![]()
Загрузить PDF
![]()
Загрузить PDF
В статистике абсолютная частота показывает, какое количество раз конкретное значение появляется в наборе данных. В отличие от нее, накопительная частота показывает сумму (или нарастающий итог) всех частот вплоть до текущей точки в наборе данных. Не беспокойтесь, если поначалу это кажется не совсем понятным: возьмите ручку и лист бумаги, и вы быстро во всем разберетесь!
-

1
Отсортируйте набор данных. «Набор данных» — это просто изучаемый вами список числовых значений. Отсортируйте его так, чтобы числа располагались по возрастанию.[1]
- Пример: предположим, список чисел представляет собой количество книг, которые каждый студент прочитал за последний месяц. После сортировки у вас получился следующий набор чисел: 3, 3, 5, 6, 6, 6, 8.
-
2
Посчитайте абсолютную частоту каждой величины. Частота значения показывает, сколько раз данное значение появляется в наборе данных. Это число можно называть абсолютной частотой, чтобы не путать его с накопительной частотой. Наиболее простой способ заключается в том, чтобы составить таблицу. Вверху левой колонки напишите «Значение» (или укажите, что измеряется данными числами). Вверху второй колонки напишите «Частота». Заполните таблицу для всех значений из списка.[2]
- Пример: вверху левой колонки напишите «Количество книг», а вверху правой колонки — «Частота».
- Во второй строке напишите первое количество прочитанных книг, то есть число 3.
- Посчитайте, сколько раз число 3 встречается в списке данных. В списке есть два числа 3, поэтому во второй строке колонки «Частота» запишите цифру 2.
- Повторите данную процедуру для всех значений списка, пока не заполните таблицу:
- 3 | Ч = 2
- 5 | Ч = 1
- 6 | Ч = 3
- 8 | Ч = 1
-
3
Найдите накопительную частоту для первого значения. Накопительная частота отвечает на вопрос «сколько раз встречается в списке данное значение или меньшая величина?». Всегда начинайте с наименьшего значения в наборе данных. Поскольку в нашем примере нет меньших значений, для данной величины накопительная частота равна абсолютной.[3]
-
Пример: наименьшее значение равно 3. Количество прочитавших 3 книги студентов составляет 2. Никто из студентов не прочитал меньшее число книг, поэтому накопительная частота равна 3. Впишите это значение в третью колонку таблицы:
- 3 | F = 2 | НЧ=2
-
Пример: наименьшее значение равно 3. Количество прочитавших 3 книги студентов составляет 2. Никто из студентов не прочитал меньшее число книг, поэтому накопительная частота равна 3. Впишите это значение в третью колонку таблицы:
-
4
Найдите накопительную частоту для следующей величины. Перейдите к следующему значению списка. Выше мы определили, сколько раз встречается в списке наименьшая величина. Чтобы определить накопительную частоту для второго значения списка, необходимо прибавить его абсолютную частоту к накопительной частоте предыдущего значения. Иными словами, следует взять последнюю накопительную частоту и прибавить к ней абсолютную частоту данной величины.[4]
-
Пример:
- 3 | Ч = 2 | НЧ = 2
- 5 | Ч = 1 | НЧ = 2+1 = 3
-
Пример:
-
5
Повторите процедуру для остальных значений. Постепенно продвигайтесь к более высоким числам. При этом каждый раз прибавляйте текущую абсолютную частоту к последней накопительной частоте.
-
Пример:
- 3 | Ч = 2 | НЧ = 2
- 5 | Ч = 1 | НЧ = 2 + 1 = 3
- 6 | Ч = 3 | НЧ = 3 + 3 = 6
- 8 | Ч = 1 | НЧ = 6 + 1 = 7
-
Пример:
-
6
Проверьте полученные результаты. В итоге вы сложите абсолютные частоты всех значений списка. Конечная накопительная частота должна соответствовать числу значений в списке. Есть два способа проверить, так ли это:
- Сложите абсолютные частоты всех значений: 2 + 1 + 3 + 1 = 7, в результате у вас получится накопительная частота.
- Посчитайте число значений в наборе данных. В нашем примере список имел следующий вид: 3, 3, 5, 6, 6, 6, 8. В этом списке семь величин, и итоговая накопительная частота также равна 7.
Реклама






-
1
Поймите разницу между дискретными и непрерывными данными. Дискретные данные можно посчитать, они не дробятся на более мелкие составляющие. Непрерывные данные часто не поддаются конечному счету, между двумя произвольными величинами обязательно найдутся другие возможные значения. Ниже приведена пара примеров:[5]
- Количество собак является дискретным множеством. Нет такого понятия, как половина собаки.
- Глубина снега представляет собой непрерывное множество. Она возрастает постепенно и непрерывно, а не на дискретные величины. Если вы измерите глубину снега в сантиметрах, то точное значение может оказаться, например, 20,6 сантиметра.
-
2
Разбейте непрерывные данные на интервалы. Наборы непрерывных данных часто имеют большое количество значений. Если попробовать представить такой набор описанным выше методом, таблица получится слишком длинной и малопонятной. В этом случае удобно разбить данные на отдельные интервалы. Эти интервалы должны быть одинаковой длины (например, 0—10, 11–20, 21–30 и так далее) независимо от того, сколько значений попадает в каждый интервал. Ниже приведена возможная таблица для непрерывного набора данных:[6]
- Набор данных: 233, 259, 277, 278, 289, 301, 303
- Таблица (в первой колонке интервал значений, во второй частота, в третьей накопительная частота):
- 200–250 | 1 | 1
- 251–300 | 4 | 1 + 4 = 5
- 301–350 | 2 | 5 + 2 = 7
-
3
Постройте линейный график. После того как вы рассчитаете накопительную частоту, возьмите лист миллиметровой бумаги. Отложите по горизонтальной оси (ось x) значения из набора данных, а по вертикальной (ось y) — накопительную частоту, и постройте график. Это значительно облегчит последующие вычисления.[7]
- Например, если набор данных включает числа от 1 до 8, отложите по горизонтальной оси 8 делений. Над каждым делением отметьте точкой соответствующее ему значение накопительной частоты. Соедините получившиеся точки линией.
- Если какое-либо значение не встречается, его абсолютная частота составляет 0. В этом случае прибавьте 0 к последней величине накопительной частоты и поставьте точку на том же уровне, что и в предыдущий раз.
- Поскольку накопительная частота всегда растет с продвижением к большим значениям, с перемещением вправо линия будет оставаться на той же самой высоте или подниматься. Если в какой-то точке линия опустилась вниз, значит, вы допустили ошибку (например, вместо накопительной частоты взяли абсолютную).
-
4
Найдите по графику медиану. Медиана — это значение, расположенное точно посередине набора данных. Половина значений находится выше медианы, а вторая половина расположена ниже нее. Медиану можно найти по графику следующим образом:
- Посмотрите на последнее значение в самом правом конце графика. Для него величина y соответствует суммарной накопительной частоте, которая равна общему числу точек в наборе данных. Предположим, эта величина равна 16.
- Умножьте эту величину на ½ и найдите соответствующее значение на оси y. В нашем примере получится 8. Найдите число 8 на оси y.
- Найдите точку на линии графика, значение y которой соответствует найденной величине. Проведите от цифры 8 на оси y горизонтальную прямую и определите точку ее пересечения с линией графика. Именно эта точка делит набор данных точно пополам.
- Найдите значение x в данной точке. Проведите из точки вертикальную прямую до пересечения с осью x. Точка пересечения определит медиану для изучаемого набора данных. Например, если получилось 65, значит половина данных расположена ниже 65, а вторая половина лежит выше этого значения.
-
5
Найдите по графику квартили. Квартили делят набор данных на четыре части. Эта процедура очень похожа на определение медианы. Единственное различие заключается в нахождении значений y:
- Чтобы определить величину y для нижнего квартиля, умножьте максимальное значение накопительной частоты на ¼. В результате вы получите значение x, ниже которого будет лежать ровно ¼ всех данных.
- Чтобы найти величину y для верхнего квартиля, умножьте максимальное значение накопительной частоты на ¾. В результате вы получите значение x, ниже которого будет лежать ¾, а выше — ¼ всех данных.
Реклама





Советы
- С помощью интервалов можно представлять любые большие, в том числе и дискретные наборы данных.
Реклама
Об этой статье
Эту страницу просматривали 73 075 раз.
Была ли эта статья полезной?

Содержание
- Формулы
- Прочие накопленные частоты
- Как получить накопленную частоту?
- Как заполнять частотную таблицу
- Таблица частотности
- Кумулятивное частотное распределение
- пример
- Предлагаемое упражнение
- Ответить
- Ссылки
В накопленная частота представляет собой сумму абсолютных частот f, от самой низкой до той, которая соответствует определенному значению переменной. В свою очередь, абсолютная частота — это количество раз, когда наблюдение появляется в наборе данных.
Очевидно, переменная исследования должна быть сортируемой. А поскольку накопленная частота получается сложением абсолютных частот, получается, что накопленная частота до последних данных должна совпадать с их суммой. В противном случае в расчетах будет ошибка.

Обычно накопленная частота обозначается как Fя (или иногда nя), чтобы отличить ее от абсолютной частоты fя и важно добавить для него столбец в таблице, с помощью которой организованы данные, известной как таблица частот.
Это упрощает, среди прочего, отслеживание того, сколько данных было подсчитано до определенного наблюдения.
А Фя он также известен как абсолютная совокупная частота. Если разделить на общие данные, мы получим относительная совокупная частота, окончательная сумма которых должна быть равна 1.
Формулы
Кумулятивная частота данного значения переменной Xя представляет собой сумму абсолютных частот f всех значений, меньших или равных ей:
Fя = f1 + f2 + f3 +… Fя
Путем сложения всех абсолютных частот получается общее количество данных N, то есть:
F1 + F2 + F3 +…. + Fп = N
Предыдущая операция кратко записывается с помощью символа суммирования ∑:
∑ Fя = N
Прочие накопленные частоты
Также могут накапливаться следующие частоты:
-Относительная частота: получается делением абсолютной частоты fя между общими данными N:
Fр = fя / N
Если относительные частоты сложить от самой низкой к той, которая соответствует определенному наблюдению, мы получим совокупная относительная частота. Последнее значение должно быть равно 1.
-Процент кумулятивной относительной частоты: накопленная относительная частота умножается на 100%.
F% = (fя / N) x 100%
Эти частоты полезны для описания поведения данных, например, при нахождении показателей центральной тенденции.
Как получить накопленную частоту?
Чтобы получить накопленную частоту, необходимо упорядочить данные и организовать их в таблице частот. Процедура иллюстрируется следующей практической ситуацией:
-В интернет-магазине, который продает сотовые телефоны, отчет о продажах определенного бренда за март месяц показал следующие значения за день:
1; 2; 1; 3; 0; 1; 0; 2; 4; 2; 1; 0; 3; 3; 0; 1; 2; 4; 1; 2; 3; 2; 3; 1; 2; 4; 2; 1; 5; 5; 3
Переменная — это количество телефонов, проданных за день и это количественно. Данные, представленные таким образом, не так легко интерпретировать, например, владельцы магазина могут быть заинтересованы в том, чтобы узнать, есть ли какая-либо тенденция, например, дни недели, когда продажи этого бренда выше.
Подобную информацию и многое другое можно получить, представив данные в упорядоченном виде и указав частоты.
Как заполнять частотную таблицу
Для расчета накопленной частоты данные сначала упорядочиваются:
0; 0; 0; 0; 1; 1; 1; 1; 1; 1; 1; 1; 2; 2; 2; 2; 2; 2; 2; 2; 3; 3; 3; 3; 3; 3; 4; 4; 4; 5; 5
Затем строится таблица со следующей информацией:
-Первый столбец слева с количеством проданных телефонов от 0 до 5 в порядке возрастания.
-Второй столбец: абсолютная частота, то есть количество дней, в течение которых было продано 0 телефонов, 1 телефон, 2 телефона и т. Д.
-Третий столбец: накопленная частота, состоящая из суммы предыдущей частоты и частоты данных, которые необходимо учитывать.
Этот столбец начинается с первых данных в столбце абсолютной частоты, в данном случае это 0. Для следующего значения сложите его с предыдущим. Это продолжается до тех пор, пока не будут достигнуты последние накопленные данные частоты, которые должны совпадать с общими данными.
Таблица частотности
В следующей таблице показаны переменная «количество телефонов, проданных за день», ее абсолютная частота и подробный расчет накопленной частоты.
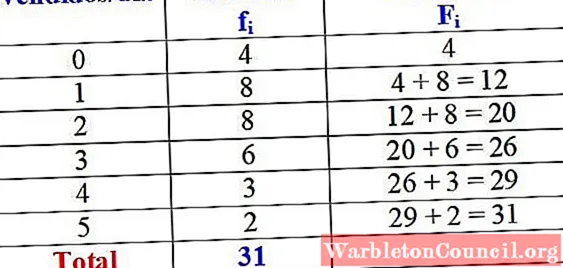
На первый взгляд, можно сказать, что у рассматриваемого бренда один или два телефона почти всегда продаются в день, поскольку максимальная абсолютная частота составляет 8 дней, что соответствует этим значениям переменной. Только за 4 дня месяца они не продали ни одного телефона.
Как уже отмечалось, таблицу легче изучить, чем изначально собранные индивидуальные данные.
Кумулятивное частотное распределение
Кумулятивное распределение частот — это таблица, в которой показаны абсолютные частоты, совокупные частоты, совокупные относительные частоты и совокупные процентные частоты.
Хотя есть преимущество организации данных в таблице, подобной предыдущей, если количество данных очень велико, может оказаться недостаточно для их организации, как показано выше, потому что, если частот много, их все равно трудно интерпретировать.
Проблему можно решить, построив Распределение частоты по интервалам, полезная процедура, когда переменная принимает большое количество значений или если это непрерывная переменная.
Здесь значения сгруппированы в интервалы равной амплитуды, называемые класс. Классы характеризуются наличием:
-Предел класса: — крайние значения каждого интервала, их два, верхний предел и нижний предел. Как правило, верхняя граница относится не к интервалу, а к следующему, а нижняя — к.
-Классовый знак: является средней точкой каждого интервала и принимается в качестве его репрезентативного значения.
-Ширина класса: Он рассчитывается путем вычитания значения самого высокого и самого низкого данных (диапазона) и деления на количество классов:
Ширина класса = Диапазон / Количество классов
Подробное описание частотного распределения приведено ниже.
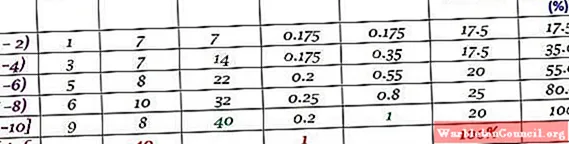
пример
Этот набор данных соответствует 40 баллам за тест по математике по шкале от 0 до 10:
0; 0;0; 1; 1; 1; 1; 2; 2; 2; 3; 3; 3; 3; 4; 4; 4; 4; 5; 5; 5; 5; 6; 6; 6; 6; 7; 7; 7; 7; 7; 7; 8; 8; 8; 9; 9; 9;10; 10.
Распределение частот может быть выполнено с определенным количеством классов, например 5 классами. Следует иметь в виду, что при использовании многих классов данные нелегко интерпретировать, и смысл группировки теряется.
А если, наоборот, они сгруппированы в очень немногие, то информация размывается и часть ее теряется. Все зависит от количества имеющихся у вас данных.
В этом примере рекомендуется иметь две оценки в каждом интервале, поскольку будет 10 оценок и будет создано 5 классов. Ранг — это вычитание между высшим и низшим классом, ширина класса составляет:
Ширина класса = (10-0) / 5 = 2
Слева интервалы закрыты, а справа открыты (кроме последнего), что обозначено скобками и круглыми скобками соответственно. Все они одинаковой ширины, но это не обязательно, хотя и является наиболее распространенным.
Каждый интервал содержит определенное количество элементов или абсолютную частоту, а в следующем столбце — накопленная частота, с которой переносится сумма. В таблице также указана относительная частота fр (абсолютная частота между общим количеством данных) и относительная частота в процентах fр ×100%.
Предлагаемое упражнение
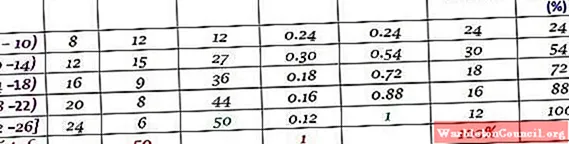
Одна компания ежедневно звонила своим клиентам в течение первых двух месяцев года. Данные следующие:
6, 12, 7, 15, 13, 18, 20, 25, 12, 10, 8, 13, 15, 6, 9, 18, 20, 24, 12, 7, 10, 11, 13, 9, 12, 15, 18, 20, 13, 17, 23, 25, 14, 18, 6, 14, 16, 9, 6, 10, 12, 20, 13, 17, 14, 26, 7, 12, 24, 7
Сгруппируйте по 5 классам и составьте таблицу с частотным распределением.
Ответить
Ширина класса:
(26-6)/5 = 4
Пожалуйста, попытайтесь понять это, прежде чем увидите ответ.
Ссылки
- Беренсон, М. 1985. Статистика для управления и экономики. Interamericana S.A.
- Деворе, Дж. 2012. Вероятность и статистика для техники и науки. 8-е. Издание. Cengage.
- Левин, Р. 1988. Статистика для администраторов. 2-й. Издание. Прентис Холл.
- Вероятность и статистика. Ширина интервала классов. Получено с: pedroprobabilidadyestadistica.blogspot.com.
- Шпигель, М. 2009. Статистика. Серия Шаум. 4-й Издание. Макгроу Хилл.
- Уолпол, Р. 2007. Вероятность и статистика для инженерии и науки. Пирсон.
Определение частотного распределения.
Частотное распределение или плотность распределения (англ. ‘frequency distribution’) представляет собой табличное отображение данных, обобщенных в относительно небольшое количество интервалов.
Распределения частот помогают в анализе больших объемов статистических данных и работают со всеми типами измерительных шкал.
Ставки доходности являются основными фундаментальными единицами, которые финансовые аналитики и портфельные менеджеры используют для принятия инвестиционных решений, и мы можем использовать распределение частот для обобщения ставок доходности.
Когда мы анализируем норму прибыли, нашей отправной точкой является доходность за период владения (HPR, от англ. ‘holding period return’), также называемая общей доходностью (англ. ‘total reutrn’).
Формула доходности за период владения.
Доходность за период владения (R_t) за период времени (t), равна:
( large R_t = (P_t — P_{t-1} + D_t) big/ P_{t-1} ) (Формула 1)
где
- (P_t) = цена за акцию в конце периода (t).
- (P_{t-1}) = цена за акцию в конце периода (t — 1). Это период времени, непосредственно предшествующий периоду (t).
- (D_t)= денежные поступления от распределений, полученные за период времени (t). (Для обыкновенных акций распределение — это дивиденды; для облигаций — купонная выплата).
Таким образом, доходность (R_t) за период времени (t) представляет собой прирост стоимости капитала (или убыток) плюс поступления от распределений, деленные на цену акций начального периода.
Формулу 1 можно использовать для определения доходности за период владения любым активом — за день, неделю, месяц или год, просто изменив интерпретацию временного интервала между последовательными значениями временного индекса (t).
Доходность за период владения, как определено в Формуле 1, имеет две важные характеристики.
- Во-первых, она характеризуется временным периодом. Например, если между последовательными наблюдениями за ценой используется месячный интервал времени, то ставка доходности является месячной цифрой.
- Во-вторых, ставка доходности не имеет связанной с ней денежной единицы. Например, предположим, что цены указаны в евро. Числитель и знаменатель Формулы 1 будут выражаться в евро, но полученное соотношение не будет выражать денежную единицу, поскольку денежные единицы в числителе и знаменателе будут взаимно аннулироваться.
Результат сохраняется независимо от валюты, в которой указаны цены на акции.
Тем не менее, обратите внимание на то, что если бы цены и денежные поступления от распределений были выражены в разных валютах, вам следовало бы конвертировать их в одну общую валюту перед расчетом доходности за период владения.
Из-за колебаний обменного курса в течение периода владения, доходность за период владения активом, рассчитанная в разных валютах, как правило, будет отличаться.
С учетом этих проблем мы переходим к частотному распределению доходности за период владения по индексу S&P 500.
- Во-первых, мы изучаем годовые ставки доходности;
- Затем мы смотрим на ежемесячные ставки доходности.
Годовые ставки доходности S&P 500, рассчитанные по Формуле 1, охватывают период с января 1926 г. по декабрь 2012 г., что составляет в общей сложности 87 ежегодных наблюдений. Ежемесячные данные о доходности охватывают период с января 1926 года по декабрь 2012 года, в общей сложности 1044 ежемесячных наблюдений.
Мы можем сформулировать основную процедуру построения частотного распределения следующим образом.
Построение частотного распределения.
- Отсортируйте данные в порядке возрастания.
- Рассчитайте размах данных Range, который определяется как
Размах (англ. ‘range’) = Максимальное значение — Минимальное значение. - Определите количество интервалов в частотном распределении, (k).
- Определите ширину интервала как ( mathrm{Range} / k ).
- Определите интервалы, последовательно добавляя ширину интервала к минимальному значению, чтобы определить конечные точки интервалов. Последним будет интервал, включающий максимальное значение.
- Подсчитайте количество наблюдений, попадающих в каждый интервал.
- Составьте таблицу полученных интервалов от наименьшего до наибольшего, в которой показано количество наблюдений, попадающих в каждый интервал.
На шаге 4 при округлении ширины интервала округляйте скорее вверх, чем вниз, чтобы убедиться, что последний интервал включает в себя максимальное значение данных.
Как видно из вышеописанной процедуры, распределение частот группирует данные в набор интервалов. Интервалы также иногда называют классами, диапазонами или ячейками (англ. class, range, bin).
Интервал (англ. ‘interval’) — это набор значений, в который попадает наблюдение. Каждое наблюдение попадает только в один интервал, и общее количество интервалов охватывает все значения, представленные в выборке данных.
Фактическое количество наблюдений в данном интервале называется абсолютной частотой (англ. ‘absolute frequency’) или просто частотой.
Частотное распределение или распределение частот (англ. ‘frequency distribution’) — это перечень интервалов вместе с соответствующими показателями частоты.
Пример построения частотного распределения.
Чтобы проиллюстрировать основную процедуру, предположим, что у нас есть 12 наблюдений, отсортированных в порядке возрастания:
-4,57, -4,04, -1,64, 0,28, 1,34, 2,35, 2,38, 4,28, 4,42, 4,68, 7,16 и 11,43
Минимальное наблюдение составляет -4,57, а максимальное наблюдение составляет +11,43, поэтому размах составляет +11,43 — (-4,57) = 16. Если мы установим (k = 4), ширина интервала составит 16/4 = 4.
Таблица 1 показывает последовательное добавление ширины интервала 4 для определения конечных точек для интервалов (шаг 5).
|
-4.57 |
+ |
4.00 = |
-0.57 |
|
-0.57 |
+ |
4.00 = |
3.43 |
|
3.43 |
+ |
4.00 = |
7.43 |
|
7.4 |
+ |
4.00 = |
11.43 |
Таким образом, интервалы составляют:
[-4,57 до -0,57),
[-0,57 до 3,43),
[3,43 до 7,43) и
[7,43 до 11,43]
Обозначения вроде [-4,57 -0,57) означают -4,57 (leq) наблюдение (<) -0,57. В этом контексте квадратная скобка указывает, что конечная точка включена в интервал.
|
Интервал |
Абсолютная |
|||
|---|---|---|---|---|
|
A |
-4.57 |
≤ наблюдение < |
-0.57 |
3 |
|
B |
-0.57 |
≤ наблюдение < |
3.43 |
4 |
|
C |
3.43 |
≤ наблюдение < |
7.43 |
4 |
|
D |
7.43 |
≤ наблюдение ≤ |
11.43 |
1 |
Обратите внимание, что интервалы не перекрываются, поэтому каждое наблюдение может быть однозначно помещено в один интервал.
На практике мы можем захотеть усовершенствовать вышеуказанную базовую процедуру. Например, мы можем захотеть, чтобы интервалы начинались и заканчивались целыми числами для простоты интерпретации.
Нам также нужно объяснить выбор количества интервалов (k). Мы обратимся к этим вопросам далее, при обсуждении построения частотных распределений для S&P 500.
Пример построения частотного распределения для ставок доходности S&P 500.
Сначала рассмотрим пример построения частотного распределения для годовых ставок доходность по S&P 500 за период с 1926 по 2012 год.
В течение этого периода доходность по S&P 500 имела минимальное значение -43,34 процента (в 1931 году) и максимальное значение +53,99 процента (в 1933 году).
Таким образом, размах данных составлял + 54% — (-43%) = 97%, приблизительно.
Теперь нужно определить количество интервалов k, в которые мы должны сгруппировать наблюдения.
Хотя учебники по статистике содержат некоторые базовые рекомендации для определения (k), на практике определение полезного значения для (k) часто включает проверку данных и вынесение оценочного суждения.
Насколько детальными должны быть интервалы?
Если мы используем слишком мало интервалов, мы обобщаем слишком много наблюдений и теряем соответствующие характеристики. Если мы используем слишком много интервалов, мы можем не получить достаточный уровень обобщения.
Мы можем установить подходящее значение для (k), оценив полезность полученной ширины интервала. Большое количество пустых интервалов может указывать на то, что мы пытаемся представить слишком много деталей.
Начав с относительно небольшой ширины интервала, мы можем видеть, являются ли интервалы в основном пустыми и не является ли слишком большим значение (k), связанное с этой шириной интервала.
Если интервалы в основном пустые или (k) очень велико, мы можем рассмотреть большие интервалы (меньшие значения (k)), пока не получим распределение частот, которое эффективно обобщает распределение.
Для годовых ставок S&P 500 интервалы доходности шириной в 1 процент привели бы к 97 интервалам, и многие из них были бы пустыми, потому что у нас есть только 87 ежегодных наблюдений.
Нам всегда нужно помнить, что целью распределения частот является обобщение данных. Предположим, что для простоты интерпретации мы хотим использовать ширину интервала, целых, а не в дробных значениях процентов.
Ширина 2-процентного интервала имеет намного меньше пустых интервалов, чем ширина 1-процентного интервала, и эффективно обобщает данные. 2-процентная ширина интервала будет связана с 97/2 = 48,5 интервалами, которые мы можем округлить до 49 интервалов.
Это количество интервалов будет покрывать 2% (times) 49 = 98%. Мы можем подтвердить, что, если мы начнем наименьший 2-процентный интервал с целого числа -44,0%, последний интервал заканчивается на -44,0% + 98% = 54% и включает максимальную доходность в выборке: 53,99%.
При построении распределения частот у нас также будут интервалы, которые заканчиваются и начинаются со значения 0 процентов, что позволяет нам подсчитывать отрицательные и положительные значения доходности. Без лишней работы мы нашли эффективный способ обобщения данных.
Мы будем использовать интервалы доходности 2%, начиная с ( -44% leq R_t < -42%) (в таблице указано «-44% до -42%») и заканчивая (52% leq R_t leq 54%).
В Таблице 3 показано распределение частот для годовых ставок доходности по S&P 500.
Таблица 3 включает три других полезных способа представления данных, которые мы можем вычислить, как только мы установили распределение частот:
- относительная частота,
- накопленная частота (также называемая накопленной абсолютной частотой) и
- накопленная относительная частота.
Определение относительной частоты.
Относительная частота (англ. ‘relative frequency’) — это абсолютная частота каждого интервала, деленная на общее количество наблюдений.
Накопленная относительная частота (англ. ‘cumulative relative frequency’) накапливает (складывает) относительные частоты, когда мы движемся от первого до последнего интервала. Она говорит нам о доле наблюдений, которые меньше верхнего предела каждого интервала.
|
Интервал доходности (%) |
Частота |
Относительная частота (%) |
Накоп- |
Накопленная относительная частота (%) |
|---|---|---|---|---|
|
-44.0 до -42.0 |
1 |
1.15 |
1 |
1.15 |
|
-42.0 до -40.0 |
0 |
0.00 |
1 |
1.15 |
|
-40.0 до -38.0 |
0 |
0.00 |
1 |
1.15 |
|
-38.0 до -36.0 |
1 |
1.15 |
2 |
2.30 |
|
-36.0 до -34.0 |
1 |
1.15 |
3 |
3.45 |
|
-34.0 до -32.0 |
0 |
0.00 |
3 |
3.45 |
|
-32.0 до -30.0 |
0 |
0.00 |
3 |
3.45 |
|
-30.0 до -28.0 |
0 |
0.00 |
3 |
3.45 |
|
-28.0 до -26.0 |
1 |
1.15 |
4 |
4.60 |
|
-26.0 to -24.0 |
1 |
1.15 |
5 |
5.75 |
|
-24.0 до -22.0 |
1 |
1.15 |
6 |
6.90 |
|
-22.0 до -20.0 |
0 |
0.00 |
6 |
6.90 |
|
-20.0 до -18.0 |
0 |
0.00 |
6 |
6.90 |
|
-18.0 до -16.0 |
0 |
0.00 |
6 |
6.90 |
|
-16.0 до -14.0 |
1 |
1.15 |
7 |
8.05 |
|
-14.0 до -12.0 |
0 |
0.00 |
7 |
8.05 |
|
-12.0 до -10.0 |
4 |
4.60 |
11 |
12.64 |
|
-10.0 до -8.0 |
7 |
8.05 |
18 |
20.69 |
|
-8.0 до -6.0 |
1 |
1.15 |
19 |
21.84 |
|
-6.0 до -4.0 |
1 |
1.15 |
20 |
22.99 |
|
-4.0 до -2.0 |
1 |
1.15 |
21 |
24.14 |
|
-2.0 до 0.0 |
3 |
3.45 |
24 |
27.59 |
|
0.0 до 2.0 |
2 |
2.30 |
26 |
29.89 |
|
2.0 до 4.0 |
1 |
1.15 |
27 |
31.03 |
|
4.0 до 6.0 |
6 |
6.90 |
33 |
37.93 |
|
6.0 до 8.0 |
4 |
4.60 |
37 |
42.53 |
|
8.0 до 10.0 |
1 |
1.15 |
38 |
43.68 |
|
10.0 до 12.0 |
4 |
4.60 |
42 |
48.28 |
|
12.0 до 14.0 |
1 |
1.15 |
43 |
49.43 |
|
14.0 до 16.0 |
4 |
4.60 |
47 |
54.02 |
|
16.0 до 18.0 |
2 |
2.30 |
49 |
56.32 |
|
18.0 до 20.0 |
6 |
6.90 |
55 |
63.22 |
|
20.0 до 22.0 |
3 |
3.45 |
58 |
66.67 |
|
22.0 до 24.0 |
5 |
5.75 |
63 |
72.41 |
|
24.0 до 26.0 |
2 |
2.30 |
65 |
74.71 |
|
26.0 до 28.0 |
2 |
2.30 |
67 |
77.01 |
|
28.0 до 30.0 |
2 |
2.30 |
69 |
79.31 |
|
30.0 до 32.0 |
5 |
5.75 |
74 |
85.06 |
|
32.0 до 34.0 |
4 |
4.60 |
78 |
89.66 |
|
34.0 до 36.0 |
0 |
0.00 |
78 |
89.66 |
|
36.0 до 38.0 |
4 |
4.60 |
82 |
94.25 |
|
38.0 до 40.0 |
0 |
0.00 |
82 |
94.25 |
|
40.0 до 42.0 |
0 |
0.00 |
82 |
94.25 |
|
42.0 до 44.0 |
2 |
2.30 |
84 |
96.55 |
|
44.0 до 46.0 |
0 |
0.00 |
84 |
96.55 |
|
46.0 до 48.0 |
1 |
1.15 |
85 |
97.70 |
|
48.0 до 50.0 |
0 |
0.00 |
85 |
97.70 |
|
50.0 до 52.0 |
0 |
0.00 |
85 |
97.70 |
|
52.0 до 54.0 |
2 |
2.30 |
87 |
100.00 |
Источник: Ibbotson Associates.
Примечание: нижний предел интервала — это нестрогое неравенство ((leq)), а верхний предел — строгое неравенство ((<)). Итоги накопленных относительных частот отражают вычисления полной точности, с округлением до двух десятичных разрядов.
Изучив частотное распределение, приведенное в Таблице 3, мы видим, что первый интервал доходности, от -44 до -42%, содержит одно наблюдение; его относительная частота составляет 1/87 или 1,15 процента.
Накопленная частота для этого интервала равна 1, поскольку только одно наблюдение составляет менее -42%. Таким образом, накопленная относительная частота составляет 1/87 или 1,15 процента.
Следующий интервал доходности включает 0 наблюдений; следовательно, его накопленная частота равна 0 + 1, а его накопленная относительная частота равна 1,15% (накопленная относительная частота от предыдущего интервала).
Мы можем найти другие накопленные частоты, добавив (абсолютную) частоту к предыдущей накопленной частоте. Таким образом, накопленная частота показывает нам число наблюдений, которые меньше верхнего предела каждого интервала доходности.
Как видно из Таблицы 3, интервалы доходности в этой выборке имеют частоты от 0 до 7. Интервал, охватывающий доходность от -10% до -8% (-10% leq R_t < -8%) имеет больше всего наблюдений: 7.
Следующей по частоте является доходность от 4 до 6% (4% leq R_t < 6%) и от 18 до 20% (18% leq R_t < 20%), с 6 наблюдениями в каждом интервале.
Из столбца накопленной частоты мы видим, что количество отрицательных значений отрицательной доходности равно 24. Число положительных значений доходности должно быть равно 87-24 или 63. Мы можем выразить количество положительных и отрицательных значений доходности в процентах от общего числа, чтобы получить представление о риске, присущем инвестициям на фондовом рынке.
В течение 87-летнего периода S&P 500 имел отрицательную годовую доходность в 27,6% случаев (то есть 24/87). Этот результат отражен в пятом столбце Таблицы 3, где указывается накопленная относительная частота.
Распределение частот дает нам представление не только о том, где находится большинство наблюдений, но также о том, является ли распределение нормальным, ассиметричным (со скосом влево или вправо) или островершинным.
(см. также: CFA — Симметрия и асимметрия в распределениях доходности)
В случае с S&P 500 мы видим, что более половины наблюдений являются положительными, а большая часть этих ставок годовой доходности превышает 10% (только 14 из 63 ставок — около 22% — составляли от 0 до 10%).
Таблица 3 позволяет нам сделать еще один важный вывод относительно выбора количества интервалов, связанного, в частности, с доходностью капитала. Из распределения частот в Таблице 3 мы видим, что только 6 наблюдений попадают в промежуток между -44% и -16%, и только 5 — между 38% и 54%.
Рыночные данные о доходности часто характеризуются несколькими очень большими или маленькими результатами.
Мы могли бы исключить интервалы доходности по краям частотного распределения, выбрав меньшее значение (k), но тогда мы потеряли бы информацию о том, насколько плохо или хорошо работала фондовая биржа.
Риск-менеджеру может потребоваться информация о наихудших возможных результатах и, следовательно, может потребоваться подробная информация о крайних значениях распределения (или хвостах распределения, от англ. ‘tail’). Для этого ему может быть полезно распределение частоты с относительно большим значением (k).
Портфельный менеджер или финансовый аналитик могут быть в равной степени заинтересованы в подробной информации о хвостах распределений. Однако, если менеджер или аналитик хочет получить картину только того, где находится большинство наблюдений, он может предпочесть использовать ширину интервала 4% (например, 25 интервалов, начинающихся с -44%).
Распределение частот для ежемесячной доходности S&P 500 выглядит совсем не так, как для годовой доходности. Серия ежемесячных ставок доходности с января 1926 года по декабрь 2012 года насчитывает 1044 наблюдения.
Доходность варьируется от минимума -30% до максимума +43%. При таком большом количестве ежемесячных данных мы должны сделать обобщение, чтобы получить представление о распределении, и поэтому мы группируем данные в 37 равных интервалов доходности, шириной в 2 процента.
Выгода от обобщения таким образом является существенной.
В Таблице 4 представлено полученное распределение частот. Абсолютные частоты находятся во втором столбце, за которым следуют относительные частоты. Относительные частоты округлены до двух десятичных знаков. Накопленные абсолютные частоты и накопленные относительные частоты находятся в четвертом и пятом столбцах соответственно.
|
Интервал доходности (%) |
Абсолютная частота |
Отно- |
Накоп- |
Накопленная относительная частота (%) |
|---|---|---|---|---|
|
-30.0 до -28.0 |
1 |
0.10 |
1 |
0.10 |
|
-28.0 до -26.0 |
0 |
0.00 |
1 |
0.10 |
|
-26.0 до -24.0 |
1 |
0.10 |
2 |
0.19 |
|
-24.0 до -22.0 |
1 |
0.10 |
3 |
0.29 |
|
-22.0 до -20.0 |
2 |
0.19 |
5 |
0.48 |
|
-20.0 до -18.0 |
2 |
0.19 |
7 |
0.67 |
|
-18.0 до -16.0 |
3 |
0.29 |
10 |
0.96 |
|
-16.0 до -14.0 |
2 |
0.19 |
12 |
1.15 |
|
-14.0 до -12.0 |
6 |
0.57 |
18 |
1.72 |
|
-12.0 до -10.0 |
7 |
0.67 |
25 |
2.39 |
|
-10.0 до -8.0 |
23 |
2.20 |
48 |
4.60 |
|
-8.0 до -6.0 |
34 |
3.26 |
82 |
7.85 |
|
-6.0 до -4.0 |
59 |
5.65 |
141 |
13.51 |
|
-4.0 до -2.0 |
98 |
9.39 |
239 |
22.89 |
|
-2.0 до 0.0 |
157 |
15.04 |
396 |
37.93 |
|
0.0 до 2.0 |
220 |
21.07 |
616 |
59.00 |
|
2.0 до 4.0 |
173 |
16.57 |
789 |
75.57 |
|
4.0 до 6.0 |
137 |
13.12 |
926 |
88.70 |
|
6.0 до 8.0 |
63 |
6.03 |
989 |
94.73 |
|
8.0 до 10.0 |
25 |
2.39 |
1,014 |
97.13 |
|
10.0 до 12.0 |
15 |
1.44 |
1,029 |
98.56 |
|
12.0 до 14.0 |
6 |
0.57 |
1,035 |
99.14 |
|
14.0 до 16.0 |
2 |
0.19 |
1,037 |
99.33 |
|
16.0 до 18.0 |
3 |
0.29 |
1,040 |
99.62 |
|
18.0 до 20.0 |
0 |
0.00 |
1,040 |
99.62 |
|
20.0 до 22.0 |
0 |
0.00 |
1,040 |
99.62 |
|
22.0 до 24.0 |
0 |
0.00 |
1,040 |
99.62 |
|
24.0 до 26.0 |
1 |
0.10 |
1,041 |
99.71 |
|
26.0 до 28.0 |
0 |
0.00 |
1,041 |
99.71 |
|
28.0 до 30.0 |
0 |
0.00 |
1,041 |
99.71 |
|
30.0 до 32.0 |
0 |
0.00 |
1,041 |
99.71 |
|
32.0 до 34.0 |
0 |
0.00 |
1,041 |
99.71 |
|
34.0 до 36.0 |
0 |
0.00 |
1,041 |
99.71 |
|
36.0 до 38.0 |
0 |
0.00 |
1,041 |
99.71 |
|
38.0 до 40.0 |
2 |
0.19 |
1,043 |
99.90 |
|
40.0 до 42.0 |
0 |
0.00 |
1,043 |
99.90 |
|
42.0 до 44.0 |
1 |
0.10 |
1,044 |
100.00 |
Источник: Ibbotson Associates.
Примечание: нижний предел интервала — это нестрогое неравенство ((leq)), а верхний предел — строгое неравенство ((<)). Относительная частота — это абсолютная частота или накопленная частота, деленная на общее количество наблюдений. Итоги накопленных относительных частот отражают вычисления полной точности, с округлением до двух десятичных разрядов.
Преимущество анализа распределения частот очевидно из Таблицы 4, которая говорит нам, что подавляющее большинство наблюдений (687/1044 = 66%) лежат в четырех интервалах, охватывающих доходность от -2% до +6%. Всего у нас 396 отрицательных и 648 положительных результатов. Почти 62% ежемесячных результатов являются положительными.
Глядя на накопленную относительную частоту в последнем столбце, мы видим, что интервал от -2 процентов до 0% показывает накопленную частоту 37,93% для верхнего предела доходности 0%. Это означает, что 37,93% наблюдений лежат ниже уровня 0%. Мы также видим, что не так много наблюдений больше +12% или меньше -12%.
Обратите внимание, что распределение частот годовой и месячной доходности не является напрямую сопоставимым. В среднем следует ожидать, что показатели доходности, измеренные с более короткими интервалами (например, месяцы), будут меньше, чем показатели доходности, измеренные с более длительными периодами (например, годами).
Далее мы построим частотное распределение средней доходности с поправкой на инфляцию за 1900-2010 гг. для 19 основных фондовых рынков.
Пример построения частотного распределения для доходности акций основных фондовых рынков.
Как в конечном итоге акции вознаграждали инвесторов в разных странах?
Чтобы ответить на этот вопрос, мы могли бы непосредственно изучить среднюю годовую доходность.
Среднее или среднее арифметическое (англ. ‘arithmetic mean’) для набора значений равно сумме значений, деленной на количество суммируемых значений. Например, чтобы найти среднее арифметическое значение 111 ставок годовой доходности, мы суммируем 111 ставок годовой доходности, а затем делим итоговое значение на 111.
Однако размер номинального уровня доходности зависит от изменений покупательной способности денег, и на международном уровне всегда присутствуют разнообразные уровни инфляции цен. Поэтому предпочтительнее сравнивать среднюю реальную доходность или доходность с учетом инфляции, полученную инвесторами в разных странах.
Димсон, Марш и Стонтон (2011) представили авторитетные доказательства доходности активов в 19 странах за 111 лет 1900-2010. В Таблице 5 приводятся их выводы для средней доходности с поправкой на инфляцию.
|
Страна |
Среднее арифметическое (%) |
|---|---|
|
Австралия |
9.1 |
|
Бельгия |
5.1 |
|
Канада |
7.3 |
|
Дания |
6.9 |
|
Финляндия |
9.3 |
|
Франция |
5.7 |
|
Германия |
8.1 |
|
Ирландия |
6.4 |
|
Италия |
6.1 |
|
Япония |
8.5 |
|
Нидерланды |
7.1 |
|
Новая Зеландия |
7.6 |
|
Норвегия |
7.2 |
|
Южная Африка |
9.5 |
|
Испания |
5.8 |
|
Швеция |
8.7 |
|
Швейцария |
6.1 |
|
Объединенное Королевство |
7.2 |
|
Соединенные Штаты |
8.3 |
Источник: Dimson, Marsh, and Staunton (2011).
Таблица 6 суммирует данные Таблицы 5 в пять интервалов, охватывающих доходность от 5 до 10%. На 19 рынках относительная частота интервала доходности от 5,0 до 6,0% рассчитывается, например, как 3/19 = 15,79%.
|
Интервал доходности (%) |
Абсолютная частота |
Относительная частота (%) |
Накопленная абсолютная частота |
Накопленная относительная частота (%) |
|---|---|---|---|---|
|
5.0 до 6.0 |
3 |
15.79 |
3 |
15.79 |
|
6.0 до 7.0 |
4 |
21.05 |
7 |
36.84 |
|
7.0 до 8.0 |
5 |
26.32 |
12 |
63.16 |
|
8.0 до 9.0 |
4 |
21.05 |
16 |
84.21 |
|
9.0 до 10 |
3 |
15.79 |
19 |
100.00 |
Как видно из Таблицы 6, в мире наблюдается значительный разброс средней реальной доходности. Более четверти наблюдений приходится на интервал от 7,0 до 8,0%, который имеет относительную частоту 26,32%. 3 или 4 наблюдения попадают в каждый из остальных 4-х интервалов.
НАШИ относительная частота это очень важно для анализа статистики, так как показывает, какой процент представляют эти данные по отношению ко всем полученным результатам. Он используется для анализа результатов, полученных в заданном наборе данных.
Для его расчета достаточно разделить абсолютную частоту на суммарные полученные данные, и преобразовать этот результат в процент, умножаем на 100. Для статистического анализа данных очень часто строят таблицу с частотами, и в нее всегда помещается относительная частота каждых данных.
Узнать больше: Что такое статистические меры центральной тенденции?
Сводка по относительной частоте
-
Это тип частоты, изучаемый в статистике.
-
Это процент, который представляют данные данные по отношению к целому.
-
Обычно его представляют в процентах.
-
Для его расчета мы делим абсолютную частоту на общее количество полученных результатов.
-
Абсолютная частота — это количество раз, когда были собраны одни и те же данные.
-
В дополнение к простой относительной частоте существует кумулятивная относительная частота, которая представляет собой накопление относительной частоты.
Не останавливайся сейчас… После рекламы есть еще 
Что такое относительная частота?
относительная частота процент, который часть данных представляет по отношению к целому. В повседневной жизни довольно часто встречаются ситуации, когда информация передается через проценты. Этот процент часто является относительной частотой, поскольку он позволяет нам сравнивать поведение одной части данных по отношению к другим.
Например, если мы говорим, что в ходе опроса можно было сделать вывод, что 87% бразильцев против гражданского оружия, это позволяет оценить полученный результат по отношению к целому. Есть и другие ситуации, в которых мы используем относительную частоту, которая по-прежнему очень важна в статистика и в принятии решений. В статистических исследованиях после сбора данных важно рассчитать относительную частоту, чтобы можно было провести анализ полученных результатов.
Как рассчитывается относительная частота?
Чтобы вычислить относительную частоту, вам нужно:
-
найти абсолютную частоту;
-
разделите его на общее количество собранных данных.
Важный: Абсолютная частота — это не что иное, как количество раз, когда были собраны одни и те же данные.
Типы относительной частоты
Существует два типа относительной частоты: простая и кумулятивная. Начнем с первого.
-
простая относительная частота
Вот как рассчитать простую относительную частоту на примере.
Пример:
В классе с 50 учениками учитель физкультуры посоветовал им, какой вид спорта будет их любимым. Полученные ответы регистрировались по их абсолютной частоте:
-
футбол → 20 учеников
-
волейбол → 12 учеников
-
сожжено → 8 студентов
-
гандбол → 6 учеников
-
другие → 4 ученика
Разрешение:
Всего было собрано 50 ответов, поэтому для расчета относительной частоты каждого из них мы разделим количество появлений каждого ответа на 50.
Относительная частота:
-
футбол → 20: 50 = 0,4
-
волейбол → 12: 50 = 0,24
-
сожжено → 8: 50 = 0,16
-
гандбол → 6: 50 = 0,12
-
другие → 4: 50 = 0,08
Относительная частота может быть выражена десятичным числом, но обычно выражается в процентах. Чтобы преобразовать найденные десятичные числа в проценты, просто умножьте на 100, так что мы имеем:
-
футбол → 20: 50 = 0,4 = 40%
-
волейбол → 12: 50 = 0,24 = 24%
-
сожжено → 8: 50 = 0,16 = 16%
-
гандбол → 6: 50 = 0,12 = 12%
-
другие → 4: 50 = 0,08 = 8%
Эти данные обычно представляются в виде таблицы, известной как таблица частот:
|
Спорт |
абсолютная частота (ВЕНТИЛЯТОР) |
относительная частота (фр.) |
Относительная частота (%) (ФР%) |
|
Футбольный |
20 |
0,4 |
40% |
|
Волейбол |
12 |
0,24 |
24% |
|
Сгорел |
8 |
0,16 |
16% |
|
Гандбол |
6 |
0,12 |
12% |
|
Другие |
4 |
0,08 |
8% |
|
Всего |
50 |
1 |
100% |
-
Накопленная относительная частота
Как следует из названия, кумулятивная относительная частота накопление относительной частоты. Для его расчета необходимо сначала вычислить относительную частоту, как и в предыдущем примере.
С данными, организованными в таблице частот:
-
сначала вставляем в частотную таблицу еще один столбец;
-
затем копируем первую полученную относительную частоту;
-
мы выполняем в этом новом столбце и позже, чтобы найти другие накопленные частоты, сумму относительной частоты строки с накопленной частотой предыдущей строки.
|
Спорт |
абсолютная частота (ВЕНТИЛЯТОР) |
относительная частота (фр.) |
относительная частота накопленный |
|
Футбольный |
20 |
0,4 |
0,4 |
|
Волейбол |
12 |
0,24 |
0,4 + 0,24 = 0,64 |
|
Сгорел |
8 |
0,16 |
0,64 + 0,16 = 0,80 |
|
Гандбол |
6 |
0,12 |
0,80 + 0,12 = 0,92 |
|
Другие |
4 |
0,08 |
0,92 + 0,08 = 1 |
|
Всего |
50 |
1 |
Тогда мы можем отобразить таблицу частот следующим образом:
|
Спорт |
абсолютная частота (ВЕНТИЛЯТОР) |
относительная частота (фр.) |
относительная частота накопленный |
|
Футбольный |
20 |
0,4 |
0,4 |
|
Волейбол |
12 |
0,24 |
0,64 |
|
Сгорел |
8 |
0,16 |
0,80 |
|
Гандбол |
6 |
0,12 |
0,92 |
|
Другие |
4 |
0,08 |
1,00 |
|
Всего |
50 |
1 |
Эта кумулятивная относительная частота также может быть выражена в процентах:
|
Спорт |
Частота абсолютный (ВЕНТИЛЯТОР) |
Частота родственник (фр.) |
Частота родственник накопленный |
Частота родственник % (ФР%) |
Частота родственник накопленный % |
|
Футбольный |
20 |
0,4 |
0,4 |
40% |
40% |
|
Волейбол |
12 |
0,24 |
0,64 |
24% |
64% |
|
Сгорел |
8 |
0,16 |
0,80 |
16% |
80% |
|
Гандбол |
6 |
0,12 |
0,92 |
12% |
92% |
|
Другие |
4 |
0,08 |
1,00 |
8% |
100% |
|
Всего |
50 |
1 |
100% |
В чем разница между абсолютной частотой и относительной частотой?
Мы видим, что абсолютная частота сама по себе не дает нам столько информации, сколько относительная частота, потому что:
-
Абсолютная частота — это количество раз, когда один и тот же ответ появлялся для данного набора.
-
Относительная частота показывает отношение этих данных ко всем собранным данным.
Важный: Стоит отметить, что оба важны, и что можно рассчитать относительную частоту только тогда, когда мы знаем абсолютную частоту набора данных.
Читайте также: Меры разброса — амплитуда и девиация
Решенные упражнения на относительную частоту
Вопрос 1
(EsSA) Определите альтернативу, которая представляет абсолютную частоту (fi) элемента (xi), относительная частота (fr) которого равна 25%, а общее количество элементов (N) в выборке равно 72.
А) 18
Б) 36
В) 9
Г) 54
Д) 45
Разрешение:
Альтернатива А
Поскольку относительная частота составляет 25%, мы знаем, что
фи: 72 = 25%
фи: 72 = 0,25
фи = 0,25 ⋅ 72
фи = 18
вопрос 2
(Cesgranrio) В таблице ниже показана абсолютная частота диапазонов месячной заработной платы 20 сотрудников небольшой компании.
|
Диапазон заработной платы (BRL) |
Количество |
|
Менее 1000,00 |
6 |
|
Больше или равно 1000,00 и меньше 2000,00 |
7 |
|
Больше или равно 2000,00 и меньше 3000,00 |
5 |
|
Больше или равно 3000,00 |
2 |
|
Всего |
20 |
Относительная частота сотрудников, зарабатывающих менее 2000 реалов в месяц, составляет:
А) 0,07
Б) 0,13
В) 0,35
Г) 0,65
Д) 0,70
Разрешение:
Альтернатива D
Всего 6 + 7 = 13 сотрудников, которые зарабатывают менее 2000 реалов. Вычисляя относительную частоту, имеем:
13: 20 = 0,65
Элементы математической статистики
Математическая
статистика — наука о принятии решений
в условиях неопределённости. Задача
математической статистики– разработка
методов, позволяющих на основании
ограниченного числа экспериментальных
данных сделать заключение о законах
распределения С.В., а также о числовых
характеристиках распределения. В задачу
математической статистики входит также
указание способов сбора и группировки
статистических сведений, полученных в
результате наблюдений или специально
поставленных экспериментов. Она указывает
способы определения числа необходимых
испытаний для получения выводов о законе
распределения С.В. и числовых
характеристиках, т.е. решает задачи
планирования эксперимента.
Генеральная
и выборочная совокупности. Повторная
и бесповторная выборки. Репрезентативная
выборка.
Пусть
требуется изучить совокупность однородных
объектов относительно качественного
или количественного признака,
характеризующего эти объекты. Например,
для партии деталей качественным признаком
является стандартность детали, а
количественным признаком контролируемый
размер детали.
Генеральной
совокупностью называют
всю подлежащую изучению совокупность
объектов.
Если
совокупность содержит очень большое
число объектов, то провести сплошное
обследование невозможно. Если обследование
объекта связано с его уничтожением или
обследование требует больших материальных
затрат, то проводить сплошное обследование
практически не имеет смысла. В таких
случаях случайно отбирают из всей
совокупности ограниченное число
объектов и подвергают их изучению.
Выборкой
или выборочной совокупностью называют
совокупность случайно отобранных
объектов.
Объемом
совокупности (выборочной
или генеральной) называют число объектов
этой совокупности. Если число объектов
генеральной совокупности велико, то
иногда полагают, что генеральная
совокупность состоит из бесчисленного
множества объектов.
После
того как объект отобран и над ним
произведено наблюдение, он может быть
либо возвращен в генеральную совокупность,
либо нет.
Повторной
называют выборку,
при которой отобранный объект возвращается
в генеральную совокупность, а бесповторной
—
при которой он не возвращается
Для
того, чтобы по данным выборки можно было
уверенно судить об интересующей нас
характеристике генеральной совокупности,
необходимо, чтобы объекты выборки
правильно представляли эту характеристику.
Выборка должна правильно представлять
пропорции генеральной совокупности,
т.е. она должна быть репрезентативной
или представительной.
В
силу закона больших чисел можно
утверждать, что выборка
будет репрезентативной, если ее
осуществить случайно, т.е.
все
объекты генеральной совокупности имеют
одинаковую вероятность попасть в
выборку.
Простой статистический ряд. Вариационный ряд. Признак, варианта. Частоты, относительные частоты, накопленные частоты.
Полигон,
кумулята, гистограмма.
Пусть
![]() – случайная величина с неизвестным
– случайная величина с неизвестным
законом распределения. Она называется
в статистике признаком. Для изучения
С.В. получено![]() значений, т.е. произведено, например,
значений, т.е. произведено, например,![]() испытаний, в каждом из которых для
испытаний, в каждом из которых для
случайной величины получено определенное
значение.
Простым
статистическим рядом
называется таблица, в первой строке
которой указан номер испытания, а во
второй соответствующее значение С.В.
Вариантами
называются
значения С.В.
Простой
статистический ряд
|
Номер |
1 |
2 |
3 |
… |
|
|
Варианта |
|
|
|
… |
|
Пусть
![]() –
–
дискретная случайная величина. Расположим
все варианты в неубывающем порядке, а
затем рассмотрим только различные
варианты, расположенные в возрастающем
порядке, причем в простой статистический
ряд каждая из вариант входит соответственно![]() раз.
раз.
Частотами
распределения
называются числа
![]() .
.
Относительными
частотами распределения
называются числа
![]() ,
,
где![]() .
.
Накопленными
частотами распределения
называются числа
![]() ,
,
где![]() .
.
Накопленными
относительными частотами распределения
называются числа
![]() ,
,
где![]() .
.
В
теории вероятностей распределение С.В.
– соответствие между возможными
значениями С.В. и их вероятностями.
В
математической статистике распределение
– соответствие между наблюдаемыми
вариантами и их частотами.
Упорядоченным
статистическим рядом или вариационным
рядом
для дискретного распределения называется
следующая таблица
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #