Как находить похожие запросы
Внизу страницы результатов сравнения в Google Trends можно просмотреть похожие запросы.
Если вы указали несколько запросов, регионов или периодов времени, популярные похожие запросы будут показаны на отдельных вкладках.
Самые популярные запросы
Популярными запросами мы называем слова или словосочетания, которые искали чаще всего вместе с указанным вами термином в рамках выбранной категории, страны или региона. Если сегодня вы еще ничего не искали, то в этом разделе представлены все популярные запросы.
Запросы, набирающие популярность
Эти запросы включают в себя термины, которые за указанное время все чаще и чаще искали пользователи вместе с указанным словом (или искали вообще, если вы пока не вводили запрос). Популярность этих запросов выражается процентным соотношением прироста и значений за предыдущие периоды. Если термин стал популярнее более чем на 5000%, то вместо доли в процентах вы увидите сообщение «Сверхпопулярность».
Как сообщить о нежелательных похожих запросах
Мы удаляем из сервиса Google Trends поисковые запросы сексуального характера, однако не весь неприемлемый контент удается таким образом исключить. Обнаружив его, вы можете сообщить нам о нем. Для этого нажмите Отправить отзыв внизу любой страницы сервиса.
Спорные темы не фильтруются в Google Trends.
«Люди ищут» — это официальный блок в поиске Яндекса, который отображает до 10 похожих запросов, то есть связанные запросы, которые чаще всего вводят пользователя до или после исходного.
Рекомендуем использовать его для расширения семантического ядра, наряду с:
-
Парсингом запросов из Яндекс.Вордстат.
-
Парсингом поисковых подсказок Яндекса и Google.
-
Парсингом запросов конкурентов.
Кроме того, знание того, что люди ищут в Яндексе вместе с запросом, поможет вам сделать страницу лучше. Например, предложить рекомендуемые товары.
Поиск похожих запросов в Яндексе
Для этого воспользуйтесь онлайн-инструментом «Вместе с запросом ищут…» от Пиксель Тулс.
-
Укажите список запросов (до 100 штук).
-
Выберите регион.
-
Запустите проверку.
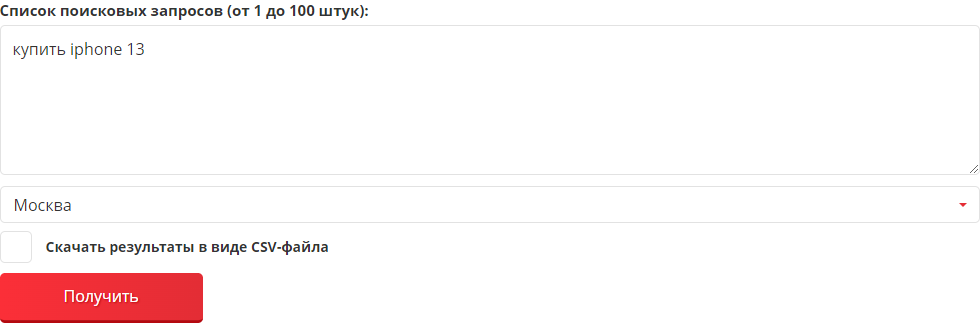
В результате вы увидите запросы ассоциации:
Формируем выводы:
По данному примеру, помимо найденных похожих запросов, можно понять, что в качестве дополнительного маркера при работе с семантикой стоит учесть вариант на русском языке «купить айфон 13», интент поискового запроса — совершение покупки, а на странице важно предложить рассрочку и порекомендовать сопутствующие товары (часы, наушники, аксессуары).
Для результатов доступен экспорт в CSV-файл, для этого кликните по ссылке «Скачать данные в CSV-файле».

Стоимость поиска похожих запросов
Стоимость одной проверки 5 лимитов (от 10 копеек).
Инструмент доступен на всех PRO-тарифах: «Профессионал», «Гуру» и «Бизнес».
Ознакомьтесь с их ценами в таблице по ссылке.
Если у вас есть идеи, как улучшить SEO-инструмент или остались вопросы по работе с ним, напишите в нашу службу поддержки, мы обязательно вам поможем.
Существует множество интернет-сервисов, облегчающих жизнь пользователей. Один из таких — «Вордстат». Он представляет собой сборник статистических данных о том, что конкретно ищут пользователи в сети. Чтобы эту статистику узнать, необходимо создать аккаунт (ссылка на регистрацию представлена ниже).
Затем вам будет открыт доступ к показателям поисковых запросов.
Для людей, занимающихся бизнесом, сервис — настоящая находка. Где же ещё можно отыскать такую детальную информацию о предпочтениях своего потенциального клиента, к тому же бесплатно? Также вы можете проанализировать конкретную продукцию или услугу и выяснить, пользуется ли она спросом.
Согласитесь, действуя в своих интересах или интересах своего заказчика, намного лучше и надёжнее опираться на статистические данные, нежели на мнимую интуицию. Шанс на успех в первом случае выше минимум на 50%. Для наглядности приведём пример.
- Тренды;
- устройства, с которых запрос поступает;
- уровень популярности;
- сезонность запросов;
- география востребованности.
С помощью этих данных можно выяснить:
Здесь отчётливо видно, что идея продавать iPhone на сайте, привлекая клиентов с помощью поиска «Яндекса», является более перспективной, нежели аналогичная идея со смартфонами. Однако встаёт вопрос — достоверны ли эти показатели и можно ли им доверять? Если вкратце, то можно, но частично и с большей долей осторожности, потому что есть много подводных камней.
Во-первых, далеко не все пользуются «Яндексом» в качестве поисковой страницы. Это значит, что реальные данные могут значительно отличаться. Во-вторых, не по всем запросам «Яндекс» даёт статистику, а только лишь по регулярным, что делает ещё шире расхождение теории с практикой.
Почему это нужно больше бизнесу, а не маркетологам
У «Вордстата» и Google Keyword Planner широкий спектр полномочий, а оттого их можно и нужно использовать как в рекламной кампании, так и при полноценном продвижении сайта. Поэтому очень недальновидно покупать услуги по продвижению, не вникая в суть вопроса и не имея представления, по каким именно запросам ваша реклама будет выскакивать.
Проверка исполняющих служб
Другое дело, если вы имеете представление о том, что конкретно ищут ваши клиенты. Тогда приходит понимание, что можно добавить на сайт, какие фишки внедрить и как удержать аудиторию. Опять же, если «Вордстат» показывает, к примеру, тысячу вариантов целевых запросов, а вашими исполнителями обрабатывается сто — вся их работа перестаёт приносить доход, и вы уходите в минус.
Представим ситуацию: вы решили строить дом, наняли соответствующих специалистов, полностью оплатили материалы и работу и ушли в закат со словами: «Я в этом не разбираюсь, просто сделайте так, чтобы было красиво». Абсурд, не правда ли? А вот интернет-маркетинг работает по большей части именно так. Вы что-то оплатили, вам что-то продвигают. Абсолютно работающая схема, если заказчик не понимает и не вникает в суть вопроса.
Узконаправленная тематика
Нужно понимать, что чем ниже уровень конкуренции в этой области, тем шире спектр забытых групп интересов.
Если я буду искать по таким запросам, как, к примеру, «ванная сантехника» или «сантехника для кухни», то не получу ни единой связки с терминами, обозначенными выше. Соответственно, не буду располагать достоверной информацией. Также важным моментом является то, что клиент, делающий узконаправленный запрос, является постоянным, и сотрудничество с ним — далеко не разовая акция.
Слишком много ответственности перекладывается на сервис. А ведь «Вордстат» — это в первую очередь средство помощи. Важно, чтобы исполнитель понимал нишу, с которой работает, и знал её основной лексикон. В противном случае вы потеряете деньги и время. К примеру, возьмём близкую для всех тематику — сантехнику. Терминология просто пестрит определяющими её словами. Однако кто знает, что такое ниппель, ёлочка, клупп?
Терминология, использование синонимов, артикулов и аббревиатур
В этом случае всё элементарно: невозможно получить объективную картину по целевым запросам без информации от заказчика. Бывает такое, что бизнес непосредственно связан с названиями. В таком случае владельцу необходимо достаточно много работать с исполнителем, иначе возможен такой вариант развития событий: весь рекламный бюджет будет слит в трубу.
Использование «Вордстата»
Здесь нет никаких сложностей и тонкостей, всё достаточно легко и понятно. С этим справится любой начинающий пользователь. Преимущество инструмента — он прекрасно работает и на телефонах, поэтому все действия не займут у вас всего пару минут. Необходимо выполнить следующие пункты:
- Войти на «Яндекс.Почту» или зайти через другие соцсети («ВКонтакте», Facebook).
- Перейти по ссылке wordstat.yandex.ru.
- В строке поиска вбить искомое слово или предложение и нажать кнопку «Подобрать».
Далее заходите в аккаунт, переходите по ссылке или же просто вбиваете в поиске «вордстат».
Выясните, есть ли у вас почта на «Яндексе». Если нет, то регистрация — это дело двух минут. Нет нужды искать другие сервисы. Тут тоже всё просто — в правом верхнем углу кликаем на кнопку «Почта», затем «Регистрация».
Вбиваете нужное слово, нажимаете «Подобрать» и получаете мгновенный результат.
«Яндекс.Вордстат» — это удобный инструмент, позволяющий быстро получить необходимую информацию. Его удобство заключается также в том, что не нужно менять падежи или время, чтобы найти то, что ищете. Например:
Кроме того, вкладку «Все» можно поменять на «Мобильные» или «Только телефоны». Она предоставит информацию о трафике, собранном только с мобильных устройств.
В «Яндекс.Вордстат» для конкретики можно использовать синтаксис. Наглядно:
Восклицательный знак («!») перед словом говорит о том, что на выходе мы получим точное вхождение слова в неизменном виде.
Знак кавычки («») сужает поиск, позволяя нам увидеть только те слова или словосочетания, которые заключены в них.
Знак минус («-») перед словом обозначает убрать все словосочетания, где это слово есть.
Знак плюс («+») обозначает обязательное присутствие слова в запросе. Чаще всего его используют для союзов и других частиц, потому что обычно «Вордстат» игнорирует такие части речи, а если быть точным, то попросту не замечает их.
Региональная сортировка
Ещё одна важная особенность «Яндекс.Вордстата» — возможность сортировать запросы по конкретным регионам. Для этого нажимаем кнопку «Все регионы» и проставляем плюсики в необходимых местах. Кстати, в этом окне есть кнопка «Быстрый выбор», которая обозначает один из наиболее востребованных вариантов.
Низкочастотные запросы
В случае, когда вам необходимы все статистические данные по конкретному запросу, можно их вставить в Excel. Для этого надо нажать Ctrl+C, предварительно выделив нужную область, затем Ctrl+V или «Вставить как» → «Текст без форматирования» в самом Excel.
Внизу после выданного списка есть переход на следующую страницу, но нет перехода на последнюю. Листать можно только по одной странице. Напротив каждого запроса сервис выдаёт их количество и к тому же собирает все словосочетания, которые искали нем менее пяти раз за последний календарный месяц. Это и есть низкочастотные запросы. Обратите внимание, что листать по одной странице быстро тоже не получится, потому что может появиться капча с целью узнать, робот вы или живой человек.
Популярные запросы — что с ними делать
«Яндекс.Вордстат» не выдаёт запросы ниже 40-й страницы. К примеру, если вбить «читать книгу», нам выпадет не один миллион запросов. Ясно, что в этой ситуации мы не сможем увидеть конец выдачи.
Но не всё так безнадёжно. Можно «обойти систему». Для этого можно воспользоваться одним из неофициальных решений — парсером. К нему относится и Key Collector, и YandexKeyParser, и Yandex Wordstat Helper, и Yandex Wordstat Assistant. Подробно познакомиться с этими инструментами вы можете в наших следующих статьях.
Похожие запросы
Полезность опции — вопрос спорный. Вбив «психология», выпадает «астрология» и «гадание». Очевидной связи между этими терминами нет, но люди почему-то искали именно такие фразы.
Если кликнем на одно из словосочетаний, увидим, что выбранный запрос перешёл в строчку. Так мы получим новый запрос.
После того как мы получили список запросов, видим справа «Запросы, похожие на…» и целый столбик ниже — это подобранные сервисом словосочетания, которые могут быть актуальны и полезны для пользователя. Есть целый алгоритм их подбора: «Вордстат» показывает те слова, которые уже искали другие пользователи совместно с вашим запросом.
Что также можно увидеть в «Яндекс.Вордстат»
В этом плане намного легче интернет-магазинам — реализация товара чаще всего идёт по всей стране, а то и по всему миру. Для различных продаваемых услуг также можно смотреть статистику по вей стране.
Для бизнеса, сосредоточенного в конкретном месте, а не раскинутого по всей стране, важным является то, что ищут в городе или области. Какой смысл опираться на статистику продажи недвижимости в Москве, если в регионе абсолютно другие показатели?
Важность данных по регионам
У «Вордстата» есть три опции выдачи запроса: «По словам», «По регионам», «История запросов». По последней можно определить сезонность запросов — графики по месяцам, годам, дням помогают оценить тренды. Сам сервис по умолчанию установлен на первую опцию из-за её высокой популярности.
Важно: для образовательного и информационного контента не принципиален регион. Лучше будет, если вы станете создавать действительно познавательные сайты, которые будут позитивно влиять на известность бренда.
При этом нужно учитывать и спрос в целом. Например, в той же Омской области из 263% купили недвижимость только половина, а в СНГ все 55%. Это уже будет совершенно иное соотношение в показателях.
Процентное соотношение говорит о уровне спроса. Например, видно, что спрос на недвижимость в Омской области заоблачно высок -263%, а в СНГ довольно низок — всего 55 %.
Минус-слова
Есть ещё одна необходимая опция, показывающая реальную картину по запросам — это минус-слова. При составлении основного запроса можно вычеркнуть те слова, которых точно не должно быть. Да, первоначальный показатель уменьшится в разы, но зато картина станет яснее и реальнее.
Часто задаваемые вопросы
1. Есть все данные. Как их анализировать? Что выделять?
Первоочерёдно — коммерческие запросы, которые имеют маленькое различие в частоте с кавычками и без. Потому что чем больше разница в показателях, то ниже шанс угадать, что именно необходимо пользователю. Плохой пример: лампа. Хороший пример: купить настольную лампу для учёбы.
2. Статистика одного города.
Город можно выбрать в настройках региона. Кроме того, важно знать свою ЦА, затачивать сайт именно под них.
3. Ограничение в восемь слов. Как обойти?
К сожалению, никак. Только собирать запросы по кусочкам.
4. Различие абсолютного и отличительного показателя.
Всё просто. Абсолютный показатель — это фактическое значение запросов, а относительный — это популярность по отношению ко всем другим запросам.
Время на прочтение
7 мин
Количество просмотров 22K
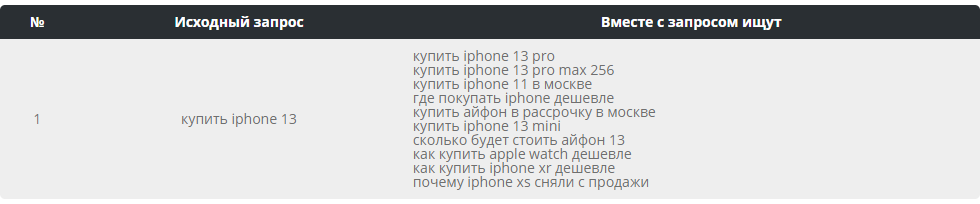
У большинства крупных поисковиков и сервисов есть механизм похожих поисковых запросов, когда пользователю предлагаются варианты, тематически близкие к тому, что он искал. Так делают в google, yandex, bing, amazon, несколько дней назад это появилось и у нас на hh.ru!
В этой статье я расскажу о том, как мы добывали похожие поисковые запросы из логов сайта hh.ru.
Для начала несколько слов о том, что такое “похожие запросы” (related searches) и зачем они нужны.
- Во-первых, не все люди, ищущие работу, точно представляют, что они хотят найти. Часто они просто исследуют предложения в нескольких сферах деятельности, вводя разные запросы. Это поведение особенно ярко проявляется у студентов, начинающих свою карьеру, и у соискателей без определенной специальности. Для такого серфинга будут полезны подсказки правильных запросов.
- Часто соискатели вводят слишком общий запрос, например, “менеджер в Москве”, по которому находится более 18 000 вакансий. Из них сложно выбрать что-то подходящее, поэтому запрос нужно сузить, например до “менеджер по продажам строительных материалов”.
- Слишком узкие запросы, наоборот, могут приводить к пустой выдаче. Например, по запросу “стажер бухгалтер по расчету заработной платы” ничего не находится, но если его исправить на более общий “бухгалтер стажер”, то появляется несколько результатов.
- Иногда соискатели и работодатели разговаривают на разных языках. Например вакансия называется “водитель автобетоносмесителя”, а соискатель ищет “водитель миксера”. Обычно мы эту проблему пытаемся решать с помощью синонимов, но не всегда это удается. Похожие запросы должны помочь пользователю сформулировать поиск на языке работодателей.
- Самый интересный случай, на мой взгляд, когда соискатель знает, что хочет найти, и четко формулирует свой запрос. Но он может не догадываться о существующей рядом сфере деятельности, которая могла бы его заинтересовать. Например, “почвовед” захочет заняться “экологией”. Эту задачу обычно решают персональными рекомендациями, но и похожие запросы могут натолкнуть такого специалиста на интересные вакансии, “сдвинуть” его в другую область поиска работы.
Мы давно думали об этой фиче, но окончательный толчок дала прекрасная статья от LinkedIn про их реализацию похожих запросов — metaphor. В ней описаны три метода извлечения таких запросов из поисковой активности пользователей, которые мы и реализовали.
Способы определения похожих запросов
Самый простой и очевидный из алгоритмов извлечения связанных запросов — это overlap или поиск пересекающихся запросов.

Все поисковые фразы разбиваем на токены и находим запросы с общими токенами. В реальности таких запросов может быть очень много, поэтому встает вопрос о выборе самых подходящих. Следуя здравому смыслу, можно определить два правила: чем больше токенов пересекается, тем ближе запросы, и пересечение в редких токенах весомее, чем в широкоиспользуемых. Отсюда получаем формулу:

где overlap — количество общих токенов в запросах q1 и q2,
Q(t) — количество запросов с токенов t,
N — число уникальных запросов.
Следующий способ — коллаборативная фильтрация (CF). Он часто используется в рекомендательных системах и хорошо подходит для рекомендации похожих запросов. За сложным названием стоит простое предположение, что в течение одной сессии пользователь делает связанные запросы. Причём для поиска работы длинной сессией можно пренебречь, потому что предпочтения пользователя меняются медленно. Трудно представить, что соискатель, который сегодня делает запрос “персональный водитель”, завтра будет искать вакансии “java разработчика”. Но такое допущение не верно для работодателей, они могут искать кандидатов на очень разные вакансии даже в течение одного часа.

Итак, при коллаборативной фильтрации мы для каждого пользователя находим все сделанные им запросы за некий период и формируем из них пары. Чтобы выбрать самые частотные пары используем вариацию формулы tf-idf.

где tf — число пар запросов q1 и q2,
df — количество пар, содержащих запрос q2,
N — число уникальных запросов,
c = 0.1, это значение пока захардкодили, но его можно подобрать из поведения пользователей.
df не дает самым распространенным запросам вроде “менеджер” и “бухгалтер” появляться в рекомендациях слишком часто.
Третий алгоритм QRQ (query-result-query) похож на CF, но пары запросов мы строим не по пользователю, а по вакансии.

Т.е. похожими считаем запросы, по которым переходят на одну и ту же вакансию. Найдя все пары запросов, нам остается выбрать из них самые подходящие. Для этого нам нужно найти самые популярные пары, не забыв понизить вес у частотных запросов и вакансий. LinkedIn в своей статье предлагает следующие формулы, и они дают интересные результаты даже для редких запросов: например, для “теория вероятностей” связанные запросы — “алгоритмическая торговля” и “фьючерс”.



Несмотря на то что формулы выглядят сложно, за ними стоят простые вещи. V — это вклад вакансии в общий ранк: отношение числа просмотров вакансии по запросу q к общему числу просмотров этой вакансии. Аналогично, Q — вклад запроса: отношение числа просмотров вакансии по запросу q к количеству просмотров других вакансий по этому запросу.
Нужно заметить, что последние два метода не симметричны, т.е.
![]()
Реализация
Мы реализовали описанные выше алгоритмы с помощью hadoop и hive. Hadoop — это система для распределенного хранения “больших данных”, управления кластером и выполнения распределённых вычислений. Каждую ночь мы загружаем туда access логи сайта за прошедший день, при этом трансформируем их в удобную структуру для анализа.

Также мы используем Apache Hive, надстройку над Hadoop, позволяющую формулировать запросы к данным в виде HiveQL (SQL-like язык заросов). HiveQL не соответствует стандартам SQL, но позволяет делать join и subselect, содержит много функций для работы со строками, датами, числами и массивами. Умеет делать Group By и поддерживает разные агрегатные функции и window-функции. Позволяет писать свои map, reduce и transform функции на любом языке программирования. Например, для того чтобы получить самые популярные поисковые запросы за день, нужно выполнить такой HiveQL:
SELECT lower(query_all_values['text']), count(*) c
FROM access_raw
WHERE
year=2014 AND month=7 AND day=16
AND path='/search/vacancy' AND query_all_values['text'] IS NOT NULL
GROUP BY lower(query_all_values['text'])
ORDER BY c DESC LiMIT 10;
Перед тем как начинать “добычу” похожих запросов, их нужно почистить от мусора и нормализовать. Мы сделали следующее:
- выкинули длинные запросы (более 5 слов и 100 символов),
- удалили мусорные символы и слова грамматики запросов,
- применили стемминг,
- объединили синонимы,
- отсортировали слова.
После такой модификации запрос “тендерный отдел начальник” превратился в “#0d26431546 начальник отдел”. Показывать пользователям такое нельзя, поэтому подобный код меняем на самую популярную форму запроса “начальник тендерного отдела”.
Затем приступаем к реализации описанных выше алгоритмов, которая заключается в применении нескольких последовательных трансформаций исходных логов. Все трансформации написаны на HiveQL, что, возможно, не очень оптимально с точки зрения производительности, зато просто, наглядно и занимает несколько строк кода. На рисунке показаны преобразования данных для коллаборативной фильтрации. QRQ реализуется аналогично.

Чтобы не рекомендовать “мусорные” запросы, мы каждый запрос прогнали через поиск вакансий на hh.ru и выкинули все, для которых находится менее 5 результатов.
Последний этап задачи — это объединение результатов трех алгоритмов. Мы рассматривали два варианта: показывать пользователям по три топ-запроса из каждого метода или попытаться просуммировать веса. Мы выбрали второй способ, нормализовав перед суммированием веса:

И все вроде получилось неплохо, но для некоторых запросов вылезли странные результаты: “начинающий специалист” -> “начальник карьера”. Во-первых, тут нас подвел стемминг, который “карьер” и “карьеру” приводит к одной форме. А во-вторых, оказалось, что у трех найденных весов разное распределение и просто так суммировать их нельзя.

Пришлось привести их к одному масштабу. Для этого отсортировали каждый вес по возрастанию, пронумеровали и полученный порядковый номер поделили на общее количество пар запросов для определенного алгоритма. Это число и стало новым весом, проблема с “начальником карьера” исчезла.
Результаты
Для нахождения похожих поисковых запросов мы использовали логи hh.ru за 4 месяца, а это — 270 миллионов поисков и 1.2 миллиарда просмотров вакансий. Всего пользователями было сделано около 1.5 миллионов уникальных текстовых запроса, после чистки и нормализации мы оставили чуть более 70 тысяч.
Уже за первый день работы этой фичи исправлением запросов воспользовалось около 50 тысяч человек. Самые популярные исправления:
водитель -> персональный водитель
администратор -> администратор салона красоты
водитель -> водитель с личным автомобилем
бухгалтер -> бухгалтер на первичную документацию
бухгалтер -> заместитель главного бухгалтера
Исправления популярных запросов в it-сфере:
| системный администратор | помощник системного администратора, helpdesk, системный администратор windows |
| программист | программист с++, удаленный программист, программист c# |
| технический директор | директор по эксплуатации, заместитель технического директора, технический руководитель |
| тестировщик | специалист по тестированию, тестировщик игр, тестировщик удаленно |
| junior | java junior, junior c++, junior qa |
Интересно было посмотреть, в каких профессиональных областях эта фича наиболее востребована:

Видно, что больше половины студентов, которые искали вакансии, пробовали другие запросы. Менее всего функция популярна в IT и Консультировании.
TODO
Что еще хотелось бы сделать:
- Aвтоматизировать. Cейчас связанные запросы построены один раз за период с 1 января по 1 мая 2014 года. При автоматизации нужно не забыть про защиту от уязвимостей, потому что, зная алгоритмы, вместо связанных запросов легко создать рекламные или просто хулиганские.
- Поэкспериментировать с весами алгоритмов и провести AB-тестирование, чтобы показывать самые полезные запросы.
- Учитывать число результатов по запросу: подсказывать только те запросы, по которым гарантированно есть результаты. Еще при большом числе найденных вакансий будет полезно показывать сужающие запросы, а при малом — расширяющие.
- Похожие запросы в поиске резюме.
- Использовать в suggest.
Ссылки
Metaphor: A System for Related Search Recommendations
Apache Hadoop
Apache Hive
Эта статья для тех, кто никогда не пользовался Вордстатом Яндекса или думает, что пользуется им неправильно. Покажем, какие данные с его помощью получать, что они значат и как помогут в продвижении сайта.
Если вы SEO-специалист, то почувствуете, что чего-то не хватает… Скорее всего, не хватает вашего комментария с полезным советом по работе с Вордстатом. Поделитесь опытом – иногда это полезнее статьи.
Как работает Яндекс.Вордстат и откуда берёт данные
Люди заходят в Яндекс каждый день и ищут кому что надо: заказать пиццу, официальный сайт городского ЗАГСа, бывает ли аллергия на доберманов и т. д. Какие-то запросы ищут чаще, например, «заказать пиццу». Какие-то реже, например, про аллергию. На каждый запрос формируется выдача, в которой показываются подходящие страницы сайтов. Вот она:
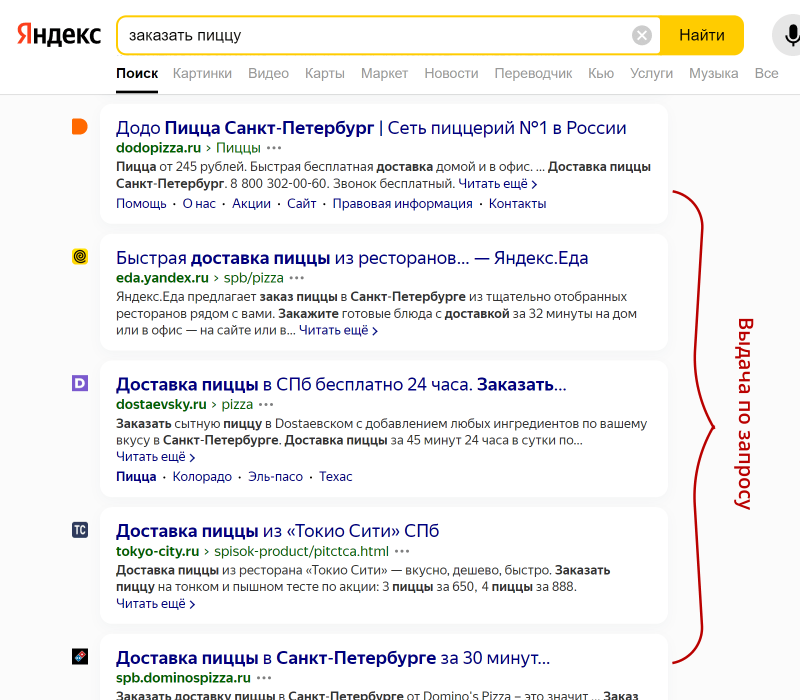
Яндекс собирает статистику по тому, сколько раз в месяц люди искали тот или иной запрос. И эту статистику можно посмотреть в инструменте «Яндекс.Вордстат» или, по-другому, «Подбор слов Яндекса».
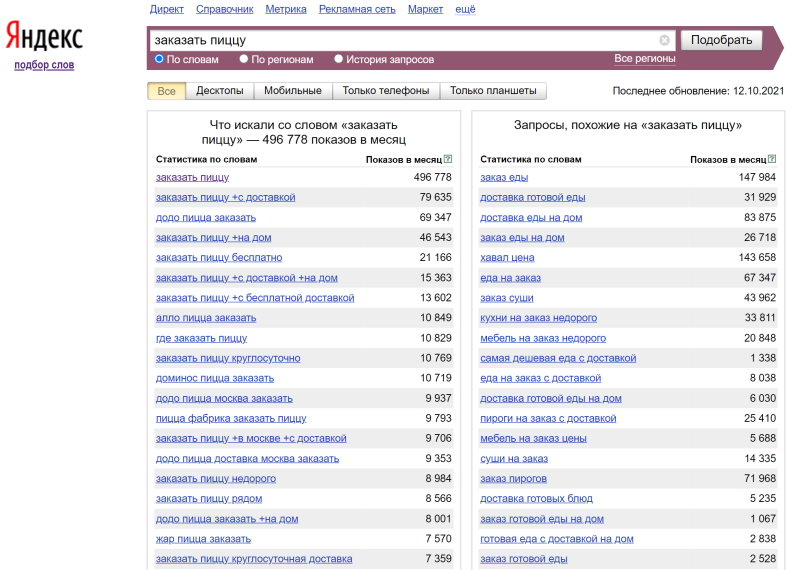
Поскольку каждый сайт именно «показывается» по определённому запросу, то статистика формируется по «показам» – сколько показов выдачи было по этому запросу за последние 30 дней. Но специалисты называют эту метрику «Частота». Чем выше частота запроса, тем он популярнее.
Можно сделать вывод, что если продвигать сайт по запросам с самой высокой частотой, то на сайт придёт больше трафика. Но всё не так просто.
Что нужно знать о Частоте в Яндекс.Вордстате
1. По умолчанию в Вордстате вы видите значение общей частоты. Это значит, что инструмент показывает вам все возможные запросы, которые включают в себя введённое вами слово в любом числе, падеже, склонении. Слова в запросах могут быть расставлены в любом порядке и к ним могут быть добавлены дополнительные слова. Поэтому общая частота обычно показывает самые высокие цифры. Например, запрос “заказать пиццу” имеет частоту 496 778, но это вовсе не значит, что именно такой запрос пользователи искали полмиллиона раз.
2. Частота запроса в первой строке левого столбца включает в себя частоты всех вариаций запроса, которые указаны на остальных строках. В примере выше частота запроса “заказать пиццу” 496 778 – это сумма частот всех запросов, указанных ниже.
3. Мы можем смотреть частоту конкретного запроса или частоту запросов, содержащих конкретные слова, используя специальные операторы для Вордстата. Это пригодится, если нужно посмотреть точные цифры и спрогнозировать потенциальный трафик.
4. Если ничего не настраивать, то Вордстат показывает частоту по всем регионам в целом. Но можно посмотреть цифры отдельно по каждому региону.
5. Чем меньше слов в запросе – тем выше будет частота. Чем больше вы добавляете слов, тем больше уточняете запрос. Запросы из четырёх и более слов называются «запросы с длинным хвостом» или «longtail-запросы». Частота длинных запросов обычно ниже, потому что их реже ищут.
Разберём все нюансы подробнее и расскажем, как правильно подбирать запросы для продвижения через Вордстат.
Виды запросов в Вордстате
По частоте
В первую очередь, запросы в инструменте делятся по Частоте: высокочастотные, среднечастотные и низкочастотные. Сокращённо их обозначают ВЧ-, СЧ- и НЧ-запросы.
Нельзя точно обозначить границы частоты, при которой запрос считается высоко- или низкочастотным. Это зависит от тематики. Например, сравним запрос “заказать пиццу” и “купить водолазку”:
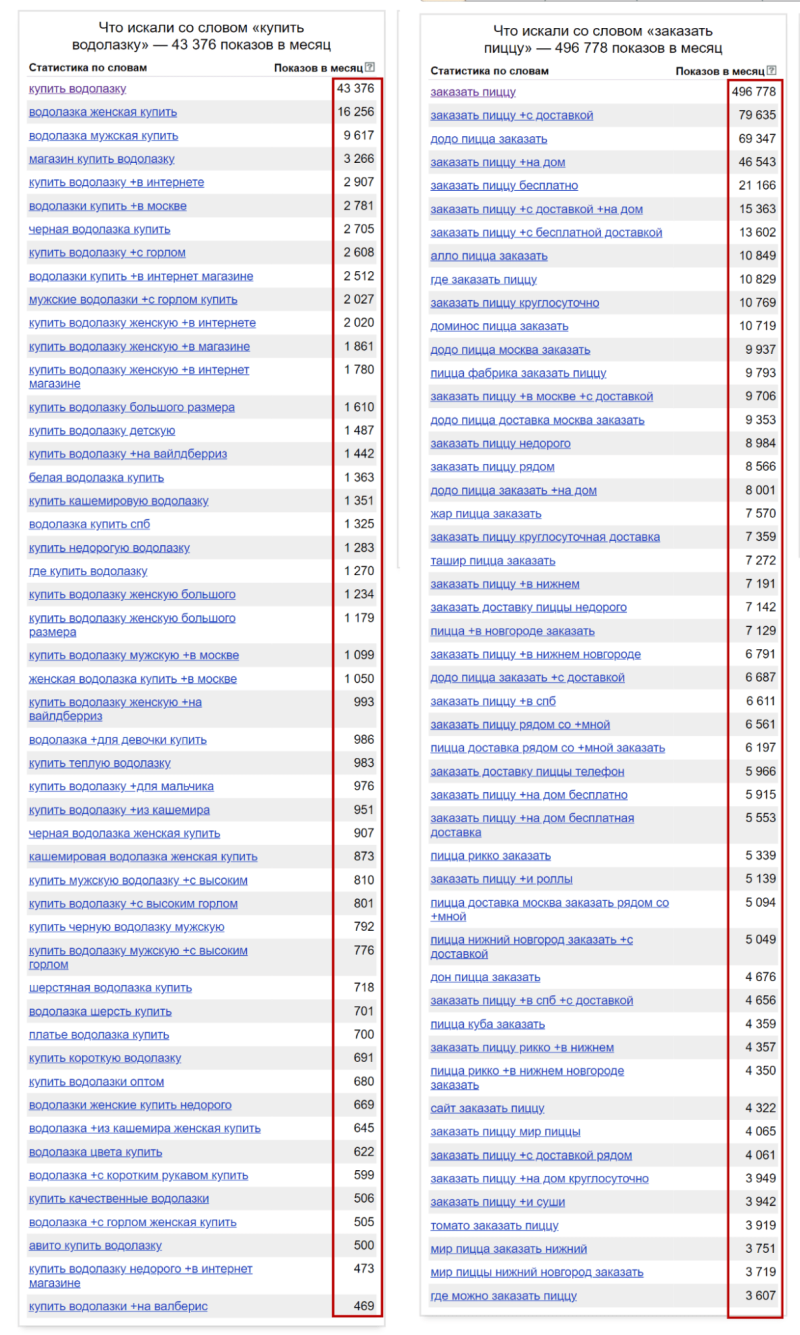
В случае с пиццей самый высокочастотный запрос имеет частоту почти 500 тыс., а с водолазкой – около 50 тыс.
Поэтому высокочастотными запросами для запроса “заказать пиццу” можно считать запросы с частотой выше 10 000, а для запроса “купить водолазку” от 3 000. Среднечастотными будут запросы от 2000 до 10 000 для пиццы и от 500 до 3000 для водолазки. Остальные запросы считаются низкочастотными.
Это примерные цифры. Строго установленной градации нет, в каждом случае специалист сам решает, какие запросы в его тематике распределить на ВЧ, СЧ и НЧ.
В продвижении используются запросы с любой частотой. Нельзя сказать, что какие-то запросы лучше, а какие-то хуже для SEO. Но на эти данные нужно ориентироваться, чтобы понять, какое количество трафика может принести страница, если оптимизировать её по тому или иному запросу.
Например, считается, что низкочастотные запросы – это те, которые пользователи реже всего ищут в поиске. Поэтому если страница оптимизирована под низкочастотные запросы, нельзя ожидать, что она принесёт полмиллиона трафика с поиска.
По типу
Кроме частоты нужно обратить внимание и на классификацию самих запросов. Даже если у запроса высокая частота, это не значит, что он подходит для продвижения.
Все запросы делятся на такие типы:
- Общие. Обычно состоят из одного слова, поэтому до конца не понятно, что именно искал пользователь по этому запросу. Например, Холодильник, Шуба, Книга. У этих запросов будет очень высокая частота, но для продвижения их не используют. Например, в запрос “Шуба” будет входить и “купить норковую шубу”, и “химчистка шуб”, и “сельдь под шубой”, и “шуба авито”. Если на вашем сайте нет услуги по химчистке шуб или вы не кулинарный блог, то большая часть запросов окажется для вас не подходящими.
- Информационные. Запросы, с помощью которых пользователь хочет найти решение своей задачи – подробную информацию. Обычно такие запросы включают в себя вопросительные слова: как, почему, зачем, можно ли, когда и т.д. По таким запросам обычно продвигают блоги, пишут SEO-статьи для привлечения трафика.
- Транзакционные. Запросы с намерением совершить какую-то покупку: “Заказать услуги SEO”, “Купить холодильник двухкамерный” и т. д. Это коммерческие запросы – по ним пользователь планирует потратить деньги, то есть совершить транзакцию.
- Навигационные. Запросы с названиями конкретной компании, сервиса или сайта. По ним пользователь хочет попасть на какую-то конкретную страницу.
- Мультимедийные. Запросы, которые содержат такие слова, как “смотреть”, “фото”, “слушать” и т. д. По ним поисковая система покажется документы, аудиофайлы, видео.
- Брендовые. Запросы содержат названия брендов. Например, “Nissan официальный сайт” или “Uniqlo одежда”. Такие запросы пересекаются с навигационными запросами.
Ещё запросы делятся на геозависимые и геонезависимые. При геонезависимых запросах пользователю неважно результаты какого региона будут в выдаче. Например, когда кто-то ищет “рецепт пиццы”, ему всё равно повар из какого региона этот рецепт выложил. А при геозависимых запросах регион важен. Например, “доставка пиццы”. Скорее всего пользователь хочет заказать пиццу, поэтому важно, чтобы в результатах поиска были рестораны того же региона, что и у него.
Заметьте, что указание региона не имеет значения для определения геозависимости запроса: “новости тула” – не геозависимый запрос. Геозависимость определяет поисковая система сама на основании множества факторов, в том числе местного номера телефона и адреса компании.
Но если в запросе пользователь укажет конкретный город, то сайты этого города получат приоритет в выдаче. Например, если из Москвы мы будем вводить запрос “адвокат волгоград”, то получим в выдаче результаты из волгограда, но запрос не будет считаться геозависимым.
Сам Вордстат не делит запросы на какие-либо типы, а только показывает список возможных запросов с их частотой. Тогда почему мы об этом говорим? Потому что это поможет вам подобрать правильные запросы для сайта с помощью Вордстата.
Как искать подходящие для продвижения запросы
Сначала определяемся с тематикой сайта. Она подскажет ориентировочные запросы, которые стоит искать в Яндекс.Вордстат.
Представим, что мы планируем продвигать сайт по продаже холодильников. Запросами-ориентирами будут “холодильник”, “новый холодильник”, “холодильник купить”. По ним можно оценить спрос на конкретные модели и марки, посмотреть, какие характеристики холодильников ищут люди и отобрать подходящие запросы. Их них формируется семантическое ядро – набор запросов, по которым сайт будет показываться в поиске.
Например, вот поиск по слову “холодильник”:
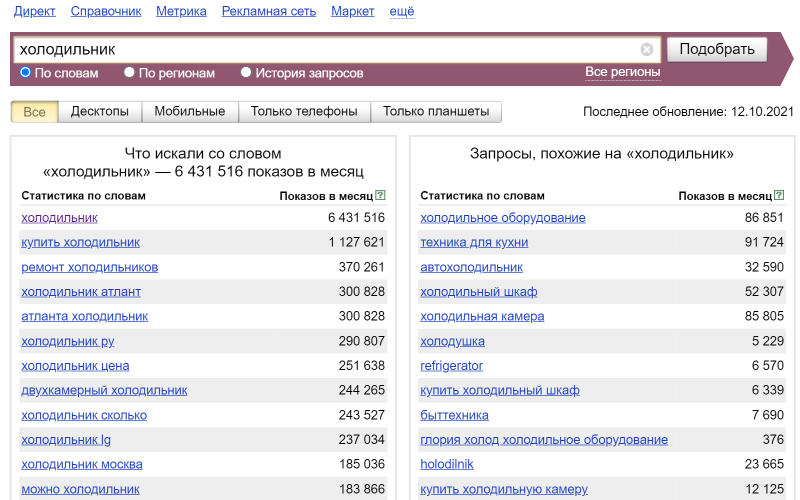
Для магазина холодильников нужно искать транзакционные запросы, потому что ваша цель – найти людей, которые хотят купить холодильник, то есть потратить деньги. Если магазин не новый и люди о нём знают, то возможно, они будут искать сайт по брендовым и навигационным запросам – их тоже стоит учесть.
Магазин холодильников – это коммерческий сайт. По коммерческим запросам в поиске обычно высокая конкуренция, потому что магазинов, которые продают холодильники, очень много. Так что если у вас маленький магазин, то продвижение по высокочастотным запросам скорее всего не принесёт результатов. Первую страницу выдачи займут крупные магазины вроде МВидео, Яндекс.Маркет, Ситилинк. А по данным исследований, только полпроцента людей переходят дальше первой страницы поиска. Возможно, в продвижении больше помогут средне- и низкочастотные запросы.
Дополнительный источник информации – правая колонка Вордстат или «Запросы, похожие на…». Тут можно найти тематические запросы, которые тоже интересны аудитории:
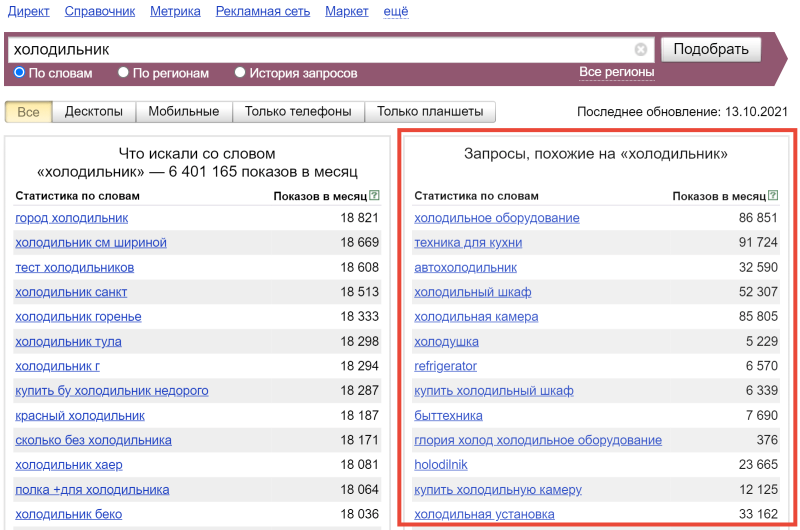
Если кликнуть на любой запрос в правой колонке, то Вордстат покажет все запросы, которые искали с этими словами и запросы, похожие на него:
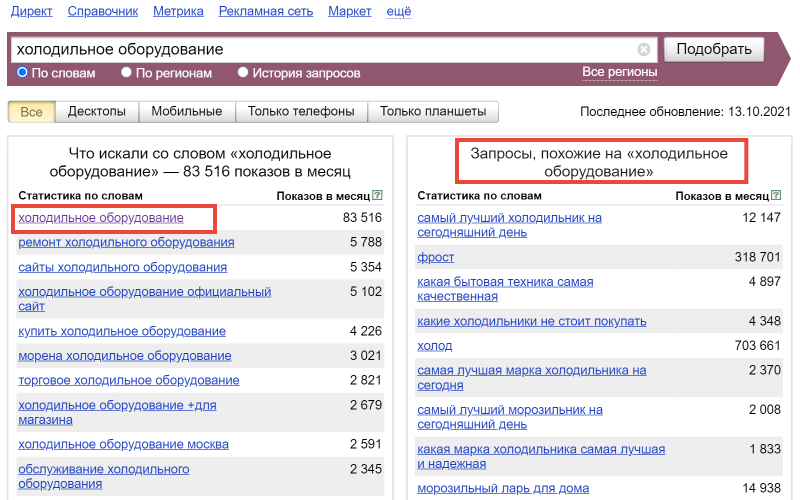
Операторы Вордстата: как найти запросы с нужными словами
Чтобы помочь нам в поиске запросов, Вордстат придумал специальные операторы.
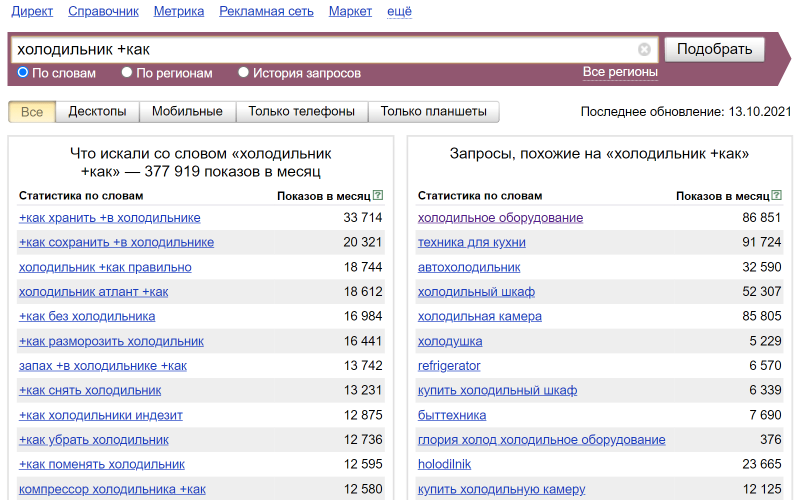
Оператор «+»
Например, иногда мы хотим найти запросы, содержащие конкретные слова или союзы, чтобы уточнить, что ищут пользователи. Для этого используется оператор «+». Порядок слов не фиксируется, но мы увидим все запросы, в которых встречается и слово “холодильник”, и слово “как” одновременно.
Попробуем найти все запросы со словом “как”:
Второй пример – найдём запросы с союзом «для»:
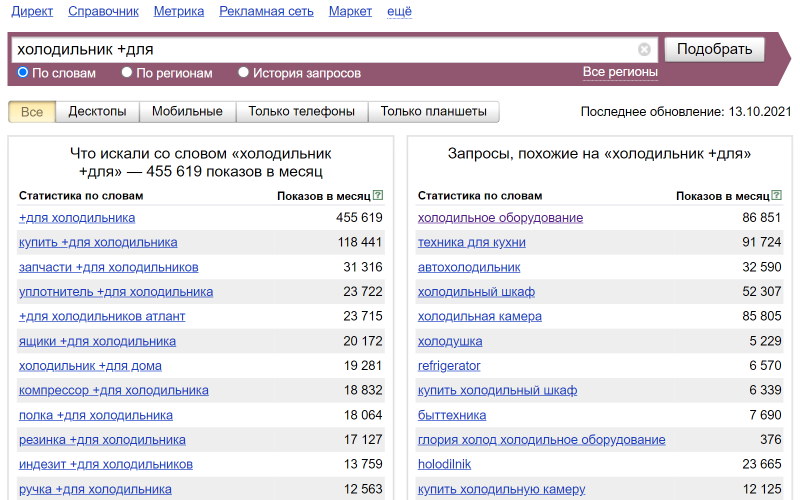
Как видим, запросы перепутались: тут и “для холодильника” и “холодильник для”. Если отбирать вручную, то можно потратить много времени. Поэтому пригодятся и другие операторы.
Оператор «!»
Это оператор фиксирует форму слова. С его помощью Вордстат покажет запросы, в которых слово упоминается именно в той форме, числе, падеже, которое ввели мы. Чтобы найти запросы, где холодильник упоминается в единственном числе, именительном падеже, добавим к нему оператор «!». Порядок слов по прежнему не фиксируется, поэтому если пользователь вводит запрос неточно, например “для холодильник”, то такие запросы тоже будут в списке:
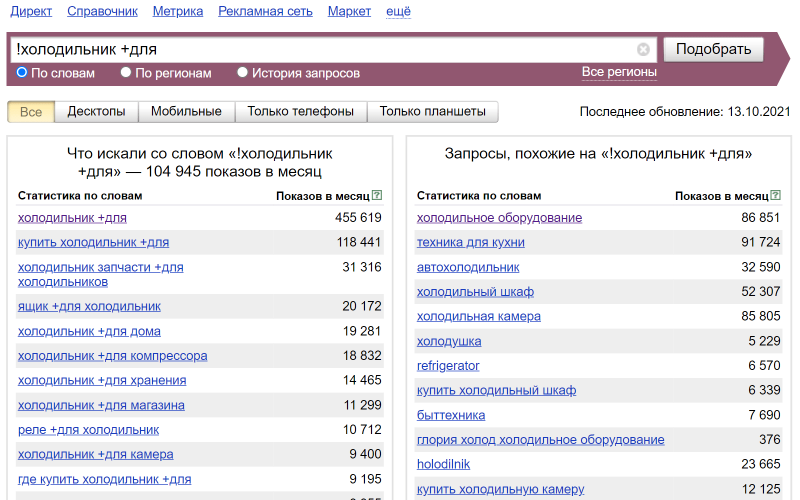
Оператор «[]»
Чтобы зафиксировать и порядок слов, используется оператор «[]» – квадратные скобки. Так мы получим чистые результаты:
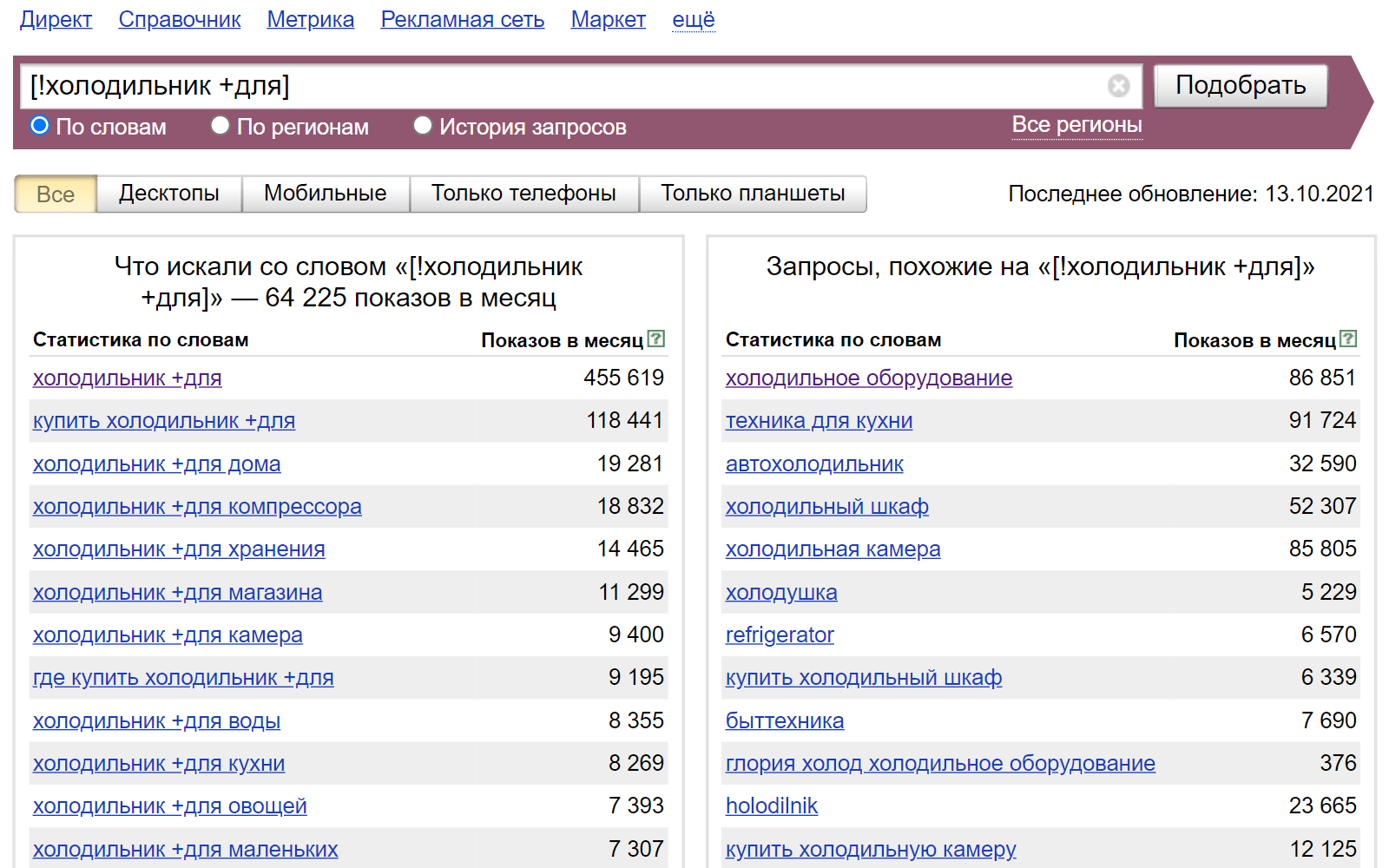
Оператор «““»
Если нам нужно найти запросы, содержащие только конкретные слова без хвостов, то используется оператор “кавычки”. Например, если мы хотим посмотреть запрос только по фразе “купить холодильник” без каких-либо хвостов. При этом порядок слов и форма слова не важны:
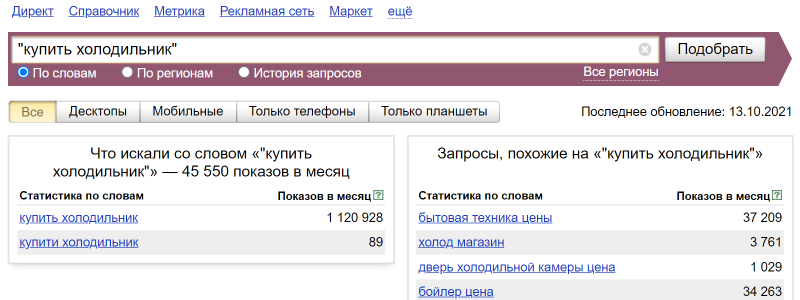
Оператор «(|)»
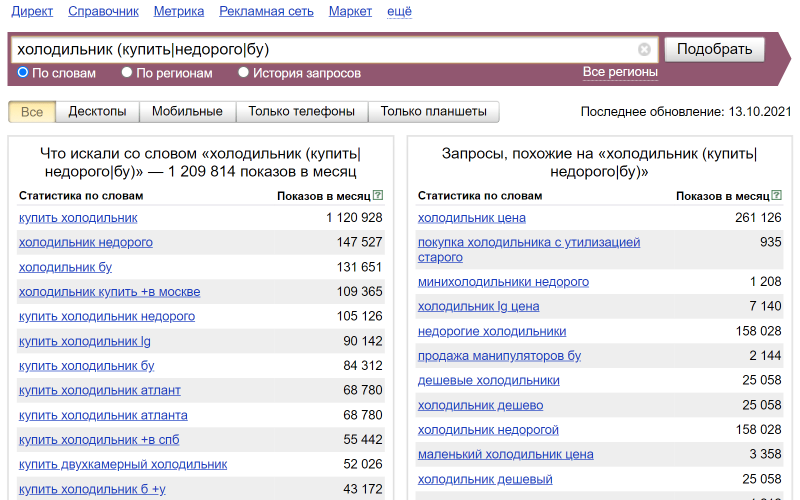
Если мы хотим найти запросы с несколькими дополнительными словами, то используется оператор «(|)». Через черту перечисляются дополнительные слова.
Этот оператор отличается от оператора «+». Если вы напишете в ряд все дополнительные слова через +, например: холодильник +купить +недорого +бу – то Вордстат будет искать запросы, в которых одновременно содержатся сразу 4 слова в любой форме и порядке: «холодильник купить недорого бу».
А при использовании оператора «(|)» Вордстат будет искать запросы которые содержат одновременно “холодильник купить” или “холодильник недорого” или “холодильник бу”:
Бонус
Представьте, что ищите запросы, состоящие из трёх слов. Вы знаете, что в них точно должны быть слова “купить” и “холодильник”, а третье слово может быть любым. Чтобы найти запросы с такими вводными, просто продублируйте последнее слово и ограничьте количество слов – используйте оператор «““»:
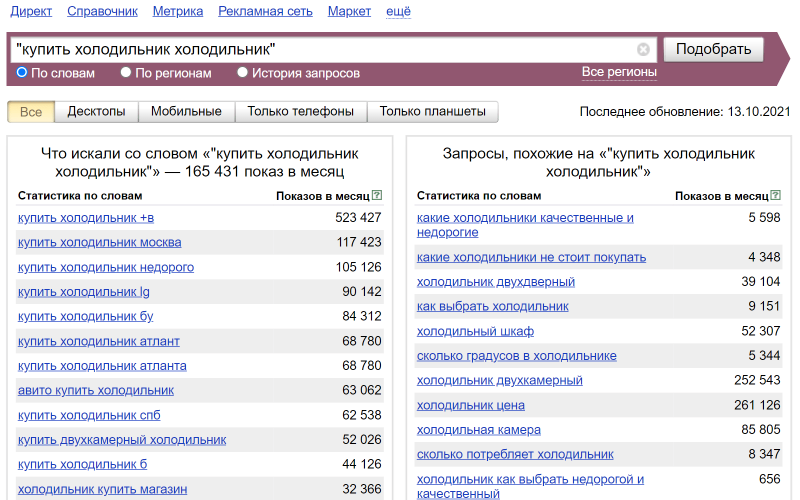
То же самое можно делать с любым количеством слов, дублируя последнее слово несколько раз:
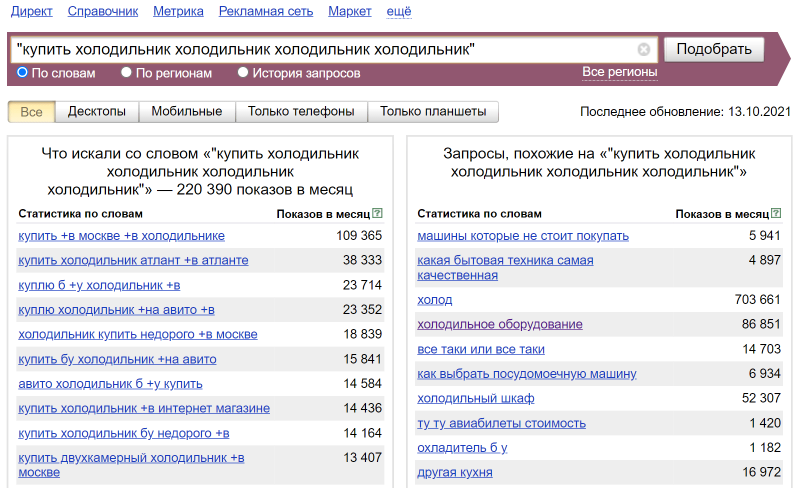
Пробуйте разные комбинации операторов, чтобы получить нужный результат. Например, зафиксируйте часть запроса и добавьте дополнительное слово:
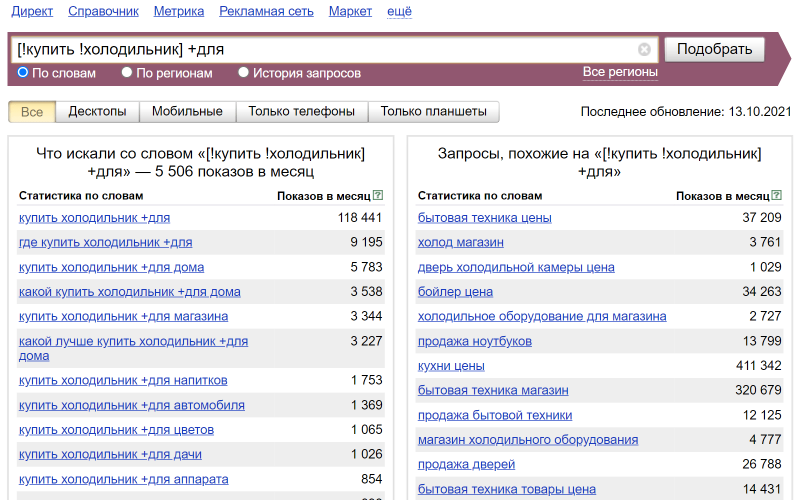
Так вы сможете найти все возможные запросы для сайта и изучить спрос.
Подробнее про операторы – в справке Яндекса.
Как смотреть точную частоту запроса
Мы уже говорили, что по умолчанию Вордстат показывает нам общую частоту запросов – включающую все возможные вариации. Благодаря этому, мы сможем собрать список запросов, которые нам подходят. Но чтобы спрогнозировать возможный трафик по ним, нужно знать точную частоту – сколько на самом деле людей ищут тот или иной запрос.
В этом нам тоже помогут операторы. Самую точную частоту можно определить, если зафиксировать порядок слов, форму слов и количество слов:
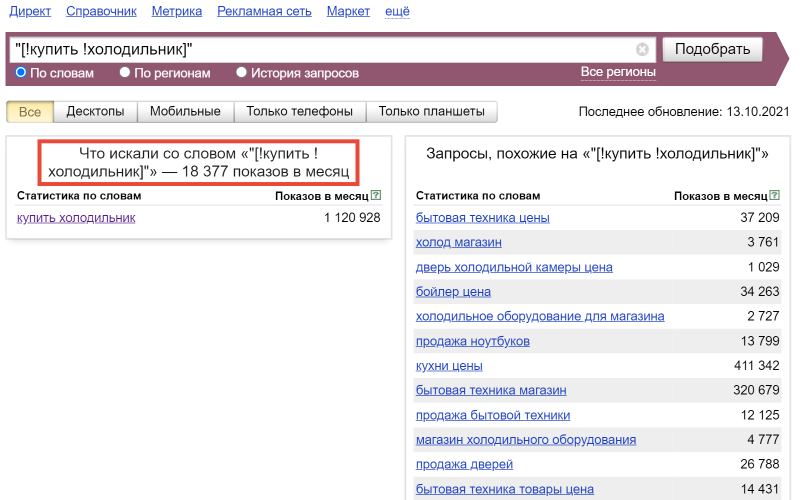
Если количество слов в запросе неважно, но важен их порядок, то убирайте оператор «““». Если, наоборот, важно количество слов, но не их порядок, убирайте оператор «[]»
Но это ещё не всё. Даже при отображении самой точной частоты Вордстат по умолчанию показывает данные по всем регионам мира. Если вы хотите оценить спрос в конкретном регионе, это нужно настроить.
Настройка региона
Для того, чтобы смотреть статистику запросов в нужной стране или городе, в системе существует фильтр выдачи по регионам:
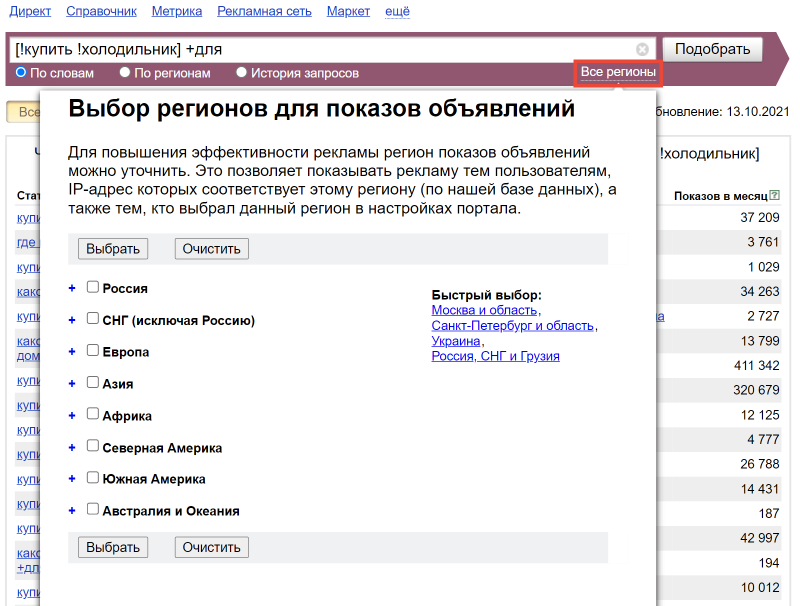
Правда, в нём самом нет поиска, поэтому, чтобы посмотреть частоту, например, в Казани, нужно знать, что она находится в Поволжье, в республике Татарстан:
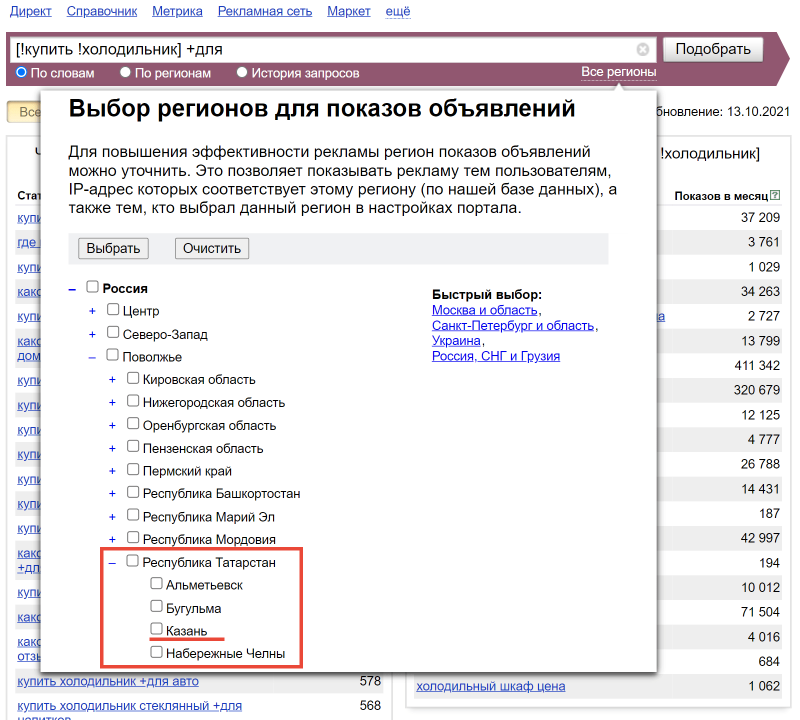
Ставим галочку, нажимаем кнопку «Выбрать» и смотрим частоту запросов:
Нужно ли учитывать регион?
Регион – это важная часть продвижения, но есть случаи, когда учитывать его при подборе семантики не обязательно. Например, если нам необходимо собрать полное семантическое ядро для сайта. В выбранном регионе может быть недостаточно данных, недостаточно спроса для определённых запросов, но они всё равно необходимы. Тогда полезно посмотреть более крупные или ближайшие города.
Но регион желательно учитывать для просмотра частоты запросов, чтобы более точно спрогнозировать потенциальный трафик. Если вы смотрите частоту в Вордстате, то выставить регион полезно, если собираете семантику – не обязательно. Всё зависит от тематики и стратегии продвижения
Что ещё можно смотреть в Яндекс.Вордстат
1. Частоту по Десктопной и Мобильной выдаче по отдельности: Десктопы (Компьютеры), Телефоны и Планшеты.

Помогает оценить, по каким запросам высокий мобильный трафик и с каких устройств пользователи чаще ищут запросы. По этому показателю, например, можно принять решение о разработке адаптивной версии сайта.
2. Статистику запроса и популярность запроса по регионам и городам.
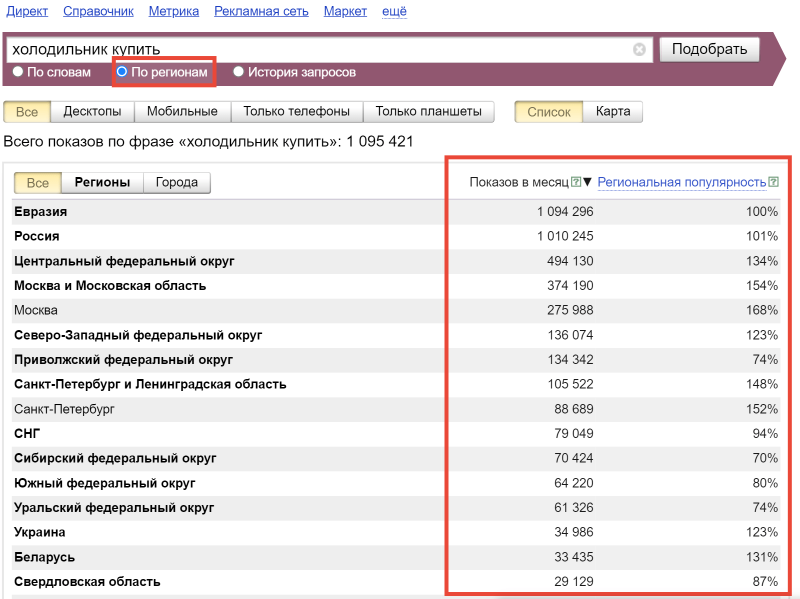
Региональная популярность указывается в процентах. Если больше 100 % – интерес в регионе повышен, если меньше – понижен. В интерфейсе Вордстата можно отсортировать регионы по показам или по популярности нажимая на «Показы» или «Региональная популярность» соответственно:
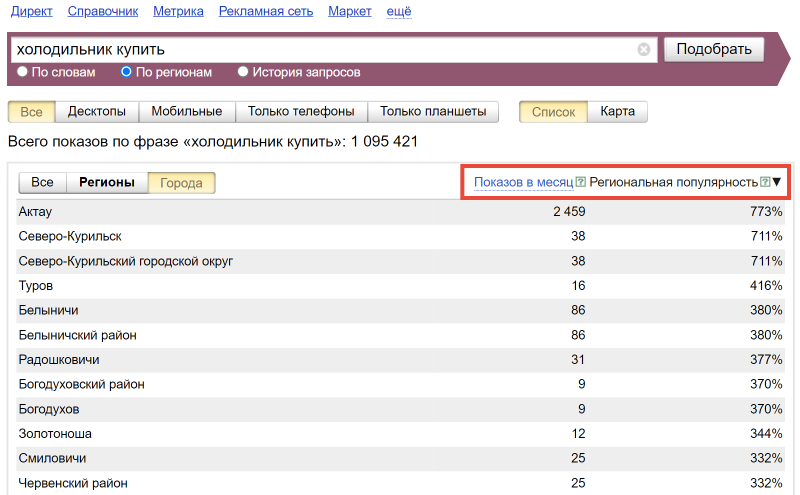
Региональная популярность помогает оценить, какая тема в каком регионе более и менее популярна.
3. Историю запросов. Этот раздел позволяет отслеживать динамику изменения популярности запроса по неделям и месяцам за два года:
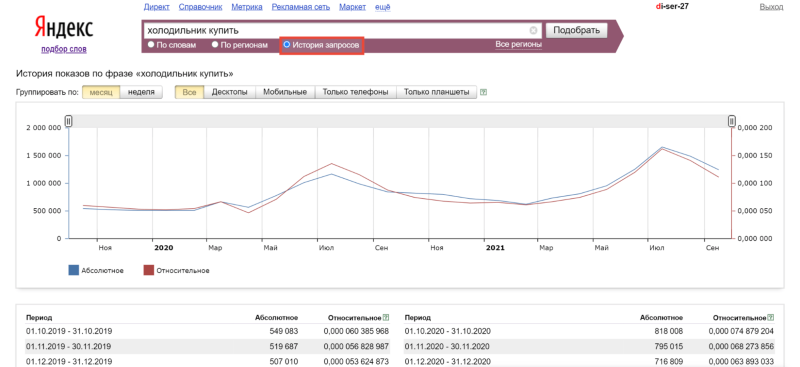
Вкладка «История запросов» – это полезные данные по сезонности запроса. Сезонность показывает, как изменяется спрос на товар или услугу в зависимости от времени года, месяца или каких-то знаковых событий. Повышенный спрос – это активность потенциальных покупателей. Зная сезонность, специалист может спрогнозировать увеличение или снижение трафика по запросу, определить знаковые в тематике события.
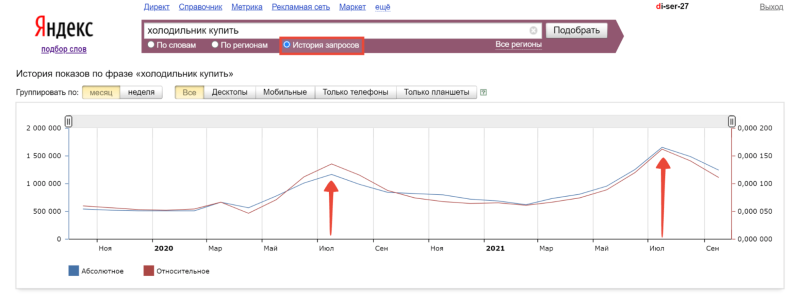
Например, на графике выше мы видим закономерность – запрос “холодильник купить” становится более популярным в июле. Так было в 2020 и в 2021 году:
Как собрать Вордстат автоматически в Топвизоре
В Вордстате есть ценные для специалистов данные. Но все их приходится собирать вручную, что занимает много времени. Из-за ручного сбора можно упустить важную семантику. Поэтому в Топвизоре есть инструмент, который поможет собрать все подходящие запросы для сайта из Вордстата за 5 минут.
Зарегистрируйтесь, создайте проект и перейдите в инструмент «Поисковые запросы», а затем в «Подбор ключевых слов»:
Введите ориентировочные запросы. Например, “холодильник”, “новый холодильник”, “холодильник купить” и соберите запросы из Яндекса в нужном регионе. Если отметить галочку напротив «+ «с этим искали»» , то одновременно Топвизор соберёт и похожие запросы из правой колонки Вордстата.
Чтобы позже выбирать из собранных запросов нужные, удобнее объединить их в одну группу с помощью галочки «Собрать все данные в одну группу»:
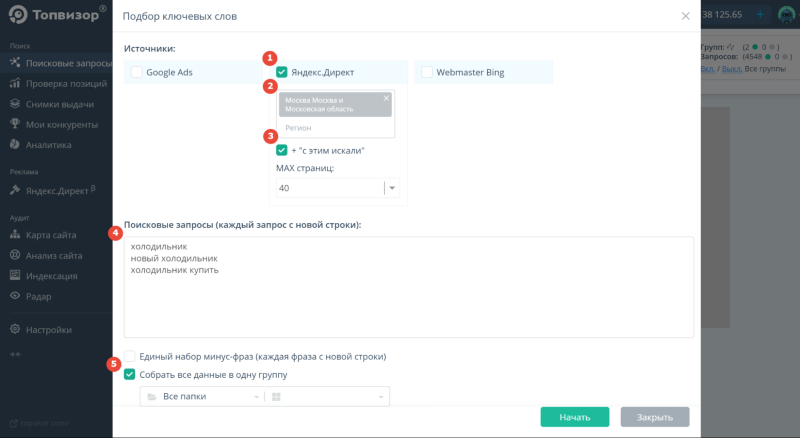
Топвизор поддерживает те же операторы Вордстата. В поле «Поисковые запросы» можно вводить запросы с любыми операторами и собрать более точную семантику:
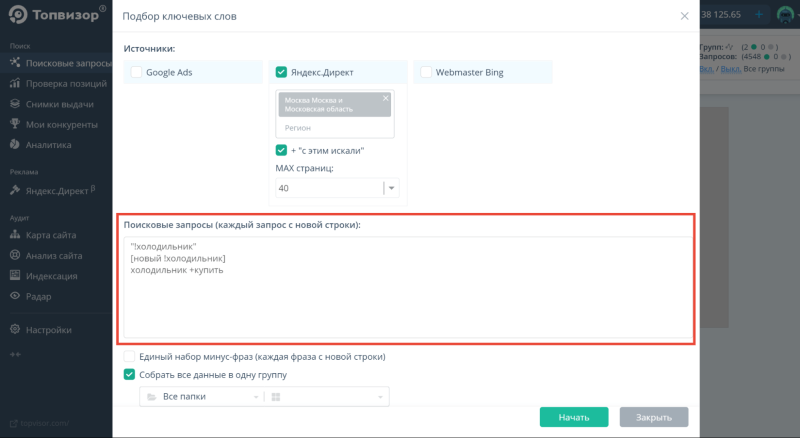
В результате вы получите список всех запросов, из которых по фильтру можно выбрать нужные. По нажатию Enter все выбранные по фильтру запросы перемещаются в одну группу:
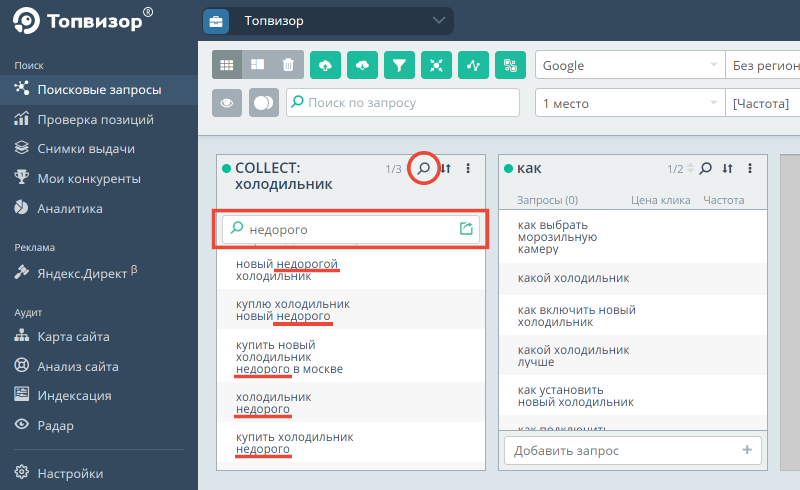
После того, как вы отберёте нужные запросы, нужно проверить их частоту в нужных регионах. Для этого сначала добавьте нужные регионы для Яндекса в Настройках:

После этого проверьте нужную частоту, учитывая операторы в инструменте «Поисковые запросы»:
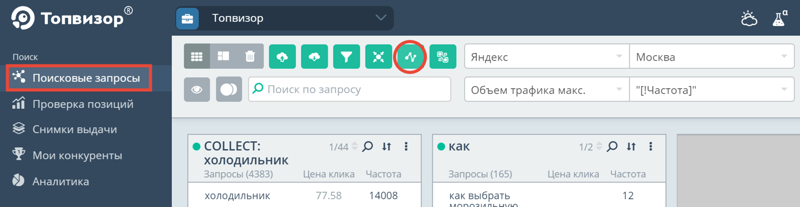
Самая точная частота будет по запросу “[!Частота]”:
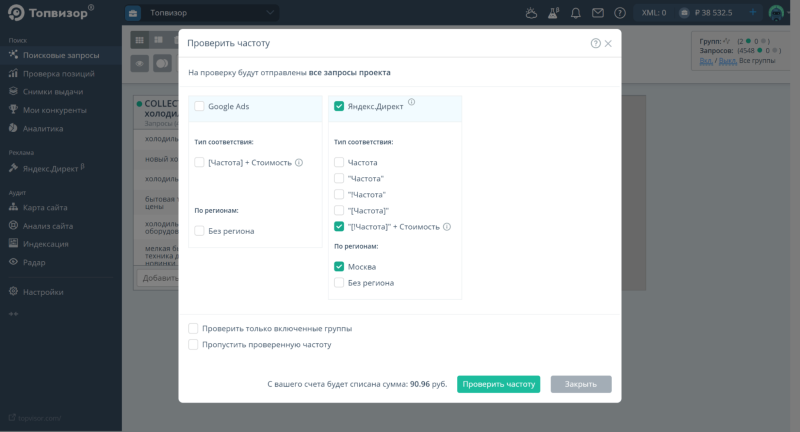
То, на что в Вордстате вы бы потратили один день, в Топвизоре займёт 5 минут. Но всё-таки Топвизор – это не только сбор данных из Вордстат.
Что есть в Топвизоре, чего нет в Вордстате
- Автоматический сбор и группировка запросов. В Вордстате всё нужно делать вручную: вбивать запросы по одному, просматривать список (иногда это 40 страниц), обращать внимание на похожие запросы, чтобы не упустить интересные, собирать всё в Excel, не забывая про частоту. В Топвизоре это один клик.
- Одновременный сбор всех нужных частот для каждого запроса. В Вордстате придётся вводить один и тот же запрос с разными операторами и фиксировать частоту в Excel. Учитывая, что частота обновляется раз в месяц, то собранные данные быстро устареют. В Топвизоре все виды частоты можно собрать одновременно и обновлять по необходимости за 5 минут.
- Фильтрация запросов по нужному слову. В Подборе слов Яндекса вам приходится отбирать запросы вручную или фильтрами Excel. В Топвизоре вы просто выбираете нужное слово и все запросы с ним отправляются в отдельную группу. Эту группу можно удалить, если такие ключи вам не нужны, или отложить для дальнейшей работы.
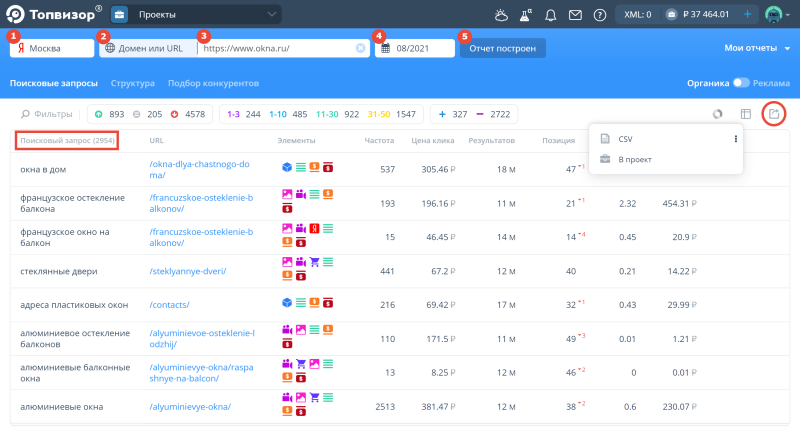
- Просмотр всех запросов, по которым продвигается конкурент. Топвизор покажет страницы и запросы, которые приносят трафик, полный список запросов для каждой страницы + похожие запросы, с помощью которых можно получить даже больше трафика, чем получают конкуренты. Отчёт можно построить по всему сайту или по каждой отдельной странице. Вордстат такое не умеет.
Чтобы в Топвизоре посмотреть посмотреть запросы, по которым продвигаются ваши конкуренты, переходите в «Анализ конкурентов». Данные из отчёта можно выгрузить в таблицу или сразу в проект, чтобы работать с ними дальше:

Как выгрузить запросы, по которым продвигаются конкуренты - Нет капчи и лимитов – работайте комфортно и без ограничений!
На основе данных из Вордстата можно собирать запросы, по которым сайт будет виден в поиске и контекстной рекламе, и прогнозировать возможный трафик. Но если вы хотите больше – используйте возможности Топвизора.