Мы используем
файлы cookie
На всех наших сайтах, включая этот,
мы используем куки, потому что эти файлы
экономят ваше время и продлевают вашу жизнь.
Характеристики сервиса по сравнению текстов
Сравнение текстов онлайн — какие опции выполняет этот сервис? Довольно часто бывает так, что копирайтеры, юристы или бухгалтеры могут работать, с двумя практически одинаковыми текстами, но при этом им необходимо понимать, где именно и в чем они отличаются. Возникает вопрос: как найти сравнение в тексте? С помощью нашей программы для сравнения двух текстов от Prostudio, вы сможете осуществить сравнение текстов на схожесть или наоборот найти различия среди них.
Наш сервис для сравнения двух текстов онлайн довольно легок в использовании и эффективен для сравнения теста или даже программного кода. С его помощью человек без труда сможет найти отличия между двумя текстами. Сравнение 2-х текстов онлайн состоит всего из одного действия: от вас лишь потребуется вставить два текста в текстовые поля и кликнуть на кнопку «Получить результат».
К тому же наша программа сравнения текстов онлайн с выделением слов и символов, которые отличаются друг от друга, поэтому вы моментально сможете увидеть все отличия. Анализ текста на соответствие или различия никогда ранее не был настолько легким. Сравнение договоров, кода, или прочих материалов будет осуществляться в разы быстрее.
Как в ворде найти повторы
Как найти повторяющиеся слова в Microsoft Word — Вокруг-Дом — 2021
Table of Contents:
Утилита Microsoft Word Find and Replace — это мощный инструмент, который позволяет пользователям быстро искать в своих документах определенные слова и фразы. Другое использование этого инструмента — найти повторяющиеся слова в тексте, используя опцию выделения, которая отображает повторяющиеся слова, так что вы можете легко просматривать и редактировать текст, чтобы исключить повторение слов.
Шаг 1
Откройте меню «Поиск» на вкладке «Главная» ленты и выберите «Расширенный поиск».
Шаг 2
Введите слово, в котором вы хотите найти дубликаты, в поле ввода «Найти что».
Шаг 3
При необходимости выберите другие параметры в разделе «Параметры поиска»; Использование параметров поиска, таких как «Поиск по регистру» и «Поиск только целых слов», делает ваш поиск более конкретным.
Шаг 4
Нажмите меню «Чтение выделения» и нажмите «Выделить все».
Как найти и выделить разные повторяющиеся слова
Есть текст, в котором объединено несколько списков фамилий.
В результате получилось, что в одном списке некоторые фамилии повторяются несколько раз.
Найти и выделить повторяющиеся слова в одном документе.
Нужно чтобы ворд сам выбрал те фамилии(слова), которые повторяются 2 и более раз и выделил их.
Например, повторяются фамилии ПУГАЧЕВА, ГАЛКИН, ЛЕНИН по нескольку раз.
Нужно выделить сразу всех галкиных, пугачевых и лениных и др. которые повторяются.
Т.к. список большой, то единичный поиск по фамилиям не пойдет.
Есть варианты?
Может макрос какой есть?
Помощь в написании контрольных, курсовых и дипломных работ здесь.
Как удалить повторяющиеся слова в Custom.DIC
Как удалить повторяющиеся слова в пользовательском словаре Custom.DIC? Может, конечно, они сами .
Как найти в списке повторяющиеся слова?
Здравствуйте! Подскажите пожалуйста, как найти в python повторяющиеся слова (в списке) и вывести.
Как найти повторяющиеся слова, записанные через дефис?
Доброго времени суток! Подскажите, возможно ли как-то с помощью регулярок(или чего-то другого).
Как удалить повторяющиеся слова и слова, которые меньше/больше 9 символов ?!
1) Надо удалить точно такие же повторяющиеся слова а их много! 2) Как из всего списка удалить.
Как выделить одинаковые слова в Ворде?
Через Ctrl+F нашла все одинаковые слова. Теперь нужно выделить их ВСЕ и сразу одним цветом, например, красным. Как это сделать?
Чтобы выделить все необходимые слова необходимо после нажатия CTRL+F нажать кнопку и в открывшемся меню выбрать пункт .

Выбираем команду изменение цвета текста, теперь изменение цвета текста будет происходить одновременно во всех найденных словах:

Объясню на примере. Допустим, у нас есть текст (я взяла отрывок из «12 стульев»), и нам нужно найти и выделить красным цветом все встречающиеся в нем местоимения ед.ч. ж.р. — «она».

1) Заходим во вкладку «Главная», в верхней панели в крайнем правом окошке жмем «заменить»:
2) Во всплывающем окне в поле «найти» пишем она. И опять пишем она в поле «заменить на»

3) Нажимаем кнопку «больше» и выбираем: формат/выделение цветом.

4) Теперь ниже фразы «заменить на» должно появиться — выделение цветом:

5) Наконец жмем кнопку «заменить все».
Теперь все слова «она», имеющиеся в тексте выделены нужным нам цветом.
Кстати, можно выделять не только целые слова, но и части слов — например, только корень или только несколько цифр в длинных числах и т.д.
Выделение всех одинаковых слов в ворде происходит следующим методом. Нажмите Ctrl + f, после чего в выберите пункт «найти в» и в всплывающем меню выбрать основной документ. После чего ввести слово, которое вам нужно в графу поиска. Всё одинаковые слова выделяется, после чего можно делать с ними что угодно, изменить цвет, подчеркнуть, выделить жирным и тд.
Как в Ворде найти повторяющийся текст
Есть текст, в котором объединено несколько списков фамилий. В результате выяснилось, что в списке некоторые фамилии повторяются несколько раз. Найдите и выделите повторяющиеся слова в одном документе. необходимо, чтобы Слово само выбирало те фамилии (слова), которые повторяются 2 и более раз, и выделяло их.
Например, фамилии ПУГАЧЕВА, ГАЛКИН, ЛЕНИН повторяются несколько раз. необходимо сразу выделить всех повторяющихся Галкина, Пугачева, Ленина и т.д. Поскольку список большой, поиск по одной фамилии не сработает.
Как выделить одинаковые слова в Ворде?
Используя Ctrl + F, я нашел все те же слова. Теперь вам нужно выделить их ВСЕ и одновременно в один цвет, например красный. Как это сделать? Чтобы выделить все необходимые слова, после нажатия CTRL + F нажмите кнопку и выберите пункт в открывшемся меню .
Выбираем команду изменить цвет текста, теперь изменение цвета текста будет происходить одновременно во всех найденных словах:
Позвольте мне объяснить на примере. Допустим, у нас есть текст (я взял отрывок из «12 стульев»), и нам нужно найти и выделить красным все местоимения в единственном числе в нем. Р. — «она».
1) Перейдите на вкладку «Главная», в верхней панели крайнего правого окна нажмите «заменить»:
2) Во всплывающем окне в поле «найти» введите его. И снова пишем в поле «заменить на»
3) Нажмите кнопку «Другое» и выберите: выбор размера / цвета.
4) Теперь внизу должна появиться фраза «заменить на» — выделение цветом:
5) Наконец, нажмите кнопку «заменить все».
Теперь все слова «она» в тексте выделены нужным нам цветом.
Кстати, вы можете выделять не только слова целиком, но и части слов, например только корень или всего несколько цифр в длинных числах и т.д.
Подбор всех одинаковых слов в слове осуществляется следующим способом. Нажмите Ctrl + f, затем выберите запись «найти в» и выберите основной документ во всплывающем меню. Затем введите нужное слово в поле поиска. Выделяются все те же слова, после чего вы можете делать с ними все, что захотите, менять цвет, подчеркивание, выделение жирным шрифтом и т.д.
Как в ворде найти повторы текста?
 Компьютеры
Компьютеры
Чтобы заменить все одинаковые слова в тексте, не обязательно вручную просматривать весь документ. Это можно сделать с помощью инструмента «Заменить» в Microsoft Word, который присутствует даже в самых старых версиях программы.
Вне зависимости от установленной версии Microsoft Word для открытия инструмента воспользуйтесь сочетанием «Ctrl + H».
Для того чтобы открыть аналогичное окно в версии 2007 года или старше, перейдите на вкладку «Главная» и в разделе «Редактирование» нажмите на «Заменить». Откроется маленькое диалоговое окно с двумя полями для ввода текста: «Найти:» и «Заменить на:».

В первом необходимо ввести текст, который вы хотите заменить. Во втором — то, что должно оказаться на его месте.
Например, введя в первом поле слово «Microsoft » (с пробелом), а во втором — «Майкрософт » (тоже с пробелом), мы заменим все повторяющиеся слова в тексте, на затрагивая те, которые используются в адресе сайта. Если пробелы не использовать, то адрес сайта также поменяется.
Нажимая «Найти далее», вы видите, как в тексте подсвечивается нужный текст. Для одиночной замены нажмите «Заменить». Если уверены, что каждый случай проверять не нужно, жмите «Заменить все» и проверяйте работу.
Нажав на кнопку «Больше >>» вы получите список дополнительных инструментов:
- «Направление» — в каком направлении осуществлять замену относительно текущего положения курсора;
- «Учитывать регистр» — брать ли в расчет большие и маленькие буквы в тексте;
- «Только слово целиком» — с этим параметром вы можете не ставить пробел при замене;
- «Шрифт» — позволит выбрать текст с конкретными примененными изменениями, например, только полужирный, курсив и так далее;
- «Подстановочные знаки» — упростит процесс поиска. Введя «а*б», вы замените все фразы, начинающиеся на «а» и заканчивающиеся на «б». Используя символ « Поиск и замена текста в Word
Поиск и замена в Word 2003
Заходим в меню — Правка — Заменить.
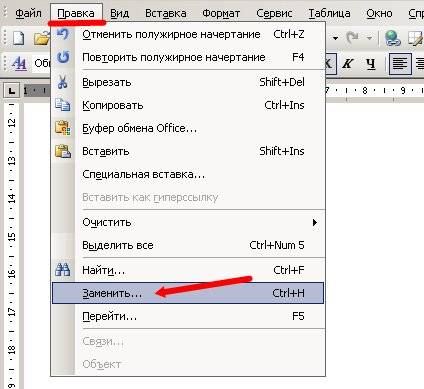
Откроется окно Найти и заменить. У этого маленького окошка очень большие возможности, но пока их все рассматривать не будем, а сразу перейдем на вкладку Заменить. В поле Найти напишем слово «статья», а в поле Заменить на, слово «книга».

Для более расширенных параметров поиска и замены, можно воспользоваться кнопкой Больше. Тогда это окошко примет такой вид.
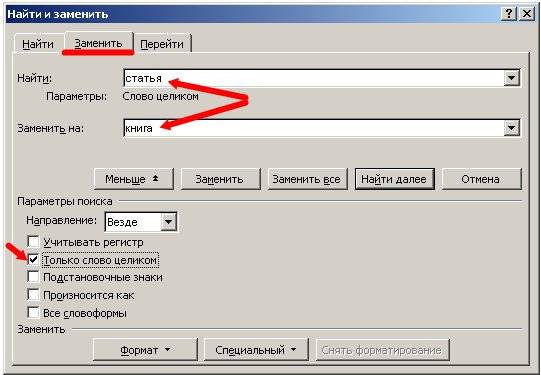
В параметрах поиска можно указать Направление поиска (Вперед, Назад, Везде). Все зависит от того, где у вас установлен курсор.
Если установить галочку Учитывать регистр, то поиск и замена будет производится строго с учетом регистра букв. Например, если в поле Найти указать слово «Статья» с большой буквы, то поиск будет ориентироваться только на слово «Статья» с большой буквы.
Так, что если указать в поле Заменить на — слово «книга» с маленькой буквы, то соответственно замена произойдет именно на слово «книга» с маленькой буквы.
Имейте в виду, что заменять можно не только одно слово в тексте, но и целые предложения и фразы. Подстановочные знаки применяются в том случае когда не так важно какая буква в слове. Например, если вы напишите слово «к*т», то поиск выдаст вам и «кот» и «кит» и «кат».
Если установить флажок на Все словоформы, то замена слова «статья» произойдет с любым окончанием этого слова (статьи, статьей, статью). Так, что думайте сразу, что на что менять, а то потом запутаетесь, и придется править весь текст вручную.
Кнопка Заменить, произведет замену первого найденного слова. Кнопка Заменить все, заменит все встречающиеся слова в тексте. Кнопка Найти далее, нужна только в том случае, если перед этим нажали кнопку Заменить. Ну а кнопка Отменить, естественно отменяет ваше предыдущее действие.
Если оставить поле Заменить на пустым, то программа просто удалит все слово, которые вы вписали в поле Найти.
Для того, чтобы найти и заменить слово или фразу в Word 2007/2010, необходимо перейти на вкладку Главная и открыть блок Редактирование, или нажать одновременно на клавиатуре клавиши Ctrl + H. Все остальное делается так, как описано выше.

Прежде, чем экспериментировать с текстом, создайте копию файла. Что бы потом не было мучительно больно за угробленный многодневный труд. Возьмите себе за правило — все эксперименты делать на копиях.
Как найти одинаковые строки с помощью программы Notepad++
Часто возникает необходимость удаления повторяющихся строк при обработке объемных текстовых документов.
Это простая, как может показаться, операция заставляет не один час искать специальные решения, отдельные программы или использовать функции MS Exel по сортировке и выборке уникальных значений. Что описано выше.
Есть более простой и удобный способ найти одинаковые строки используя бесплатный супер мега текстовый редактор Notepad++.
Найти одинаковые строки с помощью этой замечательной программы можно в два клика.
- Итак, открываем ваш текстовый документ в программе Notepad++.
- Выделяем весь текст (Ctrl+A)
- Идем в меню TextFX -> TextFX Tools -> Sort lines case insensitive
При этом должна стоять галочка возле пункта «Sort outputs only UNIQUE lines».
Результат, после нажатия «Sort lines case insensitive» — мы получаем отсортированные строки без повторов и дублей.
К примеру если у вас по тексту разбросано 10 одинаковых строк, то останется 1. Или если много строк имеют по несколько повторов то, останутся каждая по одной, без дублей.
Теперь при необходимости можно легко скопировать и вставить готовые строки в Exel или куда угодно.
Как и говорил в посте Как найти и заменить текст в Ms Office Word, Open Office Writer, Libre Office, сегодня попробуем поработать с большим количеством информации. Будем оставлять самое главное и удалять лишнее в очень большом тексте.
Текст, который мы будем «чистить»:

Итак, удаляем строки, которые выделены жирным и оставляем только нужный текст.
Обратите внимание, что длина удаляемого текста отличается. Для выделения строки независимо от количества символов нажимаем Ctrl+Shift+стрелка вниз. Под спойлером в конце поста вы увидите все команды выделения текста с помощью клавиатуры. А сейчас переводим курсор в начало текста, переходим в меню «Макросы» и включаем запись макроса.
Когда будете задавать имя макросу, не оставляйте пробелы — Word выдаст ошибку. Назначаем его для кнопки или клавиатуры. Я больше люблю работать с клавиатурой и выбрал поэтому клавиши.

Настраиваем макрос. Тут просто нажимаем любое сочетание клавиш. Если оно уже присвоено, то об этом появится информация.

Я присвоил макросу клавиатурную комбинацию Ctrl+G. Эта комбинация не используется в стандартном режиме редактирования и является свободной. Не переписывайте комбинации, которые часто используете .
- вырезать выделенный контент (текст, графика, вложения)
- скопировать выделенный контент
- выделить всё в документе
- отменить последнее действие
- повторить последнее действие (обратно сочетанию Ctrl+Z)
Начнём записывать макрос. На самом деле тут ничего сложного нет, просто делайте так, как редактируете обычно текст. Используйте чаще клавиши «Home» и «End», потому что они работают быстрее и не привязаны к количеству символов.
Таким образом, при записи вам нужно последовательно нажать после включения записи макроса следующие клавиши и комбинации клавиш. Стрелкой «вниз» сместить курсор на одну строку ниже, нажатием «Ctrl+Shift+стрелка вниз» выделить строку, клавишей « Delete » удалить строку.
- Включили запись макроса
- пропускаем строку и переходим к следующей
- выделяем 2 строку
- выделяем 3 строку
- выделяем 4 строку
- переносим строку 5 к строке 1
- переводим курсор в начало строки
- Переходим в начало следующего повторяющегося блока
- Выключаем запись макроса
Макрос записан, запись остановили. Кнопка остановки записи будет в том же месте, что и кнопка записи макроса.
Замечательно! Нажимаем Ctrl+G и лишний текст просто пропадает. Быстро, легко и удобно. А что делать, если записей… 1000 или больше?
Дадим команду обработать все вложения. А сколько этих вложений? Один из способов — найдите постоянное выражение через поиск. Я нажал Ctrl + F и ввёл в строку поиска выражение «Читайте блог Lassimarket.ru». Количество вхождений Word мне не показал, но я попросил его заменить это выражение на «*». Появилось окно с надписью «Произведено замен 24».

Запомнили число и нажали Ctrl+Z — отменили замену текста на звёздочку. Теперь я знаю, что в примере у меня 24 вхождения. Это я должен нажать 24 раза сочетание Ctrl+G для того, чтобы отформатировать текст. Будем упрощать это дело.
Нажимаем Alt+ F 11. Мы попали в редактор макросов. Это большая и сложная тема, тут самый настоящий язык программирования, но у нас всё будет просто, я вас уверяю.

Вписываем как на картинке две строки в начало и слово в конце.
Dim i As Integer
Что это значит? Мы обозначили i — числовой переменной и присвоили значения от 0 до 23, после окончания первого цикла замены число i увеличится на 1 и макрос будет снова повторяться (Next) до тех пор, пока не достигнет конца (23).
То есть эти строки дают команду после нажатия Ctrl+G повторить макрос «Удаляем3строки» 23 раза. Вот текст моего примера макроса.
Dim i As Integer
Selection.MoveDown Unit:=wdLine, Count:=1
Selection.MoveDown Unit:=wdParagraph, Count:=1, Extend:=wdExtend
Selection.Delete Unit:=wdCharacter, Count:=1
Selection.MoveDown Unit:=wdParagraph, Count:=1, Extend:=wdExtend
Selection.Delete Unit:=wdCharacter, Count:=1
Selection.MoveDown Unit:=wdParagraph, Count:=1, Extend:=wdExtend
Selection.Delete Unit:=wdCharacter, Count:=1
Selection.MoveDown Unit:=wdLine, Count:=1
Сохраняем макрос и закрываем редактор.
Обратите внимание, что после того, как мы перенесём пятую строку к первой, текст может вылезать на другую строку и макрос будет дальше работать неправильно.
Тогда можно временно заменить регулярное выражение на любой символ или уменьшить шрифт на этапе работы макроса и тому подобное.

Вернулись в редактор, нажали Ctrl+G, и текст мигом принял новый вид. Всё получилось. За пару минут обработали довольно большой текст в автоматическом режиме.
Содержание
- Как выделить одинаковые слова в Ворде?
- Как в ворде найти повторяющийся текст
- Как найти и выделить разные повторяющиеся слова
- Как выделить одинаковые слова в Ворде?
- Как в ворде найти повторяющийся текст
- Как найти повторяющиеся слова в ворде?
- Как выделить цветом одинаковые слова в ворде?
- Как посмотреть самые частые слова в ворде?
- Как выделить одно и тоже слово по тексту?
- Как удалить все повторяющиеся слова в Word?
- Как в ворде выделить текст маркером?
- Как в ворде заменить все одинаковые слова на другие?
- Как посмотреть статистику в ворде?
- Как сделать поиск по заголовкам в ворде?
- Как найти ключевые слова в ворде?
- Как выделить определенные слова в тексте?
- Как выделить отдельные слова в тексте?
- Как выделить все буквы А в тексте?
- Как удалить определенные слова в тексте?
- Как удалить слово из текста в ворде?
- Как найти в тексте повторяющиеся предложения?
- Как в ворде выделить все одинаковые слова
- Как найти повторяющиеся слова в Microsoft Word — Вокруг-Дом — 2021
- Шаг 1
- Шаг 2
- Шаг 3
- Шаг 4
- Как в ворде выделить одинаковые слова цветом?
- Как найти и выделить одинаковые слова в ворде?
- Как в ворде выделить определенные слова?
- Как в ворде выделить текст другим цветом?
- Как выделить одно и тоже слово по тексту?
- Как выделить одинаковые слова в Excel?
- Как выделить все одинаковые буквы в ворде?
- Как выделить несколько строк в разных местах?
- Как в ворде сделать содержание?
- Как сразу выделить несколько файлов?
- Как изменить цвет заливки текста в ворде?
- Как в ворде на картинке выделить текст?
- Как изменить цвет маркера в ворде?
- Как выделить отдельные слова в тексте?
- Как работает автозамена в ворде?
- Как выделить одинаковые слова в тексте?
- Как выделить определенные слова в тексте?
- Как удалить все повторяющиеся слова в Word?
- Как добавить цвет выделения текста в ворде?
- Как в ворде выделить определенные слова?
- Как удалить повторяющиеся слова в Excel?
- Как сделать фон для текста в ворде?
- Как в ворде на картинке выделить текст?
- Как сделать текст в ворде одного цвета?
- Как найти определенное слово в ворде?
- Как найти повторяющиеся слова в ворде?
- Как в ворде найти повторяющийся текст
- Как найти и выделить разные повторяющиеся слова
- Как выделить одинаковые слова в Ворде?
- Как в ворде найти повторяющийся текст
Как выделить одинаковые слова в Ворде?
Через Ctrl+F нашла все одинаковые слова. Теперь нужно выделить их ВСЕ и сразу одним цветом, например, красным. Как это сделать?
![]()

1) Заходим во вкладку «Главная», в верхней панели в крайнем правом окошке жмем «заменить»:
2) Во всплывающем окне в поле «найти» пишем она. И опять пишем она в поле «заменить на»
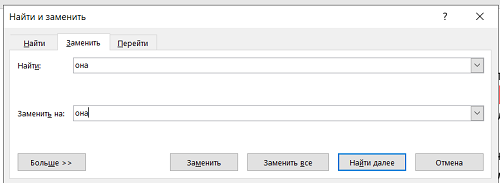
3) Нажимаем кнопку «больше» и выбираем: формат/выделение цветом.
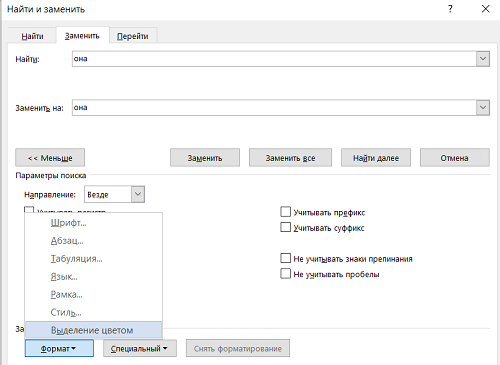
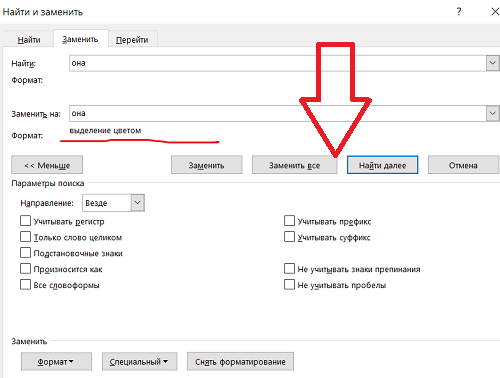
5) Наконец жмем кнопку «заменить все».
Теперь все слова «она», имеющиеся в тексте выделены нужным нам цветом.
![]()
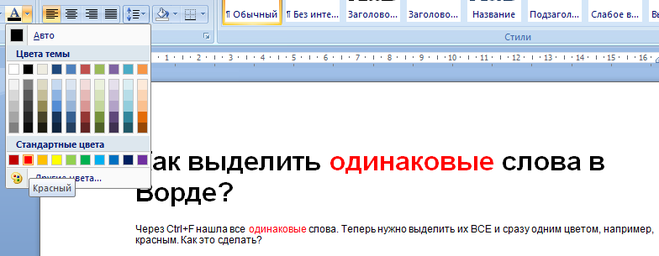
Выбираем команду изменение цвета текста, теперь изменение цвета текста будет происходить одновременно во всех найденных словах:
![]()
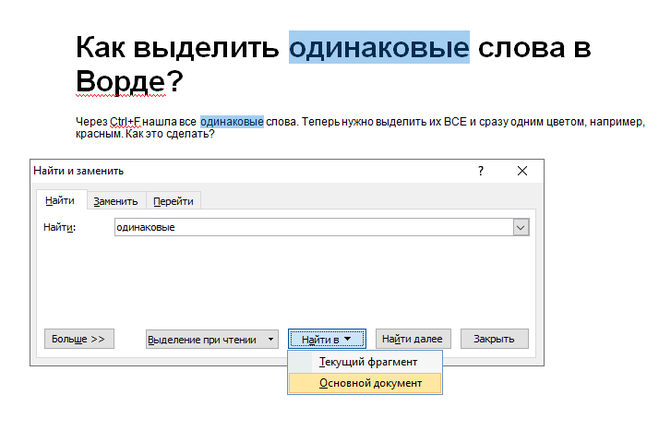
Выделение всех одинаковых слов в ворде происходит следующим методом. Нажмите Ctrl + f, после чего в выберите пункт «найти в» и в всплывающем меню выбрать основной документ. После чего ввести слово, которое вам нужно в графу поиска. Всё одинаковые слова выделяется, после чего можно делать с ними что угодно, изменить цвет, подчеркнуть, выделить жирным и тд.
![]()
В разных версиях предварительный просмотр расположен в разных меню:
Предварительный просмотр требуется очень часто, поэтому для облегчения работы в любой версии удобно использовать комбинацию клавиш Ctrl+F2.
![]()
Весь текст в Windows выделяется единым приемом и это работает не только в MS Word, но и в Google Chrome, и во множестве других приложений.
![]()
Во-первых, выделив фрагмент списка, можно изменить его уровень:
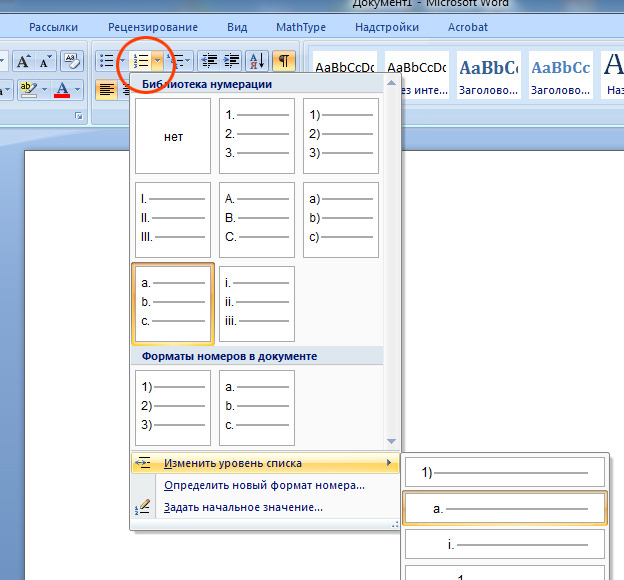
Во-вторых, обратить внимание на ползунки горизонтальной на линейке:
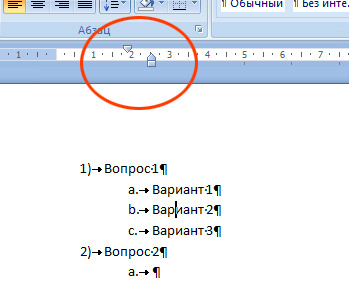
В-третьих, обратить внимание на параметры абзаца выделенного текста:
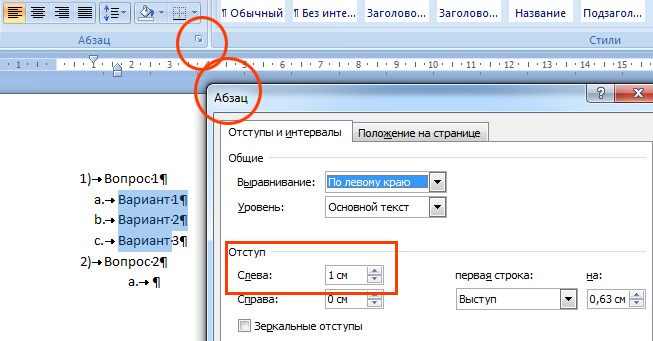
Кроме того, рядом с кнопкой библиотеки нумерации (рис.1) есть кнопки увеличения и уменьшения отступов списка.
![]()
При работе с программой Ворд (Word) иногда возникает необходимость изменять нумерацию в документе.
Например, требуется изменить стиль номера и его положение на странице, формат номера и др.
Также нередко бывает необходимо исключить из нумерации первые страницы документа (обычно 1 и 2 страницы).
Рассмотрим, как это можно сделать.
Как изменить нумерацию (параметры нумерации) страниц в Ворде (Word)
Для того, чтобы изменить параметры нумерации в документе, нужно:
1) Выбрать пункт главного меню «Вставка».
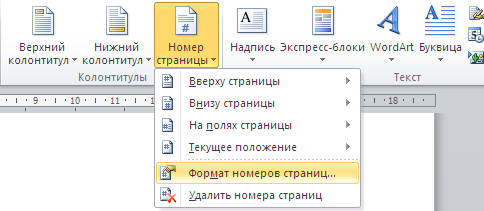
Откроется окно, в котором можно изменять формат номера и номер, с которого начинается нумерация страниц.
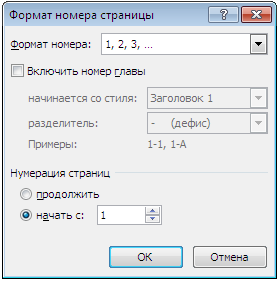
Чтобы изменить расположение номера на странице, нужно выбрать необходимый пункт в том же самом меню.
Как изменить внешний вид номера страницы в Ворде
Для того, чтобы изменить оформление нумерации на странице (шрифт, цвет, размер и др.) документа Ворд, нужно:
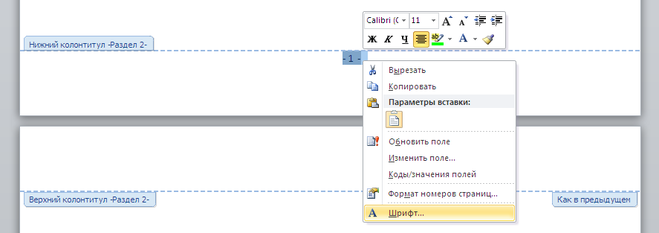
1) Щёлкнуть на любом номере левой кнопкой мыши, после чего откроется окно колонтитулов.
2) Нужно выделить номер и с помощью стандартных инструментов сделать нужное вам оформление.
Как сделать нумерацию со 2 страницы в Ворде
При оформлении научных работ в Ворде нередко возникает необходимость сделать нумерацию не с 1 страницы, а со 2.
1) Зайти в конструктор колонтитулов (щёлкнуть мышкой на номере страницы).
2) На верхней панели инструментов выбрать пункт «Особый колонтитул для первой страницы».

В результате этого нумерация в документе Word будет со 2 страницы.
Как сделать нумерацию с 3 страницы в Ворде
Если вам нужно, чтобы номер отсутствовал не только на 1 странице, но и на 2 странице (а в некоторых случаях требуется сделать нумерацию даже с 4 листа), то необходимо будет создать новый раздел.
1) Нужно поставить курсор в конец 2 страницы.
2) В главном меню Word выбрать пункт «Разметка страницы».
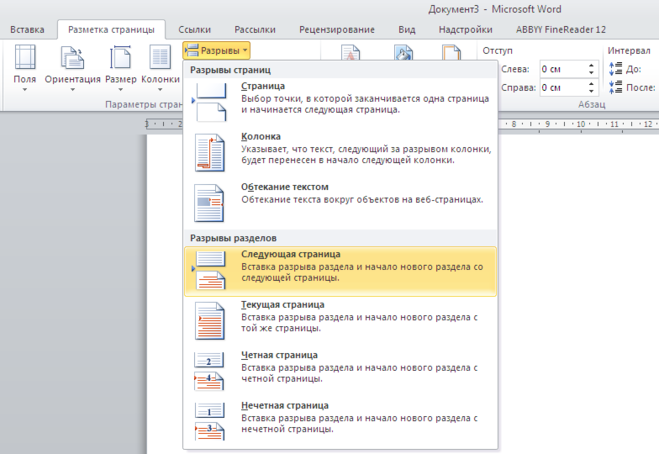
Таким образом, с 3 страницы начнётся новый раздел.
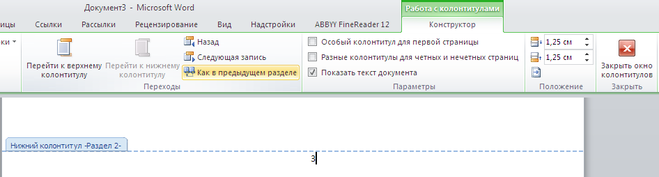
Отключаем опцию «Как в предыдущем разделе».
Теперь осталось убрать номера с первых двух страниц.
Если требуется сделать, чтобы на 3 странице нумерация начиналась не с цифры 3, а с 1, то нужно:
1) Поставить курсор на 3 страницу.
2) Зайти в «Формат номеров страниц» и в разделе «Нумерация страниц» выбрать: «Начать с 1».
В результате этого, нумерация страниц в Ворде будет начинаться с 3 страницы.
Как сделать нумерацию с 4 страницы в Ворде
В некоторых случаях бывает нужно сделать нумерацию с 4 страницы. Порядок действий аналогичен:
1) Ставим курсор в конец 3 страницы и создаём новый раздел. Он начнётся с 4 страницы.
2) Заходим в колонтитулы, расположенные на 4 странице.
3) Отключаем опцию «Как в предыдущем разделе».
4) Убираем номера с первых страниц. Ставим курсор на 4 страницу и устанавливаем начало нумерации.
Источник
Как в ворде найти повторяющийся текст
Как найти и выделить разные повторяющиеся слова
Есть текст, в котором объединено несколько списков фамилий.
В результате получилось, что в одном списке некоторые фамилии повторяются несколько раз.
Найти и выделить повторяющиеся слова в одном документе.
Нужно чтобы ворд сам выбрал те фамилии(слова), которые повторяются 2 и более раз и выделил их.
Например, повторяются фамилии ПУГАЧЕВА, ГАЛКИН, ЛЕНИН по нескольку раз.
Нужно выделить сразу всех галкиных, пугачевых и лениных и др. которые повторяются.
Т.к. список большой, то единичный поиск по фамилиям не пойдет.
Есть варианты?
Может макрос какой есть?
Помощь в написании контрольных, курсовых и дипломных работ здесь.
Как найти в списке повторяющиеся слова?
Здравствуйте! Подскажите пожалуйста, как найти в python повторяющиеся слова (в списке) и вывести.
Как найти повторяющиеся слова, записанные через дефис?
Доброго времени суток! Подскажите, возможно ли как-то с помощью регулярок(или чего-то другого).
Как выделить одинаковые слова в Ворде?
Через Ctrl+F нашла все одинаковые слова. Теперь нужно выделить их ВСЕ и сразу одним цветом, например, красным. Как это сделать?

Выбираем команду изменение цвета текста, теперь изменение цвета текста будет происходить одновременно во всех найденных словах:

Объясню на примере. Допустим, у нас есть текст (я взяла отрывок из «12 стульев»), и нам нужно найти и выделить красным цветом все встречающиеся в нем местоимения ед.ч. ж.р. — «она».

1) Заходим во вкладку «Главная», в верхней панели в крайнем правом окошке жмем «заменить»:
2) Во всплывающем окне в поле «найти» пишем она. И опять пишем она в поле «заменить на»

3) Нажимаем кнопку «больше» и выбираем: формат/выделение цветом.

4) Теперь ниже фразы «заменить на» должно появиться — выделение цветом:

5) Наконец жмем кнопку «заменить все».
Теперь все слова «она», имеющиеся в тексте выделены нужным нам цветом.
Кстати, можно выделять не только целые слова, но и части слов — например, только корень или только несколько цифр в длинных числах и т.д.
Выделение всех одинаковых слов в ворде происходит следующим методом. Нажмите Ctrl + f, после чего в выберите пункт «найти в» и в всплывающем меню выбрать основной документ. После чего ввести слово, которое вам нужно в графу поиска. Всё одинаковые слова выделяется, после чего можно делать с ними что угодно, изменить цвет, подчеркнуть, выделить жирным и тд.
Как в ворде найти повторяющийся текст
Thank you for the helping
But how can I find the same sentences in my text?
Источник
Как найти повторяющиеся слова в ворде?
Как выделить цветом одинаковые слова в ворде?
Re: Выделение в тексте цветом одинаковых слов
Как посмотреть самые частые слова в ворде?
Чтобы подсчитать количество слов в определенной части документа, выделите нужный текст. Затем в меню Сервис выберите пункт Статистика. Как и в Word для настольных систем, Word в Интернете количество слов при их введите.
Как выделить одно и тоже слово по тексту?
Способ выделения текста
Как удалить все повторяющиеся слова в Word?
Процесс удаления слов в Word можно автоматизировать. Для этого в поле «Поиск» введите слово или фразу, которую вы хотите удалить, а поле «Заменить на» оставьте пустым. Когда всё готово, нажмите кнопку «Заменить всё». В результате из всего текста будет убрано искомое слово.
Как в ворде выделить текст маркером?
Как выделить текст маркером в документе Microsoft Word 2013
Начинаем с того, что выделяем необходимый текст. Затем в разделе «Главная» жмем уголок кнопки «Цвет выделения текста» и из перечня цветов выбираем необходимый, кликая по нему. Текст выделен. Если информация оказалась Вам полезна – жмите Спасибо!
Как в ворде заменить все одинаковые слова на другие?
Как посмотреть статистику в ворде?
Для тех, кто пользуется версией Microsoft Office Word 2007 или 2010 необходимо щелкнуть мышкой на «Число слов», в нижнем левом углу окна программы. В результате этого откроется окошечко «Статистика», где указано число страниц, слов, знаков, абзацев, строк. В этой табличке указывается число строк с пробелами и без них.
Как сделать поиск по заголовкам в ворде?
Чтобы перейти к странице или заголовку в документе Word без прокрутки, используйте область навигации. Чтобы открыть область навигации, нажмите клавиши CTRL+F или выберите Вид > Область навигации.
Как найти ключевые слова в ворде?
Как выделить определенные слова в тексте?
Чтобы выделить одно слово, дважды щелкните его. Чтобы выделить строку текста, поместите курсор в ее начало и нажмите клавиши SHIFT+СТРЕЛКА ВНИЗ. Чтобы выделить абзац, поместите курсор в его начало и нажмите клавиши CTRL+SHIFT+СТРЕЛКА ВНИЗ.
Как выделить отдельные слова в тексте?
Как выделить все буквы А в тексте?
Есть и более простой способ выделить весь текст. Для этого надо воспользоваться комбинацией клавиш. Нажав и удерживая клавишу Ctrl, нажмите клавишу А. Весь ваш текст выделится.
Как удалить определенные слова в тексте?
Как удалить слово из текста в ворде?
Удерживайте клавишу Ctrl и щелкните в любом месте предложения, которое вы хотите удалить, и нажмите либо клавишу Backspace, либо клавишу Delete. Удерживая клавишу Alt, нажмите и удерживайте кнопку мыши и выделите часть текста, который вы хотите удалить; нажмите клавишу Backspace или клавишу Delete.
Как найти в тексте повторяющиеся предложения?
Нажмите клавиши Ctrl и F потом нажмите на треугольник около значка лупы и выберите «Расширенный поиск». У Вас появиться окно поиска в которым Вы можете найти все дубликаты.
Источник
Как в ворде выделить все одинаковые слова
Как найти повторяющиеся слова в Microsoft Word — Вокруг-Дом — 2021
Table of Contents:
Утилита Microsoft Word Find and Replace — это мощный инструмент, который позволяет пользователям быстро искать в своих документах определенные слова и фразы. Другое использование этого инструмента — найти повторяющиеся слова в тексте, используя опцию выделения, которая отображает повторяющиеся слова, так что вы можете легко просматривать и редактировать текст, чтобы исключить повторение слов.
Шаг 1
Откройте меню «Поиск» на вкладке «Главная» ленты и выберите «Расширенный поиск».
Шаг 2
Введите слово, в котором вы хотите найти дубликаты, в поле ввода «Найти что».
Шаг 3
При необходимости выберите другие параметры в разделе «Параметры поиска»; Использование параметров поиска, таких как «Поиск по регистру» и «Поиск только целых слов», делает ваш поиск более конкретным.
Шаг 4
Нажмите меню «Чтение выделения» и нажмите «Выделить все».
Как в ворде выделить одинаковые слова цветом?
Как найти и выделить одинаковые слова в ворде?
На вкладке Начальная страница (главная) в группе Редактирование выберите команду Найти. В поле Найти введите текст, который требуется найти. Нажмите кнопку Выделение при чтении, а затем выберите параметр Выделить все. Примечание.6 мая 2011 г.
Как в ворде выделить определенные слова?
Чтобы выделить одно слово, дважды щелкните его. Чтобы выделить строку текста, поместите курсор в ее начало и нажмите клавиши SHIFT+СТРЕЛКА ВНИЗ. Чтобы выделить абзац, поместите курсор в его начало и нажмите клавиши CTRL+SHIFT+СТРЕЛКА ВНИЗ.
Как в ворде выделить текст другим цветом?
Выделение цветом выбранного фрагмента текста
Как выделить одно и тоже слово по тексту?
Но можно сделать таким образом: нажмите клавишу Ctrl на клавиатуре и удерживайте ее нажатой. Затем мышкой выделяете нужные вам слова или отдельные предложения.
Как выделить одинаковые слова в Excel?
Как выделить все одинаковые буквы в ворде?
Как выделить несколько строк в разных местах?
Чтобы выбрать несколько строк в окне просмотра данных, выделите одну строку и, удерживая нажатой клавишу Ctrl (Windows) или Command (Mac), выберите каждую строку, которую нужно изменить или удалить.
Как в ворде сделать содержание?
Как сразу выделить несколько файлов?
Чтобы выделить несколько несмежных файлов или папок, нажмите и удерживайте клавишу Ctrl и щелкните каждый из элементов, которые нужно выделить. Чтобы выбрать все файлы и папки в окне, нажмите на панели инструментов кнопку Упорядочить и выберите команду Выделить все.
Как изменить цвет заливки текста в ворде?
Изменение цвета текста
Как в ворде на картинке выделить текст?
На вкладке Главная в группе команд Редактирование нажмите кнопку Выделить.
Как изменить цвет маркера в ворде?
Щелкните элемент Маркер и выберите нужный стиль. Выберите пункт Шрифт, а затем во всплывающем меню Цвет шрифта выберите нужный цвет.
Как выделить отдельные слова в тексте?
Как работает автозамена в ворде?
Добавить запись в список автозамены
Как выделить одинаковые слова в тексте?
Как выделить определенные слова в тексте?
Чтобы выделить одно слово, дважды щелкните его. Чтобы выделить строку текста, поместите курсор в ее начало и нажмите клавиши SHIFT+СТРЕЛКА ВНИЗ. Чтобы выделить абзац, поместите курсор в его начало и нажмите клавиши CTRL+SHIFT+СТРЕЛКА ВНИЗ.
Как удалить все повторяющиеся слова в Word?
Re: Удаление повторяющихся предложений.
Делаю с Ctrl+F (Ctrl+H) как вы пишете и ничего не открывается. При нажатии Удалить гиперссылки (Ctrl_Shift+F9) при скроллинге начинают по тексту переливаться вверх вниз подчёркивания красным цветом большинства слов!
Как добавить цвет выделения текста в ворде?
Выделение цветом выбранного фрагмента текста
Как в ворде выделить определенные слова?
В тексте документа найдите слово (фразу), которое вы хотите выделить. Установите курсор у начала слова, нажмите и удерживайте левую кнопку мыши и переместите курсор над словом до его конца.
Как удалить повторяющиеся слова в Excel?
Удаление повторяющихся значений
Как сделать фон для текста в ворде?
Делаем фон за текстом — 2 способ
Как в ворде на картинке выделить текст?
На вкладке Главная в группе команд Редактирование нажмите кнопку Выделить.
Как сделать текст в ворде одного цвета?
Вы можете изменить цвет текста в документе Word.
Как найти определенное слово в ворде?
Поиск текста в документе
Как найти повторяющиеся слова в ворде?
Источник
Как в ворде найти повторяющийся текст
Как найти и выделить разные повторяющиеся слова
Есть текст, в котором объединено несколько списков фамилий.
В результате получилось, что в одном списке некоторые фамилии повторяются несколько раз.
Найти и выделить повторяющиеся слова в одном документе.
Нужно чтобы ворд сам выбрал те фамилии(слова), которые повторяются 2 и более раз и выделил их.
Например, повторяются фамилии ПУГАЧЕВА, ГАЛКИН, ЛЕНИН по нескольку раз.
Нужно выделить сразу всех галкиных, пугачевых и лениных и др. которые повторяются.
Т.к. список большой, то единичный поиск по фамилиям не пойдет.
Есть варианты?
Может макрос какой есть?
Помощь в написании контрольных, курсовых и дипломных работ здесь.
Как найти в списке повторяющиеся слова?
Здравствуйте! Подскажите пожалуйста, как найти в python повторяющиеся слова (в списке) и вывести.
Как найти повторяющиеся слова, записанные через дефис?
Доброго времени суток! Подскажите, возможно ли как-то с помощью регулярок(или чего-то другого).
Как выделить одинаковые слова в Ворде?
Через Ctrl+F нашла все одинаковые слова. Теперь нужно выделить их ВСЕ и сразу одним цветом, например, красным. Как это сделать?
Выбираем команду изменение цвета текста, теперь изменение цвета текста будет происходить одновременно во всех найденных словах:
Объясню на примере. Допустим, у нас есть текст (я взяла отрывок из «12 стульев»), и нам нужно найти и выделить красным цветом все встречающиеся в нем местоимения ед.ч. ж.р. — «она».
1) Заходим во вкладку «Главная», в верхней панели в крайнем правом окошке жмем «заменить»:
2) Во всплывающем окне в поле «найти» пишем она. И опять пишем она в поле «заменить на»
3) Нажимаем кнопку «больше» и выбираем: формат/выделение цветом.
4) Теперь ниже фразы «заменить на» должно появиться — выделение цветом:
5) Наконец жмем кнопку «заменить все».
Теперь все слова «она», имеющиеся в тексте выделены нужным нам цветом.
Кстати, можно выделять не только целые слова, но и части слов — например, только корень или только несколько цифр в длинных числах и т.д.
Выделение всех одинаковых слов в ворде происходит следующим методом. Нажмите Ctrl + f, после чего в выберите пункт «найти в» и в всплывающем меню выбрать основной документ. После чего ввести слово, которое вам нужно в графу поиска. Всё одинаковые слова выделяется, после чего можно делать с ними что угодно, изменить цвет, подчеркнуть, выделить жирным и тд.
Как в ворде найти повторяющийся текст
Thank you for the helping
But how can I find the same sentences in my text?
Источник
Простой алгоритм для поиска всех совпадающих под-текстов в двух текстах
Время на прочтение
4 мин
Количество просмотров 28K
По долгу службы мне часто нужно находить все пересечения между текстами (например, все цитаты из одного текста в другом). Я достаточно долго искал стандартное решение, которое бы позволило бы это делать, но найти его мне так и не удалось — обычно решается какая-то совсем или немного другая задача. Например, класс SequenceMatcher из difflib в стандартной библиотеке Питона находит самую длинную общую подпоследовательность в двух последовательностях hashable элементов, а потом рекурсивно повторяет поиск слева и справа от нее. Если в одном из текстов будет более короткая подпоследовательность, которая содержится внутри уже найденной (например, если кусок длинной цитаты где-то был повторен еще раз), он ее пропустит. Кроме того, когда я загнал в него «Войну и мир» и «Анну Каренину» в виде списков слов и попросил для начала найти самую длинную подпоследовательность, он задумался на семь минут; когда я попросил все совпадающие блоки, он ушел и не вернулся (в документации обещают среднее линейное время, но что-то в прозе Льва Толстого, по-видимому, вызывает к жизни worst-case квадратичное).
В конечном итоге я придумал свой алгоритм, тем самым наверняка изобретя велосипед, который надеюсь увидеть в комментариях. Алгоритм делает ровно то, что мне нужно: находит все совпадающие последовательности слов в двух текстах (за исключением тех, что в обоих текстах входят в состав более крупных совпадающих последовательностей) и сравнивает «Войну и мир» с «Анной Карениной» за минуту.
Принцип следующий: сначала из каждого текста извлекаются все биграммы и создается хэш-таблица, где для каждой биграммы указан ее порядковый номер. Затем берется более короткий текст, его биграммы перебираются в любом порядке, и если какая-то из них есть в словаре для второго текста, то в отдельно созданный массив добавляются все пары вида (№ биграммы из первого словаря, № биграммы из второго словаря). Например, если в тексте 1 биграмма «А Б» встречается на позициях 1, 2 и 3, а во втором тексте она же встречается на позициях 17, 24 и 56, в массив попадут пары (1, 17), (1, 24), (1, 56), (2, 17)… Это самое слабое место алгоритма: если оба текста состоят из одинаковых слов, то в массив попадет n на m пар цифр. Такие тексты, однако, нам вряд ли попадутся (алгоритм ориентирован на тексты на естественном языке), а чтобы снизить количество бессмысленных совпадений, можно заменить биграммы на любые n-граммы (в зависимости того, какие минимальные совпадения нужны) или выкинуть частотные слова.
Каждая пара цифр в массиве — это совпадение на уровне биграммы. Теперь нам надо получить оттуда совпадающие последовательности, причем если у нас есть совпадение вида «А Б Б В», то тот факт, что ровно эти же фрагменты текста совпадают по «А Б», «Б Б» и «Б В» т. д. надо проигнорировать. Все это очень легко сделать за линейное время при помощи умеренно нетривиальной структуры данных — упорядоченного множества. Оно должно уметь помещать в себя и выкидывать из себя элементы за константное время и помнить, в каком порядке элементы в него добавлялись. Имплементация такого множества для Питона есть здесь: code.activestate.com/recipes/576694-orderedset Для наших нужд оно должно уметь выплевывать из себя элементы не только из конца, но и из начала. Добавляем туда сделанный на скорую руку метод popFirst:
def popFirst(self):
if not self:
raise KeyError('set is empty')
for item in self:
i = item
break
self.discard(i)
return i
Остальное совсем просто: вынимаем из множества первый элемент, кладем во временный массив и, пока можем, добавляем к нему такие элементы из множества, что у каждого следующего и первый и второй индексы на один больше, чем у предыдущего. Когда таких больше не оказывается, отправляем найденную параллельную последовательность в итоговый массив и повторяем заново. Все добавленные элементы тоже выкидываются из множества. Таким образом мы одновременно получаем макисмальные по длине параллельные последовательности, игнорируем совпадения подпоследовательностей в длинных последовательностях и не теряем связи между найденными последовательностями и другими местами в тексте (такие совпадения будут отличаться на первый или второй индекс). В конечном итоге на выходе имеем массив массивов, где каждый подмассив — совпадающая последовательность слов. Можно отсортировать эти подмассивы по длине или по индексу начала (чтобы узнать все параллельные места к тому или иному фрагменту) или отфильтровать по минимальной длине.
Код на Питоне без OrderedSet и с биграммами. compareTwoTexts сразу возвращает результат. Чтобы по номерам биграмм понять, какие именно фрагменты текста совпадают, нужно отдельно сделать словарь биграмм и из него обратный словарь (extractNGrams, getReverseDic) или просто взять список слов (extractWords): каждая биграмма начинается со слова, стоящего в той же позиции, что и она сама.
from OrderedSet import OrderedSet
russianAlphabet = {'й', 'ф', 'я', 'ц', 'ы', 'ч', 'у', 'в', 'с', 'к', 'а', 'м', 'е', 'п', 'и', 'н', 'р', 'т', 'г', 'о', 'ь', 'ш', 'л', 'б', 'щ', 'д', 'ю', 'з', 'ж', 'х', 'э', 'ъ', 'ё'}
def compareTwoTexts(txt1, txt2, alphabet = russianAlphabet):
# txt1 should be the shorter one
ngramd1 = extractNGrams(txt1, alphabet)
ngramd2 = extractNGrams(txt2, alphabet)
return extractCommonPassages(getCommonNGrams(ngramd1, ngramd2))
def extractNGrams(txt, alphabet):
words = extractWords(txt, alphabet)
ngrams = []
for i in range(len(words)-1):
ngrams.append(
(words[i] + ' ' + words[i+1], i)
)
ngramDic = {}
for ngram in ngrams:
try:
ngramDic[ngram[0]].append(ngram[1])
except KeyError:
ngramDic[ngram[0]] = [ngram[1]]
return ngramDic
def extractWords(s, alphabet):
arr = []
temp = []
for char in s.lower():
if char in alphabet or char == '-' and len(temp) > 0:
temp.append(char)
else:
if len(temp) > 0:
arr.append(''.join(temp))
temp = []
if len(temp) > 0:
arr.append(''.join(temp))
return arr
def getReverseDic(ngramDic):
reverseDic = {}
for key in ngramDic:
for index in ngramDic[key]:
reverseDic[index] = key
return reverseDic
def getCommonNGrams(ngramDic1, ngramDic2):
# ngramDic1 should be for the shorter text
allCommonNGrams = []
for nGram in ngramDic1:
if nGram in ngramDic2:
for i in ngramDic1[nGram]:
for j in ngramDic2[nGram]:
allCommonNGrams.append((nGram, i, j))
allCommonNGrams.sort(key = lambda x: x[1])
commonNGramSet = OrderedSet((item[1], item[2]) for item in allCommonNGrams)
return commonNGramSet
def extractCommonPassages(commonNGrams):
if not commonNGrams:
raise ValueError('no common ngrams')
commonPassages = []
temp = []
while commonNGrams:
if not temp:
temp = [commonNGrams.popFirst()]
if not commonNGrams:
break
if (temp[-1][0]+1, temp[-1][1]+1) in commonNGrams:
temp.append((temp[-1][0]+1, temp[-1][1]+1))
commonNGrams.discard((temp[-1][0], temp[-1][1]))
else:
commonPassages.append(temp)
temp = []
if temp:
commonPassages.append(temp)
return commonPassages
Если на проекте много похожих статей, то кроме проверки на уникальность, нужно сравнивать тексты между собой. Студия «Контентим» подготовила обзор лучших сервисов для сравнения текстов и дала рекомендации по проценту совпадений.
Екатерина Зейналова

Высшее образование в сфере Бизнес Менеджмента. Свободно владеет английским и русским языками. Также знает немецкий и арабский. Автор и редактор проектов по маркетингу, гемблингу, Амазону, HR, и многим другим тематикам
Сравнение 2 текстов между собой необходимо, если на вашем сайте много статей с похожей структурой или на близкую тему. Объясним, почему это нужно, и расскажем о хороших сервисах для такой задачи.
Все знают, что уникальный контент выше ранжируется, поэтому все перепроверяют уник размещаемых текстов. Но мало кто думает о том, что если на сайте размещено много сходных между собой материалов, то поисковик будет считать уникальной только первую страницу, которую он посетил.
Например, у вас проект про казино США. Все тексты в разделе пишутся примерно по одному плану на плюс-минус одну тему (виды казино). И вот вам прислали для размещения два текста — «Самые стремные казино США» и «Самые крутые казино США». Вы перепроверяете уник — у каждой статьи он выше 85 % по выбранному вами сервису. По идее, все в порядке и можно размещать. А потом сравниваете эти два текста между собой и выясняете, что разница между ними меньше 70 % — это означает, что после размещения обеих статей только первая будет иметь уник выше 85 %, а вторая окажется уникальной лишь на 10–30 %, что совершенно неудовлетворительно.
Мы в студии «Контентим» находили и другие удивительные вещи с помощью сравнения текстов между собой, например:
- Копипаст из одной статьи в другую. Недобросовестный автор просто копировал целые абзацы из одного текста в другой, при этом сервис проверки уника ничего не находил, потому что каждая статья была уникальной относительно контента в интернете.
- Поверхностный рерайт. Автор не пытался провести оригинальное исследование для каждого материала, а просто переписывал каждое предложение своей первой статьи во вторую, меняя отдельные слова. Например, в первой было «Стремные казино США внушают ужас игрокам», а во второй «Крутые казино США вызывают восхищение у игроков». Такое сервис проверки уника тоже не найдет. Кстати говоря, это выдает непрофессионала. Здесь мы рассказываем и о других признаках плохого копирайтера по гемблингу.
Бывает и такое, что автор не халтурит, а просто устал или стал заложником своего стиля письма и неосознанно повторяет какие-то идеи или конструкции в нескольких статьях. Это может быть вредно для уникальности точно так же, как скопированный контент.
Поэтому на всех типичных статьях мы обязательно сравниваем тексты между собой, даже если этого нет в ТЗ клиента. И мы рекомендуем включать сервисы сравнения в ТЗ с обязательным указанием нормального значения совпадений.
Такое значение зависит от объема текста, темы (терминология и устойчивый профессиональный сленг) и неизменяемого контента на странице, например, заголовки разделов. В среднем нормальная разница между двумя текстами должна быть 60–70 %, то есть совпадать должно лишь 30–40 % контента, включая ключевые слова, заголовки и другие вещи, которые нельзя менять автору.
Топ-5 сервисов для сравнения текстов
Большинство из приведенных ниже сервисов работают бесплатно и без регистрации. Интерфейс везде примерно одинаков: вы просто вставляете первый и второй текст в отдельные окошки и нажимаете «Проверить». После этого система выдает результат в процентном значении (сколько процентов совпадает) и показывает совпадающие фрагменты.
BackLinks Manager

Этот сервис мы используем чаще всего, потому что здесь можно настраивать шингл. Интерфейс только русский, но ни один из наших нейтивов не жаловался, потому что проверка запускается элементарно.
Copyscape

Хотя Copyscape обычно не входит в число сервисов для проверки текста на уникальность, он предлагает простой и, что главное, бесплатный инструмент для сравнения двух текстов. Ничего особенного, только базовый функционал: процент совпадения, количество слов.
Copyleaks

Copyleaks предлагает более продвинутую аналитику сравнения между собой двух текстов. Помимо процента совпадений и количества одинаковых слов он также показывает куски текста с минимальными изменениями, близким значением и пропущенными словами. Все это отображается разными цветами.
Countwordsfree

Используя этот сервис, можно узнать процент различия и совпадений. Эти же данные выводятся в количестве символов. Countwordsfree отображает одинаковые фрагменты без выделения, отмечая зеленым цветом добавленный текст, а красным — удаленный. Сайт также предлагает сохранить результаты в Word или PDF.
Cortical.io

Сервис автоматически определяет и работает с семью языками:
- английский;
- немецкий;
- французский;
- испанский;
- китайский;
- арабский;
- датский.
После завершения сравнения сайт показывает процент совпадений и оба текста в виде квадратных сеток с закодированными семантическими отпечатками. Если вам не нужно видеть, какие именно фразы были скопированы, Cortical.io вполне подойдет.
Выбор редакции «Контентим»
По удобству нам больше всего нравится BackLinks Manager, потому что он выдает результат в процентах и предлагает настройки шингла. Но в целом все сервисы из топа хороши, работают без накладок и удобны, если ваша цель — увидеть заимствованные фрагменты, а не быстро оценить процент совпадающего материала.