Статистические исследования числовых рядов. Статистические характеристики числовых рядов
Очень часто из-за дороговизны или слишком большого числа наблюдений невозможно получить полной информации об объектах, событиях или наблюдениях. По этой причине информацию получают на основе анализа части всего множества объектов, событий или наблюдений, называемой рядом числовых данных, рядом выборочных данных или, просто, выборкой.
Выборка представляет собой конечный ряд чисел (выборочных данных), количество чисел в котором называют объемом выборки
Для обеспечения достоверности информации об объектах, событиях или наблюдениях, полученных на основе статистических исследований числовых рядов (анализа выборочных данных), отбор выборочных данных должен носить случайный характер и иметь достаточно большой объем, то есть выборка должны быть репрезентативной (представительной).
Статистические исследования числовых рядов (рядов чисел, рядов выборочных данных) удобно проводить в соответствии со следующей схемой, которую мы изложим на примере следующей выборки X :
| X = {3,24; 3,44; 3,12; 3,25; 3,12; 3,34; 3,37; 3,44; 3,24; 3,12} | (1) |
-
Определяем объем выборки (число чисел в числовом ряде).
В числовом ряде (1) десять чисел, поэтому объем выборки равен 10.
-
Вычисляем среднее арифметическое числового ряда X (среднее выборочное значение), которое обозначают
 .
.Для числового ряда (1)



-
Производим упорядочение числового ряда по возрастанию (ранжирование числовых данных). Полученный числовой ряд, который обозначим X1 , называют вариационным рядом.
Для числового ряда X вариационный ряд X1 имеет следующий вид:
X1 = {3,12; 3,12; 3,12; 3,24; 3,24; 3,25; 3,34; 3,37; 3,44; 3,44}
-
Вычисляем размах числового ряда X , то есть разность между наибольшим числом из числового ряда и наименьшим числом из числового ряда.
В числовом ряде X , как и в вариационном ряде X1 , число 3,44 является наибольшим числом, а число 3,12 является наименьшим числом. Поэтому размах числового ряда X равен
3,44 – 3,12 = 0,32
-
Вычисляем медиану числового ряда.
В случае, когда объем выборки (число членов числового ряда) – чётное число, медианой числового ряда является число, равное половине суммы двух чисел, стоящих в середине вариационного ряда.
Число членов ряда X равно чётному числу 10 , а в середине вариационного ряда X1 стоят числа 3,24 и 3,25 . Поэтому медиана числового ряда, которую обычно обозначают символом Me , равна

В случае, когда объем выборки (число членов числового ряда) –нечётное число, медианой числового ряда является число, стоящее в середине вариационного ряда.
Например, медианой числового ряда
{2; 3; 7; 9; 15}
является число 7 .
-
Составляем таблицу частот числового ряда.
Если взглянуть на числа (выборочные данные), составляющие вариационный ряд X1 , то можно заметить, некоторые числа повторяются, а другие встречаются лишь по одному разу. Это наблюдение приводит к следующему определению.
ОПРЕДЕЛЕНИЕ 1. Если выборочное данное встречается в вариационном ряде m раз, то число m называют частотой (абсолютной частотой) этого выборочного данного.
Воспользовавшись определением 1, сформируем для числового ряда X таблицу, содержащую две строки, которую называют таблицей частот (абсолютных частот) числового ряда. Для этого в первой строке таблицы запишем числа, составляющие вариационный ряд X1 , причем запишем числа в порядке возрастания и без повторений. Во второй строке таблицы запишем частоты (абсолютные частоты), соответствующие числам из первой строки таблицы.
ТАБЛИЦА ЧАСТОТ ЧИСЛОВОГО РЯДА
Числа, составляющие вариационный ряд (без повторений) 3,12 3,24 3,25 3,34 3,37 3,44 Частоты 3 2 1 1 1 2 Числа, составляющие вариационный ряд (без повторений) Частоты 3,12 3 3,24 2 3,25 1 3,34 1 3,37 1 3,44 2 ЗАМЕЧАНИЕ. Сумма частот, то есть сумма чисел, записанных во второй строке таблицы частот числового ряда, равна объему выборки (числу чисел в числовом ряде). В рассматриваемом случае это число 10 .
-
Составляем таблицу относительных частот (в процентах).
ОПРЕДЕЛЕНИЕ 2. Относительной частотой (в процентах) выборочного данного называют число процентов, которое составляет частота этого выборочного данного от всего объема выборки (количества членов числового ряда).
Для того, чтобы сформировать таблицу относительных частот числового ряда, заменим частоты, записанные во второй строке таблицы частот числового ряда, на соответствующие им относительные частоты. В результате получим следующую таблицу.
ТАБЛИЦА ОТНОСИТЕЛЬНЫХ ЧАСТОТ (В ПРОЦЕНТАХ)
Числа, составляющие вариационный ряд (без повторений) 3,12 3,24 3,25 3,34 3,37 3,44 Относительные частоты (%) 30% 20% 10% 10% 10% 20% Числа, составляющие вариационный ряд (без повторений) Относительные частоты (%) 3,12 30% 3,24 20% 3,25 10% 3,34 10% 3,37 10% 3,44 20% -
Находим моду числового ряда.
ОПРЕДЕЛЕНИЕ 3. Модой числового ряда называют выборочное данное с наибольшей частотой.
Из таблицы частот числового ряда видно, что модой числового ряда X является число 3,12 , поскольку его частота 3 является наибольшей. Очевидно, что и относительная частота этого выборочного данного является самой большой (30%) .
ЗАМЕЧАНИЕ. Объем выборки, среднее выборочное значение, размах, медиана и мода числового ряда являются одними из статистических характеристик числовых рядов.


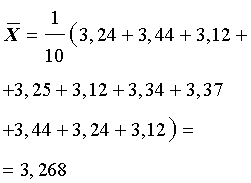
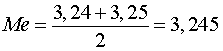
План урока:
Понятие выборки и генеральной совокупности
Среднее арифметическое выборки
Упорядоченный ряд и таблица частот
Размах выборки
Мода выборки
Медиана выборки
Ошибки в статистике
Понятие выборки и генеральной совокупности
Слово статистика, образованное от латинского status(состояние дел), появилось только в 1746 году, когда его употребил немец Готфрид Ахенвалль. Однако ещё в Древнем Китае проводились переписи населения, в ходе которых правители собирали информацию о своих владениях и жителях, проживающих в них.
В основе любого статистического исследования лежит массив информации, который называют выборкой данных. Покажем это на примере. Пусть в классе, где учится 20 учеников, проводился тест по математике, содержавший 25 вопросов. В результате учащиеся показали следующие результаты:

Ряд чисел, приведенный во второй строке таблицы (12, 19, 19, 14, 17, 16, 18, 20, 15, 25, 13, 20, 25, 16, 17, 12, 24, 13, 21, 13), будет выборкой. Также ее могут называть рядом данных или выборочной совокупностью.

В примере с классом выборка состоит из 20 чисел. Эту величину (количество чисел в ряду) называют объемом выборки. Каждое отдельное число в ряду именуют вариантой выборки.
В примере со школьным классом в выборку попали все его ученики. Это позволяет точно определить, насколько хорошо учащиеся написали математический тест. Однако иногда необходимо проанализировать очень большие группы населения, состоящие из десятков и даже сотен миллионов человек. Например, необходимо узнать, какая часть населения страны курит. Опросить каждого жителя государства невозможно, поэтому в ходе исследования опрашивают лишь его малую часть. В этом случае статистики выделяют понятие генеральная совокупность.

Так, если с помощью опроса 10 тысяч человек ученые делают выводы о распространении курения в России, то все российское население будет составлять генеральную совокупность исследования, а опрошенные 10 тысяч людей вместе образуют выборку.
Среднее арифметическое выборки
Сбор информации о выборке является лишь первой стадией статистического исследования. Далее ее необходимо обобщить, то есть получить некоторые цифры, характеризующие выборку. Самой часто используемой статистической характеристикой является среднее арифметическое.

Другими словами, для подсчета среднего арифметического необходимо просто сложить все числа в ряде данных, а потом поделить получившееся значение на количество чисел в ряде. Так, в примере с тестом по математике (таблица 1) средний балл учащихся составит: (12+19+19+14+17+16+18+20+15+25+13+20+25+16+17+12+24+13+21+13):20=
= 349:20 = 17,45.
Среднее арифметическое позволяет одним числом характеризовать какое-либо качество всех объектов группы. Чем больше средний балл учащихся в классе, тем выше их успеваемость. Чем меньше среднее количество голов, пропускаемых футбольной командой за один матч, тем лучше она играет в обороне. Если средняя зарплата программистов в городе составляет 90 тысяч рублей, а дворников – 25 тысяч рублей, то это значит, что программисты значительно более востребованы на рынке труда, а потому при выборе будущей профессии лучше предпочесть именно эту специальность.
Упорядоченный ряд и таблица частот
В ряде данных в таблице 1 числа приведены в произвольном порядке. Перепишем ряд так, чтобы все числа шли в неубывающем порядке, то есть от самого маленького к самому большому:
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Такую запись называют упорядоченным рядом данных.

Его характеристики ничем не отличаются от изначальной выборки, однако с ним удобнее работать. С его помощью можно видеть, что ни одному ученику не удалось набрать 22 или 23 балла на тесте, но сразу двое учащихся дали 25 правильных ответов. На основе упорядоченного ряда данных несложно составить таблицу частот, в которой будет указано, как часто та или иная варианта выборки встречается в ряде. Выглядеть она будет так:

При составлении этой таблицы мы исключили из нее те варианты количества набранных баллов, частота которых равна нулю (от 0 до 12, 22 и 23).Заметим, что сумма чисел в нижней строке таблицы частот должна равняться объему выборки. Действительно,
2+3+1+1+2+2+1+2+2+1+1+2 = 20.
С помощью таблицы частот можно быстрее посчитать среднее арифметическое выборки. Для этого каждую варианту надо умножить на ее частоту, после чего сложить полученные результаты и поделить их на объем выборки:
(12•2+13•3+14•1+15•1+16•2+17•2+18•1+19•2+20•2+21•1+24•1+25•2):20 =
(24+39+14+15+32+34+18+38+40+42+24+50):20 = 349:20 = 17,45.
Размах выборки
Следующий важная характеристика ряда данных – это размах выборки.

Если выборка представлена в виде упорядоченного ряда данных, то достаточно вычесть из последнего числа ряда первое число. Так, размах выборки результатов теста в классе равен:
25 – 12 = 13,
так как самые лучшие ученики смогли решить все 25 заданий, а наихудший учащийся ответил правильно только на 13 вопросов.
Размах выборки характеризует стабильность, однородность исследуемых свойств. Например, пусть два спортсмена-стрелка в ходе соревнований производят по 5 выстрелов по круговой мишени, где за попадание начисляют от 0 до 10 очков. Первый стрелок показал результаты 8, 9, 9, 8, 9 очков. Второй же спортсмен в своих попытках показал результаты 7, 10, 10, 6, 10. Средние арифметические этих рядов равны:
(8+9+9+8+9):5 = 43:5 = 8,6;
(7+10+10+6+10):5 = 43:5 = 8,6.
Получается, что в среднем оба стрелка стреляют одинаково точно, однако первый спортсмен демонстрирует более стабильные результаты. У его выборки размах равен
9 – 8 = 1,
в то время как размах выборки второго спортсмена равен
10 – 6 = 4.
Размах выборки может быть очень важен в метеорологии. Например, в Алма-Ате и Амстердаме средняя температура в течение года почти одинакова и составляет 10°С. Однако в Алма-Ате в январе и феврале иногда фиксируются температуры ниже -30°С, в то время как в Амстердаме за всю историю наблюдений она никогда не падала ниже -20°С.
Мода выборки
Иногда важно знать не среднее арифметическое выборки, а то, какая из ее вариант встречается наиболее часто. Так, при управлении магазином одежды менеджеру не важен средний размер продаваемых футболок, а необходима информация о том, какие размеры наиболее популярны. Для этого используется такой показатель, как мода выборки.

В примере с математическим тестом сразу 3 ученика набрали по 13 баллов, а частота всех других вариант не превысила 2, поэтому мода выборки равна 13. Возможна ситуация, когда в ряде есть сразу две или более вариант, которые встречаются одинаково часто и чаще остальных вариант. Например, в ряде
1, 2, 3, 3, 3, 4, 5, 5, 5
варианты 3 и 5 встречаются по три раза. В таком случае ряд имеет сразу две моды – 3 и 5, а всю выборку именуют мультимодальной. Особо выделяется случай, когда в выборке все варианты встречаются с одинаковой частотой:
6, 6, 7, 7, 8, 8.
Здесь числа 6, 7 и 8 встречаются одинаково часто (по два раза), а другие варианты отсутствуют. В таких случаях говорят, что ряд не имеет моды.
Медиана выборки
Иногда, например, при расчете средней зарплаты, среднее арифметическое не вполне адекватно отражает ситуацию. Это происходит из-за наличия в выборке чисел, очень сильно отличающихся от среднего. Так, из-за огромных зарплат некоторых начальников большинство рядовых сотрудников компаний обнаруживают, что их зарплата ниже средней. В таких случаях целесообразно использовать такую характеристику, как медиану ряда. Это такое значение, которое делит ряд данных пополам. В упорядоченном ряде 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25 медианой будет равна 12, так как именно она находится в середине ряда:

Однако таким образом можно найти только медиану ряда, в котором находится нечетное количество чисел. Если же их количество четное, то за медиану условно принимают среднее арифметическое двух средних чисел. Так, для ряда 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25, 30, содержащего 12 чисел, медиана будет равна среднему значению 12 и 15, которые занимают 6-ое и 7-ое место в ряду:


Вернемся к примеру с математическим тестом в школе. Так как его сдавали 20 учеников, а 20 – четное число, то для расчета медианы следует найти среднее арифметическое 10-ого и 11-ого числа в упорядоченном ряде
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Эти места занимают числа 17 и 17 (выделены жирным шрифтом). Медиана ряда будет равна
(17+17):2 = 34:2 = 17.
Три приведенные основные статистические характеристики выборки, а именно среднее арифметическое, мода и медиана, называются мерами центральной тенденции. Они позволяют одним числом указать значение, относительно которого группируются все числа ряда.
Рассмотрим для наглядности ещё один пример. Врач в ходе диспансеризации измерил вес мальчиков в классе. В результате он получил 10 значений (в кг):
39, 41, 67, 36, 60, 58, 46, 44, 39, 69.
Найдем среднее арифметическое, размах, моду и медиану для этого ряда.
Решение. Сначала перепишем ряд в упорядоченном виде:
36, 39, 39, 41, 44, 46, 58, 60, 67, 69.
Так как в ряде 10 чисел, то объем выборки равен 10. Найдем среднее арифметическое. Для этого сложим все числа в ряде и поделим их на объем выборки (то есть на 10):
(36+39+39+41+44+46+58+60+67+69):10 =
= 499:10 = 49,9 кг.
Размах выборки равен разнице между наибольшей и наименьшей вариантой в ней. Самый тяжелый мальчик весит 69 кг, а самый легкий – 36 кг, а потому размах ряда равен
69 – 36 = 33 кг.
В упорядоченном ряде только одно число, 39, встречается дважды, а все остальные числа встречаются по одному разу. Поэтому мода ряда будет равна 39 кг.
В выборке 10 чисел, а это четное число. Поэтому для нахождения медианы надо найти два средних по счету значение найти их среднее. На 5-ом и 6-ом месте в ряде находятся числа 44 и 46. Их среднее арифметическое равно
(44+46):2 = 90:2 = 45 кг.
Поэтому и медиана ряда будет равна 45 кг.
Ошибки в статистике
Статистика является очень мощным инструментом для исследований во всех областях человеческой деятельности. Однако иногда ее иронично называют самой точной из лженаук. Известно и ещё одно высказывание, приписываемое политику Дизраэли, согласно которому существует просто ложь, наглая ложь и статистика. С чем же связана такая репутация этой дисциплины?
Дело в том, что некоторые люди и организации часто манипулируют данными статистики, чтобы убедить других в своей правоте или преимуществах товара, которые они продают. Требуются определенные навыки, чтобы правильно пользоваться статистикой. Одна из самых распространенных ошибок – это неправильный выбор выборки.
В 1936 году перед президентскими выборами в США был проведен телефонный опрос, который показал, что с большим преимуществом победу должен одержать Альфред Лендон. Однако на выборах Франклин Рузвельт набрал почти вдвое больше голосов. Ошибка была связана с тем, что в те годы телефон могли позволить себе только богатые люди, которые в большинстве своем поддерживали Лендона. Однако бедные люди (а их, конечно же, больше, чем богатых) голосовали за Рузвельта.
Ещё один пример – это агитация в конце XIX века в США к службе на флоте. Пропагандисты в своей рекламе указывали, что, согласно статистике, смертность на флоте во время войны (испано-американской) составляет 0,09%, в то время как среди населения Нью-Йорка она равнялась 0,16%. Получалось, что служить на флоте в военное время безопаснее, чем жить мирной жизнью. Однако на самом деле причина таких цифр заключается в том, что во флот всегда отбирали молодых мужчин с хорошим здоровьем, которые не могли умереть от «старческих» болезней, в то время как в население Нью-Йорка входят больные и старые люди.
При указании среднего значения исследователь может использовать разные характеристики – среднее арифметическое, медиана, мода. При этом почти всегда среднее арифметическое несколько больше медианы. Именно поэтому большинство людей, узнающих о средней зарплате в стране, удивляются, так как они столько не зарабатывают. Правильнее ориентироваться на медианную зарплату.
Ну и наконец, нельзя забывать, что любая статистика может показать только корреляцию между двумя величинами, но это не всегда означает причинно-следственную связь. Так, известно, что чем больше в городе продается мороженого, тем больше в это же время людей тонет на пляжах. Означает ли это, что поедание мороженого увеличивает риск во время плавания? Нет. Дело в том, что оба этих показателя, продажи мороженого и количество утонувших, зависят от третьей величины – температуры в городе. Чем жарче на улице, тем большее количество людей ходят на пляж и тем больше мороженого продается в магазинах.
КОНСПЕКТ 15
15.1
ПРЕДВАРИТЕЛЬНЫЕ СВЕДЕНИЯ
Математическая
статистика возникла (XVIII в.) и создавалась
параллельно с теорией вероятностей.
Дальнейшее развитие этой дисциплины
(начало 20в.) обязано, в первую очередь,
П.Л. Чебышеву, А.А. Маркову, А.М. Ляпунову.
Основные результаты, ставшие в настоящее
время классическими, были получены
учеными англо – американской школы –
К. Пирсон, Р.Фишер, Ю.Нейман, А.Вальд,
В.Феллер и др. и российскими математиками
–В.И.Романовский, Е.Е.Слуцкий, А.Н.
Колмогоров, Н.В.Смирнов. Годом рождения
современной математической статистики
следует считать 1933 г. – год опубликования
работы академика А.Н.Колмогорова
«Основные понятия
теории
вероятностей». Именно в это время
математическую статистику выделили из
теории вероятностей в отдельную
дисциплину.
В теории
вероятностей, если мы изучаем случайную
величину X, ее закон распределения
считается заданным, и мы можем достоверно
ответить на любой вопрос, касающийся
данной случайной величины. В математической
статистике ситуация прямо противоположная
– мы ничего не знаем о законе распределения
изучаемой случайной величины X. У нас
имеются только некоторые ее наблюдения
или измерения.
Понятно, что
по конечному числу наблюдений невозможно
достоверно сделать какие-либо выводы
об изучаемой случайной величине. Ясно
также, что чем больше таких наблюдений,
тем более надежными будут наши приближенные
выводы. В этом состоит основная особенность
математической статистики – она не
определяет достоверно закономерности
поведения изучаемых случайной явлений,
а оценивает их с той или иной степенью
достоверности.
Но при неограниченном увеличении числа
наблюдений
выводы математической статистики
становятся практически
достоверными.
Поэтому содержание этой дисциплины –
как и сколько сделать
наблюдений
и как их обработать, чтобы ответить на
интересующий нас вопрос
о
случайном явлении с требуемой степенью
достоверности.
Итак,
установление закономерностей, которым
подчинены массовые
случайные
явления основано на изучении статистических
данных – результатах наблюдений.
Математическая
статистика решает две главные задачи:
указать
способы
сбора и группировки (если данных очень
много) статистических
сведений
(результатов наблюдений) и разработать
методы анализа собранных
статистических
данных в зависимости от целей исследования.
Пусть требуется
изучить совокупность однородных объектов
относительно качественного или
количественного признака, характеризующего
эти объекты.
15.2 ХАРАКТЕРИСТИКИ
ВАРИАЦИОННОГО РЯДА
Некоторое
предприятие выпускает партию одинаковых
деталей. Если контролируют детали по
размеру – это количественный признак.
Можно производить этот контроль сплошным
обследованием, то есть измерять каждый
из объектов совокупности. Но на практике
сплошное обследование применяется
редко:
а) из-за очень
большого числа объектов;
б) из-за того,
что иногда обследование заключается в
физическом уничтожении, например,
проверяем взрываемость гранат или
проверяем на крепость произведенную
посуду и т.д.
В таких случаях
производится случайный отбор ограниченного
(небольшого) числа объектов, которые и
подвергают изучению.
Выборочной совокупностью
(выборкой)
называется совокупность случайно
отобранных однородных объектов.
Генеральной совокупностью
называется
совокупность всех однородных объектов,
из которых производится выборка.
Объемом
совокупности
(выборочной или генеральной) называется
число объектов этой совокупности.
При наборе
выборки можно поступать двояко: после
того, как объект отобран и над ним
произведено наблюдение, он может быть
возвращен либо не возвращен в генеральную
совокупность. В связи с этим выборки
подразделяются на повторные и бесповторные.
Для того,
чтобы по данным выборки можно было
достаточно уверенно судить об интересующем
нас признаке генеральной совокупности,
необходимо, чтобы объекты выборки
правильно его представляли. Это требование
коротко формулируется так: выборка
должна быть репрезентативной
(представительной).
Способы
отбора выборки:
1. Отбор, не
требующий расчленения генеральной
совокупности на части:
а) простой
случайный бесповторный;
б) простой
случайный повторный.
2. Отбор, при
котором генеральная совокупность
разбивается на части (если объем
генеральной совокупности слишком
большой):
а) типический
отбор. Объекты отбираются не из всей
генеральной совокупности, а из ее
«типичных» частей. Например, цех из
тридцати станков
производит
одну и ту же деталь. Тогда отбор делается
по одной или по две детали с каждого
станка в случайные моменты времени;
б) механический
отбор. Например, если нужно выбрать 5%
деталей, то выбирают не случайно, а
каждую двадцатую деталь;
в) серийный
отбор. Объекты выбирают не по одному, а
сериями.
Итак, пусть
из генеральной совокупности значений
некоторого количественного признака
произведена выборка объема N:
X =
{ x1
, x
2
, x
3
,…, x
N
}.
Таблица вида
1.1
|
№ |
1 |
2 |
3 |
… |
N |
|
x |
x1 |
x2 |
x3 |
… |
xN |
называется
простым статистическим рядом, являющимся
первичной формой представления
статистического материала.
Из данных
табл. 1.1 находят xmin
и xmax
, соответственно наименьшее и наибольшее
значения выборки. Затем данные табл.
1.1 называемые вариантами, располагают
в порядке возрастания. Тогда выборка
X =
{
x1
, x
2
, x
3
,…, x
N
}, записанная
в порядке возрастания, называется
вариационным
рядом.
Размах выборки
– это длина основного интервала
[xmin
; xmax]
, в который попадают все значения выборки.
Пусть из
генеральной совокупности извлечена
выборка, причем x1,
наблюдалось
n1
раз,
x2
– соответственно
n2
раз, xk
— nk
раз и сумма всех
ni
и есть
объем выборки:
![]() .
.
Наблюдаемые значения![]() называют
называют
вариантами, а последовательностьвариант,
записанных в порядке возрастания, —вариационным
рядом. Числа
наблюдений называют частотами, а их
отношения к объему выборки
![]() —относительными
—относительными
частотами.
Статистическим
распределением выборки называют перечень
вариант и соответствующих им частот
или относительных частот. Статистическое
распределение можно записать также в
виде последовательности интервалов и
соответствующих им частот (в качестве
частоты, соответствующей интервалу,
принимают сумму частот, попавших в этот
интервал).
Заметим, что
в теории вероятностей под распределением
понимают соответствие между возможными
значениями случайной величины и их
вероятностями, а в математической
статистике – соответствие между
наблюдаемыми вариантами и их частотами,
или относительными частотами.
ПРИМЕР
Задано
распределение частот выборки объёма n
= 20
xi 2 6 12
ni 3 10 7
Написать
распределение относительных частот.
РЕШЕНИЕ.
Найдём относительные частоты, для чего
разделим частоты на объем выборки:
W1
= 3/20 = 0,15, W2
= 10/20 = 0,50, W3
= 7/20 = 0,35.
Напишем
распределение относительных частот:
xi 2 6 12
Wi 0,15 0,50 0,35
КОНТРОЛЬ:
0,15 + 0,50 + 0,35 = 1.
ПРАКТИКУМ 15
ЗАДАНИЕ N 1Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
 ,
,
равен …
Решение:Случайная
величина Х
принимает значение «1» − 5 раз,
значение «2» − 11 раз,
значение «3» − 29 раз и
значение «4» − 15 раз. Тогда
![]() объем
объем
выборки.
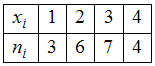
ЗАДАНИЕ N 2Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
 ,
,
равен …
Решение:Случайная
величина Х
принимает значение «1» − 3 раза,
значение «2» − 6 раз,
значение «3» − 7 раз и
значение «4» − 4 раза. Тогда
![]() объем
объем
выборки.
ЗАДАНИЕ N 3Тема:
Характеристики вариационного ряда.
Выборочное среднееВыборочное
среднее для вариационного ряда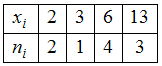 равно …
равно …
Решение:Выборочным средним
называется среднее арифметическое всех
значений выборки:![]() Значение «2»
Значение «2»
некоторая случайная величина
принимает 2 раза, значение «3» – 1 раз,
значение «6» – 4 раза и
значение «13» − 3 раза. Тогда
среднее арифметическое всех значений
выборки равно![]()
ЗАДАНИЕ N 4Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
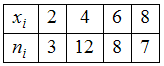 ,
,
равен …
Решение:Случайная
величина Х
принимает значение «2» − 3 раза,
значение «4» − 12 раз,
значение «6» − 8 раз и
значение «8» − 7 раз. Тогда
![]() объем
объем
выборки.
ЗАДАНИЕ N 5Тема:
Характеристики вариационного ряда.
Выборочное среднееВыборочное
среднее для вариационного ряда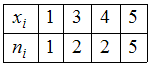 равно …
равно …
Решение:Выборочным средним
называется среднее арифметическое всех
значений выборки:![]() Значение «1»
Значение «1»
некоторая случайная величина
принимает 1 раз,
значение «3» – 2 раза,
значение «4» – 2 раза и
значение «5» − 5 раз. Тогда
среднее арифметическое всех значений
выборки равно![]()
ЗАДАНИЕ N 6Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
 ,
,
равен …
Решение:Случайная
величина Х
принимает значение «1» − 15 раз,
значение «2» − 5 раз,
значение «3» − 20 раз и
значение «4» − 10 раз.
Тогда
![]() объем
объем
выборки.
ЗАДАНИЕ N 7Тема:
Характеристики вариационного ряда.
Выборочное среднееВыборочное
среднее для вариационного ряда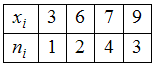 равно …
равно …
Решение:Выборочным средним
называется среднее арифметическое всех
значений выборки:![]() Обращаем
Обращаем
внимание, что значение «3» некоторая
случайная величина
принимает 1 раз,
значение «6» – 2 раза,
значение «7» – 4 раза и
значение «9» − 3 раза. Тогда
среднее арифметическое всех значений
выборки равно![]()
САМОСТОЯТЕЛЬНАЯ РАБОТА 15
ЗАДАНИЕ N 1Тема:
Характеристики вариационного ряда.
Выборочное среднееВыборочное
среднее для вариационного ряда
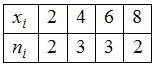 равно …
равно …
ЗАДАНИЕ N 2Тема:
Характеристики вариационного ряда.
Выборочное среднееВыборочное
среднее для вариационного ряда
 равно …
равно …
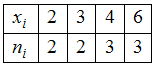
ЗАДАНИЕ N 3
Тема: Характеристики вариационного
ряда. Выборочное среднееВыборочное
среднее для вариационного ряда
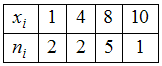 равно …
равно …
ЗАДАНИЕ N 4Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
 ,
,
равен …
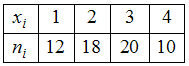
ЗАДАНИЕ N 5Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
 ,
,
равен …
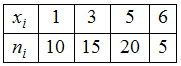
ЗАДАНИЕ N 6Тема:
Объем выборкиОбъем
выборки, заданной статистическим
распределением
 ,
,
равен …
ЗАДАНИЕ N 7
Тема: Объем выборкиОбъем
выборки, заданной статистическим
распределением
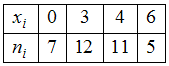 ,
,
равен …
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
При планировании научного исследования представляет интерес получение оценки минимального объёма выборки. Как правило, объем выборки вычисляют для распределений случайных величин, близких к гауссовскому в соответствии со следующим выражением [1]:

Для случая негауссовского закона распределения в формуле [2] предложено другое выражение для оценки объема выборки:

Приведенные выше выражения применяются, в основном, при небольших объемах выборки (условно до 40-50) в случае оценивания выборочных моментов первого и второго порядков – среднего и дисперсии. При большом объеме выборки законы распределения выборочных среднего и дисперсии близки к гауссовскому, и оценка объема выборки может быть получена сравнительно просто из выражения для построения доверительного интервала.
Более подробно изучить этот вопрос помогут [3][4] и, конечно, наш курс математики для Data Science.
Список источников:
1 Койчубеков Б.К. Определение размера выборки при планирования научного исследования / Койчубеков Б.К., Сорокина М.А., Мхитарян К.Э. – Международный журнал прикладных и фундаментальных исследований. 2014. №4.
2 Дианов В.Н. Перспективные направления повышения надежности вычислительной техники и систем управления // Надежность. 2004. №3 (10). С. 33–47
3 Вентцель Е.С. Теория вероятностей. — М., 1964. — 576 с.
4 https://applied-research.ru/ru/article/view?id=5074
Мода и медиана
Модой ряда чисел называется число, наиболее часто встречающееся в данном ряду.
Обратимся снова к нашему примеру со сборной по футболу:
Чему в данном примере равна мода? Какое число наиболее часто встречается в этой выборке?
Все верно, это число ( displaystyle 181), так как два игрока имеют рост ( displaystyle 181) см; рост же остальных игроков не повторяется.
Тут все должно быть ясно и понятно, да и слово знакомое, правда?
Перейдем к медиане, ты ее должен знать из курса геометрии. Но мне не сложно напомнить, что в геометрии медиана (в переводе с латинского- «средняя») — отрезок внутри треугольника, соединяющий вершину треугольника с серединой противоположной стороны.
Ключевое слово – СЕРЕДИНА. Если ты знал это определение, то тебе легко будет запомнить, что такое медиана в статистике.
Медианой ряда чисел с нечетным числом членов называется число, которое окажется посередине, если этот ряд упорядочить (проранжировать, т.е. расположить значения в порядке убывания или возрастания).
Медианой ряда чисел с четным числом членов называется среднее арифметическое двух чисел, записанных посередине, если этот ряд упорядочить.
Ну что, вернемся к нашей выборке футболистов?
Ты заметил в определении медианы важный момент, который нам еще здесь не встречался? Конечно, «если этот ряд упорядочить»!
Для того, чтобы в ряду чисел был порядок, можно расположить значения роста футболистов как в порядке убывания, так и в порядке возрастания. Мне удобней выстроить этот ряд в порядке возрастания (от самого маленького к самому большому).
Вот, что у меня получилось:
Так, ряд упорядочили, какой еще есть важный момент в определении медианы? Правильно, четное и нечетное количество членов в выборке.
Заметил, что для четного и нечетного количества даже определения отличаются? Да, ты прав, не заметить – сложно. А раз так, то нам надо определиться, четное у нас количество игроков в нашей выборке или нечетное?
Все верно – игроков ( displaystyle 11), значит, количество нечетное! Теперь можем применять к нашей выборке менее заковыристое определение медианы для нечетного количества членов в выборке.
Ищем число, которое оказалось посередине в нашем упорядоченном ряду:
Ну вот, чисел у нас ( displaystyle 11), значит, по краям остается по пять чисел, а рост ( displaystyle 183) см будет медианой в нашей выборке.
Не так уж и сложно, правда?
Частота и относительная частота
Частота представляет собой число повторений, сколько раз за какой-то период происходило некоторое событие, проявлялось определенное свойство объекта либо наблюдаемый параметр достигал данной величины.
То есть частота определяет то, как часто повторяется та или иная величина в выборке.
Разберемся на нашем примере с футболистами. Перед нами вот такой вот упорядоченный ряд:
![]()
Частота – это число повторений какой-либо величины параметра. В нашем случае, это можно считать вот так. Сколько игроков имеет рост ( 176)?
Все верно, один игрок. Таким образом, частота встречи игрока с ростом ( 176) в нашей выборке равна ( 1).
Сколько игроков имеет рост ( 178)? Да, опять же один игрок. Частота встречи игрока с ростом ( 178) в нашей выборке равна ( 1).
Задавая такие вопросы и отвечая на них, можно составить вот такую табличку:
Ну вот, все довольно просто. Помни, что сумма частот должна равняться количеству элементов в выборке (объему выборки).
То есть в нашем примере: ( 1+1+1+2+1+1+1+1+1+1=11)
Перейдем к следующей характеристике – относительная частота.
Относительная частота – это отношение частоты к общему числу данных в ряду. Как правило, относительная частота выражается в процентах.
Обратимся опять к нашему примеру с футболистами. Частоты для каждого значения мы рассчитали, общее количество данных в ряду мы тоже знаем ( left( n=11 right)) .
Рассчитываем относительную частоту для каждого значения роста и получаем вот такую табличку:
А теперь сам составь таблицы частот и относительных частот для примера с 9-классниками, решающими задачи.