Плотность распределения вероятностей непрерывной случайной величины
- Краткая теория
- Примеры решения задач
- Задачи контрольных и самостоятельных работ
Краткая теория
Ранее
непрерывная случайная величина задавалась с помощью функции распределения. Этот
способ задания не является единственным. Непрерывную случайную величину можно
также задать, используя другую функцию, которую называют плотностью
распределения или плотностью вероятности (иногда ее называют дифференциальной
функцией).
Плотностью распределения вероятностей непрерывной случайной величины
называют функцию
– первую производную от функции распределения
:
Из этого определения следует, что
функция распределения является первообразной для плотности распределения.
Заметим, что для описания
распределения вероятностей дискретной случайной величины плотность
распределения неприменима.
Зная плотность распределения, можно
вычислить вероятность того, что непрерывная случайная величина примет значение,
принадлежащее заданному интервалу.
Вероятность того, что непрерывная
случайная величина
примет
значение, принадлежащее интервалу
равна
определенному интегралу от плотности распределения, взятому в пределах от
до
:
Геометрически полученный результат
можно истолковать так: вероятность того, что непрерывная случайная величина
примет значение, принадлежащее интервалу
, равна площади криволинейной трапеции, ограниченной
осью
, кривой распределения
и прямыми
и
.
В частности, если
– четная
функция и концы интервала симметричны относительно начала координат, то:
Зная плотность распределения
можно найти
функцию распределения
по формуле:
Свойства плотности распределения
Свойство 1.
Плотность
распределения – неотрицательная функция:
Свойство 2.
Несобственный
интеграл от плотности распределения в пределах от
до
равен единице:
Смежные темы решебника:
- Дискретная случайная величина
- Непрерывная случайная величина
- Интегральная функция распределения вероятностей
Примеры решения задач
Пример 1
Задана
плотность распределения вероятностей f(x) непрерывной случайной
величины X. Требуется:
1)
определить коэффициент A;
2) найти
функцию распределения F(x);
3)
схематично построить графики F(x) и f(x);
4) найти
математическое ожидание и дисперсию X;
5) найти
вероятность того, что X примет значение из
интервала (α,β):
α=1; β=1.7
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
1)
Постоянный параметр
найдем из
свойства плотности вероятности:
В
нашем случае эта формула имеет вид:
Получаем:
2)
Функцию распределения
найдем из
формулы:
Учитывая
свойства
, сразу можем
отметить, что:
Остается
найти выражение для
, когда
принадлежит
интервалу
.
Получаем:
3) Построим графики
и
:
График плотности распределения
График функции распределения
4)
Математическое ожидание находим по формуле:
Для
нашего примера:
Дисперсию
можно найти по формуле:
5)
Вероятность того, что случайная величина примет значение из интервала
:
Пример 2
Плотность
распределения вероятности непрерывной случайной величины равна
, x∈(0,∞). Найти нормировочный множитель C,
математическое ожидание M(X) и дисперсию D(X).
Решение
Нормировочный множитель
найдем из
свойства плотности вероятности:
В
нашем случае эта формула имеет вид:
Плотность
вероятности:
Математическое
ожидание находим по формуле:
Для
нашего примера:
Дисперсию
можно найти по формуле:
Пример 3
Непрерывная
случайная величина
имеет плотность распределения:
Найти
величину a, вероятность P(X<0) и математическое
ожидание X.
Решение
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Постоянный
параметр
найдем из
свойства плотности вероятности:
В
нашем случае эта формула имеет вид:
Плотность
вероятности имеет вид:
Вероятность:
Математическое
ожидание находим по формуле:
Для
нашего примера:
Задачи контрольных и самостоятельных работ
Задача 1
Плотность
распределения непрерывной случайной величины X имеет вид:
Найти:
а)
параметр a;
б)
функцию распределения F(x);
в)
вероятность попадания случайной величины X в интервал (6.5; 11);
г)
математическое ожидание M(X) и дисперсию D(X);
Построить
график функций f(x) и F(x).
Задача 2
Задана
функция распределения непрерывной случайной величины:
Найти и
построить график функции плотности распределения вероятностей.
Задача 3
Случайная
величина X задана функцией распределения F(x).
Найти плотность распределения вероятностей, математическое ожидание и дисперсию
случайной величины. Построить график функции
F(x).
Задача 4
Задана
плотность вероятности f(x) или функции распределения
непрерывной случайной величины X. Найти a, M[X], D[X], P(α<x<β).
α=1,β=2
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 5
Непрерывная
случайная величина
задана плотностью распределения вероятностей.
Требуется
найти:
— функцию
распределения вероятностей;
—
математическое ожидание;
—
дисперсию;
— среднее
квадратическое отклонение;
— вероятность
того, что случайная величина отклонится от своего математического ожидания не
более, чем на одну четвертую длины всего интервала возможных значений этой
величины;
—
построить графики функции распределения и плотности распределения вероятностей.
Задача 6
Случайная
величина X равномерно распределена на интервале (2;7).
Составить f(x),F(x), построить графики. Найти
M(X),D(X).
Задача 7
Случайная
величина X~N(a,σ)
a=25;
σ=4; α=13; β=30; δ=0.1.
Требуется:
—
составить функцию плотности распределения и построить ее график;
— найти
вероятность того, что случайная величина в результате испытания примет
значение, принадлежащее интервалу (α; β);
— найти
вероятность того, что абсолютная величина отклонения значений случайной
величины от ее математического ожидания не превысит δ.
Задача 8
Плотность
вероятности непрерывной случайной величины ξ задана следующим выражением:
Найти
постоянную C, функцию распределения Fξ (x), математическое
ожидание и дисперсию Dξ случайной величины ξ.
На сайте можно заказать решение контрольной или самостоятельной работы, домашнего задания, отдельных задач. Для этого вам нужно только связаться со мной:
ВКонтакте
WhatsApp
Telegram
Мгновенная связь в любое время и на любом этапе заказа. Общение без посредников. Удобная и быстрая оплата переводом на карту СберБанка. Опыт работы более 25 лет.
Подробное решение в электронном виде (docx, pdf) получите точно в срок или раньше.
Задача 9
Случайная
величина X задана функцией распределения вероятностей F(x).
Требуется:
1. Найти
функцию плотности распределения f(x).
2. Найти M(X).
3. Найти
вероятность P(α<X<β)
4.
Построить графики f(x) и F(x).
α=2, β=4.5
Задача 10
Найти
функцию плотности нормально распределенной случайной величины X и
постройте ее график, зная M(X) и D(X).
M(X)=-1; D(X)=8
Задача 11
Случайная
величина X задана интегральной F(x) или дифференциальной f(x)
функцией. Требуется:
а) найти
параметр C;
б) при
заданной интегральной функции F(x) найти дифференциальную функцию f(x), а при
заданной дифференциальной функции f(x) найти интегральную функцию F(x);
в)
построить графики функций F(x) и f(x);
г) найти
математическое ожидание M(X), дисперсию D(X) и
среднее квадратическое отклонение σ(x);
д)
вычислить вероятность попадания в интервал P(a≤x≤b)
е)
определить, квантилем какого порядка является точка xp;
ж)
вычислить квантиль порядка p
a=π/4; b=π/3; xp=π/2; p=0.75
- Краткая теория
- Примеры решения задач
- Задачи контрольных и самостоятельных работ
Функция
распределения полностью характеризует
случайную величину, однако, имеет один
недостаток. По функции распределения
трудно судить о характере распределения
случайной величины в небольшой окрестности
той или иной точки числовой оси.
Определение. Плотностью
распределения вероятностей
непрерывной случайной величины Х
называется функция f(x) –
первая производная от функции
распределения F(x).
Плотность
распределения также называют дифференциальной
функцией.
Для описания дискретной случайной
величины плотность распределения
неприемлема.
Смысл
плотности распределения состоит в том,
что она показывает как часто появляется
случайная величина Х в некоторой
окрестности точки х при
повторении опытов.
После
введения функций распределения и
плотности распределения можно дать
следующее определение непрерывной
случайной величины.
Определение. Случайная
величина Х называется непрерывной,
если ее функция распределенияF(x)
непрерывна на всей оси ОХ, а плотность
распределения f(x)
существует везде, за исключением( может
быть, конечного числа точек.
Зная
плотность распределения, можно вычислить
вероятность того, что некоторая случайная
величина Х примет значение, принадлежащее
заданному интервалу.
Теорема. Вероятность
того, что непрерывная случайная величина
Х примет значение, принадлежащее
интервалу (a, b),
равна определенному интегралу от
плотности распределения, взятому в
пределах от a до b.
Доказательство
этой теоремы основано на определении
плотности распределения и третьем
свойстве функции распределения,
записанном выше.
Геометрически
это означает, что вероятность того, что
непрерывная случайная величина примет
значение, принадлежащее интервалу
(a, b),
равна площади криволинейной трапеции,
ограниченной осью ОХ, кривой
распределения f(x)
и прямыми x=a и x=b.
№31. Равномерное
распределение НСВ: ф-я распр-я, плотность
расп-я, график, мат ожидание, дисперсия
Понятие НСВ,
функция ее распределения
Случайной
непрерывной величиной является
величина,
которая может принять любое из значений
некоторого промежутка.
Здесь нельзя
отделить одно возможное значение от
другого промежутком, не содержащим
возможных значений случайной величины.
Случайной
непрерывной величиной является
величина,
функция распределения F(x)
которой, непрерывна на всей числовой
оси.
Функция распределения
HСВ
F(x)
есть кусочно-дифференцируемая функция
с непрерывной производной.
Вероятность того,
что случайная величина примет значение,
заключенное в некотором интервале (а,
b),
равна приращению функции распределения
на этом интервале;P(a
≤ X
≤b)
= F
(b)
— F
(а).
При рассмотрении
функции распределения, числовой
промежуток записывается так же в виде
[x1;
x2],
тогда вероятность того, что случайная
величина примет значение, заключенное
в этом интервале равна:
p(x1≤
x
≤ x2)
= F
(x2)
— F
(x1).-
что более понятно и привычно.
Вероятность того,
что случайная непрерывная величина X
примет одно определенное значение,
равна нулю.
Понятие
плотности распределения, функция
плотности НСВ
Плотностью
распределения вероятностей
непрерывной случайной величины X
называют
функцию f
(х) —
первую производную от функции распределения
F
(х): f
(х)= F'(х)
Из этого определения
следует, что функция распределения
F(х)
является
первообразной для плотности распределения
f
(х):
F(х)=
f
(х).
Функцию f
(х) можно
называть
дифференциальной функцией
Таким образом, зная
интегральную функцию (функцию
распределения) можно найти дифференциальную
функцию(функцию плотности) и наоборот
по формулам:f
(х)= F'(х)
F(х)=
f
(х).

Математическим
ожиданием непрерывной случайной
величины Х, возможные значения которой
принадлежат отрезку [a,b], называется
определенный интеграл
![]()
Если
возможные значения случайной величины
рассматриваются на всей числовой оси,
то математическое ожидание находится
по формуле:
При этом, конечно,
предполагается, что несобственный
интеграл сходится.
Свойства
математического ожидания НСВ аналогичны
свойствам математического ожидания
ДСВ.
Дисперсией
непрерывной случайной величины называется
математическое ожидание квадрата ее
отклонения.
![]()
По
аналогии с дисперсией дискретной
случайной величины, для практического
вычисления дисперсии используется
формула:
![]()
№32 Нормальное
расп-е
Это такое расп-е
случ.велечины Х, плотность Р которого
опис. Формулой f(x)=(1/(x)*2)*exp(-(x—M(x)2 )/(22(x),
где (х)-
сред.квадрат.отклонение, М(х)-матем.ожидание
№33
Нормальное расп-е: 1)вероятность попадания
в заданный интервал, вероятность заданого
отклонения
1)Если случайная
величина Х задана плотностью распределения
f(x), то вероятность того, что Х примет
значение, принадлежащее заданному
интервалу, вычисляется по формуле .
Подставив в формулу значение плотности
распределения из для нормального
распределения N(a, s) и сделав ряд
преобразований, вероятность того, что
Х примет значение, принадлежащее
заданному интервалу [x1,
x2],
будет равна:
|
|
Где а-мат.ожидание |
2)
|
P |
№34 Показательное
расп-е НСВ: график, ф-я расп-я, плотность
расп-я, матем ожидание, дисперсия
№35 Показательное
расп-е: ф-я надежности, показательный
закон надежности, характеристичесткое
свойство этого закона
Функция надежности
Будем называть
элементом
некоторое
устройство независимо от того, «простое»
оно или «сложное».
Пусть элемент
начинает работать в момент времени
t0=0,
а по истечении времени длительностью
t
происходит отказ. Обозначим через Т
непрерывную
случайную величину — длительность
времени безотказной работы элемента.
Если элемент проработал безотказно (до
наступления отказа) время, меньшее t
то, следовательно, за время длительностью
t
наступит
отказ.
Таким образом,
функция распределения F
(t)=P(T<t)
определяет
вероятность отказа за время длительностью
t.
Следовательно,
вероятность безотказной работы за это
же время длительностью t,
т. е. вероятность
противоположного события Т
> t,
равна
![]()
Функцией надежности
R
(t)
называют
функцию, определяющую надежность работы
элемента за время длительностью t:
Показательный
закон надежности
Часто длительность
времени безотказной работы элемента
имеет показательное распределение,
функция распределения которого![]()
Следовательно,
функция надежности в случае показательного
распределения времени безотказной
работы элемента имеет вид![]()
Показательным
законом надежности называют
функцию надежности, определяемую
равенством![]()
где
интенсивность отказов
Как следует из
определения функции надежности, эта
формула позволяет найти вероятность
безотказной работы элемента на
интервале времени длительностью tt
если время
безотказной работы имеет, показательное
распределение.
Характеристическое
свойство показательного закона
надежности.
Показательный
закон надежности весьма прост и удобен
для решения задач, возникающих на
практике. Очень многие формулы теории
надежности значительно упрощаются.
Объясняется это тем, что этот закон
обладает следующим важным свойством:
«Вероятность безотказной работы
элемента на интервале времени
длительностью t
не зависит от времени предшествующей
работы до начала рассматриваемого
интервала, а зависит только от длительности
времени t
(при заданной интенсивности отказов
)».
Итак, в случае
показательного закона надежности
безотказная работа элемента «в
прошлом» не сказывается на величине
вероятности его безотказной работы «в
ближайшем будущем».
Замечание.
Можно доказать, что рассматриваемым
свойством обладает только показательное
распределение. Поэтому если на практике
изучаемая случайная величина этим
свойством обладает, то она распределена
по показательному закону. Например, при
допущении, что метеориты распределены
равномерно в пространстве и во времени,
вероятность попадания метеорита в
космический корабль не зависит от того,
попадали или не попадали метеориты в
корабль до начала рассматриваемого
интервала времени. Следовательно,
случайные моменты времени попадания
метеоритов в космический корабль
распределены по показательному закону.
№36 Ф-я одного
случ аргумента, матем ожидание
Если каждому
возможному значению случайной величины
Х
соответствует одно возможное значение
случайной величины Y,
то Y
называют
функцией
случайного аргу-мента Х:
Y
=
φ(X).
Выясним, как найти закон распределения
функции по известному закону распределения
аргумента.
1) Пусть аргумент
Х
– дискретная случайная величина, причем
различным значениям Х
соот-ветствуют различные значения Y.
Тогда вероятности соответствующих
значений Х
и Y
равны.
2) Если разным
значениям Х
могут соответствовать одинаковые
значения Y,
то вероятности значений аргумента, при
которых функция принимает одно и то же
значение, складываются.
3) Если Х
– непрерывная случайная величина, Y
= φ(X),
φ(x)
– монотонная и дифференцируемая функция,
а ψ(у)
– функция, обратная к
φ(х),
то плотность распределения g(y)
случайно функции Y
равна:
![]()
Математическое
ожидание функции одного случайного
аргумента.
Пусть Y
= φ(X)
– функция случайного аргумента Х,
и требуется найти ее математическое
ожидание, зная закон распределения Х.
1)
Если Х
– дискретная случайная величина, то
![]()
Пример 3. Найдем
M(Y)
для примера 1: M(Y)
= 47·0,1 + 69·0,2 + 95·0,3 + 125·0,4 = 97.
2)
Если Х
– непрерывная случайная величина, то
M(Y)
можно искать по-разному. Если известна
плотность распределения g(y),
то
![]()
Если же g(y)
найти сложно, то можно использовать
известную плотность распределения
f(x):
![]()
В частности, если
все значения Х
принадлежат промежутку (а,
b),
то
№37 Ф-я двух случ
аргументов, закон расп-я![]()
Если каждой паре
возможных значений случайных величин
Х
и Y
соответ-ствует одно возможное значение
случайной величины Z,
то Z
называют
функцией двух
случайных аргументов
X
и
Y
: Z
= φ(X,
Y).
Рассмотрим в
качестве такой функции сумму Х
+ Y.
В некоторых случаях можно найти ее закон
распределения, зная законы распределения
слагаемых.
1) Если X
и
Y
– дискретные
независимые
случайные величины, то для определения
закона распределения Z
= Х + Y
нужно найти
все возможные значения Z
и соответствующие
им вероятности.
3)
Если X
и
Y
– непрерывные
независимые
случайные величины, то, если плотность
вероятно-сти хотя бы одного из аргументов
задана на (-∞, ∞) одной формулой, то
плотность суммы g(z)
можно найти по формулам
![]()
где f1(x),
f2(y)
– плотности распределения слагаемых.
Если возможные значения аргументов
неотрицательны, то
![]()
Замечание.
Плотность
распределения суммы двух независимых
случайных величин называют композицией.
№38 Закон больших
чисел: неравенство Чебышева
Вероятность того,
что отклонение случайной величины X
от ее математического ожидания по
абсолютной величине меньше положительного
числа не меньше чем :
p(
| X — M(X)|
< ε ) ≥ D(X)
/ ε².
Доказательство.
Пусть Х
задается рядом распределения
|
х1 |
х2 |
… |
хп |
||||||||||
|
р |
р1 |
р2 |
… |
рп |
Так как события |X
— M(X)|
< ε и |X —
M(X)|
≥ ε противоположны, то р
( |X — M(X)|
< ε ) + + р
( |X — M(X)|
≥ ε ) = 1, следовательно, р
( |X — M(X)|
< ε ) = 1 — р
( |X — M(X)|
≥ ε ). Найдем р
( |X — M(X)|
≥ ε ).
D(X)
= (x1
— M(X))²p1
+ (x2
— M(X))²p2
+ … + (xn
— M(X))²pn
. Исключим
из этой суммы те слагаемые, для которых
|X — M(X)|
< ε. При этом сумма может только
уменьшиться, так как все входящие в нее
слагаемые неотрицательны. Для
определенности будем считать, что
отброшены первые k
слагаемых.
Тогда
D(X)
≥ (xk+1
— M(X))²pk+1
+ (xk+2
— M(X))²pk+2
+ … + (xn
— M(X))²pn
≥ ε² (pk+1
+ pk+2
+ … + pn).
Отметим, что pk+1
+ pk+2
+ … + pn
есть вероятность того, что |X
— M(X)|
≥ ε, так как это сумма вероятностей всех
возможных значений Х,
для которых это неравенство справедливо.
Следовательно, D(X)
≥ ε² р(|X
— M(X)|
≥ ε), или р
(|X — M(X)|
≥ ε) ≤ D(X)
/ ε². Тогда вероятность противоположного
события p(
| X — M(X)|
< ε ) ≥ D(X)
/ ε², что и требо-валось доказать.
№39 Теоремы
Чебышева и Бернули
Теоремы Чебышева
и Бернулли.
Рассмотрим
последовательность случайных величин![]()
(2).
Введем среднее
арифметическое:
![]()
Запишем математическое
ожидание:
![]()
Обозначим
![]()
Def: говорят, что для
последовательности выполняется закон
больших чисел, если для любого![]()
справедливо равенство:
![]()
О равенстве (3) также
говорят, что среднее арифметическое
случайных величин в вероятностном
смысле (по вероятности) сходится к
среднему арифметическому их математических
ожиданий.
Если последовательность
случайных величин (2) удовлетворяет
закону больших чисел, то, как видно из
равенства (3), среднее арифметическое
ведет себя фактически как величина
неслучайная, поскольку ее значение в
вероятностном смысле как угодно мало
отличается от числа (среднего
арифметического математического
ожидания случайной величины ).
Теорема Чебышева:
пусть случайные величины последовательности
(2) таковы, что:
1) Они попарно
независимы.
2) Имеют конечное
математическое ожидание.
![]()
3) Имеют равномерно
ограниченные дисперсии
Тогда к
последовательности применим закон
больших чисел.
Доказательство.
Оценим дисперсию:
![]()
Применим неравенство
(1):
![]()
Левую часть выразим
через вероятность противоположного
события:
![]()
Умножим обе части
на (-1):
![]()
![]()
С другой стороны:
![]()
На основании двух
предыдущих формул получаем формулу (3)
Теорема Бернулли:
относительная частота события “А” в
вероятностном смысле сходится к
вероятности этого события:
(4)
![]()
Доказательство.
С каждым испытанием
свяжем случайную величину![]()
.
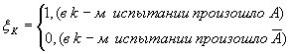
Тогда число
наступлений события “А” в “n” независимых
испытаний будет равно:
![]()
Покажем, что к этой
последовательности применим закон
больших чисел (равенство 3). Проверим
выполнение условий теоремы Чебышева:
1)
![]()
– попарно независимы.
2)
![]()
3)
![]()
Таким образом в
силу теоремы Чебышева к последовательности
случайных величин {
}
применим закон больших чисел, выражаемый
равенством (3). В данном случае среднее
арифметическое:
![]()
– относительная частота.
![]()
В
силу (3) получаем равенство (4).
№40 Оценка
отклонения распределения НСВ от
нормального коэффициента ассиметрии
и эксцесса
Коэффициент
асимметрии задает
степень асимметричности плотности
вероятности относительно оси, проходящий
через ее центр тяжести. Коэффициент
асимметрии определяется третьим
центральным моментом распределения. В
любом симметричном распределении с
нулевым математическиможиданием,
например, нормальным, все нечетные
моменты, в том числе итретий, равны нулю,
поэтому коэффициент асимметрии тоже
равен нулю.
Степень сглаженности
плотности вероятности в окрестности
главного максимума задается еще одной
величиной — коэффициентом
эксцесса. Он
показывает, насколько острую вершину
имеет плотность вероятности по сравнению
с нормальным распределением. Если
коэффициент эксцесса большенуля, то
распределение имеет более острую
вершину, чем распределениеГаусса, если
меньше нуля, то более плоскую.
Для
расчета коэффициентов асимметрии и
эксцесса в MathCAD имеютсядве встроенные
функции.
— kurt (x) — коэффициент эксцесса
(kurtosis) выборки
случайных данных х;
— skew(x) — коэффициент
асимметрии (skewness)
выборки
случайных данных X .
№41 Распределение
«хи-квадрат»
Пусть х1,х2,…,хn-независ.
Норм.расп-е случ.величины с нулевым
матем.ожиданием и сред.квадрат.отклонением=1,тогда
закон расп-я суммы кварт.величин(Х-квадрат)
х2=х1
2+х22+…+хn2
назв. Законом Х-квадрат с nстепенями
свободы. Плотность расп-я этого закона
опред:
0, при х<0
f(x)
(e—x/2*xn/2-1)/2n/2+Г’(n/2)x
≥0
№42 распределение
Стьюдента
Пусть х0,х1,…,хn-независ.
Норм.расп-е случ.величины с нулевым
матем.ожиданием и сред.квадрат.отклонением=1,
тогда величина опред по ф-ле:Т=(
х0/mn=1*x2/n)
назв. Величиной имеющей расп-е Стьюдента
с n-степенями
свободы
Плотность имеет
вид f(x)=
bn(1+
x2/2)-((n+1)/n)
bn=Г((n+1)/2)/Гn/2*n
№43 Распределение
Фишера-Снедекора
Пусть х1,х2,…,хn
,у1,у2,…,уn
независ. Норм.расп-е случ.величины с
нулевым матем.ожиданием и
сред.квадрат.отклонением=1, тогда случ
величина ,заданная ф-лой Fnm=((xi
2/n)/
yj
2/m)
назв. Случ величиной, имеющей расп-е
Фишера-Снедекора с n
и m
степенями свободы, плотность расп-я
имеет вид
F(x)=
0,при x0
C0
*(x(n-2)/2/(n+n
x(+2)/2),для
х>0
C0=Г(((n+m)/2)*nn/2
*m
m/2
))Г
n/2Г
m/2
№44 Система двух
случайных величин. Закон расп-я.Ф-я
расп-я. Свойства функции расп-я
Законом расп-я
назв перечень возможных значений двумерн
величины , т.е А(xi,уi)
и их соотв. Вероятностей Р(xi,уi).
Обычно закон задают таблицей с двойным
ходом.1строка-все возможн.значения.
составляющие х.1 столбец- все
возможн.значения. составляющие у клетки
на их пересечении (xi,уi)
заполняют соответств. Вероятность ,
причем кол-вл знач-й х,у могут быть
различными, т.к событие х=уi
и у=уi
образуют полную группу , то сумма
вероятностей помещенных во всех клетках
=1.
Ф-я расп-я:
Пусть х,у пара
действительных чисел, вероятность
события состоит в том, что составляющая
х примет знач-е меньше х; составляющая
у примет знач-е меньше у. X<x;
Y<y.
обозначение Р(X<x;
Y<y)=F(x;y)
– ф-я расп-я
Свойства функции
расп-я
1.Значения ф-и расп-я
удовлетв. Неравенству 0< F(x;y)<1
2. Ф-я F(x;y)
явл. Неубывающей ф-ей.
3. Имеют место след
соотношения:1)F(-∞;
y)=0
2) F(x;-∞)=0
3) F(-∞;-∞)=0
4) F(+∞;+∞)=1
4. При у=∞, ф-я расп-я
с-мы становиться ф-ей расп-я составляющей
х. При х=∞, ф-я расп-я с-мы становиться
ф-ей расп-я составляющей у
№45 Система двух
случайных величин: плотность совместного
расп-я вероятностей, нахождение ф-и
расп-я по плотности расп-я, свойства
двумерной плотности расп-я
Плотность совм.расп-я
вероятностей назв частную производную
второго порядка, смешанная по переменным
х, у
нахождение ф-и
расп-я по плотности расп-я
F(x,y)=sinx*siny
0x/2;
0y/2
Решение:
Fх(x,y)=cosx*siny
;Fxy=
cosx cosy. Зная
плотность расп-я можно найти ф-ю расп-я
F(x,y)=-∞∞
-∞∞f(x,y)
dx
dy
свойства двумерной
плотности расп-я:
1.плотность
вероятности не отрицательна f(x,y)≥0
2. -∞∞
-∞∞f(x,y)
dx
dy=1
3. можно найти
плотность расп-я для каждой составляющей
46.
Определение. Плотностью
совместного распределения вероятностей
двумерной случайной величины (X, Y)
называется вторая смешанная частная
производная от функции распределения.
Условные
законы распределения составляющих
системы дискретных случайных величин.

Рассмотрим
дискретную двумерную случайную величину
,
пусть возможные значения составляющих
таковы:

Предположим,
что в результате испытания случайная
величина Y
приняла значение

,
тогда X
может принять одно из своих возможных
значений. Обозначим условную вероятность
того, что X
примет значение

через
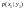
Условным
распределением случайной величины X
при условии, что Y
приняла значение
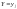
называют совокупность условных
вероятностей
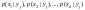
Зная
закон распределения двумерной дискретной
случайной величины можно вычислить
условные законы распределения
составляющих:

Условные
законы распределения составляющих
системы непрерывных случайных величин
Условной
дифференциальной функцией

составляющей X
при условии, что

,
называют отношение дифференциальной
функции системы к дифференциальной
функции составляющей Y.
47.
Условное математическое ожидание
Условным
математическим ожиданием
случайной величины Y
при
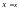
называют сумму произведений возможных
значений Y
на их условные вероятности.

Для
непрерывных величин:

48.
Зависимые и независимые случайные
величины
Теорема.
Для
того чтобы случайные величины X
и Y
были независимы, необходимо и достаточно,
чтобы интегральная функция системы

была равна произведению интегральных
функций случайных величин X
и Y.

Следствие.
Для того чтобы случайные величины X
и Y
были независимы, необходимо и достаточно,
чтобы дифференциальная функция системы
была равна произведению дифференциальных
функций случайных величин X
и Y.

КОРРЕЛЯЦИОННЫЙ
МОМЕНТ Корреляционным моментом двух случайных
величин X и Y называют математическое
ожидание произведения
отклонений этих
величин: xy = M{[X — M(X)][Y — M(Y)]}.
Корреляционный момент служит
для характеристики связи между
величинами X и Y.
Корреляционный момент двух независимых случайных
величин X и Y равен
нулю. Если корреляционный момент не
равен нулю, то X и Y — зависимые случайные
величины. Из определения корреляционного
момента следует, что он имеет размерность,
равную произведению размерностей
величин X и Y.
Другими словами, корреляционный момент
зависит от единиц измеренияслучайных
величин. Безразмерной
числовой характеристикой связи
двух случайных величин является коэффициент
корреляции.
коэффициент
корреляции.
Он рассчитывается следующим образом:
Есть
массив из n точек
{x1,i, x2,i}
Рассчитываются
средние значения для каждого параметра: ![]()
И
коэффициент корреляции: 
r изменяется
в пределах от -1 до 1. В данном случае это
линейный коэффициент корреляции, он
показывает линейную взаимосвязь
между x1 и x2: r равен
1 (или -1), если связь линейна.
Коэффициент r является
случайной величиной, поскольку вычисляется
из случайных величин. Для него можно
выдвигать и проверять следующие гипотезы:
Получаем кривую плотности распределения вероятности… быстрее и точнее
Время на прочтение
10 мин
Количество просмотров 9K
Недавно на Хабре вышла статья за авторством MilashchenkoEA , в которой автор восполняет обнаруженный им пробел в доступных материалах по методам построения кривых плотности распределения вероятности по имеющемуся набору числовых данных. Акцент в статье сделан на методическую сторону получения (оценки) плотности вероятности случайной величины, поэтому автор не преследует цели получения оптимального, с вычислительной точки зрения, алгоритма. Что ж, в данной заметке попытаемся исправить эту ситуацию, а также взглянем под другим углом на способ решения данной задачи.
Постановка задачи
Дан набор  значений случайной величины
значений случайной величины  , сэмплированный из некоторого непрерывного распределения. Необходимо оценить функцию плотности распределения вероятности случайной величины по заданной выборке. Для решения задачи можно использовать только нативные функции python; для построения графиков используется matplotlib; Pandas DataFrame используется как контейнер данных в соответствие с оригинальной статьей (хотя в общем-то можно обойтись и без него).
, сэмплированный из некоторого непрерывного распределения. Необходимо оценить функцию плотности распределения вероятности случайной величины по заданной выборке. Для решения задачи можно использовать только нативные функции python; для построения графиков используется matplotlib; Pandas DataFrame используется как контейнер данных в соответствие с оригинальной статьей (хотя в общем-то можно обойтись и без него).
Подготовка данных
Тестировать методы будем с использованием данных, сгенерированных для 4-х распределений, для которых известны аналитические выражения плотности, как в оригинальной статье: Релея, гамма, Вейбулла и экспоненциального. Для этого используем код MilashchenkoEA с небольшими изменениями (для удобства дальнейшего использования изменены сигнатуры функций, возвращающих значения аналитической функции плотности вероятности на заданном массиве значений случайной переменной):
Код
import random
import math
import matplotlib.pyplot as plt
import pandas
import pandas as pd
import numpy as np # Понадобится для расчета метрик
from time import perf_counter # Понадобится для определения времени выполнения
def rel_pdf(rel_sigma: float, X: list) -> pandas.DataFrame:
"""
Вычисляет Релеевскую кривую плотности распределения вероятности по известной формуле
:param rel_sigma: среднеквадратическое отклонение
:param X: координаты по оси абсцисс
:return: pandas.DataFrame
"""
pdf_y = [] # Координаты по оси ординат
for x in X:
pdf_y.append(((2 * x) / rel_sigma) * math.exp((-x ** 2) / rel_sigma))
return pd.DataFrame({'x': X, 'y': pdf_y})
def rel_rand(n: int, rel_sigma: float) -> list:
"""
Генерирует случайные числа с Релеевской плотностью распределения вероятности
:param n: количество отсчетов
:param rel_sigma: среднеквадратическое отклонение
:return: list
"""
rel_list = []
for i in range(n):
rel_list.append((rel_sigma / math.sqrt(2)) * math.sqrt(-2 * math.log(random.uniform(0, 1))))
return rel_list
def gam_pdf(v: float, b: float, X: list) -> pandas.DataFrame:
"""
Вычисляет кривую плотности Гамма распределения вероятности по известной формуле
:param v: параметр формы
:param b: масштабный коэффициент
:param X: координаты по оси абсцисс
:return: pandas.DataFrame
"""
pdf_y = [] # Координаты по оси ординат
for x in X:
pdf_y.append(((b ** v) / math.gamma(v) * (x ** (v - 1)) * math.exp(-b * x)))
return pd.DataFrame({'x': X, 'y': pdf_y})
def gam_rand(n: int, v: float, b: float) -> list:
"""
Генерирует случайные числа с гамма распределением плотности вероятности
:param n: количество отсчетов
:param v: параметр формы
:param b: масштабный коэффициент
:return: list
"""
gam_list = [random.gammavariate(v, 1 / b) for i in range(n)]
return gam_list
def weib_pdf(a: float, b: float, X: list) -> pandas.DataFrame:
"""
Вычисляет кривую плотности распределения вероятности Вейбулла по известной формуле
:param a: масштабный коэффициент
:param b: параметр формы
:param X: координаты по оси абсцисс
:return: pandas.DataFrame
"""
pdf_y = [] # Координаты по оси ординат
for x in X:
pdf_y.append((b / a) * ((x / a) ** (b - 1)) * math.exp(-(x / a) ** b))
return pd.DataFrame({'x': X, 'y': pdf_y})
def weib_rand(n: int, a: float, b: float) -> list:
"""
Генерирует случайные числа с распределением плотности вероятности Вейбулла
:param n: количество отсчетов
:param a: масштабный коэффициент
:param b: параметр формы
:return: list
"""
wei_list = [random.weibullvariate(a, b) for i in range(n)]
return wei_list
def exp_pdf(l: float, X: list) -> pandas.DataFrame:
"""
Вычисляет кривую экспоненциальной плотности распределения вероятности по известной формуле
:param l: обратный коэффициент масштаба
:param n: количество рассчитанных точех
:param X: координаты по оси абсцисс
:return: pandas.DataFrame
"""
pdf_y = [] # Координаты по оси ординат
for x in X:
pdf_y.append(l * math.exp(-l * x))
return pd.DataFrame({'x': X, 'y': pdf_y})
def exp_rand(n: int, l: float) -> list:
"""
Генерирует случайные числа с экспоненциальным распределением плотности вероятности
:param n: количество отсчетов
:param l: обратный коэффициент масштаба
:return: list
"""
exp_list = [random.expovariate(l) for i in range(n)]
return exp_listСгенерируем для каждого распределения наборы случайных величин, и организуем их в словарь:
random_series = {
'rrand': rel_rand(100000, 1), # генерируем случайные числа с распределением Релея
'grand': gam_rand(100000, 0.5, 0.5), # генерируем случайные числа с гамма распределением
'wrand': weib_rand(100000, 1, 5), # генерируем случайные числа с распределением Вейбулла
'exprand': exp_rand(100000, 1.5) # генерируем случайные числа с экспоненциальным распределением
}Далее, эти наборы данных будут использованы для тестирования целиком, либо срезами, содержащими  значений случайной величины.
значений случайной величины.
Оптимизируем алгоритм, основанный на бинаризации данных
В качестве алгоритма нахождения плотности распределения автор предлагает довольно широко распространенный метод, основанный на разбиении интервала значений переменной  на заданное число
на заданное число  бинов равной ширины и подсчет числа вхождений значений переменной в каждый бин, реализованный в ряде библиотек [numpy, scipy, pandas], а также собственную реализацию в соответствии с условиями (оригинальные комментарии сохранены):
бинов равной ширины и подсчет числа вхождений значений переменной в каждый бин, реализованный в ряде библиотек [numpy, scipy, pandas], а также собственную реализацию в соответствии с условиями (оригинальные комментарии сохранены):
def pdf_original(k: int, rnd_list: list) -> pandas.DataFrame:
"""
Получает кривую плотности распределения вероятности
:param k: количечиво интервалов разбиения гистограммы
:param rnd_list: случайный процесс
:return: pandas.DataFrame
"""
pdf_x = [] # Координаты по оси абсцисс
pdf_y = [] # Координаты по оси ординат
n = len(rnd_list) # количество элементов в рассматриваемой выборке
h = (max(rnd_list) - min(rnd_list)) / k # ширина одного интервала
a = min(rnd_list) # минимальное значение в рассматриваемой выборке
for i in range(0, k): # проход по интервалам
count = 0
for j in rnd_list: # подсчет количества вхождений значений из выборки в данный интервал
if (a + i * h) < j < (a + (i * h) + h):
count = count + 1
pdf_x.append(a + i * h + h / 2) # координата по оси абсцисс полученной кривой плотности распределения
# вероятности
pdf_y.append(count / (n * h)) # координата по оси ординат полученной кривой плотности распределения
# вероятности
d = {'x': pdf_x, 'y': pdf_y}
return pd.DataFrame(d)
Можно заметить, что сложность данного алгоритма составляет  , т.к. внешний цикл пробегает
, т.к. внешний цикл пробегает  значений, внутренний же, в худшем случае, пробегает
значений, внутренний же, в худшем случае, пробегает  значений. Грубо оценим время выполнения функции при различных значениях
значений. Грубо оценим время выполнения функции при различных значениях  и
и 
for k in [100, 1000, 10000]:
tic = perf_counter()
_ = pdf_original(k, rrand)
print('%.3f s' % (perf_counter() - tic))
for N in [10000, 20000, 30000]:
tic = perf_counter()
_ = pdf_original(1000, rrand[:N])
print('%.3f s' % (perf_counter() - tic))
Вывод:
0.726 s
7.006 s
69.418 s
0.783 s
1.429 s
2.145 sРазумеется, столь удручающие результаты не позволяют использовать данную реализацию метода, благо есть готовые реализации. Однако, можно добиться линейной сложности алгоритма подсчета значений в бинах по  и константной по
и константной по  , существенно, тем самым, снизив вычислительное время, всего лишь добавив предварительную сортировку значений и заменив внутренний цикл по всем значениям случайной величины на цикл лишь по тем значениям, которые попадают в бин:
, существенно, тем самым, снизив вычислительное время, всего лишь добавив предварительную сортировку значений и заменив внутренний цикл по всем значениям случайной величины на цикл лишь по тем значениям, которые попадают в бин:
def pdf_optimized(k: int, rnd_list: list) -> pandas.DataFrame:
"""
Получает кривую плотности распределения вероятности
:param k: количечиво интервалов разбиения гистограммы
:param rnd_list: случайный процесс
:return: pandas.DataFrame
"""
pdf_x = [] # Координаты по оси абсцисс
pdf_y = [] # Координаты по оси ординат
n = len(rnd_list) # количество элементов в рассматриваемой выборке
h = (max(rnd_list) - min(rnd_list)) / k # ширина одного интервала
a = min(rnd_list) # минимальное значение в рассматриваемой выборке
rnd_list = sorted(rnd_list) # сортируем значения
j = 0 # индекс значения левой границы интервала
for i in range(0, k): # проход по интервалам
count = 0
while j < n and (a + i * h) <= rnd_list[j] < (a + (i * h) + h): # подсчитываем количество значений в k-м интервале
count = count + 1
j += 1
pdf_x.append(a + i * h + h / 2) # координата по оси абсцисс полученной кривой плотности распределения
# вероятности
pdf_y.append(count / (n * h)) # координата по оси ординат полученной кривой плотности распределения
# вероятности
d = {'x': pdf_x, 'y': pdf_y}
return pd.DataFrame(d)
Выполним аналогичное тестирование времени выполнения оптимизированной функции при различных значениях  и
и  добавив некоторое число повторений:
добавив некоторое число повторений:
N_repeats = 100
for k in [100, 1000, 10000]:
tic = perf_counter()
for _ in range(N_repeats):
_ = pdf_optimized(k, random_series['rrand'])
print('%.3f s' % ((perf_counter() - tic) / N_repeats))
for N in [25000, 50000, 100000]:
tic = perf_counter()
for _ in range(N_repeats):
_ = pdf_optimized(10000, random_series['rrand'][:N])
print('%.3f s' % ((perf_counter() - tic) / N_repeats))
Вывод:
0.035 s
0.034 s
0.039 s
0.013 s
0.021 s
0.038 sС такими результатами гораздо приятнее иметь дело и такую нативную реализацию можно использовать в условиях, когда нет возможности устанавливать дополнительные пакеты. Следует, однако, заметить, что ассимптотическая сложность метода определяется алгоритмом сортировки, и в данном случае составляет  .
.
Примечание:
Представленные выше реализации используют нестрогое равенство для сравнения действительных чисел, что, вообще говоря, некорректно. Вследствие этого могут возникать граничные эффекты, поскольку вхождения минимального/максимального значений случайной величины в первый/последний бины не гарантировано. Следует немного модифицировать реализацию, добавив учет по умолчанию минимального и максимального значений случайной величины в первом и последнем бинах, соответственно, и пробегать в цикле по оставшимся значениям.
Считаем плотность распределения через функцию распределения
Далее рассмотрим несколько иной подход к получению оценки плотности распределения случайной величины. Вспомним, что плотность распределения случайной величины представляет собой первую производную от функции распределения, которая, в свою очередь, является вероятностью обнаружить значение случайной величины меньше либо равное заданному. Для того, чтобы получить оценку функции распределения вероятности, а из нее, в свою очередь, плотность распределения, предлагается выполнить следующие шаги:
-
сортируем значения переменной
 по возрастанию, получаем набор отсортированных значений ;
по возрастанию, получаем набор отсортированных значений ; -
ставим в соответствие каждому значению в массиве отсортированных значений его порядковый номер
начиная с нуля — с точностью до множителя, представляет собой оценку функции распределения случайной величины (Рисунок 1, синяя кривая); -
строим равномерную шкалу из
значений на интервале от до где — желаемое число точек кривой плотности распределения () — аналог числа бинов в гистограмме; -
интерполируем значения номеров переменных из шкалы упорядоченного массива значений переменной в равномерную шкалу, полученную в п. 3 (Рисунок 1, оранжевая кривая);
-
численно берем производную от интерполированной функции по соседним точкам (для этого и было нужно
значений) и делим на — получаем, таким образом, искомую оценку плотности вероятности.
 по возрастанию, получаем набор отсортированных значений
по возрастанию, получаем набор отсортированных значений  ;
; начиная с нуля — с точностью до множителя,
начиная с нуля — с точностью до множителя,  представляет собой оценку функции распределения случайной величины (Рисунок 1, синяя кривая);
представляет собой оценку функции распределения случайной величины (Рисунок 1, синяя кривая); значений на интервале от
значений на интервале от  до
до  где
где  — желаемое число точек кривой плотности распределения (
— желаемое число точек кривой плотности распределения ( ) — аналог числа бинов в гистограмме;
) — аналог числа бинов в гистограмме; значений) и делим на
значений) и делим на  — получаем, таким образом, искомую оценку плотности вероятности.
— получаем, таким образом, искомую оценку плотности вероятности.
Ниже представлена реализация метода:
def pdf_custom(k: int, rnd_list: list):
"""
Получает кривую плотности распределения вероятности
:param k: количечиво интервалов разбиения гистограммы
:param rnd_list: случайный процесс
:return: pandas.DataFrame
"""
X = sorted(rnd_list) # сортируем значения случайной переменной
N = len(X)
i = 0
dx = (X[-1] - X[0]) / (k + 2) # находим шаг по аргументу в равномерной шкале
result = []
result_x = []
for j in range(k + 2): # пробегаем по точкам
x = X[0] + j * dx # находим соответствующее значение аргумента в равномерной шкале
result_x.append(x)
while True: # с помощью данного цикла находим индекс i такой,
# что x лежит в пределах от X[i] до X[i+1]
if x > X[i + 1]:
i += 1
else:
break
result.append(i + (x - X[i]) / (X[i + 1] - X[i]))
norm = 0.5 / dx / N
d = {
'x': result_x[1:-1],
'y': [(right - left) * norm for right, left in zip(result[2:], result[:-2])]}
return pd.DataFrame(d)Сложность представленного алгоритма также составляет  . В результате тестирования времени выполнения получим следующие значения для
. В результате тестирования времени выполнения получим следующие значения для  = [100, 1000, 10000] при
= [100, 1000, 10000] при  = 100 000 и
= 100 000 и  = [25000, 50000, 100000] при
= [25000, 50000, 100000] при  = 10 000:
= 10 000:
0.020 s
0.020 s
0.024 s
0.009 s
0.014 s
0.024 sНовый метод оказался несколько быстрее, при той же алгоритмической сложности.
Сравниваем точность представленных методов
Для сравнения точности представленных методов будем использовать расстояние Кульбака-Лейблера от априорной функции плотности распределения  до получаемой оценки
до получаемой оценки  :
:
![]()
Для вычисления метрики уже, не мудрствуя лукаво, будем использовать numpy:
def KL_dist(P: list, Q: list):
assert len(P) == len(Q)
eps = 1e-9
P = np.asarray(P)
Q = np.asarray(Q)
return np.mean(P * (np.log(P + eps) - np.log(Q + eps)))Получим оценки плотности распределения случайной величины для разных априорных распределений при разных соотношениях  и сравним значений KL-дивергенции:
и сравним значений KL-дивергенции:
from functools import partial
pdf_function = {
'rrand': partial(rel_pdf, 1),
'grand': partial(gam_pdf, 0.5, 0.5),
'wrand': partial(weib_pdf, 1, 5),
'exprand': partial(exp_pdf, 1.5)
}
N = 10000
k_values = np.logspace(2, 4, 10, dtype=np.int)
metrics_optimized = {}
for key, val in random_series.items():
for k in k_values:
estimated_pdf = pdf_optimized(k, val[:N])
theoretical_pdf = pdf_function[key](estimated_pdf['x'])
metrics_optimized.setdefault(key, []).append(
KL_dist(theoretical_pdf['y'], estimated_pdf['y']))
metrics_custom = {}
for key, val in random_series.items():
for k in k_values:
estimated_pdf = pdf_custom(k, val[:N])
theoretical_pdf = pdf_function[key](estimated_pdf['x'])
metrics_custom.setdefault(key, []).append(
KL_dist(theoretical_pdf['y'], estimated_pdf['y']))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
for key, val in metrics_optimized.items():
plt.scatter(k_values / N, val)
plt.legend(metrics_optimized.keys())
plt.xlabel('k / N')
plt.ylabel('KL-divergency')
plt.title('Метод на основе гистограмм')
plt.subplot(1, 2, 2)
for key, val in metrics_custom.items():
plt.scatter(k_values / N, val)
plt.legend(metrics_custom.keys())
plt.xlabel('k / N')
plt.ylabel('KL-divergency')
plt.title('Метод на основе функции распределения')В результате ожидаемо в обоих случаях получаются монотонно возрастающие зависимости метрики от соотношения  (Рисунок 2), однако, метод, основанный на численном дифференцировании функции распределения случайной величины дает на порядок меньшее расхождение кривой оценки плотности распределения с теоретической кривой, чем метод, основанный на построении гистограммы, что особенно заметно при больших значениях
(Рисунок 2), однако, метод, основанный на численном дифференцировании функции распределения случайной величины дает на порядок меньшее расхождение кривой оценки плотности распределения с теоретической кривой, чем метод, основанный на построении гистограммы, что особенно заметно при больших значениях  .
.
 и метода, основанного на взятии произвоной от оценки функции распределения (справа).")
Заключение
Предложенный альтернативный метод построения оценок плотности распределения случайной величины по заданному набору наблюдений отличается более высокой точностью, по сравнению с методом, основанным на получении гистограмм.
Выражаю благодарность MilashchenkoEA за обсуждение данных проблем и за то, что убедил написать эту небольшую заметку 
2.4.3. Функция ПЛОТНОСТИ распределения вероятностей
или дифференциальная функция распределения. Она представляет собой производную функции распределения: ![]() .
.
Примечание: для дискретной случайной величины такой функции не существует
В нашем примере:
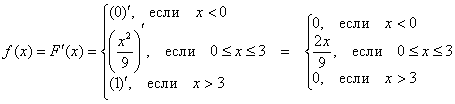
то есть, всё очень просто – берём производную от каждого куска, и порядок.
Но настоящий порядок состоит в том, что несобственный интеграл от ![]() с пределами интегрирования от «минус» до «плюс» бесконечности:
с пределами интегрирования от «минус» до «плюс» бесконечности:
![]() – равен единице, и строго единице. В противном случае перед нами не функция плотности, и если эта функция была найдена как производная, то
– равен единице, и строго единице. В противном случае перед нами не функция плотности, и если эта функция была найдена как производная, то ![]() – не является функцией распределения (несмотря на какие бы то ни было другие признаки).
– не является функцией распределения (несмотря на какие бы то ни было другие признаки).
Проверим «подлинность» наших функций. Если случайная величина ![]() принимает значения из конечного промежутка, то всё дело сводится к вычислению определённого интеграла. В силу свойства аддитивности, делим интеграл на 3 части:
принимает значения из конечного промежутка, то всё дело сводится к вычислению определённого интеграла. В силу свойства аддитивности, делим интеграл на 3 части:

Совершенно понятно, что левый и правый интегралы равны нулю и нам осталось вычислить средний интеграл:
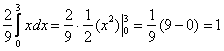 , что и требовалось проверить.
, что и требовалось проверить.
С вероятностной точки зрения это означает, что случайная величина ![]() достоверно примет одно из значений отрезка
достоверно примет одно из значений отрезка ![]() . Геометрически же это значит, что площадь между осью
. Геометрически же это значит, что площадь между осью ![]() и графиком
и графиком ![]() равна единице, и в данном случае речь идёт о площади треугольника
равна единице, и в данном случае речь идёт о площади треугольника ![]() . Сторона
. Сторона ![]() является фрагментом прямой
является фрагментом прямой ![]() и для её построения достаточно найти точку
и для её построения достаточно найти точку ![]() :
:
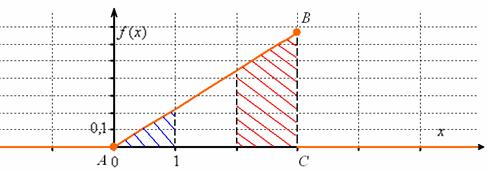
Ну вот, теперь всё наглядно – где бОльшая площадь, там и сконцентрированы более вероятные значения.
Так как функция плотности «собирает под собой» вероятности, то она неотрицательна ![]() и её график не может располагаться ниже оси
и её график не может располагаться ниже оси ![]() . В общем случае функция разрывна (смотрим, где «жирные» оранжевые точки!).
. В общем случае функция разрывна (смотрим, где «жирные» оранжевые точки!).
Теперь разберём весьма любопытный факт: поскольку действительных чисел несчётно много, то вероятность того, что случайная величина ![]() примет какое-то конкретное значение стремится к нулю. И поэтому вероятности рассчитывают не для отдельно взятых точек, а для целых промежутков (пусть даже очень малых). Как вы правильно догадываетесь:
примет какое-то конкретное значение стремится к нулю. И поэтому вероятности рассчитывают не для отдельно взятых точек, а для целых промежутков (пусть даже очень малых). Как вы правильно догадываетесь:
 (синяя площадь на чертеже) – вероятность того, что случайная величина примет значение из отрезка
(синяя площадь на чертеже) – вероятность того, что случайная величина примет значение из отрезка ![]() ;
;
![]() (красная площадь) – вероятность того, что случайная величина примет значение из отрезка
(красная площадь) – вероятность того, что случайная величина примет значение из отрезка ![]() .
.
По той причине, что отдельно взятые значения можно не принимать во внимание, с помощью этих же интегралов рассчитываются и вероятности по интервалам и полуинтервалам, в частности:

Этим же объяснятся аналогичная «вольность» с функцией ![]() .
.
Возможно, кто-то спросит: а зачем считать интегралы, если есть функция ![]() ?
?
А дело в том, что во многих задачах непрерывная случайная величина ИЗНАЧАЛЬНО задана функцией ![]() плотности распределения, которая ТОЖЕ однозначно определяет случайную величину. Но, как вариант, можно сначала найти функцию
плотности распределения, которая ТОЖЕ однозначно определяет случайную величину. Но, как вариант, можно сначала найти функцию ![]() (с помощью тех же интегралов), после чего использовать «лёгкий способ» бросить курить отыскания вероятностей. Впрочем, об этом чуть позже:
(с помощью тех же интегралов), после чего использовать «лёгкий способ» бросить курить отыскания вероятностей. Впрочем, об этом чуть позже:
Задача 105
Непрерывная случайная величина ![]() задана своей функцией распределения:
задана своей функцией распределения:
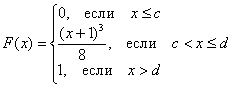
Найти значения ![]() и функцию
и функцию ![]() . Проверить, что
. Проверить, что ![]() действительно является функцией плотности распределения. Вычислить вероятности
действительно является функцией плотности распределения. Вычислить вероятности ![]() . Построить графики
. Построить графики ![]() .
.
Тренируемся самостоятельно! Если возникнут затруднения, то внимательно перечитайте вышеизложенный материал. Краткое решение и ответ в конце книги.
Вообще, типовые задачи на непрерывную случайную величину можно разделить на 2 большие группы:
1) когда дана функция ![]() , 2) когда дана функция
, 2) когда дана функция ![]() .
.
В первом случае не составляет особых трудностей отыскать функцию плотности распределения – почти всегда производные не то что простЫ, а примитивны (в чём мы только что убедились). Но вот когда НСВ задана функцией ![]() , то нахождение функции распределения – есть более кропотливый процесс:
, то нахождение функции распределения – есть более кропотливый процесс:
Задача 106
Непрерывная случайная величина ![]() задана функцией плотности распределения:
задана функцией плотности распределения:
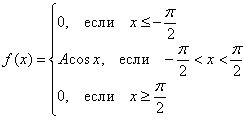
Найти значение ![]() и составить функцию распределения вероятностей
и составить функцию распределения вероятностей ![]() . Вычислить
. Вычислить ![]() .
.
Построить графики ![]() .
.
Решение: найдём константу ![]() . Это классика (в подавляющем большинстве задач вам не предложат готовую функцию плотности). Используем свойство
. Это классика (в подавляющем большинстве задач вам не предложат готовую функцию плотности). Используем свойство ![]() .
.
В данном случае:

На практике нулевые интегралы можно опускать, а константу сразу выносить за знак интеграла:
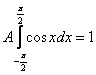 (*)
(*)
Пользуясь чётностью подынтегральной функции, вычислим интеграл:
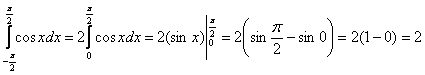 и подставим результат в уравнение (*):
и подставим результат в уравнение (*):
![]() , откуда выразим
, откуда выразим ![]()
Таким образом, функция плотности распределения:
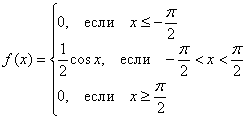
Выполним проверку, а именно, вычислим тот же самый интеграл, но уже с известной константой. Для разнообразия я не буду пользоваться чётностью:
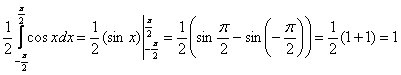 , отлично.
, отлично.
Обратите внимание, что только при ![]() и только при этом значении предложенная в условии функция является функцией плотности распределения. Ну и тут не лишним будет проконтролировать, что на интервале
и только при этом значении предложенная в условии функция является функцией плотности распределения. Ну и тут не лишним будет проконтролировать, что на интервале ![]() , т.е. условие неотрицательности действительно выполнено. Доверяй условию, да проверяй
, т.е. условие неотрицательности действительно выполнено. Доверяй условию, да проверяй  Не раз и не два мне встречались функции, которые в принципе не могли быть плотностью, что говорило об опечатках или о невнимательности авторов задач.
Не раз и не два мне встречались функции, которые в принципе не могли быть плотностью, что говорило об опечатках или о невнимательности авторов задач.
Теперь начинается самое интересное. Функции распределения вероятностей – есть интеграл:
![]()
Так как ![]() состоит из трёх кусков, то решение разобьётся на 3 шага:
состоит из трёх кусков, то решение разобьётся на 3 шага:
1) На промежутке ![]() , поэтому:
, поэтому: ![]()
2) На интервале ![]() , и мы прицепляем следующий вагончик:
, и мы прицепляем следующий вагончик:
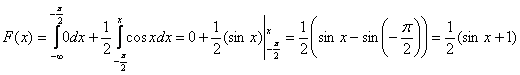
При подстановке верхнего предела интегрирования можно считать, что вместо «икс» мы подставляем «икс». Если же возник вопрос с пределом нижним, то вспоминаем график синуса либо его нечётность: ![]() .
.
3) И, наконец, на ![]() , и детский паровозик отправляется в путь:
, и детский паровозик отправляется в путь:

Внимание! А вот в этом задании нулевые интегралы пропускать НЕ НАДО. Чтобы показать своё понимание функции распределения К тому же, они могут оказаться вовсе не нулевыми, и тогда придётся иметь дело с интегралами несобственными. И такой пример я обязательно разберу ниже.
Записываем наши достижения под единую скобку:
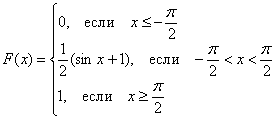
С высокой вероятностью всё правильно, но, тем не менее, устно возьмём производную: 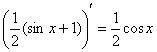 , а также «прозвоним» точки «стыка»:
, а также «прозвоним» точки «стыка»:
![]()
Правильность решения можно проконтролировать и в ходе построения графика, но, во-первых, он не всегда требуется, а во-вторых, до сего момента можно успеть «наломать дров». Ибо вероятности попадания чаще находят с помощью функции распределения:
![]()
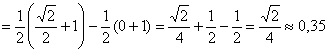 – вероятность того, что случайная величина
– вероятность того, что случайная величина ![]() примет значение из промежутка
примет значение из промежутка ![]()
Второй способ состоит в вычислении интеграла:
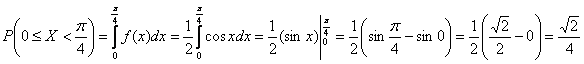 что, кстати, не труднее. И проверочка заодно получилась.
что, кстати, не труднее. И проверочка заодно получилась.
Выполним чертежи. График ![]() представляет собой
представляет собой косинусоиду, сжатую вдоль ординат в 2 раза. Тот редкий случай, когда функция плотности непрерывна:
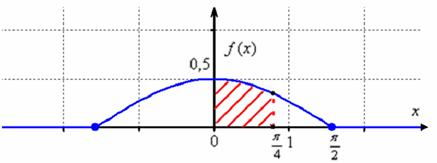
Значение ![]() численно равно заштрихованной площади – это я специально нарисовал, чтобы напомнить вероятностный смысл плотности функции распределения. И вся площадь под «дугой» равна единице, то есть, достоверным является тот факт, что случайная величина примет значение из интервала
численно равно заштрихованной площади – это я специально нарисовал, чтобы напомнить вероятностный смысл плотности функции распределения. И вся площадь под «дугой» равна единице, то есть, достоверным является тот факт, что случайная величина примет значение из интервала ![]() . Заметьте, что значения
. Заметьте, что значения ![]() по условию, невозможны.
по условию, невозможны.
Осталось изобразить функцию распределения. График ![]() представляет собой синусоиду, сжатую в 2 раза вдоль оси ординат и сдвинутую на
представляет собой синусоиду, сжатую в 2 раза вдоль оси ординат и сдвинутую на ![]() вверх:
вверх:
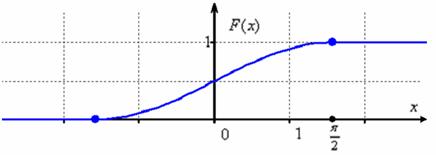
В принципе, тут можно было не заморачиваться преобразованием графиков, а найти несколько опорных точек и догадаться, как выглядит кривая (тригонометрическая таблица в помощь). Но «любительский» подход чреват тем, что график получится принципиально не точным. Так, в нашем примере в точке ![]() существует перегиб графика функции
существует перегиб графика функции ![]() , и велик риск неверно отобразить его выпуклость / вогнутость.
, и велик риск неверно отобразить его выпуклость / вогнутость.
Чертежи желательно расположить так, чтобы оси ординат (вертикальные оси) лежали ровненько одна под другой. Это будет хорошим тоном.
И я так чувствую, вам уже не терпится проверить свои силы. Как водится, пример попроще:
Задача 107
Задана плотность распределения вероятностей непрерывной случайной величины ![]() :
:
![]()
Требуется:
1) определить коэффициент ![]() ;
;
2) найти функцию распределения ![]() ;
;
3) построить графики ![]() ;
;
4) найти вероятность того, что ![]() примет значение из промежутка
примет значение из промежутка ![]()
и задачка поинтереснее:
Задача 108
Непрерывная случайная величина ![]() задана плотностью распределения вероятностей:
задана плотностью распределения вероятностей:
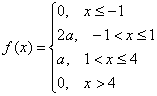
Найти значение ![]() и построить график плотности распределения. Найти функцию распределения вероятностей
и построить график плотности распределения. Найти функцию распределения вероятностей ![]() и построить её график. Вычислить вероятность
и построить её график. Вычислить вероятность ![]() .
.
Дерзайте! Свериться с решением можно внизу книги.
Следует отметить, что все эти задачи реально предлагают студентам-заочникам, и поэтому я не предлагаю вам ничего необычного.
И в заключение параграфа обещанные случаи с несобственными интегралами:
Задача 109
Непрерывная случайная величина ![]() задана своей плотностью распределения:
задана своей плотностью распределения:
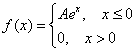
Найти коэффициент ![]() и функцию распределения
и функцию распределения ![]() . Построить графики.
. Построить графики.
Решение: по свойству функции плотности распределения:
![]()
В данной задаче ![]() состоит из 2 частей, поэтому:
состоит из 2 частей, поэтому:
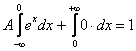
Правый интеграл равен нулю, а вот левый – есть «живой» несобственный интеграл с бесконечным нижним пределом:
![]()
Таким образом, наше уравнение превратилось в готовый результат:
![]()
и функция плотности:
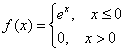
Функция ![]() , как нетрудно понять, отыскивается в 2 шага:
, как нетрудно понять, отыскивается в 2 шага:
1) На промежутке ![]() , следовательно:
, следовательно:
![]() – вот такая вот у нас замечательная экспонента. Как птица Феникс.
– вот такая вот у нас замечательная экспонента. Как птица Феникс.
2) На интервале ![]() и:
и:
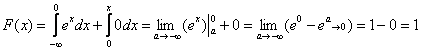 , что и должно получиться.
, что и должно получиться.
Для построения графиков найдём пару опорных точек: ![]() и аккуратно прочертим кусочки экспонент с причитающимися дополнениями:
и аккуратно прочертим кусочки экспонент с причитающимися дополнениями:

Заметьте, что теоретически случайная величина ![]() может принять сколь угодно большое по модулю отрицательное значение, и ось абсцисс является горизонтальной асимптотой для обоих графиков при
может принять сколь угодно большое по модулю отрицательное значение, и ось абсцисс является горизонтальной асимптотой для обоих графиков при ![]() .
.
В соответствующей статье сайта я рассмотрел ещё более интересный пример с функцией ![]() , где случайная величина теоретически принимает вообще ВСЕ действительные значения. Но это уже несколько повышенный уровень сложности.
, где случайная величина теоретически принимает вообще ВСЕ действительные значения. Но это уже несколько повышенный уровень сложности.
 2.4.4. Как вычислить математическое ожидание и дисперсию НСВ?
2.4.4. Как вычислить математическое ожидание и дисперсию НСВ?
 2.4.2. Вероятность попадания в промежуток
2.4.2. Вероятность попадания в промежуток
| Оглавление |
Полную и свежую версию этой книги в pdf-формате,
а также курсы по другим темам можно найти здесь.
Также вы можете изучить эту тему подробнее – просто, доступно, весело и бесплатно!
С наилучшими пожеланиями, Александр Емелин
Плотность распределения
Плотность распределения вероятностей непрерывной случайной величины
Опр Плотностью распределения вероятностей непрерывной случайной величины $X$ называют функцию $f( x )-$ первую производную от функции распределения $F( x )$ begin{equation} label { eq2 } { F } ‘( x )=f( x ) end{equation}
Следовательно, функция распределения $F( x )$ является первообразной для функции плотности распределения вероятностей $f( x )$.
Теорема Вероятность того, что непрерывная случайная величина X примет значение принадлежащее интервалу $( { a,b } )$ равна определенному интегралу от плотности. begin{equation} label { eq3 } P( { aleqslant X<b } )=intlimits_a^b { f( x )dx } end{equation}
Геометрически этот результат можно трактовать так: вероятность того, что случайная величина $X$ примет значение принадлежащее интервалу $( { a,b } )$ равна площади криволинейной трапеции.

Нахождение функции распределения по известной плотности распределения
Зная плотность распределения вероятностей $f( x )$ можно найти функцию распределения $F( x )$ по формуле: begin{equation} label { eq4 } F( x )=intlimits_ { -infty } ^x { f( x )dx } end{equation}
Пример. Найти функцию распределения по данной плотности и построить график. $ f( x )=left{ { { begin{array} { c } { 0,при,x=1 } \ { frac { 1 } { 2 } ,при,1<xleqslant 3 } \ { 0,при,x>3 } \ end{array} } }right. $
Решение. Построим график функции плотности распределения вероятностей.

$F( x )=intlimits_ { -infty } ^x { f( x )dx } $
Воспользуемся формулой
- при $xleqslant 1$ из условия $f( x )=0,Rightarrow F( x )=0 $
- при $,1<xleqslant 2,, f( x )=frac { 1 } { 2 } $, тогда
$F( x )=intlimits_ { -infty } ^x { f( x )dx } =intlimits_ { -infty } ^1 { 0dx } +intlimits_1^x { frac { 1 } { 2 } dx } =frac { 1 } { 2 } xleft| { _ { _1 } ^ { ^x } }right.=frac { x-1 } { 2 } $
если $x>3$, тогда $ F( x )=intlimits_ { -infty } ^x { f( x )dx } =intlimits_ { -infty } ^1 { 0dx } +intlimits_1^3 { frac { 1 } { 2 } dx } +intlimits_3^x { 0dx } =frac { x } { 2 } left| { _ { _1 } ^ { ^3 } }right.=1. $
Итак $ F( x )=left{ { { begin{array} { c } { 0,если,xleqslant 1 } \ { frac { x-1 } { 2 } ,если,1<xleqslant 3 } \ { 1,если,x>3 } \ end{array} } }right. $
Построим график функции распределения

Свойства плотности распределения
1). Плотность распределения неотрицательная функция $f( x )geqslant 0$.
Доказательство Известно, что функция распределения $F( x )-$ неубывающая, следовательно, ее производная $ { F } ‘( x )=f( x )$ неотрицательная функция.
Геометрически это означает, что график $f( x )$ расположен выше оси OX или на оси OX.
График $f( x )$плотности распределения называется кривой распределения.
2). Несобственный интеграл от плотности распределения в пределах от $( { -infty ,infty } )$ равен 1. begin{equation} label { eq5 } intlimits_ { -infty } ^infty { f( x ) } dx=1 end{equation}
Если $X$ задана на $( { a,b } )$, то $intlimits_a^b { f( x )dx=1 } $
Геометрически это означает, что площадь под кривой распределения равна 1.