I am trying to find if some sequences of numbers are in a list. If so, this tuple should be removed from the list. Numbers must be contiguous to one another.
Example:
list of tuples:
list_1 = [(), (1,), (3,), (2,), (4,), (1, 3), (1, 2), (1, 4), (3, 2), (3, 4), (2, 4), (1, 3, 2), (1, 3, 4), (1, 2, 4), (3, 2, 4), (1, 3, 2, 4)]
and a second list:
list_2 = [1,3,2,4]
In this case the elements (1, 3), (3, 2), (2, 4), (1, 3, 2), (3, 2, 4), (1, 3, 2, 4), (1, 3, 4), (1, 2, 4) in list_1 should be removed, because they contain numbers (not necessarily all of them!)that are contiguous in list_2.
I want to check if the elements in list
I tried something like this:
for i in range(len(lista)):
teste = []
for j in range(len(lista[i])):
for k in stuff:
if len(lista[i]) >= 2:
if lista[i][j] == k:
teste.append(k)
if len(teste) == 2:
lista.remove(lista[i])
teste=[]
else:
pass
With this output:
if len(lista[i]) >= 2:
IndexError: list index out of range
I was trying to check a number, append it to a list check the next one and if it was appended too i would remove the corresponding tuple.
Получение индекса для строк: str.index (), str.rindex() и str.find(), str.rfind()
String также имеет index метод , но и более продвинутые варианты и дополнительное str.find.Для обоих из них есть дополнительный обратный метод.
astring = 'Hello on StackOverflow'
astring.index('o') # 4
astring.rindex('o') # 20
astring.find('o') # 4
astring.rfind('o') # 20
Разница между index / rindex и find / rfind это то , что происходит , если подстрока не найдена в строке:
astring.index('q') # ValueError: substring not found
astring.find('q') # -1
Все эти методы позволяют начальный и конечный индексы:
astring.index('o', 5) # 6
astring.index('o', 6) # 6 - start is inclusive
astring.index('o', 5, 7) # 6
astring.index('o', 5, 6) # - end is not inclusive
ValueError: подстрока не найдена
astring.rindex('o', 20) # 20
astring.rindex('o', 19) # 20 - still from left to right
astring.rindex('o', 4, 7) # 6 В поисках элемента
Все встроенные в коллекции в Python реализовать способ проверить членство элемента с использованием in. Список
alist = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
5 in alist # True
10 in alist # False
Кортеж
atuple =('0', '1', '2', '3', '4')
4 in atuple # False
'4' in atuple # True
строка
astring = 'i am a string'
'a' in astring # True
'am' in astring # True
'I' in astring # False
Задавать
aset = {(10, 10), (20, 20), (30, 30)}
(10, 10) in aset # True
10 in aset # False
Dict
dict немного особенный: нормальный in проверяет только ключи. Если вы хотите , чтобы искать в значении , которые необходимо указать. То же самое , если вы хотите найти пар ключ-значение.
adict = {0: 'a', 1: 'b', 2: 'c', 3: 'd'}
1 in adict # True - implicitly searches in keys
'a' in adict # False
2 in adict.keys() # True - explicitly searches in keys
'a' in adict.values() # True - explicitly searches in values
(0, 'a') in adict.items() # True - explicitly searches key/value pairs Получение списка индексов и кортежей: list.index(), tuple.index()
list и tuple имеют index -метода получить позицию элемента:
alist = [10, 16, 26, 5, 2, 19, 105, 26]
# search for 16 in the list
alist.index(16) # 1
alist[1] # 16
alist.index(15)
Ошибка значения: 15 отсутствует в списке
Но возвращает только позицию первого найденного элемента:
atuple = (10, 16, 26, 5, 2, 19, 105, 26)
atuple.index(26) # 2
atuple[2] # 26
atuple[7] # 26 - is also 26! Поиск ключа(ей) по значению в dict
dict не имеет встроенный метода для поиска значения или ключа , потому что словари являются упорядоченными. Вы можете создать функцию, которая получает ключ (или ключи) для указанного значения:
def getKeysForValue(dictionary, value):
foundkeys = []
for keys in dictionary:
if dictionary[key] == value:
foundkeys.append(key)
return foundkeys
Это также может быть записано как эквивалентное понимание списка:
def getKeysForValueComp(dictionary, value):
return [key for key in dictionary if dictionary[key] == value]
Если вам нужен только один найденный ключ:
def getOneKeyForValue(dictionary, value):
return next(key for key in dictionary if dictionary[key] == value)
Первые две функции возвращает list всех keys , которые имеют определенное значение:
adict = {'a': 10, 'b': 20, 'c': 10}
getKeysForValue(adict, 10) # ['c', 'a'] - order is random could as well be ['a', 'c']
getKeysForValueComp(adict, 10) # ['c', 'a'] - dito
getKeysForValueComp(adict, 20) # ['b']
getKeysForValueComp(adict, 25) # []
Другой вернет только один ключ:
getOneKeyForValue(adict, 10) # 'c' - depending on the circumstances this could also be 'a'
getOneKeyForValue(adict, 20) # 'b'
и поднять StopIteration — Exception , если значение не в dict :
getOneKeyForValue(adict, 25)
StopIteration
Получение индекса для отсортированных последовательностей: bisect.bisect_left()
Отсортированные последовательности позволяют использовать более быстрый поиск алгоритмов: bisect.bisect_left() [1]:
import bisect
def index_sorted(sorted_seq, value):
"""Locate the leftmost value exactly equal to x or raise a ValueError"""
i = bisect.bisect_left(sorted_seq, value)
if i != len(sorted_seq) and sorted_seq[i] == value:
return i
raise ValueError
alist = [i for i in range(1, 100000, 3)] # Sorted list from 1 to 100000 with step 3
index_sorted(alist, 97285) # 32428
index_sorted(alist, 4) # 1
index_sorted(alist, 97286)
ValueError
Для очень больших отсортированных последовательностей выигрыш в скорости может быть достаточно высоким. В случае первого поиска примерно в 500 раз быстрее:
%timeit index_sorted(alist, 97285)
# 100000 loops, best of 3: 3 µs per loop
%timeit alist.index(97285)
# 1000 loops, best of 3: 1.58 ms per loop
Хотя это немного медленнее, если элемент является одним из самых первых:
%timeit index_sorted(alist, 4)
# 100000 loops, best of 3: 2.98 µs per loop
%timeit alist.index(4)
# 1000000 loops, best of 3: 580 ns per loop
Поиск вложенных последовательностей
Поиск во вложенных последовательностях , как в list из tuple требует такого подхода , как поиск ключей для значений в dict , но нуждается в пользовательских функциях.
Индекс самой внешней последовательности, если значение было найдено в последовательности:
def outer_index(nested_sequence, value):
return next(index for index, inner in enumerate(nested_sequence)
for item in inner
if item == value)
alist_of_tuples = [(4, 5, 6), (3, 1, 'a'), (7, 0, 4.3)]
outer_index(alist_of_tuples, 'a') # 1
outer_index(alist_of_tuples, 4.3) # 2
или индекс внешней и внутренней последовательности:
def outer_inner_index(nested_sequence, value):
return next((oindex, iindex) for oindex, inner in enumerate(nested_sequence)
for iindex, item in enumerate(inner)
if item == value)
outer_inner_index(alist_of_tuples, 'a') # (1, 2)
alist_of_tuples[1][2] # 'a'
outer_inner_index(alist_of_tuples, 7) # (2, 0)
alist_of_tuples[2][0] # 7
В общем случае (не всегда) с помощью next и выражения генератора с условиями , чтобы найти первое вхождение искомого значения является наиболее эффективным подходом.
Поиск в пользовательских классах: __contains__ и __iter__
Для того, чтобы разрешить использование in пользовательских классах класса должен либо предоставить магический метод __contains__ или, если это невозможно, в __iter__ -метод.
Предположим , у вас есть класс , содержащий list из list s:
class ListList:
def __init__(self, value):
self.value = value
# Create a set of all values for fast access
self.setofvalues = set(item for sublist in self.value for item in sublist)
def __iter__(self):
print('Using __iter__.')
# A generator over all sublist elements
return (item for sublist in self.value for item in sublist)
def __contains__(self, value):
print('Using __contains__.')
# Just lookup if the value is in the set
return value in self.setofvalues
# Even without the set you could use the iter method for the contains-check:
# return any(item == value for item in iter(self))
Использование тестирования членства возможно при использовании in :
a = ListList([[1,1,1],[0,1,1],[1,5,1]])
10 in a # False
# Prints: Using __contains__.
5 in a # True
# Prints: Using __contains__.
даже после удаления __contains__ метода:
del ListList.__contains__
5 in a # True
# Prints: Using __iter__.
Примечание: зацикливание in (как for i in a ) всегда будет использовать __iter__ даже если класс реализует __contains__ метод.
На чтение 4 мин Просмотров 5.4к. Опубликовано 03.03.2023
Содержание
- Введение
- Поиск методом count
- Поиск при помощи цикла for
- Поиск с использованием оператора in
- В одну строку
- Поиск с помощью лямбда функции
- Поиск с помощью функции any()
- Заключение
Введение
В ходе статьи рассмотрим 5 способов поиска элемента в списке Python.
Поиск методом count
Метод count() возвращает вхождение указанного элемента в последовательность. Создадим список разных цветов, чтобы в нём производить поиск:
colors = ['black', 'yellow', 'grey', 'brown']Зададим условие, что если в списке colors присутствует элемент ‘yellow’, то в консоль будет выведено сообщение, что элемент присутствует. Если же условие не сработало, то сработает else, и будет выведена надпись, что элемента отсутствует в списке:
colors = ['black', 'yellow', 'grey', 'brown']
if colors.count('yellow'):
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск при помощи цикла for
Создадим цикл, в котором будем перебирать элементы из списка colors. Внутри цикла зададим условие, что если во время итерации color приняла значение ‘yellow’, то элемент присутствует:
colors = ['black', 'yellow', 'grey', 'brown']
for color in colors:
if color == 'yellow':
print('Элемент присутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск с использованием оператора in
Оператор in предназначен для проверки наличия элемента в последовательности, и возвращает либо True, либо False.
Зададим условие, в котором если ‘yellow’ присутствует в списке, то выводится соответствующее сообщение:
colors = ['black', 'yellow', 'grey', 'brown']
if 'yellow' in colors:
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!В одну строку
Также можно найти элемент в списке при помощи оператора in всего в одну строку:
colors = ['black', 'yellow', 'grey', 'brown']
print('Элемент присутствует в списке!') if 'yellow' in colors else print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Или можно ещё вот так:
colors = ['black', 'yellow', 'grey', 'brown']
if 'yellow' in colors: print('Элемент присутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск с помощью лямбда функции
В переменную filtering будет сохранён итоговый результат. Обернём результат в список (list()), т.к. метода filter() возвращает объект filter. Отфильтруем все элементы списка, и оставим только искомый, если он конечно присутствует:
colors = ['black', 'yellow', 'grey', 'brown']
filtering = list(filter(lambda x: 'yellow' in x, colors))Итак, если искомый элемент находился в списке, то он сохранился в переменную filtering. Создадим условие, что если переменная filtering не пустая, то выведем сообщение о присутствии элемента в списке. Иначе – отсутствии:
colors = ['black', 'yellow', 'grey', 'brown']
filtering = list(filter(lambda x: 'yellow' in x, colors))
if filtering:
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Поиск с помощью функции any()
Функция any принимает в качестве аргумента итерабельный объект, и возвращает True, если хотя бы один элемент равен True, иначе будет возвращено False.
Создадим условие, что если функция any() вернёт True, то элемент присутствует:
colors = ['black', 'yellow', 'grey', 'brown']
if any(color in 'yellow' for color in colors):
print('Элемент присутствует в списке!')
else:
print('Элемент отсутствует в списке!')
# Вывод: Элемент присутствует в списке!Внутри функции any() при помощи цикла производится проверка присутствия элемента в списке.
Заключение
В ходе статьи мы с Вами разобрали целых 5 способов поиска элемента в списке Python. Надеюсь Вам понравилась статья, желаю удачи и успехов! 🙂
Найти элемент в списке можно как по значению, так и по индексу.

Рис. (1). Пример (7)
Обрати внимание!
• При поиске по индексу мы можем использовать как нумерацию с начала, так и нумерацию с конца.
• index — это метод, и он находит первое вхождение элемента с заданным значением.
Задачи нахождения в списке элемента, удовлетворяющего каким-то условиям, разнообразны.
Рассмотрим нахождение минимального и максимального элементов.
В Python есть встроенные функции, которые ищут максимум и минимум последовательности.

Рис. (2). Функции min и max
Попробуем реализовать этот алгоритм самостоятельно.
План решения задачи будет таким: перебираем в цикле for все элементы списка, заранее заготовив элементы, которые условно считаем максимальными и минимальными. Сравниваем каждый элемент списка с ними: если элемент меньше максимального — меняем минимум, если больше минимального — меняем максимум.

Рис. (3). Пример (8)
Обрати внимание!
• Сколько раз бы ты ни запускал эту задачу, результаты будут разными, потому что для заполнения списков мы использовали случайные числа. Сначала из встроенного модуля random импортировали функцию randint, которая генерирует случайные целые числа. Потом при заполнении списка сгенерировали случайное число в интервале ((-150),(120)).
• Списки (a) и (b) задали и заполнили разными известными тебе способами; вывод в операторе print организовали через метод format и без него — результат от этого не изменился.
• Всё, что нужно знать о числах (‘inf’) и ‘(-inf’), пояснили в комментариях в программе. Конкретно для этой задачи мы знаем минимальное и максимальное возможные числа — это (-150) и (120). Но если максимально допустимое (минимально допустимое) число неизвестно, то можно использовать приведённые в примере возможности.
Источники:
Рис. 1. Пример 7. © ЯКласс.
Рис. 2. Функции min и max. © ЯКласс.
Рис. 3. Пример 8. © ЯКласс.
В этой статье вы узнаете о последовательностях в Python и базовых операциях над ними.
Последовательность — это коллекция, элементы которого представляют собой некую последовательность.
На любой элемент последовательности можно ссылаться, используя его индекс, например, s[0] и s[1].
Индексы последовательности начинаются с 0, а не с 1. Поэтому первый элемент — s[0], а второй — s[1]. Если последовательность s состоит из n элементов, то последним элементом будет s[n-1].
В Python есть встроенные типы последовательностей: списки, байтовые массивы, строки, кортежи, диапазоны и байты. Последовательности могут быть изменяемыми и неизменяемыми.
Изменяемые: списки и байтовые массивы, неизменяемые: строки, кортежи, диапазоны и байты.
Последовательность может быть однородной или неоднородной. В однородной последовательности все элементы имеют одинаковый тип. Например, строки — это однородные последовательности, поскольку каждый элемент строки — символ — один и тот же тип.
А списки — неоднородные последовательности, потому что в них можно хранить элементы различных типов, включая целые числа, строки, объекты и т.д.
Примечание. C точки зрения хранения и операций однородные типы последовательностей более эффективны, чем неоднородные.
Последовательности и итерируемые объекты: разница
Итерируемый объект (iterable) — это коллекция объектов, в которой можно получить каждый элемент по очереди. Поэтому любая последовательность является итерируемой. Например, список — итерируемый объект.
Однако итерируемый объект может не быть последовательностью. Например, множество является итерируемым объектом, но не является последовательностью.
Примечание. Итерируемые объекты — более общий тип, чем последовательности.
Стандартные методы последовательностей
Ниже описаны некоторые встроенные в Python методы последовательностей:
1) Количество элементов последовательности
Чтобы получить количество элементов последовательности, можно использовать встроенную функцию len():
len(последовательность)
Пример
cities = ['Санкт-Петербург', 'Новосибирск', 'Москва']
print(len(cities))
Вывод
3
2) Проверка вхождения элемента в последовательность
Чтобы проверить, находится ли элемент в последовательности, можно использовать оператор in:
элемент in последовательность
Пример 1
Проверим, есть ли 'Новосибирск' в последовательности cities.
cities = ['Санкт-Петербург', 'Новосибирск', 'Москва']
print('Новосибирск' in cities)
Вывод
True
Чтобы проверить, отсутсвует ли элемент в последовательности, используется оператор not in.
Пример 2
Проверим, отсутсвует ли 'Новосибирск' в последовательности cities.
cities = ['Санкт-Петербург', 'Новосибирск', 'Москва']
print('Новосибирск' not in cities)
Вывод
False
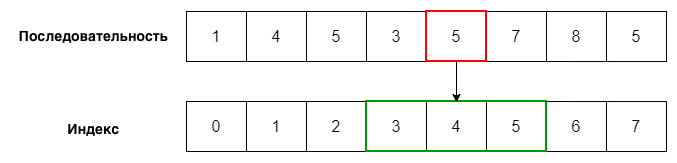
3) Поиска индекса элемента в последовательности
Чтобы узнать индекс первого вхождения определенного элемента в последовательности, используется метод index().
последовательность.index(элемент)
Пример 1
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers.index(5))
Вывод
2

Индекс первого появления числа 5 в списке numbers — 2. Если числа в последовательности нет, Python сообщит об ошибке:
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers.index(10))
Вывод
ValueError: 10 is not in list
Чтобы найти индекс вхождения элемента после определенного индекса, можно использовать метод index() в таком виде:
последовательность.index(элемент, индекс)
Пример 2
В следующем примере возвращается индекс первого вхождения числа 5 после третьего индекса:
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers.index(5, 3))Вывод
4

Чтобы найти индекс вхождения элемента между двумя определенными индексами, можно использовать метод index() в такой форме:
последовательность.index(элемент, i, j)
Поиск элемента будет осуществляться между i и j.
Пример 3
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers.index(5, 3, 5))
Вывод
4
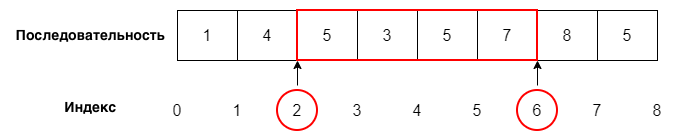
4) Слайсинг последовательности
Чтобы получить срез от индекса i до индекса j (не включая его), используйте следующий синтаксис:
последовательность[i:j]
Пример 1
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers[2:6])
Вывод
[5, 3, 5, 7]
Когда вы «слайсите» последовательность, представляйте, что индексы последовательности располагаются между двумя элементами, как показано на рисунке:
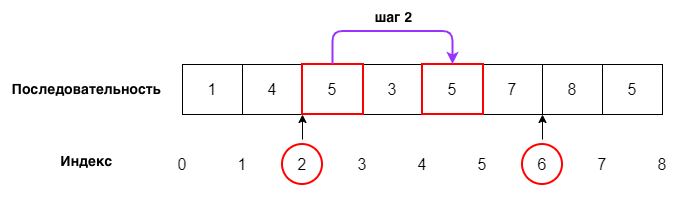
Расширенный слайсинг позволяет получить срез последовательности от индекса i до j (не включая его) с шагом k:
последовательность[i:j:k]
Пример 2
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(numbers[2:6:2])
Вывод
[5, 5]
5) Получение максимального и минимального значений из последовательности
Если задан порядок между элементами в последовательности, можно использовать встроенные функции min() и max() для нахождения минимального и максимального элементов:
numbers = [1, 4, 5, 3, 5, 7, 8, 5]
print(min(numbers)) # Вывод: 1
print(max(numbers)) # Вывод: 8
6) Объединение (конкатенация) последовательностей
Чтобы объединить две последовательности в одну, используется оператор +:
последовательность3 = последовательность1 + последовательность2
Пример
east = ['Владивосток', 'Якутск']
west = ['Санкт-Петербург', 'Москва']
cities = east + west
print(cities)Вывод
['Владивосток', 'Якутск', 'Санкт-Петербург', 'Москва']
Неизменяемые последовательно объединять безопасно. В следующем примере мы доблавяем один элемент к списку west. И это не влияет на последовательность cities:
west.append('Благовещенск')
print(west)
print(cities)Вывод
['Владивосток', 'Якутск', 'Благовещенск']
['Владивосток', 'Якутск', 'Санкт-Петербург', 'Москва']
Однако когда вы работаете с изменяемыми последовательностями, стоит быть внимательными. . В следующем примере показано, как объединить список самого с собой.
city = [['Санкт-Петербург', 900_000]]
cities = city + city
print(cities)Вывод
[[‘Санкт-Петербург’, 1000000], [‘Санкт-Петербург’, 1000000]]
Поскольку список является изменяемой последовательностью, адреса памяти первого и второго элементов из списка citites одинаковы:
print(id(cities[0]) == id(cities[1])) # Вывод: TrueКроме того, при изменении значения из исходного списка изменяется и объединенный список:
city[0][1] = 1_000_000
print(cities)Соберем все вместе:
city = [['Санкт-Петербург', 900_000]]
cities = city + city
print(cities)
print(id(cities[0]) == id(cities[1])) # Вывод: True
city[0][1] = 1_000_000
print(cities)Вывод
[['Санкт-Петербург', 900000], ['Санкт-Петербург', 900000]]
True
[['Санкт-Петербург', 1000000], ['Санкт-Петербург', 1000000]]7) Повторение последовательности
Чтобы повторить последовательность несколько раз, используется оператор умножения *.
В следующем примере строка повторяется 3 раза:
s = 'ха'
print(s*3)
Вывод
хахаха