Новичку очень трудно найти нужный символ или слово в массе кода, однако это делается очень быстро и просто. Если не знаете как, то читайте дальше.
В следующей статье, мы приступим к редактированию шаблона, и нам придётся находить нужные элементы в коде темы.
Если кто-то ещё не видел, что из себя представляет код шаблона, то зайдите в Консоль — Внешний вид — Редактор.
Перед Вами откроется код файла style.css. Покрутите его вниз, и первое, что придёт Вам в голову будет: ё-моё, как же в этой массе английских слов, цифр и символов, найти то, что нам будет нужно.
Для полноты ощущения, можно открыть один из php файлов, которые расположены в колонке справа от поля редактора.
Только сразу отгоните мысль типа: «Я в этом до самой смерти не разберусь». Разберётесь, и я Вам в этом помогу.
Рассмотрим два варианта, в зависимости от начальных условий, нахождения нужного элемента в коде.
Вариант 1.
Условие: мы точно знаем то, что нам нужно найти.
Для примера возьмём код страницы.
Комбинация клавиш Contrl-F откроет окно поиска в правом верхнем углу, в которое можно ввести искомый элемент кода. Элемент и все его повторения подсветятся.
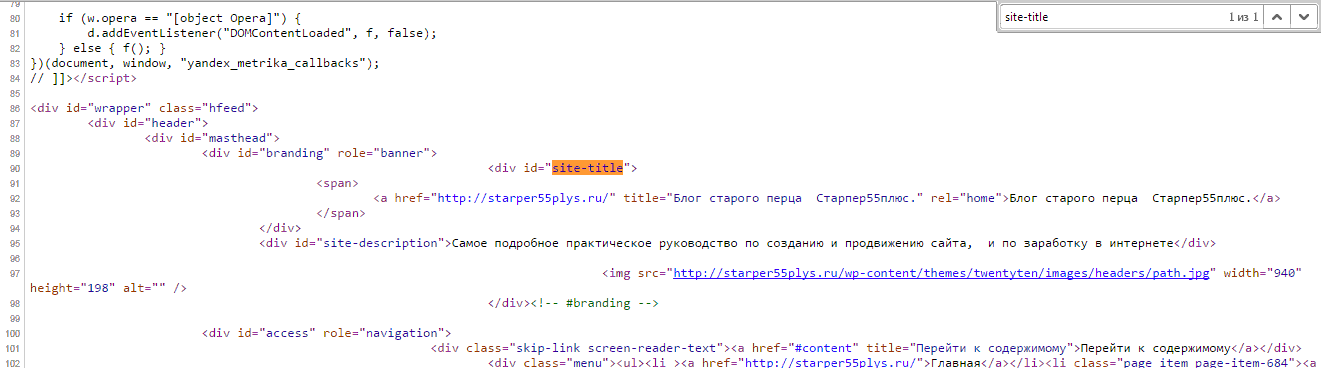
Этот поиск работает абсолютно для любого кода, открытого в браузере, то есть на странице.
Вариант 2.
Условие: мы видим элемент на странице, но не знаем ни его html, ни css.
В этом случае потребуется web-инспектор, или по другому Инструмент разработчика.
Инструмент разработчика есть во всех браузерах и открыть его можно или клавишей F12, или правой клавишей мыши, выбрав «Просмотреть код» или «Исследовать элемент». В разных браузерах по разному.
Главное не выбирайте «Просмотреть код страницы». Похоже, но не то.
После этого появится web-инспектор. Его интерфейс в разных браузерах немного отличается, но принцип действия везде одинаковый.
Я покажу на примере web-инспектора Chrome.
Заходим на страницу и открываем web-инспектор. По умолчанию он откроется в двух колонках, в левой будет html код всех элементов, находящихся на странице, а в правой — css оформление.
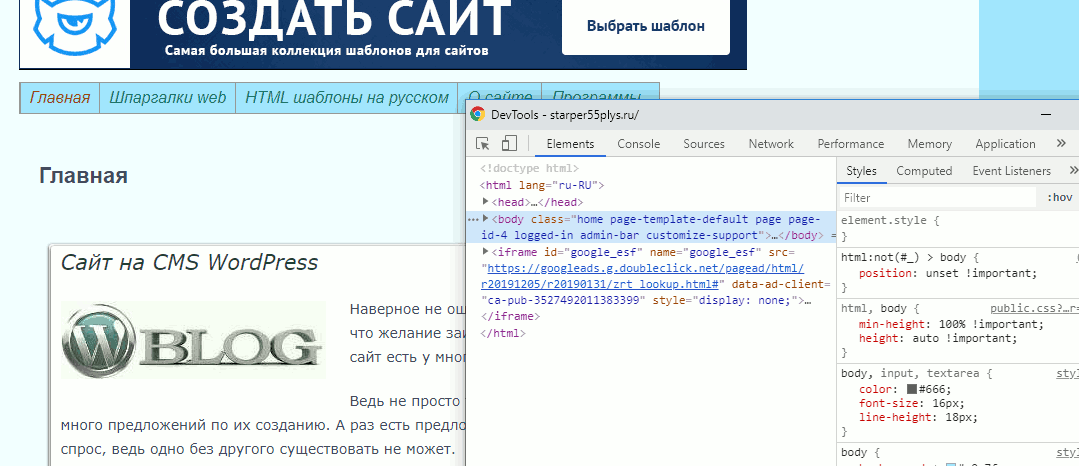
Изначально, код откроется в сложенном виде, то есть будут видны только основные элементы страницы, но если щёлкнуть по треугольничку в начале строки, то откроются все вложения, находящиеся в элементе.
И вот так, открывая вложение за вложением, можно добраться практически до любого элемента, находящегося на странице.
Определить, какой код, какому элементу соответствует, очень просто.
Надо просто вести по строкам курсором, и как только курсор оказывается на строке с кодом, так тут-же элемент, которому соответствует этот код, подсвечивается.
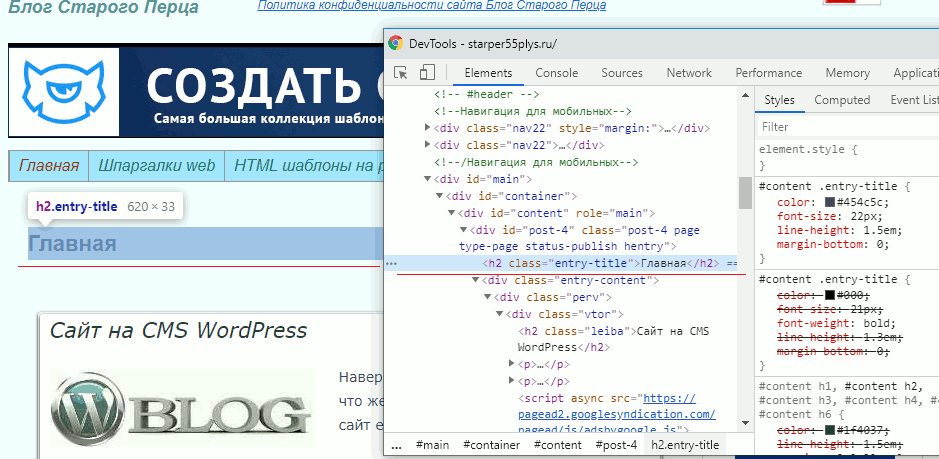
Теперь найдём css этого элемента. Для этого надо один раз щёлкнуть левой клавишей по строке с html, и в правой колонке отобразятся все стили, которые ему заданы, а так-же стили, влияющие на элемент, от родительских элементов.

Теперь, зная class или id элемента, можно спокойно идти в файл style.css, найти в нём нужный селектор, с помощью Поиска (Ctrl+F), и править внешний вид элемента.
Желаю творческих успехов.
Неужели не осталось вопросов? Спросить

Перемена
— Мам, ну почему ты думаешь, что если я была на дне рождения, то сразу пила?!
— Дочь а нечего что я папа?
Объявление в метро: «при обнаружении подозрительных предметов сделайте подозрительное лицо.
В раздел > > > Исправляем шаблон WordPress. Веб-инспектор
В этой статье мы изучим методы JavaScript для поиска элементов в HTML-документе: querySelector, querySelectorAll, getElementById и другие. Кроме них рассмотрим ещё следующие: matches, contains и closest. Первые два из них могут быть полезны для выполнения различных проверок, а третий использоваться, когда нужно получить родительский элемент по CSS-селектору.
Методы для выбора HTML-элементов
Работа с веб-страницей так или иначе связана с манипулированием HTML-элементами. Но перед тем, как над ними выполнить некоторые действия (например, добавить стили), их сначала нужно получить.
Выбор элементов в основном выполняется с помощью этих методов:
querySelector;querySelectorAll.
Они позволяют выполнить поиск HTML-элементов по CSS-селектору. При этом querySelector выбирает один элемент, а querySelectorAll – все.
Кроме них имеются ещё:
getElementById;getElementsByClassName;getElementsByTagName;getElementsByName.
Но они сейчас применяются довольно редко. В основном используется либо querySelector, либо querySelectorAll.
querySelectorAll
Метод querySelectorAll применяется для выбора всех HTML-элементов, подходящих под указанный CSS-селектор. Он позволяет искать элементы как по всей странице, так и внутри определённого элемента:
// выберем элементы по классу item во всем документе
const items = document.querySelectorAll('.item');
// выберем .btn внутри #slider
const buttons = document.querySelector('#slider').querySelectorAll('.btn');Здесь на первой строчке мы нашли все элементы с классом item. На следующей строчке мы сначала выбрали элемент с id="slider", а затем в нём все HTML-элементы с классом btn.
Метод querySelectorAll как вы уже догадались принимает в качестве аргумента CSS-селектор в формате строки, который соответственно и определяет искомые элементы. В качестве результата querySelectorAll возвращает объект класса NodeList. Он содержит все найденные элементы:

Полученный набор представляет собой статическую коллекцию HTML-элементов. Статической она называется потому, что она не изменяется. Например, вы удалили элемент из HTML-документа, а в ней как был этот элемент, так он и остался. Чтобы обновить набор, querySelectorAll нужно вызвать заново:
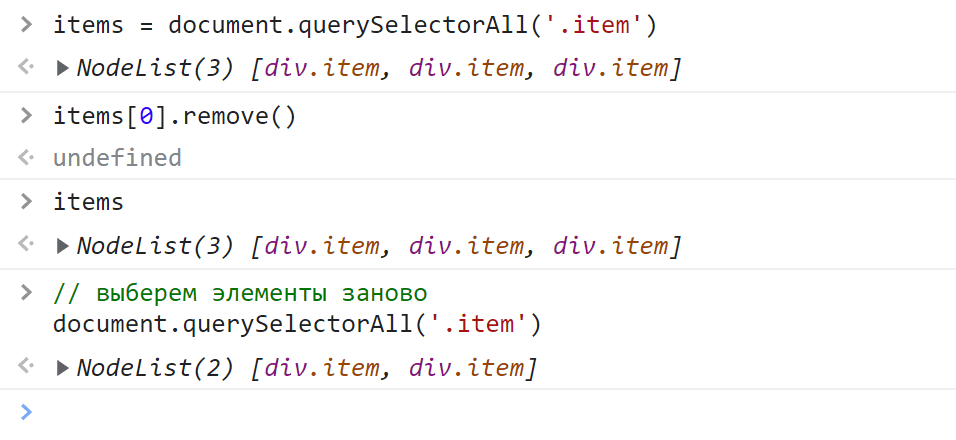
Узнать количество найденных элементов можно с помощью свойства length:
// выберем элементы с атрибутом type="submit"
const submits = document.querySelectorAll('[type="submit"]');
// получим количество найденных элементов
const countSubmits = submits.length;Обращение к определённому HTML-элементу коллекции выполняется также как к элементу массива, то есть по индексу. Индексы начинаются с 0:
// получим первый элемент
const elFirst = submits[0];
// получим второй элемент
const elSecond = submits[1];Здесь в качестве результата мы получаем HTML-элемент или undefined, если элемента с таким индексом в наборе NodeList нет.
Перебор коллекции HTML-элементов
Перебор NodeList обычно осуществляется с помощью forEach:
// получим все <p> на странице
const elsP = document.querySelectorAll('p');
// переберём выбранные элементы
elsP.forEach((el) => {
// установим каждому элементу background-color="yellow"
el.style.backgroundColor = 'yellow';
});Также перебрать набор выбранных элементов можно с помощью цикла for или for...of:
// получим все элементы p на странице
const elsP = document.querySelectorAll('p');
// for
for (let i = 0, length = elsP.length; i < length; i++) {
elsP[i].style.backgroundColor = 'yellow';
}
// for...of
for (let el of elsP) {
el.style.backgroundColor = 'yellow';
}querySelector
Метод querySelector также как и querySelectorAll выполняет поиск по CSS-селектору. Но в отличие от него, он ищет только один HTML-элемент:
// ищем #title во всём документе
const elTitle = document.querySelector('#title');
// ищем footer в <body>
const elFooter = document.body.querySelector('footer');На первой строчке мы выбираем HTML-элемент, имеющий в качестве id значение title. На второй мы ищем в <body> HTML-элемент по тегу footer.
В качестве результата этот метод возвращает найденный HTML-элемент или null, если он не был найден.
querySelector всегда возвращает один HTML-элемент, даже если под указанный CSS-селектор подходят несколько:
<ul id="list">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>
<script>
// выберем <li>, расположенный в #list
const elFirst = document.querySelector('#list > li');
elFirst.style.backgroundColor = 'yellow';
</script>Задачу, которую решает querySelector можно выполнить через querySelectorAll:
const elFirst = document.querySelectorAll('#list > li')[0];Но querySelector в отличие от querySelectorAll делает это намного быстрее, да и писать так проще. То есть querySelectorAll не возвращает как querySelector сразу же первый найденный элемент. Он сначала ищет все элементы, и только после того, как он это сделает, мы можем уже обратиться к первому HTML-элементу в этой коллекции.
Обычно перед тем, как выполнить какие-то действия с найденным HTML-элементом необходимо сначала проверить, а действительно ли он был найден:
const elModal = document.querySelector('.modal');
// если элемент .modal найден, то ...
if (elModal) {
// переключим у elModal класс show
elModal.classList.toggle('show');
}Здесь мы сначала проверили существования HTML-элемента, и только потом выполнили над ним некоторые действия.
Методы getElement(s)By* для выбора HTML-элементов
Здесь мы рассмотрим методы, которые сейчас применяются довольно редко для поиска HTML-элементов. Но в некоторых случаях они могут быть очень полезны. Это:
getElementById– получает один элемент поid;getElementsByClassName– позволяет найти все элементы с указанным классом или классами;getElementsByTagName– выбирает элементы по тегу;getElementsByName– получает все элементы с указанным значением атрибутаname.
1. Метод getElementById позволяет найти HTML-элемент на странице по значению id:
<div id="comments">...</div>
...
<script>
// получим HTMLElement и сохраним его в переменную elComments
const elComments = document.getElementById('comments');
</script>В качестве результата getElementById возвращает объект класса HTMLElement или значение null, если элемент не был найден. Этот метод имеется только у объекта document.
Указывать значение id необходимо с учётом регистра. Так например, document.getElementById('aside') и document.getElementById('ASIDE') ищут элементы с разным id.
Обратите внимание, что в соответствии со стандартом в документе не может быть несколько тегов с одинаковым id, так как значение идентификатора на странице должно быть уникальным.
Тем не менее, если вы допустили ошибку и в документе существуют несколько элементов с одинаковым id, то метод getElementById более вероятно вернёт первый элемент, который он встретит в DOM. Но на это полагаться нельзя, так как такое поведение не прописано в стандарте.
То, что делает getElementById можно очень просто решить посредством querySelector:
// получим элемент #title
const elTitle = document.getElementById('title');
// получим элемента #title, используя querySelector
const elTitleSame = document.querySelector('#nav');Кстати, оба этих метода возвращают в качестве результата один и тот же результат. Это либо HTML-элемент (экземпляр класса HTMLElement) или null, если элемент не найден.
2. Метод getElementsByClassName позволяет найти все элементы с заданным классом или классами. Его можно применить для поиска элементов как во всём документе, так и внутри указанного. В первом случае его нужно будет вызывать как метод объекта document, а во втором – как метод соответствующего HTML-элемента:
// найдем элементы с классом control в документе
const elsControl = document.getElementsByClassName('control');
// выберем элементы внутри другого элемента, в данном случае внутри формы с id="myform"
const elsFormControl = document.forms.myform.getElementsByClassName('form-control');В качестве результата он возвращает живую HTML-коллекцию найденных элементов. Чем живая коллекция отличается от статической мы рассмотрим ниже.
Здесь мы сохранили найденные элементы в переменные elsControl и elsFormControl. В первой переменной будет находиться HTMLCollection, содержащая элементы с классом control. Во второй – набор элементов с классом form-control, находящиеся в форме с id="myform". Для получения этой формы мы использовали document.forms.myform.
Метод getElementsByClassName позволяет искать элементы не только по одному классу, но и сразу по нескольким, которые должны присутствовать у элемента:
// выберем элементы .btn.btn-danger
const elsBtn = document.getElementsByClassName('btn btn-danger');На querySelectorAll этот пример решается так:
const elsBtn = document.querySelectorAll('.btn.btn-danger');3. Метод getElementsByTagName предназначен для получения коллекции элементов по имени тега:
// найдем все <a> в документе
const anchors = document.getElementsByTagName('a');
// найдем все >li> внутри #list
const elsLi = document.getElementById('list').getElementsByTagName('li');На первой строчке мы выбрали все <a> в документе и присвоили полученную HTMLCollection переменной anchors. На второй – мы сначала получили #list, а затем в нём нашли все <li>.
Задачу по выбору элементов внутри другого элемента с помощью querySelectorAll выполняется намного проще:
const elsLi = document.querySelectorAll('#list li');Для выбора всех элементов можно использовать символ *:
// выберем все элементы в <body>
const els = document.body.getElementsByTagName('*');4. В JavaScript getElementsByName можно использовать для выбора элементов, имеющих определенное значение атрибута name:
// получим все элементы с name="phone"
const elsPhone = document.getElementsByName('phone');Через querySelectorAll это выполняется так:
const elsPhone = document.querySelectorAll('[name="phone"]');getElementsBy* и живые HTML-коллекции
В JavaScript getElementsByTagName, getElementsByClassName и getElementsByName в отличие от других методов (например, querySelectorAll) возвращают живую коллекцию HTML-элементов (на английском live HTMLCollection). То есть коллекцию содержимое которой автоматически обновляется при изменении DOM. Для наглядности рассмотрим следующий пример.
Например, на странице изначально имеется два <li>. Выберем их с помощью getElementsByTagName и сохраним полученную HTMLCollection в переменную els. Теперь с помощью els мы можем получить эту коллекцию. Сейчас в ней два <li>. Затем через 5 секунд, используя setTimeout добавим ещё один <li>. Если сейчас мы обратимся к переменной els, то увидим, что в ней уже находятся три <li>:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим живую коллекцию <li>
const els = document.getElementsByTagName('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
</script>
Как вы видите, здесь полученная коллекция является живой, то есть она может автоматически измениться. В ней сначала было два <li>. Но после того, как мы на страницу добавили ещё один подходящий элемент, в ней их стало уже три.
Если в коде приведённом выше заменить выбор элементов на querySelectorAll, то мы увидим, что в ней находится статическая (не живая) коллекция элементов:
// получим статическую коллекцию
const els = document.querySelectorAll('li'); <li>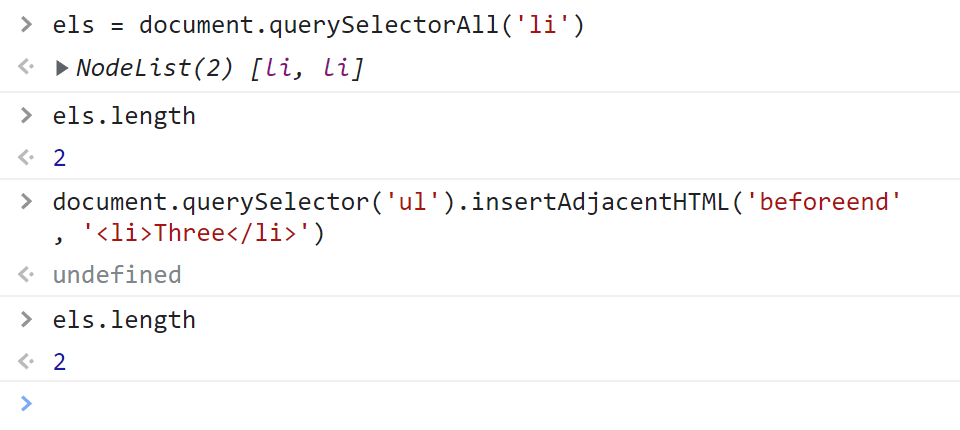
Как вы видите количество элементов в коллекции не изменилось. Чтобы после изменения DOM получить актуальную коллекцию элементов, их нужно просто выбрать заново посредством querySelectorAll:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим статическую коллекцию <li>
let els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// получим заново статическую коллекцию <li>
els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
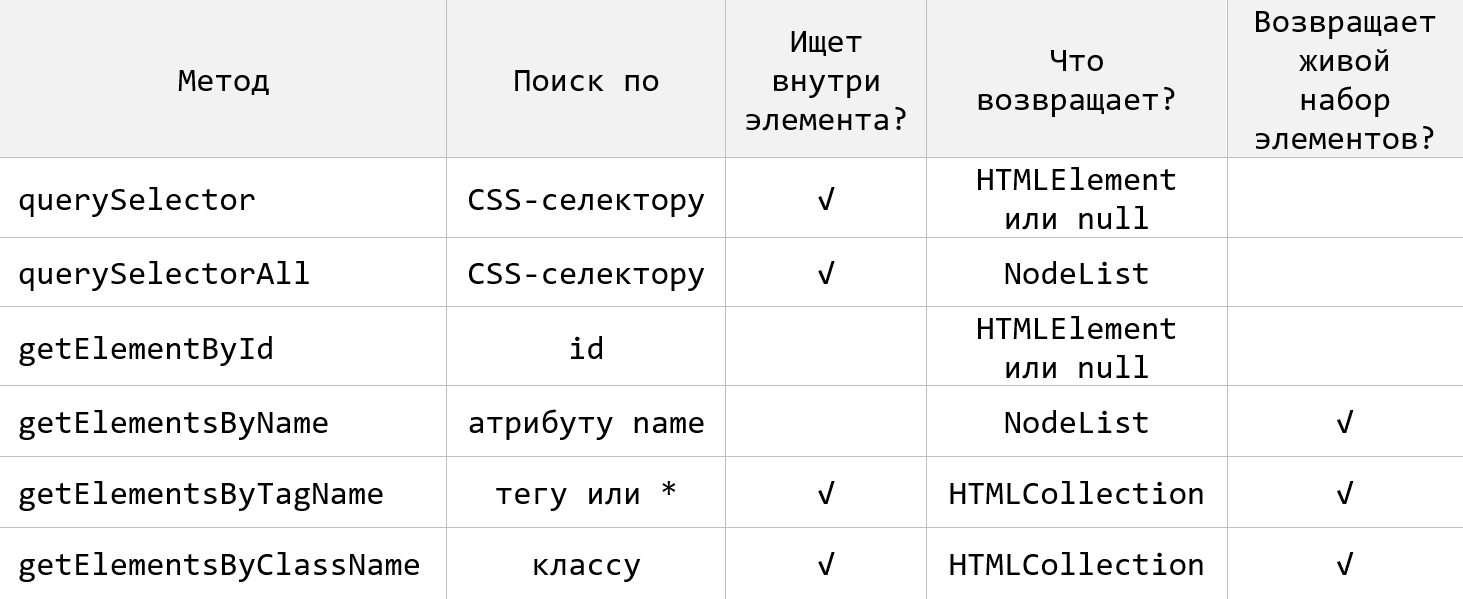
</script>Таким образом в JavaScript насчитывается 6 основных методов для выбора HTML-элементов на странице. По чему они ищут и что они возвращают приведено на следующем рисунке:
Экземпляры класса HTMLCollection не имеют в прототипе метод forEach. Поэтому если вы хотите использовать этот метод для перебора такой коллекции, её необходимо преобразовать в массив:
const items = document.getElementsByClassName('item');
[...items].forEach((el) => {
console.log(el);
});matches, closest и contains
В JavaScript имеются очень полезные методы:
matches– позволяет проверить соответствует ли HTML-элемент указанному CSS-селектору;closest– позволяет найти для HTML-элемента его ближайшего предка, подходящего под указанный CSS-селектор (поиск начинается с самого элемента);contains– позволяет проверить содержит ли данный узел другой в качестве потомка (проверка начинается с самого этого узла).
1. Метод matches ничего не выбирает, но он является очень полезным, так как позволяет проверить HTML-элемент на соответствие CSS-селектору. Он возвращает true, если элемент ему соответствует, иначе false.
// выберем HTML элемент, имеющий атрибут data-target="slider"
const elSlider = document.querySelector('[data-target="slider"]');
// проверим соответствует ли он CSS селектору 'div'
const result = element.matches('div');Пример, в котором выберем все <li>, расположенные внутри #questions, а затем удалим те из них, которые соответствуют селектору .answered:
// выберем все <li> в #questions
const els = document.querySelectorAll('#questions > li');
// переберём выбранные элементы
els.forEach((el) => {
// если элемент соответствует селектору .answered, то ...
if (el.matches('.answered')) {
// удалим элемент
el.remove();
}
});В этом примере проверим каждый <li> на соответствие селектору active. Выведем в консоль каждый такой элемент:
<ul>
<li>One</li>
<li class="active">Two</li>
<li>Three</li>
</ul>
<script>
document.querySelectorAll('li').forEach((el) => {
if (el.matches('.active')) {
console.log(el);
}
});
// li.active
</script>Ранее, в «старых» браузерах данный метод имел название matchesSelector, а также поддерживался с использованием префиксов. Если вам нужна поддержка таких браузеров, то можно использовать следующий полифилл:
if (!Element.prototype.matches) {
Element.prototype.matches = Element.prototype.matchesSelector || Element.prototype.webkitMatchesSelector || Element.prototype.mozMatchesSelector || Element.prototype.msMatchesSelector;
}2. Метод closest очень часто используется в коде. Он позволяет найти ближайшего предка, подходящего под указанный CSS-селектор. При этом поиск начинается с самого элемента, для которого данный метод вызывается. Если этот элемент будет ему соответствовать, то closest вернёт его.
<div class="level-1">
<div class="level-2">
<div class="level-3"></div>
</div>
</div>
<script>
const el = document.querySelector('.level-3');
const elAncestor = el.closest('.level-1');
console.log(elAncestor);
</script>Здесь мы сначала выбираем HTML-элемент .level-3 и присваиваем его переменной el. Далее мы пытаемся среди предков этого элемента включая его сам найти такой, который отвечает заданному CSS-селектору, в данном случае .level-1.
Начинается поиск всегда с самого этого элемента. В данном случае он не подходит под указанный селектор. Следовательно, этот метод переходит к его родителю. Он тоже не отвечает этому CSS-селектору. Значит, closest переходит дальше, то есть уже к его родителю. Этот элемент подходит под указанный селектор. Поэтому поиск прекращается и этот метод возвращает его в качестве результата.
Метод closest возвращает null, когда он дошёл бы конца иерархии и не нашёл элемент отвечающий указанному селектору. То есть, если такого элемента нет среди предков.
В этом примере найдем с помощью closest для .active его ближайшего родителя, отвечающего CSS-селектору #list > li:
<ul id="list">
<li>One</li>
<li>
Two
<ul>
<li>Four</li>
<li class="active">Five</li>
</ul>
</li>
<li>Three</li>
</ul>
<script>
const elActive = document.querySelector('.active');
const elClosest = elActive.closest('#list > li');
elClosest.style.backgroundColor = 'yellow';
</script>В JavaScript closest очень часто используется в обработчиках событий. Это связано с тем, чтобы события всплывают и нам нужно, например, узнать кликнул ли пользователь в рамках какого-то элемента:
document.addEventListener('click', (e) => {
if (e.closest.matches('.btn__action')) {
// пользователь кликнул внутри .btn__action
}
});3. Метод contains позволяет проверить содержит ли некоторый узел другой в качестве потомка. При этом проверка начинается с самого этого узла, для которого этот метод вызывается. Если узел соответствует тому для которого мы вызываем данный метод или является его потомком, то contains в качестве результата возвращает логическое значение true. В противном случае false:
<div id="div-1">
<div id="div-2">
<div id="div-3">...</div>
</div>
</div>
<div id="div-4">...</div>
<script>
const elDiv1 = document.querySelector('#div-1');
elDiv1.contains(elDiv1); // true
const elDiv3 = document.querySelector('#div-3');
elDiv1.contains(elDiv3); // true
const elDiv4 = document.querySelector('#div-4');
elDiv1.contains(elDiv4); // false
</script>Здесь выражение elDiv1.contains(elDiv1) возвращает true, так как проверка начинается с самого элемента. Это выражение elDiv1.contains(elDiv3) тоже возвращает true, так как elDiv3 находится внутри elDiv1. А вот elDiv1.contains(elDiv4) в качестве результата возвращает false, так как elDiv4 не находится внутри elDiv1.
В этом примере проверим с помощью contains содержит ли <p> другие узлы в качестве потомка:
<h1>Tag b</h1>
<p>This is <b>tag b</b>.</p>
<script>
const elP = document.querySelector('p');
const elB = document.querySelector('b');
const textNode = elB.firstChild;
const elH1 = document.querySelector('h1');
elP.contains(elP); // true
elP.contains(elB); // true
elP.contains(elH1); // false
elP.contains(textNode); // true
</script>Метод contains позволяет проверить является ли потомком не только узел-элемент, но и любой другой узел. Например, узнаем является ли потомком elDiv1 указанный текстовый узел:
const elDiv1 = document.querySelector('#div-1');
const textNode = document.querySelector('#div-3').firstChild;
elDiv1.contains(textNode); // trueЗадачи
1. Узнать количество элементов с атрибутом data-toggle="modal" на странице:
const count = document.querySelectorAll('[data-toggle="modal"]').length;
console.log(count);2. Найти все элементы <a> с классом nav внутри элемента <ul> :
const anchors = document.querySelectorAll('ul.nav a');3. Получить элемент по id, значение которого равно pagetitle:
var pagetitle = document.querySelector('#pagetitle');4. Выполнить поиск элемента по классу nav:
var el = document.querySelector('.nav');5. Найти элемент <h3>, находящийся в теге <div> с классом comments, который в свою очередь расположен в <main>:
var header = document.querySelector('main div.comments h3');6. Имеется страница. В ней следует выбрать:
- последний элемент с классом
article, расположенный в<main>(решение); - все элементы
.section, находящиеся в.asideкроме 2 второго (решение); - элемент
<nav>расположенный после<header>(решение).
Время на прочтение
8 мин
Количество просмотров 95K
Пару дней назад получил тестовое задание от компании на вакансию Front-end dev. Конечно же, задание состояло из нескольких пунктов. Но сейчас речь пойдет только об одном из них — организация поиска по странице. Т.е. банальный поиск по введенному в поле тексту (аналог Ctrl+F в браузере). Особенность задания была в том, что использование каких-либо JS фреймворков или библиотек запрещено. Все писать на родном native JavaScript.
(Для наглядности далее буду сопровождать всю статью скринами и кодом, чтоб мне и вам было понятнее, о чем речь в конкретный момент)
Поиск готового решения
Первая мысль: кто-то уже точно такое писал, надо нагуглить и скопипастить. Так я и сделал. За час я нашел два неплохих скрипта, которые по сути работали одинаково, но были написаны по-разному. Выбрал тот, в коде которого лучше разобрался и вставил к себе на старничку.
Если кому интересно, код брал тут.
Скрипт сразу заработал. Я думал, что вопрос решен, но как оказалось, не в обиду автору скрипта, в нем был огромный недостаток. Скрипт вел поиск по всему содержимому тега ... и, как вы уже наверное догадались, при поиске любого сочетания символов, которые напоминают тег или его атрибуты, ломалась вся страница HTML.
Почему скрипт работал некорректно?
Все просто. Скрипт работает следующим образом. Сперва в переменную записываем все содержимое тега body, затем ищем совпадения с регулярным выражением (задает пользователь при вводе в текстовое поле) и затем заменяем все совпадения на следующий код:
<span style="background-color: yellow;">...найденное совпадение...</span>
А затем заменяем текущий тег body на новый полученный. Разметка обновляется, меняются стили и на экране подсвечиваются желтым все найденные результаты.
Вы уже наверняка поняли, в чем проблема, но я все же объясню подробней. Представьте, что в поле поиска ввели слово «div». Как вы понимаете, внутри body есть множество других тегов, в том числе и div. И если мы всем к «div» применим стили, указанные выше, то это уже будет не блок, а непонятно что, так как конструкция ломается. В итоге после перезаписи разметки мы получим полностью сломанную веб-страницу. Выглядит это так.
Было до поиска:  Просмореть полностью
Просмореть полностью
Стало после поиска:  Просмореть полностью
Просмореть полностью
Как видите, страница полностью ломается. Короче говоря, скрипт оказался нерабочим, и я решил написать свой с нуля, чему и посвящается эта статья.
Итак пишем скрипт с нуля
Как все у меня выглядит.
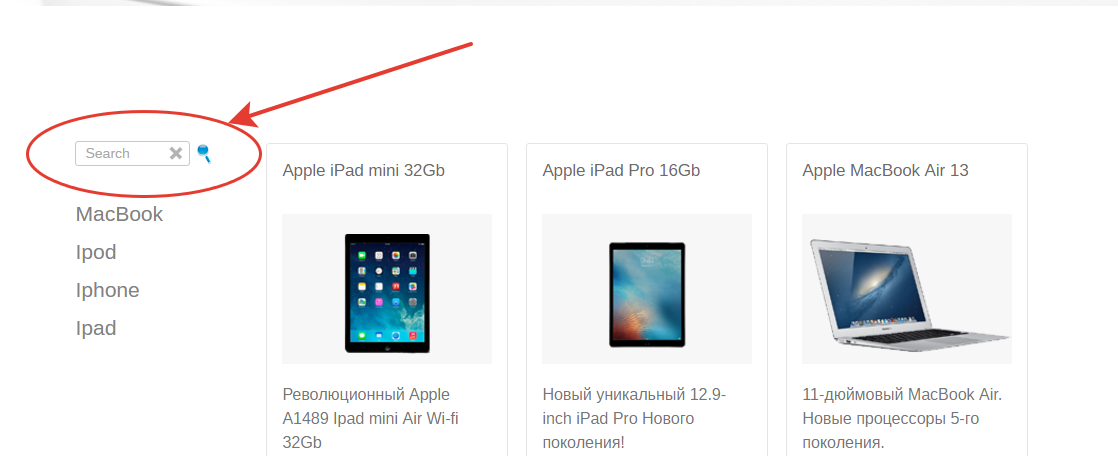
Сейчас нас интересует форма с поиском. Обвел ее красной линией.
Давайте немного разберемся. Я это реализовал следующим образом (пока чистый HTML). Форма с тремя тегами.
Первый — для ввода текста;
Второй — для для отмены поиска (снять выделение);
Третий — для поиска (выделить найденные результаты).
<form>
<input type="text" value="" placeholder="Search" autofocus>
<input type="button" value=" " title="Отменить поиск">
<input type="submit" value=" " title="Начать поиск">
</form>
Итак, у нас есть поле для ввода и 2 кнопки. JavaScript буду писать в файле js.js. Предпложим, что его вы уже создали и подключили.
Первое, что сделаем: пропишем вызовы функции при нажатии на кнопку поиска и кнопку отмены. Выглядеть будет так:
<form>
<input class="place_for_search" type="text" id="text-to-find" value="" placeholder="Search" autofocus>
<input class="button_for_turn_back" type="button" onclick="javascript: FindOnPage('text-to-find',false); return false;" value=" " title="Отменить поиск">
<input class="button_for_search" type="submit" onclick="javascript: FindOnPage('text-to-find',true); return false;" value=" " title="Начать поиск">
</form>
Давайте немного поясню что тут и зачем нужно.
Полю с текстом даем id=«text-to-find» (по этому id будем обращатсья к элементу из js).
Кнопке отмены даем такие атрибуты: type=«button» onclick=«javascript: FindOnPage(‘text-to-find’,false); return false;»
— Тип: button
— При нажатии вызывается функция FindOnPage(‘text-to-find’,false); и передает id поля с текстом, false
Кнопке поиска даем такие атрибуты: type=«button» onclick=«javascript: FindOnPage(‘text-to-find’,true); return false;»
— Тип: submit (не кнопка потому, что тут можно юзать Enter после ввода в поле, а так можете и button использовать)
— При нажатии вызывается функция FindOnPage(‘text-to-find’,true); и передает id поля с текстом, true
Вы наверняка заметили еще 1 атрибут: true/false. Его будем использовать для определения, на какую именно кнопку нажали (отменить поиск или начать поиск). Если жмем на отмену, то передаем false. Если жмем на поиск, то передаем true.
Окей, двигаемся дальше. Переходим к JavaScript
Будем считать, что вы уже создали и подключили js файл к DOM.
Прежде, чем начнем писать код, давайте отвлечемся и сперва обсудим, как все должно работать. Т.е. по сути пропишем план действий. Итак, нам надо, чтоб при вводе текста в поле шел поиск по странице, но нельзя затрагивать теги и атрибуты. Т.е. только текстовые объекты. Как этого достичь — уверен есть много способов. Но сейчас будем использовать регулярные выражения.
Итак, следующее регулярное выражение будет искать только текст след. вида: «>… текст…<«. Т.е. будет проходить поиск только текстовых объектов, в то время, как теги и атрибуты будут оставаться нетронутыми.
/>(.*?)</g
Так мы будем находить нужные части кода, которые будем парсить и искать совпадения с текстом, который ввел пользователь. Затем будем добавлять стили найденным объектам и после этого заменять html — код на новый.
Приступим. Сперва переменные, которые нам понадобятся.
var input,search,pr,result,result_arr, locale_HTML, result_store;
//input - принимаем текст, который ввел пользователь
//search - делаем из строки регулярное выражение
//pr - сохраняем в нее текущий <body></body>
//result - выборка текста из pr (т.е. отсекаем теги и атрибуты)
//result_arr - аналог pr, но со стилями для подсветки
//locale_HTML - оригинал <body></body> который менять не будем, используем для обнуления стилей
И сразу определим locale_HTML значение независимо от того, ищем мы что-то или нет. Это нужно, чтоб сразу сохранить оригинал страницы и иметь взможность обнулять стили.
var input,search,pr,result,result_arr, locale_HTML, result_store;
locale_HTML = document.body.innerHTML; // сохраняем в переменную весь body (Исходный)
Ок, теперь уже стоит создать функцию, которая вызывается у нас из DOM. Сразу прикинем, что внутри у нас должны быть 2 функции, каждая из которых срабатывает в зависимости от нажатой кнопки. Ведь мы либо проводим поиск, либо обнуляем его. И контроллируется это атрибутом true/false, как вы помните. Так же надо понимать, что при повторном поиске прежние стили должны обнуляться. Таким образом получим следующее:
var input,search,pr,result,result_arr, locale_HTML, result_store;
locale_HTML = document.body.innerHTML; // сохраняем в переменную весь body (Исходный)
function FindOnPage(name, status) {
if(status) { FindOnPageBack(); FindOnPageGo(); } //чистим прошлое и Выделяем найденное
if(!status) { FindOnPageBack(); } //Снимаем выделение
}
Ок, часть логики реализована, двигаемся дальше. Необходимо проверять полученное слово на количество символов. Ведь зачем нам искать 1 букву/символ. В общем, я решил эту возможность ограничить 3+ символа.
Итак, сперва приниамем значение, которое ввел пользователь, и, в зависимости от его длины, выполняем либо основную функцию поиска, либо функцию вывода предупреждения и обнуления. Выглядеть будет так:
var input,search,pr,result,result_arr, locale_HTML, result_store;
locale_HTML = document.body.innerHTML; // сохраняем в переменную весь body (Исходный)
function FindOnPage(name, status) {
input = document.getElementById(name).value; //получаем значение из поля в html
if(input.length<3&&status==true) {
alert('Для поиска вы должны ввести три или более символов');
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
}
if(input.length>=3)
{
//выполняем поиск
}
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
if(status) { FindOnPageBack(); FindOnPageGo(); } //чистим прошлое и Выделяем найденное
if(!status) { FindOnPageBack(); } //Снимаем выделение
}
Сейчас поясню этот участок кода. Единственное, что могло стать не ясно — вот эта строка:
function FindOnPageBack() { document.body.innerHTML = locale_HTML; }
Тут все просто: метод innerHTML возвращает html код объекта. В данном случае мы просто заменяем текущий body на оригинальный, который мы сохранили при загрузке всей страницы.
Двигаемся дальше. Даем значения основным переменным.
var input,search,pr,result,result_arr, locale_HTML, result_store;
locale_HTML = document.body.innerHTML; // сохраняем в переменную весь body (Исходный)
function FindOnPage(name, status) {
input = document.getElementById(name).value; //получаем значение из поля в html
if(input.length<3&&status==true) {
alert('Для поиска вы должны ввести три или более символов');
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
}
if(input.length>=3)
{
function FindOnPageGo() {
search = '/'+input+'/g'; //делаем из строки регуярное выражение
pr = document.body.innerHTML; // сохраняем в переменную весь body
result = pr.match(/>(.*?)</g); //отсекаем все теги и получаем только текст
result_arr = []; //в этом массиве будем хранить результат работы (подсветку)
}
}
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
if(status) { FindOnPageBack(); FindOnPageGo(); } //чистим прошлое и Выделяем найденное
if(!status) { FindOnPageBack(); } //Снимаем выделение
}
Итак, на данном этапе у нас уже есть основные переменные и значения. Теперь надо придать нужным участкам кода стили с выделенным фоном. Т.е. проверка выбранного текста на регулярное выражение (по сути мы выбранный регулярным выражением текст снова парсим регулярным выражением). Для этого надо из введенного текста сделать регулярное выражение (сделали), а затем выполнить метод, переданный в виде такста. Тут нам поможет метод eval().
В общем, после того, как мы заменим текст и получим результат со стилями, надо текущий html заменить на полученный. Делаем.
var input,search,pr,result,result_arr, locale_HTML, result_store;
locale_HTML = document.body.innerHTML; // сохраняем в переменную весь body (Исходный)
function FindOnPage(name, status) {
input = document.getElementById(name).value; //получаем значение из поля в html
if(input.length<3&&status==true) {
alert('Для поиска вы должны ввести три или более символов');
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
}
if(input.length>=3)
{
function FindOnPageGo() {
search = '/'+input+'/g'; //делаем из строки регуярное выражение
pr = document.body.innerHTML; // сохраняем в переменную весь body
result = pr.match(/>(.*?)</g); //отсекаем все теги и получаем только текст
result_arr = []; //в этом массиве будем хранить результат работы (подсветку)
for(var i=0; i<result.length;i++) {
result_arr[i] = result[i].replace(eval(search), '<span style="background-color:yellow;">'+input+'</span>'); //находим нужные элементы, задаем стиль и сохраняем в новый массив
}
for(var i=0; i<result.length;i++) {
pr=pr.replace(result[i],result_arr[i]) //заменяем в переменной с html текст на новый из новогом ассива
}
document.body.innerHTML = pr; //заменяем html код
}
}
function FindOnPageBack() { document.body.innerHTML = locale_HTML; } //обнуляем стили
if(status) { FindOnPageBack(); FindOnPageGo(); } //чистим прошлое и Выделяем найденное
if(!status) { FindOnPageBack(); } //Снимаем выделение
}
По сути все готово, и скрипт уже работает. Но добавим еще пару деталей для красоты.
1) Обрежем пробелы у текста, который вводит пользователь. Вставляем этот код:
input = numer.replace(/^s+/g,'');
input = numer.replace(/[ ]{1,}/g,' ');
После этой строки:
input = document.getElementById(name).value; //получаем значение из поля в html
2) Сделаем проверку на совпадения (если совпадений не найдено — сообщим об этом). Этот код вставляем внутрь функции function FindOnPageGo() после переменных.
var warning = true;
for(var i=0;i<result.length;i++) {
if(result[i].match(eval(search))!=null) {
warning = false;
}
}
if(warning == true) {
alert('Не найдено ни одного совпадения');
}
Посмотреть исходник можно тут.
Скачать исходник можно тут.
Теперь все. Конечно, можно добавить скролл к первому найденному результату, живой поиск ajax, да и вообще улучшать можно бесконечно. Сейчас это довольно примитивный поиск по сайту. Целью статьи было помочь новичкам, если возникет такой же вопрос как у меня. Ведь простого готового решения я не нашел.
P.S.: для корректной работы необходимо убрать переносы текста в html документе в тех местах, где есть обычный текст между тегами.
Например, вместо
<p> бла бла бла
</p>
Надо
<p> бла бла бла </p>
Это не принципиально, можно от этих переносов избаляться автоматически на сервисе, но может подскажете заодно, как это пофиксить, если поймете раньше меня.
Также, если кто писал подобное, но с живым поиском, поделитесь исходником, будет интересно разобрать.
Буду рад выслушать конструкнтиную критику, мнения, может, рекомендации.
На днях дописал немного код, сделал живой поиск по странице. Так, что вопрос снят. Код HTML не менялся. JS можете посмотреть тут.
Поиск ведется по тегам с классом «place_for_live_search». Так что для того, чтоб алгоритм парсил нужный контент, добавляем класс и готово.
Публикация в группе: Otshelnik-Fm — мои работы (код, плагины, дополнения, статьи и руководства)
Категории группы: Другое
На одном форуме поддержки задали интересный вопрос (а сегодня, это как совпадение, уже вопрос прозвучал в разных местах дважды — вопросы разные, но принцип один — найти код и функцию):
Здравствуйте. Периодически нужно найти и откорректировать какой-то фрагмент кода, но искать его на хостинге по всем папкам и файлам очень долго. Есть ли какой-то более быстрый способ поиска?
В этой заметке я вам покажу: как найти нужный блок в исходном коде и в каком файле он вызывается.
Как пример возьмем вот этот блок:
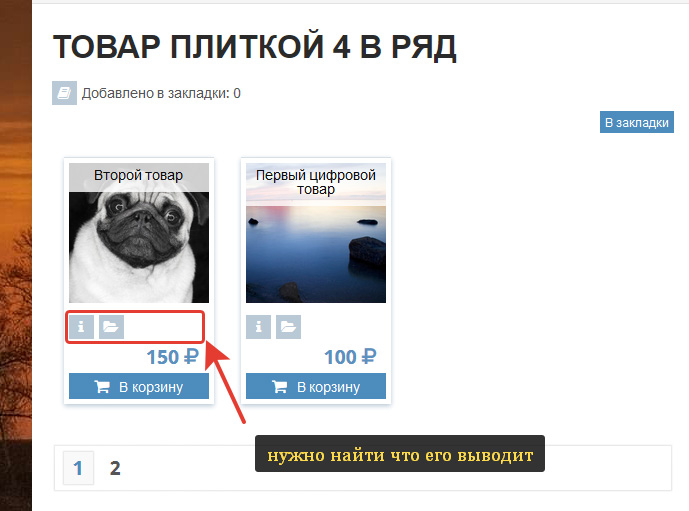
Что мы знаем о этой странице?
В вордпресс ее выводит плагин WP-Recall. А сама страница выводится шорткодом productlist с атрибутом type=slab
Ок.
Инспектируем:
В браузере жмем F12. Открывается консоль разработки. В верхнем углу, слева, в этой панели кнопка «Инспектировать» (иконка курсор с прямоугольником) жмем по ней и тыкаем на искомый элемент на странице:
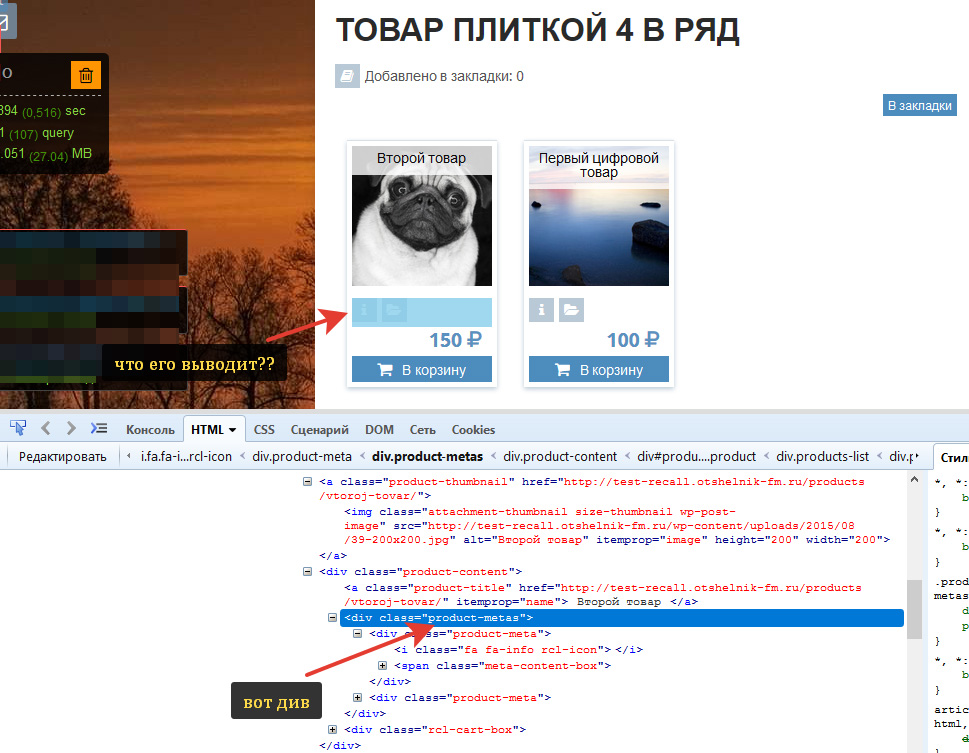
— ок. Имя дива мы знаем. Это product-metas
Теперь плагин WP-Recall (ведь именно он выводит этот контент в нашем случае) копируем на ПК, и ищем по всем файлам этого плагина (ctrl + shift + F в notepad++)
Находим:
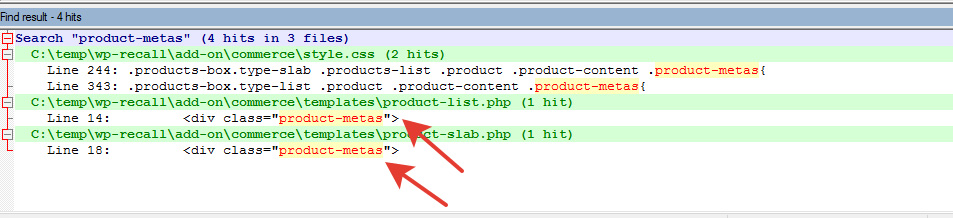
три файла. Один — таблица стилей. Два — темплейты. Этот блок я выводил шорткодом slab. Значит мой вариант — файл product-slab.php
Буквально за 2 минуты мы нашли то что искали. Это даже быстрей чем написать свой вопрос на форуме.
Удачного вам обучения юные вебмастера, веб программисты и просто те, кто настраивает себе свой персональный блог. Эти простые основы помогут вам быстро разобраться в внутреннем устройстве плагинов.
Но никогда не правьте плагин напрямую. Пользуйтесь хуками и фильтрами и как в этом примере — данный файл product-slab.php — это шаблон WP-Recall плагина
Советую к обучению новичкам — так же как работать с панелью браузера: Учимся работать с панелью разработчика браузера.
p.s. один знающий товарищ написал:
Всё, что выше написал коллеги касается файлов темы, но не движка или плагинов, потому как корректировать их код ненужно и может быть опасно.
но есть случаи не для правки (мой ответ):
не всегда чтобы что-то найти ищут именно для изменения. Мне часто надо просто глянуть исходники и найти за что зацепиться чтобы решить свою задачу — т.к. у 99% плагинов нет технического описания их api. Вот и изучаю самостоятельно.
т.е. так я могу найти нужную мне функцию (чтобы вывести какой либо блок в произвольном месте, или посмотреть аргументы функции и зависимости), посмотреть есть ли в ней хуки и фильтры или посмотреть кто же еще вызывает эту функцию.
Автор публикации

4 503
Живой, бодрый, полон идей!
Комментарии: 2267Публикации: 250Регистрация: 27-01-2013Продаж/Покупок: 0/0
 Автор: Кристин Джеквони (Kristin Jackvony)
Автор: Кристин Джеквони (Kristin Jackvony)
Оригинал статьи
Перевод: Ольга Алифанова
Недавно я прошла этот отличный курс по поиску веб-элементов от Эндрю Найта в Test Automation University. Вдобавок к полезному синтаксису доступа к элементам, я также выучила еще один способ с пользой применить инструменты разработчика!
Один из самых раздражающих моментов UI-автоматизации заключается в попытке выяснить, как найти на странице элемент без идентификатора автоматизации. Возможно, вы знаете, что если открыть инструменты разработчика в Chrome, то можно кликнуть правой клавишей на элемент страницы, выбрать Inspect, и этот элемент подсветится в DOM. Это полезно, но тут скрыто нечто еще более полезное: там есть строка поиска, позволяющая вам увидеть, правильно ли сработает локатор, который вы планируете использовать в тесте. Разберем на конкретном примере, как использовать этот ценный инструмент.
Откройте эту страницу – часть проекта Дейва Хэффнера «Welcome to the Internet», где можно попрактиковаться в поиске веб-элементов. На странице Challenging DOM есть таблица с элементами, которые трудно найти. Мы попробуем найти элемент таблицы с текстом “Iuvaret4”.
Для начала откроем инструменты разработчика. Самый простой способ это сделать – кликнуть правой кнопкой по одному из элементов на странице и выбрать «Inspect». Инструменты разработчика откроются справа или внизу страницы, и секция Elements будет отображать DOM.
Теперь откроем панель поиска. Кликните в любом месте секции Elements, и нажмите Ctrl+F. Внизу секции откроется панель поиска с текстом “Find by string, selector, or XPath”.
Мы воспользуемся этим инструментом для поиска элемента «Iuvaret4» через CSS. Кликните правой кнопкой по этому элементу в таблице и выберите Inspect. Элемент подсветится в DOM. Изучая DOM, можно увидеть, что это элемент <td> (данные таблицы), часть элемента <tr> (строка таблицы). Давайте посмотрим, что будет, если ввести tr в строку поиска и нажать Enter. Вернется 13 элементов. Сбоку от поисковой панели можно нажимать на кнопки «вверх» и «вниз», чтобы подсвечивать каждый найденный элемент. Первый tr в результатах – всего лишь часть слова «demonstrates». Следующий – часть заголовка таблицы. Все прочие tr – части тела таблицы, и там же находится и нужный нам элемент. Введем в поиск запрос tbody tr и нажмем Enter. Выдача сократилась до 10 результатов – рядов тела таблицы.
Мы знаем, что нам нужен пятый ряд в теле таблицы, поэтому поищем tbody tr:nth-child(5). Выдача сократилась до нужного ряда. Теперь найдем нужный <td>-элемент. Это первый элемент в ряду, поэтому если искать tbody tr:nth-child(5) td:nth-child(1), поиск выдаст только нужный нам элемент.
Это хороший CSS-селектор, но можно ли его сократить? Попробуйте убрать «tbody» из поиска. Оказывается, элемент отлично находится и по запросу tr:nth-child(5) td:nth-child(1).
Теперь мы знаем хороший способ найти нужный элемент через CSS, но что будет, если в таблицу добавят новую строку, или строки находятся в случайном порядке? Как только строки изменятся, мы уткнемся в неправильный элемент. Куда лучше искать точный текст. CSS этого не позволяет, поэтому попробуем найти элемент через XPath.
Удалите содержимое поисковой строки. Начнем с поиска тела таблицы. Введите в поиск //tbody и нажмите Enter. Наведясь на подсвеченную секцию DOM, вы увидите, что на странице подсветилась вся таблица целиком.
Внутри тела таблицы находится строка с нужным элементом, поэтому теперь поищем //tbody/tr. Мы получим десять результатов – десять рядов таблицы.
Мы знаем, что нам нужно выбрать специфический <td>-элемент тела: элемент, содержащий “Iuvaret4”. Поэтому введем в поиск запрос //tbody/tr/td[contains(text(), “Iuavaret4”)]. Мы получим нужный нам результат, а также XPath-выражение, которым можем пользоваться.
Но его, как и наш CSS-селектор, можно сократить. Попробуйте убрать оттуда “tbody” и “tr”. Оказывается, что все, что нам нужно для XPath – это //td[contains(text(), “Iuvaret4”)].
Без этого полезного поиска мы бы перепробовали кучу разных комбинаций CSS и XPath в тест-коде, вновь и вновь прогоняя тесты, чтобы увидеть, что сработает. Эта функция инструментов разработчика позволяет экспериментировать с разными стратегиями локаторов, получая немедленные результаты!
Обсудить в форуме