Время на прочтение
9 мин
Количество просмотров 168K
Я помню, когда я проходил свою первую зарубежную стажировку в CERN в качестве практиканта, большинство людей все еще говорили об открытии бозона Хиггса после подтверждения того, что он соответствует порогу «пять сигм» (что означает наличие p-значения 0,0000003).

Тогда я ничего не знал о p-значении, проверке гипотез или даже статистической значимости.
Я решил загуглить слово — «p-значение», и то, что я нашел в Википедии, заставило меня еще больше запутаться…
При проверке статистических гипотез p-значение или значение вероятности для данной статистической модели — это вероятность того, что при истинности нулевой гипотезы статистическая сводка (например, абсолютное значение выборочной средней разницы между двумя сравниваемыми группами) будет больше или равна фактическим наблюдаемым результатам.
— Wikipedia
Хорошая работа, Википедия.
Ладно. Я не понял, что на самом деле означает р-значение.
Углубившись в область науки о данных, я наконец начал понимать смысл p-значения и то, где его можно использовать как часть инструментов принятия решений в определенных экспериментах.
Поэтому я решил объяснить р-значение в этой статье, а также то, как его можно использовать при проверке гипотез, чтобы дать вам лучшее и интуитивное понимание р-значений.
Также мы не можем пропустить фундаментальное понимание других концепций и определение p-значения, я обещаю, что сделаю это объяснение интуитивно понятным, не подвергая вас всеми техническими терминами, с которыми я столкнулся.
Всего в этой статье четыре раздела, чтобы дать вам полную картину от построения проверки гипотезы до понимания р-значения и использования его в процессе принятия решений. Я настоятельно рекомендую вам пройтись по всем из них, чтобы получить подробное понимание р-значений:
- Проверка гипотезы
- Нормальное распределение
- Что такое P-значение?
- Статистическая значимость
Это будет весело.
Давайте начнем!
1. Проверка гипотез
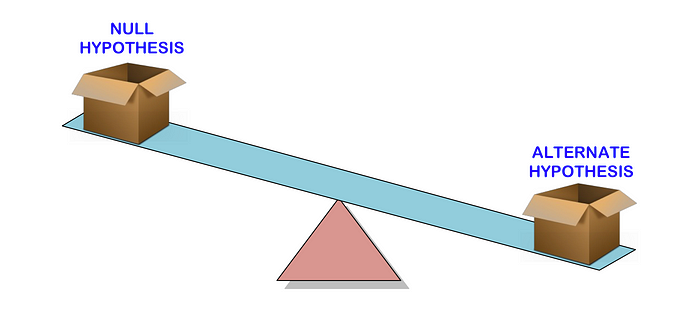
Прежде чем мы поговорим о том, что означает р-значение, давайте начнем с разбора проверки гипотез, где р-значение используется для определения статистической значимости наших результатов.
Наша конечная цель — определить статистическую значимость наших результатов.
И статистическая значимость построена на этих 3 простых идеях:
- Проверка гипотезы
- Нормальное распределение
- P-значение
Проверка гипотез используется для проверки обоснованности утверждения (нулевой гипотезы), сделанного в отношении совокупности с использованием выборочных данных. Альтернативная гипотеза — это та, в которую вы бы поверили, если бы нулевая гипотеза оказалась неверной.
Другими словами, мы создадим утверждение (нулевая гипотеза) и используем пример данных, чтобы проверить, является ли утверждение действительным. Если утверждение не соответствует действительности, мы выберем альтернативную гипотезу. Все очень просто.
Чтобы узнать, является ли утверждение обоснованным или нет, мы будем использовать p-значение для взвешивания силы доказательств, чтобы увидеть, является ли оно статистически значимым. Если доказательства подтверждают альтернативную гипотезу, то мы отвергнем нулевую гипотезу и примем альтернативную гипотезу. Это будет объяснено в следующем разделе.
Давайте воспользуемся примером, чтобы сделать эту концепцию более ясной, и этот пример будет использоваться на протяжении всей этой статьи для других концепций.
Пример. Предположим, что в пиццерии заявлено, что время их доставки составляет в среднем 30 минут или меньше, но вы думаете, что оно больше чем заявленное. Таким образом, вы проводите проверку гипотезы и случайным образом выбираете время доставки для проверки утверждения:
- Нулевая гипотеза — среднее время доставки составляет 30 минут или меньше
- Альтернативная гипотеза — среднее время доставки превышает 30 минут
- Цель здесь состоит в том, чтобы определить, какое утверждение — нулевое или альтернативное — лучше подтверждается данными, полученными из наших выборочных данных.
Мы будем использовать односторонний тест в нашем случае, так как нам важно только, чтобы среднее время доставки превышало 30 минут. Мы не будем учитывать эту возможность в другом направлении, поскольку последствия того, что среднее время доставки будет меньше или равно 30 минутам, еще более предпочтительны. Здесь мы хотим проверить, есть ли вероятность того, что среднее время доставки превышает 30 минут. Другими словами, мы хотим посмотреть, не обманула ли нас пиццерия.
Одним из распространенных способов проверки гипотез является использование Z-критерия. Здесь мы не будем вдаваться в подробности, так как хотим лучше понять, что происходит на поверхности, прежде чем погрузиться глубже.
2. Нормальное распределение
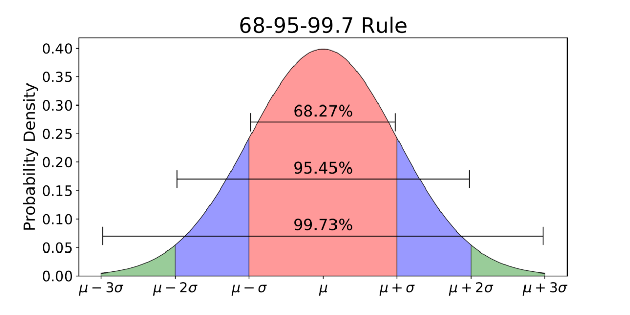
Нормальное распределение — это функция плотности вероятности, используемая для просмотра распределения данных.
Нормальное распределение имеет два параметра — среднее (μ) и стандартное отклонение, также называемое сигма (σ).
Среднее — это центральная тенденция распределения. Оно определяет местоположение пика для нормальных распределений. Стандартное отклонение — это мера изменчивости. Оно определяет, насколько далеко от среднего значения склонны падать значения.
Нормальное распределение обычно связано с правилом 68-95-99.7 (изображение выше).
- 68% данных находятся в пределах 1 стандартного отклонения (σ) от среднего значения (μ)
- 95% данных находятся в пределах 2 стандартных отклонений (σ) от среднего значения (μ)
- 99,7% данных находятся в пределах 3 стандартных отклонений (σ) от среднего значения (μ)
Помните порог «пять сигм» для открытия бозона Хиггса, о котором я говорил в начале? 5 сигм — это около 99,99999426696856% данных, которые должны быть попасть до того, как ученые подтвердили открытие бозона Хиггса. Это был строгий порог, установленный, чтобы избежать любых возможных ложных сигналов.
Классно. Теперь вы можете задаться вопросом: «Как нормальное распределение относится к нашей предыдущей проверке гипотез?»
Поскольку мы использовали Z-тест для проверки нашей гипотезы, нам нужно вычислить Z-баллы (которые будут использоваться в нашей тестовой статистике), которые представляют собой число стандартных отклонений от среднего значения точки данных. В нашем случае каждая точка данных — это время доставки пиццы, которое мы получили.
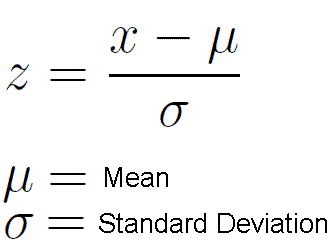
Обратите внимание, что когда мы рассчитали все Z-баллы для каждого времени доставки пиццы и построили стандартную кривую нормального распределения, как показано ниже, единица измерения на оси X изменится с минут на единицу стандартного отклонения, так как мы стандартизировали переменную, вычитая среднее и деля его на стандартное отклонение (см. формулу выше).
Изучение стандартной кривой нормального распределения полезно, потому что мы можем сравнить результаты теста с ”нормальной» популяцией со стандартизированной единицей в стандартном отклонении, особенно когда у нас есть переменная, которая поставляется с различными единицами.
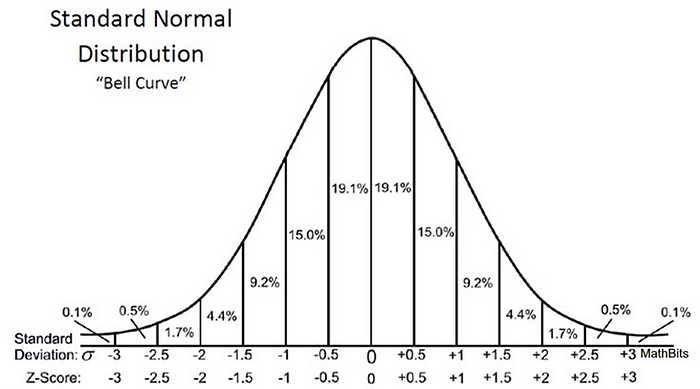
Z-оценка может сказать нам, где лежат общие данные по сравнению со средней популяцией.
Мне нравится, как Уилл Кёрсен выразился: чем выше или ниже Z-показатель, тем менее вероятным будет случайный результат и тем более вероятным будет значимый результат.
Но насколько высокий (или низкий) показатель считается достаточно убедительным, чтобы количественно оценить, насколько значимы наши результаты?
Кульминация
Здесь нам нужен последний элемент для решения головоломки — p-значение, и проверить, являются ли наши результаты статистически значимыми на основе уровня значимости (также известного как альфа), который мы установили перед началом нашего эксперимента.
3. Что такое P-значение?
Наконец… Здесь мы говорим о р-значении!
Все предыдущие объяснения предназначены для того, чтобы подготовить почву и привести нас к этому P-значению. Нам нужен предыдущий контекст и шаги, чтобы понять это таинственное (на самом деле не столь таинственное) р-значение и то, как оно может привести к нашим решениям для проверки гипотезы.
Если вы зашли так далеко, продолжайте читать. Потому что этот раздел — самая захватывающая часть из всех!
Вместо того чтобы объяснять p-значения, используя определение, данное Википедией (извини Википедия), давайте объясним это в нашем контексте — время доставки пиццы!
Напомним, что мы произвольно отобрали некоторые сроки доставки пиццы, и цель состоит в том, чтобы проверить, превышает ли время доставки 30 минут. Если окончательные доказательства подтверждают утверждение пиццерии (среднее время доставки составляет 30 минут или меньше), то мы не будем отвергать нулевую гипотезу. В противном случае мы опровергаем нулевую гипотезу.
Поэтому задача p-значения — ответить на этот вопрос:
Если я живу в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), насколько неожиданными являются мои доказательства в реальной жизни?
Р-значение отвечает на этот вопрос числом — вероятностью.
Чем ниже значение p, тем более неожиданными являются доказательства, тем более нелепой выглядит наша нулевая гипотеза.
И что мы делаем, когда чувствуем себя нелепо с нашей нулевой гипотезой? Мы отвергаем ее и выбираем нашу альтернативную гипотезу.
Если р-значение ниже заданного уровня значимости (люди называют его альфа, я называю это порогом нелепости — не спрашивайте, почему, мне просто легче понять), тогда мы отвергаем нулевую гипотезу.
Теперь мы понимаем, что означает p-значение. Давайте применим это в нашем случае.
P-значение в расчете времени доставки пиццы
Теперь, когда мы собрали несколько выборочных данных о времени доставки, мы выполнили расчет и обнаружили, что среднее время доставки больше на 10 минут с p-значением 0,03.
Это означает, что в мире, где время доставки пиццы составляет 30 минут или меньше (нулевая гипотеза верна), есть 3% шанс, что мы увидим, что среднее время доставки, по крайней мере, на 10 минут больше, из-за случайного шума.
Чем меньше p-значение, тем более значимым будет результат, потому что он с меньшей вероятностью будет вызван шумом.
В нашем случае большинство людей неправильно понимают р-значение:
Р-значение 0,03 означает, что есть 3% (вероятность в процентах), что результат обусловлен случайностью — что не соответствует действительности.
Люди часто хотят получить определенный ответ (в том числе и я), и именно поэтому я долго путался с интерпретацией p-значений.
Р-значение ничего не *доказывает*. Это просто способ использовать неожиданность в качестве основы для принятия разумного решения.
— Кэсси Козырков
Вот как мы можем использовать p-значение 0,03, чтобы помочь нам принять разумное решение (ВАЖНО):
- Представьте, что мы живем в мире, где среднее время доставки всегда составляет 30 минут или меньше — потому что мы верим в пиццерию (наше первоначальное убеждение)!
- После анализа времени доставки собранных образцов р-значение на 0,03 ниже, чем уровень значимости 0,05 (предположим, что мы установили это значение перед нашим экспериментом), и мы можем сказать, что результат является статистически значимым.
- Поскольку мы всегда верили пиццерии, что она может выполнить свое обещание доставить пиццу за 30 минут или меньше, нам теперь нужно подумать, имеет ли это убеждение смысл, поскольку результат говорит нам о том, что пиццерия не выполняет свое обещание и результат является статистически значимым.
- Так что же нам делать? Сначала мы пытаемся придумать любой возможный способ сделать наше первоначальное убеждение (нулевая гипотеза) верным. Но поскольку пиццерия постепенно получает плохие отзывы от других людей и часто приводит плохие оправдания, которые привели к задержке доставки, даже мы сами чувствуем себя нелепо, чтобы оправдать пиццерию, и, следовательно, мы решаем отвергнуть нулевую гипотезу.
- Наконец, следующее разумное решение — не покупать больше пиццы в этом месте.
К настоящему времени вы, возможно, уже что-то поняли… В зависимости от нашего контекста, p-значения не используются, чтобы что-либо доказать или оправдать.
По моему мнению, p-значения используются в качестве инструмента для оспаривания нашего первоначального убеждения (нулевая гипотеза), когда результат является статистически значимым. В тот момент, когда мы чувствуем себя нелепо с нашим собственным убеждением (при условии, что р-значение показывает, что результат статистически значим), мы отбрасываем наше первоначальное убеждение (отвергаем нулевую гипотезу) и принимаем разумное решение.
4. Статистическая значимость
Наконец, это последний этап, когда мы собираем все вместе и проверяем, является ли результат статистически значимым.
Недостаточно иметь только р-значение, нам нужно установить порог (уровень значимости — альфа). Альфа всегда должна быть установлена перед экспериментом, чтобы избежать смещения. Если наблюдаемое р-значение ниже, чем альфа, то мы заключаем, что результат является статистически значимым.
Основное правило — установить альфа равным 0,05 или 0,01 (опять же, значение зависит от вашей задачи).
Как упоминалось ранее, предположим, что мы установили альфа равным 0,05, прежде чем мы начали эксперимент, полученный результат является статистически значимым, поскольку р-значение 0,03 ниже, чем альфа.
Для справки ниже приведены основные этапы всего эксперимента:
- Сформулируйте нулевую гипотезу
- Сформулируйте альтернативную гипотезу
- Определите значение альфа для использования
- Найдите Z-показатель, связанный с вашим альфа-уровнем
- Найдите тестовую статистику, используя эту формулу
- Если значение тестовой статистики меньше Z-показателя альфа-уровня (или p-значение меньше альфа-значения), отклоните нулевую гипотезу. В противном случае не отвергайте нулевую гипотезу.
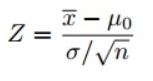
Если вы хотите узнать больше о статистической значимости, не стесняйтесь посмотреть эту статью — Объяснение статистической значимости, написанная Уиллом Керсеном.
Последующие размышления
Здесь много чего нужно переваривать, не так ли?
Я не могу отрицать, что p-значения по своей сути сбивают с толку многих людей, и мне потребовалось довольно много времени, чтобы по-настоящему понять и оценить значение p-значений и то, как они могут быть применены в рамках нашего процесса принятия решений в качестве специалистов по данным.
Но не слишком полагайтесь на p-значения, поскольку они помогают только в небольшой части всего процесса принятия решений.
Я надеюсь, что мое объяснение p-значений стало интуитивно понятным и полезным в вашем понимании того, что в действительности означают p-значения и как их можно использовать при проверке ваших гипотез.
Сам по себе расчет р-значений прост. Трудная часть возникает, когда мы хотим интерпретировать p-значения в проверке гипотез. Надеюсь, что теперь трудная часть станет для вас немного легче.
Если вы хотите узнать больше о статистике, я настоятельно рекомендую вам прочитать эту книгу (которую я сейчас читаю!) — Практическая статистика для специалистов по данным, специально написанная для data scientists, чтобы разобраться с фундаментальными концепциями статистики.

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
- Обучение профессии Data Science с нуля (12 месяцев)
- Профессия аналитика с любым стартовым уровнем (9 месяцев)
- Курс по Machine Learning (12 недель)
- Курс «Python для веб-разработки» (9 месяцев)
- Курс по DevOps (12 месяцев)
- Профессия Веб-разработчик (8 месяцев)
Читать еще
- Тренды в Data Scienсe 2020
- Data Science умерла. Да здравствует Business Science
- Крутые Data Scientist не тратят время на статистику
- Как стать Data Scientist без онлайн-курсов
- 450 бесплатных курсов от Лиги Плюща
- Data Science для гуманитариев: что такое «data»
- Data Scienсe на стероидах: знакомство с Decision Intelligence
Маркетинг – та сфера, где больше всего любят работать с большими данными (англ. big data), однако излюбленный инструмент маркетологов – A/B-тестирование – предполагает использование малых данных (англ. small data). При этом какие бы цифры ни были получены по итогам теста, все сводится к анализу статистической выборки и определению статистической значимости результатов эксперимента. Неотъемлемой частью данного исследования является P-значение, о котором мы хотим рассказать в этой статье.
Что такое P-значение
P-value или p-значение – одна из ключевых величин, используемых в статистике при тестировании гипотез. Она показывает вероятность получения наблюдаемых результатов при условии, что нулевая гипотеза верна, или вероятность ошибки в случае отклонения нулевой гипотезы.
Этот термин первым упомянул в своих работах К. А. Браунли в 1960 году. Он описал p-уровень значимости как показатель, который находится в обратной зависимости от истинности результатов. Чем выше р-value, тем ниже степень доверия в выборке зависимости между переменными.
Другими словами, в статистике p-значение – это наименьшее значение уровня значимости, при котором полученная проверочная статистика ведет к отказу от основной (нулевой) гипотезы.
Значение p-уровня чаще всего соответствует статистической значимости, равной 0,05. Если значение р меньше 0,05, нулевую гипотезу отклоняют. При этом чем меньше это значение, тем лучше, т. к. растет предполагаемая значимость альтернативной гипотезы и «сила» отвержения нулевой.
Часто p-значение понимают неправильно. Например, если значение р = 0,05, можно сказать о том, что существует 5% вероятности, что результат получен случайно и не соответствует действительности.

Кратко о главном
- Р-значение показывает вероятность того, что наблюдаемая разница в результатах могла быть случайной.
- Значение p применяется как альтернатива выбранным уровням достоверности для тестирования идей или в дополнение к ним.
- Со снижением p-значения повышается статистическая значимость разницы, полученной в ходе исследования.
Статистическая значимость
Эксперимент начинается с формулирования нулевой гипотезы. Она показывает, что два исследуемых явления никаким образом не связаны друг с другом.
Эксперимент проводится с целью выявить или показать какое-либо влияние или тип взаимодействия рассматриваемых явлений. Если в итоге анализа подтверждается нулевая гипотеза, значит, тест провалился.

Чтобы правильно интерпретировать результаты, рассчитывают показатель статистической значимости.
Статистическая значимость – это критерий, с помощью которого можно определить, необходимо ли отвергнуть или принять ту или иную гипотезу.
Перед началом тестирования следует установить порог значимости (альфа). Если значение р меньше альфа, можно говорить о том, что наш результат является статистически значимым. Это говорит о том, что наблюдаемое явление действительно имело место, и нулевую гипотезу нужно отклонить.
Порог значимости альфа устанавливается обычно на уровне 0,05 или 0,01. Выбор значения определяется поставленной задачей.
Порог значимости равен 0,05, а p-значение – 0,02. Т. к. установленное значение альфа больше p-уровня, делаем вывод, что это статистически значимый результат.
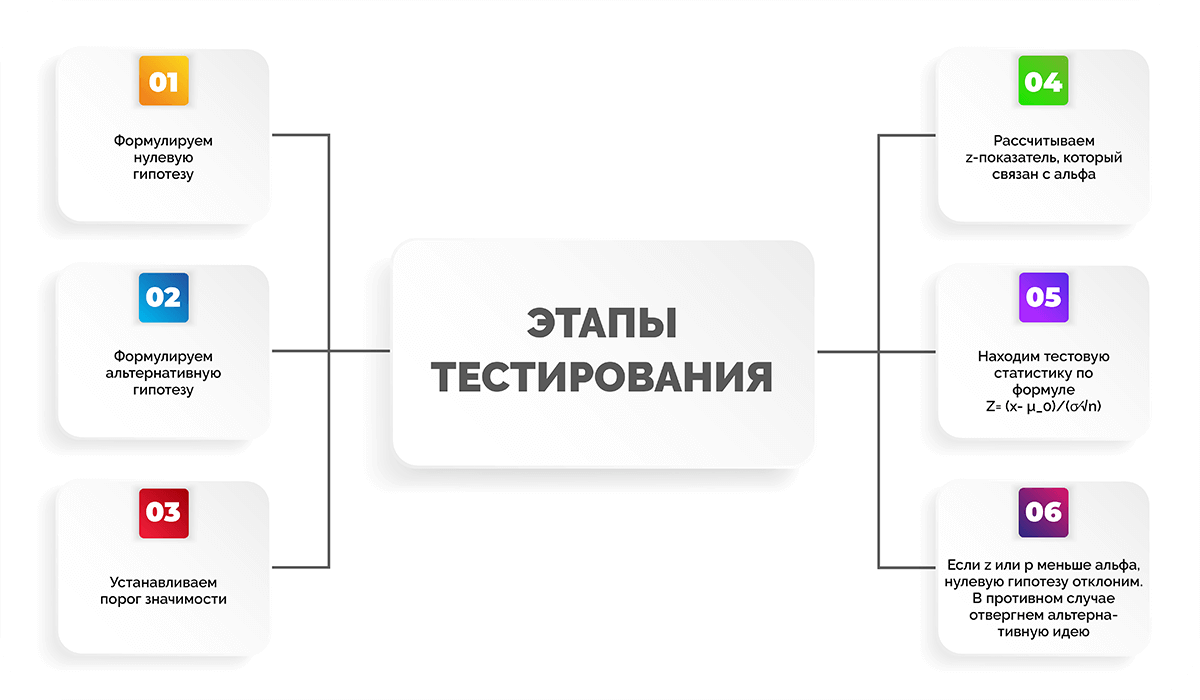
Все тестирование можно разделить на несколько этапов:
- Формулируем нулевую гипотезу.
- Формулируем альтернативную гипотезу.
- Устанавливаем порог значимости.
- Рассчитываем z-показатель, который связан с альфа.
- Находим тестовую статистику по формуле
 .
. - Если z-показатель или p-значение меньше уровня альфа, нулевую гипотезу отклоним. В противном случае отвергнем альтернативную идею.
 .
.Если идет речь о явлениях, которые управляются случайными процессами, обычно это приводит к нормальному распределению значений. В этом случае нулевую гипотезу представляют в виде кривой Гаусса, которая отражает распределение ожидаемых наблюдений. Это распределение актуально в случае, если одна переменная в эксперименте не зависит от другой.
Порог вероятности
В основе статистической значимости лежит вероятность получения определенного результата при верности нулевой гипотезы. Чтобы разобрать смысл этого определения, предположим, что в процессе тестирования получили некое число х. Это может быть любая метрика, например, прибыль от продаж, величина конверсии, количество довольных покупателей и т. д.
Используя функцию плотности вероятности, которая связана с нулевой гипотезой, можно выяснить, удастся ли получить число х (или любое другое значение, которое маловероятнее, чем х) с вероятностью менее 5% (p < 0,05) или менее 1% (p < 0,01), или другого порога, при котором p меньше заданного уровня значимости.
Таким образом, p-критерий отражает вероятность получения результата, который равен или является более экстремальным, чем фактически наблюдаемый результат, в случае отсутствия взаимосвязи между исследуемыми переменными.
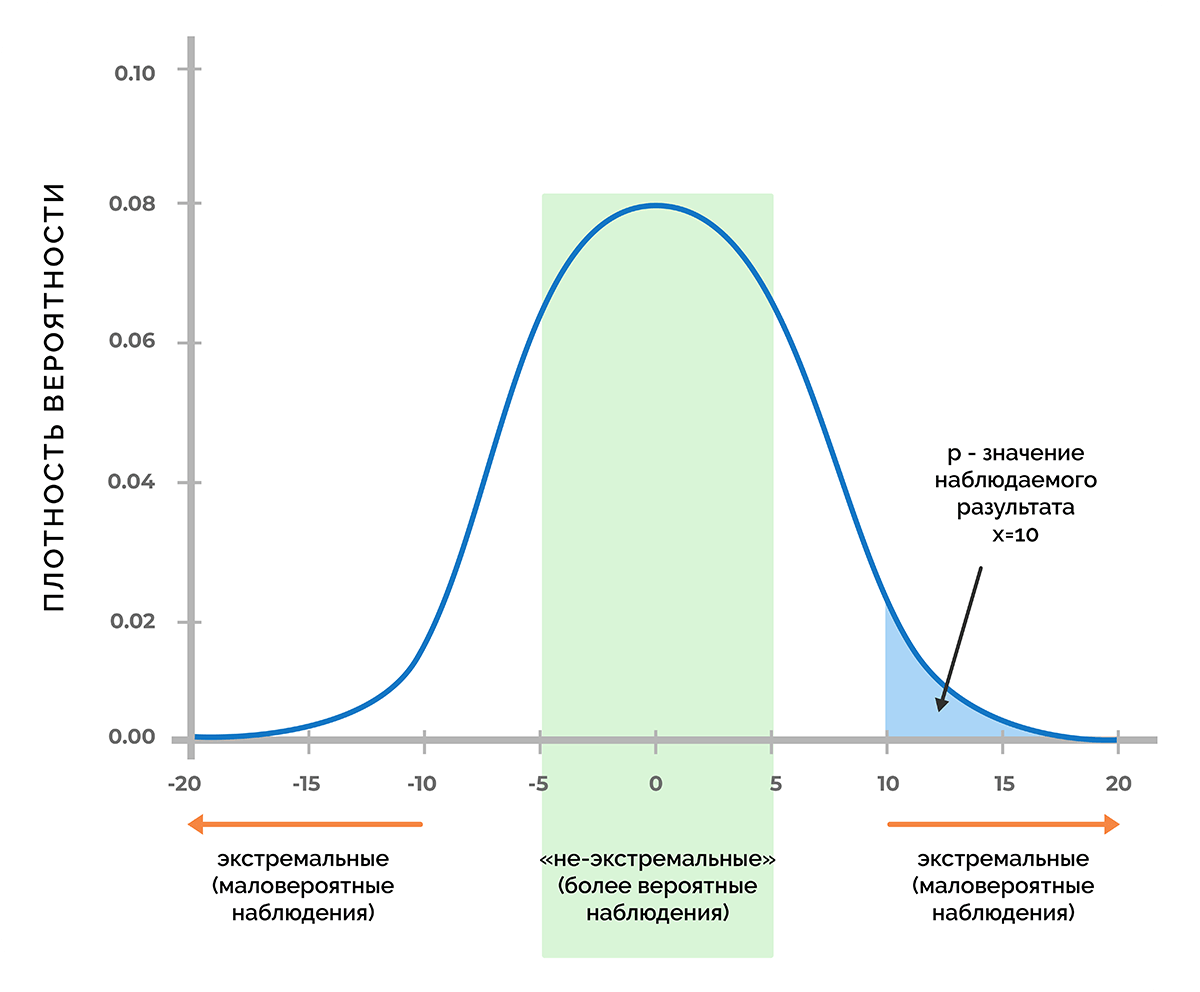
Доверительные уровни
Доверительный уровень значимости выбирается перед запуском статистического эксперимента. Чаще всего используются значения 90%, 95% или 99%.
Ниже в таблице приводим критические p-значения, а также z-оценки для разных доверительных уровней.
|
Доверительный уровень |
Стандартное отклонение (z-оценка) |
Вероятность (p-уровень) |
|
90% |
< -1,65 или > +1,65 |
< 0,10 |
|
95% |
< -1,96 или > +1,96 |
< 0,05 |
|
99% |
< -2,58 или > +2,58 |
< 0,01 |
Значения, которые находятся в пределах области нормального распределения z-оценки (стандартного отклонения), представляют ожидаемый результат.
Проверка статистических гипотез
Проверка гипотезы – это статистическое исследование, которое проводится, чтобы подтвердить или опровергнуть какую-либо гипотезу (простую или сложную).
Можно предположить, что посадочная страница с красной кнопкой CTA даст больше конверсий, чем текущая версия лендинга с синей. Проверить это можно путем тестирования, в котором будут участвовать нулевая и альтернативная гипотезы.

Нулевая гипотеза – первоначальное условие, при котором нет никакой разницы между текущей и новой версиями лендинга в плане конверсии
Альтернативная гипотеза – подразумевает, что изменение цвета кнопки на странице является причиной роста конверсии.
В статистике применяется рандомизация и нормализация нулевой гипотезы.
Рандомизация нулевой гипотезы – пространственная модель данных, которую мы наблюдаем, является одним из многих вариантов пространственных организаций данных. При этом все другие варианты не будут заметно отличаться от наблюдаемых.
Нормализация нулевой гипотезы подразумевает, что наблюдаемые значения являются одним из многих случайных вариантов выборок. При этом ни пространственное расположение данных, ни их значения не установлены.
Благодаря значению p можно увидеть, насколько нулевая гипотеза правдоподобна с учетом данных выборки. Таким образом, если нулевая гипотеза подтвердится, p-значение будет свидетельствовать об отсутствии увеличения конверсии вследствие изменения цвета кнопки.
Подход p-value к проверке гипотез
Значение р может использоваться для выявления доказательства для отклонения нулевой (первоначальной) гипотезы в ходе эксперимента.
Мы уже упоминали выше о том, что уровень значимости обозначается до начала исследования, чтобы определить, насколько малое значение p нужно получить для опровержения нулевой гипотезы. Однако в разных случаях разные люди могут использовать разные уровни значимости, поэтому при интерпретации итогов двух разных тестирований другими людьми могут возникать трудности. Решить эту проблему помогает p-value.
Рассмотрим пример, в котором в компании провели исследование, в ходе него сравнили доходность двух активов. Тест и анализ проводили два специалиста, которые брали за основу одни и те же самые исходные данные, но использовали разные уровни значимости. Есть вероятность, что эти люди сделают противоположные выводы о различии активов. Предположим, что один специалист для отклонения нулевой гипотезы взял уровень достоверности 90%, а другой – 95%. При этом среднее значение p наблюдаемой разницы между результатами равнялось 0,08, что отвечает уровню достоверности 92%. В таком случае первый специалист выявит значимое различие между двумя доходами, а второй статистически значимой разницы не обнаружит.
Чтобы избежать подобной ситуации, можно сообщить значение p-value эксперимента и дать возможность независимым наблюдателям самостоятельно оценивать статистическую значимость итоговых данных. Данный подход к проверке утверждений стали называть «подход p-value».
Как рассчитать P-value
Чаще всего p-значения определяют с помощью таблиц p-value или специализированного статистического ПО. Также помогает в этом калькулятор на тематических сайтах. Подобные расчеты основываются на известном или предполагаемом распределении вероятностей определенной статистики. Определение среднего значения р зависит от отклонения между выбранным эталонным и тестовым значением. При этом учитывается нормальное распределение вероятностей статистики.
Что касается ручного математического расчета значения р, существуют разные способы, которые рассмотрим далее в статье.
Как рассчитать p-значение, используя тестовую статистику
Распределение тестовой статистики происходит с предполагаемым условием, что верна нулевая гипотеза. Чтобы выразить вероятность того, что статистика эксперимента будет такой же экстремальной, как значение x для выборки, используется кумулятивная функция распределения.
Левосторонний эксперимент:
P-value = cdf (x)
Правосторонний эксперимент:
P-value = 1 – cdf (x)
Двусторонний эксперимент:
P-value = 2 × мин {{cdf (x), 1 – cdf (x)}}
Ручной расчет значения p затрудняют распространенные распределения вероятностей, которыми характеризуется проверка гипотез. Для расчета примерных показателей cdf удобнее использовать статистическую таблицу или ПК.
Пошаговый алгоритм расчета p-значения
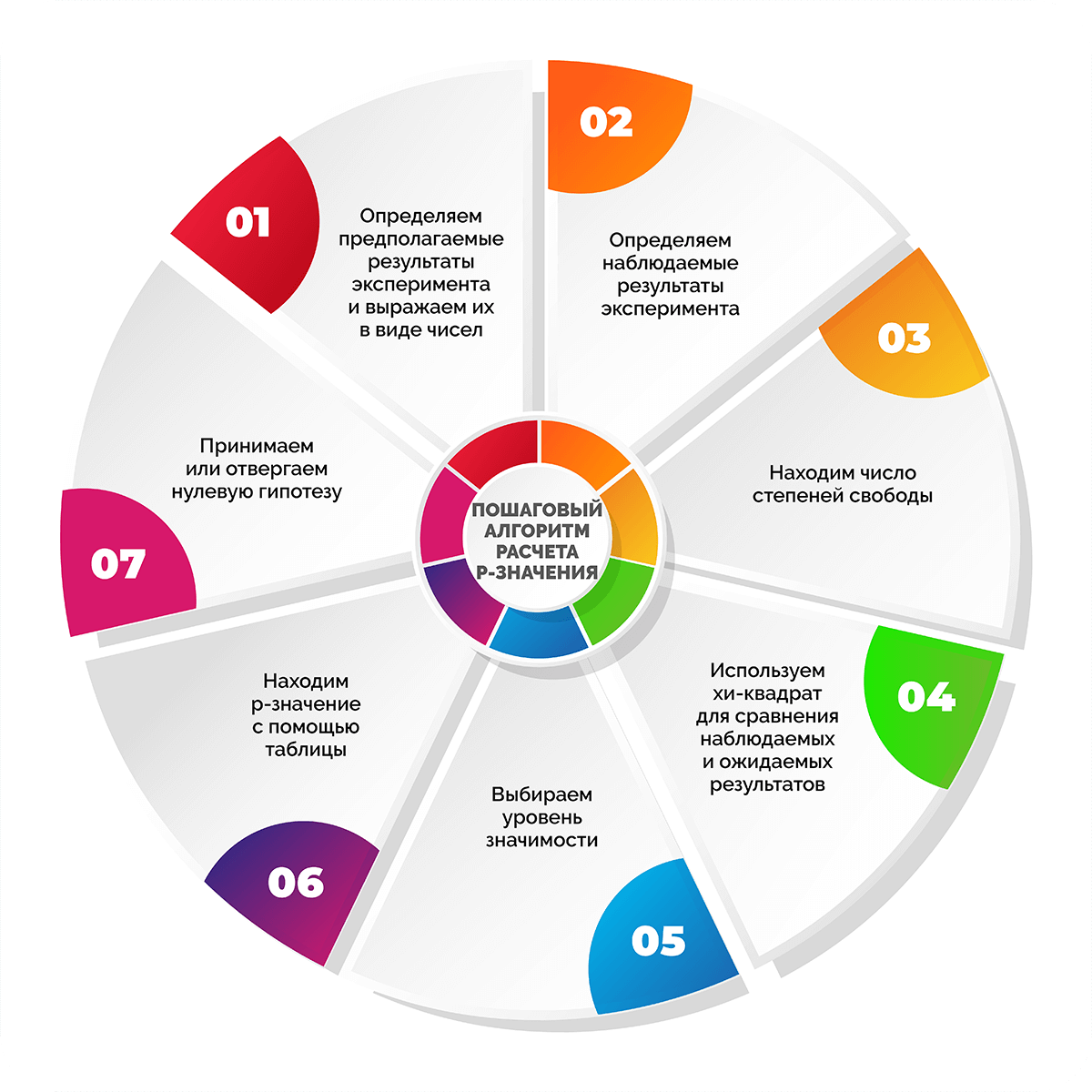
Шаг 1. Определяем предполагаемые результаты эксперимента и выражаем их в виде чисел
Как правило, на начало исследования уже есть видение того, какие числа можно считать приемлемыми. Выводы могут быть основаны на опыте проведения предыдущих экспериментов, наборах достоверных данных или общих сведеньях из научной литературы и других источников.
Опыт работы с лендингами показывает, что посадочные страницы с CTA-кнопкой на первом экране приводят примерно вдвое больше покупателей, чем версии без таких кнопок. Необходимо определить, действительно ли наличие кнопки влияет на посетителей сайта. Для этого будем анализировать конверсии в покупку. Если взять условные 300 конверсий, то предполагается, что 200 из них произойдут благодаря лендингам с CTA-кнопкой, а 100 – сайтам без кнопки при условии, что пользователи требовательны к наличию кнопок.
Шаг 2. Определяем наблюдаемые результаты эксперимента
Теперь нужно провести тест и получить реальные, т. е. наблюдаемые значения, которые таже будут выражаться в числовом формате. Если в экспериментальных условиях реальные цифры не совпадут с ожидаемыми, то будет два варианта – или это обусловлено действиями в ходе эксперимента, или получилось случайно. В данном случае цель определения p-value – понять, действительно ли наблюдаемые значения отличаются от ожидаемых настолько, что нулевая гипотеза не будет опровергнута.
Предположим, что мы выбрали 300 случайных конверсий с наших сайтов, на которых либо была кнопка на первом экране, либо ее не было. Определили, что 220 конверсий произошли благодаря лендингам с кнопкой и 80 – без нее. Результаты отличаются от ожидаемых, которые составляли 200 и 100 соответственно. Теперь предстоит узнать, действительно ли к изменению в значениях привел наш тест (добавление кнопки на первый экран) или это случайное отклонение. Определить это поможет p-значение.
Шаг 3. Находим число степеней свободы
Число степеней свободы показывает, насколько может измениться эксперимент. При этом степень изменяемости зависит от количества исследуемых категорий.
Число степеней свободы = n – 1, где n – количество анализируемых переменных или категорий.
В нашем эксперименте 2 условия и, соответственно, две категории результатов: для лендингов без кнопки на первом экране и для лендингов с ней.
Число степеней свободы = 2 – 1 = 1.
Если бы в эксперименте мы сравнивали посадочные станицы с CTA-кнопкой, без кнопки и с pop-up окном, то получили бы 2 степени свободы и т. д.
Шаг 4. Используем хи-квадрат для сравнения наблюдаемых и ожидаемых результатов
Хи-квадрат (х2) – числовое отражение разницы между наблюдаемыми (фактическими) и ожидаемыми значениями тестирования.

где:
о – наблюдаемое значение;
е – ожидаемое значение.
Подставляем наши цифры в уравнение и учитываем, что  нужно подсчитать дважды – для двух видов лендинга.
нужно подсчитать дважды – для двух видов лендинга.
х2 = ((220 – 200)2/200) + ((80 – 100)2/100) = ((20)2/200)) + ((-20)2/100) = (400/200) + (400/100) = 2 + 4 = 6.
Шаг 5. Выбираем уровень значимости
Уровень значимости отражает степень уверенности в полученных результатах. Если статистическая значимость низкая, это говорит о низкой вероятности случайного получения экспериментальных результатов.
Для большинства тестов достаточно статистической значимости, равной 0,05 или 5%. При этом будет вероятность 95%, что исследователь получил значимый результат вследствие проведенных мероприятий, а не случайно.
В нашем случае примем статистическую значимость, равную 0,05.
Шаг 6. Находим p-значение с помощью таблицы
Для облегчения расчетов статисты применяют специализированные таблицы. Они довольно простые и позволяют легко найти значение р, зная число степеней свободы и хи-значение. Слева по вертикали располагаются значения числа степеней свободы. Вверху по горизонтали находятся p-значения. По данным таблицы сначала находят нужное число степеней свободы, затем в соответствующем ему ряду выбирают первое значение, которое превышает расчетное значение хи-квадрата. Число в верхней горизонтальной строке будет соответствовать p-значению. При этом нужное значение р находится в диапазоне чисел между найденным и следующим за ним слева.
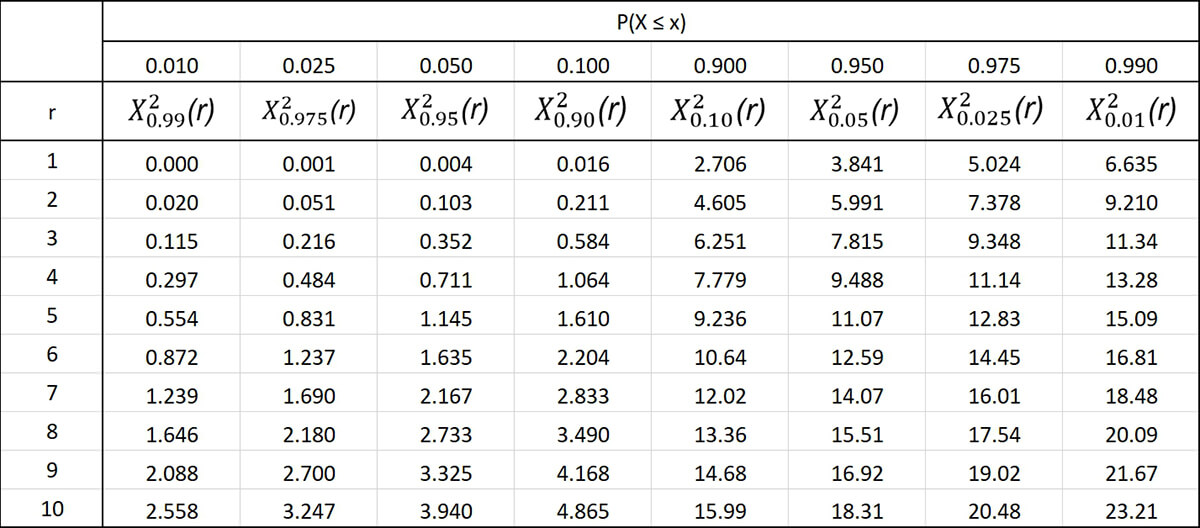
В нашем примере всего одна степень свободы, а хи-квадрат равен 6. Поэтому в таблице выбираем первую строку и движемся по ней слева направо до тех пор, пока не увидим первое значение больше 6 – это число 6,635. Оно соответствует p-значению 0,01, а значит, наше p-значение находится в диапазоне между 0,01 и 0,025.
Шаг 7. Принимаем или отвергаем нулевую гипотезу
Если найденное приблизительное значение p меньше уровня значимости, можно заключить, что вероятна связь между экспериментальными переменными и полученными результатами. В противном случае нельзя утверждать с уверенностью, связаны ли результаты с манипуляцией переменными или стали случайностью.
В нашем эксперименте диапазон значений р 0,01-0,025 определенно меньше установленной статистической значимости 0,05, что позволяет отклонить нулевую гипотезу. А значит, можно сделать вывод, что посадочные страницы с CTA-кнопкой на 1-м экране конвертируют лучше, чем аналогичные версии без такой кнопки. Вероятность того, что рост конверсий на лендингах с кнопкой является случайностью, составляет не больше 1-2,5%.
Как интерпретировать P-значение
P-уровень тесно связан с уровнем статистической значимости. Последний таже определяет исход эксперимента.
- Если p-значение меньше уровня значимости, то нулевую гипотезу можно смело отклонить и считать истинной альтернативную гипотезу.
- Если p-значение больше уровня значимости, это означает, что в ходе эксперимента выявили недостаточно оснований для отклонения нулевой гипотезы.
Отвержение нулевой гипотезы говорит о том, что в процессе исследования была обнаружена закономерная связь между тестируемыми переменными.
P-значение – это…
- вероятность того, что в ходе исследования наблюдения были случайными. То есть, если p = 0,05, есть 5% вероятности того, что наблюдаемое явление случайно и 95% вероятности того, что результат является следствием созданных условий;
- вероятность того, что будет сделан неверный вывод о взаимосвязи переменных. Если р = 0,05, то на каждые 100 экспериментов, где наблюдалась взаимосвязь, 95 их них действительно была, а 5 – нет.
Что нужно помнить о P-значениях
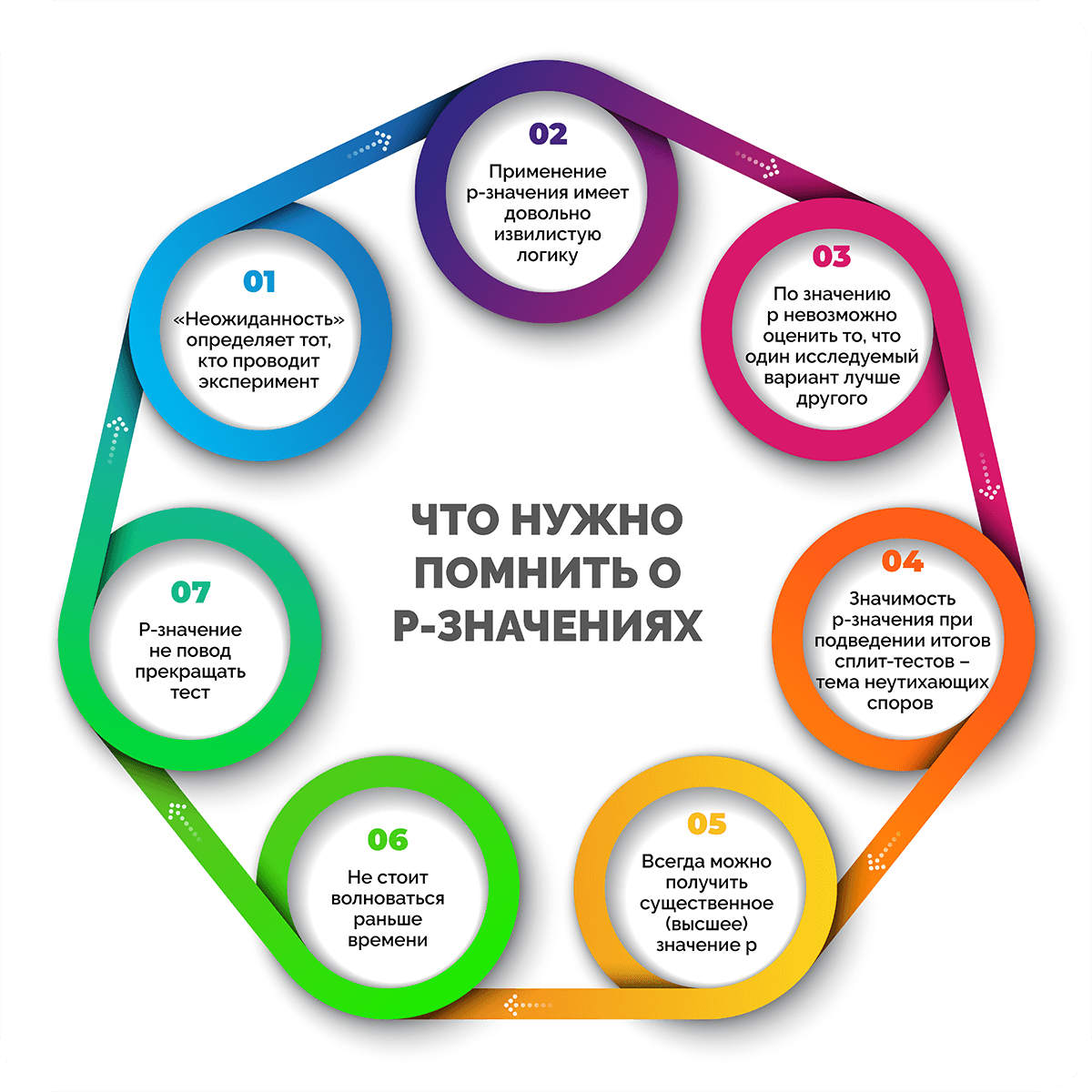
- «Неожиданность» определяет тот, кто проводит эксперимент. Подводит итоги теста по факту тот, кто его проводит. Чем выше значение р, тем чаще вы будете получать неожиданные результаты.
- Применение p-значения имеет довольно извилистую логику. Чтобы оценить аргументы в пользу отклонения нулевой гипотезы, необходимо изначально считать, что она верна. Именно это является причиной путаницы.
- По значению p невозможно оценить вероятность того, что один исследуемый вариант лучше другого. Также по этому показателю нельзя понять, какая вероятность того, что предпочтение одного варианта другому ошибочно. На самом деле, p-значение показывает лишь вероятность того, что при верности нулевой гипотезы удастся вычислить результат, отличный от нуля.
- Значимость p-значения при подведении итогов сплит-тестов – тема неутихающих споров в научном сообществе. Большинство маркетологов остаются приверженцами классической проверки на статистическую значимость и отстаивают ее как «золотой стандарт». При этом специалисты по статистике приводят аргументы в пользу других методов проверки, что провоцирует жаркие дебаты.
- Всегда можно получить существенное (высшее) значение p. Есть типичная ошибка, которая зависит с одной стороны от объема выборки, с другой – от изменений генеральной совокупности данных. Если во втором случае повлиять на изменения никак нельзя, то собирать и накапливать данные ничто не мешает. Но есть ли польза от такого количества сведений? Сам факт того, что у полученного параметра высокое p-значение, практического значения не имеет.
- Не стоит волноваться раньше времени. В первую очередь нужно собрать данные, которые помогут сформировать рабочую идею. Всегда трудно делать выбор между вариантами, которые почти не отличаются друг от друга. Если выделить предпочтительный вариант проблематично из-за похожих результатов, можно просто выбрать один из них и не беспокоиться о том, правильный ли это выбор.
- P-значение не повод прекращать тест. Для получения достоверных результатов, которые позволят интерпретировать p-значение, необходимо вычислить размер выборки, затем провести эксперимент. В процессе тестирования предстоит выбрать время, когда пора его закончить. При этом оно не должно быть связано с достижением статистической значимости или высокого показателя p-значения. Главное – получить реальные результаты в конце теста, например, обеспечить рост прибыли, оптимизировать конверсию и т. д.
Примеры интерпретации P-значений
На нескольких примерах рассмотрим, как правильно интерпретировать p-значения при проверке разных идей.
По мнению интернет-провайдера, 90% пользователей довольны качеством предоставляемых услуг. Чтобы это проверить, была собрана простая выборка, куда вошли 500 случайных абонентов. 85% дали утвердительный ответ на вопрос об удовлетворенности услугами провайдера. По данным выборки удалось вычислить p-значение, равное 0,018.
Если выдвинуть гипотезу о том, что 90% пользователей действительно довольны обслуживанием провайдера, получим реальную наблюдаемую разницу или более экстремальную разницу, которая составит 1,8% потребителей услуг вследствие ошибки случайной выборки.
Ресторан вводит услугу доставки еды и утверждает, что время доставки составляет около 30 минут или меньше. Однако есть мнение, что реальный срок доставки превышает заявленное время. Для проверки этих вариантов были отобраны случайные заказы еды с доставкой и проведены расчеты. По результатам выяснили, что среднее время доставки составляет 40 минут (больше на 10 минут, чем заявляет ресторан), а p-значение равно 0,03.
Результаты показывают, что в случае, когда нулевая гипотеза верна, т. е. доставка еды занимает 30 минут или меньше, есть вероятность 3%, что среднее время доставки будет как минимум на 10 минут больше из-за эффекта случайности.
Отдел маркетинга разрабатывает новый скрипт продаж для менеджеров. Предполагается, что с его помощью компания будет продавать минимум на 30% больше, чем со старым скриптом. Чтобы это проверить, собирается простая случайная выборка из 100 контактов с клиентами по новому скрипту и 100 – по старому. В результате эксперимента новый скрипт привел 60 покупателей, а старый – 45. Вычислили среднее значение p, равное 0,011.
Если взять за основу мнение, что новый скрипт приводит столько же клиентов, сколько и старый, или меньше, будет получена крайняя разница в 1,1% тестирований вследствие случайной ошибки выборки.
Часто задаваемые вопросы
P-значение – вероятность того, что исследуемая статистика удовлетворит конкретным условиям. Поскольку вероятности отрицательными не бывают, отрицательного значения p тоже быть не может.
Если p-значение высокое, это свидетельствует о том, что статистика эксперимента для другой выборки будет иметь столь же экстремальное значение, как и в тестируемой выборке. При высоком p-значении отвергнуть нулевую гипотезу нельзя.
Если получено низкое p-значение, это значит, что вероятность получить такое же критическое значение, как и наблюдаемое в текущей выборке, в тестовой статистике для другой выборки окажется очень низкой. При низком p-значении нулевую гипотезу отвергают и принимают альтернативную.
Некоторые считают, что p-значения показывают вероятность совершить ошибку при отклонении истинной нулевой гипотезы (ошибка первого типа) – это заблуждение. P-значения не свидетельствуют о частоте вероятных ошибок по двум причинам:
- При расчете p-значения в основе утверждение, что верна нулевая гипотеза, а разница в итоговых данных обусловлена случайностью. То есть величина p-значения не отражает вероятность того, что ноль будет ложным или истинным, т. к. с учетом изначального предположения он полностью верен.
- Несмотря на то, что при низком p-значении при условии истинности нулевого значения выборочные данные маловероятны, p-значение все еще не может четко показать, какой из вариантов имеет большую вероятность стать истиной: когда нуль действительно является ложным или когда нуль является верным, но выборка нечеткая.
Заключение
Несмотря на то, что при интерпретации результатов исследований часто допускают ошибки, неправильно используя статистическую значимость, она продолжает оставаться важным методом в экспериментах. P-значение или p-value является одной из обязательных составляющих при оценке результатов тестирования. Именно этот показатель дает возможность понять, с какой вероятностью полученные итоги удовлетворяют определенным значениям.

Олег Вершинин
Специалист по продукту
Все статьи автора
Нашли ошибку в тексте? Выделите нужный фрагмент и нажмите
ctrl
+
enter
Одним из наиболее распространенных тестов, используемых в статистике, является t-критерий , который часто используется для определения того, равно ли среднее значение генеральной совокупности некоторому значению.
Например, предположим, что мы хотим знать, равна ли средняя высота определенного вида растений 15 дюймам. Чтобы проверить это, мы могли бы собрать случайную выборку из 20 растений, найти среднее значение выборки и стандартное отклонение выборки и выполнить t-тест, чтобы определить, действительно ли средняя высота равна 15 дюймам.
Нулевая и альтернативная гипотезы для теста следующие:
H 0 : µ = 15
Н а : мк ≠ 15
Формула тестовой статистики:
т = ( х — μ) / (с / √ п )
где x — среднее значение выборки, μ — предполагаемое среднее значение (в нашем примере оно будет равно 15), s — стандартное отклонение выборки, а n — размер выборки.
Как только мы узнаем значение t , мы можем использовать статистическое программное обеспечение или онлайн-калькулятор , чтобы найти соответствующее значение p. Если p-значение меньше некоторого альфа-уровня (обычно это 0,01, 0,05 и 0,10), то мы можем отвергнуть нулевую гипотезу и сделать вывод, что средняя высота растений не равна 15 дюймам.
Однако также возможно оценить p-значение теста вручную, используя таблицу t-Distribution.В этом посте мы объясним, как это сделать.
Пример: расчет p-значения по t-критерию вручную
Задача : Боб хочет знать, равна ли средняя высота определенного вида растений 15 дюймам. Чтобы проверить это, он собирает случайную выборку из 20 растений и обнаруживает, что среднее значение выборки составляет 14 дюймов, а стандартное отклонение выборки составляет 3 дюйма. Проведите t-тест, используя альфа-уровень 0,05, чтобы определить, действительно ли истинный средний рост населения составляет 15 дюймов.
Решение:
Шаг 1: Сформулируйте нулевую и альтернативную гипотезы.
H 0 : µ = 15
Н а : мк ≠ 15
Шаг 2: Найдите тестовую статистику.
t = ( x -μ ) / ( с / √ n ) = (14-15) / (3 / √ 20 ) = -1,49
Шаг 3: Найдите p-значение для тестовой статистики.
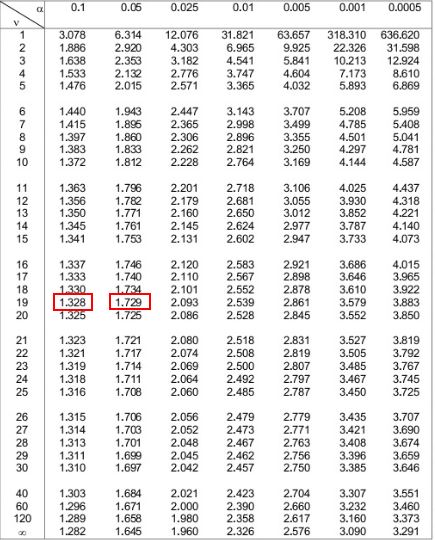
Чтобы найти p-значение вручную, нам нужно использовать таблицу t-Distribution с n-1 степенями свободы. В нашем примере размер выборки n = 20, поэтому n-1 = 19.
В приведенной ниже таблице t-Distribution нам нужно посмотреть на строку, которая соответствует «19» в левой части, и попытаться найти абсолютное значение нашей тестовой статистики 1,49 .
Обратите внимание, что 1,49 не отображается в таблице, но находится между двумя значениями 1,328 и 1,729 .
Далее мы можем посмотреть на два альфа-уровня в верхней части таблицы, которые соответствуют этим двум числам. Мы видим, что они равны 0,1 и 0,5 .
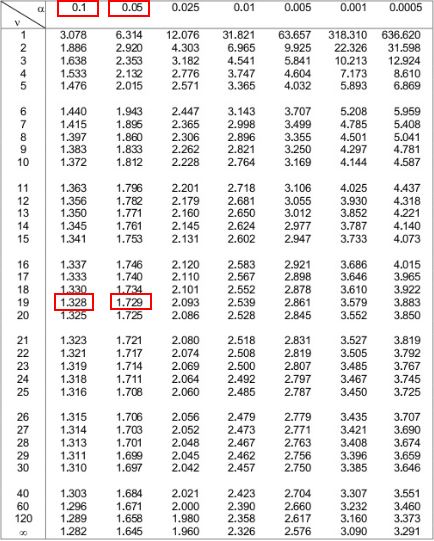
Это означает, что значение p для одностороннего теста находится в пределах от 0,1 до 0,05. Назовем его 0,075. Поскольку наш t-критерий является двусторонним, нам нужно умножить это значение на 2. Таким образом, наше оценочное значение p равно 0,075 * 2 = 0,15 .
Шаг 4: Сделайте вывод.
Поскольку это p-значение не меньше выбранного нами альфа-уровня 0,05, мы не можем отвергнуть нулевую гипотезу. Таким образом, у нас нет достаточных доказательств, чтобы сказать, что истинная средняя высота этого вида растений отличается от 15 дюймов.
Проверка результатов с помощью калькулятора
Мы можем подключить нашу тестовую статистику t и наши степени свободы к онлайн-калькулятору p-значения , чтобы увидеть, насколько близко наше оценочное значение p было к истинному значению p:

Истинное p-значение равно 0,15264 , что довольно близко к нашему оценочному p-значению 0,15 .
Вывод
В этом посте мы увидели, что можно вручную оценить p-значение t-теста, используя таблицу t-распределения. Однако в большинстве сценариев вам никогда не придется вычислять p-значение вручную, и вместо этого вы можете использовать статистическое программное обеспечение, такое как R и Excel, или онлайн-калькулятор, чтобы найти точное p-значение теста.
В большинстве случаев, особенно в строгих статистических исследованиях и экспериментах, вы захотите использовать калькулятор, чтобы найти точное значение p из t-теста, чтобы вы могли быть максимально точными, но хорошо знать, что вы все еще можете оцените p-значение из t-теста вручную, если вам это абсолютно необходимо.
Что такое p-value?
P-значение (англ. P-value) — величина, используемая при тестировании статистических гипотез. Фактически это вероятность ошибки при отклонении нулевой гипотезы (ошибки первого рода). Проверка гипотез с помощью P-значения является альтернативой классической процедуре проверки через критическое значение распределения.
Обычно P-значение равно вероятности того, что случайная величина с данным распределением (распределением тестовой статистики при нулевой гипотезе) примет значение, не меньшее, чем фактическое значение тестовой статистики. Википедия.
Иначе говоря, p-значение – это наименьшее значение уровня значимости (т.е. вероятности отказа от справедливой гипотезы), для которого вычисленная проверочная статистика ведет к отказу от нулевой гипотезы. Обычно p-значение сравнивают с общепринятыми стандартными уровнями значимости 0,005 или 0,01.
Например, если вычисленное по выборке значение проверочной статистики соответствует p = 0,005, это указывает на вероятность справедливости гипотезы 0,5%. Таким образом, чем p-значение меньше, тем лучше, поскольку при этом увеличивается «сила» отклонения нулевой гипотезы и увеличивается ожидаемая значимость результата.
Интересное объяснение этого есть на Хабре.
Статистический анализ начинает напоминать черный ящик: на вход подаются данные, на выход — таблица основных результатов и значение p-уровня значимости (p-value).
О чём говорит p-value?
Предположим, мы решили выяснить, существует ли взаимосвязь между пристрастием к кровавым компьютерным играм и агрессивностью в реальной жизни. Для этого были случайным образом сформированы две группы школьников по 100 человек в каждой (1 группа — фанаты стрелялок, вторая группа — не играющие в компьютерные игры). В качестве показателя агрессивности выступает, например, число драк со сверстниками. В нашем воображаемом исследовании оказалось, что группа школьников-игроманов действительно заметно чаще конфликтует с товарищами. Но как нам выяснить, насколько статистически достоверны полученные различия? Может быть, мы получили наблюдаемую разницу совершенно случайно? Для ответа на эти вопросы и используется значение p-уровня значимости (p-value) — это вероятность получить такие или более выраженные различия при условии, что в генеральной совокупности никаких различий на самом деле нет. Иными словами, это вероятность получить такие или еще более сильные различия между нашими группами, при условии, что, на самом деле, компьютерные игры никак не влияют на агрессивность. Звучит не так уж и сложно. Однако, именно этот статистический показатель очень часто интерпретируется неправильно.
Примеры про p-value

Итак, мы сравнили две группы школьников между собой по уровню агрессивности при помощи стандартного t-теста (или непараметрического критерия Хи — квадрат более уместного в данной ситуации) и получили, что заветный p-уровень значимости меньше 0.05 (например 0.04). Но о чем в действительности говорит нам полученное значение p-уровня значимости? Итак, если p-value — это вероятность получить такие или более выраженные различия при условии, что в генеральной совокупности никаких различий на самом деле нет, то какое, на ваш взгляд, верное утверждение:
1.Компьютерные игры — причина агрессивного поведения с вероятностью 96%.
2. Вероятность того, что агрессивность и компьютерные игры не связаны, равна 0.04.
3. Если бы мы получили p-уровень значимости больше, чем 0.05, это означало бы, что агрессивность и компьютерные игры никак не связаны между собой.
4. Вероятность случайно получить такие различия равняется 0.04.
5. Все утверждения неверны.
Если вы выбрали пятый вариант, то абсолютно правы! Но, как показывают многочисленные исследования, даже люди со значительным опытом в анализе данных часто некорректно интерпретируют значение p-value.
Давайте разберём все ответы по порядку:
Первое утверждение — пример ошибки корреляции: факт значимой взаимосвязи двух переменных ничего не говорит нам о причинах и следствиях. Может быть, это более агрессивные люди предпочитают проводить время за компьютерными играми, а вовсе не компьютерные игры делают людей агрессивнее.
Это уже более интересное утверждение. Всё дело в том, что мы изначально принимаем за данное, что никаких различий на самом деле нет. И, держа это в уме как факт, рассчитываем значение p-value. Поэтому правильная интерпретация: «Если предположить, что агрессивность и компьютерные игры никак не связаны, то вероятность получить такие или еще более выраженные различия составила 0.04».
А что делать, если мы получили незначимые различия? Значит ли это, что никакой связи между исследуемыми переменными нет? Нет, это означает лишь то, что различия, может быть, и есть, но наши результаты не позволили их обнаружить.
Это напрямую связано с самим определением p-value. 0.04 — это вероятность получить такие или ещё более экстремальные различия. Оценить вероятность получить именно такие различия, как в нашем эксперименте, в принципе невозможно!
Вот такие подводные камни могут скрываться в интерпретации такого показателя, как p-value. Поэтому очень важно понимать механизмы, заложенные в основании методов анализа и расчета основных статистических показателей.
Как найти p-value?
Источник.
1. Определите ожидаемые в вашем эксперименте результаты
Обычно когда ученые проводят эксперимент, у них уже есть идея того, какие результаты считать «нормальными» или «типичными». Это может быть основано на экспериментальных результатах прошлых опытов, на достоверных наборах данных, на данных из научной литературы, либо ученый может основываться на каких-либо других источниках. Для вашего эксперимента определите ожидаемые результаты, и выразите их в виде чисел.
Пример: Например, более ранние исследования показали, что в вашей стране красные машины чаще получают штрафы за превышение скорости, чем синие машины. Например, средние результаты показывают предпочтение 2:1 красных машин перед синими. Мы хотим определить, относится ли полиция точно так же предвзято к цвету машин в вашем городе. Для этого мы будем анализировать штрафы, выданные за превышение скорости. Если мы возьмем случайный набор из 150 штрафов за превышение скорости, выданных либо красным, либо синим автомобилям, мы ожидаем, что 100 штрафов будет выписано красным автомобилям, а 50 синим, если полиция в нашем городе так же предвзято относится к цвету машин, как это наблюдается по всей стране.
2. Определите наблюдаемые результаты вашего эксперимента
Теперь, когда вы опредили ожидаемые результаты, необходимо провести эксперимент, и найти действительные (или «наблюдаемые») значения. Вам снова необходимо представить эти результаты в виде чисел. Если мы создаем экспериментальные условия, и наблюдаемые результаты отличаются от ожидаемых, то у нас есть две возможности – либо это произошло случайно, либо это вызвано именно нашим экспериментом. Цель нахождения p-значения как раз и состоит в том, чтобы определить, отличаются ли наблюдаемые результаты от ожидаемых настолько, чтобы можно было не отвергать «нулевую гипотезу» – гипотезу о том, что между экспериментальными переменными и наблюдаемыми результатами нет никакой связи.
Пример: Например, в нашем городе мы случайно выбрали 150 штрафов за превышение скорости, которые были выданы либо красным, либо синим автомобилям. Мы определили, что 90 штрафов были выписаны красным автомобилям, и 60 синим. Это отличается от ожидаемых результатов, которые равны 100 и 50, соответственно. Действительно ли наш эксперимент (в данном случае, изменение источника данных с национального на городской) привел к данному изменению в результатах, или наша городская полиция относится предвзято точно так же, как и в среднем по стране, а мы видим просто случайное отклонение? P-значение поможет нам это определить.
3. Определите число степеней свободы вашего эксперимента
Число степеней свободы — это степень изменяемости вашего эксперимента, которая определяется числом категорий, которые вы исследуете. Уравнение для числа степеней свободы – Число степеней свободы = n-1, где «n» это число категорий или переменных, которые вы анализируете в своем эксперименте.
Пример: В нашем эксперименте две категории результатов: одна категория для красных машин, и одна для синих машин. Поэтому в нашем эксперименте у нас 2-1 = 1 степень свободы. Если бы мы сравнивали красные, синие и зеленые машины, у нас было бы 2 степени свободы, и так далее.
4. Сравните ожидаемые и наблюдаемые результаты с помощью критерия хи-квадрат
Хи-квадрат (пишется «x2») это числовое значение, которое измеряет разницу между ожидаемыми и наблюдаемыми значениями эксперимента. Уравнение для хи-квадрата следующее x2 = Σ((o-e)2/e), где «o» это наблюдаемое значение, а «e» это ожидаемое значение. Суммируйте результаты данного уравнения для всех возможных результатов (смотри ниже).
Заметьте, что данное уравнение включает оператор суммирования Σ (сигма). Другими словами, вам необходимо подсчитать ((|o-e|-.05)2/e) для каждого возможного результата, и сложить полученные числа, чтобы получить значение критерия хи-квадрат. В нашем примере у нас два возможных результата – либо машина, получившая штраф красная, либо синяя. Поэтому мы должны посчитать ((o-e)2/e) дважды – один раз для красных машин, и один раз для синих машин.
Пример: Давайте подставим наши ожидаемые и наблюдаемые значения в уравнение x2 = Σ((o-e)2/e). Помните, что из-за оператора суммирования нам необходимо посчитать ((o-e)2/e) дважды – один раз для красных автомобилей, и один раз для синих автомобилей. Мы выполним эту работу следующим образом:
x2 = ((90-100)2/100) + (60-50)2/50)
x2 = ((-10)2/100) + (10)2/50)
x2 = (100/100) + (100/50) = 1 + 2 = 3.
5. Выберите уровень значимости
Теперь, когда мы знаем число степеней свободы нашего эксперимента, и узнали значение критерия хи-квадрат, нам нужно сделать еще одну вещь перед тем, как мы найдем наше p-значение. Нам нужно определить уровень значимости. Говоря простым языком, уровень значимости показывает, насколько мы уверены в наших результатах. Низкое значение для значимости соответствует низкой вероятности того, что экспериментальные результаты получились случайно, и наоборот. Уровни значимости записываются в виде десятичных дробей (таких как 0.01), что соответствует вероятности того, что экспериментальные результаты мы получили случайно (в данном случае вероятность этого 1%).
По соглашению, ученые обычно устанавливают уровень значимости своих экспериментов равным 0.05, или 5%.[2] Это означает, что экспериментальные результаты, которые соответствуют такому критерию значимости, только с вероятностью 5% могли получиться чисто случайно. Другими словами, существует 95% вероятность, что результаты были вызваны тем, как ученый манипулировал экспериментальными переменными, а не случайно. Для большинства экспериментов 95% уверенности наличия связи между двумя переменными достаточно, чтобы считать, что они «действительно» связаны друг с другом.
Пример: для нашего примера с красными и синими машинами, давайте последуем соглашению между учеными, и установим уровень значимости в 0.05.
6. Используйте таблицу с данными распределения хи-квадрат, чтобы найти ваше p-значение
Ученые и статисты используют большие таблицы для вычисления p-значения своих экспериментов. Данные таблицы обычно имеют вертикальную ось слева, соответствующую числу степеней свободы, и горизонтальную ось сверху, соответствующую p-значению. Используйте данные таблицы, чтобы сначала найти число ваших степеней свободы, затем посмотрите на ваш ряд слева направо, пока не найдете первое значение, большее вашего значения хи-квадрат. Посмотрите на соответствующее p-значение вверху вашего столбца. Ваше p-значение находится между этим числом и следующим за ним (тем, которое находится левее вашего).
Таблицы с распределением хи-квадрат можно получить из множества источников (вот по этой ссылке можно найти одну из них).
Пример: Наше значение критерия хи-квадрат было равно 3. Так как мы знаем, что в нашем эксперименте всего 1 степень свободы, выберем самую первую строку. Идем слева направо по данной строке, пока не встретим значение, большее 3, нашего значения критерия хи-квадрат. Первое, которое мы находим это 3.84. Смотрим вверх нашего столбца, и видим, что соответствующее p-значение равно 0.05. Это означает, что наше p-значение между 0.05 и 0.1 (следующее p-значение в таблице по возрастанию).
7. Решите, отклонить или оставить вашу нулевую гипотезу
Так как вы определили приблизительное p-значение для вашего эксперимента, вам необходимо решить, отклонять ли нулевую гипотезу вашего эксперимента или нет (напоминаем, это гипотеза о том, что экспериментальные переменные, которыми вы манипулировали не повлияли на наблюдаемые вами результаты). Если ваше p-значение меньше, чем ваш уровень значимости – поздравляем, вы доказали, что очень вероятна связь между переменными, которыми вы манипулировали и результатами, которые вы наблюдали. Если ваше p-значение выше, чем ваш уровень значимости, вы не можете с уверенностью сказать, были ли наблюдаемые вами результаты результатом чистой случайности или манипуляцией вашими переменными.
Пример: Наше p-значение находится между 0,05 и 0,1. Это явно не меньше, чем 0,05, поэтому, к сожалению, мы не можем отклонить нашу нулевую гипотезу. Это означает, что мы не достигли минимум 95% вероятности того, чтобы сказать, что полиция в нашем городе выдает штрафы красным и синим автомобилям с такой вероятностью, которая достаточно сильно отличается от средней по стране.
Другими словами, существует 5-10% шанс, что наблюдаемые нами результаты – это не последствия смены места (анализа города, а не всей страны), а просто случайность. Так как мы потребовали точности меньше чем 5%, мы не можем сказать что мы уверены в том, что полиция нашего города менее предвзято относится к красным автомобилям – существует небольшая (но статистически значимая) вероятность, что это не так.
![]()
Загрузить PDF
![]()
Загрузить PDF
P-значение — это статистическая величина, которая помогает ученым определить, корректны ли их гипотезы. P-значения используются для определения того, подпадают ли результаты эксперимента в диапазон значений, нормальный для наблюдаемой величины. Обычно если P-значение для набора данных меньше, чем заранее определенное число (например 0,05), то ученые должны отклонить «нулевую гипотезу» своего эксперимента. Другими словами, они сделают вывод, что переменные в их эксперименте не оказывают достаточного эффекта на результаты. В настоящее время p-значения обычно можно найти в справочнике, если сначала посчитать значение хи-квадрат.
Шаги
-
1
Определите ожидаемые в вашем эксперименте результаты. Обычно когда ученые проводят эксперимент, у них уже есть идея того, какие результаты считать «нормальными» или «типичными». Это может быть основано на экспериментальных результатах прошлых опытов, на достоверных наборах данных, на данных из научной литературы, либо ученый может основываться на каких-либо других источниках. Для вашего эксперимента определите ожидаемые результаты и выразите их в виде чисел.
- Пример: допустим, более ранние исследования показали, что в вашей стране владельцы красных машин чаще получают штрафы за превышение скорости, чем владельцы синих. Например, средние результаты показывают предпочтение 2:1 красных машин перед синими. Наша задача — определить, относится ли полиция точно так же предвзято к цвету машин в вашем городе. Для этого мы будем анализировать штрафы, выданные за превышение скорости. Если мы возьмем случайный набор из 150 штрафов за превышение скорости, выданных либо владельцам красных, либо синих автомобилей, мы ожидаем, что 100 штрафов будет выписано владельцам красных автомобилей, а 50 — владельцам синих, если полиция в нашем городе так же предвзято относится к цвету машин, как это наблюдается по всей стране.
-
2
Определите наблюдаемые результаты вашего эксперимента. Теперь, когда вы определили ожидаемые результаты, необходимо провести эксперимент и найти действительные (или «наблюдаемые») значения. Вам снова необходимо представить эти результаты в виде чисел. Если мы создаем экспериментальные условия, и наблюдаемые результаты отличаются от ожидаемых, то у нас есть две возможности — либо это произошло случайно, либо это вызвано именно нашим экспериментом. Цель нахождения p-значения как раз и состоит в том, чтобы определить, отличаются ли наблюдаемые результаты от ожидаемых настолько, чтобы можно было не отвергать «нулевую гипотезу» — гипотезу о том, что между экспериментальными переменными и наблюдаемыми результатами нет никакой связи.
- Пример: допустим, в нашем городе мы случайно выбрали 150 штрафов за превышение скорости, которые были выданы либо владельцам красных, либо владельцам синих автомобилей. Мы определили, что 90 штрафов были выписаны владельцам красных автомобилей, и 60 — владельцам синих. Это отличается от ожидаемых результатов, которые равны 100 и 50, соответственно. Действительно ли наш эксперимент (в данном случае изменение источника данных с государственного уровня на городской) привел к данному изменению в результатах, или наша городская полиция относится к автомобилистам предвзято точно так же, как и в среднем по стране, а мы видим просто случайное отклонение? P-значение поможет нам это определить.
-
3
Определите число степеней свободы вашего эксперимента. Число степеней свободы — это степень изменяемости вашего эксперимента, которая определяется числом категорий, которые вы исследуете. Уравнение для числа степеней свободы — Число степеней свободы = n-1, где «n» — число категорий или переменных, которые вы анализируете в своем эксперименте.
- Пример: в нашем эксперименте две категории результатов: одна категория для владельцев красных машин и другая — для владельцев синих машин. Поэтому в нашем эксперименте у нас 2-1 = 1 степень свободы. Если бы мы сравнивали красные, синие и зеленые машины, у нас было бы 2 степени свободы и так далее.
-
4
Сравните ожидаемые и наблюдаемые результаты с помощью критерия хи-квадрат. Хи-квадрат (пишется «x2») — это числовое значение, которое измеряет разницу между ожидаемыми и наблюдаемыми значениями эксперимента. Уравнение для хи-квадрата следующее: x2 = Σ((o-e)2/e), где «o» — это наблюдаемое значение, а «e» — это ожидаемое значение.[1]
Суммируйте результаты данного уравнения для всех возможных результатов (смотри ниже).- Заметьте, что данное уравнение включает оператор суммирования Σ (сигма). Другими словами, вам необходимо подсчитать ((|o-e|-.05)2/e) для каждого возможного результата и сложить полученные числа, чтобы получить значение критерия хи-квадрат. В нашем примере у нас два возможных результата — либо машина, получившая штраф красная, либо синяя. Поэтому мы должны посчитать ((o-e)2/e) дважды — один раз для красных машин и один раз для синих машин.
- Пример: давайте подставим наши ожидаемые и наблюдаемые значения в уравнение x2 = Σ((o-e)2/e). Помните, что из-за оператора суммирования нам необходимо посчитать ((o-e)2/e) дважды — один раз для красных автомобилей и один раз — для синих. Мы выполним эту работу следующим образом:
- x2 = ((90-100)2/100) + (60-50)2/50)
- x2 = ((-10)2/100) + (10)2/50)
- x2 = (100/100) + (100/50) = 1 + 2 = 3 .
-
5
Выберите уровень значимости. Теперь, когда мы знаем число степеней свободы нашего эксперимента и узнали значение критерия хи-квадрат, нам нужно сделать еще одну вещь перед тем, как мы найдем наше p-значение. Нам нужно определить уровень значимости. Говоря простым языком, уровень значимости показывает, насколько мы уверены в наших результатах. Низкое значение для значимости соответствует низкой вероятности того, что экспериментальные результаты вышли случайными и наоборот. Уровни значимости записываются в виде десятичных дробей (таких как 0,01), что соответствует вероятности того, что экспериментальные результаты мы получили случайно (в данном случае вероятность этого 1 %).
- По соглашению, ученые обычно устанавливают уровень значимости своих экспериментов равным 0,05, или 5 %.[2]
Это означает, что экспериментальные результаты, которые соответствуют такому критерию значимости, только с вероятностью 5 % могли получиться чисто случайно. Другими словами, существует 95 % вероятность, что результаты были вызваны тем, как ученый манипулировал экспериментальными переменными, а не случайно. Для большинства экспериментов 95 % уверенности наличия связи между двумя переменными достаточно, чтобы считать, что они «действительно» связаны друг с другом. - Пример: для нашего примера с красными и синими машинами, давайте последуем соглашению между учеными и установим уровень значимости в 0.05.
- По соглашению, ученые обычно устанавливают уровень значимости своих экспериментов равным 0,05, или 5 %.[2]
-
6
Используйте таблицу с данными распределения хи-квадрат, чтобы найти p-значение. Ученые и статисты используют большие таблицы для вычисления p-значения своих экспериментов. Данные таблицы обычно имеют вертикальную ось слева, соответствующую числу степеней свободы, и горизонтальную ось сверху, соответствующую p-значению. Используйте данные таблицы, чтобы сначала найти число ваших степеней свободы, затем посмотрите на ваш ряд слева направо, пока не найдете первое значение, большее вашего значения хи-квадрат. Посмотрите на соответствующее p-значение вверху вашего столбца. Нужное вам p-значение находится между этим числом и следующим за ним (тем, которое находится левее вашего).
- Таблицы с распределением хи-квадрат можно получить из множества источников — их можно просто найти онлайн, либо посмотреть в научных книгах или книгах по статистике. Если у вас нет под рукой таких книг, используйте картинку выше или какую-нибудь таблицу онлайн, которую можно просматривать бесплатно, например на сайте medcalc.org. Она расположена здесь.
- Пример: наше значение критерия хи-квадрат было равно 3. Поэтому давайте используем таблицу распределения хи-квадрат на изображении выше, чтобы найти приблизительное p-значение. Так как мы знаем, что в нашем эксперименте всего 1 степень свободы, выберем самую первую строку. Идем слева направо по данной строке, пока не встретим значение, большее 3, нашего значения критерия хи-квадрат. Первое, которое мы находим, это 3,84. Смотрим вверх нашего столбца и видим, что соответствующее p-значение равно 0,05. Это означает, что наше p-значение между 0,05 и 0,1 (следующее p-значение в таблице по возрастанию).
-
7
Решите, отклонить или оставить нулевую гипотезу. Так как вы определили приблизительное p-значение для вашего эксперимента, вам необходимо решить, отклонять ли нулевую гипотезу вашего эксперимента или нет (напоминаем, это гипотеза о том, что экспериментальные переменные, которыми вы манипулировали не повлияли на наблюдаемые вами результаты). Если p-значение меньше, чем уровень значимости — поздравляем, вы доказали, что очень вероятна связь между переменными, которыми вы манипулировали, и результатами, которые вы наблюдали. Если p-значение выше, чем уровень значимости, нельзя с уверенностью сказать, были ли наблюдаемые вами результаты результатом чистой случайности или манипуляцией данными переменными.
- Пример: наше p-значение находится между 0,05 и 0,1. Это явно не меньше, чем 0,05, поэтому, к сожалению, мы не можем отклонить нашу нулевую гипотезу. Это означает, что мы не достигли минимум 95 % вероятности того, чтобы сказать, что полиция в нашем городе выдает штрафы владельцам красных и синих автомобилей с такой вероятностью, которая достаточно сильно отличается от средней по стране.
- Другими словами, существует 5–10 % шанс, что наблюдаемые нами результаты — это не последствия смены места (анализа города, а не всей страны), а просто случайность. Так как заявленная нами точность не должна превышать 5 %, мы не можем сказать с уверенностью, что полиция нашего города менее предвзято относится к владельцам красных автомобилей — существует небольшая (но статистически значимая) вероятность, что это не так.
Реклама







Советы
- Научный калькулятор позволяет облегчить вычисления. Вы также можете использовать калькуляторы онлайн.
- Вы можете подсчитать p-значение с использованием некоторых компьютерных программ, включая как часто используемые программы электронных таблиц, так и более специализированное программное обеспечение.
Реклама
Об этой статье
Эту страницу просматривали 116 247 раз.