I’ll rename the function take_closest to conform with PEP8 naming conventions.
If you mean quick-to-execute as opposed to quick-to-write, min should not be your weapon of choice, except in one very narrow use case. The min solution needs to examine every number in the list and do a calculation for each number. Using bisect.bisect_left instead is almost always faster.
The «almost» comes from the fact that bisect_left requires the list to be sorted to work. Hopefully, your use case is such that you can sort the list once and then leave it alone. Even if not, as long as you don’t need to sort before every time you call take_closest, the bisect module will likely come out on top. If you’re in doubt, try both and look at the real-world difference.
from bisect import bisect_left
def take_closest(myList, myNumber):
"""
Assumes myList is sorted. Returns closest value to myNumber.
If two numbers are equally close, return the smallest number.
"""
pos = bisect_left(myList, myNumber)
if pos == 0:
return myList[0]
if pos == len(myList):
return myList[-1]
before = myList[pos - 1]
after = myList[pos]
if after - myNumber < myNumber - before:
return after
else:
return before
Bisect works by repeatedly halving a list and finding out which half myNumber has to be in by looking at the middle value. This means it has a running time of O(log n) as opposed to the O(n) running time of the highest voted answer. If we compare the two methods and supply both with a sorted myList, these are the results:
$ python -m timeit -s " from closest import take_closest from random import randint a = range(-1000, 1000, 10)" "take_closest(a, randint(-1100, 1100))" 100000 loops, best of 3: 2.22 usec per loop $ python -m timeit -s " from closest import with_min from random import randint a = range(-1000, 1000, 10)" "with_min(a, randint(-1100, 1100))" 10000 loops, best of 3: 43.9 usec per loop
So in this particular test, bisect is almost 20 times faster. For longer lists, the difference will be greater.
What if we level the playing field by removing the precondition that myList must be sorted? Let’s say we sort a copy of the list every time take_closest is called, while leaving the min solution unaltered. Using the 200-item list in the above test, the bisect solution is still the fastest, though only by about 30%.
This is a strange result, considering that the sorting step is O(n log(n))! The only reason min is still losing is that the sorting is done in highly optimalized c code, while min has to plod along calling a lambda function for every item. As myList grows in size, the min solution will eventually be faster. Note that we had to stack everything in its favour for the min solution to win.
Для поиска ЧИСЛА ближайшего к заданному, в EXCEL существует специальные функции, например,
ВПР()
,
ПРОСМОТР()
,
ПОИСКПОЗ()
, но они работают только если исходный список сортирован по возрастанию или убыванию. Используя
формулы массива
создадим аналогичные формулы, но работающие и в случае несортированного списка.
Решение задачи поиска ближайшего числового значения в случае
сортированного
списка приведена в статье
Поиск ЧИСЛА ближайшего к заданному. Сортированный список
.
Рассмотрим задачу в более общем виде. Пусть имеется несортированный список чисел (в диапазоне
A4:A15
). (см.
Файл примера
).
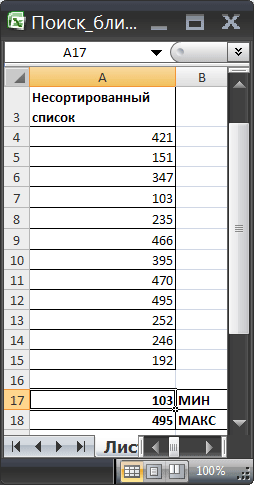
В качестве критерия для поиска используем любое число, введем его в ячейку
С4
. Найдем значение из диапазона, ближайшее к критерию с помощью
формул массива
:
|
|
|
|
|
= |
ищется |
Если заданное значение меньше минимального, то выдается ошибка #Н/Д |
|
= |
ищется |
Если заданное значение больше максимального, то выдается ошибка #Н/Д |
|
= |
ищется |
если ближайшее снизу и ближайшее сверху отстоят на одинаковое расстояние от критерия, то берется ближайшее число, расположенное первым в списке (например, ближайшее к 5 в списке 2; |
|
= |
ищется |
если обнаружено 2 ближайших числа (одно больше, другое меньше критерия), то выводится то, которое больше |
|
= |
ищется |
если обнаружено 2 ближайших числа (одно больше, другое меньше критерия), то выводится то, которое меньше |
СОВЕТ:
Для пошагового просмотра хода вычислений формул используйте клавишу
F9
.
При поиске ближайшего с дополнительным условием см. статью
Поиск ДАТЫ (ЧИСЛА) ближайшей к заданной, с условием в MS EXCEL. Несортированный список
.
Для неотсортированного массива. Для отсортированного лучше использовать бинпоиск.
Python 3.4+: tio.run
def f(a, val):
return min((x for x in a if x > val), default=None)
a = [1, 2, 5, 22, 33, 44, 312]
print(f(a, 3))
print(f(a, 10))
print(f(a, 1000))
Более ранние версии: tio.run
def f(a, val):
return min([x for x in a if x > val] or [None])
a = [1, 2, 5, 22, 33, 44, 312]
print(f(a, 3))
print(f(a, 10))
print(f(a, 1000))
Вывод в обоих случаях:
5
22
None

Напишите программу, которая находит в массиве элемент, самый близкий по величине к данному числу.
Входные данные
В первой строке содержатся список чисел — элементы массива (целые числа, не превосходящие 1000
по абсолютному значению).
Во второй строке вводится одно целое число x
, не превосходящее 1000
по абсолютному значению.
Выходные данные
Вывести значение элемента массива, ближайшего к x
. Если таких чисел несколько, выведите любое из них.
| Python | ||
|
Поиск ближайшего числа
На практике весьма часто возникают случаи, когда нам с вами нужно найти ближайшее значение в наборе (таблице) по отношению к заданному числу. Это может быть, например:
- Расчет скидки в зависимости от объема.
- Вычисление размера бонусов в зависимости от выполнения плана.
- Калькуляция тарифов на доставку в зависимости от расстояния.
- Подбор подходящей тары для товара и т.д.
Причем окргуление может требоваться как в меньшую, так и в большую сторону — в зависимости от ситуации.
Есть несколько способов — очевидных и не очень — для решения такой задачи. Давайте рассмотрим их последовательно.
Для начала, представим себе поставщика, который дает скидки на опт, причем процент скидки зависит от количества купленного товара. Например, при покупке свыше 5 штук дается скидка 2%, а при покупке от 20 штук — уже 6% и и т.д.
Как же быстро и красиво вычислить процент скидки при вводе количества купленного товара?

Способ 1. Вложенные ЕСЛИ
Способ из серии «а что тут думать — прыгать надо!». Используем вложенные функции ЕСЛИ (IF) для последовательной проверки попадания значения ячейки в каждый из интервалов и вывода скидки для соответствующего диапазона. Но формула при этом может получиться весьма громоздкой:

Думаю, очевидно, что отлаживать такую «матрёшку-монстра» или пытаться спустя какое-то время добавить в неё парочку новых условий — это весело.
Кроме того, в Microsoft Excel есть ограничение на вложенность для функции ЕСЛИ — 7 раз в старых и — 64 раза в новых версиях. А если нужно больше?
Способ 2. ВПР с интервальным просмотром
Этот способ гораздо компактнее. Для расчета процента скидки используем легендарную функцию ВПР (VLOOKUP) в режиме приблизительного поиска:

где
- B4 — значение количества товара в первой сделке, для которого мы ищем скидку
- $G$4:$H$8 — ссылка на таблицу скидок — без «шапки» и с закрепленными значком $ адресами.
- 2 — порядковый номер столбца в таблице скидок, из которого мы хотим получить значение скидки
- ИСТИНА — здесь и зарыта «собака». Если в качестве последнего аргумента функции ВПР указать ЛОЖЬ (FALSE) или 0, то функция будет искать строгое совпадение в столбце количества (и в нашем случае выдаст ошибку #Н/Д, поскольку значения 49 в таблице скидок нет). А вот если вместо ЛОЖЬ написать ИСТИНА (TRUE) или 1, то функция будет искать не точное, а ближайшее наименьшее значение и выдаст нужный нам процент скидки.
Минусом этого способа является необходимость обязательной сортировки таблицы скидок по возрастанию по первому столбцу. Если такой сортировки нет (или она выполнена в обратном порядке), то наша формула работать не будет:

Соответственно, использовать этот подход можно только для поиска ближайшего наименьшего значения. Если же необходимо найти ближайшее наибольшее, то придется использовать другой подход.
Способ 3. Поиск ближайшего наибольшего функциями ИНДЕКС и ПОИСКПОЗ
Теперь давайте рассмотрим нашу задачу с другой стороны. Предположим, что мы продаём несколько моделей промышленных насосов различной мощности. В таблице продаж слева указана требуемая для клиента мощность. Нам необходимо подобрать насос ближайшей наибольшей или равной мощности, но не меньше, чем требуется по проекту.
Функция ВПР тут не поможет, так что придётся использовать её аналог — связку функций ИНДЕКС (INDEX) и ПОИСКПОЗ (MATCH):

Здесь функция ПОИСКПОЗ с последним аргументом -1 работает в режиме поиска ближайшего наибольшего значения, а функция ИНДЕКС затем извлекает нужное нам название модели из соседнего столбца.
Способ 4. Новая функция ПРОСМОТРХ (XLOOKUP)
Если у вас версия Office 365 со всеми установленными обновлениями, то вместо ВПР (VLOOKUP) можно использовать её аналог — функцию ПРОСМОТРХ (XLOOKUP), которую я уже подробно разбирал:

Здесь:
- B4 — исходное значение количества товара, для которого мы ищем скидку
- $G$4:$G$8 — диапазон, где мы ищем совпадения
- $H$4:$H$8 — диапазон результатов, откуда нужно вернуть скидку
- Четвёртый аргумент (-1) включает нужный нам поиск ближайшего наименьшего числа вместо точного совпадения.
В плюсах у такого способа — отсутствие необходимости сортировки таблицы скидок и возможность искать, если нужно, не только ближайшее наименьшее, но и ближайшее наибольшее значение. Последний аргумент в этом случае будет равен 1.
Но, к сожалению, эта функция пока далеко не у всех — только у счастливых обладателей Office 365.
Способ 5. Power Query
Если вы ещё не знакомы с мощной и при этом совершенно бесплатной надстройкой Power Query для Excel, то вам сюда. Если уже знакомы, то давайте попробуем использовать её для решения нашей задачи.
Сначала выполним подготовительные операции:
- Преобразуем наши исходные таблицы в динамические (умные) с помощью сочетания клавиш Ctrl+T или командой Главная — Форматировать как таблицу (Home — Format as Table).
- Для наглядности дадим им имена Продажи и Скидки на вкладке Конструктор (Design).
- По очереди загрузим каждую из таблиц в Power Query используя кнопку Из таблицы/диапазона на вкладке Данные (Data — From table/range). В последних версиях Excel эту кнопку переименовали в С листа (From sheet).
- Если у таблиц различаются названия столбцов с количеством как в нашем примере («Количество товара» и «Количество от…»), то их в Power Query необходимо переименовать и назвать одинаково.
- После этого можно вернуться обратно в Excel, выбрав в окне редактора Power Query команду Главная — Закрыть и загрузить — Закрыть и загрузить в… (Home — Close&Load — Close&Load to…) и затем вариант Только создать подключение (Only create connection).

- Дальше начинается самое интересное. Если у вас есть опыт работы в Power Query, то, предполагаю, дальнейший ход мыслей должен быть в сторону слияния этих двух таблиц запросом объединения (merge) а-ля ВПР, как это было в предыдущем способе. На самом деле, нам потребуется слияние в режиме добавления, что на первый взгляд совсем не очевидно. Выбираем в Excel на вкладке Данные — Получить данные — Объединить запросы — Добавить (Data — Get Data — Combine queries — Append) и затем наши таблицы Продажи и Скидки в появившемся окне:

- После нажатия на ОК наши таблицы будут склеены в единое целое — друг под друга. Обратите внимание, что столбцы с количеством товара в этих таблицах встали друг под друга, т.к. у них одинаковые названия:

- Если вам важна исходная последовательность строк в таблице продаж, то, чтобы после всех последующих преобразований потом можно было её восстановить, добавим к нашей таблице столбец с нумерацией, используя команду Добавление столбца — Столбец индекса (Add column — Index column). Если последовательность строк для вас роли не играет, то этот шаг можно пропустить.
- Теперь с помощью выпадающего списка в шапке таблицы отсортируем её по столбцу Количество по возрастанию:

- И главный трюк: щёлкаем правой кнопкой мыши по заголовку столбца Скидка выбираем команду Заполнить — Вниз (Fill — Down). Пустые ячейки с null автоматически заполнятся предыдущими значениями скидок:

- Осталось восстановить исходную последовательность строк сортировкой по столбцу Индекс (его потом можно смело удалить) и избавиться от ненужных строк фильтром null по столбцу Код сделки:







Ссылки по теме
- Использование функции ВПР (VLOOKUP) для поиска и подстановки данных
- Использование функции ВПР (VLOOKUP) с учетом регистра
- Двумерный ВПР (VLOOKUP)