Use groupby, it group elements by value:
from itertools import groupby
group = groupby([1, 2, 2, 2, 2, 1, 1, 1, 2, 2, 1, 1])
print max(group, key=lambda k: len(list(k[1])))
And here is the code in action:
>>> group = groupby([1, 2, 2, 2, 2, 1, 1, 1, 2, 2, 1, 1])
>>> print max(group, key=lambda k: len(list(k[1])))
(2, <itertools._grouper object at 0xb779f1cc>)
>>> group = groupby([1, 2, 2, 2, 2, 1, 1, 1, 2, 2, 1, 1, 3, 3, 3, 3, 3])
>>> print max(group, key=lambda k: len(list(k[1])))
(3, <itertools._grouper object at 0xb7df95ec>)
From python documentation:
The operation of groupby() is similar
to the uniq filter in Unix. It
generates a break or new group every
time the value of the key function
changes
# [k for k, g in groupby('AAAABBBCCDAABBB')] --> A B C D A B
# [list(g) for k, g in groupby('AAAABBBCCD')] --> AAAA BBB CC D
If you also want the index of the longest run you can do the following:
group = groupby([1, 2, 2, 2, 2, 1, 1, 1, 2, 2, 1, 1, 3, 3, 3, 3, 3])
result = []
index = 0
for k, g in group:
length = len(list(g))
result.append((k, length, index))
index += length
print max(result, key=lambda a:a[1])
|
0 / 0 / 0 Регистрация: 19.11.2016 Сообщений: 28 |
|
|
1 |
|
Как посчитать и вывести наибольшее число повторяющихся элементов в массиве20.02.2017, 19:50. Показов 2377. Ответов 12
как посчитать и вывести наибольшее число повторяющихся элементов в массиве? подсчитать одинаковые элементы просто, но вот сделать так, что бы вывести число наибольших, а не всех тех, которые были повторены…не выходит
0 |

|
iHardc0re 5 / 5 / 4 Регистрация: 18.02.2017 Сообщений: 20 |
||||
|
20.02.2017, 21:16 |
2 |
|||
|
Решение в лоб, рабочое, но неэффективное, т.к. для мы несколько раз будем считать одни и те же числа. Ну и еще может быть несколько чисел с максимальным к-вом повторений.
2 |
|
LFC 737 / 542 / 416 Регистрация: 17.09.2015 Сообщений: 1,601 |
||||||||
|
21.02.2017, 04:36 |
3 |
|||||||
|
можно добавить проверку на неповторяемость
Добавлено через 1 час 19 минут
2 |
|
Форумчанин
8194 / 5044 / 1437 Регистрация: 29.11.2010 Сообщений: 13,453 |
|
|
21.02.2017, 13:02 |
4 |
|
То есть например {1233345677777} Соответственно нужно посчитать и число семерок. Если все элементы исходного массива представлены лишь одной цифрой, то задача сильно упрощается.
1 |

|
Catstail Модератор
35427 / 19452 / 4071 Регистрация: 12.02.2012 Сообщений: 32,488 Записей в блоге: 13 |
||||||||
|
22.02.2017, 17:13 |
5 |
|||||||
|
Если все элементы исходного массива представлены лишь одной цифрой, то задача сильно упрощается. — достаточно даже предположить, что все элементы массива просто меньше какого-либо не очень большого целого и неотрицательны. Тогда:
Добавлено через 28 минут
0 |
|
CoderHuligan Нарушитель 1164 / 851 / 250 Регистрация: 30.06.2015 Сообщений: 4,431 Записей в блоге: 49 |
||||
|
22.02.2017, 19:03 |
6 |
|||
0 |
|
737 / 542 / 416 Регистрация: 17.09.2015 Сообщений: 1,601 |
|
|
22.02.2017, 19:14 |
7 |
|
CoderHuligan, если считать только идущие подряд,то да
0 |
|
Нарушитель 1164 / 851 / 250 Регистрация: 30.06.2015 Сообщений: 4,431 Записей в блоге: 49 |
|
|
22.02.2017, 19:33 |
8 |
|
если считать только идущие подряд,то да Немного не врубился в задание. Да и этот алгоритм немного неправильный.. кто найдёт ошибку ставлю лайк
1 |

|
LFC 737 / 542 / 416 Регистрация: 17.09.2015 Сообщений: 1,601 |
||||||||||||||||
|
22.02.2017, 19:46 |
9 |
|||||||||||||||
|
Немного не врубился в задание посмотрев на ваш код я подумал что это я не врубился,ибо у ТС
{1233345677777}
правда это не ошибка алгоритма
скобки
1 |
|
CoderHuligan Нарушитель 1164 / 851 / 250 Регистрация: 30.06.2015 Сообщений: 4,431 Записей в блоге: 49 |
||||
|
22.02.2017, 19:50 |
10 |
|||
|
for(i=0; i<n — 1; ++i Правильно. В конце будет проверятся элемент выходящий за границы массива.
Хотя это к задаче ТС и не относится…
0 |
|
MrGluck Форумчанин
8194 / 5044 / 1437 Регистрация: 29.11.2010 Сообщений: 13,453 |
||||
|
22.02.2017, 22:24 |
11 |
|||
|
Catstail, да, вы уловили мою идею)
Все неинициализированные явно элементы (все в данном случае) будут созданы со значением 0.
1 |
|
Модератор
35427 / 19452 / 4071 Регистрация: 12.02.2012 Сообщений: 32,488 Записей в блоге: 13 |
|
|
23.02.2017, 09:55 |
12 |
|
да, вы уловили мою идею — идея классическая, известная
0 |
|
Форумчанин
8194 / 5044 / 1437 Регистрация: 29.11.2010 Сообщений: 13,453 |
|
|
23.02.2017, 20:31 |
13 |
|
Я на авторство и не претендую, просто хотел подметить, что одинаково думаем) И это хорошо.
1 |
Спасибо, на этом примере работает. А как применить это решение к немного другому виду массива чет не могу понять?
const massive = [
'Max download report 1',
'Felix download report 4',
'Roberto upload report 5',
'Alex download report 1',
'Stef download report 2',
'Sam download report 3',
'Monika upload report 54'
]нужно посчитать максимальное количество повторений подряд строки с словом download
Нужно найти в массиве максимальное кол-во повторяющихся подряд элементов и вывести какой элемент повторяется и его первый индекс.
Например дан такой массив (в массиве могут быть не только строки но и цифры):
const arr = ['re','tres','tred','test','test','test','yt','ttt','ttt','test','test'];
Где, строка ‘test’ повторяется подряд 3 раза. Вывод в консоль должен быть примерно такой объект:
object = {name = 'test',count: 3, index: 3}
Моя попытка:
const arr = ['re','tres','tred','test','test','test','yt','ttt','ttt','test','test'];
let s = [];
let count = 0;
arr.forEach((item,index,array) => {
if(item == array[index +1]) {
s.push({item,index,count});
count++;
}
})
Допустим у нас есть таблица регистра составленных заказов клиентов. Необходимо узнать с какого города поступило наибольшее количество заказов, а с какого – наименьшее. Для решения данной задачи будем использовать формулу с поисковыми и вычислительными функциями.
Поиск наиболее повторяющегося значения в Excel
Чтобы наглядно продемонстрировать работу формулы для примера воспользуемся такой схематической таблицей регистра заказов от клиентов:
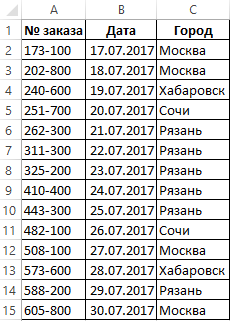
Теперь выполним простой анализ наиболее часто и редко повторяющихся значений таблицы в столбце «Город». Для этого:
- Сначала находим наиболее часто повторяющиеся названия городов. В ячейку E2 введите следующую формулу:
- Обязательно после ввода формулы нажмите комбинацию горячих клавиш CTRL+SHIFT+Enter, так как ее нужно выполнить в массиве.
- Для вычисления наиболее редко повторяющегося названия города вводим весьма похожую формулу:
Результат поиска названий самых популярных и самых редких городов клиентов в регистре заказов, отображен на рисунке:
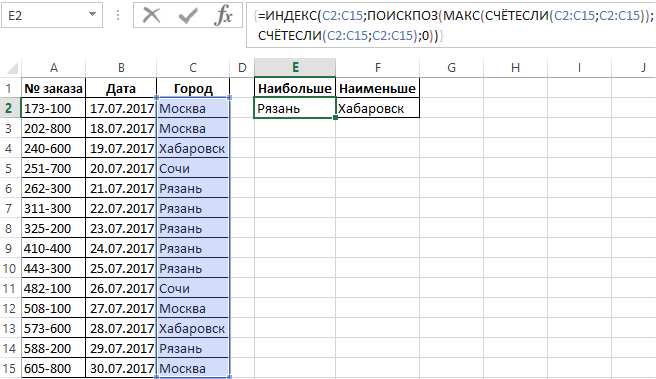
Если таблица содержит одинаковое количество двух самых часто повторяемых городов или два самых редко повторяющихся города в одном и том же столбце, тогда будет отображаться первый из них.
Принцип действия поиска популярных по повторению значений:
Если посмотреть на синтаксис формул то можно легко заметить, что они отличаются только одним из названием функций: =МАКС() и =МИН(). Все остальные аргументы формулы – идентичны. Функция =СЧЕТЕСЛИ() подсчитывает, сколько раз каждое название города повторяется в диапазоне ячеек C2:C16. Таким образом в памяти создается условный массив значений.
Скачать пример поиска наибольшего и наименьшего повторения значения
Функция МАКС или МИН выбирает из условного массива наибольшее или наименьшее значение. Функция =ПОИСКПОЗ() возвращает номер позиции на которой в столбце C название города соответственного наибольшему или наименьшему количеству повторений. Полученное значение будет передано в качестве аргумента для функции =ИНДЕКС(), которая возвращает конечный результат в ячейку.