If your code is stored locally on your computer and is tracked by Git or not tracked by any version control system (VCS), you can import the code to GitHub using GitHub CLI or Git commands.
About adding existing source code to GitHub
If you have source code stored locally on your computer that is tracked by Git or not tracked by any version control system (VCS), you can add the code to GitHub by typing commands in a terminal. You can do this by typing Git commands directly, or by using GitHub CLI.
GitHub CLI is an open source tool for using GitHub from your computer’s command line. GitHub CLI can simplify the process of adding an existing project to GitHub using the command line. To learn more about GitHub CLI, see «About GitHub CLI.»
If your source code is tracked by a different VCS, such as Mercurial, Subversion, or Team Foundation Version Control, you must convert the repository to Git before you can add the project to GitHub.
- «Importing a Subversion repository»
- «Importing a Mercurial repository»
- «Importing a Team Foundation Version Control repository»
Warning: Never git add, commit, or push sensitive information to a remote repository. Sensitive information can include, but is not limited to:
- Passwords
- SSH keys
- AWS access keys
- API keys
- Credit card numbers
- PIN numbers
For more information, see «Removing sensitive data from a repository.»
Initializing a Git repository
If your locally-hosted code isn’t tracked by any VCS, the first step is to initialize a Git repository. If your project is already tracked by Git, skip to «Importing a Git repository with the command line.»
-
Open TerminalTerminalGit Bash.
-
Navigate to the root directory of your project.
-
Initialize the local directory as a Git repository. By default, the initial branch is called
main.If you’re using Git 2.28.0 or a later version, you can set the name of the default branch using
-b.git init -b mainIf you’re using Git 2.27.1 or an earlier version, you can set the name of the default branch using
git symbolic-ref.git init && git symbolic-ref HEAD refs/heads/main -
Add the files in your new local repository. This stages them for the first commit.
$ git add . # Adds the files in the local repository and stages them for commit. To unstage a file, use 'git reset HEAD YOUR-FILE'. -
Commit the files that you’ve staged in your local repository.
$ git commit -m "First commit" # Commits the tracked changes and prepares them to be pushed to a remote repository. To remove this commit and modify the file, use 'git reset --soft HEAD~1' and commit and add the file again.
Importing a Git repository with the command line
After you’ve initialized a Git repository, you can push the repository to GitHub, using either GitHub CLI or Git.
- «Adding a local repository to GitHub with GitHub CLI»
- «Adding a local repository to GitHub using Git»
Adding a local repository to GitHub with GitHub CLI
-
To create a repository for your project on GitHub, use the
gh repo createsubcommand. When prompted, select Push an existing local repository to GitHub and enter the desired name for your repository. If you want your project to belong to an organization instead of your user account, specify the organization name and project name withorganization-name/project-name. -
Follow the interactive prompts. To add the remote and push the repository, confirm yes when asked to add the remote and push the commits to the current branch.
-
Alternatively, to skip all the prompts, supply the path to the repository with the
--sourceflag and pass a visibility flag (--public,--private, or--internal). For example,gh repo create --source=. --public. Specify a remote with the--remoteflag. To push your commits, pass the--pushflag. For more information about possible arguments, see the GitHub CLI manual.
Adding a local repository to GitHub using Git
- Create a new repository on GitHub.com. To avoid errors, do not initialize the new repository with README, license, or gitignore files. You can add these files after your project has been pushed to GitHub. For more information, see «Creating a new repository.»
- At the top of your repository on GitHub.com’s Quick Setup page, click to copy the remote repository URL.

- Open TerminalTerminalGit Bash.
- Change the current working directory to your local project.
- Add the URL for the remote repository where your local repository will be pushed.
$ git remote add origin <REMOTE_URL> # Sets the new remote $ git remote -v # Verifies the new remote URL - Push the changes in your local repository to GitHub.com.
$ git push -u origin main # Pushes the changes in your local repository up to the remote repository you specified as the origin

-
Create a new repository on GitHub.com. To avoid errors, do not initialize the new repository with README, license, or gitignore files. You can add these files after your project has been pushed to GitHub. For more information, see «Creating a new repository.»
-
At the top of your repository on GitHub.com’s Quick Setup page, click to copy the remote repository URL.
-
Open TerminalTerminalGit Bash.
-
Change the current working directory to your local project.
-
In the Command prompt, add the URL for the remote repository where your local repository will be pushed.
$ git remote add origin <REMOTE_URL> # Sets the new remote $ git remote -v # Verifies the new remote URL -
Push the changes in your local repository to GitHub.com.
$ git push origin main # Pushes the changes in your local repository up to the remote repository you specified as the origin
-
Create a new repository on GitHub.com. To avoid errors, do not initialize the new repository with README, license, or gitignore files. You can add these files after your project has been pushed to GitHub. For more information, see «Creating a new repository.»
-
At the top of your repository on GitHub.com’s Quick Setup page, click to copy the remote repository URL.
-
Open TerminalTerminalGit Bash.
-
Change the current working directory to your local project.
-
Add the URL for the remote repository where your local repository will be pushed.
$ git remote add origin <REMOTE_URL> # Sets the new remote $ git remote -v # Verifies the new remote URL -
Push the changes in your local repository to GitHub.com.
$ git push origin main # Pushes the changes in your local repository up to the remote repository you specified as the origin
Further reading
- «Adding a file to a repository»
Правильный поиск по GitHub поможет вам найти нужного разработчика или нужный репозиторий с кодом. GitHub — это один из тех сервисов, которые не нужно представлять людям, хоть немного связанным с программированием. Это ресурс, на котором каждый программист просто обязан иметь аккаунт, потому что большинство современных компаний, прежде чем нанимать к себе разработчика, проверяют его профиль на GitHub. Если в профиле «есть что посмотреть» и на самом ресурсе программист проявлял активность, то это приносит ему много плюсов в резюме.
На сегодняшний день на GitHub зарегистрировано более 35 миллионов аккаунтов, поэтому поиск нужного программиста именно по этому сервису более чем оправдан. Плюс ко всему GitHub — это огромная площадка, где разработчики размещают код своих работающих приложений, которые распространяются по свободной лицензии. То есть GitHub — это огромное хранилище исходников, поэтому поиск нужного кода или репозитория по этому ресурсу тоже более чем оправдан.
Поиск кода или разработчика по GitHub
Искать разработчика или нужный код можно разными путями. Например, разработчиков можно искать на специализированных сайтах по поиску работы, таких как hh.ru. Когда нужен код, можно воспользоваться специальным форумом или попросить помощи у других программистов. Но и в том и в другом случае очень правильно будет вести поиск по GitHub, ведь это один их тех ресурсов, где сконцентрированы лучшие программистские умы.
Поиск кода или репозитория по GitHub
Поиск нужного кода по GitHub может пригодиться в разных ситуациях. Если же вам нужен исходный код какой-либо программы, то, возможно, вам нужно искать его не на самом GitHub, а на официальном сайте той же программы, если она, конечно, распространяется с открытым исходным кодом. Обычно программы с открытыми исходниками сами оставляют ссылки на свои архивы.
Если же у вас другая ситуация, то можно воспользоваться внутренним поиском самого GitHub. Первым делом вам нужно будет позаботиться о наличии аккаунта на данной площадке, чтобы вы могли искать по всем доступным репозиториям. Когда вам нужно осуществить поиск по всему GitHub, то необходимо воспользоваться глобальной поисковой строкой на самой площадке. Если вы знаете, репозитории какой организации вы хотите найти, то можно осуществить поиск по GitHub внутри конкретной организации.
Поиск репозитория можно выполнить по следующим идентификаторам:
in:name — поиск по имени репозитория, то есть искомые слова будут искаться в наименовании репозиториев;
in:description — поиск по описанию репозитория на совпадение указанных слов поиска именно в описании;
in:readme — поиск по файлам README;
repo:owner/name — поиск по точному совпадению имени репозитория.
Также можно осуществить поиск нужного репозитория по GitHub:
по размеру репозитория;
по количеству подписчиков;
по количеству вилок;
по количеству звезд;
по дате создания;
по дате последнего обновления;
по используемому языку программирования;
по теме;
по количеству тем;
по лицензии;
по видимости репозитория;
по наличию проблем с репозиторием;
по возможности оказать спонсорскую помощь;
и др.
Как видите, вариантов поиска нужного репозитория по GitHub очень много, поэтому вы обязательно сможете найти то, что ищите.
Поиск разработчиков по GitHub
Итак, мы условились, что GitHub — это специализированный ресурс для разработчиков разного уровня, поэтому искать там нужного программиста — это нормально. Здесь работает такой же принцип, как и с поиском репозиториев, — нужно обязательно быть зарегистрированным на GitHub, иначе найти нужного разработчика не получится.
Как только зарегистрируетесь, вам станет доступно множество вариантов поиска нужного разработчика. Важно отметить, что некоторые способы поиска идентичны поиску репозиториев, и именно их изначально вам выдаст GitHub. Чтобы искать именно разработчиков, переключите результаты поиска на категорию «Users».
Среди всех популярных вариантов поиска разработчиков отметим следующие:
Поиск по ключевым словам. К примеру, если вам необходим python-разработчик, то введите в поиске слово «python».
Поиск по языкам программирования, которыми должен обладать искомый разработчик. Введите в поисковой строке любой язык программирования, и GitHub выдаст вам результат.
Поиск по технологиям. Работает так же, как и с языками программирования: просто введите название необходимого фреймворка, который не является самостоятельным языком программирования.
Искать по активности программиста. Обычно этот вид поиска осуществляют, когда уже нашли список потенциальных кандидатов, допустим, по языку программирования. Далее в качестве фильтра можно отсеять тех, кто давно не проявлял активность на GitHub.
Программист на GitHub не всегда заинтересован в поиске новой работы — нужно помнить об этом. Второй момент: не все программисты на GitHub те, за кого себя выдают, поэтому важно с потенциальными кандидатами познакомиться и побеседовать лично, чтобы можно было поподробнее расспросить о скиллах, которыми обладает найденный разработчик. Ведь на GitHubработает принцип любой соцсети — написать о себе можно много чего, также можно в своих репозиториях держать совсем не свой код и т. д.
Заключение
Поиск нужного кода или разработчика по GitHub — это логичное действие, потому что подобных специализированных площадок для программистов не так много. Вернее, они есть, но они не такого уровня, как GitHub.
С поиском кода вроде все ясно, поэтому сложностей возникнуть не должно. Тем более раз вы ищите код, то вы в нем как минимум разбираетесь. Сложнее с поиском разработчиков, потому что на GitHub очень много «пустышек», которые просто будут отнимать у вас время.
Уровень сложности
Простой
Время на прочтение
11 мин
Количество просмотров 6.9K
От запуска ознакомительной версии нового улучшенного поиска кода год назад до публичной беты, которую мы выпустили на GitHub Universe в прошлом ноябре, появилась масса инноваций и резких изменений в некоторых основных продуктах GitHub, затрагивающих то, как мы, разработчики, осознаём, читаем код и ориентируемся в нем.
Нам часто задают вопрос о новом поиске по коду: «Как он работает?». В дополнение к моей лекции на GitHub Universe, я в общих чертах отвечу на этот вопрос, а также немного расскажу о системной архитектуре и технических основах данного продукта.
Так как же он работает? Мы создали собственный поисковый движок с нуля на Rust специально для поиска по коду. Наш поисковый движок называется «Blackbird», но прежде чем я стану описывать как он работает, думаю, что нужно понять наши предпосылки. На первый взгляд, создание поискового движка с нуля выглядит спорно. Зачем это делать? Разве уже нет большого количества существующих решений с открытым исходным кодом?
Если честно, на протяжении практически всей истории существования GitHub мы пытались и продолжаем пытаться использовать существующие решения данной проблемы. О нашей работе подробнее говорится в посте Павла Августинова «Краткая история поиска по коду в GitHub», но хотелось бы кое-что подчеркнуть: нам не очень везло с использованием текстового поиска для поддержки поиска по коду. Пользовательский опыт был неудовлетворительным, индексация — медленной, а хостинг — дорогим. Существует ряд новых опенсорсных проектов, нацеленных на код, но в масштабах GitHub такие проекты работать точно не будут. Поэтому мы хотели создать собственное решение:
- У нас была мечта о полностью новом пользовательском опыте. Пользователи должны были получить возможность задавать вопросы о коде и получать ответы с помощью итеративного поиска, просмотра, навигации и чтения кода.
- Мы понимаем, что поиск по коду однозначно отличается от текстового поиска. Код пишется для понимания машинами, а мы должны быть в состоянии воспользоваться преимуществами этой структуры и релевантности. К поиску по коду также предъявляется ряд уникальных требований: нужно искать знаки препинания (к примеру, точку или открытую скобку), выделение корней не требуется, не нужно, чтобы стоп-слова удалялись из запросов, поиск идёт с использованием регулярных выражений.
- Масштаб GitHub делает эту задачу по-настоящему сложной. При первом развёртывании Elasticsearch индексирование всего кода на GitHub (тогда — около 8 миллионов репозиториев) заняло месяцы. Сейчас репозиториев более 200 миллионов, и код в них не неизменен: он постоянно меняется, и с этим поисковым движкам достаточно сложно справиться. В бета-версии доступен поиск по почти 45 миллионам репозиториев, в которых находится 115 Тб кода и 15,5 миллиардов файлов.
Ни одно из имеющихся решений нам не подходило, так что мы построили своё решение с нуля.
Просто используйте grep?
Для начала, давайте рассмотрим грубый метод решения проблемы. Нам часто задают этот вопрос: «Почему бы вам просто не использовать grep?». Чтобы ответить на него, давайте быстренько произведём расчёты для наших 115 Тб данных при помощи ripgrep. На компьютере с восьмиядерным процессором Intel ripgrep может выполнить исчерпывающий запрос с регулярным выражением к тринадцатигигабайтному файлу, кешированному в памяти, за 2,769 секунд или примерно за 0,6 Гб/сек/ядро.
Довольно быстро становится понятно, что такой подход не будет работать при больших объёмах данных. Поиск по коду работает на 64-ядерных кластерах из 32 машин. Даже если нам удастся разместить 115 Тб кода в памяти и безупречно распараллелить работу, потребуется занять 2048 процессорных ядер на протяжении 96 секунд для обработки одного запроса! Выполняться может только один запрос. Всем остальным придётся ждать в очереди. В результате получается 0,01 запросов в секунду (QPS) и удачи в удвоении QPS — забавно будет послушать, как вы объясняете своему начальству счета за инфраструктуру.
Разумного по цене способа масштабировать такой подход для использования со всем кодом и со всеми пользователями на GitHub просто не существует. Даже если выкинуть кучу денег на решение этой проблемы, нужного пользовательского опыта добиться всё равно не получится.
Вы уже понимаете, куда это ведёт: нужно создать индекс.
Поисковый индекс — основы
Быстро создавать запросы можно только если осуществляется предварительный расчёт информации в виде индексов. Можете считать их чем-то вроде сопоставления ключей с отсортированными списками идентификаторов документов, где находится этот ключ. Возьмём для примера небольшой индекс языков программирования. Сканируется каждый файл для определения того, на каком языке программирования он написан, файлу присваивается идентификатор, а затем создаётся инвертированный индекс, где язык является ключом, а список идентификаторов документов — значением.
Прямой индекс
Инвертированный индекс
Для поиска по коду нужен особый вид инвертированного индекса под названием n-граммный индекс. Он хорошо ищет подстроки в содержимом. N-грамма — это последовательность из n элементов. К примеру, если мы возьмём n=3 (триграммы), n-граммы, составляющие «limits» — это lim, imi, mit, its. В приведённых выше документах, индекс для этих триграмм выглядел бы следующим образом:
Для осуществления поиска мы скрещиваем результаты нескольких поисков и получаем список документов, где есть конкретная строка. С триграммным индексом необходимо четыре поиска lim, imi, mit и its для выполнения запроса limits.
В отличие от хэш-карты, эти индексы слишком велики, чтобы поместиться в память, так что взамен мы создаём итераторы для каждого индекса, к которому нужно получить доступ. Они возвращают отсортированные идентификаторы документов (идентификаторы присваиваются на основе ранжирования каждого документа) и мы скрещиваем и объединяем итераторы (как требует определённый запрос) и производим чтение настолько, чтобы получить запрошенное число результатов.
Индексируем 45 миллионов репозиториев
Следующий вопрос, который необходимо решить — создание такого индекса за разумное время (как вы помните, в первый раз это заняло месяцы). Как это часто бывает, сложность заключается в применении идей к данным, с которыми мы работаем. В нашем случае особенности две: использование контентно-адресуемого хеширования в Git и наличие большое количества дублирующихся данных на Github. Эти особенности привели нас к следующим решениям:
- Шард через идентификатор объекта Blob, при помощи которого можно равномерно распределить документы между шардами, при этом избегая дублирования. Горячих серверов не будет из-за специальных репозиториев, а число шардов при необходимости легко масштабируется.
- Модель индекса как дерева и использование дельта-кодирования для снижения частоты краулинга и оптимизации метаданных в индексе. Здесь метаданные — это, к примеру, список мест, где находится файл (путь, ветка и репозиторий) и информация об этих объектах (имя репозитория, владелец, видимость и т. д.). Объём таких данных для популярного контента может быть весьма большим.
Мы также создали систему, которая обеспечивает согласованность результатов запросов на уровне коммитов. Если вы ищете в репозитории, пока ваш коллега пушит код, результаты поиска не должны включать файлы из нового коммита, пока он полностью не будет обработан системой. В действительности, пока вы получаете результат запроса к репозиторию, кто-то другой может просматривать глобальные результаты и искать иное, предыдущее, но всё ещё согласованное состояние индекса. С другими поисковыми движками добиться такого поведения непросто. Устройство Blackbird позволяет работать на таком уровне согласованности запросов.
Давайте создадим индекс
Вооружившись этими идеями, давайте рассмотрим построение индекса с помощью Blackbird. На этой схеме отображена высокоуровневая общая картина обработки и индексирования в системе.
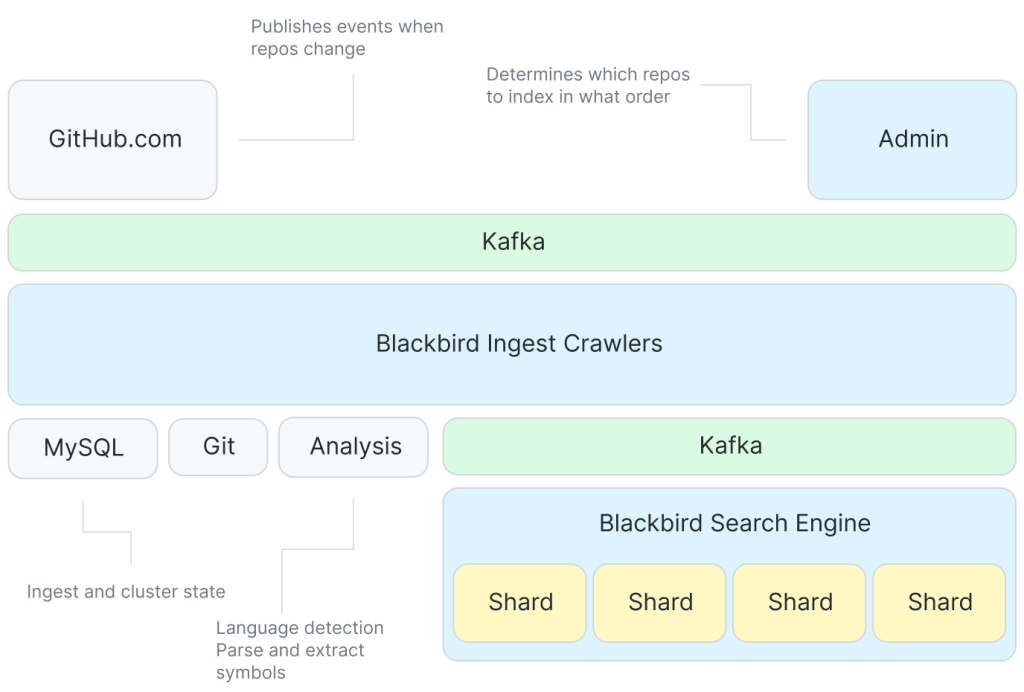
Kafka сообщает о событиях, которые говорят о необходимости что-то проиндексировать. Существует множество краулеров, взаимодействующих с Git и сервисом для извлечения символов из кода. Затем, чтобы каждый шард обрабатывал файлы для индексирования в своём ритме, снова используется Kafka.
Хотя система обычно просто отвечает на события, такие, как git push, для краулинга изменившегося содержимого необходимо проделать определённую работу для обработки всех репозиториев в первый раз. Ключевая особенность системы — это оптимизация порядка, в котором происходит эта первичная обработка, для максимально эффективного использования дельта-кодирования. Используется новая вероятностная структура данных, представляющая сходство репозиториев и определяющая порядок загрузки из обхода порядка уровней минимального остовного дерева графа сходства репозиториев[1].
Используя оптимизированный порядок обработки, каждый репозиторий краулится путём сопоставления его с родителем в созданном нами дельта-дереве. Это означает, что нужно краулить только блобы, уникальные для этого репозитория, а не весь репозиторий. Краулинг включает в себя получение содержимого блоба из Git, его анализ для извлечения символов и создание файлов, которые станут вводными данными для индексирования.
Эти файлы затем публикуются в другой теме Kafka. Там мы разделяем 2 данные между шардами. Каждый шард использует один раздел Kafka в топике. Индексирование отделено от краулинга при помощи Kafka. Согласованность запросов достигается упорядочиванием сообщений в Kafka.
Затем шарды индексатора получают эти файлы и создают их индексы: происходит токенизация для создания n-граммных индексов3 (для содержимого, символов и путей) и других нужных индексов (языков, владельцев, репозиториев и т. д.) перед сериализацией и сбросом на диск, когда накопится достаточно работы.
Наконец, шарды запускают сжатие для создания больших индексов из малых. Такие индексы более эффективны при запросах и их легче перемещать (к примеру, в реплику чтения или в резервные копии). Сжатие также использует k-образный алгоритм слияния для списков по баллам, так что релевантные файлы имеют более низкие идентификаторы и ленивые итераторы возвращают их первыми. При первоначальной обработке сжатие откладывается до большого прогона в конце, но затем, поскольку индекс не отстает от инкрементных изменений, мы выполняем сжатие с более коротким интервалом, ведь именно здесь обрабатывается, к примеру, удаления документа.
Жизненный цикл запроса
Теперь у нас есть индекс. Интересно отследить путь запроса в системе. Мы будем наблюдать за запросом-регулярным выражением к Rails organization, который ищет код, написанный на языке программирование Ruby: /arguments?/ org:rails lang:Ruby. Высокоуровневая архитектура запроса выглядит как-то так:
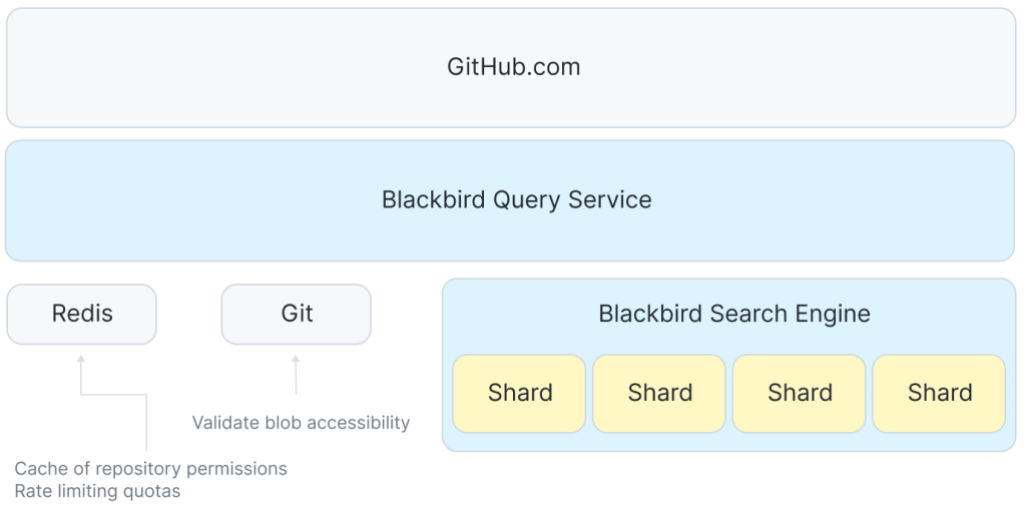
Между GitHub.com и шардами находится сервис, координирующий приём запросов пользователей и распределяющая запросы к каждому хосту в поисковом кластере. Для управления квотами и кеширования некоторых данных контроля доступа мы используем Redis.
Фронтенд принимает запрос пользователя и передаёт его в службу запросов Blackbird, где происходит запрос разбирается в абстрактное синтаксическое дерево. Затем происходит переписывание запроса, резолвинг, к примеру, языков в их канонические идентификаторы языков Linguist. Для разрешений и контекстов используются дополнительные условия. В этом случае, можно увидеть, как переписывание запроса гарантирует получение результатов из публичных репозиториев или любых доступных частных репозиториев.
And(
Owner("rails"),
LanguageID(326),
Regex("arguments?"),
Or(
RepoIDs(...),
PublicRepo(),
),
)n параллельных запросов распределяются и отправляются: по одному к каждому шарду в поисковом кластере. Из-за стратегии разделения нужно отправлять запрос к каждому шарду в кластере.
Затем в каждом отдельном шарде запрос преобразуется для поиска информации в индексах. Здесь можно увидеть, что регулярное выражение становится сериями запросов подстрок на n-граммных индексах.
and(
owners_iter("rails"),
languages_iter(326),
or(
and(
content_grams_iter("arg"),
content_grams_iter("rgu"),
content_grams_iter("gum"),
or(
and(
content_grams_iter("ume"),
content_grams_iter("ment")
)
content_grams_iter("uments"),
)
),
or(paths_grams_iter…)
or(symbols_grams_iter…)
),
…
)Если вы хотите узнать больше о том, как регулярные выражения становятся запросами подстрок, обратитесь к статье Расса Кокса о сопоставлении регулярных выражений с триграммным индексом. Мы используем другой алгоритм и динамические размеры грамм, а не триграммы (см. ниже 3). В данном случае движок использует следующие граммы: arg,rgu, gum, а затем либо ume и ment, либо 6-грамму uments.
Из каждого условия запускаются итераторы: and — это пересечение, or — объединение. В результате получается список файлов. Необходимо перепроверить каждый файл (чтобы подтвердить совпадения и определить их диапазоны) перед оценкой, сортировкой и возвратом запрошенного числа результатов.
В сервисе запросов мы соединяем результаты из всех шардов, заново сортируем их по оценке, фильтруем (для повторной проверки разрешений) и возвращаем топ-100. Фронтенд GitHub.com затем проводит подсветку синтаксиса и терминов, разбиение по страницам и, в конце концов, отображает результаты на странице.
Наше время отклика p99 от отдельных шардов составляет порядка 100 мс, но общее время отклика немного больше из-за соединения ответов, проверки разрешений и других факторов, таких, как подсветка синтаксиса. Запрос занимает 100 мс на одном ядре процессора на сервере индексации, поэтому верхняя граница 64-ядерных хостов составляет примерно 640 запросов в секунду. По сравнению с grep (0,01 QPS) это невероятно быстро. Система масштабируется. Возможно осуществление большого числа одновременных пользовательских запросов.
Заключение
После рассмотрения работы системы целиком, давайте снова обратимся к масштабу задачи. Пайплайн обработки может публиковать около 120 000 файлов в секунду, так что проход через все 15,5 миллиардов файлов займёт около 36 часов. Но дельта-индексирования сокращает число файлов, которые необходимо краулить, более, чем на 50%, что позволяет нам снова проиндексировать весь объём данных примерно за 18 часов.
Также мы добились значительного уменьшения размера индекса. Напомню, что сначала у нас было 115 Тб контента. Устранение дублей в контенте и дельта-индексирование позволило снизить размер примерно до 28 Тб уникального контента. А сам индекс занимает всего 25 Тб, и сюда включены не только все индексы (в том числе и n-граммы), но также и сжатая копия всего уникального контента. Это означает, что общий размер индекса и контента составляет около четверти размера исходных данных!
Если вы ещё не участвуйте в бета-тестировании, обязательно записывайтесь и попробуйте новый поиск по коду. Расскажите нам о своих ощущениях! Мы постоянно добавляем новые репозитории и устраняем недостатки, основываясь на обратной связи от пользователей — таких, как вы.
Примечания
-
Чтобы определить оптимальный порядок загрузки, нам нужен способ сказать, насколько один репозиторий похож на другой (с точки зрения их содержимого), поэтому мы изобрели новую вероятностную структуру данных, чтобы определять подобие в том же классе структур данных, что MinHash и HyperLogLog. Эта структура данных, которую мы называем геометрическим фильтром, позволяет вычислять сходство множеств и симметричную разницу между множествами с логарифмическим пространством. В этом случае множества, которые мы сравниваем, представляют собой содержимое каждого репозитория в кортежах (path, blob_sha). Вооружившись этими знаниями, мы можем построить граф, в котором вершины являются репозиториями, а ребра взвешены с помощью этой метрики сходства. Вычисление минимального остовного дерева этого графа (со сходством в качестве стоимости графа), а затем выполнение обхода дерева в порядке уровней дает нам порядок приема, в котором мы можем наилучшим образом применить дельта-кодирование. На самом деле этот граф огромен (миллионы узлов, триллионы ребер), поэтому наш алгоритм MST вычисляет приближение, это вычисление занимает всего несколько минут и дает 90% преимуществ дельта-сжатия, к которым мы стремимся.
-
Индекс сегментируется Git blob SHA. Шардинг означает распределение проиндексированных данных по нескольким серверам; его нужно выполнить, чтобы легко масштабироваться горизонтально для чтения (интересует количество запросов в секунду), для хранения (где основное внимание уделяется дисковому пространству) и для времени индексирования, ограниченного ЦП и памятью на отдельных хостах).
-
Используемые нами индексы ngram особенно интересны. Триграммы — лакомый кусочек в смысле архитектуры; как заметил Расс Кокс и другие: биграммы недостаточно избирательны, а квадрограммы занимают слишком много места; но триграммы вызывают некоторые проблемы в нашем масштабе.
Для обычных грамм, вроде for, триграммы недостаточно избирательны. Мы получаем слишком много ложных срабатываний, а это означает медленные запросы. Пример ложного срабатывания — это что-то вроде поиска документа, в котором есть каждая отдельная триграмма, но не рядом друг с другом. Вы не сможете понять, что оно ложное, пока не получите содержимое документа и дважды не проверите, в какой момент проделали большую работу, от которой нужно отказаться. Мы попробовали ряд стратегий, чтобы исправить это, например, добавление масок следования, которые для символа (в основном на полпути к квадрограммам) после триграммы используют битовые маски, но они слишком быстро насыщаются, чтобы быть полезными.
Мы называем решение «разреженными граммами», и оно работает следующим образом. Предположим, у вас есть некоторая функция, которая при задании биграммы дает вес. Пример — строка chester. Каждому биграмму присваиваем вес: 9 для «ch», 6 для «he», 3 для «es» и так далее.

А полезная теория и ещё больше практики с погружением в среду IT ждут вас на курсах SkillFactory:

- Профессия Data Scientist (24 месяца)
- Профессия Fullstack-разработчик на Python (16 месяцев)
26 июля, 2022 11:46 дп
6 061 views
| Комментариев нет
Development
GitHub — это облачный инструмент управления Git. Git —распределенная система управления версиями; это значит, что она хранит весь репозиторий и историю там, где вы их поместите. GitHub часто используется в бизнесе или в процессе разработки ПО в качестве управляемого хостинга для резервного копирования репозиториев. Однако GitHub также позволяет вам общаться с коллегами, друзьями, организациями и т.д.
В этом руководстве вы узнаете, как поместить проект, над которым вы работаете, на GitHub.
Требования
Чтобы инициализировать репозиторий и отправить его на GitHub, вам потребуется:
- Бесплатная учетная запись GitHub
- Установка git на вашем локальном компьютере. Инструкции вы найдете в мануале Разработка проектов с открытым исходным кодом: начало работы с Git
1: Создание репозитория GitHub
Войдите в GitHub и создайте новый пустой репозиторий. Инициализировать README или нет, решать вам. На самом деле это не имеет значения, потому что мы все равно переопределим все в этом репозитории.

Примечание: В этом руководстве мы используем условное имя пользователя GitHub (sammy) и репозитория (my-new-project). Все эти фиктивные данные нужно заменить своими данными.
2: Инициализация Git в папке проекта
Перейдите в папку, которую хотите добавить в репозиторий, и выполните в своем терминале следующие команды.
Инициализация репозитория Git
Убедитесь, что вы находитесь в корневом каталоге проекта, который хотите отправить на GitHub, и запустите:
git init
Примечание: Если у вас уже есть инициализированный проект, можете пропустить эту команду.
Этот шаг создает в папке вашего проекта скрытый каталог .git. Система git распознает его и использует для хранения всех метаданных и истории версий для данного проекта.
Добавление файлов в индекс Git
Следующая команда укажет git, какие файлы включать в коммит. Аргумент -A (то есть –all) означает «включить все».
git add -A
Коммит добавленных файлов
git commit -m 'Added my project'
Команда git commit создает новый коммит со всеми добавленными файлами. Параметр -m (или –message) задает сообщение, которое будет включено в коммит в качестве объяснения для будущей работы. В этом случае мы ввели простое сообщение ‘Added my project’.
Добавление нового удаленного репозитория
Примечание: Помните, что вам нужно заменить имя пользователя и репозитория.
git remote add origin git@github.com:sammy/my-new-project.git
В git «remote» относится к удаленной версии того же репозитория, который обычно находится где-то на сервере (в данном случае на GitHub). «origin» — это стандартное имя, которое git по умолчанию присваивает удаленному серверу (таких у вас может быть несколько). Команда git remote add origin добавит URL-адрес удаленного сервера по умолчанию для этого репозитория.
Загрузка на GitHub
git push -u -f origin main
Флаг -u (или –set-upstream) устанавливает удаленный репозиторий origin в качестве апстрим-ссылки. Это позволяет позже выполнять команды git push и git pull без указания origin.
Флаг -f (или –force) автоматически перезапишет все в удаленном каталоге. Здесь мы используем его, чтобы перезаписать стандартный файл README, автоматически инициализированный GitHub.
Примечание: Если вы не включили README по умолчанию при создании проекта на GitHub, флаг -f вам не нужен, его можно удалить из команды.
Итоги
В результате весь процесс состоит из следующих команд:
git init
git add -A
git commit -m 'Added my project'
git remote add origin git@github.com:sammy/my-new-project.git
git push -u -f origin main
Заключение
Мы успешно настроили удаленное отслеживание изменений кода в GitHub!
Читайте также:
- Краткий справочник по Git
- Создание pull-запроса на GitHub
Tags: Git, Github
#Руководства
- 25 мар 2021
-
14
Загружаем проект в удалённый репозиторий через GitHub Desktop

Автор статей о программировании. Изучает Python, разбирает сложные термины и объясняет их на пальцах новичкам. Если что-то непонятно — возможно, вы ещё не прочли его следующую публикацию.
GitHub — это облачный сервис, где разработчики хранят файлы и совместно работают над проектами. GitHub взаимодействует с системой контроля версий Git. Сегодня вы узнаете, как он работает. Мы создадим репозиторий, добавим в него файлы проекта, синхронизируем репозиторий с ПК, научимся обновлять файлы, добавлять новые ветки и сливать их в одну.
Для работы понадобится GitHub Desktop — приложение от GitHub, которое позволяет выполнять необходимые действия без командной строки. Эта статья предполагает, что вы знаете про контроль версий Git. Если нет — рекомендуем почитать об этом, а затем возвращаться к изучению GitHub.

Создаём учётную запись
Перейдите на сайт github.com, зарегистрируйтесь и верифицируйте адрес электронной почты. Выберите тип аккаунта: публичный или приватный. В публичном аккаунте репозитории видны всем, а в приватном — только тем участникам, которым вы сами открыли доступ. По умолчанию вы переходите на бесплатный тариф, который можно изменить в разделе Pricing. Платные тарифы отличаются повышенной безопасностью, размером хранилища и некоторыми специальными опциями для профессиональной разработки.
Далее рекомендуем выставить настройки безопасности и заполнить профиль — на GitHub много IT-рекрутеров, которые по информации в профиле набирают кандидатов в проекты. Поставьте фото и ссылки на соцсети, откройте доступ к электронной почте и напишите о себе: расскажите про опыт, специализацию, пройденные курсы, рабочий стек технологий и выполненные проекты. Заполненный профиль повышает вероятность трудоустройства.
Добавляем удалённый репозиторий
Репозиторий — это файловое хранилище проектов. На бесплатном тарифе можно загружать до 500 МБ данных и создавать неограниченное количество репозиториев.
Чтобы создать репозиторий, нажмите на кнопку New repository, назовите проект и кликните Create repository. Можно добавить описание проекта, сделать его публичным или приватным и прикрепить технические файлы:
- README file содержит подробное описание проекта — так другие разработчики узнают, какой репозиторий они смотрят и зачем он нужен.
- Gitignore позволяет сэкономить место и не заливать на GitHub лишние файлы. Например, можно исключить скрытые файлы Mac OS.
- License добавляет к коду ссылку на первоисточник и защищает права разработчика. Лицензия позволяет понять, как правильно использовать чужой код и можно ли его свободно внедрять в коммерческие проекты.
Мы создаём тестовый репозиторий, поэтому обойдёмся без лицензии — выберем только два дополнительных файла: README file и gitignore. Если вы пока не знаете, что писать в README file и что добавлять в gitignore, — оставьте эти файлы пустыми или посмотрите инструкцию в разделе Read the guide.
В README file отображается краткое описание проекта — сейчас этот файл не важен, поэтому мы не будем менять его описание. Изменим файл gitignore и сделаем так, чтобы он не учитывал служебные папки операционной системы:
- Переходим на сайт gitignore.io.
- Добавляем macOS или другую операционку, с которой вы работаете.
- Жмём Create и получаем нужный служебный файл.
- Копируем данные и переносим их в файл gitignore на GitHub.
После редактирования gitignore делаем коммит — записываем в историю проекта факт того, что мы установили ограничение для файлов Mac OS.
Переносим удалённый репозиторий на ПК
Перейдите на сайт desktop.github.com и скачайте GitHub Desktop — это приложение, которое позволит синхронизировать удалённый репозиторий на GitHub и файлы на вашем компьютере без командной строки терминала:
- Скачиваем приложение под свою операционную систему.
- Открываем приложение и проходим авторизацию — нужно указать электронную почту и данные вашего GitHub-аккаунта.
- Приложение синхронизируется с удалённым репозиторием и предложит выполнить одно из следующих действий: создать новый репозиторий, добавить локальную папку с компьютера в GitHub Desktop или клонировать существующий репозиторий в папку компьютера.
Мы создали тестовый удалённый репозиторий, поэтому выберем третий вариант — клонировать существующий репозиторий в папку компьютера.
После клонирования репозитория в рабочем пространстве появятся три вкладки: Current Repository, Current Branch и Fetch origin.
- Current Repository — раздел позволяет переключаться между несколькими репозиториями, отслеживать невнесённые изменения (вкладка Changes) и смотреть историю коммитов (вкладка History).
- Current Branch — раздел позволяет переключаться между несколькими ветками проекта.
- Fetch origin — раздел обновляет внесённые изменения и синхронизирует файлы локального и удалённого репозитория.
Обратите внимание на раздел Current Repository и вкладку Changes. В левом нижнем углу есть окно для добавления коммитов и комментариев — это означает, что вы можете записывать каждый шаг, не посещая сайт GitHub.
На скриншоте первый коммит технический, он указывает на то, что мы создали репозиторий. Второй коммит наш — им мы редактировали файл gitignore. История хранит все коммиты, и мы можем вернуться к любому из них. Это страховка от непредвиденных случаев
Добавляем новые файлы на ПК и переносим их в удалённый репозиторий
Папка с файлами нашего репозитория хранится на рабочем столе. Чтобы продолжить работу, откроем проект в редакторе кода: можно выбрать любую программу, и GitHub Desktop предлагает воспользоваться Atom.
Выбор редактора кода — дело вкуса. Мы будем работать с репозиторием в Visual Studio Code — это бесплатный редактор от компании Microsoft.
Создадим HTML-файл, добавим базовую структуру и посмотрим на боковое меню — HTML-файл подсвечен зелёным цветом. Это означает, что в проекте появились изменения и они ещё не добавлены в репозиторий на GitHub.
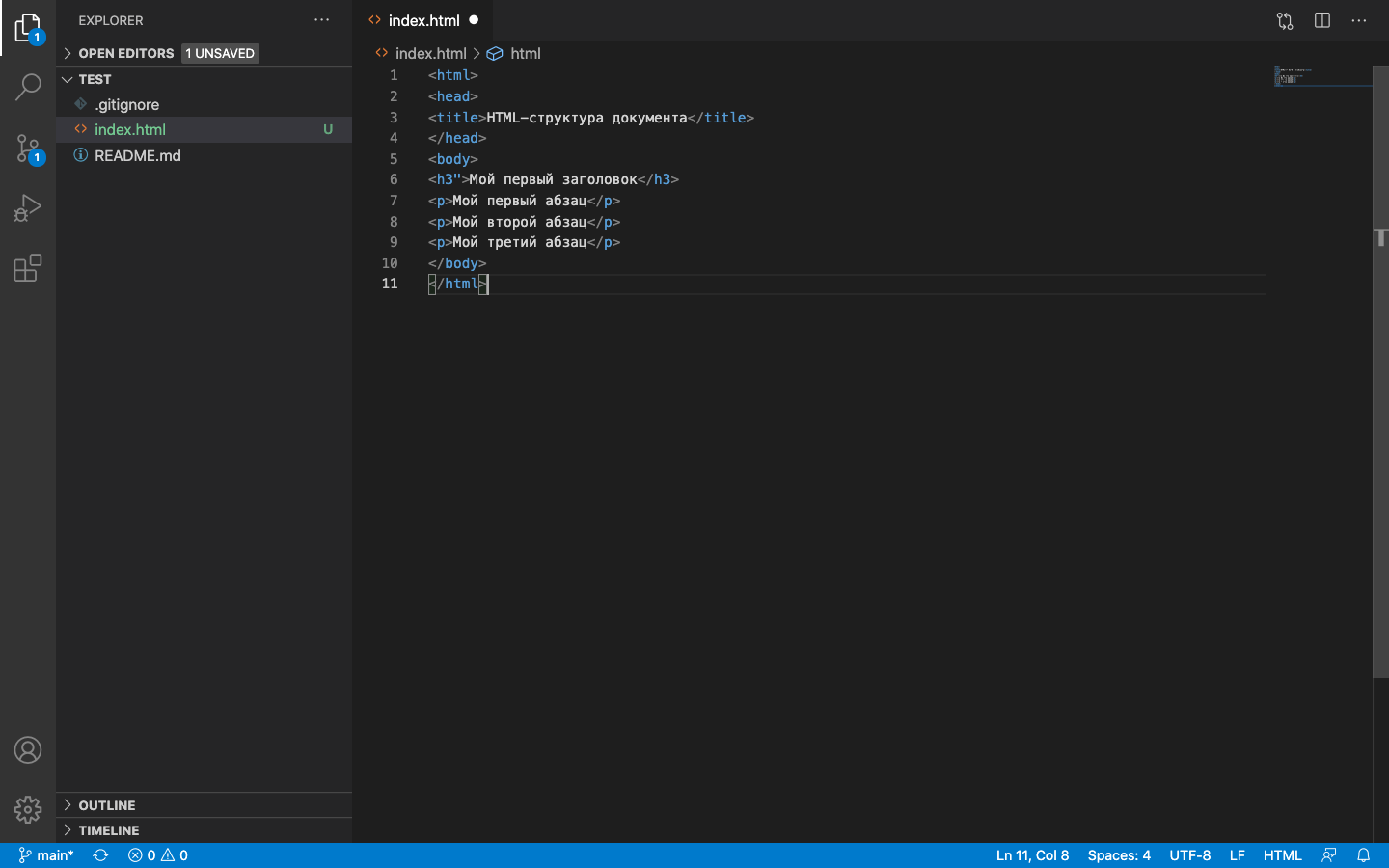
Переходим в GitHub Desktop — созданный HTML-файл появится во вкладке Changes. Для его сохранения пишем коммит и переходим во вкладку History для просмотра изменений. Если изменения сохранились, нажимаем на Push origin и отправляем изменения в удалённый репозиторий.
Создаём новую ветку и добавляем в проект внесённые изменения
Добавим к проекту пустой CSS-файл и подключим его к HTML. После этого в меню редактора появятся два цвета: HTML-файл подсветится оранжевым, а CSS-файл — зелёным. Оранжевый означает, что файл уже есть в удалённом репозитории и его нужно обновить. Зелёный — файла нет в репозитории. Переходим в GitHub Desktop и добавляем коммит для этого изменения.
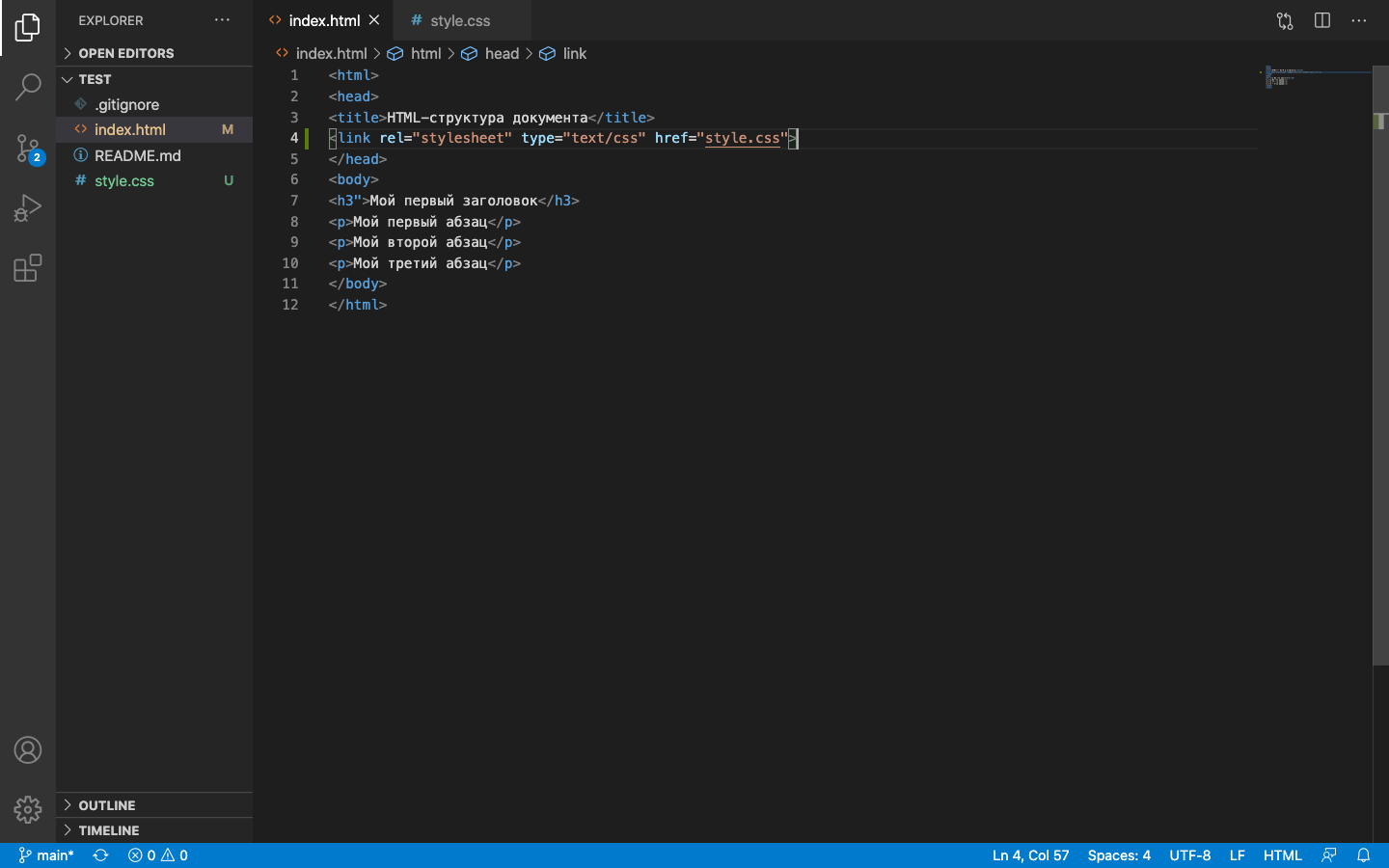
Если мы откроем созданную страницу в браузере, то это будет несколько строчек текста на белом фоне. Представим такую ситуацию: нам нельзя изменять код проекта, но нужно посмотреть, как будет выглядеть страница на красном фоне. Чтобы сделать это — добавим в репозиторий новую ветку:
- Переходим в GitHub Desktop.
- Открываем раздел Current Branch, нажимаем кнопку New Branch, пишем название новой ветки и кликаем Create New Branch.
- Возвращаемся в редактор кода и тестируем идею.
После создания новой ветки не забудьте нажать на Push origin, чтобы изменения попали в удалённый репозиторий на сайте GitHub.
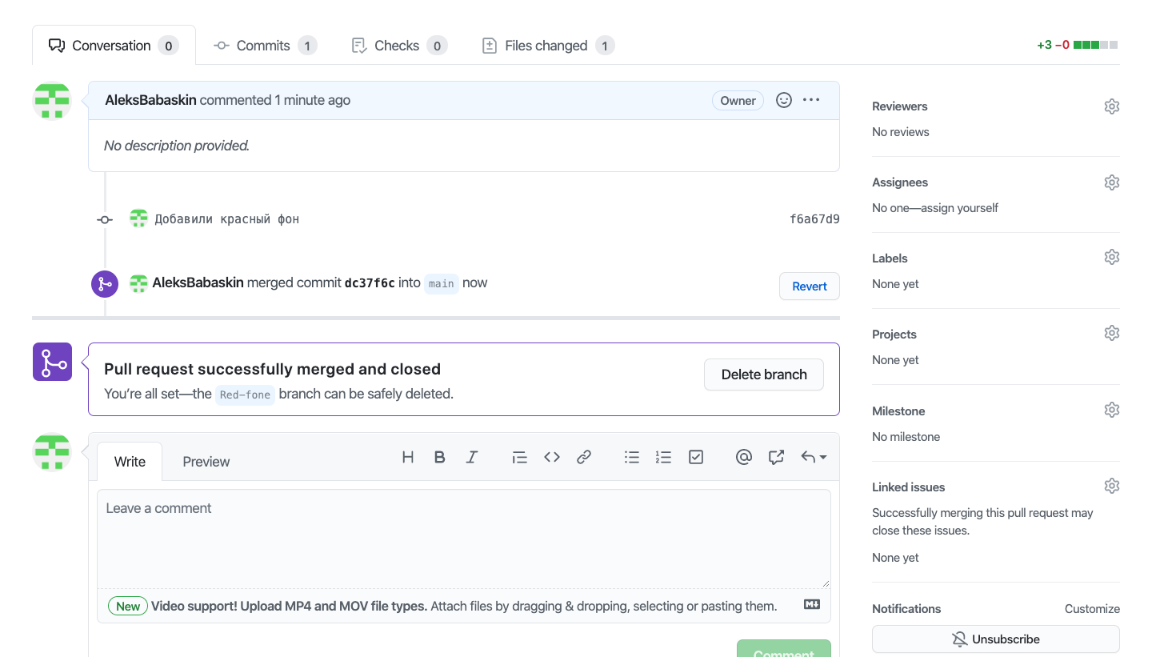
Предположим, наша идея с красным фоном оказалась удачной и код нужно залить в основную ветку. Чтобы это сделать, переходим сайт GitHub, нажимаем кнопку Сompare & pull request и подтверждаем изменения кнопкой Merge pull request. Последний шаг — переходим в GitHub Desktop, кликаем Fetch origin и синхронизируемся с удалённым репозиторием. Теперь код из дополнительной ветки попал в основную, а изменения есть на ПК и в облаке.
- Почитайте Pro Git book — это бесплатное руководство по Git.
- В футере github.com откройте раздел Training → Explore → GitHub Learning Lab — бесплатные курсы для углублённого изучения GitHub. Подходят для новичков и опытных программистов, которые учатся работать в команде.
- Посетите GitHub Community — форум с множеством тем про GitHub, где можно задавать вопросы и участвовать в обсуждениях.