Работая с текстом, особенно с большими объемами, зачастую необходимо найти слово или кусок текста. Для этого можно воспользоваться поиском по тексту в Ворде. Существует несколько вариантов поиска в Word:
- Простой поиска, через кнопку «Найти» (открывается панель Навигация);
- Расширенный поиск, через кнопку «Заменить», там есть вкладка «Найти».
Самый простой поиск в ворде – это через кнопку «Найти». Эта кнопка расположена во вкладке «Главная» в самом правом углу.

! Для ускорения работы, для поиска в Ворде воспользуйтесь комбинацией клавишей: CRL+F
После нажатия кнопки или сочетания клавишей откроется окно Навигации, где можно будет вводить слова для поиска.

! Это самый простой и быстрый способ поиска по документу Word.
Для обычного пользователя большего и не нужно. Но если ваша деятельность, вынуждает Вас искать более сложные фрагменты текста (например, нужно найти текст с синим цветом), то необходимо воспользоваться расширенной формой поиска.
Расширенный поиск в Ворде
Часто возникает необходимость поиска слов в Ворде, которое отличается по формату. Например, все слова, выделенные жирным. В этом как рас и поможет расширенный поиск.
Существует 3 варианта вызова расширенного поиска:
- В панели навигация, после обычного поиска

- На кнопке «Найти» нужно нажать на стрелочку вниз

- Нужно нажать на кнопку «Заменить» , там выйдет диалоговое окно. В окне перейти на вкладку «Найти»

В любом случае все 3 варианта ведут к одной форме – «Расширенному поиску».
Как в Word найти слово в тексте – Расширенный поиск
После открытия отдельного диалогового окна, нужно нажать на кнопку «Больше»

После нажатия кнопки диалоговое окно увеличится

Перед нами высветилось большое количество настроек. Рассмотрим самые важные:
Направление поиска
В настройках можно задать Направление поиска. Рекомендовано оставлять пункт «Везде». Так найти слово в тексте будет более реально, потому что поиск пройдет по всему файлу. Еще существуют режимы «Назад» и «Вперед». В этом режиме поиск начинается от курсора и идет вперед по документу или назад (Вверх или вниз)

Поиск с учетом регистра
Поиск с учетом регистра позволяет искать слова с заданным регистром. Например, города пишутся с большой буквы, но журналист где-то мог неосознанно написать название города с маленькой буквы. Что бы облегчить поиск и проверку, необходимо воспользоваться этой конфигурацией:

Поиск по целым словам
Если нажать на вторую галочку, «Только слово целиком», то поиск будет искать не по символам, а по целым словам. Т.е. если вбить в поиск только часть слова, то он его не найдет. Напимер, необходимо найти слово Ворд, при обычном поиске будут найдены все слова с разными окончаниями (Ворде, Ворду), но при нажатой галочке «Только слова целиком» этого не произойдет.

Подстановочные знаки
Более тяжелый элемент, это подстановочные знаки. Например, нам нужно найти все слова, которые начинаются с буквы м и заканчиваются буквой к. Для этого в диалоговом окне поиска нажимаем галочку «Подстановочные знаки», и нажимаем на кнопку «Специальный», в открывающемся списке выбираем нужный знак:

В результате Word найдет вот такое значение:

Поиск омофонов
Microsoft Word реализовал поиск омофонов, но только на английском языке, для этого необходимо выбрать пункт «Произносится как». Вообще, омофоны — это слова, которые произносятся одинаково, но пишутся и имеют значение разное. Для такого поиска необходимо нажать «Произносится как». Например, английское слово cell (клетка) произносится так же, как слово sell (продавать).

! из-за не поддержания русского языка, эффективность от данной опции на нуле
Поиск по тексту без учета знаков препинания
Очень полезная опция «Не учитывать знаки препинания». Она позволяет проводить поиск без учета знаков препинания, особенно хорошо, когда нужно найти словосочетание в тексте.

Поиск слов без учета пробелов
Включенная галочка «Не учитывать пробелы» позволяет находить словосочетания, в которых есть пробел, но алгоритм поиска Word как бы проглатывает его.

Поиск текста по формату
Очень удобный функционал, когда нужно найти текст с определенным форматированием. Для поиска необходимо нажать кнопку Формат, потом у Вас откроется большой выбор форматов:

Для примера в тексте я выделил Жирным текст «как найти слово в тексте Word». Весть текст выделен полужирным, а кусок текста «слово в тексте Word» сделал подчернутым.
В формате я выбрал полужирный, подчеркивание, и русский язык. В итоге Ворд наше только фрагмент «слово в тексте». Только он был и жирным и подчеркнутым и на русском языке.

После проделанных манипуляция не забудьте нажать кнопку «Снять форматирование». Кнопка находится правее от кнопки «Формат».
Специальный поиск от Ворд
Правее от кнопки формат есть кнопка «Специальный». Там существует огромное количество элементов для поиска
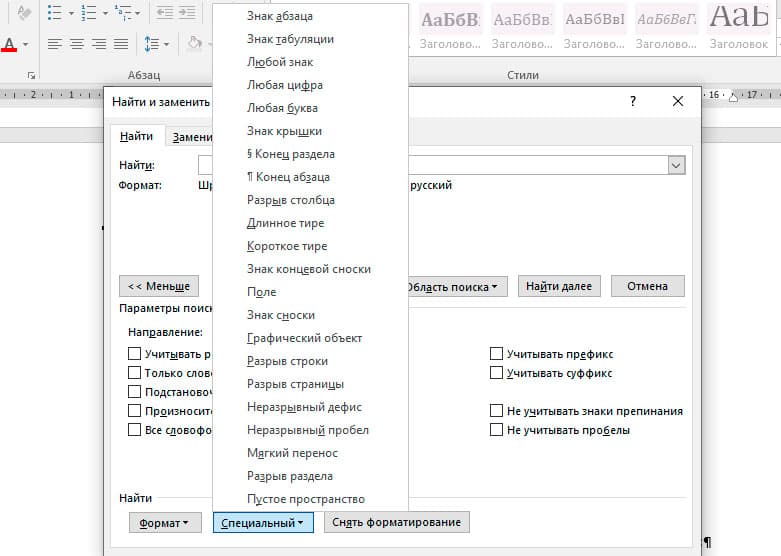
Через этот элемент можно искать:
- Только цифры;
- Графические элементы;
- Неразрывные пробелы или дефисы;
- Длинное и короткое тире;
- Разрывы разделов, страниц, строк;
- Пустое пространство (особенно важно при написании курсовых и дипломных работ);
- И много других элементов.
Опции, которые не приносят пользы
!Это мое субъективное мнение, если у вас есть другие взгляды, то можете писать в комментариях.
- Опция «произносится как». Не поддержание русского языка, делает эту опцию бессмысленной;
- Опция «все словоформы», опция полезная при замене. А если нужно только найти словоформы, то с этим справляется обычный поиск по тексту;
- Опция «Учитывать префикс» и «Учитывать суффикс» – поиск слов, с определенными суффиксами и префиксами. Этот пункт так же полезен будет при замене текста, но не при поиске. С этой функцией справляется обычный поиск.
Как найти что-то в тексте
Время на прочтение
8 мин
Количество просмотров 5.5K
Найти объект или распознать понятие в тексте — с этого начинается решение большинства NLP задач. Если вы проектируете поисковую систему, создаете голосового помощника или классифицируете пользовательские запросы, прежде всего вы должны разобрать входной текст и попытаться найти в нем именованные сущности, которые могут быть универсальными, такими как даты, страны и города, или специфичными для конкретной модели. Обратите внимание, мы сейчас говорим лишь о тех видах задач, для которых заранее известно, что именно вы ищете или что может встретиться в тексте.
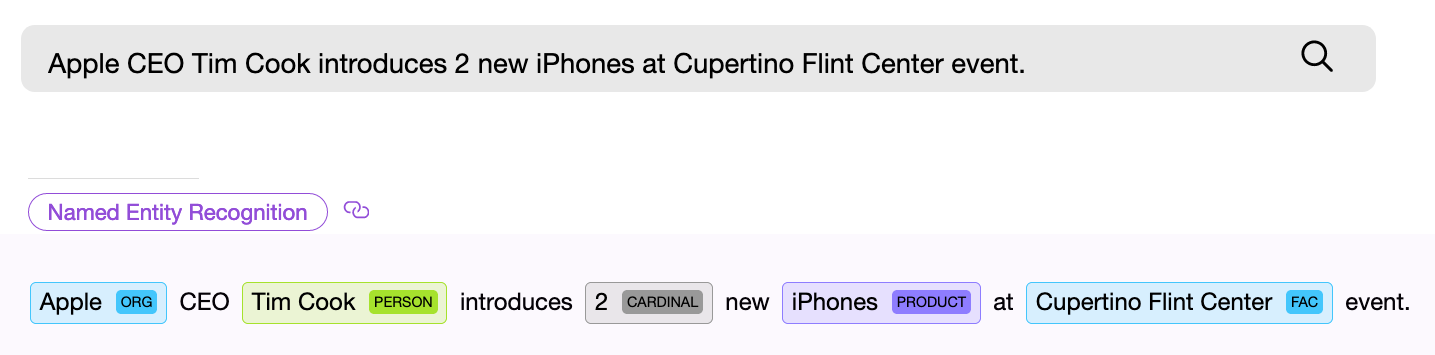
NER (named entity recognition) компонент, то есть программный компонент для поиска именованных сущностей, должен найти в тексте объект и по возможности получить из него какую-то информацию. Пример — “Дайте мне двадцать две маски”. Числовой NER компонент находит в приведенном тексте словосочетание “двадцать две” и извлекает из этих слов числовое нормализованное значение — “22”, теперь это значение можно использовать.
NER компоненты могут базироваться на нейронных сетях или работать на основе правил и каких-либо внутренних моделях. Универсальные NER компоненты часто используют второй способ.
Рассмотрим несколько готовых решений по поиску стандартных сущностей в тексте. В данной заметке мы остановимся на бесплатных или бесплатных с ограничениями библиотеках, а также расскажем о том, что сделано в проекте Apache NlpCraft в рамках данной проблематики. Представленный ниже список не является подробным и обстоятельным обзором, которых и так достаточное количество в сети, а скорее кратким описанием основных особенностей, плюсов и минусов использования этих библиотек.
Провайдеры NER компонентов
Apache OpenNlp
Apache OpenNlp предоставляет для английского языка достаточно стандартный набор NER компонентов, работающих с датами, временем, географией, организациями, числовыми процентами и персонами. Имеется небольшой набор и для других языков (испанский, голландский).
Поставка:
Java библиотека. Apache OpenNlp не поставляет модели вместе с основным проектом. Они доступны для скачивания отдельно.
Плюсы:
Apache лицензия. Модели протестированы на множестве внедрений.
Минусы:
Судя по всему, модели недаром вынесены из основного проекта. Складывается впечатление, что работа над ними или остановлена или идет в удручающе неторопливом темпе, так как новых моделей или изменений в существующих не видно уже довольно давно. Так как пользователи Apache OpenNlp могут создавать и тренировать свои собственные модели, возможно эта задача фактически полностью переложена на них.
Stanford Nlp
Stanford NLP — живой, постоянно развивающийся продукт отличного качества и широких возможностей. Для английского языка добавлена поддержка распознавания следующих сущностей: person, location, organization, misc, money, number, ordinal, percent, date, time, duration, set. Кроме того встроенный Regex NER компонент позволяет находить с высокой степенью точности такие сущности как: email, url, city, state_or_province, country, nationality, religion, (job) title, ideology, criminal_charge, cause_of_death, handle. Подробнее по ссылке. Заявлена поддержка ограниченного набора NER для немецкого, испанского и китайского языков. Качество распознавания можно попробовать с помощью онлайн демо.
Поставка:
Java библиотека. Модели можно загрузить из мавен вместе с проектом.
Я нигде не нашел перечня и детального описания NER компонентов для языков отличных от английского. По ссылкам 1, 2 — приведены примеры процесса тренировки собственных NER компонентов для разных языков. Проще говоря, возможность использовать другие языки заявлена, но придется повозиться.
Плюсы:
Ощущение от работы с проектом в целом и с готовыми моделями самое позитивное, проект живет и развивается, качество распознавания хорошее (”хорошее” — понятие условное, существуют метрики, характеризующие качество распознавания NER компонентов, но данный вопрос выходит за рамки статьи).
Минусы:
Помимо некоторого хаоса с документаций, они небольшие. Кому это важно, обратите внимание на лицензию. GNU General Public License отличается от Apache, так, например, вы не можете добавить продукт с данной лицензией в продукты, лицензируемые под Apache и т. д.
Google Language API
Google language API для английского языка поддерживает следующий список сущностей: person, location, organization, event, work_of_art, consumer_good, other, phone_number, address, date, number, price.
Платформа:
REST API, SaaS. Доступны готовые клиентские библиотеки над REST (Java, C#, Python, Go и т. д.).
Плюсы:
Большой набор NER компонентов, развитие и качество обеспечивается всем известным интернет гигантом.
Минусы:
Начиная с определенных объемов, использование платное.
Spacy
Данная библиотека предоставляет один из наиболее широких наборов поддерживаемых для распознавания сущностей, по ссылке список поддерживаемых.
Платформа:
Python.
К сожалению отсутствие личного опыта промышленного использования не позволяет мне добавить реальное описание плюсов и минусов данной библиотеки. К тому же подробный обзор питоновских NLP решений уже опубликован на habr.
Все вышеперечисленные библиотеки позволяют обучать собственные модели. Также все из них (кроме Apache OpenNlp) позволяют извлекать нормализованные значения из найденных сущностей, то есть, например, получить число “173“ из найденной в запросе числовой сущности “сто семьдесят три“.
Как мы видим вариантов решения задачи нахождения именованных сущностей представлено множество, направление их развития очевидно — расширение списка поддерживаемых языков и набора распознаваемых сущностей, улучшение качества распознавания.
Ниже описано, что привнес проект Apache NlpCraft в данную, уже широко проработанную область.
Дополнительные возможности предоставляемые NlpCraft
- Собственные NER компоненты для новых сущностей, улучшенные варианты решения для некоторых уже существующих.
- Интеграция NER компонентов всех вышеперечисленных библиотек в рамках использования продукта.
- Поддержка “составных сущностей“, что дает пользователям простую возможность создания новых собственных компонентов на основе уже имеющихся.
Теперь обо всем этом чуть подробнее.
Собственные NER компоненты
Собственные NER компоненты Apache NlpCraft — это компоненты распознавания дат, чисел, географии, координат, сортировки и сопоставления разных сущностей. Часть из них уникальна, часть — лишь улучшенная реализация существующих решений (повышена точность распознавания, добавлены дополнительные поля значений и т. д.).
Интеграция существующих решений
Все перечисленные выше решения интегрированы для использования в Apache NlpCraft.
При работе с проектом пользователю достаточно подключить нужный модуль и указать в конфигурации какие именно NER компоненты должны быть задействованы при поиске сущностей конкретной модели.
Ниже приведен пример конфигурации, для которой при поиске в тексте используется четыре различных NER компонента от двух провайдеров:
"enabledBuiltInTokens": [
"nlpcraft:num",
"nlpcraft:coordinate",
"google:organization",
"google:phone_number"
]
Подробнее об использовании Apache NlpCraft написано здесь. Для использования Google Language API необходим действующий Google developer account.
Поддержка составных сущностей
Поддержка составных сущностей — самая интересная из вышеперечисленных возможностей, остановимся на ней немного подробнее.
Составная сущность — это сущность определенная на основе другой. Рассмотрим пример. Пусть вы разрабатываете NLP систему управления, основанную на интентах (см. Alexa, Google Dialogflow, Алиса, Apache NlpСraft и т. д.), и пусть ваша модель работает с географией, но только для США. Вы можете взять любой компонент для поиска географии, например ”nlpcraft:city”, и использовать его напрямую.
Далее, при срабатывании интента, вы в соответствующей ему функции (callback), должны проверить значение поля ”country”, и если оно не удовлетворяет требуемым условиям, завершить работу функции, предотвращая ложное срабатывание. Далее вы должны вернуться к матчингу и попытаться выбрать другую, более подходящую функцию.
Что не так в данном подходе:
- Вы значительно усложняете работу с вызываемыми функциями, передавая управление из них в основной рабочий поток и обратно. Кроме того стоит учесть, что подобным функционалом передачи управления обладают далеко не все диалоговые системы.
- Вы размазываете логику матчинга между интентом и кодом исполняемого метода.
Хорошо… Вы можете с нуля создать свой собственный NER компонент по поиску американских городов, но эта задача решается не за пять минут.
Попробуем иначе. Вы можете усложнить интент (в тех системах где это возможно) и искать города, дополнительно отфильтрованные по стране. Но, повторюсь, возможность сложной фильтрации по полям элементов предоставляют далеко не все системы, кроме того вы усложняете интенты, которые должны быть максимально понятными и простыми, особенно если их много в проекте.
Apache NlpCraft предлагает механизм определения собственных NER компонентов на основе уже существующих. Ниже приведен пример конфигурации (полный синтаксис DSL доступен по ссылке, пример создания элементов — тут):
"elements": [
{
"id": "custom:city:usa",
"description": "Wrapper for USA cities",
"synonyms": [
"^^id == 'nlpcraft:city' && lowercase(~city:country) == 'usa')^^"
]
}
]
В данном примере мы описываем новую именованную сущность “американский город“ — “custom:city:usa”, основанную на уже существующей “nlpcraft:city”, отфильтрованной по определенному критерию.
Теперь вы можете создавать интенты, опирающиеся на созданный новый элемент, а встреченные в тексте города за пределами США не вызовут нежелательного срабатывания ваших интентов.
Еще пример:
"macros": [
{
"name": "<AIRPORT>",
"macro": "{airport|aerodrome|airdrome|air station}"
}
],
"elements": [
{
"id": "custom:airport:usa",
"description": "Wrapper for USA airports",
"synonyms": [
"<AIRPORT> {of|for|*} ^^id == 'nlpcraft:city' &&
lowercase(~city:country) == 'usa')^^"
]
}
]
В данном примере мы определили именованную сущность “городской аэропорт в США“ — “custom:airport:usa”. При определении этого элемента мы не только отфильтровали города по признаку принадлежности к государству, но и задали дополнительное правило, по которому названию города должен предшествовать какой-либо синоним, определяющий понятие “аэропорт”. (Подробнее о создании синонимов элементов через макросы — тут).
Составные элементы могут быть определены с любой степенью вложенности, то есть при необходимости вы можете спроектировать новые элементы на базе только что созданного “custom:airport:usa”. Также обратите внимание на то, что все нормализованные значения родительских сущностей, в данном случае базового элемента “nlpcraft:city”, доступны также в элементе “custom:airport:usa”, и могут быть использованы в теле функции сработавшего интента.
Разумеется, “составные элементы“ можно определять не только для всех поддерживаемых стандартных компонентов от OpenNlp, Stanford, Google, Spacy и NlpCraft, но и для пользовательских NER компонентов, расширяя их возможности и позволяя переиспользовать уже имеющиеся программные наработки.
Обратите внимание, фактически вы не плодите новые компоненты для каждой новой задачи, а просто конфигурируете их или “подмешиваете” их функционал в собственные элементы.
Таким образом, используя “составные сущности“ разработчик может:
- Значительно упростить логику построения интентов путем ее частичного переноса в переиспользуемые составные элементы.
- С помощью изменений конфигурации получить NER компоненты с новым поведением без обучения моделей или кодирования.
- Переиспользовать уже готовые решения с ожидаемым качеством, опираясь на существующие тесты или метрики.
Заключение
Надеюсь, что краткий обзор плюсов и минусов существующих NER компонентов будет полезен читателям, а понимание того, как с помощью Apache NlpCraft можно существенно расширить их возможности и адаптировать имеющиеся решения для новых задач, ускорит процесс разработки ваших проектов.
Надоело подолгу искать ответы в сети? Предлагаю вашему вниманию 4 способа быстро и правильно найти любую информацию в сети Интернет, с которыми поиск станет намного удобней. Приятного просмотра!
Поиск в сети Интернет. Введение

Как долго вы ищите нужный материал в Google или Яндекс? Лично у меня поиск может занимать от десятка секунд до часа. И дело вовсе не в том, что я не умею правильно составлять запросы, а в низком качестве статей в топе поисковой выдачи.
Это не абсолютное утверждение. Иногда полезные статьи находятся сразу. Но многие, особенно с кликбейтными заголовками, лишь попусту тратят время читателя. Во времена, когда сотни тысяч книг находятся в свободном доступе, а сеть ежедневно пополняется авторскими блогами, всё это выглядит дико и смешно. Хочу чуть-чуть развеять «туман войны» над сёрфингом в сети интернет и поделюсь тем, что может хоть немного, но улучшить ваши результаты.
Или намного. Увы, абсолютного решения не существуют, есть лишь удобные системы без рекламной выдачи, да способы конкретизировать запросы. Обо всём этом я и пишу ниже.

Способ № 1 — использование различных поисковых систем
Самый банальный совет из всех, но тем не менее весьма действенный. Поиск в Google и Яндекс может давать абсолютно разные результаты.
Например, Яндекс лучше работает с выдачей изображений, публикуемых на территории России, Google лучше выдаёт ссылки на страницы художников и фиксированные запросы. Меньше рекламного спама - в Google, особенно по региональным запросам внутри РФ. Наверное, это связано с тем, что большая часть издателей и SMM специалистов до сих пор предпочитает Яндекс, хотя Google уже давно переплюнул русскоязычную ПС по количеству запросов из России.
У «традиционных» поисковых систем есть существенные минусы. И Google, и Яндекс по умолчанию ориентируются на географическое положение пользователя, выдавая наиболее «подходящие» (по мнению алгоритма поисковой системы) ссылки. Для покупок в маленьком приморском магазинчике это будет плюсом, а вот если вы хотите найти что-то «честно», не разогнанное искусственно поисковой оптимизацией, тогда стоит обратиться к «тёмной лошадке» всея даркнета — DuckDuckGo.
Несмотря на то, что данную поисковую систему активно использует Tor, а также некоторые самописные решения, DDG отлично подходит для сёрфинга в сети Интернет без отслеживания поведения и навязчивой рекламы. Ни того, ни другого в поисковой сети нет от слова "совсем"! В DuckDuckGo поиск по умолчанию не зависит от географического положения, хотя вы также можете его конкретизировать, выбрав страну по умолчанию (Япония, Китай, США, Россия - всё, что вам понадобится в текущий момент времени). Как по мне, возможность быстро сменить нужный регион - отличная идея!
Минусы в DDG тоже есть. Далеко не вся информация индексируется поисковой системой, так что вместо десятков публикаций, выдаваемых в Google или Яндекс, вы можете найти 3-4. С другой стороны, многие результаты, выдаваемые в DuckDuckGo, вообще не встречаются в других поисковых системах, в том числе из-за отсутствия такой тщательной модерации.
Тем, кому полюбилась одна из систем, а желания искать что-то новое нет и не предвидится, рекомендую узнать, не обладает ли она узкоспециальными средствами поиска. Например, инструмент Google Scholar позволяет искать только по онлайн-хранилищам научных центров, университетов, академических издательств.
Способ № 2: исследование ссылок в сети Интернет
Вместо того, чтобы пытаться вдумчиво прочитать весь текст, достаточно пробежать первые 3-4 абзаца глазами, либо промотать текст сразу ближе к середине. Нет ничего подходящего — пока-пока, пора ехать дальше.
Также можно открыть сразу несколько ссылок и чуть-чуть автоматизировать процесс поиска. Например, в Mozilla Firefox достаточно нажать комбинацию клавиш CTRL + F, чтобы вылезло меню поиска на странице. Его понадобится вызывать на каждой открываемой странице, зато поиск запоминает введённое слово или фразу.
То, что вы введёте в поисковую строку, будет подсвечиваться зелёным цветом. Это заметно облегчает поиск по странице, особенно для фиксированных вопросов. Не нашли нужного в тексте - либо ответ на вопрос даётся без описания самого поискового запроса или, что намного вероятнее, статья - явный пример кликбейта.
Способ № 3: уточнение и формулирование поисковых запросов
Из-за размытых формулировок поиск в сети Интернет выдаёт совсем не те результаты, на которые здравомыслящему человеку стоит обращать внимание. Балансируйте между лаконичностью запроса и его детальностью, и получите самый лучший ответ.
Например, можно добавлять точную дату, модель техники, место происшествия, географические координаты, даже хэштеги могут пригодиться, чтобы конкретизировать запрос и сделать его точнее! Отмечу, что в затруднительной ситуации стоит попробовать составить несколько запросов, в том числе и переставив слова местами, изменив склонение, сократив предложение или же добавив пару слов.
Способ № 4: использование модификаторов (операторов поиска в сети Интернет)
Использование операторов (часто называемых в сети Интернет «модификаторами») – самая «вкусная» часть техники построения поисковых запросов, позволяющая получать точные результаты при поиске чего угодно.
Продуктивность "операторов поиска", также известных под видом "операторов поисковых систем" осуществляется за счёт возможности ограничения или расширения области поиска отдельными доменами, языками, типами файлов, временем изменения записей. Возможности акцентирования запросов практически ничем не ограничены, кроме вашего свободного времени и понимания, как именно применяются модификаторы.
Операторы поисковых запросов, позволяющие сделать поиск точнее, конкретнее и быстрее. Детальный список.
Часть 1: модификаторы, общие для большей части поисковых систем (Яндекс, Google и т.д.)
Операторы «+» и «-».
Пригодятся для поиска документов, которые обязательно должны содержать (или в которых обязательно должны отсутствовать) указанные слова. Можно использовать несколько операторов в одном запросе, причём как «плюс», так и «минус». После оператора «минус» или «плюс» не ставится пробел.Пример: «Средние века -Википедия».
Оператор «» (поиск по содержимому цитаты).
При использовании поисковая система будет искать ссылки с точным совпадением всех слов, указанных в кавычки. Можно задавать несколько раз в рамках одного запроса, а также добавить «плюс» или «минус», чтобы ещё лучше конкретизировать запрос (например, убрать ссылку на «Википедию», как в приведённом выше примере).
Оператор «ИЛИ». Равнозначные значения: OR, «вертикальная черта» (|). Обратите внимание, что данный оператор всегда записывается заглавными буквами.
В данном случае система поиска подбирает результаты, содержащие любое из слов, связанных с этим оператором, иначе говоря, несколько вариантов необходимой информации. Пример: «Кошки лысые | короткошёрстные».
Часть 2: модификаторы поиска для Google
Список операторов:
1) «..» («две точки»). Используется для поиска диапазонов между числами. Например, его можно использовать для поиска товара с оптимальной ценой, указав до и после точек минимальную и максимальную цену предполагаемого товара. Цифры до и после точек ставятся без пробелов;
2) «@». Используется для поиска данных из различных социальных сетей, например, Twitter или Instagram;
3) «#». Позволяет осуществлять поиск по хештегам;
4) «~» («тильда»). Используется для поиска документов с указанными словами или их синонимами;
5) «*». Применяется для указания пропущенных или неизвестных слов в запросе, ставится на место искомого слова. Пример: «Парк * периода»;
6) «site:». Применяется для поиска по указанному сайту или домену;
7) «link:». Осуществляет поиск страниц со ссылками на выбранный сайт;
 «related:». Осуществляет подбор страниц, похожих по содержимому на сравниваемый ресурс;
«related:». Осуществляет подбор страниц, похожих по содержимому на сравниваемый ресурс;
9) «info:». Используется для получения сведений о веб-адресе, включая ссылки на кэшированные страницы, аналогичные сайты, страницы со ссылками на выбранный пользователем сайт и тому подобными данными;
10) «cache:». Используется для просмотра последней кэшированной версии выбранного электронного ресурса;
11) «filetype:». Применяется для поиска по выбранному типу файлов, может использоваться с другими модификаторами поиска;
12) «movie:». Используется для поиска информации о выбранном кино или клипе;
13) «daterange:». Используется для поиска страниц, проиндексированных Google за определённый пользователем период времени;
14) «allintitle:». Производит поиск таких страниц, в которых слова запроса находятся в заголовке;
15) «intitle:». Практически то же самое, но часть запроса может содержаться и в других частях страницы;
16) «allinurl:». Применяется для поиска сайтов, содержащих все слова, упомянутые в url;
17) «inurl:». Осуществляет поиск сайтов, содержащих слово, упомянутое в выбранном пользователем url;
18) «allintext:». Реализует поиск по определённому тексту;
19) «intext:». Выполняет поиск по определённому слову из выбранного текста;
20) «define:». Производит поиск сайтов, содержащих определение выбранного слова или выражения.
Часть 3: модификаторы, применяемые поисковой системой Bing
Список операторов:
1) «contains:». Применяется для демонстрации результатов с сайтов, которые содержат ссылки на выбранные типы файлов;
2) «ip:». Позволяет искать сайты, размещённые на определённом IP-адресе;
3) «ext:». Демонстрирует только такие веб-адреса, в которых содержится указанное пользователем расширение;
4) «loc:». Осуществляет поиск сайтов из определённой страны или региона;
5) «url:». При использовании в поисковой системе Bing проверяет, был ли проиндексирован указанный пользователем сайт.
Часть 4: модификаторы, применяемые поисковой системой Яндекс
Список операторов:
1) «!» («восклицательный знак»). Производит поиск документов, содержащих слово или выражение в заданной пользователем форме;
2) «!!». Осуществляет поиск ресурсов, содержащих выбранные слова или фразы в любых формах и падежах;
3) «&». Позволяет осуществить поиск сайтов, содержащих указанные слова в одном предложении;
4) «&&». Производит поиск сайтов, содержащих выбранные слова в пределах одной страницы сайта или документа;
5) «()» («скобки»). Применяется для формирования сложных запросов. Внутри скобок могут содержаться любые другие операторы и запросы;
6) «title:». Осуществляет поиск по заголовкам сайтов;
7) «url:». Осуществляет поиск по выбранному пользователем url;
«site:». Производит поиск по всем страницам, разделам и доменам сайта;
9) «domain:». Реализует поиск по всем страницам и разделам, размещённым на указанном домене;
10) «mime:». Осуществляет поиск по документам, совпадающим с указанным типом файлов;
11) «lang:». Осуществляет поиск сайтов и страниц на выбранном языке;
12) «date:». Производит поиск сайтов и страниц по дате последнего внесённого изменения. При этом необходимо в обязательном порядке указывать год изменения, день и месяц можно заменить символом *;
13) «cat:». Реализует поиск сайтов и страниц сайтов, зарегистрированных в каталоге Яндекс, чья тематическая рубрика или регион совпадают с заданными пользователем параметрами;
14) «Intext». Осуществляет поиск сайтов и документов, текст в которых полностью содержит слова из поискового запроса, таким образом, поиск осуществляется именно в тексте сайтов, а не в метатегах или наименовании;
15) «image». Производит поиск ссылок, включающих в себя изображения, совпадающих с введённым пользователем наименованием;
16) «Linkmus». Производит поиск страниц, включающих в себя ссылки на музыкальные файлы, указанные в поиске пользователем;
17) «Inlink». Осуществляет поиск ссылок в тексте сайта;
18) «Linkint». Реализует поиск ссылок внутри сайта по указанному пользователем документу;
19) «Anchorint». Производит поиск документов в тексте ссылок на внутренние документы сайта, в которых содержится необходимый пользователю материал;
20) «idate». Осуществляет поиск документов по выбранной дате индексации;
Часть 5: модификаторы, применяемые поисковой системой DuckDuckGo
Список операторов:
1) «images». Применяется, когда необходимо осуществить поиск по картинкам;
2) «news». Осуществляет поиск по новостям с заданным пользователем наименованием;
3) «map». Позволяет отображать заданный пользователем запрос на страницах OpenStreetMap;
4) «site:». Поиск на страницах указанного пользователем сайта;
5) «f:». Поиск файлов (тип файлов указывается пользователем в запросе);
6) «ip». Вывод информации о IP-адресе пользователя;
7) «@». Поиск информации по социальным сетям;
«validate». Помогает определить актуальность электронной почты или адреса сайта;
9) «shorten». Используется для генерирования коротких ссылок для сайтов или статей;
10) «password». Применяется для создания паролей указанной пользователем длины;
11) «countdown». Позволяет задать таймер на нужное время.
Ещё одной особенностью DuckDuckGo является «!Bangs» - специальный тип запросов, позволяющих искать информацию сразу на определённых сайтах, не покидая поисковую систему. Запросы оформлены в виде коротких наименований, начинающихся с символа «!».
На сегодняшний день в DuckDuckGo используется больше 13000 вариантов «!Bangs», записанных в специальном разделе DuckDuckGo и генерирующих короткие ссылки для расширенного поиска. Более того, пользователи могут самостоятельно добавить сайты и запросы (для личных сайтов) в поисковую систему.
Примеры специализированных модификаторов поиска («!Bangs»), действующих только в DuckDuckGo

1) «!W» — Поиск на «Википедии». Находит страницы как на русском, так и на других языках. Пример использования: «Викка !W» отправит пользователя напрямую на страницу, содержащую поисковый запрос «Викка»;
2) «!yt» — используется для поиска на YouTube;
3) «!lh» — Lifehacker;
4) «!yaw» — поиск на ресурсе «Яндекс.Погода»;
5) «!pdf» — поиск по ресурсам, содержащим выбранное пользователем название pdf;
6) «!gphotos» — поиск по базе фотографий в Google;
7) «!flickr» — поиск фотографий на Flickr;
«!pixiv» — поиск по названию или типу артов, размещённых на страницах Pixiv;
9) «!tr» — перевод фразы на Google Translate (без указания языка);
10) «!gten» — перевод фразы на английский;
11) «!gtru» — перевод фразы на русский;
12) «!inbox» — поиск на почтовом ящике gmail;
13) «!tw» — поиск на просторах социальной сети Twitter;
14) «!vk» — поиск в социальной сети «Вконтакте»;
15) «!p» или «!pin» — используется для поиска на просторах Pinterest;
16) «!youtube2mp3» — позволяет конвертировать видео с YouTube в формат mp3 (выдаёт ссылку на сайт для конвертирования, добавлять к !Bang что-либо ещё — бессмысленно);
17) «!similarweb» — используется для проверки посещаемости веб-сайта;
18) «!2gis» — ищет информацию на картах 2ГИС;
19) «!map» — применяется для поиска на Goggle Map;
20) «!mih» — поиск на картах от сервиса Mum I’m Here;
21) «!med» — поиск на страницах Medium;
22) «!dauser» — поиск по DeviantArt;
23) «!astock» — поиск стоковых изображений на Adobe Stock;
24) «!da» — ещё один вариант поиска по DeviantArt.
Использование !Bangs и модификаторов для поиска ответов в сети Интернет. Вывод
Перечислять все ресурсы, включенные в список DDG, дело бессмысленное. Самые крупные сайты сгруппированы по разделах (Multimedia, Books, Docs и другие, вы можете посмотреть их самостоятельно), ещё больше не включены в какие-либо списки и находятся либо экспериментально, либо в описании сайтов, их использующих.
Например, я подумываю реализовать !Bang «!tengyart», но пока дальше желания дело не заходит.
Вне зависимости от того, будете ли вы использовать модификаторы поисковых систем Яндекс, Bing, Google, либо доверитесь !Bangs DuckDuckGo, я уверен, что вы сможете "выжать" из поиска больше полезной информации или как минимум отсеять ненужный "информационный шум". Не бойтесь комбинировать разные методы и ПС, но помните, что главное - это результат поиска!
Про время тоже не стоит забывать. Как бы ни были функциональны дополнительные возможности, в большей части случаев достаточно и обычного беглого поиска. Надеюсь, эти советы помогут вам разве что в самой критической ситуации, а в остальных случаях вы найдёте то, что ищите, с первой же попытки и с минимальными затратами времени. Успехов вам и спасибо за внимание!
Понравилась статья? Делитесь публикацией с друзьями, пишите комментарии, подписывайтесь на Telegram, Boosty и другие страницы, чтобы первыми видеть всё самое интересное!
Читайте также:
- Как вернуть старый дизайн Twitter в 2019 году? Инструкция
- Что делать, если интерфейс League of Legends мерцает?
- Эпичный индийский метал: 9 клипов группы “Bloodywood”
- Как удалить featured images из AMP страниц WordPress?
В разных версиях MS Word кнопка «поиск» находится в разных местах. В первоначальных версиях ее можно было найти в одной из вкладок, а в последней версии она находится справа вверху во вкладке «Главная».
Можно воспользоваться сочетанием клавиш «Ctrl+F».
В любом случае откроется окно с возможностью введения искомого слова. Однако следует обратить внимание, что у многих слов в тексте могут быть разные формы, например, разные окончания у существительных. Поэтому в поисковую строку лучше вводить не слово целиком, а его основу. Тогда поиск будет более основательным и сможет охватить все формы искомого слова.
Ну, а чтобы осуществить непосредственно поиск, ищем кнопку «искать далее». При каждом нажатии на нее система автоматически будет выделять заданную форму в тексте и демонстрировать ее вам.
Бесплатный сервис поиска слов Адвего покажет онлайн все вхождения ключевых слов, стоп-слов и слов по заданному образцу. Поиск фраз и наборов символов на любом языке.
Как работает поиск слов и фраз в тексте
Скопируйте в первое поле проверяемый текст, а во втором поле укажите все слова и фразы по одной на строку, после чего нажмите кнопку «Найти». Чтобы найти слова в документе или на странице сайта, скопируйте весь текст в поле для проверки.
По умолчанию система ищет только точные совпадения с указанной строкой (с учетом знаков препинания).
Например, по строке «номер» будет найдено слово «номер», но не будут найдены слова «номерной» или «госномер». Аналогично, при поиске по фразе «легкий завтрак» будет найдена только фраза «легкий завтрак», но не будут найдены фразы «легким завтраком» или «легкий, завтрак».
Чтобы задать поиск по маске, используйте символ звездочки * в начале, в конце или с обеих сторон каждого слова:
ра*— будут найдены все слова, начинающиеся на «ра», в том числе слово «ра»: работа, разный, рад.*ет— будут найдены все слова, заканчивающиеся на «ет», в том числе слово «ет»: работает, полет, нет.*ой*— будут найдены все слова, содержащие буквосочетание «ой» в любом месте: ойкнул, водопой, спокойствие.
Маску можно указать для одного или нескольких слов во фразе, правила будут применяться последовательно:
ра* *ет— будут найдены фразы только из двух рядом стоящих слов, первое из которых начинается на «ра», а второе заканчивается на «ет»: рабочий совет, но не будут найдены фразы «свет комет» или «равная опора».
Также можно найти все вхождения любой заданной последовательности символов в тексте — для этого необходимо добавить символ ! в начале и конце строки.
Например, по запросу !дом! будут найдены вхождения этого буквосочетания в словах «дом», «домашний», «одомашненный» и т. д., но выделены будут именно вхождения, а не слова целиком, в отличие от режима поиска по маске с символом *.
Чтобы выделить все вхождения конкретного слова или фразы в тексте, нажмите на строку с ними в таблице совпадений. Чтобы выделить все совпадения, нажмите на строку с общим количеством совпадений.
Проверять текст можно неограниченное количество раз — после его редактирования или изменения списка слов нажмите повторно кнопку «Найти» и система покажет результаты новой проверки.
Возможности сервиса:
- поиск заданных слов и фраз (ключевых, стоп-слов);
- поиск по фразе целиком или по ее части;
- поиск необходимого слова или фразы в документе;
- поиск одинаковых и повторяющихся слов;
- поиск однокоренных слов по маске;
- поиск любых последовательностей символов;
- поиск в английском тексте и на любом языке.