Оценка количества ошибок в программе. Модель Миллса
Время на прочтение
3 мин
Количество просмотров 15K
Сколько ошибок в программе? Это вопрос, который волнует каждого программиста. Особую актуальность придает ему принцип кучкования ошибок, согласно которому нахождение в некотором модуле ошибки увеличивает вероятность того, что в этом модуле есть и другие ошибки. Точного ответа на вопрос о количестве ошибок в программе очень часто дать невозможно, а вот построить некоторую оценку — можно. Для этого существуют несколько статических моделей. Рассмотрим одну из них: Модель Миллса.
В 1972 г. суперпрограммист фирмы IBM Харлан Миллс предложил следущий способ оценки количества ошибок в программе. Пусть у нас есть программа. Предположим, что в ней N ошибок. Назовем их естественными. Внесем в нее дополнительно M искусственных ошибок. Проведём тестирование программы. Пусть в ходе тестирования было обнаружено n естественных ошибок и m искусственных. Предположим, что вероятность обнаружения для естественных и искусственных ошибок одинакова. Тогда выполняется соотношение:
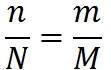
Мы нашли один и тот же процент естественных и искусственных ошибок. Отсюда количество ошибок в программе:

Количество необнаруженных ошибок равно (N-n).
Например, пусть в программу внесено 20 искусственных ошибок, в ходе тестирования было обнаружено 12 искусственных и 7 естественных ошибок. Получим следущую оценку количества ошибок в программе:

Количество необнаруженных ошибок равно (N-n) = 12 — 7 = 5.
Легко заметить, что в описанном выше способе Миллса есть один существенный недостаток. Если мы найдем 100% искусственных ошибок, это будут означать, что и естественных ошибок мы нашли 100%. Но чем меньше мы внесем искусственных ошибок, тем больше вероятность того, что мы найдём их все. Внесем единственную исскуственную ошибку, найдем ее, и на этом основании объявим, что нашли все естесственные ошибки! Для решение такой проблемы Миллс добавил вторую часть модели, предназначенную для проверки гипотезы о величине N:
Предположим, что в программе N естественных ошибок. Внесём в неё M искусственных ошибок. Будем тестировать программу до тех пор, пока не найдем все искусственные ошибки. Пусть к этому моменту найдено n естественных ошибок. На основании этих чисел вычислим величину C:
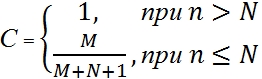
Величина C выражает меру доверия к модели. Это вероятность того, что модель будет правильно отклонять ложное предположение. Например, пусть мы считаем, что естественных ошибок в программе нет (N=0). Внесем в программу 4 искусственные ошибки. Будем тестировать программу, пока не обнаружим все искусственные ошибки. Пусть при это мы не обнаружим ни одной естественной ошибки. В этом случае мера доверия нашему предположению (об отсутствии ошибок в программе) будет равна 80% (4 / (4+0+1)). Для того чтобы довести ее до 90% количество искусственных ошибок придется поднять до 9. Следущие 5% уверенности в отсутствии естественных ошибок обойдутся нам в 10 дополнительных искусственных ошибок. M придется довести до 19.
Если мы предположим, что в программе не более 3-х естественных ошибок (N=3), внесем в нее 6 искусственных (M=6), найдем все искусственные и одну, две или три (но не больше!) естественных, то мера доверия к модели будет 60% (6 / (6+3+1)).
Значения функции С для различных значений N и M, в процентах:
Таблица 1 — с шагом 1;
Таблица 2 — с шагом 5;
Из формул для вычисления меры доверия легко получить формулу для вычисления количества искусственных ошибок, которые необходимо внести в программу для получения нужной уверенности в полученной оценке:

Количество исскуственных ошибок, которые необходимо внести в программу, для достижения нужной меры доверия, для различных значений N:
Таблица 3 — с шагом 1;
Таблица 4 — с шагом 5;
Модель Миллса достаточно проста. Ее слабое место — предположение о равновероятности нахождения ошибок. Чтобы это предположение оправдалось, процедура внесения искусственных ошибок должна обладать определенной степенью «интеллекта». Ещё одно слабое место — это требование второй части миллсовой модели отыскать непременно
все
искусственные ошибки. А этого может не произойти долго, может быть, и никогда.
Привет, Вы узнаете про статистическая модель миллса -оценка количества ошибок в программном коде , Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
статистическая модель миллса -оценка количества ошибок в программном коде , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
Модель Миллса — способ оценки количества ошибок в программном коде, созданный в 1972 году программистом Харланом Миллсом. Он получил широкое распространение благодаря своей простоте и интуитивной привлекательности .
Методология
Допустим, имеется программный код, в котором присутствует заранее неизвестное количество ошибок (багов) , требующее максимально точной оценки. Для получения этой величины можно внести в программный код
, требующее максимально точной оценки. Для получения этой величины можно внести в программный код  дополнительных ошибок, о наличии которых ничего не известно специалистам по тестированию[3][1].
дополнительных ошибок, о наличии которых ничего не известно специалистам по тестированию[3][1].
Предположим, что после проведения тестирования было обнаружено n естественных ошибок (где n[1][4].
Из которого следует, что оценка полного количества естественных ошибок в коде равна , а количество все еще не выловленных багов кода равно разности
, а количество все еще не выловленных багов кода равно разности  [1][5]. Сам Миллс полагал, что процесс тестирования необходимо сопровождать постоянным обновлением графиков для оценки количества ошибок[6].
[1][5]. Сам Миллс полагал, что процесс тестирования необходимо сопровождать постоянным обновлением графиков для оценки количества ошибок[6].
Очевидно, что такой подход не лишен недостатков. Например, если найдено 100% искусственных ошибок, то значит и естественных ошибок было найдено около 100%. Причем, чем меньше было внесено искусственных ошибок, тем больше вероятность того, что все они будут обнаружены. Из чего следует заведомо абсурдное следствие: если была внесена всего одна ошибка, которая была обнаружена при тестировании, значит ошибок в коде больше нет[6].
В целях количественной оценки доверия модели был введен следующий эмпирический критерий:

Уровень значимости  оценивает вероятность, с которой модель будет правильно отклонять ложное предположение[7][6]. Выражение для было сконструировано Миллсом[7], но в силу своей эмпирической природы при необходимости оно допускает некоторую вариативность в разумных пределах[8].
оценивает вероятность, с которой модель будет правильно отклонять ложное предположение[7][6]. Выражение для было сконструировано Миллсом[7], но в силу своей эмпирической природы при необходимости оно допускает некоторую вариативность в разумных пределах[8].
Исходя из формулы для можно получить оценку количества искусственно вносимых багов для достижения нужной меры доверия . Это количество дается выражением вида  [8].
[8].
Слабостью подхода Миллса является необходимость вести тестирование продукта до обнаружения абсолютно всех искусственно введенных багов, однако существуют обобщения этой модели, где это ограничение снято[7] . Об этом говорит сайт https://intellect.icu . Например, если порог на допустимое количество из обнаруженных внесенных ошибок равен величине  ), то критерий перезаписывается следующим образом:
), то критерий перезаписывается следующим образом:

Статистическая модель Миллса позволяет оценить не только количество ошибок до начала тестирования, но и степень отлаженности программ. Для применения модели до начала тестирования в программу преднамеренно вносят ошибки . Далее считают, что обнаружение преднамеренно внесенных и так называемых собственных ошибок программы равновероятно.
Для оценки количества ошибок в программе до начала тестирования используется выражение
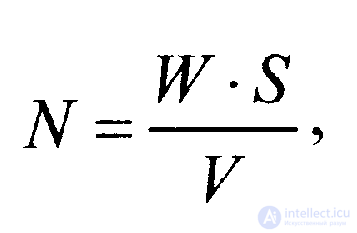 (2.2.1)
(2.2.1)
где W‘ — количество преднамеренно внесенных в программу ошибок до начала тестирования;V— количество обнаруженных в процессе тестирования ошибок из числа преднамеренно внесенных;S— количество «собственных» ошибок программы, обнаруженных в процессе тестирования.
Если продолжать тестирование до тех пор, пока все ошибки из числа преднамеренно внесенных не будут обнаружены, степень отлаженности программы С можно оценить с помощью выражения
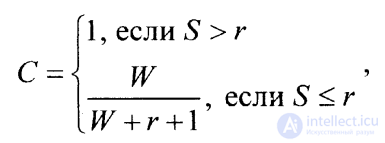 (2.2.2)
(2.2.2)
где SиW=V(равенство значенийWиVв данном случае имеет место, поскольку считается, что все преднамеренно внесенные ошибки обнаружены) имеют тот же смысл, что и в предыдущем выражении (2.2.1), аr означает верхний предел (максимум) предполагаемого количества «собственных» ошибок в программе.
Выражения (2.2.1) и (2.2.2) представляют собой статистическую модель Миллса. Необходимо заметить, что если тестирование будет закончено преждевременно (т. е. раньше, чем будут обнаружены все преднамеренно внесенные ошибки), то вместо выражения (2.2.2) следует использовать более сложное комбинаторное выражение (2.2.3). Если обнаружено только Vошибок изWпреднамеренно внесенных, используется выражение
 !!!(2.2.3)
!!!(2.2.3)
где в круглых скобках записаны обозначения для числа сочетаний из Sэлементов поV— 1 элементов в каждой комбинации и числа сочетаний изS+r+ 1 элементов поr+Vэлементов в каждой комбинации.
2.2.2. Задачи по применению модели Миллса
Задача 1
В программу преднамеренно внесли (посеяли) 10 ошибок. В результате тестирования обнаружено 12 ошибок, из которых 10 ошибок были внесены преднамеренно. Все обнаруженные ошибки исправлены. До начала тестирования предполагалось, что программа содержит не более 4 ошибок. Требуется оценить количество ошибок до начала тестирования и степень отлаженности программы.
Решение задачи
Для оценки количества ошибок до начала тестирования используем формулу (2.2.1).
Нам известно:
• количество внесенных в программу ошибок W= 10;
• количество обнаруженных ошибок из числа внесенных V= 10;
• количество «собственных» ошибок в программе S= 12 — 10 = 2.
Подставив указанные значения в формулу, получим оценку количества ошибок:
N = (W·S) /V= (10 ·2) / 10 = 2.
Таким образом, из результатов тестирования следует, что до начала тестирования в программе имелось 2 ошибки.
Для оценки отлаженности программы используем уравнение (2.2.2). Нам известно:
• количество обнаруженных «собственных» ошибок в программе S=2;
• количество предполагаемых ошибок в программе r= 4;
• количество преднамеренно внесенных и обнаруженных ошибок W= 10.
Очевидно, что обнаружено меньшее число «собственных» ошибок, чем количество предполагаемых ошибок в программе (S<r). Для оценки отлаженности программы используем уравнение
С =W/ (W +r + 1) = 10/ (10 + 4 + 1) = 0,67.
Степень отлаженности программы равна 0,67, что составляет 67%.
Задача 2
В программу было преднамеренно внесено (посеяно) 14 ошибок. Предположим, что в программе перед началом тестирования было 14 ошибок. В процессе четырех тестовых прогонов было выявлено следующее количество ошибок.
|
Номер прогона |
1 |
2 |
3 |
4 |
|
V |
6 |
4 |
2 |
2 |
|
S |
4 |
2 |
1 |
1 |
Необходимо оценить количество ошибок перед каждым тестовым прогоном. Оценить степень отлаженности программы после последнего прогона. Построить диаграмму зависимости возможного числа ошибок в данной программе от номера тестового прогона.
Решение задачи
Количество ошибок перед каждым прогоном будем оценивать в соответствии с выражением (2.2.1). Перед каждой последующей оценкой количества ошибок и степени отлаженности программы необходимо корректировать значения внесенных Wи предполагаемыхr ошибок с учетом выявленных и устраненных после каждого прогона тестов. Степень отлаженности программы на всех прогонах, кроме последнего (2.2.2), рассчитывается по комбинаторной формуле (2.2.3).
Определяя показатели программы по результатам первого прогона, необходимо учитывать, что W1= 14;S1= 4;V1= 6, тогда
N1= (W1 · S1) /V1= (14·4) / 6 = 9.
Перед вторым прогоном корректируем исходные данные для оценки параметров: r2= 14 — 4 = 10;W2= 14 — 6 = 8;S2= 2;V2= 4, тогда
N2= (W2 · S2) /V2= (8·2) / 4 = 4.
Корректировка исходных данных перед третьим прогоном дает следующие данные. r3 = 10 — 2 = 8,W3= 8 — 4 = 4;S3= 1;V3= 2, откуда количество ошибок определится следующим образом:
N3= (W3 · S3) /V3= (4 · 1) / 2 = 2.
Перед четвертым прогоном программы получим следующие исходные данные: r4 = 8 — 1 = 7,W4= 4 — 2 = 2;S4= 1;V4= 2, тогда
N4= (W4 · S4) /V4= (2 ·1) /2 = 1.
Поскольку после четвертого прогона все «посеянные» ошибки выявлены и устранены, то для оценки отлаженности программы можно воспользоваться упрощенной формулой
С=W/(W+r+ 1) =2/(2+ 7+ 1) =0,2.
Таким образом, в предположении, что до начала четвертого прогона в программе оставалось 7 ошибок, степень отлаженности программы составляет 20%.
Результат по количеству ошибок в программе до начала каждого прогона приведен ниже.
|
Номер прогона |
1 |
2 |
3 |
4 |
|
N |
9 |
4 |
2 |
1 |
Надеюсь, эта статья об статистическая модель миллса -оценка количества ошибок в программном коде , была вам интересна и не так слона для восприятия как могло показаться, удачи в ваших начинаниях! Надеюсь, что теперь ты понял что такое статистическая модель миллса -оценка количества ошибок в программном коде
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.
Mills’error seeding model proposed an error seeding method to estimate the number of errors in a program by introducing seeded errors into the program. From the debugging data, which consists of inherent errors and induced errors, the unknown number of inherent errors could be estimated. If both inherent errors and induced errors are equally likely to be detected, then the probability of k induced errors in r removed errors follows a hypergeometric distribution which is given by

where N = total number of inherent errors n1 = total number of induced errors r = total number of errors removed during debugging k = total number of induced errors in r removed errors r – k = total number of inherent errors in r removed errors Since n1, r, and k are known, the MLE of N can be shown to be
![$$hat{N} = [N_0]+1$$](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-d3a5b870709edd9f75c3de173fe9f69c_l3.png "Rendered by QuickLaTeX.com")
where

If  is an integer, then and
is an integer, then and  are both the MLEs of N.
are both the MLEs of N.
Drawbacks:
- It is expensive to conduct testing of the software and at the same time, it increases the testing effort.
- This method was also criticized for its inability to determine the type, location, and difficulty level of the induced errors such that they would be detected equally likely as the inherent errors.
Another realistic method for estimating the residual errors in a program is based on two independent groups of programmers testing the program for errors using independent sets of test cases. Suppose that out of a total number of N initial errors, the first programmer detects n1 errors (and does not remove them at all) and the second independently detects r errors from the same program. Assume that k common errors are found by both programmers. If all errors have an equal chance of being detected, then the fraction detected by the first programmer (k) of a randomly selected subset of errors (e.g., r) should equal the fraction that the first programmer detects (n1) of the total number of initial errors N. In other words,

so that an estimate of the total number of initial errors, N, is

The probability of exactly N initial errors with k common errors in r detected errors by the second programmer can be obtained using a hypergeometric distribution as follows:

and the MLE of N is
which is the same as the above.
The Mills’ Error Seeding Model, also known as the Mills’ Model, is a software testing technique that was developed by E.K. Mills in the early 1980s. The model is based on the idea that faults, or errors, are intentionally introduced into the software code in order to test the effectiveness of the software’s testing process.
Mills’ Error Seeding Model consists of the following steps:
- Introduce Errors: Errors are intentionally introduced into the software code, in a controlled and systematic manner.
- Conduct Testing: The software is then tested to see if the introduced errors are detected.
- Measure Results: The results of the testing process are measured and analyzed to determine the effectiveness of the software testing process.
- Improve Testing Process: Based on the results of the testing process, the testing process can be improved to increase its effectiveness in detecting errors.
- The Mills’ Error Seeding Model is useful for improving the software testing process and for evaluating the effectiveness of the testing process. It can help to identify weaknesses in the testing process and to make improvements that will result in a more effective and efficient testing process.
Advantages:
- Improved Testing Process: The Mills’ Error Seeding Model helps to improve the software testing process by intentionally introducing errors into the code and evaluating the effectiveness of the testing process in detecting those errors.
- Increased Confidence in Software Quality: By detecting and correcting errors in the software, the Mills’ Error Seeding Model can increase confidence in the software’s quality and reliability.
- Improved Efficiency: By identifying weaknesses in the testing process and making improvements, the Mills’ Error Seeding Model can lead to a more efficient and effective testing process.
- Early Detection of Errors: The Mills’ Error Seeding Model allows for early detection of errors in the software development process, reducing the likelihood that these errors will be discovered by users or customers after release.
- Objective Evaluation: The model provides an objective evaluation of the testing process, allowing for the identification of specific areas that need improvement.
- Cost-effective: The Mills’ Error Seeding Model can be a cost-effective way to improve the testing process, as it allows for the identification of potential issues early in the development process, which can prevent more expensive fixes later on.
- Increased Customer Satisfaction: By improving software quality and reliability, the Mills’ Error Seeding Model can increase customer satisfaction and loyalty, leading to improved business outcomes.
- Iterative Improvement: The Mills’ Error Seeding Model allows for iterative improvement of the testing process, with each iteration leading to further improvements and refinements in the testing process.
- Better Resource Allocation: By identifying areas of the software that require more testing and debugging, the Mills’ Error Seeding Model can lead to better allocation of testing resources, reducing the likelihood of errors slipping through the testing process undetected.
Disadvantages:
- Increased Development Time: Introducing errors into the software code and conducting thorough testing can increase the time required to develop the software.
- Limited Scope: The Mills’ Error Seeding Model is limited in scope to the testing process and does not address other aspects of software development such as design or coding.
- Artificial Introduction of Errors: The Mills’ Error Seeding Model involves artificially introducing errors into the software code, which may not accurately reflect the types of errors that could occur in real-world usage scenarios.
- Risk of False Positives/Negatives: The model may not accurately identify all errors in the software, leading to the risk of false positives (identifying errors that do not actually exist) or false negatives (failing to identify existing errors).
- Inaccurate Results: The accuracy of the model’s results can be impacted by the selection of errors to be seeded, the testing methodology, and other factors, which can lead to inaccurate results and undermine the effectiveness of the model.
- Difficulty in Interpreting Results: The Mills’ Error Seeding Model can produce large amounts of data and metrics, which can be difficult to interpret and act on effectively.
- Resistance to Change: The model may be met with resistance from developers or other stakeholders who may be resistant to the idea of intentionally introducing errors into the software, even for testing purposes.
- Difficulty in Implementing: Implementing the Mills’ Error Seeding Model requires significant expertise in software testing and quality assurance, making it difficult to implement for organizations without a dedicated testing team or resources.
Last Updated :
24 Apr, 2023
Like Article
Save Article
УДК 681.3.068
Н.В.Василенко, В.А.Макаров МОДЕЛИ ОЦЕНКИ НАДЕЖНОСТИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
14 of the most famous models of software safety evaluation are reviewed. According to the review, there is no absolutely safe programme, as the absolutely safety degree can&t be theoretically proved and therefore it can not be achieved.
1. Введение
В международном стандарте ISO 9126:1991 [1] надежность выделена как одна из основных характеристик качества программного обеспечения (ПО). Стандартный словарь терминов программного инжиниринга [2] определяет надежность программного обеспечения как способность системы или компонента выполнять требуемые функции в заданных условиях на протяжении указанного периода времени.
Сама проблема надежности программного обеспечения имеет, по крайней мере, два аспекта: обеспечение и оценка (измерение) надежности [3]. Практически вся имеющаяся литература посвящена первому аспекту, а вопрос оценки надежности компьютерных программ недостаточно проработан. Вместе с тем очевидно, что надежность программы гораздо важнее таких традиционных ее характеристик, как время исполнения или требуемый объем оперативной памяти, однако никакой общепринятой количественной меры надежно -сти программ до сих пор не существует.
Модели надежности программных средств подразделяются на аналитические и эмпирические [4]. Аналитические модели дают возможность рассчитать количественные показатели надежности, основываясь на данных о поведении программы в процессе тестирования. Эмпирические модели базируются на анализе структурных особенностей программ.
Аналитические модели представлены двумя группами: динамические и статические. В динамических моделях поведение ПО (появление отказов) рассматривается во времени. Если фиксируются интервалы каждого отказа, то получается непрерывная картина появления отказов во времени (модели с непрерывным временем). Может фиксироваться только число отказов за произвольный интервал времени. В этом случае поведение ПО может быть представлено только в дискретных точках (модели с дискретным временем).
В статических моделях появление отказов не связывают со временем, а учитывают зависимость количества ошибок либо от числа тестовых прогонов (модели по области ошибок), либо от характеристики входных данных (модели по области данных).
2. Аналитические динамические модели
2.1. Модель Шумана
Исходные данные для модели Шумана собираются в процессе тестирования ПО в течение фиксированных или случайных временных интервалов. Использование модели Шумана предполагает, что тестирование проводится в несколько этапов. Каждый этап представляет собой выполнение программы на полном комплексе разработанных тестовых данных. Выявленные ошибки регистрируются, но не исправляются. По завершении этапа на основе собранных данных модель Шумана может быть использована для расчета количественных показателей надежности. После этого исправляются ошибки, обнаруженные на предыдущем этапе, при необходимости корректируются тестовые наборы, и проводится новый этап тестирования. При использовании модели Шумана предполагается, что исходное количество ошибок в
программе постоянно и в процессе тестирования может уменьшаться по мере того, как ошибки выявляются и исправляются (новые ошибки не вносятся).
Базовые понятия модели заимствованы из теории надежности аппаратных средств [5]. R(t) — функция надежности — вероятность того, что ни одна ошибка не появится на интервале от 0 до t.
F(t) — функция отказов — вероятность того, что ошибка появится на интервале от 0 до t.
F(t) = 1- R(t)
dF (Л dR(t)
дО — плотность вероятности для F(t), / ^) =—————=———.
z(t) — функция риска — условная вероятность того, что ошибка появится на интервале от 0 до t + Д, при условии, что до t ошибок не было. Если Т — время появления ошибки, то
… , РС < Т < t + Д0 F(t + Дt) — F(t)
z(t)At = P{t < Т < t + Д&Т > Л = ——————— = —————-—.
Р(Т < t) R(t)
Поделив обе части на Дt и устремив Д к 0, переходим к пределу
^ /(О 1 dR(t)
z (/) =—-=—————.
R(t) R(t) dt
Решая это дифференциальное уравнение относительно R(t) при начальном условии R(0) = 1, получим
R(t) = ехр| -1 z(x)dx
4р — среднее время между отказами, t ср = | R(t )dt.
^ср V!^ср
0
В рассматриваемой модели автор предполагает, что значение функции z(t) пропорционально числу ошибок, оставшихся в ПО после израсходованного на тестирование времени т: z(t) = С • ег(т), где С — некоторая константа; t — время работы ПО без отказа; е г (т) — удельное число ошибок на одну машинную команду, оставшихся в системе после
времени тестирования т: е г (т) =—е с (т), где ЕТ — число ошибок до начала тестирова1Т
ния; 1Т — общее число машинных команд, которое предполагается постоянным в рамках этапа тестирования; е с (т) — удельное количество обнаруженных ошибок на одну машинную команду в течение времени т. Тогда
R(t, т) = ехр
С •! е~ — е с(т) )•t
&ср = 7Е~^——Т. (2)
С{ т;- е с(т))
Из величин, входящих в формулы (1) и (2), неизвестны начальное значение ошибок в ПО (ЕТ) и коэффициент пропорциональности С. Для их определения прибегают к следующим рассуждениям. В процессе тестирования собирается информация о времени и количестве ошибок на каждом прогоне, т.е. общее время тестирования т складывается из времени каждого прогона. Полагая, что интенсивность появления ошибок постоянна и равна X, а Л, — количество ошибок на /-м прогоне, можно вычислить
&ср =-^- <3>
Имея данные для двух различных моментов тестирования та и тъ, которые выбираются произвольно с учетом требования ес(тъ) > ес(та), можно сопоставить уравнения (2) и (3) при та и тъ и получить следующие выражения:
Е = 1Т (Ч • ес (та ) — Хтъ • ес (тъ )) С = Ч
а 4 — — ес (та)
1т
с помощью которых рассчитывается надежность программы по формуле (1).
2.2. Модель Ла Падула
По этой модели выполнение последовательности тестов производится в m этапов. Каждый этап заканчивается внесением изменений (исправлений) в ПО. Возрастающая функция надежности базируется на числе ошибок, обнаруженных в ходе каждого тестового прогона. Надежность ПО в течение i-го этапа
R(t) = R(t») — —, i = 1,2…,
где А — параметр роста; R(w) = limR(i) — предельная надежность ПО. Эти неизвестные величины автор предлагает вычислить, решив следующие уравнения:
Si — mi „ N Ai
—R(w) +—
Si — mi Ai Л 1
i i — R(w) +—I •= о,
, , ьч 5 / ) /
/=1 ьч 1 у
где 5 — число тестов на /-м этапе; т/ — число отказов во время /-го этапа; / = 1,2,… т.
Определяемый по этой модели показатель есть надежность ПО на /-м этапе:
R(t) = R(xl)—-, / = т +1, т + 2,…
2.3. Модель Джелинского — Моранды
Основное положение, на котором базируется модель, заключается в том, что в процессе тестирования ПО значение интервалов времени тестирования между обнаружением двух ошибок имеет экспоненциальное распределение с интенсивностью отказов, пропорциональной числу еще не выявленных ошибок. Каждая обнаруженная ошибка устраняется, число оставшихся ошибок уменьшается на единицу.
Функция плотности распределения времени обнаружения /-й ошибки, отсчитываемого от момента выявления (/ — 1)-й ошибки, имеет вид
Р(&г ) = Х/ • ехр(-^г • &г X (4)
где X — интенсивность отказов, которая пропорциональна числу еще не выявленных ошибок в программе:
X = С • (N — / +1), (5)
где N — число ошибок, первоначально присутствующих в программе; С — коэффициент пропорциональности.
Наиболее вероятные значения величин N и С определяются на основе данных, полученных при тестировании. Для этого фиксируют время выполнения программы до очередного отказа &ь&2,&3,…,4. Значения N и С можно получить, решив систему уравнений
I (N — / +1)-1 ==—К————,
^ N +1-0 •К
С А(+1 — 0 • к)
Т} к к
где 0=~ш; Л=1и;в=11 • ^
Чтобы получить числовые значения Х„ нужно подставить вместо N и С их возможные значения N и С . Рассчитав К значений по формуле (5) и подставив их в выражение (4), можно определить вероятность безотказной работы на различных временных интервалах.
2.4. Модель Шика — Волвертона
Это модификация модели Джелинского — Моранды для случая возникновения на рассматриваемом интервале более одной ошибки. При этом считается, что исправление ошибок производится лишь после истечения интервала времени, на котором они возникли. В основе модели Шика — Волвертона лежит предположение, согласно которому частота ошибок пропорциональна не только количеству ошибок в программах, но и времени тестирования, т.е. вероятность обнаружения ошибок с течением времени возрастает. Интенсивность обнаружения ошибок X; предполагается постоянной в течение интервала времени ^ и пропорциональна числу ошибок, оставшихся в программе по истечении (/ — 1)-го интервала; но она пропорциональна также и суммарному времени, уже затраченному на тестирование:
X/ = С(N — «¿-1)(Т—1 + &г /2), где С — коэффициент пропорциональности; N — число ошибок, первоначально присутствующих в программе; п/-1 — число ошибок, оставшихся в программе по истечении (/ — 1)-го интервала; Т/-1 — суммарное время, затраченное на тестирование в течение (/ — 1) этапов; ti — среднее время выполнения программы в текущем интервале.
Остальные расчеты аналогичны расчетам модели Джелинского — Моранды.
2.5. Модель Муса
Модель предполагает, что в процессе тестирования фиксируется время выполнения программы до очередного отказа. Но считается, что не всякая ошибка ПО может вызвать отказ, поэтому допускается обнаружение более одной ошибки при выполнении программы до возникновения очередного отказа.
Считается, что на протяжении всего жизненного цикла ПО может произойти М0 отказов и при этом будут выявлены все N ошибки, которые присутствовали в ПО до начала тестирования. Общее число отказов М0 связано с первоначальным числом ошибок N0 соотношением N,3 = В • М 0, где В — коэффициент уменьшения числа ошибок. После тестирования, за время которого зафиксировано т отказов и выявлено п ошибок, можно определить коэффициент В: В = п / т.
Один из основных показателей надежности, который рассчитывается по модели Муса, — средняя наработка на отказ. Этот показатель определяется как математическое ожидание временного интервала между последовательными отказами.
2.6. Модель переходных вероятностей
Процесс тестирования ПО рассматривается как марковский процесс.
Пусть в начальный момент тестирования С = 0) в ПО было п ошибок. Предполагается, что в процессе тестирования выявляется по одной ошибке. Тогда последовательность состояний системы {п, п — 1, п — 2, п — 3,…} соответствует периодам времени, когда предыдущая ошибка уже исправлена, а новая еще не обнаружена. Последовательность состояний {т, т — 1, т — 2, т — 3,.} соответствует периодам времени, когда ошибки исправляются.
Любое состояние модели определяется рядом переходных вероятностей (Ру), где Ру означает вероятность перехода из состояния / в состояние у и не зависит от предшествующих и последующих состояний системы, кроме состояний I и у. Вероятность перехода из состояния (п — к) к состоянию (т — к) есть Хп-к-А1 для к = 0,1,2., где X — интенсивность проявления ошибок.
Надежность ПО в данной модели определяется выражением
Использование этой модели предполагает необходимость перед началом тестирования искусственно «засорять» программу, т.е. вносить в нее некоторое количество известных ошибок. Ошибки вносятся случайным образом и фиксируются в протоколе искусственных ошибок. Специалист, проводящий тестирование, не знает ни количества, ни характера внесенных ошибок до момента оценки показателей надежности по модели Миллса. Предполагается, что все ошибки (как естественные, так и искусственно внесенные) имеют равную вероятность быть найденными в процессе тестирования.
Тестируя программу в течение некоторого времени, собирают статистику об ошибках. В момент оценки надежности по протоколу искусственных ошибок все ошибки делятся на собственные и искусственные. Соотношение, называемое формулой Миллса,
дает возможность оценить первоначальное число ошибок в программе N. Здесь £ — количество искусственно внесенных ошибок; п — число найденных собственных ошибок; V — число обнаруженных к моменту оценки искусственных ошибок.
Липов модифицировал модель Миллса, рассмотрев вероятность обнаружения ошибки при использовании различного числа тестов. Если сделать то же предположение, что и в модели Миллса, т.е. что собственные и искусственные ошибки имеют равную вероятность быть найденными, то вероятность обнаружения п собственных и V внесенных ошибок
где т — количество используемых тестов, q — вероятность обнаружения ошибки в каждом из
ошибок; N — количество собственных ошибок, имеющихся в ПО до начала тестирования.
Использование этой модели предполагает проведение тестирования двумя группами программистов, использующими независимые тестовые наборы, независимо одна от другой. В процессе тестирования каждая из групп фиксирует все найденные ею ошибки. При оценке числа оставшихся в программе ошибок результаты тестирования обеих групп собираются и сравниваются. Положим, первая группа обнаружила N1 ошибок, вторая — Щ, а N12 — это ошибки, обнаруженные дважды (обеими группами). Если обозначить через N неизвестное количество ошибок, присутствовавших в программе до начала тестирования, то можно эффективность тестирования каждой из групп определить как
3. Аналитические статические модели
3.1. Модель Миллса
3.2. Модель Липова
п + V
т тестов, рассчитанная по формуле q
п + V
; Б — общее количество искусственно внесенных
3.3. Простая интуитивная модель
Предполагая, что возможность обнаружения всех ошибок одинакова для обеих групп, можно допустить, что если первая группа обнаружила определенное количество всех ошибок, она могла бы определить то же количество любого случайным образом выбранного подмножества. В частности, можно допустить
В этой модели не используются параметры времени тестирования и учитывается только результат N испытаний, в которых выявлено N1 ошибок /-го типа. Модель использует изменяющиеся вероятности отказов для различных типов ошибок.
В отличие от двух рассмотренных выше статических моделей, по модели Коркорэна оценивается вероятность безотказного выполнения программы на момент оценки:
где N0 — число безотказных выполнений программы; N — общее число прогонов; К — аппри тестировании ошибки /-го типа.
В этой модели вероятность а/ должна оцениваться на основе априорной информации или данных предшествующего периода функционирования однотипных программных средств.
Пространство элементарных событий в классической модели последовательности испытаний Бернулли содержит 2п точек, где п — число испытаний (в данном случае под испытанием подразумевается запуск программы). Каждый запуск программы имеет два исхода: правильный и неправильный. Обозначим вероятность неправильного исхода р, а вероятность правильного — (1 -р). Вероятность того, что из п запусков к приведут к неправильному результату, выражается формулой биномиального распределения:
где С(п,к) — число сочетаний. Вероятность р априори неизвестна, но по результатам запусков известны п и к. Величина В как функция р имеет максимум при р = к / п. В качестве меры надежности программы принимается величина
Данная модель при расчете надежности ПО учитывает вероятность выбора определенного тестового набора для очередного выполнения программы. Предполагается, что область данных, необходимых для выполнения тестирования программного средства, разделяется на к взаимоисключающих подобластей 2, і = 1,2,…,к. Пусть Рі — вероятность того, что набор данных Хі будет выбран для очередного выполнения программы. Если к моменту оценки надежности было выполнено N1 прогонов программы на Хі наборе данных и из них пі прогонов закончились отказом, то надежность ПО определяется равенством
Тогда
3.4. Модель Коркорэна
а/, если Ni > 0, 0, если Ni = 0;
аі — вероятность выявления
3.5. Модель последовательности испытаний Бернулли
В(р, п,к) = С(п,к) • рк • (1 — р)п к,
Я = 1 — к / п = (п — к)/ п.
3.6. Модель Нельсона
4. Эмпирические модели 4.1. Модель сложности
Сложность ПО характеризуется его размером (количеством программных модулей), количеством и сложностью межмодульных интерфейсов. Под программным модулем в данном случае следует понимать программную единицу, выполняющую определенную функцию и взаимосвязанную с другими модулями ПО.
Существует несколько разновидностей модели сложности. В каждой из них дается некая оценка сложности программы, которая считается пропорциональной ее надежности.
4.2. Модель, определяющая время доводки программ
Анализ модульных связей ПО строится на том, что каждая пара модулей имеет конечную (возможно, нулевую) вероятность того, что изменения в одном модуле вызовут изменения в другом. Данная модель позволяет на этапе тестирования, а точнее при тестовой сборке системы, определять возможное число необходимых исправлений и время, необходимое для доведения ПО до рабочего состояния.
5. Вывод
Следует признать, что абсолютно надежных программ не существует, так как абсолютная степень надежности не может быть теоретически доказана и, следовательно, недостижима. Однако важно знать, насколько надежно конкретное ПО. Описанные модели представляют теоретический подход и, как правило, имеют ограниченное применение. До сих пор не предложено ни одного надежного количественного метода оценки надежности ПО, не содержащего чрезмерного количества ограничений.
Практика разработки ПО предполагает приоритет задачи обеспечения надежности над задачей ее оценки. Ситуация выглядит парадоксально: совершенно очевидно, что прежде чем обеспечивать надежность, следует научиться ее измерять. Но для этого нужно иметь практически приемлемую единицу измерения надежности ПО и модель ее расчета.
1. ISO 9126:1991. Информационная технология. Оценка программного продукта. Характеристики качества и руководство по их применению. 186 с.
2. IEEE Std 610.12-1990, IEEE Standard Glossary of Software Engineering Technology (ANSI). 1283 с.
3. Романюк С.Г. // Открытые системы. 1994. №4 — www.osp.ru/os/1994/04/68.htm
4. Благодатских В.А., Волнин В.А., Поскакалов К.Ф. Стандартизация разработки программных средств: Учеб. пособие под ред. О.С.Разумова. М.: Финансы и статистика, 2003. 284 с.
5. Майерс Г. Надежность программного обеспечения. М.: Мир, 1980. 360 с.
тестировании (например, с помощью модели Шумана). Надежность R для оперативного периода τ выражается равенством

В литературе указывается, что практическое использование рассматриваемой модели требует громоздких вычислений и делает необходимым наличие ее программной поддержки.
Статические модели надежности
Статические модели принципиально отличаются от динамических прежде всего тем, что в них не учитывается время появления ошибок в процессе тестирования. Этот тип моделей учитывает только статистические характеристики появления ошибок.
Модель Миллса. Использование этой модели предполагает внесение в программу некоторого количества известных ошибок. Они вносятся случайным образом и фиксируются в протоколе искусственных ошибок. Специалист, проводящий тестирование, не знает ни количества, ни характера внесенных ошибок до момента оценки показателей надежности по модели Миллса. Предполагается, что все ошибки (как имеющиеся в исследуемой программе, так и искусственно внесенные) имеют равную вероятность быть найденными в процессе тестирования. Тестируя программу в течение некоторого времени, собирают статистику об ошибках. В момент оценки надежности по протоколу искусственных ошибок все ошибки делятся на ошибки собственно программы и искусственные.
С помощью соотношения (формулы Миллса)

можно оценить первоначальное число ошибок в программе (N). Здесь S- количество искусственно внесенных ошибок, η — число найденных собственных ошибок, V— число обнаруженных к моменту оценки искусственных ошибок.
Например, если в программу внесено дополнительно 50 ошибок и к некоторому моменту тестирования обнаружено 25 собственных и 5 внесенных, то по формуле Миллса делается предположение, что первоначально в программе было 250 ошибок.
Вторая часть модели связана с проверкой гипотезы об оценке первоначального числа ошибок Nb программе. Допустим, что в программе имеется Л» собственных ошибок. Внесем в нее еще S ошибок.
Положим, что в процессе тестирования были обнаружены все S внесенных и л собственных ошибок программы. Тогда по формуле Миллса получим, что первоначально в программе было N= n ошибок. Вероятность, с которой можно высказать такое предположение, рассчитывается с помощью следующих соотношений:

Величина С является мерой «доверия» к модели и показывает вероятность того, насколько правильно найдено значение N. Эти два связанных между собой по смыслу соотношения образуют полезную модель ошибок: первое предсказывает возможное число первоначально имевшихся в программе ошибок, а второе используется для установления доверительного уровня прогноза. Однако приведенная выше формула для расчета С не может быть использована, если не обнаружены все внесенные ошибки.

где числитель и знаменатель при n < К являются биноминальными коэффициентами вида

Если оценка надежности производится до момента обнаружения всех внесенных ошибок (S), величина С рассчитывается по модифицированной формуле:
В реальной практике модель Миллса можно использовать для оценки N после каждой найденной ошибки. Предлагается во время всего периода тестирования отвечать на графике число найденных ошибок и текущие значения N
К достоинствам модели относят простоту применяемого математического аппарата, наглядность и возможность использования в процессе тестирования.
Самым существенным недостатком считают необходимость внесения искусственных ошибок (этот процесс плохо формализуем) и достаточно вольное допущение величины К, которое основывается исключительно на интуиции и опыте испытателя, проводящего оценку, т. е. допускает большое влияние субъективного фактора.
Модель Липова. Липов модифицировал модель Миллса, рассмотрев вероятность обнаружения ошибки при использовании различного числа тестов. Если сделать то же предположение, что и в модели Миллса, т. е. что собственные и внесенные ошибки имеют равную вероятность быть найденными, то вероятность обнаружения n собственных и Vвнесенных ошибок может быть определена с помощью соотношения

где т — количество тестов, используемых при тестировании; q— вероятность обнаружения ошибки в каждом из т тестов, рассчитанная по формуле; S— общее количество внесенных ошибок; N— количество собственных ошибок, имеющихся в программе до начала тестирования.
Оценки максимального правдоподобия (наиболее вероятное значение) для N осуществляются с помощью соотношений
Для использования модели Липова должны выполняться следующие условия:


Модель Липова дополняет модель Миллса, позволяя оценить вероятность обнаружения определенного количества ошибок к моменту оценки.
Модель Коркорэна относится к статическим моделям надежности ПО, так как в ней не используются параметры времени тестирования, а учитывается только результат N испытаний, в которых выявлено Ni ошибок i-ro типа.
Применение модели предполагает знание следующих ее показателей:
-
модель содержит изменяющуюся вероятность отказов для различных источников ошибок и соответственно разную вероятность их исправления;
-
в модели используются такие параметры, как результат Nиспытаний, в которых наблюдается Ni ошибок г-го типа;
-
обнаруженные в ходе ^испытаний ошибки г-го типа появляются с вероятностью аi
Показатель уровня надежности R вычисляют по формуле

где N0 — число безотказных (или безуспешных) испытаний, выполненных в серии из ^испытаний; к— известное число типов ошибок; Y— вероятность появления ошибок: при N>0 Y. = аi при N = 0 У>0.
Отметим, что в данной модели вероятность а. оценивается на основании априорной информации или данных предшествующего периода функционирования однотипных программных средств.
Модель Нельсона создана в аэрокосмической компании США TRW. При расчете надежности программно-информационного обеспечения учитывается вероятность выбора определенного тестового набора для очередного выполнения программы.
Для описания модели вводятся следующие обозначения.
Совокупность действий, включающая ввод Еi выполнение программы и получение результата F‘(E), называется прогоном программы. При этом значения входных переменных, образующих Ei не должны одновременно подаваться на вход программ. Таким образом, вероятность (P) того, что прогон программы приведет к обнаружению дефекта, равна вероятности того, что набор данных Ei используемый в прогоне, принадлежит множеству Ei.
Если обозначить через пе число различных наборов входных данных, содержащихся в Е. то
![]()
есть вероятность того, что прогон программы на наборе входных данных Ei случайно выбранном из E среди равновероятных, закончится обнаружением дефекта.
Однако в процессе функционирования программы выбор входных данных из E обычно осуществляется не с одинаковыми априорными вероятностями, а диктуется определенными условиями работы. Эти условия характеризуются некоторым распределением вероятностей (р) того, каким будет выбран определенный набор входных данных Ei
Распределение P может быть найдено через р. с помощью величины у., которая принимает значение О, если прогон программы на наборе £ заканчивается получением приемлемого результата, и значение 1, если этот прогон заканчивается обнаружением дефекта. Поэтому

есть вероятность того, что прогон программы на наборе входных данных Ei, выбранных случайно с распределением вероятностей рi, закончится обнаружением дефекта. При этом
![]()
есть вероятность того, что прогон программы на наборе входных данных Ei выбранных случайно с распределением вероятностей рi, приведет к получению приемлемого результата.
Так как R— вероятность того, что единичный прогон программы не закончится отказом на наборе входных данных, выбранных в соответствии с распределением рi то вероятность успешного выполнения n прогонов этой программы при независимом для каждого прогона выборе входных данных в соответствии с распределением Рбу-дет равна
![]()
Таким образом, можно дать следующее математическое определение надежности программы: надежность программы — это вероятность безотказного выполнения n прогонов программы. Поэтому прогон является единичным испытанием программы.
На практике выбор входных данных для каждого прогона нельзя считать независимым. Исключение составляют лишь такие последовательности прогонов, которые определяются возрастающими значениями некоторой входной переменной или некоторым порядком установленных процедур, как в случае программ, работающих в реальном масштабе времени.
С учетом введенного определения функциональный разрез должен быть переопределен в терминах вероятностей р выбора £ в качестве входных данных при j-м прогоне из некоторой последовательности прогонов. Тогда вероятность того, что j-й прогон закончится отказом, может быть записана в виде

Надежность R(n) программы равна вероятности того, что в последовательности из η прогонов ни один из них не закончится отказом:

Эта формула может быть представлена в виде

Некоторые свойства функции R(n) могут стать более явными при следующих допущениях:

для Рj << 1
![]()
если Рj = P для вcex j, то
С помощью соответствующих замен переменных и подстановок можно выразить функцию R(п) через время функционирования tОбозначим через Δt время выполнения j-гo прогона, а через ΣΔti — суммарное время выполнения первых jпрогонов программы. Введем h(t)

В случае Рj << 1 функция h(tj) может быть интерпретирована как функция интенсивности отказов, которая, будучи умноженной на Δt дает условную вероятность появления отказов в интервале (tj, tj+ tj) при отсутствии отказов до момента tj

Тогда
На практике вероятность выбора очередного набора данных для прогона (Pi) определяется путем разбиения всего множества значений входных данных на подмножества и нахождения вероятностей того, что выбранный для очередного прогона набор данных будет принадлежать конкретному подмножеству. Определение этих вероятностей основано на эмпирической оценке вероятности появления тех или иных входов в реальных условиях функционирования.
Поскольку в основу модели Нельсона положены свойства программного обеспечения, она допускает развитие за счет более детального описания других аспектов надежности. Некоторые из полученных обобщений модели могут рассматриваться в контексте исследования проблемы безопасности программ. Вследствие отмеченных особенностей модели ее можно рассматривать в целом как математическую теорию надежности программного и информационного обеспечения, а не как простую модель надежности.
Эмпирические модели надежности