Определение параметров линейной зависимости
Если есть основания предполагать, что исследуемая зависимость двух величин Y и X является линейной, то есть удовлетворяет формуле
 , (10.1)
, (10.1)
и экспериментальный график зависимости y(x) это подтверждает, то есть через доверительные интервалы всех экспериментальных точек можно провести прямую линию, то по результатам измерения величин Y и X, то есть по значениям координат экспериментальных точек, можно определить параметры линейной зависимости k и b. Это можно сделать по крайней мере двумя способами.
Первый способ – графический.
· Надо провести прямую линию на графике так, чтобы она пересекла доверительные интервалы всех точек и при этом как можно ближе прошла ко всем точкам. После этого можно приступить к определению k и b.
· k представляет собой угловой коэффициент прямой, поэтому его можно найти как отношение приращения функции Dy к приращению аргумента Dx. В качестве Dx удобнее всего выбрать разность координат крайних точек графика (xn – x1). При этом Dy = y(xn) – y(x1).

Графический способ определения параметров прямой линии
Обратите внимание: y(x1) и y(xn) – это не ординаты экспериментальных точек y1 и yn, физической величины Y, которые получены до построения графика зависимости y(x). Это значения линейной функции y(x), которую изображает проведённая на графике прямая.
· b – это отрезок, который прямая линия графика отсекает на оси ординат (на вертикальной оси), поэтому для нахождения b надо довести экспериментальную прямую до оси ординат и определить ординату их точки пересечения. Но это правило справедливо только в том случае, когда координатные оси пересекаются в начале координат, то есть в точке с координатами (0; 0). Если же удобнее выбрать другую точку пересечения осей, как это сделано при построении графика на рис.5, то нужно использовать другое правило: надо выбрать две точки на прямой, например, точки с координатами (x1; y(x1)) и (xn; y(xn)) и записать уравнение прямой, проходящей через эти точки:
 . (10.2)
. (10.2)
Приведение этого уравнение к виду (10.1) даёт следующее выражение для b:
 . (10.3)
. (10.3)
Описанный метод определения параметров прямой линии k и b есть метод их косвенного измерения. А так как всякое измерение обладает погрешностью, то возникает вопрос: как оценить погрешности D(k) и D(b)? Проще всего это сделать так.
· Надо провести через доверительные интервалы ещё две прямые линии: для первой из них параметры k и b должны быть максимально возможными, поэтому её надо провести как можно круче и выше, для второй – значения k и b должны быть минимально возможными, её надо провести как можно полого и ниже.
· После этого погрешности D(k) и D(b) можно определить очевидным образом:
 (10.4)
(10.4)
Второй способ определения параметров линейной зависимости, полученной экспериментальным путём, – аналитический.
Он называется методом наименьших квадратов. Его идея в том, что среди всевозможных комплектов пары чисел k и b существует такой единственный комплект, для которого сумма квадратов отклонений ординат экспериментальных точек от соответствующих ординат прямой линии с параметрами k и b, минимальна. Не рассматривая этот метод в деталях, приведём конечные выражения, позволяющие определить k и b.
 (10.2)
(10.2)
 (10.3)
(10.3)
В этих формулах n – число экспериментальных точек, а наборы чисел (xi) и (yi) – результаты измерений, то есть абсциссы и ординаты экспериментальных точек.
Проделав вычисления по формулам (10.2) – (10.3), следует сделать проверку. Для этого надо по формуле (10.1) вычислить значения ординат прямой линии при двух произвольных значениях x, например при x1 и при xn, затем нанести на график две контрольные точки, то есть точки с координатами (x1, y(x1)) и (xn, y(xn)), и соединить их прямой линией. Если все вычисления проделаны верно, то прямая автоматически пройдёт оптимальным образом, то есть пересечёт доверительные интервалы всех экспериментальных точек и при этом будет максимально приближена к экспериментальным точкам.
Погрешности косвенного измерения параметров прямой линии k и b методом наименьших квадратов определяются по следующим формулам:
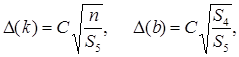 (10.4)
(10.4)
 . (10.5)
. (10.5)
Литература
1. Зайдель А.Н. Погрешности измерений физических величин. -Л.: Наука, 1985. – 110 с.
2. Рабинович С.Г. Погрешности измерений. Л.: Энергия, 1978. -258 с.
[1] Число измерений в серии n называется объёмом серии.
Корреляция — определение и вычисление с примерами решения
Содержание:
Понятие о корреляции:
Марксистская философия учит, что каждое явление природы и общества не возникает само по себе, отдельно от других, а находится в связи с другими явлениями, причем каждое из них представляет собой единство составляющих его частей и свойств. Для того чтобы познать какое-либо явление, необходимо изучить его не только во всех сложных взаимоотношениях с окружающими явлениями-факторами, но также во взаимосвязи всех его сторон.
Если всеобщая связь и взаимозависимость явлений составляют один из наиболее общих законов, то основной задачей науки является изучение этой взаимосвязи.
В математической статистике взаимосвязь явлений изучается методом корреляции. Термин корреляция происходит от английского слова correlation — соотношение, соответствие. Особенность изучения связи явлений методом корреляции состоит в том, что нельзя изолировать влияние посторонних факторов либо потому, что эти факторы неизвестны, либо потому, что их изоляция невозможна. Поэтому метод корреляции применяется для того, чтобы при сложном взаимодействии посторонних влияний выяснить, какова была бы зависимость между результатом фактором, если бы посторонние факторы не изменялись и своим изменением не искажали основную зависимость. При этом небольшое число наблюдений не дает возможности обнаружить закономерность связи.
Первая задача корреляции заключается в выявлении на основе наблюдения над большим количеством фактов того, как изменяется в среднем результативный признак в связи с изменением данного фактора. Это изменение предполагает условие неизменности ряда других факторов, хотя искажающее влияние этих других факторов на самом деле имеет место. Вторая задача заключается в определении степени влияния искажающих факторов.
Первая задача решается нахождением уравнения связи.
Вторая задача решается при помощи различных показателей тесноты связи.
Такими показателями являются меры тесноты связи, найденные разными исследователями, а также коэффициент корреляции и корреляционное отношение.
Результативный и факториальный признаки
При изучении влияния одних признаков явлений на другие из цепи признаков, характеризующих данное явление, выделяются два признака — факториальный и результативный. Необходимо установить, какой из признаков является факториальным и какой результативным. В этом помогает прежде всего логический анализ.
Пример. Себестоимость промышленной продукции отдельного предприятия зависит от многих факторов, в том числе от объема продукции на данном предприятии. Себестоимость продукции выступает в этом случае как результативный признак, а объем продукции — как факториальный.
Другой пример. Чтобы судить о преимуществах крупных предприятий перед мелкими, рассмотрим, как увеличивается производительность труда рабочих крупных предприятий, и выявим зависимость производительности труда от увеличения размеров предприятия.
Таблица!
Группировка магазинов Министерства торговли по числу рабочих мест на 1 января 1960 г.1
Группы магазинов по числу рабочих мест Число магазинов Товарооборот в расчете на одного работника за квартал (в тыс. руб.)
Всего 68 375 117
Из них
с числом рабочих мест:
- с 1 19 893 109
- с 2 18 030 108
- с 3—4 16 508 108
- с 5—7 8 321 111
- с 8—10 2 868 118
- с 11 — 15 1 559 122
- с 16 и более 1 196 139
- J
Группировка показывает прямую зависимость производительности труда торговых работников, выражающуюся в товарообороте, приходящегося на одного работника, от размера магазина. Признак группировки — число рабочих мест — является факториальным, товарооборот — результативным признаком.
От размеров производства зависит также производительность оборудования, о чем свидетельствует следующая таблица: 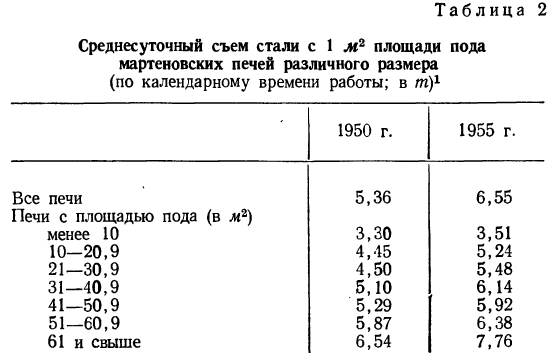
Из таблицы ясно видна связь между размерами печей и их производительностью. Эта связь прямая: чем крупнее печь, тем она производительнее.
Однако зависимость результативного признака (суточного съема стали) от факториального носит не обязательный характер. Если в общей массе мы наблюдаем эту связь, то в отдельных группах бывают и отступления от общей закономерности. Такие отступления—характерная особенность статистической связи вообще, о которой будет рассказано ниже.
Группировки позволяют выявить и зависимость нескольких результативных признаков от одного факториального. Рассмотрим табл. 3.
В этой таблице мы видим зависимость двух результативных признаков: товарооборота на одного работника и товарных запасов—от размеров магазинов. Зависимость товарооборота от размеров магазина прямая, а зависимость товарных остатков от размеров магазина — обратная. В первом случае она растет с ростом размеров магазина, во втором уменьшается. Однако то и другое благоприятно.
Графическое изображение связи
Графическое изображение изучаемых явлений позволяет не только установить наличие или отсутствие связи между ними, но и изучить характер этой связи, иначе говоря изучить форму связи и ее тесноту. 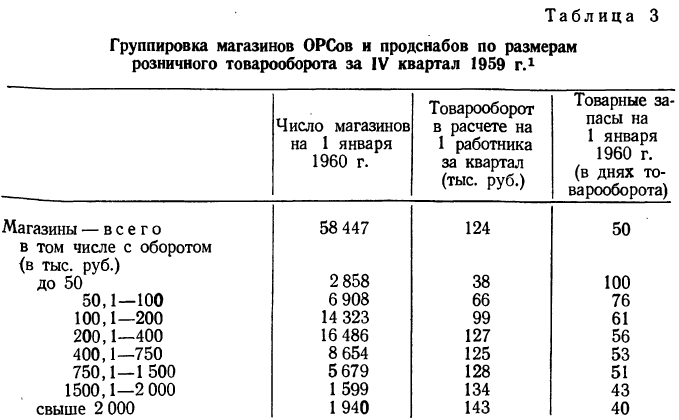
Имея перед собой числовые характеристики факториального и результативного признаков одного и того же явления, можно каждую пару чисел изобразить в виде точки на плоскости. Для этого на плоскости берем две взаимно перпендикулярные линии и образуем систему координат. В этой системе по оси абсцисс откладываем значения факториального признака, а по оси ординат— значения результативного признака. Каждая пара чисел дает при этом точку на плоскости координатного поля.
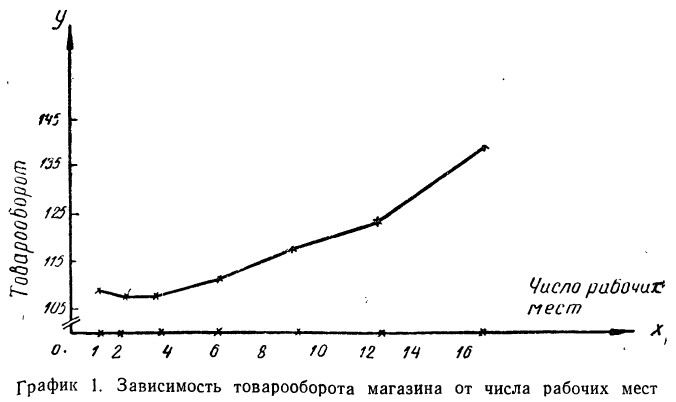
Возьмем, например, группировку магазинов по числу рабочих мест, данную на стр. 239, и будем откладывать число рабочих мест по горизонтальной оси (оси Ох), а товарооборот в расчете на одного работника — по вертикальной оси (оси Оу). Будем иметь ряд точек, соединив которые получим ломаную линию, которая называется ломаной регрессии (см. график 1).
Как видно из графика, с ростом числа рабочих мест в магазине растет и товарооборот, приходящийся на одного работника, что говорит о связи между этими признаками, причем связи прямой. График подчеркивает эту зависимость ходом ломаной линии из нижнего угла в верхний правый угол.
Такого же рода зависимость будем наблюдать на графике 2, изучая связь между величиной мартеновских печей по площади пода и среднесуточным съемом стали с 1 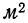 пода. Как и в предыдущем примере, факториальный признак — величину площади пода — будем откладывать на оси абсцисс, а результативный — среднесуточный съем стали с 1
пода. Как и в предыдущем примере, факториальный признак — величину площади пода — будем откладывать на оси абсцисс, а результативный — среднесуточный съем стали с 1 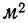 пода — на оси ординат.
пода — на оси ординат.
Здесь также ясно выраженная прямая зависимость между результативным и факториальным признаками. 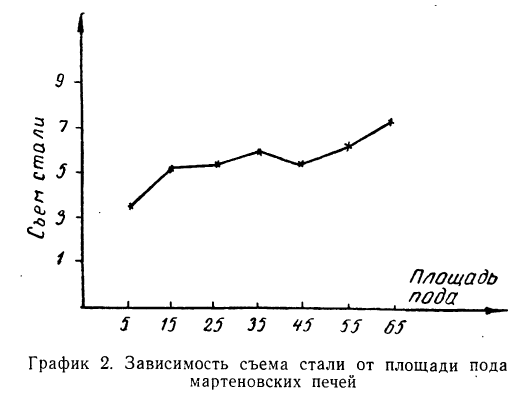
По-другому будет выглядеть график зависимости товарных запасов от размера товарооборота магазина.
Здесь мы наблюдаем ярко выраженную обратную связь между признаками: падение товарных запасов сопровождается ростом размера магазина по товарообороту. 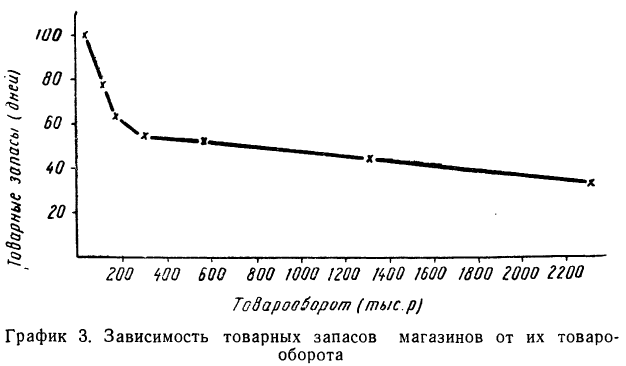
Графический метод наглядно иллюстрирует зависимость, выявленную группировкой. Недостаток графического метода изучения связи заключается в том, что он позволяет выявить связь лишь между двумя признаками.
Функциональные и статистические связи
До сих пор говорилось о связях между явлениями и их признаками без объяснения формы и степени этих связей. В приведенных примерах связи носят логически обоснованный характер, но числовое выражение этих связей говорит о том, что они проявляются не всегда одинаково. В определенных случаях имеются отступления от наблюдаемых общих закономерностей. В приведенной на стр. 240 таблице о среднесуточном съеме стали с 1 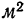 пода печи наблюдается зависимость съема стали от размера печи по площади пода, но эта зависимость за 1955 г. искажена показателями 5-й группы, где съем стали значительно ниже, чем в 4-й группе. Если бы рассматривалась при этом каждая печь в отдельности, то это несоответствие установленному правилу зависимости проявлялось бы неоднократно. Но средние величины съема стали, вычисленные на основании данных довольно большого числа печей в группе, говорят о явно выраженной зависимости. Связи между явлениями, или их признаками. проявляющиеся в изменении в зависимости от одного признака характеристик распределения (из которых главная — средняя) другого признака, называются связями статистическими.
пода печи наблюдается зависимость съема стали от размера печи по площади пода, но эта зависимость за 1955 г. искажена показателями 5-й группы, где съем стали значительно ниже, чем в 4-й группе. Если бы рассматривалась при этом каждая печь в отдельности, то это несоответствие установленному правилу зависимости проявлялось бы неоднократно. Но средние величины съема стали, вычисленные на основании данных довольно большого числа печей в группе, говорят о явно выраженной зависимости. Связи между явлениями, или их признаками. проявляющиеся в изменении в зависимости от одного признака характеристик распределения (из которых главная — средняя) другого признака, называются связями статистическими.
Статистические связи характеризуются тем, что в них результативный признак не полностью определяется влиянием признака факториального. Это влияние проявляется лишь в среднем, а в отдельных случаях получаются результаты, даже противоречащие установленной связи.
В отличие от статистических связей связи функциональные характеризуются тем, что при таких связях факториальный признак полностью определяет величину результативного признака.
Функциональные связи почти не встречаются в явлениях общественной жизни, отличающихся сложностью и многообразием существующих и проявляющихся взаимосвязей. Но во многих явлениях в основе статистических связей лежат функциональные связи. Связь функциональная может показывать зависимость между результативным признаком и несколькими аргументами. Так, площадь прямоугольника зависит от длины его двух сторон, путь, проходимый телом, зависит от скорости его движения и времени движения и т. д.
Уравнение связи
Наблюдая статистическую связь между двумя признаками, математическая статистика стремится придать этой связи форму функциональной, т. е. связи, выражаемой при помощи математической функции.
На помощь приходит ее графическое изображение при отыскании нужной функции связи. При этом необходимо стремиться найти такую функцию, которая давала бы наименьшее отклонение от полученных при наблюдении значений их признаков, которая выражала бы основную зависимость, проявляющуюся в эмпирическом материале. Уравнение этой функции будет уравнением связи между результативным и факториальным признаками.
Уравнение связи находится с помощью способа наименьших квадратов, который требует, чтобы сумма квадратов отклонений эмпирических значений от значений, получаемых на основании уравнения связи, была минимальной.
Применение способа наименьших квадратов позволяет находить параметры уравнения связи при помощи решения системы так называемых нормальных уравнений, различных для связи каждого вида.
Чтобы отметить, что зависимость между двумя признаками выражается в среднем, значения результативного признака, найденные по уравнению связи, обозначаются 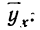
Зная уравнение связи, можно вычислить заранее среднее значение результативного признака, когда значение факториального признака известно. Таким образом, уравнение связи является методом обобщения наблюдаемых статистических связей, методом их изучения.
Применение той или иной функции в качестве уравнения связи разграничивает связи по их форме: линейную связь и криволинейную связь (параболическую, гиперболическую и др.).
Рассмотрим уравнения связи для зависимостей от одного признака при разных формах связи (линейной, криволинейной параболической, гиперболической) и для множественной связи.
Линейная зависимость
Уравнение связи как уравнение прямой 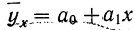 применяется в случае равномерного нарастания результативного признака с увеличением признака факториального. Такая зависимость будет зависимостью линейной (прямолинейной).
применяется в случае равномерного нарастания результативного признака с увеличением признака факториального. Такая зависимость будет зависимостью линейной (прямолинейной).
Параметры уравнения прямой линии 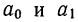 находятся путем решения системы нормальных уравнений, получаемых по способу наименьших квадратов:
находятся путем решения системы нормальных уравнений, получаемых по способу наименьших квадратов:
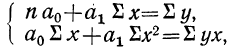
где n — число полученных при наблюдении пар взаимосвязанных величин; 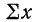 — сумма значений факториального признака;
— сумма значений факториального признака;
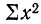 — сумма квадратов значений факториального признака;
— сумма квадратов значений факториального признака;
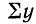 — сумма значений результативного признака;
— сумма значений результативного признака; 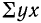 — сумма произведений значений факториального признака на значения результативного признака.
— сумма произведений значений факториального признака на значения результативного признака.
Примером расчета параметров уравнения и средних значений результативного признака 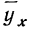 может служить следующая таблица, являющаяся результатом группировки по факториальному признаку и подсчета средних по результативному признаку.
может служить следующая таблица, являющаяся результатом группировки по факториальному признаку и подсчета средних по результативному признаку.
Группировка предприятий по стоимости основных средств и подсчет сумм необходимы для уравнения связи.
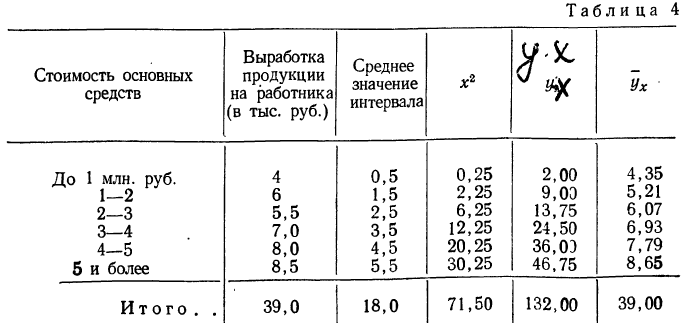
Из таблицы находим: 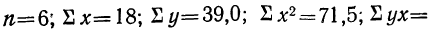 132,0. Строим систему двух уравнений с двумя неизвестными:
132,0. Строим систему двух уравнений с двумя неизвестными:
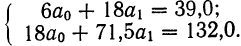
Поделив каждый член в обоих уравнениях на коэффициенты при 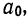 получим:
получим:
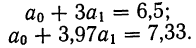
Вычтем из второго уравнения первое: 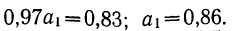 Подставив значения
Подставив значения 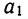 в первое уравнение
в первое уравнение 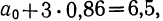 найдем
найдем 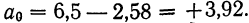
Уравнение связи примет вид: 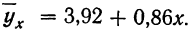 Подставив в это уравнение соответствующие х, получим значения результативного признака, отражающие среднюю зависимость у от х в виде корреляционной зависимости.
Подставив в это уравнение соответствующие х, получим значения результативного признака, отражающие среднюю зависимость у от х в виде корреляционной зависимости. 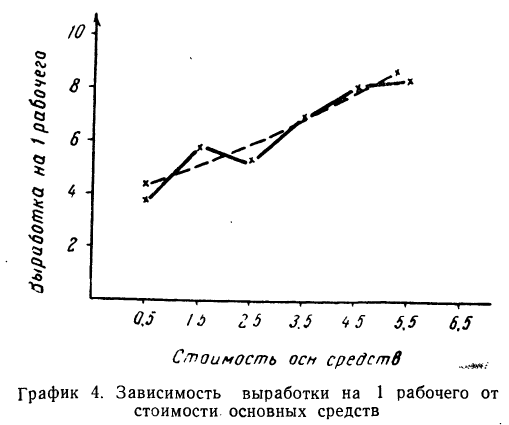
Заметим, что суммы, исчисленные по уравнению и фактические, равны между собой. Изображение фактических и вычисленных значений на графике 4 показывает, что уравнение связи отображает наблюденную зависимость в среднем.
Параболическая зависимость
Параболическая зависимость, выражаемая уравнением параболы 2-го порядка 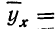
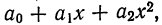 имеет место при ускоренном возрастании или убывании результативного признака в сочетании с равномерным возрастанием факториального признака.
имеет место при ускоренном возрастании или убывании результативного признака в сочетании с равномерным возрастанием факториального признака.
Параметры уравнения параболы 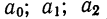 вычисляются путем решения системы 3 нормальных уравнений:
вычисляются путем решения системы 3 нормальных уравнений:
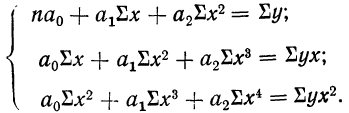
Возьмем для примера зависимость месячного выпуска продукции (у) от величины стоимости основных средств (х). Оба показателя округлены до миллионов рублей. Расчеты необходимых сумм приведем в таблице 5.
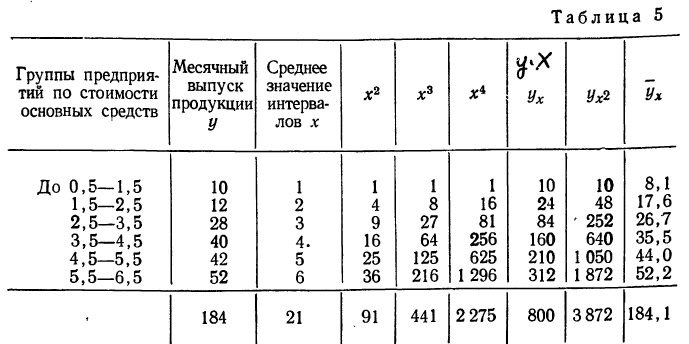
По данным таблицы, составляем систему уравнений:
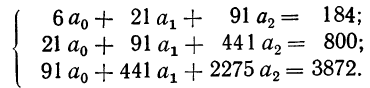
После деления всех уравнений на коэффициенты при 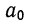 получим:
получим:
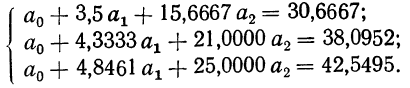
Вычтя из второго уравнения первое и из третьего второе, получим два новых уравнения с двумя неизвестными:
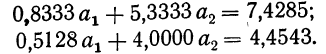
Полученные уравнения снова разделим на коэффициенты при 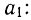
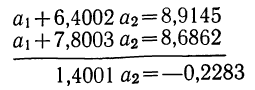
Следовательно, 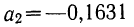
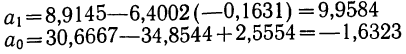
Запишем уравнение параболы, выражающей связь между х и у.
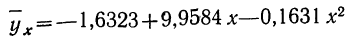
Графическое сопоставление опытных данных и данных расчета (см. график 5) показывает почти полное совпадение хода обеих линий, что говорит о хорошем воспроизведении опытных данных расчетными средними значениями результативного признака. 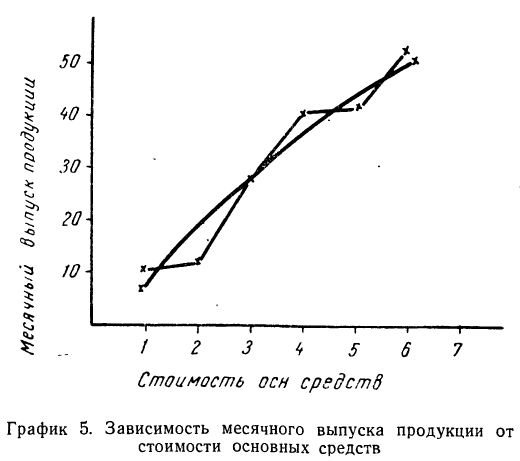
В практике изучения связи между признаками, кроме параболы 2-го порядка, применяются параболы и более высоких порядков. Чем выше порядок параболы, тем точнее он воспроизводит опытные данные.
Если уравнение связи представляет собой параболу 3-го порядка 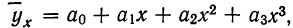 то система нормальных уравнений примет вид:
то система нормальных уравнений примет вид:
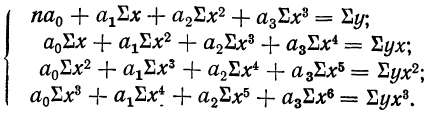
Имея соответствующие хну, можем составить Дополнительную расчетную таблицу по следующей схеме: 
которая используется для нахождения нужных сумм. Решив систему 4 уравнений, найдем параметры 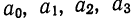 и, следовательно, уравнение связи.
и, следовательно, уравнение связи.
Уравнение гиперболы
Обратная связь указывает на убывание результативного признака при возрастании факториального. Такова линейная связь при отрицательном значении 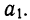 В ряде других случаев обратная связь может быть выражена уравнением гиперболы
В ряде других случаев обратная связь может быть выражена уравнением гиперболы 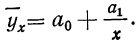
Параметры уравнения гиперболы 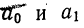 находятся из системы нормальных уравнений:
находятся из системы нормальных уравнений:
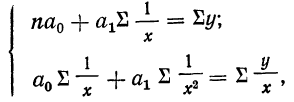
где 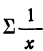 — сумма величин, обратных значениям факториального признака, а
— сумма величин, обратных значениям факториального признака, а 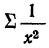 — сумма их квадратов.
— сумма их квадратов.
Примером расчета обратной связи по гиперболе может служить следующая таблица:
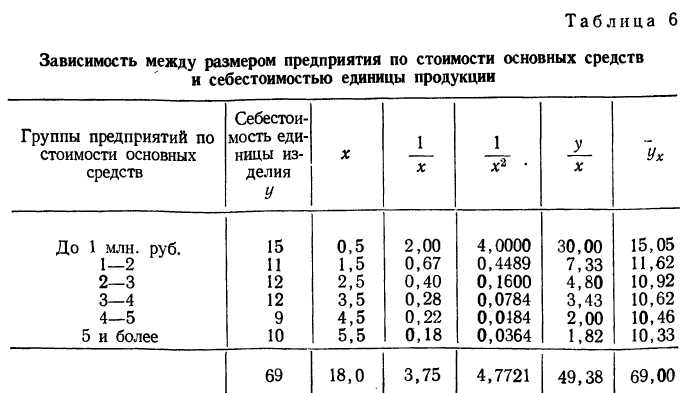
Составив по данным таблицы систему уравнений и разделив каждый член обоих уравнений на коэффициенты при а, получим:
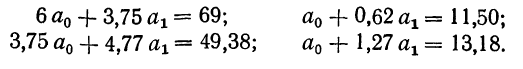
Находим вычитанием из второго уравнения первого величину 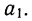
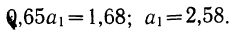
Подставив вместо 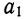 его значение, получим
его значение, получим 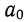
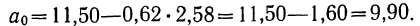
Запишем уравнение связи в общем виде 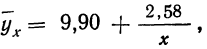 затем, подставив каждое значение х в уравнение, находим
затем, подставив каждое значение х в уравнение, находим 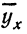 по любой строке таблицы. Строим ломаную по парам х и у и кривую по х и
по любой строке таблицы. Строим ломаную по парам х и у и кривую по х и 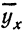 . Ломаная и кривая очень близки друг к другу.
. Ломаная и кривая очень близки друг к другу. 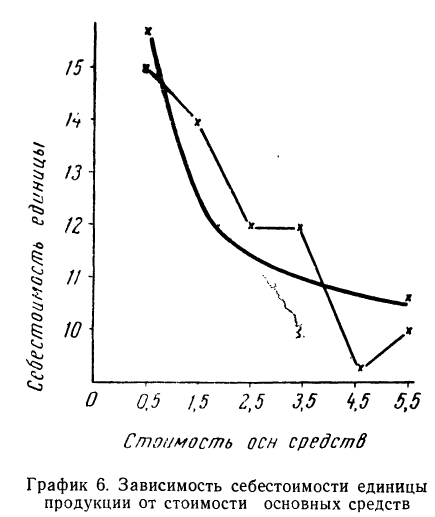
Корреляционная таблица
При большом объеме наблюдений, когда число взаимосвязанных пар велико, парные данные легко могут быть расположены в корреляционной таблице, являющейся наиболее удобной формой представления значительного количества пар чисел.
В корреляционной таблице один признак располагается в строках, а другой — в колонка таблицы. Число, расположенное в клетке на пересечении графы и колонки, показывает, как часто встречается данное значение результативного признака в сочетании с данным значением факториального признака.
Для простоты расчета возьмем небольшое число наблюдений на 20 предприятиях за средней месячной выработкой продукции на одного рабочего (тыс. руб. — у) и за стоимостью основных производственных средств (млн. руб. — х).
В обычной парной таблице эти сведения располагаются так: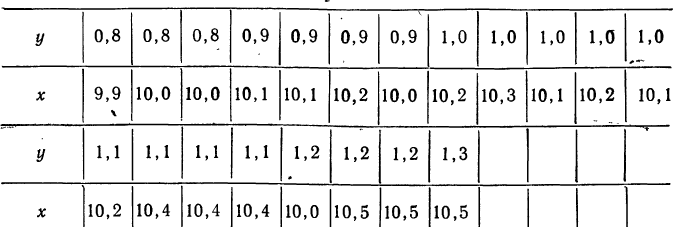
Сведем эти данные в корреляционную таблицу.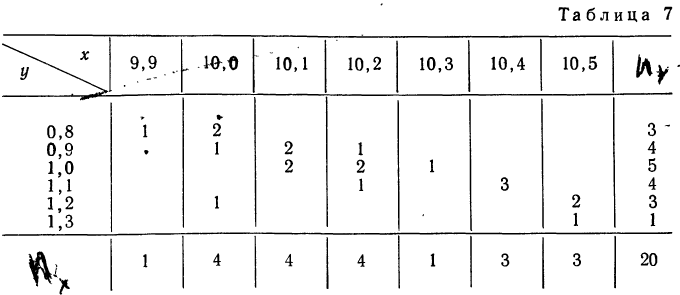
Итоги строк у показывают частоту признака  итоги граф х — частоту признака
итоги граф х — частоту признака  Числа, стоящие в клетках корреляционной таблицы, являются частотами, относящимися к обоим признакам и обозначаются
Числа, стоящие в клетках корреляционной таблицы, являются частотами, относящимися к обоим признакам и обозначаются 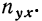
Корреляционная таблица даже при поверхностном знакомстве дает общее представление о прямой и обратной связи. Если частоты расположены по диагонали вниз направо, то связь между признаками прямая (при увеличивающихся значениях признака в строках и графах). Если же частоты расположены по диагонали вверх направо, то связь обратная.
Для предварительного суждения о связи по корреляционной таблице можно для каждого столбца рассчитать средние значения 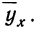 Так, в первом столбце х = 9,9, а
Так, в первом столбце х = 9,9, а 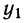 имеет лишь одно значение, равное 0,8. Найдем среднее значение для второго столбца. Оно будет равно:
имеет лишь одно значение, равное 0,8. Найдем среднее значение для второго столбца. Оно будет равно:
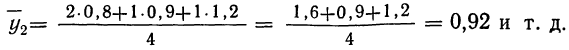
Следовательно, при 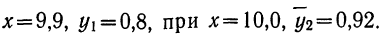 Выпишем все значения х и соответствующие им
Выпишем все значения х и соответствующие им 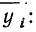

Зависимость, выраженная в таблице, более ярко и убедительно выступит в «ломаной регрессии», когда каждую пару чисел нанесем на график (см. график 7).
По корреляционной таблице можно вести расчеты параметров уравнения связи, как уравнения прямой, так и уравнений параболы и гиперболы. При этом необходимо учитывать, что сочетание каждой пары значений может встречаться не один, а несколько раз. Сами значения хну необходимо взвешивать, т. е. умножать на соответствующие частоты. Для самого признака х частота будет обозначаться 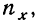 для признака
для признака 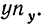 Частоту сочетаний обозначим
Частоту сочетаний обозначим 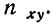
Ввиду сказанного мы можем систему нормальных уравнений написать так, чтобы были учтены веса. Тогда для линейной зависимости система нормальных уравнений примет вид:
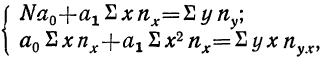
где N — число произведенных наблюдений (число пар). В приведенной корреляционной таблице N = 20. 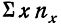 будет суммой произведений соответствующих х на их частоты. В данной таблице эта сумма составит:
будет суммой произведений соответствующих х на их частоты. В данной таблице эта сумма составит:
9,9 +10,0 • 4 +10,1 • 4 + 10,2 • 4 +10,3 • 1 +10,4 • 3 +10,5 • 3 = 204.
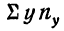 —сумма произведений у на соответствующие частоты. В нашем примере она равна:
—сумма произведений у на соответствующие частоты. В нашем примере она равна:
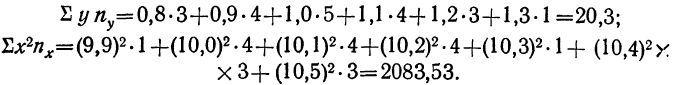
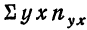 включает сумму произведений всех х на у и на
включает сумму произведений всех х на у и на 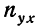 для тех клеток корреляционной таблицы, в которых записаны частоты. Рассчитаем суммы произведений для 1-й и 2-й строки
для тех клеток корреляционной таблицы, в которых записаны частоты. Рассчитаем суммы произведений для 1-й и 2-й строки
Нетрудно заметить, что в каждой строке у повторяется столько раз, сколько раз мы его суммируем, а, следовательно, у можно вынести за скобку.
- Для 1-й строки: 0,8 (9,9 • 1 +10,0 • 2) =23,92.
- Для 2-й строки:

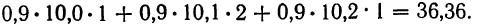
Следовательно, сумма произведений 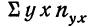 может быть записана при постоянном у, как
может быть записана при постоянном у, как 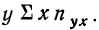 Заметим, что сумма произведений может быть записана и рассчитана как произведение
Заметим, что сумма произведений может быть записана и рассчитана как произведение 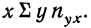
Продолжим расчет для последующих строк.
Общая сумма по всем строкам 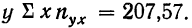
Система нормальных уравнений может быть записана по результатам подсчета в таком виде:
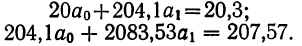
Для расчета параметров уравнения линейной связи делим каждое из уравнений на коэффициенты при 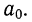
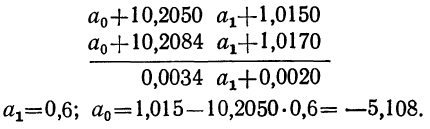
Уравнение связи 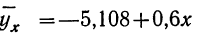 определяет среднюю зависимость выработки рабочего от стоимости основных средств. Вычислительная работа облегчается, если в самой корреляционной таблице путем записи дополнительных граф и строк производить нужные подсчеты для решения системы уравнений.
определяет среднюю зависимость выработки рабочего от стоимости основных средств. Вычислительная работа облегчается, если в самой корреляционной таблице путем записи дополнительных граф и строк производить нужные подсчеты для решения системы уравнений.
Число наблюдений N может быть подсчитано и по столбцу 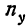 как его сумма. Она равна итогу по строке
как его сумма. Она равна итогу по строке 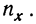 Для определения
Для определения 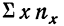 необходимо ввести новую строку
необходимо ввести новую строку 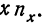 Итог этой строки и дает искомую сумму.
Итог этой строки и дает искомую сумму.
Следующая дополнительная строка 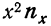 представляет возможность определить
представляет возможность определить 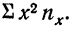 Далее,
Далее, 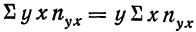 и может быть определена на основе расчета двух дополнительных граф:
и может быть определена на основе расчета двух дополнительных граф:
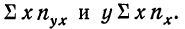
В корреляционной таблице (см. табл.  в последних строках дается расчет
в последних строках дается расчет  для построения ломаной регрессии
для построения ломаной регрессии  — для построения прямой (см. график 7).
— для построения прямой (см. график 7). 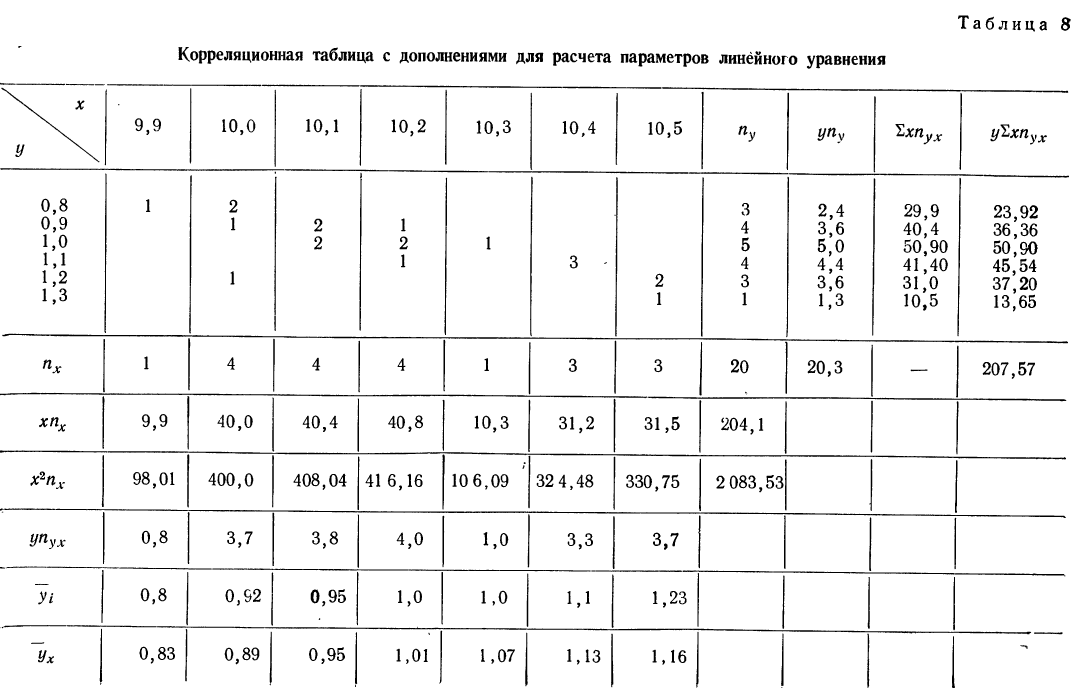
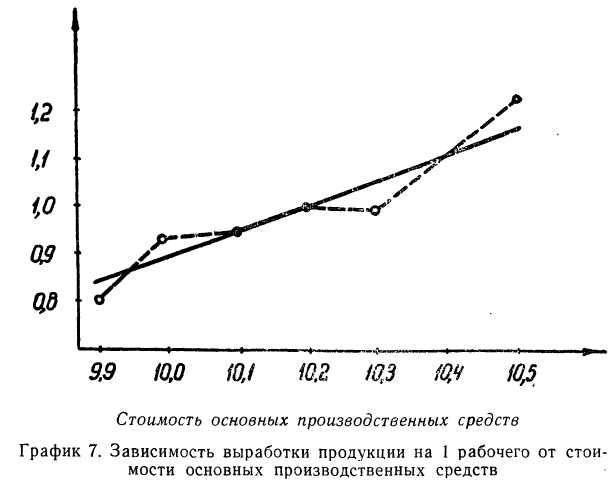
Корреляционная таблица позволяет вычислять уравнение связи для любой формы: прямой, параболы, гиперболы и др. Однако в подобной таблице видна зависимость результативного признака лишь от одного факториального.
Зависимость результативного признака от двух или более факториальных признаков носит название множественной связи.
Множественная связь
Исследование зависимости результативного признака от двух или нескольких факториальных признаков возможно при помощи уравнения множественной связи.
В простейшем уравнении множественной связи предполагается, что зависимость между признаками линейная. Сначала рассмотрим линейную зависимость результативного признака (у) от двух факториальных (х, z). Уравнение связи в этом случае выразится формулой 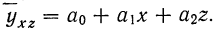 Параметры этого уравнения находятся при решении системы нормальных уравнений, получаемых для способа наименьших квадратов
Параметры этого уравнения находятся при решении системы нормальных уравнений, получаемых для способа наименьших квадратов
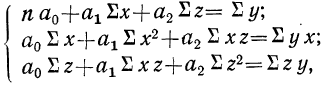
где п — число одновременных наблюдений по трем признакам;
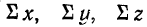 —суммы соответствующих значений по этим признакам.
—суммы соответствующих значений по этим признакам.
Все расчеты удобно сосредоточить в специальной таблице, как это делается в приводимом ниже примере.
Рассмотрим зависимость средней урожайности ячменя (у) на равных участках от количества внесенных минеральных удобрений (х) и количества выпавших в период цветения осадков (z).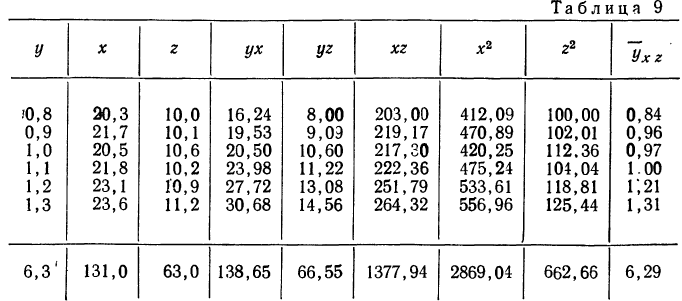
Средняя урожайность исчислялась по участкам с равным количеством внесенных удобрений и с равным количеством выпавших осадков.
Пользуясь данными таблицы, составляем систему трех уравнений:
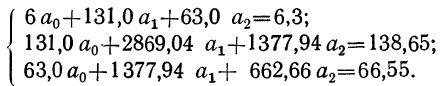
Поделив все члены уравнений на коэффициенты при 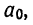 получим:
получим:
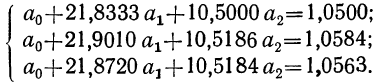
Вычитая из второго уравнения сначала первое, а затем третье, получим 2 уравнения с двумя неизвестными:
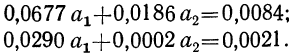
Делим каждый член обоих уравнений на коэффициенты при 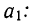
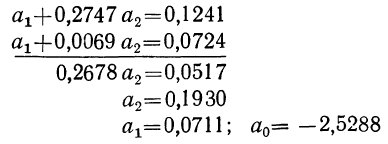
Уравнение связи, определяющее зависимость результативного признака (у) от двух факториальных
Вычислив по этому уравнению при соответствующих х и z величины 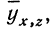 замечаем, что суммы опытных данных (y) и расчетных данных
замечаем, что суммы опытных данных (y) и расчетных данных 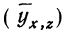 совпадают, а отдельные значения их мало отличаются друг от друга.
совпадают, а отдельные значения их мало отличаются друг от друга.
Найдем уравнение связи между урожайностью пшеницы на Безенчукской опытной станции и тремя факторами (х, z, v).
Статистические данные, полученные в результате наблюдения, и расчеты представлены в табл. 10, откуда возьмем необходимые данные для составления системы нормальных уравнений:

Следовательно,, корреляционное уравнение будет:
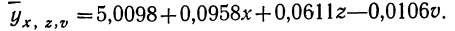
Расширив число факториальных признаков, можно найти уравнение множественной связи для 4, 5, 6 и т. д. признаков. При этом необходимо брать только такие признаки, которые оказывают существенное влияние на величину результативного признака, ибо учет несущественных, второстепенных признаков лишь увеличивает расчетную работу при нахождении уравнения связи, а не приближает к более полному изучению связи.
Если число факториальных признаков возрастает, возрастает и число членов уравнения связи. Так, для трех факториальных признаков линейное уравнение связи будет записано формулой:
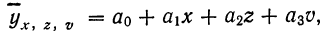
где параметры уравнения 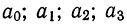 находятся путем решения системы четырех нормальных уравнений:
находятся путем решения системы четырех нормальных уравнений:
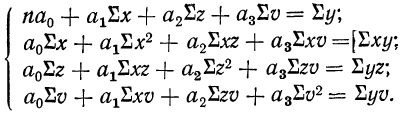
Построив соответствующую таблицу, получим в ней необходимые суммарные данные для приведенной системы уравнений (см. табл. 10).
Мерой существенности влияния того или иного факториального признака на результативный являются показатели тесноты связи.
В настоящем издании мы рассмотрим эмпирические меры тесноты связи, полученные разными исследователями, и меры тесноты связи, основанные на измерении вариации.
Эмпирические меры тесноты связи
Эмпирические меры тесноты связи позволяют оценить степень связи между явлениями или факторами, находящимися в зависимости один от другого. Эмпирические меры получены различными исследователями, занимавшимися статистической обработкой фактического материала. Они получены ранее, чем был открыт метод корреляции. Практическое пользование эмпирическими показателями довольно удобно.
К эмпирическим мерам тесноты относятся:
- а) коэффициент ассоциации:
- б) коэффициенты взаимной напряженности;
- в) коэффициент Фехнера;
- Г) коэффициент корреляции рангов;
Рассмотрим каждый из них.
а) Коэффициент ассоциации. Коэффициент ассоциации как мера тесноты связи применяется для изучения связи двух качественных признаков, состоящих только из двух групп. Для его вычисления строится четырехклеточная таблица корреляции, которая выражает связь между двумя явлениями, каждое из которых, в свою очередь, должно быть альтернативным, т. е. состоящим только из двух видов, качественно отличных друг от друга. Например, при изучении зависимости урожая от количества внесенных в почву удобрений выделяем по урожайности и по количеству внесенных удобрений лишь по две группы. При этом условии можно построить следующую четырехклеточную таблицу.
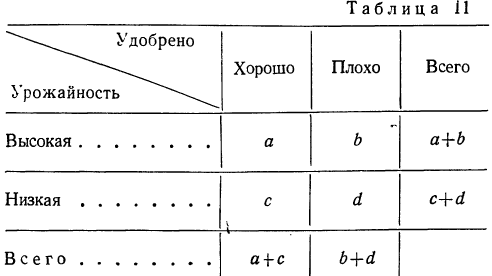
Числа, стоящие на пересечении строк и граф — a,b,c,d, показывают, сколько участков встречается с тем и другим количеством удобрений, внесенным в почву, с той и другой урожайностью.
Мера тесноты связи — коэффициент ассоциации — исчисляется по формуле:
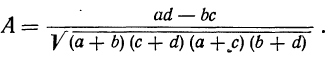
Заполнив клетки конкретными числовыми данными, получим следующую четырехклеточную таблицу, где числа, стоящие в клетках, — гектары посевов.

Коэффициент ассоциации равен: 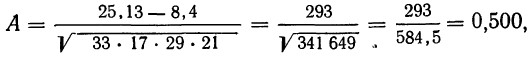
что говорит о достаточно тесной прямой связи между урожайностью и степенью удобрения почв.
Коэффициент ассоциации может иметь и отрицательные значения, когда ad
При копировании любых материалов с сайта evkova.org обязательна активная ссылка на сайт www.evkova.org
Сайт создан коллективом преподавателей на некоммерческой основе для дополнительного образования молодежи
Сайт пишется, поддерживается и управляется коллективом преподавателей
Whatsapp и логотип whatsapp являются товарными знаками корпорации WhatsApp LLC.
Cайт носит информационный характер и ни при каких условиях не является публичной офертой, которая определяется положениями статьи 437 Гражданского кодекса РФ. Анна Евкова не оказывает никаких услуг.
Корреляция и регрессия
Линейное уравнение регрессии имеет вид y=bx+a+ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид:
10a + 356b = 49
356a + 2135b = 9485
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 68.16, a = 11.17
Уравнение регрессии:
y = 68.16 x — 11.17
1. Параметры уравнения регрессии.
Выборочные средние.
1.1. Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 Y фактором X весьма высокая и прямая.
1.2. Уравнение регрессии (оценка уравнения регрессии).
Линейное уравнение регрессии имеет вид y = 68.16 x -11.17
Коэффициентам уравнения линейной регрессии можно придать экономический смысл. Коэффициент уравнения регрессии показывает, на сколько ед. изменится результат при изменении фактора на 1 ед.
Коэффициент b = 68.16 показывает среднее изменение результативного показателя (в единицах измерения у ) с повышением или понижением величины фактора х на единицу его измерения. В данном примере с увеличением на 1 единицу y повышается в среднем на 68.16.
Коэффициент a = -11.17 формально показывает прогнозируемый уровень у , но только в том случае, если х=0 находится близко с выборочными значениями.
Но если х=0 находится далеко от выборочных значений x , то буквальная интерпретация может привести к неверным результатам, и даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или вправо.
Подставив в уравнение регрессии соответствующие значения x , можно определить выровненные (предсказанные) значения результативного показателя y(x) для каждого наблюдения.
Связь между у и x определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
1.3. Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
В нашем примере коэффициент эластичности больше 1. Следовательно, при изменении Х на 1%, Y изменится более чем на 1%. Другими словами — Х существенно влияет на Y.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению среднего Y на 0.9796 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве регрессии.
1.6. Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.98 2 = 0.9596, т.е. в 95.96 % случаев изменения x приводят к изменению у . Другими словами — точность подбора уравнения регрессии — высокая. Остальные 4.04 % изменения Y объясняются факторами, не учтенными в модели.
| x | y | x 2 | y 2 | x·y | y(x) | (yi— y ) 2 | (y-y(x)) 2 | (xi— x ) 2 | |y — yx|:y |
| 0.371 | 15.6 | 0.1376 | 243.36 | 5.79 | 14.11 | 780.89 | 2.21 | 0.1864 | 0.0953 |
| 0.399 | 19.9 | 0.1592 | 396.01 | 7.94 | 16.02 | 559.06 | 15.04 | 0.163 | 0.1949 |
| 0.502 | 22.7 | 0.252 | 515.29 | 11.4 | 23.04 | 434.49 | 0.1176 | 0.0905 | 0.0151 |
| 0.572 | 34.2 | 0.3272 | 1169.64 | 19.56 | 27.81 | 87.32 | 40.78 | 0.0533 | 0.1867 |
| 0.607 | 44.5 | .3684 | 1980.25 | 27.01 | 30.2 | 0.9131 | 204.49 | 0.0383 | 0.3214 |
| 0.655 | 26.8 | 0.429 | 718.24 | 17.55 | 33.47 | 280.38 | 44.51 | 0.0218 | 0.2489 |
| 0.763 | 35.7 | 0.5822 | 1274.49 | 27.24 | 40.83 | 61.54 | 26.35 | 0.0016 | 0.1438 |
| 0.873 | 30.6 | 0.7621 | 936.36 | 26.71 | 48.33 | 167.56 | 314.39 | 0.0049 | 0.5794 |
| 2.48 | 161.9 | 6.17 | 26211.61 | 402 | 158.07 | 14008.04 | 14.66 | 2.82 | 0.0236 |
| 7.23 | 391.9 | 9.18 | 33445.25 | 545.2 | 391.9 | 16380.18 | 662.54 | 3.38 | 1.81 |
2. Оценка параметров уравнения регрессии.
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=7 находим tкрит:
tкрит = (7;0.05) = 1.895
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 94.6484 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
Sy = 9.7287 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя. (a + bxp ± ε) где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 1 (-11.17 + 68.16*1 ± 6.4554)
(50.53;63.44)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
Индивидуальные доверительные интервалы для Y при данном значении X.
(a + bx i ± ε)
где
| xi | y = -11.17 + 68.16xi | εi | ymin | ymax |
| 0.371 | 14.11 | 19.91 | -5.8 | 34.02 |
| 0.399 | 16.02 | 19.85 | -3.83 | 35.87 |
| 0.502 | 23.04 | 19.67 | 3.38 | 42.71 |
| 0.572 | 27.81 | 19.57 | 8.24 | 47.38 |
| 0.607 | 30.2 | 19.53 | 10.67 | 49.73 |
| 0.655 | 33.47 | 19.49 | 13.98 | 52.96 |
| 0.763 | 40.83 | 19.44 | 21.4 | 60.27 |
| 0.873 | 48.33 | 19.45 | 28.88 | 67.78 |
| 2.48 | 158.07 | 25.72 | 132.36 | 183.79 |
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (7;0.05) = 1.895
Поскольку 12.8866 > 1.895, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 2.0914 > 1.895, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(68.1618 — 1.895 • 5.2894; 68.1618 + 1.895 • 5.2894)
(58.1385;78.1852)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a — ta)
(-11.1744 — 1.895 • 5.3429; -11.1744 + 1.895 • 5.3429)
(-21.2992;-1.0496)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с lang=EN-US>n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=7, Fkp = 5.59
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Проверка на наличие автокорреляции остатков.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция) определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция, нежели отрицательная автокорреляция. В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию, можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности: выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения ei с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения ei (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скоре всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости ei от ei-1.
http://www.evkova.org/korrelyatsiya
http://math.semestr.ru/corel/primer.php
На практике наиболее распространен
случай m=1 (линейное уравнение)
![]()
Для этого случая из выведенных формул
получаем
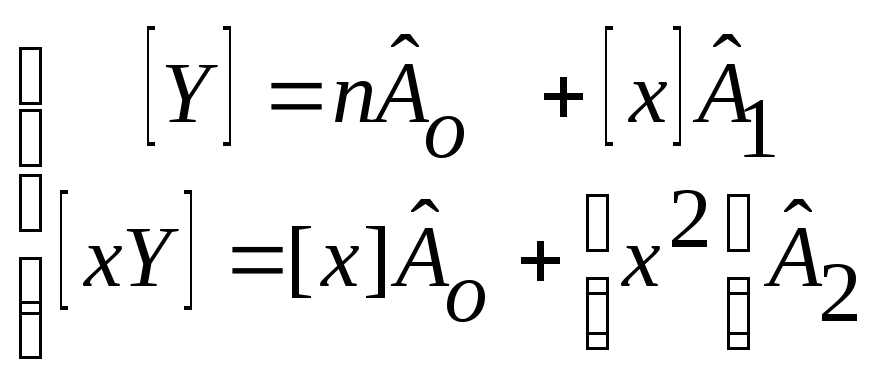 ;
;
![]() ;
;![]() ;
;![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;
![]() ;
;![]() ;
; .
.
3.3.2 Определение параметров неполиномиальных зависимостей с помощью мнк
В результате метрологических исследований
нередко приходится сталкиваться со
случаем, когда при определении нелинейной
зависимости повышение степени полинома
в разумных пределах не приводит к
существенному уменьшению погрешности
аппроксимации. В этом случае применяют
следующие приемы.
1. Разбиение области определения
функции на несколько участков с
последующей аппроксимацией ее на каждом
из участков.
2. Преобразование функции
![]() в линейную зависимость
в линейную зависимость![]() путем замены переменных
путем замены переменных![]() .
.
Этот
прием хорошо реализуется для функций
следующего вида:
а) показательная
![]() ,
,
для которой в результате замены переменной![]() ,
,
получаем![]() ,
,
где![]() ;
;
б) степенная
![]() ,
,
для которой в результате замены переменных![]() ,
,
получаем![]() ,
,
где![]() ;
;
в) логарифмическая
![]() ,
,
для которой в результате замены переменной![]() получаем
получаем![]() ;
;
г) гиперболическая
![]() ,
,
для которой в результате замены переменной![]() получаем
получаем![]() ;
;
д) дробно-линейная функция первого вида
![]() ,
,
для которой в результате замены переменной![]() получаем
получаем![]() ;
;
е) дробно-линейная функция второго вида
![]() ,
,
для которой в результате замены переменных![]() ,
,
получаем![]() .
.
Графики перечисленных функций приведены
на рис. 3.8.
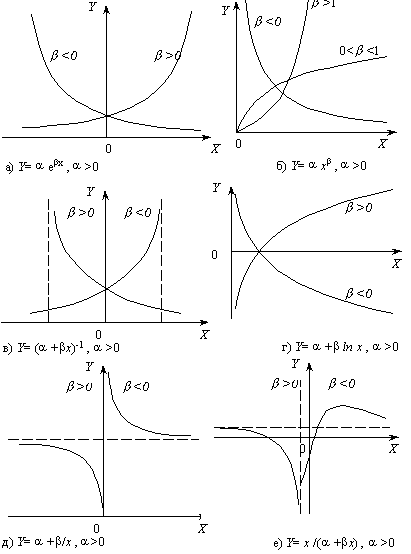
Рисунок 3.8 — Графики аппроксимирующих
функций
При определении погрешности нахождения
оценок
![]() ,
,
необходимо помнить, что в случаях
показательной и степенной функции
параметр![]() связан с параметром
связан с параметром![]() выражением
выражением![]() .
.
Поэтому погрешности
![]() и
и![]() будут связаны соотношением
будут связаны соотношением![]() .
.
3. Линеаризация нелинейных уравнений
методом последовательных приближений
Общий метод решения этой задачи основан
на допущении, что несовместность условных
уравнений невелика, т.е. их невязки малы.
Тогда, взяв из условной системы столько
уравнений, сколько в ней неизвестных,
их решением находим начальные оценки
неизвестных
![]() .
.
Полагая далее, что![]() и подставляя эти выражения в условные
и подставляя эти выражения в условные
уравнения, раскладываем условные
уравнения в ряды. Сохраняя лишь члены
с первыми степенями поправок![]() ,
,
получим
![]() .
.
Переписав полученное выражение в виде
![]() ,
,
(3.52)
можно видеть, что мы получили условную
систему линейных уравнений относительно
поправок
![]() .
.
Решение этой системы с помощью МНК дает
нам их оценки и СКО. Тогда![]() .
.
Поскольку![]() — неслучайные величины, то
— неслучайные величины, то![]() .
.
Получив оценки![]() ,
,
можно сделать второе приближение и т.д.
3.4 Совокупные измерения
Совокупные измерения– измерения,
в которых значения нескольких одновременно
измеряемых однородных величин находят
решением системы уравнений, которые
связывают разные комбинации этих
величин, измеряемые прямо или косвенно.
Систему уравнений совокупных измерений
можно записать в следующем виде
![]() ,
,
(3.53)
где i=1,2,…,n;n>m. То есть
характерной особенностью совокупных
измерений, также как и совместных,
является то обстоятельство, что число
уравнений больше, чем число неизвестных.
Здесь
![]() —
—
результаты прямых измерений различных
сочетаний искомых величинx1,x2,…,xm.
Таким образом, в отличие от косвенных
измерений, производятся измерения
нескольких искомых величин, причем
последние находятся в результате решения
системы уравнений.
Легко заметить, что система уравнений
(3.53) аналогична системе уравнений
совместных измерений. Имеется, однако,
принципиальное отличие совокупных
измерений от совместных, прежде всего
в постановке измерительной задачи: в
результате совокупных измерений
определяется не функциональная
зависимость между величинами (как это
делается при совместных измерениях), а
сами величины, причем величины одноименные.
Несмотря на отличия, обработка
экспериментальных данных при совместных
и совокупных измерениях, производится
практически одними и теми же приемами.
Классическим примером совокупных
измерений является измерение емкости
двух конденсаторов С1и С2по результатам измерения емкости каждого
из них в отдельности, а также при
параллельном и последовательном их
соединении. Такой метод применяется
для уменьшения систематической
погрешности измерения, различной в
разных точках диапазона измерения.
В этом случае, хотя каждое измерение
выполняется с одним наблюдением, но в
итоге для двух неизвестных будем иметь
систему из четырех уравнений
 .
.
(3.54)
Последнее уравнение системы – нелинейное,
поэтому применим для этой системы метод
линеаризации, рассмотренный для случая
совместных измерений, и заключающийся
в разложении всех уравнений системы в
ряд Тейлора. В этом случае получаем
следующие значения частных производных
![]() ;
;
![]() ;
;
![]() ,
,
используя которые можно записать
исходную систему линейных уравнений
 (3.55)
(3.55)
Для решения этой системы необходимо
выбрать точки разложения
![]() и
и![]() ,
,
близкие к измеренным значениям![]() и
и![]() .
.
Подставляя![]() и
и![]() в уравнение системы (3.54) можно найти
в уравнение системы (3.54) можно найти
невязки![]() .
.
![]() . (3.56)
. (3.56)
Подставляя эти невязки в уравнение
(3.55), можно получить из нее систему
нормальных уравнений (по МНК)
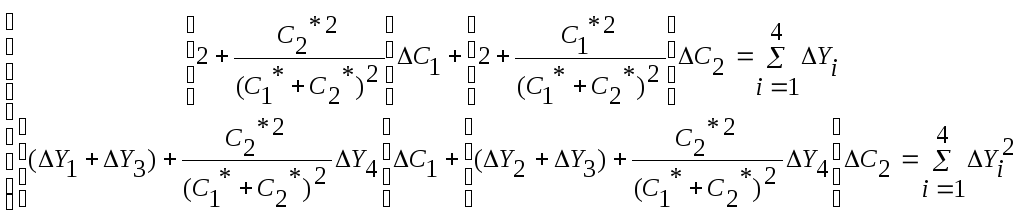 .
.
Решая систему, получаем
![]() и
и![]() ,
,
откуда можно найти
искомые![]() и
и![]() как
как
![]()
Совокупные измерения широко распространены
в метрологической практике, например,
при калибровке мер или шкал приборов.
В этом случае система уравнений совокупных
измерений имеет вид
![]() , (3.57)
, (3.57)
где
![]() — значения величин, подлежащих определению;
— значения величин, подлежащих определению;
![]() — известные коэффициенты;
— известные коэффициенты;
![]() — результаты сравнения различных
— результаты сравнения различных
комбинаций сочетаний мер или отметок
шкал;
m— количество значений величин,
подлежащих определению;
n— количество комбинаций (уравнений).
При калибровке
коэффициенты
![]() принимают следующие значения:
принимают следующие значения:
0 – если
![]() не участвует в i-ом измерении;
не участвует в i-ом измерении;
1 – если измеряется сумма нескольких
величин, в которую входит
![]() ;
;
-1 – если сумма нескольких величин
сравнивается с
![]() .
.
Если число уравнений равно числу
неизвестных, то система (3.57) решается
однозначно, а действительные значения
измеряемых величин и доверительные
интервалы их погрешностей определяются
методами обработки косвенных измерений.
Однако, для уменьшения погрешностей
калибровки производится сравнение
большего числа комбинаций, чем количество
определяемых значений величин. Тогда
оценивание результатов измерений
производится как при совместных
измерениях. Для решения системы условных
уравнений обычно применяют МНК. Этот
метод, как уже было сказано, вытекает
из принципа максимального правдоподобия
и является оптимальным при следующих
условиях:
— результаты измерения Yсодержат
независимые случайные погрешности с
нулевыми математическими ожиданиями
и одинаковыми дисперсиями;
— погрешности имеют нормальное
распределение.
При выполнении этих условий получаемые
оценки будут состоятельными, несмещенными
и эффективными.
Аналогично рассмотренному в разделе
3.4, можно записать систему уравнений
относительно невязок
![]() .
.
(3.58)
Сумма их квадратов будет равна
![]() . (3.59)
. (3.59)
Дифференцируя выражение (3.59) по параметрам
![]() ,
,
получим следующую систему
 , (3.60)
, (3.60)
преобразуя которую и применяя обозначение
Гаусса, получаем нормальную систему
уравнений относительно
![]() .
.
 . (3.61)
. (3.61)
Решение этой системы с помощью
определителей имеет вид
![]() , (3.62)
, (3.62)
где D– главный определитель системы
 , (3.63)
, (3.63)
а определитель
![]() получается
получается
из главного путем замены j –го столбца
на столбец со свободными членами
 . (3.64)
. (3.64)
Оценки СКО
![]() определяются
определяются
по формуле
![]() , (3.65)
, (3.65)
где
![]() —
—
алгебраическое дополнение главного
определителя, получаемое из последнего
вычеркиванием j–го столбца иj–й строки;
 . (3.66)
. (3.66)
Невязки
![]() находят
находят
при выполнении совокупных измерений
(3.58).
Границы погрешности совокупных измерений
определяют из выражения
![]() , (3.67)
, (3.67)
где ts–
коэффициент Стьюдента для (n—m)
степеней свободы.
Примером совокупных измерений являются
проводимые при калибровке набора из
пяти гирь массой m1= 5 кг,m2= 2 кг,m3= 2 кг,m4= 1кг,m5= 1кг по образцовой гире массойm0= 10кг. В этом случае можно получить
следующую систему из десяти уравнений:
![]()
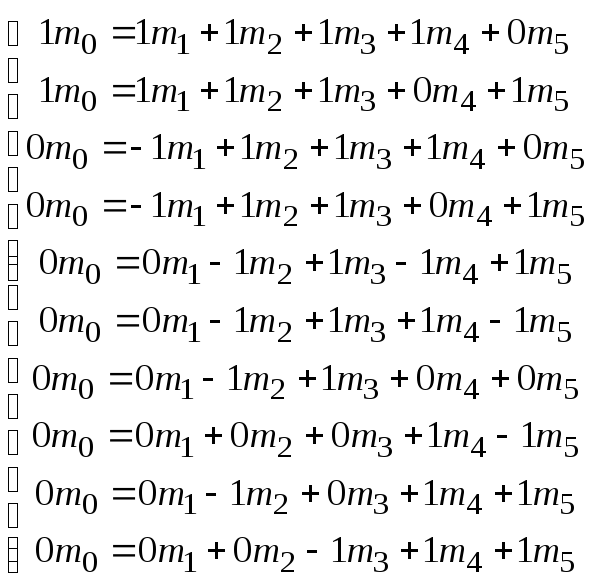 . (3.68)
. (3.68)
Невязки i
для этих уравнений получают, проводя
сравнения гирь в перечисленных сочетаниях
с помощью равноплечих весов, имеющих
шкалу для отсчета разности масс.
Обработка результатов полученных
совместных измерений осуществляется
по формуле (3.63) — (3.67).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Определение линейной зависимости
Линейная связь описывает отношение между двумя различными переменными — x и y в виде прямой линии на графике. При представлении линейной зависимости через уравнение значение y выводится через значение x, отражая их корреляцию.
Линейные отношения применяются в повседневных ситуациях, когда один фактор зависит от другого, например, повышение цены на товары снижает спрос на них. В любом случае для получения результата учитываются только две переменные.
Оглавление
- Определение линейной зависимости
- Что такое линейная зависимость?
- Уравнение линейной связи с графиком
- Линейная функция/уравнение
- Форма пересечения наклона
- Стандартная/общая форма
- Примеры
- Линейные и нелинейные отношения
- Графическое представление
- Изменение переменных
- Области применения
- Рекомендуемые статьи
- Линейная связь — это связь, в которой две переменные имеют прямую связь, что означает, что если значение x изменяется, y также должно изменяться в той же пропорции.
- Это статистический метод, позволяющий получить прямые или коррелированные значения двух переменных с помощью графика или математической формулы.
- Количество переменных, рассматриваемых в линейном уравнении, никогда не превышает двух.
- Корреляция двух переменных в повседневной жизни может быть понята с помощью этой концепции.
Что такое линейная зависимость?
Он лучше всего описывает взаимосвязь между двумя переменными (независимой и зависимой), обычно представленными x и y. В области статистики это одна из самых простых концепций для понимания.
Для линейной зависимости переменные должны образовывать прямую линию на графике каждый раз, когда значения x и y складываются вместе. С помощью этого метода можно понять, как различия между двумя факторами могут повлиять на результат и как они соотносятся друг с другом.
Возьмем реальный пример продуктового магазина, где его бюджет является независимой переменной. Независимая переменная. цель), которая измеряется в математическом, статистическом или финансовом моделировании. Читать далее, а товары, подлежащие хранению, являются зависимой переменной. Предположим, что бюджет составляет 2000 долларов США, а продуктовые товары включают 12 брендов закусок (1–2 доллара за упаковку), 12 брендов прохладительных напитков (2–4 доллара за бутылку), 5 брендов хлопьев (5–7 долларов за упаковку) и 40 брендов средств личной гигиены. ($3-$30 за продукт). Из-за бюджетных ограничений и различных цен покупка большего количества одного товара потребует покупки меньшего количества другого.
Уравнение линейной связи с графиком
Будь то графически или математически, значение y зависит от x, что дает прямую линию на графике. Вот краткая формула для понимания линейной корреляции. КорреляцияКорреляция — это статистическая мера между двумя переменными, которая определяется как изменение одной переменной, соответствующее изменению другой. Он рассчитывается как (x(i)-среднее(x))*(y(i)-среднее(y)) / ((x(i)-среднее(x))2 * (y(i)-среднее( y))2. перевод между переменными.
у = мх + б
В формуле m обозначает уклон. В то же время b является точкой пересечения оси Y или точкой на графике, пересекающей ось y с координатой x, равной нулю. Если значения m, x и b заданы, можно легко получить значение y. Можно графически изобразить то же самое, чтобы показать линейную зависимость. Давайте поймем процесс, когда значения для переменных x и y предполагаются следующим образом в сумме ниже:
- х = 2, 4, 6, 8
- у = 7, 13, 19, 25
Чтобы вычислить m, начните с поиска разности между значениями x и y, а затем представите их в виде дроби.
Следовательно, m = y2 – y1/x2 – x1
Помещая значения из значений x и y в приведенное выше уравнение,
мы получаем,
- м = 13-7/4-2
- м = 6/2
- м = 3
Следующий шаг — найти гипотетическое число (b), которое нужно добавить или вычесть в формуле, чтобы получить значение y. Как таковой,
у = мх + б
- у = 3*2 + 1
- у = 7.
Аналогично, подсчитав остальные точки, получим следующий график.
График линейной зависимости будет выглядеть так:

Практическим примером линейного уравнения может быть приготовление домашней пиццы. Здесь две переменные — это количество людей, которых нужно обслужить (постоянная или независимая переменная), и ингредиенты для пиццы (зависимая переменная). Например, предположим, что есть рецепт пиццы на четверых, но его едят только два человека. Чтобы вместить двух человек, сокращение количества ингредиентов наполовину уменьшит производительность вдвое.
Линейные и нелинейные отношения
Хотя линейные и нелинейные отношения описывают отношения между двумя переменными, обе они различаются по своему графическому представлению и тому, как переменные коррелируют.
Графическое представление
Линейная связь всегда будет отображать на графике прямую линию, отображающую отношения между двумя переменными. С другой стороны, нелинейная зависимость может создать кривую линию на графике с той же целью.
 Изменение переменных
Изменение переменных
В линейной зависимости изменение независимой переменной изменит зависимую переменную. Но это не относится к нелинейным отношениям, поскольку любые изменения одной переменной не повлияют на другую.
Области применения
Линейная зависимость лучше всего описывает ситуации, когда переменные взаимозависимы, например, физические упражнения и потеря веса. Здесь упражнения x раз в день значительно уменьшат любое количество веса.
Не существует линейной связи между переменными в нелинейной зависимости, такой как эффективность лекарства и продолжительность приема. Это связано с тем, что может быть несколько промежуточных факторов, влияющих на эффективность препарата, например:
- Если пациент принимает лекарства вовремя?
- Было ли оно принято в установленном порядке?
- Посещал ли пациент врача для периодического осмотра, как это было предложено в рецепте?
Следовательно, эффективность препарата определяется несколькими факторами, а не только продолжительностью приема, что делает зависимость нелинейной. Было проведено множество исследований, чтобы оценить жизнеспособность изучения ситуаций с точки зрения линейной корреляции. Этот Гарвардское исследование сосредоточил внимание на некоторых проблемных областях в этом отношении. Он также говорил о том, как много ситуаций неизбежно нелинейны.
Рекомендуемые статьи
В этом исчерпывающем руководстве по линейной зависимости обсуждались уравнения, примеры и отличия от нелинейная связь, вместе с ключевыми выводами. Чтобы узнать больше о его использовании в финансах, прочитайте следующие статьи:
- Регрессия
- Линейная регрессия в Excel
- Нелинейная регрессия в Excel