![]()
Загрузить PDF
![]()
Загрузить PDF
В статистике выбросы — это значения, резко отличающиеся от других значений в собранном наборе данных. Выброс может указывать на аномалии в распределении данных или на ошибки при измерениях, поэтому зачастую выбросы исключаются из набора данных. Исключив выбросы из набора данных, вы можете прийти к неожиданным или более точным выводам.[1]
Поэтому необходимо уметь вычислять и оценивать выбросы, чтобы обеспечить надлежащее понимание статистических данных.
Шаги
-

1
Научитесь распознавать потенциальный выброс. Перед тем, как исключать выделяющиеся значения из набора данных, следует определить потенциальные выбросы. Выбросы являются значениями, которые сильно отличаются от большинства значений в наборе данных; другими словами, выбросы лежат вне тренда большинства значений. Это легко обнаружить в таблицах значений или (особенно) на графиках.[2]
Если значения в наборе данных нанести на график, то выбросы будут лежать далеко от большинства других значений. Если, например, большинство значений ложатся на прямую, то выбросы лежат по обе стороны от такой прямой.- Например, рассмотрим набор данных, представляющий температуры 12 различных объектов в комнате. Если 11 объектов имеют температуру примерно 70 градусов, но двенадцатый объект (возможно, печь) имеет температуру 300 градусов, то быстрый просмотр значений может показать, что печь является вероятным выбросом.
-
2
Упорядочите данные по возрастанию. Первый шаг при определении выбросов — это вычисление медианы набора данных. Эта задача значительно упрощается, если значения в наборе данных расположены по возрастанию (от меньшего к большему).
- Продолжая приведенный выше пример, рассмотрим следующий набор данных, представляющий температуры нескольких объектов: {71, 70, 73, 70, 70, 69, 70, 72, 71, 300, 71, 69}. Этот набор должен быть упорядочен следующим образом: {69, 69, 70, 70, 70, 70, 71, 71, 71, 72, 73, 300}.
-
3
Вычислите медиану набора данных. Медиана набора данных — это величина, находящаяся в середине набора данных.[3]
Если набор данных содержит нечетное количество значений, то медиана — это значение, до которого и после которого расположено одинаковое количество значений в наборе данных. Но если набор данных содержит четное число значений, то нужно найти среднее арифметическое двух средних значений. Обратите внимание, что при вычислении выбросов медиана, как правило, обозначается как Q2, так как она лежит между Q1 и Q3 — нижним и верхним квартилями, которые мы определим позже.- Не бойтесь работать с наборами данных, количество значений в которых четное. Средним арифметическим двух средних значений будет число, которого нет в наборе данных; это нормально. Но если два средних значения — это одно и то же число, то среднее арифметическое равно этому числу; это тоже в порядке вещей.
- В приведенном выше примере средние 2 значения — это 70 и 71, так что медиана равна ((70+71)/2) = 70,5.
-
4
Вычислите нижний квартиль. Эта величина, обозначаемая как Q1, ниже которой лежит 25% значений из набора данных. Другими словами, это половина значений, расположенных до медианы. Если до медианы лежит четное количество значений из набора данных, нужно найти среднее арифметическое двух средних значений, чтобы вычислить Q1 (это аналогично вычислению медианы).
- В нашем примере 6 значений расположены после медианы и 6 значений — до нее. Это означает, что для вычисления нижнего квартиля нам нужно найти среднее арифметическое двух средних значений из шести значений, лежащих до медианы. Здесь средние значения равны 70 и 70. Таким образом, Q1 = ((70 + 70)/2) = 70.
-
5
Вычислите верхний квартиль. Эта величина, обозначаемая как Q3, выше которой лежит 25% значений из набора данных. Процесс вычисления Q3 аналогичен процессу вычисления Q1, но здесь рассматриваются значения, расположенные после медианы.
- В приведенном выше примере два средних значения из шести значений, лежащих после медианы, равны 71 и 72. Таким образом, Q3 = ((71 + 72)/2) = 71,5.
-
6
Вычислите межквартильный диапазон. Вычислив Q1 и Q3, необходимо найти расстояние между этими величинами. Для этого вычтите Q1 из Q3. Значение межквартильного диапазона крайне важно для определения границ значений, которые не являются выбросами.
- В нашем примере Q1 = 70, а Q3 = 71,5. Межквартильный диапазон равен 71,5 — 70 = 1,5.
- Обратите внимание, что это применимо и к отрицательным значениям Q1 и Q3. Например, если Q1 = -70, то межквартильный диапазон равен 71,5 — (-70) = 141,5.
-
7
Найдите «внутренние границы» значений в наборе данных. Выбросы определяются через анализ значений — попадают ли они или нет в пределы так называемых «внутренних границ» и «внешних границ».[4]
Значение, лежащее вне «внутренних границ», классифицируется как «незначительный выброс», в то время как значение, находящееся за «внешними границами», классифицируется как «значительный выброс». Чтобы найти внутренние границы, необходимо умножить межквартильный диапазон на 1,5; результат нужно прибавить к Q3 и вычесть из Q1. Два найденных числа являются внутренними границами набора данных.- В нашем примере межквартильный диапазон равен (71,5 — 70) = 1,5. Далее: 1,5 * 1,5 = 2,25. Это число нужно прибавить к Q3 и вычесть его из Q1, чтобы найти внутренние границы:
- 71,5 + 2,25 = 73,75
- 70 — 2,25 = 67,75
- Таким образом, внутренние границы равны 67,75 и 73,75.
- В нашем примере только температура печи — 300 градусов — лежит вне этих границ и может считаться незначительным выбросом. Но не спешите с выводами —нам предстоит определить, является ли эта температура значительным выбросом.
- В нашем примере межквартильный диапазон равен (71,5 — 70) = 1,5. Далее: 1,5 * 1,5 = 2,25. Это число нужно прибавить к Q3 и вычесть его из Q1, чтобы найти внутренние границы:
-
8
Найдите «внешние границы» набора данных. Это делается таким же образом, как для внутренних границ, за исключением того, что межквартильный диапазон умножается на 3, а не на 1,5. Результат нужно прибавить к Q3 и вычесть из Q1. Два найденных числа являются внешними границами набора данных.
- В нашем примере умножьте межквартильный диапазон на 3: 1,5 * 3 = 4,5. Вычислите внешние границы:
- 71,5 + 4,5 = 76
- 70 — 4,5 = 65,5
- Таким образом, внешние границы равны 65,5 и 76.
- Любые значения, которые лежат за пределами внешних границ, считаются значительными выбросами. В нашем примере температура печи — 300 градусов — считается значительным выбросом.
- В нашем примере умножьте межквартильный диапазон на 3: 1,5 * 3 = 4,5. Вычислите внешние границы:
-
9
Воспользуйтесь качественной оценкой для определения того, нужно ли исключать выбросы из набора данных. Метод, описанный выше, позволяет определить, являются ли некоторые значения выбросами (незначительными или значительными). Тем не менее, не ошибитесь — значение, классифицируемое в качестве выброса, является только «кандидатом» на исключение, то есть вы не обязаны его исключать. Причина возникновения выброса — это основной фактор, влияющий на решение об исключении выброса. Как правило, выбросы, которые возникают из-за ошибки (в измерениях, записях и так далее), исключаются.[5]
С другой стороны, выбросы, связанные не с ошибками, а с новой информацией или тенденцией, как правило, оставляют в наборе данных.- Не менее важно оценить влияние выбросов на среднее арифметическое значение набора данных (искажают ли они его или нет). Это особенно важно в том случае, когда вы делаете выводы на основе среднего значения набора данных.
- В нашем примере крайне маловероятно, что печь нагреется до температуры 300 градусов (если только не учитывать природные аномалии). Поэтому можно заключить (с высокой долей уверенности), что такая температура — это ошибка измерений, которую нужно исключить из набора данных. Более того, если вы не исключите выброс, среднее значение набора данных будет равно (69 + 69 + 70 + 70 + 70 + 70 + 71 + 71 + 71 + 72 + 73 + 300)/12 = 89,67 градусов, но если вы исключите выброс, среднее значение составит (69 + 69 + 70 + 70 + 70 + 70 + 71 + 71 + 71 + 72 + 73)/11 = 70,55 градусов.
- Выбросы — это, как правило, результат человеческих ошибок, поэтому выбросы необходимо исключать из наборов данных.
-
10
Уясните важность (иногда) выбросов, оставляемых в наборе данных. Некоторые выбросы должны быть исключены из набора данных, так как их причинами являются ошибки и технические неполадки; другие выбросы необходимо оставить в наборе данных. Если, например, выброс не является результатом ошибки и/или дает новое понимание тестируемого явления, то его нужно оставить в наборе данных. Научные эксперименты особенно чувствительны к выбросам — исключив выброс по ошибке, вы можете пропустить некоторую новую тенденцию или открытие.
- Например, мы разрабатываем новый препарат для увеличения размера рыб в рыбном хозяйстве. Мы будем использовать старый набор данных ({71, 70, 73, 70, 70, 69, 70, 72, 71, 300, 71, 69}), но на этот раз каждое значение будет представлять массу рыбы (в граммах) после приема экспериментального препарата. Другими словами, первый препарат приводит к увеличению массы рыбы до 71 г, второй препарат — до 70 г и так далее. В этой ситуации 300 — это значительный выброс, но мы не должны исключать его; если предположить, что не было ошибок измерения, то такой выброс — это значительный успех в эксперименте. Препарат, который увеличил вес рыбы до 300 граммов, действует значительно лучше других препаратов; таким образом, 300 — это самое важное значение в наборе данных.
Реклама












Советы
- Когда выбросы найдены, попытайтесь объяснить их наличие до того, как исключить их из набора данных. Они могут указывать на ошибки измерения или аномалии в распределении.
Реклама
Что вам понадобится
- Калькулятор
Об этой статье
Эту страницу просматривали 59 559 раз.
Была ли эта статья полезной?
Как найти выбросы, используя межквартильный диапазон
17 авг. 2022 г.
читать 2 мин
Выброс — это наблюдение , которое лежит аномально далеко от других значений в наборе данных. Выбросы могут быть проблематичными, поскольку они могут повлиять на результаты анализа.
Один из распространенных способов найти выбросы в наборе данных — использовать межквартильный диапазон .
Межквартильный диапазон, часто сокращенно IQR, представляет собой разницу между 25-м процентилем (Q1) и 75-м процентилем (Q3) в наборе данных. Он измеряет разброс средних 50% значений.
Один из популярных методов состоит в том, чтобы объявить наблюдение выбросом, если его значение в 1,5 раза больше, чем IQR, или в 1,5 раза меньше, чем IQR.
В этом руководстве представлен пошаговый пример того, как найти выбросы в наборе данных с помощью этого метода.
Шаг 1: Создайте данные
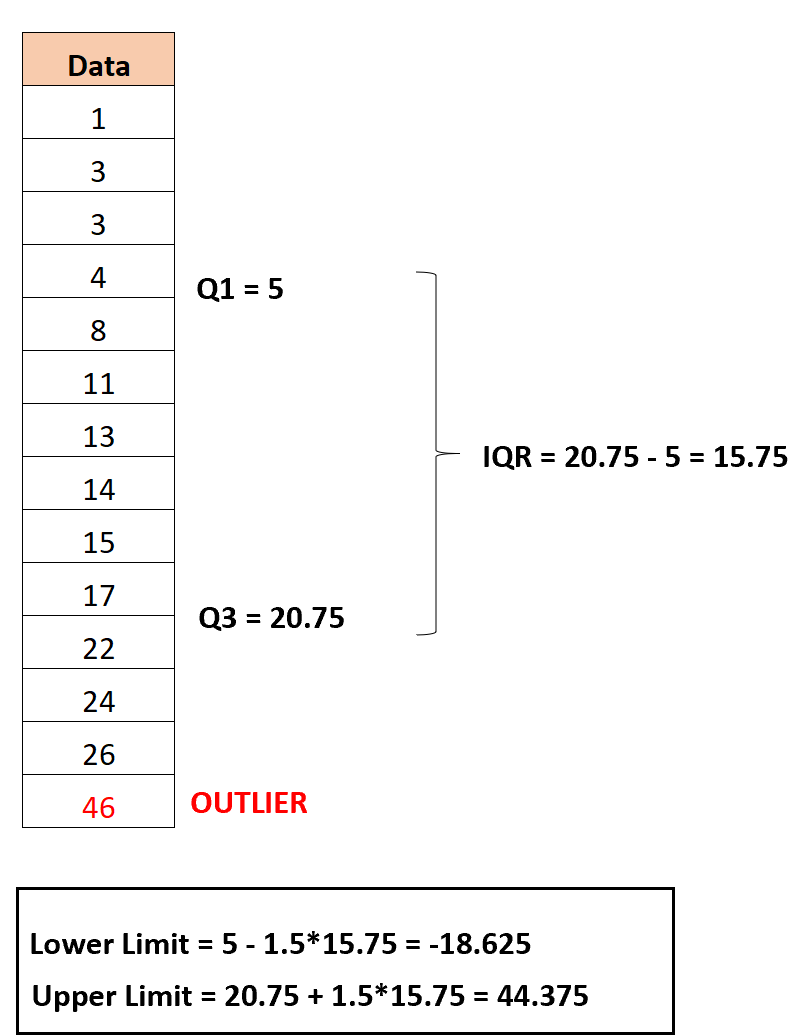
Предположим, у нас есть следующий набор данных:
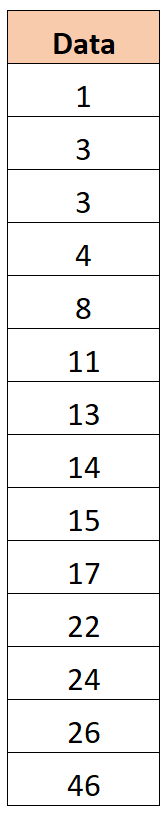
Шаг 2: Определите первый и третий квартиль
Первая квартиль оказывается равной 5 , а третья квартиль оказывается равной 20,75 .
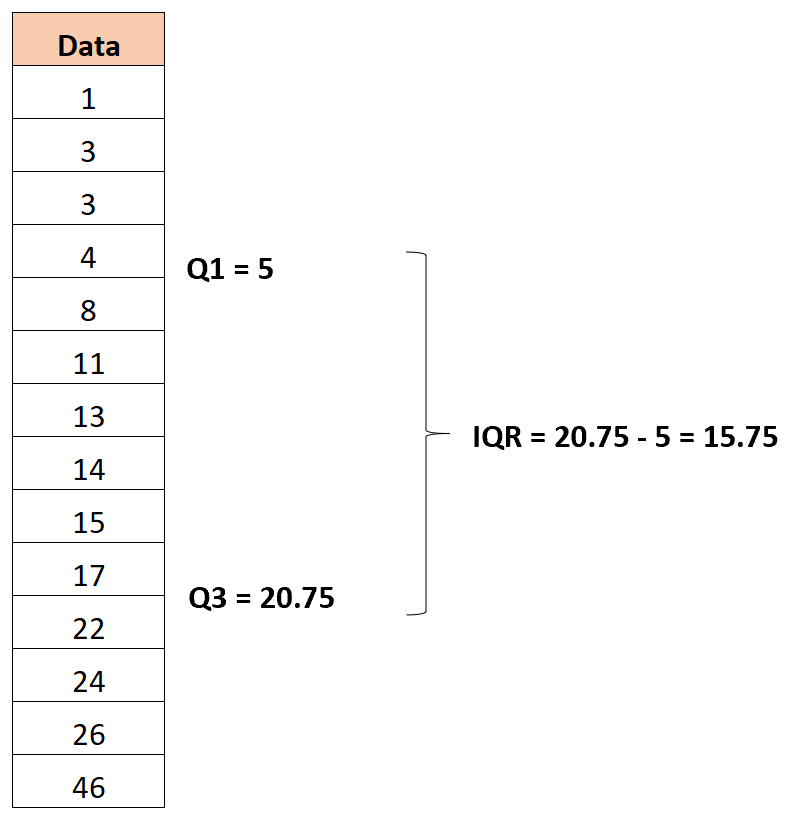
Таким образом, межквартильный размах оказывается равным 20,75 -5 = 15,75 .
Шаг 3: Найдите нижний и верхний пределы
Нижний предел рассчитывается как:
Нижний предел = Q1 – 1,5*IQR = 5 – 1,5*15,75 = -18,625
И верхний предел рассчитывается как:
Верхний предел = Q3 + 1,5 * IQR = 20,75 + 1,5 * 15,75 = 44,375
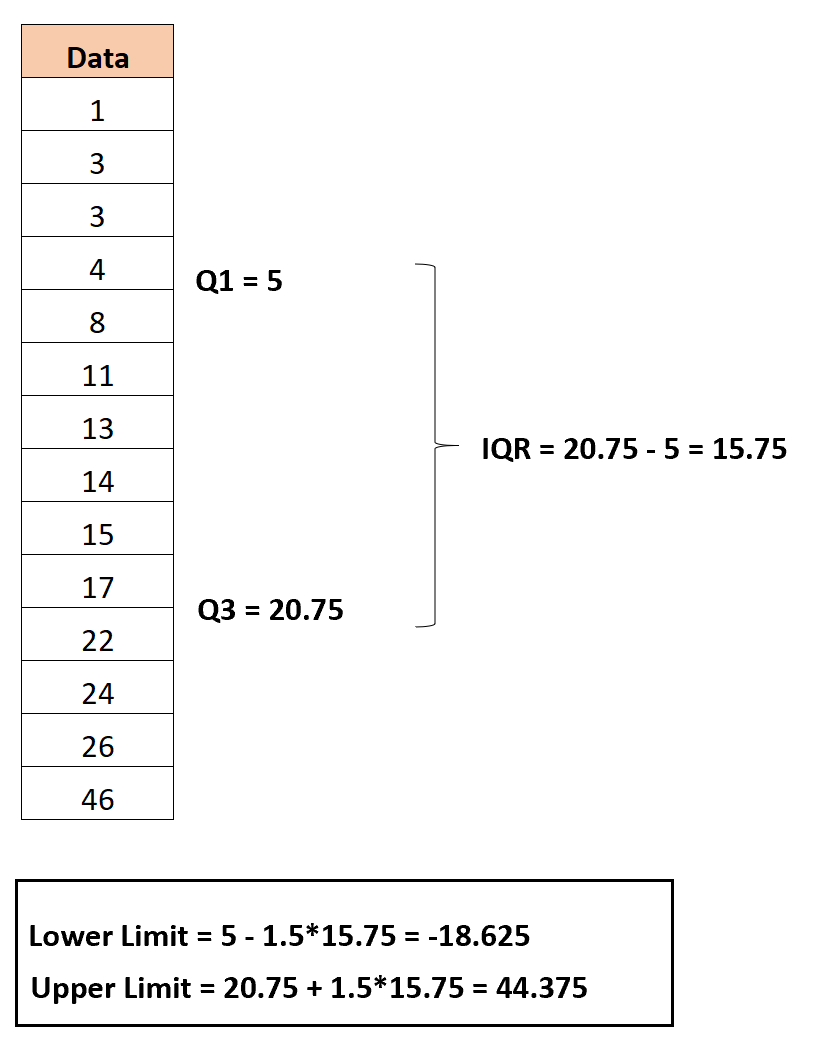
Шаг 4: Определите выбросы
Единственное наблюдение в наборе данных со значением меньше нижнего предела или больше верхнего предела — 46.Таким образом, это единственный выброс в этом наборе данных.
Примечание. Вы можете использовать этот калькулятор границ выбросов, чтобы автоматически находить верхнюю и нижнюю границы выбросов в заданном наборе данных.
Как найти выбросы на практике
В следующих руководствах объясняется, как найти выбросы, используя межквартильный диапазон в различных статистических программах:
Как найти выбросы в Excel
Как найти выбросы в R
Как найти выбросы в Python
Как найти выбросы в SPSS
В процессе анализ данных обычно прослеживается закономерность в том, что все значения колеблются возле определенного центрального уровня – медианы. Хотя очень часто некоторые из них выпадают далеко от центра. Такие значения называются статистическими выбросами (находятся далеко за прогнозируемым диапазоном). Статистические выбросы могут запачкать результаты статистического анализа, что может приводить к фальшивым или ошибочным выводам касающихся данных.
Как определить статистические выбросы и сделать выборку для их удаления в Excel
Для экспонирования и выделения цветом значений статистических выбросов от медианы можно использовать несколько простых формул и условное форматирование.
Первым шагом в поиске значений выбросов статистики является определение статистического центра диапазона данных. С этой целью необходимо сначала определить границы первого и третьего квартала. Определение границ квартала – значит разделение данных на 4 равные группы, которые содержат по 25% данных каждая. Группа, содержащая 25% наибольших значений, называется первым квартилем.
Границы квартилей в Excel можно легко определить с помощью простой функции КВАРТИЛЬ. Данная функция имеет 2 аргумента: диапазон данных и номер для получения желаемого квартиля.
В примере показанному на рисунке ниже значения в ячейках E1 и E2 содержат показатели первого и третьего квартиля данных в диапазоне ячеек B2:B19:
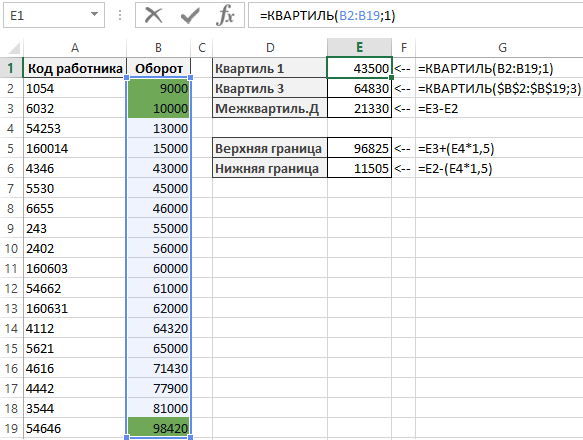
Вычитая от значения первого квартиля третьего, можно определить набор 50% статистических данных, который называется межквартильным диапазоном. В ячейке E3 определен размер межквартильного диапазона.
В этом месте возникает вопрос, как сильно данное значение может отличаться от среднего значения 50% данных и оставаться все еще в пределах нормы? Статистические аналитики соглашаются с тем, что для определения нижней и верхней границы диапазона данных можно смело использовать коэффициент расширения 1,5 умножив на значение межквартильного диапазона. То есть:
- Нижняя граница диапазона данных равна: значение первого квартиля – межкваритльный диапазон * 1,5.
- Верхняя граница диапазона данных равна: значение третьего квартиля + расширенных диапазон * 1,5.
Как показано на рисунке ячейки E5 и E6 содержат вычисленные значения верхней и нижней границы диапазона данных. Каждое значение, которое больше верхней границы нормы или меньше нижней границы нормы считается значением статистического выброса.
Чтобы выделить цветом для улучшения визуального анализа данных можно создать простое правило для условного форматирования.
Выборка статистических выбросов с помощью квартилей в Excel
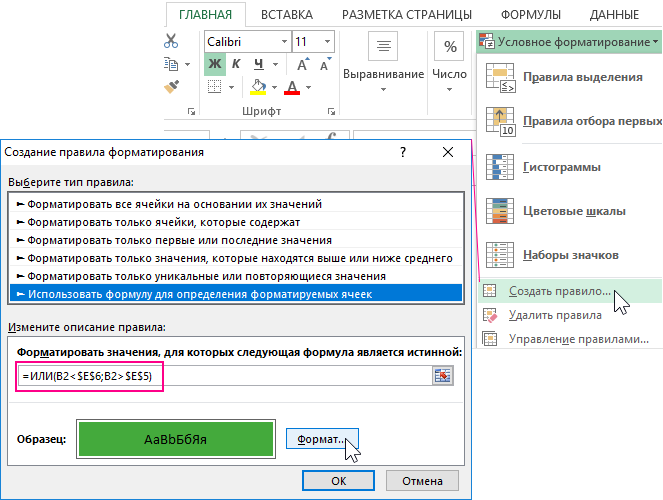
Чтобы создать правило для условного форматирования по выше описанным инструкциям, сделайте следующее:
- Выделите целевой диапазон ячеек (в данном примере B2:B19) и выберите инструмент «ГЛАВНАЯ»-«Условное форматирование»-«Создать правило». Появится окно «Создание правила форматирования ячеек», как показано ниже на рисунке:
- Из списка в верхней части окна выберите опцию «Использовать формулу для определения форматируемых ячеек». Данная опция служит для анализа значений в ячейках выделенного диапазона, с помощью определенной формулы с логическим выражением. Если в результате вычислений формулой, по какому-то из значений будет возвращено логическое значение ИСТИНА, тогда в этой ячейке будет применятся условное форматирование.
- В полю для введения формулы введите логическое выражение представленное на данном шаге. Обратите внимание на то, что в формуле используется относительная ссылка на целевую ячейку B2. А ссылки на верхнюю и нижнюю границу в ячейках $E$5 и $E$6 являются абсолютными. Два логических выражения помещены внутрь логической функции ИЛИ в качестве аргументов. Если значение целевой ячейки будет больше, чем верхняя граница или же меньше чем нижняя граница, тогда формула возвращает значение ИСТИНА и автоматически применяется условное форматирование.
=ИЛИ(B2<$E$6;B2>$E$5)
- Нажмите на кнопку «Формат» и появится окно «Формат ячеек», в котором находятся все опции для форматирования шрифтов, границ и заливки ячеек. После указания необходимых опций форматирования подтвердите их нажатием на кнопку «ОК» на всех открытых окнах, чтобы получить готовый результат.
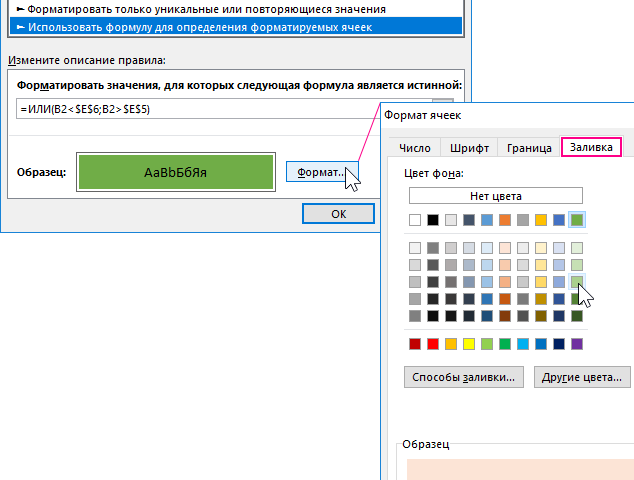
В результате выделены цветом все ячейки, которые содержат значение статистического выброса от медианы.
Отдельным вопросом работы с количественными данными являются выбросы (outliers), которые существенно влияют на многие статистические показатели, мешают масштабировать данные и ухудшают качество моделей машинного обучения.
Для визуализации некоторых результатов потребуется обновить sklearn и перезапустить среду выполнения.
Выбросы — это данные, которые сильно отличаются от общего распределения. При этом можно выделить:
Примечание. В последнем случае, хотя с точки зрения модели такой выброс будет считаться нежелательным, имеет смысл проверить, с чем связана такая цена.
Статистические показатели. На занятии по статистическому выводу мы провели тест Стьюдента, для того, чтобы определить на основе выборки вероятность того, что средний рост составляет 182 см.
|
[185.0, 179.0, 186.0, 195.0, 178.0, 178.0, 196.0, 188.0, 175.0, 185.0, 175.0, 175.0, 182.0, 161.0, 163.0, 174.0, 170.0, 183.0, 171.0, 166.0, 195.0, 178.0, 181.0, 166.0, 175.0, 181.0, 168.0, 184.0, 174.0, 177.0, 174.0, 199.0, 180.0, 169.0, 188.0, 168.0, 182.0, 160.0, 167.0, 182.0, 187.0, 182.0, 179.0, 177.0, 165.0, 173.0, 175.0, 191.0, 183.0, 162.0, 183.0, 176.0, 173.0, 186.0, 190.0, 189.0, 172.0, 177.0, 183.0, 190.0, 175.0, 178.0, 169.0, 168.0, 188.0, 194.0, 179.0, 190.0, 184.0, 174.0, 184.0, 195.0, 180.0, 196.0, 154.0, 188.0, 181.0, 177.0, 181.0, 160.0, 178.0, 184.0, 195.0, 175.0, 172.0, 175.0, 189.0, 183.0, 175.0, 185.0, 181.0, 190.0, 173.0, 177.0, 176.0, 165.0, 183.0, 183.0, 180.0, 178.0, 166.0, 176.0, 177.0, 172.0, 178.0, 184.0, 199.0, 182.0, 183.0, 179.0, 161.0, 180.0, 181.0, 205.0, 178.0, 183.0, 180.0, 168.0, 191.0, 188.0, 188.0, 171.0, 194.0, 166.0, 186.0, 202.0, 170.0, 174.0, 181.0, 175.0, 164.0, 181.0, 169.0, 185.0, 171.0, 195.0, 172.0, 177.0, 188.0, 168.0, 182.0, 193.0, 164.0, 182.0, 183.0, 188.0, 168.0, 167.0, 185.0, 183.0, 183.0, 183.0, 173.0, 182.0, 183.0, 173.0, 199.0, 185.0, 168.0, 187.0, 170.0, 188.0, 192.0, 172.0, 190.0, 184.0, 188.0, 199.0, 178.0, 172.0, 171.0, 172.0, 179.0, 183.0, 183.0, 188.0, 180.0, 195.0, 177.0, 207.0, 186.0, 171.0, 169.0, 185.0, 178.0, 187.0, 185.0, 179.0, 172.0, 165.0, 176.0, 189.0, 182.0, 168.0, 182.0, 184.0, 171.0, 182.0, 181.0, 169.0, 184.0, 186.0, 191.0, 191.0, 166.0, 171.0, 185.0, 185.0, 185.0, 219.0, 186.0, 191.0, 190.0, 187.0, 177.0, 188.0, 172.0, 178.0, 175.0, 181.0, 203.0, 161.0, 187.0, 164.0, 175.0, 191.0, 181.0, 169.0, 173.0, 187.0, 173.0, 182.0, 180.0, 173.0, 201.0, 186.0, 160.0, 182.0, 173.0, 189.0, 172.0, 179.0, 185.0, 189.0, 168.0, 177.0, 175.0, 173.0, 198.0, 184.0, 167.0, 189.0, 201.0, 190.0, 165.0, 175.0, 193.0, 173.0, 184.0, 188.0, 171.0, 179.0, 148.0, 170.0, 177.0, 168.0, 196.0, 166.0, 176.0, 181.0, 194.0, 166.0, 192.0, 180.0, 170.0, 185.0, 182.0, 174.0, 181.0, 176.0, 181.0, 187.0, 196.0, 168.0, 201.0, 160.0, 178.0, 186.0, 183.0, 174.0, 178.0, 175.0, 174.0, 188.0, 184.0, 173.0, 189.0, 183.0, 188.0, 186.0, 172.0, 174.0, 187.0, 186.0, 180.0, 181.0, 193.0, 174.0, 185.0, 178.0, 178.0, 191.0, 188.0, 188.0, 193.0, 180.0, 187.0, 177.0, 183.0, 179.0, 181.0, 186.0, 172.0, 201.0, 170.0, 168.0, 192.0, 188.0, 186.0, 186.0, 180.0, 171.0, 181.0, 173.0, 190.0, 179.0, 172.0, 177.0, 184.0, 174.0, 172.0, 182.0, 182.0, 175.0, 175.0, 182.0, 166.0, 166.0, 173.0, 178.0, 183.0, 195.0, 189.0, 178.0, 180.0, 170.0, 180.0, 177.0, 183.0, 172.0, 185.0, 195.0, 179.0, 184.0, 187.0, 176.0, 182.0, 180.0, 181.0, 172.0, 180.0, 185.0, 195.0, 190.0, 202.0, 172.0, 189.0, 182.0, 202.0, 172.0, 172.0, 174.0, 159.0, 175.0, 172.0, 182.0, 183.0, 199.0, 190.0, 174.0, 171.0, 185.0, 167.0, 198.0, 192.0, 175.0, 163.0, 194.0, 179.0, 192.0, 164.0, 174.0, 180.0, 180.0, 175.0, 186.0, 169.0, 179.0, 181.0, 185.0, 187.0, 169.0, 165.0, 193.0, 183.0, 173.0, 196.0, 181.0, 192.0, 181.0, 201.0, 198.0, 178.0, 190.0, 186.0, 194.0, 170.0, 187.0, 191.0, 162.0, 168.0, 160.0, 177.0, 187.0, 195.0, 181.0, 196.0, 166.0, 163.0, 179.0, 184.0, 180.0, 159.0, 179.0, 167.0, 187.0, 184.0, 171.0, 175.0, 169.0, 179.0, 190.0, 170.0, 185.0, 175.0, 172.0, 179.0, 170.0, 174.0, 168.0, 200.0, 180.0, 173.0, 182.0, 179.0, 178.0, 186.0, 188.0, 175.0, 174.0, 177.0, 157.0, 165.0, 194.0, 196.0, 178.0, 186.0, 183.0, 211.0, 191.0, 179.0, 170.0, 164.0, 182.0, 172.0, 166.0, 174.0, 169.0, 197.0, 189.0, 180.0, 195.0, 181.0, 171.0, 195.0, 185.0, 170.0, 178.0, 171.0, 166.0, 189.0, 199.0, 166.0, 186.0, 173.0, 175.0, 174.0, 171.0, 180.0, 172.0, 183.0, 179.0, 178.0, 171.0, 174.0, 188.0, 185.0, 170.0, 181.0, 188.0, 163.0, 185.0, 173.0, 186.0, 172.0, 162.0, 164.0, 180.0, 183.0, 171.0, 186.0, 163.0, 179.0, 168.0, 173.0, 180.0, 171.0, 176.0, 190.0, 174.0, 188.0, 169.0, 185.0, 194.0, 155.0, 172.0, 186.0, 178.0, 184.0, 174.0, 181.0, 178.0, 192.0, 183.0, 183.0, 176.0, 175.0, 176.0, 184.0, 176.0, 183.0, 201.0, 189.0, 177.0, 192.0, 176.0, 160.0, 170.0, 161.0, 176.0, 180.0, 197.0, 183.0, 178.0, 188.0, 158.0, 182.0, 188.0, 165.0, 191.0, 183.0, 176.0, 186.0, 203.0, 182.0, 182.0, 175.0, 172.0, 188.0, 171.0, 181.0, 175.0, 185.0, 183.0, 190.0, 175.0, 177.0, 170.0, 176.0, 184.0, 188.0, 171.0, 189.0, 194.0, 184.0, 199.0, 172.0, 168.0, 162.0, 195.0, 187.0, 179.0, 183.0, 169.0, 204.0, 181.0, 181.0, 187.0, 185.0, 182.0, 172.0, 185.0, 199.0, 193.0, 196.0, 175.0, 170.0, 179.0, 181.0, 191.0, 163.0, 195.0, 178.0, 176.0, 170.0, 163.0, 188.0, 181.0, 167.0, 167.0, 177.0, 197.0, 177.0, 165.0, 178.0, 177.0, 153.0, 179.0, 178.0, 187.0, 198.0, 191.0, 177.0, 169.0, 206.0, 181.0, 180.0, 180.0, 182.0, 179.0, 174.0, 175.0, 180.0, 175.0, 173.0, 181.0, 177.0, 195.0, 153.0, 191.0, 192.0, 159.0, 177.0, 176.0, 166.0, 172.0, 169.0, 198.0, 189.0, 193.0, 187.0, 169.0, 175.0, 185.0, 168.0, 187.0, 178.0, 176.0, 187.0, 184.0, 176.0, 192.0, 169.0, 186.0, 186.0, 177.0, 183.0, 167.0, 189.0, 178.0, 175.0, 190.0, 173.0, 166.0, 164.0, 186.0, 167.0, 198.0, 159.0, 197.0, 182.0, 179.0, 175.0, 184.0, 180.0, 191.0, 181.0, 182.0, 176.0, 179.0, 183.0, 163.0, 167.0, 187.0, 182.0, 178.0, 180.0, 183.0, 175.0, 172.0, 182.0, 170.0, 184.0, 163.0, 190.0, 185.0, 183.0, 190.0, 197.0, 190.0, 162.0, 167.0, 174.0, 180.0, 185.0, 173.0, 182.0, 172.0, 174.0, 166.0, 171.0, 166.0, 170.0, 191.0, 171.0, 206.0, 185.0, 182.0, 171.0, 187.0, 174.0, 181.0, 206.0, 179.0, 191.0, 173.0, 180.0, 198.0, 174.0, 198.0, 187.0, 174.0, 186.0, 190.0, 186.0, 164.0, 173.0, 178.0, 179.0, 186.0, 182.0, 167.0, 184.0, 186.0, 186.0, 191.0, 188.0, 185.0, 179.0, 163.0, 184.0, 182.0, 183.0, 167.0, 169.0, 191.0, 180.0, 187.0, 180.0, 180.0, 189.0, 175.0, 181.0, 175.0, 176.0, 177.0, 182.0, 175.0, 193.0, 171.0, 178.0, 176.0, 194.0, 182.0, 190.0, 165.0, 183.0, 189.0, 181.0, 191.0, 175.0, 194.0, 203.0, 176.0, 176.0, 195.0, 196.0, 175.0, 176.0, 177.0, 167.0, 171.0, 170.0, 172.0, 180.0, 182.0, 196.0, 170.0, 190.0, 178.0, 180.0, 187.0, 169.0, 184.0, 182.0, 185.0, 183.0, 205.0, 174.0, 175.0, 174.0, 174.0, 174.0, 192.0, 194.0, 174.0, 172.0, 185.0, 174.0, 186.0, 182.0, 165.0, 195.0, 198.0, 174.0, 176.0, 183.0, 183.0, 187.0, 200.0, 178.0, 172.0, 166.0, 173.0, 180.0, 198.0, 175.0, 182.0, 180.0, 192.0, 205.0, 175.0, 175.0, 190.0, 187.0, 198.0, 186.0, 176.0, 186.0, 191.0, 188.0, 185.0, 191.0, 192.0, 194.0, 186.0, 178.0, 181.0, 192.0, 172.0, 184.0, 176.0, 180.0, 193.0, 182.0, 180.0, 166.0, 187.0, 186.0, 202.0, 177.0, 182.0, 182.0, 196.0, 179.0, 183.0, 186.0, 182.0, 176.0, 182.0, 191.0, 170.0, 181.0, 173.0, 192.0, 165.0, 174.0, 184.0, 196.0, 179.0, 174.0, 199.0, 166.0, 158.0, 184.0, 175.0, 170.0, 187.0, 182.0, 174.0, 167.0, 189.0, 187.0, 179.0, 198.0, 169.0, 165.0, 173.0, 180.0, 182.0, 178.0, 184.0, 167.0, 194.0, 179.0, 191.0, 183.0, 185.0, 186.0, 184.0, 186.0, 193.0, 182.0, 187.0, 179.0, 194.0, 173.0, 198.0, 180.0, 166.0, 181.0, 173.0, 188.0, 173.0, 176.0, 161.0, 175.0, 156.0, 164.0, 188.0, 188.0, 184.0, 170.0, 180.0, 180.0, 168.0, 195.0, 189.0, 178.0, 180.0, 182.0, 160.0, 178.0, 173.0, 170.0, 177.0, 198.0, 186.0, 174.0, 186.0] |
Напомню, что исходя из данных мы смогли отвергнуть нулевую гипотезу, которая утверждала, что рост дейсвительно составляет 182 см.
Добавим выброс и повторно проверим гипотезу.
Как мы видим, одно сильно отличающееся наблюдение изменило результаты теста.
Масштабирование данных. Как мы только что видели, сильно отличающиеся от остальных значения мешают качественному масштабированию данных.
Модели ML. Выбросы влияют на качество модели линейной регрессии. Возьмем третий набор данных из квартета Энскомба (Anscombe’s quartet).
Посмотрим на коэффициент корреляции.
Удалим выброс.
Вновь посмотрим на график и коэффициент корреляции.
Выбросы особенно сильны, когда мы располагаем небольшим количеством данных.
Отличающееся наблюдение можно разделить на выбросы (outlier) и новые отличающиеся наблюдения (novelty). Выброс уже присутствует в данных. То есть мы смотрим на данные и понимаем, что часть содержащихся в них наблюдений существенно отличаются от общей массы. Во втором случае, у нас уже есть набор данных, нас просят определить, является ли новое наблюдение выбросом или нет.
Так как для выявления уже присутствующих выбросов у нас нет никакой разметки, это обучение без учителя. Во втором случае, это частичное обучение с учителем (semi-supervised). На практике это означает, что при использовании продвинутых алгоритмов для выявления выбросов, если речь идет о новых отличающихся наблюдениях (novelty), мы должны использовать .fit() на обучающей выборке, а .predict(), .decision_function() и .score_samples() на тестовой (про алгоритмы и эти методы поговорим дальше). Подробнее здесь⧉.
Начнем с более простых методов. Скачаем и подгрузим данные.
Выбросы можно увидеть на boxplot. По умолчанию, длина «усов» рассчитывается как $ 1,5 times IQR $. Данные, которые выходят за их пределы — выбросы.
Кроме того, выбросы можно попытаться выявить на точечной диаграмме.
Количественно выбросы можно найти через стандартизированную оценку (z-оценку, z-score). Эта оценка показывает на сколько средних квадратических отклонений значение отличается от среднего.
Так как мы знаем, что 99,7 процентов наблюдений лежат в пределах трех СКО от среднего, то можем предположить, что выбросами будут оставшиеся 0,3 процента.
Выведем эти значения.
Посмотрим, как удалить выбросы в отдельном столбце.
Теперь удалим выбросы во всем датафрейме.
Выведем корреляцию до и после удаления выбросов.
В данном случае корреляция увеличилась.
Важно понимать, что z-score, который мы используем для идентификации выбросов сам по себе зависит от сильно отличающихся значений, поскольку для расчета используется среднее арифметическое и СКО.
Вместо z-оценки можно использовать изменнную z-оценку (modified z-score), которая использует метрики робастной статистики.
где MAD представляет собой среднее абсолютное отклонение (median absolute deviation) и рассчитывается по формуле $MAD = median(|x-Q2|). Заметим⧉, что $MAD=0,6745sigma$.
Iglewicz и Hoaglin рекомендуют считать выбросами те значения, для которых $|z_{mod} > 3,5|$. Применим этот метод.
Обратите внимание, что в данном случае мы очень агрессивно удаляли значения. Посмотрим на корреляцию.
Еще одним распространенным способом выявления и удаления выбросов является правило $ 1,5 times IQR $. Рассмотрим, почему именно 1,5? В стандартном нормальном распределении Q1 и Q3 соответствуют $-0.6745sigma$ и $0.6745sigma$.
Зная эти показатели, мы можем рассчитать верхнюю и нижнюю границу.
Замечу, что для того, чтобы этот метод нахождения выбросов был аналогичен z-score, было бы точнее использовать показатель $ 1,75 times IQR $. При таком решении выбросами будет считаться большее количество наблюдений.
Найдем и удалим выбросы в столбце.
Найдем и удалим выбросы во всем датафрейме.
Как мы видим, несмотря на более активное удаление значений, коэффициент корреляции стал даже меньше, чем в изначальных данных.
Теперь посмотрим на методы выявления выбросов, основанные на модели (model-based approaches)
Изолирующий лес (Isolation Forest или iForest) использует принципы решающего дерева (Decision Tree) и построенного на его основе ансамблевого метода случайного леса (Random Forest).
Принцип построения изолирующиего дерева (Isolation Tree или iTree) довольно прост. Алгоритм случайным образом выбирает признак, затем в пределах диапазона этого признака случайно выбирает разделяющую границу (split). Та часть наблюдений, которая меньше либо равна этой границые. оказывается в левом потомке (left child node), та которая больше — в правом (right child node). Затем процесс рекурсивно повторяется.
Что интересно, в получившейся древовидной структуре путь (то есть количество сплитов) от корневого узла (root node) до выброса будет существенно короче, чем до обычного наблюдения. Это логично, например, в задаче классификации с помощью решающего дерева в первую очередь удается отделить тот класс, который наиболее удален от остальных.
Приведем классификацию с помощью решающего дерева на примере датасета цветов ириса.
Как вы видите, нулевой, наиболее удаленный класс (синие точки) удалось отделить уже на первом шаге. По этому же принципу отделяются выбросы.
Лес изолирующих деревьев соответственно дает усредненное расстояние до каждой из точек.
Рассмотрим как количественно выразить среднее расстояние до каждой из точек или показатель аномальности (anomaly score). Приведем формулу.
где x — это конкретное наблюдение из общего числа n наблюдений. При этом c(n) — это средний путь до листа в аналогичном по структуре двоичном дереве поиска (binary search tree, BST) с n наблюдений, а $ E(h(x)) $ — усредненное по всем деревьям расстояние до конкретного наблюдения x. Нормализуя показатель $ E(h(x)) $ по c(n) мы получаем, что:
При этом расстояние $h(x)$ находится в диапазоне $(0, n-1]$, а s в диапазоне $(0, 1]$. Таким образом,
Разберем пример⧉, приведенный на сайте sklearn. Вначале создадим синтетические данные с выбросами.
Разделим выборку.
Обучим класс изолирующего леса. Так как наблюдений мало, для каждого дерева будем брать все объекты обучающей выборки.
Сделаем прогноз на тесте и посмотрим на результат.
Выведем решающую границу.
Продемонстрируем особенности параметра contamination на простом примере. Возьмем небольшой набор данных и поочередно применим параметры contamination = ‘auto’, 0.1, 0.2. Несколько пояснений:
Применим алгоритм изолирующего леса к датасету boston.
Посмотрим на взаимосвязь признака RM с целевой переменной после удаления выбросов.
Для того чтобы увидеть недостаток алгоритма, рассмотрим тепловую карту, на которой цветом будут выводиться области с одинаковым anomaly score.
Как вы видите, в верхнем левом и нижнем правом углу также находятся области (их называют ghost areas), в которых объекты могли бы быть классифицированы как обычные наблюдения, хотя это неправильно (ложноположительный результат). Это связано с тем, что границы, проводимые алгоритмом параллельны осям координат.
Приведем иллюстрацию из статьи⧉ исследователей, усовершенствовавших этот алгоритм.
Для решения этой проблемы был предложен расширенный алгоритм изолирующего леса.
Расширенный алгоритм изолирующего леса (Extended Isolation Forest) делит пространство с помощью случайных, не обязательно параллельных осям координат, гиперплоскостей. Авторами этого алгоритма являются Sahand Hariri, Matias Carrasco Kind и Rober J. Brunner⧉. Для данных на предыдущей иллюстрации разделение с помощью расширенного алгоритма могло бы выглядеть вот так.
Рассмотрим работу этого алгоритма на практике. Приведу две библиотеки, в которых реализован Extended Isolation Forest.
Используем второй вариант.
Установим h2o в Google Colab.
Запустим сервер h2o.
Импортируем класс алгоритма⧉, создадим объекты этого класса для модели обычного изолирующего леса (без наклона гиперплоскостей) и для модели с максимальным наклоном гиперплоскостей.
Максимальный наклон задается параметром extension_level и находится в диапазоне $[0, P-1]$, где P — это количество признаков. В нашем случае признаков два, поэтому для расширенного алгоритма используем extension_level = 1.
Так как Extended Isolation Forest — это алгоритм без учителя (метод .predict() выдает anomaly_score), мы не можем напрямую посчитать точность прогноза. С другой стороны, так как в созданных нами данных есть разметка, мы можем провести косвенное сравнение.
Например, мы можем отсортировать данные по anomaly_score в убывающем порядке (то есть в начале будут наблюдения, которые наиболее вероятно являются выбросами) и посмотреть, какое количество единиц (то есть не выбросов), оказалось в результатах сортировки каждого из алгоритмов.
Начнем с алгоритма обычного изолирующего леса. Сделаем прогноз.
Создадим датафрейм из исходных признаков и целевой переменной.
Определимся с долей наблюдений, в которых будем считать количество выбросов и не выбросов.
Соединим датафрейм с признаками и целевой переменной с показателями аномальности. Затем отсортируем по этой метрике в убывающем порядке и рассчитаем количество выбросов и не выбросов в имеющихся данных.
Итак, в 60-ти наблюдениях с наибольшим anomaly score обычный алгоритм поместил 39 выбросов и 21 не выброс.
Сделаем то же самое с расширенным алгоритмом.
Расширенный алгоритм сделал чуть менее качественный прогноз.
Сравним тепловые карты обоих алгоритмов.
В данном случае, как мы видим, расширенному алгоритму не удалось сформировать два обособленных кластера.
На сегодняшнем занятии мы разобрали статистические методы выявления выбросов (boxplot, scatter plot, z-score и 1,5 IQR), а также два метода, основанные на модели (алгоритмы обычного и расширенного изолирующего леса).
Выброс в статистике — это любая точка данных, которая значительно отличается от других точек данных. Выбросы могут быть ошибками или важными наблюдениями, поэтому их необходимо найти и понять. В этой статье мы обсуждаем выбросы в статистике, как найти выбросы в ваших данных и приводим примеры.
Почему важно находить выбросы в статистике?
Выбросы в статистике могут значительно изменить результат ваших данных, особенно если вы пытаетесь вычислить среднее или среднее значение набора данных, где все остальные точки данных имеют другой диапазон значений.
В конечном итоге вы можете удалить выброс из своих результатов, если обнаружите, что он был записан по ошибке, но необходимо сначала проанализировать его, чтобы понять его значение.
Выбросы также могут выявить несоответствия в методах исследования и сбора данных и помочь вам уточнить ваши процедуры.
Вот пять способов найти выбросы в вашем наборе данных:
1. Сортируйте данные
Простой способ определить выбросы — отсортировать данные, что позволяет увидеть любые необычные точки данных в вашей информации. Попробуйте отсортировать данные по возрастанию или убыванию, а затем проверьте данные, чтобы найти выбросы. Необычно высокий или низкий уровень данных может быть выбросом.
Например, если у вас есть эти числа в порядке возрастания: 3, 6, 7, 10 и 54, вы можете увидеть, что 54 намного больше, чем остальные точки данных. Статистики сочли бы 54 выбросом.
Подробнее: Как сортировать данные в Excel (с пошаговыми инструкциями)
2. График ваших данных
Вы также можете использовать графики, такие как диаграммы рассеяния или гистограммы, чтобы найти выбросы. Графики представляют ваши данные визуально, что позволяет легко увидеть, когда часть данных отличается от остального набора данных. Точечная диаграмма отображает ваши точки данных в виде точек на графике, основанном на двух переменных, нанесенных на оси x и y. Диаграммы рассеивания полезны для визуализации выбросов, потому что вы можете видеть, когда одна точка находится далеко от других точек, которые обычно сгруппированы вместе. Следовательно, точка данных, которая находится далеко от группы, является выбросом.
Гистограмма отображает данные в группах, называемых «ячейками». Гистограммы обычно группируют данные в диапазонах, что отличает гистограммы от гистограмм. Ваш диапазон данных обычно представляет собой ось X, а другая ваша переменная обычно представляет собой ось Y. Это может помочь определить необычные точки данных. Например, если большинство ваших точек данных находятся на правой стороне графика, а один бин данных находится на левой стороне графика, вы можете сделать вывод, что крайний левый бин является выбросом.
3. Рассчитайте z-значение
Z-оценка, или стандартная оценка, показывает, насколько далеко точка данных находится от среднего значения данных. Чтобы рассчитать z-оценку, вы вычитаете среднее значение из исходного измерения и делите его на стандартное отклонение.
Уравнение для расчета z-показателя:
Z = (X−µ) ÷ σ
куда:
X = необработанное измерение
µ = среднее значение
σ = стандартное отклонение
Чем дальше z-оценка от 0, тем более необычна точка данных. Например, если z-оценки для ваших точек данных: -0,35, -0,26, -0,021, -0,18 и 4,7, вы можете сказать, что точка данных с z-оценкой 4,7 находится дальше всего от 0 и является выбросом.
Подробнее: Как рассчитать Z-оценку
4. Рассчитайте межквартильный размах
Межквартильный диапазон (IQR) измеряет дисперсию точек данных между отметками первого и третьего квартилей. Общее правило его использования для расчета выбросов заключается в том, что точка данных является выбросом, если она более чем в 1,5 раза превышает IQR ниже первого квартиля или в 1,5 раза превышает IQR выше третьего квартиля.
Для расчета IQR необходимо знать процентиль первого и третьего квартилей. Медиана верхней половины набора данных является процентилем для третьего квартиля, а медиана нижней половины набора данных является процентилем для первого квартиля.
Чтобы найти IQR, вы вычитаете первый квартиль из третьего квартиля:
IQR = Q3 − Q1
куда:
Q3 = третий квартиль = медиана верхней половины набора данных
Q1 = первый квартиль = медиана нижней половины набора данных
Затем вы можете использовать IQR, чтобы найти любые выбросы в вашем наборе данных. Уравнения для расчета низких или высоких выбросов с помощью диапазона IQR:
Высокий выброс ≥ Q3 + (1,5 x IQR)
Низкий выброс ≤ Q1 − (1,5 x IQR)
Подробнее: Как найти медиану набора данных в статистике
5. Используйте проверку гипотез
Если вы хотите попробовать более продвинутые варианты поиска выбросов, рассмотрите возможность проверки гипотез, таких как тест Граббса, обобщенный ESD или критерий Пирса. Тесты гипотез включают обработку данных с помощью уравнений, чтобы увидеть, соответствуют ли они предсказанным результатам. Критерий Граббса можно использовать, когда вы подозреваете только один выброс в нормально распределенном наборе данных.
Обобщенный тест экстремальных студенческих отклонений (ESD) может использовать данные только с одной переменной для проверки более чем одного выброса. Статистики используют критерий Пирса, чтобы находить и устранять выбросы, вычисляя, как стандартное отклонение сравнивается со средним значением набора данных.
Поскольку трудно выбрать правильный тест гипотезы, если вы не знаете много о своем наборе данных, они могут быть неточными или сложными для выполнения. Вы можете изучить их заранее, чтобы выбрать правильный, или подумать, могут ли более простые методы позволить вам найти выбросы в ваших данных.