Один из способов решения этой задачи — использовать словарь. Можно создать словарь, в котором каждому элементу списка соответствует количество его повторений, и в цикле перебрать элементы списка, добавляя их в словарь.
Вот пример такой функции:
def count_repeats(lst):
"""
Возвращает словарь, в котором каждому элементу списка lst соответствует
количество его повторений.
"""
repeats = {}
for item in lst:
if item in repeats:
repeats[item] += 1
else:
repeats[item] = 1
return repeats
# Пример использования функции
lst = [10, 10, 23, 10, 123, 66, 78, 123]
repeats = count_repeats(lst)
print(repeats) # {10: 3, 123: 2}
Функция count_repeats принимает на вход список lst, перебирает его элементы и добавляет их в словарь repeats. Если элемент уже есть в словаре, то увеличивается значение соответствующей пары ключ-значение, если же элемента еще нет в словаре, то добавляется пара с ключом равным этому элементу и значением 1.
Вы можете использовать эту функцию, чтобы найти повторяющиеся элементы в списке и количество их повторений.
Вы также можете использовать функцию Counter из модуля collections, чтобы посчитать количество повторений элементов списка. Эта функция возвращает словарь, в котором каждому элементу списка соответствует количество его повторений.
Вот пример кода, который использует функцию Counter:
from collections import Counter
def count_repeats(lst):
"""
Возвращает словарь, в котором каждому элементу списка lst соответствует
количество его повторений.
"""
return Counter(lst)
# Пример использования функции
lst = [10, 10, 23, 10, 123, 66, 78, 123]
repeats = count_repeats(lst)
print(repeats) # Counter({10: 3, 123: 2})
В этом коде сначала импортируется модуль collections и функция Counter, а затем определяется функция count_repeats, которая принимает список lst и возвращает результат вызова функции Counter на этом списке.
Вы также можете использовать функцию most_common из модуля collections, чтобы найти топ-N самых часто встречающихся элементов в списке. Эта функция принимает список и число N, и возвращает список кортежей, каждый из которых содержит элемент и количество его повторений.
Вот пример кода, который использует функцию most_common:
from collections import Counter
def find_top_repeats(lst, n):
"""
Возвращает топ-N самых часто встречающихся элементов в списке lst.
"""
return Counter(lst).most_common(n)
# Пример использования функции
lst = [10, 10, 23, 10, 123, 66, 78, 123]
top_repeats = find_top_repeats(lst, 2)
print(top_repeats) # [(10, 3), (123, 2)]
В этом коде сначала импортируется модуль collections и функция Counter, а затем определяется функция find_top_repeats, которая принимает список lst и число n, и возвращает результат вызова функции most_common
Если вам нужно найти только уникальные элементы в списке, то можете использовать функцию set. Эта функция создает множество из элементов списка, удаляя повторяющиеся элементы. Множество не содержит повторяющихся элементов, поэтому вы можете использовать его, чтобы найти уникальные элементы в списке.
Вот пример кода, который использует функцию set:
def find_unique(lst):
"""
Возвращает список уникальных элементов в списке lst.
"""
return list(set(lst))
# Пример использования функции
lst = [10, 10, 23, 10, 123, 66, 78, 123]
unique = find_unique(lst)
print(unique) # [66, 78, 10, 123, 23]
В этом коде определяется функция find_unique, которая принимает список lst и возвращает список уникальных элементов. Для этого список преобразуется в множество
Если вам нужно найти только уникальные элементы в списке и посчитать их количество, то можете соединить два предыдущих подхода: сначала использовать функцию set для нахождения уникальных элементов, а затем функцию count_repeats для подсчета их количества.
Вот пример кода, который реализует этот подход:
def count_unique(lst):
"""
Возвращает словарь, в котором каждому уникальному элементу списка lst соответствует
количество его повторений.
"""
repeats = {}
for item in set(lst):
repeats[item] = lst.count(item)
return repeats
# Пример использования функции
lst = [10, 10, 23, 10, 123, 66, 78, 123]
unique_counts = count_unique(lst)
print(unique_counts) # {66: 1, 78: 1, 10: 3, 123: 2}
В этом коде определяется функция count_unique, которая принимает список lst и возвращает словарь, в котором каждому уникальному элементу списка
My problem is to find the repeating sequence of characters in the given array. simply, to identify the pattern in which the characters are appearing.
.---.---.---.---.---.---.---.---.---.---.---.---.---.---.
1: | J | A | M | E | S | O | N | J | A | M | E | S | O | N |
'---'---'---'---'---'---'---'---'---'---'---'---'---'---' .---.---.---.---.---.---.---.---.---.---.---.---.---.---.---.
2: | R | O | N | R | O | N | R | O | N | R | O | N | R | O | N |
'---'---'---'---'---'---'---'---'---'---'---'---'---'---'---' .---.---.---.---.---.---.---.---.---.---.---.---.
3: | S | H | A | M | I | L | S | H | A | M | I | L |
'---'---'---'---'---'---'---'---'---'---'---'---' .---.---.---.---.---.---.---.---.---.---.---.---.---.---.---.---.---.---.
4: | C | A | R | P | E | N | T | E | R | C | A | R | P | E | N | T | E | R |
'---'---'---'---'---'---'---'---'---'---'---'---'---'---'---'---'---'---'Example
Given the previous data, the result should be:
"JAMESON""RON""SHAMIL""CARPENTER"
Question
- How to deal with this problem efficiently?
![]()
ggorlen
43.5k7 gold badges70 silver badges101 bronze badges
asked Sep 9, 2010 at 9:36
![]()
4
Tongue-in-cheek O(NlogN) solution
Perform an FFT on your string (treating characters as numeric values). Every peak in the resulting graph corresponds to a substring periodicity.
answered Sep 9, 2010 at 13:02
![]()
3
For your examples, my first approach would be to
- get the first character of the array (for your last example, that would be
C) - get the index of the next appearance of that character in the array (e.g. 9)
- if it is found, search for the next appearance of the substring between the two appearances of the character (in this case
CARPENTER) - if it is found, you’re done (and the result is this substring).
Of course, this works only for a very limited subset of possible arrays, where the same word is repeated over and over again, starting from the beginning, without stray characters in between, and its first character is not repeated within the word. But all your examples fall into this category — and I prefer the simplest solution which could possibly work 
If the repeated word contains the first character multiple times (e.g. CACTUS), the algorithm can be extended to look for subsequent occurrences of that character too, not only the first one (so that it finds the whole repeated word, not only a substring of it).
Note that this extended algorithm would give a different result for your second example, namely RONRON instead of RON.
answered Sep 9, 2010 at 9:47
![]()
Péter TörökPéter Török
114k31 gold badges268 silver badges328 bronze badges
4
In Python, you can leverage regexes thus:
def recurrence(text):
import re
for i in range(1, len(text)/2 + 1):
m = re.match(r'^(.{%d})1+$'%i, text)
if m: return m.group(1)
recurrence('abcabc') # Returns 'abc'
I’m not sure how this would translate to Java or C. (That’s one of the reasons I like Python, I guess.
answered Sep 9, 2010 at 9:51
![]()
Marcelo CantosMarcelo Cantos
180k38 gold badges325 silver badges364 bronze badges
First write a method that find repeating substring sub in the container string as below.
boolean findSubRepeating(String sub, String container);
Now keep calling this method with increasing substring in the container, first try 1 character substring, then 2 characters, etc going upto container.length/2.
answered Sep 9, 2010 at 9:58
![]()
fastcodejavafastcodejava
39.6k28 gold badges131 silver badges185 bronze badges
Pseudocode
len = str.length
for (i in 1..len) {
if (len%i==0) {
if (str==str.substr(0,i).repeat(len/i)) {
return str.substr(0,i)
}
}
}
Note: For brevity, I’m inventing a «repeat» method for strings, which isn’t actually part of Java’s string; «abc».repeat(2)=»abcabc»
answered Sep 9, 2010 at 9:49
![]()
Erich KitzmuellerErich Kitzmueller
36.2k5 gold badges79 silver badges102 bronze badges
Using C++:
//Splits the string into the fragments of given size
//Returns the set of of splitted strings avaialble
set<string> split(string s, int frag)
{
set<string> uni;
int len = s.length();
for(int i = 0; i < len; i+= frag)
{
uni.insert(s.substr(i, frag));
}
return uni;
}
int main()
{
string out;
string s = "carpentercarpenter";
int len = s.length();
//Optimistic approach..hope there are only 2 repeated strings
//If that fails, then try to break the strings with lesser number of
//characters
for(int i = len/2; i>1;--i)
{
set<string> uni = split(s,i);
if(uni.size() == 1)
{
out = *uni.begin();
break;
}
}
cout<<out;
return 0;
}
answered Sep 9, 2010 at 9:56
![]()
AshaAsha
11k6 gold badges43 silver badges66 bronze badges
The first idea that comes to my mind is trying all repeating sequences of lengths that divide length(S) = N. There is a maximum of N/2 such lengths, so this results in a O(N^2) algorithm.
But i’m sure it can be improved…
answered Sep 9, 2010 at 10:22
![]()
Eyal SchneiderEyal Schneider
22.1k5 gold badges47 silver badges76 bronze badges
Here is a more general solution to the problem, that will find repeating subsequences within an sequence (of anything), where the subsequences do not have to start at the beginning, nor immediately follow each other.
given an sequence b[0..n], containing the data in question, and a threshold t being the minimum subsequence length to find,
l_max = 0, i_max = 0, j_max = 0;
for (i=0; i<n-(t*2);i++) {
for (j=i+t;j<n-t; j++) {
l=0;
while (i+l<j && j+l<n && b[i+l] == b[j+l])
l++;
if (l>t) {
print "Sequence of length " + l + " found at " + i + " and " + j);
if (l>l_max) {
l_max = l;
i_max = i;
j_max = j;
}
}
}
}
if (l_max>t) {
print "longest common subsequence found at " + i_max + " and " + j_max + " (" + l_max + " long)";
}
Basically:
- Start at the beginning of the data, iterate until within 2*t of the end (no possible way to have two distinct subsequences of length t in less than 2*t of space!)
- For the second subsequence, start at least t bytes beyond where the first sequence begins.
- Then, reset the length of the discovered subsequence to 0, and check to see if you have a common character at i+l and j+l. As long as you do, increment l.
When you no longer have a common character, you have reached the end of your common subsequence.
If the subsequence is longer than your threshold, print the result.
answered Jun 24, 2017 at 13:55
![]()
Rogan DawesRogan Dawes
3502 silver badges9 bronze badges
Just figured this out myself and wrote some code for this (written in C#) with a lot of comments. Hope this helps someone:
// Check whether the string contains a repeating sequence.
public static bool ContainsRepeatingSequence(string str)
{
if (string.IsNullOrEmpty(str)) return false;
for (int i=0; i<str.Length; i++)
{
// Every iteration, cut down the string from i to the end.
string toCheck = str.Substring(i);
// Set N equal to half the length of the substring. At most, we have to compare half the string to half the string. If the string length is odd, the last character will not be checked against, but it will be checked in the next iteration.
int N = toCheck.Length / 2;
// Check strings of all lengths from 1 to N against the subsequent string of length 1 to N.
for (int j=1; j<=N; j++)
{
// Check from beginning to j-1, compare against j to j+j.
if (toCheck.Substring(0, j) == toCheck.Substring(j, j)) return true;
}
}
return false;
}
Feel free to ask any questions if it’s unclear why it works.
![]()
BurnsBA
4,25725 silver badges36 bronze badges
answered Feb 17, 2018 at 20:46
![]()
and here is a concrete working example:
/* find greatest repeated substring */
char *fgrs(const char *s,size_t *l)
{
char *r=0,*a=s;
*l=0;
while( *a )
{
char *e=strrchr(a+1,*a);
if( !e )
break;
do {
size_t t=1;
for(;&a[t]!=e && a[t]==e[t];++t);
if( t>*l )
*l=t,r=a;
while( --e!=a && *e!=*a );
} while( e!=a && *e==*a );
++a;
}
return r;
}
size_t t;
const char *p;
p=fgrs("BARBARABARBARABARBARA",&t);
while( t-- ) putchar(*p++);
p=fgrs("0123456789",&t);
while( t-- ) putchar(*p++);
p=fgrs("1111",&t);
while( t-- ) putchar(*p++);
p=fgrs("11111",&t);
while( t-- ) putchar(*p++);
answered Sep 9, 2010 at 16:20
![]()
user411313user411313
3,94018 silver badges16 bronze badges
1
Not sure how you define «efficiently». For easy/fast implementation you could do this in Java:
private static String findSequence(String text) {
Pattern pattern = Pattern.compile("(.+?)\1+");
Matcher matcher = pattern.matcher(text);
return matcher.matches() ? matcher.group(1) : null;
}
it tries to find the shortest string (.+?) that must be repeated at least once (1+) to match the entire input text.
answered Sep 16, 2010 at 15:16
![]()
user85421user85421
28.9k10 gold badges64 silver badges87 bronze badges
This is a solution I came up with using the queue, it passed all the test cases of a similar problem in codeforces. Problem No is 745A.
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
int main()
{
ios_base::sync_with_stdio(false);
cin.tie(NULL);
string s, s1, s2; cin >> s; queue<char> qu; qu.push(s[0]); bool flag = true; int ind = -1;
s1 = s.substr(0, s.size() / 2);
s2 = s.substr(s.size() / 2);
if(s1 == s2)
{
for(int i=0; i<s1.size(); i++)
{
s += s1[i];
}
}
//cout << s1 << " " << s2 << " " << s << "n";
for(int i=1; i<s.size(); i++)
{
if(qu.front() == s[i]) {qu.pop();}
qu.push(s[i]);
}
int cycle = qu.size();
/*queue<char> qu2 = qu; string str = "";
while(!qu2.empty())
{
cout << qu2.front() << " ";
str += qu2.front();
qu2.pop();
}*/
while(!qu.empty())
{
if(s[++ind] != qu.front()) {flag = false; break;}
qu.pop();
}
flag == true ? cout << cycle : cout << s.size();
return 0;
}
![]()
answered Feb 2, 2020 at 7:18
![]()
I’d convert the array to a String object and use regex
answered Sep 16, 2010 at 14:20
![]()
manolowarmanolowar
6,6525 gold badges23 silver badges18 bronze badges
1
Put all your character in an array e.x. a[]
i=0; j=0;
for( 0 < i < count )
{
if (a[i] == a[i+j+1])
{++i;}
else
{++j;i=0;}
}
Then the ratio of (i/j) = repeat count in your array.
You must pay attention to limits of i and j, but it is the simple solution.
![]()
Daniel
19k7 gold badges60 silver badges74 bronze badges
answered Aug 22, 2013 at 22:53
![]()
Содержание
- Введение
- Поиск одинаковых элементов в списке с помощью словаря
- Поиск одинаковых элементов в списке с помощью модуля collections
- Поиск одинаковых элементов в списке с помощью функции filter()
- Заключение
Введение
В данной статье разберём три способа нахождения повторяющихся элементов в неупорядоченном списке Python.
Поиск одинаковых элементов в списке с помощью словаря
Для начала создадим неупорядоченный список с числами и пустой словарь:
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7]
duplicate_elements = {}Теперь пройдёмся по нашему неупорядоченному списку при помощи цикла for. Внутри цикла добавим условие, что если итерабельный элемент присутствует в словаре duplicate_elements, то прибавляем к значению ключа единицу, т.к. этот элемент уже присутствует в словаре, и был найден его дубликат. Если же условие оказалось ложным, то сработает else, где в словарь будет добавляться новый ключ, которого в нём ранее не было:
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7]
duplicate_elements = {}
for item in unordered_list:
if item in duplicate_elements:
duplicate_elements[item] += 1
else:
duplicate_elements[item] = 1Выведем результат:
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7]
duplicate_elements = {}
for item in unordered_list:
if item in duplicate_elements:
duplicate_elements[item] += 1
else:
duplicate_elements[item] = 1
print(duplicate_elements)
# Вывод: {6: 2, 8: 1, 7: 2, 5: 2, 1: 1, 4: 2}В выводе мы видим, что было найдено две шестёрки, одна восьмёрка, две семёрки, две пятёрки, одна единица и две четвёрки.
Поиск одинаковых элементов в списке с помощью модуля collections
В данном способе для поиска одинаковых элементов в неупорядоченном списке мы будем использовать модуль collections, а точнее класс Counter из него. Сам модуль входит в стандартную библиотеку Python, поэтому устанавливать его не придётся.
Для начала импортируем сам модуль collections и добавим неупорядоченный список:
import collections
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7]Далее при помощи класса Counter из модуля collections подсчитаем количество повторяющихся элементов:
import collections
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7]
count_frequency = collections.Counter(unordered_list)Выведем результат в виде словаря:
import collections
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7]
count_frequency = collections.Counter(unordered_list)
print(dict(count_frequency))
# Вывод: {6: 2, 8: 1, 7: 2, 5: 2, 1: 1, 4: 2}Поиск одинаковых элементов в списке с помощью функции filter()
В данном способе мы просто будем выводить повторяющиеся элементы в списке, но не указывать количество их повторений.
При помощи функции filter() отфильтруем наш список. Внутри неё анонимной функцией lambda будем производить проверку поэлементно, и если определённый элемент встречается больше одного раза, мы добавляем его в count_frequency:
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7]
count_frequency = filter(lambda x: unordered_list.count(x) > 1, unordered_list)При помощи функции set() преобразуем полученные данные в count_frequency в множество, а множество в список:
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7]
count_frequency = filter(lambda x: unordered_list.count(x) > 1, unordered_list)
count_frequency = list(set(count_frequency))Выведем полученный результат:
unordered_list = [6, 6, 8, 7, 5, 1, 4, 5, 4, 7]
count_frequency = filter(lambda x: unordered_list.count(x) > 1, unordered_list)
count_frequency = list(set(count_frequency))
print(count_frequency)
# Вывод: [4, 5, 6, 7]Т.е. в неупорядоченном списке повторяются четвёрки, пятёрки, шестёрки и семёрки.
Заключение
В ходе статьи мы с Вами разобрали целых три способа нахождения повторяющихся элементов в списке Python. Надеюсь Вам понравилась статья, желаю удачи и успехов! 🙂

Проблема
- Найти дубликат в массиве
Given an array of n + 1 integers between 1 and n, find one of the duplicates.
If there are multiple possible answers, return one of the duplicates.
If there is no duplicate, return -1.
Example:
Input: [1, 2, 2, 3]
Output: 2
Input: [3, 4, 1, 4, 1]
Output: 4 or 1Категория: массивы
Процесс решения задачи
Перед тем как вы увидите решение, давайте немного поговорим о самой проблеме. У нас есть: массив n + 1 элементов с целочисленными переменными в диапазоне от 1 до n.


Например: массив из пяти integers подразумевает, что каждый элемент будет иметь значение от 1 до 4 (включительно). Это автоматически означает, что будет по крайней мере один дубликат.
Единственное исключение — это массив размером 1. Это единственный случай, когда мы получим -1.
Brute Force
Метод Brute Force можно реализовать двумя вложенными циклами:
for i = 0; i < size(a); i++ {
for j = i+1; j < size(a); j++ {
if(a[i] == a[j]) return a[i]
}
}O(n²) — временная сложность и O(1) — пространственная сложность.
Count Iterations
Другой подход, это иметь структуру данных, в которой можно перечитать количество итераций каждого элемента integer. Такой метод подойдёт как для массивов, так и для хэш-таблиц.
Реализация на Java:
public int repeatedNumber(final List<Integer> list) {
if(list.size() <= 1) {
return -1;
}
int[] count = new int[list.size() - 1];
for (int i = 0; i < list.size(); i++) {
int n = list.get(i) - 1;
count[n]++;
if (count[n] > 1) {
return list.get(i);
}
}
return -1;
}Значение индекса i представляет число итераций i+1.
Временная сложность этого решения — O(n), но и пространственная — O(n), так как нам требуется дополнительная структура.
Sorted Array
Если мы применяем метод упрощения, то можно попытаться найти решение с отсортированным массивом.
В этом случае, нам нужно сравнить каждый элемент с его соседом справа.
Реализация на Java:
public int repeatedNumber(final List<Integer> list) {
if (list.size() <= 1) {
return -1;
}
Collections.sort(list);
for (int i = 0; i < list.size() - 1; i++) {
if (list.get(i) == list.get(i + 1)) {
return list.get(i);
}
}
return -1;
}Пространственная сложность O(1), но временная O(n log(n)), так как нам нужно отсортировать коллекцию.
Sum of the Elements
Ещё один способ — это суммирование элементов массива и их сравнение с помощью 1 + 2 + … + n.
Рассмотрим пример:
Input: [1, 4, 3, 3, 2, 5]
Sum = 18
As in this example, we have n = 5:
Sum of 1 to 5 = 1 + 2 + 3 + 4 + 5 = 15
=> 18 - 15 = 3 so 3 is the duplicateВ этом примере мы можем добиться результата временной сложности O(n) и пространственной O(1). Тем не менее, это решение работает только в случае, когда мы имеем один дубликат.
Нерабочий пример:
Input: [1, 2, 3, 2, 3, 4]
Sum = 15
As in this example we have n = 5,
Sum of 1 to 5 = 1 + 2 + 3 + 4 + 5 = 15
/! Not workingТакой способ приведёт в тупик. Но иногда, чтобы найти оптимальное решение, нужно перепробовать всё.
Marker
Кое-что интересное стоит упомянуть. Мы рассматривали решения, не учитывая условия, что диапазон значений integer может быть от 1 до n. Из-за этого примечательного условия каждое значение имеет свой собственный, соответствующий ему индекс в массиве.
Суть этого решения в том, чтобы рассматривать данный массив как список связей. То есть значение индекса указывает на его содержание.
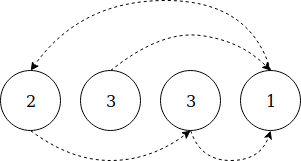
Мы проходим через каждый элемент и помечаем соответствующий индекс, прибавляя к нему знак минус. Элемент является дубликатом, если его индекс уже помечен минусом.
Давайте рассмотрим конкретный пример, шаг за шагом:
Input: [2, 3, 3, 1]
* Iteration 0:
Absolute value = 2
Put a minus sign to a[2] => [2, 3, -3, 1]
* Iteration 1:
Absolute value = 3
Put a minus sign to a[3] => [2, 3, -3, -1]
* Iteration 2:
Absolute value = 3
As a[3] is already negative, it means 3 is a duplicateРеализация на Java:
public int repeatedNumber(final List<Integer> list) {
if (list.size() <= 1) {
return -1;
}
for (int i = 0; i < list.size(); i++) {
if (list.get(Math.abs(list.get(i))) > 0) {
list.set(Math.abs(list.get(i)), -1 * list.get(Math.abs(list.get(i))));
} else {
return Math.abs(list.get(i));
}
}
return 0;
}Это решение даёт результат временной сложности O(n) и пространственной O(1). Тем не менее, потребуется изменять список ввода.
Runner Technique
Есть ещё один способ, который предполагает рассматривать массив как некий список связей (повторюсь, это возможно благодаря ограничению диапазона значений элементов).
Давайте проанализируем пример [1, 2, 3, 4, 2]:
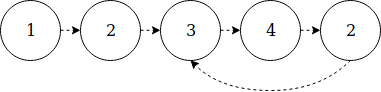
Такое представление даёт нам понять, что дубликат существует, когда есть цикл. Более того, дубликат проявляется на точке входа цикла (в этом случае, второй элемент).
Мы можем взять за основу алгоритм нахождения цикла по Флойду, тогда мы придём к следующему алгоритму:
- Инициировать два указателя
slowиfast - С каждым шагом: slow смещается на шаг со значением
slow = a[slow], fast смещается на два шага со значениемfast = a[a[fast]] - Когда
slow == fast― мы в цикле.
Можно ли считать этот алгоритм завершённым? Пока нет. Точка входа этого цикла будет обозначать дубликат. Нам нужно сбросить slow и двигать указатели шаг за шагом, пока они снова не станут равны.
Возможная реализация на Java:
public int repeatedNumber(final List<Integer> list) {
if (list.size() <= 1)
return -1;
int slow = list.get(0);
int fast = list.get(list.get(0));
while (fast != slow) {
slow = list.get(slow);
fast = list.get(list.get(fast));
}
slow = 0;
while (fast != slow) {
slow = list.get(slow);
fast = list.get(fast);
}
return slow;
}Это решение даёт результат временной сложности O(n) и пространственной O(1) и не требует изменения входящего списка.
Перевод статьи Teiva Harsanyi : Solving Algorithmic Problems: Find a Duplicate in an Array
Иногда возникает необходимость найти дубликаты в массиве. В данной статье мы расскажем, как это сделать двумя способами.
Задача
Итак, у нас есть массив. Это может быть массив любых объектов или примитивов. Для примера возьмём массив строк:
String[] animals = {"cat", "dog", "cow", "sheep", "cat", "dog"};
Теперь попробуем найти дублирующиеся строки в этом массиве.
Поиск дубликатов перебором
Сначала объявим вспомогательную коллекцию для хранения дубликатов – HashSet:
Set<T> duplicates = new HashSet<>();
Каждый раз, находя дубликат в массиве, мы будет его класть в данный HashSet.
Далее мы будем проходить по элементам массива, используя два цикла. В первом цикле мы извлекаем элемент массива и поочерёдно сравниваем его с остальными элементами массива, используя второй цикл:
for (int i = 0; i < a.length; i++) {
T e1 = a[i];
if (e1 == null) continue; // игнорируем null
// сравниваем каждый элемент со всеми остальными
for (int j = 0; j < a.length; j++) {
if (i == j) continue; // не проверяем элемент с собой же
T e2 = a[j];
if (e1.equals(e2)) {
// дубликат найден, сохраним его
duplicates.add(e2);
}
}
}
И в конце возвратим найденные дубликаты:
return new ArrayList<>(duplicates);
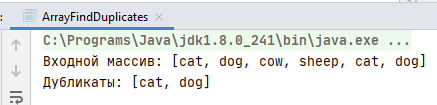
Проверка
Проверим нашу программу:
String[] animals = {"cat", "dog", "cow", "sheep", "cat", "dog"};
System.out.println("Входной массив: " + Arrays.toString(animals));
System.out.println("Дубликаты: " + getDuplicatesWithIteration(animals));
Исходный код
package ru.javalessons.arrays;
import java.util.*;
public class ArrayFindDuplicates {
public static void main(String[] args) {
String[] animals = {"cat", "dog", "cow", "sheep", "cat", "dog"};
System.out.println("Входной массив: " + Arrays.toString(animals));
System.out.println("Дубликаты: " + getDuplicatesWithIteration(animals));
}
public static <T> List<T> getDuplicatesWithIteration(T[] a) {
Set<T> duplicates = new HashSet<>();
for (int i = 0; i < a.length; i++) {
T e1 = a[i];
if (e1 == null) continue; // игнорируем null
// сравниваем каждый элемент со всеми остальными
for (int j = 0; j < a.length; j++) {
if (i == j) continue; // не проверяем элемент с собой же
T e2 = a[j];
if (e1.equals(e2)) {
// дубликат найден, сохраним его
duplicates.add(e2);
}
}
}
return new ArrayList<>(duplicates);
}
}
Заключение
На данном примере мы разобрали, как находить дубликаты в массиве. Это может быть массив любых объектов.