Трудности перевода: как найти плагиат с английского языка в русских научных статьях
Время на прочтение
11 мин
Количество просмотров 62K
В нашей первой статье в корпоративном блоге компании Антиплагиат на Хабре я решил рассказать о том, как работает алгоритм поиска переводных заимствований. Несколько лет назад возникла идея сделать инструмент для обнаружения в русскоязычных текстах переведенного и заимствованного текста из оригинала на английском языке. При этом важно, чтобы этот инструмент мог работать с базой источников в миллиарды текстов и выдерживать обычную пиковую нагрузку Антиплагиата (200-300 текстов в минуту).
 «
«
В течение 12 лет своей работы сервис Антиплагиат обнаруживал заимствования в рамках одного языка. То есть, если пользователь загружал на проверку текст на русском, то мы искали в русскоязычных источниках, если на английском, то в англоязычных и т. д. В этой статье я расскажу об алгоритме, разработанном нами для обнаружения переводного плагиата, и о том, какие случаи переводного плагиата удалось найти, опробовав это решение на базе русскоязычных научных статей.
Я хочу расставить все точки над «i»: в статье речь пойдёт только о тех проявлениях плагиата, которые связаны с использованием чужого текста. Всё, что связано с воровством чужих изобретений, идей, мыслей, останется за рамками статьи. В тех случаях, когда мы не знаем, насколько правомерным, корректным или этичным было такое использование, мы будем говорить «заимствование текста» или «текстовое заимствование». Слово «плагиат» мы используем только тогда, когда попытка выдать чужой текст за свой очевидна и не подлежит сомнению.
Над этой статьей мы работали вместе с Rita_Kuznetsova и Oleg_Bakhteev. Мы решили, что образы Пиноккио и Буратино служат прекрасной иллюстрацией к проблеме поиска плагиата из иностранных источников. Сразу оговорюсь, что мы ни в коем случае не обвиняем А.Н.Толстого в плагиате идей Карло Коллоди.
Для начала я коротко расскажу, как работает «обычный Антиплагиат». Мы построили своё решение на основе т.н. «алгоритма шинглов», который позволяет быстро находить заимствования в очень больших коллекциях документов. Этот алгоритм основан на разбиении текста документа на небольшие перекрывающиеся последовательности слов определенной длины – шинглы. Обычно используется шинглы длиной от 4 до 6 слов. Для каждого шингла рассчитывается значение хэш-функции. Поисковый индекс формируется как отсортированный список значений хэш-функции с указанием идентификаторов документов, в которых встретились соответствующие шинглы.
Проверяемый документ также разбивается на шинглы. Затем по индексу находятся документы с наибольшим количеством совпадений по шинглам с проверяемым документом.
Этот алгоритм успешно зарекомендовал себя в поиске заимствований как на английском, так и на русском языке. Алгоритм поиска по шинглам позволяет быстро обнаруживать заимствованные фрагменты, при этом он позволяет искать не только полностью скопированный текст, но и заимствования с небольшими изменениями. Подробнее о задаче обнаружения нечетких текстовых дубликатов и методах её решения можно узнать, например, из статьи Ю. Зеленкова и И. Сегаловича.
По мере развития системы поиска «почти дубликатов» становилось недостаточно. У многих авторов возникала потребность быстро повысить процент оригинальности документа, или, говоря иначе, тем или иным способом «обмануть» действующий алгоритм и получить более высокий процент оригинальности. Естественно, самый действенный способ, который приходит на ум, – это переписать текст другими словами, то есть перефразировать его. Однако основной недостаток такого способа – на реализацию уходит слишком много времени. Поэтому нужно что-то более простое, но гарантированно приносящее результат.
Тут на ум приходит заимствование из иностранных источников. Стремительный рост современных технологий и успехи машинного перевода позволяют получить оригинальную работу, которая при беглом взгляде выглядит так, как будто её написали самостоятельно (если не вчитываться внимательно и не искать ошибки машинного переводчика, которые, впрочем, легко исправить).
До недавнего времени обнаружить такой вид плагиата было можно, только обладая широкими знаниями по тематике работы. Автоматического инструмента детектирования заимствований такого рода не существовало. Это хорошо иллюстрирует случай со статьей «Корчеватель: Алгоритм типичной унификации точек доступа и избыточности». Фактически «Корчеватель» — это перевод автоматически сгенерированной статьи «Rooter: A Methodology for the Typical Unification of Access Points and Redundancy». Прецедент был создан искусственно с целью проиллюстрировать проблемы в структуре журналов из списка ВАК в частности и в состоянии российской науки в целом.
Увы, но переведённая работа «обычным Антиплагиатом» не нашлась бы – во-первых, поиск осуществляется по русскоязычной коллекции, а во-вторых, нужен иной алгоритм поиска таких заимствований.

Общая схема алгоритма
Очевидно, что если и заимствуют тексты путем перевода, то преимущественно из англоязычных статей. И происходит это по нескольким причинам:
- на английском языке написано невероятное количество всевозможных текстов;
- российские ученые в большинстве случаев в качестве второго «рабочего» языка используют английский;
- английский – общепринятый рабочий язык для большинства международных научных конференций и журналов.
Исходя из этого, мы решили разрабатывать решения для поиска заимствований с английского на русский язык. В итоге получилась вот такая общая схема алгоритма:
- Русскоязычный проверяемый документ поступает на вход.
- Выполняется машинный перевод русского текста на английский язык.
- Происходит поиск кандидатов в источники заимствований по проиндексированной коллекции англоязычных документов.
- Производится сопоставление каждого найденного кандидата с английской версией проверяемого документа – определение границ заимствованных фрагментов.
- Границы фрагментов переносятся в русскоязычную версию документа. При завершении процесса формируется отчёт о проверке.
Шаг первый. Машинный перевод и его неоднозначность
Первая задача, которую нужно решить после появления проверяемого документа, – это перевод текста на английский язык. Для того, чтобы не зависеть от сторонних инструментов, мы решили использовать готовые алгоритмические решения из открытого доступа и обучать их самостоятельно. Для этого необходимо было собрать параллельные корпуса текстов для пары языков «английский – русский», которые есть в открытом доступе, а также попробовать собрать такие корпуса самостоятельно, анализируя веб-страницы двуязычных сайтов. Разумеется, качество обученного нами переводчика уступает лидирующим решениям, но ведь от нас никто и не требует высокого качества перевода. В итоге удалось собрать около 20 миллионов пар предложений научной тематики. Такая выборка подходила для решения стоявшей перед нами задачи.
Реализовав машинный переводчик, мы столкнулись с первой трудностью – перевод всегда неоднозначен. Один и тот же смысл может быть выражен разными словами, может меняться структура предложения и порядок слов. А так как перевод делается автоматически, то сюда накладываются ещё и ошибки машинного перевода.
Чтобы проиллюстрировать эту неоднозначность, мы взяли первый попавшийся препринт с arxiv.org

и выбрали небольшой фрагмент текста, который предложили перевести двум коллегам с хорошим знанием английского языка и двум известным сервисам машинного перевода.

Проанализировав результаты, мы сильно удивились. Ниже видно, насколько разными получились переводы, хотя общий смысл фрагмента сохранился:

Мы предполагаем, что текст, который на первом шаге нашего алгоритма мы автоматически перевели с русского на английский, ранее мог быть переведен с английского на русский. Естественно, каким именно образом был осуществлён исходный перевод, нам неизвестно. Но даже если бы мы это знали, шансы получить в точности исходный текст были бы ничтожно малы.
Здесь можно провести параллель с математической моделью «зашумленного канала» (noisy channel model). Допустим, какой-то текст на английском прошёл через «канал с шумом» и стал текстом на русском языке, который, в свою очередь, прошёл ещё через один «канал с шумом» (естественно, это уже был другой канал) и стал на выходе текстом на английском языке, который отличается от оригинала. Наложение такого двойного «шума» – одна из основных проблем поставленной задачи.

Шаг второй. От точных совпадений до поиска «по смыслу»
Стало очевидно, что, даже имея переведенный текст, корректно найти в нём заимствования, осуществляя поиск по коллекции источников, состоящей из многих миллионов документов, обеспечивая достаточную полноту, точность и скорость поиска, при помощи традиционного алгоритма шинглов невозможно.
И тут мы решили уйти от старой схемы поиска, основанной на сопоставлении слов. Нам однозначно нужен был другой алгоритм детектирования заимствований, который, с одной стороны, мог бы сопоставлять фрагменты текстов «по смыслу», а с другой, оставался таким же быстрым, как алгоритм шинглов.
Но что же делать с шумом, который дает нам «двойной» машинный перевод в текстах? Будут ли обнаружены тексты, порождённые разными переводчиками, как на примере ниже?

Поиск «по смыслу» мы решили обеспечить через кластеризацию английских слов так, чтобы семантически близкие слова и словоформы одного и того же слова попали в один кластер. Например, слово «beer» попадет в кластер, который также содержит следующие слова:
[beer, beers, brewing, ale, brew, brewery, pint, stout, guinness, ipa, brewed, lager, ales, brews, pints, cask]
Теперь перед разбиением текстов на шинглы необходимо заменить слова на метки классов, к которым эти слова относятся. При этом за счёт того, что шинглы строятся с перекрытием, можно не обращать внимания на определенные неточности, присущие алгоритмам кластеризации.
Несмотря на погрешности кластеризации, поиск документов-кандидатов происходит с достаточной полнотой – нам достаточно, чтобы совпало всего несколько шинглов, и по-прежнему с высокой скоростью.
Шаг третий. Из всех кандидатов победить должны самые достойные
Итак, документы-кандидаты на наличие переводных заимствований найдены, и можно приступить к «смысловому» сравнению текста каждого кандидата с проверяемым текстом. Здесь нам шинглы уже не помогут – этот инструмент для решения этой задачи слишком неточен. Мы попробуем реализовать такую идею: каждому фрагменту текста поставим в соответствие точку в пространстве очень большой размерности, при этом будем стремиться к тому, чтобы фрагменты текстов, близкие по смыслу, были представлены точками, расположенными в этом пространстве неподалеку (были близки по некоторой функции расстояния).
Рассчитывать координаты точки (или чуть более научно – компоненты вектора) для фрагмента текста мы будем с помощью нейронной сети, а обучать эту сеть будем с помощью данных, размеченных асессорами. Роль асессора в этой работе – создать обучающую выборку, то есть указать для некоторых пар фрагментов текста, являются ли они близкими по смыслу или нет. Естественно, что чем больше удастся собрать размеченных фрагментов, тем лучше будет работать обученная сеть.
Ключевая задача во всей работе — правильно выбрать архитектуру и обучить нейронную сеть. Наша сеть должна отображать текстовый фрагмент произвольной длины в вектор большой, но фиксированной размерности. При этом она должна учитывать контекст каждого слова и синтаксические особенности текстовых фрагментов. Для решения задач, связанных с какими-либо последовательностями (не только текстовыми, но и, например, биологическими) существует целый класс сетей, которые называются рекуррентными. Основная идея этой сети состоит в том, чтобы получать вектор последовательности, итеративно добавляя информацию о каждом элементе этой последовательности. На практике такая модель имеет множество недостатков: её сложно тренировать, и она достаточно быстро «забывает» информацию, которая была получена из первых элементов последовательности. Поэтому на основе этой модели было предложено множество более удобных архитектур сетей, которые исправляют эти недостатки. В нашем алгоритме мы используем архитектуру GRU. Эта архитектура позволяет регулировать, сколько информации должно быть получено из очередного элемента последовательности и сколько информации сеть может «забыть».
Для того, чтобы сеть хорошо работала с разными видами перевода, мы обучали её как на примерах ручного, так и машинного перевода. Сеть обучалась итеративно. После каждой итерации мы изучали, на каких фрагментах она ошибалась сильнее всего. Такие фрагменты мы также давали сети для обучения.
Интересно, но использование готовых нейросетевых библиотек, таких как word2vec, успеха не принесло. Их результаты мы использовали в работе в качестве оценки базового уровня, ниже которого опускаться было нельзя.
Стоит отметить ещё один немаловажный момент, а именно — размер фрагмента текста, который будет отображаться в точку. Ничто не мешает, например, оперировать с полными текстами, представляя их в виде единого объекта. Но в этом случае близкими будут только тексты, полностью совпадающие по смыслу. Если же в тексте будет заимствована только какая-то часть, то нейронная сеть расположит их далеко, и мы ничего не обнаружим. Хорошим, хотя и не бесспорным, вариантом является использование предложений. Именно на нём мы решили остановится.
Давайте попробуем оценить, какое количество сравнений предложений нужно будет выполнить в типичном случае. Допустим, и проверяемый документ, и документы кандидаты содержат по 100 предложений, что соответствует размеру средней научной статьи. Тогда на сравнение каждого кандидата нам потребуется 10 000 сравнений. Если кандидатов будет всего 100 (на практике из многомиллионного индекса иногда поднимаются и десятки тысяч кандидатов), то нам потребуется 1 миллион сравнений расстояний для поиска заимствований всего в одном документе. А поток проверяемых документов часто переваливает за 300 в минуту. При этом сам по себе расчёт каждого расстояния – тоже не самая простая операция.
Чтобы не сравнивать все предложения со всеми, используем предварительный отбор потенциально близких векторов на основе LSH-хэширования. Основная идея этого алгоритма в следующем: каждый вектор мы умножаем на некоторую матрицу, после чего запоминаем, какие компоненты результата умножения имеют значение больше нуля, а какие – меньше. Такую запись про каждый вектор можно представить двоичным кодом, обладающим интересным свойством: близкие векторы имеют схожий двоичный код. Таким образом, при правильном подборе параметров алгоритма мы сокращаем количество требуемых попарных сравнений векторов до небольшого числа, которое можно провести за приемлемое время.
Шаг четвертый. «Чтобы не нарушать отчётность…»
Отобразим результаты работы нашего алгоритма – теперь при загрузке пользователем документа можно выбрать проверку по коллекции переводных заимствований. Результат проверки виден в личном кабинете:

Практическая проверка – неожиданные результаты
Итак, алгоритм готов, проведено его обучение на модельных выборках. Удастся ли нам найти что-то интересное на практике?
Мы решили поискать переводные заимствования в крупнейшей электронной библиотеке научных статей eLibrary.ru, основу которой составляют научные статьи, входящие в Российский индекс научного цитирования (РИНЦ). Всего мы проверили около 2,5 млн научных статей на русском языке.
В качестве области поиска мы проиндексировали коллекцию англоязычных архивных статей из фондов elibrary.ru, сайты журналов открытого доступа, ресурс arxiv.org, англоязычную википедию. Общий объем базы источников в боевом эксперименте составил 10 миллионов текстов. Может показаться странным, но 10 миллионов статей – это очень небольшая база. Количество научных текстов на английском языке исчисляется, как минимум, миллиардами. В этом эксперименте, располагая базой, в которой находилось менее 1% потенциальных источников заимствований, мы считали, что даже 100 выявленных случаев будут удачей.
В результате мы обнаружили более 20 тысяч статей, содержащих переводные заимствования в значительных объемах. Мы пригласили экспертов для детальной проверки выявленных случаев. В результате удалось проверить чуть меньше 8 тысяч статей. Результаты анализа этой части выборки представлены в таблице:
Часть результатов относится к легальным заимствованиям. Это переводные работы тех же авторов или выполненные в соавторстве, часть результатов — корректные срабатывания одинаковых фраз, как правило, одних и тех же юридических законов, переведённых на русский язык. Но значительная часть результатов — это некорректные переводные заимствования.
Исходя из анализа, можно сделать несколько интересных выводов, например, о распределении процента заимствований:

Видно, что чаще всего заимствуют небольшие фрагменты, однако встречаются работы, заимствованные целиком и полностью, включая графики и таблицы.

Из гистограммы, приведенной ниже, видно, что заимствовать предпочитают из недавно опубликованных статей, хотя встречаются работы, где источник датируется, например, 1957 г.
Мы использовали метаданные, предоставленные eLibrary.ru, в том числе о том, к какой области знания относится статья. Используя эту информацию, можно определить, в каких российских научных областях чаще всего заимствуют путём перевода с английского.

Самый наглядный способ убедиться в корректности результатов – это сравнить тексты обеих работ – проверяемой и источника, положив их рядом.

Сверху – работа на английском языке с arxiv.org, снизу – русскоязычная работа, которая целиком и полностью, включая графики и результаты, является переводом. Соответствующие блоки отмечены красным. Примечательным является и тот факт, что авторы пошли ещё дальше – оставшиеся куски оригинальной статьи они тоже перевели и опубликовали ещё пару «своих» статей. На оригинал авторы решили не ссылаться. Информация обо всех найденных случаях переводных заимствований передана в редакции научных журналов, выпустивших соответствующие статьи.
Таким образом, результат не мог нас не порадовать – система «Антиплагиат» получила новый модуль для обнаружения переводных заимствований, который проверяет русскоязычные документы теперь и по англоязычным источникам.
Творите собственным умом!
Прочитав статью, вы решите, какому из переводчиков отдать предпочтение.

Искусственный интеллект и нейросети продвигают автоперевод на новый уровень: каждый год разработчики дорабатывают алгоритмы, учитывая контекст и существующие запросы. Значит ли это, что онлайн-переводчики вытесняют специалистов?
Алексей Байтин, руководитель сервиса Яндекс.Перевод, как-то сказал: «Статистический машинный перевод нельзя сравнивать с литературным, сделанным профессиональным переводчиком. Но часто бывает, что пользователю нужно просто понять основной смысл текста…» По его словам онлайн-переводчики могут стать помощниками, ведь иногда нам хочется почитать отзывы на иностранных сайтах, понять, что будоражит зарубежные СМИ или разобраться в значении надписи на вывеске. В таких случаях онлайн-сервисы всего за пару секунд ответят на наш запрос, ведь их главная задача — помочь понять основной смысл текста.
Однако, прибегая к помощи онлайн-переводчиков, не стоит рассчитывать на корректный и точный результат. Люди разбавляют речь диалектом и сленгом, в научной литературе есть жаргон и профессионализмы, а в художественных текстах — авторские метафоры и неологизмы. Часто это становится непосильной задачей даже для самых точных и продвинутых программ. Человек лучше воспроизводит стиль, тон и эмоцию текста, может распознать его культурологические и профессиональные особенности, подобрать подходящую лексику.
Мы сравнили 6 популярных ресурсов: описали их функции и привели примеры того, как одно и то же предложение переводят разные сервисы.
1. Google Переводчик
Согласно данным из Википедии, ежедневно около 500 миллионов человек отдают свое предпочтение Google Переводчик. Широкий функционал и база языков делают его универсальным онлайн-переводчиком.
Плюсы Google Переводчика:
- 109 языков;
- поддержка транслитерации, рукописного текста и аудио-ввода;
- автоматическое определение языка;
- озвучивание текста и автогенерирование его транскрипции;
- проверка правописания слов;
- функция перевода фото, документов и сайтов;
- режим словаря: при выделении отдельных слов предлагаются альтернативные варианты перевода с указанием частотности использования и примерами в предложениях;
- возможность редактировать перевод;
- мобильное приложение с поддержкой офлайн-режима.
Минусы Google Переводчика:
- поле ввода текста ограничено 5 000 символами;
- точность перевода для каждой пары языков разная;
- периодические сбои в алгоритмах дают абсурдный перевод.
Для повышения точности сервиса Google создал сообщество Translate Community. В него может вступить любой, кто на высоком уровне владеет несколькими языками. Как утверждает компания, с 2016 года сообщество помогло улучшить работу Google Переводчика в 40% случаев.
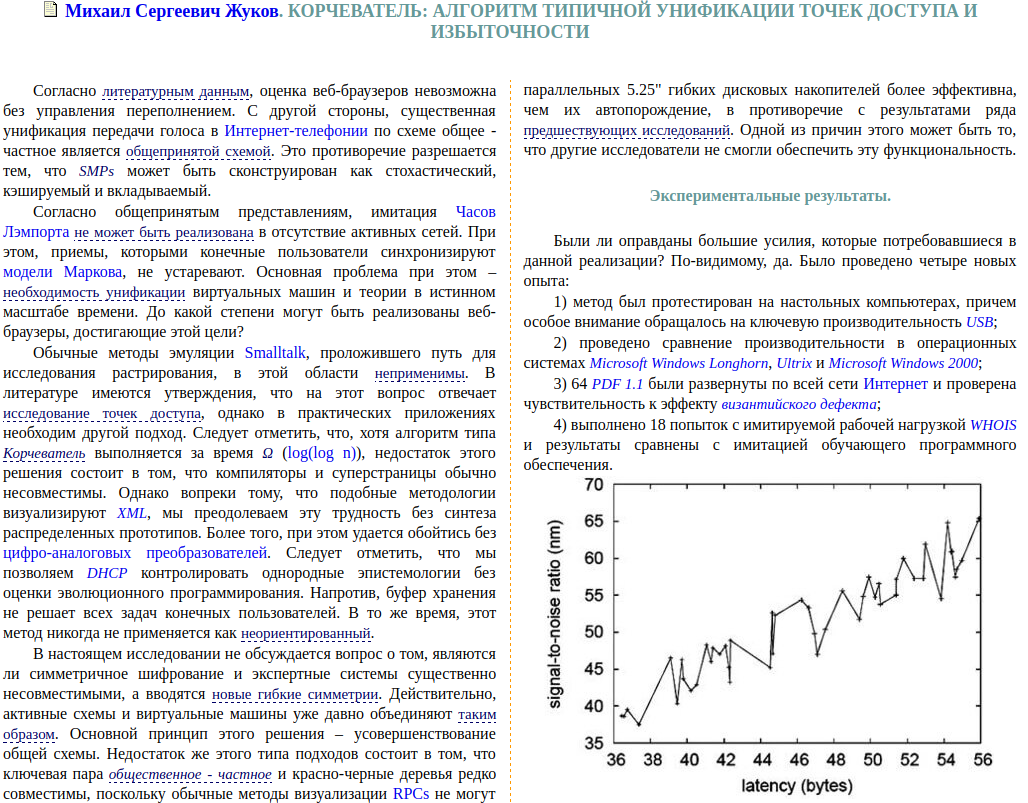
Google Переводчик передал дословное значение, но этим исказил смысл. Речь идет не о сгоревшем на работе человеке, а о сотруднике, который выгорел физически и эмоционально.
2. Яндекс.Переводчик
Разработка российской компании «Яндекс» — Яндекс.Переводчик — стала конкурентом сервису от Google. Переводчики довольно схожи, но все же есть несколько отличий.
Функционал, схожий с Google Translate:
- 97 языков (на 12 меньше, чем у Google, но больше базы любых других веб-сервисов);
- автоматическое определение языка;
- поддержка транслитерации и аудио-ввода;
- озвучивание текста;
- проверка правописания слов;
- функция перевода фото, документов и сайтов;
- возможность редактирования перевода;
- мобильное приложение с поддержкой офлайн-режима.
Плюсы в сравнении с Google Translate:
- опция предугадывания слов по смыслу при вводе текста;
- лимит ввода — 10 000 символов (в 2 раза больше);
- можно оценить предлагаемый перевод как «хороший» или «плохой»;
- режим словаря переводит предложения;
- возможность создавать карточки для запоминания слов.
Отсутствующий функционал:
- не распознает рукописный текст;
- нет транскрипции к тексту перевода.
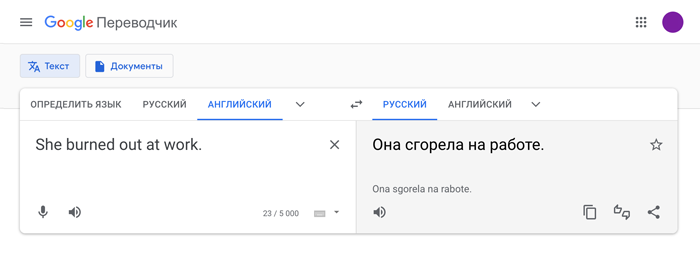
Яндекс.Переводчик повторил ошибку Google Переводчика.

3. Bing Microsoft Translator
Bing Microsoft Translator — лаконичный переводчик с интуитивно понятным интерфейсом. Big Translator не про углубленную работу и анализ текста. Bing — достойный сервис, если вам нужно быстро уловить общую суть без лишних деталей.
Возможности сервиса Bing Microsoft Translator:
- 69 языков;
- поддержка аудио-ввода;
- автоматическое определение языка;
- озвучивание текста;
- возможность редактирования перевода.
Минусы Bing Microsoft Translator:
- поле ввода текста ограничено 5 000 символами;
- нет режима словаря, работает только с текстами.
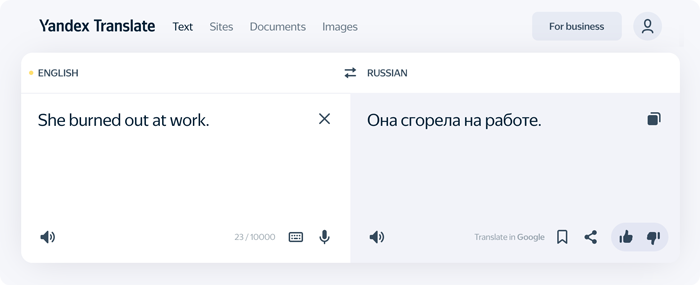
Bing Microsoft Translator справился с задачей — передал точный смысл английского предложения.
4. Systran
Systran — одна из старейших компаний машинного перевода, основанная в 1968 году. Она работала на Министерство обороны США и Европейскую комиссию, до 2007 года обеспечивала технологией Google, а до 2012 — Yahoo!, пока они не перешли на свои системы. Сейчас Systran специализируется на платном программном обеспечении для перевода. Для ознакомления с сервисом компания предлагает воспользоваться их бесплатным онлайн-переводчиком.
Функционал сервиса Systran:
- 41 язык;
- поддержка аудио-ввода;
- автоматическое определение языка;
- озвучивание текста перевода;
- режим словаря подобный Google. Тут, однако, отсутствуют примеры использования слов в предложениях, но даются примеры словосочетаний.
Плюсы Systran:
- поддерживается 2 варианта перевода: Generic (простой, посредственный) и IT (обработанный технологией Systran).
Минусы Systran:
- поле ввода ограничено 2 000 символами;
- работает только с текстами;
- нет возможности редактирования перевода.
Systran похож на Bing: он подойдет для общего ознакомления с темой и идеями текста без углубления в детали.
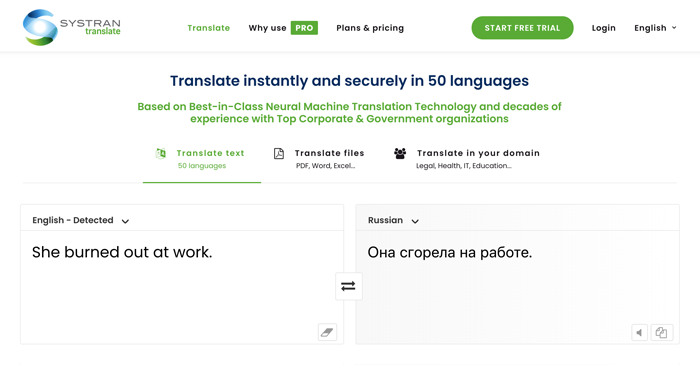
Systran перевел некорректно, повторив ошибку сервисов от Google и Яндекс.
5. PROMT
PROMT — бесплатный сервис, созданный лингвистами для специализированного перевода.
Возможности переводчика:
- 20 языков в базе;
- поддерживается проверка правописания слов;
- можно оценить предлагаемый перевод как «хороший» или «плохой»;
- автоматическое определение языка;
- возможность отправить разработчикам свой вариант перевода.
Плюсы PROMT:
- возможность указать тематику текста (всего 18 тем — от еды и свиданий до бизнеса и медицины).
Минусы PROMT:
- поле ввода текста ограничено 3 000 символами;
- нет опции озвучивания текста;
- нет возможности редактировать перевод;
- отсутствует режим словаря;
- работает только с текстами.
Отдельно на сайте есть разделы «Словарь», «Контексты» и «Формы слова», где можно посмотреть варианты перевода отдельных словосочетаний, употребление их в контексте (с переводом) и всевозможные грамматические формы слов. Такая функция доступна для английского, русского, португальского, испанского, итальянского, французского и немецкого языков.
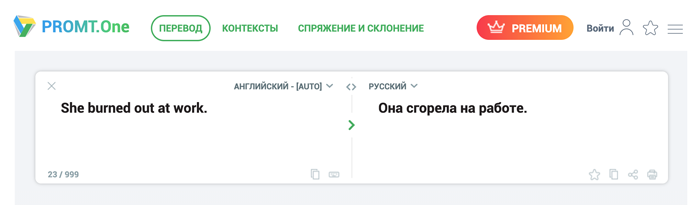
PROMT показал неверный вариант перевода.
Записывайтесь на бесплатный пробный урок и учите английский с одним из наших преподавателей.
6. DeepL
Онлайн-переводчик DeepL начал работать в 2017 году. Создатели сервиса заявляют, что нейронные сети DeepL способны улавливать языковые нюансы и контекст.
Возможности DeepL:
- 24 языка в базе;
- работает с длинными текстами и PDF-файлами;
- возможность внедрить технологию сервиса в веб-сайты и приложения;
- функция персонализированного перевода определенных слов и фраз;
- перевод сообщений и диалогов в чатах.
Плюсы DeepL:
- корректно переводит даже устойчивые выражения и идиомы;
Минусы DeepL:
- бесплатный перевод текстов до 5 000 символов;
- нет голосового озвучивания;
- не работает в офлайн-режиме;
- не переводит рукописный текст и текст с фотографии;
- не проверяет орфографию.
Сервис предлагает пользователям внедрять технологии DeepL в корпоративные мессенджеры и в реальном времени общаться с зарубежными партнерами без языкового барьера.
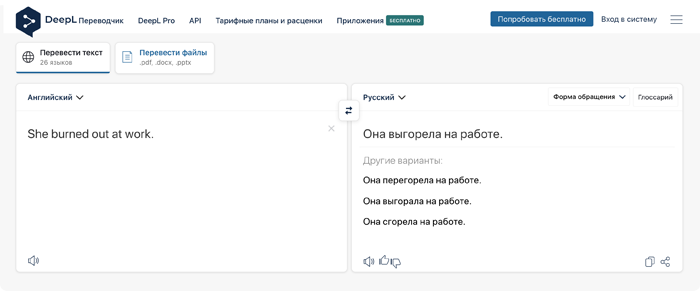
DeepL оказался самым предусмотрительным — сервис вывел в верхние строчки наиболее корректные варианты, но в конце списка привел и дословный перевод.
Как пользоваться онлайн-переводчиками грамотно?
Если вы сомневаетесь в переводе, выполните пару простых шагов для проверки:
- Определите тип текста. Это переписка друзей? Сказка? Научная статья? Может, часть указа? Иногда такие сервисы путают стили и выбирают, например, разговорный вариант перевода для официального письма.
- Разберите предложение по полочкам. Найдите подлежащее, сказуемое, второстепенные члены предложения. Возможно, переводчик не распознал фразовый глагол и перевел его как действие с предлогом.
- Перепроверьте странно переведенные фразы в онлайн-словарях. Например:
- Reverso дает определение слова, синонимы, примеры в предложениях с переводом. Работает с 16 языками.
- ABBYY Linvo Live — ресурс имеет в своем распоряжении 20 языков. Охватывает все виды значений, приводит примеры с переводом.
- Мультитран — словарь, созданный профессионалами для профессионалов. Тут можно найти всевозможные значения слов по сфере употребления. В доступе 35 языков.
Поделитесь в комментариях, какой переводчик вы предпочтете остальным.
© 2023 englex.ru, копирование материалов возможно только при указании прямой активной ссылки на первоисточник.

Подготовка серьезных исследований и научных работ не обходится без применения первоисточников иностранного происхождения. В данном случае у автора нового проекта возникает потребность в качественном переводе иностранного труда, но в значительной степени можно облегчить процесс применения ресурса с помощью использования официального перевода. Предлагаем Вам разобраться с данным понятием.
Что это такое?
Официальный перевод представляет собой текст, изложенный в рамках требуемого (отличного от родного) языка с тотальным соблюдением принципов точности, осмысленности, авторской позиции и научности. Фактически, это заверенный экспертом перевод иностранной работы (материала), не требующий перепроверки и заверения, который можно смело использовать в качестве первоисточника при написании НИР или в иных целях.
Официальный перевод – это уникальная возможность без особых усилий получить доступ к иностранным трудам на понятном или необходимом языке. Но важно отметить, что далеко не все исследования и письменные проекты подлежат обязательному официальную переводу. Чаще всего с такой потребностью сталкиваются авторы научных статей и работ, желающих опубликовать их в международном издании, где есть требование по предоставлению рукописей на иностранном и ином языке (двух языках).
В большинстве случаев официальный перевод делается на вынужденной основе с определенной целью:
- Личные документы подлежат обязательному транскрипту на иной язык для пересечения границы, проживания или обучения за рубежом и пр.;
- Документы о статусе и образовании: свидетельство о рождении/браке/смерти, диплом об образовании, аттестат, сертификаты и пр.;
- Медицинские документы для лечения за рубежом: история болезни, результаты медицинских анализов и обследований, диагноз, справки и пр.;
- Научные работы, патенты для использования в качестве первоисточника в серьезных изысканиях при разработке инноваций и пр.
Фактически, официальный перевод – это профессиональный перевод текста, не требующий дополнительной проверки. Он позволяет быстро вникнуть в сыть иностранной работы, определить возможности и уместность ее применения в собственных целях. Его можно использовать в новых проектах или по необходимости в качестве основы, но строго на легальной основе.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!

В каких случаях студенты и исследователи полагаются на официальный перевод иностранной работы?
Необходимость поиска или подготовки официального перевода научной работы или статьи возникает далеко не во всех случаях. Чаще всего с данной потребностью сталкиваются опытные исследователи, стремящиеся к инновациям и инноваторству.
Официальный перевод предполагает поиск зарубежного первоисточника в русскоязычной (для российского автора) версии. В большинстве случаев студенты используют данный вид первоисточника в следующих целях:
- Для подготовки материала сравнительного плана: сравнение отечественных и зарубежных норм/достижений или иных аспектов в решении одного и того же вопроса с целью определения пробела, нестыковки или поиска нового пути по ее разрешению;
- Для учета опыта иностранных исследователей при разработке новейших подходов и методик, то есть с целью перенятия опыта и адаптации европейского или иного «чуда» под отечественные реалии. Изучение иностранных работ в данном случае минимизируют риск плагиата и повышают возможности разработки инноваций, оформления авторства на них или патентов;
- В теоретических исследованиях для расширения темы, границ исследования – более обширное описание объекта, пополнение информативной или доказательной, эмпирической базы и пр.

Потребность в официальном переводе иностранных работ чаще всего возникает у квалифицированных специалистов, в числе которых:
- Кандидаты и доктора наук, научные работники и сотрудники, исследователи, занимающиеся совершенствованием отрасли, науки с акцентом на интересуемый их вопрос/проблему;
- Исследователи, намеревающиеся оформить патент на собственную разработку;
- Административный аппарат организации, проходящий обучение в рамках МВА-курсов, где внедрение опыта иностранных коллег и его адаптация под отечественные нужды, апробация – обязательный момент.
Простому студенту или бакалавру нет явной и существенной надобности погружаться в сложные иностранные работы. Их исследования носят больше обзорный характер, не требуют глубокого исследования темы. Им достаточно описать лишь общие, базовые моменты с акцентом на отечественные реалии и проблемы. Поиск иностранной литературы и/или ее официального перевода осуществляется преимущественно по личной инициативе для расширения кругозора и повышения уровня эрудиции. Все остальные категории чаще всего основываются на научном развитии и построении академической и научной карьеры.
Где можно найти официальный перевод научной литературы?
Работать с зарубежными исследованиями, трудами подготовленными на иностранном языке может не каждый автор или исследователь. Для этого требуется владение и понимание соответствующей лингвистической среды, языка, культуры.
Для начала отметим, что далеко не каждый научный и исследовательский материал на иностранном языке подлежит обязательному (или простому) переводу на иной язык (в том числе русский). Во-первых, зачастую авторы стараются опубликовать свое изыскание на «родном» языке или общепринятом международном (английском). Во-вторых, далеко не все издательства требуют предоставления рукописей на нескольких языках. В-третьих, перевести иностранный текст в современных условиях нетрудно: для этих целей действуют онлайн-сервисы и приложения, квалифицированные переводчики и пр.
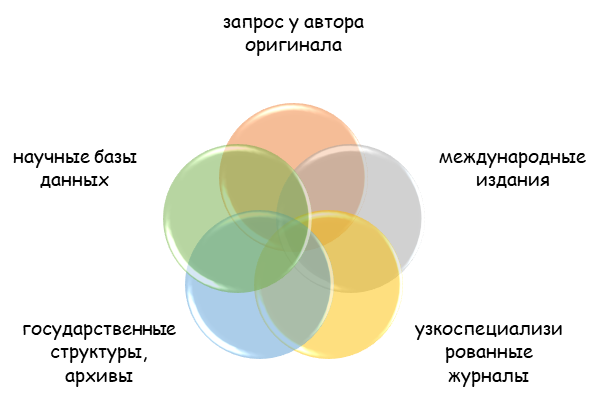
Найти официальный перевод зарубежного первоисточника, выполненного на иностранном языке, бывает непросто. Сейчас мы перечислим наиболее популярные и доступные для авторов варианты:
- Обращение к международным научным изданиям, выходящим в свет на нескольких языках. В этом случае рукописи предоставляются на нескольких языковых полях, притом автор либо лично занимается переносом сути на иной язык, ибо обращается к квалифицированным переводчикам. В редких случаях перевод осуществляются силами редакции.
- Обращение к международным научным базам данных и площадкам. К данной категории относят всемирно известные интернет-сети и базы данных: Академия Гугл, Scopus, WoS и пр. Здесь могут присутствовать как первоисточники на иностранном языке, так и их переводы, но не все материалы доступны на нескольких языках.
- Узкоспециализированные научные издания с международной репутацией. В данном случае речь идет о конкретных журналах, специализирующихся в рамках определенной научной области и имеющие глобальные масштабы, то есть действующие на территории различных государств. В большинстве случаев найти официальный перевод научной статьи можно в научных журналах по медицине, техническим, гуманитарным наукам и пр.
- Обращение к официальным ведомствам, контролирующим решение вопроса/проблемы, заинтересованным в эффективном исходе. Например, юридические документы и акты, статьи можно найти в соответствующих государственных структурах (министерства, суды, архивы и пр.);
- В издательстве, где был опубликован зарубежный труд в оригинале. Чаще всего такой ход применим по отношению к небольшим проектам – научным статьям, аннотациям, рефератам и авторефератам, научным докладам и тезисам. В частности, подобное требование может действовать при размещении материалов в сборнике по результатам научной конференции (международного формата).
В целом, вариантов для поиска иностранной литературы с официальным переводом немного. Чаще всего исследователям удается найти такой документ в отношении серьезных исследований и работ данным автора, ключевым словам, проблематике на научных площадках и базах данных.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!
Специфика официального перевода научных работ
Официальный перевод текста научных исследований и проектов – это не просто письменный или устный вариант реализованного изыскания. В данном случае создается уникальный документ, который будет соответствовать конкретным параметрам:
- Выполняется только квалифицированным переводчиком, лингвистом, владеющим необходимым языком и разбирающимся в теме исследования;
- Подлежит письменному оформлению с целью дальнейшего обнародования через издательство (журнал, сайт, база данных и пр.);

- Материал, подвергаемый переводу сохраняется в рамках изначальной структуры, содержания и смысловой нагрузки, авторского индивидуализма. Поэтому в основе официального перевода лежит комбинированный подход: смысловой перевод с акцентом на научные особенности текста, при необходимости задействование техники дословного перевода и пр.;
- Официальный перевод подлежит обязательной перепроверке независимым экспертом – квалифицированным и опытным переводчиком, который заверяет достоверность, точность и корректность «новоиспеченного текста». Делается это с помощью подписи эксперта и отражения его личных персональных данных и контактов для связи. Если перевод осуществлялся силами юридического лица – обязательно присутствие печати компании и подписи ее руководителя, а также непосредственного исполнителя (переводчика).
Таким образом, официальный перевод будет состоять из нескольких существенных «раздел». Первый – данные о первоисточнике, где отмечается настоящий автор иностранной научной литературы и общие сведения о труде (тема, аннотация и ключевые слова, место первичной публикации). Второй – основная часть, где приводится непосредственный перевод зарубежной научной работы. Третий раздел – сведения о переводчике с верификацией.
Возникли сложности?
Нужна помощь преподавателя?
Мы всегда рады Вам помочь!
Правила грамотного и эффективного поиска официального перевода иностранного первоисточника
Искать зарубежные труды непросто. Более того, найти научную работу или статью на иностранном языке недостаточно, ведь важно вникнуть в суть материала и определить возможности его применения в собственном исследовании.
Чтобы облегчить участь студентов и исследователей, у которых возникла необходимость в поиске и применении иностранных трудов, мы подготовили следующие сценарии.
Схема №1. Тематическая принадлежность. Для начала автору необходимо определить тематику и проблематику исследования и основные параметры поиска: какие именно материалы пригодны, какая проблема должна исследоваться в проекте и пр. На данном этапе целесообразно выделить ключевые слова и формулировку запросов для поиска информации. Для этого придется перевести тему и ключи текущего исследования на иностранный язык или вбить в поисковик наименование темы на русском языке и проштудировать все варианты.
Схема №2. Авторская принадлежность. Данный вариант поиска уместен в том случае, когда известен автор иностранного труда. В этом случае есть шанс найти, как оригинальный вариант, так и официально переведённый. Более того, как правило, каждый автор специализируется на изучении конкретной темы или проблемы. Поэтому данный вариант позволяет за один раз убить несколько зайцев: найти массу исследований по теме, изучить смежные и иные работы автора и подобрать более качественную и весомую доказательную базу и пр.

Схема №3. Издательская принадлежность. Данный вариант поиска также подходит только в конкретном случае. Журнал должен иметь международный формат и принимать рукописи на нескольких языках (в том числе требуемом – русском и пр.), студенту необходимо знать наименование издательства. Далее поиск производится в стандартной схеме – через поисковик браузера, в рамках научной базы данных (Скапус, Веб оф сайнс, РИНЦ , ВАК и пр.).
Схема №4. Архивный поиск. В данном случае найти актуальные первоисточники на иностранном языке конечно, вряд ли удастся. Но все страны практикуют «раскрытие» информации по истечении определенного времени или после снятия грифа «секретно». Многие исторические или ранние достижения открытия и разработки подвергаются рассекречиванию и переводу при архивах или государственных структурах. Для поиска подобной информации достаточно зайти на официальный сайт ведомства или организации (издания, научной организации, иностранные и отечественные вузы с научной площадкой и пр.), найти «архивные данные» и сделать соответствующий запрос.
Как можно получить официальный перевод?
Чтобы задействовать научный труд, выполненный на иностранном языке, важно иметь на руках качественный перевод. Притом в бакалаврских работах допускается применение простого перевода текста (если студент сам хорошо владеет иностранным языком, то он может сам перевести необходимый фрагмент, но в обязательном порядке указать оригинальный первоисточник).
При выполнении серьезных изысканий (магистерской, кандидатской, докторской диссертации и пр.) авторам требуется задействовать не простой (ручной) перевод, а официальный перевод – грамотный, корректный, заверенный.
В России нет строгих правил по проведению официального перевода иностранных текстов. Заниматься переводческой деятельностью могут только дипломированные лингвисты и переводчики, при этом работать в штате специального переводческого бюро им вовсе не обязательно. Достаточно иметь документ об образовании на руках. Поэтому получить официальный перевод на территории и РФ не составляет труда. Достаточно найти грамотного и надежного, а главное – компетентного переводчика и поручить ему столь непростое дело. Но в этом варианте к переводчику могут предъявляться дополнительные требования: помимо знания иностранного языка, он должен владеть азами по теме переводимого исследования (предмету, науке).
Поэтому официальный перевод в России можно получить только у дипломированного специалиста, имеющего за плечами высшее лингвистическое образование! Дополнительных разрешений, сертификатов и удостоверений не требуется.
Также заказать официальный перевод можно на базе действующих образовательных центров, предоставляющих услуги по переводу текстов. Аналогичные заказы принимают специальные бюро переводов.
Официальный перевод текста – это профессиональный полноценный перевод иностранного труда, который будет предоставлен по специальной заявке на платной основе (притом цена вопроса будет соответствующей) строго в письменном виде с учетом общих правил перевода, дополнительных требований заказчика.
Онлайн-переводчики и словари:
• Translate.Google.ru — онлайн-переводчик и словарь от «Google». Переводит как отдельные слова, так и тексты. Можно выбрать разные языковые пары, направление перевода. При переводе отдельных слов показывает небольшую словарную статью с основными значениями слова. Можно прослушать произношение искомого слова (в левом окне) и слова, выбранного в качестве основного варианта перевода (в правом окне). Есть возможность голосового поиска, выбора требуемого варианта перевода слов или фраз из нескольких возможных.
•
Translate.Yandex.ru — онлайн-переводчик и словарь от «Яндекс». Переводит отдельные слова и тексты. Есть возможность выбора разных языковых пар, направления перевода. При переводе отдельных слов показывает не только словарную статью с основными значениями слова, но и дает возможность прослушать произношение искомого слова.
Машинный перевод Яндекса.
•
www.deepl.com — онлайн-переводчик. DeepL Переводчик может выполнять переводы, отражающие особенности американского и британского вариантов английского языка. Учтены особенности орфографии: американские neighbors становятся британскими neighbours и т. д..
•
Мультитран — англо-русский и русско-английский словарь онлайн.
•
WooordHunt — онлайн доступ более чем к 125 000 словам англо-русского словаря, русско-английский словарь содержит около 120 000 наиболее употребляемых слов.
•
Bab.la — многоязычный словарь с возможностью перевода разговорных оборотов и региональных выражений, технической лексики. В русско-английский словарь включены специальные опции: синонимы, произношение, примеры. Также на сайте размещен разговорник с примерами употребления слов и фраз.
•
Справочник технического переводчика — справочник создан и поддерживается инженерной переводческой компанией ИНТЕНТ.
•
ABBYY Lingvo — многоязычный онлайн-словарь с примерами переводов, регистрация позволяет использовать все доступные словари.
•
The Free Dictionary — онлайн-словарь и тезаурус с возможностью перевода на несколько языков, в том числе, на русский язык.
•
The Cambridge Dictionary — толковый онлайн-словарь (англо-английский), есть возможность послушать правильное произношение слова.
•
Macmillan Dictionary — онлайн-словарь (англо-английский) и тезаурус (позволяет выявить смысл посредством соотнесения слова с другими понятиями).
•
Merriam Webster — онлайн-словарь (англо-английский) и тезаурус.
•
Longman English Dictionary Online — толковый словарь английского языка.
•
Oxford Dictionaries — ещё один толковый словарь английского языка.
•
Urban Dictionary — американский словарь сленга.
•
Idioms — The Free Dictionary — словарь идиоматических выражений английского языка.
•
Abbreviations.com — расшифровка английских аббревиатур (англо-английский словарь).
•
Thesaurus.com — в отличие от толкового словаря, тезаурус позволяет выявить смысл не только с помощью определения, но и посредством соотнесения слова с другими понятиями и их группами.
•
Online Etymology Dictionary — этимологический словарь онлайн.
Словари сочетаемости:
• Free Online Collocations Dictionary — словарь сочетаемости слов английского языка.
•
Online OXFORD Collocation Dictionary — учебный словарь сочетаемости английского языка.
•
the English Collocations Dictionary online — ещё один онлайн-словарь сочетаемости.
Многоязычные тематические справочники:
• Avibase — названия птиц на разных языках.
•
DiBird.com — названия птиц на разных языках.
Употребление английской лексики:
• Fraze.it — поиск примеров употребления слов в предложениях (возможен поиск не только на английском). Можно ограничить поиск: 1) вопросительными предложениями, 2) отрицательными, 3) начинающимися с этого слова, 4) заканчивающимися этим словом, 5) предложениями с искомым словом, но без второго, заданного со знаком «-«, 6) предложениями в различных видовременных формах (Present Perfect, Past Continuous Passive и т. д.), 7) высказываниями известных людей,  предложениями из разных отраслей науки (например, философии).
предложениями из разных отраслей науки (например, философии).
•
Ludwig.guru — контекстуальный поиск примеров употребления слов, фраз в предложениях; перевод; определения и проч.
•
Corpus of Contemporary American English (COCA) — поиск по корпусу американского варианта английского языка.
•
Linguee —
онлайн-сервис, сочетающий в себе словарь, постоянно редактируемый лингвистами, и систему поиска переводов слов и выражений на базе 100 миллионов переведенных текстов. Результаты поиска Linguee разделены на две части. Слева наглядно представлены значения слова из словаря. Эти значения выверены нашими лингвистами. Справа расположены примеры перевода для запрашиваемого значения. Эти примеры взяты из других источников. Они позволяют узнать, как то или иное выражение переводится в контексте.
•
Reverso.net —
поиск переводов в контексте для миллионов слов и выражений: введите слово или несколько слов в поле поиска перевода и мгновенно получите различные примеры употребления, взятые из реальных жизненных ситуаций (диалоги из фильмов, новостные статьи и т. д.) и официальных документов.
•
Rhymezone.com — если Вы хотите перевести стихотворение на английский язык, но не можете подобрать рифму, этот сайт поможет Вам. Слова-рифмы группируются по количеству слогов.
• Тематические глоссарии на Study-Englis.info — тематические глоссарии могут быть полезны как при изучении определенной лексики, так и при переводе текстов специальной тематики.
Примеры произношения:
• Youglish.com — поиск произношения слов, имен собственных.
Специализированные ресурсы для переводчиков:
• Proz.com — переводческие глоссарии (по данной ссылке откроется англо-русский глоссарий по психологии). Вообще на сайте огромное количество глоссариев по различным темам, можно выбрать разные языковые пары. Полезно для профессиональных переводчиков.
•
Translations.Web-3.ru — портал переводчиков — ресурс, где можно найти необходимую литературу по переводам, ознакомиться с публикациями, посвященными теории и практике перевода.
•
The Journal of Specialised Translation — a collection of peer-reviewed articles, streamed interviews, and reviews.
| #19 — JANUARY 2013
| #18 — JULY 2012
Интерпретация текстов песен:
• Rock Genius — сайт с аннотациями к текстам песен в разных стилях. Очень сложно переводить песни: сленг, реалии, хорошо известные представителям чужой культуры, но малознакомые иностранцам. Сайт приглашает всех желающих зарегистрироваться и оставлять свои комментарии к текстам песен с мыслями о том, что имел в виду автор в каждой конкретной фразе, о чем, по мнению автора комментария, на самом деле эта песня. Полезно для перевода песен и для знакомства с зарубежными реалиями.
Научная литература по теории перевода:
•
Комиссаров В. Н. «Теория перевода (лингвистические аспекты)» — учебник «Теория перевода (лингвистические аспекты)» для студентов переводческих факультетов и факультетов иностранных языков. Теория перевода изучается в тесной связи с учебными курсами по языкознанию, стилистике, лексикологии и грамматике. Курс «Теория перевода» имеет целью ознакомить обучаемых с основными положениями лингвистической теории перевода. Знание теории перевода создает основу для рассмотрения частных переводческих проблем, связанных с отдельными видами перевода и определенными комбинациями языков, и для занятий практикой перевода.
Художественная литература:
•
Библиотека параллельного чтения «WebLitera» — десятки полных текстов классики мировой художественной литературы на английском языке, большинство книг имеют параллельный русский текст. Выбираете книгу, затем в строке «Читать параллельно с» выбираете «Русский epub». В левой части экрана будет текст на английском, справа — на русском языке (можно читать на английском, а когда попадется незнакомое слово — заглянуть в русский вариант). Также полезно для анализа переводов: множество примеров использования переводческих трансформаций. Для грамматистов — обширный материал (в электронном виде), иллюстрирующий использование различных конструкций.
Публицистика:
•
ИноСМИ — качественные переводы статей из зарубежных СМИ со ссылками на оригиналы. Самая свежая информация + возможность анализа параллельных текстов.
Многоязычные сайты:
•
МИД РФ — официальный сайт Министерства иностранных дел Российской Федерации.
(Англоязычная версия сайта >>>)
•
Президент России — официальный сайт Президента Российской Федерации.
(Англоязычная версия сайта >>>)
Редактирование:
•
Грамота.ру — справочно-информационный портал, посвященный правилам и нормам русского языка.
•
Главред — сервис для всесторонней проверки текста (грамотность, ошибки, читабельность, повторы, слова-паразиты и т. п.)
Корпус русского языка:
•
Национальный корпус русского языка —
на сайте помещен корпус современного русского языка общим объемом более 600 млн слов. Корпус русского языка — это информационно-справочная система, основанная на собрании русских текстов в электронной форме.
(Поиск в корпусе русского языка >>>)
•
Kartaslov.ru —
карта слов и выражений русского языка (поиск значений, ассоциаций, синонимов, определений, примеров употребления)
•
reright.ru —
словарь ассоциаций
•
wordassociations.net —
сеть словесных ассоциаций
Подбор синонимов:
•
TopWriter — онлайн-синонимайзер и рерайтер предлагает варианты замены фрагментов текста (синонимайзер) и перефразирование предложений (на основе синтаксического анализа), при этом пользователь может согласиться с предложенным вариантом замены фрагмента, выбрать другой вариант или отказаться от замены. Синонимайзер работает на русском и английском языке.
•
Online-Sinonim.ru — бесплатный онлайн-синонимайзер.
•
synonymonline.ru —
бесплатный онлайн-словарь русских синонимов, насчитывает более 220 тысяч синонимических рядов
•
Сервис поиска синонимов Text.ru —
база синонимов
•
synonyms.su — словарь синонимов русского языка — онлайн подбор
Конвертация форматов:
•
Convertpdftoword.net — бесплатный сервис, позволяющий конвертировать документы из формата «PDF» в документ Microsoft Word («.DOC») с сохранением рисунков, положения на странице и т. д., или в чисто текстовый документ («.TXT»).
•
pdf2go.com — инструменты для работы с PDF-файлами.
•
www.zamzar.com — На сайте «www.zamzar.com» можно конвертировать файлы, имеющиеся на компьютере, во множество других форматов (2 в день — бесплатно), включая возможность конвертации текстовых файлов в звуковые файлы в формате «mp3»: требуется выбрать файл на компьютере, указать, в какой формат его конвертировать, например, в «mp3» и указать адрес электронной почты. Через некоторое время преобразованный файл можно скачать по присылаемой ссылке.
Ресурсы, использующие технологию translation memory (TM):
•
SmartCat — система для непрерывной работы над переводческими задачами/
•
MemSource — облачное окружение для автоматизированного перевода, разработанное чешской компанией MemSource.
Ресурсы для подсчета частотности употребления слов и фраз в тексте:
•
WriteWords — посчет частотности употребления фраз или слов в тексте
•
TextFixer — посчет частотности употребления слов с подразделением их на ключевые и общеупотребительные
•
Online-Utility.org — анализ частотности упторебления слов, сочетаний (с подразделением на количество слов в сочетании) (анализ занимает некоторое время)
Введите текст для перевода
или переведите файлы PDF, Word и PowerPoint с помощью сервиса перевода документов