На чтение 7 мин. Просмотров 31.7k.
Содержание
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
Получить первое не пустое значение в списке
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Получить первое текстовое значение в списке
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Получить первое текстовое значение с ГПР
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; С5: Е5; 1; 0 )
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Получить позицию последнего совпадения
{ = МАКС( ЕСЛИ ( Величины = знач ; СТРОКА(величина) — СТРОКА(ИНДЕКС( Величины; 1 ; 1 )) + 1 )) }
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

В примере формула в G6:
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Получить последнее совпадение содержимого ячейки
= ПРОСМОТР( 2 ; 1 / ПОИСК ( вещи ; А1 ); вещи )
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

В примере формула в С5:
=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
Получить n-е совпадение
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }

Чтобы получить n-ое совпадение, используя ИНДЕКС и ПОИСКПОЗ, вы можете использовать формулу массива с функциями ЕСЛИ и НАИМЕНЬШИЙ, чтобы выяснить номер строки совпадения.
Получить n-ое совпадение с ВПР
= ВПР( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных. Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
Если ячейка содержит одну из многих вещей
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Поиск первой ошибки
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Поиск следующего наибольшего значения
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС(C5:C9;ПОИСКПОЗ(F4;B5:B9)+1)
Несколько совпадений в списке, разделенных запятой
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Частичное совпадение чисел с шаблоном
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Решение
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой вариант
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Частичное совпадение с ВПР
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Положение первого частичного совпадения
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

В примере формула в Е7:
=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
НАЙТИ, НАЙТИБ (функции НАЙТИ, НАЙТИБ)
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование функций НАЙТИ и НАЙТИБ в Microsoft Excel.
Описание
Функции НАЙТИ и НАЙТИБ находят вхождение одной текстовой строки в другую и возвращают начальную позицию искомой строки относительно первого знака второй строки.
Важно:
-
Эти функции могут быть доступны не на всех языках.
-
Функция НАЙТИ предназначена для языков с однобайтовой кодировкой, а функция НАЙТИБ — для языков с двухбайтовой кодировкой. Заданный на компьютере язык по умолчанию влияет на возвращаемое значение указанным ниже образом.
-
Функция НАЙТИ при подсчете всегда рассматривает каждый знак, как однобайтовый, так и двухбайтовый, как один знак, независимо от выбранного по умолчанию языка.
-
Функция НАЙТИБ при подсчете рассматривает каждый двухбайтовый знак как два знака, если включена поддержка языка с БДЦС и такой язык установлен по умолчанию. В противном случае функция НАЙТИБ рассматривает каждый знак как один знак.
К языкам, поддерживающим БДЦС, относятся японский, китайский (упрощенное письмо), китайский (традиционное письмо) и корейский.
Синтаксис
НАЙТИ(искомый_текст;просматриваемый_текст;[нач_позиция])
НАЙТИБ(искомый_текст;просматриваемый_текст;[нач_позиция])
Аргументы функций НАЙТИ и НАЙТИБ описаны ниже.
-
Искомый_текст — обязательный аргумент. Текст, который необходимо найти.
-
Просматриваемый_текст — обязательный аргумент. Текст, в котором нужно найти искомый текст.
-
Начальная_позиция — необязательный аргумент. Знак, с которого нужно начать поиск. Первый знак в тексте «просматриваемый_текст» имеет номер 1. Если номер опущен, он полагается равным 1.
Замечания
-
Функции НАЙТИ и НАЙТИБ работают с учетом регистра и не позволяют использовать подстановочные знаки. Если необходимо выполнить поиск без учета регистра или использовать подстановочные знаки, воспользуйтесь функцией ПОИСК или ПОИСКБ.
-
Если в качестве аргумента «искомый_текст» задана пустая строка («»), функция НАЙТИ выводит значение, равное первому знаку в строке поиска (знак с номером, соответствующим аргументу «нач_позиция» или 1).
-
Искомый_текст не может содержать подстановочные знаки.
-
Если find_text не отображаются в within_text, find и FINDB возвращают #VALUE! значение ошибки #ЗНАЧ!.
-
Если start_num не больше нуля, то найти и найтиБ возвращает значение #VALUE! значение ошибки #ЗНАЧ!.
-
Если start_num больше, чем длина within_text, то поиск и НАЙТИБ возвращают #VALUE! значение ошибки #ЗНАЧ!.
-
Аргумент «нач_позиция» можно использовать, чтобы пропустить нужное количество знаков. Предположим, например, что для поиска строки «МДС0093.МесячныеПродажи» используется функция НАЙТИ. Чтобы найти номер первого вхождения «М» в описательную часть текстовой строки, задайте значение аргумента «нач_позиция» равным 8, чтобы поиск в той части текста, которая является серийным номером, не производился. Функция НАЙТИ начинает со знака 8, находит искомый_текст в следующем знаке и возвращает число 9. Функция НАЙТИ всегда возвращает номер знака, считая от левого края текста «просматриваемый_текст», а не от значения аргумента «нач_позиция».
Примеры
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
Владимир Егоров |
||
|
Формула |
Описание |
Результат |
|
=НАЙТИ(«В»;A2) |
Позиция первой «В» в ячейке A2 |
1 |
|
=НАЙТИ(«в»;A2) |
Позиция первой «в» в ячейке A2 |
6 |
|
=НАЙТИ(«и»;A2;3) |
Позиция первой «и» в строке А2, начиная с третьего знака |
8 |
Пример 2
|
Данные |
||
|
Керамический изолятор №124-ТД45-87 |
||
|
Медная пружина №12-671-6772 |
||
|
Переменный резистор №116010 |
||
|
Формула |
Описание (результат) |
Результат |
|
=ПСТР(A2;1;НАЙТИ(» №»;A2;1)-1) |
Выделяет текст от позиции 1 до знака «№» в строке («Керамический изолятор») |
Керамический изолятор |
|
=ПСТР(A3;1;НАЙТИ(» №»;A3;1)-1) |
Выделяет текст от позиции 1 до знака «№» в ячейке А3 («Медная пружина») |
Медная пружина |
|
=ПСТР(A4;1;НАЙТИ(» №»;A4;1)-1) |
Выделяет текст от позиции 1 до знака «№» в ячейке А4 («Переменный резистор») |
Переменный резистор |
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
lockser
Гость
#9
06.02.2011 23:40:53
По всей строке у меня не получиться, т.к. в первых десяти столбцах у меня другие данные.
Вот, правда, придумал хитрость. Первый столбец массива скрыл, данные ввожу начиная со второго столбца. Теперь вставка столбца происходит внутри массива. При этом задняя граница массива расширяется, что для меня очень хорошо.
Спасибо за помощь. 
Если будут еще идеи, пишите. Буду сюда часто заглядывать.
Это глава из книги Билла Джелена Гуру Excel расширяют горизонты: делайте невозможное с Microsoft Excel.
Задача: требуется формула, которая позволяла найти первое непустое значение в строке, т.е., возвращала бы номер первой непустой ячейки в строке. Предположим, что данные представлены в столбцах С:K (рис. 1).
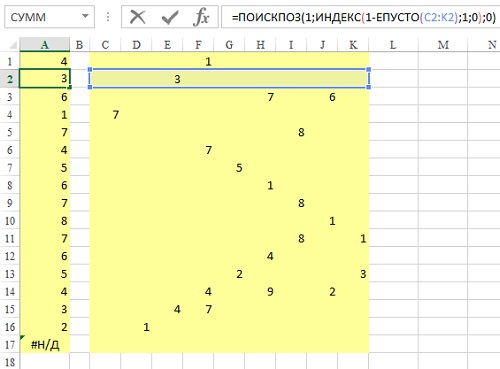
Рис. 1. Формула находит первую непустую ячейку в каждой строке и возвращает ее номер в массиве
Скачать заметку в формате Word или pdf, примеры в формате Excel
Решение: формула в А2: =ПОИСКПОЗ(1;ИНДЕКС(1-ЕПУСТО(C2:K2);1;0);0). Хотя эта формула имеет дело с массивом ячеек, она в конечном счете возвращает одно значение, так что использовать при вводе нажатие Ctrl+Shift+Enter не требуется (о формулах массива см. Майкл Гирвин. Ctrl+Shift+Enter. Освоение формул массива в Excel).
Рассмотрим работу формулы подробнее. Функция ЕПУСТО возвращает ИСТИНА, если ячейка является пустой, и ЛОЖЬ, если ячейка – не пустая. Посмотрите на строку данных в С2:К2. ЕПУСТО(С2:К2) возвратит массив: {ИСТИНА;ИСТИНА;ЛОЖЬ;ИСТИНА;ИСТИНА;ИСТИНА;ИСТИНА;ИСТИНА;ИСТИНА}.
Обратите внимание, что далее этот массив вычитается из 1. При попытке использовать значения ИСТИНА и ЛОЖЬ в математической формуле, значение ИСТИНА интерпретируется как 1, а значение ЛОЖЬ – как 0. Задавая 1-ЕПУСТО(С2:К2), вы преобразуете массив логических значений ИСТИНА/ЛОЖЬ в числовую последовательность нулей и единиц: {0;0;1;0;0;0;0;0;0}.
Итак, фрагмент формулы 1-ЕПУСТО(С2:К2) возвращает массив {0;0;1;0;0;0;0;0;0}. Это немного странно, так как от такого фрагмента Excel ожидает, что вернется одно значение. Странно, но не смертельно. Функция ИНДЕКС также обычно возвращает одно значение. Но вот, что написано в Справке Excel: Если указать в качестве аргумента номер_строки или номер_столбца значение 0 (ноль), функция ИНДЕКС возвратит массив значений для целого столбца или целой строки соответственно. Чтобы использовать значения, возвращенные как массив, введите функцию ИНДЕКС как формулу массива в горизонтальный диапазон ячеек для строки и в вертикальный — для столбца.
Если функция ИНДЕКС возвращает массив, ее можно использовать внутри других функций, ожидающих, что аргумент является массивом.
Итак, указав в качестве третьего аргумента функции ИНДЕКС(1-ЕПУСТО(C2:K2);1;0) значение ноль, мы получим массив {0;0;1;0;0;0;0;0;0}.
Функция ПОИСКПОЗ выполняет поиск искомого значения в одномерном массиве и возвращает относительную позицию первого найденного совпадения. Формула =ПОИСКПОЗ(1,МАССИВ,0) просит Excel найти номер ячейки в МАССИВЕ, которая содержит первую встретившуюся единицу. Функция ПОИСКПОЗ определяет в каком столбце содержится первая непустая ячейка. Когда вы просите ПОИСКПОЗ найти первую 1 в массиве {0;0;1;0;0;0;0;0;0}, она возвращает 3.
Итак =ПОИСКПОЗ(1;ИНДЕКС(1-ЕПУСТО(C2:K2);1;0);0) превращается в =ПОИСКПОЗ(1;{0;0;1;0;0;0;0;0;0};0) и возвращает результат 3.
В этот момент, вы знаете, что третий столбец строки С2:К2 содержит первое непустое значение. Отсюда довольно просто, используя функцию ИНДЕКС, узнать само это первое непустое значение: =ИНДЕКС(МАССИВ;1;3) или =ИНДЕКС(C2:K2;1;ПОИСКПОЗ(1;ИНДЕКС(1-ЕПУСТО(C2:K2);1;0);0)).
Результат: 3

Рис. 2. Формула находит первую непустую ячейку в каждой строке и возвращает значение этой ячейки
Дополнительные сведения: если все ячейки пустые, то формула возвращает ошибку #Н/Д.
Альтернативные стратегии: когда вы из единицы вычитаете значение ЕПУСТО, вы преобразуете логические значения ИСТИНА/ЛОЖЬ в числовые 1/0. Вы могли бы пропустить этот шаг, но тогда вам придется искать ЛОЖЬ в качестве первого аргумента функция ПОИСКПОЗ: =ИНДЕКС(C2:K2;1;ПОИСКПОЗ(ЛОЖЬ;ИНДЕКС(ЕПУСТО(C2:K2);1;0);0)).
Источник.
Ссылка на это место страницы:
#title
- Получить первое не пустое значение в списке
- Получить первое текстовое значение в списке
- Получить первое текстовое значение с ГПР
- Получить позицию последнего совпадения
- Получить последнее совпадение содержимого ячейки
- Получить n-е совпадение
- Получить n-ое совпадение с ИНДЕКС/ПОИСКПОЗ
- Получить n-ое совпадение с ВПР
- Если ячейка содержит одну из многих вещей
- Поиск первой ошибки
- Поиск следующего наибольшего значения
- Несколько совпадений в списке, разделенных запятой
- Частичное совпадение чисел с шаблоном
- Частичное совпадение с ВПР
- Положение первого частичного совпадения
- Скачать файл
Ссылка на это место страницы:
#punk01
{ = ИНДЕКС( диапазон ; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( диапазон ); 0 )) }
{ = INDEX( диапазон ; MATCH( FALSE; ISBLANK ( диапазон ); 0 )) }

Если вам нужно получить первое не пустое значение (текст или число) в диапазоне в одной колонке вы можете использовать формулу массива на основе функций ИНДЕКС, ПОИСКПОЗ и ЕПУСТО.
В данном примере мы используем эту формулу:
{ = ИНДЕКС( B3: B11; ПОИСКПОЗ( ЛОЖЬ; ЕПУСТО ( B3: B11 ); 0 )) }
{ = INDEX( B3:B11; MATCH( FALSE; ISBLANK ( B3:B11 ); 0 )) }
Таким образом, суть проблемы заключается в следующем: мы хотим получить первую не пустую ячейку, но для этого нет конкретной формулы в Excel. Мы могли бы использовать ВПР с шаблоном *, но это будет работать только для текста, а не для чисел.
Таким образом, нам нужно строить функциональные возможности для нужных нам формул. Способ сделать это состоит в использовании функции массива, которая «тестирует» ячейки и возвращает массив истина/ложь значения, которые мы можем сопрягать с ПОИСКПОЗ.
Работая изнутри, ЕПУСТО оценивает ячейки в диапазоне В3: В11 и возвращает результат и массив, который выглядит следующим образом:
{ИСТИНА; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА}
Каждая ЛОЖЬ представляет собой ячейку в диапазоне, который не является пустой.
Далее, ПОИСКПОЗ ищет ЛОЖЬ внутри массива и возвращает позицию первого наденного совпадения, в этом случае 2. На данный момент, формула в примере теперь выглядит следующим образом:
{ = ИНДЕКС( B3: B11; 2; 0 )) }
{ = INDEX( B3:B11; 2; 0 )) }
И, наконец, функция ИНДЕКС выводит значение в положении 2 в массиве, в этом случае число 10.
Ссылка на это место страницы:
#punk02
= ВПР ( «*»; диапазон; 1; ЛОЖЬ)
= VLOOKUP ( «*»; диапазон; 1; FALSE)
Если вам нужно получить первое текстовое значение в списке (диапазон один столбец), вы можете использовать функцию ВПР, чтобы установить точное соответствие, с шаблонным символом для поиска.

В данном примере формула в D7 является:
= ВПР ( «*» ; B5: B11 ; 1 ; ЛОЖЬ)
= VLOOKUP ( «*» ; B5:B11 ; 1 ; FALSE)
Групповой символ звездочка (*) соответствует любому текстовому значению.
Ссылка на это место страницы:
#punk03
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)

Для поиска и получения первого текстового значения во всем диапазоне столбцов, вы можете использовать функцию ГПР с групповым символом. В примере формула в F5 является:
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)
Значение поиска является «*», групповым символом, который соответствует одному или более текстовому значению.
Ссылка на это место страницы:
#punk04
= ГПР ( «*»; диапазон; 1; ЛОЖЬ)
= HLOOKUP ( «*»; диапазон; 1; FALSE)
Для того, чтобы получить позицию последнего совпадения (т.е. последнего вхождения) от значения поиска, вы можете использовать формулу, основанную на ЕСЛИ, СТРОКА, ИНДЕКС, ПОИСКПОЗ и MAКС функций.

=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Суть этой формулы состоит в том, что мы строим список номеров строк для данного диапазона, соответствующие по значению, а затем используем функцию MAКС, чтобы получить наибольшее количество строк, что соответствует последнему значению соответствия.
Ссылка на это место страницы:
#punk05
=МАКС(ЕСЛИ(B4:B11=G5;СТРОКА(B4:B11)-СТРОКА(ИНДЕКС(B4:B11;1;1))+1))
=MAX(IF(B4:B11=G5;ROW(B4:B11)-ROW(INDEX(B4:B11;1;1))+1))
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть последнее совпадение, найденное в списке, вы можете использовать формулу, основанную на ПРОСМОТР и ПОИСК функций. В случае нескольких найденных совпадений, формула вернет последнее совпадение из списка «вещей».

=ПРОСМОТР(2;1/ПОИСК($E$4:$E$7;B4);$E$4:$E$7)
=LOOKUP(2;1/SEARCH($E$4:$E$7;B4);$E$4:$E$7)
Ссылка на это место страницы:
#punk06
= НАИМЕНЬШИЙ( ЕСЛИ( логический тест; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); n )
= SMALL( IF( логический тест; СТРОКА( список ) — MIN( ROW( список )) + 1 ); n )
Для того, чтобы получить позицию n-го совпадения (например, второе значение соответствия заданному, третье значение соответствия и т.д.), вы можете использовать формулу, основанную на функции НАИМЕНЬШИЙ.
= НАИМЕНЬШИЙ( ЕСЛИ( список = E5 ; СТРОКА( список ) — МИН( СТРОКА( список )) + 1 ); F5 )
= SMALL( IF( список = E5 ; ROW( список ) — MIN( ROW( список )) + 1 ); F5 )
Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk07
{ = ИНДЕКС( массив; НАИМЕНЬШИЙ( ЕСЛИ( величины = знач ; СТРОКА ( величины ) — СТРОКА ( ИНДЕКС( величины; 1 ; 1 )) + 1 ); n-й )) }
{ = INDEX( массив; SMALL( IF( величины = знач ; ROW ( величины ) — ROW ( INDEX( величины; 1 ; 1 )) + 1 ); n-й )) }

Эта формула возвращает позицию второго появления «красных» в списке.
Сутью этой формулы является функция НАИМЕНЬШИЙ, которая просто возвращает n-е наименьшее значение в списке значений, которое соответствует номеру строки. Номера строк были «отфильтрованы» функцией ЕСЛИ, которая применяет логику для совпадения.
Ссылка на это место страницы:
#punk08
= ВПР( id_формулы; стол; 4; 0 )
= VLOOKUP( id_формулы; стол; 4; 0 )
Чтобы получить n-ое совпадение с ВПР, вам необходимо добавить вспомогательный столбец в таблицу , которая строит уникальный идентификатор , который включает счетчик.

Эта формула зависит от вспомогательного столбца, который добавляется в качестве первого столбца таблицы исходных данных.
Вспомогательный столбец содержит формулу, которая строит уникальное значение взгляда вверх от существующего идентификатора и счетчика. Счетчик подсчитывает сколько раз уникальный идентификатор появился в таблице данных.
В примере, формула ячейки J6 вспомогательного столбца выглядит следующим образом:
=ВПР(J3&»-«&I6;B4:G11;4;0)
=VLOOKUP(J3&»-«&I6;B4:G11;4;0)
Ссылка на это место страницы:
#punk09
{ = ИНДЕКС( результаты ;ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК( вещи ; A1 )); 0 )) }
{ = INDEX( результаты ;MATCH( TRUE ; ISNUMBER( SEARCH( вещи ; A1 )); 0 )) }
Чтобы проверить ячейку для одной из нескольких вещей, и вернуть пользовательский результат для первого найденного совпадения, вы можете использовать формулу ИНДЕКС/ПОИСКПОЗ, основанную на функции поиска.
{ = ИНДЕКС( результаты ; ПОИСКПОЗ( ИСТИНА ; ЕЧИСЛО( ПОИСК ( вещи ; B5 )); 0 )) }
= INDEX( результаты ; MATCH( TRUE ; ISNUMBER( SEARCH ( вещи ; B5 )); 0 ))
Эта формула использует два названных диапазона: E5: E8 называется «вещи» и F5: F8 называется «Результаты». Убедитесь, что вы используете диапазоны имен с одинаковыми именами (на основе ваших данных). Если вы не хотите использовать именованные диапазоны, используйте абсолютные ссылки вместо этого.
Ссылка на это место страницы:
#punk10
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА(диап ); 0 ) }
{ = MATCH( TRUE ; ISERROR(диап ); 0 ) }
Если вам нужно найти первую ошибку в диапазоне ячеек, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ЕОШИБКА функциях.

В приведенном примере формула:
{ = ПОИСКПОЗ( ИСТИНА ; ЕОШИБКА( B4: B11 ); 0 ) }
{ = MATCH( TRUE ; ISERROR( B4:B11 ); 0 ) }
Работая изнутри, функция ЕОШИБКА возвращает значение ИСТИНА, если значение является признанной ошибкой, и ЛОЖЬ, если нет.
Когда дается диапазон ячеек (массив ячеек) функция ЕОШИБКА будет возвращать массив истина/ложь значений. В примере, это результирующий массив выглядит следующим образом:
{ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ЛОЖЬ; ИСТИНА; ЛОЖЬ; ЛОЖЬ}
Обратите внимание, что 6-е значение (что соответствует 6-й ячейке в диапазоне) истинно, так как ячейка В9 содержит #Н/A.
Ссылка на это место страницы:
#punk11
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )

Для того, чтобы найти «следующее наибольшее» значение в справочной таблице, можно использовать формулу, основанную на ИНДЕКС и ПОИСКПОЗ. В примере формула в F6 является:
=ИНДЕКС ( данные; ПОИСКПОЗ( поиск ; значения ) + 1 )
=INDEX ( данные; MATCH( поиск ; значения ) + 1 )
Ссылка на это место страницы:
#punk12
{ = ОБЪЕДИНИТЬ ( «;» ; ИСТИНА ; ЕСЛИ( диапазон1 = E5 ; диапазон2 ; «» )) }
{ = ОБЪЕДИНИТЬ ( «;» ; TRUE ; IF( диапазон1 = E5 ; диапазон2 ; «» )) }
Для поиска и извлечения нескольких совпадений, разделенных запятыми (в одной ячейке), вы можете использовать функцию ЕСЛИ с функцией ОБЪЕДИНИТЬ.
{ = ОБЪЕДИНИТЬ( «;» ; ИСТИНА ; ЕСЛИ( группа = E5 ; имя ; «» )) }
Эта формула использует «имя» — именованный диапазон (B5: B11) и «группа» — (C5: C11).
Ссылка на это место страницы:
#punk13
{ = ПОИСКПОЗ( «*» & номер & «*» ; ТЕКСТ( диапазон ; «0» ); 0 ) }
{ = MATCH( «*» & номер & «*» ; TEXT( диапазон ; «0» ); 0 ) }
Для того, чтобы выполнить частичное совпадение (подстроки) против чисел, вы можете использовать формулу массива, основанную на ПОИСКПОЗ и ТЕКСТ.

Excel поддерживает символы подстановки «*» и «?». Тем не менее, если вы используете специальные символы с номером, вы будете преобразовывать числовое значение в текстовое значение. Другими словами, «*» & 99 & «*» = «* 99 *» (текстовая строка).
Если попытаться найти текстовое значение в диапазоне чисел, совпадение завершится неудачно.
Одно из решений заключается в преобразовании чисел в диапазоне поиска для текстовых значений, а затем сделать нормальный поиск с ПОИСКПОЗ, ВПР и т.д.
Другой способ, чтобы преобразовать числа в текст, чтобы сцепить пустую строку. Эта формула работает так же, как выше формуле:
= ПОИСКПОЗ ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
= MATCH ( «*» & Е5 & «*» ; В5: В10 & «» ; 0 )
Ссылка на это место страницы:
#punk14
Если вы хотите получить информацию из таблицы на основе частичного совпадения, вы можете сделать это с помощью ВПР в режиме точного соответствия, и групповые символы.

В примере формула ВПР выглядит следующим образом:
=ВПР($H$2&»*»;$B$3:$E$12;2;0)
=VLOOKUP($H$2&»*»;$B$3:$E$12;2;0)
В этой формуле, значение представляет собой именованный диапазон, который относится к Н2, а также данные , представляет собой именованный диапазон , который относится к B3: E102. Без названных диапазонов, формула может быть записана следующим образом:
Ссылка на это место страницы:
#punk15
= ПОИСКПОЗ ( «* текст *» ; диапазон; 0 )
= MATCH ( «* текст *» ; диапазон; 0 )
Для того, чтобы получить позицию первого частичного совпадения (то есть ячейку, которая содержит текст, который вы ищете), вы можете использовать функцию ПОИСКПОЗ со специальными символами.

=ПОИСКПОЗ(«*»&E6&»*»;B5:B10;0)
=MATCH(«*»&E6&»*»;B5:B10;0)
Функция ПОИСКПОЗ возвращает позицию или «индекс» в первом совпадении на основании значения поиска в диапазоне.
ПОИСКПОЗ поддерживает подстановочное согласование со звездочкой «*» (один или несколько символов) или знаком вопроса «?» (один символ), но только тогда, когда третий аргумент, тип_сопоставления, установлен в ЛОЖЬ или ноль.
Ссылка на это место страницы:
#punk16
Файлы статей доступны только зарегистрированным пользователям.
1. Введите свою почту
2. Нажмите Зарегистрироваться
3. Обновите страницу
Вместо этого блока появится ссылка для скачивания материалов.

Привет! Меня зовут Дмитрий. С 2014 года Microsoft Cretified Trainer. Вместе с командой управляем этим сайтом. Наша цель — помочь вам эффективнее работать в Excel.
Изучайте наши статьи с примерами формул, сводных таблиц, условного форматирования, диаграмм и макросов. Записывайтесь на наши курсы или заказывайте обучение в корпоративном формате.

Подписывайтесь на нас в соц.сетях: