Определить, какие акции купить для вашего портфеля, чтобы быть финансово безопасным, но при этом получать деньги, может быть огромным усилием. Ковариация — это один из показателей, который вы можете использовать для анализа риска добавления еще одной акции в свой портфель.
Знание того, как рассчитать ковариацию, может дать вам представление о взаимосвязи между двумя акциями, независимо от того, есть ли они у вас или те, которые вы рассматриваете в будущем. В этой статье мы обсудим, что такое ковариация, чем она отличается от дисперсии, как ее рассчитать за шесть шагов, ее применение и пример расчета.
Что такое ковариация?
Ковариация — это измерение, используемое в статистике для определения того, изменяются ли две переменные в одном и том же направлении. Это измерение разницы между двумя переменными, и две переменные, используемые для определения ковариации, не связаны между собой.
Вы можете измерить ковариацию с точки зрения единиц, связанных с двумя переменными в наборах данных. Например, в финансах два набора данных могут быть стоимостью акций одной компании, а другой — акциями несвязанной компании. Поскольку обе величины представлены в долларах, единицей измерения будут доллары.
Ковариация сравнивает две переменные с точки зрения положительного и отрицательного. Если значение ковариации отрицательное, то две переменные движутся в противоположных направлениях. Если значение ковариации положительное, то две переменные движутся в одном направлении.
Примечательно, что это означает, что две переменные могут уменьшаться в одном и том же направлении, и ковариация все равно будет иметь положительное значение. Например, если две компании владеют акциями, которые со временем дешевеют, то их ковариация будет положительной.
Ковариация против дисперсии
Дисперсия — это измерение расстояния между переменной и средним значением набора данных. В отличие от ковариации, одна точка данных или тенденция является средним значением, а другая представляет собой интересующую точку или тенденцию, которую вы решили измерить.
Используя приведенный выше пример, если акции первой компании растут с течением времени, но общая тенденция для всех акций падает, то разница между средним значением и акциями компании может увеличиться. Если акции второй компании также растут с той же скоростью, что и акции первой, то ковариация будет положительной.
Как рассчитать ковариацию
Для расчета ковариации можно использовать формулу:
Cov(X, Y) = Σ(Xi-µ)(Yj-v)/n
Где части уравнения:
-
Cov(X, Y) представляет собой ковариацию переменных X и Y.
-
Σ представляет собой сумму других частей формулы.
-
(Xi) представляет все значения переменной X.
-
µ представляет собой среднее значение переменной X.
-
Yj представляет все значения переменной Y.
-
v представляет собой среднее значение Y-переменной.
-
Σ представляет собой сумму значений для (Xi-µ) и (Yj-v).
-
n представляет собой общее количество точек данных по обеим переменным.
Вы можете использовать следующие шаги и формулу ковариации, чтобы найти ковариацию ваших данных:
1. Получите данные
Первым шагом в нахождении ковариации двух переменных является сбор данных для обоих наборов. Например, в таблице ниже показана стоимость акций двух новых компаний в период с 2015 по 2020 год:
Год Компания X Стоимость акций ($) Компания Y Стоимость акций ($) 2015 1 245 100 2016 1 415 123 2017 1 312 129 2018 1 427 143 2019 1 510 150 2020 1 590 197
2. Рассчитайте среднее значение для каждой переменной
Чтобы найти среднее значение для каждой акции, сложите все значения X вместе и разделите на общее количество значений X. Затем сделайте то же самое для значений Y:
-
µ = 1 245 + 1 415 + 1 312 + 1 427 + 1 510 + 1 590 / 6
-
µ = 1416,5
-
v = 100 + 123 + 129 + 143 + 150 + 197 / 6
-
v = 140,3
3. Найдите разницу между каждым значением и средним значением для обеих переменных.
Вычтите среднее значение для каждого набора переменных из каждой переменной в этом наборе. Например:
Год Компания X (Xi-µ) Компания Y (Yj-v) 2015 1 245 — 1 416,5 = -171,5 100 — 140,3 = -40,3 2016 1 415 — 1 416,5 = -1,5 123 — 140,3 = -17,3 2017 1 312 — 1 416,5 = -1 209,5 140,2 = -11,2 2018 г. 1 427 — 1 416,5 = 10,5 143 — 140,3 = 2,7 2019 г. 1 510 — 1 416,5 = 93,5 150 — 140,3 = 9,7 2020 г. 1 590 — 1 416,5 = 5 6,7 — 4 0,7
4. Умножьте значения двух переменных
Как только вы нашли значения для обеих переменных на предыдущем шаге, вы можете перемножить их вместе. Например:
Год Компания X (Xi-µ) Компания Y (Yj-v) (Xi-µ)(Yj-v) 2015 1 245 — 1 416,5 = -171,5 100 — 140,3 = -40,3 (-171,5)(-40,3) = 6 911,45 2016 1 415 — 1 416,5 = -1,5 123 — 140,3 = -17,3 (-1,5)(-17,3) = 25,95 2017 1 312 — 1 416,5 = -104,5 129 — 140,2 = -11,2 (-104,5)(-11,3) = 1 180,85 2016 — 1 4218 1 143 — 140,3 = 2,7 (10.5) (2.7) = 28,35 2019 1,510 — 140,3 — 93,5 150 — 140,3 = 9,7 (93,5) (9.7) = 906,95 2020 1 590 — 1 416,5 = 173,5 197 — 140,3 = 56,7 (173,5) (56.7) = 9 837,45
5. Сложите значения вместе
После того, как вы вычислили произведение двух переменных вместе, вы можете сложить значения, чтобы получить предпоследнюю часть уравнения. Например, вы можете добавить значения продуктов из компаний выше, чтобы получить сумму всех значений:
6 911,45 + 25,95 + 1 180,85 + 28,35 + 906,95 + 9 837,45 = 18 891
6. Используйте значения из предыдущих шагов, чтобы найти ковариацию данных.
После того, как вы рассчитали части уравнения, вы можете ввести в него свои значения. Например, вы можете поместить акции компании сверху в уравнение, как показано ниже:
Cov(X, Y) = 18 891/6
Где значения:
-
18 891 = Σ(Xi-µ)(Yj-v)
-
6 = п
Как подсчитано выше, ковариация акций компании X и компании Y составляет 3148,5. Положительный характер значения ковариации показывает, что акции двух компаний движутся в одном направлении.
Приложения ковариации
Одно применение ковариации в финансах. Вы можете использовать ковариацию для оценки риска конкретных акций, сравнивая, движутся ли они вместе или против друг друга. Например, если стоимость двух акций увеличивается и уменьшается противоположно друг другу, то они будут дополнять друг друга с минимальным риском, потому что они минимизируют финансовые потери, поскольку одна растет, а другая сокращается.
Вы также можете использовать ковариацию с корреляцией, чтобы определить, движутся ли переменные вместе и как, и инвесторы часто используют и то, и другое, чтобы определить, добавлять ли акции в портфель. В то время как ковариация может сказать вам, как двигаются два или более набора данных, корреляция может сказать вам, какие другие факторы влияют на это движение и связаны ли две переменные друг с другом.
Пример расчета
Ниже приведен пример расчета ковариации продаж двух новых игрушек, проданных одной и той же компанией:
1. Найдите свои данные
Сначала найдите интересующие вас данные. В данном примере это количество двух игрушек, проданных с января по апрель:
Месяц Игрушка X Игрушка Y 12 января 67 13 февраля 45 25 марта 32 39 апреля 21
2. Найдите количество проданных игрушек
Затем найдите количество игрушек, проданных за указанные выше месяцы, и вы сможете найти среднее количество игрушек, проданных для каждой из них:
-
µ = 12 + 13 + 25 + 39 / 4
-
м = 22,25
-
v = 67 + 45 + 32 + 21/4
-
v = 41,25
3. Найдите разницу в значениях
В-третьих, вычислите разницу между каждым значением X и µ. Затем вычислите разницу между каждым значением Y и v:
Месяц Toy X (Xi-µ) Toy Y (Yj-v) 12 января — 22,25 = -10,25 67 — 41,25 = 25,75 13 февраля — 22,25 = -9,25 45 — 41,25 = 3,75 25 марта — 22,25 = 2,75 32 — 41,25 = — 9,25 39 апреля — 22,25 = 16,75 21 — 41,25 = -20,25
4. Рассчитайте произведение
В-четвертых, вы можете вычислить произведение (Xi-µ) и (Yj-v):
-
(-10,25)(25,75) = -263,94
-
(-9,25)(3,75) = -34,69
-
(2,75)(-9,25) = -25,44
-
(16,75)(-20,25) = -339,19
5. Добавляйте товары вместе
В-пятых, вы можете сложить произведения драгоценных вычислений, чтобы получить сумму -663,26:
-
Σ = (-263,94) + (-34,69) + (-25,44) + (-339,19) = -663,26
6. Замените значения
Наконец, вы можете подставить значения в уравнение из предыдущего:
-
Cov(X, Y) = -663,26/4
-
Cov(X, Y) = -165,82
Используя эту ковариацию, вы можете определить, что когда количество проданных игрушек увеличивается для одной игрушки, оно уменьшается для другой. Это связано с тем, что значение ковариации отрицательно.
![]()
Download Article
![]()
Download Article
Covariance is a statistical calculation that helps you understand how two sets of data are related to each other. For example, suppose anthropologists are studying the heights and weights of a population of people in some culture. For each person in the study, the height and weight can be represented by an (x,y) data pair. These values can be used with a standard formula to calculate the covariance relationship. This article will first explain the calculations that go into finding the covariance of a data set. It will then address two more automated ways to find the result.
-

1
Learn the standard covariance formula and its parts. The standard formula for calculating covariance is
. To use this formula, you need to understand the meaning of the variables and symbols:[1]
-
2
Set up your data table. Before you begin working, it is helpful to collect your data. You should make a table that consists of five columns. You should label each column as follows:
Advertisement
-
3
Calculate the average of the x-data points. This sample data set contains 9 numbers. To find the average, add them together and divide the sum by 9. This gives you the result of 1+3+2+5+8+7+12+2+4=44. When you divide by 9, the average is 4.89. This is the value that you will use as x(avg) for the coming calculations.[3]
-
4
Calculate the average of the y-data points. Similarly, the y-column should consist of 9 data points that coincide with the x-data points. Find the average of these. For this sample data set, this will be 8+6+9+4+3+3+2+7+7=49. Divide this sum by 9 to get an average of 5.44. You will use 5.44 as the value of y(avg) for the coming calculations.[4]
-
5
Calculate the
values. For each item in the x column, you need to find the difference between that number and the average value. For this sample problem, this means subtracting 4.89 from each x-data point. If the original data point is less than the average, then your result will be negative. If the original data point is greater than the average, then your result will be positive. Make sure that you keep track of the negative signs.[5]
- For example, the first data point in the x column is 1. The value to enter on the first line of the column is 1-4.89, which is -3.89.
- Repeat the process for each data point. Therefore, the second line will be 3-4.89, which is -1.89. The third line will be 2-4.89, or -2.89. Continue the process for all the data points. The nine numbers in this column should be -3.89, -1.89, -2.89, 0.11, 3.11, 2.11, 7.11, -2.89, -0.89.
- For example, the first data point in the x column is 1. The value to enter on the first line of the
-
6
Calculate the
values. In this column, you will perform similar subtractions, using the y-data points and the y average. If the original data point is less than the average, then your result will be negative. If the original data point is greater than the average, then your result will be positive. Make sure that you keep track of the negative signs.[6]
- For the first line, therefore, your calculation will be 8-5.44, which is 2.56.
- The second line will be 6-5.44, which is 0.56.
- Continue these subtractions to the end of the data list. When you finish, the nine values in this column should be 2.56, 0.56, 3.56, -1.44, -2.44, -2.44, -3.44, 1.56, 1.56.
-
7
Calculate the products for each data row. You will fill in the rows of the final column by multiplying the numbers that you calculated in the two previous columns of
and . Be careful to work row by row, and multiply the two numbers for the corresponding data points. Keep track of any negative signs as you go.[7]
- On the first row of this data sample, the that you calculated is -3.89, and the value is 2.56. The product of these two numbers is -3.89*2.56=-9.96.
- For the second row, you will multiply the two numbers -1.88*0.56=-1.06.
- Continue multiplying row by row to the end of the data set. When you finish, the nine values in this column should be -9.96, -1.06, -10.29, -0.16, -7.59, -5.15, -24.46, -4.51, -1.39.
- On the first row of this data sample, the
-
8
Find the sum of the values in the last column. This is where the Σ symbol comes into play. After conducting all the calculations that you have done so far, you will add the results. For this sample data set, you should have nine values in the final column. Add those nine numbers together. Pay careful attention to whether each number is positive or negative.
- For this sample data set, the sum should be -64.57. Write this total in the space at the bottom of the column. This represents the value of the numerator of the standard covariance formula.
-
9
Calculate the denominator for the covariance formula. The numerator for the standard covariance formula is the value that you have just completed calculating. The denominator is represented by (n-1), which is just one less than the number of data pairs in your data set.
- For this sample problem, there are nine data pairs, so n is 9. The value of (n-1), therefore, is 8.
-
10
Divide the numerator by the denominator. The final step in calculating the covariance is to divide your numerator,
by your denominator, . The quotient is the covariance of your data.[8]
- For this sample data set, this calculation is -64.57/8, which gives the result of -8.07.















Advertisement
-
1
Notice the repetitive calculations. Covariance is a calculation that you should perform a few times by hand, so you understand the meaning of the result. However, if you are going to be using covariance values routinely in interpreting data, you will want to find a faster and more automated way to get your results. You should notice by now that for our relatively small data set of only nine pairs of data, the calculations included finding two averages, performing eighteen individual subtractions, nine separate multiplications, one addition, and a final division. That is 31 relatively minor calculations in order to find one solution. Along the way, you risk dropping negative signs or copying your results incorrectly, thereby ruining the result.
-
2
Create a spreadsheet to calculate covariance. If you are comfortable using Excel (or some other spreadsheet with calculation abilities), you can easily set up a table to find covariance. Label the headings of five columns as for the hand calculations: x, y, (x(i)-x(avg)), (y(i)-y(avg)) and Product.[9]
- To simplify your labelling, you could call the third column something like “x difference” and the fourth column “y difference,” as long as you remember the meaning of the data.
- If you begin your table in the top left corner of the spreadsheet, then cell A1 will be the x label, with the other labels going across to cell E1.
-
3
Fill in the data points. Enter your data values in the two columns labelled x and y. Remember that the order of the data points matters, so you need to pair each y with its corresponding x value.[10]
- Your x values will begin in cell A2 and will continue down for as many data points as you need.
- Your y values will begin in cell B2 and will continue down for as many data points as you need.
-
4
Find the averages of the x and y values. Excel will calculate the averages for you very quickly. In the first vacant cell below each column of data, enter the formula =AVG(A2:A___). Fill in the blank space with the number of the cell that corresponds to your last data point.[11]
- For example, if you have 100 data points, they will fill in cells A2 through A101, so you will enter =AVG(A2:A101).
- For the y data, enter the formula =AVG(B2:B101).
- Remember that you begin a formula in Excel with an = sign.
-
5
Enter the formula for the (x(i)-x(avg)) column. In cell C2, you will need to enter the formula to calculate the first subtraction. This formula will be =A2-____. You will fill in the blank space with the cell address that contains the average of your x data.[12]
- For the example of 100 data points, the average would be in cell A103, so your formula will be =A2-A103.
-
6
Repeat the formula for the (y(i)-y(avg)) data points. Following the same example, this would go into cell D2. The formula will be =B2-B103.
-
7
Enter the formula for the “Product” column. In the fifth column, into cell E2, you will need to enter the formula to calculate the product of the two prior cells. This would simply be =C2*D2.[13]
-
8
Copy the formulas down to fill the table. So far, you have only programmed the first pair of data points in row 2. Using your mouse, highlight cells C2, D2 and E2. Then position your cursor over the small box in lower right-hand corner until a plus-sign appears. Click your mouse button, hold it down, and drag the mouse downward to expand the highlighted box to fill your entire data table. This step will automatically copy the three formulas from cells C2, D2 and E2 into the whole table. You should see the table automatically fill with all the calculations.[14]
-
9
Program the sum of the last column. You need to find the sum of the items in the “Product” column. In the vacant cell immediately under the last data point in that column, enter the formula =sum(E2:E___). Fill in the blank space with the cell address of the last data point.[15]
- For the example of 100 data points, this formula will go into cell E103. You will enter =sum(E2:E102).
-
10
Find the covariance. You can have Excel perform the final calculation for you as well. The last calculation, in cell E103 in our example, represents the numerator of the covariance formula. Immediately below that cell, you can enter the formula =E103/___. Fill in the blank space with the number of data points that you have. In our example, this will be 100. The result will be the covariance of your data.[16]










Advertisement
-
1
Search the Internet for covariance calculators. Several schools, programming companies or other sources have created websites that will very easily calculate covariance values for you. Using any search engine, enter the search term “covariance calculator.”
-
2
Enter your data. Read the instructions on the website carefully to make sure that you enter your data properly. It is important that your data pairs are kept in order, or you will generate an incorrect covariance result. Different websites have different styles for entering your data.
- For example, at the website http://ncalculators.com/statistics/covariance-calculator.htm, there is a horizontal box for entering x-values and a second horizontal box for entering y-values. You are instructed to enter your terms, separated only by commas. Thus, the x-data set that was calculated earlier in this article would be entered as 1,3,2,5,8,7,12,2,4. The y-data set would be 8,6,9,4,3,3,2,7,7.
- At another site, https://www.thecalculator.co/math/Covariance-Calculator-705.html, you are prompted to enter your x-data in the first box. Data is entered vertically, with one item per line. Therefore, the entry on this site would look like:
- 1
- 3
- 2
- 5
- 8
- 7
- 12
- 2
- 4
-
3
Calculate your results. The attraction of these calculation sites is that after you enter your data, you generally need only to click on the button that says “Calculate,” and the results will appear automatically. Most sites will provide you with the intermediate calculations of the x(avg), y(avg), and n.



Advertisement
-
1
Look for a positive or negative relationship. The covariance is a single statistical figure that represents how one data set relates to another. In the example mentioned in the introduction, height and weight are being measured. You would expect that as individuals grow taller, their weight would also increase, leading to a positive covariance figure. As another example, suppose data is collected representing the number of hours someone practices golf and the score he or she may earn. In this case, you would expect a negative covariance, which means that as the number of practice hours increases, the golf score will decrease. (In golf, a lower score is better.)
- Consider the sample data set that was calculated above. The resulting covariance is -8.07. The negative sign here means that as the x-values increase, the y-values will tend to decrease. In fact, you can see that this is true by looking at a few of the values. For example, the x-values of 1 and 2 correspond to y-values of 7, 8 and 9. The x-values of 8 and 12 are paired respectively with y-values of 3 and 2.
-
2
Interpret the magnitude of the covariance. If the number of the covariance score is large, either a large positive number or a large negative number, then you can interpret this as meaning that the two data elements are very strongly connected, either in a positive or negative way.
- For the sample data set, the covariance of -8.07 is fairly large. Notice that the data values range from 1 through 12, so 8 is a pretty high number. This indicates a strong connection between the x and y data sets.
-
3
Understand a lack of relationship. If you wind up with a covariance equal to or very near 0, you can conclude that the data points are relatively unrelated. That is, an increase in one value may or may not lead to an increase in the other. The two terms are almost randomly connected.
- For example, suppose you are comparing shoes sizes against SAT scores. Because there are so many factors that affect a student’s SAT scores, we would expect a covariance score of near 0. This would indicate almost no connection between the two values.
-
4
View the relationship graphically. To understand covariance visually, you can plot your data points on the x-y coordinate plane. When you do that, you should see fairly easily that the points, although not in an exactly straight line, tend to form a cluster that approximates a diagonal line from the upper left to the lower right. This is the description of a negative covariance. Also, notice that the covariance value is -8.07. This is a fairly large number compared to the data points. The high number suggests that the covariance is fairly strong, which you can see by the linear appearance of the data points.
- To review plotting points on the coordinate plane, see Graph Points on the Coordinate Plane.




Advertisement
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Thanks for submitting a tip for review!
-
Covariance has a limited application in statistics. It is often a step toward calculating correlation coefficients or other terms. Be cautious about interpreting too much based on a covariance score.
Advertisement
Video
References
About This Article
Article SummaryX
To calculate covariance, start by subtracting the average of the x-data points from each of the x-data points. Then, repeat with the y-data points. Next, multiply the results for each x-y pair of data points and add all of the products together. Finally, divide that number by the total number of data pairs minus 1 to get the covariance. To learn how to calculate covariance using an Excel spreadsheet, scroll down!
Did this summary help you?
Thanks to all authors for creating a page that has been read 596,357 times.
Reader Success Stories
-

«I liked the step-by-step approach linking with each formula. It gave me more confidence in solving covariance…» more
Did this article help you?
Многие статистические задачи требуют оценки ковариационной матрицы совокупности, которую можно рассматривать как оценку формы диаграммы разброса набора данных. В большинстве случаев такая оценка должна выполняться на выборке, свойства которой (размер, структура, однородность) имеют большое влияние на качество оценки. Пакет sklearn.covariance предоставляет инструменты для точной оценки ковариационной матрицы для данной популяции в различных условиях.
Мы предполагаем, что наблюдения независимы и одинаково распределены (iid).
2.6.1. Эмпирическая ковариация
Ковариационная матрица набора данных хорошо аппроксимируется классической оценкой максимального правдоподобия (или «эмпирической ковариацией») при условии, что количество наблюдений достаточно велико по сравнению с количеством признаков (переменных, описывающих наблюдения). Точнее, оценщик максимального правдоподобия выборки — это асимптотически несмещенный оценщик ковариационной матрицы соответствующей совокупности.
Эмпирическая ковариационная матрица выборки может быть вычислена с использованием empirical_covariance функции пакета или путем подгонки EmpiricalCovariance объекта к выборке данных с помощью EmpiricalCovariance.fit метода. Будьте осторожны, чтобы результаты зависели от центрирования данных, поэтому можно использовать assume_centered параметр точно. Точнее, если assume_centered=False, то предполагается, что тестовый набор имеет тот же средний вектор, что и обучающий набор. В противном случае оба должны быть центрированы пользователем и assume_centered=True использоваться.
Примеры
- См. В разделе Оценка ковариации усадки: LedoitWolf против OAS и максимальное правдоподобие пример того, как подогнать
EmpiricalCovarianceобъект к данным.
2.6.2. Уменьшение ковариации
2.6.2.1. Базовая усадка
Несмотря на то, что он является асимптотически несмещенным оценщиком ковариационной матрицы, оценщик максимального правдоподобия не является хорошим оценщиком собственных значений ковариационной матрицы, поэтому матрица точности, полученная в результате ее обращения, не является точной. Иногда даже оказывается, что эмпирическая ковариационная матрица не может быть инвертирована по числовым причинам. Для того, чтобы избежать такой проблемы инверсии, преобразование эмпирической ковариационной матрицы было введено: shrinkage.
В scikit-learn это преобразование (с определяемым пользователем коэффициентом усадки) можно напрямую применить к предварительно вычисленной ковариации с помощью shrunk_covariance метода. Кроме того, сжатая оценка ковариации может быть адаптирована к данным с помощью ShrunkCovariance объекта и его ShrunkCovariance.fit метода. Опять же, результаты зависят от того, центрированы ли данные, поэтому можно использовать assume_centered параметр точно.
Математически это сжатие состоит в уменьшении отношения между наименьшим и наибольшим собственными значениями эмпирической ковариационной матрицы. Это можно сделать, просто сдвинув каждое собственное значение в соответствии с заданным смещением, что эквивалентно нахождению оценщика максимального правдоподобия со штрафом l2 ковариационной матрицы. На практике усадка сводится к простому выпуклому преобразованию: $Sigma_{rm shrunk} = (1-alpha)hat{Sigma} + alphafrac{{rm Tr}hat{Sigma}}{p}rm Id$.
Выбирая величину усадки, $alpha$ сводится к установлению компромисса смещения/дисперсии и обсуждается ниже.
Примеры
- См. В разделе Оценка ковариации усадки: LedoitWolf против OAS и максимальное правдоподобие пример того, как подогнать
ShrunkCovarianceобъект к данным.
2.6.2.2. Усадка Ледуа-Вольфа
В своей статье 1 2004 г. О. Ледуа и М. Вольф предлагают формулу для расчета оптимального коэффициента усадки.α который минимизирует среднеквадратичную ошибку между оценочной и реальной ковариационной матрицей.
Оценщик Ледойта-Вольфа ковариационной матрицы может быть вычислен на выборке с ledoit_wolf функцией sklearn.covariance пакета, или ее можно получить иным способом, подгоняя LedoitWolf объект к той же выборке.
Примечание Случай, когда ковариационная матрица популяций изотропна
Важно отметить, что когда количество образцов намного превышает количество элементов, можно ожидать, что усадка не потребуется. Интуиция, лежащая в основе этого, заключается в том, что если ковариация совокупности имеет полный ранг, когда количество выборок растет, ковариация выборки также станет положительно определенной. В результате усадка не потребуется, и метод должен делать это автоматически.
Однако это не так в процедуре Ледуа-Вольфа, когда ковариация совокупности оказывается кратной единичной матрице. В этом случае оценка усадки Ледуа-Вольфа приближается к 1 по мере увеличения количества образцов. Это указывает на то, что оптимальная оценка ковариационной матрицы в смысле Ледуа-Вольфа кратна единице. Поскольку ковариация населения уже кратна единичной матрице, решение Ледуа-Вольфа действительно является разумной оценкой.
Примеры
- См. В разделе Оценка ковариации усадки: LedoitWolf против OAS и максимальное правдоподобие пример того, как подогнать
LedoitWolfобъект к данным и визуализировать характеристики оценщика Ледуа-Вольфа с точки зрения правдоподобия.
Рекомендации
О. Ледойт и М. Вольф, «Хорошо обусловленная оценка для многомерных ковариационных матриц», Журнал многомерного анализа, том 88, выпуск 2, февраль 2004 г., страницы 365-411.
2.6.2.3. Приблизительная усадка Oracle
Предполагая, что данные распределены по Гауссу, Chen et al. 2 выведена формула, направленная на выбор коэффициента усадки, который дает меньшую среднеквадратичную ошибку, чем та, которая дается формулой Ледуа и Вольфа. Результирующая оценка известна как оценка ковариации Oracle Shrinkage Approximating.
Оценщик OAS ковариационной матрицы может быть вычислен на выборке с помощью oas функции sklearn.covariance пакета, или он может быть получен иным образом путем подгонки OAS объекта к той же выборке.
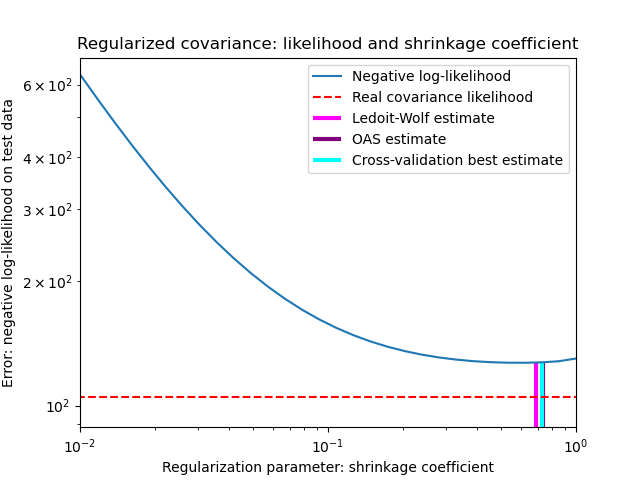
Компромисс смещения и дисперсии при установке усадки: сравнение вариантов оценок Ледуа-Вольфа и OAS
Рекомендации
Чен и др., «Алгоритмы сжатия для оценки ковариации MMSE», IEEE Trans. на знак. Proc., Volume 58, Issue 10, October 2010.
Примеры
- См. В разделе Оценка ковариации усадки: LedoitWolf против OAS и максимальное правдоподобие пример того, как подогнать
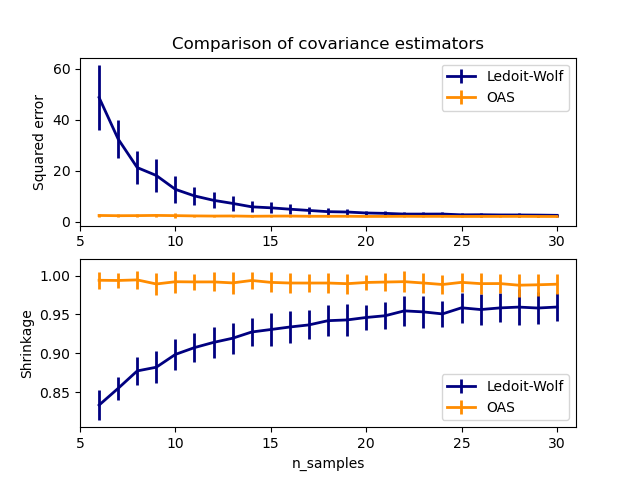
OASобъект к данным. - См. Оценку Ледуа-Вольфа и OAS для визуализации разницы среднеквадратических ошибок между a
LedoitWolfиOASоценкой ковариации.
2.6.3. Редкая обратная ковариация
Матрица, обратная ковариационной матрице, часто называемая матрицей точности, пропорциональна матрице частичной корреляции. Это дает частичную независимость отношениям. Другими словами, если два признака независимы друг от друга условно, соответствующий коэффициент в матрице точности будет равен нулю. Вот почему имеет смысл оценивать матрицу разреженной точности: оценка ковариационной матрицы лучше обусловлена изучением отношений независимости от данных. Это называется ковариационным отбором .
В ситуации с малой выборкой, в которой n_samples порядок n_features или меньше, разреженные оценки обратной ковариации, как правило, работают лучше, чем оценки сжатой ковариации. Однако в противоположной ситуации или для сильно коррелированных данных они могут быть численно нестабильными. Кроме того, в отличие от оценщиков усадки, разреженные оценщики могут восстанавливать недиагональную структуру.
Оценщик GraphicalLasso использует l1 штраф для обеспечения разреженности на высокоточной матрице: тем выше его alpha параметр, тем более разреженной прецизионную матрицу. Соответствующий GraphicalLassoCV объект использует перекрестную проверку для автоматической установки alpha параметра.
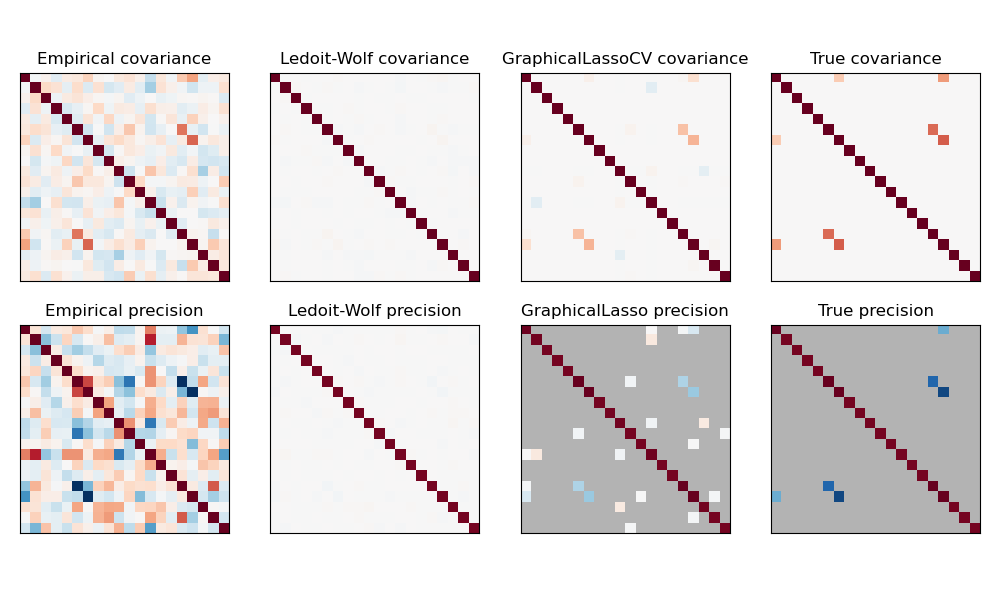
Сравнение максимального правдоподобия, усадки и разреженных оценок ковариации и матрицы точности в настройках очень малых выборок.
Примечание Восстановление структуры
Восстановление графической структуры из корреляций в данных — непростая задача. Если вы заинтересованы в таком восстановлении, имейте в виду, что:
- Восстановление легче из корреляционной матрицы, чем из ковариационной матрицы: стандартизируйте свои наблюдения перед запуском
GraphicalLasso - Если в нижележащем графе есть узлы с гораздо большим количеством соединений, чем в среднем узле, алгоритм пропустит некоторые из этих соединений.
- Если количество ваших наблюдений невелико по сравнению с количеством ребер в вашем нижележащем графе, вы не сможете его восстановить.
- Даже если вы находитесь в благоприятных условиях восстановления, альфа-параметр, выбранный путем перекрестной проверки (например, с использованием
GraphicalLassoCVобъекта), приведет к выбору слишком большого количества ребер. Однако соответствующие ребра будут иметь больший вес, чем нерелевантные.
Математическая формулировка следующая:
$$hat{K} = mathrm{argmin}_K big( mathrm{tr} S K — mathrm{log} mathrm{det} K + alpha |K|_1 big)$$
Где $K$ — матрица точности, которую необходимо оценить, и $S$ — это выборочная ковариационная матрица. $|K|_1$ — сумма модулей недиагональных коэффициентов $K$. Для решения этой проблемы используется алгоритм GLasso из статьи Friedman 2008 Biostatistics. Это тот же алгоритм, что и в glasso пакете R.
Примеры
- Оценка разреженной обратной ковариации: пример синтетических данных, показывающих восстановление структуры и сравнение с другими оценками ковариации.
- Визуализация структуры фондового рынка: пример реальных данных фондового рынка, определение наиболее связанных символов.
Рекомендации
- Фридман и др., «Оценка разреженной обратной ковариации с помощью графического лассо» , Biostatistics 9, стр. 432, 2008 г.
2.6.4. Оценка робастной ковариации
Реальные наборы данных часто подвержены ошибкам измерения или записи. Регулярные, но необычные наблюдения также могут появляться по разным причинам. Наблюдения, которые случаются очень редко, называются выбросами. Эмпирическая оценка ковариации и сжатая оценка ковариации, представленные выше, очень чувствительны к наличию выбросов в данных. Следовательно, следует использовать надежные оценщики ковариации для оценки ковариации реальных наборов данных. В качестве альтернативы можно использовать робастные оценщики ковариации для обнаружения выбросов и отбрасывания / уменьшения веса некоторых наблюдений в соответствии с дальнейшей обработкой данных.
В sklearn.covariance пакете реализована надежная оценка ковариации, определитель минимальной ковариации 3 .
2.6.4.1. Определитель минимальной ковариации
Оценщик, определяющий минимальную ковариацию, — это надежный оценщик ковариации набора данных, представленный PJ Rousseeuw в 3 . Идея состоит в том, чтобы найти заданную пропорцию (h) «хороших» наблюдений, которые не являются выбросами, и вычислить их эмпирическую ковариационную матрицу. Эта эмпирическая ковариационная матрица затем масштабируется, чтобы компенсировать выполненный выбор наблюдений («этап согласованности»). Вычислив оценку определителя минимальной ковариации, можно присвоить веса наблюдениям в соответствии с их расстоянием Махаланобиса, что приведет к повторной оценке ковариационной матрицы набора данных («этап повторного взвешивания»).
Rousseeuw и Van Driessen 4 разработали алгоритм FastMCD для вычисления определителя минимальной ковариации. Этот алгоритм используется в scikit-learn при подгонке объекта MCD к данным. Алгоритм FastMCD также одновременно вычисляет надежную оценку местоположения набора данных.
Сырые оценки могут быть доступны как raw_location_ и raw_covariance_ атрибутами из MinCovDet надежного объекта ковариационной оценивани.
Рекомендации
- 3 PJ Rousseeuw. Наименьшая медиана квадратов регрессии. Дж. Ам Стат Асс, 79: 871, 1984.
- 4 Быстрый алгоритм для определения определителя минимальной ковариации, 1999, Американская статистическая ассоциация и Американское общество качества, TECHNOMETRICS.
Примеры
- См. Пример надежной и эмпирической ковариационной оценки, чтобы узнать, как подогнать
MinCovDetобъект к данным, и посмотрите, насколько оценка остается точной, несмотря на наличие выбросов. - См оценку ковариационной Robust и Махаланобиса расстояния Актуальность визуализировать разницу между
EmpiricalCovarianceиMinCovDetковариации оценок с точки зрения расстояния Махаланобиса (так мы получим более точную оценку точности матрицы тоже).
Есть несколько
важных правил, которые вытекают
непосредственно из определения
ковариации.
Правило 1.
Если у = а
+ в,
то Cov
(x,y
) = Cov
(x
,а) + Cov
(x
, в) 2.
Доказательство
правила 1
( x
—
![]()
а
+ в
—
![]()
= (х —
![]()
Таким образом, мы
доказали, что Соv
(х,у) является суммой ковариаций
Cov
(x,a)
и Cov
(x
,в).
Это правило можно
пояснить на следующем примере. Допустим,
х — доход семьи, у — расходы на питание и
одежду, которые
в свою очередь можно разбить на а
— расходы на питание и в
— расходы на одежду. Тогда, согласно
правилу 1, ковариация доходов с общими
расходами (у) может быть определена как
сумма ковариации доходов с расходами
на питание (а)
и ковариации доходов с расходами на
одежду (в).
Правило 2
Если у = к с, где к
— константа, то Cov
( х, у) = к Cov
(х,с) 3.
Доказательство
правила 2
Cov
(x,
y)
=
![]()
=
![]()
![]()
=
![]()
=
к Cov
(x,c)
Правило 3
Если у = а, где а
— константа, то Cov
(х,у) = 0. 4.
Доказательство
правила 3
Это совсем просто.
Поскольку а — константа, то
![]()
=
а . Отсюда а —
![]()
и,
следовательно, (х —
![]()
=0.
Поэтому Cov
( х, а) = 0.
Пользуясь
этими основными правилами, вы можете
упрощать значительно более сложные
выражения с ковариациями. Например,
если какая то переменная равна сумме
трех переменных — u
, v
и w,
то, пользуясь правилом 1 и разбив у на
две части ( u
и v
+ w
), получим :
Cov (x
, y) = Cov (x, u + v + w) = Cov (x, u ) + Cov (x , v + w ) = Cov (x
,u ) + Cov (x , v ) + Cov ( x , w ).
Итак,
выборочная ковариация между х и у
определяется по формуле 1.1.
Другим эквивалентным выражением
является
Cov
(x,
y)
=
![]()
5.
( доказательство
эквивалентности указанных уравнений
здесь опускается).
1.4. Теоретическая ковариация.
Если х и у —
случайные величины, то теоретическая
ковариация ху
определяется как математическое
ожидание произведения отклонений этих
величин от их средних значений :
рор.cov
(х , у ) = ху
= Е {(x
— x
) (у — у)}
6.
Если
теоретическая ковариация неизвестна,
то для ее оценки может быть использована
выборочная ковариация, вычисленная по
ряду наблюдений. К сожалению, оценка
будет иметь отрицательное смещение,
так как
Е
{Cov
(x
,y)}
=
![]()
pop.cov
(x
, y
) 7.
Причина
заключается в том, что выборочные
отклонения измеряются по отношению к
выборочным средним значениям величин
х и у и имеют тенденцию к занижению
отклонений от истинных средних значений.
Очевидно , мы можем рассчитать несмещенную
оценку путем умножения выборочной
оценки на п
/п -1. Правила
для теоретической ковариации точно
такие же, как и для выборочной ковариации,
но их доказательства мы опускаем,
поскольку для этого требуется интегральное
исчисление.
Если х и у
независимы, то их теоретическая ковариация
равна нулю благодаря свойству независимости
и факту , что Е (х) и Е(у) равняются
соответственно
х
и
у
.
Е {(x
— x)
(y
—
y)}
= E
( x
—
x)
( y
—
y
) = 0 x
0 8.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Функция КОВАРИАЦИЯ.В в Excel предназначена для расчета коэффициента ковариации двух наборов данных (массивов или диапазонов ячеек, хранящих числовые значения), являющихся выборками соответствующих диапазонов данных, и возвращает соответствующее числовое значение.
Функция КОВАРИАЦИЯ.Г в Excel используется для расчета коэффициента ковариации всей совокупности двух диапазонов данных (генеральной совокупности) и возвращает соответствующее значение.
Функция КОВАР в Excel предназначена для расчета коэффициента ковариации двух любых наборов числовых данных, являющихся генеральными совокупностями.
Использование функций КОВАР, КОВАРИАЦИЯ.В и КОВАРИАЦИЯ.Г в Excel
Пример 1. В таблице Excel содержится два диапазона данных, значения первого из которых характеризуют количество прочитанных книг за год каждым учеником, отобранным из нескольких классов школы, а второй – итоговую оценку по литературе по 10-бальной шкале. Определить коэффициент ковариации двух диапазонов данных.
Вид исходной таблицы:
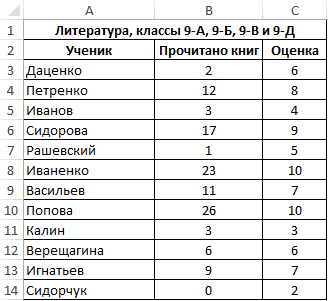
Поскольку для анализа были отобраны по несколько учеников различных классов, оба диапазона можно считать выборками из генеральной совокупности, которой являются все ученики 9-го класса данной школы. Используем следующую функцию:
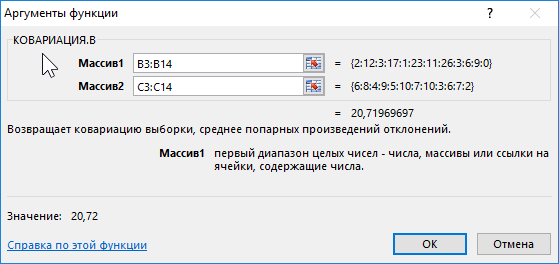
Описание аргументов:
- B3:B14 – диапазон ячеек, содержащих данные о количестве прочитанных книг;
- C3:C14 – диапазон ячеек с итоговыми оценками по предмету.
Полученный результат:
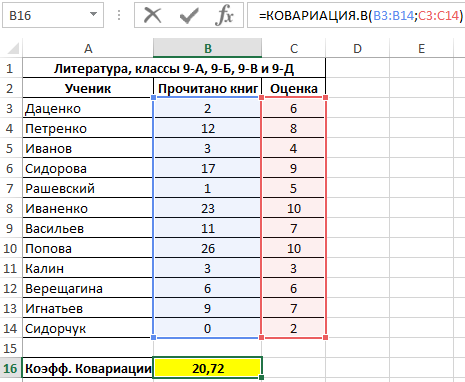
Полученное значение свидетельствует о наличии прямой связи между значениями из двух диапазонов. То есть, можно полагать, что ученик, прочитавший большее количество книг, получит более высокую оценку за предмет.
Расчет ковариации роста и падения цен двух видов акций в Excel
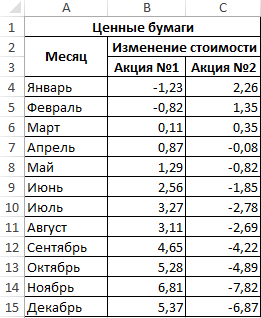
Пример 2. В таблице Excel внесены данные роста (положительное число) или падения цены (отрицательное) двух различных ценных бумаг на протяжении 12 месяцев года относительно некоторой начальной величины. Определить ковариацию двух диапазонов данных и сделать выводы. Сделать отчет доступным для пользователей Excel 2007.
Вид исходной таблицы:
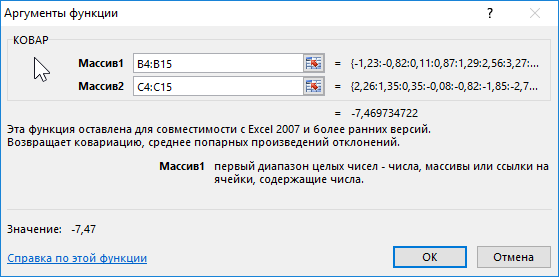
В данном примере исследуется вся генеральная выборка. Для расчета можно использовать функцию КОВАРИАЦИЯ.Г, однако результаты не будут доступны для пользователей более старых версий Excel. Применим следующую формулу:
В результате получим:
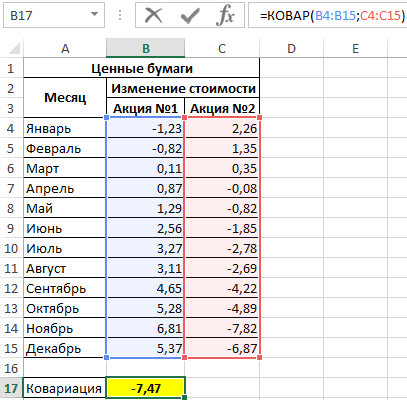
Это значение свидетельствует о достаточно большой взаимосвязи между исследуемыми значениями. Поскольку число отрицательное, данная взаимосвязь является обратной. То есть, с ростом цены одной акции наблюдается падение цены второй и наоборот. Можно предположить, что эти акции принадлежат двум конкурирующим компаниям.
Статистический анализ ковариации показателей в Excel
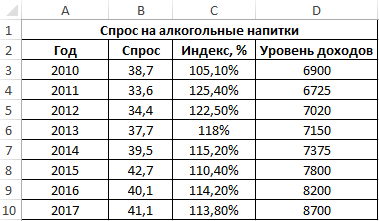
Пример 3. В таблице Excel введены данные о спросе на алкогольные напитки, индексе цен и уровне дохода населения государства. Проанализировать взаимосвязи между имеющимися данными.
Вид исходной таблицы данных:
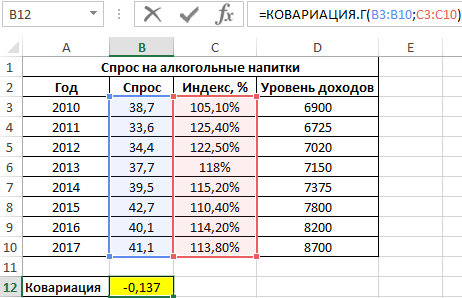
Вначале рассчитаем ковариацию между спросом и индексом цен по формуле:
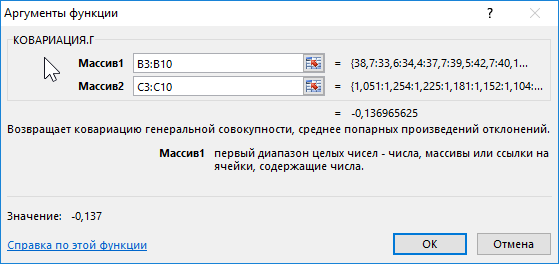
Полученный результат:
Для оценки степени взаимосвязи двух диапазонов данных удобнее использовать коэффициент корреляции, который можно рассчитать без использования функции КОРРЕЛ следующим способом:
=B12/КОРЕНЬ(ДИСП.Г(B3:B10)*ДИСП.Г(C3:C10))
Функция ДИСП.Г используется для расчета дисперсии генеральной совокупности. Приведенная выше формула наглядно демонстрирует взаимосвязь между коэффициентами ковариации и корреляции.
Полученный результат:
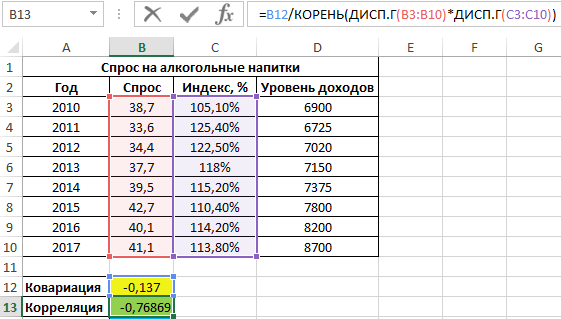
Как видно, между ценами и спросом существует довольно сильная обратная связь. Однако для определения степени влияния спроса определим коэффициент детерминации r2 по формуле:
=СТЕПЕНЬ(B13;2)
Полученное значение, выраженное в процентах:
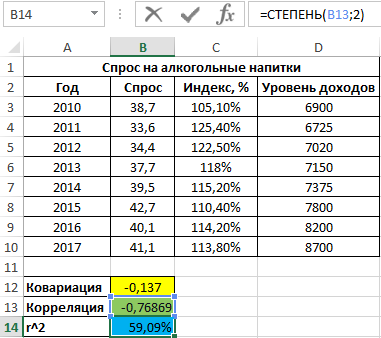
То есть, примерно 59% вариации спроса за исследуемый период обусловлены изменчивостью цены. Остальные 41% — прочими факторами. А еще одним фактором в данном примере является уровень дохода. Рассчитаем коэффициент корреляции между спросом и доходами с помощью следующей функции:
=КОРРЕЛ(B3:B10;D3:D10)
Результат:
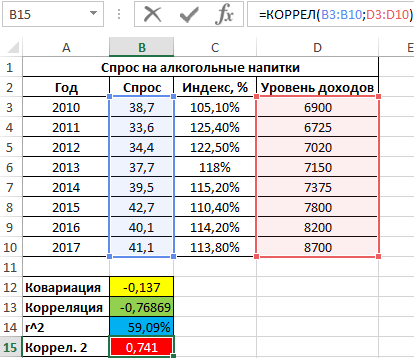
Положительное значение 0,741 соответствует о наличии довольно сильной зависимости между ростом уровня доходов и спросом. Чтобы определить общий коэффициент корреляции и сделать выводы, найдем коэффициент корреляции между индексом цен и уровнем доходов:
=КОРРЕЛ(C3:C10;D3:D10)
Результат:
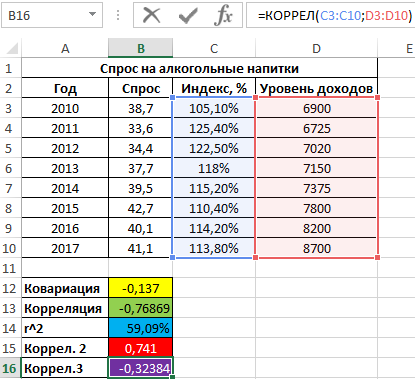
Имеем не сильно выраженную обратную взаимосвязь. Теперь выполним расчет общего коэффициента корреляции по формуле:
=(B13-B15*B16)/КОРЕНЬ((1-СТЕПЕНЬ(B15;2))*(1-СТЕПЕНЬ(B16;2)))
Результат:
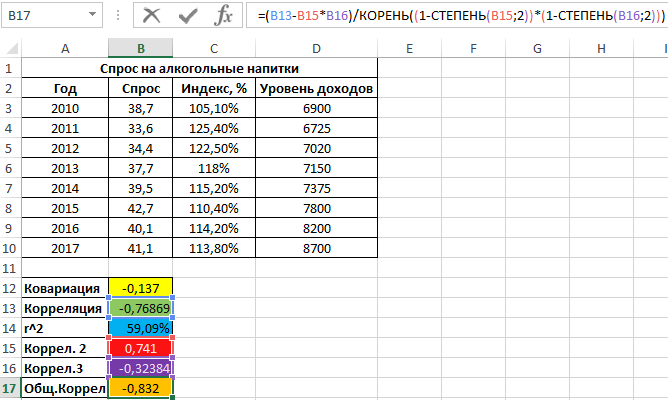
Расчеты показывают, что влияние роста цен на уровень спроса «сглаживается» благодаря росту уровня дохода населения. Корень квадратный из последнего значения, взятого по модулю, равен примерно 91%, показывая, насколько вариация цен определяла вариация спроса на алкогольные напитки, если не брать в учет параллельное изменение уровня дохода.
Особенности использования функций КОВАР, КОВАРИАЦИЯ.В и КОВАРИАЦИЯ.Г в Excel
Функция КОВАР имеет следующий синтаксис:
= КОВАР(массив1;массив2)
Функция КОВАРИАЦИЯ.В имеет следующую синтаксическую запись:
= КОВАРИАЦИЯ.В(массив1;массив2)
Синтаксис функции КОВАРИАЦИЯ.Г:
= КОВАРИАЦИЯ.Г(массив1;массив2)
Все рассматриваемые функции принимают на вход следующие аргументы:
- массив1 – обязательный аргумент, характеризующий первый массив или диапазон ячеек, содержащих данные числового типа, которые являются всей генеральной совокупностью данных (для функций КОВАРИАЦИЯ.Г и КОВАР) или выборкой (для функции КОВАРИАЦИЯ.В);
- массив2 – обязательный аргумент, характеризующий второй массив или диапазон ячеек с числовыми значениями (генеральная совокупность либо выборка, чем обусловлен выбор функции для расчета).
Примечания 1:
- Все рассматриваемые функции принимают в качестве аргументов массивы или ссылки на диапазоны ячеек, содержащие текстовые, логические, числовые и данные других типов.
- Число элементов в диапазонах или массивах, переданных в качестве аргументов массив1 и массив2 должны совпадать. В противном случае все рассматриваемые функции вернут код ошибки #Н/Д.
- При расчете не учитываются значения типа Текст, Имя, логические значения (ИСТИНА, ЛОЖЬ), ссылки на пустые ячейки. Однако ячейки, содержащие числовое значения 0 (нуль), будут учтены.
- Если рассматриваемые функции в качестве аргументов принимают:
- Диапазоны пустых ячеек, результатом их выполнения будет код ошибки #ЗНАЧ! (принимают по одной пустой ячейке в качестве каждого аргумента) или #ДЕЛ/0! (принимают по несколько пустых ячеек в качестве аргументов);
- Массивы, состоящие из одного элемента или по одной ячейке в качестве каждого аргумента, функции КОВАРИАЦИЯ.Г и КОВАР вернут числовое значение 0, а функция КОВАРИАЦИЯ.В – код ошибки #ДЕЛ/0!.
Примечания 2:
- Ковариация – величина, характеризующая линейную зависимость, установившуюся между двумя рядами случайных величин X и Y. Она соответствует математическому ожиданию произведения отклонений X и Y от их центров распределений. Коэффициент ковариации может быть выражен отрицательным, положительным числами и нулем, при этом:
- Если с ростом значений X более вероятные появления больших значений Y и наоборот, между двумя диапазонами существует прямая связь, о чем свидетельствует положительное значение коэффициента ковариации;
- Если с ростом X величина Y имеет тенденцию к снижению и наоборот, устанавливается обратная зависимость, выражаемая отрицательным значением коэффициента ковариации;
- Если между X и Y устанавливается слабая взаимосвязь (при изменениях X изменения Y являются непоследовательными, хаотичными), значение коэффициента ковариации стремится к нулю.
Примечания 3:
- Функция КОВАР являлась стандартной функцией для расчета ковариации в ранних версиях Excel (2007 и более старых) и оставлена для обеспечения совместимости. В последующих версиях Excel она может отсутствовать, поэтому рекомендуется использовать функции КОВАРИАЦИЯ.В и КОВАРИАЦИЯ.Г.
- Выборка – это подмножество величин одного множества, называемого генеральной совокупностью. Другими словами, выборкой считается результат ограниченного ряда наблюдений какого-либо одно или нескольких признаков. Например, при изучении банковской системы государства генеральной совокупностью являются все банковские организации страны, а выборкой – банки города Санкт-Петербург.
- В отличие от коэффициента корреляции, значение коэффициента ковариации не ограничено диапазоном чисел от -1 до 1.
- При определении коэффициента ковариации одних и тех же двух диапазонов чисел функции КОВАР и КОВАРИАЦИЯ.Г вернут одинаковый результат, отличающийся от числового значения, которое вернет функция КОВАРИАЦИЯ.В, поскольку они используют разные алгоритмы расчетов.