(PHP 4, PHP 5, PHP 7, PHP 
strpos — Возвращает позицию первого вхождения подстроки
Описание
strpos(string $haystack, string $needle, int $offset = 0): int|false
Список параметров
-
haystack -
Строка, в которой производится поиск.
-
needle -
До PHP 8.0.0, если параметр
needleне является строкой,
он преобразуется в целое число и трактуется как код символа.
Это поведение устарело с PHP 7.3.0, и полагаться на него крайне не рекомендуется.
В зависимости от предполагаемого поведения,
параметрneedleдолжен быть либо явно приведён к строке,
либо должен быть выполнен явный вызов chr(). -
offset -
Если этот параметр указан, то поиск будет начат с указанного количества символов с
начала строки. Если задано отрицательное значение, отсчёт позиции начала поиска
будет произведён с конца строки.
Возвращаемые значения
Возвращает позицию, в которой находится искомая строка, относительно
начала строки haystack (независимо от смещения (offset)).
Также обратите внимание на то, что позиция строки отсчитывается от 0, а не от 1.
Возвращает false, если искомая строка не найдена.
Внимание
Эта функция может возвращать как логическое значение false, так и значение не типа boolean, которое приводится к false. За более подробной информацией обратитесь к разделу Булев тип. Используйте оператор === для проверки значения, возвращаемого этой функцией.
Список изменений
| Версия | Описание |
|---|---|
| 8.0.0 |
Передача целого числа (int) в needle больше не поддерживается.
|
| 7.3.0 |
Передача целого числа (int) в needle объявлена устаревшей.
|
| 7.1.0 |
Добавлена поддержка отрицательных значений offset.
|
Примеры
Пример #1 Использование ===
<?php
$mystring = 'abc';
$findme = 'a';
$pos = strpos($mystring, $findme);// Заметьте, что используется ===. Использование == не даст верного
// результата, так как 'a' находится в нулевой позиции.
if ($pos === false) {
echo "Строка '$findme' не найдена в строке '$mystring'";
} else {
echo "Строка '$findme' найдена в строке '$mystring'";
echo " в позиции $pos";
}
?>
Пример #2 Использование !==
<?php
$mystring = 'abc';
$findme = 'a';
$pos = strpos($mystring, $findme);// Оператор !== также можно использовать. Использование != не даст верного
// результата, так как 'a' находится в нулевой позиции. Выражение (0 != false) приводится
// к false.
if ($pos !== false) {
echo "Строка '$findme' найдена в строке '$mystring'";
echo " в позиции $pos";
} else {
echo "Строка '$findme' не найдена в строке '$mystring'";
}
?>
Пример #3 Использование смещения
<?php
// Можно искать символ, игнорируя символы до определённого смещения
$newstring = 'abcdef abcdef';
$pos = strpos($newstring, 'a', 1); // $pos = 7, не 0
?>
Примечания
Замечание: Эта функция безопасна для обработки данных в двоичной форме.
Смотрите также
- stripos() — Возвращает позицию первого вхождения подстроки без учёта регистра
- str_contains() — Определяет, содержит ли строка заданную подстроку
- str_ends_with() — Проверяет, заканчивается ли строка заданной подстрокой
- str_starts_with() — Проверяет, начинается ли строка с заданной подстроки
- strrpos() — Возвращает позицию последнего вхождения подстроки в строке
- strripos() — Возвращает позицию последнего вхождения подстроки без учёта регистра
- strstr() — Находит первое вхождение подстроки
- strpbrk() — Ищет в строке любой символ из заданного набора
- substr() — Возвращает подстроку
- preg_match() — Выполняет проверку на соответствие регулярному выражению
Suggested re-write for pink WARNING box ¶
15 years ago
WARNING
As strpos may return either FALSE (substring absent) or 0 (substring at start of string), strict versus loose equivalency operators must be used very carefully.
To know that a substring is absent, you must use:
=== FALSE
To know that a substring is present (in any position including 0), you can use either of:
!== FALSE (recommended)
> -1 (note: or greater than any negative number)
To know that a substring is at the start of the string, you must use:
=== 0
To know that a substring is in any position other than the start, you can use any of:
> 0 (recommended)
!= 0 (note: but not !== 0 which also equates to FALSE)
!= FALSE (disrecommended as highly confusing)
Also note that you cannot compare a value of "" to the returned value of strpos. With a loose equivalence operator (== or !=) it will return results which don't distinguish between the substring's presence versus position. With a strict equivalence operator (=== or !==) it will always return false.
martijn at martijnfrazer dot nl ¶
11 years ago
This is a function I wrote to find all occurrences of a string, using strpos recursively.
<?php
function strpos_recursive($haystack, $needle, $offset = 0, &$results = array()) {
$offset = strpos($haystack, $needle, $offset);
if($offset === false) {
return $results;
} else {
$results[] = $offset;
return strpos_recursive($haystack, $needle, ($offset + 1), $results);
}
}
?>
This is how you use it:
<?php
$string = 'This is some string';
$search = 'a';
$found = strpos_recursive($string, $search);
if(
$found) {
foreach($found as $pos) {
echo 'Found "'.$search.'" in string "'.$string.'" at position <b>'.$pos.'</b><br />';
}
} else {
echo '"'.$search.'" not found in "'.$string.'"';
}
?>
fabio at naoimporta dot com ¶
7 years ago
It is interesting to be aware of the behavior when the treatment of strings with characters using different encodings.
<?php
# Works like expected. There is no accent
var_dump(strpos("Fabio", 'b'));
#int(2)
# The "á" letter is occupying two positions
var_dump(strpos("Fábio", 'b')) ;
#int(3)
# Now, encoding the string "Fábio" to utf8, we get some "unexpected" outputs. Every letter that is no in regular ASCII table, will use 4 positions(bytes). The starting point remains like before.
# We cant find the characted, because the haystack string is now encoded.
var_dump(strpos(utf8_encode("Fábio"), 'á'));
#bool(false)
# To get the expected result, we need to encode the needle too
var_dump(strpos(utf8_encode("Fábio"), utf8_encode('á')));
#int(1)
# And, like said before, "á" occupies 4 positions(bytes)
var_dump(strpos(utf8_encode("Fábio"), 'b'));
#int(5)
mtroy dot student at gmail dot com ¶
11 years ago
when you want to know how much of substring occurrences, you'll use "substr_count".
But, retrieve their positions, will be harder.
So, you can do it by starting with the last occurrence :
function strpos_r($haystack, $needle)
{
if(strlen($needle) > strlen($haystack))
trigger_error(sprintf("%s: length of argument 2 must be <= argument 1", __FUNCTION__), E_USER_WARNING);
$seeks = array();
while($seek = strrpos($haystack, $needle))
{
array_push($seeks, $seek);
$haystack = substr($haystack, 0, $seek);
}
return $seeks;
}
it will return an array of all occurrences a the substring in the string
Example :
$test = "this is a test for testing a test function... blah blah";
var_dump(strpos_r($test, "test"));
// output
array(3) {
[0]=>
int(29)
[1]=>
int(19)
[2]=>
int(10)
}
Paul-antoine
Malézieux.
rjeggens at ijskoud dot org ¶
11 years ago
I lost an hour before I noticed that strpos only returns FALSE as a boolean, never TRUE.. This means that
strpos() !== false
is a different beast then:
strpos() === true
since the latter will never be true. After I found out, The warning in the documentation made a lot more sense.
m.m.j.kronenburg ¶
6 years ago
<?php/**
* Find the position of the first occurrence of one or more substrings in a
* string.
*
* This function is simulair to function strpos() except that it allows to
* search for multiple needles at once.
*
* @param string $haystack The string to search in.
* @param mixed $needles Array containing needles or string containing
* needle.
* @param integer $offset If specified, search will start this number of
* characters counted from the beginning of the
* string.
* @param boolean $last If TRUE then the farthest position from the start
* of one of the needles is returned.
* If FALSE then the smallest position from start of
* one of the needles is returned.
**/
function mstrpos($haystack, $needles, $offset = 0, $last = false)
{
if(!is_array($needles)) { $needles = array($needles); }
$found = false;
foreach($needles as $needle)
{
$position = strpos($haystack, (string)$needle, $offset);
if($position === false) { continue; }
$exp = $last ? ($found === false || $position > $found) :
($found === false || $position < $found);
if($exp) { $found = $position; }
}
return $found;
}/**
* Find the position of the first (partially) occurrence of a substring in a
* string.
*
* This function is simulair to function strpos() except that it wil return a
* position when the substring is partially located at the end of the string.
*
* @param string $haystack The string to search in.
* @param mixed $needle The needle to search for.
* @param integer $offset If specified, search will start this number of
* characters counted from the beginning of the
* string.
**/
function pstrpos($haystack, $needle, $offset = 0)
{
$position = strpos($haystack, $needle, $offset);
if($position !== false) { return $position; }
for(
$i = strlen($needle); $i > 0; $i--)
{
if(substr($needle, 0, $i) == substr($haystack, -$i))
{ return strlen($haystack) - $i; }
}
return false;
}/**
* Find the position of the first (partially) occurrence of one or more
* substrings in a string.
*
* This function is simulair to function strpos() except that it allows to
* search for multiple needles at once and it wil return a position when one of
* the substrings is partially located at the end of the string.
*
* @param string $haystack The string to search in.
* @param mixed $needles Array containing needles or string containing
* needle.
* @param integer $offset If specified, search will start this number of
* characters counted from the beginning of the
* string.
* @param boolean $last If TRUE then the farthest position from the start
* of one of the needles is returned.
* If FALSE then the smallest position from start of
* one of the needles is returned.
**/
function mpstrpos($haystack, $needles, $offset = 0, $last = false)
{
if(!is_array($needles)) { $needles = array($needles); }
$found = false;
foreach($needles as $needle)
{
$position = pstrpos($haystack, (string)$needle, $offset);
if($position === false) { continue; }
$exp = $last ? ($found === false || $position > $found) :
($found === false || $position < $found);
if($exp) { $found = $position; }
}
return $found;
}?>
jexy dot ru at gmail dot com ¶
6 years ago
Docs are missing that WARNING is issued if needle is '' (empty string).
In case of empty haystack it just return false:
For example:
<?php
var_dump(strpos('foo', ''));var_dump(strpos('', 'foo'));var_dump(strpos('', ''));
?>
will output:
Warning: strpos(): Empty needle in /in/lADCh on line 3
bool(false)
bool(false)
Warning: strpos(): Empty needle in /in/lADCh on line 7
bool(false)
Note also that warning text may differ depending on php version, see https://3v4l.org/lADCh
greg at spotx dot net ¶
5 years ago
Warning:
this is not unicode safe
strpos($word,'?') in e?ez-> 1
strpos($word,'?') in è?ent-> 2
usulaco at gmail dot com ¶
12 years ago
Parse strings between two others in to array.
<?php
function g($string,$start,$end){
preg_match_all('/' . preg_quote($start, '/') . '(.*?)'. preg_quote($end, '/').'/i', $string, $m);
$out = array();
foreach(
$m[1] as $key => $value){
$type = explode('::',$value);
if(sizeof($type)>1){
if(!is_array($out[$type[0]]))
$out[$type[0]] = array();
$out[$type[0]][] = $type[1];
} else {
$out[] = $value;
}
}
return $out;
}
print_r(g('Sample text, [/text to extract/] Rest of sample text [/WEB::http://google.com/] bla bla bla. ','[/','/]'));
?>
results:
Array
(
[0] => text to extract
[WEB] => Array
(
[0] => http://google.com
)
)
Can be helpfull to custom parsing :)
akarmenia at gmail dot com ¶
12 years ago
My version of strpos with needles as an array. Also allows for a string, or an array inside an array.
<?php
function strpos_array($haystack, $needles) {
if ( is_array($needles) ) {
foreach ($needles as $str) {
if ( is_array($str) ) {
$pos = strpos_array($haystack, $str);
} else {
$pos = strpos($haystack, $str);
}
if ($pos !== FALSE) {
return $pos;
}
}
} else {
return strpos($haystack, $needles);
}
}// Test
echo strpos_array('This is a test', array('test', 'drive')); // Output is 10?>
eef dot vreeland at gmail dot com ¶
6 years ago
To prevent others from staring at the text, note that the wording of the 'Return Values' section is ambiguous.
Let's say you have a string $myString containing 50 'a's except on position 3 and 43, they contain 'b'.
And for this moment, forget that counting starts from 0.
strpos($myString, 'b', 40) returns 43, great.
And now the text: "Returns the position of where the needle exists relative to the beginning of the haystack string (independent of offset)."
So it doesn't really matter what offset I specify; I'll get the REAL position of the first occurrence in return, which is 3?
... no ...
"independent of offset" means, you will get the REAL positions, thus, not relative to your starting point (offset).
Substract your offset from strpos()'s answer, then you have the position relative to YOUR offset.
ohcc at 163 dot com ¶
8 years ago
Be careful when the $haystack or $needle parameter is an integer.
If you are not sure of its type, you should convert it into a string.
<?php
var_dump(strpos(12345,1));//false
var_dump(strpos(12345,'1'));//0
var_dump(strpos('12345',1));//false
var_dump(strpos('12345','1'));//0
$a = 12345;
$b = 1;
var_dump(strpos(strval($a),strval($b)));//0
var_dump(strpos((string)$a,(string)$b));//0
?>
ilaymyhat-rem0ve at yahoo dot com ¶
15 years ago
This might be useful.
<?php
class String{
//Look for a $needle in $haystack in any position
public static function contains(&$haystack, &$needle, &$offset)
{
$result = strpos($haystack, $needle, $offset);
return $result !== FALSE;
}
//intuitive implementation .. if not found returns -1.
public static function strpos(&$haystack, &$needle, &$offset)
{
$result = strpos($haystack, $needle, $offset);
if ($result === FALSE )
{
return -1;
}
return $result;
}
}
//String
?>
yasindagli at gmail dot com ¶
13 years ago
This function finds postion of nth occurence of a letter starting from offset.
<?php
function nth_position($str, $letter, $n, $offset = 0){
$str_arr = str_split($str);
$letter_size = array_count_values(str_split(substr($str, $offset)));
if( !isset($letter_size[$letter])){
trigger_error('letter "' . $letter . '" does not exist in ' . $str . ' after ' . $offset . '. position', E_USER_WARNING);
return false;
} else if($letter_size[$letter] < $n) {
trigger_error('letter "' . $letter . '" does not exist ' . $n .' times in ' . $str . ' after ' . $offset . '. position', E_USER_WARNING);
return false;
}
for($i = $offset, $x = 0, $count = (count($str_arr) - $offset); $i < $count, $x != $n; $i++){
if($str_arr[$i] == $letter){
$x++;
}
}
return $i - 1;
}
echo
nth_position('foobarbaz', 'a', 2); //7
echo nth_position('foobarbaz', 'b', 1, 4); //6
?>
bishop ¶
19 years ago
Code like this:
<?php
if (strpos('this is a test', 'is') !== false) {
echo "found it";
}
?>
gets repetitive, is not very self-explanatory, and most people handle it incorrectly anyway. Make your life easier:
<?php
function str_contains($haystack, $needle, $ignoreCase = false) {
if ($ignoreCase) {
$haystack = strtolower($haystack);
$needle = strtolower($needle);
}
$needlePos = strpos($haystack, $needle);
return ($needlePos === false ? false : ($needlePos+1));
}
?>
Then, you may do:
<?php
// simplest use
if (str_contains('this is a test', 'is')) {
echo "Found it";
}// when you need the position, as well whether it's present
$needlePos = str_contains('this is a test', 'is');
if ($needlePos) {
echo 'Found it at position ' . ($needlePos-1);
}// you may also ignore case
$needlePos = str_contains('this is a test', 'IS', true);
if ($needlePos) {
echo 'Found it at position ' . ($needlePos-1);
}
?>
Jean ¶
4 years ago
When a value can be of "unknow" type, I find this conversion trick usefull and more readable than a formal casting (for php7.3+):
<?php
$time = time();
$string = 'This is a test: ' . $time;
echo (strpos($string, $time) !== false ? 'found' : 'not found');
echo (strpos($string, "$time") !== false ? 'found' : 'not found');
?>
Anonymous ¶
10 years ago
The most straightforward way to prevent this function from returning 0 is:
strpos('x'.$haystack, $needle, 1)
The 'x' is simply a garbage character which is only there to move everything 1 position.
The number 1 is there to make sure that this 'x' is ignored in the search.
This way, if $haystack starts with $needle, then the function returns 1 (rather than 0).
marvin_elia at web dot de ¶
5 years ago
Find position of nth occurrence of a string:
function strpos_occurrence(string $string, string $needle, int $occurrence, int $offset = null) {
if((0 < $occurrence) && ($length = strlen($needle))) {
do {
} while ((false !== $offset = strpos($string, $needle, $offset)) && --$occurrence && ($offset += $length));
return $offset;
}
return false;
}
digitalpbk [at] gmail.com ¶
13 years ago
This function raises a warning if the offset is not between 0 and the length of string:
Warning: strpos(): Offset not contained in string in %s on line %d
Achintya ¶
13 years ago
A function I made to find the first occurrence of a particular needle not enclosed in quotes(single or double). Works for simple nesting (no backslashed nesting allowed).
<?php
function strposq($haystack, $needle, $offset = 0){
$len = strlen($haystack);
$charlen = strlen($needle);
$flag1 = false;
$flag2 = false;
for($i = $offset; $i < $len; $i++){
if(substr($haystack, $i, 1) == "'"){
$flag1 = !$flag1 && !$flag2 ? true : false;
}
if(substr($haystack, $i, 1) == '"'){
$flag2 = !$flag1 && !$flag2 ? true : false;
}
if(substr($haystack, $i, $charlen) == $needle && !$flag1 && !$flag2){
return $i;
}
}
return false;
}
echo
strposq("he'llo'character;"'som"e;crap", ";"); //16
?>
spinicrus at gmail dot com ¶
16 years ago
if you want to get the position of a substring relative to a substring of your string, BUT in REVERSE way:
<?phpfunction strpos_reverse_way($string,$charToFind,$relativeChar) {
//
$relativePos = strpos($string,$relativeChar);
$searchPos = $relativePos;
$searchChar = '';
//
while ($searchChar != $charToFind) {
$newPos = $searchPos-1;
$searchChar = substr($string,$newPos,strlen($charToFind));
$searchPos = $newPos;
}
//
if (!empty($searchChar)) {
//
return $searchPos;
return TRUE;
}
else {
return FALSE;
}
//
}?>
lairdshaw at yahoo dot com dot au ¶
8 years ago
<?php
/*
* A strpos variant that accepts an array of $needles - or just a string,
* so that it can be used as a drop-in replacement for the standard strpos,
* and in which case it simply wraps around strpos and stripos so as not
* to reduce performance.
*
* The "m" in "strposm" indicates that it accepts *m*ultiple needles.
*
* Finds the earliest match of *all* needles. Returns the position of this match
* or false if none found, as does the standard strpos. Optionally also returns
* via $match either the matching needle as a string (by default) or the index
* into $needles of the matching needle (if the STRPOSM_MATCH_AS_INDEX flag is
* set).
*
* Case-insensitive searching can be specified via the STRPOSM_CI flag.
* Note that for case-insensitive searches, if the STRPOSM_MATCH_AS_INDEX is
* not set, then $match will be in the haystack's case, not the needle's case,
* unless the STRPOSM_NC flag is also set.
*
* Flags can be combined using the bitwise or operator,
* e.g. $flags = STRPOSM_CI|STRPOSM_NC
*/
define('STRPOSM_CI' , 1); // CI => "case insensitive".
define('STRPOSM_NC' , 2); // NC => "needle case".
define('STRPOSM_MATCH_AS_INDEX', 4);
function strposm($haystack, $needles, $offset = 0, &$match = null, $flags = 0) {
// In the special case where $needles is not an array, simply wrap
// strpos and stripos for performance reasons.
if (!is_array($needles)) {
$func = $flags & STRPOSM_CI ? 'stripos' : 'strpos';
$pos = $func($haystack, $needles, $offset);
if ($pos !== false) {
$match = (($flags & STRPOSM_MATCH_AS_INDEX)
? 0
: (($flags & STRPOSM_NC)
? $needles
: substr($haystack, $pos, strlen($needles))
)
);
return $pos;
} else goto strposm_no_match;
}// $needles is an array. Proceed appropriately, initially by...
// ...escaping regular expression meta characters in the needles.
$needles_esc = array_map('preg_quote', $needles);
// If either of the "needle case" or "match as index" flags are set,
// then create a sub-match for each escaped needle by enclosing it in
// parentheses. We use these later to find the index of the matching
// needle.
if (($flags & STRPOSM_NC) || ($flags & STRPOSM_MATCH_AS_INDEX)) {
$needles_esc = array_map(
function($needle) {return '('.$needle.')';},
$needles_esc
);
}
// Create the regular expression pattern to search for all needles.
$pattern = '('.implode('|', $needles_esc).')';
// If the "case insensitive" flag is set, then modify the regular
// expression with "i", meaning that the match is "caseless".
if ($flags & STRPOSM_CI) $pattern .= 'i';
// Find the first match, including its offset.
if (preg_match($pattern, $haystack, $matches, PREG_OFFSET_CAPTURE, $offset)) {
// Pull the first entry, the overall match, out of the matches array.
$found = array_shift($matches);
// If we need the index of the matching needle, then...
if (($flags & STRPOSM_NC) || ($flags & STRPOSM_MATCH_AS_INDEX)) {
// ...find the index of the sub-match that is identical
// to the overall match that we just pulled out.
// Because sub-matches are in the same order as needles,
// this is also the index into $needles of the matching
// needle.
$index = array_search($found, $matches);
}
// If the "match as index" flag is set, then return in $match
// the matching needle's index, otherwise...
$match = (($flags & STRPOSM_MATCH_AS_INDEX)
? $index
// ...if the "needle case" flag is set, then index into
// $needles using the previously-determined index to return
// in $match the matching needle in needle case, otherwise...
: (($flags & STRPOSM_NC)
? $needles[$index]
// ...by default, return in $match the matching needle in
// haystack case.
: $found[0]
)
);
// Return the captured offset.
return $found[1];
}strposm_no_match:
// Nothing matched. Set appropriate return values.
$match = ($flags & STRPOSM_MATCH_AS_INDEX) ? false : null;
return false;
}
?>
qrworld.net ¶
8 years ago
I found a function in this post http://softontherocks.blogspot.com/2014/11/buscar-multiples-textos-en-un-texto-con.html
that implements the search in both ways, case sensitive or case insensitive, depending on an input parameter.
The function is:
function getMultiPos($haystack, $needles, $sensitive=true, $offset=0){
foreach($needles as $needle) {
$result[$needle] = ($sensitive) ? strpos($haystack, $needle, $offset) : stripos($haystack, $needle, $offset);
}
return $result;
}
It was very useful for me.
Lurvik ¶
9 years ago
Don't know if already posted this, but if I did this is an improvement.
This function will check if a string contains a needle. It _will_ work with arrays and multidimensional arrays (I've tried with a > 16 dimensional array and had no problem).
<?php
function str_contains($haystack, $needles)
{
//If needles is an array
if(is_array($needles))
{
//go trough all the elements
foreach($needles as $needle)
{
//if the needle is also an array (ie needles is a multidimensional array)
if(is_array($needle))
{
//call this function again
if(str_contains($haystack, $needle))
{
//Will break out of loop and function.
return true;
}
return
false;
}//when the needle is NOT an array:
//Check if haystack contains the needle, will ignore case and check for whole words only
elseif(preg_match("/b$needleb/i", $haystack) !== 0)
{
return true;
}
}
}
//if $needles is not an array...
else
{
if(preg_match("/b$needlesb/i", $haystack) !== 0)
{
return true;
}
}
return
false;
}
?>
gambajaja at yahoo dot com ¶
12 years ago
<?php
$my_array = array ('100,101', '200,201', '300,301');
$check_me_in = array ('100','200','300','400');
foreach ($check_me_in as $value_cmi){
$is_in=FALSE; #asume that $check_me_in isn't in $my_array
foreach ($my_array as $value_my){
$pos = strpos($value_my, $value_cmi);
if ($pos===0)
$pos++;
if ($pos==TRUE){
$is_in=TRUE;
$value_my2=$value_my;
}
}
if ($is_in) echo "ID $value_cmi in $check_me_in I found in value '$value_my2' n";
}
?>
The above example will output
ID 100 in $check_me_in I found in value '100,101'
ID 200 in $check_me_in I found in value '200,201'
ID 300 in $check_me_in I found in value '300,301'
ah dot d at hotmail dot com ¶
13 years ago
A strpos modification to return an array of all the positions of a needle in the haystack
<?php
function strallpos($haystack,$needle,$offset = 0){
$result = array();
for($i = $offset; $i<strlen($haystack); $i++){
$pos = strpos($haystack,$needle,$i);
if($pos !== FALSE){
$offset = $pos;
if($offset >= $i){
$i = $offset;
$result[] = $offset;
}
}
}
return $result;
}
?>
example:-
<?php
$haystack = "ASD is trying to get out of the ASDs cube but the other ASDs told him that his behavior will destroy the ASDs world";
$needle = "ASD";
print_r(strallpos($haystack,$needle));
//getting all the positions starting from a specified position
print_r(strallpos($haystack,$needle,34));
?>
teddanzig at yahoo dot com ¶
14 years ago
routine to return -1 if there is no match for strpos
<?php
//instr function to mimic vb instr fucntion
function InStr($haystack, $needle)
{
$pos=strpos($haystack, $needle);
if ($pos !== false)
{
return $pos;
}
else
{
return -1;
}
}
?>
Tim ¶
14 years ago
If you would like to find all occurences of a needle inside a haystack you could use this function strposall($haystack,$needle);. It will return an array with all the strpos's.
<?php
/**
* strposall
*
* Find all occurrences of a needle in a haystack
*
* @param string $haystack
* @param string $needle
* @return array or false
*/
function strposall($haystack,$needle){
$s=0;
$i=0;
while (
is_integer($i)){
$i = strpos($haystack,$needle,$s);
if (
is_integer($i)) {
$aStrPos[] = $i;
$s = $i+strlen($needle);
}
}
if (isset($aStrPos)) {
return $aStrPos;
}
else {
return false;
}
}
?>
user at nomail dot com ¶
16 years ago
This is a bit more useful when scanning a large string for all occurances between 'tags'.
<?php
function getStrsBetween($s,$s1,$s2=false,$offset=0) {
/*====================================================================
Function to scan a string for items encapsulated within a pair of tags
getStrsBetween(string, tag1, <tag2>, <offset>
If no second tag is specified, then match between identical tags
Returns an array indexed with the encapsulated text, which is in turn
a sub-array, containing the position of each item.
Notes:
strpos($needle,$haystack,$offset)
substr($string,$start,$length)
====================================================================*/
if( $s2 === false ) { $s2 = $s1; }
$result = array();
$L1 = strlen($s1);
$L2 = strlen($s2);
if(
$L1==0 || $L2==0 ) {
return false;
}
do {
$pos1 = strpos($s,$s1,$offset);
if(
$pos1 !== false ) {
$pos1 += $L1;$pos2 = strpos($s,$s2,$pos1);
if(
$pos2 !== false ) {
$key_len = $pos2 - $pos1;$this_key = substr($s,$pos1,$key_len);
if( !
array_key_exists($this_key,$result) ) {
$result[$this_key] = array();
}$result[$this_key][] = $pos1;$offset = $pos2 + $L2;
} else {
$pos1 = false;
}
}
} while($pos1 !== false );
return
$result;
}
?>
philip ¶
18 years ago
Many people look for in_string which does not exist in PHP, so, here's the most efficient form of in_string() (that works in both PHP 4/5) that I can think of:
<?php
function in_string($needle, $haystack, $insensitive = false) {
if ($insensitive) {
return false !== stristr($haystack, $needle);
} else {
return false !== strpos($haystack, $needle);
}
}
?>
Lhenry ¶
5 years ago
note that strpos( "8 june 1970" , 1970 ) returns FALSE..
add quotes to the needle
gjh42 — simonokewode at hotmail dot com ¶
11 years ago
A pair of functions to replace every nth occurrence of a string with another string, starting at any position in the haystack. The first works on a string and the second works on a single-level array of strings, treating it as a single string for replacement purposes (any needles split over two array elements are ignored).
Can be used for formatting dynamically-generated HTML output without touching the original generator: e.g. add a newLine class tag to every third item in a floated list, starting with the fourth item.
<?php
/* String Replace at Intervals by Glenn Herbert (gjh42) 2010-12-17
*/
//(basic locator by someone else - name unknown)
//strnposr() - Find the position of nth needle in haystack.
function strnposr($haystack, $needle, $occurrence, $pos = 0) {
return ($occurrence<2)?strpos($haystack, $needle, $pos):strnposr($haystack,$needle,$occurrence-1,strpos($haystack, $needle, $pos) + 1);
}//gjh42
//replace every nth occurrence of $needle with $repl, starting from any position
function str_replace_int($needle, $repl, $haystack, $interval, $first=1, $pos=0) {
if ($pos >= strlen($haystack) or substr_count($haystack, $needle, $pos) < $first) return $haystack;
$firstpos = strnposr($haystack, $needle, $first, $pos);
$nl = strlen($needle);
$qty = floor(substr_count($haystack, $needle, $firstpos + 1)/$interval);
do { //in reverse order
$nextpos = strnposr($haystack, $needle, ($qty * $interval) + 1, $firstpos);
$qty--;
$haystack = substr_replace($haystack, $repl, $nextpos, $nl);
} while ($nextpos > $firstpos);
return $haystack;
}
//$needle = string to find
//$repl = string to replace needle
//$haystack = string to do replacing in
//$interval = number of needles in loop
//$first=1 = first occurrence of needle to replace (defaults to first)
//$pos=0 = position in haystack string to start from (defaults to first)
//replace every nth occurrence of $needle with $repl, starting from any position, in a single-level array
function arr_replace_int($needle, $repl, $arr, $interval, $first=1, $pos=0, $glue='|+|') {
if (!is_array($arr)) return $arr;
foreach($arr as $key=>$value){
if (is_array($arr[$key])) return $arr;
}
$haystack = implode($glue, $arr);
$haystack = str_replace_int($needle, $repl, $haystack, $interval, $first, $pos);
$tarr = explode($glue, $haystack);
$i = 0;
foreach($arr as $key=>$value){
$arr[$key] = $tarr[$i];
$i++;
}
return $arr;
}
?>
If $arr is not an array, or a multilevel array, it is returned unchanged.
amolocaleb at gmail dot com ¶
4 years ago
Note that strpos() is case sensitive,so when doing a case insensitive search,use stripos() instead..If the latter is not available,subject the string to strlower() first,otherwise you may end up in this situation..
<?php
//say we are matching url routes and calling access control middleware depending on the route$registered_route = '/admin' ;
//now suppose we want to call the authorization middleware before accessing the admin route
if(strpos($path->url(),$registered_route) === 0){
$middleware->call('Auth','login');
}
?>
and the auth middleware is as follows
<?php
class Auth{
function
login(){
if(!loggedIn()){
return redirect("path/to/login.php");
}
return true;
}
}//Now suppose:
$user_url = '/admin';
//this will go to the Auth middleware for checks and redirect accordingly
//But:
$user_url = '/Admin';
//this will make the strpos function return false since the 'A' in admin is upper case and user will be taken directly to admin dashboard authentication and authorization notwithstanding
?>
Simple fixes:
<?php
//use stripos() as from php 5
if(stripos($path->url(),$registered_route) === 0){
$middleware->call('Auth','login');
}
//for those with php 4
if(stripos(strtolower($path->url()),$registered_route) === 0){
$middleware->call('Auth','login');
}
//make sure the $registered_route is also lowercase.Or JUST UPGRADE to PHP 5>
ds at kala-it dot de ¶
3 years ago
Note this code example below in PHP 7.3
<?php
$str = "17,25";
if(
FALSE !== strpos($str, 25)){
echo "25 is inside of str";
} else {
echo "25 is NOT inside of str";
}
?>
Will output "25 is NOT inside of str" and will throw out a deprication message, that non string needles will be interpreted as strings in the future.
This just gave me some headache since the value I am checking against comes from the database as an integer.
sunmacet at gmail dot com ¶
2 years ago
To check that a substring is present.
Confusing check if position is not false:
if ( strpos ( $haystack , $needle ) !== FALSE )
Logical check if there is position:
if ( is_int ( strpos ( $haystack , $needle ) ) )
binodluitel at hotmail dot com ¶
9 years ago
This function will return 0 if the string that you are searching matches i.e. needle matches the haystack
{code}
echo strpos('bla', 'bla');
{code}
Output: 0
hu60 dot cn at gmail dot com ¶
3 years ago
A more accurate imitation of the PHP function session_start().
Function my_session_start() does something similar to session_start() that has the default configure, and the session files generated by the two are binary compatible.
The code may help people increase their understanding of the principles of the PHP session.
<?php
error_reporting(E_ALL);
ini_set('display_errors', true);
ini_set('session.save_path', __DIR__);my_session_start();
echo
'<p>session id: '.my_session_id().'</p>';
echo
'<code><pre>';
var_dump($_SESSION);
echo '</pre></code>';$now = date('H:i:s');
if (isset($_SESSION['last_visit_time'])) {
echo '<p>Last Visit Time: '.$_SESSION['last_visit_time'].'</p>';
}
echo '<p>Current Time: '.$now.'</p>';$_SESSION['last_visit_time'] = $now;
function
my_session_start() {
global $phpsessid, $sessfile;
if (!isset(
$_COOKIE['PHPSESSID']) || empty($_COOKIE['PHPSESSID'])) {
$phpsessid = my_base32_encode(my_random_bytes(16));
setcookie('PHPSESSID', $phpsessid, ini_get('session.cookie_lifetime'), ini_get('session.cookie_path'), ini_get('session.cookie_domain'), ini_get('session.cookie_secure'), ini_get('session.cookie_httponly'));
} else {
$phpsessid = substr(preg_replace('/[^a-z0-9]/', '', $_COOKIE['PHPSESSID']), 0, 26);
}$sessfile = ini_get('session.save_path').'/sess_'.$phpsessid;
if (is_file($sessfile)) {
$_SESSION = my_unserialize(file_get_contents($sessfile));
} else {
$_SESSION = array();
}
register_shutdown_function('my_session_save');
}
function
my_session_save() {
global $sessfile;file_put_contents($sessfile, my_serialize($_SESSION));
}
function
my_session_id() {
global $phpsessid;
return $phpsessid;
}
function
my_serialize($data) {
$text = '';
foreach ($data as $k=>$v) {
// key cannot contains '|'
if (strpos($k, '|') !== false) {
continue;
}
$text.=$k.'|'.serialize($v)."n";
}
return $text;
}
function
my_unserialize($text) {
$data = [];
$text = explode("n", $text);
foreach ($text as $line) {
$pos = strpos($line, '|');
if ($pos === false) {
continue;
}
$data[substr($line, 0, $pos)] = unserialize(substr($line, $pos + 1));
}
return $data;
}
function
my_random_bytes($length) {
if (function_exists('random_bytes')) {
return random_bytes($length);
}
$randomString = '';
for ($i = 0; $i < $length; $i++) {
$randomString .= chr(rand(0, 255));
}
return $randomString;
}
function
my_base32_encode($input) {
$BASE32_ALPHABET = 'abcdefghijklmnopqrstuvwxyz234567';
$output = '';
$v = 0;
$vbits = 0;
for ($i = 0, $j = strlen($input); $i < $j; $i++) {
$v <<= 8;
$v += ord($input[$i]);
$vbits += 8;
while ($vbits >= 5) {
$vbits -= 5;
$output .= $BASE32_ALPHABET[$v >> $vbits];
$v &= ((1 << $vbits) - 1);
}
}
if ($vbits > 0) {
$v <<= (5 - $vbits);
$output .= $BASE32_ALPHABET[$v];
}
return $output;
}
msegit post pl ¶
4 years ago
This might be useful, I often use for parsing file paths etc.
(Some examples inside https://gist.github.com/msegu/bf7160257037ec3e301e7e9c8b05b00a )
<?php
/**
* Function 'strpos_' finds the position of the first or last occurrence of a substring in a string, ignoring number of characters
*
* Function 'strpos_' is similar to 'str[r]pos()', except:
* 1. fourth (last, optional) param tells, what to return if str[r]pos()===false
* 2. third (optional) param $offset tells as of str[r]pos(), BUT if negative (<0) search starts -$offset characters counted from the end AND skips (ignore!, not as 'strpos' and 'strrpos') -$offset-1 characters from the end AND search backwards
*
* @param string $haystack Where to search
* @param string $needle What to find
* @param int $offset (optional) Number of characters to skip from the beginning (if 0, >0) or from the end (if <0) of $haystack
* @param mixed $resultIfFalse (optional) Result, if not found
* Example:
* positive $offset - like strpos:
* strpos_('abcaba','ab',1)==strpos('abcaba','ab',1)==3, strpos('abcaba','ab',4)===false, strpos_('abcaba','ab',4,'Not found')==='Not found'
* negative $offset - similar to strrpos:
* strpos_('abcaba','ab',-1)==strpos('abcaba','ab',-1)==3, strrpos('abcaba','ab',-3)==3 BUT strpos_('abcaba','ab',-3)===0 (omits 2 characters from the end, because -2-1=-3, means search in 'abca'!)
*
* @result int $offset Returns offset (or false), or $resultIfFalse
*/
function strpos_($haystack, $needle, $offset = 0, $resultIfFalse = false) {
$haystack=((string)$haystack); // (string) to avoid errors with int, float...
$needle=((string)$needle);
if ($offset>=0) {
$offset=strpos($haystack, $needle, $offset);
return (($offset===false)? $resultIfFalse : $offset);
} else {
$haystack=strrev($haystack);
$needle=strrev($needle);
$offset=strpos($haystack,$needle,-$offset-1);
return (($offset===false)? $resultIfFalse : strlen($haystack)-$offset-strlen($needle));
}
}
?>
Базовые операции¶
# Конкатенация (сложение) >>> s1 = 'spam' >>> s2 = 'eggs' >>> print(s1 + s2) 'spameggs' # Дублирование строки >>> print('spam' * 3) spamspamspam # Длина строки >>> len('spam') 4 # Доступ по индексу >>> S = 'spam' >>> S[0] 's' >>> S[2] 'a' >>> S[-2] 'a' # Срез >>> s = 'spameggs' >>> s[3:5] 'me' >>> s[2:-2] 'ameg' >>> s[:6] 'spameg' >>> s[1:] 'pameggs' >>> s[:] 'spameggs' # Шаг, извлечения среза >>> s[::-1] 'sggemaps' >>> s[3:5:-1] '' >>> s[2::2] 'aeg'
Другие функции и методы строк¶
# Литералы строк
S = 'str'; S = "str"; S = '''str'''; S = """str"""
# Экранированные последовательности
S = "snptanbbb"
# Неформатированные строки (подавляют экранирование)
S = r"C:tempnew"
# Строка байтов
S = b"byte"
# Конкатенация (сложение строк)
S1 + S2
# Повторение строки
S1 * 3
# Обращение по индексу
S[i]
# Извлечение среза
S[i:j:step]
# Длина строки
len(S)
# Поиск подстроки в строке. Возвращает номер первого вхождения или -1
S.find(str, [start],[end])
# Поиск подстроки в строке. Возвращает номер последнего вхождения или -1
S.rfind(str, [start],[end])
# Поиск подстроки в строке. Возвращает номер первого вхождения или вызывает ValueError
S.index(str, [start],[end])
# Поиск подстроки в строке. Возвращает номер последнего вхождения или вызывает ValueError
S.rindex(str, [start],[end])
# Замена шаблона
S.replace(шаблон, замена)
# Разбиение строки по разделителю
S.split(символ)
# Состоит ли строка из цифр
S.isdigit()
# Состоит ли строка из букв
S.isalpha()
# Состоит ли строка из цифр или букв
S.isalnum()
# Состоит ли строка из символов в нижнем регистре
S.islower()
# Состоит ли строка из символов в верхнем регистре
S.isupper()
# Состоит ли строка из неотображаемых символов (пробел, символ перевода страницы ('f'), "новая строка" ('n'), "перевод каретки" ('r'), "горизонтальная табуляция" ('t') и "вертикальная табуляция" ('v'))
S.isspace()
# Начинаются ли слова в строке с заглавной буквы
S.istitle()
# Преобразование строки к верхнему регистру
S.upper()
# Преобразование строки к нижнему регистру
S.lower()
# Начинается ли строка S с шаблона str
S.startswith(str)
# Заканчивается ли строка S шаблоном str
S.endswith(str)
# Сборка строки из списка с разделителем S
S.join(список)
# Символ в его код ASCII
ord(символ)
# Код ASCII в символ
chr(число)
# Переводит первый символ строки в верхний регистр, а все остальные в нижний
S.capitalize()
# Возвращает отцентрованную строку, по краям которой стоит символ fill (пробел по умолчанию)
S.center(width, [fill])
# Возвращает количество непересекающихся вхождений подстроки в диапазоне [начало, конец] (0 и длина строки по умолчанию)
S.count(str, [start],[end])
# Возвращает копию строки, в которой все символы табуляции заменяются одним или несколькими пробелами, в зависимости от текущего столбца. Если TabSize не указан, размер табуляции полагается равным 8 пробелам
S.expandtabs([tabsize])
# Удаление пробельных символов в начале строки
S.lstrip([chars])
# Удаление пробельных символов в конце строки
S.rstrip([chars])
# Удаление пробельных символов в начале и в конце строки
S.strip([chars])
# Возвращает кортеж, содержащий часть перед первым шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий саму строку, а затем две пустых строки
S.partition(шаблон)
# Возвращает кортеж, содержащий часть перед последним шаблоном, сам шаблон, и часть после шаблона. Если шаблон не найден, возвращается кортеж, содержащий две пустых строки, а затем саму строку
S.rpartition(sep)
# Переводит символы нижнего регистра в верхний, а верхнего – в нижний
S.swapcase()
# Первую букву каждого слова переводит в верхний регистр, а все остальные в нижний
S.title()
# Делает длину строки не меньшей width, по необходимости заполняя первые символы нулями
S.zfill(width)
# Делает длину строки не меньшей width, по необходимости заполняя последние символы символом fillchar
S.ljust(width, fillchar=" ")
# Делает длину строки не меньшей width, по необходимости заполняя первые символы символом fillchar
S.rjust(width, fillchar=" ")
Форматирование строк¶
S.format(*args, **kwargs)
Примеры¶
Python: Определение позиции подстроки (функции str.find и str.rfind)¶
Определение позиции подстроки в строке с помощью функций str.find и str.rfind.
In [1]: str = 'ftp://dl.dropbox.com/u/7334460/Magick_py/py_magick.pdf'
Функция str.find показывает первое вхождение подстроки. Все позиции возвращаются относительно начало строки.
In [2]: str.find('/') Out[2]: 4 In [3]: str[4] Out[3]: '/'
Можно определить вхождение в срезе. первое число показывает начало среза, в котором производится поиск. Второе число — конец среза. В случае отсутствия вхождения подстроки выводится -1.
In [4]: str.find('/', 8, 18) Out[4]: -1 In [5]: str[8:18] Out[5]: '.dropbox.c' In [6]: str.find('/', 8, 22) Out[6]: 20 In [7]: str[8:22] Out[7]: '.dropbox.com/u' In [8]: str[20] Out[8]: '/'
Функция str.rfind осуществляет поиск с конца строки, но возвращает позицию подстроки относительно начала строки.
In [9]: str.rfind('/') Out[9]: 40 In [10]: str[40] Out[10]: '/'
Python: Извлекаем имя файла из URL¶
Понадобилось мне отрезать от URL всё, что находится после последнего слэша, т.е.названия файла. URL можеть быть какой угодно. Знаю, что задачу запросто можно решить с помощью специального модуля, но я хотел избежать этого. Есть, как минимум, два способа справиться с поставленным вопросом.
Способ №1¶
Достаточно простой способ. Разбиваем строку по слэшам с помощью функции split(), которая возвращает список. А затем из этого списка извлекаем последний элемент. Он и будет названием файла.
In [1]: str = 'http://dl.dropbox.com/u/7334460/Magick_py/py_magick.pdf' In [2]: str.split('/') Out[2]: ['http:', '', 'dl.dropbox.com', 'u', '7334460', 'Magick_py', 'py_magick.pdf']
Повторим шаг с присвоением переменной:
In [3]: file_name = str.split('/')[-1] In [4]: file_name Out[4]: 'py_magick.pdf'
Способ №2¶
Второй способ интереснее. Сначала с помощью функции rfind() находим первое вхождение с конца искомой подстроки. Функция возвращает позицию подстроки относительно начала строки. А далее просто делаем срез.
In [5]: str = 'http://dl.dropbox.com/u/7334460/Magick_py/py_magick.pdf' In [6]: str.rfind('/') Out[6]: 41
Делаем срез:
In [7]: file_name = str[42:] In [8]: file_name Out[8]: 'py_magick.pdf'
Поиск подстроки и смежные вопросы
Время на прочтение
13 мин
Количество просмотров 112K
Здравствуйте, уважаемое сообщество! Недавно на Хабре проскакивала неплохая обзорная статья о разных алгоритмах поиска подстроки в строке. К сожалению, там отсутствовали подробные описания каких либо из упомянутых алгоритмов. Я решил восполнить данный пробел и описать хотя бы парочку тех, которые потенциально можно запомнить. Те, кто еще помнит курс алгоритмов из института, не найдут, видимо, ничего нового для себя.
Сначала хотел бы предотвратить вопрос «на кой это надо? все уже и так написано». Да, написано. Но во-первых, полезно знать как работает используемые тобой иструменты на более низком уровне чтобы лучше понимать их ограничения, а во-вторых, есть достаточно большие смежные области, где работающей из коробочки функции strstr() окажется недостаточно. Ну и в-третьих, вам может неповезти и придется разрабатывать под мобильную платформу с неполноценным runtime, а тогда лучше знать на что подписываетесь, если решитесь самостоятельно его дополнять (чтобы убедиться, что это не сферическая проблема в вакууме, достаточно попробовать wcslen() и wcsstr() из Android NDK).
А разве просто поискать нельзя?
Дело в том, что очевидный способ, который все формулирует как «взять и поискать», является отнюдь не самым эффективным, а для такой низкоуровневой и сравнительно частовызываемой функции это немаловажно. Итак, план такой:
- Постановка задачи: здесь перечислены определения и условные обозначения.
- Решение «в лоб»: здесь будет описано, как делать не надо и почему.
- Z-функция: простейший вариант правильной реализации поиска подстроки.
- Алгоритм Кнута-Морриса-Пратта: еще один вариант правильного поиска.
- Другие задачи поиска: вкратце пробегусь по ним без подробного описания.
Постановка задачи
Канонический вариант задачи выглядит так: есть у нас строка A (текст). Необходимо проверить, есть ли в ней подстрока X (образец), и если есть, то где она начинается. То есть именно то, что делает функция strstr() в C. Дополнительно к этому можно еще попросить найти все вхождения образца. Очевидно, что задача имеет смысл только если X не длинее A.
Для простоты дальнейшего объяснения введу сразу пару понятий. Что такое строка все, наверное, понимают — это последовательность символов, возможно пустая. Символы, или буквы, принадлежат некоторому множеству, которое называют алфавитом (данный алфавит, вообще говоря, может не иметь ничего общего с алфавитом в бытовом понимании). Длина строки |A| — это, очевидно, количество символов в ней. Префикс строки A[..i] — это строка из i первых символов строки A. Суффикс строки A[j..] — это строка из |A|-j+1 последних символов. Подстроку из A будем обозначать как A[i..j], а A[i] — i-ый символ строки. Вопрос про пустые суффиксы и префиксы и т.д. не трогаем — с ними разобраться не сложно по месту. Еще есть такое понятие как сентинел — некий уникальный символ, не встречающийся в алфавите. Его обозначают значком $ и дополняют допустимый алфавит таким символом (это в теории, на практике проще применить дополнительные проверки, чем придумать такой символ, которого не могло бы оказаться во входных строках).
В выкладках будем считать символы в строке с первой позиции. Код писать традиционно проще отсчитывая от нуля. Переход от одного к другому не составляет трудностей.
Решение «в лоб»
Прямой поиск, или, как еще часто говорят, «просто взять и поискать»- это Первое решение, которое приходит в голову неискушенному программисту. Суть проста: идти по проверяемой строке A и искать в ней вхождение первого символа искомой строки X. Когда находим, делаем гипотезу, что это и есть то самое искомое вхождение. Затем остается проверять по очереди все последующие символы шаблона на совпадение с соответствующими символами строки A. Если они все совпали — значит вот оно, прямо перед нами. Но вот если какой-то из символов не совпал, то ничего не остается, как признать нашу гипотезу неверной, что возвращает нас к символу, следующему за вхождением первого символа из X.
Многие люди ошибаются в этом пункте, считая, что не надо возвращаться назад, а можно продолжать обработку строки A с текущей позиции. Почему это не так легко продемонстрировать на примере поиска X=«AAAB» в A=«AAAAB». Первая гипотеза нас приведет к четвертому символу A: «AAAAB», где мы обнаружим несоответствие. Если не откатиться назад, то вхождение мы так и не обнаружим, хотя оно есть.
Неправильные гипотезы неизбежны, а из-за таких откатываний назад при плохом стечении обстоятельств может оказаться, что мы каждый символ в A проверили около |X| раз. То есть вычислительная сложность сложность алгоритма O(|X||A|). Так поиск фразы в параграфе может и затянуться…
Справедливости ради следует отметить, что если строки невелики, то такой алгоритм может работать быстрее «правильных» алгоритмов за счет более предсказуемого с точки зрения процессора поведения.
Z-функция
Одна из категорий правильных способов поиска строки сводится к вычислению в каком-то смысле корреляции двух строк. Сначала отметим, что задача сравнения начал двух строк проста и понятна: сравниваем соответствующие буквы, пока не найдем несоответствие либо какая-нибудь из строк закончится. Рассмотрим множество всех суффиксов строки A: A[|A|..] A[|A|-1..],… A[1..]. Будем сравнивать начало самой строки с каждым из ее суффиксов. Сравнение может дойти до конца суффикса, либо оборваться на каком-то символе ввиду несовпадения. Длину совпавшей части и назовем компонентой Z-функции для данного суффикса.
То есть Z-функция — это вектор длин наибольшего общего префикса строки с ее суффиксом. Ух! Отличная фраза, когда надо кого-то запутать или самоутвердиться, а чтобы понять что же это такое, лучше рассмотреть пример.
Исходная строка «ababcaba». Сравнивая каждый суффикс с самой строкой получим табличку для Z-функции:
| суффикс | строка | Z | |
|---|---|---|---|
| ababcaba | ababcaba | -> | 8 |
| babcaba | ababcaba | -> | 0 |
| abcaba | ababcaba | -> | 2 |
| bcaba | ababcaba | -> | 0 |
| caba | ababcaba | -> | 0 |
| aba | ababcaba | -> | 3 |
| ba | ababcaba | -> | 0 |
| a | ababcaba | -> | 1 |
Префикс суффикса это ничто иное, как подстрока, а Z-функция — длины подстрок, которые встречаются одновременно в начале и в середине. Рассматривая все значения компонент Z-функции, можно заметить некоторые закономерности. Во-первых, очевидно, что значение Z-функции не превышает длины строки и совпадает с ней только для «полного» суффикса A[1..] (и поэтому это значение нас не интересует — мы его будем опускать в своих рассуждениях). Во-вторых, если в строке есть некий символ в единственном экземпляре, то совпасть он может только с самим собой, и значит он делит строку на две части, а значение Z-функции нигде не может превысить длины более короткой части.
Использовать эти наблюдения предлагается следующим образом. Допустим в строке «ababcabсacab» мы хотим поискать «abca». Берем эти строчки и конкатенируем, вставляя между ними сентинел: «abca$ababcabсacab». Вектор Z-функции выглядит для такой строки так:
| a b c a $ a b a b c a b с a c a b |
| 17 0 0 1 0 2 0 4 0 0 4 0 0 1 0 2 0 |
Если отбросить значение для полного суффикса, то наличие сентинела ограничивает Zi длиной искомого фрагмента (он является меньшей половиной строки по смыслу задачи). Но вот если этот максимум и достигается, то только в позициях вхождения подстроки. В нашем примере четверками отмечены
все
позиции вхождения искомой строки (отметьте, что найденные участки расположены внахлест друг с другом, но все-равно наши рассуждения остаются верны).
Ну, значит если мы сможем быстро строить вектор Z-функции, то поиск с его помощью всех вхождений строки сводится к поиску в нем значения ее длины. Вот только если вычислять Z-функцию для каждого суффикса, то будет это явно не быстрее, чем решение «в лоб». Выручает нас то, что значение очередного элемента вектора можно узнать опираясь на предыдущие элементы.
Допустим, мы каким-то образом посчитали значения Z-функции вплоть до соответствующего i-1-ому символу. Рассмотрм некую позицию r<i, где мы уже знаем Zr.
Значит Zr символов начиная с этой позиции точно такие же, как и в начале строки. Они образуют так называемый Z-блок. Нас будет интересовать самый правый Z-блок, то-есть тот, кто заканчивается дальше всех (самый первый не в счет). В некоторых случаях самый правый блок может быть нулевой длины (когда никакой из непустых блоков не покрывает i-1, то самым правым будет i-1-ый, даже если Zi-1= 0).
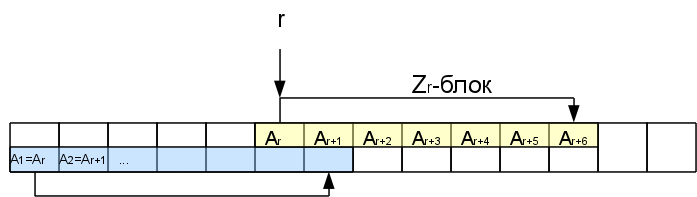
Когда мы будем рассматривать последующие символы внутри этого Z-блока, сравнивать очередной суффикс с самого начала не имеет смысла, так как часть этого суфикса уже встречалась в начале строки, а значит уже была обработана. Можно будет сразу пропускать символы аж до конца Z-блока.
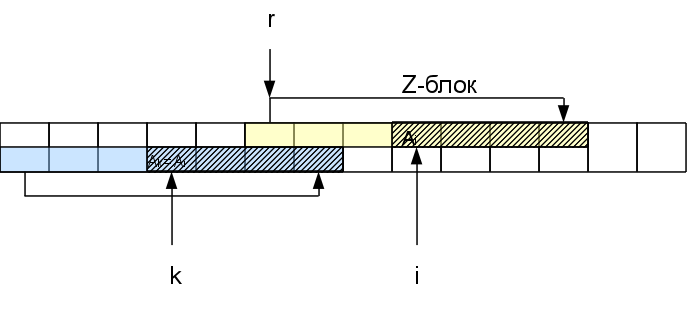
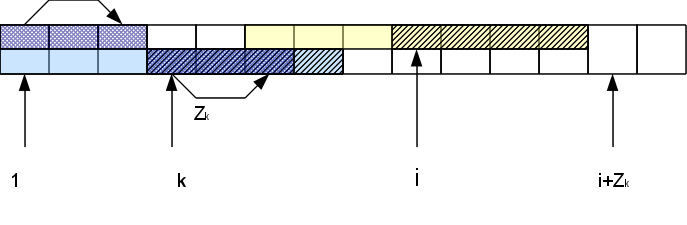
А именно, если мы рассматриваем i-й символ, находящийся в Zr-блоке, то есть соответствующий символ в начале строки на позиции k=i-r+1. Функция Zk нам уже известна. Если она меньше, чем оставшееся до конца Z-блока расстояние Zr-(i-r), то сразу можем быть уверены, что вся область совпадения для этого символа лежит внутри r-того Z-блока и значит результат будет тот же, что и в начале строки: Zi=Zk. Если же Zk >= Zr-(i-r), то Zi тоже больше или равна Zr-(i-r). Чтобы узнать насколько именно она больше, нам надо будет проверять следующие за Z-блоком символы. При этом в случае совпадения h этих символов с соответствующими им в начале строки, Zi увеличивается на h: Zi=Zk + h. В результате у нас может появиться новый самый правый Z-блок (если h>0).
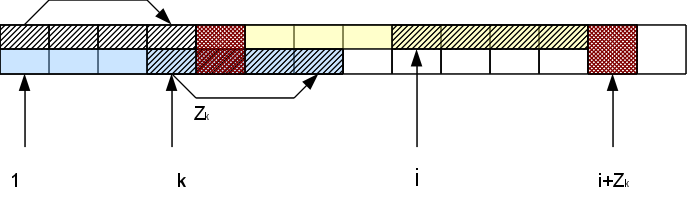
Таким образом, сравнивать символы нам приходится только правее самого правого Z-блока, причем за счет успешных сравнений блок «продвигается» правее, а неуспешные сообщают, что вычисление для данной позиции окончено. Это обеспечивает нам построение всего вектора Z-функции за линейное по длине строки время.
Применив этот алгоритм для поиска подстроки получим сложность по времени O(|A|+|X|), что значительно лучше, чем произведение, которое было в первом варианте. Правда, нам пришлось хранить вектор для Z-функции, на что уйдет дополнительной памяти порядка O(|A|+|X|). На самом деле, если не нужно находить все вхождения, а достаточно только одного, то можно обойтись и O(|X|) памяти, так как длина Z-блока все-равно не может быть больше чем |X|, кроме этого можно не продолжать обработку строки после обнаружения первого вхождения.
Напоследок, пример функции, вычисляющей Z-функцию. Просто модельный вариант без каких либо хитростей.
void z_preprocess(vector<int> & Z, const string & str)
{
const size_t len = str.size();
Z.clear();
Z.resize(len);
if (0 == len)
return;
Z[0] = len;
for (size_t curr = 1, left = 0, right = 1; curr < len; ++curr)
{
if (curr >= right)
{
size_t off = 0;
while ( curr + off < len && str[curr + off] == str[off] )
++off;
Z[curr] = off;
right = curr + Z[curr];
left = curr;
}
else
{
const size_t equiv = curr - left;
if (Z[equiv] < right - curr)
Z[curr] = Z[equiv];
else
{
size_t off = 0;
while ( right + off < len && str[right - curr + off] == str[right + off] )
++off;
Z[curr] = right - curr + off;
right += off;
left = curr;
}
}
}
}
Алгоритм Кнута-Морриса-Пратта (КМП)
Не смотря на логическую простоту предыдущего метода, более популярным является другой алгоритм, который в некотором смысле обратный Z-функции — алгоритм Кнута-Морриса-Пратта (КМП). Введем понятие префикс-функции. Префикс-функция для i-ой позиции — это длина максимального префикса строки, который короче i и который совпадает с суффиксом префикса длины i. Если определение Z-функции не сразило оппонента наповал, то уж этим комбо вам точно удастся поставить его на место  А на человеческом языке это выглядит так: берем каждый возможный префикс строки и смотрим самое длинное совпадение начала с концом префикса (не учитывая тривиальное совпадение самого с собой). Вот пример для «ababcaba»:
А на человеческом языке это выглядит так: берем каждый возможный префикс строки и смотрим самое длинное совпадение начала с концом префикса (не учитывая тривиальное совпадение самого с собой). Вот пример для «ababcaba»:
| префикс | префикс | p |
|---|---|---|
| a | a | 0 |
| ab | ab | 0 |
| aba | aba | 1 |
| abab | abab | 2 |
| ababc | ababc | 0 |
| ababca | ababca | 1 |
| ababcab | ababcab | 2 |
| ababcaba | ababcaba | 3 |
Опять же наблюдаем ряд свойств префикс-функции. Во-первых, значения ограничены сверху своим номером, что следует прямо из определения — длина префикса должна быть больше префикс-функции. Во-вторых, уникальный символ точно так же делит строку на две части и ограничивает максимальное значение префикс-функции длиной меньшей из частей — потому что все, что длиннее, будет содержать уникальный, ничему другому не равный символ.
Отсюда получается интересующий нас вывод. Допустим, мы таки достигли в каком-то элементе этого теоретического потолка. Это значит, что здесь закончился такой префикс, что начальная часть совпадает с конечной и одна из них представляет «полную» половинку. Понятно, что в префиксе полная половинка обязана быть спереди, а значит при таком допущении это должна быть более короткая половинка, максимума же мы достигаем на более длинной половинке.
Таким образом, если мы, как и в предыдущей части, конкатенируем искомую строчку с той, в которой ищем, через сентинел, то точка вхождения длины искомой подстроки в компоненту префикс-функции будет соответствовать месту окончания вхождения. Возьмем наш пример: в строке «ababcabсacab» мы ищем «abca». Конкатенированный вариант «abca$ababcabсacab». Префикс-функция выглядит так:
| a b c a $ a b a b c a b с a c a b |
| 0 0 0 1 0 1 2 1 2 3 4 2 3 4 0 1 2 |
Снова мы нашли все вхождения подстроки одним махом — они оканчиваются на позициях четверок. Осталось понять как же эффективно посчитать эту префикс-функцию. Идея алгоритма незначительно отличается от идеи построения Z-функции.

Самое первое значение префикс-функции, очевидно, 0. Пусть мы посчитали префикс-функцию до i-ой позиции включительно. Рассмотрим i+1-ый символ. Если значение префикс-функции в i-й позиции Pi, то значит префикс A[..Pi] совпадает с подстрокой A[i-Pi+1..i]. Если символ A[Pi+1] совпадет с A[i+1], то можем спокойно записать, что Pi+1=Pi+1. Но вот если нет, то значение может быть либо меньше, либо такое же. Конечно, при Pi=0 сильно некуда уменьшаться, так что в этом случае Pi+1=0. Допустим, что Pi>0. Тогда есть в строке префикс A[..Pi], который эквивалентен подстроке A[i-Pi+1..i]. Искомая префикс-функция формируется в пределах этих эквивалентных участков плюс обрабатываемый символ, а значит нам можно забыть о всей строке после префикса и оставить только данный префикс и i+1-ый символ — ситуация будет идентичной.
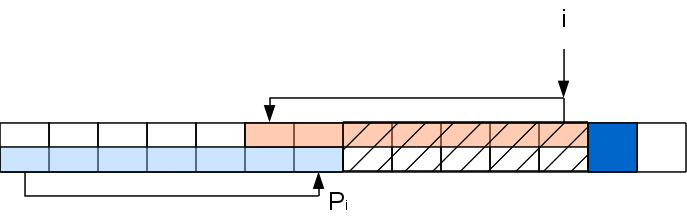
Задача на данном шаге свелась к задаче для строки с вырезанной серединкой: A[..Pi]A[i+1], которую можно решать рекурсивно таким же способом (хотя хвостовая рекурсия и не рекурсия вовсе, а цикл). То есть если A[PPi+1] совпадет с A[i+1], то Pi+1=PPi+1, а иначе снова выкидываем из рассмотрения часть строки и т.д. Повторяем процедуру пока не найдем совпадение либо не дойдем до 0.
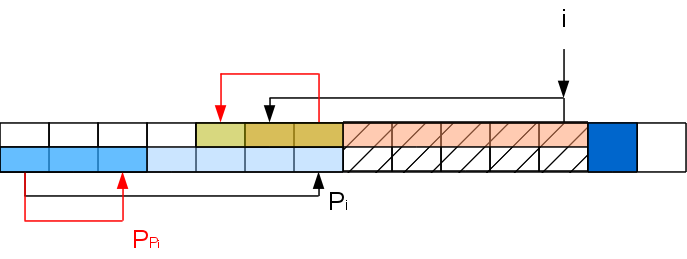
Повторение этих операций должно насторожить — казалось бы получается два вложенных цикла. Но это не так. Дело в том, что вложенный цикл длиной в k итераций уменьшает префикс-функцию в i+1-й позиции хотя бы на k-1, а для того, чтобы нарастить префикс-функцию до такого значения, нужно хотя бы k-1 раз успешно сопоставить буквы, обработав k-1 символов. То есть длина цикла соответствует промежутку между выполнением таких циклов и поэтому сложность алгоритма по прежнему линейна по длине обрабатываемой строки. С памятью тут такая-же ситуация, как и с Z-функцией — линейная по длине строки, но есть способ сэкономить. Кроме этого есть удобный факт, что символы обрабатываются последовательно, то есть мы не обязаны обрабатывать всю строку, если первое вхождение мы уже получили.
Ну и для примера фрагмент кода:
void calc_prefix_function(vector<int> & prefix_func, const string & str)
{
const size_t str_length = str.size();
prefix_func.clear();
prefix_func.resize(str_length);
if (0 == str_length)
return;
prefix_func[0] = 0;
for (size_t current = 1; current < str_length; ++current)
{
size_t matched_prefix = current - 1;
size_t candidate = prefix_func[matched_prefix];
while (candidate != 0 && str[current] != str[candidate])
{
matched_prefix = prefix_func[matched_prefix] - 1;
candidate = prefix_func[matched_prefix];
}
if (candidate == 0)
prefix_func[current] = str[current] == str[0] ? 1 : 0;
else
prefix_func[current] = candidate + 1;
}
}
Не смотря на то, что алгоритм более замысловат, реализация его даже проще, чем для Z-функции.
Другие задачи поиска
Дальше пойдет просто много букв о том, что этим задачи поиска строк не ограничиваются и что есть другие задачи и другие способы решения, так что если кому не интересно, то дальше можно не читать. Эта информация просто для ознакомления, чтобы в случае необходимости хотя бы осознавать, что «все уже украдено до нас» и не переизобретать велосипед.
Хоть вышеописанные алгоритмы и гарантируют линейное время выполнения, звание «алгоритма по умолчанию» получил алгоритм Бойера-Мура. В среднем он тоже дает линейное время, но еще и имеет лучше константу при этой линейной функции, но это в среднем. Бывают «плохие» данные, на которых он оказываются не лучше простейшего сравнения «в лоб» (ну прямо как с qsort). Он на редкость запутан и рассматривать его не будем — все-равно не упомнить. Есть еще ряд экзотических алгоритмов, которые ориентированы на обработку текстов на естественном языке и опираются в своих оптимизациях на статистические свойства слов языка.
Ну ладно, есть у нас алгоритм, который так или иначе за O(|X|+|A|) ищет подстроку в строке. А теперь представим, что мы пишем движок для гостевой книги. Есть у нас список запрещенных матерных слов (понятно, что так не поможет, но задача просто для примера). Мы собираемся фильтровать сообщения. Будем каждое из запрещенных слов искать в сообщении и… на это у нас уйдет O(|X1|+|X2|+…+|Xn|+n|A|). Как-то так себе, особенно если словарь «могучих выражений» «великого и могучего» очень «могуч». Для этого случая есть способ так предобработать словарь искомых строк, что поиск будет занимать только O(|X1|+|X2|+…+|Xn|+|A|), а это может быть существенно меньше, особенно если сообщения длинные.
Такая предобработка сводится к построению бора (trie) из словаря: дерево начинается в некотором фиктивном корне, узлы соответствует буквам слов в словаре, глубина узла дерева соответствует номеру буквы в слове. Узлы, в которых заканчивается слово из словаря называются терминальными и помечены неким образом (красным цветом на рисунке).
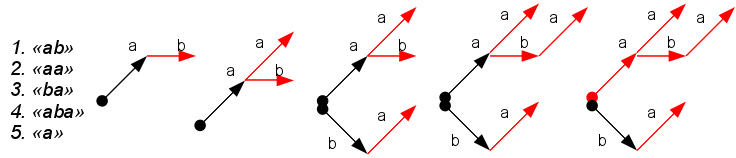
Полученное дерево является аналогом префикс-функции алгоритма КМП. С его помощью можно найти все вхождения всех слов словаря в фразе. Надо идти по дереву, проверяя наличие очередного символа в виде узла дерева, попутно отмечая встречающиеся терминальные вершины — это вхождения слов. Если соответствующего узла в дереве нет, то как и в КМП, происходит откат выше по дереву по специальным ссылкам. Данный алгоритм носит название алгоритма Ахо-Корасика. Такую же схему можно применять для поиска во время ввода и предсказания следующего символа в электронных словарях.
В данном примере построение бора несложно: просто добавляем в бор слова по очереди (нюансы только с дополнительными ссылками для «откатов»). Есть ряд оптимизаций, направленный на сокращение использования памяти этим деревом (т.н. сжатие бора — пропуск участков без ветвлений). На практике эти оптимизации чуть ли не обязательны. Недостатком данного алгоритма является его алфавитозависимость: время на обработку узла и занимаемая память зависят от количества потенциально возможных детей, которое равно размеру алфавита. Для больших алфавитов это серьезная проблема (представляете себе набор символов юникода?). Подробнее про это все можно почитать в этом хабратопике или воспользовавшись гуглояндексом — благо инфы по этомоу вопросу много.
Теперь посмотрим на другую задачу. Если в предыдущей мы знали заранее, что мы должны будем найти в поступающих потом данных, то здесь с точностью до наоборот: нам заранее выдали строчку, в которой будут искать, но что будут искать — неизвестно, а искать будут много. Типичный пример — поисковик. Документ, в котором ищется слово, известен заранее, а вот слова, которые там ищут, сыпятся на ходу. Вопрос, опять же, как вместо O(|X1|+|X2|+…+|Xn|+n|A|) получить O(|X1|+|X2|+…+|Xn|+|A|)?
Предлагается построить бор, в котором будут все возможные суффиксы имеющейся строки. Тогда поиск шаблона сведется к проверки наличия пути в дереве, соответствующего искомому шаблону. Если строить такой бор перебором всех суффиксов, то эта процедура может занять O(|A|2) времени, да и по памяти много. Но, к счастью, существуют алгоритмы, которые позволяют построить такое дерево сразу в сжатом виде — суффиксное дерево, причем сделать это за O(|A|). Недавно на Хабре была по этому поводу статья, так что интересующиеся могут прочитать про алгоритм Укконена там.
Плохо в суффиксном дереве, как обычно, две вещи: то, что это дерево, и то, что узлы дерева алфавитозависимы. От этих недостатков избавлен суффиксный массив. Суть суффиксного массива заключается в том, что если все суффиксы строки отсортировать, то поиск подстроки сведется к поиску группы расположенных рядом суффиксов по первой букве искомого образца и дальнейшего уточнения диапазона по последующим. При этом сами суффиксы в отсортированном виде хранить незачем, достаточно хранить позиции, в которых они начинаются в исходных данных. Правда, временные зависимости у данной структуры несколько хуже: единичный поиск будет обходиться O(|X| + log|A|) если подумать и сделать все аккуратно, и O(|X|log|A|) если не заморачиваться. Для сравнения в дереве для фиксированного алфавита O(|X|). Но зато то, что это массив, а не дерево, может улучшить ситуацию с кэшированием памяти и облегчить задачу предсказателю переходов процессора. Строится суффиксный массив за линейное время с помощью алгоритма Kärkkäinen-Sanders (уж извините, но плохо представляю как это должно звучать на русском). Нынче это один из самых популярных методов индексирования строк.
Вопросов приближенного поиска строк и анализа степени похожести мы тут касаться не будем совсем — слишком большая область для того, чтобы запихнуть в эту статью. Просто упомяну, что там люди зря хлеб не ели и придумали много всяких подходов, поэтому если столкнетесь с подобной задачей — найдите и почитайте. Весьма возможно такая задача уже решена.
Спасибо тем, кто читал! А тем, кто дочитал досюда, спасибо особенное!
UPD: Добавил ссылку на содержательную статью про бор (он же луч, он же префиксное дерево, он же нагруженное дерево, он же trie).
Строки — это последовательность символов в языке JavaScript. Например:
const a = 'lorem ipsum';
var b = "съешь ещё этих мягких французских булок, да выпей чаю";
Здесь мы задали переменную a и присвоили ей текстовое значение lorem ipsum, а переменной b присвоили значение съешь ещё этих мягких французских булок, да выпей чаю.
Кавычки
Если вы хотите задать строку, то нужно использовать одинарные или двойные кавычки. Возьмем код из предыдущего примера:
const a = 'lorem ipsum';//одинарные кавычки
var b = "съешь ещё этих мягких французских булок, да выпей чаю";//двойные кавычки
Вместо кавычек из примера можно использовать обратные кавычки. Например:
var b = `съешь ещё этих мягких французских булок, да выпей чаю`;//обратные кавычки
У обратных кавычек есть особенности:
- В них можно оборачивать выражение типа
${}. - Выражения в них можно записывать на нескольких строках кода.
- В них можно задавать функцию вида func
`string`.
Если в строке есть кавычки, то их экранируют с помощью слеша. Это делают для того, чтобы при выводе кавычки были частью строки.
В одинарных кавычках экранируют одинарные кавычки. В двойных кавычках экранируют двойные кавычки. Символ слеша тоже экранируется.
Например:
var str = "I'm a JavaScript "programmer" ";
alert( str ); // I'm a JavaScript "programmer"
var str = ' символ \ ';
alert( str ); // символ
Спецсимволы
Спецсимволы начинаются с обратного слеша – . И каждый имеет свое предназначение. Рассмотрим их.
| Спецсимвол | Описание |
| n | Перевод строки |
| ‘, « | Кавычки |
| t | Табуляция |
| xXX | Символ в Юникоде, например: u00A9 — то же самое, что © |
| uXXXX | Символ в UTF-8, например: u00A9 — то же самое, что © |
Длина строки length
Вы можете получить длину строки с помощью свойства length.
Например:
var str = 'lorem ipsum'.length;// получается 11, знак пробела тоже считается
Обратите внимание, что после length нет скобок. Скобки используют при работе с числовыми значениями.
Доступ к символам
Получить символ из определенной позиции в строке можно с помощью квадратных скобок [ ]:
var str = 'lorem ipsum';
console.log(str[0]);//выведет l
console.log(str[100]);//выведет undefined, потому что в позиции 100 нет символов
Строку можно перебрать посимвольно с помощью цикла for…of, который мы используем для перебора массива:
for (let char of "lorem ipsum") {
console.log(char);
};
Строки неизменяемы
Если строку создали, то её нельзя изменить:
let str = 'lorem ipsum';
str[0] = 'L'; // команда не работает, потому что мы попытались на место первого символа вставит другой
console.log( str[0] ); // l
Чтобы изменить строку, можно создать новую строку и присоединить к ней другую строку или её часть:
let str = 'ok';// Имеем строку
str = 'O' + str[1]; // Создаем новую строку `O` и присоединяем к ней второй символ из строки str
console.log( str ); // Ok
Поиск подстроки
Подстрока – это часть строки. Например, в строке 'lorem ipsum' можно найти две подстроки: 'lorem' и 'ipsum', а можно найти две подстроки 'm'.
Рассмотрим способы поиска.
Метод str.indexOf
Ищет подстроку и ее позицию. Синтаксис такой: str.indexOf(substr, pos). Substr — подстрока, pos — позиция строки.
Pos принимает значение позиции, на которой находится подстрока или значение — 1, если подстроки нет:
let str = 'lorem ipsum';
console.log(str.indexOf('sum'));//начинается с позиции 8
console.log(str.indexOf('Sum'));//— 1
console.log(str.indexOf('m'));//на позиции 4
Чтобы найти все подстроки 'm' в строке 'lorem ipsum', используют цикл:
let str = 'lorem ipsum';
let target = 'm'; // цель поиска
let pos = 0;
while (true) {
let foundPos = str.indexOf(target, pos);
if (foundPos == — 1) break;
alert( `Искомая подстрока на позиции: ${foundPos}` );
pos = foundPos + 1; // продолжаем со следующей позиции
};
Методы includes, startsWith, endsWith
Метод includes возвращает true, если подстрока есть и false, если подстроки нет:
let str = 'lorem ipsum';
console.log( str.includes("m") ); // true
console.log( str.includes("v") ); // false
Методы startsWith и endsWith определяют, начинается или и заканчивается строка определённой подстрокой:
let str = 'lorem ipsum';
console.log( str.startsWith("lo") ); // true
console.log( str.endsWith("un") ); // false
Получение подстроки
Чтобы получить подстроку, можно использовать 3 метода: substring, substr и slice.
Метод substring используют, чтобы получить подстроку. Её конец и начало определяются индексами, которые указывают в скобках.
Синтаксис такой: str.substring(start [, end]), где start — начальное значение строки, end — конечное значение строки и в подстроку не включается.
Например:
let str = 'lorem ipsum';
console.log( str.substring(0, 4) );\lore 0 — l, 1 — o, 2 — r, 3 — e, 4 — хоть и обозначается в коде, но значение строки не возвращает.
В этом методе начало строки можно задать большим числом, нежели конец строки. Тогда метод сам поменяет числа местами и вернет правильное значение подстроки:
let str = 'lorem ipsum';
// для substring эти два примера — одинаковы
console.log( str.substring(0, 4) ); // lore первое и последнее значение может быть указан в любом порядке
console.log( str.substring(4, 0) ); // lore первое и последнее значение может быть указан в любом порядке
Метод substr возвращает подстроку от начального значения — start, до определенной длины length. Синтаксис такой: str.substr(start, length). Например:
let str = 'lorem ipsum';
console.log( str.substr(2, 5) ); // rem i
Значение start может быть отрицательными. Тогда позиция подстроки определяется справа. Например:
let str = 'lorem ipsum';
console.log( str.substr(-4, 3) ); // psu
Метод slice используют как метод substring. Начальное и конечное значение подстроки задается точно также. Синтаксис такой: str.slice(start,end), end — не включается. Например:
let str = 'lorem ipsum';
console.log( str.slice(0, 4) ); // lore
console.log( str.substring(1) ); // orem ipsum
Если последний аргумент не указан, то подстрока возвращается с указанного до последнего символа.
Когда в качестве аргументов подстроки передаются отрицательные числа, то порядок элементов строки отсчитывается справа налево:
let str = 'lorem ipsum';
console.log( str.slice(-4, -1) ); // psu
Сравнение строк
Строки сравниваются посимвольно в алфавитном порядке. Алгоритм сравнения двух строк такой:
- Сравнить первые символы строк.
- Если первый символ первой строки больше (меньше), чем первый символ второй, то первая строка больше (меньше) второй. Сравнение завершено.
- Если первые символы равны, сравниваем вторые символы строк.
- Сравнение продолжается, пока не закончится одна из строк.
- Если обе строки заканчиваются одновременно, то они равны. Иначе большей считается более длинная строка.
Например:
alert( 'Я' > 'А' ); // true
alert( 'Коты' > 'Кода' ); // true
Сравнение 'Я' > 'А' завершится на первом шаге.
Строки 'Коты' и 'Кода' будут сравниваться посимвольно:
'К'равна'К'.'о'равна'о'.'т'больше, чем'д'.
Сравнение заканчивается. Первая строка больше.
В некоторых случаях удобно сравнивать не посимвольно, а в кодировке UTF-8. Для этого используют метод codePointAt. Синтаксис такой: str.codePointAt(pos). Например, символы 'A' и 'a' будут иметь разное значение в UTF-8.
alert( "a".codePointAt(0) ); // 97
alert( "A".codePointAt(0) ); // 65
alert(`a`>`A`);//true
Метод fromCodePoint создает символ по его коду. Синтаксис такой: String.fromCodePoint(code). Например:
alert( String.fromCodePoint(97) ); // a
Правильное сравнение
При правильном сравнении можно сравнивать строки из разных языков. Например: 'Österreich' — немецкий языки 'Zealand' — английский язык.
Для этого используют метод localeCompare. Этот метод возвращает:
- Отрицательное число, если
str1меньшеstr2. - Положительное число, если
str1большеstr2. 0, если строки равны.
Например:
alert( 'Österreich'.localeCompare('Zealand') ); // -1, 'Österreich' — str1, 'Zealand' — str2
alert('Zealand'.localeCompare('Österreich') ); // 1, 'Zealand' — str1, 'Österreich' — str2
alert('Österreich'.localeCompare('Österreich') ); // 0
Как всё устроено, Юникод
Суррогатные пары
Буквы в европейских языках представлены в виде 2-х байтовых символов. Всего в таком виде можно представить 65536 комбинаций символов. Поэтому редкие символы кодируются не одним символом, а парой символов. Помните, что смайлик мы можем сделать с помощью двух символов: двоеточия и скобки?
Такие символы называют суррогатной парой и их длина равна 2.
Например:
alert( '😂'.length );//2
//Части суррогатной пары не имеют смысла, поэтому они будут определяться, как неизвестные символы.
alert( '😂'[0] ); // �
alert( '😂'[1] ); // �
Суррогатные пары можно обнаружить по их кодам. В диапазоне 0xd800..0xdbff — можно обнаружить первый символ, в диапазоне 0xdc00..0xdfff — второй символ.
Например:
alert( '😂'.charCodeAt(0).toString(16) ); //получить код со значением 0 в 16-тиричной системе: d83d
alert( '😂'.charCodeAt(1).toString(16) ); //получить код со значением 0 в 16-тиричной системе: de02
Диакритические знаки и нормализация
В некоторых языках: немецком, шведском, венгерском, турецком есть диакритические символы. Например буква `a` служит основой для диакритических символов àáâäãåā.
Чтобы работать с диакритическими знаками в языке JavaScript, используют специальные символы. Например, чтобы добавить сверху буквы `a` точку, используют символ u0307.
alert( 'Su0307' );ȧ
Чтобы сравнить диакритические знаки используют метод normalize(). Синтаксис такой: str.normalize():
alert( "Su0307u0323".normalize() == "Su0323u0307".normalize() );//true
Если этот метод не использовать, то при сравнении одинаковых символов мы увидим false:
alert( "Su0307u0323" == "Su0323u0307" );//false
Нестандартные методы объекта String
Метод anchor
Создает закладку с name и заключает ее в теги <a>...</a>:
let str = 'lorem ipsum'.anchor('Закладка');
alert(str);
Метод big
Заключает строку в теги <big>...</big>:
let str = 'lorem ipsum'.big();
document.write(str);
Метод blink
Заключает строку в теги <blink>…</blink>. Строка между этими тегами мигает. Метод поддерживается браузерами Netscape и WebTV. Например:
let str = 'lorem ipsum'.blink();
document.write(str);
Метод bold
Заключает строку в теги <b>…</b>. Шрифт строки между ними становится жирным:
let str = 'lorem ipsum'.bold();
document.write(str);
Метод charAt
Метод возвращает какой-либо символ строки из указанной позиции:
let str = 'lorem ipsum'.charAt(0);// l
document.write(str);
Метод charCodeAt
Метод возвращает код Юникода в определенной позиции:
et str = 'lorem ipsum'.charCodeAt(0);// Код символа `l` в позиции [0] в Юникоде — это 108.
document.write(str);
Метод concat
Метод соединяет строки:
let str = 'lorem ipsum';
document.write(str.concat('dolor sit amet'));//lorem ipsum dolor sit amet
Метод fixed
Метод заключает строку в теги <tt>…</tt>. Эти теги отображают строку телетайпным шрифтом:
let str = 'lorem ipsum'.fixed();
document.write(str);
Метод fontcolor
Метод помещает строку в тег <font color=цвет>…</font> и окрасит ее в любой цвет:
let str = 'lorem ipsum'.fontcolor('green');
document.write(str);//строка 'lorem ipsum' стала зеленым цвета
Метод fontsize
Метод помещает строку в тег <font size=`размер`>…</font> и задаст ее размер:
let str = 'lorem ipsum'.fontsize('20px');
document.write(str);//строка 'lorem ipsum' стала размером 20px
Метод fromCharCode
Метод создает новую строку из символов по коду из Юникод:
let str = String.fromCharCode(108,111, 114, 101, 109, 32, 105, 112, 115, 117, 109);
document.write(str);//lorem ipsum
Метод indexOf
Метод возвращает первую позицию подстроки:
let str = 'lorem ipsum'.indexOf('l');
document.write(str);//0
Метод italics
Метод помещает строку в теги <i>...</i>:
let str = 'lorem ipsum'.italics();
document.write(str);//строка str выводится курсивом
Метод lastIndexOf
Метод возвращает позицию указанной подстроки:
let str = 'lorem ipsum'.lastIndexOf('ip');
document.write(str);//6 — позиция, с которой начинается подстрока 'ip'
Метод link
Метод помещает строку в теги <a href="uri">…</a>. Строка становится ссылкой:
let str = 'lorem ipsum'.link('https://proglib.io/');
document.write(str);
Метод localeCompare
Метод сравнивает две строки и возвращает:
-1— строка меньше,1— строка больше,0— строки равны.
Например:
let str1 = 'lorem ipsum'.localeCompare('lorem ipsum');
document.write(str1);//0
let str2 = 'lorem ipsum'.localeCompare('lorem ipsu');
document.write(str2);//1
let str3 = 'lorem ipsum'.localeCompare('lorem ipsum dolor sit amet');
document.write(str3);//-1
Метод match
Метод сопоставляет строковое значение и значение метода. Возвращает совпадение строки и значение, которое указано в скобках:
let str = 'lorem ipsum'.match('lor');
document.write(str);/ часть переменной srt 'lor' совпало со значением метода match('lor').
Метод replace
Метод сопоставляет выражение строки и меняет его на указанное:
let str = 'lorem ipsum'.replace('lor', 'dol');
document.write(str);//Метод нашел в строке подстроку 'lor', и заменил на 'dol', получилось — dolem ipsum
Метод search
Сопоставляет выражение в скобках и строку. В результате получается позиция первого элемента подстроки:
let str = 'lorem ipsum'.search('or');
document.write(str);//1
Метод small
Метод помещает строку в теги <small>...</small>:
let str = 'lorem ipsum'.small();
document.write(str);//строка на экране будет выглядеть меньше
Метод strike
Метод помещает строку в теги <strike>...</strike>:
let str = 'lorem ipsum'.strike();
document.write(str);
Метод split
Метод разбивает строку на массив подстрок с помощью указанного разделителя:
let str = 'lorem ipsum'.split(' ');
document.write(str);//lorem,ipsum
В скобках метода указывается разделитель и количество знаков, которые нужно вывести при разделении:
let str = 'lorem ipsum'.split('', 3);
document.write(str);//l,o,r — метод разбил строку на символы с помощью запятой и вывел три знака
Метод sub
Метод заключает строку в теги <sub>...</sub>:
let str = 'lorem ipsum'.sub();
document.write(str);
Метод sup
Метод заключает строку в теги <sup>...</sup>:
let str = 'lorem ipsum'.sup();
document.write(str);
Метод toLocaleLowerCase
Метод возвращает строчные буквы:
let str = 'LOREM IPSUM'.toLocaleLowerCase();
document.write(str);
Метод toLocaleUpperCase
Метод возвращает прописные буквы:
let str = 'lorem ipsum'.toLocaleUpperCase();
document.write(str);//LOREM IPSUM
Метод toLowerCase
Метод заменяет все буквы исходной строки на строчные:
let str = 'Lorem ipSum'.toLowerCase();
document.write(str);//lorem ipsum
Метод toString
Метод возвращает исходное значение строки:
let str = 'Lorem ipSum'.toString();
document.write(str);//Lorem ipSum
Метод toUpperCase
Метод меняет символы строки на прописные:
let str = 'Lorem ipSum'.toUpperCase();
document.write(str);//LOREM IPSUM
Метод valueOf
Метод возвращает значение строки:
let str = 'Lorem ipSum'.valueOf();
document.write(str);//Lorem ipSum
***
В этой статье мы:
- узнали, как задавать строку и искать в подстроках;
- как работать с Юникодом и что такое суррогатные пары;
- познакомились с основными и нестандартными методами для работы со строками.
Материалы по теме
- ☕📚 Методы массивов в JavaScript для новичков: советы, рекомендации и примеры
- ☕ 5+5=? Преобразование значений в строку или число в JavaScript
- ☕ Распространенные алгоритмы и структуры данных в JavaScript: полезные алгоритмы для веб-разработки
Поиск подстроки
Последнее обновление: 02.03.2023
Функция find() возвращает индекс первого вхождения подстроки или отдельного символа в строке в виде значние я типа size_t:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
std::cout << text.find("ed") << std::endl; // 14
std::cout << text.find("friend") << std::endl; // 2
std::cout << text.find('d') << std::endl; // 7
std::cout << text.find("apple") << std::endl; // 18446744073709551615
}
Если строка или символ не найдены (как в примере выше в последнем случае), то возвращается специальная константа std::string::npos,
которая представляет очень большое число (как видно из примера, число 18446744073709551615). И при поиске мы можем проверять результат функции find() на равенство этой константе:
if (text.find("banana") == std::string::npos)
{
std::cout << "Not found" << std::endl;
}
Функция find имеет ряд дополнительных версий. Так, с помощью второго параметра мы можем указать индекс, с которого надо вести поиск:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
// поиск с 10-го индекса
std::cout << text.find("friend", 10) << std::endl; // 22
}
Используя эту версию, мы можем написать программу для поиска количества вхождений строки в тексте, то есть выяснить, сколько раз строка встречается в тексте:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
std::string word {"friend"};
unsigned count{}; // количество вхождений
for (unsigned i {}; i <= text.length() - word.length(); )
{
// получаем индекс
size_t position = text.find(word, i);
// если не найдено ни одного вхождения с индекса i, выходим из цикла
if (position == std::string::npos) break;
// если же вхождение найдено, увеличиваем счетчик вхождений
++count;
// переходим к следующему индексу после position
i = position + 1;
}
std::cout << "The word is found " << count << " times." << std::endl; // The word is found 2 times.
}
Здесь в цикле пробегаемся по тексту, в котором надо найти строку, пока счетчик i не будет равен text.length() - word.length().
С помощью функции find() получаем индекс первого вхождения слова в тексте, начиная с индекса i. Если таких вхождений не найдено, то выходим из цикла.
Если же найден индекс, то счетчик i получает индекс, следующий за индексом найденного вхождения.
В итоге, поскольку искомое слово «friend» встречается в тексте два раза, то программа выведет
The word is found 2 times.
В качестве альтернативы мы могли бы использовать цикл while:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
std::string word {"friend"};
unsigned count{}; // количество вхождений
size_t index{}; // начальный индекс
while ((index = text.find(word, index)) != std::string::npos)
{
++count;
index += word.length(); // перемещаем индекс на позицию после завершения слова в тексте
}
std::cout << "The word is found " << count << " times." << std::endl;
}
Еще одна версия позволяет искать в тексте не всю строку, а только ее часть. Для этого в качестве третьего параметра передается количество символов из искомой строки, которые программа будет искать в тексте:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
std::string word {"endless"};
// поиск с 10-го индекса 3 первых символов слова "endless", то есть "end"
std::cout << text.find("endless", 10, 3) << std::endl; // 25
}
Стоит отметить, что в этом случае искомая строка должна представлять строковый литерал или строку в С-стиле (например, символьный массив с концевым нулевым байтом).
Функция rfind. Поиск в обратном порядке
Функция rfind() работает аналогично функции find(), принимает те же самые параметры, только ищет подстроку в обратном порядке — с конца строки:
#include <iostream>
#include <string>
int main()
{
std::string text {"A friend in need is a friend indeed."};
std::cout << text.rfind("ed") << std::endl; // 33
std::cout << text.rfind("friend") << std::endl; // 22
std::cout << text.rfind('d') << std::endl; // 34
std::cout << text.rfind("apple") << std::endl; // 18446744073709551615
}
Поиск любого из набора символов
Пара функций — find_first_of() и find_last_of() позволяют найти соответственно первый и последний индекс любого из набора символов:
#include <iostream>
#include <string>
int main()
{
std::string text {"Phone number: +23415678901"};
std::string letters{"0123456789"}; // искомые символы
std::cout << text.find_first_of(letters) << std::endl; // 15
std::cout << text.find_last_of(letters) << std::endl; // 25
}
В данном случае ищем в строке «Phone number: +23415678901» первую и последнюю позицию любого из символов из строки «0123456789». То есть таким образом мы найдем начальный и конечный индекс
номера телефона.
Если нам, наоборот, надо найти позиции символов, которые НЕ представляют любой символ из набора, то мы можем использовать функции find_first_not_of() (первая позиция)
и find_last_not_of() (последняя позиция):
#include <iostream>
#include <string>
int main()
{
std::string text {"Phone number: +23415678901"};
std::string letters{"0123456789"}; // искомые символы
std::cout << text.find_first_not_of(letters) << std::endl; // 0
std::cout << text.find_last_not_of(letters) << std::endl; // 14
}
Мы можем комбинировать функции. Например, найдем количество слов в строке:
#include <iostream>
#include <string>
int main()
{
std::string text {"When in Rome, do as the Romans do."}; // исходный текст
const std::string separators{ " ,;:."!?'*n" }; // разделители слов
unsigned count{}; // счетчик слов
size_t start { text.find_first_not_of(separators) }; // начальный индекс первого слова
while (start != std::string::npos) // если нашли слово
{
// увеличиваем счетчик слов
count++;
size_t end = text.find_first_of(separators, start + 1); // находим, где кончается слово
if (end == std::string::npos)
{
end = text.length();
}
start = text.find_first_not_of(separators, end + 1); // находим начальный индекс следующего слова и переустанавливаем start
}
// выводим количество слов
std::cout << "Text contains " << count << " words" << std::endl; // Text contains 8 words
}
Вкратце рассмотрим данный код. В качестве текста, где будем подсчитывать слова, определям переменную text. И также определяем строку разделителей, такие как знаки пунктуации, пробелы, символ перевода строки, которые не являются словами:
const std::string separators{ " ,;:."!?'*n" }; // разделители слов
Перед обработкой введенного текста фиксируем индекс первого символа первого слова в тексте. Для этого применяется функция find_first_not_of(), которая возвращает
первый индекс любого символа, который не входит в строку separators:
size_t start { text.find_first_not_of(separators) };
Далее в цикле while смотрим, является ли полученный индекс действительным индексом:
while (start != std::string::npos)
Например, если в строке одни только символы из набора separators, тогда функция find_first_not_of() возвратит значение std::string::npos,
что будет означать, что в тексте больше нет непунктационных знаков.
И если start указывает на действительный индекс начала слова, то увеличиваем счетчик слово. Далее находим индекс первого символа из separators, который идет сразу после слова. То есть фактически это индекс после
последнего символа слова, который помещаем в переменную end:
size_t end = text.find_first_of(separators, start + 1); // находим, где закончилось слово
Для нахождения позиции окончания слова используем функцию find_first_of(), которая возвращает первую позицию любого символа из separators, начиная с индекса start+1
Причем может быть, что функция find_first_of() не найдет ни одного символа из separators (например, слово является поседним в тексте, и после него нет никаких знаков пунктуации или пробелов),
в этом случае конечный индекс равен длине текста.
if (end == std::string::npos) // если НЕ найден ни один из символов-разделителей
end = text.length(); // устанавливаем переменную end на конец текста
После того, как мы нашли начальный индексы слова и его конец, переустанавливаем start на начальный индекс следующего слова и повторяем действия цикла:
start = text.find_first_not_of(separators, end + 1); // находим начальный индекс следующего слова и переустанавливаем start
В конце выводим количество найденных слов.