НАЙТИ, НАЙТИБ (функции НАЙТИ, НАЙТИБ)
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще…Меньше
В этой статье описаны синтаксис формулы и использование функций НАЙТИ и НАЙТИБ в Microsoft Excel.
Описание
Функции НАЙТИ и НАЙТИБ находят вхождение одной текстовой строки в другую и возвращают начальную позицию искомой строки относительно первого знака второй строки.
Важно:
-
Эти функции могут быть доступны не на всех языках.
-
Функция НАЙТИ предназначена для языков с однобайтовой кодировкой, а функция НАЙТИБ — для языков с двухбайтовой кодировкой. Заданный на компьютере язык по умолчанию влияет на возвращаемое значение указанным ниже образом.
-
Функция НАЙТИ при подсчете всегда рассматривает каждый знак, как однобайтовый, так и двухбайтовый, как один знак, независимо от выбранного по умолчанию языка.
-
Функция НАЙТИБ при подсчете рассматривает каждый двухбайтовый знак как два знака, если включена поддержка языка с БДЦС и такой язык установлен по умолчанию. В противном случае функция НАЙТИБ рассматривает каждый знак как один знак.
К языкам, поддерживающим БДЦС, относятся японский, китайский (упрощенное письмо), китайский (традиционное письмо) и корейский.
Синтаксис
НАЙТИ(искомый_текст;просматриваемый_текст;[нач_позиция])
НАЙТИБ(искомый_текст;просматриваемый_текст;[нач_позиция])
Аргументы функций НАЙТИ и НАЙТИБ описаны ниже.
-
Искомый_текст — обязательный аргумент. Текст, который необходимо найти.
-
Просматриваемый_текст — обязательный аргумент. Текст, в котором нужно найти искомый текст.
-
Начальная_позиция — необязательный аргумент. Знак, с которого нужно начать поиск. Первый знак в тексте «просматриваемый_текст» имеет номер 1. Если номер опущен, он полагается равным 1.
Замечания
-
Функции НАЙТИ и НАЙТИБ работают с учетом регистра и не позволяют использовать подстановочные знаки. Если необходимо выполнить поиск без учета регистра или использовать подстановочные знаки, воспользуйтесь функцией ПОИСК или ПОИСКБ.
-
Если в качестве аргумента «искомый_текст» задана пустая строка («»), функция НАЙТИ выводит значение, равное первому знаку в строке поиска (знак с номером, соответствующим аргументу «нач_позиция» или 1).
-
Искомый_текст не может содержать подстановочные знаки.
-
Если find_text не отображаются в within_text, find и FINDB возвращают #VALUE! значение ошибки #ЗНАЧ!.
-
Если start_num не больше нуля, то найти и найтиБ возвращает значение #VALUE! значение ошибки #ЗНАЧ!.
-
Если start_num больше, чем длина within_text, то поиск и НАЙТИБ возвращают #VALUE! значение ошибки #ЗНАЧ!.
-
Аргумент «нач_позиция» можно использовать, чтобы пропустить нужное количество знаков. Предположим, например, что для поиска строки «МДС0093.МесячныеПродажи» используется функция НАЙТИ. Чтобы найти номер первого вхождения «М» в описательную часть текстовой строки, задайте значение аргумента «нач_позиция» равным 8, чтобы поиск в той части текста, которая является серийным номером, не производился. Функция НАЙТИ начинает со знака 8, находит искомый_текст в следующем знаке и возвращает число 9. Функция НАЙТИ всегда возвращает номер знака, считая от левого края текста «просматриваемый_текст», а не от значения аргумента «нач_позиция».
Примеры
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
|
Данные |
||
|
Владимир Егоров |
||
|
Формула |
Описание |
Результат |
|
=НАЙТИ(«В»;A2) |
Позиция первой «В» в ячейке A2 |
1 |
|
=НАЙТИ(«в»;A2) |
Позиция первой «в» в ячейке A2 |
6 |
|
=НАЙТИ(«и»;A2;3) |
Позиция первой «и» в строке А2, начиная с третьего знака |
8 |
Пример 2
|
Данные |
||
|
Керамический изолятор №124-ТД45-87 |
||
|
Медная пружина №12-671-6772 |
||
|
Переменный резистор №116010 |
||
|
Формула |
Описание (результат) |
Результат |
|
=ПСТР(A2;1;НАЙТИ(» №»;A2;1)-1) |
Выделяет текст от позиции 1 до знака «№» в строке («Керамический изолятор») |
Керамический изолятор |
|
=ПСТР(A3;1;НАЙТИ(» №»;A3;1)-1) |
Выделяет текст от позиции 1 до знака «№» в ячейке А3 («Медная пружина») |
Медная пружина |
|
=ПСТР(A4;1;НАЙТИ(» №»;A4;1)-1) |
Выделяет текст от позиции 1 до знака «№» в ячейке А4 («Переменный резистор») |
Переменный резистор |
Нужна дополнительная помощь?
Нужны дополнительные параметры?
Изучите преимущества подписки, просмотрите учебные курсы, узнайте, как защитить свое устройство и т. д.
В сообществах можно задавать вопросы и отвечать на них, отправлять отзывы и консультироваться с экспертами разных профилей.
Найти подстроку в строке
Время на прочтение
6 мин
Количество просмотров 20K
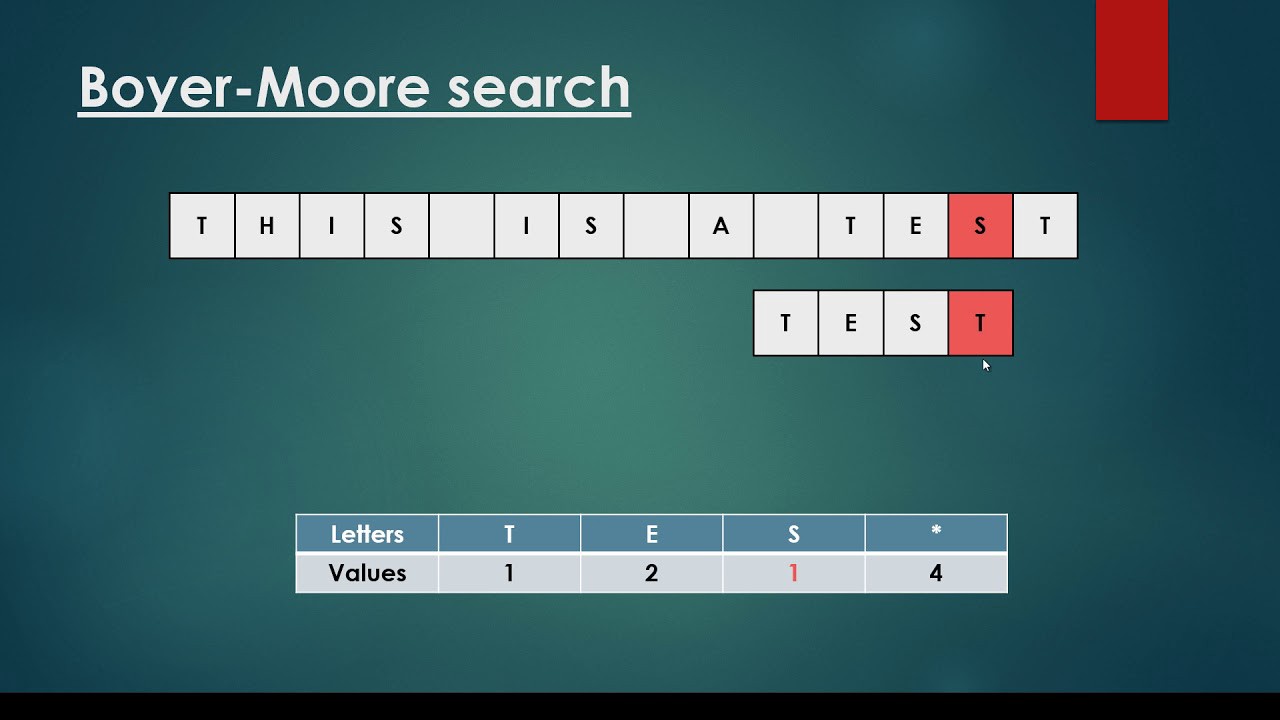
Алгоритм поиска строки Бойера — Мура — алгоритм общего назначения, предназначенный для поиска подстроки в строке.
Давайте попробуем найти вхождение подстроки в строку.
Наш исходный текст будет:
Text: somestringИ паттерн, который мы будем искать
Pattern: stringДавайте расставим индексы в нашем тексте, чтобы видеть на каком индексе находится какая буква.
0 1 2 3 4 5 6 7 8 9
s o m e s t r i n gНапишем метод, который определяет, находится ли шаблон в строке. Метод будет возвращать индекс откуда шаблон входит в строку.
int find (string text, string pattern){}В нашем примере должно будет вернуться 4.
0 1 2 3 4 5 6 7 8 9
text: s o m e s t r i n g
pattern: s t r i n gЕсли ответ не найден, мы будем возвращать -1
int find (string text, string pattern) {
int t = 0; создадим индекс для прохода по тексту.
int last = pattern.length — 1; это индекс последнего элемента в шаблонеСоздадим цикл для прохода по тексту.
while (t < text.length — last)Почему именно такое условие? Потому что если останется символов меньше чем длина нашего паттерна, нам уже нет смысла проверять дальше. Наш паттерн точно не входит в строку.
В нашем примере:
last = 5 (Последний индекс паттерна string равен 5)
Длина текста равна 10 (somestring)
Это значит что text.length — last = 10–5 = 5;
0 1 2 3 4 5 6 7 8 9
text: s o m e s t r i n g
pattern: s t r i n g Можно заметить, что если мы стоим на 5м индексе в строке, а 4й не подошел, то наш паттерн не входит в строку, например
0 1 2 3 4 5 6 7 8 9
text: s o m e X t r i n g
^
pattern: s t r i n gПолучится что длина паттерна, больше чем длина оставшейся строки.
На данный момент у нас есть код вида :
int find (string text, string pattern) {
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last){
}
}Теперь введем переменную int p = 0, которая будет двигаться по нашему паттерну.
И запустим внутренний цикл
while( p <= last && text[ t + p ] == pattern[p] ){
}p <= last — пока меньше или равно последнему индексу символа шаблона
text[ t + p ] = pattern[p] — пока очередной сивмол текста совпадает с символом в шаблоне.
Давайте детальнее разберем, что значит text[ t + p ] = pattern[p]
Допустим мы в тексте стоим на индексе 4
0 1 2 3 4 5 6 7 8 9
text: s o m e s t r i n g
^
pattern: s t r i n gПолучается t = 4, p = 0; text[ t + p ] = text[ 4 + 0 ] = s, pattern[0] = s, значит условие цикла выполняется.
Код на текущий момент:
int find (string text, string pattern) {
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last) {
int p = 0;
while( p <= last && text[ t + p ] = pattren[p] ){
Если условие цикла выполняется, сдвигаем p вперед.
p ++;
}
В результате если p == pattern.length
мы можем вернуть индекс на котором паттерн входит в текст.
if (p == pattern.length){
return t;
}
В противном случае идем к следующему индексу в строке.
t ++;
}
}Получается мы имеем такой метод:
int find (string text, string pattern) {
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last) {
int p = 0;
while( p <= last && text[ t + p ] == pattern[p] ) {
p ++;
}
if (p == pattern.length) {
return t;
}
t ++;
}
return — 1;
}Как можно ускорить этот алгоритм? Какие есть варианты?
Представим что у нас в тексте есть символ, которого нет в паттерне.
text: some*string , то на сколько можно сдвигать паттерн?
А если есть повторяющиеся символы?
Например можно начать бежать с конца паттерна, то есть
text: somestring
^
pattern: string
^Начинаем бежать с конца паттерна. Если символы не совпадают, на сколько можно сдвинуть паттерн?
Если символ из текста есть в нашем паттерне, то можно сразу сдвинуть до этого символа.
text: somestring
pattern: stringСдвигаем на длину паттерна минус индекс символа на котором мы стоим в тексте.
То есть в данном случае
text: somestring
^
pattern: string
^Когда мы начинаем бежать по паттерну с конца у нас pattern[i] = ‘g’, а text[i] = ’t’,
мы можем сдвинуть наш паттерн на pattern.length — индекс ’t’ в паттерне.
Индекс ’t’ в паттерне = 1, получается 5–1 = 4, сдвигаем паттерн на 4 символа вперед.
text: somestring
^
pattern: >>>>string
^Мы можем предварительно создать таблицу для нашего паттерна.
Посчитаем позицию каждого символа в паттерне, чтобы знать на сколько сдвигаться.
Составляем таблицу смещений, для каждого символа алфавита. Я буду в примере использовать символ * чтобы не расписывать весь алфавит.
Таблица смещений:
s 0
t 1
r 2
i 3
n 4
g 5
* -1Давайте возьмем другой паттерн, чтобы символы повторялись и было ясно, на сколько нужно двигать паттерн, если символы повторяются:
pattern: колокол
к 4
л 2 — если символ последний в строке, то оставляем его первый вход
м -1
н -1
о 5Мы сдвигаем на последние вхождение символа, потому что если сдвигать на первое, то можно упустить часть входа паттерна в строку.
Попробуем реализовать эту часть алгоритма:
int[] createOffsetTable(string pattern) {
int[] offset = new int[128]; // количество символов зависит от
// алфавита с которым мы работаем
for (int i = 0; i < offset.length; i++){
offset[i] = -1; // заполняем базовыми значениями
}
for (int i = 0; i < pattern.length; i++){
offset[pattern[i]] = i;
}
return offset;
}Добавим таблицу смещений в алгоритм поиска, что мы написали выше:
int find (string text, string pattern) {
int[] offset = createOffsetTable(pattern);
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last){
int p = last; // начнем двигаться с конца паттерна
//Чуть чуть меняем условие цикла,
//так как теперь мы двигаемся с конца
while( p >= 0 && text[ t + p ] == pattern[p] ){
p — ;
}
if (p == -1){
return t;
}
t += last — offset[ text[ t + last ] ];
}
return — 1;
}Почему t + last ? Смотрим на каком символе стоим в тексте и прибавляем длину шаблона. Если при поиске входа, какая то часть не совпала, то мы должны сдвинуться на символ текста в котором стоим + длина шаблона.
Например:
Таблица смещений для колокол:
к = 4
л = 2
о = 5Шаг 1:
0 1 2 3 4 5 6 7 8 9 10
text: а а к о л о л о к о л о к о л
pattern: к о л о к о л
last = 7;
t += last — offset[text[t + last]]
t += last — offset[text[0 + 7]]
t += last — offset[‘о’]
t += 7–5 = 2;
t = 2;Шаг 2:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text: а а к о л о л о к о л о к о л
pattern: > > к о л о к о л
t = 2;
t += last — offset[text[t + last]]
t += last — offset[text[2 + 7]]
t += last — offset[‘о’]
t += 7–5 = 2;
t = 4;Шаг 3:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text: а а к о л о л о к о л о к о л
pattern: > > > > к о л о к о л
t = 4;
t += last — offset[text[t + last]]
t += last — offset[text[4 + 7]]
t += last — offset[‘о’]
t += 7–5 = 2;
t = 6;Шаг 4:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text: а а к о л о л о к о л о к о л
pattern: > > > > > > к о л о к о л
t = 6;
t += last — offset[text[t + last]]
t += last — offset[text[6 + 7]]
t += last — offset[‘о’]
t += 7–5 = 2;
t = 8;Шаг 5:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
text: а а к о л о л о к о л о к о л
pattern: > > > > > > > > к о л о к о лСовпадение найдено.
На этом разбор упрощенного алгоритма Бойера-Мура закончен.
Пока мы отталкивались только от крайних символов. Но возможно ли как то использовать информацию по уже пройденным символам?
Допустим есть строка
abcdadcd
Как составить таблицу смещений мы уже знаем. Теперь составим таблицу суффиксов.
Когда мы стоим на символе d, на сколько можно сдвинуть паттерн? Сдвигаем на на расстояние до ближайшего такого же символа. В примере ниже у нас есть 2 символа d с расстояниями 2 и 4. Мы выберем 2 потому что оно меньше.
4
-----—
| 2
| ---
| | |
abcdadcd
^Дальше рассмотрим суффикс cd. Для d мы уже записали 2.
2
abcdadcd
У нас есть только один суффикс cd, это значит что можно
-- сдвинуться на 4 символа.
Запишем для с = 4.
842
abcdadcd
Далее dcd. dcd в тексте больше нигде не встречается.
--- Двигаем на длину шаблона = 8И для всех остальных символов пишем 8, потому что суффиксы не будут совпадать.
Теперь вернемся к нашему паттерну колокол.
колокол* В конце всегда будет *, еcли символ не совпал, сдвинем на 1.
1
колокол*
—
41
колокол*
-—
441
колокол*
--—
4441
колокол*
---—
4441
колокол*
----Для окол мы тоже запишем 4. Потому что у нас префикс совпадает с суффиксом.
Попробуем написать код для этого
createSuffix(string pattern){
int[] suffix = new int[pattern.length + 1]; // +1 для символа звездочки
for(int i = 0; i < pattern.length; i ++){
suffix[i] = pattern.length; // изначальное значение,
//длина шаблона. на сколько сдвигать если нет совпадения суффиксов
}
suffix[pattern.length] = 1; // для звездочки ставим 1
//Сначала создадим переменную, которая идет справа на лево.
for (int i = pattern.length — 1; i >= 0; i — ) {
for (int at = i; at < pattern.lenth; at ++){
string s = pattern.substring(at); // с какого символа берем подстрокуНапример колокол с чем сравниваем?
--—
колокол
--—
---
---
---
кол мы сравним с око, лок, оло, кол
for (int j = at — 1; j >= 0; j — ) {
string p = pattern.substring(j, s.length); // берем подстроку той же длинны
//что и суффикс
if (p.equals(s)) {
suffix[j] = at — i;
break;
}
}
}
}
return suffix;}Существует более оптимальный алгоритм, но дальше индивидуально.
Какой код у нас есть на данный момент?
int[] createSuffix (string pattern) {
int[] suffix = new int[pattern.length + 1];
for (int i = 0; i < pattern.length; i ++){
suffix[i] = pattern.length;
}
suffix[pattern.length] = 1;
for (int i = pattern.length — 1; i >=0; i — ){
for(int at = i; i < pattern.length; i ++){
string s = pattern.substring(at);
for (int j = at — 1; j >= 0; j — ){
string p = pattern.substring(j, s.length);
if (p == s) {
suffix[i] = at — 1;
at = pattern.length;
break;
}
}
}
}
return suffix;
}
int find(string text, string pattern) {
int[] offset = createOffset(pattern);
int[] suffix = createSuffix(pattern);
int t = 0;
int last = pattern.length — 1;
while (t < text.length — last) {
int p = last;
while (p >= 0 && text[t + p] == pattern[p]) {
p — ;
}
if (p == -1) {
return t;
}
t += Math.max (p — offset[text[t + p]], suffix[p + 1]);
}
return -1;
}p — prefix[text[t + p]] — последний символ, который нашли и под него подстроить сдвиг нашего шаблона
suffix[p + 1] — значение суффикса для последнего элемента, который был сравнен.
И двигаем на максимальное значение, чтобы двигаться максимально быстро.
На этом разбор алгоритма Бойера-Мура закончен. Спасибо за внимание! =)

В этой статье поговорим про строки в Python, особенности поиска, а также о том, как искать подстроку или символ в строке.

Но сначала давайте вспомним основные методы для обработки строк в Python:
• isalpha(str): если строка в Python включает в себя лишь алфавитные символы, возвращается True;
• islower(str): True возвращается, если строка включает лишь символы в нижнем регистре;
• isupper(str): True, если символы строки в Python находятся в верхнем регистре;
• startswith(str): True, когда строка начинается с подстроки str;
• isdigit(str): True, когда каждый символ строки — цифра;
• endswith(str): True, когда строка в Python заканчивается на подстроку str;
• upper(): строка переводится в верхний регистр;
• lower(): строка переводится в нижний регистр;
• title(): для перевода начальных символов всех слов в строке в верхний регистр;
• capitalize(): для перевода первой буквы самого первого слова строки в верхний регистр;
• lstrip(): из строки в Python удаляются начальные пробелы;
• rstrip(): из строки в Python удаляются конечные пробелы;
• strip(): из строки в Python удаляются и начальные, и конечные пробелы;
• rjust(width): когда длина строки меньше, чем параметр width, слева добавляются пробелы, строка выравнивается по правому краю;
• ljust(width): когда длина строки в Python меньше, чем параметр width, справа от неё добавляются пробелы для дополнения значения width, при этом происходит выравнивание строки по левому краю;
• find(str[, start [, end]): происходит возвращение индекса подстроки в строку в Python. В том случае, если подстрока не найдена, выполняется возвращение числа -1;
• center(width): когда длина строки в Python меньше, чем параметр width, слева и справа добавляются пробелы (равномерно) для дополнения значения width, причём происходит выравнивание строки по центру;
• split([delimeter[, num]]): строку в Python разбиваем на подстроки в зависимости от разделителя;
• replace(old, new[, num]): в строке одна подстрока меняется на другую;
• join(strs): строки объединяются в одну строку, между ними вставляется определённый разделитель.
Обрабатываем строку в Python
Представим, что ожидается ввод числа с клавиатуры. Перед преобразованием введенной нами строки в число можно легко проверить, введено ли действительно число. Если это так, выполнится операция преобразования. Для обработки строки используем такой метод в Python, как isnumeric():
string = input("Введите какое-нибудь число: ") if string.isnumeric(): number = int(string) print(number)Следующий пример позволяет удалять пробелы в конце и начале строки:
string = " привет мир! " string = string.strip() print(string) # привет мир!Так можно дополнить строку пробелами и выполнить выравнивание:
print("iPhone 7:", "52000".rjust(10)) print("Huawei P10:", "36000".rjust(10))В консоли Python будет выведено следующее:
iPhone 7: 52000 Huawei P10: 36000Поиск подстроки в строке
Чтобы в Python выполнить поиск в строке, используют метод find(). Он имеет три формы и возвращает индекс 1-го вхождения подстроки в строку:
• find(str): поиск подстроки str производится с начала строки и до её конца;
• find(str, start): с помощью параметра start задаётся начальный индекс, и именно с него и выполняется поиск;
• find(str, start, end): посредством параметра end задаётся конечный индекс, поиск выполняется до него.
Когда подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!" index = welcome.find("wor") print(index) # 6 # ищем с десятого индекса index = welcome.find("wor",10) print(index) # 21 # ищем с 10-го по 15-й индекс index = welcome.find("wor",10,15) print(index) # -1Замена в строке
Чтобы в Python заменить в строке одну подстроку на другую, применяют метод replace():
• replace(old, new): подстрока old заменяется на new;
• replace(old, new, num): параметр num показывает, сколько вхождений подстроки old требуется заменить на new.Пример замены в строке в Python:
phone = "+1-234-567-89-10" # дефисы меняются на пробелы edited_phone = phone.replace("-", " ") print(edited_phone) # +1 234 567 89 10 # дефисы удаляются edited_phone = phone.replace("-", "") print(edited_phone) # +12345678910 # меняется только первый дефис edited_phone = phone.replace("-", "", 1) print(edited_phone) # +1234-567-89-10Разделение на подстроки в Python
Для разделения в Python используется метод split(). В зависимости от разделителя он разбивает строку на перечень подстрок. В роли разделителя в данном случае может быть любой символ либо последовательность символов. Этот метод имеет следующие формы:
• split(): в роли разделителя применяется такой символ, как пробел;
• split(delimeter): в роли разделителя применяется delimeter;
• split(delimeter, num): параметром num указывается, какое количество вхождений delimeter применяется для разделения. При этом оставшаяся часть строки добавляется в перечень без разделения на подстроки.Соединение строк в Python
Рассматривая простейшие операции со строками, мы увидели, как объединяются строки через операцию сложения. Однако есть и другая возможность для соединения строк — метод join():, объединяющий списки строк. В качестве разделителя используется текущая строка, у которой вызывается этот метод:
words = ["Let", "me", "speak", "from", "my", "heart", "in", "English"] # символ разделителя - пробел sentence = " ".join(words) print(sentence) # Let me speak from my heart in English # символ разделителя - вертикальная черта sentence = " | ".join(words) print(sentence) # Let | me | speak | from | my | heart | in | EnglishА если вместо списка в метод join передать простую строку, разделитель будет вставляться уже между символами:
word = "hello" joined_word = "|".join(word) print(joined_word) # h|e|l|l|o

I’m working with Python, and I’m trying to find out if you can tell if a word is in a string.
I have found some information about identifying if the word is in the string — using .find, but is there a way to do an if statement. I would like to have something like the following:
if string.find(word):
print("success")
![]()
mkrieger1
18.2k4 gold badges53 silver badges64 bronze badges
asked Mar 16, 2011 at 1:10
![]()
0
What is wrong with:
if word in mystring:
print('success')
![]()
Martin Thoma
122k156 gold badges604 silver badges941 bronze badges
answered Mar 16, 2011 at 1:13
![]()
fabrizioMfabrizioM
46.2k15 gold badges100 silver badges118 bronze badges
13
if 'seek' in 'those who seek shall find':
print('Success!')
but keep in mind that this matches a sequence of characters, not necessarily a whole word — for example, 'word' in 'swordsmith' is True. If you only want to match whole words, you ought to use regular expressions:
import re
def findWholeWord(w):
return re.compile(r'b({0})b'.format(w), flags=re.IGNORECASE).search
findWholeWord('seek')('those who seek shall find') # -> <match object>
findWholeWord('word')('swordsmith') # -> None
answered Mar 16, 2011 at 1:52
![]()
Hugh BothwellHugh Bothwell
55k8 gold badges84 silver badges99 bronze badges
6
If you want to find out whether a whole word is in a space-separated list of words, simply use:
def contains_word(s, w):
return (' ' + w + ' ') in (' ' + s + ' ')
contains_word('the quick brown fox', 'brown') # True
contains_word('the quick brown fox', 'row') # False
This elegant method is also the fastest. Compared to Hugh Bothwell’s and daSong’s approaches:
>python -m timeit -s "def contains_word(s, w): return (' ' + w + ' ') in (' ' + s + ' ')" "contains_word('the quick brown fox', 'brown')"
1000000 loops, best of 3: 0.351 usec per loop
>python -m timeit -s "import re" -s "def contains_word(s, w): return re.compile(r'b({0})b'.format(w), flags=re.IGNORECASE).search(s)" "contains_word('the quick brown fox', 'brown')"
100000 loops, best of 3: 2.38 usec per loop
>python -m timeit -s "def contains_word(s, w): return s.startswith(w + ' ') or s.endswith(' ' + w) or s.find(' ' + w + ' ') != -1" "contains_word('the quick brown fox', 'brown')"
1000000 loops, best of 3: 1.13 usec per loop
Edit: A slight variant on this idea for Python 3.6+, equally fast:
def contains_word(s, w):
return f' {w} ' in f' {s} '
answered Apr 11, 2016 at 20:32
![]()
user200783user200783
13.6k12 gold badges68 silver badges132 bronze badges
6
You can split string to the words and check the result list.
if word in string.split():
print("success")
![]()
Martin Thoma
122k156 gold badges604 silver badges941 bronze badges
answered Dec 1, 2016 at 18:26
![]()
CorvaxCorvax
7727 silver badges13 bronze badges
3
find returns an integer representing the index of where the search item was found. If it isn’t found, it returns -1.
haystack = 'asdf'
haystack.find('a') # result: 0
haystack.find('s') # result: 1
haystack.find('g') # result: -1
if haystack.find(needle) >= 0:
print('Needle found.')
else:
print('Needle not found.')
![]()
Martin Thoma
122k156 gold badges604 silver badges941 bronze badges
answered Mar 16, 2011 at 1:13
![]()
Matt HowellMatt Howell
15.7k7 gold badges48 silver badges56 bronze badges
0
This small function compares all search words in given text. If all search words are found in text, returns length of search, or False otherwise.
Also supports unicode string search.
def find_words(text, search):
"""Find exact words"""
dText = text.split()
dSearch = search.split()
found_word = 0
for text_word in dText:
for search_word in dSearch:
if search_word == text_word:
found_word += 1
if found_word == len(dSearch):
return lenSearch
else:
return False
usage:
find_words('çelik güray ankara', 'güray ankara')
![]()
answered Jun 22, 2012 at 22:51
![]()
Guray CelikGuray Celik
1,2811 gold badge14 silver badges13 bronze badges
0
If matching a sequence of characters is not sufficient and you need to match whole words, here is a simple function that gets the job done. It basically appends spaces where necessary and searches for that in the string:
def smart_find(haystack, needle):
if haystack.startswith(needle+" "):
return True
if haystack.endswith(" "+needle):
return True
if haystack.find(" "+needle+" ") != -1:
return True
return False
This assumes that commas and other punctuations have already been stripped out.
![]()
IanS
15.6k9 gold badges59 silver badges84 bronze badges
answered Jun 15, 2012 at 7:23
![]()
daSongdaSong
4071 gold badge5 silver badges9 bronze badges
1
Using regex is a solution, but it is too complicated for that case.
You can simply split text into list of words. Use split(separator, num) method for that. It returns a list of all the words in the string, using separator as the separator. If separator is unspecified it splits on all whitespace (optionally you can limit the number of splits to num).
list_of_words = mystring.split()
if word in list_of_words:
print('success')
This will not work for string with commas etc. For example:
mystring = "One,two and three"
# will split into ["One,two", "and", "three"]
If you also want to split on all commas etc. use separator argument like this:
# whitespace_chars = " tnrf" - space, tab, newline, return, formfeed
list_of_words = mystring.split( tnrf,.;!?'"()")
if word in list_of_words:
print('success')
![]()
Martin Thoma
122k156 gold badges604 silver badges941 bronze badges
answered Dec 18, 2017 at 11:44
![]()
tstempkotstempko
1,1761 gold badge15 silver badges17 bronze badges
2
As you are asking for a word and not for a string, I would like to present a solution which is not sensitive to prefixes / suffixes and ignores case:
#!/usr/bin/env python
import re
def is_word_in_text(word, text):
"""
Check if a word is in a text.
Parameters
----------
word : str
text : str
Returns
-------
bool : True if word is in text, otherwise False.
Examples
--------
>>> is_word_in_text("Python", "python is awesome.")
True
>>> is_word_in_text("Python", "camelCase is pythonic.")
False
>>> is_word_in_text("Python", "At the end is Python")
True
"""
pattern = r'(^|[^w]){}([^w]|$)'.format(word)
pattern = re.compile(pattern, re.IGNORECASE)
matches = re.search(pattern, text)
return bool(matches)
if __name__ == '__main__':
import doctest
doctest.testmod()
If your words might contain regex special chars (such as +), then you need re.escape(word)
answered Aug 9, 2017 at 10:11
![]()
Martin ThomaMartin Thoma
122k156 gold badges604 silver badges941 bronze badges
Advanced way to check the exact word, that we need to find in a long string:
import re
text = "This text was of edited by Rock"
#try this string also
#text = "This text was officially edited by Rock"
for m in re.finditer(r"bofb", text):
if m.group(0):
print("Present")
else:
print("Absent")
![]()
Martin Thoma
122k156 gold badges604 silver badges941 bronze badges
answered Nov 2, 2016 at 8:39
![]()
RameezRameez
5545 silver badges11 bronze badges
What about to split the string and strip words punctuation?
w in [ws.strip(',.?!') for ws in p.split()]
If need, do attention to lower/upper case:
w.lower() in [ws.strip(',.?!') for ws in p.lower().split()]
Maybe that way:
def wcheck(word, phrase):
# Attention about punctuation and about split characters
punctuation = ',.?!'
return word.lower() in [words.strip(punctuation) for words in phrase.lower().split()]
Sample:
print(wcheck('CAr', 'I own a caR.'))
I didn’t check performance…
answered Dec 26, 2020 at 5:18
![]()
marciomarcio
5267 silver badges19 bronze badges
You could just add a space before and after «word».
x = raw_input("Type your word: ")
if " word " in x:
print("Yes")
elif " word " not in x:
print("Nope")
This way it looks for the space before and after «word».
>>> Type your word: Swordsmith
>>> Nope
>>> Type your word: word
>>> Yes
![]()
Martin Thoma
122k156 gold badges604 silver badges941 bronze badges
answered Feb 26, 2015 at 14:23
![]()
PyGuyPyGuy
433 bronze badges
1
I believe this answer is closer to what was initially asked: Find substring in string but only if whole words?
It is using a simple regex:
import re
if re.search(r"b" + re.escape(word) + r"b", string):
print('success')
![]()
Martin Thoma
122k156 gold badges604 silver badges941 bronze badges
answered Aug 25, 2021 at 13:25
![]()
Milos CuculovicMilos Cuculovic
19.5k50 gold badges159 silver badges264 bronze badges
One of the solutions is to put a space at the beginning and end of the test word. This fails if the word is at the beginning or end of a sentence or is next to any punctuation. My solution is to write a function that replaces any punctuation in the test string with spaces, and add a space to the beginning and end or the test string and test word, then return the number of occurrences. This is a simple solution that removes the need for any complex regex expression.
def countWords(word, sentence):
testWord = ' ' + word.lower() + ' '
testSentence = ' '
for char in sentence:
if char.isalpha():
testSentence = testSentence + char.lower()
else:
testSentence = testSentence + ' '
testSentence = testSentence + ' '
return testSentence.count(testWord)
To count the number of occurrences of a word in a string:
sentence = "A Frenchman ate an apple"
print(countWords('a', sentence))
returns 1
sentence = "Is Oporto a 'port' in Portugal?"
print(countWords('port', sentence))
returns 1
Use the function in an ‘if’ to test if the word exists in a string
answered Mar 18, 2022 at 9:37
![]()
iStuartiStuart
4054 silver badges6 bronze badges
Нужно найти в строке: входит ли данная строчка в строку или нет. например, есть строка
sdfssf sddff svvsef xbsdf sdfwwe нужно узнать входит ли в нее dff или нет.
![]()
m9_psy
6,3144 золотых знака32 серебряных знака56 бронзовых знаков
задан 12 июл 2013 в 7:30
![]()
if "dff" in "sdfssf sddff svvsef xbsdf sdfwwe":
print u"Входит!"
ответ дан 12 июл 2013 в 7:31
![]()
LinnTrollLinnTroll
4,64616 серебряных знаков15 бронзовых знаков
7
https://pythonworld.ru/tipy-dannyx-v-python/stroki-funkcii-i-metody-strok.html
Это ссылка на сайт, где все есть. А так можно посчитать количество вхождений:
S1 = 'sdfssf sddff svvsef xbsdf sdfwwe'
S2 = 'dff'
Count = S1.count(S2)
if Count == 0:
print('Не входит')
else:
print('Входит')
Если что — S.count(str) — это функция, которая считает количество вхождений str в S
ответ дан 8 июл 2018 в 14:00
![]()
1
Можно с помощью множеств, например при чтении с файла пропускать строки, в которые входит определенное слово:
ignore = ['str1', 'str2', 'str3', 'str4']
with open(file,"r") as f:
for line in f.readlines():
if not (set(ignore) & set(line.split())):
print(line, end="")
ответ дан 12 фев 2018 в 21:58
![]()
1
Если нужно найти слово в строке с % вероятностью вот ссылка:
https://github.com/AndreSci/Find-word-in-string-percent/blob/main/Percent_text_find.py
line_1 — слово которое ищешь.
line_2 — где ищешь.
100 — это вероятное совпадения.
def find_word_per(line_1, line_2, percent=100):
max_found = 0
for item_1 in range(len(line_1)):
for item_2 in range(len(line_2)):
index_found = 0
if line_1[item_1] == line_2[item_2]:
for index in range(len(line_2) - item_2):
if item_1 + index >= len(line_1):
break
elif line_1[item_1 + index] == line_2[item_2 + index]:
index_found += 1
if max_found < index_found:
max_found = index_found
result_per = (100 / len(line_1)) * max_found
return result_per >= percent
Может кому поможет, мою проблему решил.
ответ дан 13 янв 2022 в 13:39
![]()
8