Перед запуском рекламной кампании принято проводить A/B-тестирование. Однако не всякий тест может считаться показательным. И первая ошибка – неверно определена репрезентативная выборка. Следствие такой ошибки – впустую потраченные деньги на запуск неэффективной рекламы.
Что такое репрезентативная выборка и как ее правильно посчитать, рассказываем ниже.
Что такое репрезентативная выборка
Выборка в тестах: зачем считать и что еще влияет на результаты
Как определить размер выборки
Метод SurveyMonkey
Optimizely
Mindbox
Основные сложности в тестах при расчете выборки
Недостаточное количество просмотров
Узкая тематика
Низкий бюджет
Высокий бюджет
Советы по расчету выборки
Что такое репрезентативная выборка
С понятиями «генеральная совокупность» и «репрезентативная выборка» сталкиваются все, кто запускают A/B-тесты и хотят получить статистически значимые результаты. Ведь чаще всего провальные тесты случаются по двум причинам: маленькая выборка и недостаточный объем данных.
Для расчета репрезентативной выборки сейчас совсем не нужно знать сложные формулы и рассчитывать их вручную. Для этого есть удобные онлайн-калькуляторы (Optimizely, Mindbox, VWO) и методика SurveyMonkey.
Для работы со всеми перечисленными инструментами надо знать правила проведения тестов, оперировать основными понятиями и понимать, как работают инструменты расчета репрезентативной выборки.
Вот основные понятия, которые нужно знать для расчета выборки:
- Генеральная совокупность. Вся группа людей, мнение/действия которых для нас имеют значение. Для рекламодателей это все люди, на которых распространяются результаты A/B-теста. Это может быть аудитория ремаркетинга, подписчики в социальных сетях, покупатели в оффлайн-магазинах или даже просто мужчины в возрасте от 25 до 40 лет;
- Репрезентативная выборка. Определенный процент людей из генеральной совокупности, который будет проходить A/B-тестирование. То есть это часть нашей целевой аудитории;
- Достоверность (уровень доверия). Этот показатель характеризует вероятность того, что выборка окажется значимой для отобранных результатов. Задается в пределах 80–99%. Если достоверность ниже 80%, то таким данным нельзя доверять. Чаще всего достоверность задают на уровне 95%;
- Погрешность. Отображает уверенность в том, что полученные результаты характеризуют мнение (для контекста – поведение) генеральной совокупности. Допустимый процент ошибки в результатах. Обычно составляет от 1 до 10%. Наиболее часто используемый предел погрешности равен 5%.
Каждый из перечисленных онлайн-калькуляторов имеет свою специфику. Об этом мы расскажем ниже.
Выборка в тестах: зачем считать и что еще влияет на результаты
Перед запуском рекламной кампании принято запускать тестирование. Это позволяет определить наиболее эффективный вариант объявления. В объявлении может тестироваться любой элемент: заголовки, креативы, описания, расширения, CTA-кнопки и т. д.
Тестирование разных вариантов объявлений может проводиться для повышения кликабельности объявления, увеличения коэффициента конверсии. Однако, по данным AppSumo, значимые результаты дают только 1 из 8 тестов.
Правильное определение репрезентативной выборки для тестовых групп обеспечивает достоверные результаты по тестам. Ниже рассмотрим причины, по которым тест может не дать значимых результатов.
1. Недостаточно данных
Допустим, мы запустили тестирование двух вариантов объявлений с разными заголовками. Вечером получаем такие результаты:

По результатам первого дня может показаться, что текущее объявление работает более эффективно.
В этом случае у рекламодателя возникают такие вопросы:
- достаточно ли данных собрано в аналитике, чтобы делать выводы об эффективности текущего объявления;
- останавливать ли тест или продолжать эксперимент.
Нельзя делать выводы об эффективности кампании по нескольким десяткам переходов и паре кликов. Для принятия решения необходимо собрать достаточное количество аналитических данных.
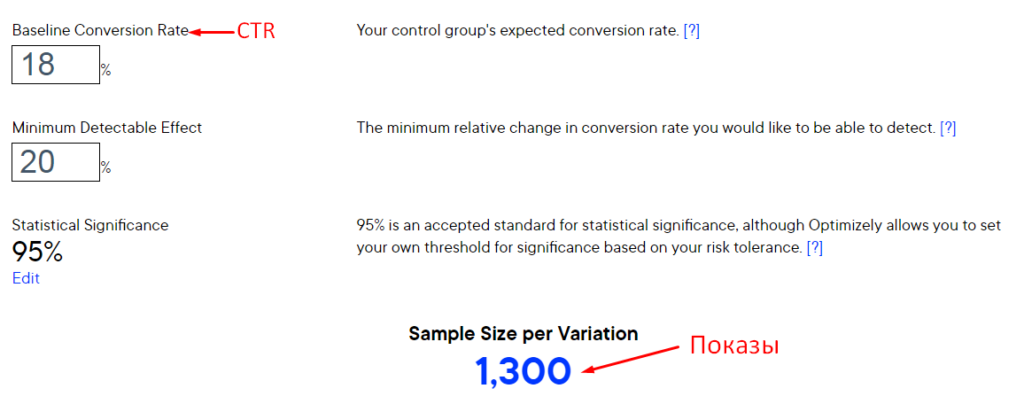
Для определения размера нашей выборки воспользуемся онлайн-калькулятором Optimizely.
Проводим такие действия:
- указываем коэффициент конверсии по текущему объявлению. Допустим, 18%;
- задаем статистическую значимость на уровне 95%;
- указываем минимальное относительное изменение коэффициента конверсии, которое хотелось бы получить – 20%.
Расчеты показывают, что для получения статистически значимых данных выборка для тестируемой группы должна состоять из 1300 человек.
2. Неправильно поставлена гипотеза
Это еще одна распространенная причина получения непоказательных результатов тестирования.
Например, в ходе теста была выдвинута гипотеза, что новое описание в объявлении принесет больше трафика на целевую страницу и мы получим более высокую конверсию. Но в результате тестирования трех вариантов описания не было обнаружено значительной разницы.
В таких ситуациях возникает вопрос о том, как сделать тест показательным и улучшить результаты. Один из способов — заинтересовать целевую аудиторию. Для этого может быть недостаточно просто изменить описание в объявлении или заголовок. Нужны более значимые изменения. Можно поменять креатив или изменить торговое предложение (увеличить скидку, изменить цену, предложить покупателям рассрочку).
3. Выбрана не та метрика
Для получения значимых результатов важно выбрать только один показатель, который надо улучшить. Например, цель – повысить коэффициент конверсии к покупке для новых посетителей. Именно с учетом этого показателя и рассчитывают выборку большинство онлайн-калькуляторов.
Однако если данных по конверсиям недостаточно, то нужно ориентироваться на другие метрики. Например, на рост CTR. В таких случаях расчет выборки можно провести с помощью онлайн-калькулятора Mindbox.
С помощью Mindbox можно определить размер выборки для 2–5 вариантов тестирования по таким показателям:
- Open Rate. Отношение открытых за период писем к общему количеству доставленных писем;
- Click Rate. Кликнутые письма (были открыты хотя бы один раз) к общему количеству доставленных писем. По сути, для рекламных объявлений это CTR;
- Conversion Rate. Конверсия в заказы. Для объявлений рассчитывается как количество конверсий к общему количеству посетителей сайта;
- Конверсия в другие целевые действия.
Размер выборки напрямую зависит от выбранного тестируемого показателя и количества тестируемых вариантов.
Например, посмотрим, какой размер выборки понадобится нам при тестировании показателя Open Rate. При таких условиях: средний Open Rate – 15%, ожидаемый прирост показателя – 30%.

Получается, размер выборки для каждого варианта объявления составляет 2 224 человека.
А вот скольким людям надо показать объявление при тестировании показателя конверсия в заказы при средней конверсии по истории 5%:

Размер выборки для каждой тестируемой группы составляет 29 827 человек.
Вывод: чем ближе к деньгам, тем более показательны результаты. Поэтому все A/B-тесты измерялись бы по Conversion Rate. Но проблема в том, что чем ниже по этой воронке продаж, тем больше людей потребуется для проведения теста. Для расширения охвата и получения достоверных данных в этом случае надо ориентироваться на повышение показателя Click Rate или Open Rate.
Как определить размер выборки
Метод SurveyMonkey
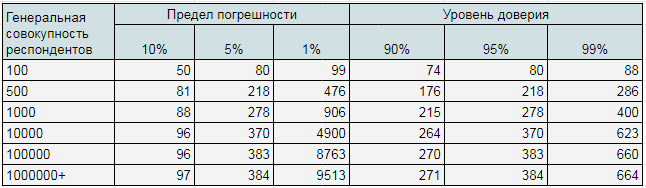
Компания SurveyMonkey предложила метод определения репрезентативной выборки с учетом предела погрешности и уровня доверия.
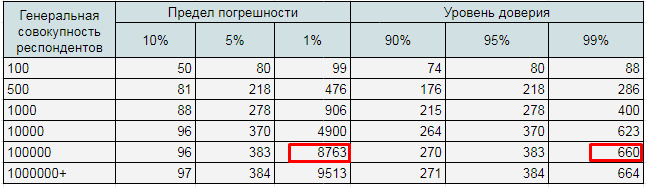
Сделать это можно с помощью такой таблицы:
Методика расчета репрезентативной выборки состоит из пяти этапов. Показываем, как это сделать на примере интернет-магазина электроинструментов.
Исходные данные: магазин находится в Курске и хочет запустить рекламу для привлечения новых клиентов на сайт.
Перед запуском кампания проводит A/B-тест и тестирует два объявления с разными вариантами заголовков. Выдвигается гипотеза, что второй вариант объявления понравится целевой аудитории больше и по нему будет больше кликов и конверсий.
1 этап – определяем генеральную совокупность. Интернет-магазин собрал достаточно данных о покупателях. И знает, что их целевая аудитория – это мужчины в возрасте от 25 до 70 лет, которые живут в Курске и интересуются ремонтом, строительством, обустройством дома.
Для оценки приблизительного размера целевой аудитории воспользуемся myTarget. Эта платформа предоставляет гибкие настройки таргетинга и позволяет приблизительно определить рекламный охват, который мы и примем как генеральную совокупность.
В примере мы не будем запускать кампанию через myTarget, а просто используем его для определения размера ЦА. Подробнее о том, как запустить рекламу в системе, читайте в пошаговом гайде «Как настроить рекламу в myTarget».
Заходим в профиль myTarget. Выбираем цель – «Конверсии» – «Трафик», ниже указываем URL. Слева появится прогноз аудитории за 7 дней. По мере настройки таргетинга рекламный охват будет сокращаться.
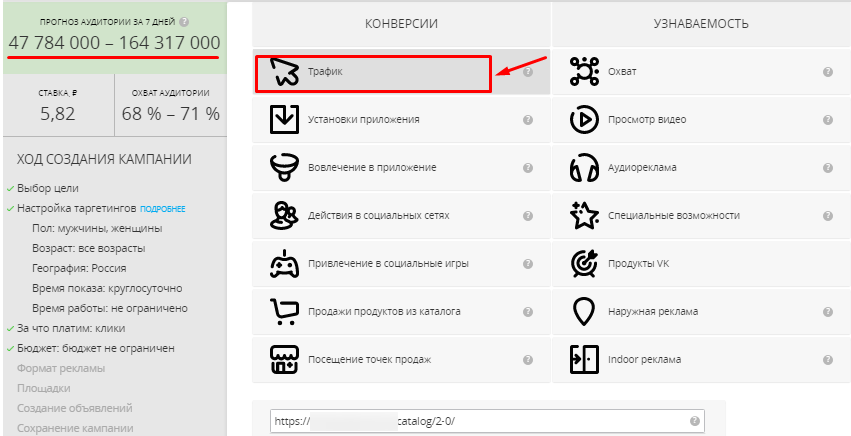
Сократим рекламный охват. Для этого указываем такие настройки:
- пол – мужчины;
- возраст – 25–70 лет;
- география – Курск.
Уже после этих настроек размер аудитории сократится до 43 000 – 144 000 человек:
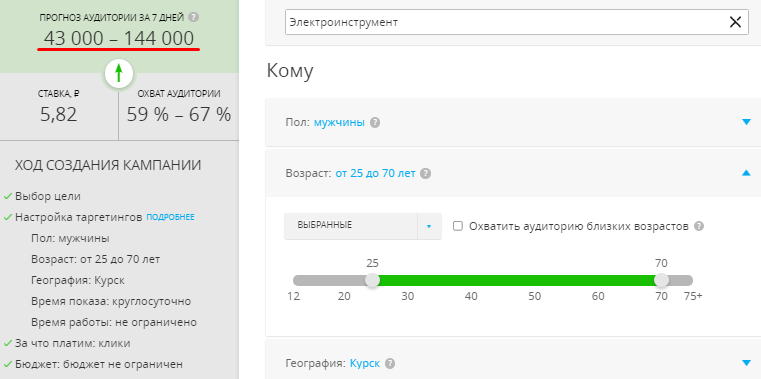
Указываем интересы. Потенциальные покупатели интересуются автомобилями, ремонтными и строительными работами, благоустройством дома:
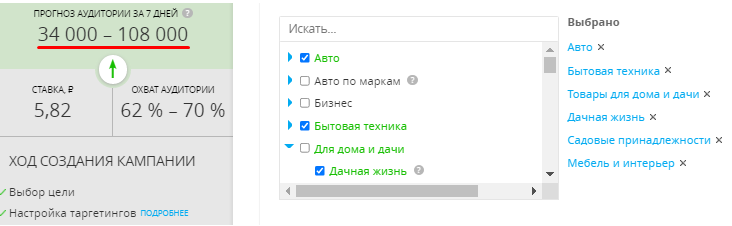
Таким образом размер нашей целевой аудитории находится в пределах 34 000 – 108 000 человек.
2. Определяем точность теста. Для получения статистически значимых результатов рекомендуется устанавливать предел погрешности в районе 1–5%, а уровень доверия – 95–99%.
Например, мы поставили гипотезу, что пользователи чаще будут кликать по второму объявлению. Уровень погрешности принимаем 1%, значит, уровень доверия составляет 99%. Это означает, что фактически 98–100% пользователям второй вариант объявления понравится больше, чем первый.
3. Определяем размер выборки с помощью таблицы. Приблизительно наша генеральная совокупность составляет 100 000 человек. Подходящая нам выборка составляет – от 383 до 8763 человек. Для получения максимально значимых данных устанавливаем уровень доверия на уровне 99%. Поэтому остановимся на 660.
4. Прикидываем ожидаемую конверсию по объявлению. Средний показатель по предыдущим кампаниям составлял 12%. Поэтому принимаем CR = 12%.
5. Узнаем, скольким людям надо показать наши объявления, чтобы получить статистически значимые результаты:
660/0,12=5500 пользователям
То есть выборка для одного тестовой группы составляет 5500 человек. Мы тестируем два варианта объявления. Поэтому и второе объявление (при распределении аудитории 50/50) должно увидеть 5500 пользователей.
Optimizely
Сравним, насколько размер выборки, полученный методом SurveyMonkey, будет отличаться от результатов онлайн-калькуляторов.
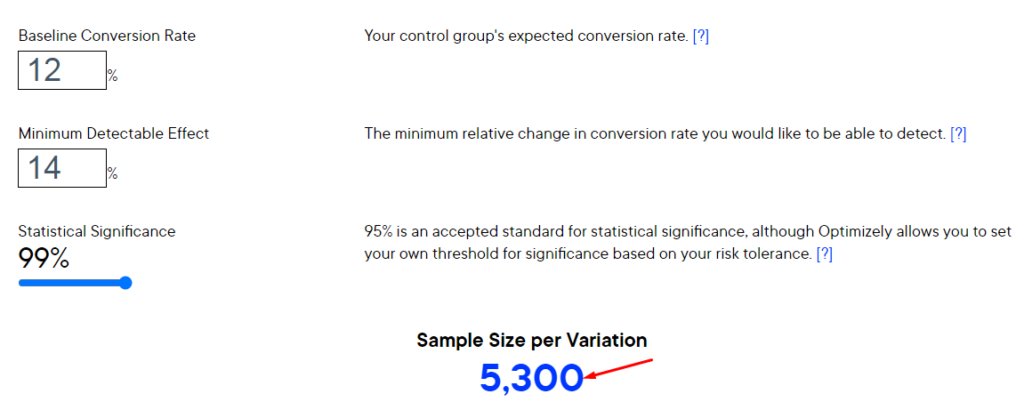
Заходим в онлайн-калькулятор и задаем там такие значения:
- Ожидаемую конверсию (Conversation rate). Берем средний показатель ожидаемой конверсии, учитывая предыдущий опыт. CR = 12% (как и в примере выше);
- Минимальное относительное изменение конверсии после изменения заголовка объявления. Принимаем этот показатель на уровне 14%. Поскольку максимальный показатель конверсии по предыдущим кампаниям был 13,7% ((13,7/12-1)*100%=14%);
- Уровень доверия. В предыдущем примере мы устанавливали его на уровне 99%. Для сравнения результатов также установим его на этом уровне.
Вводим все эти значения и получаем, что контрольная группа должна состоять из 5300 человек.
В результате мы получили почти такие же числа, как и методом SurveyMonkey. Только во втором расчете контрольная группа должна состоять из 5300 человек, а не 5500 человек.
Mindbox
Посмотрим, какой размер тестируемой выборки для нашего примера получится с помощью калькулятора Mindbox.
Вносим свои показатели в калькулятор:
- Тестируемый показатель – конверсия в заказы;
- Средняя конверсия по истории – 12%;
- Количество вариантов тестирования – 2;
- Ожидаемый абсолютный прирост конверсии – приблизительно 2%;
- Достоверность – 99%. Этот показатель демонстрирует, какой процент уверенности в верности результатов теста, если он показал разницу;
- Мощность – 80%. Это процент уверенности в результатах теста, если он не показал разницу.
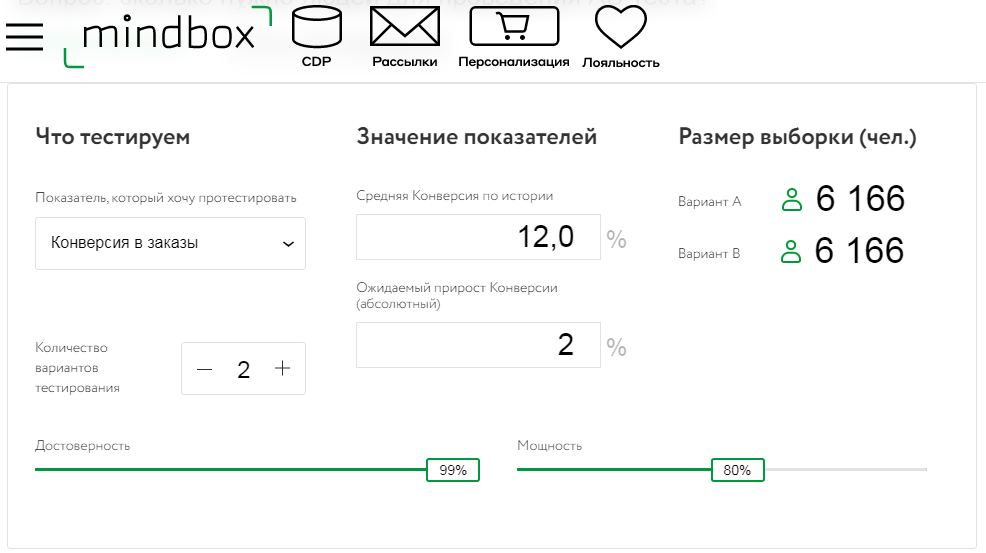
По результатам Mindbox размер выборки для каждой тестируемой группы должен составлять 6 166 человек. Это больше, чем мы получили по методу SurveyMonkey (5500 человек в контрольной группе) или с помощью калькулятора Optimezely (5300 человек). Однако цифры вполне сопоставимы.
По настройке Mindbox отличается от Optimezely следующими моментами:
- ожидаемый прирост конверсии в Mindbox указывается в абсолютных величинах, а в Optimizely – в относительных;
- указывается показатель мощности. В Optimezely этот показатель не учитывается;
- в Optimezely можно проследить изменения только по показателю конверсии. Mindbox же позволяет получить выборку для тестов, в которых тестируются показатели Click rate и Open rate;
- в Mindbox можно посчитать выборку для 2–5 тестовых групп. Optimezely не предоставляет такой возможности.
Таким образом, на примере мы показали как тремя способами посчитать размер репрезентативной выборки для тестовых кампаний.
Основные сложности в тестах при расчете выборки
Недостаточное количество просмотров
Зачастую для получения статистически значимых результатов размер выборки должен составлять от 2000–3000 человек. И это большая проблема в том случае, если за неделю было всего несколько сотен переходов.
Один из вариантов сократить размер выборки – понизить уровень доверия в настройках онлайн-калькулятора до приемлемых величин (не ниже 80%). А если репрезентативная выборка определяется калькулятором Mindbox, то можно уменьшить еще и показатель мощности. В этом случае данные будут менее достоверными, но все еще не утратят своей статистической значимости.
Например, в Mindbox задаем уровень доверия 99% и мощность 98%. В результате размер выборки для одной тестируемой группы составляет 5 030 человек:

Понижаем уровень достоверности до 85%, а мощность до 80%. Остальные данные оставляем без изменений.
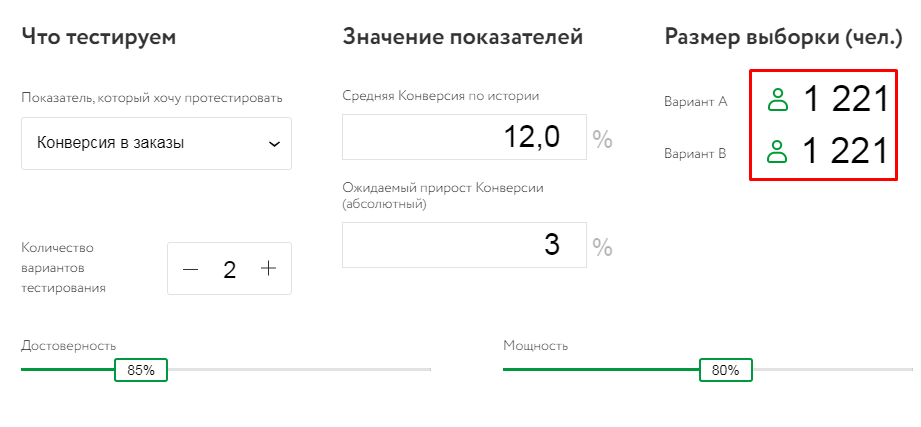
В результате требуемый размер выборки уменьшился почти в 5 раз. Это очень ощутимое сокращения с учетом низкого трафика по рекламе.
Узкая тематика
Основная проблема узкой тематики заключается в том, что всего несколькими десятками ключевых фраз можно описать все запросы, по которым пользователи ищут услугу. Отсюда и низкий трафик.
Решить проблему можно так:
- понизить уровень доверия при расчете выборки. Как это работает, мы описали выше;
- не запускать тест на конверсию в заказы. Для рекламы в узкой тематике эта метрика не подходит. При небольшом количестве переходов и уровень конверсии в заказы будет очень низкий. При этом для получения статистически значимых результатов надо показать рекламу большему количеству пользователей, чем при выборе показателя Click Rate.
Например, при средней конверсии по истории 3% размер выборки составит 18 273 человека:
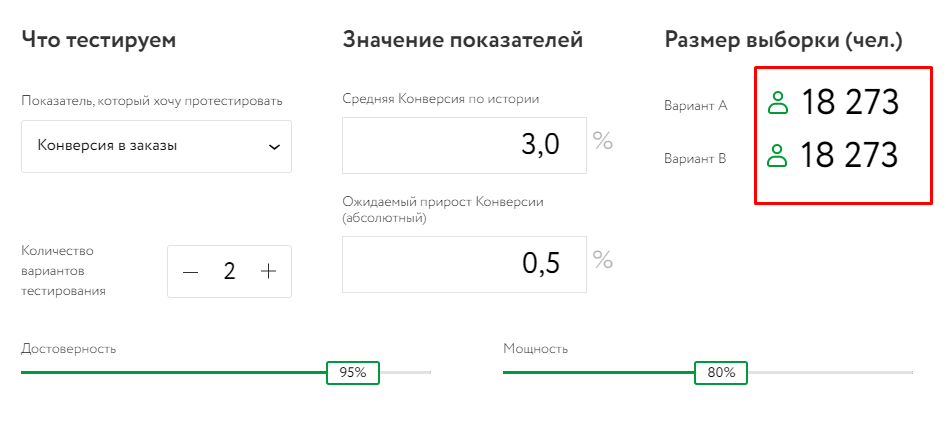
Оставляем тот же уровень достоверности и мощности. В показателях выбираем Click Rate. Устанавливаем средний по истории показатель и ожидаемый абсолютный прирост:
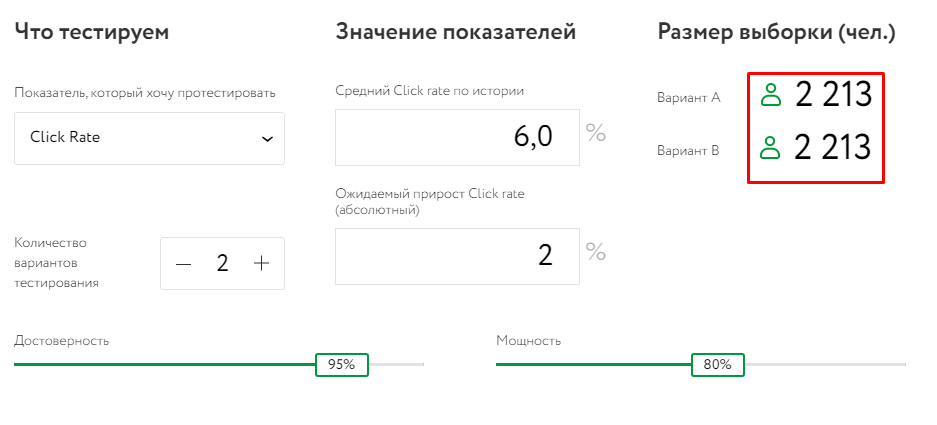
Получаем, что выборка для одной тестируемой группы составляет 2213 человек. Это все равно очень много для узкой тематики. Поэтому понижаем достоверность и мощность:
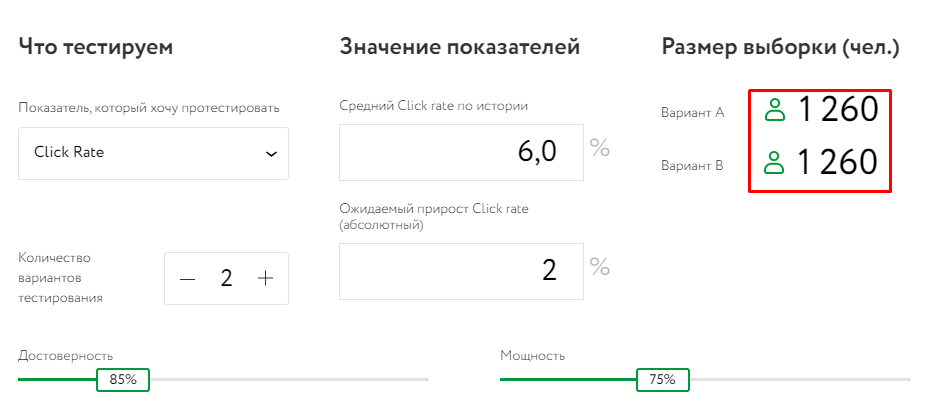
Таким образом, изменение тестируемой метрики и уменьшение показателей достоверности позволило нам сократить размер выборки с 18 273 до 1200 человек.
Рекламироваться в узкой тематике сложно, но есть способы, позволяющие увеличить трафик по объявлениям. Подробнее об этом читайте в нашей статье «Реклама в узкой тематике: 9 советов по повышению эффективности».
Низкий бюджет
В условиях ограниченного бюджета у рекламодателя нет возможности тестировать каждый заголовок, креатив или текст объявления.
Вот советы, которые помогут сэкономить бюджет:
1. Сравнивайте разные объявления. На поступательное тестирование сначала заголовков, потом текстов объявлений, креативов и других элементов потребуется время и немалые бюджеты. Поэтому в условиях ограниченных средств лучше кардинально менять заголовки, тесты, креативы и сравнивать радикально разные варианты объявлений;
2. Используйте системы автоматизации. Если стоит цель сэкономить, то можно создать тестовые объявления самостоятельно, а не платить деньги специалистам. Это позволит высвободить дополнительный ресурс на тестирование большей выборки. Быстро составить объявления можно с помощью систем автоматизации.
Например, для составления объявлений по ключевым словам можно воспользоваться инструментом медиапланирования Click.ru. Он собирает семантику исходя из контента вашего сайта, слов конкурентов или данных счетчиков статистики. А потом на основании отобранных слов составляет объявления:
Вам остается только отредактировать их и запустить тестовые кампании.
Еще один вариант – использовать генератор объявлений из YML. Этот инструмент подходит интернет-магазинам, которые используют выгрузку товаров/услуг в XML.
Подробнее о том, как работать с генератором объявлений из YML, читайте в статье «Как быстро составить 1000 объявлений контекстной рекламы из YML-файла».
Высокий бюджет
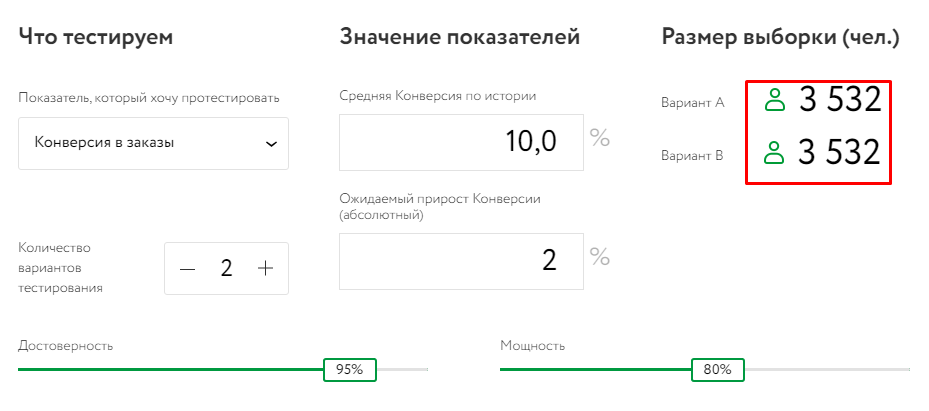
При высоком бюджете открываются дополнительные возможности: можно тестировать отдельно разные элементы объявления, запускать больше тестов, настраивать не две, а три и более тестовых групп – в этом случае размер выборки увеличивается.
Вот какой размер выборки может быть при двух тестовых группах:
А вот размер выборки при тестировании трех групп (при этом остальные настройки остаются неизменными же):
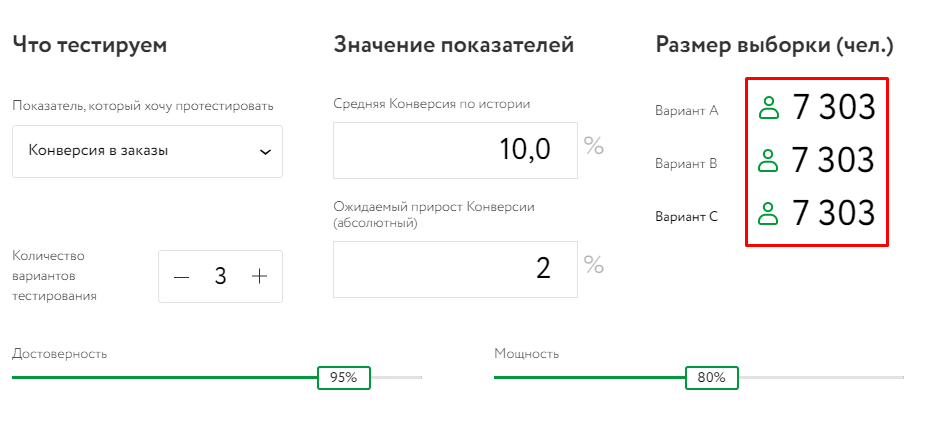
Но при высоком бюджете важно помнить об эффективности мероприятий. Нельзя допускать того, чтобы затраты превосходили ожидаемый эффект от тестирования. Дополнительные средства можно перенаправить на SEO или другие каналы привлечения клиентов.
Советы по расчету выборки
Вот несколько рекомендаций, которые помогут правильно рассчитать репрезентативную выборку и получить показательное тестирование.
- Наберитесь терпения. Для получения результатов может потребоваться несколько тысяч посещений или 2 недели. Лучше тестировать более крупные изменения, чтобы не ждать небольших улучшений.
- Будьте последовательны. Определите, кто ваша целевая аудитория, кому показывать рекламу, чтобы достигнуть поставленных целей. Неверный таргетинг израсходует ваш тестовый бюджет и результаты по тестовым группам будут не показательны.
- Помните о правилах подсчета выборки. При расчетах устанавливайте высокий уровень достоверности данных. Помните, что уменьшение этого показателя приводит к снижению значимости результатов.
Помогаете клиентам запускать контекстную и таргетированную рекламу? Тогда для вас актуален вопрос эффективного управления кампаниями. Подключите аккаунты ваших клиентов к Click.ru и получайте вознаграждение по партнерской программе до 18%.

Советы
Репрезентативная выборка в рекламе: что это и как определить
Невозможно узнать наверняка, какая реклама откликнется у целевой аудитории. Но можно строить гипотезы и проводить тесты перед полноценным запуском. Сделать это поможет репрезентативная выборка.
Что такое репрезентативная выборка и зачем она нужна
Репрезентативная выборка в рекламе — это выделение сегментов целевой аудитории для дальнейшего изучения. Термин «репрезентативная» означает, что характеристики изученной группы будут отражать показатели всей ЦА.
Представьте такую ситуацию. Компания, которая оказывает услуги по разработке сайтов, решила запустить контекстную рекламу. Целевая аудитория рекламной кампании — посетители сайта и бывшие клиенты. Всего таких людей 5000 — это генеральная совокупность.
Проблема в том, что тесты на такой большой выборке невозможны. Исследование получится слишком дорогим и займет много времени. А еще есть вероятность впустую слить бюджет.
Но можно сделать проще. Допустим, мы сегментируем аудиторию по полу и знаем, что среди нашей ЦА 45% — это женщины, а 55% — мужчины. Тогда мы можем взять 200 пользователей, среди которых будет 90 женщин и 110 мужчин. Если соблюсти гендерную пропорцию, выборка будет репрезентативной.
Кроме пола потенциальных клиентов можно сегментировать и по другим критериям: возрасту, месту жительства, образованию, сфере деятельности. Чтобы выборка была качественной, нужно учесть все характеристики, которые важны для проекта.
Иными словами, репрезентативная выборка — это целевая аудитория в миниатюре. С помощью нее можно быстро узнать, будет ли реклама работать, если запустить ее на всех пользователей. А затем — спрогнозировать количество целевых действий.
Как составить репрезентативную выборку
Наполнение выборки зависит от признаков всех представителей ЦА. Чтобы выявить эти признаки, нужно правильно составить портрет целевой аудитории и разбить его на подгруппы. Давайте разбираться на примере.
Агентство детских праздников запустило таргетированную рекламу. Объявления просмотрели 8000 человек. 57% из них проживают в Москве, а 43% — в Московской области. При этом у 30% двое детей, а у 70% — один ребенок.
Агентство решило изменить объявления. Чтобы протестировать изменения, маркетолог рассчитал репрезентативную выборку в количестве 400 человек:
- 228 живут в Москве, у 69 из них двое детей, у 159 — один ребенок;
- 172 живут в Московской области, у 52 двое детей, у 120 — один ребенок.
Количество участников в каждом сегменте не обязательно должно совпадать. Допустим, у онлайн-магазина 10 000 подписчиков: 9 750 женщин и 250 мужчин, которые закупаются подарками для жен, девушек, коллег. В этой ситуации можно анализировать только действия женщин, потому что количество пользователей-мужчин незначительное.
Рассчитать количество участников выборки помогут специальные сервисы. Например, Socioline или QuestionStar. Чтобы результаты были достоверными, устанавливайте погрешность не более 1-5%, а коэффициент степени доверия — 95-99%.
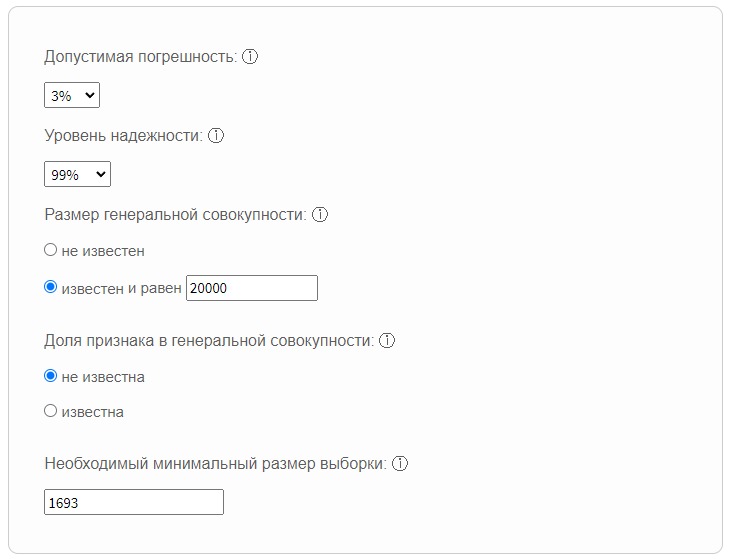
Пример расчетов в онлайн-калькуляторе
Пример нарушения репрезентативности
Сервисом по доставке пиццы пользуются люди 20-50 лет, это мужчины и женщины с доходом выше среднего. Представим, что они разделены на три возрастных сегмента: 20-30, 30-40 и 40-50 лет.
Если объем выборки составит 600 человек, 300 из которых — это мужчины 20–30 лет, то она будет нерепрезентативной. Тестирование объявления даст ложный результат.
Если из 600 человек 33% составят люди в возрасте от 20 до 30 лет, 33% — от 30 до 40 лет, а 34% — от 40 до 50 лет, при этом по 50% придется на мужчин и женщин, то выборка будет репрезентативной. Она отразит особенности всей целевой аудитории сервиса. Значит, результатам исследования можно доверять.
Выборка в A/B-тестах: зачем считать, и что еще влияет на результаты
Цель A/B-тестов — повысить количество кликов и увеличить коэффициент конверсии. Однако согласно исследованиям, достоверную информацию дает только 1 из 8 тестов. Результаты будут значимыми только в том случае, если маркетолог верно рассчитал репрезентативную выборку.
На достоверность тестов влияют такие ошибки.
Недостаточно данных. Предположим, мы изучаем эффективность нескольких заголовков и получаем такие результаты:
| Показы | Клики | CTR, % | |
| Текущее объявление | 72 | 12 | 0,17 |
| Тестируемое объявление | 46 | 1 | 0,02 |
Кажется, что текущее объявление работает лучше. Тогда маркетолог начинает задумываться:
- Достаточно ли в аналитике данных, чтобы делать выводы об эффективности рекламы?
- Останавливать или продолжать тестирование?
Не стоит верить немногочисленным кликам — это будут поспешные выводы, которые могут не иметь ничего общего с действительностью. Чтобы принимать решение, нужно собрать больше данных. С помощью программы Optimizely давайте узнаем, сколько людей нужно включить в выборку. Для этого:
- Прописываем значение конверсии действующего объявления. В нашем случае — 17%.
- Задаем коэффициент степени доверия 95%.
- Указываем показатель коэффициента конверсии, который хотим получить в результате тестов — 20%.
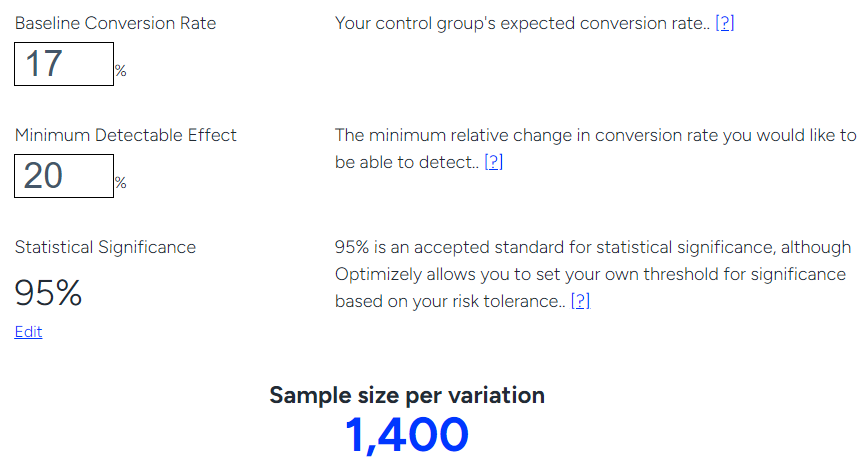
Калькулятор показывает, что для достоверного тестирования нам нужно включить в выборку 1400 участников
Ошибочная гипотеза. Например, в ходе тестов мы предположили, что на лендинге нужно изменить описание товара — тогда конверсия в покупку вырастет. Затем мы запустили в рекламу три варианта лендинга с разными описаниями, но покупок больше не стало.
Дело в том, что мало изменить текст или заголовок на сайте. Нужно еще и заинтересовать целевую аудиторию в покупке. Например, подарить промокод на первый заказ или предложить рассрочку. Т.е. изменения должны быть более значимыми, а не косметическими.
Выбрана не та метрика. Результату можно будет верить, если выбрать только одну метрику для улучшения. Например, стоит задача — увеличить конверсию в покупку для новых пользователей. Большинство онлайн-калькуляторов считают размер выборки, учитывая именно эту метрику.
Но если вводных по переходам недостаточно, необходимо обращаться к другим показателям. Например, на рост CTR. В этом случае поможет калькулятор Mindbox. Он рассчитает размер выборки для тестов по таким показателям:
- Open Rate. Отношение открытых писем к общему количеству доставленных.
- Conversion Rate. Отношение покупок к общему числу пользователей, которые перешли на сайт.
- Конверсия в другие целевые действия.
Размер репрезентативной выборки зависит от выбранной метрики и количества тестируемых показателей. Например, узнаем, сколько пользователей нужно включить в выборку при тесте Open Rate. Зададим ограничения: текущий Open Rate — 27%, ожидаемый прирост — 20%, количество тестируемых вариантов — 5.

Получается, в выборке должно быть 1895 человек, по 379 для каждого теста
Сложности работы с репрезентативной выборкой
Самый эффективный способ составить репрезентативную выборку — сегментировать ЦА, а затем выбрать несколько человек из каждой группы. Некоторые маркетологи делают выборку рандомно. Но этот способ работает только для однородной аудитории, представители которой совпадают по полу, возрасту и другим характеристикам.
При тестировании рекламы на репрезентативной выборке возникают такие сложности.
Недостаточное количество просмотров. Чтобы получить статистически значимые результаты, объем выборки при тысячной ЦА должен составлять 500-600 человек. Если по объявлению перешло меньше пользователей, то исследование теряет объективность. В этой ситуации можно снизить уровень доверия до 80%. Только не забудьте учесть это при анализе полученных результатов.
Узкая тематика. Предварительный тест не будет иметь смысла, если вы продвигаете объявление по нескольким ключевым словам.
Низкий бюджет. Если рекламный бюджет ограничен, не стоит тестировать много элементов объявления. В этом случае лучше исследовать принципиально разные типы объявлений, а не одну рекламу с десятком разных заголовков.
Высокий бюджет. Когда бюджет не ограничен, маркетолог может проводить тестирование с размахом и задействовать в тестах несколько тысяч пользователей. Однако в случае с тестированием рекламы подход «чем больше, тем лучше» не работает — это будет долго, дорого и неинформативно.
Советы по расчету выборки
Эти советы помогут рассчитать репрезентативную выборку и получить достоверные результаты тестирования.
Проявите терпение. Две недели — оптимальное время для получения результата, а несколько тысяч просмотров — оптимальное количество. Лучше тестировать более крупные изменения, чтобы не ждать небольших улучшений.
Действуйте последовательно. Изучите свою ЦА, чтобы реклама попала точно в цель. Неправильно настроенный таргетинг только зря израсходует бюджет, а достоверных результатов вы не получите.
Не забудьте о правилах подсчета выборки. При расчете установите уровень достоверности данных от 95%. Помните, что снижение этого показателя снизит и качество результатов.
ЭКСКЛЮЗИВЫ ⚡️
Читайте только в блоге
Unisender
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
![]()
![]()
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
«Честно» — авторская рассылка от редакции Unisender
Искренние письма о работе и жизни. Свежие статьи из блога. Эксклюзивные кейсы
и интервью с экспертами диджитала.

О размере выборки и статистической ошибке измерений подробно написано в статье «Выборка. Размер – не главное. Или главное» . В этой статье будет рассмотрено второе требование к выборке, также обеспечивающее качество исследования – репрезентативность.
Согласно теории выборочного метода, неоднократно подтвержденной практикой, опрашивать всех нет необходимости, а можно опросить лишь часть группы, которая может быть в тысячи раз меньше. Эта маленькая часть называется выборкой (или выборочной совокупностью), а большая группа, которую она представляет, называется генеральной совокупностью.
При этом если выборка сформирована правильно, выводы, полученные на основе изучения выборки, могут быть перенесены и на генеральную совокупность. Например, если в выборке женщины значимо чаще, чем мужчины, пользуются дезодорантами, то делается вывод, что и в генеральной совокупности (например, в исследованном городе) присутствует такая закономерность. Процесс переноса выводов с выборки на генеральную совокупность называется генерализацией. А свойство выборки отражать характеристики генеральной совокупности называется репрезентативностью. Для более комфортного запоминания термина на рис.1. приведены иллюстрации, когда выборка отражает свойства генеральной совокупности и когда свойства выборки отличаются от свойств генеральной совокупности.



Рис.1. Иллюстративные примеры соответствия (несоответствия) свойств генеральной совокупности и выборки
Не стоит путать понятие репрезентативности с такими понятиями как валидность и релевантность, хотя они тоже относятся к характеристикам качества исследования. В социальных науках валидность понимается довольно широко, но чаще всего – как обоснованность. Понятие валидности относится не к выборке, а к исследовательской методике. Методика или измерение (анкета, блок вопросов, тест) считается валидным, если фиксирует именно то понятие или свойство, которое планируется измерить. Например, если мы захотим оценить уровень лояльности клиента к магазину и выберем для этого лишь показатель частоты посещения магазина, валидность этого подхода будет неполной: возможно, респондент часто заходит в магазин только из-за банкомата, который там установлен. Валидная методика в данном примере должна включать и другие показатели: предпочтение магазина, суммы покупок в этом и других магазинах, готовность переключиться на другие магазины, готовность рекомендовать магазин и др.
При установлении валидности решающую роль играет обоснование и последующая проверка гипотезы релевантности, то есть соответствия измеряемых параметров характеристикам исследуемого объекта. Житейский пример нерелевантности – измерять уровень счастья человека количеством денег у него (хотя, наверное, не все с этим согласятся). Очевидный пример нерелевантности – попытка измерить массу тела по его температуре.
Но вернемся к понятию репрезентативности. В то время как точность измерений зависит от размера выборки, размер выборки не гарантирует ее репрезентативности. Репрезентативность выборки главным образом обеспечивается способом отбора ее участников (респондентов). Примером явного нарушения репрезентативности может послужить шутка о том, что интернет-опрос показал, что 100% людей пользуется интернетом.
Можно выделить несколько вариантов нарушения репрезентативности выборки: когда опрошены не те люди и когда опрошено слишком много (или мало) определенных людей (например, женщин намного больше, чем мужчин). Кроме того, чем меньше размер выборки, тем меньше вероятность того, что она будет репрезентативной. Например, допустим, 1% населения мог бы заинтересоваться новой услугой. Это 1 из 100 людей. Если размер выборки составляет всего 60 человек, то в вашей выборке может отсутствовать человек, который, скорее всего, будет заинтересован в услуге. Ваша выборка менее репрезентативна, потому что она меньше. Ваши результаты будут разными в зависимости от того, содержит ли ваша выборка одного из этих людей или нет. Пример репрезентативной и нерепрезентативной выборки показан на рис.2.

Рис.2. Пример репрезентативной и нерепрезентативной выборки
На рис.3 показана та же по составу генеральная совокупность, но с другим расположением объектов внутри круга.

Рис.3. Пример репрезентативной и нерепрезентативной выборки при другом расположении объектов генеральной совокупности
Говоря простым языком, репрезентативная выборка – это такая выборка, в которой представлены все подгруппы, важные для исследования. Помимо этого, характер распределения рассматриваемых параметров в выборке должен быть таким же, как в генеральной совокупности.
Простой случайный отбор респондентов представляется оптимальным способом формирования репрезентативной выборки. Поскольку в этом случае у любого представителя генеральной совокупности одинаковая вероятность попасть в выборку, в нее попадут люди с разными характеристиками пропорционально их долям в генеральной совокупности. В итоге выборка будет представлять собой нечто вроде уменьшенной копии генеральной совокупности.
Случайность отбора респондентов в выборку обеспечивается разными способами. Например, для телефонного опроса жителей города берется база данных всех телефонных номеров, и номера респондентов случайным образом выбираются компьютером (с использованием генератора случайных чисел). При уличном опросе интервьюеров распределяют по случайно выбранным точкам и инструктируют опрашивать каждого N-ного прохожего.
Наглядным примером репрезентативной выборки может служить пицца. Если целая пицца – это генеральная совокупность, которую мы хотим изучить, то кусок пиццы – это выборка. Как правило, достаточно одного куска пиццы, чтобы судить обо всей пицце (при условии, что ингредиенты равномерно распределены по ее поверхности). Таким образом, кусок пиццы пиццы на рис.4 – это репрезентативная выборка из пиццы.
")
Рис.4. Наглядный пример репрезентативной выборки (пицца)
Важно отметить, что не любой кусок пиццы будет репрезентативной выборкой. Разные способы получения куска пиццы могут принципиально повлиять на качество исследования и выводы, которые будут получены при анализе каждого варианта выборки (рис.4)
(рисунок в сушильной камере, готовится к публикации)
Рис.5. Наглядный пример формирования репрезентативной и нерепрезентативной выборки.
Еще один показательный пример формирования репрезентативной выборки – кастрюля, содержимое которой мы должны узнать (допустим, там скрывается борщ). Мы только один раз можем зачерпнуть из кастрюли ложкой (провести исследование). В нашем примере ложка – это выборка, а содержимое кастрюли – генеральная совокупность.
Если мы зачерпнем сверху, то придем к выводу, что в кастрюле бульон. Если снизу – решим, что в кастрюле мясо. Зачерпнув где-то посередине, мы получим картошку или капусту. В любом из трех случаев выводы будут неверны. Чтобы получить достоверный результат, нам стоит хорошенько перемешать содержимое кастрюли, перед тем как пробовать его. Перемешивание в данном случае – аналог процедуры простого случайного отбора, поскольку оно предоставляет всем ингредиентам примерно равную вероятность попадания в ложку-выборку (или тарелку-выборку).

Рис.6. Борщ как модель, демонстрирующая репрезентативность выборки.
В реальности применить простой случайный отбор респондентов не всегда удается в полной мере. Например, мы можем абсолютно корректно отобрать в выборку нужное количество номеров домашних телефонов случайным образом, но при их прозвоне выяснится, что дозвониться и поговорить удается преимущественно с пенсионерами, а «поймать» дома молодежь и работающих людей получается плохо.
Возвращаясь к примеру с борщом, если у нас вместо кастрюли – огромный ресторанный котел, а в руках все та же обычная ложка, перемешивание будет неэффективным. Чтобы решить задачу, потребуются иные подходы. Например, мы можем теоретически разделить глубину котла на несколько слоев и постараться зачерпнуть содержимое из каждого слоя (из случайного места слоя: не только в центре, но и по краям). Таким образом, наша итоговая выборка будет состоять уже из нескольких выборок и при этом адекватно отражать содержимое всех слоев котла. Подобные альтернативные подходы называются типами выборки, которых придумано достаточно много для того, чтобы максимизировать репрезентативность выборки в сложных условиях реального мира.
Последствия нарушения репрезентативности выборки: некорректные выводы исследования, выброшенный на ветер бюджет исследования, финансовые потери вследствие применения неправильных выводов. Вы можете выбрать валидную исследовательскую методику, рассчитать объем выборки, обеспечивающий приемлемую точность измерений, но, если выборка исследования нерепрезентативна, получить достоверную информацию не удастся.
ПРИМЕРЫ НАРУШЕНИЯ РЕПРЕЗЕНТАТИВНОСТИ ВЫБОРКИ
ПРЕДВЫБОРНЫЙ ОПРОС
Самым известным примером нарушения репрезентативности выборки является история провала американского журнала «Литературный дайджест».
В 1936 году журнал в очередной раз провел почтовый опрос общественного мнения о вероятных результатах грядущих президентских выборов в США. До 1936 года опрос всегда правильно предсказывал победителя. Опрос 1936 года показал, что победителем с большим отрывом станет кандидат от республиканцев, но в итоге победителем оказался представитель демократов.
Таким образом, гигантская выборка (около 2,4 млн. человек) не обеспечила достоверных результатов. В чем же заключалась причина ошибки?
Называются две основные причины провала: смещение при формировании выборки и смещение вследствие отказа респондентов от участия в опросе.
Прежде всего, журнал включил своих подписчиков в список для рассылки анкет и, желая расширить выборку, использовал два других доступных тогда списка граждан: зарегистрированных автовладельцев и пользователей телефонов. Во времена Великой Депрессии представители этих групп отличались от остального населения более высоким доходом, как и подписчики самого журнала. Таким образом, полученная база для рассылки не являлась корректным отражением структуры населения США.
Вторая проблема с опросом заключалась в том, что из 10 миллионов человек, чьи имена были в первоначальном списке рассылки, только 2,4 миллиона ответили на опрос. Вероятно, высокий процент отказов был связан с тем, что опрос проводился по почте. Уже в те времена американцы относились к почтовым рассылкам как к спаму. Таким образом, размер выборки составил примерно одну четверть от того, что первоначально планировалось. Когда доля ответивших низка (как это было в данном случае), считается, что исследование страдает от необъективности ответов.
У этой истории две морали: Большая, но неправильно сформированная выборка гораздо хуже маленькой, но правильно сформированной выборки. При проведении опроса не упускайте из внимания смещение отбора и смещение в результате отказов.
СИСТЕМАТИЧЕСКАЯ ОШИБКА ВЫЖИВШЕГО
Пример из военной практики. Во Вторую мировую войну американские военные столкнулись со следующей проблемой. Не все американские бомбардировщики после задания возвращались на базу. На вернувшихся самолетах оставалось множество пробоин от выстрелов противника, но распределены они были неравномерно: больше всего на фюзеляже и прочих частях, меньше в топливной системе и гораздо меньше — в двигателе. Командованию казалось логичным, что в наиболее поврежденных местах нужно установить больше брони.
Привлеченный к решению задачи математик возразил: данные как раз показывают, что самолет, получивший пробоины в этих местах, еще может вернуться на базу. А самолет, которому попали в бензобак или двигатель, выходит из строя и не возвращается. Поэтому укреплять следует те места, которые у вернувшихся самолетов повреждены меньше всего.

Рис .7. Пробоины на вернувшихся самолётах.
Получившие повреждения в других местах не смогли вернуться на базу
Эта задача служит примером нарушения репрезентативности выборки, когда в нее включены не те респонденты: в данном случае, вернувшиеся самолеты, в то время как не вернувшиеся проигнорированы.
Применительно к маркетинговым исследованиям, эта ситуация подобна следующей. При опросе клиентов бизнеса будет ошибкой опрашивать только текущих клиентов и не опрашивать потерянных клиентов (а какие «пробоины» получили они?).
НЕПРАВИЛЬНЫЕ МЕСТА ОПРОСА
При опросе посетителей ТРЦ важно правильно расставить интервьюеров. Например, если поставить интервьюеров только у главного входа, в выборку не попадут посетители, приехавшие в ТРЦ на автомобиле и попавшие в него через парковку. Как следствие, выводы, полученные на собранных данных, будут корректны только для той части посетителей, которые приходят в ТРЦ пешком, а значит, делают меньше покупок, не покупают габаритные товары, живут ближе к ТРЦ, чем приезжающие на автомобиле.
ОТСУТСТВИЕ КВОТИРОВАНИЯ
Другой пример. Бывает, что в разных районах города сбор анкет идет с разной скоростью: где-то (например, в центре города) большой пешеходный поток и у людей есть время на участие в опросе (отдыхающие, в отпуске, офисные сотрудники на обеде), а на окраинах либо мало людей на улицах, либо все спешат на работу и отказываются участвовать. В результате, если не ограничивать доли районов, в выборке будут преобладать люди из центрального района, которые могут значимо отличаться от остальных людей родом занятий, уровнем дохода и образования, уровнем осведомленности о магазинах и др. Таким образом, собранная выборка уже не будет репрезентативной по отношению к населению всего города.
ОНЛАЙН-ОПРОСЫ (ОНЛАЙН-ПАНЕЛИ)
Несмотря на многие положительные стороны онлайн-опросов, такие как экономичность, оперативность сбора информации, удобство ее обработки и т. д., некоторые их особенности напрямую угрожают репрезентативности исследования:
Во-первых, участники онлайн-опросов – это, как правило, активные пользователи интернета, хорошо в нем разбирающиеся и больше подверженные влиянию интернет-культуры, чем обычные люди.
Во-вторых, люди, у которых есть время и желание регулярно участвовать в онлайн-опросах за небольшое вознаграждение, скорее всего, значительно отличаются от остальных людей как по социально-демографическим, так и по психографическим характеристикам.
В-третьих, профессиональное участие в опросах приводит к так называемой профессиональной деформации, когда ответы респондентов на вопросы новых исследований обусловлены предыдущим опытом, но не жизненным, а опытом участия в других опросах.
Таким образом, в данном случае возникает та ситуация, когда опрашиваются не те люди, хотя по формальным характеристикам они подходят под описание целевой аудитории.
ВЫВОДЫ
Итак, чтобы получить достаточно точные данные об интересующей нас группе людей, необязательно опрашивать их всех, благодаря свойству репрезентативности выборки.
«Чем больше, тем лучше» – неправильный подход к формированию выборки.
Небольшая репрезентативная выборка лучше большой, но нерепрезентативной выборки. Применительно к выборке не стоит пугаться слова «случайная». Это вовсе не значит, что в исследовании будут получены случайные результаты. Напротив, случайный подход к формированию выборки делает ее максимально похожей на генеральную совокупность, а значит, репрезентативной.
При проектировании выборки следует учитывать опасность смещения структуры выборки вследствие особенностей сбора информации и других условий.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Что такое репрезентативная выборка и как ее определить


Содержание

Предугадать, какое рекламное объявление «выстрелит», а какое нет — невозможно. Давно прошли времена, когда существовало 5-6 форматов рекламы и все они давали примерно одинаковый результат. Сейчас, чтобы успешно продавать товары, обучать иностранным языкам, оказывать юридические и другие услуги, важно верная маркетинговая стратегия.
Рассказываем, как протестировать рекламу перед запуском на репрезентативной выборке.
https://unsplash.com/photos/vVHXeu0YNbk
Что такое репрезентативная выборка и зачем она нужна
Репрезентативная выборка в контекстной рекламе — это деление целевой аудитории (ЦА) на подгруппы, приоритетные для исследования. «Репрезентативной» называют только ту выборку, чьи параметры соответствуют показателям всей целевой аудитории.
Вот простой пример, иллюстрирующий преимущества репрезентативной выборки:
Компания занимается разработкой дизайн-проектов квартир и планирует запуск контекстной рекламной кампании. Объявления нацелены на пользователей, которые уже посещали страницу на сайте или обращались за услугами ранее.
Вся целевая аудитория, подпадающая под эти критерии, — это генеральная совокупность. Однако она включает более 5 000 человек и тестировать рекламу на таком количестве потенциальных клиентов — долго, дорого и малоинформативно. Поэтому целесообразно сделать репрезентативную выборку.
Если 50% из этих 5 000 человек — мужчины, а 50% — женщины, то выборка из 100 человек с таким же гендерным соотношением будет репрезентативной.
Репрезентативная выборка по полу приведена только в качестве примера. На деле представителей ЦА объединяют в подгруппы по возрасту, региону проживания, социальному статусу, уровню дохода и другим специфическим критериям. Только с учетом всех особенностей ЦА, которые важны для вашего проекта, можно составить качественную репрезентативную выборку.
То есть репрезентативная выборка — «мини-версия» вашей целевой аудитории.
Выборка нужна, чтобы быстро и объективно протестировать, насколько эффективно будет рекламное объявление при запуске масштабной кампании. По ней можно предсказать, какими окажутся кликабельность, коэффициент конверсий, результаты кампании.

https://unsplash.com/photos/NDfqqq_7QWM
Как составить репрезентативную выборку
Содержание репрезентативной выборки зависит от характеристик генеральной совокупности. Главное — иметь правильно составленный портрет целевой аудитории.
Для удобства ЦА можно разделить на сегменты, а затем убедиться, что в репрезентативную выборку вошли пользователи всех групп в одинаковом процентном соотношении.
Например, по рекламным объявлениям международного бюро переводов кликают около 10 000 человек. 50% из них — пользователи из России, остальные 50% — из Беларуси.
Задача маркетолога — протестировать новый формат объявления. Для этого ему необходимо подготовить репрезентативную выборку. Маркетолог рассчитал, что достаточный объем для исследования — 450 человек. В выборку вошли 225 пользователей из Беларуси, и столько же из России.
Необязательно, чтобы выборка отражала особенности генеральной совокупности вплоть до процента. Допустимая погрешность варьируется в пределах 1–5%.
Например, на страницу онлайн-магазина женских аксессуаров подписано 12 000 человек. Из них 11 760 — женщины, остальные 240 — мужчины, которые покупают подарки женам и подругам. В этом случае в репрезентативную выборку можно включить только женщин и это будет корректно, потому что доля мужчин — всего 2%.
Современные технологичные сервисы решают целый ряд задач в сферах продаж и маркетинга. Речевая аналитика Calltouch Предикт автоматически записывает и расшифровывает разговоры операторов с потенциальными покупателями. Все записи доступны в личном кабинете. Вы в любой момент сможете их проанализировать. Это позволит узнать, кто звонит чаще — мужчины или женщины, какие вопросы они задают, насколько качественно операторы обрабатывают обращения.
![]()
Технология
речевой аналитики
Calltouch Predict
- Автотегирование звонков
- Текстовая расшифровка записей разговоров
Узнать подробнее

Как определить размер выборки
Число пользователей или объем выборки — критерий относительный. Если тестировать рекламное объявление на группе из 50–100 человек, то вероятность ошибки будет выше, чем при опросе 300 пользователей.
Для крупных проектов оптимальный объем выборки — 500–600 человек. Если охватывать больше пользователей, то сроки тестирования, как и расходы, ощутимо возрастут. Если же численность ЦА составляет менее 400–500 человек, то делать выборку смысла не имеет — проводите тестирование на генеральной совокупности.
Для расчета размера репрезентативной выборки воспользуйтесь специализированными онлайн-калькуляторами — например Socioline или QuestionStar. Чтобы получить статистически значимые результаты, указывайте допустимую погрешность в пределах 1–5%, а уровень доверия — 95–99%.

https://unsplash.com/photos/ZzOa5G8hSPI
Сложности работы с репрезентативной выборкой
Самый эффективный способ составить репрезентативную выборку — сегментировать ЦА, а затем выбрать несколько человек из каждой группы. Некоторые поступают проще и делают случайную выборку из всей ЦА. Но этот способ работает только для однородной аудитории, представители которой совпадают по полу, возрасту и другим характеристикам.
Сложности, которые возникают при тестировании контекстной рекламы на репрезентативной выборке:
- Недостаточное количество просмотров. Чтобы получить статистически значимые результаты, объем выборки при тысячной ЦА должен составлять около 500–600 человек. Если по объявлению перешло меньше пользователей, то исследование теряет объективность. Что делать? Понизьте уровень доверия до 80–85% и учтите это при анализе результатов тестирования.
- Узкая тематика. Если вы продвигаете объявление по нескольким ключевым словам, то в предварительном тесте смысла нет.
- Низкий бюджет. Если рекламный бюджет ограничен, то откажитесь от тестирования большинства элементов объявления. Исследуйте принципиально разные виды рекламных сообщений. Помимо тестирования на репрезентативной выборке есть и другие способы проверить эффективность объявлений — например сравнить их с удачными креативами конкурентов.
- Высокий бюджет. Когда рекламный бюджет не ограничен, маркетологи могут составить репрезентативную выборку объемом в несколько тысяч человек. Однако в случае с тестированием рекламы подход «чем больше, тем лучше» не работает — это будет долго, дорого и неинформативно.
Эффективный маркетинг с Calltouch
- Анализируйте весь маркетинг и продажи в одном окне
- Удобные дашборды и воронки от показов рекламы до ROI
Узнать подробнее

Примеры нарушения репрезентативности
Например, сервисом для заказа вегетарианской еды пользуются мужчины и женщины в возрасте от 20 до 50 лет с доходом выше среднего. Представим, что все они разделены на три равные группы: 20–30 лет, 30–40 лет, 40–50 лет.
Если объем выборки 500 человек, 80% из которых — мужчины и женщины 20–30 лет, то она будет нерепрезентативной. Тестирование объявления даст ложный результат.
Если из 500 человек 32% составят люди в возрасте от 20 до 30 лет, 32% — от 30 до 40 лет, а 36% — от 40 до 50 лет, то выборка будет репрезентативной. Она отразит особенности всей целевой аудитории сервиса, а значит, результатам исследования можно доверять.
Коротко о главном
- Репрезентативная выборка — часть целевой аудитории, которая отражает ключевые характеристики всей совокупности пользователей: пол, возраст, местоположение, интересы.
- Если ЦА большая, то ее нужно сегментировать. Выборка должна включать пользователей из каждого сегмента в равном процентном соотношении.
- Средний объем репрезентативной выборки для крупных компаний — 500–600 человек.
- Допустимая погрешность при расчете должна составлять не более 5%, а уровень доверия — от 95 до 99%.
- К особенностям, которые нужно учитывать при тестировании контекстной рекламы на репрезентативной выборке, относятся узкая тематика, малое число просмотров и небольшой бюджет.

Что такое репрезентативная выборка?
Определение репрезентативной выборки: Репрезентативная выборка определяется как небольшое количество или подмножество чего-то большего. В ней представлены те же свойства и пропорции, что и в более крупной популяции.
Например, рассмотрим бренд, который собирается запустить новый продукт в одном из городов США. Практически невозможно отправить опрос для сбора информации об особенностях продукта от каждого жителя города. Поэтому исследователи собирают небольшую выборку людей, которые будут представлять население города, и проводят среди них опрос, чтобы узнать их мнение о продукте. Такая выборка называется репрезентативной.
Выбор респондентов
Репрезентативной выборкой могут быть люди или даже химические вещества в научных исследованиях, которые могут быть протестированы в лаборатории для анализа результата той или иной химической реакции. Однако в этом блоге мы сосредоточимся на людях и разберем важность репрезентативной выборки населения в маркетинговых исследованиях и другие полезные аспекты.
Почему необходимо использовать репрезентативную выборку в исследованиях?
Репрезентативная выборка позволяет исследователям абстрагировать собранную информацию на более крупную популяцию. Большинство маркетинговых и психологических исследований не подходят с точки зрения времени, денег и ресурсов для сбора данных обо всех. Практически невозможно собрать данные от каждого человека, особенно для большой популяции, такой как целая страна.
Хорошая новость заключается в том, что «вам и не нужно этого делать!». Здесь важнее получить хорошую репрезентативную выборку, чтобы большая часть вашего времени и энергии ушла на получение ответов от небольшой группы людей, которые будут представлять большую популяцию.
Вновь и вновь в научных исследованиях для проведения исследований, сбора данных и анализа результатов привлекалась меньшая группа людей. Давайте разберемся в важности репрезентативной выборки для значимых исследований.
Важность репрезентативной выборки для практических исследований
- Репрезентативная выборка будет работать в вашу пользу для проведения успешных маркетинговых исследований. Можете ли вы представить себе, что нужно опросить всех жителей страны или даже города? Это прозвучало бы как самый непрактичный план, было бы слишком сложно и заняло бы много времени.
- Репрезентативная выборка — это небольшое количество людей, которые максимально точно отражают более обширную группу. Тогда мы можем применить, например, онлайн-опрос к выборке населения, стремясь к тому, чтобы она была наиболее представительной для нашей целевой аудитории.
- Мы не получим лучших результатов, если, например, отправим опрос без учета репрезентативности, и не будем знать, кто на него отвечает и отражают ли результаты мнение нашей целевой аудитории.
- Если у нас нет репрезентативности, действительно, у нас будут данные, которые не будут служить нам вообще. Мы должны гарантировать, что выборка несет в себе характеристики, которые важны для нашего исследования.
- Примите во внимание, что у нас всегда будет смещение выборки, потому что всегда найдутся люди, которые не ответят на опрос по разным причинам или ответят неполно. В этом случае мы не сможем полностью получить необходимые нам данные. Что касается размера выборки, то чем больше размер выборки, тем больше вероятность того, что она будет точно представлять широкую популяцию.
- Большая репрезентативная выборка дает нам большую уверенность в том, что в нее включены именно те люди, которые нам нужны, а также уменьшает возможную предвзятость. Поэтому, если мы хотим избежать неточностей в наших опросах, мы должны иметь репрезентативные и сбалансированные выборки.
Как построить репрезентативную выборку
Исследователи используют два метода построения репрезентативных выборок — вероятностная выборка и не вероятностная выборка
1. Вероятностная выборка: Вероятностная выборка — это метод, при котором исследователь выбирает выборку из большей популяции, используя метод, основанный на теории вероятности. Чтобы участник считался вероятностной выборкой, он должен быть отобран с помощью случайного отбора.
Если мы будем использовать вероятностную выборку для получения репрезентативной выборки, то простая случайная выборка является лучшим выбором. Выборка делается случайным образом, что гарантирует, что каждый член совокупности будет иметь одинаковую вероятность отбора и включения в выборочную группу.
2. Невероятностная выборка: Невероятностная выборка — это метод выборки, при котором исследователь отбирает выборки на основе субъективного суждения исследователя, а не случайного отбора. При непроизвольной выборке не все члены популяции имеют шанс принять участие в исследовании, в отличие от вероятностной выборки, где каждый член популяции имеет известный шанс быть отобранным.
Знание демографических характеристик отобранной выборки, несомненно, поможет ограничить профиль желаемой выборки и определить интересующие нас переменные, такие как пол, возраст, место проживания и т.д. Зная эти критерии до получения информации, мы можем контролировать создание эффективной репрезентативной выборки. Мы должны избегать выборки, которая не отражает целевую популяцию. Идея заключается в том, чтобы получить максимально точные данные для успеха нашего проекта.
Избежать ошибки выборки для лучшей репрезентативности
Когда выборка не является репрезентативной, мы получим ошибку выборки, известную как предел ошибки. Если мы хотим получить репрезентативную выборку из 100 сотрудников, мы должны выбрать одинаковое количество мужчин и женщин. Например, если у нас есть выборка, склонная к определенному жанру, то у нас будет ошибка выборки.
Размер выборки важен, но он не гарантирует, что она точно представляет нужную нам совокупность. В большей степени, чем размер, репрезентативность связана с рамкой выборки, то есть со списком, из которого отбираются люди, например, в рамках опроса. Поэтому мы должны позаботиться о том, чтобы люди из нашей целевой аудитории были включены в этот список, чтобы сказать, что это репрезентативная выборка.
Пример репрезентативной выборки
Группа граждан, представляющая всю страну, обозначается как национальная репрезентативная выборка. Исследователи используют ее для отражения и прогнозирования национальной реальности. Это могут быть предпочтения любого рода, поведение или социально-демографические профили.
В лучшем случае репрезентативная выборка будет создавать впечатление, что это все население, независимо от его внешнего вида. Количество мужчин и женщин должно соответствовать национальным пропорциям, процент в каждой возрастной группе или в каждом регионе будет точно соответствовать населению и т.д. В недемографических показателях (таких как владение продуктом или психографическая сегментация) выборка должна соответствовать населению.
Выбор респондентов
Возьмем пример с возрастом: если исследователь установит квоты от 16 до 34, от 35 до 54 или свыше 55, то выборка будет представлена в этих пропорциях. Но если он/она анализирует возрастные диапазоны от 16 до 20, от 21 до 30, от 31 до 40 и т.д., нет никакой гарантии, что выборка останется верной.
Степень, в которой возможен контроль квот в выборке, зависит от размера выборки и справочных данных, имеющихся в исследовании. Шесть возрастных периодов, два рода и 15 регионов создают сетку из 180 ячеек. Если объем выборки составляет всего 100, то заполнить все ячейки невозможно. Даже при большем объеме выборки, раздел может потребовать только половину человека, и поэтому в нем не будет данных.
Для того чтобы сделать выборку более репрезентативной, можно использовать взвешивание. В качестве альтернативы чередующимся ячейкам, квотные ячейки могут быть структурированы независимо друг от друга. Недостатком здесь является то, что в выборке могут быть значительные «пробелы». Например, если все молодые люди — мужчины, то использовать взвешивание для исправления пробелов будет невозможно.