Решаем задачу нахождения длины наибольшей возрастающей подпоследовательности
Время на прочтение
7 мин
Количество просмотров 50K
Задача
«Найти длину самой большой возрастающей подпоследовательности в массиве.»
Вообще, это частный случай задачи нахождения общих элементов 2-х последовательностей, где второй последовательностью является та же самая последовательность, только отсортированная.
На пальцах
Есть последовательность:
5, 10, 6, 12, 3, 24, 7, 8
Вот примеры подпоследовательностей:
10, 3, 8
5, 6, 3
А вот примеры возрастающих подпоследовательностей:
5, 6, 7, 8
3, 7, 8
А вот примеры возрастающих подпоследовательностей наибольшей длины:
5, 6, 12, 24
5, 6, 7, 8
Да, максимальных тоже может быть много, нас интересует лишь длина.
Здесь она равна 4.
Теперь когда задача определена, решать мы ее начинаем с (сюрприз!) вычисления чисел Фибоначчи, ибо вычисление их — это самый простой алгоритм, в котором используется “динамическое программирование”. ДП — термин, который лично у меня никаких правильных ассоциаций не вызывает, я бы назвал этот подход так — “Программирование с сохранением промежуточного результата этой же задачи, но меньшей размерности”. Если же посчитать числа Фибоначчи с помощью ДП для вас проще пареной репы — смело переходите к следующей части. Сами числа Фибоначчи не имеют отношения к исходной задаче о подпоследовательностях, я просто хочу показать принцип ДП.
Последовательность Фибоначчи O(n)

Последовательность Фибоначчи популярна и окружена легендами, разглядеть ее пытаются (и надо признать, им это удается) везде, где только можно. Принцип же ее прост. n-ый элемент последовательности равен сумме n-1 и n-2 элемента. Начинается соответственно с 0 и 1.
0, 1, 1, 2, 3, 5, 8, 13, 21, 34 …
Берем 0, прибавляем 1 — получаем 1.
Берем 1, прибавляем 1 — получаем 2.
Берем 1, прибавляем 2 — получаем, ну вы поняли, 3.
Собственно нахождение n-го элемента этой последовательности и будет нашей задачей. Решение кроется в самом определении этой последовательности. Мы заведем один мутабельный массив, в который будем сохранять промежуточные результаты вычисления чисел Фибоначчи, т.е. те самые n-1 и n-2.
Псевдокод:
int numberForIndex(int index) {
int[] numbers = [0, 1]; // мутабельный массив, можем добавлять к нему элементы
for (int i = 2; i < index + 1; i++) {
numbers[index] = numbers[i - 1] + numbers[i - 2];
}
return numbers[index];
}→ Пример решения на Objective-C
→ Тесты
Вот и всё, в этом массиве numbers вся соль ДП, это своего рода кэш (Caсhe), в который мы складываем предыдущие результаты вычисления этой же задачи, только на меньшей размерности (n-1 и n-2), что дает нам возможность за одно действие найти решение для размерности n.
Этот алгоритм работает за O(n), но использует немного дополнительной памяти — наш массив.
Вернемся к нахождению длины максимальной возрастающей подпоследовательности.
Решение за O( n ^ 2)

Рассмотрим следующую возрастающую подпоследовательность:
5, 6, 12
теперь взглянем на следующее число после последнего элемента в последовательности — это 3.
Может ли оно быть продолжением нашей последовательности? Нет. Оно меньше чем 12.
А 24 ?
Оно да, оно может.
Соответственно длина нашей последовательности равна теперь 3 + 1, а последовательность выглядит так:
5, 6, 12, 24
Вот где переиспользование предыдущих вычислений: мы знаем что у нас есть подпоследовательность 5, 6, 12, которая имеет длину 3 и теперь нам легко добавить к ней 24. Теперь у вас есть ощущение того, что мы можем это использовать, только как?
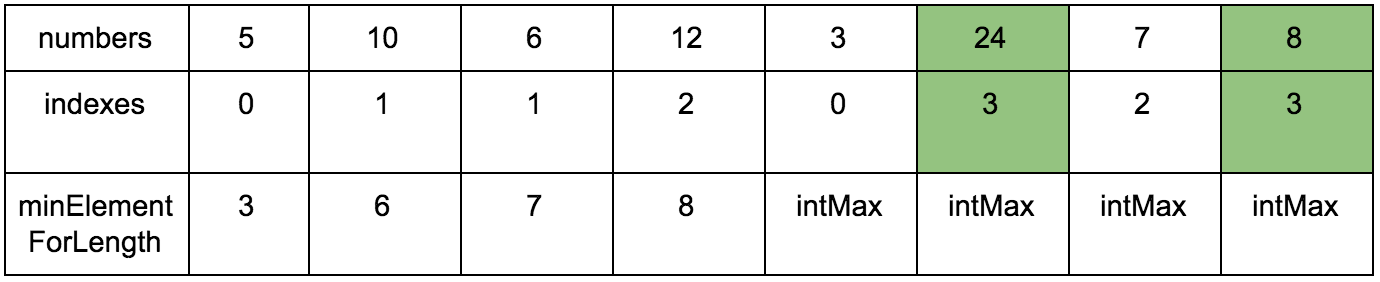
Давайте заведем еще один дополнительный массив (вот он наш cache, вот оно наше ДП), в котором будем хранить размер возрастающей подпоследовательности для n-го элемента.
Выглядеть это будет так:

Наша задача — заполнить массив counts правильными значениями. Изначально он заполнен единицами, так как каждый элемент сам по себе является минимальной возрастающей подпоследовательностью.
“Что за загадочные i и j?” — спросите вы. Это индексы итераторов по массиву, которые мы будем использовать. Изменяться они будут с помощью двух циклов, один в другом. i всегда будет меньше чем j.
Сейчас j смотрит на 10 — это наш кандидат в члены последовательностей, которые идут до него. Посмотрим туда, где i, там стоит 5.
10 больше 5 и 1 <= 1, counts[j] <= counts[i]? Да, значит counts[j] = counts[i] + 1, помните наши рассуждения в начале?
Теперь таблица выглядит так.

Смещаем j.

Промежуточные шаги, их много
Результат:

Имея перед глазами эту таблицу и понимая какие шаги нужно делать, мы теперь легко можем реализовать это в коде.
Псевдокод:
int longestIncreasingSubsequenceLength( int numbers[] ) {
if (numbers.count == 1) {
return 1;
}
int lengthOfSubsequence[] = Аrray.newArrayOfSize(numbers.count, 1);
for (int j = 1; j < numbers.count; j++) {
for (int k = 0; k < j; k++) {
if (numbers[j] > numbers[k]) {
if (lengthOfSubsequence[j] <= lengthOfSubsequence[k]) {
lengthOfSubsequence[j] = lengthOfSubsequence[k] + 1;
}
}
}
}
int maximum = 0;
for (int length in lengthOfSubsequence) {
maximum = MAX(maximum, length);
}
return maximum;
}→ Реализация на Objective-C
→ Тесты
Вы не могли не заметить два вложенных цикла в коде, а там где есть два вложенных цикла проходящих по одному массиву, есть и квадратичная сложность O(n^2), что обычно не есть хорошо.
Теперь, если вы билингвал, вы несомненно зададитесь вопросом “Can we do better?”, обычные же смертные спросят “Могу ли я придумать алгоритм, который сделает это за меньшее время?”
Ответ: “да, можете!”
Чтобы сделать это нам нужно вспомнить, что такое бинарный поиск.
Бинарный поиск O(log n)

Бинарный поиск работает только на отсортированных массивах. Например, нам нужно найти позицию числа n в отсортированном массиве:
1, 5, 6, 8, 14, 15, 17, 20, 22
Зная что массив отсортирован, мы всегда можем сказать правее или левее определенного числа в массиве искомое число должно находиться.
Мы ищем позицию числа 8 в этом массиве. С какой стороны от середины массива оно будет находиться? 14 — это число в середине массива. 8 < 14 — следовательно 8 левее 14. Теперь нас больше не интересует правая часть массива, и мы можем ее отбросить и повторять ту же самую операцию вновь и вновь пока не наткнемся на 8. Как видите, нам даже не нужно проходить по всем элементам массива, сложность этого алгоритма < O( n ) и равна O (log n).
Для реализации алгоритма нам понадобятся 3 переменные для индексов: left, middle, right.
Ищем позицию числа 8.
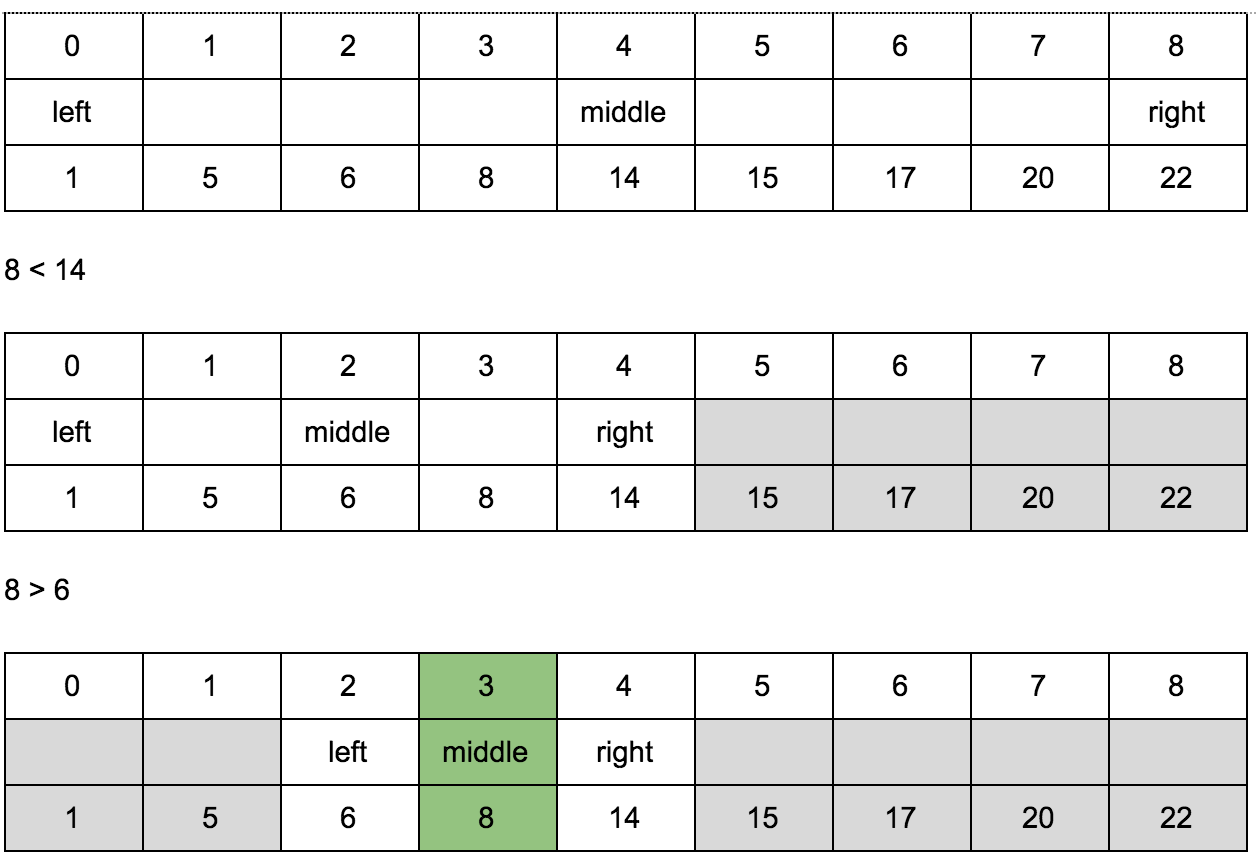
Мы отгадали где находится 8 с трёх нот.
Псевдокод:
int binarySearch(int list [], int value) {
if !list.isEmpty {
int left = list.startIndex
int right = list.endIndex-1
while left <= right {
let middle = left + (right - left)/2
if list[middle] == value{
return middle
}
if value < list[middle]{
right = middle - 1
}
else{
left = middle + 1
}
}
}
return nil
}Решение за O (n * log n)

Теперь мы будем проходить по нашему исходному массиву при этом заполняя новый массив, в котором будет храниться возрастающая подпоследовательность. Еще один плюс этого алгоритма: он находит не только длину максимальной возрастающей подпоследовательности, но и саму подпоследовательность.
Как же двоичный поиск поможет нам в заполнении массива подпоследовательности?
С помощью этого алгоритма мы будем искать место для нового элемента в вспомогательном массиве, в котором мы храним для каждой длины подпоследовательности минимальный элемент, на котором она может заканчиваться.
Если элемент больше максимального элемента в массиве, добавляем элемент в конец. Это просто.
Если такой элемент уже существует в массиве, ничего особо не меняется. Это тоже просто.
Что нам нужно рассмотреть, так это случай когда следующий элемент меньше максимального в этом массиве. Понятно, что мы не можем его поставить в конец, и он не обязательно вообще должен являться членом именно максимальной последовательности, или наоборот, та подпоследовательность, которую мы имеем сейчас и в которую не входит этот новый элемент, может быть не максимальной.
Все это запутанно, сейчас будет проще, сведем к рассмотрению 2-х оставшихся случаев.
- Рассматриваемый элемент последовательности (x) меньше чем наибольший элемент в массиве (Nmax), но больше чем предпоследний.
- Рассматриваемый элемент меньше какого-то элемента в середине массива.
В случае 1 мы просто можем откинуть Nmax в массиве и поставим на его место x. Так как понятно, что если бы последующие элементы были бы больше чем Nmax, то они будут и больше чем x — соответственно мы не потеряем ни одного элемента.
Случай 2: для того чтобы этот случай был нам полезен, мы заведем еще один массив, в котором будем хранить размер подпоследовательности, в которой этот элемент является максимальным. Собственно этим размером и будет являться та позиция в первом вспомогательном массиве для этого элемента, которую мы найдем с помощью двоичного поиска. Когда мы найдем нужную позицию, мы проверим элемент справа от него и заменим на текущий, если текущий меньше (тут действует та же логика как и в первом случае)
Не расстраивайтесь, если не все стало понятно из этого текстового объяснения, сейчас я покажу все наглядно.
Нам нужны:
- Исходная последовательность
- Создаем мутабельный массив, где будем хранить возрастающие элементы для подпоследовательности
- Создаем мутабельный массив размеров подпоследовательности, в которой рассматриваемый элемент является максимальным.
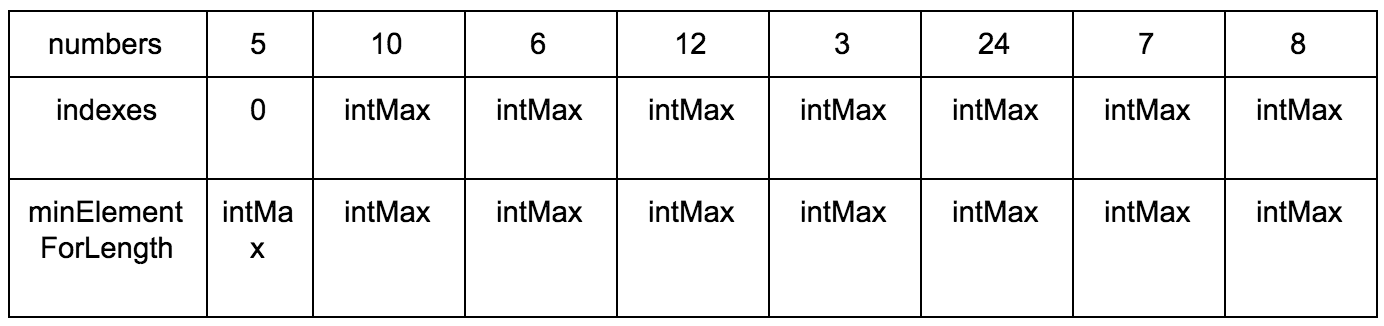
Промежуточные шаги
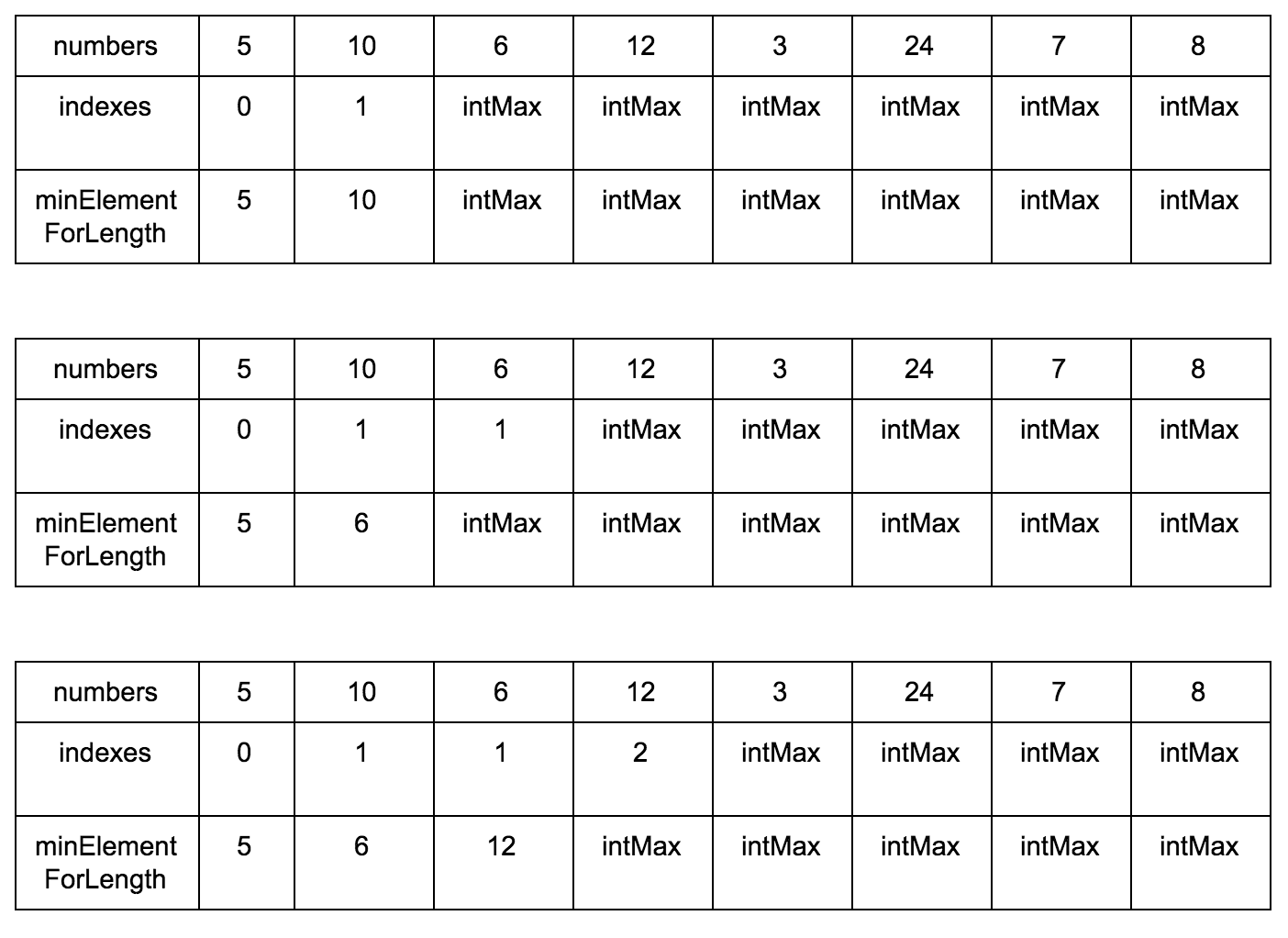
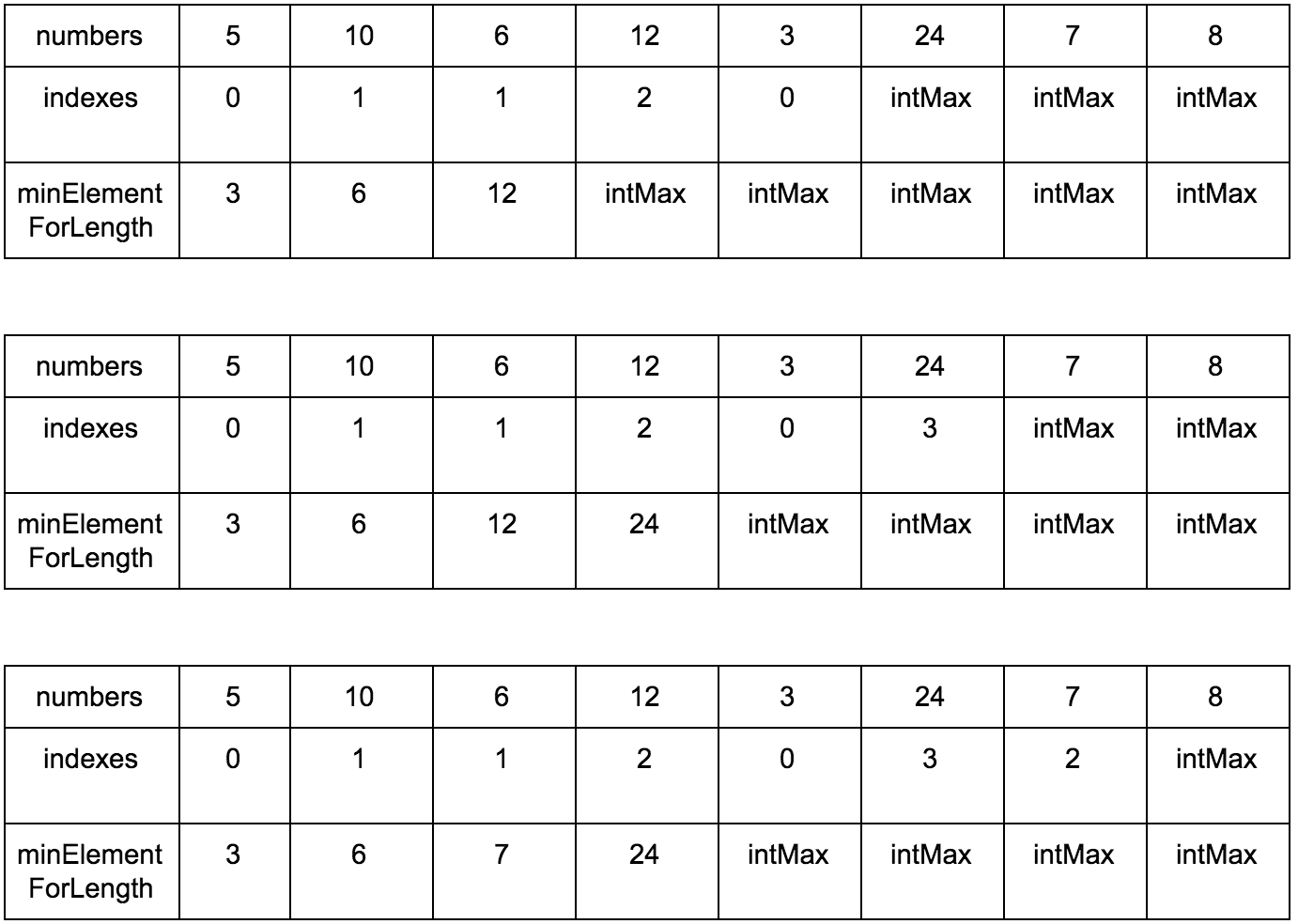
Результат:
Псевдокод:
int longestIncreasingSubsequenceLength(int numbers[]) {
if (numbers.count <= 1) {
return 1;
}
int lis_length = -1;
int subsequence[];
int indexes[];
for (int i = 0; i < numbers.count; ++i) {
subsequence[i] = INT_MAX;
subsequence[i] = INT_MAX;
}
subsequence[0] = numbers[0];
indexes[0] = 0;
for (int i = 1; i < numbers.count; ++i) {
indexes[i] = ceilIndex(subsequence, 0, i, numbers[i]);
if (lis_length < indexes[i]) {
lis_length = indexes[i];
}
}
return lis_length + 1;
}
int ceilIndex(int subsequence[],
int startLeft,
int startRight,
int key){
int mid = 0;
int left = startLeft;
int right = startRight;
int ceilIndex = 0;
bool ceilIndexFound = false;
for (mid = (left + right) / 2; left <= right && !ceilIndexFound; mid = (left + right) / 2) {
if (subsequence[mid] > key) {
right = mid - 1;
}
else if (subsequence[mid] == key) {
ceilIndex = mid;
ceilIndexFound = true;
}
else if (mid + 1 <= right && subsequence[mid + 1] >= key) {
subsequence[mid + 1] = key;
ceilIndex = mid + 1;
ceilIndexFound = true;
} else {
left = mid + 1;
}
}
if (!ceilIndexFound) {
if (mid == left) {
subsequence[mid] = key;
ceilIndex = mid;
}
else {
subsequence[mid + 1] = key;
ceilIndex = mid + 1;
}
}
return ceilIndex;
}→ Реализация на Objective-C
→ Тесты
Итоги
Мы с вами сейчас рассмотрели 4 алгоритма разной сложности. Это сложности, с которыми вам приходится встречаться постоянно при анализе алгоритмов:
О( log n ), О( n ), О( n * log n ), О( n ^ 2 )
Эта картинка из вот этой статьи
Еще мы рассмотрели примеры использования Динамического Программирования, тем самым расширив наш инструмент разработки и понимания алгоритмов. Эти принципы пригодятся вам при изучении других проблем.
Для лучшего понимания я рекомендую вам закодировать эти проблемы самим на привычном вам языке. А еще было бы здорово, если бы вы запостили ссылку на ваше решение в комментах.
Еще предлагаю подумать над тем как доработать последний алгоритм за O (n * log n ) так чтобы вывести еще и саму наибольшую подпоследовательность. Ответ напишите в комментах.
Всем спасибо за внимание, до новых встреч!
Ссылки:
Вопрос на Stackoverflow.com
Примеры реализации на C++ и Java
Видео с объяснением
| Задача: |
| Дан массив из чисел: . Требуется найти в этой последовательности строго возрастающую подпоследовательность наибольшей длины. |
| Определение: |
| Наибольшая возрастающая подпоследовательность (НВП) (англ. Longest increasing subsequence, LIS) строки длины — это последовательность символов строки таких, что , причем — наибольшее из возможных. |
Содержание
- 1 Решение за время O(N2)
- 1.1 Псевдокод алгоритма
- 2 Решение за O(N log N)
- 2.1 Псевдокод алгоритма
- 3 Ещё одно решение за О(N log N)
- 4 См. также
- 5 Примечания
- 6 Источники информации
Решение за время O(N2)
Построим массив , где — это длина наибольшей возрастающей подпоследовательности, оканчивающейся в элементе, с индексом . Массив будем заполнять постепенно — сначала , потом и т.д. Ответом на нашу задачу будет максимум из всех элементов массива .
Заполнение массива будет следующим: если , то искомая последовательность состоит только из числа . Если , то перед числом в подпоследовательности стоит какое-то другое число. Переберем его: это может быть любой элемент , но такой, что . Пусть на каком-то шаге нам надо посчитать очередное . Все элементы массива до него уже посчитаны. Значит наше мы можем посчитать следующим образом: при условии, что .
Пока что мы нашли лишь максимальную длину наибольшей возрастающей подпоследовательности, но саму ее мы вывести не можем. Для восстановления ответа заведем массив , где будет означать индекс в массиве , при котором достигалось наибольшее значение . Для вывода ответа будем идти от элемента с максимальным значениям по его предкам.
Псевдокод алгоритма
vector<int> findLIS(vector<int> a): int n = a.size //размер исходной последовательности int prev[0..n - 1] int d[0..n - 1] for i = 0 to n - 1 d[i] = 1 prev[i] = -1 for j = 0 to i - 1 if (a[j] < a[i] and d[j] + 1 > d[i]) d[i] = d[j] + 1 prev[i] = j pos = 0 // индекс последнего элемента НВП length = d[0] // длина НВП for i = 0 to n - 1 if d[i] > length pos = i length = d[i] // восстановление ответа vector<int> answer while pos != -1 answer.push_back(a[pos]) pos = prev[pos] reverse(answer) return answer
Решение за O(N log N)
Для более быстрого решения данной задачи построим следующую динамику: пусть — число, на которое оканчивается возрастающая последовательность длины , а если таких чисел несколько — то наименьшее из них. Изначально мы предполагаем, что , а все остальные элементы .
Заметим два важных свойства этой динамики: , для всех и каждый элемент обновляет максимум один элемент . Это означает, что при обработке очередного , мы можем за c помощью двоичного поиска в массиве найти первое число, которое больше либо равно текущего и обновить его.
Для восстановления ответа будем поддерживать заполнение двух массивов: и . В будем хранить индекс элемента, на который заканчивается оптимальная подпоследовательность длины , а в — позицию предыдущего элемента для .
Псевдокод алгоритма
vector<int> findLIS(vector<int> a): int n = a.size //размер исходной последовательности int d[0..n] int pos[0..n] int prev[0..n - 1] length = 0 pos[0] = -1 d[0] = -INF for i = 1 to n d[i] = INF for i = 0 to n - 1 j = binary_search(d, a[i]) if (d[j - 1] < a[i] and a[i] < d[j]) d[j] = a[i] pos[j] = i prev[i] = pos[j - 1] length = max(length, j) // восстановление ответа vector<int> answer p = pos[length] while p != -1 answer.push_back(a[p]) p = prev[p] reverse(answer) return answer
Ещё одно решение за О(N log N)
Существует ещё одно решение, которое позволяет нам найти длину наибольшей возрастающей подпоследовательности, но без возможности восстановления данной подпоследовательности. Для этого мы воспользуемся таблом Юнга. Оно обладает таким свойством, что длина первой строки табла и будет являться искомой величиной[1].
Само табло представляет из себя расположение различных целых чисел в массиве строк, выровненных по левому краю, где в строке содержится элементов; при этом в каждой строке элементы возрастают слева направо, а элементы каждого столбца возрастают сверху вниз. Чтобы построить табло требуется прочитать очередной элемент , если он больше либо равен , где — длина строки, то просто добавить в конец строки, если меньше, то требуется найти первый элемент , который больше данного . Поставить элемент вместо . С элементом требуется провести те же действия, что и с , только уже на строке табла.
Пример построения табла на массиве :
1. Берём элемент . Видим, что , который расположен на первой строке в ячейке с индексом . Увеличиваем и .
2. Берём элемент . Видим, что . Увеличиваем и .
3. Аналогично для элемента .
4. Берём элемент . Так как , то бинарным поиском находим нужную нам позицию , такую, что . В данном случае это
первая позиция. Присваиваем и проделываем такую же операцию, но для строки с индексом .
5. Аналогично для элемента .
6. Аналогично для элемента .
Таким образом, длина наибольшей возрастающей подпоследовательности для массива равна (например, подпоследовательность из элементов ).
См. также
- Задача о наибольшей общей подпоследовательности
- Наибольшая общая возрастающая подпоследовательность
- Задача о наибольшей общей палиндромной подпоследовательности
Примечания
- ↑ Wikipedia — Robinson–Schensted correspondence
Источники информации
- Википедия — Задача поиска наибольшей увеличивающейся подпоследовательности
- Wikipedia — Longest increasing subsequence
- Дистанционная подготовка — Наибольшая возрастающая подпоследовательность (НВП, Longest Increasing Subsequence, LIS)
- MAXimal :: algo :: Длиннейшая возрастающая подпоследовательность за O (N log N)
Here is my C++ solution of the problem. The solution is simpler than all of the provided here so far, and it is fast: N*log(N) algorithmic time complexity. I submitted the solution at leetcode, it runs 4 ms, faster than 100% of C++ solutions submitted.

The idea is (in my opinion) clear: traverse the given array of numbers from left to right. Maintain additionally array of numbers (seq in my code), that holds increasing subsequence. When the taken number is bigger than all numbers that the subsequence holds, put it at the end of seq and increase the subsequence length counter by 1. When the number is smaller than the biggest number in the subsequence so far, put it anyway in seq, in the place where it belongs to keep the subsequence sorted by replacing some existing number. The subsequence is initialized with the length of the original numbers array and with initial value -inf, what means smallest int in the given OS.
Example:
numbers = { 10, 9, 2, 5, 3, 7, 101, 18 }
seq = {-inf, -inf, -inf, -inf, -inf, -inf, -inf}
here is how the sequence changes when we traverse the numbers from left to right:
seq = {10, -inf, -inf, -inf, -inf, -inf, -inf}
seq = {9, -inf, -inf, -inf, -inf, -inf, -inf}
seq = {2, -inf, -inf, -inf, -inf, -inf, -inf}
seq = {2, 5, -inf, -inf, -inf, -inf, -inf}
seq = {2, 3, -inf, -inf, -inf, -inf, -inf}
seq = {2, 3, 7, -inf, -inf, -inf, -inf}
seq = {2, 3, 7, 101, -inf, -inf, -inf}
seq = {2, 3, 7, 18, -inf, -inf, -inf}
The longest increasing subsequence for the array has length 4.
Here is the code:
int longestIncreasingSubsequence(const vector<int> &numbers){
if (numbers.size() < 2)
return numbers.size();
vector<int>seq(numbers.size(), numeric_limits<int>::min());
seq[0] = numbers[0];
int len = 1;
vector<int>::iterator end = next(seq.begin());
for (size_t i = 1; i < numbers.size(); i++) {
auto pos = std::lower_bound(seq.begin(), end, numbers[i]);
if (pos == end) {
*end = numbers[i];
end = next(end);
len++;
}
else
*pos = numbers[i];
}
return len;
}
Well, so far so good, but how do we know that the algorithm computes the length of the longest (or one of the longest, here may be several subsequences of the same size) subsequence? Here is my proof:
Let’s assume that the algorithm does not computes length of the longest subsequence. Then in the original sequence must exist a number such that the algorithm misses and that would make the subsequence longer. Let’s say, for a subsequence x1, x2, …, xn there exists a number y such that xk < y < xk+1, 1 <= k <= n. To contribute to the subsequence y must be located in the original sequence between xk and xk+1. But then we have contradiction: when the algorithm traverses original sequence from left to right, every time it meets a number bigger than any number in the current subsequence, it extends the subsequence by 1. By the time algorithm would meet such number y the subsequence would have length k and contain numbers x1, x2, …, xk. Because xk < y, the algorithm would extend the subsequence by 1 and include y in the subsequence. The same logic applies when y is the smallest number of the subsequence and located to the left of x1 or when y is the biggest number of the subsequence and located to the right of xn.
Conclusion: such number y does not exists and the algorithm computes the longest increasing subsequence.
I hope that makes sense.
In the final statement, I would like to mention that the algorithm can be easily generalized to compute longest decreasing subsequence as well, for any data types which elements can be ordered.
The idea is the same, here is the code:
template<typename T, typename cmp = std::less<T>>
size_t longestSubsequence(const vector<T> &elements)
{
if (elements.size() < 2)
return elements.size();
vector<T>seq(elements.size(), T());
seq[0] = elements[0];
size_t len = 1;
auto end = next(seq.begin());
for (size_t i = 1; i < elements.size(); i++) {
auto pos = std::lower_bound(seq.begin(), end, elements[i], cmp());
if (pos == end) {
*end = elements[i];
end = next(end);
len++;
}
else
*pos = elements[i];
}
return len;
}
Examples of usage:
int main()
{
vector<int> nums = { 0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15 };
size_t l = longestSubsequence<int>(nums); // l == 6 , longest increasing subsequence
nums = { 0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15 };
l = longestSubsequence<int, std::greater<int>>(nums); // l == 5, longest decreasing subsequence
vector<string> vstr = {"b", "a", "d", "bc", "a"};
l = longestSubsequence<string>(vstr); // l == 2, increasing
vstr = { "b", "a", "d", "bc", "a" };
l = longestSubsequence<string, std::greater<string>>(vstr); // l == 3, decreasing
}
Проблема самой длинной возрастающей подпоследовательности состоит в том, чтобы найти подпоследовательность данной последовательности, в которой элементы подпоследовательности отсортированы в порядке от низшего к высшему, и в которой подпоследовательность является максимально возможной. Эта подпоследовательность не обязательно непрерывна или уникальна.
Обратите внимание, что проблема конкретно нацелена подпоследовательности которые не обязательно должны быть непрерывными, т. е. не требуется, чтобы подпоследовательности занимали последовательные позиции в исходных последовательностях.
Например, самая длинная возрастающая подпоследовательность [0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15] является [0, 2, 6, 9, 11, 15].
Эта подпоследовательность имеет длину 6; входная последовательность не имеет 7-членных возрастающих подпоследовательностей. Самая длинная возрастающая подпоследовательность в этом примере не уникальна.
Например, [0, 4, 6, 9, 11, 15] или же [0, 4, 6, 9, 13, 15] другие возрастающие подпоследовательности той же длины в той же входной последовательности.
Потренируйтесь в этой проблеме
Идея состоит в том, чтобы использовать рекурсия Для решения этой проблемы. Для каждого элемента есть две возможности:
- Включить текущий элемент в ЛИС, если он больше, чем предыдущий элемент в ЛИС, и повторить для остальных элементов.
- Исключить текущий элемент из LIS и повторить для остальных элементов.
Наконец, верните максимальное значение, которое мы получим, включив или исключив текущий элемент. Базовым случаем рекурсии будет отсутствие элементов. Ниже приведена реализация этой идеи на C++, Java и Python:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
#include <iostream> #include <climits> using namespace std; // Функция для нахождения длины самой длинной возрастающей подпоследовательности int LIS(int arr[], int i, int n, int prev) { // Базовый случай: ничего не осталось if (i == n) { return 0; } // случай 1: исключить текущий элемент и обработать // оставшиеся элементы int excl = LIS(arr, i + 1, n, prev); // случай 2: включить текущий элемент, если он больше // чем предыдущий элемент в LIS int incl = 0; if (arr[i] > prev) { incl = 1 + LIS(arr, i + 1, n, arr[i]); } // вернуть максимум из двух вышеперечисленных вариантов return max(incl, excl); } int main() { int arr[] = { 0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15 }; int n = sizeof(arr) / sizeof(arr[0]); cout << «The length of the LIS is « << LIS(arr, 0, n, INT_MIN); return 0; } |
Скачать Выполнить код
результат:
The length of the LIS is 6
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
class Main { // Функция для нахождения длины самой длинной возрастающей подпоследовательности public static int LIS(int[] arr, int i, int n, int prev) { // Базовый случай: ничего не осталось if (i == n) { return 0; } // случай 1: исключить текущий элемент и обработать // оставшиеся элементы int excl = LIS(arr, i + 1, n, prev); // случай 2: включить текущий элемент, если он больше // чем предыдущий элемент в LIS int incl = 0; if (arr[i] > prev) { incl = 1 + LIS(arr, i + 1, n, arr[i]); } // вернуть максимум из двух вышеперечисленных вариантов return Integer.max(incl, excl); } public static void main(String[] args) { int[] arr = { 0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15 }; System.out.print(«The length of the LIS is « + LIS(arr, 0, arr.length, Integer.MIN_VALUE)); } } |
Скачать Выполнить код
результат:
The length of the LIS is 6
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import sys # Функция для нахождения длины самой длинной возрастающей подпоследовательности def LIS(arr, i, n, prev): # Базовый вариант: ничего не осталось if i == n: return 0 #, случай 1: исключить текущий элемент и обработать # остальные элементы excl = LIS(arr, i + 1, n, prev) #, случай 2: включить текущий элемент, если он больше #, чем предыдущий элемент в LIS incl = 0 if arr[i] > prev: incl = 1 + LIS(arr, i + 1, n, arr[i]) # возвращает максимум из двух вышеперечисленных вариантов. return max(incl, excl) if __name__ == ‘__main__’: arr = [0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15] print(‘The length of the LIS is’, LIS(arr, 0, len(arr), —sys.maxsize)) |
Скачать Выполнить код
результат:
The length of the LIS is 6
Временная сложность приведенного выше решения экспоненциальна и занимает место в стеке вызовов.
Проблема имеет оптимальное основание. Это означает, что проблема может быть разбита на более мелкие, простые “подзадачи”, которые затем могут быть разделены на еще более простые, более мелкие подзадачи, пока решение не станет тривиальным. Приведенное выше решение также демонстрирует перекрывающиеся подзадачи. Если мы нарисуем дерево рекурсии решения, мы увидим, что одни и те же подзадачи вычисляются повторно. Мы знаем, что задачи с оптимальной структурой и перекрывающимися подзадачами могут быть решены с помощью динамического программирования, где решения подзадач памятка, а не вычисляется повторно. памяткаИзмененная версия следует нисходящему подходу, поскольку сначала мы разбиваем задачу на подзадачи, а затем вычисляем и сохраняем значения.
Мы также можем решить эту проблему восходящим способом. При подходе «снизу вверх» сначала решайте меньшие подзадачи, а затем решайте из них более крупные подзадачи. Следующий восходящий подход вычисляет L[i], для каждого 0 <= i < n, в котором хранится длина самой длинной возрастающей подпоследовательности подмассива arr[0…i] что заканчивается arr[i]. Вычислять L[i], рассмотрим ЛИС всех меньших значений i (сказать j) уже рассчитано и выбрать максимальное L[j], куда arr[j] меньше, чем текущий элемент arr[i]. У него такое же асимптотическое время выполнения, как и у Memoization, но нет накладных расходов на рекурсию.
Ниже приведена реализация этой идеи на C++, Java и Python:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
#include <iostream> #include <vector> #include <climits> using namespace std; // Итерационная функция для нахождения длины самой длинной возрастающей подпоследовательности // данного массива int LIS(vector<int> const &arr) { int n = arr.size(); // базовый вариант if (n == 0) { return 0; } // массив для хранения решения подзадачи. `L[i]` хранит длину // самой длинной возрастающей подпоследовательности, заканчивающейся на `arr[i]` int L[n] = { 0 }; // самая длинная возрастающая подпоследовательность, заканчивающаяся на `arr[0]`, имеет длину 1 L[0] = 1; // начинаем со второго элемента массива for (int i = 1; i < n; i++) { // делаем для каждого элемента подмассива `arr[0…i-1]` for (int j = 0; j < i; j++) { // найти самую длинную возрастающую подпоследовательность, заканчивающуюся на `arr[j]` // где `arr[j]` меньше, чем текущий элемент `arr[i]` if (arr[j] < arr[i] && L[j] > L[i]) { L[i] = L[j]; } } // включить `arr[i]` в ЛИС L[i]++; } // найти самую длинную возрастающую подпоследовательность (имеющую максимальную длину) int lis = INT_MIN; for (int x: L) { lis = max(lis, x); } return lis; } int main() { vector<int> arr = { 0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15 }; cout << «The length of the LIS is « << LIS(arr); return 0; } |
Скачать Выполнить код
результат:
The length of the LIS is 6
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
import java.util.Arrays; class Main { // Итерационная функция для нахождения длины самой длинной возрастающей подпоследовательности // данного массива public static int LIS(int[] arr) { // базовый вариант if (arr == null || arr.length == 0) { return 0; } // массив для хранения решения подзадачи. `L[i]` хранит длину // самой длинной возрастающей подпоследовательности, заканчивающейся на `arr[i]` int[] L = new int[arr.length]; // самая длинная возрастающая подпоследовательность, заканчивающаяся на `arr[0]`, имеет длину 1 L[0] = 1; // начинаем со второго элемента массива for (int i = 1; i < arr.length; i++) { // делаем для каждого элемента подмассива `arr[0…i-1]` for (int j = 0; j < i; j++) { // найти самую длинную возрастающую подпоследовательность, заканчивающуюся на `arr[j]` // где `arr[j]` меньше, чем текущий элемент `arr[i]` if (arr[j] < arr[i] && L[j] > L[i]) { L[i] = L[j]; } } // включить `arr[i]` в ЛИС L[i]++; } // вернуть самую длинную возрастающую подпоследовательность (имеющую максимальную длину) return Arrays.stream(L).max().getAsInt(); } public static void main(String[] args) { int[] arr = { 0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15 }; System.out.print(«The length of the LIS is « + LIS(arr)); } } |
Скачать Выполнить код
результат:
The length of the LIS is 6
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
# Итерационная функция для нахождения длины самой длинной возрастающей подпоследовательности # данного списка def LIS(arr): # Базовый вариант if not arr: return 0 # Список # для хранения решений подзадач. `L[i]` хранит длину # самой длинной возрастающей подпоследовательности, заканчивающейся на `arr[i]` L = [0] * len(arr) # самая длинная возрастающая подпоследовательность, оканчивающаяся на `arr[0]`, имеет длину 1 L[0] = 1 # старт со второго элемента в списке for i in range(1, len(arr)): # сделать для каждого элемента в подсписке `arr[0…i-1]` for j in range(i): # найти самую длинную возрастающую подпоследовательность, которая заканчивается на `arr[j]` #, где `arr[j]` меньше, чем текущий элемент `arr[i]` if arr[j] < arr[i] and L[j] > L[i]: L[i] = L[j] # включает `arr[i]` в LIS L[i] = L[i] + 1 # возвращает самую длинную возрастающую подпоследовательность (имеющую максимальную длину) return max(L) if __name__ == ‘__main__’: arr = [0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15] print(‘The length of the LIS is’, LIS(arr)) |
Скачать Выполнить код
результат:
The length of the LIS is 6
Временная сложность приведенного выше решения равна O(n2) и требует O(n) дополнительное пространство, где n — размер заданной последовательности.
Как распечатать ЛИС?
Рассмотренные выше методы печатают только длину LIS, но не печатают саму LIS. Чтобы распечатать LIS, мы должны сохранить самую длинную возрастающую подпоследовательность в таблице поиска, а не хранить только длину LIS.
Например, рассмотрим массив arr = [ 0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15]. Самая длинная возрастающая подпоследовательность подмассива arr[0…i] что заканчивается arr[i] находятся:
LIS[0] — 0
LIS[1] — 0 8
LIS[2] — 0 4
LIS[3] — 0 8 12
LIS[4] — 0 2
LIS[5] — 0 8 10
LIS[6] — 0 4 6
LIS[7] — 0 8 12 14
LIS[8] — 0 1
LIS[9] — 0 4 6 9
LIS[10] — 0 4 5
LIS[11] — 0 4 6 9 13
LIS[12] — 0 2 3
LIS[13] — 0 4 6 9 11
LIS[14] — 0 4 6 7
LIS[15] — 0 4 6 9 13 15
Ниже приведена реализация этой идеи на C++, Java и Python:
C++
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
#include <iostream> #include <vector> using namespace std; // Итерационная функция для поиска самой длинной возрастающей подпоследовательности // данного массива void findLIS(vector<int> const &arr) { int n = arr.size(); // базовый вариант if (n == 0) { return; } // LIS[i] хранит самую длинную возрастающую подпоследовательность подмассива // `arr[0…i]`, оканчивающийся на `arr[i]` vector<vector<int>> LIS(n, vector<int>{}); // LIS[0] обозначает самую длинную возрастающую подпоследовательность, заканчивающуюся на `arr[0]` LIS[0].push_back(arr[0]); // начинаем со второго элемента массива for (int i = 1; i < n; i++) { // делаем для каждого элемента подмассива `arr[0…i-1]` for (int j = 0; j < i; j++) { // найти самую длинную возрастающую подпоследовательность, заканчивающуюся на `arr[j]` // где `arr[j]` меньше, чем текущий элемент `arr[i]` if (arr[j] < arr[i] && LIS[j].size() > LIS[i].size()) { LIS[i] = LIS[j]; } } // включить `arr[i]` в `LIS[i]` LIS[i].push_back(arr[i]); } // раскомментируйте следующий код, чтобы вывести содержимое `LIS` /* for (int i = 0; i < n; i++) { cout << «LIS[» << i << «] — «; for (int j: LIS[i]) { cout << j << » «; } cout << конец; } */ // `j` будет хранить индекс LIS int j = 0; for (int i = 0; i < n; i++) { if (LIS[j].size() < LIS[i].size()) { j = i; } } // распечатать ЛИС for (int i: LIS[j]) { cout << i << » «; } } int main() { vector<int> arr = { 0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15 }; findLIS(arr); return 0; } |
Скачать Выполнить код
результат:
0 4 6 9 13 15
Java
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
import java.util.ArrayList; import java.util.List; class Main { // Итерационная функция для поиска самой длинной возрастающей подпоследовательности // данного массива public static void findLIS(int[] arr) { // базовый вариант if (arr == null || arr.length == 0) { return; } // LIS[i] хранит самую длинную возрастающую подпоследовательность подмассива // `arr[0…i]`, оканчивающийся на `arr[i]` List<List<Integer>> LIS = new ArrayList<>(); for (int i = 0; i < arr.length; i++) { LIS.add(new ArrayList<>()); } // LIS[0] обозначает самую длинную возрастающую подпоследовательность, заканчивающуюся на `arr[0]` LIS.get(0).add(arr[0]); // начинаем со второго элемента массива for (int i = 1; i < arr.length; i++) { // делаем для каждого элемента подмассива `arr[0…i-1]` for (int j = 0; j < i; j++) { // найти самую длинную возрастающую подпоследовательность, заканчивающуюся на `arr[j]` // где `arr[j]` меньше, чем текущий элемент `arr[i]` if (arr[j] < arr[i] && LIS.get(j).size() > LIS.get(i).size()) { LIS.set(i, new ArrayList<>(LIS.get(j))); } } // включить `arr[i]` в `LIS[i]` LIS.get(i).add(arr[i]); } // раскомментируйте следующий код, чтобы вывести содержимое `LIS` /*for (int i = 0; i < arr.length; i++) { System.out.println(«LIS[» + i + «] — » + LIS.get(i)); }*/ // `j` будет хранить индекс LIS int j = 0; for (int i = 0; i < arr.length; i++) { if (LIS.get(j).size() < LIS.get(i).size()) { j = i; } } // распечатать ЛИС System.out.print(LIS.get(j)); } public static void main(String[] args) { int[] arr = { 0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15 }; findLIS(arr); } } |
Скачать Выполнить код
результат:
[0, 4, 6, 9, 13, 15]
Python
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
# Итеративная функция для поиска самой длинной возрастающей подпоследовательности заданного списка def findLIS(arr): # Базовый вариант if not arr: return [] # LIS[i] хранит самую длинную возрастающую подпоследовательность подсписка # `arr[0…i]`, оканчивающийся на `arr[i]` LIS = [[] for _ in range(len(arr))] # LIS[0] обозначает самую длинную возрастающую подпоследовательность, заканчивающуюся на `arr[0]` LIS[0].append(arr[0]) # старт со второго элемента в списке for i in range(1, len(arr)): # сделать для каждого элемента в подсписке `arr[0…i-1]` for j in range(i): # найти самую длинную возрастающую подпоследовательность, которая заканчивается на `arr[j]` #, где `arr[j]` меньше, чем текущий элемент `arr[i]` if arr[j] < arr[i] and len(LIS[j]) > len(LIS[i]): LIS[i] = LIS[j].copy() # включает `arr[i]` в `LIS[i]` LIS[i].append(arr[i]) # `j` будет хранить индекс LIS j = 0 for i in range(len(arr)): if len(LIS[j]) < len(LIS[i]): j = i # печать ЛИС print(LIS[j]) if __name__ == ‘__main__’: arr = [0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15] findLIS(arr) |
Скачать Выполнить код
результат:
[0, 4, 6, 9, 13, 15]
Временная сложность приведенного выше решения равна O(n2) и требует O(n2) дополнительное пространство, где n — размер заданной последовательности.
Обратитесь к следующему сообщению для O(n.log(n)) решение, чтобы найти длину и вывести самую длинную возрастающую подпоследовательность.
Проблема самой длинной возрастающей последовательности
Использованная литература:
1. Самая длинная возрастающая подпоследовательность — Википедия.
2. Динамическое программирование #1: самая длинная возрастающая подпоследовательность — YouTube.
Видимо я тут чего-то важного не понимаю.
#include <stdio.h>
struct range {
int start, end;
};
// inclusive range
struct range
max_gtseq (int *a, int n)
{
struct range result = {0, 0};
int max = 0, start = 0, end = 0;
for (int i = 0; i < n - 1; i++)
if (a[i] < a[i + 1])
end++;
else {
if (end - start > max) {
max = end - start;
result.start = start;
result.end = end;
}
end = start = i + 1;
}
if ((n - 1) - start > max) {
result.start = start;
result.end = n - 1;
}
return result;
}
int
main (int ac, char *av[])
{
int x[] = {1, 2, 3, 10, 1, 2, 100, 1, 2, 3, 4, 5, 6, 0}; //{10, 9, 8};
struct range r = max_gtseq(x, sizeof(x) / sizeof(x[0]));
printf ("start = %d end = %dn", r.start, r.end);
return puts("End") == EOF;
}
Неужели такой тривиальный однопроходный алгоритм не работает?