ячейку B2:
=ВЫБОР(A31;«А»;«Б»;«В»;;«Г»)
Как видно, значение «4» в формуле нам приходится оставить пустым и перенести результат «Г» на порядковый номер «5».
Альтернативное решение_2:
Вот мы и подошли к одной из самых популярных функций Excel, овладение которой автоматически превращает любого офисного работника в «опытного пользователя excel» /sarcasm/.
Синтаксис формулы:
ВПР(искомое_значение, таблица, номер_столбца, [интервальный_просмотр])
- Искомое_значение – значение, поиск которого осуществляется функцией.
- Таблица – диапазон ячеек, содержащий данные. Именно в этих ячейках будет происходить поиск. Значения могут быть текстовыми, числовыми или логическими.
- Номер_столбца — номер столбца в аргументе «Таблица», из которого будет выводиться значение в случае совпадения. Важно понимать, что отсчет столбцов происходит не по общей сетке листа (A.B,C,D и т.д.), а внутри массива, указанного в аргументе «Таблица».
- Интервальный_просмотр — определяет, какое совпадение должна найти функция — точное или приблизительное.
Важно: функция «ВПР» ищет совпадение только по первой уникальной записи, если искомое_значение присутствует в аргументе «Таблица» несколько раз и имеет разные значения, то функция «ВПР» найдет только самое ПЕРВОЕ совпадение, результаты по всем остальным совпадениям показаны не будутИспользование формулы «ВПР» (VLOOKUP) связано с еще одним подходом в работе с данными, а именно с формированием «справочников».
Суть подхода в создании «справочника» соответствия аргумента «Искомое_значение» определенному результату, отдельно от основного массива, в котором прописываются условия и соответствующие им значения:
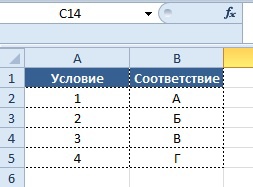
Затем в рабочей части таблицы уже прописывается формула со ссылкой на справочник, заполненный ранее. Т.е. в справочнике в столбце «D» происходит поиск значения из столбца «А» и при нахождении соответствия выводится значение из столбца «Е» в столбец «В».
Синтаксис формулы:
Вывод результата в ячейку B2:
=ВПР(A2;$D$2:$E$5;2;0)
Результат:
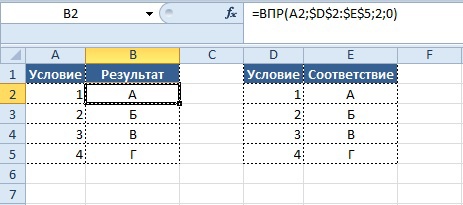
Теперь представим ситуацию, когда необходимо подтянуть данные в одну таблицу из другой, при этом таблицы не идентичны. См. пример ниже
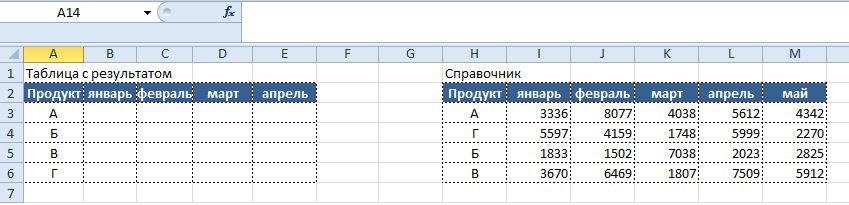
Видно, что строки в столбцах «Продукт» обеих таблиц не совпадают, однако, это не является препятствием для использования функции «ВПР».
Вывод результата в ячейку B2:
=ВПР($A3;$H$3:$M$6;2;0)
Но при решении сталкиваемся с новой проблемой – при «протягивании» написанной нами формулы вправо от столбца «В» до столбца «Е», нам придется вручную заменять аргумент «номер_столбца». Дело это трудоемкое и неблагодарное, потому, на помощь нам приходит другая функция — «СТОЛБЕЦ» (COLUMN).
Синтаксис функции:
СТОЛБЕЦ([ссылка])
- Ссылка — ячейка или диапазон ячеек, для которых требуется возвратить номер столбца.
Если использовать запись типа:
=СТОЛБЕЦ()
то функция выведет номер текущего столбца (в ячейке которого написана формула).
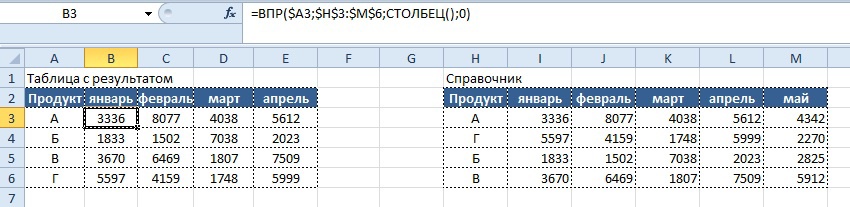
В результате получается число, которое можно использовать в функции «ВПР», чем мы и воспользуемся и получаем следующую запись формулы:
Вывод результата в ячейку B2:
=ВПР($A3;$H$3:$M$6; СТОЛБЕЦ();0)
Функция «СТОЛБЕЦ» определит номер текущего столбца, который будет использоваться аргументом «Номер_столбца» для определения номера столбца поиска в справочнике.
Кроме того, можно использовать конструкцию:
=СТОЛБЕЦ()-1
Вместо числа «1» можно использовать любое число (а также не только вычитать его, но и прибавлять к полученному значению), для получения желаемого результата, если нет желания ссылаться на определенную ячейку в столбце с нужным нам номером.
Получившийся результат:
Продолжаем развивать тему и усложняем условие: представим, что у нас есть два справочника с разными данными по продуктам и необходимо вывести в таблицу с результатом значения в зависимости от того, какой тип справочника указан в колонке «Справочник»
Условие:
- Если в столбце «Справочник» указано число 1, данные должны тянуться из таблицы «Справочник_1», если число 2, то из таблицы «Справочник_2» в соответствии с указанным месяцем
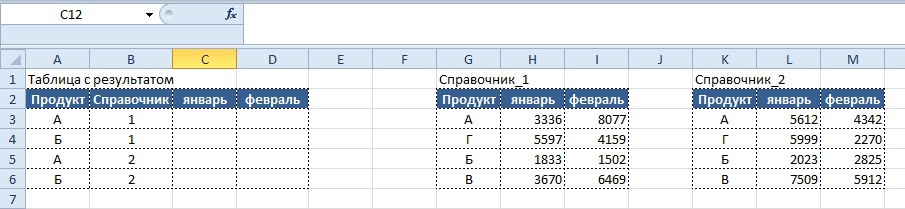
Вариант решения, который сразу приходит на ум, следующий:
Вывод результата в ячейку C3:
=ЕСЛИ($B3=1; ВПР($A3;$G$3:$I$6; СТОЛБЕЦ()-1;0); ВПР($A3;$K$3:$M$6; СТОЛБЕЦ()-1;0))
Плюсы: наименование справочника может быть любым (текст, цифры и их сочетание), минусы – плохо подходит, если вариантов более 3-х.
Если же номера справочников всегда представляют собой числа, имеет смысл использовать следующее решение:
Вывод результата в ячейку C3:
=ВПР($A3; ВЫБОР($B3;$G$3:$I$6;$K$3:$M$6); СТОЛБЕЦ()-1;0)
Плюсы: формула может включать до 254 наименований справочников, минусы – их наименование должно быть строго числовым.
Результат для формулы с использованием функции «ВЫБОР»:
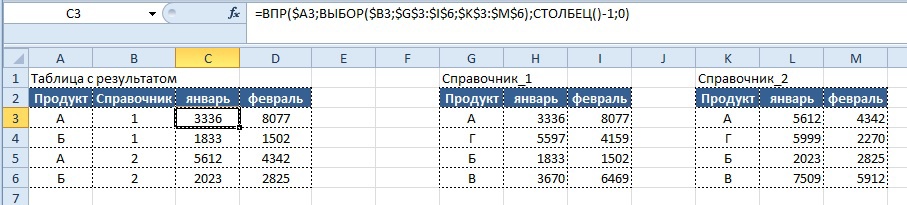
Бонус: ВПР по двум и более признакам в аргументе «искомое_значение».
Условие:
- Представим, что у нас как всегда есть массив данных в табличной форме (если нет, то мы к нему приводим данные), из массива по определенным признакам необходимо получить значения и поместить их в другую табличную форму.
Обе таблицы приведены ниже:
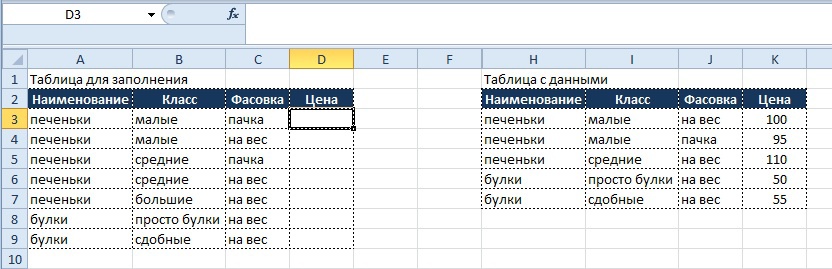
Как видно из табличных форм, каждая позиция имеет не только наименование (которое не является уникальным), но также и относится к определенному классу и имеет свой вариант фасовки.
Используя сочетание имени и класса и фасовки, мы можем создать новый признак, для этого в таблице с данными создаем дополнительный столбец «Доп.признак», который заполняем при помощи следующей формулы:
=H3&»_»&I3&»_»&J3
Используя символ «&», объединяем три признака в один (разделитель между словами может быть любым, как и не быть вовсе, главное использовать аналогичное правило и для поиска)
Аналогом формулы может быть функция «СЦЕПИТЬ» (CONCATENATE), в этом случае она будет выглядеть следующим образом:
=СЦЕПИТЬ(H3;»_»;I3;»_»;J3)
После того, как дополнительный признак создан для каждой записи в таблице с данными, приступаем к написанию функции поиска по этому признаку, которая будет иметь вид:
Вывод результата в ячейку D3:
=ЕСЛИОШИБКА(ВПР(A2&»_»&B2&»_»&C2;$G$2:$K$6;5;0);0)
В функции «ВПР» в качестве аргумента «искомое_значение» используем все ту же связку трех признаков (наименование_класс_фасовка), но берем ее уже в таблице для заполнения и заносим непосредственно в аргумент (как вариант, можно было бы выделить значение для аргумента в дополнительный столбец в таблице для заполнения, но это действие будет излишним).
Напоминаю, что использование функции «ЕСЛИОШИБКА» (IFERROR) необходимо, если искомое значение так и не будет найдено, и функция «ВПР» выведет нам значение «#Н/Д» (об этом ниже).
Результат на картинке ниже:
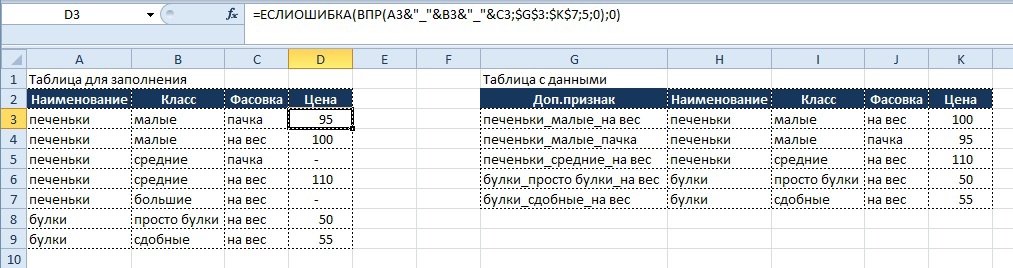
Данный прием можно использовать и для большего количества признаков, единственное условие – уникальность получаемых комбинаций, если она не соблюдается, то результат будет некорректным.
Кейс_3 Поиск значения в массиве, или когда ВПР не в силах нам помочь
Рассмотрим ситуацию, когда необходимо понять, есть ли в массиве ячеек нужные нам значения.
Задача:
- в столбце «Условие поиска» указано значение и необходимо определить, присутствует ли оно в столбце «Массив для поиска»
Визуально все выглядит в следующем виде:
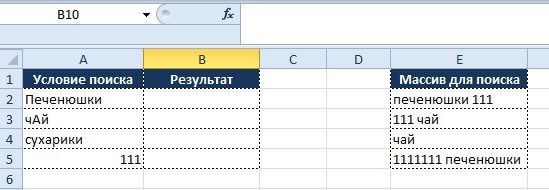
Как мы видим, функция «ВПР» тут бессильна, т.к. мы ищем не точное совпадение, а именно наличие в ячейке нужного нам значения.
Для решения задачи необходимо использовать комбинацию нескольких функций, а именно:
«ЕСЛИ»
«ЕСЛИОШИБКА»
«СТРОЧН»
«НАЙТИ»
По порядку обо всех, «ЕСЛИ» мы уже разобрали ранее, потому перейдем к функции «ЕСЛИОШИБКА» (IFERROR)
ЕСЛИОШИБКА(значение, значение_при_ошибке)
- Значение — аргумент, проверяемый на возникновение ошибок.
- Значение_при_ошибке — значение, возвращаемое при ошибке при вычислении по формуле. Возможны следующие типы ошибок: #Н/Д, #ЗНАЧ!, #ССЫЛКА!, #ДЕЛ/0!, #ЧИСЛО!, #ИМЯ? и #ПУСТО!.
Важно: данная формула практически всегда обязательна при работе с массивами информации и справочниками, т.к. зачастую бывает, что искомое значение не находится в справочнике и в этом случае функция возвращает ошибку. Если же в ячейке выводится ошибка и ячейка участвует, например, в вычислении, то оно так же произойдет с ошибкой. Плюс ко всему, ячейкам, где формула возвратила ошибку можно присваивать различные значения, которые облегчают их статистическую обработку. Также, в случае ошибки можно выполнять другие функции, что очень удобно при работе с массивами и позволяет строить формулы с учетом довольно разветвленных условий.
«СТРОЧН» (LOWER)
СТРОЧН(текст)
- Текст — текст, преобразуемый в нижний регистр.
Важно: функция «СТРОЧН» не заменяет знаки, не являющиеся буквами.
Роль в формуле: поскольку функция «НАЙТИ» (FIND) осуществляет поиск и учетом регистра текста, то необходимо привести весь текст к одному регистру, в противном случае «чАй» будет не равно «чай» и т.д. Это актуально, если значение регистра не является условием поиска и отбора значений, в противном случае формулу «СТРОЧН» можно не использовать, так поиск будет более точным.
Теперь подробнее о синтаксисе функции «НАЙТИ» (FIND).
НАЙТИ(искомый_текст, просматриваемый_текст, [нач_позиция])
- Искомый_текст — текст, который необходимо найти.
- Просматриваемый_текст — текст, в котором нужно найти искомый текст.
- Нач_позиция — знак, с которого нужно начать поиск. Первый знак в тексте «просматриваемый_текст» имеет номер 1. Если номер не указан, он по умолчанию считается равным 1.
Синтаксис формулы-решения будет иметь вид:
Вывод результата в ячейку B2:
=ЕСЛИ(ЕСЛИОШИБКА(НАЙТИ(СТРОЧН(A2); СТРОЧН(E2);1);0)=0;«fail»;«bingo!»)
Разберем логику формулы по действиям:
- СТРОЧН(A2) – преобразует аргумент «Искомый_текст» в ячейке в А2 в текст с нижним регистром
- Функция «НАЙТИ» начинает поиск преобразованного аргумента «Искомый_текст» в массиве «Просматриваемый_текст», который преобразовывается функцией «СТРОЧН(E2)», также в текст с нижним регистром.
- В случае если, функция находит совпадение, т.е. возвращает порядковый номер первого символа совпадающего слова/значения, срабатывает условие ИСТИНА в формуле «ЕСЛИ», т.к. полученное значение не равно нулю. Как результат, в столбце «Результат» будет выведено значение «Bingo!»
- Если же, функция не находит совпадение т.е. порядковый номер первого символа совпадающего слова/значения не указывается и вместо значения возвращается ошибка, срабатывает условие, заложенное в формулу «ЕСЛИОШИБКА» и возвращается значение равное «0», что соответствует условию ЛОЖЬ в формуле «ЕСЛИ», т.к. полученное значение равно «0». Как результат, в столбце «Результат» будет выведено значение «fail».
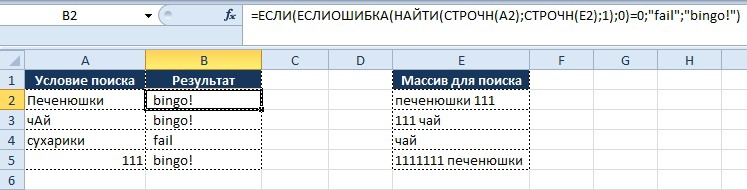
Как видно из рисунка выше, благодаря функциям «СТРОЧН» и «НАЙТИ» мы находим искомые значения вне зависимости от регистра символов, и места нахождения в ячейке, но необходимо обратить внимание на строку 5.
Условие поиска задано как «111», но в массиве поиска указано значение «1111111 печенюшки», однако формула выдает результат «Bingo!». Это происходит потому, что значение «111» входит в ряд значений «1111111», как следствие находится совпадение. В обратном случае данное условие не сработает.
Кейс_4 Поиск значения в массиве по нескольким условиям, или когда ВПР тем более не в силах нам помочь
Представим ситуацию, когда необходимо найти значение из «Таблица с результатом» в двумерном массиве «Справочник» по нескольким условиям, а именно по значению «Наименование» и «Месяц».
Табличная форма задания будет иметь следующий вид:
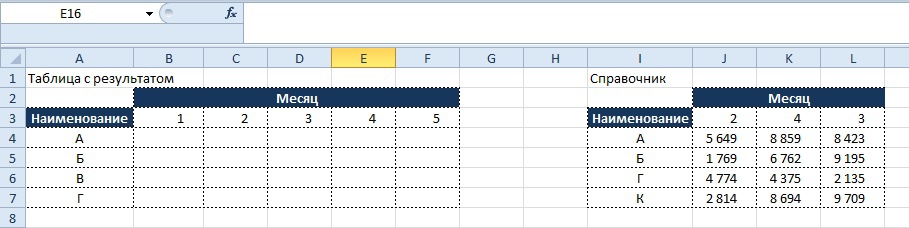
Условие:
- В таблицу с результатом необходимо подтянуть данные в соответствии с совпадением условий «Наименование» и «Месяц».
Для решения подобной задачи подойдет комбинация функций «ИНДЕКС» и «ПОИСКПОЗ»
Синтаксис функции «ИНДЕКС» (INDEX)
ИНДЕКС(массив, номер_строки, [номер_столбца])
- Массив — диапазон ячеек, из которого будут показываться значения в случае совпадения условий их поиска.
- Если массив содержит только одну строку или один столбец, аргумент «номер_строки» или «номер_столбца» соответственно не является обязательным.
- Если массив занимает больше одной строки и одного столбца, а из аргументов «номер_строки» и «номер_столбца» задан только один, то функция «ИНДЕКС» возвращает массив, состоящий из целой строки или целого столбца аргумента «массив».
- Номер_строки — номер строки в массиве, из которой требуется возвратить значение.
- Номер_столбца — номер столбца в массиве, из которого требуется возвратить значение.
Иными словами функция возвращает из указанного массива в аргументе «Массив» значение, которое находится на пересечении координат, указанных в аргументах «Номер_строки» и «Номер_столбца».
Синтаксис функции «ПОИСКПОЗ» (MATCH)
ПОИСКПОЗ(искомое_значение, просматриваемый_массив, [тип_сопоставления])
- Искомое_значение — значение, которое сопоставляется со значениями в аргументе просматриваемый_массив. Аргумент искомое_значение может быть значением (числом, текстом или логическим значением) или ссылкой на ячейку, содержащую такое значение.
- Просматриваемый_массив — диапазон ячеек, в которых производится поиск.
- Тип_сопоставления — необязательный аргумент. Число -1, 0 или 1.
Функция ПОИСКПОЗ выполняет поиск указанного элемента в диапазоне ячеек и возвращает относительную позицию этого элемента в диапазоне.
Суть использования комбинации функций «ИНДЕКС» и «ПОИСКПОЗ» в том, то мы производим поиск координат значений по их наименованию по «осям координат».
Осью Y будет столбец «Наименование», а осью X – строка «Месяцы».
часть формулы:
ПОИСКПОЗ($A4;$I$4:$I$7;0)
возвращает число по оси Y, в данном случае оно будет равно 1, т.к. значение «А» присутствует в искомом диапазоне и имеет относительную позицию «1» в этом диапазоне.
часть формулы:
ПОИСКПОЗ(B$3;$J$3:$L$3;0)
возвращает значение #Н/Д, т.к. значение «1» отсутствует в просматриваемом диапазоне.
Таким образом, мы получили координаты точки (1; #Н/Д) которые функция «ИНДЕКС» использует для поиска в аргументе «Массив».
Полностью написанная функция для ячейки B4 будет иметь следующий вид:
=ИНДЕКС($J$4:$L$7; ПОИСКПОЗ($A4;$I$4:$I$7;0); ПОИСКПОЗ(B$3;$J$3:$L$3;0))
По сути, если бы мы знали координаты нужного нам значения, функция выглядела бы следующим образом:
=ИНДЕКС($J$4:$L$7;1;#Н/Д))
Поскольку, аргумент «Номер_столбца» имеет значение «#Н/Д», то результат для ячейки «B4» будет соответствующий.
Как видно из получившегося результата не все значения в таблице с результатом находят совпадение со справочником и в итоге мы видим, что часть значений в таблице выводится в виде «#Н/Д», что затрудняет использование данных для дальнейших расчетов.
Результат:
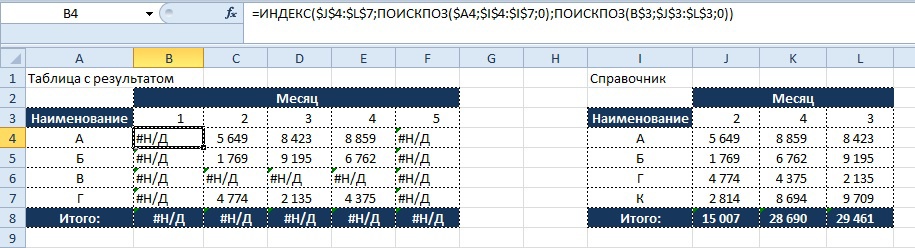
Что бы нейтрализовать этот негативный эффект используем функцию «ЕСЛИОШИБКА», о которой мы читали ранее, и заменяем значение, возвращающееся при ошибке на «0», тогда формула будет иметь вид:
Вывод результата в ячейку B4:
=ЕСЛИОШИБКА(ИНДЕКС($J$4:$L$7; ПОИСКПОЗ($A4;$I$4:$I$7;0); ПОИСКПОЗ(B$3;$J$3:$L$3;0));0)
Демонстрация результата:
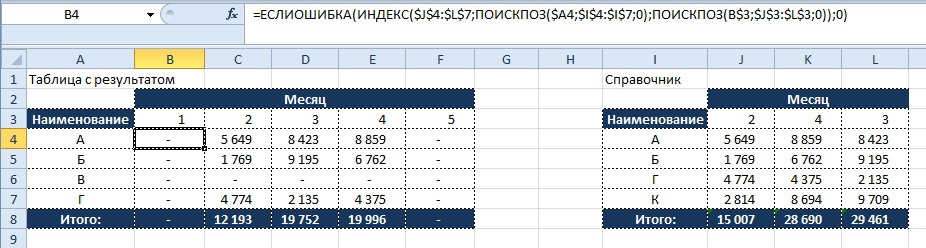
Как видно на картинке, значения «#Н/Д» более не мешают нам в последующих вычислениях с использованием значений в таблице с результатом.
Кейс_5 Поиск значения в диапазоне чисел
Представим, что нам необходимо дать определенный признак числам, входящим в определенный диапазон.
Условие:
В зависимости от стоимости продукта ему должна присваиваться определенная категория
Если значение находится в диапазоне
- От 0 до 1000 = А
- От 1001 до 1500 = Б
- От 1501 до 2000 = В
- От 2001 до 2500 = Г
- Более 2501 = Д

Функция ПРОСМОТР (LOOKUP) возвращает значение из строки, столбца или массива. Функция имеет две синтаксических формы: векторную и форму массива.
ПРОСМОТР(искомое_значение; просматриваемый_вектор; [вектор_результатов])
- Искомое_значение — значение, которое функция ПРОСМОТР ищет в первом векторе. Искомое_значение может быть числом, текстом, логическим значением, именем или ссылкой на значение.
- Просматриваемый_вектор — диапазон, состоящий из одной строки или одного столбца. Значения в аргументе просматриваемый_вектор могут быть текстом, числами или логическими значениями.
- Значения в аргументе просматриваемый_вектор должны быть расположены в порядке возрастания: …, -2, -1, 0, 1, 2, …, A-Z, ЛОЖЬ, ИСТИНА; в противном случае функция ПРОСМОТР может возвратить неправильный результат. Текст в нижнем и верхнем регистрах считается эквивалентным.
- Вектор_результатов — диапазон, состоящий из одной строки или столбца. Вектор_результатов должен иметь тот же размер, что и просматриваемый_вектор.
Вывод результата в ячейку B3:
=ПРОСМОТР(E3;$A$3:$A$7;$B$3:$B$7)

Аргументы «Просматриваемый_вектор» и «Вектор_результата» можно записать в форме массива – в этом случае не придется выводить их в отдельную таблицу на листе Excel.
В этом случае функция будет выглядеть следующим образом:
Вывод результата в ячейку B3:
=ПРОСМОТР(E3;{0;1001;1501;2001;2501};{«А»;«Б»;«В»;«Г»;«Д»})
Кейс_6 Суммирование чисел по признакам
Для суммирования чисел по определенным признакам можно использовать три разных функции:
СУММЕСЛИ (SUMIF) – суммирует только по одному признаку
СУММЕСЛИМН (SUMIFS) – суммирует по множеству признаков
СУММПРОИЗВ (SUMPRODUCT) – суммирует по множеству признаков
Существует также вариант с использованием «СУММ» (SUM) и функции формулы массивов, когда формула «СУММ» возводится в массив:
({=СУММ(()*())}
но такой подход довольно неудобен и полностью перекрывается по функционалу формулой «СУММПРОИЗВ»
Теперь подробнее по синтаксису «СУММПРОИЗВ»:
СУММПРОИЗВ(массив1, [массив2], [массив3],…)
- Массив1 — первый массив, компоненты которого нужно перемножить, а затем сложить результаты.
- Массив2, массив3… — от 2 до 255 массивов, компоненты которых нужно перемножить, а затем сложить результаты.
Условие:
- Найти общую сумму по стоимости отгрузок по каждому из продуктов за определенный период:

Как видно из таблицы с данными, что бы посчитать стоимость необходимо цену умножить на количество, а полученное значение, применив условия отбора переносить в таблица с результатом.
Однако, формула «СУММПРОИЗ» позволяет проводить такие расчеты внутри формулы.
Вывод результата в ячейку B4:
=СУММПРОИЗВ(($A4=$H$3:$H$11)*($K$3:$K$11>=B$3)*($K$3:$K$11<C$3);($M$3:$M$11)*($L$3:$L$11))
Разберем формулу по частям:
($A4=$H$3:$H$11)
– задаем условие по отбору в столбце «Наименование» таблицы с данными по столбцу «Наименование» в таблице с результатом
($K$3:$K$11>=B$3)*($K$3:$K$11<C$3)
– задаем условие по временным рамкам, дата больше или равна первого числа текущего месяца, но меньше первого числа месяца следующего. Аналогично – условие в таблице с результатом, массив – в таблице с данными.
($M$3:$M$11)*($L$3:$L$11)
– перемножаем столбцы «Количество» и «Цена» в таблице с данными.
Несомненным плюсом данной функции является свободный порядок записи условий, их можно записывать в любом порядке, на результат это не повлияет.
Результат:
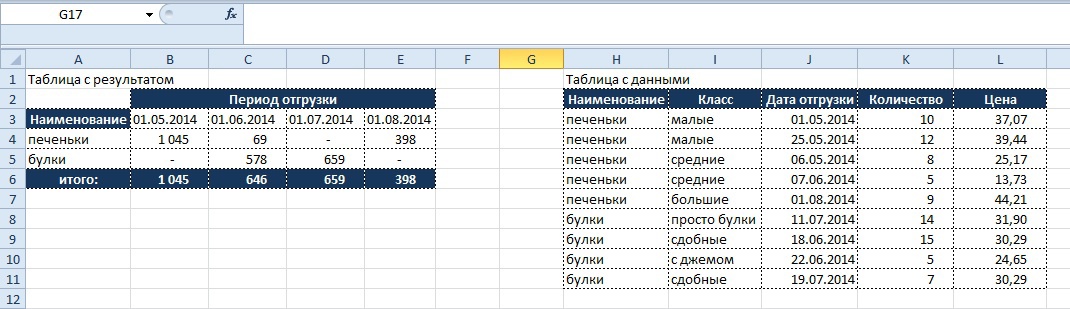
Теперь усложним условие и добавим требование, что бы отбор по наименованию «печеньки» происходил только по классам «малые» и «большие», а по наименованию «булки» все, кроме по классу «с джемом»:
Вывод результата в ячейку B4:
=СУММПРОИЗВ(($A4=$H$3:$H$11)*($J$3:$J$11>=B$3)*($J$3:$J$11<C$3)*(($I$3:$I$11=«малые»)+($I$3:$I$11=«большие»));($L$3:$L$11*$K$3:$K$11))
В формуле для отбора по печенькам добавилось новое условие:
(($I$3:$I$11=«малые»)+($I$3:$I$11=«большие»))
– как видно, два или более условия по одному столбцу выделяются в отдельную группу при помощи символа «+» и заключения условий в дополнительные скобки.
В формуле для отбора по булкам также добавилось новое условие:
=СУММПРОИЗВ(($A5=$H$3:$H$11)*($J$3:$J$11>=B$3)*($J$3:$J$11<C$3)*($I$3:$I$11<>«с джемом»);($L$3:$L$11)*($K$3:$K$11))
это:
($I$3:$I$11<>«с джемом»)
– на самом деле, в данной формуле можно было написать условие отбора также как и при отборе по печенькам, но тогда, пришлось бы перечислять три условия в формуле, в данном случае, проще написать исключение – не равно «с джемом» для этого используем значение «<>».
Вообще, если группы признаков/классов заранее известны, то лучше объединять их в эти группы, создавая справочники, чем записывать все условия в функцию, раздувая ее.
Результат:

Что ж, вот мы и подошли к концу нашего краткого мануала, который на самом деле мог бы быть намного больше, но целью было все-таки дать решение наиболее встречающихся ситуаций, а не описывать решение частных (но гораздо более интересных случаев).
Надеюсь, что мануал поможет кому-нибудь в решении задач при помощи Excel, ведь это будет значить, что мой труд не пропал зря!
Спасибо за уделенное время!
На этом занятии рассмотрим
основные методы массивов. Некоторые из них мы уже рассмотрели на предыдущем
занятии – это push/pop и shift/unshift. Здесь мы
продолжим эту тему и чтобы было проще воспринимать материал, все методы разбиты
на группы и начнем с группы добавления/удаления элементов массива. В нее входят
рассмотренные нами методы push/pop и shift/unshift и следующий
метод – это splice.
Метод splice() – это
универсальный «швейцарский нож» для работы с массивами. Умеет всё: добавлять,
удалять и заменять элементы. Его синтаксис такой:
Array.splice(index[,
deleteCount, elem1, …, elemN])
Он начинает с
позиции index, удаляет deleteCount элементов и
вставляет elem1, …, elemN на их место.
Возвращает массив из удалённых элементов. Этот метод проще всего понять,
рассмотрев примеры. Начнем с удаления. Предположим, имеется массив:
let ar = ["Я", "смотрю", "этот", "обучающий", "урок"];
Удалим 3-й и 4-й
элементы «этот» и «обучающий»:
мы здесь указали
индекс элемента, с которого происходит удаление и число удаляемых элементов.
Выведем результат в консоль:
Видим, в массиве
остались строки «я», «смотрю», «урок».
В следующем
примере мы удалим первые три элемента и добавим два других:
let delElem = ar.splice(0, 3, "Это", "классный");
получаем массив ar:
«Это»,
«классный», «обучающий», «урок»
и массив delElem, состоящий из
удаленных элементов. Этот пример также показывает, что метод splice возвращает
массив из удаленных величин.
С помощью метода
splice можно вставлять
элементы, не удаляя существующие. Для этого аргумент deleteCount
устанавливается в 0:
ar.splice(3, 0, "интересный");
Получим массив:
«Я»,
«смотрю», «этот», «интересный», «обучающий»,
«урок»
В этом и в
других методах массива допускается использование отрицательного индекса. Он
позволяет начать отсчёт элементов с конца:
ar.splice(-3, 3, "это", "обучающее", "видео");
Здесь удаляются
последние 3 элемента и вместо них вставляются новые строчки.
slice
Метод slice имеет синтаксис:
Array.slice([start], [end])
возвращает
массив, в который копирует элементы, начиная с индекса start и заканчивая
индексом end-1. Например:
let ar = ["Я", "смотрю", "этот", "обучающий", "урок"]; let res1 = ar.slice(2, 4); //этот, обучающий let res2 = ar.slice(3); //обучающий, урок let res3 = ar.slice(-3); //этот, обучающий, урок
В res1 копируются
элементы с индексами 2 и 3, в res2 с индекса 3 и до конца массива, а в res3 от 3-го
индекса с конца и до конца массива. Если вызвать просто
let copyArr = ar.slice(); console.log(copyArr);
то будет
скопирован массив целиком. Этим часто пользуются, если нужно создать копию
массива.
concat
Метод concat возвращает
новый массив, состоящий из элементов текущего массива, плюс элементы, указанные
в качестве аргументов:
Array.concat(arg1,
arg2…)
Здесь arg1, arg2
могут быть как примитивными данными (строки, числа), так и массивами. Например:
let ar = [1, 2]; let res1 = ar.concat([3, 4]); // 1,2,3,4 console.log( res1 ); let res2 = ar.concat([3, 4], [5, 6]); // 1,2,3,4,5,6 console.log( res2 ); console.log( ar.concat([3, 4], 5, 6) ); // 1,2,3,4,5,6
По идее, этот
метод работает и с объектами, вот так:
let obj = {name: "guest"}; let ar = [1, 2]; let res = ar.concat(obj); console.log( res );
но здесь
копируется лишь ссылка на объект, а не он сам.
forEach
Данный метод
перебирает элементы массива и при этом позволяет с ними выполнить какие-либо
действия. Имеет следующий синтаксис:
ar.forEach(function(item,
index, array) {
// … делать
что-то с item
});
Например, здесь
выводятся элементы массива в консоль:
let ar = ["Я", "смотрю", "этот", "обучающий", "урок"]; ar.forEach(function(item) { console.log(item); });
Обратите
внимание, что нам нет необходимости указывать все аргументы функции, достаточно
лишь те, что необходимы. В реализацию метода forEach очень хорошо
вписываются стрелочные функции, о которых мы говорили ранее, например так:
let dig = [1, 2, 3, 4, 5, 6, 7]; dig.forEach( (item) => console.log(item) );
или так для
вывода только четных значений:
dig.forEach( (item, index) => { if(item % 2 == 0) console.log(`${item} с индексом ${index}`); });
А вот так все
нечетные элементы можно заменить на 1:
dig.forEach( (item, index, array) => { if(item % 2 != 0) array[index] = 1; });
Далее мы
рассмотрим группу методов для поиска элементов в массиве.
indexOf, lastIndexOf и includes
Данные методы
имеют одинаковый синтаксис и делают по сути одно и то же с небольшими
отличиями. Их синтаксис следующий:
-
ar.indexOf(item,
from) ищет item, начиная с индекса from, и возвращает индекс, на котором был
найден искомый элемент, в противном случае -1. -
ar.lastIndexOf(item,
from) – то же самое, но ищет справа налево. -
ar.includes(item,
from) – ищет item, начиная с индекса from, и возвращает true, если такой
элемент был найден.
Например:
let ar = ["Я", "смотрю", "этот", "обучающий", "урок", 0, false, null]; let res1 = ar.indexOf("смотрю", 0); // 1 let res2 = ar.lastIndexOf(null, 0); // -1 let res3 = ar.includes(0, 3); // true
Получим индекс,
равный 1 для элемента «смотрю», -1 для null и true для нуля.
Почему метод lastIndexOf вернул значение
-1 (то есть, элемент null не найден), хотя он присутствует в
массиве? Дело в том, что аргумент from – это индекс с
которого мы просматриваем массив в обратном направлении. Так как здесь from=0, то мы идет
назад с нулевого элемента, т.е. мы просматриваем только 1-й элемент. Чтобы
просмотреть весь массив, этот индекс можно либо не указывать, либо указать
индекс последнего элемента:
let res2 = ar.lastIndexOf(null); // 7
Теперь значение null находится как
надо. Также обратите внимание, что эти методы используют строгое сравнение ===.
То есть, если мы ищем false, они находят именно false, а не ноль (числовой
эквивалент false).
find и findIndex
Метод find позволяет найти
элемент массива по какому-либо критерию (условию). Она имеет следующий синтаксис:
let result = ar.find(function(item, index, array) {
// если true –
возвращается текущий элемент и перебор прерывается
// если все итерации оказались
ложными, возвращается undefined
});
Функция
вызывается по очереди для каждого элемента массива:
-
item
– очередной элемент; -
index
– его индекс; -
array
– сам массив.
Предположим, у
нас имеется массив объектов:
let cars = [ {model: "toyota", price: 1000}, {model: "opel", price: 800}, {model: "reno", price: 1200} ];
Найдем в нем
первую машину со стоимостью меньше 1000 единиц:
let res = cars.find(item => item.price < 1000); console.log(res);
Результатом
будет элемент opel. Так как на
практике в JavaScript часто
применяются массивы из объектов, то метод find бывает весьма
полезным для поиска нужного элемента. Также обратите внимание, что в примере мы
в find передаем стрелочной функции только один аргумент – item. Так тоже можно
делать и это довольно типичная ситуация.
Метод
ar.findIndex – по сути, то же самое, что и find, но возвращает
индекс, по которому элемент был найден, и -1 в противном случае:
let res = cars.findIndex(item => item.price < 1000);
filter
Рассмотренные
методы find и findIndex ищут первый
подходящий элемент. Если же нужно найти все элементы по заданному критерию
(условию), то следует использовать метод filter:
let results = ar.filter(function(item, index, array) {
// если true –
элемент добавляется к результату, и перебор продолжается
// возвращается пустой массив в
случае, если ничего не найдено
});
Перепишем наш
пример:
let res = cars.filter(item => item.price <= 1000);
Получаем массив
из двух найденных элементов.
Методы преобразования массива: map
Метод map довольно часто
используется на практике и позволяет получить результаты обработки элементов
массива. Его синтаксис похож на предыдущие функции:
let result = arr.map(function(item, index, array) {
// возвращается
новое значение вместо элемента
});
И может быть
использован так:
let cars = ["toyota", "opel", "reno"]; let res = cars.map(function (item) { return item.length; });
Мы здесь
получаем массив длин строк массива cars.
sort
Данный метод
сортирует массив по тому критерию, который указывается в ее необязательной callback-функции:
ar.sort(function(a, b) {
if (a > b) return 1; // если первое значение больше второго
if (a == b) return 0; // если равны
if (a < b) return -1; // если первое значение меньше второго
})
Сортировка
выполняется непосредственно внутри массива ar, но функция
также и возвращает отсортированный массив, правда это возвращаемое значение,
обычно игнорируется. Например:
let dig = [4, 25, 2]; dig.sort(); console.log( dig );
И получим
неожиданный результат: 2, 25, 4. Дело в том, что по умолчанию метод sort рассматривает
значения элементов массива как строки и сортирует их в лексикографическом
порядке. В результате, строка «2» < «4» и «25» < «4», отсюда и результат.
Для указания другого критерия сортировки, мы должны записать свою callback-функцию:
dig.sort(function(a, b) { if(a > b) return 1; else if(a < b) return -1; else return 0; });
Теперь
сортировка с числами проходит так как нам нужно. Кстати, чтобы изменить
направление сортировки (с возрастания на убывание), достаточно поменять знаки
больше и меньше на противоположные. И второй момент: callback-функция не
обязательно должна возвращать именно 1 и -1, можно вернуть любое положительное,
если a>b и отрицательное
при a<b. В частности,
это позволяет переписать приведенный выше пример вот в такой краткой форме:
dig.sort( (a, b) => a-b );
По аналогии
можно формировать и более сложные алгоритмы сортировки самых разных типов данных:
строк, чисел, объектов, булевых переменных и так далее.
reverse
Данный метод
прост, он меняет порядок следования элементов на обратный. Например:
let dig = [4, 25, 2, 1]; dig.reverse();
Получим этот же
массив со значениями: 1, 2, 25, 4.
split, join
Метод split применяется к
строкам и позволяет разбить строку по указанному разделителю на массив строк.
Например, мы в строке указываем email адреса, на которые хотим отправить
письма:
let emailsTo = "alex12@m.ru; m2@m.com; pp@g.com; upr@g.ru";
Но в программе
нам было бы удобнее оперировать массивами из этих адресов. Чтобы разбить строку
по email мы вызовем для
строки метод split и укажем
разделитель «; »:
let arEmails = emailsTo.split("; "); for( let email of arEmails) console.log( email );
Все, теперь
можно использовать массив arEmails вместо строки с email адресами.
У данного метода
есть второй необязательный аргумент, указывающий максимальное число элементов в
выходном массиве. Обычно, он опускается, но если, например, указать вот так:
let arEmails = emailsTo.split("; ", 2);
то в выходном
массиве будет только два первых элемента.
Метод join работает в
точности наоборот: он из массива строк формирует единую строку, например:
let strEmails = arEmails.join(", "); console.log( strEmails );
Получаем строку
из email-адресов через
запятую.
reduce и reduceRight
Если нам нужно
перебрать массив – мы можем использовать forEach, for или for..of. Если нужно
перебрать массив и вернуть данные для каждого элемента – мы используем map.
Методы reduce и reduceRight
похожи на методы выше, но они немного сложнее и, как правило, используются для
вычисления какого-нибудь единого значения на основе всего массива.
Синтаксис:
let value =
ar.reduce(function(previousValue, item, index, array) {
// …
}, [initial]);
Функция
применяется по очереди ко всем элементам массива и «переносит» свой результат
на следующий вызов. Ее аргументы:
-
previousValue
– результат предыдущего вызова этой функции, равен initial при первом вызове
(если передан initial); -
item
– очередной элемент массива; -
index
– его индекс; -
array
– сам массив.
Например,
требуется вычислить сумму значений элементов массива. Это очень легко
реализовать этим методом, например, так:
let digs = [1, -2, 100, 3, 9, 54]; let sum = digs.reduce((sum, current) => sum+current, 0); console.log(sum);
Здесь значение sum при первом
вызове будет равно 0, так как мы вторым аргументом метода reduce указали 0 – это
начальное значение previousValue (то есть sum). Затем, на
каждой итерации мы будем иметь ранее вычисленное значение sum, к которому
прибавляем значение текущего элемента – current. Так и
подсчитывается сумма.
А вот примеры
вычисления произведения элементов массива:
let pr = digs.reduce((pr, current) => pr*current, 1); console.log(pr);
Здесь мы уже
указываем начальное значение 1, иначе бы все произведение было бы равно нулю.
Если начальное
значение не указано, то в качестве previousValue берется первый элемент массива
и функция стартует сразу со второго элемента. Поэтому во всех наших примерах
второй аргумент можно было бы и не указывать. Но такое использование требует
крайней осторожности. Если массив пуст, то вызов reduce без начального значения
выдаст ошибку:
let digs = []; let pr = digs.reduce((pr, current) => pr*current);
Поэтому, лучше
использовать начальное значение.
Метод
reduceRight работает аналогично, но проходит по массиву справа налево.
Array.isArray
Массивы не
образуют отдельный тип языка. Они основаны на объектах. Поэтому typeof не может
отличить простой объект от массива:
console.log(typeof {}); // object console.log (typeof []); // тоже object
Но массивы
используются настолько часто, что для этого придумали специальный метод: Array.isArray(value). Он возвращает
true, если value массив, и false, если нет.
console.log(Array.isArray({})); // false console.log(Array.isArray([])); // true
Подведем итоги
по рассмотренным методам массивов. У нас получился следующий список:
|
Для |
|
|
push(…items) |
добавляет элементы в конец |
|
pop() |
извлекает элемент с конца |
|
shift() |
извлекает элемент с начала |
|
unshift(…items) |
добавляет элементы в начало |
|
splice(pos, deleteCount, …items) |
начиная с индекса pos, удаляет |
|
slice(start, end) |
создаёт новый массив, копируя в него |
|
concat(…items) |
возвращает новый массив: копирует все |
|
Для поиска |
|
|
indexOf/lastIndexOf(item, pos) |
ищет item, начиная с позиции pos, и |
|
includes(value) |
возвращает true, если в массиве |
|
find/filter(func) |
фильтрует элементы через функцию и |
|
findIndex(func) |
похож на find, но возвращает индекс |
|
Для перебора |
|
|
forEach(func) |
вызывает func для каждого элемента. |
|
Для |
|
|
map(func) |
создаёт новый массив из результатов |
|
sort(func) |
сортирует массив «на месте», а потом |
|
reverse() |
«на месте» меняет порядок следования |
|
split/join |
преобразует строку в массив и обратно |
|
reduce(func, initial) |
вычисляет одно значение на основе |
Видео по теме
I’m wondering if there’s a known, built-in/elegant way to find the first element of a JS array matching a given condition. A C# equivalent would be List.Find.
So far I’ve been using a two-function combo like this:
// Returns the first element of an array that satisfies given predicate
Array.prototype.findFirst = function (predicateCallback) {
if (typeof predicateCallback !== 'function') {
return undefined;
}
for (var i = 0; i < arr.length; i++) {
if (i in this && predicateCallback(this[i])) return this[i];
}
return undefined;
};
// Check if element is not undefined && not null
isNotNullNorUndefined = function (o) {
return (typeof (o) !== 'undefined' && o !== null);
};
And then I can use:
var result = someArray.findFirst(isNotNullNorUndefined);
But since there are so many functional-style array methods in ECMAScript, perhaps there’s something out there already like this? I imagine lots of people have to implement stuff like this all the time…
asked May 4, 2012 at 23:14
![]()
6
Since ES6 there is the native find method for arrays; this stops enumerating the array once it finds the first match and returns the value.
const result = someArray.find(isNotNullNorUndefined);
Old answer:
I have to post an answer to stop these filter suggestions 
since there are so many functional-style array methods in ECMAScript, perhaps there’s something out there already like this?
You can use the some Array method to iterate the array until a condition is met (and then stop). Unfortunately it will only return whether the condition was met once, not by which element (or at what index) it was met. So we have to amend it a little:
function find(arr, test, ctx) {
var result = null;
arr.some(function(el, i) {
return test.call(ctx, el, i, arr) ? ((result = el), true) : false;
});
return result;
}
var result = find(someArray, isNotNullNorUndefined);
answered Aug 29, 2013 at 20:20
![]()
BergiBergi
621k146 gold badges947 silver badges1365 bronze badges
12
As of ECMAScript 6, you can use Array.prototype.find for this. This is implemented and working in Firefox (25.0), Chrome (45.0), Edge (12), and Safari (7.1), but not in Internet Explorer or a bunch of other old or uncommon platforms.
For example, x below is 106:
const x = [100,101,102,103,104,105,106,107,108,109].find(function (el) {
return el > 105;
});
console.log(x);If you want to use this right now but need support for IE or other unsupporting browsers, you can use a shim. I recommend the es6-shim. MDN also offers a shim if for some reason you don’t want to put the whole es6-shim into your project. For maximum compatibility you want the es6-shim, because unlike the MDN version it detects buggy native implementations of find and overwrites them (see the comment that begins «Work around bugs in Array#find and Array#findIndex» and the lines immediately following it).
answered Feb 3, 2014 at 23:33
![]()
Mark AmeryMark Amery
140k78 gold badges402 silver badges457 bronze badges
1
What about using filter and getting the first index from the resulting array?
var result = someArray.filter(isNotNullNorUndefined)[0];
![]()
answered Aug 28, 2013 at 15:54
![]()
Phil ManderPhil Mander
1,81915 silver badges20 bronze badges
5
Summary:
- For finding the first element in an array which matches a boolean condition we can use the
ES6find() find()is located onArray.prototypeso it can be used on every array.find()takes a callback where abooleancondition is tested. The function returns the value (not the index!)
Example:
const array = [4, 33, 8, 56, 23];
const found = array.find(element => {
return element > 50;
});
console.log(found); // 56![]()
answered Aug 19, 2018 at 11:46
![]()
2
It should be clear by now that JavaScript offers no such solution natively; here are the closest two derivatives, the most useful first:
-
Array.prototype.some(fn)offers the desired behaviour of stopping when a condition is met, but returns only whether an element is present; it’s not hard to apply some trickery, such as the solution offered by Bergi’s answer. -
Array.prototype.filter(fn)[0]makes for a great one-liner but is the least efficient, because you throw awayN - 1elements just to get what you need.
Traditional search methods in JavaScript are characterized by returning the index of the found element instead of the element itself or -1. This avoids having to choose a return value from the domain of all possible types; an index can only be a number and negative values are invalid.
Both solutions above don’t support offset searching either, so I’ve decided to write this:
(function(ns) {
ns.search = function(array, callback, offset) {
var size = array.length;
offset = offset || 0;
if (offset >= size || offset <= -size) {
return -1;
} else if (offset < 0) {
offset = size - offset;
}
while (offset < size) {
if (callback(array[offset], offset, array)) {
return offset;
}
++offset;
}
return -1;
};
}(this));
search([1, 2, NaN, 4], Number.isNaN); // 2
search([1, 2, 3, 4], Number.isNaN); // -1
search([1, NaN, 3, NaN], Number.isNaN, 2); // 3
![]()
answered Sep 17, 2013 at 4:57
![]()
Ja͢ckJa͢ck
170k38 gold badges263 silver badges309 bronze badges
1
If you’re using underscore.js you can use its find and indexOf functions to get exactly what you want:
var index = _.indexOf(your_array, _.find(your_array, function (d) {
return d === true;
}));
Documentation:
- http://underscorejs.org/#find
- http://underscorejs.org/#indexOf
answered Sep 17, 2013 at 3:12
![]()
Matt WoelkMatt Woelk
1,9101 gold badge19 silver badges24 bronze badges
1
As of ES 2015, Array.prototype.find() provides for this exact functionality.
For browsers that do not support this feature, the Mozilla Developer Network has provided a polyfill (pasted below):
if (!Array.prototype.find) {
Array.prototype.find = function(predicate) {
if (this === null) {
throw new TypeError('Array.prototype.find called on null or undefined');
}
if (typeof predicate !== 'function') {
throw new TypeError('predicate must be a function');
}
var list = Object(this);
var length = list.length >>> 0;
var thisArg = arguments[1];
var value;
for (var i = 0; i < length; i++) {
value = list[i];
if (predicate.call(thisArg, value, i, list)) {
return value;
}
}
return undefined;
};
}
answered May 2, 2016 at 18:48
![]()
0
foundElement = myArray[myArray.findIndex(element => //condition here)];
answered Apr 4, 2019 at 9:29
![]()
DotistaDotista
3862 silver badges12 bronze badges
1
answered Feb 22, 2016 at 16:28
![]()
Dan OchianaDan Ochiana
3,3001 gold badge30 silver badges27 bronze badges
0
Use findIndex as other previously written. Here’s the full example:
function find(arr, predicate) {
foundIndex = arr.findIndex(predicate);
return foundIndex !== -1 ? arr[foundIndex] : null;
}
And usage is following (we want to find first element in array which has property id === 1).
var firstElement = find(arr, e => e.id === 1);
answered Nov 6, 2020 at 8:46
![]()
michal.jakubeczymichal.jakubeczy
7,9571 gold badge57 silver badges61 bronze badges
I have got inspiration from multiple sources on the internet to derive into the solution below. Wanted to take into account both some default value and to provide a way to compare each entry for a generic approach which this solves.
Usage: (giving value «Second»)
var defaultItemValue = { id: -1, name: "Undefined" };
var containers: Container[] = [{ id: 1, name: "First" }, { id: 2, name: "Second" }];
GetContainer(2).name;
Implementation:
class Container {
id: number;
name: string;
}
public GetContainer(containerId: number): Container {
var comparator = (item: Container): boolean => {
return item.id == containerId;
};
return this.Get<Container>(this.containers, comparator, this.defaultItemValue);
}
private Get<T>(array: T[], comparator: (item: T) => boolean, defaultValue: T): T {
var found: T = null;
array.some(function(element, index) {
if (comparator(element)) {
found = element;
return true;
}
});
if (!found) {
found = defaultValue;
}
return found;
}
answered Aug 7, 2019 at 16:49
![]()
HenrikHenrik
1,8671 gold badge16 silver badges9 bronze badges
const employees = [
{id: 1, name: 'Alice', country: 'Canada'},
{id: 2, name: 'Bob', country: 'Belgium'},
{id: 3, name: 'Carl', country: 'Canada'},
{id: 4, name: 'Dean', country: 'Germany'},
];
// 👇️ filter with 1 condition
const filtered = employees.filter(employee => {
return employee.country === 'Canada';
});
// 👇️ [{id: 1, name: 'Alice', country: 'Canada'},
// {id: 3, name: 'Carl', 'country: 'Canada'}]
console.log(filtered);
// 👇️ filter with 2 conditions
const filtered2 = employees.filter(employee => {
return employee.country === 'Canada' && employee.id === 3;
});
// 👇️ [{id: 3, name: 'Carl', country: 'Canada'}]
console.log('filtered2: ', filtered2);
const employee = employees.find(obj => {
return obj.country === 'Canada';
});
// 👇️ {id: 1, name: 'Alice', country: 'Canada'}
console.log(employee);
answered Dec 6, 2022 at 6:24
![]()
Engr.Aftab UfaqEngr.Aftab Ufaq
2,8223 gold badges19 silver badges42 bronze badges
There is no built-in function in Javascript to perform this search.
If you are using jQuery you could do a jQuery.inArray(element,array).
![]()
Eranga
32.1k5 gold badges97 silver badges96 bronze badges
answered May 4, 2012 at 23:22
![]()
PedroSenaPedroSena
6456 silver badges14 bronze badges
3
A less elegant way that will throw all the right error messages (based on Array.prototype.filter) but will stop iterating on the first result is
function findFirst(arr, test, context) {
var Result = function (v, i) {this.value = v; this.index = i;};
try {
Array.prototype.filter.call(arr, function (v, i, a) {
if (test(v, i, a)) throw new Result(v, i);
}, context);
} catch (e) {
if (e instanceof Result) return e;
throw e;
}
}
Then examples are
findFirst([-2, -1, 0, 1, 2, 3], function (e) {return e > 1 && e % 2;});
// Result {value: 3, index: 5}
findFirst([0, 1, 2, 3], 0); // bad function param
// TypeError: number is not a function
findFirst(0, function () {return true;}); // bad arr param
// undefined
findFirst([1], function (e) {return 0;}); // no match
// undefined
It works by ending filter by using throw.
answered Aug 29, 2013 at 18:46
![]()
Paul S.Paul S.
64.4k9 gold badges120 silver badges138 bronze badges
Перевод статьи 4 Methods to Search Through Arrays in JavaScript.
В JavaScript существует несколько довольно эффективных способов поиска элементов в массивах. В самом простом случае вы всегда можете прибегнуть помощи базового цикла for, однако в стандарте ES6 + предусмотрено гораздо большое число методов, предназначенных для циклического перебора элементов массива и поиска среди них тех, что нам нужны.
С таким количеством различных методов поиска и перебора, какой из них рациональнее использовать в каждом из отдельных случаев? Например, в ходе поиска в массиве вы хотите просто узнать, находится ли нужный нам элемент в массиве вообще? А может вам нужен только индекс этого элемента или же он сам?
В отношении каждого отдельного метода, который мы рассмотрим далее, важно понимать, что все они являются встроенными, то есть доступны через свойство прототип Array.prototype. Это означает, что вы можете вызвать их для любого массива, используя точечную нотацию. Это также означает, что все эти методы недоступны для объектов или других типов данных, кроме массивов (хотя частично они могут использоваться для строк).
Далее мы рассмотрим следующие методы массивов Array:
- Array.includes
- Array.find
- Array.indexOf
- Array.filter
includes
const alligator = ["thick scales", 80, "4 foot tail", "rounded snout"];
alligator.includes("thick scales"); // вернет true
Метод .include() возвращает логическое значение и идеально подходит для определения факта наличия искомого элемента в массиве. То есть он просто отвечает true или false. Ниже представлен общий вид его синтаксиса:
arr.includes(valueToFind, [fromIndex]);
Как мы можем заметить, этот метод принимает только один обязательный параметр — valueToFind. Это значение затем используется для сопоставления со значениями элементов массива arr. Необязательный параметр fromIndex — это целое число, предписывающее с какого индекса будет начат поиск. По умолчанию это значение равно 0, и поэтому поиск будет осуществляться по всему массиву.
Итак, поскольку в нашем примере выше элемент, с которого начнется поиск имеет индекс 0, то возвращается true. А вот следующая инструкция вернет ложное значение: alligator.include ("thick scales", 1);, так как в этом случае поиск начинается с элемента с индексом 1.
Теперь подробнее рассмотрим несколько важных деталей, на которые стоит обратить внимание. Первое — метод .includes() использует строгое сравнение. Это означает, с учетом уже рассмотренного нами выше примера, что следующая инструкция: alligator.includes('80'); вернет false . Это происходит потому, что хотя вычисление логического выражения 80 == '80' приведет к получению результата true, однако, так как в нашем случае используется строгое сравнение, то 80 === '80' вернет false, то есть значения с разными типами никогда не будут проходить эту проверку.
find
Чем же метод .find() отличается от .include()? Так если бы мы в нашем примере выше изменили название метода «include» на «find», то получили бы следующую ошибку:
Uncaught TypeError: thick scales is not a function
Это произошло потому, что метод .find() требует передачи в качестве параметра функцию. Метод .find() использует не просто оператор сравнения, он передает каждый элемент массива в функцию, передаваемую ему в качестве параметра, и проверяет, возвращает ли она значение true или false.
Таким образом, и хотя следующая инструкция будет работать корректно: alligator.find (() => 'thick scale');, но вы, вероятно, захотите добавить в качестве функции-аргумента свой собственный оператор сравнения для того, чтобы он возвращал что-то нужное нам.
const alligator = ["thick scales", 80, "4 foot tail", "rounded snout"]; alligator.find(el => el.length < 12); // вернет '4 foot tail'
Эта простая функция, передаваемая нашему методу .find(), проверяет каждый элемент массива, доступный по присваиваемому псевдониму el. Перебор элементов прекращается, когда находится первое совпадение. В нашем случае возвращается true для такого элемента массива, у которого есть свойство length, и его значение менее 12 (напомним, что числа не имеют свойства length). Конечно же, вы можете сделать эту функцию настолько сложной, насколько вам это необходимо, и возвращаемое ей значение соответствовало вашим требованиям.
Заметьте, что результат выполнения нашего кода, из примера выше, не возвращает true, как это было ранее. Это происходит потому, что метод .find() не возвращает логическое значение, а возвращает первый элемент, который соответствует критерию, определенному в функции. Если соответствующего элемента, который соответствует критериям, определенным в вашей функции, то метод вернет undefined. Также обратите внимание, что он возвращает только первый элемент, соответствующий критерию. Таким образом если в массиве более одного элемента, соответствующего критерию в функции, то все равно будет возвращаться только первый, соответствующий критерию в функции. В нашем примере, если бы после элемента со значением 4 foot tail, был другой со значением, в виде строки длиной менее 12 символов, то это ни как не изменило бы наш результат.
В нашем примере мы по сути использовали функцию обратного вызова, но только с одним параметром. При вызове метода .find() вы можете использовать еще один параметр у функции: ссылку на индекс текущего элемента нашего массива. Еще одним параметром может быть ссылка на наш массив, но я нахожу, что его использование может пригодиться в очень редких случаях. Вот пример использования ссылки на индекс нашего обрабатываемого массива:
alligator.find((el, idx) => typeof el === "string" && idx === 2); // вернет '4 foot tall'
И так в нашем массиве три различных элемента, которые удовлетворяют условию (typeof el === 'string'). Если бы это было наше единственное условие, то наш скрипт вернул бы первый элемент массива: thick scales. Но дело в том, что только у одного из элементов нашего массива индекс равен 2 и это элемент со значением 4 foot tall.
Говоря об индексах элементов, схожим методом перебора элементов массива является .findIndex(). Этот метод тоже в качестве параметра принимает функцию, но, как вы уже можете догадаться, он возвращает индекс соответствующего ее критерию элемента, а не его значение.
indexOf
const alligator = ["thick scales", 80, "4 foot tail", "rounded snout"];
alligator.indexOf("rounded snout"); // будет возвращено 3
Как и .include(), метод .indexOf() использует строгое сравнение, а не функцию, как мы это видели рассматривая особенности использования метода .find(). Но, в отличие от метода include(), он возвращает индекс элемента, а не логическое значение. Также вы можете указать, с какого индекса в массиве начинать поиск.
Лично я считаю, что метод .indexOf() может оказаться весьма полезен. Он позволяет легко определить местоположение искомого элемент в массиве, а также проверить присутствует ли в нем элемент с указанным значением. Как же нам понять существует ли указанный элемент в массиве или нет? По сути, мы можем легко определить это, то есть в случае его наличия метод вернет положительное число, и если нет — то -1, что указывает на его отсутствие.
alligator.indexOf("soft and fluffy"); // вернет -1
alligator.indexOf(80); // вернет 1
alligator.indexOf(80, 2); // вернет -1
И, как вы можете видеть, хотя мы могли бы получить методы .find() или .findIndex(), чтобы предоставить нам ту же информацию, писать это намного меньше. Нам не нужно выписывать функцию для сравнения, так как она уже есть в методе .indexOf().
Теперь мы знаем что, метод indexOf() возвращает индекс первого элемента, соответствующего нашему критерию. Тем не менее JavaScript предоставляет нам альтернативный метод поиска элемента в массиве: .lastIndexOf(). Как вы можете догадаться, он делает то же самое, что и метод indexOf(), но начинает поиск с последнего элемента массива в обратном направлении. У этого метода вы также можете указать второй параметр, но помните, что порядок индексов массива остается прежним, не смотря на обратное направление его перебора.
const alligator = ["thick scales", 80, "4 foot tail", "rounded snout", 80]; alligator.indexOf(80); // вернет 1 alligator.lastIndexOf(80); // вернет 4 alligator.indexOf(80, 2); // вернет 4 alligator.lastIndexOf(80, 4); // вернет 4 alligator.lastIndexOf(80, 3); // вернет 1
filter
const alligator = ["thick scales", 80, "4 foot tail", "rounded snout", 80]; alligator.filter(el => el === 80); //вернет [80, 80]
Метод .filter() похож на метод .find() тем, что требует передачи в качестве параметра функции, которая определяет критерий для выбора элементов массива, возвращаемых методом. Основное отличие этих методов состоит в том, что .filter() всегда возвращает массив, даже если найден только один, соответствующий критерию выбора, элемент. То есть он вернет все найденные элементы, тогда как .find() вернет только первый найденный элемент.
Говоря о методе .filter() важно понимать, что он возвращает все элементы, соответствующие вашему критерию, то есть все элементы, которые вы хотите “отфильтровать”.
Заключение
В самом простом случае, когда мне необходимо найти в массиве какое-либо значение я использую метод .find(), но, как вы могли заметить, применение какого-либо метода зависит от конкретного случая.
Вам нужно только узнать существует ли в массиве элемент с определенным значением? Используйте метод .includes().
Вам нужно получить сам элемент массива, значение которого соответствует определенному критерию? Используйте методы .find() или .filter() для получения элементов.
Вам нужно найти индекс какого-либо элемента? Используйте методы .indexOf() или .findIndex() для использования более сложного критерия поиска.
Массивы в примерах, которые мы здесь рассмотрели на самом деле простые. Однако на практике вы можете столкнуться с более сложными случаями, например, с массивами объектов. Вот несколько простых примеров практик, которые вам могут пригодится, для работы с массивами, состоящими из вложенных объектов:
const jungle = [
{ name: "frog", threat: 0 },
{ name: "monkey", threat: 5 },
{ name: "gorilla", threat: 8 },
{ name: "lion", threat: 10 }
];
// разберем объект, перед использованием методов поиска .include () или .indexOf ()
const names = jungle.map(el => el.name); // веренет ['frog', 'monkey', 'gorilla', 'lion']
console.log(names.includes("gorilla")); // веренет true
console.log(names.indexOf("lion")); // веренет 3 - что будет соответствовать верному положению элемента, при условии, что сортировка нового массива names не проводилась
// methods we can do on the array of objects
console.log(jungle.find(el => el.threat == 5)); // веренет объект - {name: "monkey", threat: 5}
console.log(jungle.filter(el => el.threat > 5)); // вернет массив - [{name: "gorilla", threat: 8}, {name: 'lion', threat: 10}]
В общем, это отличный пример для ознакомления с методами поиска в массивах. Изучив их, возможно скоро вы сможете стать настоящими профессионалами эффективного использования массивов JavaScript!
Массивы в JavaScript — это специальный тип данных, который предназначен для хранения коллекции элементов (часто однотипных). У массивов есть встроенные свойства и методы для добавления, удаления и получения элементов, а также для их перебора. Любому JavaScript-разработчик стоит хорошо знать эти методы, так как они здорово облегчают работу.

В этой статье мы разберем 15 встроенных методов объекта Array.prototype:
- forEach()
- find()
- findIndex()
- some()
- every()
- includes()
- reverse()
- map()
- filter()
- reduce()
- sort()
- concat()
- fill()
- flat()
- flatMap()
Практически все они принимают в качестве параметра функцию-коллбэк, которая вызывается последовательно для разных элементов массива. Для удобства во всех примерах мы будем использовать стрелочные функции с кратким синтаксисом:
// вместо такого кода
myAwesomeArray.some(test => {
if (test === "d") {
return test
}
})
// мы будем использовать такой
myAwesomeArray.some(test => test === "d")Коллбэк в большинстве случаев принимает три параметра: текущий элемент массива, его индекс в исходном массиве и сам массив. В примерах мы используем только первый параметр (сам элемент), но важно помнить и про остальные.
forEach()
Параметры метода: функция-коллбэк, значение this для коллбэка (необязательный)
Параметры функции-коллбэка: текущий элемент массива, его индекс в исходном массиве, сам массив
Результат: undefined
Этот метод просто выполняет функцию-коллбэк для каждого элемента в массиве.
const myAwesomeArray = [
{ id: 1, name: "john" },
{ id: 2, name: "Ali" },
{ id: 3, name: "Mass" },
]
myAwesomeArray.forEach(element => console.log(element.name))
// john
// Ali
// Massfind()
Параметры метода: функция-коллбэк, значение this для коллбэка (необязательный)
Параметры функции-коллбэка: текущий элемент массива, его индекс в исходном массиве, сам массив
Результат: первый подходящий элемент массива или undefined
Функции-коллбэк должна вернуть true, если элемент соответствует определенным критериями, или false, если не соответствует. Если вернулся результат true, итерация прекращается. Результатом работы метода становится найденный элемент.
const myAwesomeArray = [
{ id: 1, name: "john" },
{ id: 2, name: "Ali" },
{ id: 3, name: "Mass" },
]
myAwesomeArray.find(element => element.id === 3) // {id: 3, name: "Mass"}
myAwesomeArray.find(element => element.id === 7) // undefinedfindIndex()
Параметры метода: функция-коллбэк, значение this для коллбэка (необязательный)
Параметры функции-коллбэка: текущий элемент массива, его индекс в исходном массиве, сам массив
Результат: индекс первого подходящего элемента массива или -1
Работает аналогично методу find, но возвращает не сам элемент, а его индекс в исходном массиве.
const myAwesomeArray = [
{ id: 1, name: "john" },
{ id: 2, name: "Ali" },
{ id: 3, name: "Mass" },
]
myAwesomeArray.findIndex(element => element.id === 3) // 2
myAwesomeArray.findIndex(element => element.id === 7) // -1some()
Параметры метода: функция-коллбэк, значение this для коллбэка (необязательный)
Параметры функции-коллбэка: текущий элемент массива, его индекс в исходном массиве, сам массив
Результат: true или false
Этот метод используется, чтобы найти в массиве хотя бы один элемент, который соответствует определенному условию. Если функция-коллбэк вернет true, то итерация по элементам остановится и весь метод вернет true. Если для всех элементов вернулось false, то весь метод вернет false.
const myAwesomeArray = ["a", "b", "c", "d", "e"]
myAwesomeArray.some(test => test === "d") // trueevery()
Параметры метода: функция-коллбэк, значение this для коллбэка (необязательный)
Параметры функции-коллбэка: текущий элемент массива, его индекс в исходном массиве, сам массив
Результат: true или false
Этот метод предназначен, чтобы убедиться, что каждый элемент массива соответствует определенному условию. Он возвращает true только в случае, если функция-коллбэк вернет true для каждого элемента, в ином случае будет false.
const myAwesomeArray = ["a", "b", "c", "d", "e"]
myAwesomeArray.every(test => test === "d") // false
const myAwesomeArray2 = ["a", "a", "a", "a", "a"]
myAwesomeArray2.every(test => test === "a") // trueincludes()
Параметры метода: значение для сравнения, индекс, с которого нужно начинать поиск (необязательный, по умолчанию — 0)
Результат: true или false
Работает аналогично методу some, то есть проверяет, есть ли в массиве хоть один подходящий под условие элемент. Однако в отличие от some принимает не функцию, а конкретное значение для сравнения. Сравнение строгое.
const myAwesomeArray = [1, 2, 3, 4, 5]
myAwesomeArray.includes(3) // true
myAwesomeArray.includes(8) // false
myAwesomeArray.includes('3') // falsereverse()
Результат: «перевернутый массив»
Мутация исходного массива: да, «переворот» массива происходит «на месте», без создания копии
Метод обращает порядок следования элементов массива — «переворачивает» его. Последний элемент становится первый, предпоследний — вторым и т. д.
const myAwesomeArray = ["e", "d", "c", "b", "a"]
myAwesomeArray.reverse() // ['a', 'b', 'c', 'd', 'e']map()
Параметры метода: функция-коллбэк, значение this для коллбэка (необязательный)
Параметры функции-коллбэка: текущий элемент массива, его индекс в исходном массиве, сам массив
Результат: новый массив такой же длины, состоящий из преобразованных элементов старого
Мутация исходного массива: нет
Функция-коллбэк получает элемент исходного массива и должна вернуть преобразованный элемент для нового массива.
const myAwesomeArray = [5, 4, 3, 2, 1]
myAwesomeArray.map(x => x * x) // [25, 16, 9, 4, 1]filter()
Параметры метода: функция-коллбэк, значение this для коллбэка (необязательный)
Параметры функции-коллбэка: текущий элемент массива, его индекс в исходном массиве, сам массив
Результат: новый массив, состоящий только отобранных элементов исходного
Мутация исходного массива: нет
Функция-коллбэк должна «фильтровать» элементы исходного массива, возвращая для них true (элемент удовлетворяет условию и должен быть в результирующем массиве) или false (элемент не удовлетворяет условию).
const myAwesomeArray = [
{ id: 1, name: "john" },
{ id: 2, name: "Ali" },
{ id: 3, name: "Mass" },
{ id: 4, name: "Mass" },
]
myAwesomeArray.filter(element => element.name === "Mass")
// [ {id: 3, name: "Mass"}, {id: 4, name: "Mass"} ]reduce()
Параметры метода: функция-коллбэк, начальное значение аккумулятора
Параметры функции-коллбэка: текущее накопленное значение, текущий элемент массива, его индекс в исходном массиве, сам массив
Результат: «накопленное значение» аккумулятора
Коллбэк этого метода при итерации по массиву получает не только текущий элемент, но и «накопленное значение» — accumulator. Функция может изменять его в зависимости от значения элемента и обязательно должна вернуть новое «накопленное значение». Результатом работы всего метода является именно аккумулятор, измененный во всех коллбэках.
Вторым аргументом метода является начальное значение аккумулятора, которое будет передано в коллбэк для самого первого элемента массива. Если это значение не указано, то им станет первый элемент массива, а перебор начнется со второго.
const myAwesomeArray = [1, 2, 3, 4, 5]
myAwesomeArray.reduce((accumulator, value) => accumulator * value)
// 1 * 2 * 3 * 4 * 5 = 120sort()
Параметры метода: функция-компаратор для сравнения двух значений
Результат: отсортированный массив
Мутация исходного массива: да, сортировка происходит «на месте» без создания копии массива
Функция-компаратор получает элементы исходного массива попарно (порядок сравнения зависит от используемого алгоритма сортировки). Если первый элемент условно «меньше» второго, то есть должен идти в отсортированном массиве перед ним, компаратор должен вернуть любое отрицательное число. Если первый элемент «больше» второго, то нужно вернуть положительное число. Если же элементы условно «равны», то есть их порядок в отсортированном массиве не важен, функция должна вернуть 0.
const myAwesomeArray = [5, 4, 3, 2, 1]
// Сортировка по возрастанию
myAwesomeArray.sort((a, b) => a - b) // [1, 2, 3, 4, 5]
// Сортировка по убыванию
myAwesomeArray.sort((a, b) => b - a) // [5, 4, 3, 2, 1]concat()
Параметры метода: массивы для объединения с исходным (количество параметров не ограничено)
Результат: новый массив, состоящий из элементов всех полученных массивов
Мутация исходного массива: нет
Метод просто объединяет несколько массивов в один
const myAwesomeArray = [1, 2, 3, 4, 5]
const myAwesomeArray2 = [10, 20, 30, 40, 50]
myAwesomeArray.concat(myAwesomeArray2) // [1, 2, 3, 4, 5, 10, 20, 30, 40, 50]fill()
Параметры метода: значение, которым нужно заменить текущие элементы массива, индекс элемента, с которого начинается замена (необязательный), индекс элемента, которым заканчивается замена (необязательный, не включительно).
Результат: Массив с измененными значениями.
Мутация исходного массива: да
Этот метод заменяет текущие элементы массива на указанное значение — «заполняет» массив указанным значением.
const myAwesomeArray = [1, 2, 3, 4, 5]
// Первый аргумент (0) - само значение для заполнения
// Второй аргумент (1) - индекс элемента, с которого нужно начать замену
// Третий аргумент (3) - индекс элемента, на котором нужно закончить замену
myAwesomeArray.fill(0, 1, 3) // [1, 0, 0, 4, 5]flat()
Параметры метода: глубина разворачивания (по умолчанию 1)
Результат: новый массив, состоящий из элементов развернутых подмассивов
Мутация исходного массива: нет
Если в вашем исходном массиве есть вложенные массивы, то этот метод «развернет» их, уменьшив «мерность».
const myAwesomeArray = [[1, 2], [3, 4], 5]
myAwesomeArray.flat() // [1, 2, 3, 4, 5]
const myAwesomeArray2 = [[[1, 2], [3, 4]], 5]
myAwesomeArray2.flat(2) // [1, 2, 3, 4, 5]flatMap()
Параметры метода: функция-коллбэк, значение this для коллбэка (необязательный)
Параметры функции-коллбэка: текущий элемент массива, его индекс в исходном массиве, сам массив
Комбинация методов flat() и map(). При этом сначала отрабатывает map — к каждому элементу применяется функция-коллбэк, которая должна вернуть его модифицированную версию. После этого отрабатывает flat с глубиной 1- мерность массива уменьшается.
const myAwesomeArray = [[1], [2], [3], [4], [5]]
myAwesomeArray.flatMap(arr => arr * 10) // [10, 20, 30, 40, 50]
// то же самое с flat() + map()
myAwesomeArray.map(arr => arr * 10).flat() // [10, 20, 30, 40, 50]Больше информации о массивах:
Работа с массивами в JavaScript