Find the Wayback Machine useful?
DONATE

deviantart.com
Oct 15, 2013 21:28:20

cl.cam.ac.uk
Feb 29, 2000 18:34:39

foodnetwork.com
Oct 20, 2013 22:40:56

yahoo.com
Dec 20, 1996 15:45:10

spiegel.com
Oct 01, 2013 15:26:30

imdb.com
Oct 21, 2013 16:53:47

stackoverflow.com
Oct 14, 2013 21:22:10

ubl.com
Dec 27, 1996 20:38:47

bloomberg.com
Oct 01, 2013 23:10:45

reference.com
Oct 18, 2013 07:12:58

feedmag.com
Dec 23, 1996 10:53:17

wikihow.com
Oct 21, 2013 20:56:46

nbcnews.com
Oct 21, 2013 17:24:52

goodreads.com
Oct 21, 2013 00:42:42

obamaforillinois.com
Nov 09, 2004 04:28:06

geocities.com
Feb 22, 1997 17:47:51

amazon.com
Feb 04, 2005 00:47:33

nytimes.com
Oct 01, 2013 01:42:36

bbc.co.uk
Oct 01, 2013 00:13:32

huffingtonpost.com
Oct 21, 2013 17:11:12

reddit.com
Oct 01, 2013 03:15:39

cnet.com
Oct 21, 2013 02:07:03

whitehouse.gov
Dec 27, 1996 06:25:41

aol.com
Oct 01, 2013 05:01:31

yelp.com
Oct 19, 2013 02:44:53

etsy.com
Jun 01, 2013 01:38:52

foxnews.com
Oct 01, 2013 01:08:27

well.com
Jan 08, 1997 06:53:37

w3schools.com
Oct 19, 2013 00:55:10

buzzfeed.com
Oct 21, 2013 17:32:21

nasa.gov
Dec 31, 1996 23:58:47

mashable.com
Oct 21, 2013 02:16:14

nfl.com
Oct 21, 2013 07:39:25
![]()
Tools
Banish broken links from your blog.
Help users get where they were going.
![]()
Save Page Now
Capture a web page as it appears now for use as a trusted citation in the future.
Only available for sites that allow crawlers.
К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
![]()
Download Article
An easy-to-follow guide so you can use the Wayback Machine to see an older version of a website
![]()
Download Article
- Using the Wayback Machine
- Using Alternative Tools
- Q&A
- Tips
- Warnings
|
|
|
|
What did your Facebook page look like in 2009? Fortunately, you can use the Wayback Machine, as well as some alternatives, to see a web page’s old version. This wikiHow article teaches you how to use the Internet Archive’s «Wayback Machine» tool to view archived snapshots of Web pages.
Things You Should Know
- Try using the Wayback Machine to see an old web page.
- Use the URL or keywords to search or browse pages.
- For a completely throwback experience, use «OldWeb.today» instead.
-

1
Go to https://web.archive.org in a web browser. You can use the Wayback Machine in any web browser to view old versions of websites.
- Although not all websites are archived by the Wayback Machine, it’s the most reliable way to see old versions of websites dating back to 1996!
-
2
Enter the URL of the web page you want to browse. You can also enter keywords to search for a page as well.
Advertisement
-
3
Select a year in the timeline. If an archived snapshot is available, a vertical black bar will appear in the timeline for each time a snapshot of the page was archived.
-
4
Scroll down and click on a date highlighted with a blue or green circle. This will either take you directly to the older version of the website or open a pop-out menu with a list of times.
- The blue and green circles represent the dates on which the snapshot was archived by the Internet Archive’s Web crawler.
-
5
Click on a time in the pop-out menu. If a pop-out menu appeared, it will list several times that day the website was archived. Select a time to see what the website looked at during that time on the date you specified.





Advertisement
-
1
-
2
Use https://OldWeb.today to browse old websites with vintage flair. Not only does this website give you archived websites, but it also displays them in an old browser, giving you the immersion of web browsing in the early days of the internet. Use browser themes like Navigator, Internet Explorer, Firefox, and Mosaic.
- To complete the experience of browsing in the old days, websites load slower. Using OldWeb.today would be a great way to show younger kids how others experienced the Internet.
-
3
Browse the Library of Congress web archive at https://www.loc.gov/web-archives. This is an official archive that keeps an extensive record of books, newspapers, images, web pages, etc. A source like this would be best utilized by researchers or scholars.
-
4
View cached pages on Google. Your search engine most likely contains previous versions of websites. Simply search Google for the URL you’d like to see, click Tools, select Any time, then choose a Custom Range. You can input a specific time to search old versions of that website.
-
5
Use the Web Cache Viewer Chrome extension. Get this Chrome extension from the Google Web Store. Simply go to the website you want to see an older version of, right-click on the page, and select Web Cache Viewer.
- This is an extension and not an actual service. Web Cache Viewer gets information and screenshots from the Wayback Machine and Google.
-
6
Try UK Web Archive at https://www.webarchive.org.uk/ukwa. This tool works especially if you’re looking for an older UK site. UKWA allows you to search by keyword, phrase, or URL.
-
7
Browse Memento Time Travel at https://timetravel.mementoweb.org. This is yet another aggregating search tool, which uses all services like the Wayback Machine and Google to find what you’re looking for.







Advertisement
Add New Question
-
Question
Are there any pages that are not archived when browsing for old versions of websites?

You may find this to be the case, as when some website administrators update their websites, their changes automatically trigger the creation of a new web page with a slightly different URL. This will not have been archived and an older version of the same page will not be available.
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
-
Images and flash content may not be archived, but all text content should still be visible.
-
There is more than just websites at the Internet Archive. You can also watch nearly a million digitized movies and listen to live music concerts, sounds, spoken word recordings. You can also check out old books and magazines, and read about everything from the history of Arpanet and articles about ants to works of science fiction, Federal Court documents, and microfilm records.
Thanks for submitting a tip for review!
Advertisement
-
Some sites may be password-protected or blocked with a robots.txt file, so Wayback Machine is unable to access them. If you encounter this, you’re most likely out of luck.
Advertisement
About This Article
Thanks to all authors for creating a page that has been read 822,236 times.
Is this article up to date?
![]()
Загрузить PDF
![]()
Загрузить PDF
Хотите посмотреть, как выглядела ваша страница Facebook в 2009 году? Существуют инструменты, позволяющие это сделать. Из нашей статьи вы узнаете, как пользоваться архивом интернета «Wayback Machine» для просмотра архивных копий веб-страниц, а также альтернативными сервисами.
-
1
-
2
Введите URL-адрес страницы, которую хотите просмотреть. Также можно запустить поиск страницы по ключевым словам.
-
3
Выберите год на временной шкале. Если у страницы есть архивные копии, они отобразятся на временной шкале в виде вертикальных черных полос.
-
4
Прокрутите вниз и нажмите на дату, подсвеченную голубым или зеленым кружком. После этого либо вы либо будете перенаправлены непосредственно на старую версию страницы, либо увидите всплывающее меню со списком дат.
- Голубые и зеленые круги обозначают моменты, когда копия страницы была заархивирована поисковым роботом архива интернета.
-
5
Нажмите на момент времени в всплывающем меню. Если на экране появится всплывающее меню, в нем будут перечислены все те разы, когда за этот день страница была сохранена. Выберите время, чтобы узнать, как выглядела страница в указанный момент времени выбранного дня.
Реклама





-
1
-
2
Используйте https://OldWeb.today, чтобы просматривать старые сайты в стиле ретро. Этот сервис не только дает доступ к архивным версиям сайтов, но и показывает их в старом браузере, создавая эффект погружения в ранние дни интернета. Используйте такие темы браузера, как Navigator, Internet Explorer, Firefox или Mosaic.
- Чтобы впечатление, будто вы просматриваете сайты на заре интернета, было полным, они загружаются медленнее. OldWeb.today — отличный способ показать детям, как пользовались интернетом раньше.
-
3
Зайдите в веб-архив Библиотеки Конгресса https://www.loc.gov/web-archives. Это официальный архив, в котором хранится обширная база книг, газет, изображений, веб-страниц и прочего. Это лучший ресурс для исследователей и ученых.
-
4
Просматривайте кешированные страницы в Google. Ваш поисковик, скорее всего, содержит предыдущие версии сайтов. Просто найдите в Google адрес нужного вам сайта, нажмите «Инструменты», выберите «За все время» и «За период…». Можете указать конкретное время, чтоб найти старые версии сайта.
-
5
Воспользуйтесь расширением Web Cache Viewer для Chrome. Скачайте это расширение из магазина расширений Google. Затем перейдите на сайт, старую версию которого вы хотите увидеть, щелкните правой кнопкой на странице и выберите «Web Cache Viewer».
- Это расширение, а не сервис как таковой. Web Cache Viewer получает информацию и снимки экрана от Wayback Machine и Google.
-
6
Попробуйте воспользоваться веб-архивом Великобритании https://www.webarchive.org.uk/ukwa. Этот инструмент лучше всего подойдет, если вы ищете старый британский сайт. UKWA позволяет осуществлять поиск по ключевому слову, фразе или веб-адресу.
-
7
Попробуйте инструмент Memento Time Travel, расположенный по адресу https://timetravel.mementoweb.org. Это еще один поисковик-агрегатор, который пользуется всеми сервисами вроде Wayback Machine и Google, чтобы найти то, что вы ищете.
Реклама







Советы
- Изображения и другие графические элементы обычно не сохраняются, но весь текст на странице должен присутствовать.
- В архиве интернета можно найти не только копии страниц, но и видео архив с почти миллионом оцифрованных фильмов, живых концертов, звуков и звукозаписей, а также тексты книг и журналов — все, начиная от истории Arpanet (компьютерная сеть, созданная в 1969 году в США Агентством Министерства обороны США по перспективным исследованиям (DARPA) и явившаяся прототипом сети интернет) и статей о муравьях до произведений научной фантастики, документов федерального суда и микрофильмов.
Реклама
Предупреждения
- Некоторые сайты могут быть защищены паролем или блокироваться файлом robots.txt, так что у Wayback Machine не будет к ним доступа. Если вы с этим столкнулись, вам, увы, просто не повезло.
__Sections__
Реклама
Об этой статье
Эту страницу просматривали 212 720 раз.
Была ли эта статья полезной?
Веб-архив: импортозамещение
Время на прочтение
3 мин
Количество просмотров 29K
Понадобилось найти старую версию одного сайта. В Wayback Machine (https://archive.org/web/) версии от нужной даты не оказалось, и я решил поискать альтернативные архивы интернетов. В основном находились сервисы, реализующие идею «вы нам дайте URL, а мы его заархивируем» (типа уважаемого мной http://archive.md), то есть совсем не то, что было нужно в данный момент.
И тут вдруг находится искомое — http://web-arhive.ru/ Сначала порадовался за соотечественников, сделавших полезный сервис, но через несколько минут меня начали терзать смутные сомнения…
При внимательном рассмотрении даты создания снимков на archive.org и на web-arhive.ru оказались полностью совпадающими. Поковырявшись ещё, я сделал вывод, что web-arhive.ru представляет собой прокси: получает запрос, пересылает его на archive.org, парсит ответ, вычищает из него интерфейсные куски и все упоминания о Wayback Machine, меняет URL ссылок внутри на свои, заворачивает в собственный интерфейс и отдаёт ничего не подозревающему пользователю.
Интересно, как к этому отнесётся archive.org, когда узнает? Во втором абзаце правил использования сказано: «Access to the Archive’s Collections is provided at no cost to you and is granted for scholarship and research purposes only.»
Сайт выглядит так (с отключённым блокировщиком рекламы):
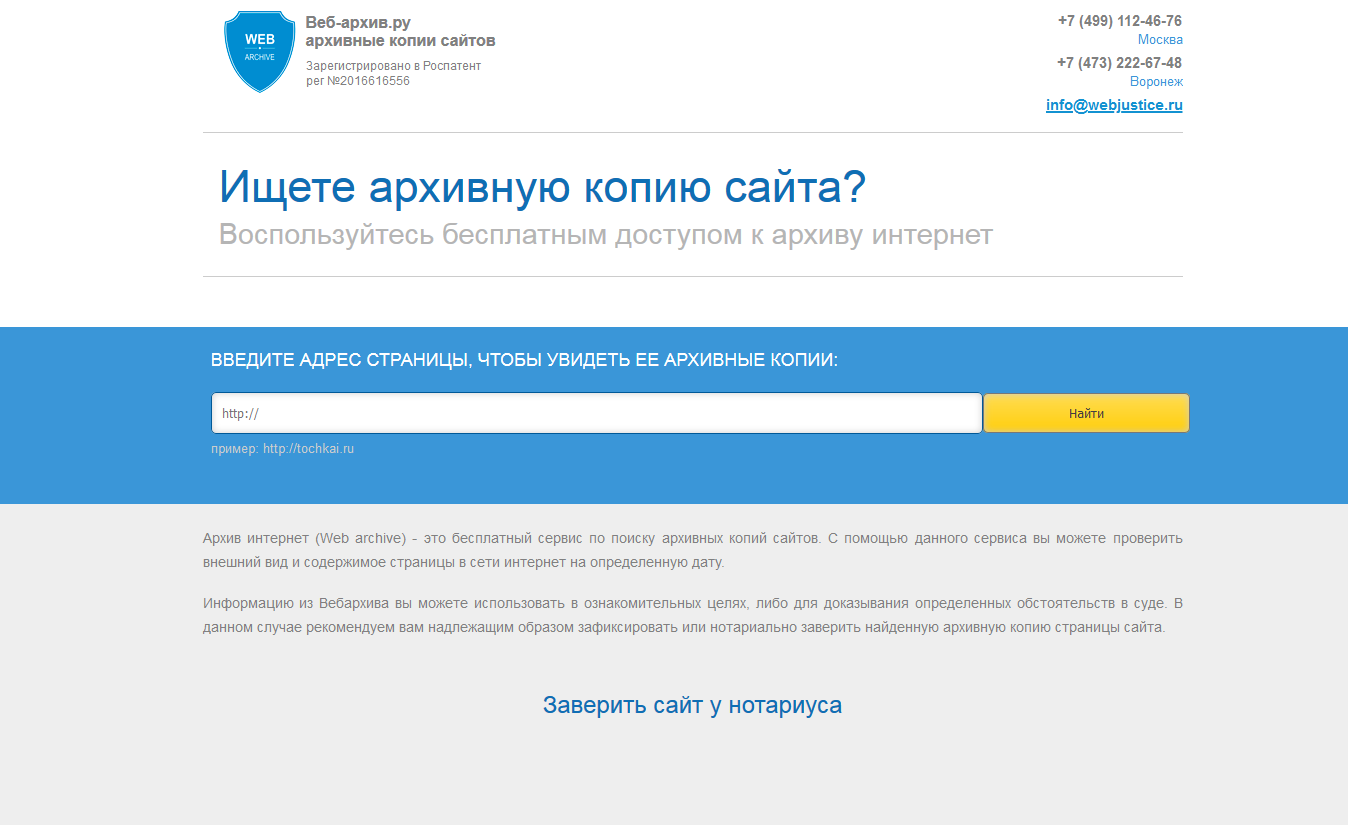
Смысл его существования, видимо, сводится к ссылке «Заверить сайт у нотариуса».
Также в глаза бросается нажористый шильдик «Зарегистрировано в Роспатент, рег №2016616556».
Стало любопытно почитать, что же там зарегистрировано, и…
http://patinfo.ru/files/fips/pevm2016/_TXT/2016616556.txt
РОССИЙСКАЯ ФЕДЕРАЦИЯ
ФЕДЕРАЛЬНАЯ СЛУЖБА ПО ИНТЕЛЛЕКТУАЛЬНОЙ СОБСТВЕННОСТИ
ГОСУДАРСТВЕННАЯ РЕГИСТРАЦИЯ ПРОГРАММЫ ДЛЯ ЭВМНомер регистрации (свидетельства): 2016616556
Дата регистрации: 15.06.2016
Номер и дата поступления заявки: 2016612809 29.03.2016
Дата публикации: 20.07.2016
Контактные реквизиты:
(8-473)222-67-48, bastionvrn@yandex.ruАвторы:
Седых Евгений Николаевич,
Дубинин Сергей ВикторовичПравообладатель:
Седых Евгений НиколаевичНазвание программы для ЭВМ:
Программный комплекс по доступу к архивным копиям сайтов в сети Интернет «Веб-архив.ру» версия 1.0Реферат:
Программный комплекс предназначен для доступа к архивным копиям страниц (сайтов) в сети Интернет, хранящимся в архиве Интернет, в том числе текста, фотоизображений, графических изображений, размещенных на страницах сайтов. Программный комплекс обеспечивает выполнение следующих функций: направление запроса к архиву Интернет в отношении архивной копии страницы, адрес которой задается пользователем в интерфейсе программного комплекса; получение ответа от архива Интернет о количестве, дате и времени архивных копий страницы, адрес которой задан пользователем; отображение архивной копии страницы в сети Интернет в интерфейсе браузера в том виде, в котором данная страница существовала на дату, выбранную пользователем из доступных дат; инициирование процедуры автоматической фиксации информации, отображаемой на архивной копии заданной страницы в виде графического образа (скриншота) заданной страницы.Тип реализующей ЭВМ: Сервер
Язык программирования: РНР
Вид и версия операционной системы: FreeBSD 8.3-STABLE
Объем программы для ЭВМ: 355 Мб
В принципе, всё честно написано про это чудо-ПО (вернее даже, целый программный комплекс, это вам не хрен собачий!) Ах, да, они ещё и скриншотик умеют делать. Ладно, хоть что-то новое от себя привнесли.
Можно было бы и не докапываться особо до них, но:
— они на первых местах в Гугле и Яндексе по запросам типа «веб архив», «архив сайтов», «архив интернета» (где-то сразу под archive.org, а где-то и вообще на первом месте),
— люди воспринимают web-arhive.ru как самостоятельный сервис (например, https://qna.habr.com/q/440257) и публикуют ссылки на архивные страницы на нём,
— разные SEO-информационные сайты говорят про от 600 до 2300 уникальных посетителей в день.
То есть, это не маргинальная фиговина в дальнем углу интернета, а что-то, путающееся у людей под ногами.
Так-то!
UPD
В комментариях жалуются на слово «импортозамещение» в заголовке.
Не воспринимайте его как «по заказу государства». Оно имелось в виду в ироничном смысле. Как по мне, один в один тот случай, когда на мониторах логотипы переклеивали.