Погрешности измерений, представление результатов эксперимента
- Шкала измерительного прибора
- Цена деления
- Виды измерений
- Погрешность измерений, абсолютная и относительная погрешность
- Абсолютная погрешность серии измерений
- Представление результатов эксперимента
- Задачи
п.1. Шкала измерительного прибора
Шкала – это показывающая часть измерительного прибора, состоящая из упорядоченного ряда отметок со связанной с ними нумерацией. Шкала может располагаться по окружности, дуге или прямой линии.
Примеры шкал различных приборов:
п.2. Цена деления
Цена деления измерительного прибора равна числу единиц измеряемой величины между двумя ближайшими делениями шкалы. Как правило, цена деления указана на маркировке прибора.
Алгоритм определения цены деления
Шаг 1. Найти два ближайшие пронумерованные крупные деления шкалы. Пусть первое значение равно a, второе равно b, b > a.
Шаг 2. Посчитать количество мелких делений шкалы между ними. Пусть это количество равно n.
Шаг 3. Разделить разницу значений крупных делений шкалы на количество отрезков, которые образуются мелкими делениями: $$ triangle=frac{b-a}{n+1} $$ Найденное значение (triangle) и есть цена деления данного прибора.
Пример определения цены деления:
 |
Определим цену деления основной шкалы секундомера. Два ближайших пронумерованных деления на основной шкале:a = 5 c b = 10 cМежду ними находится 4 средних деления, а между каждыми средними делениями еще 4 мелких. Итого: 4+4·5=24 деления. Цена деления: begin{gather*} triangle=frac{b-a}{n+1}\ triangle=frac{10-5}{24+1}=frac15=0,2 c end{gather*} |
п.3. Виды измерений
Вид измерений
Определение
Пример
Прямое измерение
Физическую величину измеряют с помощью прибора
Измерение длины бруска линейкой
Косвенное измерение
Физическую величину рассчитывают по формуле, куда подставляют значения величин, полученных с помощью прямых измерений
Определение площади столешницы при измеренной длине и ширине
п.4. Погрешность измерений, абсолютная и относительная погрешность
Погрешность измерений – это отклонение измеренного значения величины от её истинного значения.
Составляющие погрешности измерений
Причины
Инструментальная погрешность
Определяется погрешностью инструментов и приборов, используемых для измерений (принципом действия, точностью шкалы и т.п.)
Погрешность метода
Определяется несовершенством методов и допущениями в методике.
Погрешность теории (модели)
Определяется теоретическими упрощениями, степенью соответствия теоретической модели и реальности.
Погрешность оператора
Определяется субъективным фактором, ошибками экспериментатора.
Инструментальная погрешность измерений принимается равной половине цены деления прибора: $$ d=frac{triangle}{2} $$
Если величина (a_0) — это истинное значение, а (triangle a) — погрешность измерения, результат измерений физической величины записывают в виде (a=a_0pmtriangle a).
Абсолютная погрешность измерения – это модуль разности между измеренным и истинным значением измеряемой величины: $$ triangle a=|a-a_0| $$
Отношение абсолютной погрешности измерения к истинному значению, выраженное в процентах, называют относительной погрешностью измерения: $$ delta=frac{triangle a}{a_0}cdot 100text{%} $$
Относительная погрешность является мерой точности измерения: чем меньше относительная погрешность, тем измерение точнее. По абсолютной погрешности о точности измерения судить нельзя.
На практике абсолютную и относительную погрешности округляют до двух значащих цифр с избытком, т.е. всегда в сторону увеличения.
Значащие цифры – это все верные цифры числа, кроме нулей слева. Результаты измерений записывают только значащими цифрами.
Примеры значащих цифр:
0,403 – три значащих цифры, величина определена с точностью до тысячных.
40,3 – три значащих цифры, величина определена с точностью до десятых.
40,300 – пять значащих цифр, величина определена с точностью до тысячных.
В простейших измерениях инструментальная погрешность прибора является основной.
В таких случаях физическую величину измеряют один раз, полученное значение берут в качестве истинного, а абсолютную погрешность считают равной инструментальной погрешности прибора.
Примеры измерений с абсолютной погрешностью равной инструментальной:
- определение длины с помощью линейки или мерной ленты;
- определение объема с помощью мензурки.
Пример получения результатов прямых измерений с помощью линейки:
 |
Измерим длину бруска линейкой, у которой пронумерованы сантиметры и есть только одно деление между пронумерованными делениями. Цена деления такой линейки: begin{gather*} triangle=frac{b-a}{n+1}= frac{1 text{см}}{1+1}=0,5 text{см} end{gather*} Инструментальная погрешность: begin{gather*} d=frac{triangle}{2}=frac{0,5}{2}=0,25 text{см} end{gather*} Истинное значение: (L_0=4 text{см}) Результат измерений: $$ L=L_0pm d=(4,00pm 0,25) text{см} $$ Относительная погрешность: $$ delta=frac{0,25}{4,00}cdot 100text{%}=6,25text{%}approx 6,3text{%} $$ |
 |
Теперь возьмем линейку с n=9 мелкими делениями между пронумерованными делениями. Цена деления такой линейки: begin{gather*} triangle=frac{b-a}{n+1}= frac{1 text{см}}{9+1}=0,1 text{см} end{gather*} Инструментальная погрешность: begin{gather*} d=frac{triangle}{2}=frac{0,1}{2}=0,05 text{см} end{gather*} Истинное значение: (L_0=4,15 text{см}) Результат измерений: $$ L=L_0pm d=(4,15pm 0,05) text{см} $$ Относительная погрешность: $$ delta=frac{0,05}{4,15}cdot 100text{%}approx 1,2text{%} $$ |
Второе измерение точнее, т.к. его относительная погрешность меньше.
п.5. Абсолютная погрешность серии измерений
Измерение длины с помощью линейки (или объема с помощью мензурки) являются теми редкими случаями, когда для определения истинного значения достаточно одного измерения, а абсолютная погрешность сразу берется равной инструментальной погрешности, т.е. половине цены деления линейки (или мензурки).
Гораздо чаще погрешность метода или погрешность оператора оказываются заметно больше инструментальной погрешности. В таких случаях значение измеренной физической величины каждый раз немного меняется, и для оценки истинного значения и абсолютной погрешности нужна серия измерений и вычисление средних значений.
Алгоритм определения истинного значения и абсолютной погрешности в серии измерений
Шаг 1. Проводим серию из (N) измерений, в каждом из которых получаем значение величины (x_1,x_2,…,x_N)
Шаг 2. Истинное значение величины принимаем равным среднему арифметическому всех измерений: $$ x_0=x_{cp}=frac{x_1+x_2+…+x_N}{N} $$ Шаг 3. Находим абсолютные отклонения от истинного значения для каждого измерения: $$ triangle_1=|x_0-x_1|, triangle_2=|x_0-x_2|, …, triangle_N=|x_0-x_N| $$ Шаг 4. Находим среднее арифметическое всех абсолютных отклонений: $$ triangle_{cp}=frac{triangle_1+triangle_2+…+triangle_N}{N} $$ Шаг 5. Сравниваем полученную величину (triangle_{cp}) c инструментальной погрешностью прибора d (половина цены деления). Большую из этих двух величин принимаем за абсолютную погрешность: $$ triangle x=maxleft{triangle_{cp}; dright} $$ Шаг 6. Записываем результат серии измерений: (x=x_0pmtriangle x).
Пример расчета истинного значения и погрешности для серии прямых измерений:
Пусть при измерении массы шарика с помощью рычажных весов мы получили в трех опытах следующие значения: 99,8 г; 101,2 г; 100,3 г.
Инструментальная погрешность весов d = 0,05 г.
Найдем истинное значение массы и абсолютную погрешность.
Составим расчетную таблицу:
| № опыта | 1 | 2 | 3 | Сумма |
| Масса, г | 99,8 | 101,2 | 100,3 | 301,3 |
| Абсолютное отклонение, г | 0,6 | 0,8 | 0,1 | 1,5 |
Сначала находим среднее значение всех измерений: begin{gather*} m_0=frac{99,8+101,2+100,3}{3}=frac{301,3}{3}approx 100,4 text{г} end{gather*} Это среднее значение принимаем за истинное значение массы.
Затем считаем абсолютное отклонение каждого опыта как модуль разности (m_0) и измерения. begin{gather*} triangle_1=|100,4-99,8|=0,6\ triangle_2=|100,4-101,2|=0,8\ triangle_3=|100,4-100,3|=0,1 end{gather*} Находим среднее абсолютное отклонение: begin{gather*} triangle_{cp}=frac{0,6+0,8+0,1}{3}=frac{1,5}{3}=0,5 text{(г)} end{gather*} Мы видим, что полученное значение (triangle_{cp}) больше инструментальной погрешности d.
Поэтому абсолютная погрешность измерения массы: begin{gather*} triangle m=maxleft{triangle_{cp}; dright}=maxleft{0,5; 0,05right} text{(г)} end{gather*} Записываем результат: begin{gather*} m=m_0pmtriangle m\ m=(100,4pm 0,5) text{(г)} end{gather*} Относительная погрешность (с двумя значащими цифрами): begin{gather*} delta_m=frac{0,5}{100,4}cdot 100text{%}approx 0,050text{%} end{gather*}
п.6. Представление результатов эксперимента
Результат измерения представляется в виде $$ a=a_0pmtriangle a $$ где (a_0) – истинное значение, (triangle a) – абсолютная погрешность измерения.
Как найти результат прямого измерения, мы рассмотрели выше.
Результат косвенного измерения зависит от действий, которые производятся при подстановке в формулу величин, полученных с помощью прямых измерений.
Погрешность суммы и разности
Если (a=a_0+triangle a) и (b=b_0+triangle b) – результаты двух прямых измерений, то
- абсолютная погрешность их суммы равна сумме абсолютных погрешностей
$$ triangle (a+b)=triangle a+triangle b $$
- абсолютная погрешность их разности также равна сумме абсолютных погрешностей
$$ triangle (a-b)=triangle a+triangle b $$
Погрешность произведения и частного
Если (a=a_0+triangle a) и (b=b_0+triangle b) – результаты двух прямых измерений, с относительными погрешностями (delta_a=frac{triangle a}{a_0}cdot 100text{%}) и (delta_b=frac{triangle b}{b_0}cdot 100text{%}) соответственно, то:
- относительная погрешность их произведения равна сумме относительных погрешностей
$$ delta_{acdot b}=delta_a+delta_b $$
- относительная погрешность их частного также равна сумме относительных погрешностей
$$ delta_{a/b}=delta_a+delta_b $$
Погрешность степени
Если (a=a_0+triangle a) результат прямого измерения, с относительной погрешностью (delta_a=frac{triangle a}{a_0}cdot 100text{%}), то:
- относительная погрешность квадрата (a^2) равна удвоенной относительной погрешности
$$ delta_{a^2}=2delta_a $$
- относительная погрешность куба (a^3) равна утроенной относительной погрешности
$$ delta_{a^3}=3delta_a $$
- относительная погрешность произвольной натуральной степени (a^n) равна
$$ delta_{a^n}=ndelta_a $$
Вывод этих формул достаточно сложен, но если интересно, его можно найти в Главе 7 справочника по алгебре для 8 класса.
п.7. Задачи
Задача 1. Определите цену деления и объем налитой жидкости для каждой из мензурок. В каком случае измерение наиболее точно; наименее точно? 
Составим таблицу для расчета цены деления:
| № мензурки | a, мл | b, мл | n | (triangle=frac{b-a}{n+1}), мл |
| 1 | 20 | 40 | 4 | (frac{40-20}{4+1}=4) |
| 2 | 100 | 200 | 4 | (frac{200-100}{4+1}=20) |
| 3 | 15 | 30 | 4 | (frac{30-15}{4+1}=3) |
| 4 | 200 | 400 | 4 | (frac{400-200}{4+1}=40) |
Инструментальная точность мензурки равна половине цены деления.
Принимаем инструментальную точность за абсолютную погрешность и измеренное значение объема за истинное.
Составим таблицу для расчета относительной погрешности (оставляем две значащих цифры и округляем с избытком):
| № мензурки | Объем (V_0), мл | Абсолютная погрешность (triangle V=frac{triangle}{2}), мл |
Относительная погрешность (delta_V=frac{triangle V}{V_0}cdot 100text{%}) |
| 1 | 68 | 2 | 3,0% |
| 2 | 280 | 10 | 3,6% |
| 3 | 27 | 1,5 | 5,6% |
| 4 | 480 | 20 | 4,2% |
Наиболее точное измерение в 1-й мензурке, наименее точное – в 3-й мензурке.
Ответ:
Цена деления 4; 20; 3; 40 мл
Объем 68; 280; 27; 480 мл
Самое точное – 1-я мензурка; самое неточное – 3-я мензурка
Задача 2. В двух научных работах указаны два значения измерений одной и той же величины: $$ x_1=(4,0pm 0,1) text{м}, x_2=(4,0pm 0,03) text{м} $$ Какое из этих измерений точней и почему?
Мерой точности является относительная погрешность измерений. Получаем: begin{gather*} delta_1=frac{0,1}{4,0}cdot 100text{%}=2,5text{%}\ delta_2=frac{0,03}{4,0}cdot 100text{%}=0,75text{%} end{gather*} Относительная погрешность второго измерения меньше. Значит, второе измерение точней.
Ответ: (delta_2lt delta_1), второе измерение точней.
Задача 3. Две машины движутся навстречу друг другу со скоростями 54 км/ч и 72 км/ч.
Цена деления спидометра первой машины 10 км/ч, второй машины – 1 км/ч.
Найдите скорость их сближения, абсолютную и относительную погрешность этой величины.
Абсолютная погрешность скорости каждой машины равна инструментальной, т.е. половине деления спидометра: $$ triangle v_1=frac{10}{2}=5 (text{км/ч}), triangle v_2=frac{1}{2}=0,5 (text{км/ч}) $$ Показания каждого из спидометров: $$ v_1=(54pm 5) text{км/ч}, v_2=(72pm 0,5) text{км/ч} $$ Скорость сближения равна сумме скоростей: $$ v_0=v_{10}+v_{20}, v_0=54+72=125 text{км/ч} $$ Для суммы абсолютная погрешность равна сумме абсолютных погрешностей слагаемых. $$ triangle v=triangle v_1+triangle v_2, triangle v=5+0,5=5,5 text{км/ч} $$ Скорость сближения с учетом погрешности равна: $$ v=(126,0pm 5,5) text{км/ч} $$ Относительная погрешность: $$ delta_v=frac{5,5}{126,0}cdot 100text{%}approx 4,4text{%} $$ Ответ: (v=(126,0pm 5,5) text{км/ч}, delta_vapprox 4,4text{%})
Задача 4. Измеренная длина столешницы равна 90,2 см, ширина 60,1 см. Измерения проводились с помощью линейки с ценой деления 0,1 см. Найдите площадь столешницы, абсолютную и относительную погрешность этой величины.
Инструментальная погрешность линейки (d=frac{0,1}{2}=0,05 text{см})
Результаты прямых измерений длины и ширины: $$ a=(90,20pm 0,05) text{см}, b=(60,10pm 0,05) text{см} $$ Относительные погрешности (не забываем про правила округления): begin{gather*} delta_1=frac{0,05}{90,20}cdot 100text{%}approx 0,0554text{%}approx uparrow 0,056text{%}\ delta_2=frac{0,05}{60,10}cdot 100text{%}approx 0,0832text{%}approx uparrow 0,084text{%} end{gather*} Площадь столешницы: $$ S=ab, S=90,2cdot 60,1 = 5421,01 text{см}^2 $$ Для произведения относительная погрешность равна сумме относительных погрешностей слагаемых: $$ delta_S=delta_a+delta_b=0,056text{%}+0,084text{%}=0,140text{%}=0,14text{%} $$ Абсолютная погрешность: begin{gather*} triangle S=Scdot delta_S=5421,01cdot 0,0014=7,59approx 7,6 text{см}^2\ S=(5421,0pm 7,6) text{см}^2 end{gather*} Ответ: (S=(5421,0pm 7,6) text{см}^2, delta_Sapprox 0,14text{%})

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка
выборки
показывает, насколько отклоняется в
среднем параметр выборочной
совокупности
от соответствующего параметра генеральной.
Если рассчитать среднюю из ошибок всех
возможных выборок определенного вида
заданного объема (n),
извлеченных из одной и той же генеральной
совокупности,
то получим их обобщающую характеристику
среднюю
ошибку выборки
().
В
теории выборочного наблюдения
выведены формулы для определения ,
которые индивидуальны для разных
способов отбора (повторного и
бесповторного), типов используемых
выборок и видов оцениваемых статистических
показателей.
Например, если
применяется повторная собственно
случайная выборка, то
определяется как:
![]()
при
оценивании среднего значения признака;
![]()
если
признак альтернативный, и оценивается
доля.
При бесповторном
собственно случайном отборе в формулы
вносится поправка
![]()
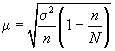
для
среднего значения признака;
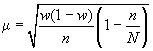
для
доли.
Вероятность
получения именно такой величины ошибки
всегда равна 0,683. На практике же
предпочитают получать данные с большей
вероятностью, но это приводит к возрастанию
величины ошибки выборки.
Предельная
ошибка выборки ()
равна t-кратному
числу средних ошибок выборки (в теории
выборки принято коэффициент t
называть
коэффициентом доверия):
t
.
Если ошибку выборки
увеличить в два раза (t
2), то получим гораздо большую вероятность
того, что она не превысит определенного
предела (в нашем случае
двойной средней ошибки)
0,954. Если взять t
3, то доверительная вероятность составит
0,997
практически достоверность.
Уровень предельной
ошибки выборки зависит от следующих
факторов:
степени вариации
единиц генеральной совокупности;
объема выборки;
выбранных схем
отбора (бесповторный отбор дает меньшую
величину ошибки);
уровня
доверительной вероятности.
Если объем выборки
больше 30, то значение t
определяется по таблице нормального
распределения, если меньше
по таблице распределения Стьюдента
(Приложение
1).
Приведем некоторые
значения коэффициента доверия из таблицы
нормального распределения.
![]()
Доверительный
интервал для среднего значения признака
и для доли в генеральной
совокупности
устанавливается следующим образом:
![]()
Итак, определение
границ генеральной средней и доли
состоит из следующих этапов:
нахождение в
выборке среднего значения признака
(или доли);
определение
в соответствии с выбранной схемой отбора
и вида выборки;
задание
доверительной вероятности Р
и определение коэффициента доверия t
по
соответствующей таблице;
вычисление
предельной ошибки выборки ;
построение
доверительного интервала для средней
(или доли).
Ошибки выборки
при различных видах отбора
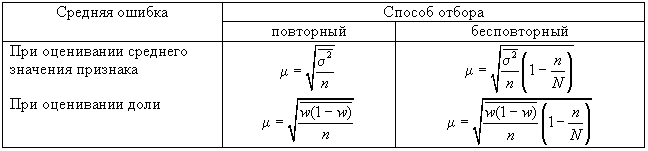
1. Собственно
случайная и механическая выборка.
Средняя
ошибка собственно случайной и механической
выборки находятся по формулам,
представленным в табл. 11.1.
Таблица 1
Формулы для
расчета средней ошибки
собственно
случайной и механической выборки ()

где
2
дисперсия
признака в выборочной совокупности.
Пример 2. Для
изучения уровня фондоотдачи было
проведено выборочное обследование 90
предприятий из 225 методом случайной
повторной выборки, в результате которого
получены данные, представленные в
таблице.

В рассматриваемом
примере имеем 40%-ную выборку (90 : 225
0,4, или 40%). Определим ее предельную ошибку
и границы для среднего значения признака
в генеральной совокупности по шагам
алгоритма:
1. По результатам
выборочного обследования рассчитаем
среднее значение и дисперсию в выборочной
совокупности:
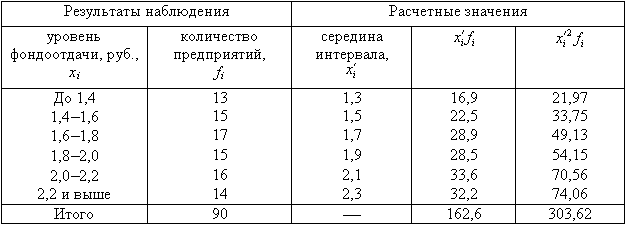
Выборочная средняя
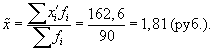
Выборочная
дисперсия изучаемого признака
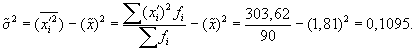
2. Определяем
среднюю ошибку повторной случайной
выборки
![]()
3. Зададим
вероятность, на уровне которой будем
говорить о величине предельной ошибки
выборки. Чаще всего она принимается
равной 0,999; 0,997; 0,954.
Для наших данных
определим предельную ошибку выборки,
например, с вероятностью 0,954. По таблице
значений вероятности функции нормального
распределения (см. выдержку из нее,
приведенную в Приложении 1) находим
величину коэффициента доверия t,
соответствующего вероятности 0,954. При
вероятности 0,954 коэффициент t
равен 2.
4. Предельная
ошибка выборки с вероятностью 0,954 равна
![]()
5. Найдем доверительные
границы для среднего значения уровня
фондоотдачи в генеральной совокупности
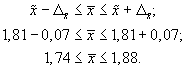
Таким образом, в
954 случаях из 1000 среднее значение
фондоотдачи будет не выше 1,88 руб. и не
ниже 1,74 руб.
Выше была
использована повторная схема случайного
отбора. Посмотрим, изменятся ли результаты
обследования, если предположить, что
отбор осуществлялся по схеме бесповторного
отбора. В этом случае расчет средней
ошибки проводится по формуле
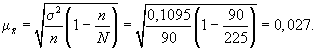
Тогда при вероятности
равной 0,954 величина предельной ошибки
выборки составит:
![]()
Доверительные
границы для среднего значения признака
при бесповторном случайном отборе будут
иметь следующие значения:
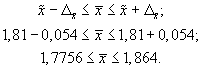
Сравнив результаты
двух схем отбора, можно сделать вывод
о том, что применение бесповторной
случайной выборки дает более точные
результаты по сравнению с применением
повторного отбора при одной и той же
доверительной вероятности. При этом,
чем больше объем выборки, тем существеннее
сужаются границы значений средней при
переходе от одной схемы отбора к другой.
По данным примера
определим, в каких границах находится
доля предприятий с уровнем фондоотдачи,
не превышающим значения 2,0 руб., в
генеральной совокупности:
1) рассчитаем
выборочную долю.
Количество
предприятий в выборке с уровнем
фондоотдачи, не превышающим значения
2,0 руб., составляет 60 единиц. Тогда
m
60, n
90, w
m/n
60 : 90
0,667;
2) рассчитаем
дисперсию доли в выборочной совокупности
w2
w(1
w)
0,667(1
0,667)
0,222;
3) средняя ошибка
выборки при использовании повторной
схемы отбора составит
![]()
Если предположить,
что была использована бесповторная
схема отбора, то средняя ошибка выборки
с учетом поправки на конечность
совокупности составит
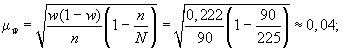
4) зададим
доверительную вероятность и определим
предельную ошибку выборки.
При значении
вероятности Р
0,997 по таблице нормального распределения
получаем значение для коэффициента
доверия t
3 (см. выдержку из нее, приведенную в
Приложении 1):
![]()
5) установим границы
для генеральной доли с вероятностью
0,997:

Таким образом, с
вероятностью 0,997 можно утверждать, что
в генеральной совокупности доля
предприятий с уровнем фондоотдачи, не
превышающим значения 2,0 руб., не меньше,
чем 54,7%, и не больше 78,7%.
2. Типическая
выборка. При
типической выборке генеральная
совокупность объектов разбита на k
групп, тогда
N1
N2
…
Ni
…
Nk
N.
Объем извлекаемых
из каждой типической группы единиц
зависит от принятого способа отбора;
их общее количество образует необходимый
объем выборки
n1
n2
…
ni
…
nk
n.
Существуют
следующие два способа организации
отбора внутри типической группы:
пропорциональной объему типических
групп и пропорциональной степени
колеблемости значений признака у единиц
наблюдения в группах. Рассмотрим первый
из них, как наиболее часто используемый.
Отбор, пропорциональный
объему типических групп, предполагает,
что в каждой из них будет отобрано
следующее число единиц совокупности:
![]()
где ni
количество извлекаемых единиц для
выборки из i-й
типической группы;
n
общий объем выборки;
Ni
количество единиц генеральной
совокупности, составивших i-ю
типическую группу;
N
общее количество единиц генеральной
совокупности.
Отбор единиц
внутри групп происходит в виде случайной
или механической выборки.
Формулы для
оценивания средней ошибки выборки для
среднего и доли представлены в табл.
11.2.
Таблица 2
Формулы для
расчета средней ошибки выборки ()
при использовании типического отбора,
пропорционального объему типических
групп
Здесь
![]()
средняя из групповых дисперсий типических
групп.
Пример 3. В
одном из московских вузов проведено
выборочное обследование студентов с
целью определения показателя средней
посещаемости вузовской библиотеки
одним студентом за семестр. Для этого
была использована 5%-ная бесповторная
типическая выборка, типические группы
которой соответствуют номеру курса.
При отборе, пропорциональном объему
типических групп, получены следующие
данные:
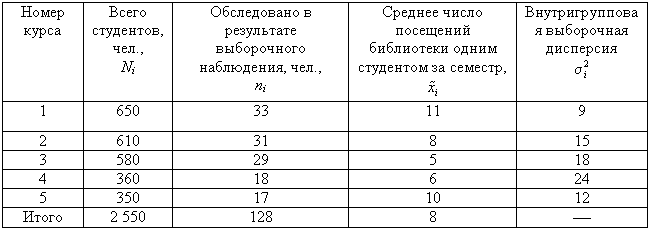
Число студентов,
которое необходимо обследовать на
каждом курсе, рассчитаем следующим
образом:
общий объем
выборочной совокупности:
![]()
количество
единиц, отобранных из каждой типической
группы:
![]()
аналогично для
других групп:
п2
31 (чел.);
п3
29 (чел.);
п4
18 (чел.);
п5
17 (чел.).
Проведем необходимые
расчеты.
1. Выборочная
средняя, исходя из значений средних
типических групп, составит:

2. Средняя из
внутригрупповых дисперсий
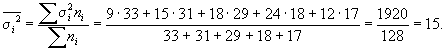
3. Средняя ошибка
выборки:
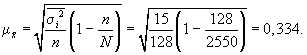
С вероятностью
0,954 находим предельную ошибку выборки:
![]()
4. Доверительные
границы для среднего значения признака
в генеральной совокупности:
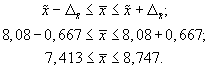
Таким образом, с
вероятностью 0,954 можно утверждать, что
один студент за семестр посещает
вузовскую библиотеку в среднем от семи
до девяти раз.
3.
Малая выборка. В
связи с небольшим объемом выборочной
совокупности
те формулы для определения ошибок
выборки,
которые использовались нами ранее при
«больших» выборках, становятся
неподходящими и требуют корректировки.
Среднюю ошибку
малой выборки
определяют по формуле
![]()
Предельная
ошибка малой выборки:
![]()
Распределение
значений выборочных средних всегда
имеет нормальный закон распределения
(или приближается к нему) при п
100, независимо от характера распределения
генеральной
совокупности.
Однако в случае малых выборок действует
иной закон распределения
распределение Стьюдента.
В этом случае коэффициент доверия
находится по таблице t-распределения
Стьюдента в зависимости от величины
доверительной вероятности Р
и объема выборки п.
В Приложении
1
приводится фрагмент таблицы t-распределения
Стьюдента, представленной в виде
зависимости доверительной вероятности
от объема выборки и коэффициента доверия
t.
Пример 4.
Предположим,
что выборочное обследование восьми
студентов академии показало, что на
подготовку к контрольной работе по
статистике они затратили следующее
количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4;
6,6.
Оценим выборочные
средние затраты времени и построим
доверительный интервал для среднего
значения признака в генеральной
совокупности, приняв доверительную
вероятность равной 0,95.
1. Среднее значение
признака в выборке равно
![]()
2. Значение среднего
квадратического отклонения составляет
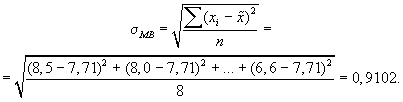
3. Средняя ошибка
выборки:
![]()
4. Значение
коэффициента доверия t
2,365 для п
8 и Р
0,95 (Приложение 1).
5. Предельная
ошибка выборки:
![]()
6. Доверительный
интервал для среднего значения признака
в генеральной совокупности:
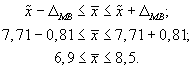
То есть с вероятностью
0,95 можно утверждать, что затраты времени
студента на подготовку к контрольной
работе находятся в пределах от 6,9 до 8,5
ч.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
 Приведенная ниже формула для расчета объема выборки используется в тех случаях, когда опрашиваемым (респондентам) задается только один вопрос, на который существует только два варианта ответа. Например: «Да» и «Нет», «Покупаю» и «Не покупаю», «Пользуюсь» и «Не пользуюсь». Конечно, данную формулу можно применять только при проведении простейших исследований. Если Вам нужно определить объем выборочной совокупности при проведении более масштабных исследований, например анкетирования, то следует использовать другие формулы.
Приведенная ниже формула для расчета объема выборки используется в тех случаях, когда опрашиваемым (респондентам) задается только один вопрос, на который существует только два варианта ответа. Например: «Да» и «Нет», «Покупаю» и «Не покупаю», «Пользуюсь» и «Не пользуюсь». Конечно, данную формулу можно применять только при проведении простейших исследований. Если Вам нужно определить объем выборочной совокупности при проведении более масштабных исследований, например анкетирования, то следует использовать другие формулы.
Содержание:
- формула с пояснениями;
- пример расчета объема выборки;
- нормированное отклонение (таблица);
- область применения;
- особенности формулы.
Простая формула для расчета объема выборки
Ниже приведена простая формула для расчета объема выборки для тех случаев когда на заданный вопрос возможны лишь два варианта ответа:

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности (доверительного интервала, доверительной вероятности).
Этот показатель характеризует вероятность попадания ответов в специальный доверительный интервал — диапазон, границам которого соответствует определенный процент определенных ответов на некоторый вопрос.
Можно сказать, что уровень доверительности выражает вероятность того, что респонденты генеральной совокупности ответят так же, как и представители анализируемой выборки.
На практике доверительный интервал при проведении маркетинговых исследований часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58.
Также существует специальная таблица «Значение интеграла вероятностей», используя которую можно найти значение z для различных доверительных интервалов. Сокращенный вариант такой таблицы приведен ниже;
p – вариация для выборки, в долях.
Вариация характеризует величину схожести / несхожести ответов респондентов на вопрос. По сути, p — вероятность того, что респонденты выберут той или иной вариант ответа.
Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = 1 — p.
Можно сказать, что q — это вероятность того, что респонденты не выберут анализируемый вариант ответа (в нашем примере ответят «Нет»). Например, если p = 0,25, то q = 1 — 0,25 = 0,75;
e – допустимая ошибка, в долях.
Значение допустимой ошибки заранее определяют исследователь и заказчик маркетингового исследования.
Пример расчета объема выборочной совокупности
Маркетинговая компания получила заказ на проведение социологического исследования с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95% (одно из стандартных значений для маркетинговых исследований), тогда нормированное отклонение z = 1,96. Проведя предварительный анализ населения города, вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они — «Да». Тогда p = 0,5. Отсюда находим q = 1 – p = 1 – 0,5 = 0,5. исходя из требуемой заказчиком точности, допустимую ошибку выборки принимаем за 10%, то есть e = 0,1.
Подставляем эти данные в формулу и считаем:

Округлив расчетное значение, получаем объем выборки n = 96 человек.
Следовательно, для проведения исследования с заданными параметрами (уровень доверительности, допустимая ошибка) компании необходимо опросить 96 человек.
Значение нормированного отклонения для различных доверительных интервалов
В таблице приведены некоторые значения нормированного отклонения (z) для важнейших уровней доверительности, или, иначе, доверительной вероятности (α):
| α (%) | 60 | 70 | 80 | 85 | 90 | 95 | 97 | 99 | 99,7 |
|---|---|---|---|---|---|---|---|---|---|
| z | 0,84 | 1,03 | 1,29 | 1,44 | 1,65 | 1,96 | 2,18 | 2,58 | 3,0 |
Конечно, в таблице приведены значения z только для основных уровней доверительности. Полную версию таблицы можно найти в интернете.
Область применения простой формулы выборки
При проведении простых исследований, когда нужно получить ответ всего на один простой вопрос. При этом шкала ответов, как правило, дихотомического характера. То есть предлагаются (или подразумеваются) варианты ответов по типу «Да» — «Нет», «Черное» — «Белое», «Куплю» — «Не куплю», и т. д. Иными словами возможны лишь два варианта ответа на заданный вопрос.
Особенности формулы расчета размера выборки
Для рассмотренной нами простой формулы определения объема выборки можно выделить несколько характерных особенностей:
- перед тем, как рассчитывать объем выборки в данном случае желательно предварительно провести качественный анализ изучаемой генеральной совокупности. В частности установить степень схожести, близости изучаемых единиц совокупности в части их социальных, демографических, географических, иных характеристик. Также полезно провести пилотное (разведочное) исследование, чтобы установить приблизительную величину p;
- нужно иметь в виду, что максимальная изменчивость (вариация ответов) соответствует значению p = 50%, так как тогда q = 50% и p × q = 0,5 × 0,5 = 0,25. Это наихудший случай, все другие значения p дадут изменчивость меньшего размера (например, при p = 80%, p × q = 0,8 × 0,2 = 0,16; а при p = 10%, p × q = 0,1 × 0,9 = 0,09). Впрочем, данный показатель влияет на объем выборки не очень сильно.
Также стоит отметить, что существует ряд иных формул для определения объема выборки в случаях с дихотомической шкалой ответов на единственный вопрос. Для более сложных маркетинговых исследований применяются другие формулы.
Источники
- Голубков Е. П. Маркетинговые исследования: теория, методология и практика. — М.: Издательство «Финпресс», 1998.
Статья дополнена и доработана автором 10 дек 2020 г.
© Копирование любых материалов статьи допустимо только при указании прямой индексируемой ссылки на источник: Галяутдинов Р.Р.
Нашли опечатку? Помогите сделать статью лучше! Выделите орфографическую ошибку мышью и нажмите Ctrl + Enter.
Библиографическая запись для цитирования статьи по ГОСТ Р 7.0.5-2008:
Галяутдинов Р.Р. Формула выборки — простая // Сайт преподавателя экономики. [2020]. URL: http://galyautdinov.ru/post/formula-vyborki-prostaya (дата обращения: 29.01.2023).
Введение
Все, что сказано в этом введении, запоминать не нужно. это справочный материал, к которому вы будете обращаться при выполнении лабораторных работ.
1. Как определять погрешности измерений
Выполнение лабораторных работ связано с измерением различных физических величин и последующей обработкой их результатов.
Измерение — нахождение значения физической величины опытным путем с помощью средств измерений.
Прямое измерение — определение значения физической величины непосредственно средствами измерения.
Косвенное измерение — определение значения физической величины по формуле, связывающей ее с другими физическими величинами, определяемыми прямыми измерениями.
Введем следующие обозначения:
A, B, C, … — физические величины.
Aпр — приближенное значение физической величины, т.е. значение, полученное путем прямых или косвенных измерений.
ΔA — абсолютная погрешность измерения физической величины.
ε — относительная погрешность измерения физической величины, равная:
ΔиA — абсолютная инструментальная погрешность, определяемая конструкцией прибора (погрешность средств измерения; указывается в каждой работе при описании прибора в разделе Оборудование и средства измерения)
ΔоA — абсолютная погрешность отсчета (получающаяся от недостаточно точного отсчета показаний средств измерения), она равна в большинстве случаев половине цены деления; при измерении времени — цене деления секундомера или часов.
Максимальная абсолютная погрешность прямых измерений складывается из абсолютной инструментальной погрешности и абсолютной погрешности отсчета при отсутствии других погрешностей:
ΔA=ΔиA + ΔоA
Абсолютную погрешность измерения обычно округляют до одной значащей цифры (ΔA≈0,17=0,2); численное значение результата измерений округляют так, чтобы его последняя цифра оказалась в том же разряде, что и цифра погрешности (А=10,332≈10,3).
Результаты повторных измерений физической величины А, проведенных при одних и тех же контролируемых условиях и при использовании достаточно чувствительных и точных (с малыми погрешностями) средств измерения, отличаются друг от друга.
В этом случае Aпр находят как среднее арифметическое значение всех измерений, а ΔA (ее в этом случае называют случайной погрешностью) определяют методами математической статистики.
В школьной лабораторной практике такие средства измерения практически не используются. Поэтому при выполнении лабораторных работ необходимо определять максимальные погрешности измерения физических величин. При этом для получения результата достаточно одного измерения.
Относительная погрешность косвенных измерений определяется, как показано в таблице 1.
Абсолютная погрешность косвенных измерений определяется по формуле ΔA=Aпрε (ε выражается десятичной дробью).
Таблица 1
Формулы для нахождения относительной погрешности косвенных измерений
| Nº п/п | Формула физической величины | Формула относительной погрешности |
|---|---|---|
| 1 | ||
| 2 | ||
| 3 |
A=B+C |
|
| 4 |
2. О классе точности электроизмерительных приборов
Для определения абсолютной инструментальной погрешности прибора надо знать его класс точности. Класс точности γпр измерительного прибора показывает, сколько процентов составляет абсолютная инструментальная погрешность ΔиA от всей шкалы прибора (Amax):
Класс точности указывается при описании прибора в разделе Оборудование и средства измерения. Cуществуют следующие классы точности электроизмерительных приборов: 0,1; 0,2; 0,5; 1; 1,5; 2,5; 4. Зная класс точности прибора (γпр) и всю его шкалу (Amax), определяют абсолютную погрешность ΔиA измерения физической величины А этим прибором:
3. Как сравнивать результаты измерений
1. Записать результаты измерений в виде двойных неравенств:
A1 пр – ΔA1 < A1 пр < A1 пр + ΔA1
A2 пр – ΔA2 < A2 пр < A2 пр + ΔA2
2. Сравнить полученные интервалы значений (рис.1): если интервалы не перекрываются, то результаты неодинаковы, если перекрываются — одинаковы при данной относительной погрешности измерений.
 Рисунок 1.
Рисунок 1.
4. Как оформлять отчет о проделанной работе
Отчетом о проделанной работе является форма, находящаяся в левом нижнем окне. После ее заполнения надо нажать на кнопку «Отправить результаты на сервер».
Значения измеренных физических величин переносятся в таблицу результатов автоматически после нажатия соответствующей кнопки.
Значения остальных величин и ответ на контрольный вопрос вводятся с клавиатуры.
домашней странице BARSIC
Расчёт ошибок косвенных измерений
Пусть искомая
величина Апри выбранном
методе косвенных измерений рассчитывается
по формуле:
A
= f(x1
,x2
,x3
,…,xn
) (12)
где x1,x2,…,xn
— величины, найденные в результате прямых
измерений, с учётом ошибок о которых
шла речь выше. Из-за этих ошибок величина
«А»
так же будет определяться с ошибками.
Пусть X1,X2,…,XN
— значения f(x1
,x2
,x3
,…,xn), вычисленные
для разных серий измерений (x1,x2,…,xn).
Таблица 1
Таблица коэффициентов
Стьюдента
|
Число измерений |
Доверительная |
|||||
|
0.7 |
0.8 |
0.9 |
0.95 |
0.99 |
0.999 |
|
|
2 |
2.0 |
3.1 |
6.3 |
12.7 |
63.7 |
636.6 |
|
3 |
1.3 |
1.9 |
2.9 |
4.3 |
9.9 |
31.6 |
|
4 |
1.3 |
1.6 |
2.4 |
3.2 |
5.8 |
12.9 |
|
5 |
1.2 |
1.5 |
2.1 |
2.8 |
4.6 |
8.6 |
|
10 |
1.1 |
1.4 |
1.8 |
2.3 |
3.3 |
4.8 |
|
15 |
1.1 |
1.3 |
1.8 |
2.1 |
3.0 |
4.1 |
|
20 |
1.1 |
1.3 |
1.7 |
2.1 |
2.9 |
3.9 |
Абсолютной ошибкой
косвенных измерений, по аналогии с
абсолютной ошибкой прямых измерений,
называют разность между истинным
значением «А» и её значениями,
полученными в результате измерений:
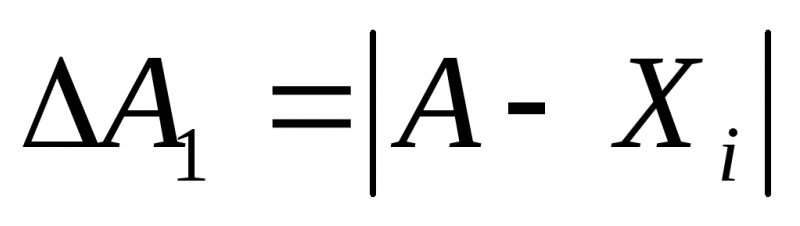 (13)
(13)
Размерность
абсолютной ошибки совпадает с размерностью
определяемой величины. Относительной
ошибкой косвенных измерений называют
отвлечённое число:
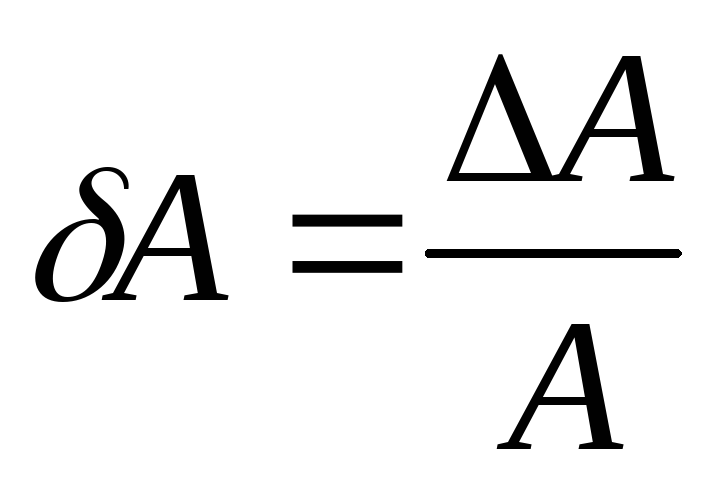 (14)
(14)
Иногда относительную
ошибку выражают в процентах:
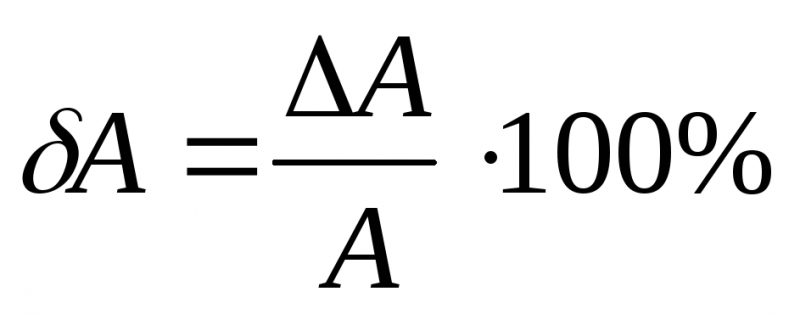 (15)
(15)
Для определения
величины «А» в формулах (12)…(15) по
теории
вероятностей
следует брать величину Х, которую можно
определить двумя способами:
1) А
= Х
= (Х1
+ Х2
+…+Хn)/n
(16)
2) A
= X
= f(x1
+ x2
+…+xn)
(17)
где x1,x2
,…, xn
определяют по формуле (3). Если ошибки
измерений малы, то оба способа дают
практически тождественные результаты.
Рассмотрим способы
нахождения ошибки величины А,
определённой из косвенных измерений,
по найденным значениям оши
бок прямых измерений.
Выше отмечалось, что возможны различные
соотношения между приборной систематической
и случайными ошибками.
1-й случай. Преобладают
приборные ошибки. В этом случае можно
дать только оценку максимальной ошибки.
Формулы для нахождения предельной
ошибки косвенных измерений по внешнему
виду совпадают с формулами дифференциального
исчисления. В связи с этим для предельной
абсолютной ошибки используется формула:
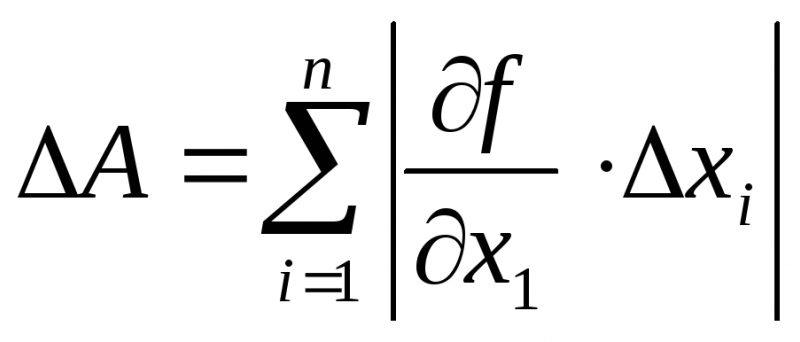 (18)
(18)
а для расчёта
предельной относительной ошибки пригодна
фор
— 19 —
мула:
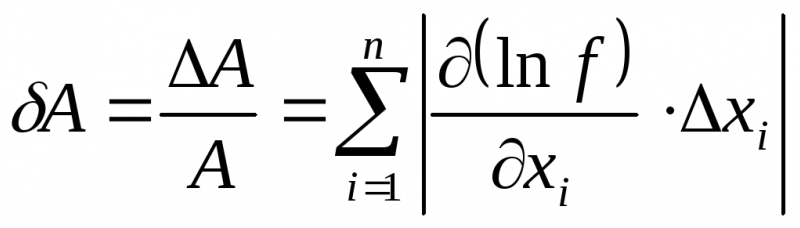 (19)
(19)
Формулы для расчёта
предельных ошибок некоторых часто
встречающихся функций, когда приборные
ошибки превышают случайные, приведены
в Таблице 2. Эти выражения легко
рассчитываются по формулам (18) и (19).
2-й случай. Преобладают
случайные ошибки. Для определения
среднеквадратичной ошибки теория
вероятностей даёт следующую формулу:
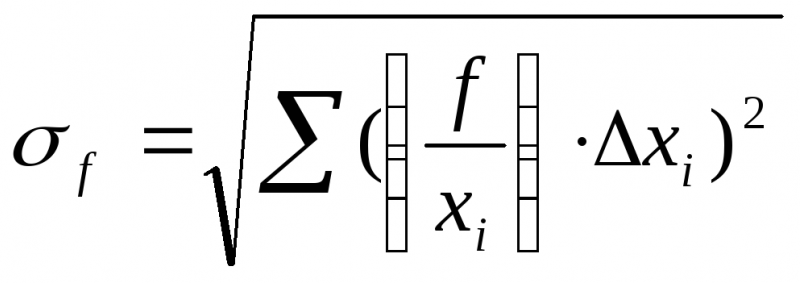 (20)
(20)
Относительная
ошибка вычисляется по формуле:
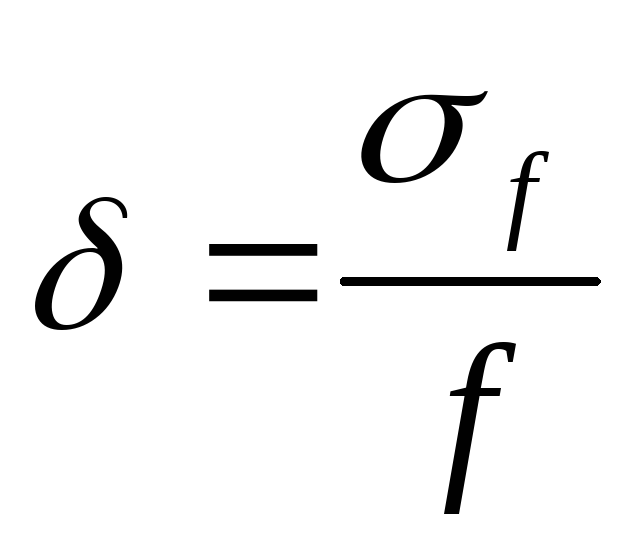 (21)
(21)
При выполнении
промежуточных расчётов необходимо
помнить, что число точных цифр в результате
расчётов не может увеличиваться. Поэтому
промежуточные результаты округляют,
сохраняя
1…2 избыточных
знака. При этом последующие цифры,
меньшие
5,отбрасываются;если
первая из отбрасываемых цифр больше 5,
то последняя из
оставшихся цифр увеличивается на
единицу. Ес
ли первая
отбрасываемая цифра 5, то предыдущая
цифра остаётся
без изменений,
если она чётная, и увеличивается на
единицу, если
она нечётная.
Выражения для среднеквадратичной ошибки
некоторых часто встречающихся функций
приведены в Таблице 3. Для определения
ошибок косвенных измерений используют
большую из инструментальной или случайной
ошибок прямого измерения.
Методики расчета
Существует несколько методов определения отклонения. Наиболее простой и доступный способ:
Необходимые измерения проводят не менее 5 раз. Это дает возможность вычислить наиболее точное значение параметра. Результаты вносят в таблицу excel.
Полученные величины складывают и делят на количество замеров. В результате получится действительное значение. Его обычно применяют вместо истинного, так как нет возможности вычислить последнее.
Следующий шаг — определение абсолютной погрешности. Ее считают для каждого измерения. Чтобы узнать величину этого показателя, из результата каждого замера вычитают действительное значение
Для обработки данных неважно, положительная или отрицательная получилась цифра. Используют модули полученных чисел, пренебрегая знаками.
Чтобы определить относительную погрешность измерения, нужно разделить абсолютную на действительное значение
Полученное число умножают на 100%.
Для определения предельного отклонения выбирают наибольшее значение из всех полученных.
Чтобы получить наиболее точные показатели дискретности цифровых приборов, пользуются средним квадратическим отклонением. Вычислить его можно следующим способом:
- Каждый показатель абсолютной погрешности возводят в квадрат и записывают.
- Полученные результаты складывают между собой.
- Сумму всех квадратов делят на число, которое на единицу меньше количества измерений.
- Из результата вычислений извлекают квадратный корень — это и будет среднее квадратическое отклонение.
Чтобы вычислить, чему равна относительная погрешность измерения, важно придерживаться некоторых правил. Складывая или вычитая числа, учитывают абсолютные отклонения
Если числа нужно разделить или перемножить, прибегают к относительным показателям. Возведение числа в степень требует умножить относительную погрешность на показатель этой степени.
Результаты фиксируются в виде десятичных дробей. Точное значение может быть очень длинным, вплоть до бесконечного. Для удобства используют только среднее значение
При этом важно помнить о существовании верных и сомнительных цифр. У первой категории цифр разряд бывает выше допустимой погрешности, у второй — ниже.
При расчете относительной погрешности измерения времени формула включает в себя отношение среднего отклонения к среднему значению времени, умноженное на 100%. Эта же закономерность применяется для оценки температуры и других физических величин.
а a изм аист ед.изм. 4
Это
размерная, положительная величина, характеризующая отклонение измеренного от
истинного значений.
Относительная погрешность – это
отношение абсолютной погрешности к истинному значению измеряемой величины.
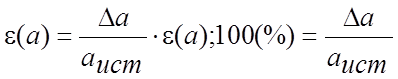 (5)
(5)
Относительная
погрешность (5) – безразмерная величина, она измеряется в долях или процентах и
показывает какую часть от истинного значения измеряемой величины составляет
погрешность.
На
практике вместо неизвестного истинного значения используют среднее значение
измеряемой величины.
Формула (5) позволяет по
известной одной из характеристик определить другую. Часто вначале удобнее найти
относительную, а через неё абсолютную.
Если
измерение выполнено и погрешности определены, то окончательный результат
записывается в виде
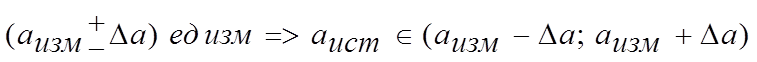 . (6)
. (6)
что эквивалентно заданию
интервала, в котором лежит истинное значение искомой величины. И чем уже данный
интервал, тем точнее измерения и наоборот.
4.
Вычисление погрешностей.
За
абсолютную погрешность однократно измеряемой величины применяют приборную
погрешность.
Для
простых измерительных и цифровых приборов приборная погрешностьравная
половине цены деления прибора.
. (7)
Например:
приборная погрешность
миллиметровой линейки (с=1 мм/дел) равна, Δапр
= 0,5 мм.
штангенциркуля (с=0,05 мм/дел) – Δапр
= 0,025 мм.
эл.
секундомера (с=0,001 с/дел) – Δапр
= 0,0005 с.
Для
стрелочных электроизмерительных приборов приборная погрешность определятся
через класс точности прибора (характеристика прибора указанная на его
шкале).
,
(8)
представляющая
собой отношение приборной погрешности к максимальному значению измеряемой
прибором величины. Из (8) для приборной погрешности стрелочных
электроизмерительных приборов получаем:
ΔАприб. = 0,01 · К · Аmax
.
(9)
Часто
в расчетах приходится использовать физические и математические постоянные,
которые как правило выражаются сложными десятичными дробями
(π=
3.141593… , е = 2.718282… , с = 2.99792… · 108 м/с
qe =
1,60219… · 10-19 Kл , mе =
1.67265… · 10-31к2 и т.д.).
При
использовании постоянных мы вынуждены их округлять т.е. брать приближённые
значения, это также даёт вклад в погрешность. К погрешностям табличных величин
относятся так же как и к приборным.
За
погрешность табличной величины принимают половину единицы последнего разряда
табличной величины, выбранной с заданной точностью.
Например; при определении
плотности тела цилиндрической формы необходимо использовать число π.
Предварительно оговаривается точность расчётов (например вычисления проводят с
точностью до
четырёх значащих цифр).
Тогда используемое число π и погрешность Δπ соответственно будут равны:
π =
3.142, Δπ = 0.0005
и окончательная запись числа
π с погрешностью имеет вид:
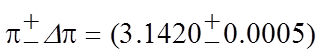
б)
Погрешности многократно измеряемых величин.
Погрешности
многократных измерений в рамках линейной теории оцениваются по следующей схеме
Что такое погрешность?
Представьте, что вас отправили в магазин купить сахар, но вот незадача: фасованный в пачках как раз закончился и остался только на развес. Что делать, вы просите продавца тогда отмерить вам ровно килограмм. Продавец взял лопатку, наполнил пакет, положил его на весы, и они выдают значение — 1.000 кг.
Как удачно положили.
Вы рассчитываетесь и счастливым возвращаетесь домой. А теперь представим, что по необыкновенной случайности у вас дома имеются весы, показывающие массу с точностью до миллиграмма. Вы решаете интереса ради перевесить пакет, чтобы посмотреть, действительно ли его масса равна строго килограмму.
И какого же удивление, когда более точные весы показывают массу не в 1.000 кг, а в 0.999990 кг. Иными словами, вас обсчитали. Обсчитали, между прочим, на десять миллиграмм!
Чем меньше цена деления прибора, тем точнее измерение. Ваши весы с учетом массы до миллиграмма оказались точнее магазинных «граммовых» весов. Однако и это не предел, ведь существуют фармакологические весы, определяющие массу до микрограмма — одной миллиардной килограмма. Так можно продолжать до бесконечности, пока у нас не закончатся технологические возможности сконструировать еще более точные весы.
Однако все измерительные приборы, пусть и самые точные, несовершенны. Несовершенно даже само то, как мы видим, слышим и ощущаем мир вокруг. Это, наряду с прочими факторами, приводит к тому, что при измерении величины получается ее приближенное значение, не истинное.
Разница между приближенным и истинным значениями и называется погрешностью.
Важно. Погрешность не равно ошибке
В обычном, бытовом языке мы привыкли к тому, что слово «погрешность» у нас ассоциируется с просчетом или упущением.
В физике погрешность — обыденное явление, присутствующее внутри практически каждой величины, и мало что имеет общего с ошибкой в привычном понимании слова.
Все величины, которые, к примеру, вы видите в типовых физических задачах на вычисление, так или иначе содержат погрешность. Ее не обозначают для удобства. Поэтому помните о невозможности проводить эксперименты в идеальных условиях и о том, что ни один прибор чаще всего не сможет показать результат таким, каков он есть на самом деле.
Как правило, при однократном проведении измерения определить значение погрешности крайне затруднительно: для ее выявления обычно проводят серию равноточных измерений — измерений, произведенных в одинаковых условиях.
После результаты сличаются, то есть сравниваются между собой и, при необходимости, сопоставляются с различными экспериментальными величинами. На основе данных, полученных в результате измерений и сличения, вычисляется погрешность.
ПОГРЕШНОСТИ ИЗМЕРЕНИЙ
При многократном измерении одной и той же величины каждый раз получают несколько отличающиеся результаты, как по абсолютной величине, так и по знакам, каким бы опытом не обладал исполнитель и какими бы высокоточными приборами он не пользовался.
Погрешности различают: грубые, систематические и случайные.
Появление грубых погрешностей (промахов) связано с серьезными ошибками при производстве измерительных работ. Эти ошибки легко выявляются и устраняются в результате контроля измерений.Систематические погрешностивходят в каждый результат измерений по строго определенному закону. Они обусловлены влиянием конструкции измерительных приборов, погрешностями градуировки их шкал, износом и т. д. (инструментальные погрешности)иливозникают из-за недоучета условий измерений и закономерностей их изменений, приближенности некоторых формул и др. (методические погрешности). Систематические погрешности делятся на постоянные (неизменные по знаку и вели чине) и переменные (изменяющие свою величину от одного измерения к другому по определенному закону).
Такие погрешности заранее определимы и могут быть сведены к необходимому минимуму путем введения соответствующих поправок.Например, заранее может быть учтено влияние кривизны Земли на точность определения вертикальных расстояний, влияние температуры воздуха и атмосферного давления при определении длин линий светодальномерами или электронными тахеометрами, заранее можно учесть влияние рефракции атмосферы и т. д.
Если не допускать грубых погрешностей и устранять систематические, то качество измерений будет определяться только случайными погрешностями. Эти погрешности неустранимы, однако их поведение подчиняется законам больших чисел. Их можно анализировать, контролировать и сводить к необходимому минимуму.
Для уменьшения влияния случайных погрешностей на результаты измерений прибегают к многократным измерениям, к улучшению условий работы, выбирают более совершенные приборы, методы измерений и осуществляют тщательное их производство.
Сопоставляя ряды случайных погрешностей равноточных измерений можно обнаружить, что они обладают следующими свойствами:
а) для данного вида и условий измерений случайные погрешности не могут превышать по абсолютной величине некоторого предела;
б) малые по абсолютной величине погрешности появляются чаще больших;
в) положительные погрешности появляются так же часто, как и равные им по абсолютной величине отрицательные;
г) среднее арифметическое из случайных погрешностей одной и той же величины стремится к нулю при неограниченном увеличении числа измерений.
Распределение ошибок, соответствующее указанным свойствам, называется нормальным (рис. 12.1).
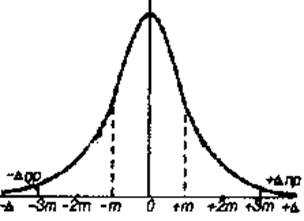 Рис. 12.1. Кривая нормального распределения случайных погрешностей Гаусса
Рис. 12.1. Кривая нормального распределения случайных погрешностей Гаусса
Разность между результатом измерения некоторой величины (l) и ее истинным значением (X) называют абсолютной (истинной) погрешностью.
Δ = l — X
Истинное (абсолютно точное) значение измеряемой величины получить невозможно, даже используя приборы самой высокой точности и самую совершенную методику измерений. Лишь в отдельных случаях может быть известно теоретическое значение величины. Накопление погрешностей приводит к образованию расхождений между результатами измерений и действительными их значениями.Разность суммы практически измеренных (или вычисленных) величин и теоретического ее значения называется невязкой. Например, теоретическая сумма углов в плоском треугольнике равна 180º, а сумма измеренных углов оказалась равной 180º02′; тогда погрешность суммы измеренных углов составит +0º02′. Эта погрешность будет угловой невязкой треугольника.
Абсолютная погрешность не является, полным показателем точности выполненных работ. Например, если некоторая линия, фактическая длина которой составляет 1000 м, измерена землемерной лентой с ошибкой 0,5 м, а отрезок длиною 200 м – с ошибкой 0,2 м, то, несмотря на то, что абсолютная погрешность первого измерения больше второго, все же первое измерение было выполнено с точностью в два раза более высокой. Поэтому вводят понятие относительной погрешности:
Отношение абсолютной погрешности измеряемой величины Δ к измеренной величине l называют относительной погрешностью.
Относительные погрешности всегда выражаются дробью с числителем, равным единице (аликвотная дробь). Так, в приведенном выше примере относительная погрешность первого измерения составляет
,
а второго
30 Поверка и калибровка си. Определения. Правовые основы.
В
соответствии с законом РК «Об обеспечении
единства измерений» введены следующие
понятия:
— поверка
средства измерений —
совокупность операций, выполняемых
органами Государственной метрологической
службы (другими уполномоченными на то
органами, организациями) с целью
определения и подтверждения соответствия
средства измерений установленным
требованиям;
— калибровка
средств измерений —
совокупность операций, выполняемых с
целью определения и подтверждения
действительных значений метрологических
характеристик и/или пригодности к
применению средства измерений, не
подлежащего государственному
метрологическому контролю и надзору.
В
обоих случаях, как при поверке, так и
при калибровке, определяются метрологические
характеристики средств измерений,
причем часто по одной и той же методике,
называемой методикой
поверки,
но на этом их сходство заканчивается. Различия
между этими понятиями имеют
более принципиальный характер.
Во-первых,
в сферах распространения ГМКиН могут
применяться только поверенные СИ, а
калиброванные — не могут.
Во-вторых,
поверке могут подвергаться только СИ
утвержденного типа, то есть внесенные
в Государственный реестр СИ, а калибровке
— любые, в том числе нестандартизованные
и изготовленные в одном экземпляре.
В-третьих,
при поверке проверяется соответствие
СИ своему типу, внесенному в Государственный
реестр, тогда как при калибровке
определяются действительные
метрологические характеристики, которые
прибор имеет на момент калибровки.
Если
при поверке СИ обнаружено его несоответствие
хотя бы одному пункту утвержденного
типа, средство измерений должно быть
забраковано. При калибровке этому СИ
будут приписаны новые значения
метрологических характеристик.
Положительные
результаты поверки удостоверяются
поверительным клеймом или свидетельством
о поверке. Если средство измерений по
результатам поверки признано непригодным
к применению, оттиск поверительного
клейма и свидетельство о поверке
аннулируются и выписывается извещение
о непригодности или делаются соответствующие
записи в технической документации.
Результаты
калибровки удостоверяются калибровочным
знаком (клеймом), наносимым на средство
измерений, или сертификатом о калибровке,
а также, записью в эксплуатационных
документах. В соответствии с законом
РК «Об обеспечении единства измерений»
калибровка средств измерений является
процедурой добровольной и осуществляемой
по желанию владельца прибора с целью,
например, получения достоверных
результатов измерений, влияющих, в
конечном счете, на результаты труда.
ГМКиН на такие средства измерений не
распространяется.
Абсолютная погрешность — измерительный прибор
Абсолютная погрешность измерительного прибора представляет собой расхождение ( разность) между измеренным Ли и действительным ( истинным) Лд значениями измеряемой величины ДЛ — / 4н — Ац. Истинное значение измеряемой величины находят с учетом поправки. Поправка — это величина, обратная по знаку абсолютной погрешности: ДР — ДЛ Ал-А. Абсолютная погрешность электроизмерительных приборов со стрелочным показателем практически неизменна в пределах всей шкалы, поэтому с уменьшением значения измеряемой величины она возрастает. Для повышения точности измерения измеряемой величины на показывающих приборах со стрелочным указателем следует выбирать такие пределы измерения, чтобы отсчитывать показания примерно в пределах 2 / 3 всей шкалы.
Абсолютная погрешность измерительного прибора равна разности между показанием прибора и действительным ( точным) значением измеряемой величины.
Абсолютная погрешность измерительного прибора определяется разностью между показанием прибора и истинным значением измеряемой величины. Погрешность показаний прибора имеет своими источниками погрешности отдельных его элементов: чувствительного элемента, передаточного механизма и шкалы. Погрешность чувствительного элемента заключается в том, что действительная зависимость его перемещений от измеряемой величины не совпадает с расчетной, заложенной в схему прибора. Погрешность шкалы складывается из ошибки положения ее штрихов и эксцентриситета шкалы.
Абсолютной погрешностью измерительного прибора называется разность между его показанием и истинным значением измеряемой величины. Так как истинное значение измеряемой величины установить нельзя, в измерительной технике используется так называемое действительное значение, полученное с помощью образцового прибора.
Абсолютной погрешностью измерительного прибора называется разность между его показанием и истинным значением измеряемой величины. Поскольку последнее установить нельзя, то в измерительной технике используют так называемое действительное значение, полученное посредством образцового прибора.
Абсолютной погрешностью измерительного прибора называется разность между его показанием и истинным значением измеряемой величины Так как величину истинного значения измеряемой величины установить нельзя, в измерительной технике используется так называемое действительное значение, полученное с помощью образцового прибора.
Приведенная погрешность измерительного прибора — отношение абсолютной погрешности измерительного прибора к нормирующему значению, выраженное в процентах.
Корректность поставленных экспериментов доказана отсутствием превышения абсолютных ошибок измерения как при определении перемещений, так и напряжений над абсолютной погрешностью используемых измерительных приборов.
В некоторых случаях ( для образцовых и рабочих средств измерений повышенной точности) для исключения систематической погрешности показаний вводят поправку, равную абсолютной погрешности измерительного прибора.
Абсолютная погрешность измерительного прибора определяется разностью между показанием прибора и действительным значением измеряемой величины.
В данном разделе будут рассмотрены виды погрешностей, свойственные мерам, отдельным элементам и устройствам, а также средствам измерений в целом. Под абсолютной погрешностью меры понимают разность ( отклонение от номинального значения) между номинальным значением меры и истинным значением воспроизводимой ею величины. Так как истинное значение величины остается неизвестным, то на практике вместо него используют действительное значение величины. Следует различать абсолютную погрешность измерительного преобразователя по входу и по выходу. Абсолютную погрешность измерительного преобразователя по входу находят как разность между значением величины на входе преобразователя, определяемой в принципе по истинному значению величины на его выходе с помощью градуировочной характеристики, приписанной преобразователю, и истинным значением величины на входе преобразователя. Абсолютную погрешность измерительного преобразователя по выходу находят как разность между истинным значением величины на выходе преобразователя, отображающей измеряемую величину, и значением величины на выходе, определяемой в принципе по истинному значению величины на выходе с помощью градуировочной характеристики, приписанной преобразователю. Относительная погрешность измерительного прибора определяется как отношение абсолютной погрешности измерительного прибора к истинному значению измеряемой им величины.
Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!
Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:
где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).
Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:
Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)
где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.
Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).
Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.
Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.
При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
бюджетное
профессиональное образовательное учреждение Вологодской области «Череповецкий
металлургический колледж имени академика И.П. Бардина»
Для всех специальностей
ОПРЕДЕЛЕНИЕ ОБЪЕМА ТЕЛА С ПОМОЩЬЮ
ИЗМЕРЕНИЙ
И ВЫЧИСЛЕНИЕ ПОГРЕШНОСТЕЙ ИЗМЕРЕНИЙ
Методические рекомендации и лабораторная работа по
дисциплине «Физика» для студентов I курса
Разработчик Изотова
Е.А.,
преподаватель
колледжа
Череповец
2017
Определение объема тела с помощью измерений и
вычисление погрешностей измерений. Методические рекомендации и лабораторная
работа по дисциплине «Физика» для студентов I курса. /Разработчик
Изотова Е.А./ — Череповец: БПОУ ВО «ЧМК» Череповецкий
металлургический колледж, 2017. — 12 с.
РАССМОТРЕНО:
на заседании цикловой
комиссии
«Математические и
естественнонаучные дисциплины»
« » 2017
г., протокол №
председатель ПЦК
__________________
И.А.Масыгина
(подпись)
Содержание
|
1 |
Цель работы |
4 |
|
2 |
Средства обучения |
4 |
|
3 |
Теоретические сведения и |
4 |
|
4 |
Задание ……………………………………………………………………… |
9 |
|
5 |
Ход выполнения лабораторной работы |
9 |
|
6 |
Контрольные вопросы |
11 |
|
7 |
Рекомендации по оформлению отчета |
12 |
|
Литература …………………………………………………………………… |
12 |
Лабораторная работа
Определение объема тела с помощью измерений и вычисление
погрешностей измерений
1 Цель работы
Ознакомиться с методами измерения линейных величин, а
также с методами обработки экспериментальных данных и оценки точности измерений
микрометром, штангенциркулем.
2 Средства обучения
§ лабораторное оборудование: образцы для измерений,
штангенциркуль, микрометр;
§ методические рекомендации по выполнению работы, микрокалькулятор.
3 Теоретические сведения и
методические рекомендации по выполнению лабораторной работы
Любые вычисления, которые приходится
выполнять человеку, должны быть достоверными (безошибочными, хотя в некоторых
случаях и приближенными) и своевременными. Грубая ошибка может привести к
неправильным научным результатам, что может вызвать отрицательные последствия и
нанести огромный материальный ущерб. Достоверность достигается безошибочностью
выполнения математических действий над числами, контролем промежуточных и
окончательных результатов. При выполнении лабораторных работ все значения
величин, кроме постоянных коэффициентов, показателей степеней и других
постоянных, вычисленных с метрологической точностью, являются приближенными.
Поэтому расчеты в лабораторных работах проводятся по правилам приближенных
вычислений с использованием микрокалькуляторов или компьютеров.
При работе с приближенными числами
необходимо соблюдать следующие правила:
1)
при сложении и вычитании
приближенных чисел в конечном результате следует сохранять столько десятичных
знаков, сколько их имеет наименее точное данное (число с наименьшим числом
десятичных знаков);
2)
в результате, полученном
после умножения и деления, следует сохранять столько значащих цифр, сколько их
имеет наименее точное данное;
3)
при возведении
приближенного числа в квадрат и куб следует сохранять в результате столько
значащих цифр, сколько их имеет возводимое в степень приближенное число;
4)
при извлечении квадратного
и кубического корней из приближенного числа следует сохранять столько значащих
цифр, сколько их имеет подкоренное выражение;
5)
при выполнении промежуточных
результатов необходимо брать одной цифрой больше, чем рекомендуют предыдущие
правила.
Ошибки (погрешности), возникающие при
измерениях, объясняются несовершенством методов измерения, измерительных
приборов, условиями опыта. Для повышения степени точности необходимо проводить
минимум три измерения, а затем найти среднее арифметическое (истинное
значение):
![]() ,
,
(1)
где Х ист.
– истинное значение величины;
Х1, Х2, Х3 – измеренные значения
величины.
Разность между истинным значением и измеренным
значением искомой величины называется абсолютной погрешностью.
DХ = |Х ист. –
Х| , (2)
где DХ – абсолютная погрешность величины.
Абсолютная погрешность не в полной
мере характеризует измерения.
Отношение абсолютной погрешности к действительному
значению измеренной величины называется относительной погрешностью измерения:
![]() ,
,
(3)
где ![]() – относительная погрешность величины.
– относительная погрешность величины.
Если истинное значение искомой величины известно, то
для определения погрешностей можно воспользоваться методом среднего
арифметического.
1)
Производят измерение
искомой величины Х несколько раз и среднее арифметическое результатов этих
измерений принимают за истинное значение измеренной величины:
![]() ,
,
(4)
2)
Находят абсолютные
погрешности каждого измерения:
DХ1 =
|X1 – Х ср. | DХ2 =
| Х2 – Х ср. | DХ3
= |Х3 – Х ср. | (5)
Определяют среднее арифметическое этих погрешностей и
принимают его за абсолютную погрешность измерения:
![]() ,
,
(6)
3)
Находят относительную
погрешность:
![]() ,
,
(7)
Измерения могут быть прямыми,
косвенными. Измерения, в которых результат находится непосредственно в
процессе считывания со шкалы прибора, называются прямыми. Измерения,
в которых результат определяется на основе расчетов, называются косвенными.
При косвенных измерениях искомой величины погрешности можно определить
следующими методами.
1) Способ оценки результатов.
Погрешность вычисляют по формулам теории приближенных вычислений:
Таблица 1 – Формулы
теории приближенных вычислений
|
Математическая операция |
Погрешности |
|
|
абсолютная |
относительная |
|
|
Х=А*В |
А D В + В D А |
|
|
|
|
|
|
Х=А2 |
2 А D А |
|
|
|
|
|
Истинное значение измеряемой величины:
Ист. = Х ± DХ
, (8)
(Х — DХ) < Ист.
< (Х + DХ)
2) Способ оценки погрешности нахождением
верхней и нижней границ измерения:
·
находят верхнюю (В. Г.) и
нижнюю (Н. Г.) границы измеряемой величины;
·
определяют среднее
значение искомой величины Х как полусумму верхней и нижней границ измерения:
![]() ,
,
(9)
·
определяют абсолютную
погрешность Х как полуразность верхней и нижней границ:
![]() ,
,
(10)
В лабораторных работах для
проведения прямых однократных измерений используются измерительные приборы и
меры. Меры- это тело или устройство, служащее для воспроизведения одного или
нескольких известных значений данной величины. Это гири, линейки, измерительные
цилиндры и др. В данной работе используются приборы микрометр и штангенциркуль.
Микрометр (рисунок 1) состоит из упора,
микрометрического винта, неподвижной втулки со шкалой в миллиметрах. Головки
винта со шкалой. При измерении микрометром предмет помещают между упором и
винтом. Вращая винт за головку, доводят его до соприкосновения с предметом.
Затем по шкале отсчитывают целые миллиметры, а по шкале головки винта —
десятые и сотые доли миллиметра.

Рисунок 1 — Микрометр
Штангенциркуль (рисунок 2) имеет линейку со шкалой , нониус
со шкалой. Измеряемый предмет помещают между ножками штангенциркуля так, чтобы
предмет был слегка зажат, и закрепляют нониус винтом. По шкале линейки
отсчитывают целое число миллиметров до нуля нониуса (первого деления). Затем
тщательно определяют, какое деление шкалы нониуса точно совпадает с некоторым
делением шкалы линейки. Это деление шкалы нониуса соответствует десятым долям
миллиметра.

Рисунок 2 – Штангенциркуль
Погрешность прямых измерений связана,
прежде всего, с основными погрешностями мер и измерительных приборов
(инструментальные погрешности). Для большинства измерительных приборов
инструментальная погрешность задается при помощи числа, называемого классом
точности. Абсолютная погрешность прибора:
![]() , (11)
, (11)
Класс точности обозначается на
шкале прибора. Погрешность отсчета принимают равной половине цены деления.
Отсчет надо проводить тщательно. Избегая погрешности, обусловленной
параллаксом. Параллакс-это кажущееся смещение объекта, вызванное изменением
точки наблюдения. Абсолютная погрешность прямого измерения:
D= D прибора + Dотсчета , (12)
Результаты экспериментов удобнее
всего записывать в виде таблиц. Такая запись компактнее и проще для чтения. В
начале каждого столбца напишите название или символ соответствующей величины и
укажите единицу измерения. В таблице должны быть записаны значения величин, как
полученные непосредственно в эксперименте, так и рассчитанные затем на основе
экспериментальных данных. Например, измерить объем монеты можно по формулам:
![]() ,
,
(13)
где V –
истинный объем монеты, м3;
Vср – средний объем монеты, м3;
DVср – средняя абсолютная погрешность объема, м3.
 ,
,
(14)
где D –
средний диаметр монеты, м;
h – средняя
толщина монеты, м.
![]() , (15)
, (15)
где ![]() – среднее значение относительной погрешности объема;
– среднее значение относительной погрешности объема;
![]() – среднее значение относительной погрешности диаметра;
– среднее значение относительной погрешности диаметра;
![]() — среднее значение относительной погрешности толщины.
— среднее значение относительной погрешности толщины.
 , (16)
, (16)
4 Задание
4.1
Определить объем монеты с
помощью микрометра или штангенциркуля. Вычислить абсолютные и относительные
погрешности измерений.
4.2
Записать результат полученного
объема.
5 Ход
выполнения лабораторной работы
5.1 Измерить 3 раза толщину
монеты и 3 раза диаметр монеты микрометром или штангенциркулем.
5.2
Результаты опытов и
расчетов занести в таблицу.
5.3
Таблица 2 — Результаты
измерений и вычислений.
|
Диаметр монеты |
Средний диаметр монеты |
Абсолютная погрешность диаметра |
Среднее значение абсолютной |
Средняя относительная |
Толщина монеты |
Средняя толщина монеты |
Абсолютная погрешность толщины |
Среднее значение абсолютной |
Средняя относительная |
Средний объем монеты |
Средняя абсолютная погрешность |
Средняя относительная |
|
D |
Dср |
DD |
DDср |
|
h |
h ср |
Dh |
Dh ср |
|
Vср |
(DV)ср |
e |
|
м |
м |
м |
м |
% |
м |
м |
м |
м |
% |
м3 |
м3 |
% |
5.3
Выполнить вычисления:
5.3.1 Вычислить
средний диаметр монеты:
![]()
5.3.2 Вычислить
абсолютную погрешность диаметра монеты:
![]() =
=
![]() =
=
![]() = .
= .
5.3.3 Рассчитать
среднюю абсолютную погрешность диаметра монеты:
![]()
5.3.4 Рассчитать
среднюю относительную погрешность диаметра:
![]() .
.
5.3.5Вычислить
среднюю толщину монеты:
![]() =
=
5.3.6 Рассчитать абсолютную
погрешность толщины монеты:
𝛥h1=![]() =
=
𝛥h2=![]() =
=![]()
𝛥h3=![]() =
=
5.3.6 Вычислить среднее
значение абсолютной погрешности толщины монеты:
![]()
5.3.7 Рассчитать средняя
относительную погрешность толщины:
![]() =
=
5.3.8 Вычислить средний
объем монеты:
![]() =
=
5.3.9
Определить погрешности проведенных измерений по формулам:
![]()
𝛥Vср=ℇVср
5.4 Сделать вывод. В выводе указать истинный объем монеты,
записав его в виде: ![]() .
.
5.5 Ответить
на контрольные вопросы
.
6
Контрольные вопросы
6.1 Какими приборами следует пользоваться для
измерения толщины образца?
6.2 Какие виды измерений и способы определения
погрешностей этих измерений вы знаете?
6.3 Как определить погрешность прибора?
6.4 Какие величины называются абсолютной и
относительной погрешностями измерений?
7
Рекомендации по оформлению отчета по лабораторной работе
Отчет по работе оформляется в соответствии с
едиными требованиями, принятыми в колледже и должен включать:
·
вид работы;
·
название работы;
·
цель работы;
·
оборудование;
·
ход работы;
·
алгоритм выполнения
работы;
·
расчеты;
·
вывод.
Литература
1. Бекаревич А. Н. и др. Вычисления в школьном
курсе физики. — Минск, 1987.
2. Гершензон Е.М., Малов Н.Н Лабораторный
практикум по общей физике. — М.: Просвещение,1985.
3. Дик Ю.И. и др. Физический практикум для
классов с углубленным изучением физики. — М.: Просвещение, 1993.
4. Руководство по проведению лабораторных работ
по физике для средних специальных учебных заведений. — М.: Высшая школа,1988.