Как рассчитать ожидаемую частоту
17 авг. 2022 г.
читать 2 мин
Ожидаемая частота — это теоретическая частота, которую мы ожидаем получить в эксперименте.
Этот тип частоты чаще всего встречается в двух типах тестов хи-квадрат:
- Хи-квадрат критерия согласия
- Хи-квадрат тест независимости
В этом руководстве объясняется, как рассчитать ожидаемую частоту для каждого из этих двух тестов.
Ожидаемая частота в тесте согласия хи-квадрат
Критерий согласия Хи-квадрат используется, чтобы определить, следует ли категориальная переменная гипотетическому распределению. С помощью этого типа теста мы сравниваем наблюдаемые частоты категориальной переменной с ожидаемыми частотами.
Например, предположим, что владелец магазина утверждает, что каждый будний день в его магазин заходит одинаковое количество покупателей. Чтобы проверить эту гипотезу, независимый исследователь записывает количество покупателей, которые заходят в магазин на определенной неделе, и обнаруживает следующее:

Чтобы рассчитать ожидаемую частоту клиентов каждый день, мы можем использовать следующую формулу:
Ожидаемая частота = ожидаемый процент * общее количество
В этом конкретном примере владелец магазина ожидает, что каждый день в магазин будет приходить одинаковое количество покупателей, поэтому ожидаемый процент покупателей, приходящих в данный день, составляет 20% от общего числа покупателей за неделю.
Это означает, что мы можем рассчитать ожидаемую частоту клиентов каждый день как:
Ожидаемая частота = 20% * 250 клиентов = 50

Ожидаемая частота в критерии качества независимости хи-квадрат
Критерий независимости Хи-квадрат используется для определения того, существует ли значительная связь между двумя категориальными переменными. С помощью этого типа теста мы также сравниваем набор наблюдаемых частот с набором ожидаемых частот.
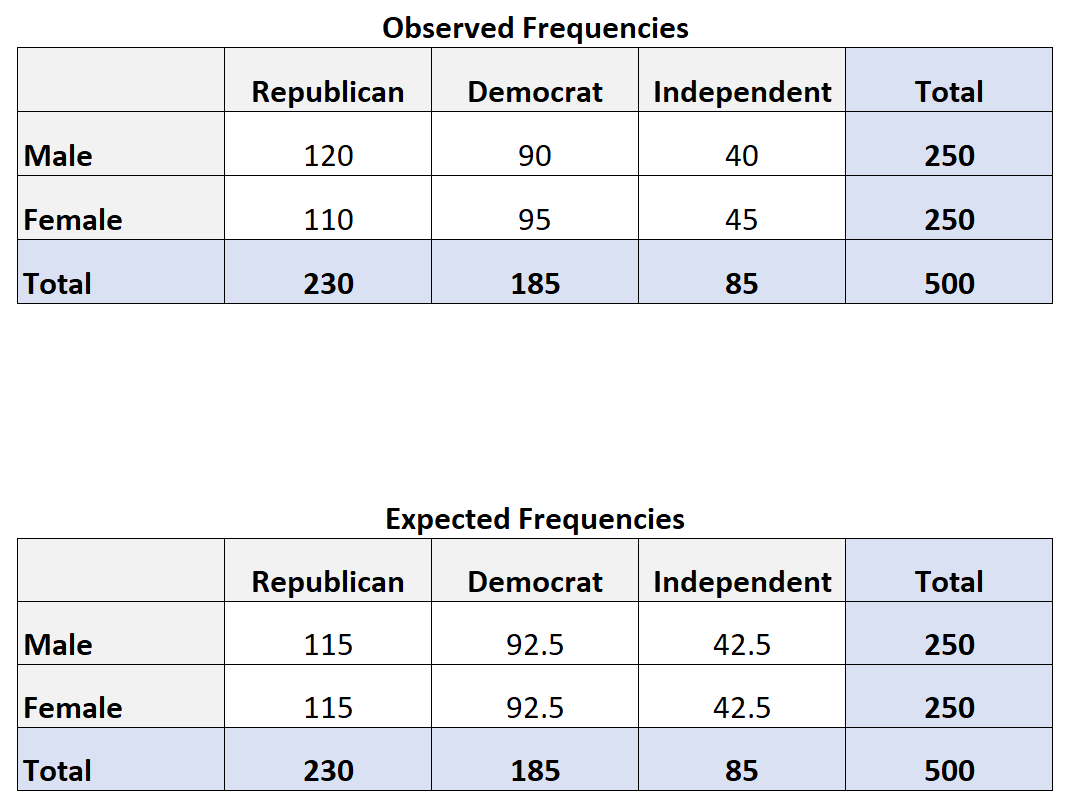
Например, предположим, что мы хотим знать, связан ли пол с предпочтениями политической партии. Мы берем простую случайную выборку из 500 избирателей и опрашиваем их об их предпочтениях в отношении политических партий. В следующей таблице представлены результаты опроса:

Чтобы рассчитать ожидаемую частоту каждой ячейки в таблице, мы можем использовать следующую формулу:
Ожидаемая частота = (сумма строк * сумма столбцов) / сумма таблицы
Например, ожидаемое значение для мужчин-республиканцев: (230*250) / 500 = 115 .
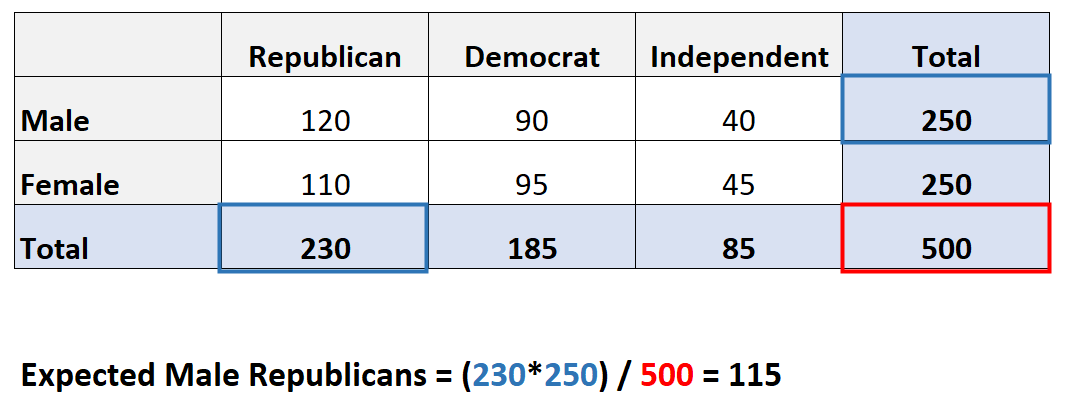
Мы можем повторить эту формулу, чтобы получить ожидаемое значение для каждой ячейки в таблице:
Вы можете найти больше руководств по статистике на нашей странице здесь .

Ожидаемая частотаколичество появлений, ожидаемых в результате многократного проведения экспериментов, которые также известны как экспериментальные испытания.
Или произведение вероятности события, например, события А на количество проведенных экспериментов.
Проще говоря, вы когда-нибудь играли в Людо? Бросить два кубика одновременно и ожидать, что на обоих кубиках выпадет шестерка? Если это так, это означает, что вы применили теорию ожидаемой частоты .
Формулы ожидаемой частоты
В общем, формула ожидаемой частоты выглядит следующим образом:
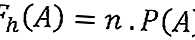
Информация:
F h (A) = ожидаемая частота события A
n = количество вхождений A
P (A) = вероятность события A.
Примеры вопросов с ожидаемой частотой
Пример проблемы 1
- Два кубика бросаются вместе 144 раза. Определите шанс возникновения надежды
- Шесть на обоих умирают.
- Число на обоих кубиках составляет шесть.
Решение:
Чтобы решить такую проблему, сначала подсчитайте общее количество вхождений. Все события обозначаются буквой S, тогда:
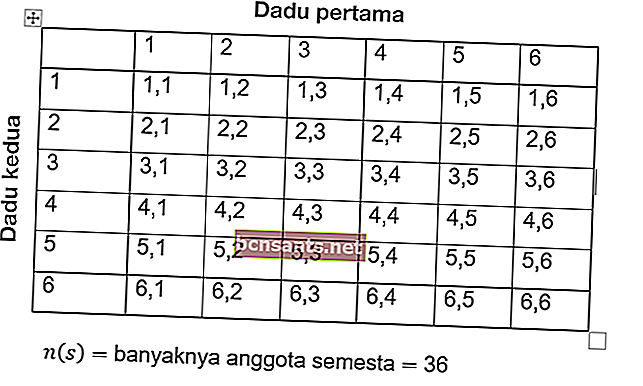
Так что количество членов вселенной чисел равно n (s) = 36.
1. Появление числа шесть на обоих кубиках.
Из двух появившихся чисел только одно — (6,6), тогда:
п (1) = 1
Количество экспериментов было 144 раза, затем
n = 144
Таким образом,
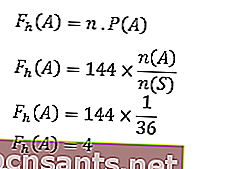
Итак, ожидаемая частота появления числа шесть на обоих кубиках — 4 раза.
2. Появление шести кубиков.
Для общего количества игральных костей шесть, а именно
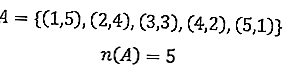
Количество экспериментов было 144 раза, затем
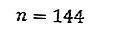
Таким образом,
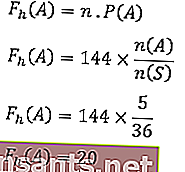
Итак, ожидаемая частота выпадения шести игральных костей — 20 раз.
Пример задачи 2
Одна монета, которая была подброшена в воздух 30 раз. Определите ожидаемую частоту появления на числовой стороне.
Также прочтите: Формулы ускорения + примеры проблем и решений
Решение:
Вселенная этого инцидента состоит только из двух, а именно: сторона числа и сторона изображения, или записанная.
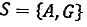
тогда n (S) = 2
Количество подброшенных монет 30 раз, тогда n = 30
У числа только одна сторона, поэтому n (A) = 1
Ожидаемая частота событий:
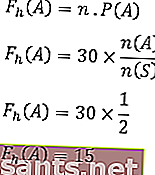
Таким образом, ожидаемая частота появления номера стороны — 20 раз.
Вывод
Таким образом, ожидаемая частота — это частота или количество испытаний, умноженное на вероятность события, в результате которого получится количество ожиданий, возникающих в отношении конкретного события.
Итак, после объяснения выше, можете ли вы рассчитать свои надежды на выигрыш в лотерею? Какие уловки нужно делать, чтобы ваши надежды на победу были высоки?
Напишите свой верный трюк в комментариях и дайте им знать.
Таким образом, объяснение формулы и понимания, а также примеры частоты ожиданий, надеюсь, это будет полезно и до встречи в следующем материале
Наблюдаемые и ожидаемые частоты генотипов и аллелей
|
Наблюдаемое |
Наблюдаемая |
Ожидаемая |
|
|
АА |
1 |
0,2 |
0,30 |
|
Аа |
3 |
0,6 |
0,50 |
|
аа |
1 |
0,2 |
0,20 |
|
Аллель |
2 (АА)+3 (Аа)=5 |
0,50 |
0,55 |
|
Аллель |
2(аа)+3(Аа)=5 |
0,50 |
0,45 |
6.
Делаем заключение: Наблюдается небольшое
смещение от равновесия Харди-Вайнберга,
что объясняется малочисленностью
изученной выборки – эффект колебания
частот аллелей (популяционные волны) в
малых популяциях.
-
Применение
закона Харди-Вайнберга для расчета
частот генотипов, аллелей и характеристики
генетической структуры популяции
(группы) по умению сворачивать язык в
трубочку (аутосомно-доминантный признак)
1. Поскольку умение
сворачивать язык в трубочку –
аутосомно-доминантный признак,
следовательно, лица с доминантным
признаком могут быть гомозиготными
(генотип АА), или гетерозиготными (генотип
Аа). Составляем суммарную таблицу
студентов группы (табл. 2.1):
Таблица 2.1
Наблюдаемые частоты генотипов и аллелей
|
№ п/п |
Умение сворачивать |
Генотипы |
|
1 |
Умею (да) |
А_ |
|
2 |
Не |
аа |
|
3 |
Нет |
аа |
|
4 |
Да |
А_ |
|
5… |
Да |
А_ |
2.
Подсчитываем число индивидов с
гомозиготным рецессивным генотипоми
«аа» (в нашем примере 2 случая из 5
проанализированных):
-
Вычисляем
частоту генотипа «аа», т.е. q2=2:5=0,4
-
Используя
формулу Харди-Вайнберга, вычисляем
ожидаемые частоты генотипов и аллелей
в следующей последовательности:
-
Зная
q2,
можно вычислить q=√q
2 т.е.√0,4=0,63 -
Зная
q,
можно вычислить p=1-q,
т.е. p=1-0,63=0,37 -
Зная
p,
можно вычислить p2
=0,37*0,37=0,14 -
Зная
p
и q
можно вычислить 2pq=2*0,37*0,63=0,46 -
Генетическая
структура популяции, т.е. частота всех
генотипов, выражается формулой
0,14+0,46+0,4=1
-
Молекулярно-генетический метод: моделирование пцр-анализа делеции f508 гена cftr при диагностике муковисцидоза
1.
Конструирование праймеров размером 10
нуклеотидов для правого и левого участков
интересующего фрагмента ДНК размером
30 пн:
смысловая
цепь ДНК — 5’ act
gcg
agc
tta
cgg
ttt
cat
ggg
cga
gat
3’
антисмысловая
цепь ДНК — 3’ tga
cgc
tcg
aat
gcc
aaa
gta
ccc
gct
cta
5’
Праймеры:
Прямой
5’ Act gcg agc t 3’
антисмысл.
ДНК
— 3’ tga cgc tcg aat gcc
aaa gta ccc gct cta 5’
Обратный
смысловая
ДНК
— 5’ act gcg agc tta cgg
ttt cat ggg cga gat 3’
3’A ccc gct cta 5’
2. Проведение ПЦР
и интерпретация результатов.
1)
В норме у здорового человека размер
искомого фрагмента ДНК равен 30 пн. Это
нормальный аллель, обозначаемый как А.
2)
При делеции 3-х пар нуклеотидов в 13-м,
14-м и 15-м положениях смысловой цепи ДНК
триплет cgg)
будет амплифицироваться фрагмент
размером 27 пн. Это мутантный аллель,
обозначаемый как а.
3)
Идентификация результатов амплификации
путем разделения фрагментов ДНК на
электрофорезе (см. рис. 1):
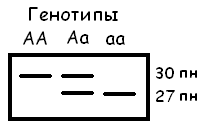
Рис
1. Электрофореграмма и интерпретация
результатов амплификации образцов ДНК
индивидов с генотипами АА, Аа, аа.
Интерпретация
полученных результатов:
Генотип
«АА» – норма
– поскольку
оба аллеля имеют одинаковый размер, на
электрофореграмме будет выявляться
одна полоса размером 30 пн – аллели А
(см. рис. 1).
Генотип
«Аа» – гетерозиготный носитель
— на электрофореграмме будет выявляеться
две полосы, соответствующие размерам
фрагментов 27 и 30 пн (аллели А и а).
Генотип
« аа» – гомозигота по мутантным аллелям
— поскольку оба фрагмента ДНК имеют
одинаковый размер, на электрофореграмме
будет выявляться одна полоса размером
27 пн.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Вступление
«Наука продвигается, предлагая и проверяя гипотезы, а не объявляя вопросы неразрешимыми» — Ник Мацке
Давайте начнем с тематического исследования. Я хочу, чтобы вы прямо сейчас подумали о вашем любимом ресторане. Допустим, вы хотите предсказать количество людей, приезжающих на обед пять дней в неделю. В конце недели вы заметили, что ожидаемое количество отличался от фактического.
Похоже на главную проблему статистики? Это идея!
Итак, как вы будете проверять статистическую значимость между наблюдаемыми и ожидаемыми значениями? Помните, что это категориальная переменная — «дни недели» — с пятью категориями [понедельник, вторник, среда, четверг, пятница].
Один из лучших способов справиться с этим — использовать критерий хи-квадрат.
Мы всегда можем выбрать z-тесты, t-тесты или ANOVA, когда имеем дело с непрерывными переменными. Но ситуация становится более сложной при работе с категориальными функциями (как подтвердит большинство ученых!). Я обнаружил, что тест хи-квадрат очень полезен в моих собственных проектах.
Итак, давайте углубимся в статью, чтобы понять все о тесте хи-квадрат, что это такое, как он работает и как мы можем реализовать его в R.
Если вы новичок в области статистики и данных, я бы порекомендовал следующие ресурсы, чтобы получить исчерпывающий обзор этих двух общих тем:
Я уверен, что вы уже сталкивались с категориальными переменными, даже если вы не могли их интуитивно распознать. С ними может быть сложно разобраться в мире наук о данных, поэтому давайте сначала определим их.
Категориальные переменные попадают в особую категорию тех переменных, которые можно разделить на конечные категории. Эти категории обычно являются именами или ярлыками. Эти переменные также называются качественными переменными, поскольку они отображают качество или характеристики этой конкретной переменной.
Например, категория «Жанр фильма» в списке фильмов может содержать категориальные переменные — «Боевик», «Фэнтези», «Комедия», «Мелодрама» и т. д.
Существует два типа категориальных переменных:
Номинальная переменная: не имеет естественного упорядочения по своим категориям. У них могут быть две или более категории. Например, семейное положение (холост, женат, разведен); пол (мужской, женский, трансгендерный) и т. д.
Порядковая переменная: переменная, для которой категории могут быть размещены в определенном порядке. Например, удовлетворенность клиентов (отлично, очень хорошо, хорошо, средне, плохо) и т. д.
Когда данные, которые мы хотим проанализировать, содержат переменные этого типа, мы обращаемся к критерию хи-квадрат, обозначенному χ², чтобы проверить нашу гипотезу.
Что такое критерий хи-квадрат и почему мы его используем?
Критерий хи-квадрат — это критерий статистической значимости для категориальных переменных.
Давайте научимся использовать хи-квадрат на интуитивном примере.
Исследователь интересуется взаимоотношениями между приемом абитуриентов на статистический факультет известного университета и их оценкой C.G.P.A (итоговая оценка).
Он получает записи о зачислении за последние пять лет из базы данных (случайным образом). Он записывает, сколько абитуриентов попало в каждую из следующих групп: категории баллов — 9-10, 8-9, 7-8, 6-7 и ниже 6.
Если нет никакой связи между процентом зачисления и C.G.P.A., тогда принятые абитуриенты должны быть в равной степени распределены по разным категориям C.G.P.A. (т.е. в каждой категории должно быть одинаковое количество абитуриентов).
Тем не менее, если абитуриенты, имеющие C.G.P.A более 8, с большей вероятностью будут зачислены, то в высшей категории C.G.P.A. будет больше абитуриентов по сравнению с более низкими категориями C.G.P.A. В этом случае собранные данные будут составлять наблюдаемые частоты.
Таким образом, вопрос в том, являются ли эти частоты случайными?
Здесь вступает в дело тест хи-квадрат! Он помогает нам ответить на поставленный выше вопрос, сравнивая наблюдаемые частоты с частотами, которые можно получить случайно.
Критерий хи-квадрат в проверке гипотез используется для проверки гипотезы о распределении наблюдений/частот по различным категориям.
Примечание. Я настоятельно рекомендую ознакомиться с этой статьей, если вам нужно освежить свои концепции проверки гипотез.
Мы находимся почти на стадии реализации тестов хи-квадрат, но есть еще одна вещь, которую мы должны изучить, прежде чем попасть туда.
Допущения теста Хи-квадрат
Как и любой другой статистический тест, тест хи-квадрат имеет несколько собственных предположений:
- χ2 предполагает, что данные для исследования получены путем случайного отбора, то есть они выбираются из популяции случайным образом.
- Категории являются взаимоисключающими, то есть каждый предмет относится только к одной категории. Например, из приведенного выше примера, число людей, которые обедали в вашем ресторане в понедельник, не может быть включено в категорию вторника.
- Данные должны быть представлены в виде частот или количеств определенной категории, а не в процентах.
- Данные не должны состоять из парных выборок или групп, то есть мы можем сказать, что наблюдения должны быть независимы друг от друга.
- Когда более 20% ожидаемых частот имеют значение меньше 5, то хи-квадрат не может использоваться. Чтобы решить эту проблему, нужно либо объединить категории, только если это уместно, или получить больше данных.
Типы тестов хи-квадрат (с вычислениями вручную и с реализацией в R)
Тест хи-квадрат на адекватность модели
Это непараметрический тест. Обычно мы используем его, чтобы определить, насколько значительно наблюдаемое значение данного события отличается от ожидаемого значения. В этом случае у нас есть категориальные данные для одной независимой переменной, и мы хотим проверить, является ли распределение данных аналогичным или отличным от распределения ожидаемых значений.
Давайте рассмотрим приведенный выше пример, в котором ученый-исследователь интересовался взаимоотношениями между приемом студентов на факультет статистики известного университета и их C.G.P.A.
В этом случае независимой переменной является C.G.P.A с категориями 9-10, 8-9, 7-8, 6-7 и ниже 6.
Статистический вопрос здесь заключается в следующем: одинаково ли распределены наблюдаемые частоты принятых студентов для разных категорий C.G.P.A (так, чтобы наше теоретическое распределение частот содержало одинаковое количество студентов в каждой из категорий C.G.P.A).
Мы упорядочим эти данные, используя таблицу сопряженности, которая будет состоять из наблюдаемых и ожидаемых значений, как показано ниже:
|
C.G.P.A |
||||||
|
10-9 |
9-8 |
8-7 |
7-6 |
менее 6 |
всего |
|
|
Наблюдаемая частота принятых студентов |
30 |
35 |
20 |
10 |
5 |
100 |
|
Ожидаемая частота принятых студентов |
20 |
20 |
20 |
20 |
20 |
100 |
После построения таблицы сопряженности следующая задача — вычислить значение статистики хи-квадрат. Формула для хи-квадрат имеет вид:

где,
χ 2 = значение хи-квадрат
Oi = наблюдаемая частота
Ei = ожидаемая частота
Давайте посмотрим на пошаговый подход для вычисления значения хи-квадрат:
Шаг 1: Вычтите каждую ожидаемую частоту из соответствующей наблюдаемой частоты. Например, для категории C.G.P.A 10-9 это будет «30-20 = 10». Примените аналогичную операцию для всех категорий.
Шаг 2: возведите в квадрат каждое значение, полученное на шаге 1, то есть (O-E)2. Например: для категории C.G.P.A 10-9 значение, полученное на шаге 1, равно 10. Оно становится равным 100 при возведении в квадрат. Примените аналогичную операцию для всех категорий.
Шаг 3: Разделите все значения, полученные на шаге 2, на соответствующие ожидаемые частоты, то есть (O-E)2
/E. Например: для категории C.G.P.A 10-9 значение, полученное на шаге 2, равно 100. При делении его на соответствующую ожидаемую частоту, равную 20, оно становится равным 5. Примените аналогичную операцию для всех категорий.
Шаг 4: Сложите все значения, полученные на шаге 3, чтобы получить значение хи-квадрат. В этом случае значение хи-квадрат получается равным 32,5.
Шаг 5: После того, как мы вычислили значение хи-квадрат, следующая задача — сравнить его с критическим значением хи-квадрат. Мы можем найти его в приведенной ниже таблице хи-квадрат для различного количества степеней свободы (количество категорий — 1) и уровня значимости:

В этом случае степени свободы 5-1 = 4. Таким образом, критическое значение при уровне значимости 5% составляет 9,49.
Полученное нами значение 32,5 намного больше, чем критическое значение 9,49. Поэтому можно сказать, что наблюдаемые частоты значительно отличаются от ожидаемых частот. Другими словами, C.G.P.A связан с количеством зачислений на факультет статистики.
Давайте еще больше укрепим наше понимание, выполнив тест хи-квадрат в R.
Тест хи-квадрат на адекватность модели в R
Давайте реализуем критерий пригодности хи-квадрат в R. Время запустить RStudio!
Постановка задачи
Давайте разберемся с постановкой задачи, прежде чем погрузиться в R.
Организация утверждает, что опыт работы сотрудников разных отделов распределяется по следующим категориям:
11 — 20 лет = 20%
21 — 40 лет = 17%
6 — 10 лет = 41% и
До 5 лет = 22%
Произведена случайная выборка из 1470 сотрудников. Предоставляет ли эта случайная выборка доказательства против жалоб на компанию?
Вы можете скачать данные здесь.
Формулирование гипотезы
Нулевая гипотеза: истинные пропорции опыта работы сотрудников различных отделов распределены по следующим категориям: 11–20 лет = 20%, 21–40 лет = 17%, 6–10 лет = 41% и до 5 лет. = 22%
Альтернативная гипотеза: распределение опыта сотрудников разных отделов отличается от того, что заявляет организация
Давайте начнем!
Шаг 1. Сначала импортируйте данные
Шаг 2: Подтвердите их правильность в R:
# Шаг 1 — Импорт данных
#Импорт данных csv
data<-read.csv(file.choose())
#Шаг 2: Подтвердите их правильность в R:
#Количество строк и столбцов
dim(data)
#Посмотрим первые 10 rows строк из набора данных
head(data,10)
Вывод:
#Количество строк и столбцов
[1] 1470 2
#Посмотрим первые 10 rows строк из набора данных
age.intervals Experience.intervals
1 41 — 50 6 — 10 Years
2 41 — 50 6 — 10 Years
3 31 — 40 6 — 10 Years
4 31 — 40 6 — 10 Years
5 18 — 30 6 — 10 Years
6 31 — 40 6 — 10 Years
7 51 — 60 11 — 20 Years
8 18 — 30 Upto 5 Years
9 31 — 40 6 — 10 Years
10 31 — 40 11 — 20 Years
Шаг 3: Создайте таблицу сопряженности для ожидаемых частот:
# Шаг 3 — Рассчитать долю опыта работы сотрудников
# Таблица сопряженности для наблюдаемых частот
prop.table((table(data$Experience.intervals)))
Вывод:
11 — 20 Years 21 — 40 Years 6 — 10 Years Upto 5 Years
0.2312925 0.1408163 0.4129252 0.2149660
Шаг 4: Рассчитать значение хи-квадрат:
# Шаг 4 — Рассчитать значение хи-квадрат
chisq.test(x = table(data$Experience.intervals),
p = c(0.2, 0.17, 0.41, 0.22))
Вывод:
Chi-square test for given probabilities
data: table(data$Experience.intervals)
X-squared = 14.762, df = 3, p-value = 0.002032
Значение р здесь меньше 0,05. Поэтому мы отвергнем нашу нулевую гипотезу. Следовательно, распределение опыта работы сотрудников разных отделов отличается от того, что заявляет компания.
Критерий хи-квадрат для независимости
Второй тип теста хи-квадрат — это критерий согласия Пирсона. Этот тест используется, когда у нас есть категориальные данные для двух независимых переменных, и мы хотим увидеть, есть ли какая-либо связь между переменными.
Давайте возьмем другой пример. Учитель хочет знать ответ на вопрос, связан ли результат теста по математике с полом человека, проходящего тест. Или, другими словами, он хочет знать, показывают ли мужчины результаты, отличные от женщин.
Итак, вот две категориальные переменные: пол (мужской и женский) и результат теста по математике (успешно или не успешно). Давайте теперь посмотрим на таблицу сопряженности:
| Boys | Girls | |
| Pass | 17 | 20 |
| Fail | 8 | 5 |
Изучив приведенную выше таблицу непредвиденных обстоятельств, мы можем видеть, что у девочек сравнительно более высокий уровень прохождения теста, чем у мальчиков. Однако, чтобы проверить, является ли эта наблюдаемая разница значимой или нет, мы выполним тест хи-квадрат.
Шаги для вычисления значения хи-квадрат следующие:
Шаг 1: Рассчитать суммарные значения по строкам и столбцам приведенной выше таблицы сопряженности:
| Boys | Girls | Total | |
| Pass | 17 | 20 | 37 |
| Fail | 8 | 5 | 13 |
| Total | 25 | 25 | 50 |
Шаг 2: Рассчитайте ожидаемую частоту для каждой отдельной ячейки путем умножения суммы по строке на сумму по столбцу и делению на общее число наблюдений:
Ожидаемая частота = (сумма по строке x сумма по столбцу) / общая сумма
Для первой ячейки ожидаемая частота будет (37 * 25) / 50 = 18,5. Теперь напишите их ниже наблюдаемых частот в скобках:
| Boys | Girls | Total | |
| Pass | 17 (18.5) |
20 (18.5) |
37 |
| Fail | 8 (6.5) |
5 (6.5) |
13 |
| Total | 25 | 25 | 50 |
Шаг 3: Рассчитать значение хи-квадрат по формуле:

Рассчитайте правую часть каждой ячейки. Например, для первой ячейки
((17-18,5)^2)/18,5 = 0,1216.
Шаг 4: Затем сложите все значения, полученные для каждой ячейки. В этом случае значения будут:
0.1216+0.1216+0.3461+0.3461 = 0.9354
Шаг 5: Рассчитать степени свободы, т. е.
(Количество строк-1) * (количество столбцов-1) = 1 * 1 = 1
Следующая задача — сравнить его с критическим значением хи-квадрат из таблицы, которую мы видели выше.
Расчетное значение хи-квадрат составляет 0,9354, что меньше критического значения 3,84. Таким образом, в этом случае мы не можем отклонить нулевую гипотезу. Это означает, что между этими двумя переменными нет существенной связи, т. е. у мальчиков и девочек статистически схожая картина прохождения/неудач в их математических тестах.
Давайте еще больше укрепим наше понимание, выполнив тест хи-квадрат в R.
Тест хи-квадрат на независимость в R
Постановка задачи
Отдел кадров организации хочет проверить, зависят ли возраст и опыт сотрудников друг от друга. Для этой цели, собирается случайная выборка из 1470 сотрудников с учетом их возраста и опыта. Вы можете скачать данные здесь.
Формулирование гипотезы
Нулевая гипотеза: возраст и опыт — две независимые переменные
Альтернативная гипотеза: возраст и опыт — две зависимые переменные
Давайте начнем!
Шаг 1. Сначала импортируйте данные
Шаг 2: Подтвердите их правильность в R:
# Шаг 1 — Импорт данных
# Импорт данных csv
data<-read.csv(file.choose())
# Шаг 2 — проверка данных на корректность
# Число строк и столбцов
dim(data)
#Выводим первые 10 строк набора данных
head(data,10)
Вывод:
# Число строк и столбцов
[1] 1470 2
> # Выводим первые 10 строк набора данных
age.intervals Experience.intervals
1 41 — 50 6 — 10 Years
2 41 — 50 6 — 10 Years
3 31 — 40 6 — 10 Years
4 31 — 40 6 — 10 Years
5 18 — 30 6 — 10 Years
6 31 — 40 6 — 10 Years
7 51 — 60 11 — 20 Years
8 18 — 30 Upto 5 Years
9 31 — 40 6 — 10 Years
10 31 — 40 11 — 20 Years
Шаг 3: Постройте таблицу сопряженности и вычислите значение хи-квадрат:
# Шаг 3 — Создание таблицы и вычисление значение хи-квадрат
ct<-table(data$age.intervals,data$Experience.intervals)
ct
chisq.test(ct)
Вывод:
ct<-table(data$age.intervals,data$Experience.intervals)<-table age.intervals=»» data=»» font=»» xperience.intervals=»»>
> ct
11 — 20 Years 21 — 40 Years 6 — 10 Years Upto 5 Years
18 — 30 22 0 172 192
31 — 40 190 20 308 101
41 — 50 85 112 110 15
51 — 60 43 75 17 8
> chisq.test(ct)
Pearson’s Chi-squared test
data: ct
X-squared = 679.97, df = 9, p-value < 2.2e-16
Значение р здесь меньше 0,05. Поэтому мы отвергнем нашу нулевую гипотезу. Мы можем сделать вывод, что возраст и опыт являются двумя зависимыми переменными, то есть, по мере того, как опыт увеличивается, возраст также увеличивается (и наоборот).
-

-
November 24 2013, 21:24

Ожидаемые частоты для таблиц из многоответных переменных
Коллеги, подскажите, как можно было бы корректно посчитать сабж?
Задача — оценка марок по батарее высказываний. Каждой марке респондент может присвоить несколько высказываний.
Так как марки есть большие и маленькие, атрибуты марок есть распространенные и уникальные, то в анализе хотелось бы учесть «размер» марок и высказываний.
Я в этих целях планировал для таблички «марки * высказывания» посчитать в каждой ячейке «наблюдаемая частота минус ожидаемая».
В принципе, это прямая задача для анализа соответствий. С одной оговоркой — для анализа соответствий на вход подается таблица сопряженности.
В моем случае как вариант можно было бы рассматривать не всю таблицу марки*высказывания целиком, а для каждого высказывания отдельно построить таблицу сопряженности с учетом вариантов «высказывание выбрано» / «высказывание не выбрано». Но и здесь есть минус — тогда размер марок не принимается в расчет. Он всегда одинаков и равен размеру выборки.
Поиск по интернетам натолкнул на идею использовать лог-линейный анализ. Но я как-то не сумел в нем разобраться — ожидаемые частоты получались всегда равны наблюдаемым 
Что делать? как быть? Наверняка ведь есть какой-то выход..