Все, что познается, имеет число, ибо невозможно ни понять ничего, ни познать без него – Пифагор
В этой статье:
Матрица смежности
Матрица инцидентности
Список смежности (инцидентности)
Взвешенный граф (коротко)
Итак, мы умеем задавать граф графическим способом. Но есть еще два способа как можно задавать граф, а точнее представлять его. Для экономии памяти в компьютере граф можно представлять с помощью матриц или с помощью списков.
Матрица является удобной для представления плотных графов, в которых число ребер близко к максимально возможному числу ребер (у полного графа).
Другой способ называется списком. Данный способ больше подходит для более разреженных графов, в котором число ребер намного меньше максимально возможного числа ребер (у полного графа).
Перед чтением материала рекомендуется ознакомится с предыдущей статьей, о смежности и инцидентности, где данные определения подробно разбираются.
Матрица смежности
Но тем кто знает, но чуть забыл, что такое смежность есть краткое определение.
Смежность – понятие, используемое только в отношении двух ребер или в отношении двух вершин: два ребра инцидентные одной вершине, называются смежными; две вершины, инцидентные одному ребру, также называются смежными.
Матрица (назовем ее L) состоит из n строк и n столбцов и поэтому занимает n^2 места.
Каждая ячейка матрицы равна либо 1, либо 0;
Ячейка в позиции L (i, j) равна 1 тогда и только тогда, когда существует ребро (E) между вершинами (V) i и j. Если у нас положение (j, i), то мы также сможем использовать данное правило. Из этого следует, что число единиц в матрице равно удвоенному числу ребер в графе. (если граф неориентированный). Если ребра между вершинами i и j не существует, то ставится 0.
Для практического примера возьмем самый обыкновенный неориентированный граф:
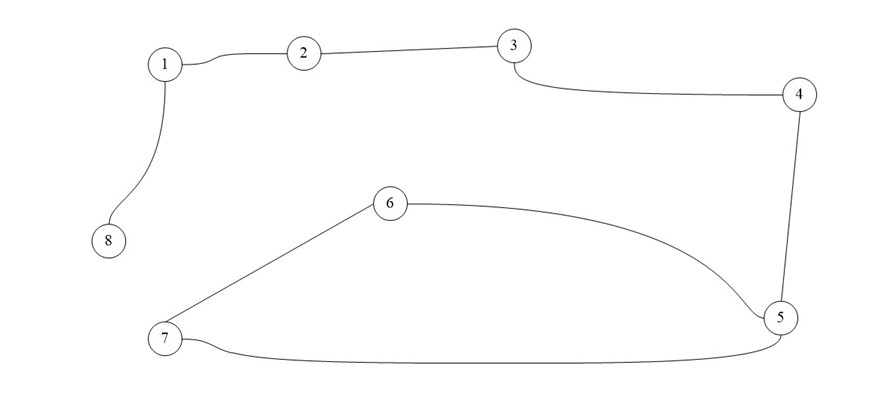
А теперь представим его в виде матрицы:
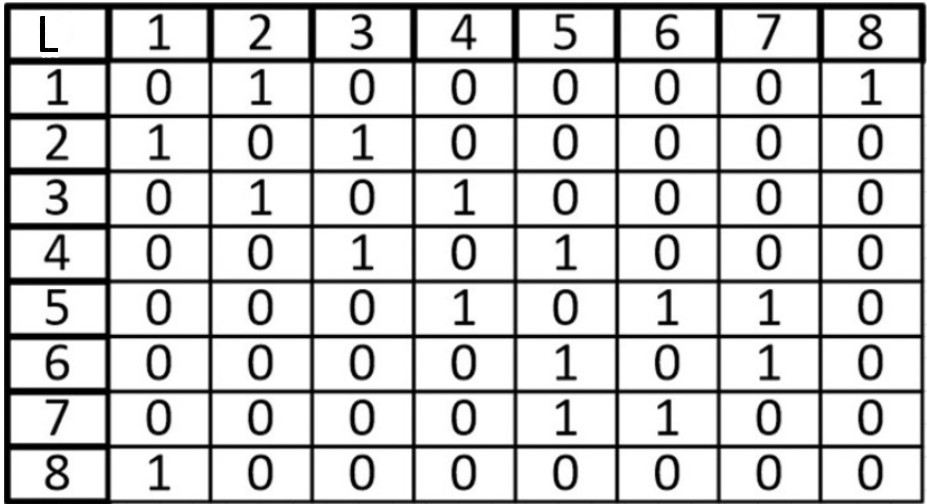
Ячейки, расположенные на главной диагонали всегда равны нулю, потому что ни у одной вершины нет ребра, которое и начинается, и заканчивается в ней только если мы не используем петли. То есть наша матрица симметрична относительно главной диагонали. Благодаря этому мы можем уменьшить объем памяти, который нам нужен для хранения.
С одной стороны объем памяти будет:
![]()
Но используя вышеописанный подход получается:
![]()
Потому что нижнюю часть матрицы мы можем создать из верхней половины матрицы. Только при условии того, что у нас главная диагональ должна быть пустой, потому что при наличии петель данное правило не работает.
Если граф неориентированный, то, когда мы просуммируем строку или столбец мы узнаем степень рассматриваемой нами вершины.
Если мы используем ориентированный граф, то кое-что меняется.
Здесь отсутствует дублирование между вершинами, так как если вершина 1 соединена с вершиной 2, наоборот соединена она не может быть, так у нас есть направление у ребра.
Возьмем в этот раз ориентированный граф и сделаем матрицу смежности для него:

В виде матрицы:

Если мы работаем со строкой матрицы, то мы имеем элемент из которого выходит ребро, в нашем случаи вершина 1 входит в вершину 2 и 8. Когда мы работаем со столбцом то мы рассматриваем те ребра, которые входят в данную вершину. В вершину 1 ничего не входит, значит матрица верна.
Объем памяти:
![]()
Если бы на главной диагонали была бы 1, то есть в графе присутствовала петля, то мы бы работали уже не с простым графом, с каким мы работали до сих пор.
Используя петли мы должны запомнить, что в неориентированном графе петля учитывается дважды, а в ориентированном — единожды.
Матрица инцидентности
Инцидентность – понятие, используемое только в отношении ребра и вершины: две вершины (или два ребра) инцидентными быть не могут.
Матрица (назовем ее I) состоит из n строк которое равно числу вершин графа, и m столбцов, которое равно числу ребер. Таким образом полная матрица имеет размерность n x m. То есть она может быть, как квадратной, так и отличной от нее.
Ячейка в позиции I (i, j) равна 1 тогда, когда вершина инцидентна ребру иначе мы записываем в ячейку 0, такой вариант представления верен для неориентированного графа.
Сразу же иллюстрируем данное правило:

В виде матрицы:
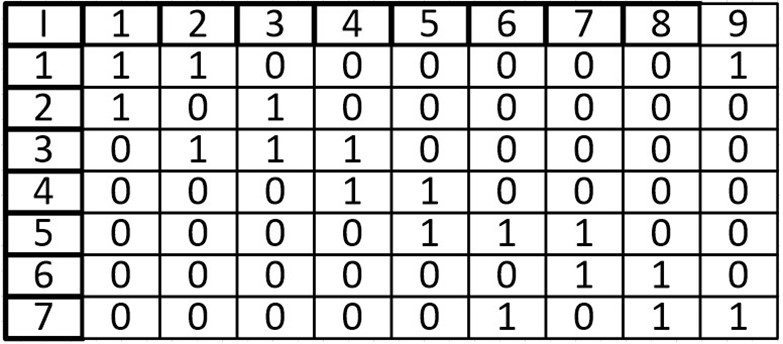
Сумма элементов i-ой строки равна степени вершины.
При ориентированным графе, ячейка I (i, j) равна 1, если вершина V (i) начало дуги E(j) и ячейка I (i, j) равна -1 если вершина V (i) конец дуги E (j), иначе ставится 0.
Ориентированный граф:
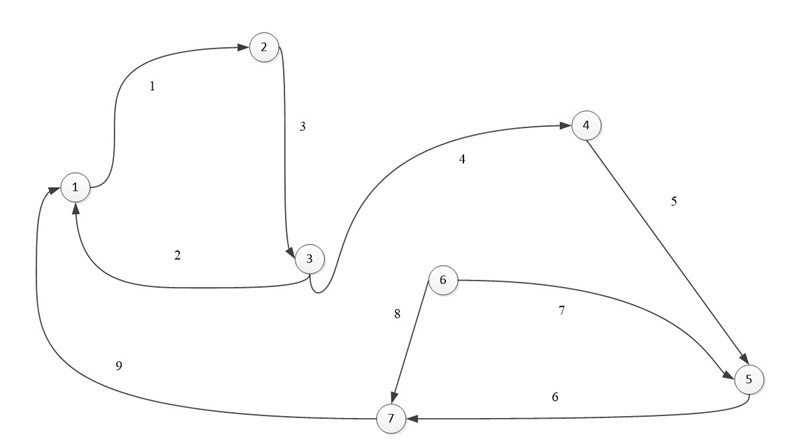
В виде матрицы:
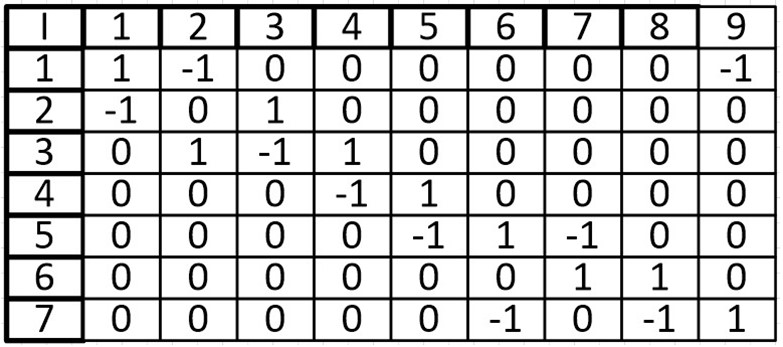
Одной из особенностей данной матрицы является то, что в столбце может быть только две ненулевых ячейки. Так как у ребра два конца.
При суммировании строки, ячейки со значением -1, могут складываться только с ячейками, также имеющими значение -1, то же касается и 1, мы можем узнать степень входа и степень выхода из вершины. Допустим при сложении первой вершины, мы узнаем, что из нее исходит 1 ребро и входят два других ребра. Это является еще одной особенностью (при том очень удобной) данной матрицы.
Объем памяти:
![]()
Список смежности (инцидентности)
Список смежности подразумевает под собой, то что мы работаем с некоторым списком (массивом). В нем указаны вершины нашего графа. И каждый из них имеет ссылку на смежные с ним вершины.

В виде списка это будет выглядеть так:
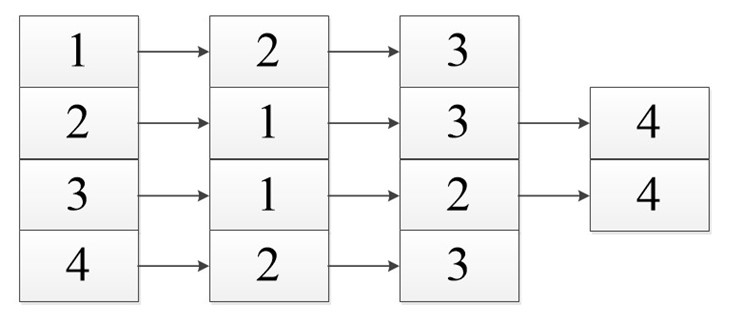
Неважно в каком порядке вы расположите ссылку так как вы рассматриваете смежность относительно первой ячейки, все остальные ссылки указывают лишь на связь с ней, а не между собой.
Так как здесь рассматривается смежность, то здесь не обойдется без дублирования вершин. Поэтому сумма длин всех списков считается как:
![]()
Объем памяти:
![]()
Когда мы работаем с ориентированным графом, то замечаем, что объем задействованной памяти будет меньше, чем при неориентированном (из-за отсутствия дублирования).
В виде списка:
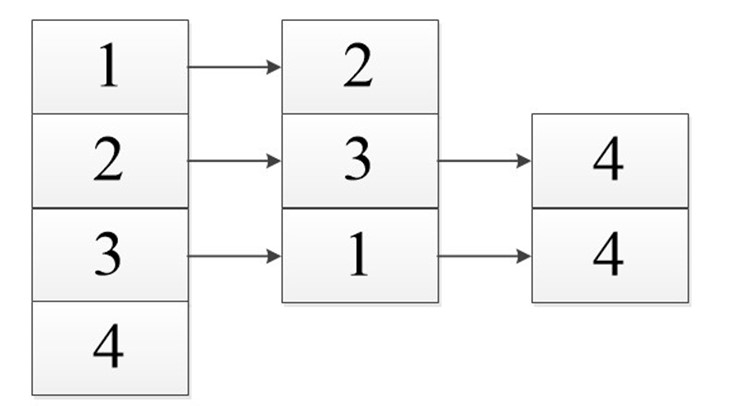
Сумма длин всех списков:
![]()
Объем памяти:
![]()
Со списком инцидентности все просто. Вместо вершин в список (массив) вы вставляете рёбра и потом делаете ссылки на те вершины, с которыми он связан.
К недостатку списка смежности (инцидентности) относится то что сложно определить наличие конкретного ребра (требуется поиск по списку). А если у вас большой список, то удачи вам и творческих успехов! Поэтому, чтобы работать максимальной отдачей в графе должно быть мало рёбер.
Взвешенность графа
Взвешенный граф — это граф, в котором вместо 1 обозначающее наличие связи между вершинами или связи между вершиной и ребром, хранится вес ребра, то есть определённое число с которым мы будем проводить различные действия.
К примеру, возьмем граф с весами на ребрах:

И сделаем матрицу смежности:
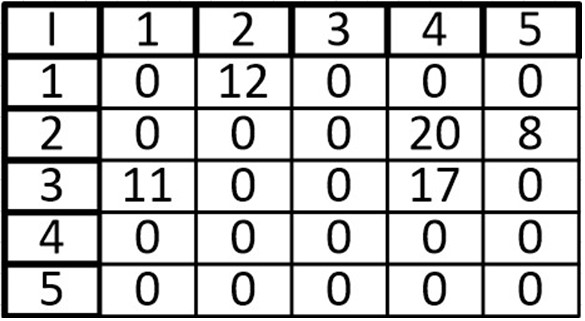
В ячейках просто указываем веса ребра, а в местах где отсутствует связь пишем 0 или -∞.
Более подробно данное определение будет рассмотрено при нахождении поиска кратчайшего пути в графе.
Итак, мы завершили разбор представления графа с помощью матрицы смежности и инцидентности и списка смежности (инцидентности). Это самые известные способы представления графа. В дальнейшем мы будем рассматривать и другие матрицы, и списки, которые в свою очередь будут удобны для представления графа с определёнными особенностями.
Если заметили ошибку или есть предложения пишите в комментарии.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
На каком языке программирования проводить операции с графами
21.28%
Использовать оба
10
Проголосовали 47 пользователей.
Воздержались 8 пользователей.
Говорить о том, что ребро g и каждая из вершин u и y инцидентна g, стоит лишь в том случае, если g соединяет u и y. Уяснив это, перейдем к рассмотрению данного метода. Матрица инцидентности строиться по похожему, но не по тому же принципу, что и матрица смежности. Так если последняя имеет размер n×n, где n – число вершин, то матрица инцидентности – n×m, здесь n – число вершин графа, m – число ребер. То есть теперь чтобы задать значение какой-либо ячейки, нужно сопоставить не вершину с вершиной, а вершину с ребром.
В каждой ячейки матрицы инцидентности неориентированного графа стоит 0 или 1, а в случае ориентированного графа, вносятся 1, 0 или -1. То же самое, но наиболее структурировано:
1) Неориентированный граф
a. 1 – вершина инцидентна ребру
b. 0 – вершина не инцидентна ребру
2) Ориентированный граф
a. 1 – вершина инцидентна ребру, и является его началом
b. 0 – вершина не инцидентна ребру
c. -1 – вершина инцидентна ребру, и является его концом
Построим матрицу инцидентности сначала для неориентированного графа, а затем для орграфа.

Ребра обозначены буквами от a до e, вершины – цифрами. Все ребра графа не направленны, поэтому матрица инцидентности заполнена положительными значениями.

Для орграфа графа матрица имеет немного другой вид. В каждую из ее ячеек внесено одно из трех значений. Обратите внимание, что нули в двух этих матрицах (рис. 1 и 2) занимают одинаковые позиции, ведь в обоих случаях структура графа одна. Но некоторые положительные единицы сменились на отрицательные, например, в неориентированном графе ячейка (1, b) содержит 1, а в орграфе -1. Действительно, это уместно, т. к. в первом случае ребро b не направленное, а во втором – направленное, и, причем вершиной входа для него является вершина «1».
Каждый столбец отвечает за какое-либо одно ребро, поэтому граф, описанный при помощи матрицы инцидентности, всегда будет иметь следующий признак: любой из столбцов матрицы инцидентности содержит две единицы, либо 1 и -1 когда это ориентированное ребро, все остальное в нем – нули.
В программе матрица инцидентности задается, также как и матрица смежности, а именно при помощи двумерного массива. Его элементы могут быть инициализированы при объявлении, либо по мере выполнения программы.
( 2 оценки, среднее 5 из 5 )
Содержание
- 1 Определения для ориентированного и неориентированного графов
- 2 Свойства
- 3 Пример
- 4 См. также
- 5 Источники
Определения для ориентированного и неориентированного графов
| Определение: |
| Матрицей инцидентности (инциденций) (англ. Incidence matrix) неориентированного графа называется матрица , для которой , если вершина инцидентна ребру , в противном случае . |
| Определение: |
| Матрицей инцидентности (инциденций) (англ. Incidence matrix) ориентированного графа называется матрица , для которой , если вершина является началом дуги , , если является концом дуги , в остальных случаях . |
Свойства
| Утверждение: |
|
Для неориентированных графов без петель и кратных рёбер матрица инцидентности бинарна (состоит из нулей и единиц). |
| Утверждение: |
|
Для ориентированных графов без петель и кратных рёбер матрица инцидентности состоит из нулей, единиц и . |
| Утверждение (о сумме элементов строки матрицы инцидентности для неориентированного графа): |
|
Сумма элементов -й строки равна . |
| Утверждение (о сумме элементов строки матрицы инцидентности для ориентированного графа): |
|
Сумма элементов -й строки равна . |
Пример
| Граф | Матрица инцидентности | Ориентированный граф | Матрица инцидентности |
|---|---|---|---|
|
|
См. также
- Матрица смежности графа
Источники
- Харари Фрэнк :Теория графов. Под ред. Л. Б. Штейнпресс. Изд. 2-е. — М.: Мир, 1973. — 180 с. — ISBN 5-354-00301-6
- Асанов М. О., Баранский В. А., Расин В. В.: Дискретная математика: графы, матроиды, алгоритмы — НИЦ РХД, 2001. — 288 с. — ISBN 5-93972-076-5
- Википедия — Incidence matrix
From Wikipedia, the free encyclopedia
In mathematics, an incidence matrix is a logical matrix that shows the relationship between two classes of objects, usually called an incidence relation. If the first class is X and the second is Y, the matrix has one row for each element of X and one column for each element of Y. The entry in row x and column y is 1 if x and y are related (called incident in this context) and 0 if they are not. There are variations; see below.
Graph theory[edit]
Incidence matrix is a common graph representation in graph theory. It is different to an adjacency matrix, which encodes the relation of vertex-vertex pairs.
Undirected and directed graphs[edit]
In graph theory an undirected graph has two kinds of incidence matrices: unoriented and oriented.
The unoriented incidence matrix (or simply incidence matrix) of an undirected graph is a  matrix B, where n and m are the numbers of vertices and edges respectively, such that
matrix B, where n and m are the numbers of vertices and edges respectively, such that

For example, the incidence matrix of the undirected graph shown on the right is a matrix consisting of 4 rows (corresponding to the four vertices, 1–4) and 4 columns (corresponding to the four edges,  ):
):
|
= |
|

If we look at the incidence matrix, we see that the sum of each column is equal to 2. This is because each edge has a vertex connected to each end.
The incidence matrix of a directed graph is a matrix B where n and m are the number of vertices and edges respectively, such that

(Many authors use the opposite sign convention.)
The oriented incidence matrix of an undirected graph is the incidence matrix, in the sense of directed graphs, of any orientation of the graph. That is, in the column of edge e, there is one 1 in the row corresponding to one vertex of e and one −1 in the row corresponding to the other vertex of e, and all other rows have 0. The oriented incidence matrix is unique up to negation of any of the columns, since negating the entries of a column corresponds to reversing the orientation of an edge.
The unoriented incidence matrix of a graph G is related to the adjacency matrix of its line graph L(G) by the following theorem:

where A(L(G)) is the adjacency matrix of the line graph of G, B(G) is the incidence matrix, and Im is the identity matrix of dimension m.
The discrete Laplacian (or Kirchhoff matrix) is obtained from the oriented incidence matrix B(G) by the formula

The integral cycle space of a graph is equal to the null space of its oriented incidence matrix, viewed as a matrix over the integers or real or complex numbers. The binary cycle space is the null space of its oriented or unoriented incidence matrix, viewed as a matrix over the two-element field.
Signed and bidirected graphs[edit]
The incidence matrix of a signed graph is a generalization of the oriented incidence matrix. It is the incidence matrix of any bidirected graph that orients the given signed graph. The column of a positive edge has a 1 in the row corresponding to one endpoint and a −1 in the row corresponding to the other endpoint, just like an edge in an ordinary (unsigned) graph. The column of a negative edge has either a 1 or a −1 in both rows. The line graph and Kirchhoff matrix properties generalize to signed graphs.
Multigraphs[edit]
The definitions of incidence matrix apply to graphs with loops and multiple edges. The column of an oriented incidence matrix that corresponds to a loop is all zero, unless the graph is signed and the loop is negative; then the column is all zero except for ±2 in the row of its incident vertex.
Weighted graphs[edit]

A weighted undirected graph
A weighted graph can be represented using the weight of the edge in place of a 1. For example, the incidence matrix of the graph to the right is:
|
= |
|

Hypergraphs[edit]
Because the edges of ordinary graphs can only have two vertices (one at each end), the column of an incidence matrix for graphs can only have two non-zero entries. By contrast, a hypergraph can have multiple vertices assigned to one edge; thus, a general matrix of non-negative integers describes a hypergraph.
Incidence structures[edit]
The incidence matrix of an incidence structure C is a p × q matrix B (or its transpose), where p and q are the number of points and lines respectively, such that Bi,j = 1 if the point pi and line Lj are incident and 0 otherwise. In this case, the incidence matrix is also a biadjacency matrix of the Levi graph of the structure. As there is a hypergraph for every Levi graph, and vice versa, the incidence matrix of an incidence structure describes a hypergraph.
Finite geometries[edit]
An important example is a finite geometry. For instance, in a finite plane, X is the set of points and Y is the set of lines. In a finite geometry of higher dimension, X could be the set of points and Y could be the set of subspaces of dimension one less than the dimension of the entire space (hyperplanes); or, more generally, X could be the set of all subspaces of one dimension d and Y the set of all subspaces of another dimension e, with incidence defined as containment.
Polytopes[edit]
In a similar manner, the relationship between cells whose dimensions differ by one in a polytope, can be represented by an incidence matrix.[1]
Block designs[edit]
Another example is a block design. Here X is a finite set of «points» and Y is a class of subsets of X, called «blocks», subject to rules that depend on the type of design. The incidence matrix is an important tool in the theory of block designs. For instance, it can be used to prove Fisher’s inequality, a fundamental theorem of balanced incomplete 2-designs (BIBDs), that the number of blocks is at least the number of points.[2] Considering the blocks as a system of sets, the permanent of the incidence matrix is the number of systems of distinct representatives (SDRs).
See also[edit]
- Parry–Sullivan invariant
References[edit]
- ^ Coxeter, H.S.M. (1973) [1963], Regular Polytopes (3rd ed.), Dover, pp. 166-167, ISBN 0-486-61480-8
- ^ Ryser, Herbert John (1963), Combinatorial Mathematics, The Carus Mathematical Monographs #14, The Mathematical Association of America, p. 99
Further reading[edit]
- Diestel, Reinhard (2005), Graph Theory, Graduate Texts in Mathematics, vol. 173 (3rd ed.), Springer-Verlag, ISBN 3-540-26183-4
- Jonathan L Gross, Jay Yellen, Graph Theory and its applications, second edition, 2006 (p 97, Incidence Matrices for undirected graphs; p 98, incidence matrices for digraphs)
External links[edit]
- Weisstein, Eric W. «Incidence matrix». MathWorld.
Матрица инцидентности и матрица смежности
На рис. 1,2 изображено
множество точек
![]()
и
множество линий
![]() ,
,
соединяющих эти точки,
которые все вместе образуют граф
![]() .Если линии имеют
.Если линии имеют
стрелки, то граф называется ориентированным
или орграфом
![]() (рис. 2).
(рис. 2).
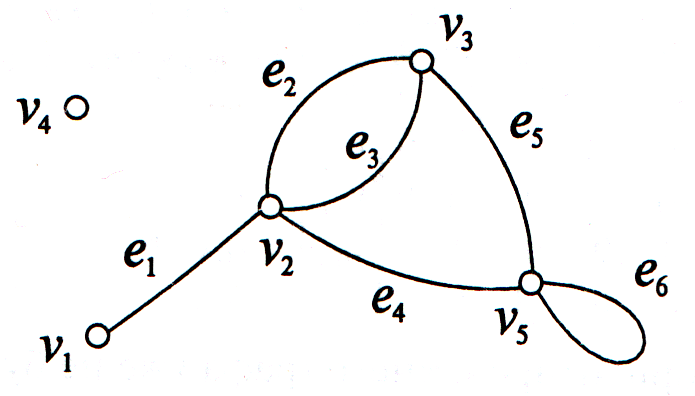

Рис. 1. Граф
![]() .
.
Рис. 2.
Орграф
![]()
.
Графы
![]() и
и
![]() можно представить в
можно представить в
аналитической форме либо матрицей
смежности
![]() ,либо матрицей
,либо матрицей
инцидентности
![]() .
.
Для нашего конкретного
неориентированного графа
![]()
матрицы
![]() и
и
![]() выглядят следующим
выглядят следующим
образом:
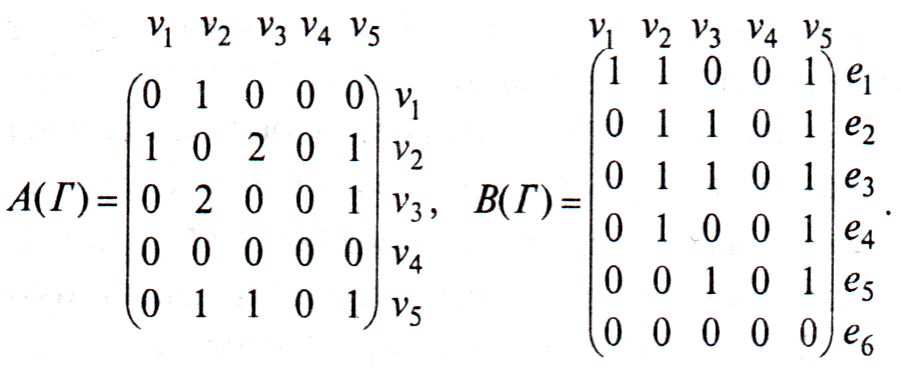
Матрица смежности для неориентированного
графа всегда симметрична.
Фигурирующая в ней 2 может быть в некоторых
случаях заменена на 1.
В матрице инцидентности
сумма единиц по столбцам указывает на
степень вершины vi.
Нередко расположение вершин и ребер в
этой матрице меняют местами (транспонируют).
Так, для нашего конкретного орграфа
матрицы
![]() и
и
![]() выглядят существенно
выглядят существенно
иначе:
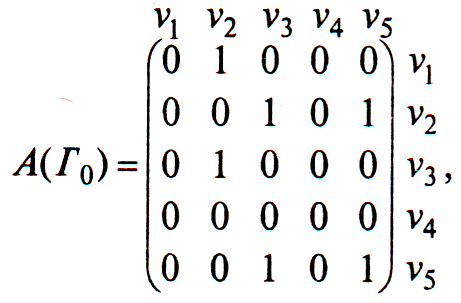
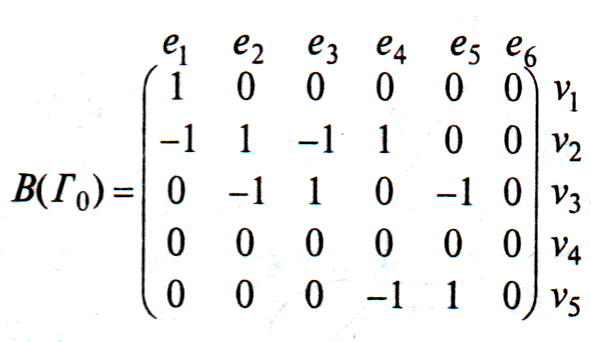
В общем случае матрица
смежности для ориентированного графа
![]()
уже не будет симметричной. В матрице
инцидентности ставится 1, если дуга
исходит из вершины, и —1, если дуга
заходит в нее.
Матрица
смежности и матрица инцидентности
Есть два стандартных способа представить
граф G = (V,E)
-
– как набор списков смежных вершин
-
как матрицу смежности.
Первый обычно предпочтительнее, ибо
дает более компактное представление
разреженных графов– тех, у
которых |E| много меньше
|V|2.
Большинство стандартных алгоритмов
используют именно это представление.
Но в некоторых ситуациях удобнее
пользоваться матрицей смежности –
например, для плотных графов, у
которых |EG| сравнимо с |VG|2.
Матрица смежности позволяет быстро
определить, соединены ли две данные
вершины ребром. Алгоритмы отыскания
кратчайших путей для всех пар вершин,
используют представление графа с помощью
матрицы смежности.
-
Определение Матрицей смежностиграфа G = (V, E) называется квадратная
булева матрицаAпорядкаn,элементы которой определяются
следующим образом:
![]()
Свойства
-
А – симметрическая матрица
-
На главной диагонали матрицы смежности
всегда стоят 0. -
Число единиц в строке равно степени
соответствующей вершины.
Матрицей инцидентностиграфаGназывается булева матрица размера
|V|´|G|
вида
![]()
Свойства:
-
В каждом столбце матрицы ровно две
единицы -
Равных столбцов нет.
Например, на следующем рисунке граф
задан графически, списком смежных
вершин, матрицей смежности и матрицей
инцидентности.
|
графически
|
список смежных вершин
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
матрица смежности
|
матрица инцидентности
|

Рассматриваются
также графы
с нагруженными ребрами
или взвешенные –
графы, у которых каждому ребру поставлено
в соответствие некоторое вещественное
число – вес или нагрузка ребра.
Такой граф можно
задать матрицей
расстояний –
квадратной матрицей размера |V|´|V|,
где на пересечении i-ой
строки и j-го
столбца записан вес ребра (i,
j),
если ребро есть, ¥,
если ребра нет и 0, если i = j.
Соседние файлы в папке ДМ ВВО
- #
- #
- #
- #
- #
- #
- #