Содержание
- Как проверить расположение элемента на компьютере
- Почему пишет не удается удалить папку элемент не найден
- Проверка прав на папку
- Ремонт реестра
- Переименовывание файла
- Элемент не найден. Не удалось найти этот элемент
- 1. Удалить проблемный файл
- 2. Переименовать файл
- 3. Удалить папку или файл
- «Не удалось найти этот элемент. Его больше нет в «E:». Проверьте расположение элемента и повторите попытку» — ошибка при попытке удалить папку
- Что можно посоветовать для устранения ошибки
- Причины возникновения и способы решения ошибки «Элемент не найден»
- Причины и решение
- Заключение
- Не удалось найти этот элемент, он больше не находится в пути ошибки в Windows 10
- Не удалось найти этот предмет, он больше не находится в пути
- 1] Удалить проблемный файл
- 2] Переименовать файл
Как проверить расположение элемента на компьютере

Добрый день! Уважаемые читатели и гости блога pyatilistnik.org. Не так давно мы с вами разбирали тему, установки windows 8.1 с флешки, лично для меня данная операционная система является самой подходящей, но это на любителя. В какой-то момент вы можете столкнуться с проблемой, что у вас не удаляется папка, хотя все права на нее есть. ОС сообщает вам, что не удалось найти этот элемент, хотя он у вас перед глазами. Давайте разбираться как это решить и удалить не нужный элемент. Кстати такую проблему вы можете встретить и в Windows 10 и в семерке.
И так, у меня есть папка на рабочем столе, которую я планировал удалить, но когда вы нажимаете клавишу Delete, вам выскакивает вот такое предупреждение:

Нажатие кнопки «Повторить попытку» не дадут ни каких результатов. Давайте разбираться как удалить папку которая не удаляется.
Почему пишет не удается удалить папку элемент не найден
Ответ очень простой, это очередной глюк операционной системы Windows, коих очень много, вспомните хоть случай со сценарием run vbs. Возможные причины:
Проверка прав на папку
Если вы видите сообщение не удалось найти этот элемент, проверим права, делается это просто, щелкаете правым кликом по папке и выбираете свойства.

Переходите на вкладку «Безопасность» и в идеале вы должны увидеть вот такое окно, где вы видите у кого какие права и есть возможность их изменить, добавим себе полный доступ.

В случае с ошибкой: Не удалось найти этот элемент. Его больше нет. Проверьте расположение этого элемента и повторите попытку, вы увидите вот такую красоту:
Как видите прав вам поменять не дадут, давайте искать другие методы решения.

Ремонт реестра
Про оптимизацию реестра я уже не однократно писал, можете посмотреть вот тут и тут. Там все подробно описано, так, что не будем на этом останавливаться. Если у вас и после этого не удаляется папка, то делаем следующий пункт.
Переименовывание файла
Вы наверняка читали в новостях, что разные мобильные устройства из-за специфического сочетания текста в сообщениях или именах, можно сломать, примером может служить недавний случай с Apple. В Windows 8.1 или 10, все тоже самое. Для устранения проблемы пробуем переименовать папку. Делается это через клавишу F2 (Полный список возможностей на клавиатуре с помощью комбинаций, читайте в статье про горячие клавиши Windows)
Лично я при выполнении этой операции, так же получил сообщение, что опять не удалось найти этот элемент, видимо, что-то блокирует данный элемент в системе, идем дальше. В таких ситуациях я использую некоторые утилиты:
Начнем c Total Commander, я не буду описывать, где ее взять, думаю вы все умеете пользоваться Google. После того как вы скачаете и запустите его, вам необходимо перейти в то место, где у вас располагается папка, которую не получается удалить средствами Windows. У меня это рабочий стол, для перемещения между дисками, в самом верху есть соответствующие значки дисков.
Свою папку я обнаружил, пробуем ее удалить.

щелкаем правым кликом по ней? из контекстного меню выбираем пункт «Удалить»


Все у меня папка удалилась без каких либо проблем, что еще раз подтверждает, что права на нее были и, что это явный косяк Windows. Если вы запустите Far, то там будет все так же. Если вам это не помогло, это бывает очень редко, то попробуйте утилиту Unlocker, ее смысл в том, что она проверяет нет ли каких либо блокировок со стороны программ или процессов, кто мог бы взаимодействовать с вашей папкой, и если они есть, то утилита просто эту связь разрывает.
Когда откроется Unlocker, он вас попросит указать папку или файл, который требуется проверить на блокировку процессом.

У вас откроется следующее окно, в котором будут вот такие действия:
Выбираем нужный пункт и пробуем. По идее это должно помочь в решении проблемы с невозможностью удалить папку и сообщением, что его больше нет. Проверьте расположение этого элемента и повторите попытку.
Источник
Элемент не найден. Не удалось найти этот элемент

1. Удалить проблемный файл
Смотрите, смысл заключается, чтобы запустить командную строку или PowerShell в самой папке, где находится проблемный файл, который нужно удалить. Как показано выше на картинке, ошибка у меня в файле mywebpc.ru, я его нахожу через поиск и открываю местоположение файла или вручную захожу по пути, так как я знаю, где он лежит. Далее нажмите правой кнопкой мыши на поле в папке, где находится проблемный файл, и выберите из контекстного меню «Открыть окно PowerShell здесь«.
Хочу заметить, что у вас может быть не PowerShell, а «Запустить CMD Здесь». Разницы нет.

В окне CMD или PowerShell задайте следующую команду:
Как только команда будет успешно выполнена, файл будет удален с вашего компьютера.

Другим обходным решением выше описанного метода является то, что вы перемещаете неисправный файл в новую пустую папку, а затем пытаетесь удалить папку. В некоторых случаях это может сработать и снова сделать файл удаляемым.
2. Переименовать файл
Если вы не хотите удалять файл, и хотите его использовать в дальнейшем, то вы можете попробовать переименовать его, а затем открыть его с помощью других программ. Данный метод не будет работать в PowerShell. Если у вас нет «Запустить командную строку здесь», как описано выше способом, то просто запустите CMD и задайте путь, где находится проблемный файл или папка. К примеру, у меня файл лежит в корне диска E. Я запускаю командную строку и пишу:
Файл будет переименован, и вы сможете получить к нему обычный доступ.

3. Удалить папку или файл
Выше указанные способы мне помогали много раз, но как-то я не смог ими добиться решения этой проблемы, и предложу вам другой быстрый и надежный способ. Наверняка у большинства из вас, стоит архиватор winrar или zip и т.п. Так вот, открываете папку или файл, который выдает ошибку, что «Элемент не найден. Не удалось найти этот элемент» и нажимаете на нем правой кнопкой мыши и добавляем в архив.

Далее поставьте галочку «Удалить файлы после упаковки«. После чего создастся архив, а те удалятся. Архив тоже можно удалить, если он вам не нужен.
Хочу заметить, что открыв проблемные файлы через архиватор, можно переименовать и попробовать удалить их.
Источник
«Не удалось найти этот элемент. Его больше нет в «E:». Проверьте расположение элемента и повторите попытку» — ошибка при попытке удалить папку
 Доброго дня!
Доброго дня!
Вообще, чаще всего это происходит из-за:
Собственно, не так давно и сам сталкивался с этой ошибкой. Чуть ниже приведу несколько шагов для устранения оной. Инструкция должна помочь в не зависимости от причины. 😉

Не удалось найти этот элемент. Его больше нет в «E:». Проверьте расположение элемента и повторите попытку (пример ошибки)
Что можно посоветовать для устранения ошибки
👉 ШАГ 1
Банально, но самая первая рекомендация — просто перезагрузить компьютер (ноутбук).
Нередко, когда ошибка связана с некорректной работой проводника и файловой системы («не удаляемый» элемент (файл/папка) — после перезагрузки начнет «вести» себя, как и все остальные, и вы без труда удалите ее. ).

Перезагрузка компьютера / Windows 10
👉 ШАГ 2
Далее скопировать путь до той папки, которая не удаляется классическим способом (в моем случае «C:111»).

Копируем путь до папки, которую удаляем
После, в командной строке потребуется написать следующее: RD /S «C:111» (и нажать Enter).
Это команда удалит и сам указанный каталог, и все файлы, что в нем есть. Будьте аккуратны, т.к. командная строка не всегда переспрашивает.

Пример удаления каталога
Более подробно о том, как избавиться от папки/файла с помощью командной строки
👉 ШАГ 3
Еще один весьма действенный способ решения вопроса — воспользоваться безопасным режимом загрузки Windows (при нем будут запущены только самые необходимые приложения и службы). И уже из-под него попробовать удалить нужные файл/папку.
Подробно не останавливаюсь — ссылка ниже поможет загрузить ОС в нужном режиме (работа же в нем не отличается от обычного режима).
Как зайти в безопасный режим в Windows 7÷10 — см. инструкцию.
👉 ШАГ 4
Есть один замечательный коммандер (👉 речь о FAR) для работы с большим количеством файлов. Сейчас для многих он смотрится как анахронизм, но поверьте — эта штука до сих пор делает некоторые вещи надежнее, чем проводник!
Так вот, если в нем выделить «проблемный» элемент (скажем, папку) и нажать сочетание ALT+DEL — то запустится функция Wipe (уничтожение файла). Она отлично справляется со своей задачей (даже с весьма проблемными файлами), рекомендую попробовать!
Примечание : будьте аккуратнее с этим способом, т.к. файлы будут удалены, минуя корзину.

Far Manager — пример удаления папки
👉 ШАГ 5
Программы для удаления не удаляемых файлов и папок — моя подборка

Как удалить папку в Unlocker
👉 ШАГ 6
Разумеется, после, вы сможете «прошерстить» все свои накопители на компьютере и удалить с них любые файлы. Только будьте аккуратнее, т.к. при работе с LiveCD вы сможете удалять и системные, и обычные, и скрытые файлы.
LiveCD для аварийного восстановления Windows — моя подборка (там же в заметке указано как подготовить такой накопитель)

Какие программы есть на диске «Стрельца. » // Пример рабочего стола при загрузке с LiveCD-флешки
Если из вышеперечисленного ничего не помогло — проверьте свой диск на ошибки (в ряде случаев при возникновении «потерянных элементов» могут быть найдены ошибки файловой системы. При проверке, кстати, они исправляются автоматически).
Если удалось вопрос решить иначе — дайте знать ⇓ (заранее спасибо!).
Источник
Причины возникновения и способы решения ошибки «Элемент не найден»
Залогом стабильной работы операционной системы, в числе прочих, является постоянное поддержание её «чистоты». Под этим термином можно понимать многое, но одним из ключевых элементов выступает своевременное удаление файлов и папок, попросту засоряющих операционную систему. Но достаточно часто попытка пользователей удалить какой-либо файл или папку может сопровождаться целым рядом различных ошибок, которые могут отнять много сил и нервных клеток. В настоящей статье речь пойдёт об одном из представителей названых выше проблем, который сопровождается текстовым сообщением в виде «Не удалось найти этот элемент» или «Элемент не найден», а также о существующих способах его исправления.

Исправление ошибки «Элемент не найден в Windows».
Причины и решение
Не каждый пользователь может самостоятельно разобраться в том, почему не удалось найти этот элемент и как удалить его со своего компьютера. Для ответа на этот вопрос нужно сначала разобраться в причинах появления подобной ошибки. Из этого во многом следует путь решения проблемы.
При работе с Windows 10, столкнувшись с ошибкой «Элемент не найден», от слов нужно переходить к действиям.
Итак, причины могут быть достаточно прозаичными, например, проблемного файла или папки попросту нет, о чём и свидетельствует операционная система. При этом стоит отметить, что рассматриваемая ошибка может возникать не только при попытках удаления, но и при желании открыть, скопировать или перенести что-то. И если проблематика заключается в этом, то первое, что необходимо сделать, это просто обновиться, нажав кнопку F5, или перезайти в место расположения файла и проверить его доступность.
Поскольку элемент не найден, нужно искать решения, как удалить файл и очистить компьютер от разного мусора и ненужных программ, папок и пр. Как оказалось, проблема не такая банальная, как хотелось бы. Если ситуация осталась прежней, тогда следует попробовать воспользоваться следующими возможными вариантами. Они актуальны в ситуациях, когда не удаляется папка, а попытка деинсталляции сопровождается сообщением о том, что элемент не найден. Итак, выполняем действия:
Для его использования не требуется наличие каких-то определённых специфичных познаний, и вариант её применения заключается в следующем:
Зачастую предпринятые меры позволяют справиться с проблемой, когда при удалении папки или файла операционная система сообщает, что ей не удалось найти этот элемент.
Заключение
К сожалению, гарантированного способа устранения рассматриваемой ошибки нет, всё очень индивидуально, так как неизвестно как, кто и для каких целей создал и использовал проблемный элемент, а также у кого имеются соответствующие права. Поэтому возможны ситуации, в которых ни один из 8 приведённых способов решения не поможет. В таком случае наиболее оптимальным вариантом будет обратиться на тематические форумы и привести подробный перечень всех имеющихся данных и предпринятых мер.
Источник
Не удалось найти этот элемент, он больше не находится в пути ошибки в Windows 10

Не удалось найти этот предмет, он больше не находится в пути
1] Удалить проблемный файл
Все методы, описанные в этом посте, сильно зависят от командной строки. Поэтому убедитесь, что вам удобно выполнять эти команды внутри окна CMD. Обычно эти файлы имеют большой размер, и их удаление может освободить место. Если вы ищете способы удалить любой такой файл, выполните следующие действия:
Сделав это, выполните эту команду:
Как только команда будет успешно выполнена, файл будет удален с вашего компьютера. Он больше не должен быть виден в проводнике, и занимаемое им пространство также будет доступно для других файлов.
Другим обходным решением этой техники является то, что вы перемещаете неисправный файл в новую пустую папку, а затем пытаетесь удалить папку. В некоторых случаях это может сработать и снова сделать файл «удаляемым».
Если у вас возникли проблемы с файлом, который не имеет расширения, попробуйте выполнить
Команда в этой папке внутри командного окна.
2] Переименовать файл
Если вы не хотите удалять файл, используйте его. Вы можете попробовать переименовать его, а затем открыть его с помощью других программ. Переименование также похоже, и вам нужно выполнить несколько команд в окне CMD. Чтобы переименовать проблемный файл, выполните следующие действия:
Откройте окно CMD в расположении папки элементов, как показано выше, и выполните следующую команду, чтобы получить список всех файлов в этой папке:
Теперь, чтобы переименовать файл, выполните:
Файл будет переименован, и, надеюсь, вы сможете получить к нему обычный доступ. Файл по-прежнему будет виден в проводнике, и вы можете попробовать открыть его в любом приложении.
Эта ошибка часто встречается пользователями с файлами, которые обычно создаются сторонним программным обеспечением. Эта ошибка по существу делает невозможным работу с этими файлами, когда они видны в Проводнике. Решения, обсуждаемые в этом посте, могут помочь вам решить эту проблему.
Источник
При работе с Selenium если элемент на веб-странице не обнаруживаются общеизвестными локаторами locators, использующими значения атрибутов дерева DOM таких как id, class и name, то для его поиска используют либо CSS селекторы, либо локаторы XPath (XML Path).
Важным отличием локаторов, основанных на синктаксисе XPath от CSS селекторов является то, что используя XPath, мы можем при поиске нужного элемента перемещаться как вглубь иерархии дереву документа, так и возвращаться назад (вверх по дереву). Что касается CSS, то тут мы можем двигаться только в глубину. Это означает, например, что с XPath мы сможем найти родительский элемент по дочернему.
В этом руководстве мы познакомимся с некоторами особенностями языка ХРath применительно к практике использования выражений XPath для поиска сложных или динамически подгружаемых элементов, атрибуты которых также могут динамически изменяться (обновляться).
При рассмотрении примеров, я буду использовать следующий скрипт, который осуществляет поиск элементов на странице поиска Яндекса:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import os
import time
from pprint import pprint
# тестовая страница, на которой мы ищем
target_page = "https://yandex.ru/"
# то самое выражение XPath, которое мы тестируем
xpath_testing = "//div[contains(@class, 'home-logo')]//child::*"
dir_current = os.getcwd()
driverLocation = dir_current + "chromedriver.exe"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = Chrome(driverLocation, chrome_options=chrome_options)
data_text = driver.get(target_page)
time.sleep(3)
try:
elements_ = driver.find_elements(By.XPATH, xpath_testing)
for element_ in elements_:
pprint(f"Выбран элемент с тегом: "{element_.tag_name }"")
pprint(f"Содержимое атрибута class: "{element_.get_attribute('class')}"")
pprint(f"Текстовое содержимое элемента: {'Нет содержимого' if not element_.text else element_.text}")
except:
print('Элемент по заданному XPath выражению не найден :(')
finally:
driver.quit()
Переменной target_page присваивается строковое значение, содержащие адрес страницы, на которой мы будем осуществлять поиск элементов. Критерий поиска будем задавать с использованием XPath выражения, которое также в виде строки присваиваем переменной xpath_testing.
Содержание
- Коротко о XML и XPath
- Маршруты поиска
- Абсолютные пути
- Относительные пути
- Подстановочные выражения
- Предикаты
- Используем индексы для указания позиции элемента
- Используем логические операторы OR и AND в выражения XPath
- Используем функции языка XPath
- Функция text()
- Функция contains()
- Функция starts-with()
- Функция last()
- Функция position()
- Используем полные маршруты поиска элементов
- Ось предков (ancestor axis)
- Ось следующих одноуровневых узлов (following-sibling axis)
- Ось дочерних элементов (child axis)
- Ось следующих узлов (following axis)
- Ось предыдущих одноуровневых узлов (preceding-sibling axis)
- Ось предыдущих узлов (preceding axis)
- Ось потомков (descendant axis)
- Ось потомков, включая контекстный узел (descendant-or-self axis)
- Ось предков, включая контекстный узел (ancestor-or-self axis)
Коротко о XML и XPath
Некоторые разработчики ошибочно полагают, что язык Html является подмножеством XML, но на самом деле это не так, код на обоих языка не возможно комбинировать в одном документе. Так язык XML предназначен для хранения и передачи структурированных данных. В свою очередь HTML предназначен для их более или менее читаемого отображения. Самое существенное различие между HTML и XML в том, что в HTML есть предопределенные элементы и атрибуты, поведение которых так предопределено и ожидаемо, в то время как в XML такого нет. Кроме того существуют определенные различия в синктаксисе инструкций этих внешне схожих языков.
Однако есть у этих двух языков одно основное сходство, которое, в нашем случае, мы можем эффективно использовать для поиска маршрутов к нужным элементам на странице.
- HTML и XML документы состоят из элементов, каждый из которых включает «начальный тэг» (<element>), «конечный тэг» (</element>), а также информацию, заключенную между этими двумя тэгами (содержимое элемента).
- Элементы могут быть аннотированы атрибутами, содержащими метаданные об элементе и его содержимом.
- Любой документ представляет собой дерево, состоящее из узлов (элементов). Некоторые типы узлов могут содержать другие узлы.
- Существует единственный корневой узел, который в конечном счете включает в себя все остальные узлы.
Для выбора узлов и наборов узлов дерева документа и последующей обработки Xml использует особый язык XPath. XPath – это отличный от XML язык, используемый для идентификации определенных частей XML документов (элементов страницы). Применительно к html страницам XPath позволяет писать выражения, позволяющие получить, например, ссылку на первый элемент li неупордоченного списка ul, седьмой дочерний элемент третьего элемента div, ссылку а, содержащую строку «Купить по акции» и т. д. XPath позволяет получать ссылки на элементы по их положению на странице (дереве документа), положению относительно другого элемента, тегу, текстовому содержимому и другим критериям.
Согласно методологии XPath существует пять типов узлов, которые могут находиться в дереве документа на обычной html странице:
- Корневой узел;
- Узлы элементов;
- Текстовые узлы;
- Узлы атрибутов;
- Узлы комментариев.
В дальнейшем при формировании путей поиска к искомым элементам страницы мы будем иметь дело с первыми четырьмя типами узлов. И хотя технически мы можем обратиться, также и к узлу комментариев, расположенного в определенном элементе, рационального применения этой возможности при парсинге страниц нет и поэтому далее рассматриваться не будут.
Маршруты поиска
И хотя выражения XPath в Xml могут также возвращать числа, логические и строковые выражения, то есть производить обработку элементов и их содержимого. В Selenium используется лишь подмножество выражений XPath, называемых маршрутами поиска. Маршруты поиска указывают на определенный узел или набор узлов документа (элементов страницы), отвечающих заданным критериям поиска. Каждый маршрут поиска использует как минимум один шаг для идентификации узла или набора узлов документа. Этот набор может быть пустым, содержать один или содержать несколько узлов. Узел может быть корневым, узлом определенного элемента, атрибута, текста или комментария.
Абсолютные пути
Простейшим маршрутом поиска является тот, который указывает на корневой узел документа (страницы). Этот маршрут представляется простой наклонной чертой / и всегда обозначает одно и то же: корневой узел документа. Каждый документ имеет только один корневой узел, являющийся общим корнем дерева узлов. Корневой узел не имеет родительских узлов. Значением корневого узла является значение элемента документа.
С наклонной черты / всегда начинается абсолютный путь к элементу (маршрут поиска). Получить его можно используя либо специальные расширения браузера, либо так как это делается в браузере Chrome. Вызвать окно Chrome DevTools, выделить нужный элемент, кликнув правой клавишей мыши, вызвать контекстное меню, выбрать команду Copy , а затем Copy full XPath.

Абсолютный путь представляет собой полный и уникальный путь к элементу, начиная от корневого узла. Путь полученный выше описанным способом будет иметь следующий вид:
/html/body/div[1]/div[3]/div[3]/div/edvrt/aqwf/ftgr/fdpprt/fgn/dbgrsae/fwap/fwap/ftgr/div/fgn/dhtaq/div/div/div[1]/div[1]/a/div
Если вы используете в качестве тестируемого выражения XPath этот путь, и запустите на выполнение скрипт приведенный выше, то получите ссылку на логотип Яндекса, который находится на главной странице поисковика.
Абсолютный путь, по аналогии с абсолютным путем к любому файлу в файловой системе операционной системы, всегда однозначно указывает на нужный элемент. Однако у него есть один существенный недостаток: если разметка страницы изменится, то он с большой вероятностью может перестать работать. Особенно это актуально если на странице используется много различных интерактивных возможностей Javascript или анимаций элементов.
Отметим, что корневой элемент страницы имеет абсолютный путь (маршрут) /html и если в качестве XPath выражения мы введем просто ‘/’, то будет возбуждено исключения типа InvalidSelectorException с сообщением «Селектор некоректен. Результат поиска с использованием XPath выражения не возвратил объект элемента. Элемент не найден».
Вывод. Символ / объединяет различные шаги в составной маршрут поиска. Каждый шаг в маршруте является относительным по отношению к предшествующему. Если маршрут начинается с /, то путь является абсолютным, а его первый шаг является относительным по отношению к корневому узлу.
Относительные пути
Относительный путь начинается с двух наклонных черт и следующим за ним одиночным тегом нужного нам элемента. Он может идентифицировать элементы в любом месте веб-страницы. И это позволяет избегать необходимости писать весь длинный абсолютный XPath путь, и вы можете начать его с середины структуры документа страницы (DOM). Он позволяет выбрать все элементы, по заданному тегу на странице, удовлетворяющие указанному критерию поиска. Например, выражение XPath //li ссылается на все элементы li находящиеся на странице (в дереве DOM). Так относительный путь к логотипу Яндекса на странице поиска будет выглядеть следующим образом:
//div[@role = 'img']
Пусть вас пока не смущает выражение в квадратных скобках. Они называются предикатами и служат для сужения диапазона поиска элементов, то есть придания специфичности нашему маршруту поиска. Синтаксис предикатов и их использование мы рассмотрим в нашем руководстве далее. А пока отметим, выражение в квадратных скобках говорит нам о том, что искомый элемент div, должен иметь атрибут role со значением img.
Логично было бы думать, что при задании относительных путей можно задавать начальную точку поиска нужных элементов страницы или, как принято говорить в терминологии XPath контекстный узел. В этом случае маршрут поиска будет иметь следующий вид:
//ol[@class = 'list news__list']/li/a
Это XPath выражение позволяет получить пути к ссылкам из списка новостей, размещенного на главной странице поисковика Яндекс. Отметим, этот маршрут получился намного короче чем маршрут, использующий абсолютный путь, а также более понятна его логика. Также отметим, что значение атрибута класса элемента упорядоченного списка ol представляет собой строковое значение состоящее из двух имен соответствующих CSS классов. Если вы укажете в выражении наименование только одного из них, например, так //ol[@class = 'news__list'] ,то получите пустой набор элементов.
Попробуем теперь переписать выражение выше следующим образом:
//ol[@class='list news__list']//a
И мы получим точно такой же результат, как и для выражения выше. Фактически мы заменили все промежуточные элементы из пути к ссылкам на две наклонные черты // и упростили его вид. Таким образом можно убирать из пути к искомому элементу любое количество промежуточных шагов (элементов).
Вывод. В начале выражения XPath символы // по сути позволяют выбрать всех потомков корневого узла с указанным тегом. Например, выражение XPath //div выбирает в документе все элементы div. Если мы будем использовать символ // в маршруте для разделения отдельных шагов, то можем опускать промежуточные шаги сокращая при этом запись маршрута. Относительный путь Xpath всегда предпочтительнее, так как он является более логичным и понятным, а также устойчивым к динамическому изменению структуры дерева DOM страницы средствами движка Javascript.
Подстановочные выражения
Подстановочные выражения позволяют выбирать несколько типов элементов одновременно. Существуе два следующих вида подстановочных выражений, которые выможете использовать при парсинге страниц: * , @ *.
Звездочка * или астерикс соответствует любому узлу элемента, независимо от его типа. Звездочка * является одним из наиболее часто используемых подстановочных выражений, используемых в XPath выражениях в Selenium.
Символ @ указывает, что слдующий за ним идентификатор является наименованием атрибута элемента и используется для задания предикатов. Так выражение @ * мы можем использовать вместо любого имени атрибута.
Приведем некоторые примеры их использования.
//*– соответствует всем элементам, находящимся на странице (включая тег html).//div/*– соответствует всем элементам, являющимися непосредственными потомками элемента с тегомdiv.//input[@*]– соответствует всем элементам с тегомinput, которые имеют хотя бы один любой атрибут, при этом значение атрибута может быть любым, присутствовать или отсутствовать.//*[@*]– соответствует всем элементам на странице, имеющим хотя бы один атрибут.
Предикаты
Как мы уже знаем, что в общем случае выражение XPath может ссылаться более чем на один узел (элемент страницы), то есть метод, в котором оно используется будет возвравращать массив элементов. Иногда это именно то, что нам нужно, однако в некоторых случаях приходится «просеивать» его по определенным критериям, чтобы выбрать только некоторые из них. Для этих целей в XPath используется синктаксис предикатов. Каждый шаг в маршруте поиска может иметь свой предикат или даже несколько, который задает свой критерий выбора из текущего списка узлов на каждом шаге маршрута поиска. То есть на каждом шаге поиска могут существовать один или более предикатов. По сути предикат содержит логическое выражение, которое проверяется для каждого узла в полученном по указанному пути наборе элементов страницы. Если выражение ложно, этот узел удаляется из набора, в противном случае соответствено сохраняется.
Предикат – это часть выражения XPath, заключенная в квадратные скобки, которое следует в инструкции для шага поиска за критерием выбора узла (элемента). В общем виде выражение с предикатом будет выглядеть следующим образом:
//выбор_элементов[правило_предиката1][правило_предиката2][правило_предиката3]
Предположим, требуется найти кнопку для отправки поискового запроса на главной странице Яндекса. XPath выражение, которое позволяет это осуществить будет выглядеть следующим образом:
//div[@class='search2__button']/button[@role='button']
В начале на первом шаге выбираем все элементы div, для которых справедливо следующее логическое значение предиката: значение атрибута класса соответствует строке search2__button. На втором шаге выбираем у них элементы с тегом button, являющиеся их непосредственными потомками, у которых значение атрибута role содержит строковое значение button.
В следующем примере выбираем ссылку на корзину Яндекс Маркет, которая находится также на основной странице поисковика. Использование нескольких атрибутов в выражении XPath сужает поиск нужного элемента на странице до одного.
//а[@title='Корзина на Маркете'][@class='home-link market-cart']
Вывод. Механизм предикатов весьма полезен для сужения диапазона выбираемых на странице элементов по заданным критериям, который основан на логических выражениях. Используя предикаты мы можем задавать сколь угодно специфичные идентификаторы для искомых элементов.
Используем индексы для указания позиции элемента
С помощью синтаксиса индексов можно выбрать из набора элементов нужный, указав его номер в квадратных скобках по аналогии с синтаксисом массивов. В примере ниже мы получаем третий элемент из списка новостей на странице Яндекса.
//ol[@class='list news__list']/li[2] //ol[@class='list news__list']/li[2]//span[@class='news__item-content']
Второе выражение XPath позволянт получить у выбранного элемента списка элемент с тегом span, который содержит текстовое содержимое заголовока новости. Отметим, что индексы элементов начинают отсчитываться от 1, а не от 0, как принято для индексации массивов в языке Python.
Используем логические операторы OR и AND в выражения XPath
Логические оператры используются в инструкциях предикатов для комбинирования критериев поиска нужных элементов на странице.
В примере ниже приведены выражения для фильтрации ссылок на новости, которые показывают на странице поиска Яндекс.
//a[@rel='noopener' or @target='_blank'] //a[@rel='noopener' and @target='_blank'] //a[@rel='noopener' and @target='_blank' and contains(@class, 'home-link_black_yes')]
Как видно в предикате для фильтрации элементов можно применять сколько угодно логических операторов, а также комбинировать их с XPath функциями, которые рассмотрим ниже.
Функция text()
Функция XPath text() – это встроенная в синтаксис XPath Selenium функция, которая используется для поиска элементов на основе строкового значения, содержащегося в его текстовом узле. То есть если элемент имеет текстовое содержимое в виде строки, то элемент можно найти следующим образом:
<span class="button__text">Найти</span> //span[text()='Найти']
Функция contains()
Функция contains() часто используется в предикатах выражений XPath для случаев если значение атрибута элемента или его текстовое содержимое может динамически изменяться.
Например в значение атрибута класса элемента //element[@class='class1 class2'] средствами Javascript может быть добавлен для его анимации класс class3, а потом также динамически убран. При этом значение предиката в случае добавления нового класса станет ложным, то есть элемент не будет выбран. Для этого случая мы можем использовать функцию contains() следующим образом:
//element[contains(@class, 'class1 class2')]
Если выражение выбора элемента переписать в указанном выше виде, то мы ориентируясь на атрибут класса элемента будем выбирать его в любом случае.
Функция contains() позволяет находить элемент по текстовой подстроке значения атрибута или его текстового содержимого, как показано в примере XPath ниже.
//a[contains(@title, 'Корзина')] //span[contains(text(),'Найти')]
В примере мы нашли ссылку на корзину Яндекс маркета из примера выше по части значения атрибута title. А также по части текстового содержимого кнопку отправки запроса поисковику.
Функция starts-with()
Эта функция используется если нам известна первая часть (начальная подстрока) текстового содержимого искомого элемента на странице, либо часть значения его атрибута.
//a[starts-with(@title, 'Корзина')] //span[starts-with(text(),'Найти')]
Функция last()
Эта функция позволяет выбрать последний элемент (указанного типа) из набора элементов. Пример ее использования представлен ниже.
//ol[@class='list news__list']/li[last()]//span[@class='news__item-content']
Это выражение возвращает элемент, содержащий наименование последней новости из списка новостей со страницы поисковика Яндекс.
В следующем примере показано как можно получить предпоследнюю новость.
//ol[@class='list news__list']/li[last()-1]//span[@class='news__item-content']
Функция position()
Эта функция позволяет выбирать из полученного набора элементы в зависимости от указанного номера позиции. Начало отсчета позиции элемента, по аналогии с индексами также начинается с 1. Действие этой функции полностью идентично индексам, о которых мы говорили выше. В примере ниже представлены два эквивалентных по результату выполнения выражения.
//ol[@class='list news__list']/li[position()=1]")) //ol[@class='list news__list']/li[1]
Используем полные маршруты поиска элементов
До этого момента мы говорили о том, что в терминологии языка XPath называется сокращенными маршрутами поиска. Эти маршруты значительно проще для набора, менее многословны и знакомы большинству разработчиков. Кроме того, они являются именно теми выражениями XPath, которые лучше всего подходят для использования в простейших шаблонов поиска. Однако в XPath также предлагается полный синтаксис для маршрутов поиска, который более многословен, но, возможно, менее загадочен и определенно более гибок.
Так каждый шаг в полном маршруте поиска имеет две обязательные части: так называю ось и критерий узла (тег элемента), а также необязательную часть – предикаты. Ось указывает направление перемещения от контекстного узла для поиска следующих узлов. Критерий узла определяет, какие узлы будут выбраны на текущем шаге поиска вдоль этой оси. В полном маршруте они разделяются двумя двоеточиями ::.
По сути в сокращенном маршруте поиска ось и критерий узла объединены вместе. Например, следующий сокращенный маршрут поиска состоит из трех шагов.
//ol/li/a[@rel='noopener']
Первый шаг выбирает на странице элементы упорядоченных списков ol по оси дочерних узлов, второй – элементы li вдоль оси дочерних узлов, третий шаг – так же по оси дочерних узлов выбирает элементы ссылок a, а затем с помощью предиката выбирает из них только содержащие атрибут rel='noopener' с заданным значением . Если переписать это выражение в полной форме тот же маршрут поиска будет выглядеть следующим образом:
//child::ol/child::li/child::a[@rel='noopener']
Полные несокращенные маршруты поиска, как и сокращенные, могут быть также абсолютными, если начинаются с корневого узла.
В целом полная форма очень многословна и мало используется на практике. Однако она предоставляет одну исключительную возможность, которая делает эту форму записи XPAth выражений достойной внимания. Это единственный способ использования направлений осей поиска, по которым выражения XPath осуществляют выбор нужных элементов.
Так сокращенный синтаксис позволяет перемещаться по оси непосредственно дочерних узлов (child), оси атрибутов (attribute) и оси всех его потомков с включением контекстного узла (descendant-or-self). Полный синтаксис добавляет еще восемь осей, которые применимы для использования в XPath выражениях и поиска элементов на страницах с использованием Selenium:
Ось предков (ancestor axis)
Все узлы элементов, содержащие контекстный узел; родительский узел, родитель родителя, родитель родителя родителя и т.д. вверх вплоть до корневого узла в порядке, обратном расположению узлов в документе.
//div[text()='Маркет']//ancestor::a //div[text()='Маркет']//ancestor::*
В данном примере мы получаем ссылку на Яндекс Маркет по текстовому содержимому элемента div находящегося внутри нее. А следующее выражение позволяет выбрать последовательность всех предков этого элемента до корня документа /html.
Ось следующих одноуровневых узлов (following-sibling axis)
Все узлы элементов страницы, следующие за контекстным узлом и содержащиеся в том же узле родительского элемента, в том же порядке, в каком элементы расположены в документе.
//div[contains(@class, 'home-logo')]//following-sibling::div
В примере выше выражение выбирает блок div по содержимому атрибута класса, который содержит элементы строки ввода слов для поиска.
Ось дочерних элементов (child axis)
Ось содержит все дочерние узлы текущего контекстного, то есть выбирает все элементы, содержащиеся в текущем узле. В примере ниже будут выбраны все элементы находящиеся внутри блока div содержащего логотип Яндекса.
//div[contains(@class, 'home-arrow__search-wrapper')]//child::*
Ось следующих узлов (following axis)
Все узлы, следующие после контекстного узла, в том же порядке, в каком узлы присутствуют в документе. Отличием поиска вдоль этой оси от оси following-sibling является то, что будут выбраны все узлы (элементы) находящиеся в документе за закрывающим тегом контекстного узла. Так в аналогичном примере ниже будут выбраны все элементы div, следующие в документе за разметкой логотипа Яндекс. Сравните результаты поиска с примером выше.
//div[contains(@class, 'home-logo')]//following::div
Ось предыдущих одноуровневых узлов (preceding-sibling axis)
Выбирает все узлы, предшествующие контекстному узлу и содержащиеся в том же узле родительского элемента последовательно в обратном порядке.
//div[contains(@class, 'search2__input')]//preceding-sibling::input[@type='hidden']
В этом примере выражение позволяет выбрать скрытые поля в блоке со строкой основного поиска Яндекса.
Ось предыдущих узлов (preceding axis)
Все узлы, предшествующие началу контекстного узла, в порядке, обратном порядку в документе. Отличием поиска вдоль этой оси от оси following-sibling является то, что будут выбраны все узлы (элементы) находящиеся в документе перед открывающим тегом контекстного узла. Так в аналогичном примере ниже будут выбраны все элементы div, следующие в документе перед разметкой логотипа Яндекс. Сравните результаты поиска с примерами выше.
//div[contains(@class, 'home-logo')]//preceding::div
Ось потомков (descendant axis)
Поиск вдоль оси потомков descendant выбирает все дочерние элементы, а также их дочерние элементы «внуков». В примере ниже мы выбираем все элементы находящиеся в блоке со строкой поиска на главной странице Яндекса.
//div[contains(@class, 'home-arrow__search-wrapper')]//descendant::*
Ось потомков, включая контекстный узел (descendant-or-self axis)
Ее действие аналогично оси потомков descendant за исключением того, в набор будет включен и сам контекстный узел.
//div[contains(@class, 'home-arrow__search-wrapper')]//descendant-or-self ::*
Ось предков, включая контекстный узел (ancestor-or-self axis)
Все предки контекстного узла, включая сам контекстный узел. В примере ниже будут выбраны все предки элемента div блока с логотипом Яндекса, а также сам элемент.
//div[contains(@class, 'home-arrow__search-wrapper')]//ancestor-or-self::*
В этой статье мы рассмотрели основы использования синтаксиса XPath при составлении выражений для поиска элементов на странице. Отличительной особенностью такого поиска является то, что используется информация о структуре документа страницы, что позволяет более гибко составлять выражения маршрутов к искомым элементам в любом направлении от заданного контекстного узла. В отличии от использования CSS селекторов, которые позволяю осуществлять поиск только в глубину, выражения XPath позволяют выбирать как родительские узлы так и узлы предков выше до любого уровня вложенности.
Использование функций языка XPath позволяет находить элементы как по их текстовому содержимому, так и по содержимому их атрибутов. Существенно расширяют их возможности возможность использования логических выражений для комбинирования различных условий формирования маршрута поиска.
Надеюсь, что это руководство поможет вам разобраться с принципом использования XPath выражений при работе в Selenium Python. А также в дальнейшем послужит справочным пособием для разработки.
Как узнать где находится элемент массива?
Есть массив, допустим c 9 элементами:[1,2,3,4,5,6,7,8,9] (элементов может быть любое кол-во).
Я могу проверить есть ли цифра 5 в этом массиве или нет[1,2,3,4,5,6,7,8,9].indexOf(5)
Но как узнать где эта 5 находится, то есть в центре массива или нет, если нет, то куда ближе, к концу или к началу, как далеко от конца массива и как далеко от начала.
-
Вопрос заданболее трёх лет назад
-
693 просмотра
var index = [1,2,3,4,5,6,7,8,9].indexOf(5);
Вот так  index будет содержать позицию начиная с 0, в данном случае index будет равен 4, а далее при помощи
index будет содержать позицию начиная с 0, в данном случае index будет равен 4, а далее при помощи
var length = [1,2,3,4,5,6,7,8,9].length;
узнаете длину массива, и определяет в центре, ближе к началу, или ближе к концу эта 5 находиться.
function midArr(arr, indexOf){
var ind = arr.indexOf(indexOf);
var qrtStep = arr.length/4;
var qrt1 = qrtStep,
qrt2 = qrtStep*2,
qrt3 = qrtStep*3;
if(ind == 0 || ind <= qrt1)
return('"'+indexOf+'" находится в начале');
else if(ind <= qrt2 || ind < qrt3)
return('"'+indexOf+'" находится в середине');
else
return('"'+indexOf+'" находится в конце');
}
var array = [0,1,2,3,4,5,6,7,8,9,10,11];
alert(midArr(array, 8));codepen.io/anon/pen/EKmxeR?editors=0011
var arr = [1,2,3,4,5,6,7,8,9]; // исходный массив
(function(num){ // объявили самовызывающую функцию
if((arr.length % num) > 0){
console.log('Центр массива находит на элементе ' + Math.round((arr.length / 2)) ); // находим цетр, если массив нечетный
var center = Math.round((arr.length / 2)); // запоминаем точку центра
}else{
console.log('Центр массива находит на элементе ' + (arr.length / 2) + ' и ' + (arr.length / 2 + 1)); // находим цетр, если массив четный
var center = (arr.length / 2); // запоминаем точку центра ( левую))
}
console.log('Элемент отстаёт от начала на ' + arr.indexOf(num) + ' элемента. И на ' + (arr.length - 1 - arr.indexOf(num)) + ' от конца');
if(num === center){ // проверяем 'центральность'
console.log('Бинго! число в центре');
}else{
console.log('Элемент отстаёт от центра :');
(center > num)?console.log((center - num) + ' элементов слева'):console.log(-(center-num) + ' элементов справа'); // тернарный оператором определяем положение от центра
}
})(5); // указываем число из массива, которое будем искать , в данном случаи - 5всё в консоле, новых переменных минимум. Для массива с четным числом данных, возможно, нужно будет подпилить что то … но мне лень %)
Пригласить эксперта
-
Показать ещё
Загружается…
28 мая 2023, в 17:41
15000 руб./за проект
28 мая 2023, в 17:31
1200 руб./в час
28 мая 2023, в 17:26
8000 руб./за проект
Минуточку внимания
Доброго дня!
В некоторых случаях при работе с проводником в Windows (в частности, при удалении каталогов и файлов) можно увидеть ошибку о не найденных элементах (как это выглядит — привел ниже на скрине 👇).
Вообще, чаще всего это происходит из-за:
- блокировки папки (файла) другим процессом (например, защитником);
- ошибок проводника (когда, например, файл уже был удален, и вы пытаетесь удалить его второй раз*);
- у файла слишком длинное имя (и стоит системный атрибут);
- каталог/файл принадлежат другой учетной записи и пр.
Собственно, не так давно и сам сталкивался с этой ошибкой… Чуть ниже приведу несколько шагов для устранения оной. Инструкция должна помочь в не зависимости от причины. 😉
Не удалось найти этот элемент. Его больше нет в «E:». Проверьте расположение элемента и повторите попытку (пример ошибки)
*
Что можно посоветовать для устранения ошибки
👉 ШАГ 1
Банально, но самая первая рекомендация — просто перезагрузить компьютер (ноутбук).
Нередко, когда ошибка связана с некорректной работой проводника и файловой системы («не удаляемый» элемент (файл/папка) — после перезагрузки начнет «вести» себя, как и все остальные, и вы без труда удалите ее…).
Перезагрузка компьютера / Windows 10
*
👉 ШАГ 2
В ряде случаев проблемные каталоги достаточно легко удалить с помощью командной строки. Запустить ее нужно 👉 будет от имени админа.
Далее скопировать путь до той папки, которая не удаляется классическим способом (в моем случае «C:111»).
Копируем путь до папки, которую удаляем
После, в командной строке потребуется написать следующее: RD /S «C:111» (и нажать Enter).
Это команда удалит и сам указанный каталог, и все файлы, что в нем есть. Будьте аккуратны, т.к. командная строка не всегда переспрашивает…
Пример удаления каталога
👉 В помощь!
Более подробно о том, как избавиться от папки/файла с помощью командной строки
*
👉 ШАГ 3
Еще один весьма действенный способ решения вопроса — воспользоваться безопасным режимом загрузки Windows (при нем будут запущены только самые необходимые приложения и службы). И уже из-под него попробовать удалить нужные файл/папку.
Подробно не останавливаюсь — ссылка ниже поможет загрузить ОС в нужном режиме (работа же в нем не отличается от обычного режима).
👉 В помощь!
Как зайти в безопасный режим в Windows 7÷10 — см. инструкцию.
*
👉 ШАГ 4
Есть один замечательный коммандер (👉 речь о FAR) для работы с большим количеством файлов. Сейчас для многих он смотрится как анахронизм, но поверьте — эта штука до сих пор делает некоторые вещи надежнее, чем проводник!
Так вот, если в нем выделить «проблемный» элемент (скажем, папку) и нажать сочетание ALT+DEL — то запустится функция Wipe (уничтожение файла). Она отлично справляется со своей задачей (даже с весьма проблемными файлами), рекомендую попробовать!
Примечание: будьте аккуратнее с этим способом, т.к. файлы будут удалены, минуя корзину.
Far Manager — пример удаления папки
*
👉 ШАГ 5
Есть спец. программы для удаления «не удаляющихся» файлов (извиняюсь за тавтологию). Одна из самых известных — Unlocker. После ее установки — в меню проводника появится соответствующее меню (использование крайне простое!). См. скрин ниже. 👇
👉 В помощь!
Программы для удаления не удаляемых файлов и папок — моя подборка
Как удалить папку в Unlocker
*
👉 ШАГ 6
Также сейчас достаточно популярны загрузочные образы ISO (LiveCD называются), которые можно записать на флешку и загрузиться с нее как будто бы это был жесткий диск с Windows.
Разумеется, после, вы сможете «прошерстить» все свои накопители на компьютере и удалить с них любые файлы. Только будьте аккуратнее, т.к. при работе с LiveCD вы сможете удалять и системные, и обычные, и скрытые файлы…
👉 В помощь!
LiveCD для аварийного восстановления Windows — моя подборка (там же в заметке указано как подготовить такой накопитель)
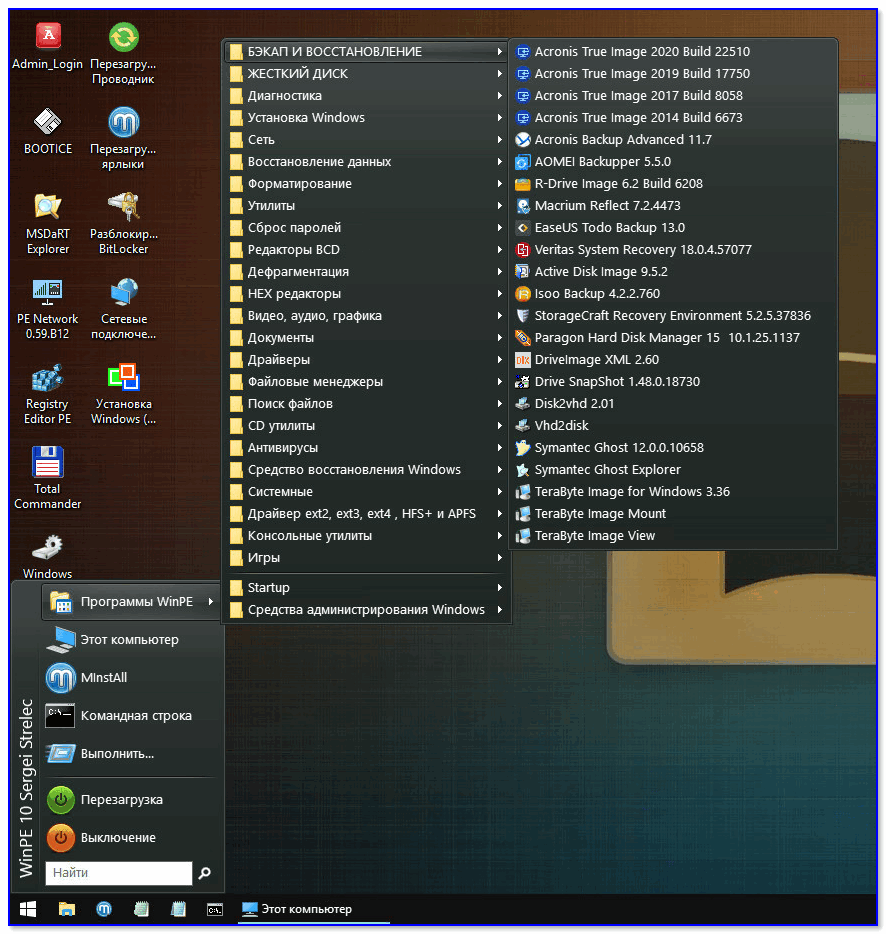
Какие программы есть на диске «Стрельца…» // Пример рабочего стола при загрузке с LiveCD-флешки
*
PS
Если из вышеперечисленного ничего не помогло — проверьте свой диск на ошибки (в ряде случаев при возникновении «потерянных элементов» могут быть найдены ошибки файловой системы. При проверке, кстати, они исправляются автоматически).
*
Дополнения по теме — приветствуются!
Если удалось вопрос решить иначе — дайте знать ⇓ (заранее спасибо!).
Удачи!
👣


Полезный софт:
-

- Видео-Монтаж

Отличное ПО для создания своих первых видеороликов (все действия идут по шагам!).
Видео сделает даже новичок!
-
- Ускоритель компьютера

Программа для очистки Windows от «мусора» (удаляет временные файлы, ускоряет систему, оптимизирует реестр).
Is there a simple way to locate all DOM elements that «cover» (that is, have within its boundaries) a pixel with X/Y coordinate pair?
![]()
Nakilon
34.9k14 gold badges107 silver badges142 bronze badges
asked Jan 24, 2011 at 19:12
![]()
3
You can have a look at document.elementFromPoint though I don’t know which browsers support it.
Firefox and Chrome do. It is also in the MSDN, but I am not so familiar with this documentation so I don’t know in which IE version it is included.
Update:
To find all elements that are somehow at this position, you could make the assumption that also all elements of the parent are at this position. Of course this does not work with absolute positioned elements.
elementFromPoint will only give you the most front element. To really find the others you would have to set the display of the front most element to none and then run the function again. But the user would probably notice this. You’d have to try.
answered Jan 24, 2011 at 19:18
![]()
Felix KlingFelix Kling
790k174 gold badges1084 silver badges1136 bronze badges
6
I couldn’t stop myself to jump on Felix Kling’s answer:
var $info = $('<div>', {
css: {
position: 'fixed',
top: '0px',
left: '0px',
opacity: 0.77,
width: '200px',
height: '200px',
backgroundColor: '#B4DA55',
border: '2px solid black'
}
}).prependTo(document.body);
$(window).bind('mousemove', function(e) {
var ele = document.elementFromPoint(e.pageX, e.pageY);
ele && $info.html('NodeType: ' + ele.nodeType + '<br>nodeName: ' + ele.nodeName + '<br>Content: ' + ele.textContent.slice(0,20));
});
updated: background-color !
answered Jan 24, 2011 at 19:41
![]()
jAndyjAndy
231k57 gold badges305 silver badges358 bronze badges
2
This does the job (fiddle):
$(document).click(function(e) {
var hitElements = getHitElements(e);
});
var getHitElements = function(e) {
var x = e.pageX;
var y = e.pageY;
var hitElements = [];
$(':visible').each(function() {
var offset = $(this).offset();
if (offset.left < x && (offset.left + $(this).outerWidth() > x) && (offset.top < y && (offset.top + $(this).outerHeight() > y))) {
hitElements.push($(this));
}
});
return hitElements;
}
When using :visible, you should be aware of this:
Elements with visibility: hidden or opacity: 0 are considered visible,
since they still consume space in the layout. During animations that
hide an element, the element is considered to be visible until the end
of the animation. During animations to show an element, the element is
considered to be visible at the start at the animation.
So, based on your need, you would want to exclude the visibility:hidden and opacity:0 elements.
answered Oct 22, 2012 at 16:42
![]()
Luca FagioliLuca Fagioli
12.5k5 gold badges58 silver badges57 bronze badges