Вряд ли стал писать на эту простую тему, если бы не статья, которая начинается так:
Узнать, сколько страниц было проиндексировано Google, можно с помощью Search Console. Но как отыскать те URL, которые отсутствуют в индексе поисковой системы? Справиться с этой задачей поможет специальный скрипт на Python.
цитата из перевода на searchengines.ru
Вот это да, подумал я. Автор предлагает:
- Установить на компьютер Phyton 3.
- Установить библиотеку BeautifulSoup.
- Установить Tor в качестве прокси-сервера.
- Установить Polipo для преобразования socks-прокси в http-прокси.
- Провести настройки в консоли (не Search Conosole! в терминале операционной системы!).
- Увидеть предупреждение в конце статьи “Если скрипт не работает, то Google, возможно, блокирует Tor. В этом случае используйте свой собственный прокси-сервер”.
- Побиться головой о стену (ой, тут все-таки прорвался мой сарказм).
Как проверять индексацию без лишних мучений?
Автор опирается на верный в основе способ – запросы к выдаче с оператором info:. Это самый надежный метод, но у него есть огромный минус. Один запрос проверяет один url. А что если у нас их 10 000? Или больше?
Очевидно, что нужен более экономный путь. И он есть. Рассказываю.
Во-первых, получаем полный список страниц сайта. Если вы следуете стандартам веб-разработки и минимально заботитесь об индексации, то он должен содержаться в sitemap.xml.
Для удобства работы выгружаем url в виде простого списка. Это можно сделать, открыв xml-файл в Excel:
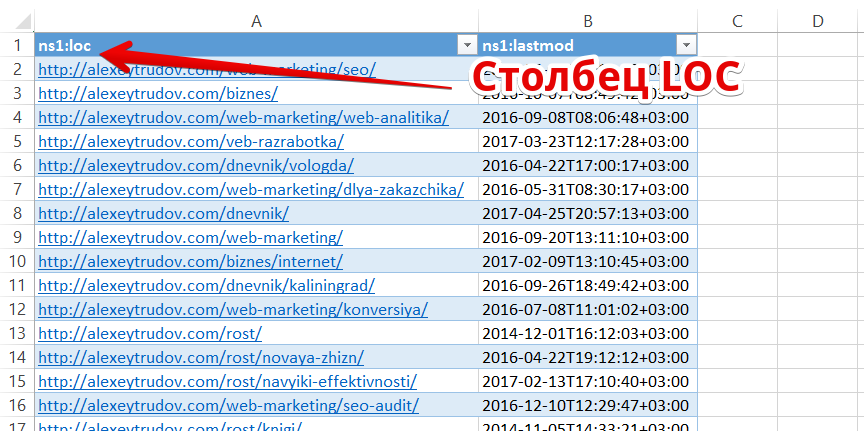
Вся дальнейшая работа сводится к тому, чтобы удалить из списка те страницы, которые есть в индексе.
В посте Как проверить индексацию сайта или раздела в Google? Ответ не так уж прост! я писал о том, что традиционно используемые для пробивки индекса операторы “site:” и “inurl:” не дают точных результатов. Если страница не обнаруживается поиском с оператором, это не значит, что ее нет в базе Googe.
Но! Если уж страница нашлась – это значит, что она в индексе. Понимаете разницу? Оператор находит не все, но уж что находит – то в индексе. Этим и воспользуемся.
Смотрим основные разделы и типичные паттерны в url, формируем список запросов для проверки индекса в них.
Например, для этого блога:
- site:alexeytrudov.com/dnevnik/
- site:alexeytrudov.com/web-marketing/
- site:alexeytrudov.com/veb-razrabotka/
Как быть, если в url нет ЧПУ и явной структуры? Можно придумать много способов. Например, помимо site: указывать фразу, которая есть только в шаблоне определенного раздела. Или наоборот – добавить слово со знаком минус, чтобы найти url, где оно не содержится.
Суть в том, чтобы а) покрыть разные части сайта и б) использовать достаточно сложный запрос, на который Гугл выдаст много результатов (см. предыдущую статью).
Каждый из запросов способен принести нам до 1000 новых url. Нужно выгрузить результаты по ним для сравнения со списком из карты сайта.
Как парсить выдачу?
Способов миллион. Два примера.
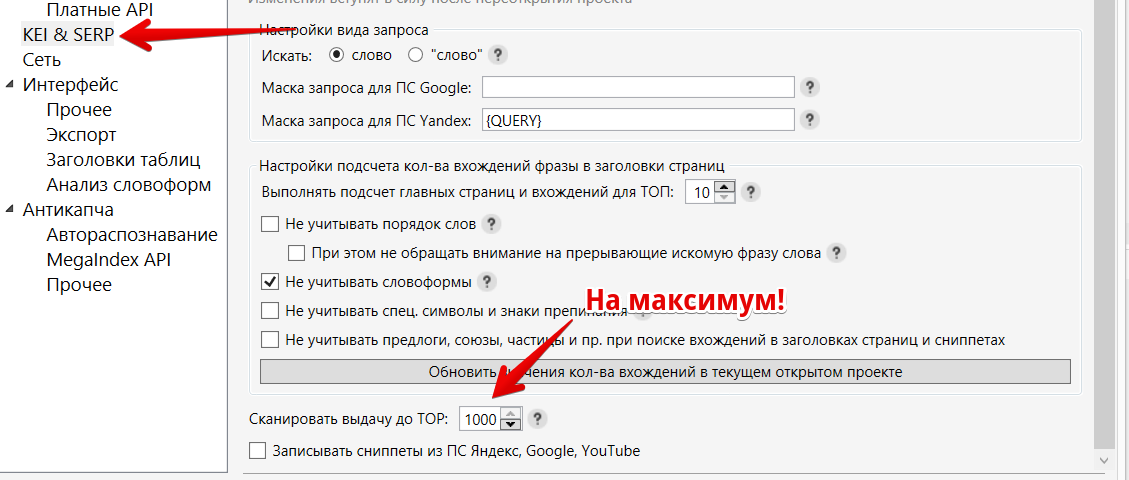
Можно воспользоваться Key Collector (куплен у каждого оптимизатора еще в прошлой жизни). Добавляем как фразы запросы с операторами:

Перед запуском настроим максимальное количество результатов в выдаче:
Теперь сам сбор данных:
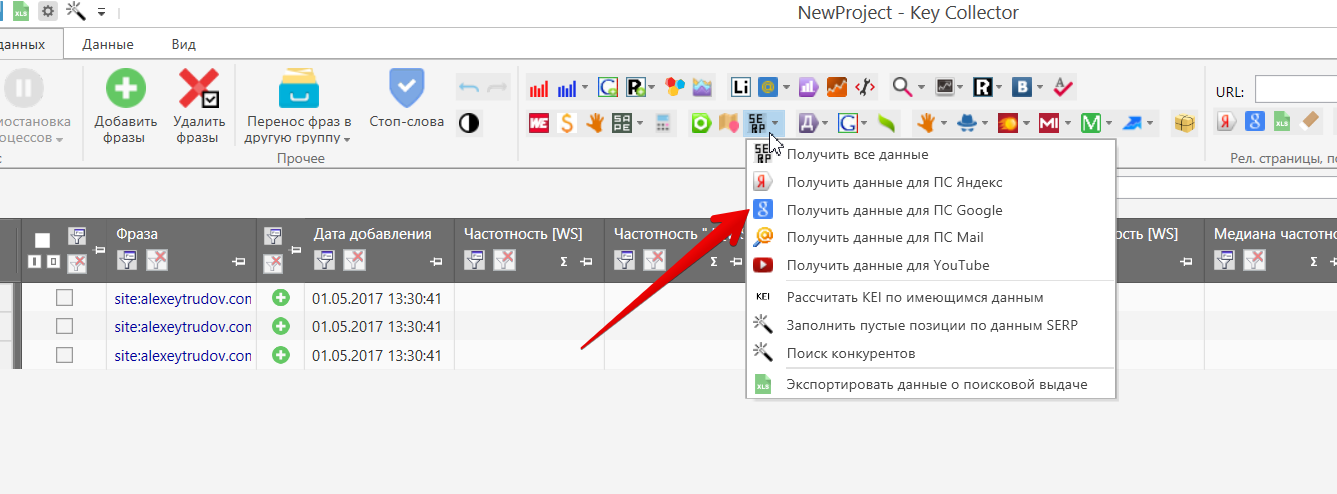
Дожидаемся сбора и выгружаем список url (то же меню, “Экспортировать данные о поисковой выдаче”). Получаем csv-файл со множеством ссылок (у меня на 3 запроса – 136 url, половина сайта, добавив ключи по остальным рубрикам наверняка нашел бы почти все).
Можно ли справиться без Key Collector и вообще без платных программ? Конечно!
- Устанавливаете расширение gInfinity в Chrome (https://chrome.google.com/webstore/detail/ginfinity/dgomfdmdnjbnfhodggijhpbmkgfabcmn).
- Устанавливаете расширение Web Developer (http://chrispederick.com/work/web-developer/) – оно крайне полезно и для других нужд.
Первый плагин нам позволяет загружать в выдаче Google больше 100 результатов простой прокруткой.

Для формирования перечня ссылок нажимаем на значок Web Developer:
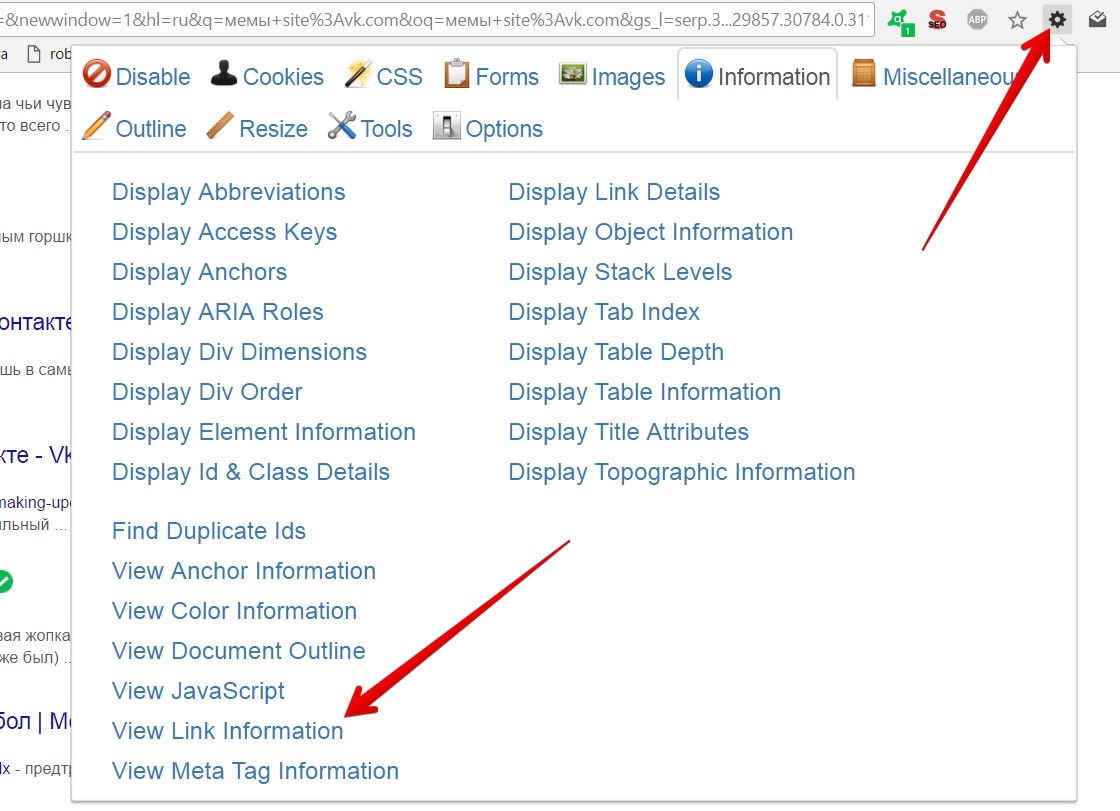
Запрос – зажатая кнопка PageDown – выгрузка.
Теперь нам остается только сравнить списки и вычленить url, которые есть в карте, но отсутствуют в выгрузках из выдачи.
Для сравнения можно использовать бесплатный онлайн-сервис: https://bez-bubna.com/free/compare.php (ну или Excel). Заодно, кстати, не помешает найти страницы, которые есть в выдаче и отсутствуют в карте сайта. Это признак либо неполной карты, либо генерации “мусорных” документов и неправильных настроек индексации.
Если вы корректно подобрали запросы, то наверняка нашли 90% проиндексированных url и сильно сократили объем работы. С оставшимися можно разобраться с помощью оператора info. Разумеется, не стоит это делать руками – можно использовать Rush Analytics. Анализ 100 ссылок будет стоить 5 рублей. Благодаря предыдущим операциям мы существенно экономим. Или можно собрать выдачу тем же Кейколлектором (тут уже правда уже может потребоваться антикапча).
Если хотите еще сократить список кандидатов на платную проверку, то можете также определить список страниц, приносивших трафик за последнюю неделю-две (уж они-то почти наверняка в индексе!) и отсеять найденные. О том, как выгружать url точек входа см. в статье об анализе страниц, потерявших трафик.
Как видите, с задачей поиска непроиндексированных страниц у небольших и средних (где-нибудь до 50 тысяч страниц) вполне можно справиться без возни с консолью, прокси, phyton-библиотеками и так далее. Достаточно иметь под рукой популярные инструменты, пригодные для множества других задач.
UPD: Виталий Шаповал резонно заметил, что:
Наверняка, есть публичный индекс и его непубличная часть, поэтому “непроиндексированные Google страницы” является терминологией вводящей в заблуждение. Корректно говорить об отсутствии в индексе, что меняет постановку вопроса почему такие страницы отсутствуют.
Согласен с этим уточнением; использовал термин из исходной статьи по инерции. Впрочем для практики разница небольшая – так или иначе результирующий список url требуется проработать, рассмотрев разные причины отсутствия (не было визита робота/запрещена индексация/неподходящий контент).
-

28.07.2011 21:21
Старый оптимист
- Репутация: 367
- Webmoney BL: ?
Решил отметиться тут полезным «мануальчиком» для форумчан…
В общем многие задаются вопросом как найти сайты, которые Яндекс не проиндексировал.
Как в дальнейшем использовать эту инфу спросите вы? Отвечу — в большинстве случаев это тонны контента для ваших будущих сайтов Начнем.
Многие знают, что Гугл индексит гораздо больше сайтов чем Яша. Этим мы и воспользуемся.
Берем вот тут парсер гугла (описание прожки тут)Задаем нужные вопросы и собираем выдачу.
Далее полученный список загоняем в эту программу (описание тут), выставляем проверку проиндексированности в Яше.Вуаля — мы получили список сайтов, которые не проиндексированы в Яндексе.
Пользуйтесь - 35
Спасибо сказали:
Artoha(15.09.2011), Asin(29.07.2011), audit(02.10.2014), b00mer(28.01.2012), Cyberflow(30.01.2012), CyCJIuK(10.09.2014), dev1(17.03.2012), Eardor(28.07.2011), Event(15.09.2011), exclus(21.01.2012), feuer81(01.02.2012), Gaya(27.01.2012), genesis33(06.08.2013), grazer(02.09.2011), hromov(26.01.2012), hronny(14.01.2012), intern(31.08.2011), koysara(31.12.2011), Krez(19.12.2011), levko(02.09.2011), lexa82(28.12.2011), maXdonalds(28.07.2011), OKyJIucT(25.09.2011),
procsi(20.02.2012), semyon(01.09.2011), Seopublic(06.12.2013), ShadowCaster(23.12.2012), sinneren(27.12.2011), Tipatot(02.09.2011), vefaro(16.06.2016), VictorSamus(23.12.2012), viczzz(13.11.2012), web31(30.01.2012), Xalson(20.01.2014), zhurik(08.05.2013), Андреев(03.09.2011), Вадим(31.08.2011),
-
28.07.2011 21:28
Banned
- Репутация: 243
- Webmoney BL: ?
я писал статью у себя на блоге и анонсировал ее в дайджесте, что проще искать такие сайты на разных биржах ссылок, например в сапе можно выбрать сайты которые под фильтром яндекса и это сделать можно не только в сапе, этот способ намного проще.
- 1
Спасибо сказали:
-
28.07.2011 21:32
Старый оптимист
- Репутация: 367
- Webmoney BL: ?
в сапе по «запросу» труднее найти нужное, проще и правильнее пользоваться напрямую поисковиками
- 1
Спасибо сказали:
-
28.07.2011 21:35
Banned
- Репутация: 243
- Webmoney BL: ?
там тоже можно вбить нужные кеи и будет список только с тематических сайтов, но сапа — это для примера, еще куча подобных бирж.
- 0
-
28.07.2011 21:37
Старый оптимист
- Репутация: 367
- Webmoney BL: ?
likos, а подумать? сапа откуда нужные нам данные берет?
Ответ очевиден
Так что проще и ПРАВИЛЬНЕЕ исключать всегда разных «посредников» - 0
-
28.07.2011 21:48
Banned
- Репутация: 243
- Webmoney BL: ?
сапа выдает сайты из своей базы, из сайтов которые добавлены в систему.
А по поводу выдачи. Гугл индексирует все, но это не значит, что любой сайт будет в топе, обычно сайты которые банит яндекс, гугл тоже не любит ( бывают исключения ) и вот эти сайты гугл кидает под фильтр, обычно этот фильтр — сопли и такие сайты находятся не в основной выдаче и их обычно не найти на первой сотни страниц.- 0
-
28.07.2011 21:53
Старый оптимист
- Репутация: 367
- Webmoney BL: ?
сравни базу сапы и гугла
каждый метод имеет место быть, хотя… я считаю, что мой дает гораздо больше нужных результатоd - 0
Спасибо сказали:
Jast(27.01.2012),
-
28.07.2011 21:55
Banned
- Репутация: 243
- Webmoney BL: ?
Сообщение от Думка дает гораздо больше нужных результатоd
я уже выше обьяснил, что результатов будет больше, но вот нужных — меньше.
- 0
-
28.07.2011 21:57
Старый оптимист
- Репутация: 367
- Webmoney BL: ?
К чему спор? Давай послушаем мнение форумчан, которые и рассудят нас
- 0
-
28.07.2011 22:16
Дипломник
- Репутация: 32
Я, конечно, не судья, но мне кажется, что метод likos более простой, так как отнимает меньше времени.
Но тут еще один момент забыли упомянуть. Если сайт забанен Яшей, то вряд ли у него будет уникальный, мегаинтересный контент. Скорее всего обычный копипаст или даже синонимайз. Поэтому еще надо все сайты на уникальность контента проверять. А так, спасибо.- 4



 ?
?

 ?
?
Как проверить индексацию для неподтвержденного сайта мы рассказали ранее. Сейчас же расскажем о проверке с помощью данных, которые предоставляет Яндекс Вебмастер и Google Search Console.
Список проиндексированных страниц
Для того чтобы получить полный список проиндексированных страниц в Яндексе, необходимо зайти в раздел Индексация > Страницы в поиске > вкладка «Все страницы».
Ниже представлен список всех страниц, находящихся в поиске, и возможность выгрузить таблицу в XLS и CSV.
В новой версии Google Search Console также появилась возможность увидеть список всех проиндексированных страниц. Для этого нужно зайти в отчет «Покрытие» (в разделе «Индекс»).
В списке ниже представлена информация о страницах, о которых известно поисковой системе и дополнительная информация по ним.
Детальный список проиндексированных страниц можно получить из списка со статусом «Страница без ошибок».
Проверка индексации
Чтобы обнаружить «мусорные страницы», нужно следовать следующему алгоритму:
- Получаем полный список страниц, которые должны быть проиндексированы. Для этого мы используем программу Screaming Frog SEO Spider. При правильной настройке файла robots.txt спарсится список всех доступных для индексации страниц.
- Выгружаем индексируемые страницы сайта из Вебмастеров.
- Сравниваем попарно получившиеся списки с помощью инструмента «Условное форматирование» в Excel, подсветив все уникальные значения.
В ходе сравнения могут возникнуть следующие ситуации:
- подсветка страниц, которые есть только в списке парсера. В таком случае нужно диагностировать причину, почему страница не находится в индексе. Если она должна индексироваться, то отправляем ее на переобход.
- подсветка страниц, которые есть только в индексе. В данном случае пытаемся понять, почему ее нет в списке всех страниц сайта. Возможно, это страница с кодом 404, которая так и не была удалена поисковым роботом или деактивированный элемент, у которого неверно настроен код ответа.
Для удаления страниц в Вебмастере существует инструмент «Удаление страниц из поиска», позволяющий единовременно удалить до 500 отдельных страниц или группу страниц по префиксу в url. Главное, чтобы страницы были закрыты от индексации.
Инструмента для принудительного удаления страниц у Google нет, но можно временно удалить свои URL из результатов поиска.
Для этого необходимо зайти в старую версию Search Console и в левом меню выбрать «Индекс Google» > «Удалить URL-адреса».
Далее указываем URL страницы, которую вы хотите скрыть. Выбираем из списка необходимое действие и отправляем запрос.
Ждите новые заметки в блоге или ищите на нашем сайте.
Такой вопрос, как найти сайты, которые не индексируется поисковиками? Нужно сканировать айпишки и порты, пытаться понять, что это какой-то веб ап, либо хтмл? Или просто подставлять все возможные адреса в урл и пытаться к ним законектиться?
-
Вопрос заданболее трёх лет назад
-
1753 просмотра
Долго копался в поисках ответа, решил оформить в виде инструкции для себя прежде всего.
Что имеем:
- сайт videosites.ru,
- в индексе Яндекса — 131 страница,
- в индексе Google — 283.
Разница. Первый вопрос — откуда?
Для ответа посмотрим количество страниц в карте сайта — https://videosites.ru/sitemap.xml — 97 страниц.
В моем случае Яндекс ухватил лишние страницы, Google — взял страниц значительно больше.

- Анализ на проиндексированность страниц в Яндекс согласно карте сайта
Начнем с этого этапа, узнаем есть ли проблемы с индексацией некоторых страниц(в данном случае я проверяю свой блог, на других сайтах проблем куда выше).
Для проверки я нашел по крайней мере два инструмента бесплатный и не бесплатный.
- Бесплатный способ проверки на индексацию страниц сайта через YCCY
«Поиск» подсказал эту программку, с ней все очень просто. Качаете архив, распаковываете — запускаете и выбираете «Indexator«.
В Excel я копирую содержимое карты сайта https://videosites.ru/sitemap.xml

Выделяю первую колонку и закидываю ее в YCCY в левое окошко. А дальше все просто — жмем на «Начать проверку» предварительно выбрав Яндекс.

Позже получаем список страниц Не проиндексированных в Яндекс в отдельном окне. Так же можно проверить на другие поисковые системы. Программа кривоватая — возникают «Глюк какой-то.» и она останавливается. Поэтому я пользуюсь платным вариантом через Allsubmitter.
- Платный способ проверки на индексацию страниц сайта через Allsubmitter
Платный — потому что программу нужно приобрести, попробуйте на Демке сделать — возможно все и так получится.
Довольно странно, но я так и не нашел инструкции по работе через Аллсабмиттер, поэтому пришлось поковыряться.
Запускаем программу и переходим в режим — Анализатор бирж Sape.ru, Linkfeed.ru.

Проваливаемся в «Учетные записи»-«Добавить свои данные» Вставляем Название, URL, и через Обзор выбираем файл для списка ссылок(в текстовой файл сохраняем список страниц из карты сайта, по аналогии с Excel — описано выше). И жмем «Создать» и закрываем окошко.
В Левом меню выбираем наш проект.
Обращаем внимание на подчеркнутое и обведенное. Слева — «Определить параметры сайтов» — именно на нее и нажимаем и выбираем параметр «YAP» и нажимаем «ОК». Запустится процесс анализа страниц вашего сайта на индексацию.
После через фильтр выбираем «YAP», «нет», и жмем на красный «фильтр».
Получаем всего лишь одну страницу — которая не проиндексирована.
- А дальше анализируем почему так случилось что Яндекс ее не «скушал».
Можно проверить уникальность статьи через ETXT например. Но в данном случае она состоит из двух предложений — я про нее давным давно забыл =)). Вот про такие забытые страницы легко вспомнить прогнав их таким способом.
Например, у вы прогнали и получили список из 1000 страниц.
- Первые что бы я сделал, загнал бы их в индекс — мало ли — может робот так и не дошел.
Для этого я использую seobudget — и через «Инструменты → Добавление страниц сайта в индекс» — за копейки можно закинуть весь этот список. Через пару АПов уже копать сам сайт, и искать — что не так со страницами.
Данные манипуляции можно проводить и с Google — для этого нужно выбрать просто другую поисковую систему во время анализа. Но как обычно он кушает все — даже то что закрыто от индексации.
Если кто-то предложит варианты как упросить все — с радостью выслушаю, сам потратил пол дня на поиски.