В статистике есть целый набор показателей, которые характеризуют центральную тенденцию. Выбор того или иного индикатора в основном зависит от характера данных, целей расчетов и его свойств.
Что подразумевается под характером данных? Прежде всего, мы говорим о количественных данных, которые выражены в числах. Но набор числовых данных может иметь разное распределение. Под распределением понимаются частоты отдельных значений. К примеру, в классе из 23 человек 2 школьника написали контрольную работу на двойку, 5 – на тройку, 10 – на четверку и 6 – на пятерку. Это и есть распределение оценок. Распределение очень наглядно можно представить с помощью специальной диаграммы – гистограммы. Для данного примера получится следующая гистограмма.

Во многих случаях количество уникальных значений намного больше, а распределение похоже на нормальное. Ниже приведена примерная иллюстрация нормального распределения случайных чисел.

Итак, центральная тенденция. Если частоты анализируемых значений распределены по нормальному закону, то есть симметрично вокруг некоторого центра, то центральная тенденция определяется вполне однозначно – это есть тот самый центр, и математически он соответствует средней арифметической.
Как нетрудно заметить, в этом же центре находится и максимальная частота значений. То есть при нормальном распределении центральная тенденция есть не только средняя арифметическая, но и максимальная частота, которая в статистике называется модой или модальным значением.

На диаграмме оба значения центральной тенденции совпадают и равны 10.
Но такое распределение встречается далеко не всегда, а при малом числе данных – совсем редко. Чаще бывает так, что частоты распределяются асимметрично. Тогда мода и среднее арифметическое не будут совпадать.

На рисунке выше среднее арифметическое по-прежнему составляет 10, а вот мода уже равна 9. Что в таком случае считать значением центральной тенденции? Ответ зависит от поставленных целей анализа. Если интересует уровень, сумма отклонений от которого равна нулю со всеми вытекающим отсюда свойствами и последствиями, то это средняя арифметическая. Если нужно максимально частое значение, то это мода.
Итак, зачем нужна мода? Приведу пару примеров. Экономист планово-экономического отдела обувной фабрики интересуется, какой размер обуви пользуется наибольшим спросом. Средний размер обуви, скорее всего, здесь не подойдет, тем более, что число может получится дробным. А вот мода – как раз нужный показатель.
Расчет моды
Теперь посмотрим, как рассчитать моду. Мода – это то значение в анализируемой совокупности данных, которое встречается чаще других, поэтому нужно посмотреть на частоты значений и отыскать максимальное из них. Например, в наборе данных 3, 4, 6, 7, 3, 5, 3, 4 модой будет значение 3 – повторяется чаще остальных. Это в дискретном ряду, и здесь все просто. Если данных много, то моду легче всего найти с помощью соответствующей гистограммы. Бывает так, что совокупность данных имеет бимодальное распределение.

Без диаграммы очень трудно понять, что в данных не один, а два центра. К примеру, на президентских выборах предпочтения сельских и городских жителей могут отличаться. Поэтому распределение доли отданных голосов за конкретного кандидата может быть «двугорбым». Первый «горб» – выбор городского населения, второй – сельского.
Немного сложнее с интервальными данными, когда вместо конкретных значений имеются интервалы. В этом случае говорят о модальном интервале (при анализе доходов населения, например), то есть интервале, частота которого максимальна относительно других интервалов. Однако и здесь можно отыскать конкретное модальное значение, хотя оно будет условным и примерным, так как нет точных исходных данных. Представим, что есть следующая таблица с распределением цен.

Для наглядности изобразим соответствующую диаграмму.

Требуется найти модальное значение цены.
Вначале нужно определить модальный интервал, который соответствует интервалу с наибольшей частотой. Найти его так же легко, как и моду в дискретном ряду. В нашем примере это третий интервал с ценой от 301 до 400 руб. На графике – самый высокий столбец. Теперь нужно определить конкретное значение цены, которое соответствует максимальному количеству. Точно и по факту сделать это невозможно, так как нет индивидуальных значений частот для каждой цены. Поэтому делается допущение о том, что интервалы выше и ниже модального в зависимости от своей частоты имеют разные вес и как бы перетягивают моду в свою сторону. Если частота интервала следующего за модальным больше, чем частота интервала перед модальным, то мода будет правее середины модального интервала и наоборот. Давайте еще раз посмотрим на рисунок, чтобы понять формулу, которую я напишу чуть ниже.

На рисунке отчетливо видно, что соотношение высоты столбцов, расположенных слева и справа от модального определяет близость моды к левому или правому краю модального интервала. Задача по расчету модального значения состоит в том, чтобы найти точку пересечения линий, соединяющих модальный столбец с соседними (как показано на рисунке пунктирными линиями) и нахождении соответствующего значения признака (в нашем примере цены). Зная основы геометрии (7-й класс), по данному рисунку нетрудно вывести формулу расчета моды в интервальном ряду.
Формула моды имеет следующий вид.
![]()
Где Мо – мода,
x0 – значение начала модального интервала,
h – размер модального интервала,
fМо – частота модального интервала,
fМо-1 – частота интервала, находящего перед модальным,
fМо1 – частота интервала, находящего после модального.
Второе слагаемое формулы моды соответствует длине красной линии на рисунке выше.
Рассчитаем моду для нашего примера.
![]()
Таким образом, мода интервального ряда представляет собой сумму, состоящую из значения начального уровня модального интервала и отрезка, который определяется соотношением частот ближайших интервалов от модального.
Расчет моды в Excel
В настоящее время большинство вычислений делается в MS Excel, где для расчета моды также предусмотрена специальная функция. В Excel 2013 я таких нашел ажно 3 штуки.
МОДА – пережиток старых изданий Excel. Функция оставлена для совмещения со старыми версиями.
МОДА.ОДН – рассчитывает моду по заданным значениям. Здесь все просто. Вставили функцию, указали диапазон данных и «Ок».
МОДА.НСК – позволяет рассчитать сразу несколько модальных значений (одинаковых максимальных частот) для одного ряда данных, если они есть. Функцию нужно вводить как формулу массива, перед этим выделив количество ячеек равное количеству требуемых модальных значений. Иногда действительно модальных значений может быть несколько. Однако для этих целей предварительно лучше посмотреть на диаграмму распределения.
Моду для интервальных данных одной функцией в Excel рассчитать нельзя. То есть такая функция в готовом виде не предусмотрена. Придется прописывать вручную.
Следующая статья посвящена медиане.
До встречи на statanaliz.info.
Поделиться в социальных сетях:
Структурные
средние величины
Мода —
это наиболее часто встречающийся вариант
ряда. Мода применяется, например, при
определении размера одежды, обуви,
пользующейся наибольшим спросом у
покупателей. Модой для дискретного ряда
является варианта, обладающая наибольшей
частотой. При вычислении моды для
интервального вариационного ряда
необходимо сначала определить модальный
интервал (по максимальной частоте), а
затем — значение модальной величины
признака по формуле:Кроме степенных
средних в статистике для относительной
характеристики величины варьирующего
признака и внутреннего строения рядов
распределения пользуются структурными
средними, которые представлены ,в
основном, модой и медианой.
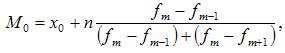
где:
![]() —
—
значение моды
![]() —
—
нижняя граница
модального интервала
![]() —
—
величина интервала
![]() —
—
частота модального
интервала
![]() —
—
частота интервала,
предшествующего модальному
![]() —
—
частота интервала,
следующего за модальным
Медиана
— это значение признака, которое
лежит в основе ранжированного ряда и
делит этот ряд на две равные по численности
части.
Для
определения медианы в дискретном
ряду при наличии частот сначала
вычисляют полусумму частот ![]() ,
,
а затем определяют, какое значение
варианта приходится на нее. (Если
отсортированный ряд содержит нечетное
число признаков, то номер медианы
вычисляют по формуле:
Ме =
(n(число
признаков в совокупности) +
1)/2,
в
случае четного числа признаков медиана
будет равна средней из двух признаков
находящихся в середине ряда).
При
вычислении медианы для интервального
вариационного ряда сначала определяют
медианный интервал, в пределах которого
находится медиана, а затем — значение
медианы по формуле:
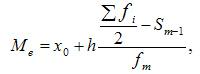
где:
![]() —
—
искомая медиана
![]() —
—
нижняя граница
интервала, который содержит медиану
![]() —
—
величина интервала
![]() —
—
сумма частот или
число членов ряда
![]() —
—
сумма накопленных частот интервалов,
предшествующих медианному
![]() —
—
частота медианного
интервала
Пример.
Найти моду и медиану.
|
Возрастные |
Число |
Сумма |
|
До |
346 |
346 |
|
20 — |
872 |
1218 |
|
25 |
1054 |
2272 |
|
30 — |
781 |
3053 |
|
35 — |
212 |
3265 |
|
40 — |
121 |
3386 |
|
45 |
76 |
3462 |
|
Итого |
3462 |
Решение:
В
данном примере модальный интервал
находится в пределах возрастной группы
25-30 лет, так как на этот интервал приходится
наибольшая частота (1054).
Рассчитаем
величину моды:
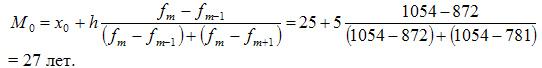
Это
значит что модальный возраст студентов
равен 27 годам.
Вычислим
медиану. Медианный интервал находится
в возрастной группе 25-30 лет, так как в
пределах этого интервала расположена
варианта, которая делит совокупность
на две равные части (Σfi/2
= 3462/2 = 1731). Далее подставляем в формулу
необходимые числовые данные и получаем
значение медианы:

Это
значит что одна половина студентов
имеет возраст до 27,4 года, а другая свыше
27,4 года.
Кроме
моды и медианы могут быть использованы
такие показатели, как квартили, делящие
ранжированный ряд на 4 равные части,
децили -10 частей и перцентили — на 100
частей.
Определение
моды и медианы графическим методом
Моду
и медиану в интервальном ряду можно
определить графически.
Мода определяется по гистограмме
распределения. Для этого выбирается
самый высокий прямоугольник, который
является в данном случае модальным.
Затем правую вершину модального
прямоугольника соединяем с правым
верхним углом предыдущего прямоугольника.
А левую вершину модального прямоугольника
– с левым верхним углом последующего
прямоугольника. Из точки их пересечения
опускаем перпендикуляр на ось абсцисс.
Абсцисса точки пересечения этих прямых
и будет модой распределения (рис.
5.3).
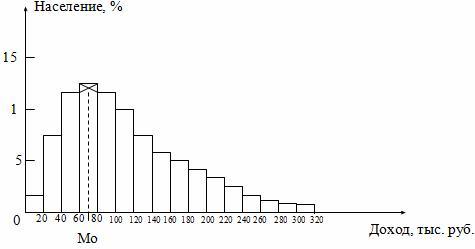
Рис.
5.3. Графическое определение моды по
гистограмме.
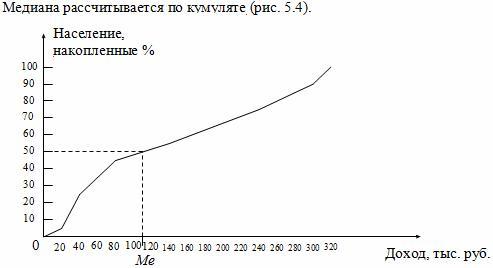
Рис.
5.4. Графическое определение медианы по
кумуляте
Для
определения медианы из точки на шкале
накопленных частот (частостей),
соответствующей 50 %, проводится прямая,
параллельная оси абсцисс до пересечения
с кумулятой. Затем из точки пересечения
опускается перпендикуляр на ось абсцисс.
Абсцисса точки пересечения является
медианой.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Аннотация: Для получения более полной характеристики вариационного ряда помимо средней величины рассчитываются так называемые структурные показатели. К ним относятся мода, медиана, квартили, децили, перцентили, квартильные и децильные коэффициенты.
8.1. Мода
Мода (Мо) — это наиболее часто встречающееся значение признака, или иначе говоря, значение варианты с наибольшей частотой. В дискретных и интервальных рядах моду рассчитывают по-разному.
8.1.1. Определение моды в дискретных вариационных рядах
В дискретных вариационных рядах для определения моды не требуется специальных вычислений: значение признака, которому соответствует наибольшая частота, и будет значением моды.
Пример 8.1. По представленным ниже результатам проведения контрольной работы по статистике определим моду.
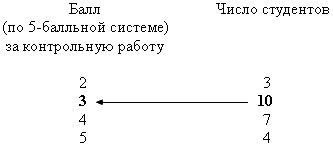
Здесь наибольшая частота — 10, она принадлежит варианте со значением 3, значит, Мо = 3. Таким образом, самой распространенной оценкой, полученной студентами за контрольную работу, была «тройка».
8.1.2. Определение моды в интервальных вариационных рядах с равными интервалами
Для определения моды в интервальных вариационных рядах с равными интервалами сначала находят модальный интервал, которым является интервал с наибольшей частотой, а затем ведут расчет по формуле
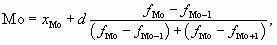
где хМо — нижняя граница модального интервала;
d — величина интервала;
fMo — частота модального интервала;
fMo — 1 — частота интервала, предшествующего модальному;
fMo + 1 — частота интервала, следующего за модальным.
Пример 8.2. Имеются данные по группе банков.
| Сумма выданных кредитов, млн ден. ед. | Количество банков |
|---|---|
| До 40 | 8 |
| 40-60 | 15 |
| 60-80 | 21 |
| 80-100 | 12 |
| 100-120 | 9 |
| 120-140 | 7 |
| 140 и выше | 4 |
| Итого | 77 |
Определим модальный размер выданных кредитов:
- модальным является интервал 60-80, так как ему соответствует наибольшая частота (21);
- нижняя граница модального интервала xМо = 60; величина интервала d = 20 (80 — 60 = 20);
- частота модального интервала fМо = 21; частота интервала, предшествующего модальному, fМо — 1 = 15; частота интервала, следующего за модальным, fМо + 1 = 12.
Подставив в формулу соответствующие величины, получим
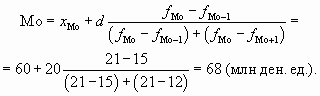
Определить модальное значение признака можно и по графику. Для этого в случае дискретных вариационных рядов строится полигон распределения. Напомним, что у него на оси абсцисс помещаются значения признака (варианты), а на оси ординат — соответствующие им частоты. Значение абсциссы, соответствующее наибольшей вершине полигона, будет значением моды.
Пример 8.3. По результатам проведения контрольной работы по статистике, приведенным в примере 8.1, определим моду графическим способом.
Для этого построим полигон распределения и найдем абсциссу его вершины (рис. 8.1).
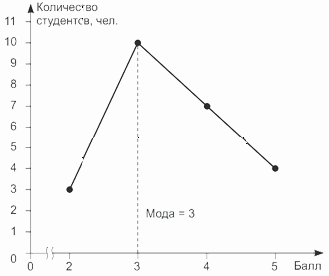
Рис.
8.1.
Определение моды по полигону распределения
Если имеется интервальный вариационный ряд с равными интервалами, то для определения моды строится гистограмма, у которой на оси абсцисс находятся значения границ интервалов, а на оси ординат — соответствующие интервалам частоты. На гистограмме модальный интервал будет иметь наибольшую высоту столбца. Затем надо провести линии, соединяющие вершины модального столбца с прилегающими вершинами соседних столбцов. Для нахождения значения моды из точки пересечения проведенных линий на ось абсцисс опускают перпендикуляр. Абсцисса точки пересечения будет значением моды. Продемонстрируем это на примере.
Пример 8.4. По данным о распределении банков по сумме выданных кредитов, приведенным в примере 8.2, определим моду графическим способом (рис. 8.2).

Рис.
8.2.
Определение моды по гистограмме распределения
Вариационный ряд может содержать несколько модальных значений. Чаще всего это происходит, когда в один ряд объединяют разнородные единицы наблюдения, которые желательно разделить на подгруппы и анализировать по отдельности. Вариационный ряд, имеющий одну моду, называется унимодальным, две — бимодальным, три и более — мультимодальным.
Как определить подходящую меру центральной тенденции?
Время на прочтение
6 мин
Количество просмотров 5.2K

Мера центральной тенденции (measure of central tendency) представляет из себя статистическую величину, которая характеризует целый набор данных одним единственным числом. Ее также называют мерой центрального расположения (measure of central location). Она описывает, как выглядит приблизительный центр набора данных.
Но сам по себе термин “центр” может подразумевать немного разные значения в зависимости от конкретной ситуации. Вы можете считать “центром” среднее арифметическое. Вы также можете назвать “центром” данные, которые просто находятся в середине вашей выборки. А еще вы можете рассматривать в качестве “центра” данные, которые повторяются чаще всего. Все эти центры по-своему характеризуют ваши данные.
Поскольку человеческое понимание “центра” может разниться, статистика позаботилась определить каждый вариант. Таким образом мы имеем следующие общепринятые меры центральной тенденции:
-
Среднее арифметическое.
-
Медиана.
-
Мода.
В этой статье я расскажу, каким образом распределение вашего набора данных играет роль в выборе подходящей меры центральной тенденции. А объяснять я буду это на примере реальных наборов данных.
1. Среднее арифметическое
Среднее арифметическое — это среднее значение всех элементов в наборе данных. Оно рассчитывается как сумма всех значений, деленная на общее количество значений.
Среднее арифметическое = сумма всех значений / общее количество значений
Когда следует использовать среднее арифметическое?
Среднее арифметическое лучше всего использовать для описания данных, которые имеют нормальное распределение. Нормальное распределение — это когда построив график по “значениям” и их “частоте” (количеству появлений каждого значения в наборе данных), вы получаете кривую, по форме напоминающую колокол. Центр этой кривой совпадает со средним арифметическим.
Пример — набор данных с длинами крыльев комнатной мухи
В качестве примера я буду использовать реальный набор данных — это набор данных с длинами крыльев комнатной мухи, который естественным образом имеет нормальное распределение.
Источник набора данных: [Sokal, R.R. and F.J. Rohlf, 1968. Biometry, Freeman Publishing Co., p 109. Original data from Sokal, R.R. and P.E. Hunter. 1955. A morphometric analysis of DDT-resistant and non-resistant housefly strains Ann. Entomol. Soc. Amer. 48: 499-507.]
Набор данных содержит длины крыльев комнатной мухи в миллиметрах. В нем 100 элементов.

Я построил гистограмму (по “значениям” и “количествам повторений этих значений”) этих данных, которую вы можете наблюдать ниже. Если мы проведем по внешним краям столбцов плавную линию, то она образует колоколообразную кривую. Вычислив среднее арифметическое значение этих данных, мы получим 45,5. А теперь давайте поищем на приведенном ниже графике полученное значение 45,5. Он находится прямо по середине.
Колоколообразная кривая со средним значением в центре дает нам четкое понимание, что этот набор данных имеет нормальное распределение.
import numpy as np
import matplotlib.pyplot as plt
data_housefly = np.loadtxt("housefly_wing_length.txt")
plt.hist(data_housefly)
plt.xlabel("Wing length")
plt.ylabel("Number of occurences")
plt.title("Histogram - Housefly wing lengths")
plt.show()
Это хороший пример, наглядно демонстрирующий, что для нормально распределенных данных имеет смысл использовать “среднее арифметическое” как меру центральной тенденции.
Когда НЕ стоит использовать среднее арифметическое?
Хотя среднее арифметическое является одной из основных мер центральной тенденции, иногда (на самом деле очень часто) оно наоборот может ввести вас в заблуждение. Данные из реального мира не всегда имеют нормальное распределение. В подавляющем большинстве случаев есть вероятность, что ваши данные ассиметричны.
Ассиметричные данные — это данные, в которых несколько элементов у верхнего или нижнего пределов имеют заметно отличающийся паттерн по сравнению с остальной частью набора данных.
Пример — набор данных с зарплатами игроков NBA
Давайте посмотрим на набор данных с зарплатами игроков NBA. Этот набор данных содержит зарплаты в долларах США за период с 2017 по 2018 годы.

Я построил гистограмму столбца c зарплатой (название столбца “season17_18”).
import numpy as np
import matplotlib.pyplot as plt
data_nba = pd.read_csv("NBA_player_salary.csv")
plt.hist(data_nba.season17_18)
plt.xlabel("Salary in US Dollars")
plt.ylabel("Number of occurrences")
plt.title("NBA Player Salary - Histogram")
plt.show()
Глядя на приведенное выше распределение, становится очевидным, что данные распределены не нормально. Из 573 игроков более 300 получают зарплату ниже 2,5 миллионов долларов (из графика выше). Но когда мы вычисляем среднее арифметическое заработной платы, оно составляет 5,85 миллиона долларов.
Как вы считаете, годится ли среднее арифметическое в качестве лучшего представления этих данных в целом?
Уж точно нет. Те немногие игроки, которые получали огромные зарплаты, утащили среднее арифметическое далеко от центра. Это называется асимметрией данных.
Не имеет смысла и говорить о том, что среднее арифметическое, которое составляет 5,85 миллиона, является центром, потому что абсолютное большинство из игроков получили зарплату менее 2,5 миллиона долларов.
Таким образом, в случае подобных асимметрий наборов данных среднее арифметическое хорошим выбором для представления данных не является. Здесь нам может помочь медиана.
2. Медиана
Медиана — это значение, которое находится в центре (прямо посередине), если данные расположены в порядке возрастания или убывания.
Если общее количество значений в наборе данных нечетное, то в центральной позиции будет только одно число. Это и будет наша медиана. Если общее количество значений в наборе данных четное, в центральной позиции будет два значения. В этом случае медиана представляет собой среднее значение этих двух значений.
Когда следует использовать медиану?
Если набор данных асимметричен или содержит выбросы, среднее арифметическое — не лучший способ представления данных. В таком случае как меру центральной тенденции можно использовать медиану. Выбросы не портят медиану. Потому что само название “выбросы” означает, что они располагаются снаружи, либо в нижнем, либо в верхнем диапазоне. В таком случае медиана — это среднее значение, не нарушенное выбросами.
Еще раз давайте рассмотрим ассиметричный набор данных с зарплатами игроков NBA. (Который мы рассматривали в предыдущем разделе “Когда НЕ стоит использовать среднее арифметическое?”). Медиана по зарплате составляет 2,38 миллиона долларов.

Это значение находится в первой столбце. Обратите внимание, что ось X это 10^7. Итак, первый столбик представляет зарплату до 2,5 миллионов. Таким образом, медианное значение 2,38 миллиона лучше всего представляет эти данные, потому что большинство игроков получают зарплату, близкую к этому показателю.
Когда НЕ стоит использовать медиану?
Если и среднее арифметическое, и медиана одного и того же набора данных не сильно отклоняются, то можно использовать обе эти меры. В любом случае расчет среднего арифметического предполагает учет всех элементов данных и их усреднение. Таким образом, логичнее, что среднее арифметическое является более точной мерой (когда среднее арифметическое и медиана не сильно отклоняются).
Как определить, является ли ваш набор данных асимметричным или содержит выбросы?
Самый банальный способ определить, является ли ваш набор данных асимметричным или содержит выбросы, — это вычислить среднее арифметическое и медиану. Если обе меры не сильно отклоняются, то с вашим набором данных все в порядке. И вы сэкономили время, которое в противном случае было бы потрачено на очистку и преобразование данных.
Если среднее арифметическое и медиана очень сильно отклоняются, ваш набор данных асимметричен или содержит выбросы. Следующий шаг — провести исследование с целью выявить и удалить выбросы, если таковые имеются. Или применить какое-либо преобразование, чтобы уменьшить асимметрию в ваших данных, если таковая имеется.
3. Мода
Мода — это значение, которое чаще всего встречается в наборе данных. В гистограмме мода — это значение с самым высоким столбцом.
Если набор данных имеет более одного значения с одинаковой максимальной частотой появления, набор данных имеет мультимодальное распределение, поскольку он имеет несколько мод. Если в наборе данных нет повторяющихся значений, то и моды у него тоже нет.
Когда стоит использовать моду?
Моду можно использовать для анализа часто встречающихся значений как числовых, так и категориальных данных.
Мода — единственная мера центральной тенденции, которую можно использовать с категориальными данными. Для категориальных данных вы не можете вычислить среднее арифметическое или медиану. Мода — единственный выбор в таких случаях.
Пример — Простое перечисление
Ниже приведен учебный набор данных, отражающий любимый вид искусства семерых человек. Построим частотный график (гистограмму).
data_art = [‘music’, ‘painting’, ‘pottery’, ‘painting’, ‘dance’, ‘music’, ‘music’]
import matplotlib.pyplot as plt
data_art = ['music', 'painting', 'pottery', 'painting', 'dance', 'music', 'music']
plt.hist(data_art)
plt.xlabel("Favorite art")
plt.ylabel("Number of occurrences")
plt.title("Histogram of favorite art")
plt.show()
Во многих областях машинного обучения возникают функции многих переменных и их производные. Такие производные ещё называют «матричными». На открытом уроке мы поговорим про отличие таких производных от обычных, изучаемых в школе, разберём необходимую теорию, научимся такие производные считать, а также посмотрим, где и как матричные производные используются. Регистрация открыта по ссылке для всех желающих.