In this tutorial, we will look at how to get the median value of a list of values in Python. We will walk you through the usage of the different methods with the help of examples.
What is median?
Median is a descriptive statistic that is used as a measure of central tendency of a distribution. It is equal to the middle value of the distribution. There are equal number of values smaller and larger than the median. It is also not much sensitive to the presence of outliers in the data like the mean (another measure of central tendency).
To calculate the median of a list of values –
- Sort the values in ascending or descending order (either works).
- If the number of values, n, is odd, then the median is the value in the
(n+1)/2position in the sorted list(or array) of values.
If the number of values, n, is even, then the median is the average of the values inn/2andn/2 + 1position in the sorted list(or array) of values.
For example, calculate the median of the following values –
![]()
First, let’s sort these numbers in ascending order.
![]()
Now, since the total number of values is even (8), the median is the average of the 4th and the 5th value.

Thus, median comes out to be 3.5
Now that we have seen how is the median mathematically calculated, let’s look at how to compute the median in Python.
To compute the median of a list of values in Python, you can write your own function, or use methods available in libraries like numpy, statistics, etc. Let’s look at these methods with the help of examples.
1. From scratch implementation of median in Python
You can write your own function in Python to compute the median of a list.
def get_median(ls):
# sort the list
ls_sorted = ls.sort()
# find the median
if len(ls) % 2 != 0:
# total number of values are odd
# subtract 1 since indexing starts at 0
m = int((len(ls)+1)/2 - 1)
return ls[m]
else:
m1 = int(len(ls)/2 - 1)
m2 = int(len(ls)/2)
return (ls[m1]+ls[m2])/2
# create a list
ls = [3, 1, 4, 9, 2, 5, 3, 6]
# get the median
print(get_median(ls))
Output:
3.5
Here, we use the list sort() function to sort the list, and then depending upon the length of the list return the median. We get 3.5 as the median, the same we manually calculated above.
Note that, compared to the above function, the libraries you’ll see next are better optimized to compute the median of a list of values.
2. Using statistics library
You can also use the statistics standard library in Python to get the median of a list. Pass the list as argument to the statistics.median() function.
import statistics # create a list ls = [3, 1, 4, 9, 2, 5, 3, 6] # get the median print(statistics.median(ls))
Output:
3.5
We get the same results as above.
For more on the statistics library in Python, refer to its documentation.
3. Using numpy library
The numpy library’s median() function is generally used to calculate the median of a numpy array. You can also use this function on a Python list.
import numpy as np # create a list ls = [3, 1, 4, 9, 2, 5, 3, 6] print(np.median(ls))
Output:
3.5
You can see that we get the same result.
Subscribe to our newsletter for more informative guides and tutorials.
We do not spam and you can opt out any time.
-

Piyush is a data professional passionate about using data to understand things better and make informed decisions. He has experience working as a Data Scientist in the consulting domain and holds an engineering degree from IIT Roorkee. His hobbies include watching cricket, reading, and working on side projects.
View all posts

Sometimes, while working with Python list we can have a problem in which we need to find Median of list. This problem is quite common in the mathematical domains and generic calculations. Let’s discuss certain ways in which this task can be performed.
Method #1 : Using loop + “~” operator This task can be performed in brute force manner using the combination of above functionalities. In this, we sort the list and the by using the property of “~” operator to perform negation, we access the list from front and rear, performing the required computation required for finding median.
Python3
test_list = [4, 5, 8, 9, 10, 17]
print("The original list : " + str(test_list))
test_list.sort()
mid = len(test_list) // 2
res = (test_list[mid] + test_list[~mid]) / 2
print("Median of list is : " + str(res))
Output
The original list : [4, 5, 8, 9, 10, 17] Median of list is : 8.5
Time Complexity: O(n) where n is the number of elements in the list “test_list”. loop + “~” operator performs n number of operations.
Auxiliary Space: O(1), constant extra space is required.
Method #2 : Using statistics.median() This is the most generic method to perform this task. In this we directly use inbuilt function to perform the median of the list.
Python3
import statistics
test_list = [4, 5, 8, 9, 10, 17]
print("The original list : " + str(test_list))
res = statistics.median(test_list)
print("Median of list is : " + str(res))
Output
The original list : [4, 5, 8, 9, 10, 17] Median of list is : 8.5
Using python heapq.nlargest() or heapq.nsmallest()
Explanation: Using python’s heapq module, we can use the nlargest() or nsmallest() function to find the median of a list of numbers. This method is useful when we are working with large amount of data and we want to find median of large dataset with minimum memory footprint.
Python3
import heapq
test_list = [4, 5, 8, 9, 10, 17]
print("The original list : " + str(test_list))
mid = len(test_list) // 2
if len(test_list) % 2 == 0:
res = (heapq.nlargest(mid, test_list)[-1] + heapq.nsmallest(mid, test_list)[-1]) / 2
else:
res = heapq.nlargest(mid+1, test_list)[-1]
print("Median of list is : " + str(res))
Output
The original list : [4, 5, 8, 9, 10, 17] Median of list is : 8.5
Time complexity: O(n log(k)) where k = len(test_list)/2
Auxiliary Space: O(k) where k = len(test_list)/2
Method : Using sort the list:
Python3
test_list = [4, 5, 8, 9, 10, 17]
print("The original list : " + str(test_list))
test_list.sort()
n = len(test_list)
if n % 2 == 0:
median = (test_list[n//2 - 1] + test_list[n//2]) / 2
else:
median = test_list[n//2]
print("Median of list is : " + str(median))
Output
The original list : [4, 5, 8, 9, 10, 17] Median of list is : 8.5
Time complexity: O(n log n)
Auxiliary Space: O(n)
Last Updated :
12 Apr, 2023
Like Article
Save Article
Мой любимый алгоритм: нахождение медианы за линейное время
Время на прочтение
7 мин
Количество просмотров 82K

Нахождение медианы списка может казаться тривиальной задачей, но её выполнение за линейное время требует серьёзного подхода. В этом посте я расскажу об одном из самых любимых мной алгоритмов — нахождении медианы списка за детерминированное линейное время с помощью медианы медиан. Хотя доказательство того, что этот алгоритм выполняется за линейное время, довольно сложно, сам пост будет понятен и читателям с начальным уровнем знаний об анализе алгоритмов.
Нахождение медианы за O(n log n)
Самым прямолинейным способом нахождения медианы является сортировка списка и выбор медианы по её индексу. Самая быстрая сортировка сравнением выполняется за O(n log n), поэтому от неё зависит время выполнения1, 2.
def nlogn_median(l):
l = sorted(l)
if len(l) % 2 == 1:
return l[len(l) / 2]
else:
return 0.5 * (l[len(l) / 2 - 1] + l[len(l) / 2])У этого способа самый простой код, но он определённо не самый быстрый.
Нахождение медианы за среднее время O(n)
Следующим нашим шагом будет нахождение медианы в среднем за линейное время, если нам будет везти. Этот алгоритм, называемый «quickselect», разработан Тони Хоаром, который также изобрёл алгоритм сортировки с похожим названием — quicksort. Это рекурсивный алгоритм, и он может находить любой элемент (не только медиану).
- Выберем индекс списка. Способ выбора не важен, на практике вполне подходит и случайный. Элемент с этим индексом называется опорным элементом (pivot).
- Разделим список на две группы:
- Элементы меньше или равные pivot,
lesser_els - Элементы строго большие, чем pivot,
great_els
- Элементы меньше или равные pivot,
- Мы знаем, что одна из этих групп содержит медиану. Предположим, что мы ищем k-тый элемент:
- Если в
lesser_elsесть k или больше элементов, рекурсивно обходим списокlesser_elsв поисках k-того элемента. - Если в
lesser_elsменьше, чем k элементтов, рекурсивно обходим списокgreater_els. Вместо поиска k мы ищемk-len(lesser_els).
- Если в
Вот пример алгоритма, выполняемого для 11 элементов:
Возьмём представленный ниже список. Мы хотим найти медиану.
l = [9,1,0,2,3,4,6,8,7,10,5]
len(l) == 11, поэтому мы ищем шестой наименьший элемент
Сначала нам нужно выбрать опорный элемент (pivot). Мы случайным образом выбираем индекс 3.
Значение элемента с этим индексом равно 2.
Разбиваем список на группы согласно pivot:
[1,0,2], [9,3,4,6,8,7,10,5]
Нам нужен шестой элемент. 6-len(left) = 3, поэтому нам нужен
третий наименьший элемент в правом массиве
Теперь мы ищем третий наименьший элемент в следующем массиве:
[9,3,4,6,8,7,10,5]
Мы случайным образом выбираем индекс, который будет нашим pivot.
Мы выбрали индекс 2, значение в котором равно l[2]=6
Разбиваем на группы согласно pivot:
[3,4,5,6] [9,7,10]
Нам нужен третий наименьший элемент, поэтому мы знаем, что это
третий наименьший элемент в левом массиве
Теперь мы ищем третий наименьший в следующем массиве:
[3,4,5,6]
Мы случайным образом выбираем индекс, который будет нашим pivot.
Мы выбрали индекс 1, значение в котором равно l[1]=4
Разбиваем на группы согласно pivot:
[3,4] [5,6]
Нам нужен третий наименьший элемент, поэтому мы знаем, что это
наименьший элемент в правом массиве.
Теперь мы ищем наименьший элемент в следующем массиве:
[5,6]
На этом этапе у нас есть базовый вариант, выбирающий наибольший
или наименьший элемент на основании индекса.
Нам нужен наименьший элемент, то есть 5.
return 5
Чтобы найти с помощью quickselect медиану, мы выделим quickselect в отдельную функцию. Наша функция quickselect_median будет вызывать quickselect с нужными индексами.
import random
def quickselect_median(l, pivot_fn=random.choice):
if len(l) % 2 == 1:
return quickselect(l, len(l) / 2, pivot_fn)
else:
return 0.5 * (quickselect(l, len(l) / 2 - 1, pivot_fn) +
quickselect(l, len(l) / 2, pivot_fn))
def quickselect(l, k, pivot_fn):
"""
Выбираем k-тый элемент в списке l (с нулевой базой)
:param l: список числовых данных
:param k: индекс
:param pivot_fn: функция выбора pivot, по умолчанию выбирает случайно
:return: k-тый элемент l
"""
if len(l) == 1:
assert k == 0
return l[0]
pivot = pivot_fn(l)
lows = [el for el in l if el < pivot]
highs = [el for el in l if el > pivot]
pivots = [el for el in l if el == pivot]
if k < len(lows):
return quickselect(lows, k, pivot_fn)
elif k < len(lows) + len(pivots):
# Нам повезло и мы угадали медиану
return pivots[0]
else:
return quickselect(highs, k - len(lows) - len(pivots), pivot_fn)
В реальном мире Quickselect отлично себя проявляет: он почти не потребляет лишних ресурсов и выполняется в среднем за O(n). Давайте докажем это.
Доказательство среднего времени O(n)
В среднем pivot разбивает список на две приблизительно равных части. Поэтому каждая последующая рекурсия оперирует с 1⁄2 данных предыдущего шага.

Существует множество способов доказательства того, что этот ряд сходится к 2n. Вместо того, чтобы приводить их здесь, я сошлюсь на замечательную статью в Википедии, посвящённую этому бесконечному ряду.
Quickselect даёт нам линейную скорость, но только в среднем случае. Что, если нас не устраивает среднее, и мы хотим гарантированного выполнения алгоритма за линейное время?
Детерминированное O(n)
В предыдущем разделе я описал quickselect, алгоритм со средней скоростью O(n). «Среднее» в этом контексте означает, что в среднем алгоритм будет выполняться за O(n). С технической точки зрения, нам может очень не повезти: на каждом шаге мы можем выбирать в качестве pivot наибольший элемент. На каждом этапе мы сможем избавляться от одного элемента из списка, и в результате получим скорость O(n^2), а не O(n).
С учётом этого, нам нужен алгоритм для подбора опорных элементов. Нашей целью будет выбор за линейное время pivot, который в худшем случае удаляет достаточное количество элементов для обеспечения скорости O(n) при использовании его вместе с quickselect. Этот алгоритм был разработан в 1973 году Блумом (Blum), Флойдом (Floyd), Праттом (Pratt), Ривестом (Rivest) и Тарьяном (Tarjan). Если моего объяснения вам не хватит, то можете изучить их статью 1973 года. Вместо того, чтобы описывать алгоритм, я подробно прокомментирую мою реализацию на Python:
def pick_pivot(l):
"""
Выбираем хорошй pivot в списке чисел l
Этот алгоритм выполняется за время O(n).
"""
assert len(l) > 0
# Если элементов < 5, просто возвращаем медиану
if len(l) < 5:
# В этом случае мы возвращаемся к первой написанной нами функции медианы.
# Поскольку мы выполняем её только для списка из пяти или менее элементов, она не
# зависит от длины входных данных и может считаться постоянным
# временем.
return nlogn_median(l)
# Сначала разделим l на группы по 5 элементов. O(n)
chunks = chunked(l, 5)
# Для простоты мы можем отбросить все группы, которые не являются полными. O(n)
full_chunks = [chunk for chunk in chunks if len(chunk) == 5]
# Затем мы сортируем каждый фрагмент. Каждая группа имеет фиксированную длину, поэтому каждая сортировка
# занимает постоянное время. Поскольку у нас есть n/5 фрагментов, эта операция
# тоже O(n)
sorted_groups = [sorted(chunk) for chunk in full_chunks]
# Медиана каждого фрагмента имеет индекс 2
medians = [chunk[2] for chunk in sorted_groups]
# Возможно, я немного повторюсь, но я собираюсь доказать, что нахождение
# медианы списка можно произвести за доказуемое O(n).
# Мы находим медиану списка длиной n/5, поэтому эта операция также O(n)
# Мы передаём нашу текущую функцию pick_pivot в качестве создателя pivot алгоритму
# quickselect. O(n)
median_of_medians = quickselect_median(medians, pick_pivot)
return median_of_medians
def chunked(l, chunk_size):
"""Разделяем список `l` на фрагменты размером `chunk_size`."""
return [l[i:i + chunk_size] for i in range(0, len(l), chunk_size)]Давайте докажем, что медиана медиан является хорошим pivot. Нам поможет, если мы представим визуализацию нашего алгоритма выбора опорных элементов:
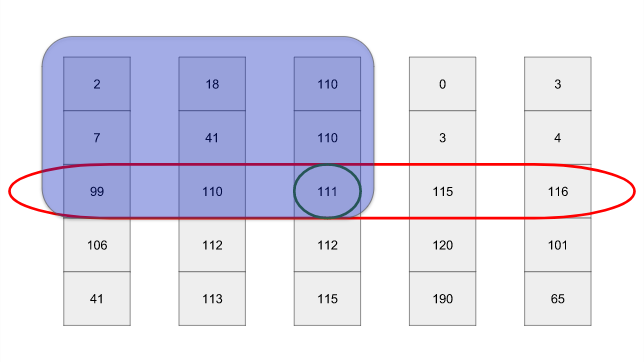
Красным овалом обозначены медианы фрагментов, а центральным кругом — медиана медиан. Не забывайте, мы хотим, чтобы pivot разделял список как можно ровнее. В худшем возможном случае каждый элемент в синем прямоугольнике (слева вверху) будет меньше или равен pivot. Верхний правый прямоугольник содержит 3⁄5 половины строк — 3/5*1/2=3/10. Поэтому на каждом этапе мы избавляемся по крайней мере от 30% строк.
Но достаточно ли нам отбрасывать 30% элементов на каждом этапе? На каждом этапе наш алгоритм должен выполнять следующее:
- Выполнять работу O(n) по разбиению элементов
- Для рекурсии решать одну подзадачу размером в 7⁄10 от исходной
- Для вычисления медианы медиан решать одну подзадачу размером с 1⁄5 от исходной
В результате мы получаем следующее уравнение полного времени выполнения T(n):

Не так уж просто доказать, почему это равно O(n). Быстрое решение заключается в том, чтобы положиться на основную теорему о рекуррентных соотношениях. Мы попадаем в третий случай теоремы, при котором работа на каждом уровне доминирует над работой подзадач. В этом случае общая работа будет просто равна работе на каждом уровне, то есть O(n).
Подводим итог
У нас есть quickselect, алгоритм, который находит медиану за линейное время при условии наличия достаточно хорошей опорного элемента. У нас есть алгоритм медианы медиан, алгоритм O(n) для выбора опорного элемента (который достаточно хорош для quickselect). Соединив их, мы получили алгоритм нахождения медианы (или n-ного элемента в списка) за линейное время!
Медианы за линейное время на практике
В реальном мире почти всегда достаточно случайного выбора медианы. Хотя подход с медианой медиан всё равно выполняется за линейное время, на практике его вычисление длится слишком долго. В стандартной библиотеке C++ используется алгоритм под названием introselect, в котором применено сочетание heapselect и quickselect; предел его выполнения O(n log n). Introselect позволяет использовать обычно быстрый алгоритм с плохим верхним пределом в сочетании с алгоритмом, который медленнее на практике, но имеет хороший верхний предел. Реализации начинают с быстрого алгоритма, но возвращаются к более медленному, если не могут выбрать эффективные опорные элементы.
В завершение приведу сравнение элементов, используемых в каждой из реализаций. Это не скорость выполнения, а общее количество элементов, которые рассматривает функция quickselect. Здесь не учитывается работа по вычислению медианы медиан.
Именно этого мы и ожидали! Детерминированный опорный элемент почти всегда рассматривает при quickselect меньшее количество элементов, чем случайный. Иногда нам везёт и мы угадываем pivot с первой попытки, что проявляется как впадины на зелёной линии. Математика работает!
- Это может стать интересным применением поразрядной сортировки (radix sort), если вам нужно найти медиану в списке целых чисел, каждое из которых меньше 232.
- На самом деле в Python используется Timsort, впечатляющее сочетание теоретических пределов и практической скорости. Заметки о списках в Python.
Введение Когда мы пытаемся описать и обобщить выборку данных, мы, вероятно, начинаем с нахождения среднего [https://en.wikipedia.org/wiki/Mean] (или среднего), медианы [https: // en .wikipedia.org / wiki / Median] и режим [https://en.wikipedia.org/wiki/Mode_(statistics)] данных. Это центральная тенденция [https://en.wikipedia.org/wiki/Central_tendency] меры и часто первый взгляд на набор данных. В этом руководстве мы узнаем, как найти или вычислить среднее значение, медиану,
Вступление
Когда мы пытаемся описать и обобщить выборку данных, мы, вероятно,
начинаем с нахождения среднего
(или среднего), медианы и
режима данных. Это
основные меры
тенденций, которые
часто являются нашим первым взглядом на набор данных.
В этом руководстве мы узнаем, как найти или вычислить среднее значение,
медиану и режим в Python. Сначала мы закодируем функцию Python для
каждой меры, а затем воспользуемся
statistics
Python для выполнения той же задачи.
Обладая этими знаниями, мы сможем быстро взглянуть на наши наборы данных
и получить представление об общей тенденции данных.
Оглавление
- Вычисление среднего значения выборки
- Расчет среднего с помощью
Python - Использование Python mean ()
- Расчет среднего с помощью
- Нахождение медианы выборки
- Поиск медианы с помощью Python
- Использование медианы Python ()
- Нахождение моды образца
- Поиск режима с помощью Python
- Использование режима Python ()
Расчет среднего значения выборки
Если у нас есть выборка числовых значений, то ее среднее или среднее
- это общая сумма значений (или наблюдений), деленная на количество
значений.
Допустим, у нас есть образец [4, 8, 6, 5, 3, 2, 8, 9, 2, 5] . Мы можем
вычислить его среднее значение, выполнив операцию:
(4 + 8 + 6 + 5 + 3 + 2 + 8 + 9 + 2 + 5) / 10 = 5,2
Среднее арифметическое — это общее описание наших данных. Предположим,
вы купили 10 фунтов помидоров. Если пересчитать дома помидоры, получится
25 помидоров. В этом случае вы можете сказать, что средний вес помидора
составляет 0,4 фунта. Это было бы хорошее описание ваших помидоров.
Среднее также может быть плохим описанием выборки данных. Допустим, вы
анализируете группу собак. Если вы возьмете совокупный вес всех собак и
разделите его на количество собак, то это, вероятно, будет плохим
описанием веса отдельной собаки, поскольку разные породы собак могут
иметь очень разные размеры и вес.
Насколько хорошо или плохо среднее значение описывает выборку, зависит
от того, насколько разбросаны данные. В случае помидоров, они почти
одинакового веса, и среднее значение является хорошим их описанием. В
случае с собаками нет актуальных собак. Они могут варьироваться от
крошечного чихуахуа до гигантского немецкого мастифа. Итак, среднее само
по себе в данном случае не очень хорошее описание.
Теперь пора приступить к делу и узнать, как вычислить среднее значение с
помощью Python.
Расчет среднего с помощью Python
Чтобы вычислить среднее значение выборки числовых данных, мы будем
использовать две встроенные функции Python. Один для вычисления общей
суммы значений, а другой для вычисления длины выборки.
Первая функция — это
sum() . Эта
встроенная функция принимает итерацию числовых значений и возвращает их
общую сумму.
Вторая функция —
len() . Эта
встроенная функция возвращает длину объекта. len() может принимать в
качестве аргумента последовательности (строка, байты, кортеж, список или
диапазон) или коллекции (словарь, набор или замороженный набор).
Вот как мы можем вычислить среднее значение:
>>> def my_mean(sample):
... return sum(sample) / len(sample)
...
>>> my_mean([4, 8, 6, 5, 3, 2, 8, 9, 2, 5])
5.2
Сначала мы суммируем значения в sample используя sum() . Затем мы
делим эту сумму на длину sample , которая является результирующим
значением len(sample) .
Использование Python mean ()
Поскольку вычисление среднего — это обычная операция, Python включает
эту функцию в модуль statistics Он предоставляет некоторые функции для
расчета базовой статистики по наборам данных. Функция
statistics.mean()
берет образец числовых данных (любых итерируемых) и возвращает их
среднее значение.
Вот как работает функция mean() Python:
>>> import statistics
>>> statistics.mean([4, 8, 6, 5, 3, 2, 8, 9, 2, 5])
5.2
Нам просто нужно
импортировать statistics
а затем вызвать mean() с нашим образцом в качестве аргумента. Это
вернет среднее значение выборки. Это быстрый способ найти среднее
значение с помощью Python.
Нахождение медианы выборки
Медиана выборки числовых данных — это значение, которое находится
посередине при сортировке данных. Данные могут быть отсортированы по
возрастанию или убыванию, медиана остается прежней.
Чтобы найти медиану, нам необходимо:
- Отсортировать образец
- Найдите значение в середине отсортированного образца
При нахождении числа в центре отсортированной выборки мы можем
столкнуться с двумя типами ситуаций:
- Если в выборке есть нечетное количество наблюдений , то среднее
значение в отсортированной выборке — это медиана. - Если в выборке есть четное количество наблюдений , нам нужно
вычислить среднее из двух средних значений в отсортированной
выборке.
Если у нас есть выборка [3, 5, 1, 4, 2] и мы хотим найти ее медиану,
то сначала мы сортируем выборку по [1, 2, 3, 4, 5] . Медиана будет
равна 3 поскольку это значение посередине.
С другой стороны, если у нас есть выборка [1, 2, 3, 4, 5, 6] , то ее
медиана будет (3 + 4) / 2 = 3.5 .
Давайте посмотрим, как мы можем использовать Python для вычисления
медианы.
Поиск медианы с помощью Python
Чтобы найти медиану, нам сначала нужно отсортировать значения в нашей
выборке . Этого можно
добиться с помощью встроенной функции
sorted()
sorted() принимает итерацию и возвращает отсортированный list
содержащий те же значения, что и исходная итерация.
Второй шаг — найти значение, которое находится в середине
отсортированной выборки. Чтобы найти это значение в выборке с нечетным
количеством наблюдений, мы можем разделить количество наблюдений на 2.
Результатом будет индекс значения в середине отсортированной выборки.
Поскольку оператор деления ( / ) возвращает число с плавающей запятой,
нам нужно использовать оператор деления этажа ( //
),
чтобы получить целое число. Итак, мы можем использовать его как индекс в
операции индексации ( [] ).
Если в выборке есть четное количество наблюдений, нам нужно найти два
средних значения. Скажем, у нас есть образец [1, 2, 3, 4, 5, 6] . Если
мы разделим его длину ( 6 ) на 2 с помощью деления пола, то получим
3 . Это индекс нашего верхнего среднего значения ( 4 ). Чтобы найти
индекс нашего нижнего среднего значения ( 3 ), мы можем уменьшить
индекс верхнего среднего значения на 1 .
Давайте объединим все это в функцию, которая вычисляет медиану выборки.
Вот возможная реализация:
>>> def my_median(sample):
... n = len(sample)
... index = n // 2
... # Sample with an odd number of observations
... if n % 2:
... return sorted(sample)[index]
... # Sample with an even number of observations
... return sum(sorted(sample)[index - 1:index + 1]) / 2
...
>>> my_median([3, 5, 1, 4, 2])
3
>>> my_median([3, 5, 1, 4, 2, 6])
3.5
Эта функция берет образец числовых значений и возвращает их медиану.
Сначала мы находим длину образца n . Затем мы вычисляем индекс
среднего значения (или верхнего среднего значения) путем деления n на
2 .
Оператор if проверяет, есть ли в имеющейся выборке нечетное количество
наблюдений. Если да, то медиана — это значение index .
Окончательный return выполняется, если в выборке есть четное
количество наблюдений. В этом случае мы находим медиану, вычисляя
среднее из двух средних значений.
Обратите внимание, что операция
нарезки
[index - 1:index + 1] получает два значения. Значение в index - 1 и
значение в index поскольку операции нарезки исключают значение в
конечном индексе ( index + 1 ).
Использование медианы Python ()
Функция Python statistics.median() берет выборку данных и возвращает
ее медиану. Вот как работает метод:
>>> import statistics
>>> statistics.median([3, 5, 1, 4, 2])
3
>>> statistics.median([3, 5, 1, 4, 2, 6])
3.5
Обратите внимание, что median() автоматически обрабатывает вычисление
медианы для выборок с нечетным или четным числом наблюдений.
Поиск режима образца
Режим — это наиболее частое наблюдение (или наблюдения) в выборке.
Если у нас есть образец [4, 1, 2, 2, 3, 5] , то его режим равен 2
потому что 2 появляется в образце два раза, тогда как другие элементы
появляются только один раз.
Режим не обязательно должен быть уникальным. Некоторые образцы имеют
более одного режима. Скажем, у нас есть образец [4, 1, 2, 2, 3, 5, 4]
. В этом примере есть два режима — 2 и 4 потому что эти значения
появляются чаще и оба появляются одинаковое количество раз.
Этот режим обычно используется для категориальных данных.
Распространенными категориальными типами данных являются:
- логическое значение — может принимать только два значения,
напримерtrueилиfalse,maleилиfemale - номинальный — может принимать более двух значений, например,
American - European - Asian - African - порядковый — может принимать более двух значений, но значения
имеют логический порядок, например,few - some - many
Когда мы анализируем набор категориальных данных, мы можем использовать
этот режим, чтобы узнать, какая категория является наиболее
распространенной в наших данных.
Мы можем найти образцы, у которых нет режима. Если все наблюдения
уникальны (нет повторяющихся наблюдений), то в вашей выборке не будет
режима.
Теперь, когда мы знаем основы режима, давайте посмотрим, как его найти с
помощью Python.
Поиск режима с помощью Python
Чтобы найти режим с помощью Python, мы начнем с подсчета количества
вхождений каждого значения в рассматриваемом примере. Затем мы получим
значения с большим количеством вхождений.
Поскольку подсчет объектов — обычная операция, Python предоставляет
класс
collections.Counter
Этот класс специально разработан для подсчета предметов.
Класс Counter предоставляет метод, определенный как
.most_common([n]) . Этот метод возвращает list кортежей из двух
элементов с n более общими элементами и их соответствующими
счетчиками. Если n опущено или None , то .most_common() возвращает
все элементы.
Давайте воспользуемся Counter и .most_common() чтобы закодировать
функцию, которая берет образец данных и возвращает свой режим.
Вот возможная реализация:
>>> from collections import Counter
>>> def my_mode(sample):
... c = Counter(sample)
... return [k for k, v in c.items() if v == c.most_common(1)[0][1]]
...
>>> my_mode(["male", "male", "female", "male"])
['male']
>>> my_mode(["few", "few", "many", "some", "many"])
['few', 'many']
>>> my_mode([4, 1, 2, 2, 3, 5])
[2]
>>> my_mode([4, 1, 2, 2, 3, 5, 4])
[4, 2]
Сначала мы подсчитываем наблюдения в sample с помощью объекта
Counter c ). Затем мы используем составление
списка, чтобы создать list
содержащий наблюдения, которые встречаются в выборке одинаковое
количество раз.
Поскольку .most_common(1) возвращает list с одним tuple формы
(observation, count) , нам нужно получить наблюдение с индексом 0 в
list а затем элемент с индексом 1 во вложенном tuple . Это можно
сделать с помощью выражения c.most_common(1)[0][1] . Это значение
является первым режимом нашего образца.
Обратите внимание, что условие понимания сравнивает счетчик каждого
наблюдения ( v ) со счетчиком наиболее распространенного наблюдения (
c.most_common(1)[0][1] ). Это позволит нам получить несколько
наблюдений ( k ) с одним и тем же подсчетом в случае многомодовой
выборки.
Использование режима Python ()
Python statistics.mode() принимает некоторые data и возвращает свой
(первый) режим. Посмотрим, как это можно использовать:
>>> import statistics
>>> statistics.mode([4, 1, 2, 2, 3, 5])
2
>>> statistics.mode([4, 1, 2, 2, 3, 5, 4])
4
>>> st.mode(["few", "few", "many", "some", "many"])
'few'
В одномодовом примере функция Python mode() возвращает наиболее
распространенное значение 2 . Однако в следующих двух примерах он
вернул 4 и few . В этих образцах были другие элементы, встречающиеся
такое же количество раз, но они не были включены.
Начиная с Python
3.8 мы также
можем использовать statistics.multimode() который принимает итерацию и
возвращает list режимов.
Вот пример использования multimode() :
>>> import statistics
>>> statistics.multimode([4, 1, 2, 2, 3, 5, 4])
[4, 2]
>>> statistics.multimode(["few", "few", "many", "some", "many"])
['few', 'many']
>>> st.multimode([4, 1, 2, 2, 3, 5])
[2]
Примечание . Функция всегда возвращает list , даже если вы
передаете одномодовый образец.
Заключение
Среднее (или среднее), медиана и мода обычно являются нашим первым
взглядом на выборку данных, когда мы пытаемся понять центральную
тенденцию данных.
В этом руководстве мы узнали, как найти или вычислить среднее значение,
медиану и режим с помощью Python. Сначала мы пошагово рассмотрели, как
создавать наши собственные функции для их вычисления, а затем как
использовать statistics Python как быстрый способ найти эти
показатели.
Медиана (x̃, M; Мера центральной тенденции) – это центральное значение Выборки (Sample).
В математике медиана также представляет собой тип Среднего значения (Average), который используется для нахождения «центра». Поэтому ее еще называют мерой центральной тенденции.
Нечетное количество элементов ряда
Если в ряду нечетное количество элементов, то мы сортируем значения в возрастающем или убывающем порядке, а затем выбираем центральное.
Пример. Найдем медиану следующего ряда:
4, 17, 77, 25, 22, 23, 92, 82, 40, 24, 14, 12, 67, 23, 29
Расставив эти числа по порядку, мы получим:
4, 12, 14, 17, 22, 23, 23, 24, 25, 29, 40, 67, 77, 82, 92
Всего пятнадцать элементов, то есть 8-й будет центральным. Медианное значение этого набора чисел – 24.
Четное количество элементов ряда
Если в ряду четное количество элементов, медиана рассчитывается с помощью формулы:
$$M = frac{n + 1}{2}, где$$
$$Mspace{–}space{медиана,}$$
$$nspace{–}space{количество}space{элементов}space{в}space{выборке}$$
Пример. Найдем медиану следующего ряда:
1.79, 1.61, 2.09, 1.84, 1.96, 2.11
Выполнив подстановку, мы получим:
$$M = frac{6 + 1}{2} = 3.5$$
Центральная тенденция
Помимо медианы, выделяют еще две другие меры центральной тенденции – Среднее значение (Mean) и Мода (Mode). Среднее – это частное от суммы всех Наблюдений (Observation) к их количеству. Мода – это наиболее часто повторяющееся значение выборки.
В Науке о данных (Data Science) медиана иногда используется вместо среднего значения, когда в последовательности есть выбросы, которые могут исказить среднее. Выбросы меньше влияют на медианное значение, чем на среднее. Медиана отделяет верхнюю половину выборки, генеральной совокупности или Распределения вероятностей (Probability Distribution) от нижней.

Медиана и NumPy
Медиану можно вычислить с помощью NumPy. Для начала импортируем все необходимые библиотеки:
import numpy as npСоздадим массив из 6 элементов и вызовем встроенный метод median():
a = [10, 7, 4, 3, 2, 1]
np.median(a)NumPy определяет четность числа элементов массива (6) и применяет тот или иной метод расчета (согласно формуле):
3.5Ноутбук, не требующий дополнительной настройки на момент написания статьи, можно скачать здесь.
Фото: @garciasaldana_