Можно проще:
#!/usr/bin/env python3
import re
text = '.... пример, строки'
first_word = re.findall(r'w+', text)[0]
это подходит для коротких текстов. Для больших текстов, чтобы искать только первое слово вместо всех сразу:
first_word = next(m.group() for m in re.finditer(r'w+', text))
Без регулярных выражений, itertools алгоритмов, итд это можно выразить как:
def first_word(text):
it = iter(text)
for char in it:
if char.isalnum(): # found first char
word = [char]
for char in it: # start with second char
if char.isalnum():
word.append(char)
else:
break
return ''.join(word)
raise ValueError("no words")
Пример:
>>> first_word('.... пример, строки')
'пример'
Код пользуется тем что итераторы в Питоне являются однопроходными, поэтому второй цикл for char in it начинает со второго символа в слове (где предыдущий цикл остановился). Просто for char in text начинает каждый раз с начала с первого символа, если text это последовательность (строка в данном случае).
text is :
WYATT - Ranked # 855 with 0.006 %
XAVIER - Ranked # 587 with 0.013 %
YONG - Ranked # 921 with 0.006 %
YOUNG - Ranked # 807 with 0.007 %
I want to get only
WYATT
XAVIER
YONG
YOUNG
I tried :
(.*)?[ ]
But it gives me the :
WYATT - Ranked
![]()
Nick
4,2942 gold badges23 silver badges38 bronze badges
asked Dec 6, 2012 at 18:38
![]()
Regex is unnecessary for this. Just use some_string.split(' ', 1)[0] or some_string.partition(' ')[0].
answered Dec 6, 2012 at 18:41
![]()
Silas RaySilas Ray
25.6k5 gold badges48 silver badges63 bronze badges
5
If you want to feel especially sly, you can write it as this:
(firstWord, rest) = yourLine.split(maxsplit=1)
This is supposed to bring the best from both worlds:
- optimality tweak with
maxsplitwhile splitting with any whitespace - improved reliability and readability, as argued by the author of the technique.
I kind of fell in love with this solution and it’s general unpacking capability, so I had to share it.
![]()
Neuron
5,0035 gold badges38 silver badges57 bronze badges
answered Oct 18, 2016 at 12:58
![]()
HugeHuge
6617 silver badges14 bronze badges
4
You shoud do something like :
print line.split()[0]
answered Jan 12, 2016 at 13:52
![]()
NadoNado
2774 silver badges7 bronze badges
3
Use this regex
^w+
w+ matches 1 to many characters.
w is similar to [a-zA-Z0-9_]
^ depicts the start of a string
About Your Regex
Your regex (.*)?[ ] should be ^(.*?)[ ] or ^(.*?)(?=[ ]) if you don’t want the space
answered Dec 6, 2012 at 18:39
![]()
AnirudhaAnirudha
32.3k7 gold badges67 silver badges88 bronze badges
1
Don’t need a regex.
string[: string.find(' ')]
answered Dec 6, 2012 at 18:47
![]()
4
You don’t need regex to split a string on whitespace:
In [1]: text = '''WYATT - Ranked # 855 with 0.006 %
...: XAVIER - Ranked # 587 with 0.013 %
...: YONG - Ranked # 921 with 0.006 %
...: YOUNG - Ranked # 807 with 0.007 %'''
In [2]: print 'n'.join(line.split()[0] for line in text.split('n'))
WYATT
XAVIER
YONG
YOUNG
answered Dec 6, 2012 at 18:42
![]()
Lev LevitskyLev Levitsky
63k20 gold badges146 silver badges175 bronze badges
0

В этой статье поговорим про строки в Python, особенности поиска, а также о том, как искать подстроку или символ в строке.

Но сначала давайте вспомним основные методы для обработки строк в Python:
• isalpha(str): если строка в Python включает в себя лишь алфавитные символы, возвращается True;
• islower(str): True возвращается, если строка включает лишь символы в нижнем регистре;
• isupper(str): True, если символы строки в Python находятся в верхнем регистре;
• startswith(str): True, когда строка начинается с подстроки str;
• isdigit(str): True, когда каждый символ строки — цифра;
• endswith(str): True, когда строка в Python заканчивается на подстроку str;
• upper(): строка переводится в верхний регистр;
• lower(): строка переводится в нижний регистр;
• title(): для перевода начальных символов всех слов в строке в верхний регистр;
• capitalize(): для перевода первой буквы самого первого слова строки в верхний регистр;
• lstrip(): из строки в Python удаляются начальные пробелы;
• rstrip(): из строки в Python удаляются конечные пробелы;
• strip(): из строки в Python удаляются и начальные, и конечные пробелы;
• rjust(width): когда длина строки меньше, чем параметр width, слева добавляются пробелы, строка выравнивается по правому краю;
• ljust(width): когда длина строки в Python меньше, чем параметр width, справа от неё добавляются пробелы для дополнения значения width, при этом происходит выравнивание строки по левому краю;
• find(str[, start [, end]): происходит возвращение индекса подстроки в строку в Python. В том случае, если подстрока не найдена, выполняется возвращение числа -1;
• center(width): когда длина строки в Python меньше, чем параметр width, слева и справа добавляются пробелы (равномерно) для дополнения значения width, причём происходит выравнивание строки по центру;
• split([delimeter[, num]]): строку в Python разбиваем на подстроки в зависимости от разделителя;
• replace(old, new[, num]): в строке одна подстрока меняется на другую;
• join(strs): строки объединяются в одну строку, между ними вставляется определённый разделитель.
Обрабатываем строку в Python
Представим, что ожидается ввод числа с клавиатуры. Перед преобразованием введенной нами строки в число можно легко проверить, введено ли действительно число. Если это так, выполнится операция преобразования. Для обработки строки используем такой метод в Python, как isnumeric():
string = input("Введите какое-нибудь число: ") if string.isnumeric(): number = int(string) print(number)Следующий пример позволяет удалять пробелы в конце и начале строки:
string = " привет мир! " string = string.strip() print(string) # привет мир!Так можно дополнить строку пробелами и выполнить выравнивание:
print("iPhone 7:", "52000".rjust(10)) print("Huawei P10:", "36000".rjust(10))В консоли Python будет выведено следующее:
iPhone 7: 52000 Huawei P10: 36000Поиск подстроки в строке
Чтобы в Python выполнить поиск в строке, используют метод find(). Он имеет три формы и возвращает индекс 1-го вхождения подстроки в строку:
• find(str): поиск подстроки str производится с начала строки и до её конца;
• find(str, start): с помощью параметра start задаётся начальный индекс, и именно с него и выполняется поиск;
• find(str, start, end): посредством параметра end задаётся конечный индекс, поиск выполняется до него.
Когда подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!" index = welcome.find("wor") print(index) # 6 # ищем с десятого индекса index = welcome.find("wor",10) print(index) # 21 # ищем с 10-го по 15-й индекс index = welcome.find("wor",10,15) print(index) # -1Замена в строке
Чтобы в Python заменить в строке одну подстроку на другую, применяют метод replace():
• replace(old, new): подстрока old заменяется на new;
• replace(old, new, num): параметр num показывает, сколько вхождений подстроки old требуется заменить на new.Пример замены в строке в Python:
phone = "+1-234-567-89-10" # дефисы меняются на пробелы edited_phone = phone.replace("-", " ") print(edited_phone) # +1 234 567 89 10 # дефисы удаляются edited_phone = phone.replace("-", "") print(edited_phone) # +12345678910 # меняется только первый дефис edited_phone = phone.replace("-", "", 1) print(edited_phone) # +1234-567-89-10Разделение на подстроки в Python
Для разделения в Python используется метод split(). В зависимости от разделителя он разбивает строку на перечень подстрок. В роли разделителя в данном случае может быть любой символ либо последовательность символов. Этот метод имеет следующие формы:
• split(): в роли разделителя применяется такой символ, как пробел;
• split(delimeter): в роли разделителя применяется delimeter;
• split(delimeter, num): параметром num указывается, какое количество вхождений delimeter применяется для разделения. При этом оставшаяся часть строки добавляется в перечень без разделения на подстроки.Соединение строк в Python
Рассматривая простейшие операции со строками, мы увидели, как объединяются строки через операцию сложения. Однако есть и другая возможность для соединения строк — метод join():, объединяющий списки строк. В качестве разделителя используется текущая строка, у которой вызывается этот метод:
words = ["Let", "me", "speak", "from", "my", "heart", "in", "English"] # символ разделителя - пробел sentence = " ".join(words) print(sentence) # Let me speak from my heart in English # символ разделителя - вертикальная черта sentence = " | ".join(words) print(sentence) # Let | me | speak | from | my | heart | in | EnglishА если вместо списка в метод join передать простую строку, разделитель будет вставляться уже между символами:
word = "hello" joined_word = "|".join(word) print(joined_word) # h|e|l|l|o


Напишите функцию first_word, которая в переданной строке найдет ее первое слово.
При решении задачи обратите внимание на следующие моменты:
В строке могут встречаются точки и запятые
Строка может начинаться с буквы или, к примеру, с пробела или точки
В слове может быть апостроф и он является частью слова
Весь текст может быть представлен только одним словом и все
Входные параметры: Строка.
Выходные параметры: Строка.
Пример:
first_word(«Hello world») == «Hello»
first_word(«greetings, friends») == «greetings»
first_word(«don’t touch it») == «don’t»
first_word(«… and so on …») == «and»
first_word(«hi») == «hi»
first_word(«Hello.World») == «Hello»
Рассмотрим регулярные выражения в Python, начиная синтаксисом и заканчивая примерами использования.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
- Основы регулярных выражений
- Регулярные выражения в Python
- Задачи
Основы регулярных выражений
Регулярками в Python называются шаблоны, которые используются для поиска соответствующего фрагмента текста и сопоставления символов.
Грубо говоря, у нас есть input-поле, в которое должен вводиться email-адрес. Но пока мы не зададим проверку валидности введённого email-адреса, в этой строке может оказаться совершенно любой набор символов, а нам это не нужно.
Чтобы выявить ошибку при вводе некорректного адреса электронной почты, можно использовать следующее регулярное выражение:
r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+(?:.[a-zA-Z0-9-]+)+$'По сути, наш шаблон — это набор символов, который проверяет строку на соответствие заданному правилу. Давайте разберёмся, как это работает.
Синтаксис RegEx
Синтаксис у регулярок необычный. Символы могут быть как буквами или цифрами, так и метасимволами, которые задают шаблон строки:
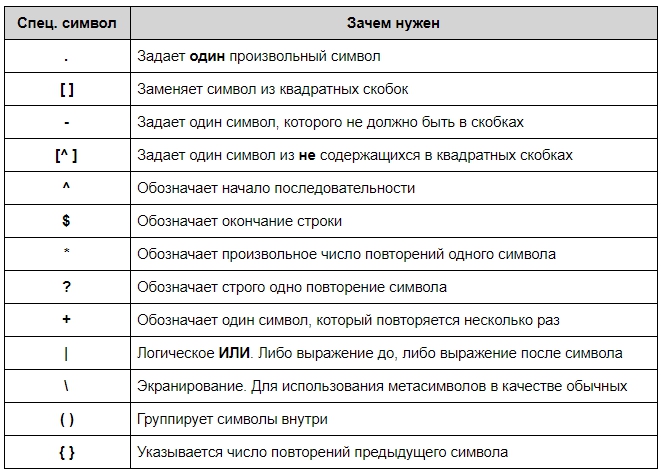
Также есть дополнительные конструкции, которые позволяют сокращать регулярные выражения:
- d — соответствует любой одной цифре и заменяет собой выражение [0-9];
- D — исключает все цифры и заменяет [^0-9];
- w — заменяет любую цифру, букву, а также знак нижнего подчёркивания;
- W — любой символ кроме латиницы, цифр или нижнего подчёркивания;
- s — соответствует любому пробельному символу;
- S — описывает любой непробельный символ.
Для чего используются регулярные выражения
- для определения нужного формата, например телефонного номера или email-адреса;
- для разбивки строк на подстроки;
- для поиска, замены и извлечения символов;
- для быстрого выполнения нетривиальных операций.
Синтаксис таких выражений в основном стандартизирован, так что вам следует понять их лишь раз, чтобы использовать в любом языке программирования.
Примечание Не стоит забывать, что регулярные выражения не всегда оптимальны, и для простых операций часто достаточно встроенных в Python функций.
Хотите узнать больше? Обратите внимание на статью о регулярках для новичков.
В Python для работы с регулярками есть модуль re. Его нужно просто импортировать:
import reА вот наиболее популярные методы, которые предоставляет модуль:
re.match()re.search()re.findall()re.split()re.sub()re.compile()
Рассмотрим каждый из них подробнее.
re.match(pattern, string)
Этот метод ищет по заданному шаблону в начале строки. Например, если мы вызовем метод match() на строке «AV Analytics AV» с шаблоном «AV», то он завершится успешно. Но если мы будем искать «Analytics», то результат будет отрицательный:
import re
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result
Результат:
<_sre.SRE_Match object at 0x0000000009BE4370>
Искомая подстрока найдена. Чтобы вывести её содержимое, применим метод group() (мы используем «r» перед строкой шаблона, чтобы показать, что это «сырая» строка в Python):
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
AVТеперь попробуем найти «Analytics» в данной строке. Поскольку строка начинается на «AV», метод вернет None:
result = re.match(r'Analytics', 'AV Analytics Vidhya AV')
print result
Результат:
NoneТакже есть методы start() и end() для того, чтобы узнать начальную и конечную позицию найденной строки.
result = re.match(r'AV', 'AV Analytics Vidhya AV')
print result.start()
print result.end()
Результат:
0
2Эти методы иногда очень полезны для работы со строками.
re.search(pattern, string)
Метод похож на match(), но ищет не только в начале строки. В отличие от предыдущего, search() вернёт объект, если мы попытаемся найти «Analytics»:
result = re.search(r'Analytics', 'AV Analytics Vidhya AV')
print result.group(0)
Результат:
AnalyticsМетод search() ищет по всей строке, но возвращает только первое найденное совпадение.
re.findall(pattern, string)
Возвращает список всех найденных совпадений. У метода findall() нет ограничений на поиск в начале или конце строки. Если мы будем искать «AV» в нашей строке, он вернет все вхождения «AV». Для поиска рекомендуется использовать именно findall(), так как он может работать и как re.search(), и как re.match().
result = re.findall(r'AV', 'AV Analytics Vidhya AV')
print result
Результат:
['AV', 'AV']re.split(pattern, string, [maxsplit=0])
Этот метод разделяет строку по заданному шаблону.
result = re.split(r'y', 'Analytics')
print result
Результат:
['Anal', 'tics']В примере мы разделили слово «Analytics» по букве «y». Метод split() принимает также аргумент maxsplit со значением по умолчанию, равным 0. В данном случае он разделит строку столько раз, сколько возможно, но если указать этот аргумент, то разделение будет произведено не более указанного количества раз. Давайте посмотрим на примеры Python RegEx:
result = re.split(r'i', 'Analytics Vidhya')
print result
Результат:
['Analyt', 'cs V', 'dhya'] # все возможные участки.result = re.split(r'i', 'Analytics Vidhya',maxsplit=1)
print result
Результат:
['Analyt', 'cs Vidhya']Мы установили параметр maxsplit равным 1, и в результате строка была разделена на две части вместо трех.
re.sub(pattern, repl, string)
Ищет шаблон в строке и заменяет его на указанную подстроку. Если шаблон не найден, строка остается неизменной.
result = re.sub(r'India', 'the World', 'AV is largest Analytics community of India')
print result
Результат:
'AV is largest Analytics community of the World're.compile(pattern, repl, string)
Мы можем собрать регулярное выражение в отдельный объект, который может быть использован для поиска. Это также избавляет от переписывания одного и того же выражения.
pattern = re.compile('AV')
result = pattern.findall('AV Analytics Vidhya AV')
print result
result2 = pattern.findall('AV is largest analytics community of India')
print result2
Результат:
['AV', 'AV']
['AV']До сих пор мы рассматривали поиск определенной последовательности символов. Но что, если у нас нет определенного шаблона, и нам надо вернуть набор символов из строки, отвечающий определенным правилам? Такая задача часто стоит при извлечении информации из строк. Это можно сделать, написав выражение с использованием специальных символов. Вот наиболее часто используемые из них:
| Оператор | Описание |
|---|---|
| . | Один любой символ, кроме новой строки n. |
| ? | 0 или 1 вхождение шаблона слева |
| + | 1 и более вхождений шаблона слева |
| * | 0 и более вхождений шаблона слева |
| w | Любая цифра или буква (W — все, кроме буквы или цифры) |
| d | Любая цифра [0-9] (D — все, кроме цифры) |
| s | Любой пробельный символ (S — любой непробельный символ) |
| b | Граница слова |
| [..] | Один из символов в скобках ([^..] — любой символ, кроме тех, что в скобках) |
| Экранирование специальных символов (. означает точку или + — знак «плюс») | |
| ^ и $ | Начало и конец строки соответственно |
| {n,m} | От n до m вхождений ({,m} — от 0 до m) |
| a|b | Соответствует a или b |
| () | Группирует выражение и возвращает найденный текст |
| t, n, r | Символ табуляции, новой строки и возврата каретки соответственно |
Больше информации по специальным символам можно найти в документации для регулярных выражений в Python 3.
Перейдём к практическому применению Python регулярных выражений и рассмотрим примеры.
Задачи
Вернуть первое слово из строки
Сначала попробуем вытащить каждый символ (используя .)
result = re.findall(r'.', 'AV is largest Analytics community of India')
print result
Результат:
['A', 'V', ' ', 'i', 's', ' ', 'l', 'a', 'r', 'g', 'e', 's', 't', ' ', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', ' ', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', ' ', 'o', 'f', ' ', 'I', 'n', 'd', 'i', 'a']Для того, чтобы в конечный результат не попал пробел, используем вместо . w.
result = re.findall(r'w', 'AV is largest Analytics community of India')
print result
Результат:
['A', 'V', 'i', 's', 'l', 'a', 'r', 'g', 'e', 's', 't', 'A', 'n', 'a', 'l', 'y', 't', 'i', 'c', 's', 'c', 'o', 'm', 'm', 'u', 'n', 'i', 't', 'y', 'o', 'f', 'I', 'n', 'd', 'i', 'a']Теперь попробуем достать каждое слово (используя * или +)
result = re.findall(r'w*', 'AV is largest Analytics community of India')
print result
Результат:
['AV', '', 'is', '', 'largest', '', 'Analytics', '', 'community', '', 'of', '', 'India', '']И снова в результат попали пробелы, так как * означает «ноль или более символов». Для того, чтобы их убрать, используем +:
result = re.findall(r'w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India']Теперь вытащим первое слово, используя ^:
result = re.findall(r'^w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV']Если мы используем $ вместо ^, то мы получим последнее слово, а не первое:
result = re.findall(r'w+$', 'AV is largest Analytics community of India')
print result
Результат:
[‘India’]Вернуть первые два символа каждого слова
Вариант 1: используя w, вытащить два последовательных символа, кроме пробельных, из каждого слова:
result = re.findall(r'ww', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'la', 'rg', 'es', 'An', 'al', 'yt', 'ic', 'co', 'mm', 'un', 'it', 'of', 'In', 'di']Вариант 2: вытащить два последовательных символа, используя символ границы слова (b):
result = re.findall(r'bw.', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'la', 'An', 'co', 'of', 'In']Вернуть домены из списка email-адресов
Сначала вернём все символы после «@»:
result = re.findall(r'@w+', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz')
print result
Результат:
['@gmail', '@test', '@analyticsvidhya', '@rest']Как видим, части «.com», «.in» и т. д. не попали в результат. Изменим наш код:
result = re.findall(r'@w+.w+', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz')
print result
Результат:
['@gmail.com', '@test.in', '@analyticsvidhya.com', '@rest.biz']Второй вариант — вытащить только домен верхнего уровня, используя группировку — ( ):
result = re.findall(r'@w+.(w+)', 'abc.test@gmail.com, xyz@test.in, test.first@analyticsvidhya.com, first.test@rest.biz')
print result
Результат:
['com', 'in', 'com', 'biz']Извлечь дату из строки
Используем d для извлечения цифр.
result = re.findall(r'd{2}-d{2}-d{4}', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009')
print result
Результат:
['12-05-2007', '11-11-2011', '12-01-2009']Для извлечения только года нам опять помогут скобки:
result = re.findall(r'd{2}-d{2}-(d{4})', 'Amit 34-3456 12-05-2007, XYZ 56-4532 11-11-2011, ABC 67-8945 12-01-2009')
print result
Результат:
['2007', '2011', '2009']Извлечь слова, начинающиеся на гласную
Для начала вернем все слова:
result = re.findall(r'w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'largest', 'Analytics', 'community', 'of', 'India']А теперь — только те, которые начинаются на определенные буквы (используя []):
result = re.findall(r'[aeiouAEIOU]w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'argest', 'Analytics', 'ommunity', 'of', 'India']Выше мы видим обрезанные слова «argest» и «ommunity». Для того, чтобы убрать их, используем b для обозначения границы слова:
result = re.findall(r'b[aeiouAEIOU]w+', 'AV is largest Analytics community of India')
print result
Результат:
['AV', 'is', 'Analytics', 'of', 'India']Также мы можем использовать ^ внутри квадратных скобок для инвертирования группы:
result = re.findall(r'b[^aeiouAEIOU]w+', 'AV is largest Analytics community of India')
print result
Результат:
[' is', ' largest', ' Analytics', ' community', ' of', ' India']В результат попали слова, «начинающиеся» с пробела. Уберем их, включив пробел в диапазон в квадратных скобках:
result = re.findall(r'b[^aeiouAEIOU ]w+', 'AV is largest Analytics community of India')
print result
Результат:
['largest', 'community']Проверить формат телефонного номера
Номер должен быть длиной 10 знаков и начинаться с 8 или 9. Есть список телефонных номеров, и нужно проверить их, используя регулярки в Python:
li = ['9999999999', '999999-999', '99999x9999']
for val in li:
if re.match(r'[8-9]{1}[0-9]{9}', val) and len(val) == 10:
print 'yes'
else:
print 'no'
Результат:
yes
no
noРазбить строку по нескольким разделителям
Возможное решение:
line = 'asdf fjdk;afed,fjek,asdf,foo' # String has multiple delimiters (";",","," ").
result = re.split(r'[;,s]', line)
print result
Результат:
['asdf', 'fjdk', 'afed', 'fjek', 'asdf', 'foo']Также мы можем использовать метод re.sub() для замены всех разделителей пробелами:
line = 'asdf fjdk;afed,fjek,asdf,foo'
result = re.sub(r'[;,s]',' ', line)
print result
Результат:
asdf fjdk afed fjek asdf fooИзвлечь информацию из html-файла
Допустим, нужно извлечь информацию из html-файла, заключенную между <td> и </td>, кроме первого столбца с номером. Также будем считать, что html-код содержится в строке.
Пример содержимого html-файла:
1NoahEmma2LiamOlivia3MasonSophia4JacobIsabella5WilliamAva6EthanMia7MichaelEmilyС помощью регулярных выражений в Python это можно решить так (если поместить содержимое файла в переменную test_str):
result = re.findall(r'd([A-Z][A-Za-z]+)([A-Z][A-Za-z]+)', test_str)
print result
Результат:
[('Noah', 'Emma'), ('Liam', 'Olivia'), ('Mason', 'Sophia'), ('Jacob', 'Isabella'), ('William', 'Ava'), ('Ethan', 'Mia'), ('Michael', 'Emily')]Адаптированный перевод «Beginners Tutorial for Regular Expressions in Python»