stringContain variants (compatible or case independent)
As these Stack Overflow answers tell mostly about Bash, I’ve posted a case independent Bash function at the very bottom of this post…
Anyway, there is my
Compatible answer
As there are already a lot of answers using Bash-specific features, there is a way working under poorer-featured shells, like BusyBox:
[ -z "${string##*$reqsubstr*}" ]
In practice, this could give:
string='echo "My string"'
for reqsubstr in 'o "M' 'alt' 'str';do
if [ -z "${string##*$reqsubstr*}" ] ;then
echo "String '$string' contain substring: '$reqsubstr'."
else
echo "String '$string' don't contain substring: '$reqsubstr'."
fi
done
This was tested under Bash, Dash, KornShell (ksh) and ash (BusyBox), and the result is always:
String 'echo "My string"' contain substring: 'o "M'.
String 'echo "My string"' don't contain substring: 'alt'.
String 'echo "My string"' contain substring: 'str'.
Into one function
As asked by @EeroAaltonen here is a version of the same demo, tested under the same shells:
myfunc() {
reqsubstr="$1"
shift
string="$@"
if [ -z "${string##*$reqsubstr*}" ] ;then
echo "String '$string' contain substring: '$reqsubstr'.";
else
echo "String '$string' don't contain substring: '$reqsubstr'."
fi
}
Then:
$ myfunc 'o "M' 'echo "My String"'
String 'echo "My String"' contain substring 'o "M'.
$ myfunc 'alt' 'echo "My String"'
String 'echo "My String"' don't contain substring 'alt'.
Notice: you have to escape or double enclose quotes and/or double quotes:
$ myfunc 'o "M' echo "My String"
String 'echo My String' don't contain substring: 'o "M'.
$ myfunc 'o "M' echo "My String"
String 'echo "My String"' contain substring: 'o "M'.
Simple function
This was tested under BusyBox, Dash, and, of course Bash:
stringContain() { [ -z "${2##*$1*}" ]; }
Then now:
$ if stringContain 'o "M3' 'echo "My String"';then echo yes;else echo no;fi
no
$ if stringContain 'o "M' 'echo "My String"';then echo yes;else echo no;fi
yes
… Or if the submitted string could be empty, as pointed out by @Sjlver, the function would become:
stringContain() { [ -z "${2##*$1*}" ] && [ -z "$1" -o -n "$2" ]; }
or as suggested by Adrian Günter’s comment, avoiding -o switches:
stringContain() { [ -z "${2##*$1*}" ] && { [ -z "$1" ] || [ -n "$2" ];};}
Final (simple) function:
And inverting the tests to make them potentially quicker:
stringContain() { [ -z "$1" ] || { [ -z "${2##*$1*}" ] && [ -n "$2" ];};}
With empty strings:
$ if stringContain '' ''; then echo yes; else echo no; fi
yes
$ if stringContain 'o "M' ''; then echo yes; else echo no; fi
no
Case independent (Bash only!)
For testing strings without care of case, simply convert each string to lower case:
stringContain() {
local _lc=${2,,}
[ -z "$1" ] || { [ -z "${_lc##*${1,,}*}" ] && [ -n "$2" ] ;} ;}
Check:
stringContain 'o "M3' 'echo "my string"' && echo yes || echo no
no
stringContain 'o "My' 'echo "my string"' && echo yes || echo no
yes
if stringContain '' ''; then echo yes; else echo no; fi
yes
if stringContain 'o "M' ''; then echo yes; else echo no; fi
no
Работа со строками в bash осуществляется при помощи встроенных в оболочку команд.
Термины
- Консольные окружения — интерфейсы, в которых работа выполняется в текстовом режиме.
- Интерфейс — механизм взаимодействия пользователя с аппаратной частью компьютера.
- Оператор — элемент, задающий законченное действие над каким-либо объектом операционной системы (файлом, папкой, текстовой строкой и т. д.).
- Текстовые массивы данных — совокупность строк, записанных в переменную или файл.
- Переменная — поименованная область памяти, позволяющая осуществлять запись и чтение данных, которые в нее записываются. Она может принимать любые значения: числовые, строковые и т. д.
- Потоковый текстовый редактор — программа, поддерживающая потоковую обработку текстовой информации в консольном режиме.
- Регулярные выражения — формальный язык поиска части кода или фрагмента текста (в том числе строки) для дальнейших манипуляций над найденными объектами.
- Bash-скрипты — файл с набором инструкций для выполнения каких-либо манипуляций над строкой, текстом или другими объектами операционной системы.
Сравнение строковых переменных
Для выполнения операций сопоставления 2 строк (str1 и str2) в ОС на основе UNIX применяются операторы сравнения.
Основные операторы сравнения
- Равенство «=»: оператор возвращает значение «истина» («TRUE»), если количество символов в строке соответствует количеству во второй.
- Сравнение строк на эквивалентность «==»: возвращается «TRUE», если первая строка эквивалентна второй (дом == дом).
- Неравенство «str1 != str2»: «TRUE», если одна строковая переменная не равна другой по количеству символов.
- Неэквивалентность «str1 !== str2»: «TRUE», если одна строковая переменная не равна другой по смысловому значению (дерево !== огонь).
- Первая строка больше второй «str1 > str2»: «TRUE», когда str1 больше str2 по алфавитному порядку. Например, «дерево > огонь», поскольку литера «д» находится ближе к алфавитному ряду, чем «о».
- Первая строка меньше второй «str1 < str2»: «TRUE», когда str1 меньше str2 по алфавитному порядку. Например, «огонь < дерево», поскольку «о» находится дальше к началу алфавитного ряда, чем «д».
- Длина строки равна 0 «-z str2»: при выполнении этого условия возвращается «TRUE».
- Длина строки отлична от нулевого значения «-n str2»: «TRUE», если условие выполняется.
Пример скрипта для сравнения двух строковых переменных
- Чтобы сравнить две строки, нужно написать bash-скрипт с именем test.

- Далее необходимо открыть терминал и запустить test на выполнение командой:
./test
- Предварительно необходимо дать файлу право на исполнение командой:
chmod +x test
- После указания пароля скрипт выдаст сообщение на введение первого и второго слова. Затем требуется нажать клавишу «Enter» для получения результата сравнения.


Создание тестового файла
Обработка строк не является единственной особенностью консольных окружений Ubuntu. В них можно обрабатывать текстовые массивы данных.
- Для практического изучения команд, с помощью которых выполняется работа с текстом в интерпретаторе bash, необходимо создать текстовый файл txt.
- После этого нужно наполнить его произвольным текстом, разделив его на строки. Новая строка не должна сливаться с другими элементами.
- Далее нужно перейти в директорию, в которой находится файл, и запустить терминал с помощью сочетания клавиш — Ctrl+Alt+T.
Основы работы с grep
Поиск строки в файле операционной системы Linux Ubuntu осуществляется посредством специальной утилиты — grep. Она позволяет также отфильтровать вывод информации в консоли. Например, вывести все ошибки из log-файла утилиты ps или найти PID определенного процесса в ее отчете.
Команда grep работает с шаблонами и регулярными выражениями. Кроме того, она применяется с другими командами интерпретатора bash.
Синтаксис команды
Для работы с утилитой grep необходимо придерживаться определенного синтаксиса
- grep [options] pattern [file_name1 file_name2 file_nameN] (где «options» — дополнительные параметры для указания настроек поиска и вывода результата; «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет осуществляться поиск; «file_name1 file_name2 file_nameN» — имя одного или нескольких файлов, в которых производится поиск).
- instruction | grep [options] pattern (где «instruction» — команда интерпретатора bash, «options» — дополнительные параметры для указания настроек поиска и вывода результата, «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет производиться поиск).
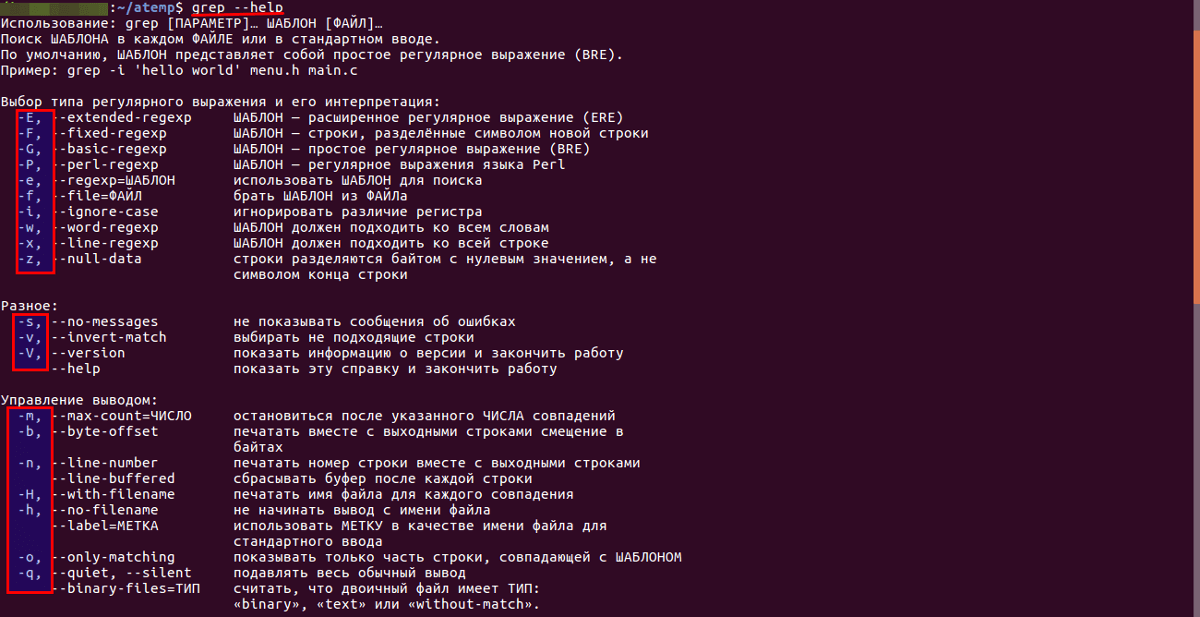
Основные опции
- Отобразить в консоли номер блока перед строкой — -b.
- Число вхождений шаблона строки — -с.
- Не выводить имя файла в результатах поиска — -h.
- Без учета регистра — -i.
- Отобразить только имена файлов с совпадением строки — -l.
- Показать номер строки — -n.
- Игнорировать сообщения об ошибках — -s.
- Инверсия поиска (отображение всех строк, в которых не найден шаблон) — -v.
- Слово, окруженное пробелами, — -w.
- Включить регулярные выражения при поиске — -e.
- Отобразить вхождение и N строк до и после него — -An и -Bn соответственно.
- Показать строки до и после вхождения — -Cn.
Практическое применение grep
Поиск подстроки в строке

В окне терминала выводятся все строки, содержащие подстроку. Найденные совпадения подсвечиваются другим цветом.
- С учетом регистра:
grep Bourne firstfile.txt
- Без учета регистра:
grep -i "Bourne"txt
Вывод нескольких строк
- Строка с вхождением и две после нее:
grep -A2 "Bourne"txt
- Строка с вхождением и три до нее:
grep -B3 "Bourne"txt
- Строка, содержащая вхождение, и одну до и после нее:
grep -C1 "Bourne"txt
Чтение строки из файла с использованием регулярных выражений
Регулярные выражения расширяют возможности поиска и позволяют выполнить разбор строки на отдельные элементы. Они активируются при помощи ключа -e.
- Вывод строки, в начале которой встречается слово «Фамилия».
 В регулярных выражения для обозначения начала строки используется специальный символ «^».
В регулярных выражения для обозначения начала строки используется специальный символ «^».
grep "^Фамилия" firstfile.txt
Чтобы вывести первый символ строки, нужно воспользоваться конструкцией
grep "^Ф" firstfile.txt
- Конец строки, заканчивающийся словом «оболочка». Для обозначения конца строки используется мета-символ «$».
grep «оболочка$» firstfile.txt Если требуется вывести символ конца строки, то следует применять конструкцию
grep «а.$» firstfile.txt. В этом случае будут выведены все строки, заканчивающиеся на литеру «а».

- Строки, содержащие числа.
grep -C1 "Bourne"txt
Если воспользоваться числовыми интервалами, то можно вывести все строки, в которых встречаются числа:
grep "[0-9]"txt

Рекурсивный режим поиска
- Чтобы найти строку или слово в нескольких файлах, расположенных в одной папке, нужно использовать рекурсивный режим поиска:
grep -r "оболочка$"
- Если нет необходимости выводить имена файлов, содержащих искомую строку, то можно воспользоваться ключом-параметром деактивации отображения имен:
grep -h -r "оболочка$"
Точное вхождение
При поиске союза «и» grep будет выводить все строки, в которых он содержится. Чтобы этого избежать, требуется использовать специальный ключ «w»:
grep -w "и" firstfile.txt
Поиск нескольких слов
Утилита «w» позволяет искать не только одно слово, но и несколько одновременно
grep -w "и | но" firstfile.txt
Количество строк в файле
При помощи grep можно определить число вхождений строки или подстроки в текстовом файле и вывести ее номер.
![]()
- Число вхождений:
grep -с "Bourne"txt
- Номера строк с совпадениями:
grep -n "Bourne"txt
Инверсия
Если в тексте требуется найти определенные строки, которые не содержат какого-либо слова или подстроки, то рекомендуется использовать инверсионный режим поиска.
grep -v "Unix" firstfile.txt
Вывод только имени файла
Чтобы не выводить все строки с совпадением, а вывести только имя файла, нужно воспользоваться конструкцией:
grep -I "Unix" *.txt
Использование sed
Потоковый текстовый редактор «sed» встроен в bash Linux Ubuntu. Он использует построчное чтение, а также позволяет выполнить фильтрацию и преобразование текста.
Синтаксис
Для работы с потоковым текстовым редактором sed используется следующий синтаксис:
sed [options] instructions [file_name] (где «options» — ключи-опции для указания метода обработки текста, «instructions» — команда, совершаемая над найденным фрагментом текста, «file_name» — имя файла, над которым совершаются действия).
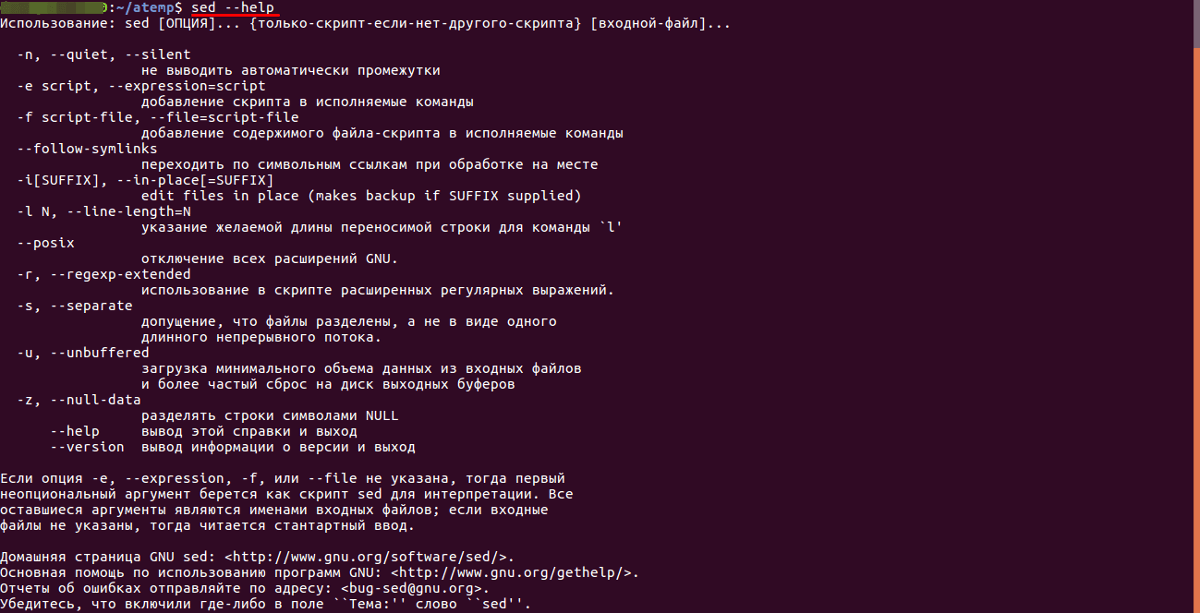
Для вывода всех опций потокового текстового редактора нужно воспользоваться командой:
sed --help
Распространенные конструкции с sed
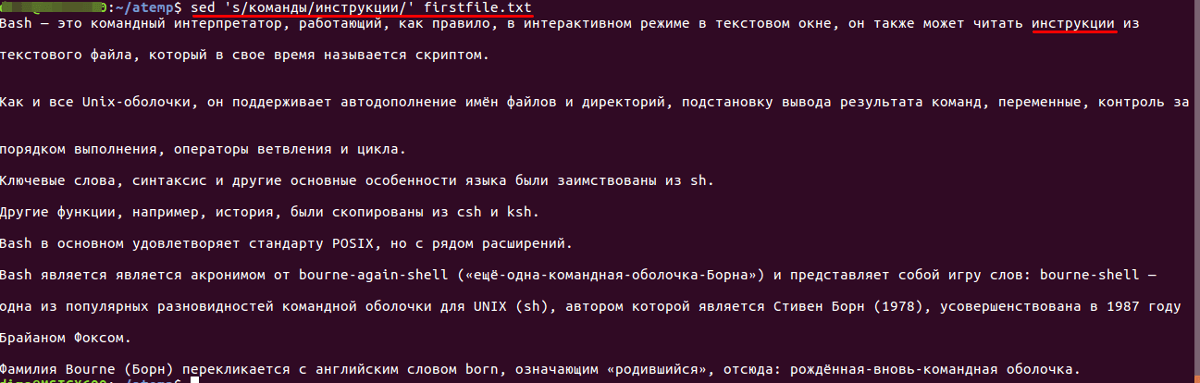
Замена слова
Например, если требуется заменить строку в файле или слово с «команды» на «инструкции». Для этого нужно воспользоваться следующими конструкциями:
- Для первого вхождения:
sed 's/команды/инструкции/' firstfile.txt

- Для всех вхождений (используется параметр инструкции — g):
sed 's/команды/инструкции/g' firstfile.txt
- Замена подстроки с несколькими условиями (используется ключ — -e):
sed -e 's/команды/инструкции/g' -e 's/команд/инструкций/g' firstfile.txt
- Заменить часть строки, если она содержит определенный набор символов (например, POSIX):
sed '/POSIX/s/Bash/оболочка/g' firstfile.txt
- Выполнить замену во всех строках, начинающихся на «Bash»
sed '/^Bash/s/Bash/оболочка/g' firstfile.txt
- Произвести замену только в строках, которые заканчиваются на «Bash»:
sed '/команды/s/Bash/оболочка/g' firstfile.txt
- Заменить слово с пробелом на слово с тире:
sed 's/Bash /оболочка-/g' firstfile.txt
- Заменить символ переноса строки на пробел
sed 's/n/ /g' firstfile.txt
- Перенос строки обозначается символом — n.
Редактирование файла
Чтобы записать строку в файл, нужно указать параметр замены одной строки на другую, воспользовавшись ключом — -i:
sed -i 's/команды/инструкции/' firstfile.txt
После выполнения команды произойдет замена слова «команды» на «инструкции» с последующим сохранением файла.
Удаление строк из файла
- Удалить первую строку из файла:
sed -i '1d' firstfile.txt
- Удалить строку из файла, содержащую слово «окне»:
sed '/окне/d' firstfile.txt
После выполнения команды будет удалена первая строка, поскольку она содержит указанное слово.
- Удалить пустые строки:
sed '/^$/d' firstfile.txt
- Убрать пробелы в конце строки:
sed 's/ *$//' firstfile.txt
- Табуляция удаляется при помощи конструкции:
sed 's/t*$//' firstfile.txt
- Удалить последний символ в строке:
sed 's/ ;$//' firstfile.txt
Нумерация строк
Строки в файле будут пронумерованы следующим образом: первая строка — 1, вторая — 2 и т. д.
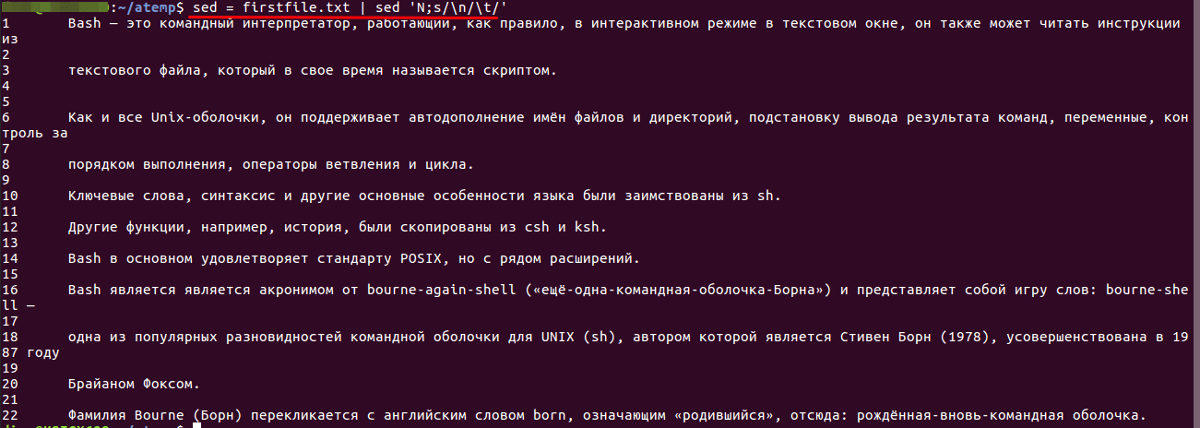
Следует обратить внимание, что нумерация начинается не с «0», как в языках программирования.
sed = firstfile.txt | sed 'N;s/n/t/'
Удаление всех чисел из текста
sed -i 's/[0-9] [0-9]//g' firstfile.txt
Замена символов
Чтобы заменить набор символов, нужно воспользоваться инструкцией, содержащей команду «y»:
sed 'y/1978/1977/g' firstfile.txt
Обработка указанной строки
Утилита производит манипуляции не только с текстом, но и со строкой, указанной в правиле шаблона (3 строка):
sed '3s/директорий/папок' firstfile.txt
Работа с диапазоном строк
Для выполнения замены только в 3 и 4 строках нужно использовать конструкцию:
sed '3,4s/директорий/папок' firstfile.txt
Вставка содержимого файла после строки
Иногда требуется вставить содержимое одного файла (input_file.txt) после определенной строки другого (firstfile.txt). Для этой цели используется команда:
sed ‘5r input_file.txt’ firstfile.txt (где «5r» — 5 строка, «input_file.txt» — исходный файл и «firstfile.txt» — файл, в который требуется вставить массив текста).
9.2. ������ �� ��������
Bash ������������ �� ��������� ������� ���������� �������� ���
��������. � ���������, ���� ������ Bash ���������� ����������
����������. ���� �������� �������� ������������� �������� ����������� ����������, �
������ — ��������� � ����������������� ������� UNIX — expr. ��� �������� � �������������
� ���������� ������ � ���������� �������������� ������������, ��
������ ��� � ����������� ��������.
����� ������
- ${#string}
- expr length $string
- expr «$string» : ‘.*’
-
stringZ=abcABC123ABCabc echo ${#stringZ} # 15 echo `expr length $stringZ` # 15 echo `expr "$stringZ" : '.*'` # 15
������ 9-10. ������� ������ ����� ����� �����������
� ��������� �����
#!/bin/bash
# paragraph-space.sh
# ������� ������ ����� ����� ����������� � ��������� �����.
# ������� �������������: $0 <FILENAME
MINLEN=45 # �������� ����������� �������� ��� ��������.
# ������, ���������� ���������� �������� �������, ��� $MINLEN
#+ ����������� �� ��������� ������ ���������.
while read line # ���������� ������ ����� �� ������ �� �����...
do
echo "$line" # ����� ������.
len=${#line}
if [ "$len" -lt "$MINLEN" ]
then echo # ���������� ������ ������ ����� ��������� ������ ���������.
fi
done
exit 0
����� ��������� � ������ (������� �����������
�������� ������� � ������ ������)
- expr match «$string» ‘$substring’
-
��� $substring — ���������� ���������.
- expr «$string» : ‘$substring’
-
��� $substring — ����������
���������.stringZ=abcABC123ABCabc # |------| echo `expr match "$stringZ" 'abc[A-Z]*.2'` # 8 echo `expr "$stringZ" : 'abc[A-Z]*.2'` # 8
Index
- expr index $string $substring
-
����� ������� ������� ���������� � $string c ������
�������� � $substring.stringZ=abcABC123ABCabc echo `expr index "$stringZ" C12` # 6 # ������� ������� C. echo `expr index "$stringZ" 1c` # 3 # ������ 'c' (� #3 �������) ������ ������, ��� '1'.��� ������� �������� ������ � ������� strchr() � ����� C.
���������� ���������
- ${string:position}
-
��������� ��������� �� $string, ������� �
������� $position.���� ������ $string — «*« ��� «@«, �� ����������� ����������� ��������
(��������), [1] � ������� $position. - ${string:position:length}
-
��������� $length �������� �� $string, ������� �
������� $position.stringZ=abcABC123ABCabc # 0123456789..... # ���������� ���������� � 0. echo ${stringZ:0} # abcABC123ABCabc echo ${stringZ:1} # bcABC123ABCabc echo ${stringZ:7} # 23ABCabc echo ${stringZ:7:3} # 23A # ��������� 3 �������. # �������� �� ���������� � "������" ������� ������? echo ${stringZ:-4} # abcABC123ABCabc # ��-��������� ��������� ������ ������. # ������ . . . echo ${stringZ:(-4)} # Cabc echo ${stringZ: -4} # Cabc # ������ ��������� ���������. # ������� ������ ��� �������������� ������ "����������" �������� �������. # ������� Dan Jacobson, �� �����������.���� $string — «*« ��� «@«, �� ����������� �� $length ����������� ����������
(����������), ������� � $position.echo ${*:2} # ����� 2-�� � ����������� ����������. echo ${@:2} # �� �� �����. echo ${*:2:3} # ����� 3-� ����������, ������� �� 2-��. - expr substr $string $position $length
-
��������� $length �������� �� $string, ������� �
������� $position.stringZ=abcABC123ABCabc # 123456789...... # ���������� ���������� � 1. echo `expr substr $stringZ 1 2` # ab echo `expr substr $stringZ 4 3` # ABC
- expr match «$string»
‘($substring)’ -
������� � ��������� ������ ���������� $substring � $string, ��� $substring — ��� ���������� ���������.
- expr «$string» : ‘($substring)’
-
������� � ��������� ������ ���������� $substring � $string, ��� $substring — ���
���������� ���������.stringZ=abcABC123ABCabc # ======= echo `expr match "$stringZ" '(.[b-c]*[A-Z]..[0-9])'` # abcABC1 echo `expr "$stringZ" : '(.[b-c]*[A-Z]..[0-9])'` # abcABC1 echo `expr "$stringZ" : '(.......)'` # abcABC1 # ��� ��������������� �������� ���� ���� � ��� �� ���������.
- expr match «$string»
‘.*($substring)’ -
������� � ��������� ������ ���������� $substring � $string, ��� $substring — ���
���������� ���������. ����� ���������� � ����� $string. - expr «$string» :
‘.*($substring)’ -
������� � ��������� ������ ���������� $substring � $string, ��� $substring — ���
���������� ���������. ����� ���������� � ����� $string.stringZ=abcABC123ABCabc # ====== echo `expr match "$stringZ" '.*([A-C][A-C][A-C][a-c]*)'` # ABCabc echo `expr "$stringZ" : '.*(......)'` # ABCabc
�������� ����� ������
- ${string#substring}
-
�������� ����� ��������, �� ���������, ��������� $substring � ������ $string. ����� ������� �
������ ������ - ${string##substring}
-
�������� ����� �������, �� ���������, ��������� $substring � ������ $string. ����� ������� �
������ ������stringZ=abcABC123ABCabc # |----| # |----------| echo ${stringZ#a*C} # 123ABCabc # �������� ����� �������� ���������. echo ${stringZ##a*C} # abc # �������� ����� ������� ���������. - ${string%substring}
-
�������� ����� ��������, �� ���������, ��������� $substring � ������ $string. ����� ������� �
����� ������ - ${string%%substring}
-
�������� ����� �������, �� ���������, ��������� $substring � ������ $string. ����� ������� �
����� ������stringZ=abcABC123ABCabc # || # |------------| echo ${stringZ%b*c} # abcABC123ABCa # ��������� ����� �������� ����������. ����� ������� � ����� $stringZ. echo ${stringZ%%b*c} # a # ��������� ����� ������� ����������. ����� ������� � ����� $stringZ.������ 9-11. �������������� ����������� ������
�� ������ ������� � ������, � ���������� �����
�����#!/bin/bash # cvt.sh: # �������������� ���� ������ � �������� ��������, #+ �� ������������ ������� MacPaint, � ������ "pbm". # ������������ ������� "macptopbm", �������� � ������ ������ "netpbm", #+ ������� �������������� Brian Henderson (bryanh@giraffe-data.com). # Netpbm -- ����������� ����� ��� ����������� ������������� Linux. OPERATION=macptopbm SUFFIX=pbm # ����� ���������� �����. if [ -n "$1" ] then directory=$1 # ���� ������� ����� � ��������� ������ ��� ������ �������� else directory=$PWD # ����� ��������������� ������� �������. fi # ��� ����� � ��������, ������� ���������� ".mac", ��������� ������� #+ ������� MacPaint. for file in $directory/* # ����������� ���� ������. do filename=${file%.*c} # ������� ���������� ".mac" �� ����� ����� #+ ( � �������� '.*c' ��������� ��� ��������� #+ ������������ � '.' � ��������������� 'c', $OPERATION $file > "$filename.$SUFFIX" # �������������� � ���������������� � ���� � ����� ������ rm -f $file # �������� ������������� ����� ����� ��������������. echo "$filename.$SUFFIX" # ����� �� stdout. done exit 0 # ����������: # -------- # ������ ���� �������� ������������ *���* ����� � �������� # �������� ��� ���, ����� �� ������������� *������* �� �����, #+ ������� ����� ���������� ".mac".
������ ���������
- ${string/substring/replacement}
-
�������� ������ ��������� $substring ������� $replacement.
- ${string//substring/replacement}
-
�������� ��� ��������� $substring ������� $replacement.
stringZ=abcABC123ABCabc echo ${stringZ/abc/xyz} # xyzABC123ABCabc # ������ ������ ��������� 'abc' ������� 'xyz'. echo ${stringZ//abc/xyz} # xyzABC123ABCxyz # ������ ���� �������� 'abc' ������� 'xyz'. - ${string/#substring/replacement}
-
����������� ������ $replacement ������ $substring. �����
������� � ������ ������ $string. - ${string/%substring/replacement}
-
����������� ������ $replacement ������ $substring. �����
������� � ����� ������ $string.stringZ=abcABC123ABCabc echo ${stringZ/#abc/XYZ} # XYZABC123ABCabc # ����� ������� � ������ ������ echo ${stringZ/%abc/XYZ} # abcABC123ABCXYZ # ����� ������� � ����� ������
9.2.1. ������������� awk ��� ������
�� ��������
� �������� ������������, Bash-������� ����� ������������
�������� awk ��� ������ �� ��������.
������ 9-12. �������������� ������ ����������
��������
#!/bin/bash
# substring-extraction.sh
String=23skidoo1
# 012345678 Bash
# 123456789 awk
# �������� �������� �� �������� � ����������:
# Bash �������� ���������� � '0'.
# Awk �������� ���������� � '1'.
echo ${String:2:4} # � 3 ������� (0-1-2), 4 �������
# skid
# � ���������� � awk: substr(string,pos,length).
echo | awk '
{ print substr("'"${String}"'",3,4) # skid
}
'
# �������� ������� "echo" �� ������ � awk, �������� ��������� ����,
#+ �����, ��� �����, �������� �������������� ����� �����.
exit 0
We’re Earthly. We make building software simpler and, therefore, faster. This article is about bash – which has its quirks but is a tool we find ourselves often reaching for. If you are looking for an open-source tool to improve how you build software, then check us out.
One thing that bash is excellent at is manipulating strings of text. If you’re at the command line or writing a small script, then knowing some bash string idioms can be a lot of help.
So in this article, I’m going to go over techniques for working with strings in bash.
You can run any of the examples at the bash prompt:
Or you can put the same commands into a file with a bash shebang.
And then make it executable using chmod and run it at the command line:
> chmod +x strings.sh
> ./strings.sh
testBackground
If you need a review of the basics of bash scripting, check out Understanding Bash. If not, know that everything covered will work in bash version 3.2 and greater. Much covered will also work in ZSH. That means everything here will work on macOS, Windows under WSL and WSL 2, and most Linux distributions. Of course, if you’re on Alpine, or some minimal linux distribution, you will need to install bash first.
Let’s start at the beginning.
Bash Concatenate Strings
In bash, I can declare a variable like this:
and then I can refer to it in a double-quoted string like this:
Concatenating strings follows easily from this same pattern:
#!/bin/bash
one="1"
two="2"
three="$one$two"
echo "$three"
12Side Note: Globs and File Expansions
You can, in theory, refer to variables directly like this:
but if you do that, you might have unexpected things happen.
#!/bin/bash
comment="/* begin comment block"
echo $comment/Applications /Library /System /Users /Volumes /bin /cores /dev /etc
/home /opt /private /sbin /tmp /usr /var begin comment blockWithout quotes, bash splits your string on whitespace and then does a pathname expansion on /*.
I’m going to use whitespace splitting later on, but for now remember: You should always use double quotes, when echoing, if you want the literal value of a variable.
Another Concatenate Method +=
Another way to combine strings is using +=:
#!/bin/bash
concat=""
concat+="1"
concat+="2"
echo "$concat"12Next, let’s do string length.
Bash String Length
The "$var" syntax is called variable expansion in bash and you can also write it as "${var}". This expansion syntax allows you to do some powerful things. One of those things is getting the length of a string:
> words="here are some words"
> echo "'$words' is ${#words} characters long
'here are some words' is 19 characters longBash SubString
If I need to get a portion of an existing string, then the substring syntax of parameter expansion is here to help.
The format you use for this is ${string:position:length}. Here are some examples.
Bash First Character
You can get the first character of a string like this:
> word="bash"
> echo "${word:0:1}"
bSince I’m asking to start at position zero and return a string of length one, I can also shorten this a bit:
> word="bash"
> echo "${word::1}"
bHowever, this won’t work in ZSH (where you must provide the 0):
> word="zsh"
> echo "${word::1}"
zsh: closing brace expectedYou can get the inverse of this string, the portion starting after the first character, using an alternate substring syntax ${string:position} (Note the single colon and single parameter). It ends up looking like this:
#!/bin/bash
word="bash"
echo "Head: ${word:0:1}"
echo "Rest: ${word:1}"Head: b
Rest: ashThis substring works by telling the parameter expansion to return a new string starting a position one, which drops the first character.
Bash Last Character
To return the last character of a string in bash, I can use the same single-argument substring parameter expansion but use negative indexes, which will start from the end.
#!/bin/bash
word="bash"
echo "${word:(-1)}"
echo "${word:(-2)}"
echo "${word:(-3)}"h
sh
ashTo drop the last character, I can combine this with the string length expansion (${#var}):
#!/bin/bash
word="bash"
echo "${word:0:${#word}-1}"
echo "${word:0:${#word}-2}"
echo "${word:0:${#word}-3}"bas
ba
bThat is a bit long, though, so you could also use the pattern expansion for removing a regex from the end of a string (${var%<<regex>>}) and the regular expression for any single character (?):
#!/bin/bash
word="bash"
echo "${word%?}
echo "${word%??}
echo "${word%???}bas
ba
bThis regex trim feature only removes the regex match if it finds one. If the regex doesn’t match, it doesn’t remove anything.
> word="one"
> echo "${word%????}" # remove first four characters
one You can also use regular expressions to remove characters from the beginning of a string by using # like this:
#!/bin/bash
word="bash"
echo "${word#?}
echo "${word#??}
echo "${word#???}Running that I get characters dropped from the beginning of the string if they match the regex:
ash
sh
hBash String Replace
Another common task I run into when working with strings in bash is replacing parts of an existing string.
Let’s say I want to change the word create to make in this quote:
When you don’t create things, you become defined by your tastes rather than ability. Your tastes only narrow & exclude people. So create.
Why The Lucky Stiff
There is a parameter expansion for string replacement:
#!/bin/bash
phrase="When you don't create things, you become defined by your tastes
rather than ability. Your tastes only narrow & exclude people. So create."
echo "${phrase/create/make}"When you don't make things, you become defined by your tastes
rather than ability. Your tastes only narrow & exclude people. So create.You can see that my script only replaced the first create.
To replace all, I can change it from test/find/replace to /text//find/replace (Note the double slash //):
#!/bin/bash
phrase="When you don't create things, you become defined by your tastes
rather than ability. Your tastes only narrow & exclude people. So create."
echo "${phrase//create/make}"When you don't make things, you become defined by your tastes
rather than ability. Your tastes only narrow & exclude people. So make.You can do more complicated string placements using regular expressions. Like redact a phone number:
#!/bin/bash
number="Phone Number: 234-234-2343"
echo "${number//[0-9]/X}Phone number: XXX-XXX-XXXXIf the substitution logic is complex, this regex replacement format can become hard to understand, and you may want to consider using regex match (below) or pulling in an outside tool like sed.
Bash String Conditionals
You can compare strings for equality (==), inequality (!=), and ordering (> or <):
if [[ "one" == "one" ]]; then
echo "Strings are equal."
fi
if [[ "one" != "two" ]]; then
echo "Strings are not equal."
fi
if [[ "aaa" < "bbb" ]]; then
echo "aaa is smaller."
fiStrings are equal.
Strings are not equal.
aaa is smaller.You can also use = to compare strings to globs:
#!/bin/bash
file="todo.gz"
if [[ "$file" = *.gz ]]; then
echo "Found gzip file: $file"
fi
if [[ "$file" = todo.* ]]; then
echo "Found file named todo: $file"
fiFound gzip file: todo.gz
Found file named todo: todo.gz(Note that in the above the glob is not quoted.)
You can see it matched in both cases. Glob patterns have their limits, though. And so when I need to confirm a string matches a specific format, I usually more right to regular expression match(=~).
Bash String Regex Match
Here is how I would write a regex match for checking if a string starts with aa:
#!/bin/bash
name="aardvark"
if [[ "$name" =~ ^aa ]]; then
echo "Starts with aa: $name"
fiStarts with aa: aardvarkAnd here using the regex match to find if the string contains a certain substring:
#!/bin/bash
name="aardvark"
if [[ "$name" =~ dvark ]]; then
echo "Contains dvark: $name"
fiContains dvark: aardvarkUnfortunately, this match operator does not support all of modern regular expression syntax: you can’t use positive or negative look behind and the character classes are a little different then you would find in most modern programming languages. But it does support capture groups.
Bash Split Strings
What if I want to use regexes to spit a string on pipes and pull out the values? This is possible using capture groups :
if [[ "1|tom|1982" =~ (.*)|(.*)|(.*) ]];
then
echo "ID = ${BASH_REMATCH[1]}" ;
echo "Name = ${BASH_REMATCH[2]}" ;
echo "Year = ${BASH_REMATCH[3]}" ;
else
echo "Not proper format";
fiID = 1
Name = tom
Year = 1982Capture groups can be convenient for doing some light-weight string parsing in bash. However, there is a better method for splitting strings by a delimiter. It requires a little explanation, though.
Internal Field Separator Split
By default, bash treats spaces as the delimiter between separate elements. This can lead to problems, though, and is one of the reasons I mentioned earlier for double quoting your variable assignments. However, this space delimiting can also be a helpful feature:
list="foo bar baz"
for word in $list; do # <-- $list is not in double quotes
echo "Word: $word"
doneWord: foo
Word: bar
Word: bazIf you wrap space-delimited items in brackets, you get an array.
You can access this array like this:
list="foo bar baz"
array=($list)
echo "Zeroth: ${array[0]}"
echo "First: ${array[1]}"
echo "Whole Array: ${array[*]}" Zeroth: foo
First: bar
Whole Array: foo bar bazI can use this feature to split a string on a delimiter. All I need to do change the internal field separator (IFS), create my array, and then change it back.
#!/bin/bash
text="1|tom|1982"
IFS='|'
array=($text)
unset IFS;And now I have an array split on my chosen delimiter:
echo "ID = ${array[1]}" ;
echo "Name = ${array[2]}" ;
echo "Year = ${array[3]}" ; ID = 1
Name = tom
Year = 1982Reaching Outside of Bash
Many things are hard to do directly in pure bash but easy to do with the right supporting tools. For example, trimming the whitespace from a string is verbose in pure bash, but its simple to do by piping to existing POSIX tools like xargs:
> echo " lol " | xargs
lolBash regular expressions have some limitations but sed, grep, and awk make it easy to do whatever you need, and if you have to deal with JSON data jq will make your life easier.
Conclusion
I hope this overview of string manipulation in bash gave you enough details to cover most of your use cases.
Also, if you’re the type of person who’s not afraid to solve problems in bash then take a look at Earthly. It’s a great tool for creating repeatable builds in a approachable syntax.
Earthly makes CI/CD super simple
Fast, repeatable CI/CD with an instantly familiar syntax – like Dockerfile and Makefile had a baby.
Go to our homepage to learn more
Feedback
If you have any clever tricks for handling strings in bash, or spot any problems with my examples, let me know on Twitter @AdamGordonBell:
How many of these bash string parameter expansions idioms do you use? https://t.co/9UIuLPgELy
— Adam Gordon Bell 🤓 (@adamgordonbell) October 27, 2021
Одна из самых распространенных операций при работе со строками в Bash — определить, содержит ли строка другую строку.
В этой статье мы покажем вам несколько способов проверить, содержит ли строка подстроку.
Самый простой подход заключается в том, чтобы окружить подстроку подстановочными символами звездочки (звездочкой) * и сравнить ее со строкой. Подстановочный знак — это символ, используемый для обозначения нуля, одного или нескольких символов.
Если тест возвращается true, подстрока содержится в строке.
В приведенном ниже примере мы используем оператор if и оператор равенства ( ==), чтобы проверить SUB, найдена ли подстрока в строке STR:
#!/bin/bash STR='GNU/Linux это операционная система' SUB='Linux' if [[ "$STR" == *"$SUB"* ]]; then echo "Присутствует." fi
После выполнения скрипт выдаст:
Присутствует.
Вместо использования оператора if вы также можете использовать оператор case, чтобы проверить, содержит ли строка другую строку.
#!/bin/bash
STR='GNU/Linux это операционная система'
SUB='Linux'
case $STR in
*"$SUB"*)
echo -n "Присутствует."
;;
esac
Другим вариантом определения того, встречается ли указанная подстрока в строке, является использование оператора регулярного выражения =~. Когда используется этот оператор, правильная строка рассматривается как регулярное выражение.
Точка, за которой следует звездочка .* соответствует нулю или большему количеству вхождений любого символа, кроме символа новой строки.
#!/bin/bash STR='GNU/Linux это операционная система' SUB='Linux' if [[ "$STR" =~ .*"$SUB".* ]]; then echo "Присутствует." fi
Скрипт отобразит следующее:
Присутствует.
Команда grep также может использоваться для поиска строк в другой строке.
В следующем примере мы передаем строку $STR в качестве входных данных для grep и проверяем $SUB, найдена ли строка во входной строке. Команда вернет true или false при необходимости.
#!/bin/bash STR='GNU/Linux это операционная система' SUB='Linux' if grep -q "$SUB" <<< "$STR"; then echo "Присутствует" fi
Опция -q говорит Grep, чтобы быть спокойным и пропустить выход.
Проверка, содержит ли строка подстроку, является одной из самых основных и часто используемых операций в сценариях Bash.
Прочитав эту статью, вы должны хорошо понимать, как проверить, содержит ли строка другую строку. Вы также можете использовать другие команды, такие как команда awk или sed для тестирования.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.