
Привет! Меня зовут Иван, я руковожу горизонталью автоматизации тестирования в Skyeng. Часть моей работы — обучать ручных тестировщиков ремеслу автоматизации. И тема с поиском локаторов, по моему опыту, самая тяжкая для изучения. Здесь куча нюансов, которые надо учитывать. Но стоит разобраться, и локаторы начинают бросаться в глаза сами. Хороший автоматизатор должен идеально уметь находить читабельные и краткие локаторы на странице. Об этом и пойдет речь ниже.
Наливаем чай-кофе и погнали!
Что такое локатор
Локатор — обычный текст, которой идентифицирует себя как элемент DOM’а страницы. Простым языком: с помощью локатора на странице можно найти элементы. В случае CSS — локатор включает в себя набор уникальных атрибутов элемента, а в случае XPath — это путь по DOM’у к элементу.
Если вы изучали CSS ранее, то в конструкции ниже p будет являться локатором элемента, также и атрибут color: red может являться его локатором. Атрибут элемента это всё, что идёт после тега. Например, в теге <p class=”element” id=”value”> атрибутами являются class и id.
p: {
color: red;
}Сразу оговорка по терминологии, локатор = селектор.
Локатор — это название селектора на русском. Иногда встречаю в интернете, что селектор относится только к CSS, но это не совсем так. XPath-локатор тоже может быть, просто означает он путь к элементу в DOM’е. Давайте похоливарим в комментах, чем же всё-таки локатор отличается от селектора 
DOM страницы — это HTML-код, написанный человеком или сгенерированный фреймворком, который преобразуется браузером в DOM. То есть набор объектов, где каждый объект — это HTML-тег.

Есть очень много видов локаторов, но чаще всего в работе применяется лишь часть из них. Их можно искать по следующим видам:
-
имя элемента
-
id
-
классы
-
кастомные атрибуты
-
родители и дети элементов
-
ссылки
-
и так далее.
Полное строение элемента
Элемент состоит из имени, то есть самого HTML-тега. Например, div, span, input, button и другие. Внутри него перечислены атрибуты, которые отвечают за все возможные свойства элемента. Например, цвет, размер, действие, которое будет происходить по клику на элемент.

У элемента может быть родитель и ребёнок. Родитель может быть один, а детей может быть несколько. Если детей несколько, то они являются соседями и каждый из них образует свою ось. 1 ребёнок = 1 ось со своими особенностями и своими вложенными элементами. А — родитель, B D E F W X Y — дети A. У каждого элемента есть свои дети, свои дальнейшие ветки, это и называется оси.

Поиск локаторов в браузере
Для поиска элементов в DOM’е страницы нужны средства разработчиков в браузере. Рассмотрим их на примере Chrome. Они же называются DevTools (F12). Нас интересует вкладка Elements, именно там находятся все элементы. Чтобы найти локатор в поле Elements, нужно нажать Ctrl+F. Внизу появится небольшое поле поиска, с ним мы будем работать всё время.
Давайте попробуем найти элемент по названию HTML-тега. Искать просто: в строке поиска вводим название тега. Скорее всего этот локатор элемента будет не уникальным и по его значению найдутся много элементов. Для тестов важно, чтобы был только один элемент для взаимодействия. Если одному локатору будут соответствовать несколько элементов, то тест или будет взаимодействовать с первым из них, или просто упадёт с ошибкой. Элементы можно искать не только с помощью тегов (p, span, div и т.д.), но и с помощью атрибутов тега. Например, color=”red” и class=”button”. Подробнее об этом чуть ниже.

Микро-задание: попробуй открыть DevTools на этой страничке (F12) и найти (Ctrl + F) количество элементов с тегом button.
P.S. поздравляю, ты уже написал свой первый локатор! Дальше — больше 
Уникальные локаторы
Где будем практиковаться? https://eu.battle.net/login/ru/ — простая и понятная форма авторизации.


Рассмотрим поиск на примере формы авторизации и регистрации. В коде страницы есть 2 поля («Почта» и «Пароль») и кнопка «Авторизация». Сравним, по каким атрибутам можно найти локатор и определим уникальные атрибуты.

Подробно разберём, как можно найти локатор поля Почта:

Разберём, как можно найти локатор поля Пароль:

Разберём, как можно найти локатор поля Авторизация:

Начнём с разбора не уникальных локаторов. Если по локатору находятся 2 и более элементов на HTML-странице, такой локатор можно назвать неуникальным. Тест при обнаружении большого количества элементов по данному локатору упадёт или возьмёт первый. Ненадежно, точно не наш бро.
Уникальный, но non-suitable локатор. Если мы в DevTools введем вышеуказанные названия, то найдется элемент. И здесь мы опускаемся до следующего уровня написания локаторов — уровня понятности, читаемости и надёжности локатора.
-
title=»Электронная почта или телефон» — считается плохим паттерном писать локаторы с русским текстом. Тем более в примере текст в title еще и длинный, это визуально громоздко. На текст завязываться можно в крайнем случае, но нужно быть готовым к тому, что тексты часто меняются, любая правка может сломать автотесты.
-
title=»Пароль» — аналогично ^
-
type=»text» — представь, ты открываешь среду разработки и видишь локатор “тип=текст”. Совсем не ясно, к какому элементу относится локатор. Со смысловой точки зрения, это неудачный локатор, потому что он не передаёт смысл локатора.
-
type=»password» — этот атрибут говорит о том, что у поля тип «password» и все символы, которые мы вводим заменяются на звёздочки/точки. При добавлении еще одного поля с type=”password” (например, поле «Подтвердите пароль») локатор сразу станет неактуальным. Стараемся думать наперёд.
Уникальные локаторы. Они найдут только один элемент, они осмысленные, иногда читабельные и краткие. Как раз уникальные атрибуты — это class, id, name и подобные. Они точно наши бро!
Небольшой итог
Хороший локатор — краткий, читабельный и осмысленный. Например, у поля «Пароль» хорошо иметь в локаторе слово password.
Возникает вопрос, почему class=»btn-block btn btn-primary submit-button btn-block» был вынесен в категорию уникальных? Такие локаторы встречаются повсеместно, и именно их мы берём за основу и приводим к красивому виду.
Поиск элементов с помощью CSS
id и class — самые важные атрибуты, с помощью которых мы будем искать бóльшую часть элементов на странице. Есть очень много тонкостей по работе с ними, постараемся рассмотреть все из них.
Кнопка «Авторизация» имеет несколько классов в одном:
-
btn-block
-
btn
-
btn-primary
-
submit-button
-
btn-block
Каждый из этих классов определяет свой визуал кнопки. Например, btn-primary определяет цвет кнопки, submit-button увеличивает её размер (это лишь догадки, основное значение знают только Blizzard). Несколько классов внутри атрибута class разделяются пробелом.
Наличие более одного класса внутри атрибута говорит о том, что он комбинированный. Бывают и комбинированные атрибуты кроме классов. Но классы необязательно будут уникальны для одного элемента. В данном случае у кнопки «Авторизация» такие атрибуты:
class="btn-block btn btn-primary submit-button btn-block"
Но если добавить туда кнопку «Регистрация», то может отличаться лишь один класс. Например, он будет выглядеть следующим образом:
class="btn-block btn btn-primary registration-button btn-block"
Сразу заметно, что отличается всего лишь один класс — submit-button сменился на registration-button. Остальные свойства могут иметь и другие кнопки.
Читабельность локатора
Допустим, мы ищем элемент по полному классу. Это хороший и действенный способ. Почти всегда элемент будет уникальным, но очень нечитабельным и громоздким, как в случае с кнопкой «Авторизация».
class с помощью CSS можно записать следующим образом:
-
.locator (точка — сокращенная запись class’а)
-
или выделяем название и значение класса в квадратные скобочки: [class=”value”]
Полный класс элемента кнопки «Авторизация» состоит из 5 классов: btn-block btn btn-primary submit-button btn-block, а выглядеть полный локатор будет так:
[class=”btn-block btn btn-primary submit-button btn-block”]
Разделение происходит с помощью пробела внутри. Для класса его сокращенной формой является точка, поэтому можно записать локатор так:
btn-block.btn.btn-primary.submit-button.btn-block
Да, стало короче, но всё равно есть смысловая перегрузка. Сокращаем дальше.
Отдельно здесь стоит добавить про поиск по подстроке. Запись [class=”локатор”] ищет только всю строку класса элемента. Если мы напишем [class=”btn-block”] или любой другой класс, то кнопка «Авторизация» не будет найдена. Но если мы запишем локатор полностью [class=”btn-block btn btn-primary submit-button btn-block”], то кнопка найдётся.
Из данной ситуации помогает найти выход символ звёздочки. Он ищет ПОДстроку в строке, то есть часть локатора может найти элемент.
Краткость локатора
Про подстроку
Можно почитать на википедии, там приведён доступный пример для общего понимания поиска по подстроке. Также поиск по подстроке можно сравнить с методом includes из JS
Локатор кнопки«Авторизация» [class=”btn-block btn btn-primary submit-button btn-block”] можно записать следующим образом:
-
[class*=”btn-block”]
-
[class*=”submit-button”]
-
[class*=”btn-block btn”]
-
[class*=”btn btn-primary”]
-
[class*=”primary submit”] (конец одного класса и начала другого, но только в том случае, если они написаны подряд, друг за другом)
-
можно даже сократить название подкласса: не длинное submit-button, а просто submit, например, [class*=”submit”]. Можно даже сократить слово submit — [class*=”sub”].
Важно понимать, это будет работать, если классы идут только последовательно. Если мы укажем [class*=”btn-block submit-button”], то локатор работать не будет, потому что между btn-block и submit-button идут несколько классов: btn и btn-primary. Но это можно обойти, разделив локатор на 2 разных. Например, 2 класса слитно — [class*=”btn-block”][class*=”submit-button”]. Это работает и часто пригождается, когда нужно уточнить, в каком именно элементе мы ищем определенный класс.
Также можно комбинировать краткую запись с помощью точки и тега элемента:
-
.submit-button = [class*=”submit-button”]
-
.btn = [class*=”btn”]
-
.btn-block = [class*=”btn-block”]
-
button[class*=”submit-button”] = button.submit-button
-
button[class*=”btn”] = button.btn
-
button[class*=”btn”][class*=“submit-button”] = button.btn.submit-button
-
button[class*=”submit”]
Краткую запись (через точку) предпочтительнее использовать, чем полную (в квадратных скобках).
Лаконичность локатора
Мы можем определить кнопку «Авторизация» по классу submit-button. Это не самый лаконичный локатор, но дословно означает действие отправки данных на сервер с формы авторизации. Но что делать, если у кнопки нет контекста? Например, классы кнопки Авторизации будут выглядеть так: [class=”btn-block btn btn-primary btn-block”]. Если нет контекста из слова submit (отправка), то можно очень быстро потеряться и сразу не ясно, к какому элементу относится этот локатор. В данном случае нам поможет название текущего элемента или его родителя.
Для наглядности рассмотрим весь блок с кнопкой «Авторизация».
Как вариант — к локатору можно добавить сам тег button. Например, button[class*=”btn”] (сократил класс для наглядности). В таком случае можно взять тег или класс родителя за основу, а именно div или [class=»control-group submit no-cancel»]. Если нужно указать родителя, то эта связь пишется через пробел. Через пробел можно обращаться на любой уровень вложенности, например, из form сразу прыгнуть к button. Полный путь будет выглядеть так: form div button.
С полученными знаниями можно расширить пул локаторов:
-
form button
-
form [type=”submit”]
-
#password-form #submit (решётка — сокращённая форма id, точка — сокращённая форма class)
-
и еще много-много локаторов, которые можно найти комбинаторикой, главное, чтобы по итогу локатор выглядел кратко и лаконично, передавал суть элемента
А как с ID
С ID работает всё точно также, только краткая запись ID — это решётка, например, <form id=”password-form”> можно записать как form#password-form, по такому же принципу, как и с классом
Поиск по кастомным атрибутам
Кастомные атрибуты тоже заслуживают упоминания. У элемента могут быть не только классы и айдишники, но и еще бесконечно множество атрибутов. В исключительных случаях можно искать элементы по этим атрибутам, но только в случае их приличного вида. Например, в случае кнопки «Авторизация» указаны несколько необычных атрибутов, которые вряд ли можно использовать за основу для её поиска:
-
data-loading-text
-
tabindex=»0″
Очень хорошей практикой на проекте является обвешивание интерактивных элементов кастомным атрибутом data-qa или data-qa-id. Например, <button id=”css-1232” data-qa=”login-button”>. Если поменяют локатор, то этот атрибут останется и тесты будут стабильными долгое время. Добавлять эти атрибуты могут фронтенд-разработчики или автоматизаторы, если имеют доступ к коду фронтенда и возможность пушить в него правки.
Локаторы можно и нужно комбинировать! Элементы, состоящие из нескольких классов, айди и других атрибутов, можно объединять в один локатор. Например, возьмем элемент формы, который находится выше кнопки «Авторизация»: form#password-form[method=”post”][class*=”username”]
Итоги поиска локаторов с помощью CSS
-
классы и id можно писать сокращенно с помощью точки и решетки
-
<button class=”login”>: .login = [class=”login”] = [class*=”log”] = button.login = button[class=”login”]
-
<button id=”size”>: #size = [id=”size”] = [id*=”ze”] = button#size = button[id=”size”]
-
всё, что не class, и не id в сокращённом виде пишем в [] (квадратных скобках), например, [name=”phone”], [data-qa-id=”regButton”]
-
если тег лежит внутри другого тега, то переходим к нему через пробел (независимо от степени вложенности), например, <span> -> <button> -> <a> = span a = button a = span button a
Поиск элементов с помощью XPath
XPath в корне отличается от CSS как идеей, так и реализацией. XPath — это полноценный язык для поиска элементов в дереве, причём неважно каком, будь это XML или XHTML. Можно использовать XPath в веб-страницах, нативной мобильной вёрстке и других инструментах.
Я изучал XPath больше месяца с нуля. Проблема была в том, что я никак не понимал принцип его работы — мы ходим от элемента к элементу, но не ясно, как это происходит, как писать красивые пути, какие преимущества у такого подхода. Неделями изучал документацию, статьи на блогах (к сожалению, тогда еще не было человекопонятных статей на Хабре) и видео в ютубе. Мне очень помогло одно видео, где автор объяснял базовые принципы XPath, после чего меня осенило и в голове сложилась картинка. Поэтому хочу поделиться с вами этой информацией, чтобы сократить время на изучение тонны материала. Изучение XPath самостоятельно полезно, но я бы с огромным удовольствием потратил полтора месяца на вещи поважнее.
Предположим, у нас есть следующая структура документа:
<div class="popup">
<div id="payment-popup">
<button name="regButton">
<span href="/doReg">Кнопка</span>
</button>
</div>
</div>XPath — это путь от элемента к элементу. Можно представить, что структура тегов — это дерево каталогов, как в любой ОС. Например, в данном случае теги можно представить в виде папок: div -> div -> button -> span. В терминале по ним можно переключаться через команду cd, а именно: cd div/div/button/span
div/div/button/span — это и есть путь к элементу с помощью XPath, только первый элемент ищут по всему дереву элементов, поэтому пишут // в начале строки. В данном случае это будет выглядеть так: //div/div/button/span. 2 слэша можно использовать не только в начале — они обозначают то, что мы ищем элемент где-то внутри. Например, //div//span — элемент будет найден, мы пропустили второй div и button.
Главная отличительная особенность XPath — возможность проходить не только от родителя к детям, но и от детей к родителям. Например, есть структура:
<div class=”popup”>
<div id=”payment-popup”>
<button name=”regButton”>
<span href=”/doReg” />
</button>
<button name=”loginButton”>
<span href=”/doLogin” />
</button>
</div>
</div>
Мы можем перейти от кнопки doLogin в кнопку doReg вот так:
//*[@href=”/doLogin”]/../..//*[@href=”/doReg”]
Чтобы перейти на уровень выше, как и терминале ОС, нужно написать 2 точки, как показано в примере. С помощью 2 точек мы поднимаемся с уровня span сначала до button, а с button до общего div.
Главный вопрос, который может возникнуть, а где это может пригодиться? Практически всюду, где есть одинаковые блоки, которые отличаются по какому-то одному признаку. Возьмем страницу RDR2 в Epic Games. На середине страницы сейчас перечислены 3 издания:

В DevTools отчётливо видно, что блоки идентичные. Отличия только в названии издания, описании и цене.

Есть задача: нажмите на кнопку «Купить сейчас» у издания Red Dead Online. Для этого надо завязаться на текст издания, подняться до первого общего элемента у названия издания и кнопки и опуститься до кнопки «Купить сейчас».
//*[contains(text(), “Red Dead Online”)]/ancestor::*[contains(@data-component, "OfferCard")]//*[contains(@data-component, "Purchase")]
Лайфхак: как найти первый общий элемент у двух элементов?
Нажимаем на любом элементе ПКМ -> Посмотреть код, открывается вкладка Elements. Наводим курсором на текущий элемент и он выделяется синим цветом. Просто тащим курсор наверх, пока визуально не найдём элемент, который объединяет 2 элемента — в нашем случае текст и кнопку «Купить сейчас».

В XPath, как и в CSS, можно искать по элементам и по атрибутам в элементе. Например:
<div class=”popup”>
<div id=”payment-popup”>
<button name=”regButton”>
<span href=”/doReg” />
</button>
<button name=”loginButton”>
<span href=”/doLogin” />
</button>
</div>
</div>Можно найти кнопку регистрации:
-
//*[@href=”/doReg”] или //span[@href=”/doReg”] -
//*[@name=”regButton”] или //button[@name=”regButton”]
Как мы можем заметить — звёздочка заменяет название элемента. Где стоит звёздочка, означает, что элемент может называться как угодно. Главное, чтобы внутри него был заданный атрибут. Если мы хотим указать конкретный элемент, то подставляем его вместо звёздочки. Например, путь //span[@href=”/doReg”] — сразу говорит нам, что в элементе span мы ищем @href=”/doReg”, но если нам не важен элемент, то тогда span заменяем на звёздочку //*[@href=”/doReg”].
Атрибуты всегда пишутся со знаком @ в начале, это тоже особенность языка.
Еще следует упомянуть переходы по смежным осям. В примере выше есть 2 разные оси — 2 button: элементы одинаковые, но отвечают за разные кнопки. Это можно сделать с помощью зарезервированных слов: following-sibling и preceding-sibling.
Например, нам нужно достать кнопку Войти, зная кнопку Регистрация: //*[@name=”regButton”]/following-sibling::*[@name=”loginButton”]. Если нужно найти кнопку Регистрации зная кнопку Войти, то делается это точно также, только ищем в осях, идущих до кнопки Регистрации: //*[@name=”loginButton”]/preceding-sibling::*[@name=”regButton”]. Переходы между осями или дереву (вверх-вниз) всегда происходит через 2 точки, если мы пишем полное название направления, например, following-sibling::, ancestor::
Не всегда есть возможность искать элементы по полному названию класса, так как оно может являться достаточно большим и нечитабельным. В CSS мы это делали с помощью символа звёздочки. Здесь звёздочку заменяет слово contains и работает точно также, как и в CSS. Например, ищем кнопку Войти: //*[contains(@name, “Login”)]. Как мы видим, contains — это что-то вроде функции в XPath. 1 параметр — атрибут, в котором ищем часть текста, 2 — сам текст.
Последней функцией, которую мы рассмотрим, будет text(). Она позволяет искать элемент по тексту, который в нём находится. Например, есть HTML-разметка:
<button>
<span>Кнопка Войти</span>
</button>
<button>
<span>Кнопка Регистрация</span>
</button>Чтобы найти текст по точному совпадению, нужно писать следующий путь: //*[text()=”Кнопка Войти”]. Но если мы захотим искать по 1 слову, то на помощь приходит комбинация со словом contains, а именно: //*[contains(text(), “Войти”)].
Коротко про «Гибкие локаторы»
Термин «гибкий локатор» применяется к поиску локаторов через CSS и с XPath. Называется он гибким, потому что независимо от текста внутри — локатор не изменится. Для примера снова возьмём страничку с игрой RDR2. На ней есть 3 издания. Сами локаторы не меняются, меняется только текст (название, описание, цена). Общий шаблон локатора будет выглядеть так: //*[contains(text(), “Название издания”)]/ancestor::*[contains(@data-component, «OfferCard»)]//*[contains(@data-component, «Purchase»)]. Текст уже можем в него передавать любой, какой захотим. Так вот именно этот локатор будет называться гибким — его тело остаётся неизменным, а меняются лишь параметры внутри него. В автоматизации мы очень часто пользуемся гибкими локаторами.
Выводы
Мы разобрали 2 основных способа поиска элементов на странице, с помощью CSS и XPath. Небольшое сравнение этих методов:
|
Плюсы CSS |
Минусы CSS |
|
— краткий — читабельный — простой для освоения и полностью граничит с изучением базового CSS — что-то вроде мифа — он работает быстрее, то есть быстрее ищет элемент на странице, но на фоне мощности современных процессоров эта разница во времени неощутима и составляет пару миллисекунд |
— может переходить только от родителя к ребёнку, но не наоборот — вверх подниматься нельзя — более ограниченный набор функций для поиска элементов, например, нельзя искать элемент по тексту, который в нём находится — CSS заточен только под веб-страницы |
|
Плюсы XPath |
Минусы XPath |
|
— полноценный язык для поиска элементов не только в вебе, но и в других средах и документах — позволяет перемещаться по дереву вниз и вверх — гибко работает с осями элементов — есть очень много функций, которые помогают в поиске локаторов, например, поиску по тексту в элементе или аналог normalize-space, который убирает пробелы у строки по бокам |
— громоздкий — нечитабельный — сложен в освоении — работает дольше, чем поиск по CSS, хоть и незначительно |
В тестах лучше использовать CSS, но это не всегда реально. Именно поэтому в таких случаях приходит на помощь XPath.
Полезные ссылки
CSS:
-
https://flukeout.github.io/ — практика в поиске локаторов.
-
https://code.tutsplus.com/ru/tutorials/the-30-css-selectors-you-must-memorize—net-16048 — полезно узнать про различные виды селекторов. Мы используем не все, но всегда бывает ситуация, когда раз в жизни придётся использовать тот или иной локатор.
-
https://appletree.or.kr/quick_reference_cards/CSS/CSS%20selectors%20cheatsheet.pdf — локаторы наглядно.
-
https://learn.javascript.ru/css-selectors — оформление в виде документации.
XPath:
-
https://topswagcode.com/xpath/ — практика в поиске локаторов.
-
https://www.w3schools.com/xml/xpath_nodes.asp — подробнее про ноды.
-
https://www.w3schools.com/xml/xpath_syntax.asp — синтаксис.
-
https://www.w3schools.com/xml/xpath_axes.asp — оси.
-
https://soltau.ru/index.php/themes/dev/item/413-kratkoe-rukovodstvo-po-xpath — более подробная информация с примерами на русском.
Иногда при работе с сайтом необходимо посмотреть исходный код страницы. Это нужно, например, для проверки корректности заполнения метаданных, если на сайте не установлен плагин, для того, чтобы найти код какого-то определенного элемента, и т.д. В этом материале мы покажем, как открыть исходный код страницы на разных устройствах и в разных браузерах.
Крупнейшее региональное интернет-агентство России. ТОП-10 в рейтинге Рунета.
1200+ проектов
90 специалистов
15 лет на рынке
Коммерческое предложение
Как открыть исходный код страницы на компьютере
Любой современный браузер «из коробки» обладает функционалом, необходимым для просмотра исходного кода страницы.
Google Chrome
Чтобы открыть исходный код страницы в Google Chrome, нужно нажатием правой кнопки мыши вызвать контекстное меню и в нем кликнуть на «Просмотр кода страницы».

Открываем исходный код страницы в Google Chrome
Также просмотреть код можно с помощью сочетания клавиш Ctrl + U. Что касается операционной системы MacOS, здесь работает сочетание клавиш
Option + Command + U. В обоих случаях код открывается в отдельной вкладке.
Нет времени разбираться?
Комплексное продвижение в онлайне
Разрабатываем стратегии продвижения бизнеса в онлайне с пошаговым планом действий, и обеспечиваем его реализацию. Проектируем, реализуем, поддерживаем и развиваем сайты, приводим на сайт целевой трафик (реклама, SEO, email-рассылки), расширяем присутствие компании на сторонних площадках, настраиваем аналитику и проводим постклик анализ.
Ваш сайт:

Пример исходного кода
Для удобства поиска определенных значений нажмите клавиши Ctrl + F. Искомый фрагмент кода будет подсвечиваться желтым цветом.
Microsoft Edge, Opera и Mozilla Firefox
Чтобы посмотреть исходный код в этих браузерах, нужно, аналогично действия в Google Chrome, вызвать правой кнопкой мыши контекстное меню и выбрать в нем пункт «Посмотреть исходный код». Страница с кодом также откроется в отдельной вкладке.
Кроме того, здесь работает та же комбинация клавиш Ctrl + U.

Открываем исходный код в Microsoft Edge

Открываем исходный код в Opera

Открываем исходный код в Mozilla Firefox
Как посмотреть код конкретного элемента страницы
С помощью указанных способов вы можете посмотреть не только код всей страницы, но и коды отдельно взятых элементов. Однако для этого вам придется вручную определять местоположение необходимого фрагмента, что может занять довольно много времени.
Опытные разработчики пользуются специальным инструментом, который доступен во всех перечисленных браузерах. Рассмотрим принцип его работы в Google Chrome.
Чтобы открыть консоль, зажимаем клавиши Ctrl + Shift + I или вызываем контекстное меню и кликаем «Просмотреть код».

Открываем код элемента в Google Chrome

Панель с кодом в Google Chrome
Как видим, панель открылась справа от страницы. Ее положение можно менять в зависимости от размеров монитора или личных предпочтений. Для этого открываем меню и в разделе «Dock side» выбираем месторасположение панели либо открываем ее в отдельном окне.
Привлекли 35.000.000 людей на 185 сайтов
Мы точно знаем, как увеличить онлайн–продажи
Применяем лучшие практики digital–продвижения как из вашей тематики, так и из смежных областей бизнеса. Именно это сделает вас на голову выше конкурентов и принесёт лиды и продажи.
Ваш сайт:

Настраиваем расположение панели в «Dock side»
Во вкладке «Elements» в основной части консоли открывается код страницы, который ранее мы открывали в отдельной вкладке. Здесь он представлен в более удобном виде: каждый элемент (например, <div>) можно раскрыть, чтобы посмотреть иерархию. Справа (если панель расположена в нижней части экрана) отображается CSS-код выбранного элемента. К слову, эти параметры можно править. Для этого необходимо выделить их двойным щелчком мыши. Имейте в виду, что это действие повлияет на отображение элементов на странице (до момента перезагрузки). Аналогичным образом правятся значения в коде странице в левом окне.

Код страницы
Теперь переходим к поиску нужного элемента. В качестве примера возьмем название одной из товарных позиций каталога. Чтобы найти ее в исходном коде, нажимаем значок стрелки в левом верхнем углу панели и кликаем на нужный элемент страницы.

Код отдельного элемента

Нужный фрагмент кода
Таким образом выводится нужный фрагмент кода, который отвечает за отображение элемента. В окне справа располагается относящийся к нему CSS-код.
Так можно получить код абсолютно любого элемента на странице, чтобы скопировать или исправить (удобно при тонкой настройке CSS-стилей) его.
Как посмотреть исходный код на смартфоне
Мобильные версии браузеров имеют достаточно ограниченный функционал. Например, в них нет таких инспекторов кода, как в десктопных версиях. Однако посмотреть код все-таки можно. Для этого необходимо добавить в начало URL параметр «view-source:».

Отображение исходного кода страницы сайта на смартфоне
Для получения расширенных возможностей в работе с исходным кодом на Android установите приложение VT View Source. При запуске потребуется ввести URL изучаемой страницы.
Приложение доступно только на английском языке. Что касается функционала, он достаточно широк:
- поиск по коду,
- копирование,
- возможность сохранения кода в отдельный файл целиком или частями,
- проверка валидности,
- шаринг кода.
Также в приложении можно менять цвета фона и текста, размеры и тип шрифта и другие параметры.
Данная статья написана, чтобы помочь быстро разобраться с тем, как парсить данные при помощи расширения от iDatica. Статья рассчитана на людей не знакомых с Xpath и CSS. Рассмотрим совсем немного теории и базовый (для парсинга данных) синтаксис которые позволят понять как собирать данные с подавляющего большинства сайтов.
Применение Xpath для парсинга
Прежде всего, нужно разобраться, что такое Xpath (XML Path Language) — это язык запросов к элементам хml-разметки. Это означает, что отправляя определенным образом составленный запрос, вы получаете в ответ нужные данные. Простая аналогия — адрес в строке браузера или путь в эксплорере до нужной папки, набирая правильный путь вы попадаете на нужный сайт или в нужную папку. С Xpath так же — пишем путь и попадаем к нужным данным, только в отличии от строки браузера Xpath применяем для поиска. И в нашем случаем для поиска по xml документам в формате html, другими словами по коду на котором построен сайт.
Если вы нажмете на пустом месте сайта правой клавишей мыши и выберете в контекстном меню «исходный код сайта» или «посмотреть код страницы», в разных браузерах по разному, вы как раз попадете на страницу с кодом из которого парсер извлекает данные.
Например, код может выглядеть так:
<html>
<body>
<div>Заголовок
<H1>Название</H1>
</div>
<div>Описание</div>
<div>Характеристики
<span class="text">Высота</span>
<span class="text">Ширина</span>
<span>Цена</span>
</div>
<a href="https://site.com/pic.png">Фотография товара</a>
</body>
</html>Как видно код представляет собой древовидную структуру, в которой каждый элемент определенным образом размечен, наша задача заключается в том, чтобы указать парсеру путь к нужному нам элементу.
Дальнейшие действия будем рассматривать на примере нашего каталога баз данных по этому адресу.
Для дальнейшей работы нам понадобится инструмент разработчика встроенный в браузер, в Chrome — контекстное меню — посмотреть код, в Firefox — контекстное меню — исследовать.
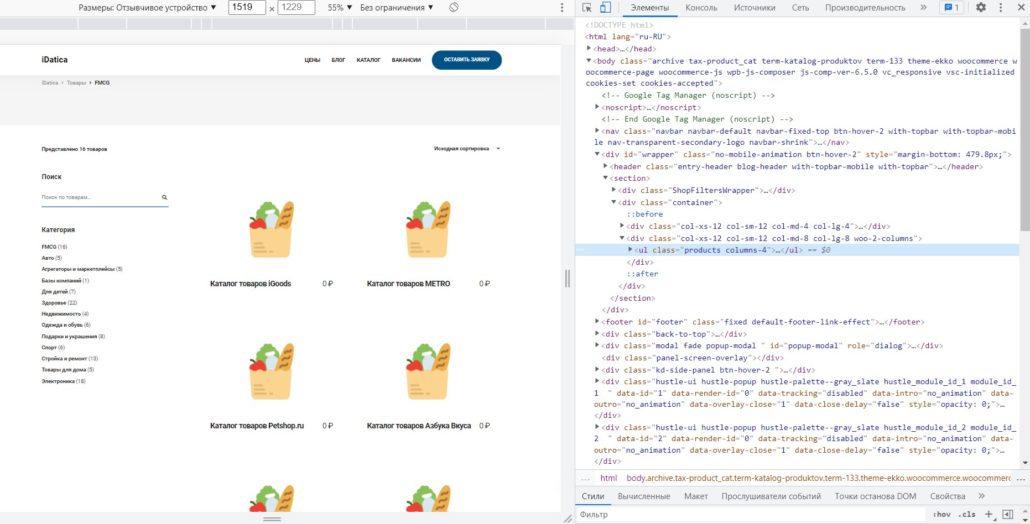
Итак, давайте найдем путь до названия карточки товара:

Кликаем на название товара правой клавишей мыши — откроется контекстное меню, выбераем — «посмотреть код» — нашли нужный элемент в коде. Как можно определить путь до него? Как и в случае с проводником опускаемся из верхней категории до «нужной папки». Верхняя директория «html», далее «body» , далее несколько блоков «div», «ul», если на каком-то уровне несколько блоков с одинаковым названием, то в квадратных скобках пишем какой элемент по счету нам нужен:
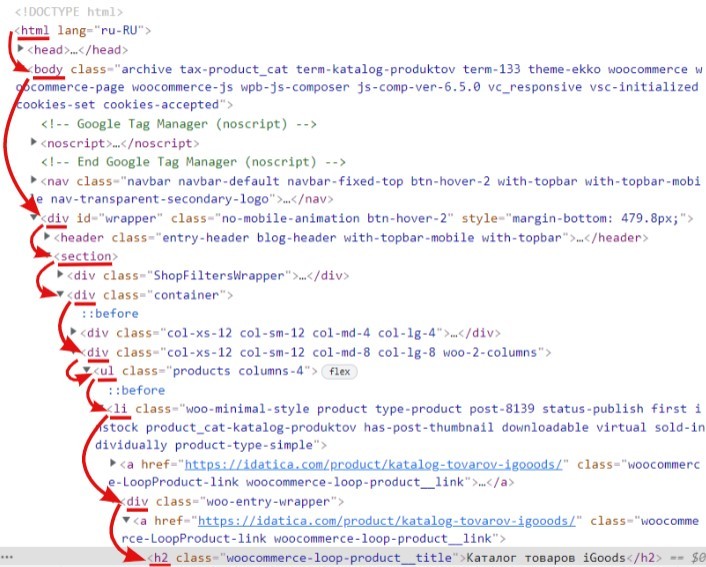
Если записать, этот путь то получится:
/html/body/div/section/div[2]/div[2]/ul/li/div/a/h2Этот путь можно проверить в том же инструменте разработчика, нажав Ctrl+F и записать путь:
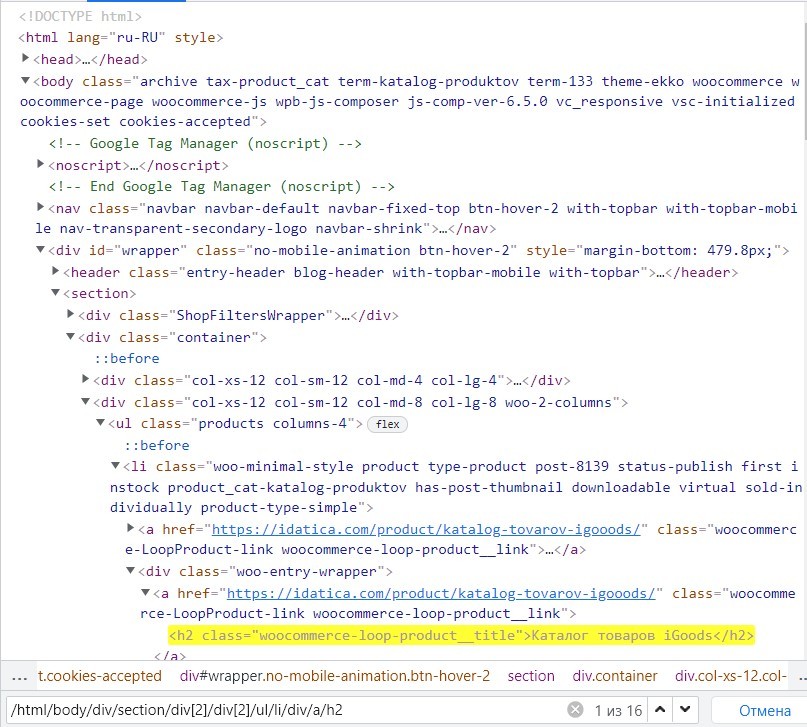
Можно проверить путь в расширении iDatica, нажав на пиктограмму поиска:
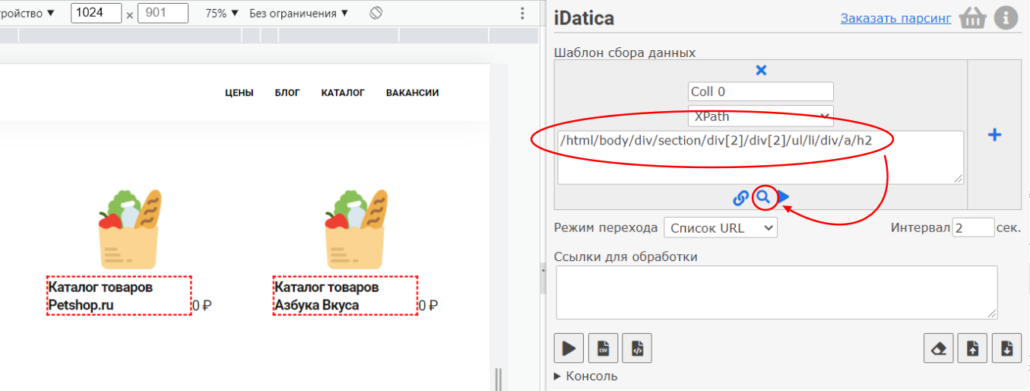
Если в расширении нажать на пиктограмму play, то программа покажет все элементы которые нашла на странице по этому пути — в нашем случае это все названия. Если нажать на кнопку парсинга и сохранить результат — то вы спарсите все названия, поздравляю — вы собрали первые данные!
Как быть с остальными элементами на странице? Так же — пишем путь и получаем данные. Можно получить этот путь сразу в инструменте разработчика — кликнуть правой клавишей мыши на нужном элементе в коде, выбрать — копировать и выбрать xpath:
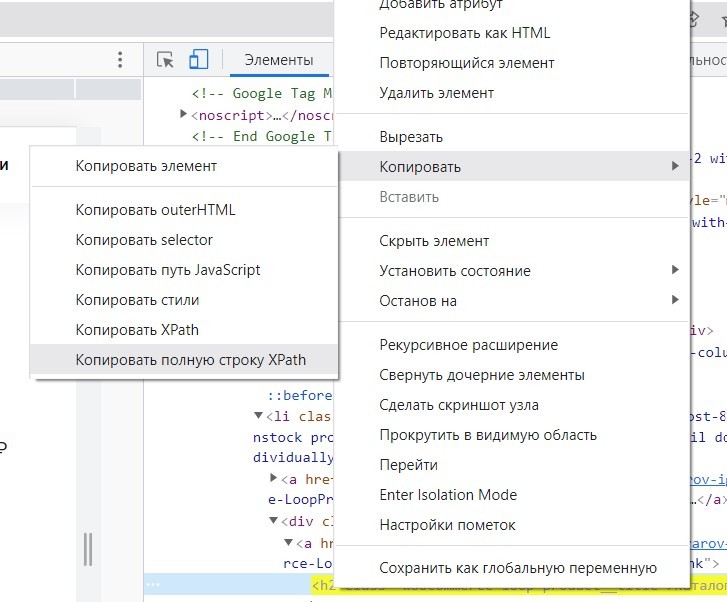
Можно получить этот путь сразу в расширении, нажав на пиктограмму ссылки и кликнув на нужный элемент на странице.
Работать с такими длинными путями не удобно и не на всех сайтах можно получить путь сразу ко всем элементам, в некоторых случаях его придется дорабатывать изучая особенности структуры сайта. Но составить путь к данным на много проще и быстрее. Тут нам нужно познакомится с синтаксисом Xpath.
Синтаксис Xpath
Относительный путь
Двойной слеш // — означает относительный путь и позволяет найти все варианты того, что вы ищете на странице. Таким образом — тк мы искали конечный элемент h2, то запись «//h2», даст тот же результат, что и длинный путь который мы написали в начале:
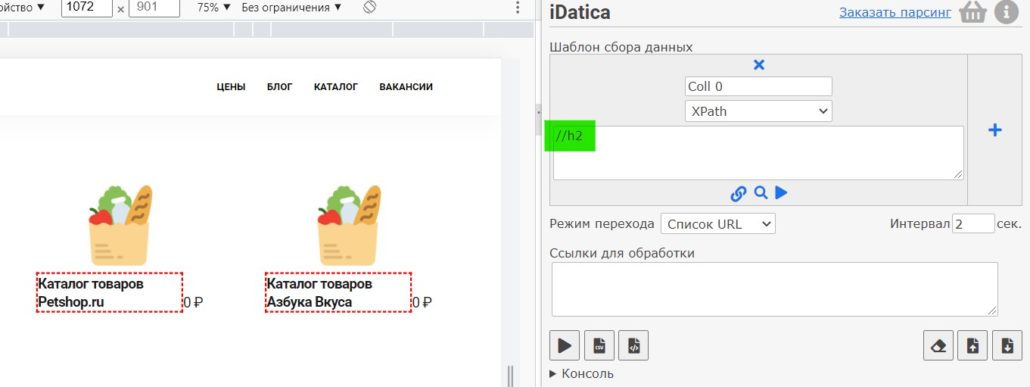
Таким образом можно обращаться к любым элементам на странице.
Условия поиска
Хорошо, идем дальше, скачаем цену. В коде она не обозначена одним элементом, как заголовок h2, цена находится в строковом элементе span, но их много на странице и они отвечают за разные данные, как нам обратиться к нужному?
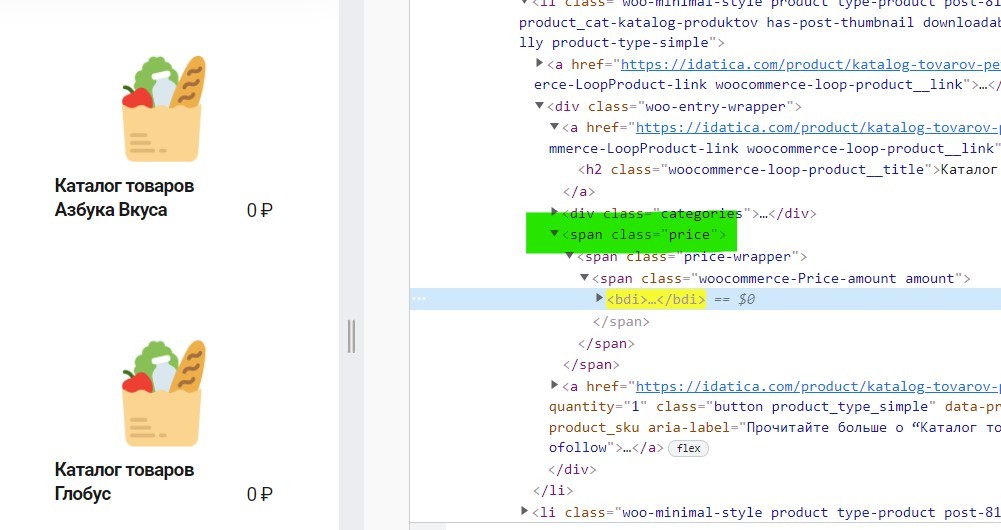
Если посмотреть на код то можно увидеть, что многие элементы на странице содержат атрибуты и названия, например, элемент цены — «span» имеет атрибут «class» с названием «price» — вот к этому названию мы и сможем обратиться. Для этого в квадратных скобках, после указания элемента который мы ищем, нужно прописать условия поиска этого элемента:
//span[@class="price"]Такая конструкция найдет все вложенные в этот элемент данные.
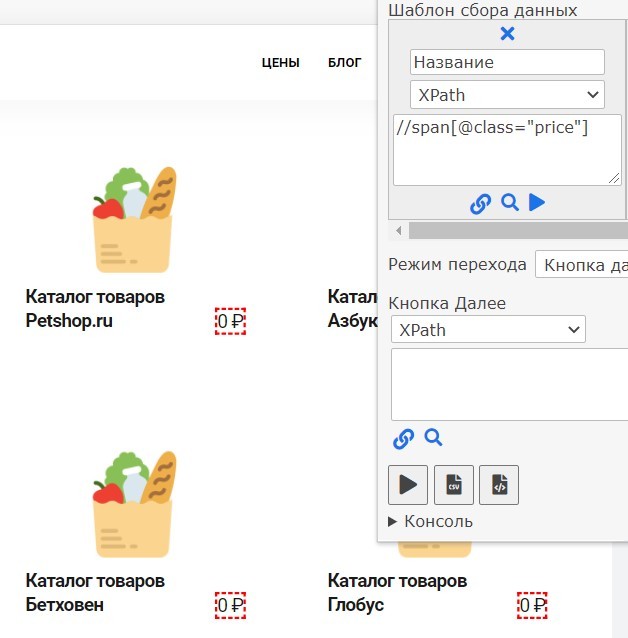
Таким образом можно обращаться ко всем элементам на странице, //div — будет искать во всех элементах «div», //a — во всех элементах «a» итд.
//* — будет искать во всех элементах
Поиск по части вхождения
Бывают ситуации, когда название атрибута не уникально, как например в списке категорий:
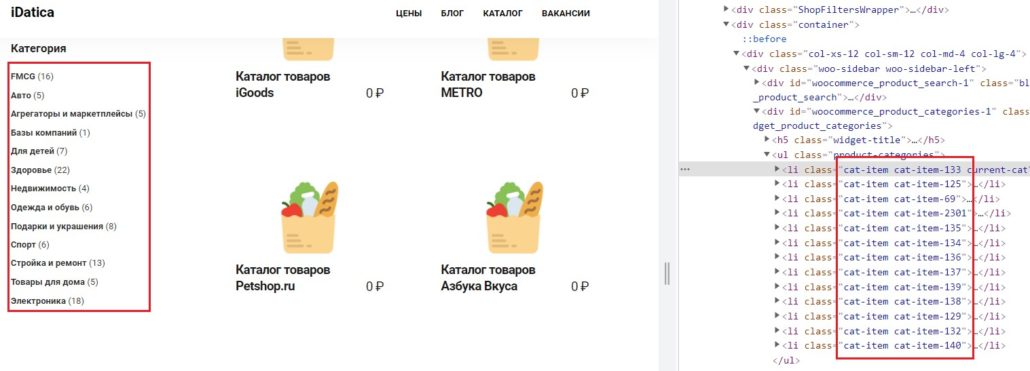
В таком случае можно искать нужные элементы по части вхождения, в данной ситуации — «cat-item», такие элементы найдет команда — «contains», обратите внимание в случае с «contains» элемент пишется в скобках и через «,» вместо «=».
//*[contains(@class,"cat-item")]При этом парсер захватит весь текст внутри элемента, т.е. и название и количество, чтобы получить только название нужно сузить поиск, указать, что внутри нужно взять только значения элемента «а»:

Необходимо через слеш указать дальнейший путь, вложенность может быть такой, какая вам необходима, в нашем случае:
//li[contains(@class,"cat-item")]/aСоответственно, если нужно получить только количество — обращаемся к элементу span:
//li[contains(@class,"cat-item")]/spanЕсли нужно получить данные из определенного элемента по счету, указываем номер элемента в квадратных скобках:
//*[contains(@class,"cat-item")][5]Чтобы получить первый элемент используем индекс — [1]
Получить только последний элемент — last():
/*[contains(@class,"cat-item")][last()]Поиск по тексту
Бывают ситуации, когда можно привязаться только к тексту на странце, в таком случае используем «text» позволяющий находить элементы с нужным текстовым вхождением. Например такая конструкция найдет все элементы в которых есть слово «Каталог»:
//*[contains(text(),'Каталог')]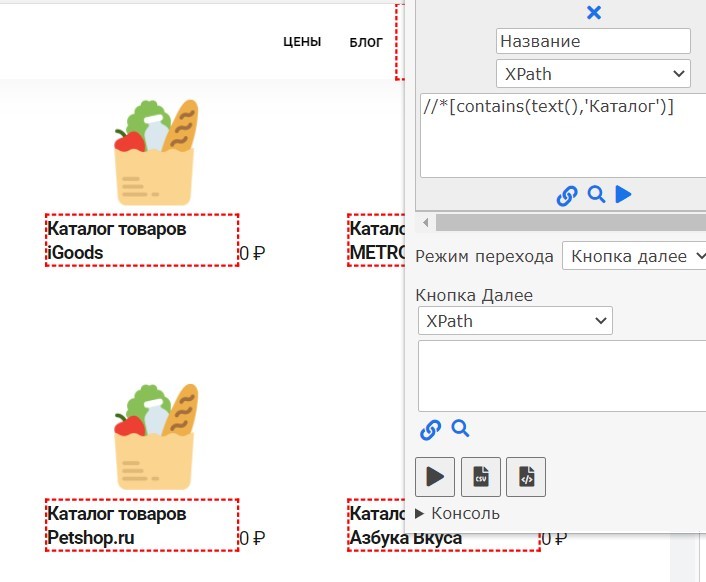
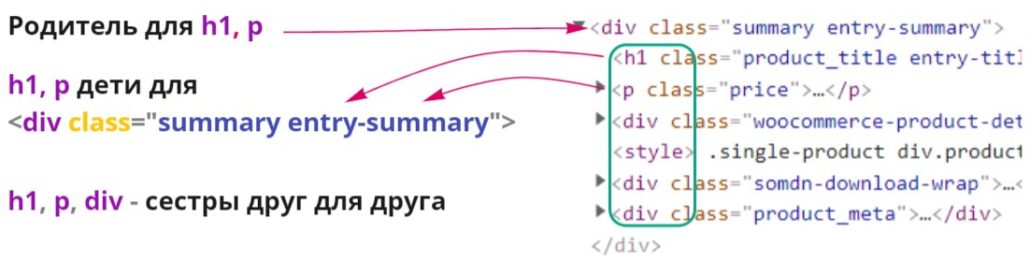
Родственные связи xpath
Можно сказать, что это уже продвинутые команды, они не часто требуются, но бывают ситуации когда они не заменимы. Html код представляет из себя древовидную структуру в которой одни элементы вложены в другие и xpath позволяет использовать вложенность элементов, чтобы поднимать или опускаться по такому дереву, для поиска нужного элемента. В терминах языка xpath элементы, которые содержат другие — являются предками (ancestor) по отношению к во всем вложенным в него. Вложенные в свою очередь — являются его потомками (descendant). Синтаксис использования будет такой — //начальный элемент/команда родственной связи::тег(фильтр) искомого элемента.
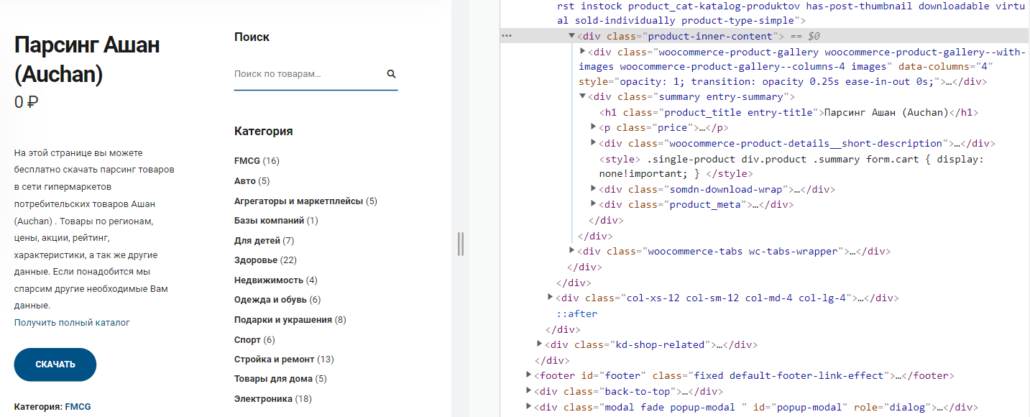
Родственные связи удобно использовать тогда, когда нет возможности привязаться к элементу, например класс не уникален, но рядом есть элемент за который можно «зацепиться». В приведенном примере можно найти нужные элементы проще, указывая вложенность последовательно перечисляя элементы, рассмотрим код в качестве примера работы команд. На примере этой страницы.
Sibling — cестринский элемент
Sibling перемещается к соседним элементам, расположенным на одном уровне. Бывают двух типов — preceding-sibling — сестринский элемент расположенный выше указанного и following-sibling – сестринский элемент, расположенный ниже указанного.
Например, получим цену отталкиваясь от заголовка:
//h1/following-sibling::pИ наоборот, получим заголовок отталкиваясь от цены:
//p[@class="price"]/preceding-sibling::h1Parent и child — родитель и ребенок
Команды позволяющие опускаться или подниматься на уровень. Уровней вложенности может быть несколько, если вам нужно спуститься или подняться на несколько уровней, используйте / в качестве разделителя.
Child — дети, элемент который является вложенным на один уровень вниз от родителя. Например, найдем цену от родительского элемента div:
//div[contains(@class,"entry-summary")]/child::pParent — родительский элемент позволяющий подниматься на уровень выше, находиться от вложенного элемента. Например, получим название категории с количеством товаров, отталкиваясь от названия категории:
//*[contains(text(),'Электроника')]/parent::liParent так же можно заменить на /.. те код выше будет выглядеть так:
//*[contains(text(),'Электроника')]/..Синтаксис и применение CSS для парсинга
CSS локаторы или стили, еще один вариант для получения данных с сайта. CSS удобно использовать тем, что можно указать класс элемента (если он уникален). Вернемся для примеров на эту страницу. Например, чтобы получить все названия достаточно написать стиль с точкой перед ним. Стиль можно посмотреть в инструменте разработчика на вкладке стили (не забудьте в расширении в типе селектора выбрать CSS):
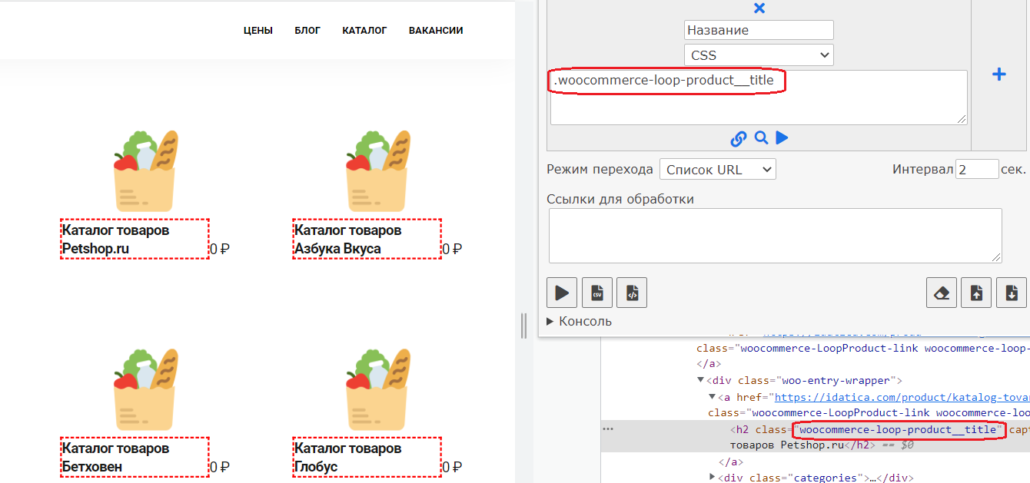
.woocommerce-loop-product__titleЧтобы получить цену, достаточно указать ее стиль: .price попробуйте, это просто.
id для поиска нужных данных
Далее перейдем на страницу поисковой выдачи, тк она содержит нужные нам элементы. Если в коде элементы размечены id, то достаточно указать символ # и значение id:
#hdtbMenus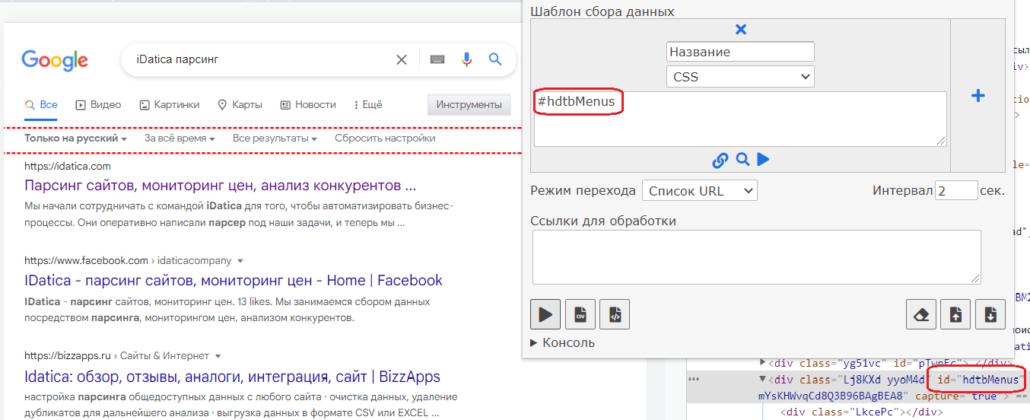
Поиск по значению атрибутов
Поиск по значению атрибутов применяется тогда, когда нет уникального класса или id является сгенерированным. Синтаксис: элемент[атрибут=»значение атрибута»]. Например:
div[class="KTBKoe"]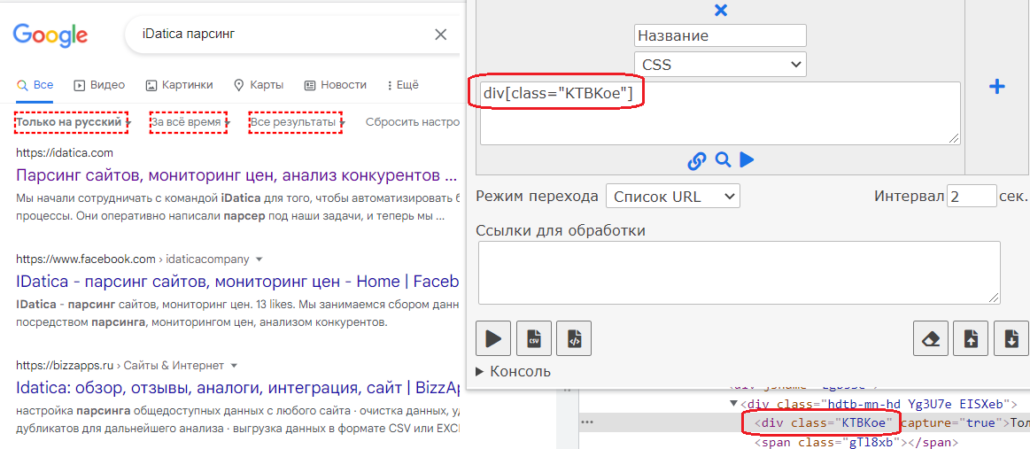
Поиск по частичному вхождению
Бывают случаи когда нужно использовать значение атрибута не циликом, а частично, например в случае когда множество элементов содержит общую часть. Рассмотрим на примере кода написаного выше, все предложенные варианты дадут тоже результат.
Если известна часть значения распологающаяся в любой его части, используется *
div[class*="TBKo"]Если нужно искать по начальной части значения, испоьзуется ^
div[class^="KTB"]Если нужно искать по конечной части значения, испоьзуется $
div[class$="Koe"]Если в значении слова разделены пробелом одно из которых точно известно, используется ~
div[class~="KTBKoe"]Родственные связи CSS
Принцип тот же, что и в xpath. Если нужно получить значение вложеного элемента, на уровень ниже используем >
div[class="Lj8KXd yyoM4d"]>spanЕсли нужно получить значение вложеного элемента, на уровень ниже используем пробел
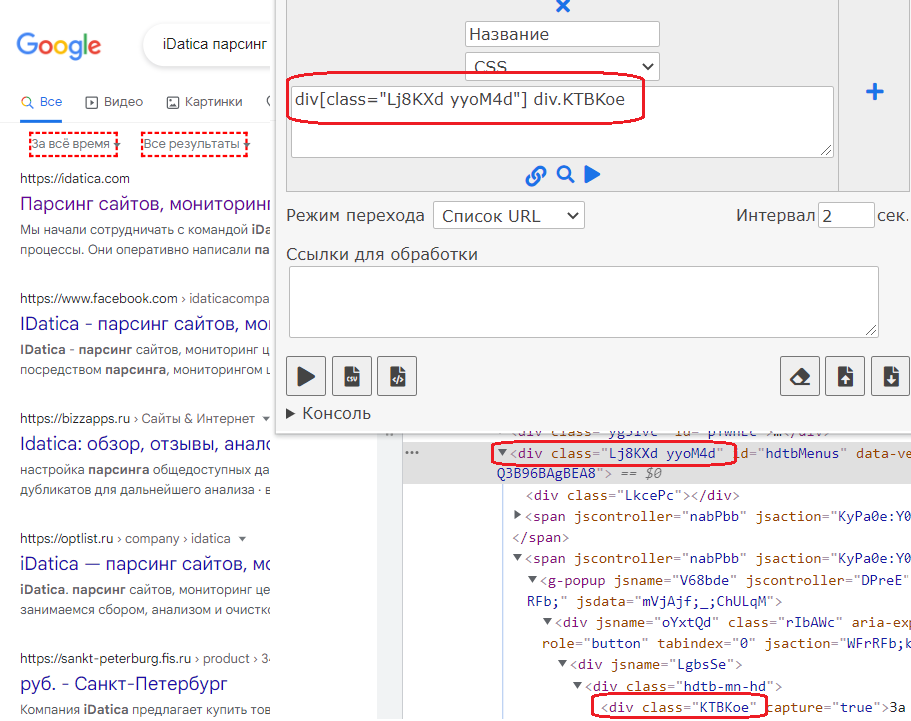
div[class="Lj8KXd yyoM4d"] div.KTBKoeCSS не позволяет найти родителя, тк поиск идет сверху вниз.
Возможности Xpath и CSS гораздо шире, но рассмотренные примеры хорошая база, каторая позволит решать большинство задач. Вы всегда можете поискать готовый пресет в нашем каталоге или если ваши задачи более масштабны, то обратиться за парсингом данных к нашим специалистам.
![]()
Загрузить PDF
![]()
Загрузить PDF
XPath-путь к элементам сайта можно найти в большинстве браузеров с помощью инструментов разработчика. Firebug для Firefox позволит скопировать XPath-путь непосредственно в буфер обмена. В большинстве других браузеров XPath-путь к элементу можно найти посредством инструментов разработчика, но его придется форматировать вручную.
-

1
Установите Firebug для Firefox. Firebug является веб-инспектором для Firefox.
- Нажмите кнопку меню Firefox (☰) и выберите «Дополнения».
- Нажмите «Получить дополнения» – «Посмотрите больше дополнений».
- Найдите расширение Firebug и нажмите «Добавить в Firefox».
- Подтвердите, что вы хотите установить Firebug, а затем перезапустите Firefox (по запросу).
-
2
Откройте нужный веб-сайт. Firebug можно использовать для поиска XPath-пути к любому элементу сайта.
-
3
Нажмите кнопку Firebug. Она находится в правом верхнем углу окна браузера. В нижней части окна Firefox откроется панель Firebug.
-
4
Нажмите кнопку инспектора элементов. Она находится в верхнем ряду кнопок на панели Firebug (справа от кнопки «Параметры Firebug»). Значок этой кнопки имеет вид прямоугольника с курсором.
-
5
Щелкните по нужному элементу веб-страницы. По мере перемещения курсора по веб-странице на панели Firebug будут выделяться различные элементы. Остановитесь на элементе, XPath-путь к которому нужно узнать.
-
6
Щелкните правой кнопкой мыши по выделенному коду на панели Firebug. Если щелкнуть по нужному элементу веб-страницы, на панели Firebug выделится соответствующий код. Щелкните правой кнопкой мыши по выделенному коду.
-
7
В меню выберите «Копировать XPath». XPath-путь скопируется в буфер обмена.
- Если в меню выбрать «Скопировать мини-XPath», будет скопирован только короткий XPath-путь.
-
8
Вставьте скопированный XPath-путь куда нужно. Скопированный путь можно вставить куда угодно; для этого щелкните правой кнопкой мыши и в меню выберите «Вставить».
Реклама








-
1
Откройте нужный веб-сайт. В Chrome не нужны никакие расширения, чтобы найти XPath-путь к любому элементу веб-сайта.
-
2
Нажмите F12, чтобы открыть веб-инспектор. Он отобразится в правой части окна.
-
3
Нажмите кнопку инспектора элементов. Она находится в верхнем левом углу панели веб-инспектора. Значок этой кнопки имеет вид прямоугольника с курсором.
-
4
Щелкните по нужному элементу веб-страницы. По мере перемещения курсора по веб-странице на панели веб-инспектора будут выделяться различные элементы.
-
5
На панели веб-инспектора щелкните правой кнопкой мыши по выделенному коду. Если щелкнуть по нужному элементу веб-страницы, на панели веб-инспектора выделится соответствующий код. Щелкните правой кнопкой мыши по выделенному коду.
-
6
В меню выберите «Копировать» – «Копировать XPath». XPath-путь выбранного элемента скопируется в буфер обмена.
- Обратите внимание, что будет скопирован короткий XPath-путь. Расширенный путь можно скопировать с помощью расширения Firebug для браузера Firefox.
-
7
Вставьте скопированный XPath-путь. Скопированный путь можно вставить как любую другую информацию; для этого щелкните правой кнопкой мыши и в меню выберите «Вставить».
Реклама







-
1
Откройте меню Safari и выберите «Настройки». Чтобы получить доступ к веб-инспектору, нужно активировать функцию «Разработка».
-
2
Перейдите на вкладку «Дополнительно». Откроются расширенные настройки Safari.
-
3
Отметьте опцию «Показать меню разработки в строке меню». В строке меню отобразится меню «Разработка».
-
4
Откройте нужный веб-сайт. Закройте настройки Safari и перейдите на нужный веб-сайт.
-
5
Откройте меню «Разработка» и выберите «Показать веб-инспектор». Панель веб-инспектора откроется в нижней части окна.
-
6
Нажмите «Запустить поиск элемента». Эта кнопка имеет значок в виде перекрестья и находится в верхнем ряду кнопок на панели веб-инспектора.
-
7
Щелкните по нужному элементу веб-сайта. Код элемента будет выделен на панели веб-инспектора.
-
8
В верхней части панели веб-инспектора обратите внимание на XPath-путь. Скопировать XPath-путь нельзя, но расширенный путь отобразится над кодом на панели веб-инспектора. Каждая вкладка является формулой пути.[1]
Реклама








-
1
Откройте нужный веб-сайт. В IE не нужны никакие расширения, чтобы найти XPath-путь к любому элементу веб-сайта. Сначала откройте нужный веб-сайт.
-
2
Нажмите F12, чтобы открыть инструменты разработчика. Панель инструментов разработчика отобразится в нижней части окна браузера.
-
3
Нажмите «Выбрать элемент». Эта кнопка находится в левом верхнем углу панели инструментов разработчика.
-
4
Щелкните по нужному элементу веб-страницы. Будут выделены элемент и его код (на панели инструментов разработчика).
-
5
В нижней части панели обратите внимание на XPath-путь. Каждая вкладка (отображаются в нижней части панели) является формулой пути к выбранному элементу. Скопировать XPath-путь нельзя (это можно сделать с помощью расширения Firebug для браузера Firefox).
Реклама





Об этой статье
Эту страницу просматривали 17 538 раз.
Была ли эта статья полезной?
Любая страница в интернете — это по сути HTML-код, который по-другому называют «исходный код».
В нём можно посмотреть некоторую полезную информацию для SEO. Например, как прописаны теги и метатеги, вроде title, description и Last-Modified, установлены ли счётчики аналитики и многое другое. Посмотреть код можно и с компьютера, и с телефона.
Покажем, как вызвать код страницы и как найти любой элемент в коде.
Что такое исходный код страницы и зачем его смотреть
Код страницы — это структура тегов, в которой зашифрованы все видимые и невидимые элементы контента: тексты, изображения, счётчики, скрипты и т. д.
HTML-код сайта выглядит так:

Просмотр кода поможет выявить ошибки, найти баги в отображении отдельных элементов или подсмотреть интересные SEO-решения у конкурентов.
Как посмотреть код сайта с компьютера
Покажем на примере самых популярных браузеров: Google Chrome, Яндекс.Браузер, Apple Safari, Microsoft Edge, Mozilla Firefox, Opera. Но принцип одинаковый во всех браузерах.
Google Chrome
Чтобы открыть код страницы в браузере, достаточно нажать комбинацию клавиш:
- на Windows — Ctrl + U;
- на Mac — Cmd (⌘) + Option (⌥) + U.
Если не любите горячие клавиши, то можно кликнуть правой кнопкой мыши на странице и в открывшемся меню выбрать пункт «Просмотр кода страницы»:
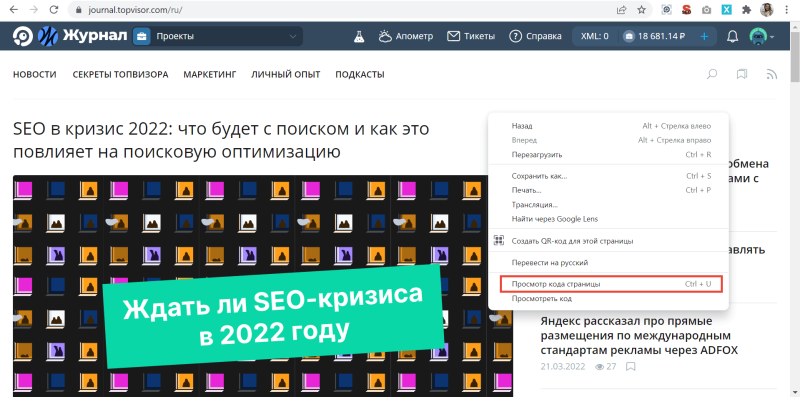
Откроется новая вкладка с кодом.
Можно и по-другому — через меню браузера. Для этого нужно кликнуть на три вертикальные точки в правом верхнем углу окна и перейти в «Дополнительные инструменты» → «Инструменты разработчика».
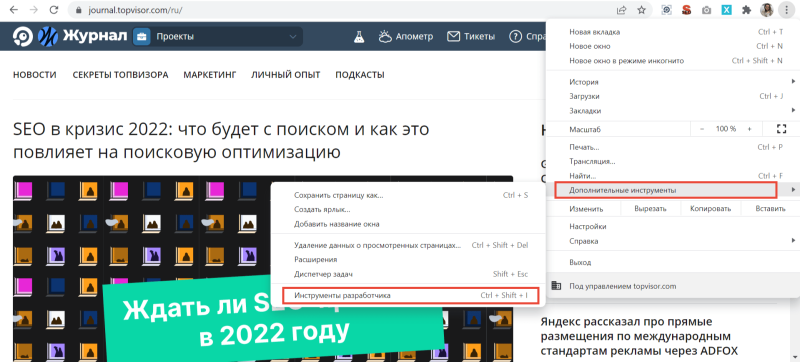
В этом случае код откроется справа или снизу на той же вкладке. При клике на отдельные его части, на странице подсветится соответствующий элемент сайта.
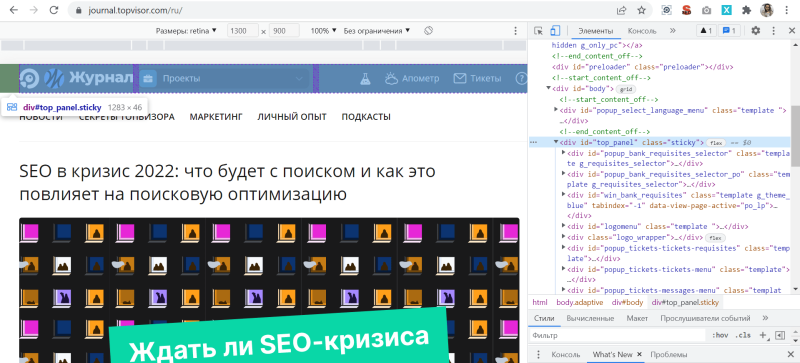
Более быстрые способы сделать то же самое:
- с помощью горячих клавиш Ctrl + Shift + I на Windows, Cmd (⌘) + Option (⌥) + I на Mac;
- правой кнопки мыши, кликнув «Просмотреть код».
Яндекс.Браузер
Первый способ посмотреть код страницы в Яндекс.Браузере — с помощью правой кнопки мыши. В меню нужно выбрать пункт «Посмотреть код страницы».
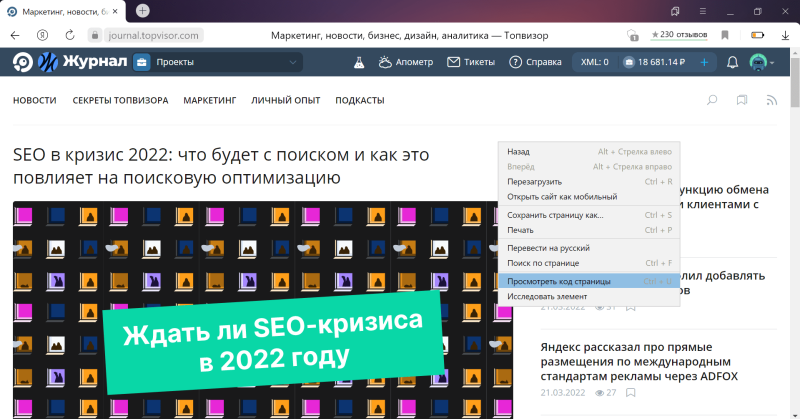
Второй — через меню браузера. Для этого необходимо кликнуть на три горизонтальные полоски в верхнем правом углу, затем «Дополнительно» → «Дополнительные инструменты» → «Посмотреть код страницы».
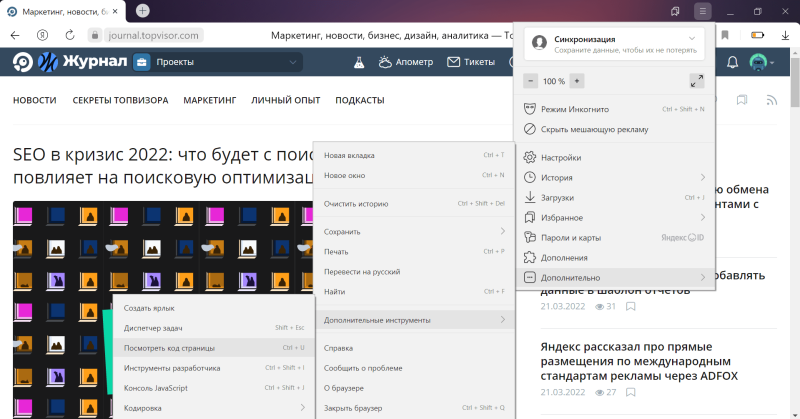
В обоих случаях код откроется в отдельной вкладке. Также код можно посмотреть с помощью горячих клавиш Ctrl + U.
Чтобы открыть код в той же вкладке, что и просматриваемая страница, вместо «Посмотреть код страницы» нужно выбрать пункт «Инструменты разработчика» или нажать Ctrl + Shift + I на Windows, Cmd (⌘) + Option (⌥) + I на Mac, как и в Chrome.
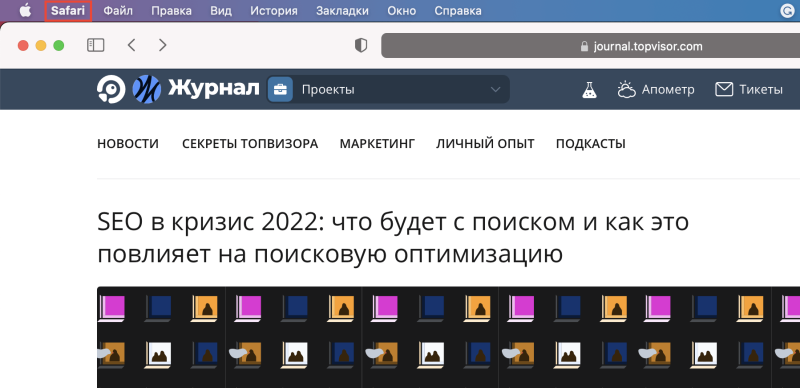
Apple Safari
Для просмотра кода в Safari необходимо сначала войти в «Настройки» браузера, кликнув по надписи Safari в верхнем левом углу экрана.
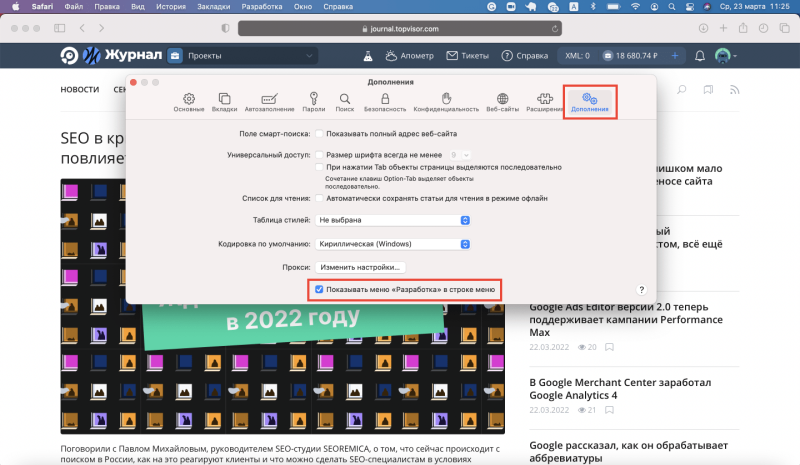
Затем в открывшемся окне выбрать раздел «Дополнительно» и поставить галочку напротив «Показывать меню «Разработка» в строке меню» в нижней части окна:
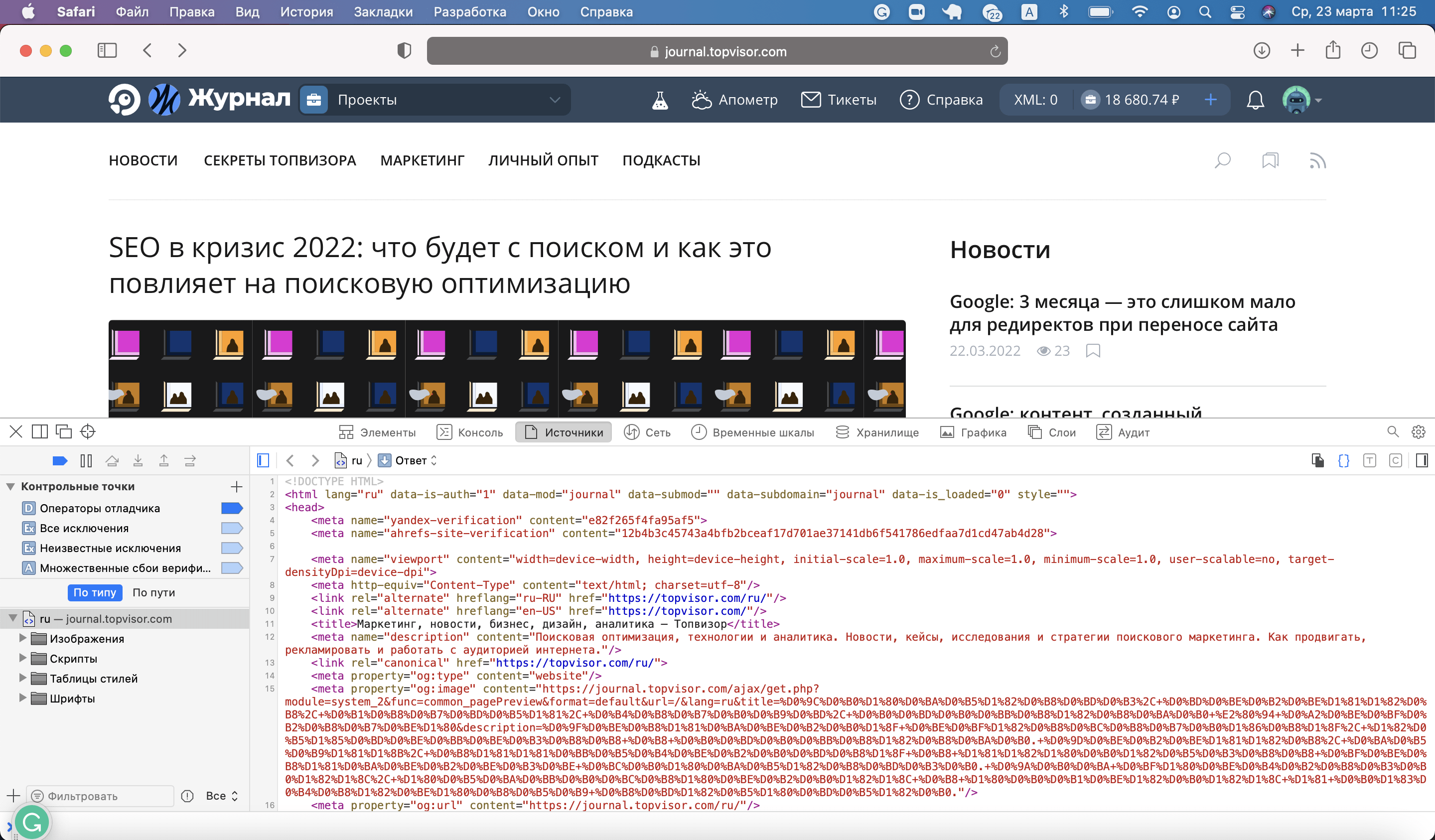
После этого в верхнем меню окна появится вкладка «Разработка», в которой для просмотра кода страницы необходимо кликнуть на пункт «Показать программный код страницы»:

Код откроется в нижней части страницы:
Microsoft Edge
Просмотреть код в Microsoft Edge можно с помощью правой кнопки мыши → команда «Просмотреть исходный код»:

Код откроется в новой вкладке. Можно и с помощью горячих клавиш Ctrl + U.
Также его можно посмотреть через меню браузера. Для этого нужно в правом верхнем углу кликнуть на три горизонтальные точки и выбрать команду «Другие инструменты» → «Средства разработчика»:
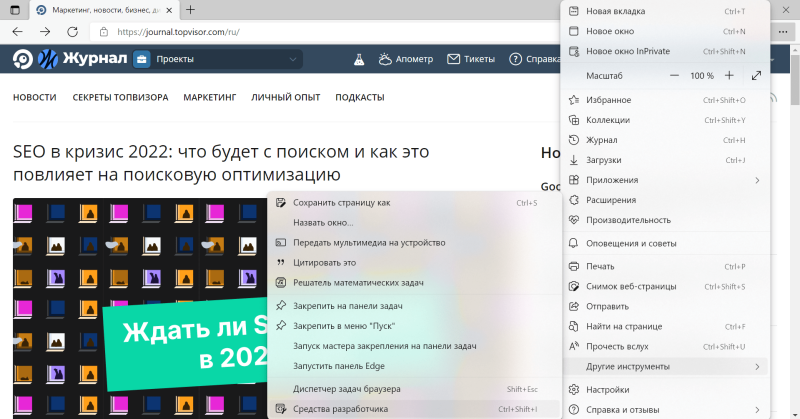
Панель откроется снизу или справа на просматриваемой странице. Чтобы увидеть код, нужно выбрать вкладку «Элементы»:
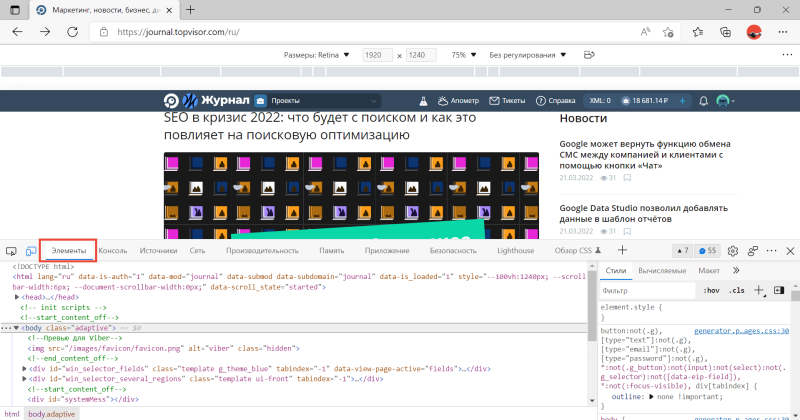
Горячие клавиши здесь тоже работают: Ctrl + Shift + I на Windows, Cmd (⌘) + Option (⌥) + I на Mac.
Mozilla Firefox
Код открывается в отдельной вкладке с помощью правой кнопкой мыши по команде «Исходный код страницы»:
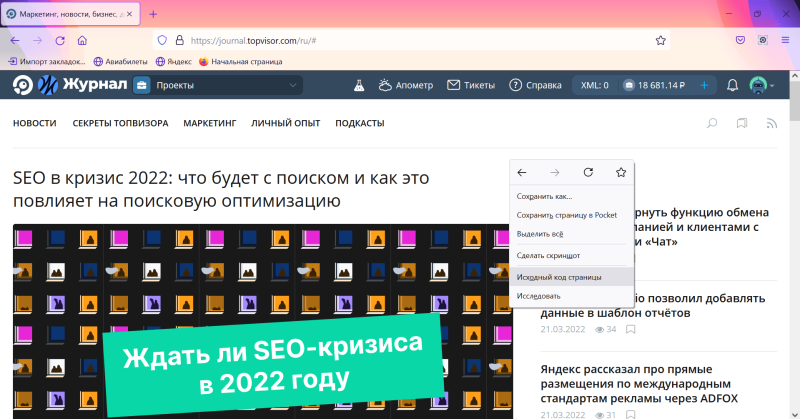
Также открыть исходный код в отдельной вкладке можно через меню браузера. Для этого в правом верхнем углу кликните на три горизонтальные черты и в открывшемся меню выберите команду «Другие инструменты» → «Исходный код страницы»:
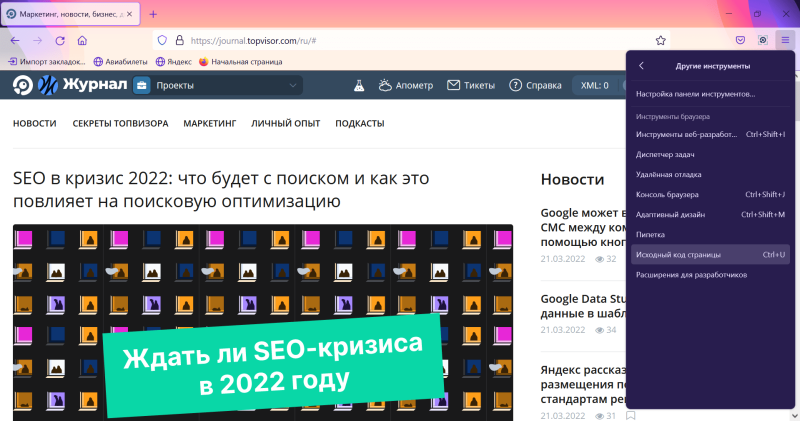
А можно и просто нажать горячие клавиши Ctrl + U — это работает во всех браузерах.
Инструменты разработчика здесь тоже можно открыть горячими клавишами Ctrl + Shift + I на Windows, Cmd (⌘) + Option (⌥) + I на Mac или кликнув правой кнопкой мыши и выбрав пункт «Исследовать»:
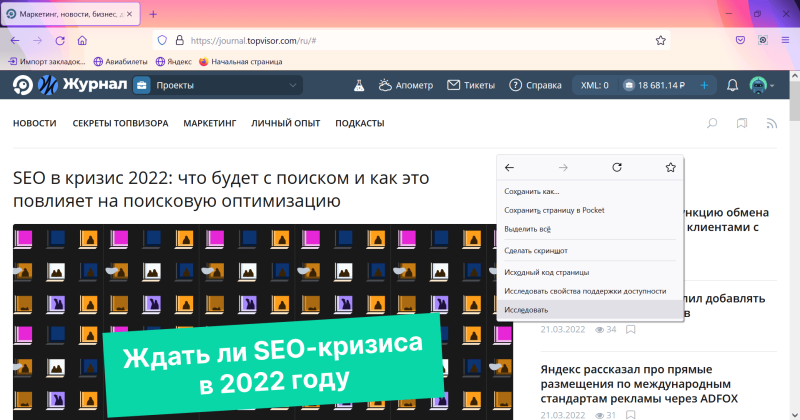
Панель откроется снизу или справа на странице.
Opera
В последних версиях Opera просмотр кода страницы доступен по клику правой кнопкой мыши, с помощью горячих клавиш или с помощью инструментов разработчика.
Чтобы открыть код, кликните правой кнопкой мыши в любой части страницы и выберите команду «Исходный текст страницы»:
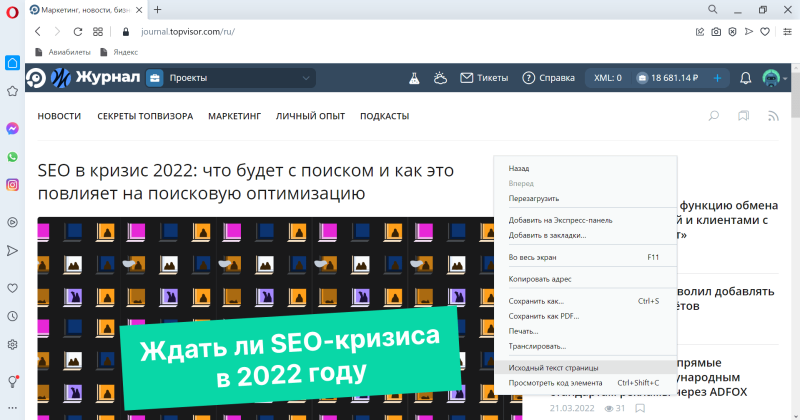
То же самое можно сделать сочетанием клавиш Ctrl + U.
Чтобы открыть инструменты разработчика, в этом же меню можно выбрать «Проверить код элемента» или нажать комбинацию горячих клавиш Ctrl + Shift + I на Windows, Cmd (⌘) + Option (⌥) + I на Mac.
Как посмотреть код страницы на телефоне
Способы отличаются в зависимости от операционной системы телефона.
Android
Открыть код элемента на телефоне можно с помощью команды view-source, которую необходимо добавить перед URL в адресную строку:
view-source:https://site.ru/page-1
Во вкладке откроется исходный код страницы:
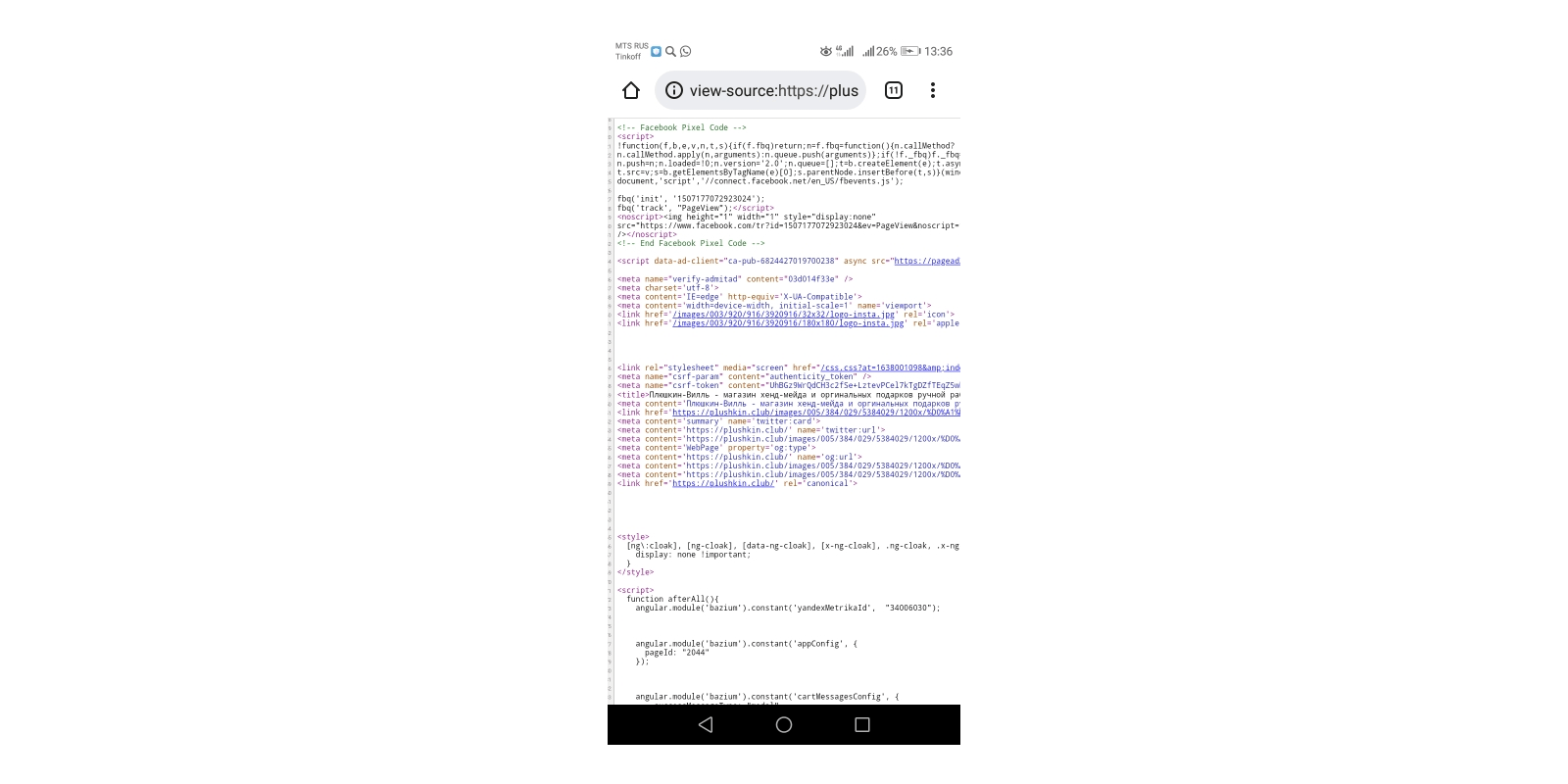
Открыть инструменты разработчика подобным способом не получится. Если это необходимо, установите специальные приложения. Например, VT View Source.
iOS
На iPhone ни в Safari, ни в Google Chrome по команде «view-source:» код не откроется. Необходимо установить специальные приложения для просмотра кода. Например, HTML Viewer Q или iSource Browser.
iSource Browser — полноценный браузер для iOS, с помощью которого можно просматривать HTML-код страниц:
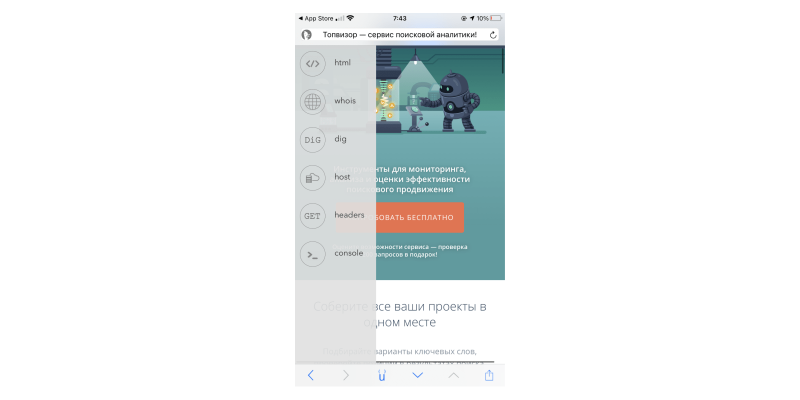
Как найти любой элемент в коде
Чтобы найти что угодно в открытом исходном коде, откройте поиск по странице. Обычно это можно сделать сочетанием клавиш Ctrl + F или через меню браузера и команду «Найти…» или «Найти на странице…»:
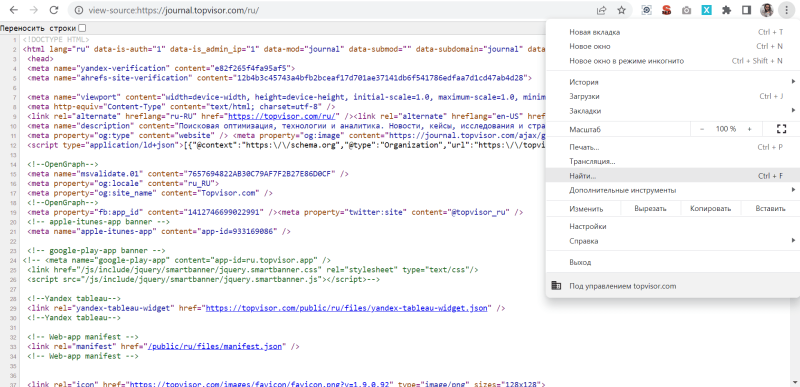
В открывшемся окошке введите начало фразы или тег, который хотите найти. Например, viewport:
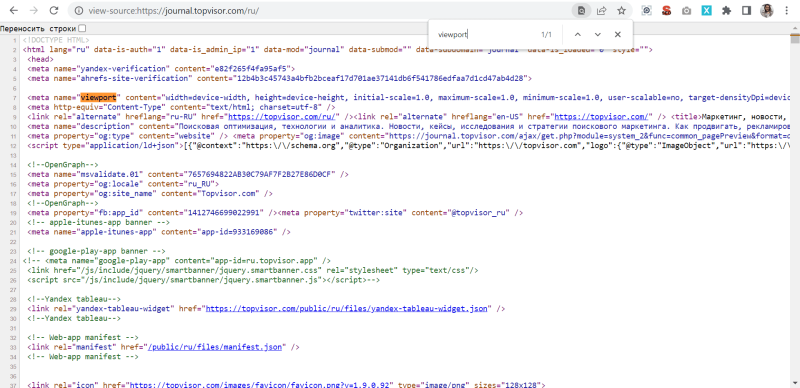
Найденный элемент браузер выделит цветом.
Продолжение: На какие элементы в исходном коде обращать внимание SEO-специлисту
Мы уже пишем другие интересные и полезные статьи для вас. Подписывайтесь на наш Телеграм-канал, чтобы читать новые статьи первыми.
Подписаться