1.3.1. Решение матричных игр в чистых стратегиях
Целью участников любой матричной игры является выбор наиболее выгодных стратегий, доставляющих игроку А максимальный выигрыш, а игроку В минимальный проигрыш.
Определение. Чистую стратегию Ai игрока А называют оптимальной, если при ее применении выигрыш игрока А не уменьшается, какими бы своими стратегиями не пользовался игрок В. Оптимальной для игрока В называют чистую стратегию Bj, при использовании которой проигрыш игрока В не увеличивается, какие бы стратегии не применял игрок А.
При поиске оптимальных стратегий опираются на основополагающий принцип теории игр – принцип осторожности, в соответствии с которым каждый игрок, считая партнера по игре весьма разумным соперником, выбирает свои стратегии с учетом того, что противник ни в коем случае не упустит ни единой возможности использовать любую его ошибку в своих интересах. Поэтому игроки должны быть предельно внимательны при выборе каждый своей чистой стратегии.
Предположим, что игроку А надлежит сделать свой выбор. Анализируя платежную матрицу (aij)i=1,m j=1,n он для каждой чистой стратегии Ai сначала найдет минимальное значение ![]() ожидаемого выигрыша:
ожидаемого выигрыша:
![]() ,
,
А затем из всех ![]() выделит наибольшее
выделит наибольшее
![]()
И выберет соответствующую ему чистую стратегию Ai. Это и будет наиболее предпочтительная в данных условиях стратегия игрока А. Ее называют максиминной, поскольку она отвечает величине
![]() (1)
(1)
Определение. Число ![]() , определяемое по этой формуле называется нижней чистой ценой игры (максимином). Оно показывает, какой минимальный выигрыш может получить игрок А, правильно применяя свои чистые стратегии при любых действиях игрока В.
, определяемое по этой формуле называется нижней чистой ценой игры (максимином). Оно показывает, какой минимальный выигрыш может получить игрок А, правильно применяя свои чистые стратегии при любых действиях игрока В.
Игрок В при оптимальном своём поведении должен стремиться по возможности за счёт своих стратегий максимально уменьшить выигрыш игрока А. Поэтому для игрока В отыскивается число
![]()
Т. е. определяется максимальный выигрыш игрока А, при условии, что игрок В применит свою J-ю чистую стратегию, затем игрок В отыскивает такую свою стратегию, при которой игрок А получит минимальный выигрыш, т. е. находит число
![]() (2)
(2)
Определение. Число ![]() , определяемое по формуле (2), называется чистой верхней ценой игры (минимаксом) и показывает, какой минимальный проигрыш за счёт своих стратегий может себе гарантировать игрок В (что соответственно определяет максимальный выигрыш игрока А при выборе правильных стратегий игроком В).
, определяемое по формуле (2), называется чистой верхней ценой игры (минимаксом) и показывает, какой минимальный проигрыш за счёт своих стратегий может себе гарантировать игрок В (что соответственно определяет максимальный выигрыш игрока А при выборе правильных стратегий игроком В).
Другими словами, применяя свои чистые стратегии игрок А может обеспечить себе выигрыш не меньше ![]() , а игрок В за счёт применения своих чистых стратегий может не допустить выигрыш игрока А больше, чем
, а игрок В за счёт применения своих чистых стратегий может не допустить выигрыш игрока А больше, чем ![]() .
.
Определение. Если в игре с матрицей А a=b, то говорят, что эта игра имеет седловую точку в чистых стратегиях и чистую цену игры v =![]() =
=![]()
Седловая точка – определяет пару чистых стратегий (iо, jо) соответственно игроков А и В, при которых достигается равенство ![]() =
=![]() . В это понятие вложен следующий смысл: если один из игроков придерживается стратегии, соответствующей седловой точке, то другой игрок не сможет поступить лучше, чем так же придерживаться стратегии, соответствующей седловой точке. Математически это можно записать и иначе:
. В это понятие вложен следующий смысл: если один из игроков придерживается стратегии, соответствующей седловой точке, то другой игрок не сможет поступить лучше, чем так же придерживаться стратегии, соответствующей седловой точке. Математически это можно записать и иначе:
![]() (3)
(3)
Где I, j – любые чистые стратегии соответственно игроков 1 и 2; (iо, jо) – стратегии, образующие седловую точку.
Таким образом, исходя из (3), седловой элемент ![]() является минимальным в iо-й строке и максимальным в jо-м столбце в матрице А. Отыскание седловой точки матрицы А происходит следующим образом: В матрице А последовательно в каждой строке находят минимальный элемент и проверяют, является ли этот элемент максимальным в своём столбце. Если да, то он и есть седловой элемент, а пара стратегий, ему соответствующая, образует седловую точку. Пара чистых стратегий (iо, jо) игроков 1 и 2, образующая седловую точку и седловой элемент
является минимальным в iо-й строке и максимальным в jо-м столбце в матрице А. Отыскание седловой точки матрицы А происходит следующим образом: В матрице А последовательно в каждой строке находят минимальный элемент и проверяют, является ли этот элемент максимальным в своём столбце. Если да, то он и есть седловой элемент, а пара стратегий, ему соответствующая, образует седловую точку. Пара чистых стратегий (iо, jо) игроков 1 и 2, образующая седловую точку и седловой элемент ![]() , называется решением игры. При этом Iо и Jо называются оптимальными чистыми стратегиями соответственно игроков А и В.
, называется решением игры. При этом Iо и Jо называются оптимальными чистыми стратегиями соответственно игроков А и В.
Пример 1
![]()
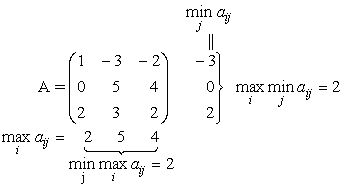
Седловой точкой является пара (Iо = 3; Jо = 1), при которой цена игры v=![]() =
=![]() =2.
=2.
Заметим, что хотя выигрыш в ситуации (3;3) также равен 2, она не является седловой точкой, т. к. этот выигрыш не является максимальным среди выигрышей третьего столбца.
Пример 2 (см. Пример 1 из п. 1.2) Анализируя платежную матрицу игры, можно найти нижнюю чистую цену игры – минус 2. Таким образом, для игрока А максиминной стратегией будет являться А2 – запись чисел 1 и 2. Верхняя чистая цена игры равна двум, а минимаксной стратегией для игрока В является В2 – запись такой же числовой комбинации. Так что по разумным соображениям эта игра обречена на ничью.
Пример 3

Из анализа платежной матрицы H видно, что ![]() <
<![]() , т. е. данная матрица не имеет седловой точки. Если игрок А выбирает свою чистую максиминную стратегию I = 2, то игрок В, выбрав свою минимаксную J = 2, проиграет только 20. В этом случае игроку А выгодно выбрать стратегию i = 1, т. е. отклониться от своей чистой максиминной стратегии и выиграть 30. Тогда игроку В будет выгодно выбрать стратегию j = 1, т. е. отклониться от своей чистой минимаксной стратегии и проиграть 10. В свою очередь игрок А должен выбрать свою 2-ю стратегию, чтобы выиграть 40, а игрок В ответит выбором 2-й стратегии и т. д.
, т. е. данная матрица не имеет седловой точки. Если игрок А выбирает свою чистую максиминную стратегию I = 2, то игрок В, выбрав свою минимаксную J = 2, проиграет только 20. В этом случае игроку А выгодно выбрать стратегию i = 1, т. е. отклониться от своей чистой максиминной стратегии и выиграть 30. Тогда игроку В будет выгодно выбрать стратегию j = 1, т. е. отклониться от своей чистой минимаксной стратегии и проиграть 10. В свою очередь игрок А должен выбрать свою 2-ю стратегию, чтобы выиграть 40, а игрок В ответит выбором 2-й стратегии и т. д.
Теорема 1. В матричной игре нижняя чистая цена игры не превосходит верхней чистой цены игры, т. е. ![]() .
.
Доказательство. По определению ![]() ;
; ![]() . Объединяя эти соотношения, получим
. Объединяя эти соотношения, получим ![]() . Отсюда
. Отсюда ![]() или
или ![]() . Это неравенство справедливо при любых комбинациях i и j. Будет оно справедливо и для тех i и j, для которых реализуются максимальное и минимальное значения
. Это неравенство справедливо при любых комбинациях i и j. Будет оно справедливо и для тех i и j, для которых реализуются максимальное и минимальное значения ![]() и
и ![]() . Что и требовалось доказать.
. Что и требовалось доказать.
Исследование в матричных играх начинается с нахождения её седловой точки в чистых стратегиях. Если матричная игра имеет седловую точку в чистых стратегиях, то нахождением этой седловой точки заканчивается исследование игры. Если же в игре нет седловой точки в чистых стратегиях, то можно найти нижнюю и верхнюю чистые цены этой игры, которые указывают, что игрок А не должен надеяться на выигрыш больший, чем верхняя цена игры, и может быть уверен в получении выигрыша не меньше нижней цены игры. Улучшение решений матричных игр следует искать в использовании секретности применения чистых стратегий и возможности многократного повторения игр в виде партии. Этот результат достигается путём применения чистых стратегий случайно, с определённой вероятностью. Об этом будет рассказано в следующем разделе.
| < Предыдущая | Следующая > |
|---|
Решение игр в чистых стратегиях
Рассмотрим
процесс принятия решений обеими
сторонами, предполагая, что оба игрока
будут действовать рационально. Если
игрок А не знает, как поступит его
противник, то, действуя наиболее
целесообразно и не желая рисковать, он
выберет такую стратегию, которая
гарантирует ему наибольший из наименьших
выигрышей при любой стратегии противника.
|
B1 |
B2 |
B3 |
|
|
A1 |
2 |
–3 |
4 |
|
A2 |
–3 |
4 |
–5 |
|
A3 |
4 |
–5 |
6 |
Т.е.
А предполагает, что В умен и будет вести
себя так, чтобы доставить противнику
набольшие неприятности. Тогда, при
выборе 1-й стратегии, А может рассчитывать
лишь на худший для себя результат –3.
При выборе 2-й и 3-й стратегий он может
рассчитывать на –5. Из всех возможных
стратегий целесообразнее выбрать ту,
что принесет максимальный возможный
доход (минимальные возможные убытки,
как в нашем случае). В рассматриваемом
случае это стратегия 1.
Принято
говорить, что при таком образе действий
игрок А руководствуется принципом
максиминноговыигрыша. Этот выигрыш
определяется формулой:

Величина
 называется нижней ценой игры, максиминным
называется нижней ценой игры, максиминным
выигрышем, или сокращенно максимином.
Это тот гарантированный минимум, который
игрок А может себе обеспечить, придерживаясь
наиболее осторожной стратегии.
Очевидно,
аналогичное рассуждение можно провести
и за игрока В. Так как он заинтересован
в том, чтобы обратить выигрыш А в минимум,
он должен просмотреть каждую свою
стратегию с точки зрения максимального
выигрыша при этой стратегии. Поэтому
внизу матрицы выпишем максимальные
значения по каждому столбцу:

Все
эти максимумы хороши для А, но крайне
неприятны для В. Поскольку противник
также учитывает нашу разумность, то
выбирает из этих вариантов наименьший:

—
больше
этой суммы игрок В точно не потеряет.
Величина
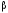 называется верхней ценой игры, или
называется верхней ценой игры, или
минимаксом.
Принцип
осторожности, который определяет выбор
партнерами стратегий, соответствующих
максиминному выигрышу или минимаксному
проигрышу, часто называют принципом
минимакса, а стратегии, вытекающие из
этого принципа, — минимаксными
стратегиями. Можно доказать, что всегда
 ,
,
чем и объясняются названия «нижняя
цена» и «верхняя цена».
|
B1 |
B2 |
B3 |
αi |
|
|
A1 |
2 |
–3 |
4 |
-3 |
|
A2 |
–3 |
4 |
–5 |
-5 |
|
A3 |
4 |
–5 |
6 |
-5 |
|
βj |
4 |
4 |
6 |
Матрица
игры в общем виде:
|
B1 |
B2 |
… |
Bm |
αi |
|
|
A1 |
a11 |
a12 |
… |
a1m |
α1 |
|
A2 |
a21 |
a22 |
… |
a2m |
α2 |
|
… |
… |
… |
… |
… |
… |
|
An |
an1 |
an2 |
… |
anm |
αn |
|
βj |
β1 |
β1 |
… |
βm |
Нижняя
цена игры α = – 3; верхняя цена игры β= 4. Наша максиминная стратегия есть А1;
применяя ее систематически, мы можем
твердо рассчитывать выиграть не менее
–3 (проиграть не более 3). Минимаксная
стратегия противника есть любая из
стратегий В1и В2, применяя
их систематически, он, во всяком случае,
может гарантировать, что проиграет не
более 4. Если мы отступим от своей
максиминной стратегии (например, выберем
стратегию А2), противник может нас
«наказать» за это, применив стратегию
В3и сведя наш выигрыш к — 5. Но
если противник выберет стратегиюB3,
то мы в свою очередь можем выбратьA3и он проиграет 6 и т.д. Таким образом,
положение, при котором оба игрока
пользуются своими минимаксными
стратегиями, является неустойчивым и
может быть нарушено поступившими
сведениями о стратегии противной
стороны.
Однако
существуют некоторые игры, для которых
минимаксные стратегии являются
устойчивыми. Это те игры, для которых
нижняя цена равна верхней:
α=β
Если
нижняя цена игры равна верхней, то их
общее значение называется ценой игры,
и обозначают γ.
Например,
в игре, матрица которой приведена ниже,
верхняя и нижняя цены игры оказываются
равными: α=β=γ= 0,6.
Элемент
0,6, выделенный в платежной матрице,
является одновременно минимальным в
своей строке и максимальным в своем
столбце. В геометрии точку на поверхности,
обладающую аналогичным свойством
(одновременный минимум по одной координате
и максимум по другой), называют седловой
точкой. По аналогии этот термин
применяется и в теории игр. Элемент
матрицы, обладающий этим свойством,
называется седловой точкой матрицы, а
про игру говорят, что она имеетседловую
точку.
|
B1 |
B2 |
B3 |
B4 |
αi |
|
|
A1 |
0,4 |
0,5 |
0,7 |
0,3 |
0,3 |
|
A2 |
0,8 |
0,4 |
0,3 |
0,7 |
0,3 |
|
A3 |
0,7 |
0,6 |
0,8 |
0,9 |
0,6 |
|
A4 |
0,7 |
0,2 |
0,4 |
0,6 |
0,2 |
|
βj |
0,8 |
0,6 |
0,8 |
0,9 |
Для
игр с седловой точкой решение игры
обладает следующим свойством: если один
из игроков (например А) придерживается
своей оптимальной стратегии, а другой
игрок (В) будет любым способом отклоняться
от своей оптимальной стратегии, то для
игрока, допустившего отклонение, это
никогда не может оказаться выгодным.
Это утверждение легко проверить на
примере рассматриваемой игры с седловой
точкой.
В
этом случае наличие у любого игрока
сведений о том, что противник избрал
свою оптимальную стратегию, не может
изменить собственного поведения игрока:
если он не хочет действовать против
своих же интересов, он должен придерживаться
своей оптимальной стратегии. Т.е. пара
оптимальных стратегий в игре с седловой
точкой является как бы положением
равновесия.
Анализируя
матрицу игры, можно прийти к заключению,
что если каждому игроку предоставлен
выбор одной-единственной стратегии, то
в расчете на разумно действующего
противника этот выбор должен определяться
принципом минимакса. Придерживаясь
этой стратегии, мы при любом поведении
противника заведомо гарантируем себе
выигрыш, равный нижней цене игры α.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
«Теория систем и системный анализ»
И. Б. Родионов
Лекция 11: Теория игр и принятие решений
Предмет и задачи теории игр
Классическими задачами системного анализа являются игровые задачи принятия решений в условиях риска и неопределенности.
Неопределенными могут быть как цели операции, условия выполнения операции, так и сознательные действия противников или других лиц, от которых зависит успех операции.
Разработаны специальные математические методы, предназначенные для обоснования решений в условиях риска и неопределенности. В некоторых, наиболее простых случаях эти методы дают возможность фактически найти и выбрать оптимальное решение. В более
сложных случаях эти методы доставляют вспомогательный материал, позволяющий глубже разобраться в сложной ситуации и оценить каждое из возможных решений с различных точек зрения, и принять решений с учетом его возможных последствий. Одним из важных условий принятия решений в этом случае является минимизация риска.
При решении ряда практических задач исследования операций (в области экологии, обеспечения безопасности жизнедеятельности и т. д.) приходится анализировать ситуации, в которых сталкиваются две (или более) враждующие стороны, преследующие различные цели, причем результат любого мероприятия каждой из сторон зависит от того, какой образ действий выберет противник. Такие ситуации мы можно отнести к конфликтным ситуациям.
Теория игр является математической теорией конфликтных ситуаций, при помощи которой можно выработать рекомендации по рациональному образу действий участников конфликта. Чтобы сделать возможным математический анализ ситуации без учета второстепенных факторов, строят упрощенную, схематизированную модель ситуации, которая называется игрой. игра ведется по вполне определенным правилам, под которыми понимается система условий, регламентирующая возможные варианты действий игроков; объем информации каждой стороны о поведении другой; результат игры, к которому приводит каждая данная совокупность ходов.
Результат игры (выигрыш или проигрыш) вообще не всегда имеет количественное выражение, но обычно можно, хотя бы условно, выразить его числовым значением.
Ход — выбор одного из предусмотренных правилами игры действий и его осуществление. Ходы делятся на личные и случайные. Личным ходом называется сознательный выбор игроком одного из возможных вариантов действий и его осуществление. Случайным ходом называется выбор из ряда возможностей, осуществляемый не решением игрока, а каким-либомеханизмом случайного выбора (бросание монеты, выбор карты из перетасованной колоды и т. п.). Для каждого случайного хода правила игры определяют распределение вероятностей возможных исходов. Игра может состоять только их личных или только из случайных ходов, или из их комбинации. Следующим основным понятием теории игр является понятие стратегии. Стратегия — это априори принятая игроком система решений (вида «если — то»), которых он придерживается во время ведения игры, которая может быть представлена в виде алгоритма и выполняться автоматически.
Целью теории игр является выработка рекомендаций для разумного поведения игроков в конфликтной ситуации, т. е. определение «оптимальной стратегии» для каждого из них. Стратегия, оптимальная по одному показателю, необязательно будет оптимальной по другим. Сознавая эти ограничения и поэтому не придерживаясь слепо рекомендаций, полученных игровыми методами, можно все же разумно использовать математический аппарат теории игр для выработки, если не в точности оптимальной, то, во всяком случае «приемлемой» стратегии.
Игры можно классифицировать: по количеству игроков, количеству стратегий, характеру взаимодействия игроков, характеру выигрыша, количеству ходов, состоянию информации и т.д. [2, 7, 8].
В зависимости от количества игроков различают игры двух и n игроков. Первые из них наиболее изучены. Игры трех и более игроков менее исследованы из-за возникающих принципиальных трудностей и технических возможностей получения решения.
В зависимости от числа возможных стратегий игры делятся на «конечные» и «бесконечные».
Игра называется конечной, если у каждого игрока имеется только конечное число стратегий, и бесконечной, если хотя бы у одного
из игроков имеется бесконечное число стратегий.
По характеру взаимодействия игры делятся на бескоалиционные: игроки не имеют права вступать в соглашения, образовывать коалиции; коалиционные (кооперативные) — могут вступать в коалиции.
В кооперативных играх коалиции заранее определены.
По характеру выигрышей игры делятся на: игры с нулевой суммой (общий капитал всех игроков не меняется, а перераспределяется между игроками; сумма выигрышей всех игроков равна нулю) и игры с ненулевой суммой.
По виду функций выигрыша игры делятся на: матричные, биматричные, непрерывные, выпуклые и др.
Матричная игра — это конечная игра двух игроков с нулевой суммой, в которой задается выигрыш игрока 1 в виде матрицы (строка матрицы соответствует номеру применяемой стратегии игрока 1, столбец — номеру применяемой стратегии игрока на пересечении строки и столбца матрицы находится выигрыш игрока 1, соответствующий применяемым стратегиям).
Для матричных игр доказано, что любая из них имеет решение и оно может быть легко найдено путем сведения игры к задаче линейного программирования.
Биматричная игра — это конечная игра двух игроков с ненулевой суммой, в которой выигрыши каждого игрока задаются матрицами отдельно для соответствующего игрока (в каждой матрице строка соответствует стратегии игрока 1, столбец — стратегии игрока 2, на пересечении строки и столбца в первой матрице находится выигрыш игрока 1, во второй матрице — выигрыш игрока )
Непрерывной считается игра, в которой функция выигрышей каждого игрока является непрерывной. Доказано, что игры этого класса имеют решения, однако не разработано практически приемлемых методов их нахождения.
Если функция выигрышей является выпуклой, то такая игра называется выпуклой. Для них разработаны приемлемые методы решения, состоящие в отыскании чистой оптимальной стратегии (определенного числа) для одного игрока и вероятностей применения чистых оптимальных стратегий другого игрока. Такая задача решается сравнительно легко.
Запись матричной игры в виде платежной матрицы
Рассмотрим конечную игру, в которой первый игрок А имеет m стратегий, а второй игрок B-n стратегий. Такая игра называется игрой m×n. Обозначим стратегии A1, А2, …, Аm; и В1, В2, …, Вn. Предположим, что каждая сторона выбрала определенную стратегию: Ai или Bj. Если игра состоит только из личных ходов, то выбор стратегий однозначно определяет исход игры — выигрыш одной из сторон aij. Если игра содержит кроме личных случайные ходы, то выигрыш при паре стратегий Ai и B является случайной величиной, зависящей от исходов всех случайных ходов. В этом случае естественной оценкой ожидаемого выигрыша является математическое ожидание случайного выигрыша, которое также обозначается за aij.
Предположим, что нам известны значения aij при каждой паре стратегий. Эти значения можно записать в виде прямоугольной таблицы (матрицы), строки которой соответствуют стратегиям Ai, а столбцы — стратегиям Bj.
Тогда, в общем виде матричная игра может быть записана следующей платежной матрицей:
| B1 | B2 | … | Bn | |
|---|---|---|---|---|
| A1 | a11 | a12 | … | a1n |
| A2 | a21 | a22 | … | a2n |
| … | … | … | … | … |
| Am | am1 | am2 | … | amn |
Таблица — Общий вид платежной матрицы матричной игры
где Ai — названия стратегий игрока 1, Bj — названия стратегий игрока 2, aij — значения выигрышей игрока 1 при выборе им i–й стратегии, а игроком 2 — j-й стратегии. Поскольку данная игра является игрой с нулевой суммой, значение выигрыша для игрока 2 является величиной, противоположенной по знаку значению выигрыша игрока 1.
Понятие о нижней и верхней цене игры. Решение игры в чистых стратегиях
Каждый из игроков стремится максимизировать свой выигрыш с учетом поведения противодействующего ему игрока. Поэтому для игрока 1 необходимо определить минимальные значения выигрышей в каждой из стратегий, а затем найти максимум из этих значений, то есть определить величину
Vн = maxi minj aij
или найти минимальные значения по каждой из строк платежной матрицы, а затем определить максимальное из этих значений. Величина Vн называется максимином матрицы или нижней ценой игры. Та стратегия игрока, которая соответствует максимину Vн называется максиминной стратегией.
Очевидно, если мы будем придерживаться максиминной стратегии, то нам при любом поведении противника гарантирован выигрыш, не меньший Vн. Поэтому величина Vн — это тот гарантированный минимум, который мы можем себе обеспечить, придерживаясь своей наиболее осторожной стратегии.
Величина выигрыша игрока 1 равна, по определению матричной игры, величине проигрыша игрока Поэтому для игрока 2 необходимо определить значение
Vв = minj maxi aij
Или найти максимальные значения по каждому из столбцов платежной матрицы, а затем определить минимальное из этих значений. Величина Vв называется минимаксом матрицы, верхней ценой игры или минимаксным выигрышем. Соответствующая выигрышу стратегия противника называется его минимаксной стратегией. Придерживаясь своей наиболее осторожной минимаксной стратегии, противник гарантирован, что в любом случае он проиграет не больше Vв.
В случае, если значения Vн и Vв не совпадают, при сохранении правил игры (коэффициентов aij ) в длительной перспективе, выбор стратегий каждым из игроков оказывается неустойчивым. Устойчивость он приобретает лишь при равенстве Vн = Vв = V. В этом случае говорят, что игра имеет решение в чистых стратегиях, а стратегии, в которых достигается V — оптимальными чистыми стратегиями. Величина V называется чистой ценой игры [8].
Например, в матрице:
| B1 | B2 | B3 | B4 | Minj | |
|---|---|---|---|---|---|
| A1 | 17 | 16 | 15 | 14 | 14 |
| A2 | 11 | 18 | 12 | 13 | 11 |
| A3 | 18 | 11 | 13 | 12 | 11 |
| Maxi | 18 | 18 | 15 | 14 |
Таблица — Платежная матрица, в которой существует решение в чистых стратегиях
существует решение в чистых стратегиях. При этом для игрока 1 оптимальной чистой стратегией будет стратегия A1, а для игрока 2 — стратегия B4.
В матрице решения в чистых стратегиях не существует, так как нижняя цена игры достигается в стратегии A1 и ее значение равно 12, в то время как верхняя цена игры достигается в стратегии B4 и ее значение равно 13.
| B1 | B2 | B3 | B4 | Minj | |
|---|---|---|---|---|---|
| A1 | 17 | 16 | 15 | 12 | 12 |
| A2 | 11 | 18 | 12 | 13 | 11 |
| A3 | 18 | 11 | 13 | 12 | 11 |
| Maxi | 18 | 18 | 15 | 13 |
Таблица — Платежная матрица, в которой не существует решения в чистых стратегиях
Уменьшение порядка платежной матрицы
Порядок платежной матрицы (количество строк и столбцов) может быть уменьшен за счет исключения доминируемых и дублирующих стратегий.
Стратегия K* называется доминируемой стратегией K**, если при любом варианте поведения противодействующего игрока выполняется соотношение
Ak* < Ak**,
где Ak* и Ak** — значения выигрышей при выборе игроком, соответственно, стратегий K* и K**.
В случае, если выполняется соотношение
Ak* = Ak**,
стратегия K* называется дублирующей по отношению к стратегии K**.
Например, в матрице с доминируемыми и дублирующими стратегиями стратегия A1 является доминируемой по отношению к стратегии A2, стратегия B6 является доминируемой по отношению к стратегиям B3, B4 и B5, а стратегия B5 является дублирующей по отношению к стратегии B4.
| B1 | B2 | B3 | B4 | B5 | B6 | |
|---|---|---|---|---|---|---|
| A1 | 1 | 2 | 3 | 4 | 4 | 7 |
| A2 | 7 | 6 | 5 | 4 | 4 | 8 |
| A3 | 1 | 8 | 2 | 3 | 3 | 6 |
| A4 | 8 | 1 | 3 | 2 | 2 | 5 |
Таблица — Платежная матрица с доминируемыми и дублирующими стратегиями
Данные стратегии не будут выбраны игроками, так как являются заведомо проигрышными и удаление этих стратегий из платежной матрицы не повлияет на определение нижней и верхней цены игры, описанной данной матрицей.
Множество недоминируемых стратегий, полученных после уменьшения размерности платежной матрицы, называется еще множеством Парето.
Примеры игр
1. Игра «Цыпленок»
Игра «Цыпленок» заключается в том, что игроки вступают во взаимодействие, которое ведет в нанесению серьезного вреда каждому из них, пока один из игроков не выйдет из игры. Пример использования этой игры — взаимодействие автотранспортный средств, например, ситуации, когда два автомобиля идут навстречу друг другу, и тот, который первым сворачивает в сторону, считается «слабаком» или «цыпленком». Смысл игры заключается в создании напряжения, которое бы привело к устранению игрока. Подобная ситуация часто встречается в среде подростков или агрессивно настроенных молодых людей, хотя иногда несет в себе меньший риск. Еще одно из применений этой игры — ситуация, в которой две политические партии вступают в контакт, при котором они не могут ничего выиграть, и только гордость заставляет их сохранять противостояние. Партии медлят с уступками до тех пор, пока не дойдут до финальной точки. Возникающее психологическое напряжение может привести одного из игроков к неправильной стратегии поведения: если никто из игроков не уступает, то столкновение и фатальная развязка неизбежны.
Платежная матрица игры выглядит следующей:
| Уступить | Не уступать | |
|---|---|---|
| Уступить | 0, 0 | -1, +1 |
| Не уступать | +1, -1 | -100, -100 |
2. Игра «коршун и голубь»
Игра «коршун и голубь» является биологическим примером игры. В этой версии двое игроков, обладающих неограниченными ресурсами, выбирают одну из двух стратегий поведения. Первая («голубь») заключается в том, что игрок демонстрирует свою силу, запугивая противника, а вторая («коршун») — в том, что игрок физически атакует противника. Если оба из игроков выбирают стратегию «коршуна», они сражаются, наносф друг другу увечья. Если один из игроков выбирает стратегию «коршуна», а второй «голубя» — то первый побеждает второго. В случае, если оба игрока — «голуби», то соперники приходит к компромиссу, получая выигрыш, который оказывается меньше, чем выигрыш «коршуна», побеждающего «голубя», как это следует из платежной матрицы этой игры.
| Коршун | Голубь | |
|---|---|---|
| Коршун | 1/2*(V-C), 1/2*(V-C) | V, 0 |
| Голубь | 0, V | V/2, V/2 |
Здесь V — цена соглашения, C — цена конфликта, причем V<C.
В игре «коршун и голубь» есть три точки равновесия по Нэшу:
- первый игрок выбирает «коршуна», а второй «голубя».
- первый игрок выбирает «голубя», а второй «коршуна».
- оба игрока выбирают смешанную стратегию, в которой «коршун» выбирается с вероятностью p, а «голубь» — с вероятностью 1-p.
3. Дилемма заключенного
«Дилемма заключенного» — одна из наиболее распространенных конфликтных ситуаций, рассматриваемая в теории игр.
Классическая «дилемма заключенного» звучит следующим образом: двое подозреваемых, A и B, находятся в разных камерах. Следователь, навещая их поодиночке, предлагает сделку следующего содержания: если один из них будет свидетельствовать против другого, а второй будет молчать, то первый заключенный будет освобожден, а второго осудят на 10 лет. Если оба будут молчать, то отсидят по 6 месяцев. Если оба предадут друг друга, то каждый получит по 2 года. Каждый из заключенных должен принять решение: предать подельника или молчать, не зная о том, какое решение принял другой. Дилемма: какое решение примут заключенные?
Платежная матрица игры:
| — | Заключенный B молчит | Заключенный B предает |
|---|---|---|
| Заключенный A молчит | Оба осуждены на 6 месяцев | Заключенного А осуждают на 10 лет Заключенный В выходит на свободу |
| Заключенный A предает | Заключенный A выходит на свободу Заключенного B осуждают на 10 лет |
Оба осуждены на 2 года |
В данном случае, результат базируется на решении каждого из заключенных. Положение игроков осложняется тем, что они не знают о том, какое решение принял другой, и тем, что они не доверяют друг другу.
Наилучшей стратегией игроков будет кооперация, при которой оба молчат, и получают максимальный выигрыш (меньший срок), каждое другое решение будет менее выигрышным.
Проанализируем «дилемму заключенного», перейдя для наглядности к платежной матрице канонического вида:
| — | Кооперация | Отказ от кооперации |
|---|---|---|
| Кооперация | 3, 3 | 0, 5 |
| Отказ от кооперации | 5, 0 | 1, 1 |
Согласно этой матрице, цена взаимного отказа от кооперации (S) составляет по 1 баллу для каждого из игроков, цена за кооперацию (R) — по 3 балла, а цена соблазна предать другого (T) составляет 5 баллов. Можем записать следующее неравенство: T > R > S. При повторении игры несколько раз, выбор кооперации превосходит соблазн предать и получить максимальный выигрыш: 2 R > T + S.
Равновесие по Нэшу.
Равновесие по Нэшу — это ситуация, когда ни у одного игрока нет стимулов изменять свою стратегию при данной стратегии другого игрока (другой фирмы), позволяющая игрокам достичь компромиссного решения.
Определение равновесия по Нэшу и его существование определяется следующим образом.
Пусть (S, f) — это игра, в которой S — множество стратегий, f — множество выигрышей. Когда каждый из игроков i ∈ {1, …, n} выбирает стратегию xi &isin S, где x = (x1, …, xn), тогда игрок i получает выигрыш fi(x). Выигрыш зависит от стратегии, выбранной всеми игроками. Стратегия x* ∈ S является равновесием по Нэшу, если никакое отклонение от нее каким-то одним игроком не приносит ему прибыль, то есть, для всех i выполняется следующее неравенство:
fi(x*) ≥ fi(xi, x*-i)
Например, игра «дилемма заключенного» имеет одно равновесие по Нэшу — ситуацию, когда оба заключенных предают друг друга.
Проще всего определить равновесие по Нэшу можно по платежной матрице, особенно в случаях, когда в игре участвуют два игрока, имеющие в арсенале более двух стратегий. Так как в этом случае формальный анализ будет достаточно сложным, применяется мнемоническое правило, которое заключается в следующем: ячейка платежной матрицы представляет собой равновесие по Нэшу, если первое число, стоящее в ней, является максимальным среди всех значений, представленных в столбцах, а второе число, стоящее в ячейке — максимальное число среди всех строк.
Например, применим это правило для матрицы 3×3:
| A | B | C | |
|---|---|---|---|
| A | 0, 0 | 25, 40 | 5, 10 |
| B | 40, 25 | 0, 0 | 5, 15 |
| C | 10, 5 | 15, 5 | 10, 10 |
Точки равновесия по Нэшу: (B,A), (A,B) и (C,C). Indeed, for cell (B,A), так как 40 — максимальное значение в первом столбце, 25 максимальное значение во втором ряду. Для ячейки (A,B) 25 — это максимальное значение во втором столбце, 40 — максимальное значение во втором ряду. То же самое и для ячейки (C,C).
Рассмотрим пример игры в загрязнения (окружающей среды). Здесь объектом нашего внимания станет такой вид побочных эффектов производства, как загрязнение. Если бы фирмы никогда и никого не спрашивали о том, как им поступить, любая из них скорее предпочла бы создавать загрязнения, чем устанавливать дорогостоящие очистители. Если же какая-нибудь фирма решилась бы уменьшить вредные выбросы, то издержки, а, следовательно, и цены на ее продукцию, возросли бы, а спрос бы упал. Вполне возможно, эта фирма просто обанкротилась бы. Живущие в жестоком мире естественного отбора, фирмы скорее предпочтут оставаться в условиях равновесия по Нэшу (ячейка D), при котором не нужно расходовать средства на очистные сооружения и технологии. Ни одной фирме не удастся повысить прибыль, уменьшая загрязнение.
| Фирма 1 | ||
|---|---|---|
| Фирма 2 | Низкий уровень загрязнения | Высокий уровень загрязнения |
| Низкий уровень загрязнения | А 100,100 |
В -30,120 |
| Высокий уровень загрязнения | С 120,-30 |
D 100,100 |
Таблица — Платежная матрица игры в загрязнение окружающей среды.
Вступив в экономическую игру, каждая неконтролируемая государством и максимизирующая прибыль сталелитейная фирма будет производить загрязнения воды и воздуха. Если какая-либо фирма попытается очищать свои выбросы, то тем самым она будет вынуждена повысить цены и потерпеть убытки. Некооперативное поведение установит равновесие по Нэшу в условиях высоких выбросов. Правительство может предпринять меры с тем, чтобы равновесие переместилось в ячейку А. В этом положении загрязнение будет незначительным, прибыли же останутся теми же.
Игры загрязнения — один из случаев того, как механизм действия «невидимой руки» не срабатывает. Это ситуация, когда равновесие по Нэшу неэффективно. Иногда подобные неконтролируемые игры становятся угрожающими, и здесь может вмешаться правительство. Установив систему штрафов и квот на выбросы, правительство может побудить фирмы выбрать исход А, соответствующий низкому уровню загрязнения. Фирмы зарабатывают ровно столько же, сколько и прежде, при больших выбросах, мир же становится несколько чище.
Пример решения матричной игры в чистых стратегиях
Рассмотрим пример решения матричной игры в чистых стратегиях, в условиях реальной экономики, в ситуации борьбы двух предприятий за рынок продукции региона.
Задача.
Два предприятия производят продукцию и поставляют ее на рынок региона. Они являются единственными поставщиками продукции в регион, поэтому полностью определяют рынок данной продукции в регионе.
Каждое из предприятий имеет возможность производить продукцию с применением одной из трех различных технологий. В зависимости от экологичности технологического процесса и качества продукции, произведенной по каждой технологии, предприятия могут установить цену единицы продукции на уровне 10, 6 и 2 денежных единиц соответственно. При этом предприятия имеют различные затраты на производство единицы продукции.
| Технология | Цена реализации единицы продукции, д.е. | Полная себестоимость единицы продукции, д.е. | |
|---|---|---|---|
| Предприятие 1 | Предприятие 2 | ||
| I | 10 | 5 | 8 |
| II | 6 | 3 | 4 |
| III | 2 | 1 | 1 |
Таблица — Затраты на единицу продукции, произведенной на предприятиях региона (д.е.).
В результате маркетингового исследования рынка продукции региона была определена функция спроса на продукцию:
Y = 6 — 0.5⋅X,
где Y — количество продукции, которое приобретет население региона (тыс. ед.), а X — средняя цена продукции предприятий, д.е.
Данные о спросе на продукцию в зависимости от цен реализации приведены в таблице:
|
Цена реализации 1 ед. продукции, д.е. |
Средняя цена реализации 1 ед. продукции, д.е. |
Спрос на продукцию, тыс. ед. |
|
|---|---|---|---|
| Предприятие 1 | Предприятие 2 | ||
| 10 | 10 | 10 | 1 |
| 10 | 6 | 8 | 2 |
| 10 | 2 | 6 | 3 |
| 6 | 10 | 8 | 2 |
| 6 | 6 | 6 | 3 |
| 6 | 2 | 4 | 4 |
| 2 | 10 | 6 | 3 |
| 2 | 6 | 4 | 4 |
| 2 | 2 | 2 | 5 |
Таблица — Спрос на продукцию в регионе, тыс. ед.
Значения Долей продукции предприятия 1, приобретенной населением, зависят от соотношения цен на продукцию предприятия 1 и предприятия В результате маркетингового исследования эта зависимость установлена и значения вычислены:
| Цена реализации 1 ед. продукции, д.е. | Доля продукции предприятия 1, купленной населением | |
|---|---|---|
| Предприятие 1 | Предприятие 2 | |
| 10 | 10 | 0,31 |
| 10 | 6 | 0,33 |
| 10 | 2 | 0,18 |
| 6 | 10 | 0,7 |
| 6 | 6 | 0,3 |
| 6 | 2 | 0,2 |
| 2 | 10 | 0,92 |
| 2 | 6 | 0,85 |
| 2 | 2 | 0,72 |
Таблица — Доля продукции предприятия 1, приобретаемой населением в зависимости от соотношения цен на продукцию
По условию задачи на рынке региона действует только 2 предприятия. Поэтому долю продукции второго предприятия, приобретенной населением, в зависимости от соотношения цен на продукцию можно определить как единица минус доля первого предприятия.
Стратегиями предприятий в данной задаче являются их решения относительно технологий производства продукции. Эти решения определяют себестоимость и цену реализации единицы продукции. В задаче необходимо определить:
- Существует ли в данной задаче ситуация равновесия при выборе технологий производства продукции обоими предприятиями?
- Существуют ли технологии, которые предприятия заведомо не будут выбирать вследствие невыгодности?
- Сколько продукции будет реализовано в ситуации равновесия? Какое предприятие окажется в выигрышном положении?
Решение задачи
- Определим экономический смысл коэффициентов выигрышей в платежной матрице задачи. Каждое предприятие стремится к максимизации прибыли от производства продукции. Но кроме того, в данном случае предприятия ведут борьбу за рынок продукции в регионе. При этом выигрыш одного предприятия означает проигрыш другого. Такая задача может быть сведена к матричной игре с нулевой суммой. При этом коэффициентами выигрышей будут значения разницы прибыли предприятия 1 и предприятия 2 от производства продукции. В случае, если эта разница положительна, выигрывает предприятие 1, а в случае, если она отрицательна — предприятие 2.
- Рассчитаем коэффициенты выигрышей платежной матрицы. Для этого необходимо определить значения прибыли предприятия 1 и предприятия 2 от производства продукции.
Прибыль предприятия в данной задаче зависит:
- от цены и себестоимости продукции;
- от количества продукции, приобретаемой населением региона;
- от доли продукции, приобретенной населением у предприятия.
Таким образом, значения разницы прибыли предприятий, соответствующие коэффициентам платежной матрицы, необходимо определить по формуле:
D = p⋅(S⋅R1 — S⋅C1) — (1 — p)⋅(S⋅R2 — S⋅C2),
где D — значение разницы прибыли от производства продукции предприятия 1 и предприятия
p — доля продукции предприятия 1, приобретаемой населением региона;
S — количество продукции, приобретаемой населением региона;
R1 и R2 — цены реализации единицы продукции предприятиями 1 и
C1 и C2 — полная себестоимость единицы продукции, произведенной на предприятиях 1 и
Вычислим один из коэффициентов платежной матрицы.
Пусть, например, предприятие 1 принимает решение о производстве продукции в соответствии с технологией III, а предприятие 2 — в соответствии с технологией II. Тогда цена реализации единицы. продукции для предприятия 1 составит 2 д.е. при себестоимости единицы. продукции 1,5 д.е. Для предприятия 2 цена реализации единицы. продукции составит 6 д.е. при себестоимости 4 д.е..
Количество продукции, которое население региона приобретет при средней цене 4 д.е., равно 4 тыс. ед. (таблица 1). Доля продукции, которую население приобретет у предприятия 1, составит 0,85, а у предприятия 2 — 0,15 (табл. 1.3). Вычислим коэффициент платежной матрицы a32 по формуле:
a32 = 0,85⋅(4⋅2 — 4×1,5) — 0,15⋅(4⋅6 — 4⋅4) = 0,5 тыс. ед.
где i=3 — номер технологии первого предприятия, а j=2 — номер технологии второго предприятия.
Аналогично вычислим все коэффициенты платежной матрицы. В платежной матрице стратегии A1 — A3– представляют собой решения о технологиях производства продукции предприятием 1, стратегии B1– B3 — решения о технологиях производства продукции предприятием 2, коэффициенты выигрышей — разницу прибыли предприятия 1 и предприятия
| B1 | B2 | B3 | Minj | |
|---|---|---|---|---|
| A1 | 0,17 | 0,62 | 0,24 | 0,17 |
| A2 | 0,3 | -1,5 | -0,8 | -1 |
| A3 | 0,9 | 0,5 | 0,4 | 0,4 |
| Maxi | 3 | 0,62 | 0,4 |
Таблица — Платежная матрица в игре «Борьба двух предприятий».
В данной матрице нет ни доминируемых, ни дублирующих стратегий. Это значит, что для обоих предприятий нет заведомо невыгодных технологий производства продукции. Определим минимальные элементы строк матрицы. Для предприятия 1 каждый из этих элементов имеет значение минимально гарантированного выигрыша при выборе соответствующей стратегии. Минимальные элементы матрицы по строкам имеют значения: 0,17, -1,5, 0,4.
Определим максимальные элементы столбцов матрицы. Для предприятия 2 каждый из этих элементов также имеет значение минимально гарантированного выигрыша при выборе соответствующей стратегии. Максимальные элементы матрицы по столбцам имеют значения: 3, 0,62, 0,4.
Нижняя цена игры в матрице равна 0,4. Верхняя цена игры также равна 0,4. Таким образом, нижняя и верхняя цена игры в матрице совпадают. Это значит, что имеется технология производства продукции, которая является оптимальной для обоих предприятий в условиях данной задачи. Эта технология III, которая соответствует стратегиям A3 предприятия 1 и B3 предприятия Стратегии A3 и B3 — чистые оптимальные стратегии в данной задаче.
Значение разницы прибыли предприятия 1 и предприятия 2 при выборе чистой оптимальной стратегии положительно. Это означает, что предприятие 1 выиграет в данной игре. Выигрыш предприятия 1 составит 0,4 тыс. д.е. При этом на рынке будет реализовано 5 тыс. ед. продукции (реализация равна спросу на продукцию, таблица 1).. Оба предприятия установят цену за единицу продукции в 2 д.е. При этом для первого предприятия полная себестоимость единицы продукции составит 1,5 д.е., а для второго — 1 д.е. Предприятие 1 окажется в выигрыше лишь за счет высокой доли продукции, которую приобретет у него население.
Критерии принятия решения
ЛПР определяет наиболее выгодную стратегию в зависимости от целевой установки, которую он реализует в процессе решения задачи. Результат решения задачи ЛПР определяет по одному из критериев принятия решения. Для того, чтобы прийти к однозначному и по возможности наиболее выгодному варианту решению, необходимо ввести оценочную (целевую) функцию. При этом каждой стратегии ЛПР (Ai) приписывается некоторый результат Wi, характеризующий все последствия этого решения. Из массива результатов принятия решений ЛПР выбирает элемент W, который наилучшим образом отражает мотивацию его поведения.
В зависимости от условий внешней среды и степени информативности ЛПР производится следующая классификация задач принятия решений:
- в условиях риска;
- в условиях неопределенности;
- в условиях конфликта или противодействия (активного противника).
Принятие решений в условиях риска.
1. Критерий ожидаемого значения.
Использование критерия ожидаемого значения обусловлено стремлением максимизировать ожидаемую прибыль (или минимизировать ожидаемые затраты). Использование ожидаемых величин предполагает возможность многократного решения одной и той же задачи, пока не будут получены достаточно точные расчетные формулы. Математически это выглядит так: пусть Х — случайная величина с математическим ожиданием MX и дисперсией DX. Если x1, x2, …, xn — значения случайной величины (с.в.) X, то среднее арифметическое их (выборочное среднее) значений x^=(x1+x2+…+xn)/n имеет дисперсию DX/n. Таким образом, когда n→∞ DX/n→∞ и X→MX.
Другими словами при достаточно большом объеме выборки разница между средним арифметическим и математическим ожиданием стремится к нулю (так называемая предельная теорема теории вероятности). Следовательно, использование критерия ожидаемое значение справедливо только в случае, когда одно и тоже решение приходится применять достаточно большое число раз. Верно и обратное: ориентация на ожидания будет приводить к неверным результатам, для решений, которые приходится принимать небольшое число раз.
Пример 1. Требуется принять решение о том, когда необходимо проводить профилактический ремонт ПЭВМ, чтобы минимизировать потери из-за неисправности. В случае если ремонт будет производится слишком часто, затраты на обслуживание будут большими при малых потерях из-за случайных поломок.
Так как невозможно предсказать заранее, когда возникнет неисправность, необходимо найти вероятность того, что ПЭВМ выйдет из строя в период времени t. В этом и состоит элемент »риска».
Математически это выглядит так: ПЭВМ ремонтируется индивидуально, если она остановилась из-за поломки. Через T интервалов времени выполняется профилактический ремонт всех n ПЭВМ. Необходимо определить оптимальное значение m, при котором минимизируются общие затраты на ремонт неисправных ПЭВМ и проведение профилактического ремонта в расчете на один интервал времени.
Пусть рt — вероятность выхода из строя одной ПЭВМ в момент t, а nt — случайная величина, равная числу всех вышедших из строя ПЭВМ в тот же момент. Пусть далее С1 – затраты на ремонт неисправной ПЭВМ и С2 — затраты на профилактический ремонт одной машины.
Применение критерия ожидаемого значения в данном случае оправдано, если ПЭВМ работают в течение большого периода времени. При этом ожидаемые затраты на один интервал составят
ОЗ = (C1∑M(nt)+C1n)/T,
где M(nt) — математическое ожидание числа вышедших из строя ПЭВМ в момент t. Так как nt имеет биномиальное распределение с параметрами (n, pt), то M(nt) = npt . Таким образом
ОЗ = n(C1∑pt+C2)/T.
Необходимые условия оптимальности T* имеют вид:
ОЗ (T*-1) ≥ ОЗ (T*),
ОЗ (T*+1) ≥ ОЗ (T*).
Следовательно, начиная с малого значения T, вычисляют ОЗ(
T), пока не будут удовлетворены необходимые условия оптимальности.
Пусть С1 = 100; С2 = 10; n = 50. Значенияpt имеют вид:
| T | рt | ∑рt | ОЗ(Т) |
|---|---|---|---|
| 1 | 0.05 | 0 | 50(100⋅0+10)/1=500 |
| 2 | 0.07 | 0.05 | 375 |
| 3 | 0.10 | 0.12 | 366.7 |
| 4 | 0.13 | 02 | 400 |
| 5 | 0.18 | 0.35 | 450 |
T*→3, ОЗ(Т*)→366.7
Следовательно профилактический ремонт необходимо делать через T*=3 интервала времени.
Критерий «ожидаемое значение — дисперсия».
Критерий ожидаемого значения можно модифицировать так, что его можно будет применить и для редко повторяющихся ситуаций.
Если х — с. в. с дисперсией DX, то среднее арифметическое x^ имеет дисперсию DX/n, где n — число слагаемых в x^. Следовательно, если DX уменьшается, и вероятность того, что x^ близко к MX, увеличивается. Следовательно, целесообразно ввести критерий, в котором максимизация ожидаемого значения прибыли сочетается с минимизацией ее дисперсии.
Пример 2. Применим критерий «ожидаемое значение — дисперсия» для примера 1. Для этого необходимо найти дисперсию затрат за один интервал времени, т.е. дисперсию
зТ=(C1∑nt+C2n)/T
Т.к. nt, t = {1, T-1} — с.в., то зТтакже с.в. С.в. ntимеет биномиальное распределение с M(nt) = nptи D(nt) = npt(1–pt). Следовательно,
D(зТ) = D((C1∑nt+C2n)/T) = (C1/T)2 D(∑nt) =
= (C1/T)2 ∑Dnt = (C1/T)2 ∑npt(1-pt) = (C1/T)2 {∑pt — ∑pt2},
где С2n = const.
Из примера 1 следует, что
М(зТ) = М(з(Т)).
Следовательно искомым критерием будет минимум выражения
М(з(Т)) + к D(зТ).
Замечание. Константу «к» можно рассматривать как уровень не склонности к риску, т.к. «к» определяет «степень возможности» дисперсии Д(зТ) по отношению к математическому ожиданию. Например, если предприниматель, особенно остро реагирует на большие отрицательные отклонения прибыли вниз от М(з(Т)), то он может выбрать «к» много больше 1. Это придает больший вес дисперсии и приводит к решению, уменьшающему вероятность больших потерь прибыли.
При к=1 получаем задачу
M(з(T))+D(з(T)) = n { (C1/T+C12/T2)∑pt — C12/T2∑pt2 + C2/T }
По данным из примера 1 можно составить следующую таблицу
| T | pt | pt2 | ∑pt | ∑pt2 | М(з(Т))+D(з(Т)) |
|---|---|---|---|---|---|
| 1 | 0,05 | 0,0025 | 0 | 0 | 500.00 |
| 2 | 0,07 | 0,0049 | 0,05 | 0,0025 | 6312,50 |
| 3 | 0,10 | 0,0100 | 0,12 | 0,0074 | 6622,22 |
| 4 | 0,13 | 0,0169 | 0,2 | 0,0174 | 6731,25 |
| 5 | 0,18 | 0,0324 | 0,35 | 0,0343 | 6764,00 |
Из таблицы видно, что профилактический ремонт необходимо делать в течение каждого интервала Т*=1.
3. Критерий предельного уровня
Критерий предельного уровня не дает оптимального решения, максимизирующего, например, прибыль или минимизирующего затраты. Скорее он соответствует определению приемлемого способа действий.
Пример 3. Предположим, что величина спроса x в единицу времени (интенсивность спроса) на некоторый товар задается непрерывной функцией распределения f(x). Если запасы в начальный момент невелики, в дальнейшем возможен дефицит товара. В противном случае к концу рассматриваемого периода запасы нереализованного товара могут оказаться очень большими. В обоих случаях возможны потери.
Т.к. определить потери от дефицита очень трудно, ЛПР может установить необходимый уровень запасов таким образом, чтобы величина ожидаемого дефицита не превышала A1 единиц, а величина ожидаемых излишков не превышала A2 единиц. Иными словами, пусть I — искомый уровень запасов. Тогда
ожидаемый дефицит = ∫(x-I)f(x)dx ≤ A1,
ожидаемые излишки = ∫(I-x)f(x)dx ≤ A2.
При произвольном выборе A1 и A2 указанные условия могут оказаться противоречивыми. В этом случае необходимо ослабить одно из ограничений, чтобы обеспечить допустимость.
Пусть, например,
f(x) = 20/x2, 10≤x≤20,
f(x) = 0, x≤10 и x≥20.
Тогда
∫(x-I)f(x)dx = ∫(x-I)(20/x2)dx = 20(ln(20/I) + I/20 – 1)
∫(I-x)f(x)dx = ∫(I-x)(20/x2)dx = 20(ln(10/I) + I/10 – 1)
Применение критерия предельного уровня приводит к неравенствам
ln(I) — I/20 ≥ ln(20) – A1/20 – 1 = 1,996 — A1/20
ln(I) — I/10 ≥ ln(10) – A2/20 – 1 = 1,302 — A2/20
Предельные значения A1 и A2 должны быть выбраны так, что бы оба неравенства выполнялись хотя бы для одного значения I.
Например, если A1 = 2 и A2 = 4, неравенства принимают вид
ln(I) — I/20 ≥ 1,896
ln(I) — I/10 ≥ 1,102
Значение I должно находиться между 10 и 20, т.к. именно в этих пределах изменяется спрос. Из таблицы видно, что оба условия выполняются для I, из интервала (13,17)
| I | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ln(I) — I/20 | 1,8 | 1,84 | 1,88 | 1,91 | 1,94 | 1,96 | 1,97 | 1,98 | 1,99 | 1,99 | 1,99 |
| ln(I) — I/10 | 1,3 | 19 | 18 | 16 | 14 | 11 | 1,17 | 1,13 | 1,09 | 1,04 | 0,99 |
Любое из этих значений удовлетворяет условиям задачи.
Принятие решений в условиях неопределенности
Будем предполагать, что лицу, принимающему решение не противостоит разумный противник.
Данные, необходимо для принятия решения в условии неопределенности, обычно задаются в форме матрицы, строки которой соответствуют возможным действиям, а столбцы — возможным состояниям системы.
Пусть, например, из некоторого материала требуется изготовить изделие, долговечность которого при допустимых затратах невозможно определить. Нагрузки считаются известными. Требуется решить, какие размеры должно иметь изделие из данного материала.
Варианты решения таковы:
Е1 — выбор размеров из соображений максимальной долговечности ;
Еm — выбор размеров из соображений минимальной долговечности ;
Ei — промежуточные решения.
Условия требующие рассмотрения таковы:
F1 — условия, обеспечивающие максимальной долговечность;
Fn — условия, обеспечивающие min долговечность;
Fi — промежуточные условия.
Под результатом решения eij = е(Ei ; Fj) здесь можно понимать оценку, соответствующую варианту Ei и условиям Fj и характеризующие прибыль, полезность или надежность. Обычно мы будем называть такой результат полезностью решения.
Тогда семейство (матрица) решений ||eij|| имеет вид:
| F1 | F2 | … | Fn | |
|---|---|---|---|---|
| E1 | e11 | e12 | … | e1n |
| E2 | e21 | e22 | … | e2n |
| … | … | … | … | … |
| Em | em1 | em2 | … | emn |
Чтобы прийти к однозначному и по возможности наивыгоднейшему варианту решению необходимо ввести оценочную (целевую) функцию. При этом матрица решений ||eij|| сводится к одному столбцу. Каждому варианту Ei приписывается, т.о., некоторый результат eir, характеризующий, в целом, все последствия этого решения. Такой результат мы будем в дальнейшем обозначать тем же символом eir.
Классические критерии принятия решений
1. Минимаксный критерий.
Правило выбора решения в соответствии с минимаксным критерием (ММ-критерием) можно интерпретировать следующим образом:
матрица решений дополняется еще одним столбцом из наименьших результатов eir каждой строки. Необходимо выбрать те варианты в строках которых стоят наибольшее значение eir этого столбца.
Выбранные т.о. варианты полностью исключают риск. Это означает, что принимающий решение не может столкнуться с худшим результатом, чем тот, на который он ориентируется. Это свойство позволяет считать ММ-критерий одним из фундаментальных.
Применение ММ-критерия бывает оправдано, если ситуация, в которой принимается решение следующая:
- О возможности появления внешних состояний Fjничего не известно;
- Приходится считаться с появлением различных внешних состояний Fj;
- Решение реализуется только один раз;
- Необходимо исключить какой бы то ни было риск.
2. Критерий Байеса—Лапласа.
Обозначим через qi — вероятность появления внешнего состояния Fj.
Соответствующее правило выбора можно интерпретировать следующим образом:
матрица решений дополняется еще одним столбцом содержащим математическое ожидание значений каждой из строк. Выбираются те варианты, в строках которых стоит наибольшее значение eir этого столбца.
При этом предполагается, что ситуация, в которой принимается решение, характеризуется следующими обстоятельствами:
- Вероятности появления состояния Fj известны и не зависят от времени.
- Решение реализуется (теоретически) бесконечно много раз.
- Для малого числа реализаций решения допускается некоторый риск.
При достаточно большом количестве реализаций среднее значение постепенно стабилизируется. Поэтому при полной (бесконечной) реализации какой-либо риск практически исключен.
Т.о. критерий Байеса-Лапласа (B-L-критерий) более оптимистичен, чем минимаксный критерий, однако он предполагает большую информированность и достаточно длительную реализацию.
3. Критерий Сэвиджа.
aij:= maxi(eij) — eij
eir:= maxi(aij) = maxj(maxi(eij) — eij)
Величину aij можно трактовать как максимальный дополнительный выигрыш, который достигается, если в состоянии Fj вместо варианта Eiвыбирать другой, оптимальный для этого внешнего состояния вариант. Величину aij можно интерпретировать и как потери (штрафы) возникающие в состоянии Fj при замене оптимального для него варианта на вариант Ei. В последнем случае eir представляет собой максимально возможные (по всем внешним состояниям Fj , j = {1,n}) потери в случае выбора варианта Ei.
Соответствующее критерию Сэвиджа правило выбора теперь трактуется так:
- Каждый элемент матрицы решений ||eij|| вычитается из наибольшего результата max(eij) соответствующего столбца.
- Разности aij образуют матрицу остатков ||eij||. Эта матрица пополняется столбцом наибольших разностей eir. Выбирают те варианты, в строках которых стоит наименьшее для этого столбца значение.
Требования, предъявляемые к ситуации, в которой принимается решение, совпадают с требованием к ММ-критерию.
4. Пример и выводы.
Из требований, предъявляемых к рассмотренным критериям становится ясно, что в следствии их жестких исходных позиций они применимы только для идеализированных практических решений. В случае, когда возможна слишком сильная идеализация, можно применять одновременно поочередно различные критерии. После этого среди нескольких вариантов ЛПР волевым методом выбирает окончательное решение. Такой подход позволяет, во-первых, лучше проникнуть во все внутренние связи проблемы принятия решений и, во-вторых, ослабляет влияние субъективного фактора.
Пример. При работе ЭВМ необходимо периодически приостанавливать обработку информации и проверять ЭВМ на наличие в ней вирусов. Приостановка в обработке информации приводит к определенным экономическим издержкам. В случае же если вирус вовремя обнаружен не будет, возможна потеря и некоторой части информации, что приведет и еще к большим убыткам.
Варианты решения таковы:
Е1 — полная проверка;
Е2 — минимальная проверка;
Е3 — отказ от проверки.
ЭВМ может находиться в следующих состояниях:
F1 — вирус отсутствует;
F2 — вирус есть, но он не успел повредить информацию;
F3 — есть файлы, нуждающиеся в восстановлении.
Результаты, включающие затраты на поиск вируса и его ликвидацию, а также затраты, связанные с восстановлением информации имеют вид:
| F1 | F2 | F3 | ММ-критерий | критерий B-L | |||
|---|---|---|---|---|---|---|---|
| eir = minj(eij) | maxi(eir) | eir = ∑eij | maxi(eir) | ||||
| E1 | -20,0 | -20 | -25,0 | -25,0 | -25,0 | -22,33 | |
| E2 | -14,0 | -23,0 | -31,0 | -31,0 | -22,67 | ||
| E3 | 0 | -24.0 | -40.0 | -40.0 | -21.33 | -21.33 |
Согласно ММ-критерию следует проводить полную проверку. Критерий Байеса-Лапласа, в предположении, что все состояния машины равновероятны.
P(Fj) = qj = 0,33,
рекомендуется отказаться от проверки. Матрица остатков для этого примера и их оценка (в тысячах) согласно критерию Сэвиджа имеет вид:
| F1 | F2 | F3 | Критерий Сэвиджа | ||
|---|---|---|---|---|---|
| eir = minj(aij) | minj(eir) | ||||
| E1 | +20,0 | 0 | 0 | +20,0 | |
| E2 | +14,0 | +1,0 | +6,0 | +14,0 | +14,0 |
| E3 | 0 | +2,0 | +15,0 | +15,0 |
Пример специально подобран так, что каждый критерий предлагает новое решение. Неопределенность состояния, в котором проверка застает ЭВМ, превращается в неясность, какому критерию следовать.
Поскольку различные критерии связаны с различными условиями, в которых принимается решение, лучшее всего для сравнительной оценки рекомендации тех или иных критериев получить дополнительную информацию о самой ситуации. В частности, если принимаемое решение относится к сотням машин с одинаковыми параметрами, то рекомендуется применять критерий Байеса-Лапласа. Если же число машин не велико, лучше пользоваться критериями минимакса или Севиджа.
Производные критерии.
1. Критерий Гурвица.
Стараясь занять наиболее уравновешенную позицию, Гурвиц предположил оценочную функцию, которая находится где-то между точкой зрения крайнего оптимизма и крайнего пессимизма:
maxi(eir) = { C⋅minj(eij) + (1-C)⋅maxj(eij) },
где С — весовой множитель.
Правило выбора согласно критерию Гурвица, формируется следующим образом:
матрица решений ||eij|| дополняется столбцом, содержащим среднее взвешенное наименьшего и наибольшего результатов для каждой строки. Выбираются только те варианты, в строках которых стоят наибольшие элементыe eirэтого столбца.
При С=1 критерий Гурвица превращается в ММ-критерий. При С = 0 он превращается в критерий «азартного игрока»
maxi(eir) = maxi(maxj(eij)),
т.е. мы становимся на точку зрения азартного игрока, делающего ставку на то, что «выпадет» наивыгоднейший случай.
В технических приложениях сложно выбрать весовой множитель С, т.к. трудно найти количественную характеристику для тех долей оптимизма и пессимизма, которые присутствуют при принятии решения. Поэтому чаще всего С:=1/2.
Критерий Гурвица применяется в случае, когда:
- о вероятностях появления состояния Fj ничего не известно;
- с появлением состояния Fj необходимо считаться;
- реализуется только малое количество решений;
- допускается некоторый риск.
2. Критерий Ходжа–Лемана.
Этот критерий опирается одновременно на ММ-критерий и критерий Баеса-Лапласа. С помощью параметра n выражается степень доверия к используемому распределений вероятностей. Если доверие велико, то доминирует критерий Баеса-Лапласа, в противном случае — ММ-критерий, т.е. мы ищем
maxi(eir) = maxi{v⋅∑eij⋅qi + (1-v) minj(eir)}, 0 ≤ n ≤ 1.
Правило выбора, соответствующее критерию Ходжа-Лемана формируется следующим образом:
матрица решений ||eij|| дополняется столбцом, составленным из средних взвешенных (с весом v≡const) математическое ожиданиями и наименьшего результата каждой строки (*). Отбираются те варианты решений в строках которого стоит набольшее значение этого столбца.
При v = 1 критерий Ходжа-Лемана переходит в критерий Байеса-Лапласа, а при v = 0 становится минимаксным.
Выбор v субъективен т. к. Степень достоверности какой-либо функции распределения — дело темное.
Для применения критерия Ходжа-Лемана желательно, чтобы ситуация в которой принимается решение, удовлетворяла свойствам:
- вероятности появления состояния Fj неизвестны, но некоторые предположения о распределении вероятностей возможны;
- принятое решение теоретически допускает бесконечно много реализаций;
- при малых числах реализации допускается некоторый риск.
3. Критерий Гермейера.
Этот критерий ориентирован на величину потерь, т.е. на отрицательные значения всех eij. При этом
maxi(eir) = maxi(minj(eij)qj).
Т.к. в хозяйственных задачах преимущественно имеют дело с ценами и затратами, условиеe eij<0 обычно выполняется. В случае же, когда среди величин eij встречаются и положительные значения, можно перейти к строго отрицательным значениям с помощью преобразования eij-a при подходящем образом подобранном a>0. При этом оптимальный вариант решения зависит от а.
Правило выбора согласно критерию Гермейера формулируется следующим образом:
матрица решений ||eij|| дополняется еще одним столбцом содержащим в каждой строке наименьшее произведение имеющегося в ней результата на вероятность соответствующего состояния Fj. Выбираются те варианты в строках которых находится наибольшее значениеe eij этого столбца.
В каком-то смысле критерий Гермейера обобщает ММ-критерий: в случае равномерного распределения qj = 1/n, j={1,n}, они становятся идентичными.
Условия его применимости таковы:
- вероятности появления состояния Fj неизвестны;
- с появлением тех или иных состояний, отдельно или в комплексе, необходимо считаться;
- допускается некоторый риск;
- решение может реализоваться один или несколько раз.
Если функция распределения известна не очень надежно, а числа реализации малы, то, следуя критерию Гермейера, получают, вообще говоря, неоправданно большой риск.
4. Объединенный критерий Байеса-Лапласа и минимакса.
Стремление получить критерии, которые бы лучше приспосабливались к имеющейся ситуации, чем все до сих пор рассмотренные, привело к построению так называемых составных критериев. В качестве примера рассмотрим критерий, полученный путем объединения критериев Байеса-Лапласа и минимакса (BL(MM)-критерий).
Правило выбора для этого критерия формулируется следующим образом:
матрица решений ||eij|| дополняется еще тремя столбцами. В первом из них записываются математические ожидания каждой из строк, во втором — разность между опорным значением
ei0j0 = maxi(maxj(eij))
и наименьшим значением
minj(eij)
соответствующей строки. В третьем столбце помещаются разности между наибольшим значением
maxj(eij)
каждой строки и наибольшим значением maxj(ei0j) той строки, в которой находится значение ei0j0. Выбираются те варианты, строки которых (при соблюдении приводимых ниже соотношений между элементами второго и третьего столбцов) дают наибольшее математическое ожидание. А именно, соответствующее значение
ei0j0 — maxj(eij)
из второго столбца должно быть или равно некоторому заранее заданному уровню риска Eдоп. Значение же из третьего столбца должно быть больше значения из второго столбца.
Применение этого критерия обусловлено следующими признаками ситуации, в которой принимается решение:
- вероятности появления состояний Fj неизвестны, однако имеется некоторая априорная информация в пользу какого-либо определенного распределения;
- необходимо считаться с появлением различных состояний как по отдельности, так и в комплексе;
- допускается ограниченный риск;
- принятое решение реализуется один раз или многократно.
BL(MM)-критерий хорошо приспособлен для построения практических решений прежде всего в области техники и может считаться достаточно надежным. Однако заданные границы риска Eдоп и, соответственно, оценок риска Ei не учитывает ни число применения решения, ни иную подобную информацию. Влияние субъективного фактора хотя и ослаблено, но не исключено полностью.
Условие
maxj(eij)-maxj(ei0j)≥Ei
существенно в тех случаях, когда решение реализуется только один или малое число раз. В этих условиях недостаточно ориентироваться на риск, связанный только с невыгодными внешними состояниями и средними значениями. Из-за этого, правда, можно понести некоторые потери в удачных внешних состояниях. При большом числе реализаций это условие перестает быть таким уж важным. Оно даже допускает разумные альтернативы. При этом не известно, однако, четких количественных указаний, в каких случаях это условие следовало бы опускать.
5. Критерий произведений.
maxi(eir):= maxi(∏eij)
Правило выбора в этом случае формулируется так:
Матрица решений ||eij|| дополняется новым столбцом, содержащим произведения всех результатов каждой строки. Выбираются те варианты, в строках которых находятся наибольшие значения этого столбца.
Применение этого критерия обусловлено следующими обстоятельствами:
- вероятности появления состояния Fj неизвестны;
- с появлением каждого из состояний Fj по отдельности необходимо считаться;
- критерий применим и при малом числе реализаций решения;
- некоторый риск допускается.
Критерий произведений приспособлен в первую очередь для случаев, когда все eij положительны. Если условие положительности нарушается, то следует выполнять некоторый сдвиг eij+а с некоторой константой а>|minij(eij)|. Результат при этом будет, естественно зависеть от а. На практике чаще всего
а:= |minij(eij)|+1.
Если же никакая константа не может быть признана имеющей смысл, то критерий произведений не применим.
Пример.
Рассмотрим тот же пример, что и ранее (см. выше).
Построение оптимального решения для матрицы решений о проверках по критерию Гурвица имеет вид (при С=0, в 103):
| ||eij|| | С⋅minj(eij) | (1-С)⋅maxj(eij) | eir | maxi(eir) | ||
|---|---|---|---|---|---|---|
| -20,0 | -22,0 | -25,0 | -12,5 | -10.0 | -22,5 | |
| -14,0 | -23.0 | -31.0 | -15,5 | -7.0 | -22,5 | |
| 0 | -24.0 | -40.0 | -20.0 | 0 | -20.0 | -20.0 |
В данном примере у решения имеется поворотная точка относительно весового множителя С: до С=0,57 в качестве оптимального выбирается Е3, а при больших значениях — Е1.
Применение критерия Ходжа-Лемана (q=0,33, v=0, в 103):
| ∑eij⋅qj | minj(eij) | v⋅∑eij⋅qj | (1-v)⋅∑eij⋅qj | eir | maxi(eir) |
|---|---|---|---|---|---|
| -22,33 | -25,0 | -11,17 | -12,5 | -23,67 | -23,67 |
| -22,67 | -31,0 | -11,34 | -15,5 | -26,84 | |
| -21,33 | -40,0 | -10,67 | -20,0 | -30,76 |
Критерий Ходжа-Лемана рекомендует вариант Е1 (полная проверка) — так же как и ММ-критерий. Смена рекомендуемого варианта происходит только при v=0,94. Поэтому равномерное распределение состояний рассматриваемой машины должно распознаваться с очень высокой вероятностью, чтобы его можно было выбрать по большему математическому ожиданию. При этом число реализаций решения всегда остается произвольным.
Критерий Гермейера при qj = 0.33 дает следующий результат (в 103):
| ||eij|| | ||eijqj|| | eir = minj(eijqj) | maxi(eir) | ||||
|---|---|---|---|---|---|---|---|
| -20,0 | -22,0 | -25,0 | -6,67 | -7,33 | -8,33 | -8,33 | -8,33 |
| -14,0 | -23,0 | -31,.0 | -4,67 | -7,67 | -10,33 | -10,33 | |
| 0 | -24,0 | -40,0 | 0 | -8,0 | -13,33 | -13,33 |
В качестве оптимального выбирается вариант Е1. Сравнение вариантов с помощью величинe eirпоказывает, что способ действия критерия Гермейера является даже более гибким, чем у ММ-критерия.
В таблице, приведенной ниже, решение выбирается в соответствии с BL(MM)-критерием при q1=q2=q3=1/2 (данные в 103).
| ||eij|| | ∑eijqj | ei0j0 — minj(eij) | maxj(eij) | maxj(eij) — maxj(ei0j) | ||
|---|---|---|---|---|---|---|
| -20,0 | -22,0 | -25,0 | -23,33 | 0 | -20,0 | 0 |
| -14,0 | -23,0 | -31,0 | -22,67 | +6,0 | -14,0 | +6,0 |
| 0 | -24,0 | -40,0 | -21,33 | +15,0 | 0 | +20,0 |
Вариант Е3 (отказ от проверки) принимается этим критерием только тогда, когда риск приближается к Eвозм = 15⋅103. В противном случае оптимальным оказывается Е1. Во многих технических и хозяйственных задачах допустимый риск бывает намного ниже, составляя обычно только незначительный процент от общих затрат. В подобных случаях бывает особенно ценно, если неточное значение распределения вероятностей сказывается не очень сильно. Если при этом оказывается невозможным установить допустимый риск Eдоп заранее, не зависимо от принимаемого решения, то помочь может вычисление ожидаемого риска Eвозм. Тогда становится возможным подумать, оправдан ли подобный риск. Такое исследование обычно дается легче.
Результаты применения критерия произведения при а = 41⋅103 и а = 200⋅103 имеют вид:
| a | ||eij + a|| | eir = ∏jeij | maxieir | ||
|---|---|---|---|---|---|
| 41 | +21 | +19 | +16 | 6384 | 6384 |
| +27 | +18 | +10 | 4860 | ||
| +41 | +17 | +1 | 697 | ||
| 200 | +180 | +178 | +175 | 5607 | |
| +186 | +177 | +169 | 5563 | ||
| +200 | +176 | +160 | 5632 | 5632 |
Условие eij > 0 для данной матрицы не выполнимо. Поэтому к элементам матрицы добавляется (по внешнему произволу) сначала а = 41⋅103, а затем а = 200⋅103.
Для а = 41⋅103 оптимальным оказывается вариант Е1, а для а = 200⋅103 — вариант Е3, так что зависимость оптимального варианта от а очевидна.
Время на прочтение
18 мин
Количество просмотров 29K
Теория игр — математическая дисциплина, рассматривающая моделирование действий игроков, которые имеют цель, заключающуюся в выбор оптимальных стратегий поведения в условиях конфликта. На Хабре эта тема уже освещалась, но сегодня мы поговорим о некоторых ее аспектах подробнее и рассмотрим примеры на Kotlin.
Так вот, стратегия – это совокупность правил, определяющих выбор варианта действий при каждом личном ходе в зависимости от сложившейся ситуации. Оптимальная стратегия игрока – стратегия, обеспечивающая наилучшее положение в данной игре, т.е. максимальный выигрыш. Если игра повторяется неоднократно и содержит, кроме личных, случайные ходы, то оптимальная стратегия обеспечивает максимальный средний выигрыш.
Задача теории игр – выявление оптимальных стратегий игроков. Основное предположение, исходя из которого находятся оптимальные стратегии, заключается в том, что противник (или противники) не менее разумен, чем сам игрок, и делает все для того, чтобы добиться своей цели. Расчет на разумного противника – лишь одна из потенциальных позиций в конфликте, но в теории игр именно она кладется в основу.
Существуют игры с природой в которых есть только один участник, максимизирующий свою прибыль. Игры с природой – математические модели, в которых выбор решения зависит об объективной действительности. Например, покупательский спрос, состояние природы и т.д. «Природа» – это обобщенное понятие не преследующего собственных целей противника. В таком случае для выбора оптимальной стратегии используется несколько критериев.
Различают два вида задач в играх с природой:
- задача о принятии решений в условиях риска, когда известны вероятности, с которыми природа принимает каждое из возможных состояний;
- задачи о принятии решений в условиях неопределенности, когда нет возможности получить информацию о вероятностях появления состояний природы.
Кратко об этих критериях рассказано здесь.
Сейчас мы рассмотрим критерии принятия решений в чистых стратегиях, а в конце статьи решим игру в смешанных стратегиях аналитическим методом.
Оговорочка
Я не являюсь специалистом в теории игр, а в этой работе использовал Kotlin в первый раз. Однако решил поделиться своими результатами. Если вы заметили ошибки в статье или хотите дать совет, прошу в личку.
Постановка задачи
Все критерии принятия решений мы разберем на сквозном примере. Задача такова: фермеру необходимо определить, в каких пропорциях засеять свое поле тремя культурами, если урожайность этих культур, а, значит, и прибыль, зависят от того, каким будет лето: прохладным и дождливым, нормальным, или жарким и сухим. Фермер подсчитал чистую прибыль с 1 гектара от разных культур в зависимости от погоды. Игра определяется следующей матрицей:

Далее эту матрицу будем представлять в виде стратегий:

Искомую оптимальную стратегию обозначим
 . Решать игру будем с помощью критериев Вальда, оптимизма, пессимизма, Сэвиджа и Гурвица в условиях неопределенности и критериев Байеса и Лапласа в условиях риска.
. Решать игру будем с помощью критериев Вальда, оптимизма, пессимизма, Сэвиджа и Гурвица в условиях неопределенности и критериев Байеса и Лапласа в условиях риска.
Как и говорилось выше примеры будут на Kotlin. Замечу, что вообще-то существуют такие решения как Gambit (написан на С), Axelrod и PyNFG (написанные на Python), но мы будем ехать на своем собственном велосипеде, собранном на коленке, просто ради того, чтобы немного потыкать стильный, модный и молодежный язык программирования.
Чтобы программно реализовать решение игры заведем несколько классов. Сначала нам понадобится класс, позволяющий описать строку или столбец игровой матрицы. Класс крайне простой и содержит список возможных значений (альтернатив или состояний природы) и соответствующего им имени. Поле key будем использовать для идентификации, а также при сравнении, а сравнение понадобится при реализации доминирования.
Строка или столбец игровой матрицы
import java.text.DecimalFormat
import java.text.NumberFormat
open class GameVector(name: String, values: List<Double>, key: Int = -1) : Comparable<GameVector> {
val name: String
val values: List<Double>
val key: Int
private val formatter:NumberFormat = DecimalFormat("#0.00")
init {
this.name = name;
this.values = values;
this.key = key;
}
public fun max(): Double? {
return values.max();
}
public fun min(): Double? {
return values.min();
}
override fun toString(): String{
return name + ": " + values
.map { v -> formatter.format(v) }
.reduce( {f1: String, f2: String -> "$f1 $f2"})
}
override fun compareTo(other: GameVector): Int {
var compare = 0
if (this.key == other.key){
return compare
}
var great = true
for (i in 0..this.values.lastIndex){
great = great && this.values[i] >= other.values[i]
}
if (great){
compare = 1
}else{
var less = true
for (i in 0..this.values.lastIndex){
less = less && this.values[i] <= other.values[i]
}
if (less){
compare = -1
}
}
return compare
}
}
Игровая матрица содержит информацию об альтернативах и состояниях природы. Кроме того в ней реализованы некоторые методы, например нахождение доминирующего множества и чистой цены игры.
Игровая матрица
open class GameMatrix(matrix: List<List<Double>>, alternativeNames: List<String>, natureStateNames: List<String>) {
val matrix: List<List<Double>>
val alternativeNames: List<String>
val natureStateNames: List<String>
val alternatives: List<GameVector>
val natureStates: List<GameVector>
init {
this.matrix = matrix;
this.alternativeNames = alternativeNames
this.natureStateNames = natureStateNames
var alts: MutableList<GameVector> = mutableListOf()
for (i in 0..matrix.lastIndex) {
val currAlternative = alternativeNames[i]
val gameVector = GameVector(currAlternative, matrix[i], i)
alts.add(gameVector)
}
alternatives = alts.toList()
var nss: MutableList<GameVector> = mutableListOf()
val lastIndex = matrix[0].lastIndex // нет провеврки на равенство длин всех строк, считаем что они равны
for (j in 0..lastIndex) {
val currState = natureStateNames[j]
var states: MutableList<Double> = mutableListOf()
for (i in 0..matrix.lastIndex) {
states.add(matrix[i][j])
}
val gameVector = GameVector(currState, states.toList(), j)
nss.add(gameVector)
}
natureStates = nss.toList()
}
open fun change (i : Int, j : Int, value : Double) : GameMatrix{
var mml = this.matrix.toMutableList()
var rowi = mml[i].toMutableList()
rowi.set(j, value)
mml.set(i, rowi)
return GameMatrix(mml.toList(), alternativeNames, natureStateNames)
}
open fun changeAlternativeName (i : Int, value : String) : GameMatrix{
var list = alternativeNames.toMutableList()
list.set(i, value)
return GameMatrix(matrix, list.toList(), natureStateNames)
}
open fun changeNatureStateName (j : Int, value : String) : GameMatrix{
var list = natureStateNames.toMutableList()
list.set(j, value)
return GameMatrix(matrix, alternativeNames, list.toList())
}
fun size() : Pair<Int, Int>{
return Pair(alternatives.size, natureStates.size)
}
override fun toString(): String {
return "Состояния природы:n" +
natureStateNames.reduce { n1: String, n2: String -> "$n1;n$n2" } +
"nМатрица игры:n" +
alternatives
.map { a: GameVector -> a.toString() }
.reduce { a1: String, a2: String -> "$a1;n$a2" }
}
protected fun dominateSet(gvl: List<GameVector>, list: MutableList<String>, dvv: Int) : MutableSet<GameVector>{
var dSet: MutableSet<GameVector> = mutableSetOf()
for (gv in gvl){
for (gvv in gvl){
if (!dSet.contains(gv) && !dSet.contains(gvv)) {
if (gv.compareTo(gvv) == dvv) {
dSet.add(gv)
list.add("[$gvv] доминирует [$gv]")
}
}
}
}
return dSet
}
open fun newMatrix(dCol: MutableSet<GameVector>, dRow: MutableSet<GameVector>)
: GameMatrix{
var result: MutableList<MutableList<Double>> = mutableListOf()
var ralternativeNames: MutableList<String> = mutableListOf()
var rnatureStateNames: MutableList<String> = mutableListOf()
val dIndex = dCol.map { c -> c.key }.toList()
for (i in 0 .. natureStateNames.lastIndex){
if (!dIndex.contains(i)){
rnatureStateNames.add(natureStateNames[i])
}
}
for (gv in this.alternatives){
if (!dRow.contains(gv)){
var nr: MutableList<Double> = mutableListOf()
for (i in 0 .. gv.values.lastIndex){
if (!dIndex.contains(i)){
nr.add(gv.values[i])
}
}
result.add(nr)
ralternativeNames.add(gv.name)
}
}
val rlist = result.map { r -> r.toList() }.toList()
return GameMatrix(rlist, ralternativeNames.toList(), rnatureStateNames.toList())
}
fun dominateMatrix(): Pair<GameMatrix, List<String>>{
var list: MutableList<String> = mutableListOf()
var dCol: MutableSet<GameVector> = dominateSet(this.natureStates, list, 1)
var dRow: MutableSet<GameVector> = dominateSet(this.alternatives, list, -1)
val newMatrix = newMatrix(dCol, dRow)
var ddgm = Pair(newMatrix, list.toList())
val ret = iterate(ddgm, list)
return ret;
}
protected fun iterate(ddgm: Pair<GameMatrix, List<String>>, list: MutableList<String>)
: Pair<GameMatrix, List<String>>{
var dgm = this
var lddgm = ddgm
while (dgm.size() != lddgm.first.size()){
dgm = lddgm.first
list.addAll(lddgm.second)
lddgm = dgm.dominateMatrix()
}
return Pair(dgm,list.toList().distinct())
}
fun minClearPrice(): Double{
val map: List<Double> = this.alternatives.map { a -> a?.min() ?: 0.0 }
return map?.max() ?: 0.0
}
fun maxClearPrice(): Double{
val map: List<Double> = this.natureStates.map { a -> a?.max() ?: 0.0 }
return map?.min() ?: 0.0
}
fun existsClearStrategy() : Boolean{
return minClearPrice() >= maxClearPrice()
}
}Опишем интерфейс, соответствующий критерию
Критерий
interface ICriteria {
fun optimum(): List<GameVector>
}
Принятие решений в условиях неопределенности
Принятие решений в условиях неопределённости предполагает, что игроку не противостоит разумный противник.
Критерий Вальда
В критерии Вальда максимизируется наихудший из возможных результатов:
![$u_{opt} = max_{i} min_{j} [U]$](https://habrastorage.org/getpro/habr/formulas/056/9ec/d68/0569ecd68e96fba4cbe838a90553041c.svg)
Использование критерия страхует от наихудшего результата, но цена такой стратегии – потеря возможности получить наилучший из возможных результатов.
Рассмотрим пример. Для стратегий
найдем минимумы и получим следующую тройку
 . Максимумом для указанной тройки будет являться значение 1, следовательно, по критерию Вальда выигрышной стратегией является стратегия
. Максимумом для указанной тройки будет являться значение 1, следовательно, по критерию Вальда выигрышной стратегией является стратегия
 , соответствующая посадке Культуры 2.
, соответствующая посадке Культуры 2.
Программная реализация критерия Вальда незатейлива:
class WaldCriteria(gameMatrix : GameMatrix) : ICriteria {
val gameMatrix: GameMatrix
init{
this.gameMatrix = gameMatrix
}
override fun optimum(): List<GameVector> {
val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) }
val max = mins.maxWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)})
return mins
.filter { m -> m.second == max!!.second }
.map { m -> m.first }
}
}
Для большей понятности в первый раз покажу, как решение выглядело бы в виде теста:
Тест
private fun matrix(): GameMatrix {
val alternativeNames: List<String> = listOf("Культура 1", "Культура 2", "Культура 3")
val natureStateNames: List<String> = listOf("Прохладное и дождливое", "Нормальное", "Жаркое и сухое")
val matrix: List<List<Double>> = listOf(
listOf(0.0, 2.0, 5.0),
listOf(2.0, 3.0, 1.0),
listOf(4.0, 3.0, -1.0)
)
val gm = GameMatrix(matrix, alternativeNames, natureStateNames)
return gm;
}
}
private fun testCriteria(gameMatrix: GameMatrix, criteria: ICriteria, name: String){
println(gameMatrix.toString())
val optimum = criteria.optimum()
println("$name. Оптимальная стратегия: ")
optimum.forEach { o -> println(o.toString()) }
}
@Test
fun testWaldCriteria() {
val matrix = matrix();
val criteria = WaldCriteria(matrix)
testCriteria(matrix, criteria, "Критерий Вальда")
}
Нетрудно догадаться, что для других критериев отличие будет только в создании объекта criteria.
Критерий оптимизма
При использовании критерия оптимиста игрок выбирает решение, дающее лучший результат, при этом оптимист предполагает, что условия игры будут для него наиболее благоприятными:
![$u_{opt} = max_{i} max_{j} [U]$](https://habrastorage.org/getpro/habr/formulas/72e/03d/eb9/72e03deb976f27ccec1a6154b384a99a.svg)
Стратегия оптимиста может привести к отрицательным последствиям, когда максимальное предложение совпадает с минимальным спросом – фирма может получить убытки при списании нереализованной продукции. В тоже время стратегия оптимиста имеет определённый смысл, например, не нужно заботиться о неудовлетворённых покупателях, поскольку любой возможный спрос всегда удовлетворяется, поэтому нет нужды поддерживать расположения покупателей. Если реализуется максимальный спрос, то стратегия оптимиста позволяет получить максимальную полезность в то время, как другие стратегии приведут к недополученной прибыли. Это даёт определённые конкурентные преимущества.
Рассмотрим пример. Для стратегий
найдем найдем максимум и получим следующую тройку
 . Максимумом для указанной тройки будет являться значение 5, следовательно, по критерию оптимизма выигрышной стратегией является стратегия
. Максимумом для указанной тройки будет являться значение 5, следовательно, по критерию оптимизма выигрышной стратегией является стратегия
 , соответствующая посадке Культуры 1.
, соответствующая посадке Культуры 1.
Реализация критерия оптимизма почти не отличается от критерия Вальда:
class WaldCriteria(gameMatrix : GameMatrix) : ICriteria {
val gameMatrix: GameMatrix
init{
this.gameMatrix = gameMatrix
}
override fun optimum(): List<GameVector> {
val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) }
val max = mins.maxWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)})
return mins
.filter { m -> m.second == max!!.second }
.map { m -> m.first }
}
}
Критерий пессимизма
Данный критерий предназначен для выбора наименьшего элемента игровой матрицы из ее минимально возможных элементов:
![$u_{opt} = min_{i} min_{j} [U]$](https://habrastorage.org/getpro/habr/formulas/4e0/12f/384/4e012f3848e121cdb3a87c181afccbb5.svg)
Критерий пессимизма предполагает, что развитие событий будет неблагоприятным для лица, принимающего решение. При использовании этого критерия лицо принимающее решение ориентируется на возможную потерю контроля над ситуацией, поэтому, старается исключить потенциальные риски выбирая вариант с минимальной доходностью.
Рассмотрим пример. Для стратегий
найдем найдем минимум и получим следующую тройку
. Минимумом для указанной тройки будет являться значение -1, следовательно, по критерию пессимизма выигрышной стратегией является стратегия
 , соответствующая посадке Культуры 3.
, соответствующая посадке Культуры 3.
После знакомства с критериями Вальда и оптимизма то, как будет выглядеть класс критерия пессимизма, думаю, легко догадаться:
class PessimismCriteria(gameMatrix : GameMatrix) : ICriteria {
val gameMatrix: GameMatrix
init{
this.gameMatrix = gameMatrix
}
override fun optimum(): List<GameVector> {
val mins = gameMatrix.alternatives.map { a -> Pair(a, a.min()) }
val min = mins.minWith( Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!)})
return mins
.filter { m -> m.second == min!!.second }
.map { m -> m.first }
}
}
Критерий Сэвиджа
Критерий Сэвиджа (критерий сожалеющего пессимиста) предполагает минимизацию наибольшей потерянной прибыли, иными словами минимизируется наибольшее сожаление по потерянной прибыли:
![$u_{opt} = min_{i} max_{j}[S]\ s_{i,j} = (max begin{bmatrix} u_{1,j} \ u_{2,j}\ ...\u_{n,j} end{bmatrix} - u_{i,j})$](https://habrastorage.org/getpro/habr/formulas/0da/e8b/7ad/0dae8b7adbc50d7690888f3ace1aaf24.svg)
В данном случае S — это матрица сожалений.
Оптимальное решение по критерию Сэвиджа должно давать наименьшее сожаление из найденных на предыдущем шаге решения сожалений. Решение, соответствующее найденной полезности, будет оптимальным.
К особенностям полученного решения относятся гарантированное отсутствие самых больших разочарований и гарантированное снижение максимальных возможных выигрышей других игроков.
Рассмотрим пример. Для стратегий
составим матрицу сожалений:
Тройка максимальных сожалений
 . Минимальным значением из указанных рисков будет являться значение 4, которое соответствует стратегиям
. Минимальным значением из указанных рисков будет являться значение 4, которое соответствует стратегиям
 и
и
 .
.
Запрограммировать критерий Сэвиджа немного сложнее:
class SavageCriteria(gameMatrix: GameMatrix) : ICriteria {
val gameMatrix: GameMatrix
init {
this.gameMatrix = gameMatrix
}
fun GameMatrix.risk(): List<Pair<GameVector, Double?>> {
val maxStates = this.natureStates.map { n -> Pair(n, n.values.max()) }
.map { n -> n.first.key to n.second }.toMap()
var am: MutableList<Pair<GameVector, List<Double>>> = mutableListOf()
for (a in this.alternatives) {
var v: MutableList<Double> = mutableListOf()
for (i in 0..a.values.lastIndex) {
val mn = maxStates.get(i)
v.add(mn!! - a.values[i])
}
am.add(Pair(a, v.toList()))
}
return am.map { m -> Pair(m.first, m.second.max()) }
}
override fun optimum(): List<GameVector> {
val risk = gameMatrix.risk()
val minRisk = risk.minWith(Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!) })
return risk
.filter { r -> r.second == minRisk!!.second }
.map { m -> m.first }
}
}
Критерий Гурвица
Критерий Гурвица является регулируемым компромиссом между крайним пессимизмом и полным оптимизмом:

A(0) — стратегия крайнего пессимиста, A(k) — стратегия полного оптимиста,
 — задаваемое значение весового коэффициента:
— задаваемое значение весового коэффициента:
 ;
;
 — крайний пессимизм,
— крайний пессимизм,
— полный оптимизм.
При небольшом числе дискретных стратегий, задавая желаемое значение весового коэффициента
 , а затем округлять получаемый результат до ближайшего возможного значения с учётом выполненной дискретизации.
, а затем округлять получаемый результат до ближайшего возможного значения с учётом выполненной дискретизации.
Рассмотрим пример. Для стратегий
. Примем, что коэффициент оптимизма
 . Теперь составим таблицу:
. Теперь составим таблицу:
Максимальным значением из рассчитанных H будет являться значение 3, которое соответствует стратегии
.
Реализация критерия Гурвица уже более объемная:
class HurwitzCriteria(gameMatrix: GameMatrix, optimisticKoef: Double) : ICriteria {
val gameMatrix: GameMatrix
val optimisticKoef: Double
init {
this.gameMatrix = gameMatrix
this.optimisticKoef = optimisticKoef
}
inner class HurwitzParam(xmax: Double, xmin: Double, optXmax: Double){
val xmax: Double
val xmin: Double
val optXmax: Double
val value: Double
init{
this.xmax = xmax
this.xmin = xmin
this.optXmax = optXmax
value = xmax * optXmax + xmin * (1 - optXmax)
}
}
fun GameMatrix.getHurwitzParams(): List<Pair<GameVector, HurwitzParam>> {
return this.alternatives.map { a -> Pair(a, HurwitzParam(a.max()!!, a.min()!!, optimisticKoef)) }
}
override fun optimum(): List<GameVector> {
val hpar = gameMatrix.getHurwitzParams()
val maxHurw = hpar.maxWith(Comparator { o1, o2 -> o1.second.value.compareTo(o2.second.value) })
return hpar
.filter { r -> r.second == maxHurw!!.second }
.map { m -> m.first }
}
}
Принятие решений в условиях риска
Методы принятия решений могут полагаться на критерии принятия решений в условиях риска при соблюдении следующих условий:
- отсутствия достоверной информации о возможных последствиях;
- наличия вероятностных распределений;
- знания вероятности наступления исходов или последствий для каждого решения.
Если решение принимается в условиях риска, то стоимости альтернативных решений описываются вероятностными распределениями. В связи с этим принимаемое решение основывается на использовании критерия ожидаемого значения, в соответствии с которым альтернативные решения сравниваются с точки зрения максимизации ожидаемой прибыли или минимизации ожидаемых затрат.
Критерий ожидаемого значения может быть сведен либо к максимизации ожидаемой (средней) прибыли, либо к минимизации ожидаемых затрат. В данном случае предполагается, что связанная с каждым альтернативным решением прибыль (затраты) является случайной величиной.
Постановка таких задач как правило такова: человек выбирает какие-либо действия в ситуации, где на результат действия влияют случайные события. Но игрок имеет некоторые знания о вероятностях этих событий и может рассчитать наиболее выгодную совокупность и очередность своих действий.
Чтобы можно было и дальше приводить примеры, дополним игровую матрицу вероятностями:
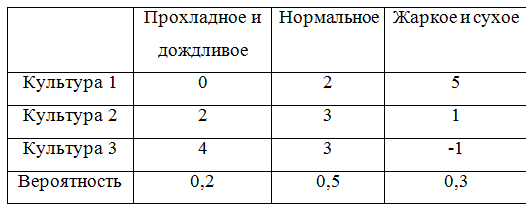
Для того, чтобы учесть вероятности придется немного переделать класс, описывающий игровую матрицу. Получилось, по правде говоря, не очень-то изящно, ну да ладно.
Игровая матрица с вероятностями
open class ProbabilityGameMatrix(matrix: List<List<Double>>, alternativeNames: List<String>,
natureStateNames: List<String>, probabilities: List<Double>) :
GameMatrix(matrix, alternativeNames, natureStateNames) {
val probabilities: List<Double>
init {
this.probabilities = probabilities;
}
override fun change (i : Int, j : Int, value : Double) : GameMatrix{
val cm = super.change(i, j, value)
return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities)
}
override fun changeAlternativeName (i : Int, value : String) : GameMatrix{
val cm = super.changeAlternativeName(i, value)
return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities)
}
override fun changeNatureStateName (j : Int, value : String) : GameMatrix{
val cm = super.changeNatureStateName(j, value)
return ProbabilityGameMatrix(cm.matrix, cm.alternativeNames, cm.natureStateNames, probabilities)
}
fun changeProbability (j : Int, value : Double) : GameMatrix{
var list = probabilities.toMutableList()
list.set(j, value)
return ProbabilityGameMatrix(matrix, alternativeNames, natureStateNames, list.toList())
}
override fun toString(): String {
var s = ""
val formatter: NumberFormat = DecimalFormat("#0.00")
for (i in 0 .. natureStateNames.lastIndex){
s += natureStateNames[i] + " = " + formatter.format(probabilities[i]) + "n"
}
return "Состояния природы:n" +
s +
"Матрица игры:n" +
alternatives
.map { a: GameVector -> a.toString() }
.reduce { a1: String, a2: String -> "$a1;n$a2" }
}
override fun newMatrix(dCol: MutableSet<GameVector>, dRow: MutableSet<GameVector>)
: GameMatrix{
var result: MutableList<MutableList<Double>> = mutableListOf()
var ralternativeNames: MutableList<String> = mutableListOf()
var rnatureStateNames: MutableList<String> = mutableListOf()
var rprobailities: MutableList<Double> = mutableListOf()
val dIndex = dCol.map { c -> c.key }.toList()
for (i in 0 .. natureStateNames.lastIndex){
if (!dIndex.contains(i)){
rnatureStateNames.add(natureStateNames[i])
}
}
for (i in 0 .. probabilities.lastIndex){
if (!dIndex.contains(i)){
rprobailities.add(probabilities[i])
}
}
for (gv in this.alternatives){
if (!dRow.contains(gv)){
var nr: MutableList<Double> = mutableListOf()
for (i in 0 .. gv.values.lastIndex){
if (!dIndex.contains(i)){
nr.add(gv.values[i])
}
}
result.add(nr)
ralternativeNames.add(gv.name)
}
}
val rlist = result.map { r -> r.toList() }.toList()
return ProbabilityGameMatrix(rlist, ralternativeNames.toList(), rnatureStateNames.toList(),
rprobailities.toList())
}
}
}
Критерий Байеса
Критерий Байеса (критерий математического ожидания) используется в задачах принятия решения в условиях риска в качестве оценки стратегии
 выступает математическое ожидание соответствующей ей случайной величины. В соответствии с этим правилом оптимальная стратегия игрока
выступает математическое ожидание соответствующей ей случайной величины. В соответствии с этим правилом оптимальная стратегия игрока
находится из условия:

Иными словами, показателем неэффективности стратегии
по критерию Байеса относительно рисков является среднее значение (математическое ожидание ожидание) рисков i-й строки матрицы
 , вероятности которых, совпадают с вероятностями природы. Тогда оптимальной среди чистых стратегий по критерию Байеса относительно рисков является стратегия
, вероятности которых, совпадают с вероятностями природы. Тогда оптимальной среди чистых стратегий по критерию Байеса относительно рисков является стратегия
, обладающая минимальной неэффективностью то есть минимальным средним риском. Критерий Байеса эквивалентен относительно выигрышей и относительно рисков, т.е. если стратегия
является оптимальной по критерию Байеса относительно выигрышей, то она является оптимальной и по критерию Байеса относительно рисков, и наоборот.
Перейдем к примеру и рассчитаем математические ожидания:

Максимальным математическим ожиданием является
 , следовательно, выигрышной стратегией является стратегия
, следовательно, выигрышной стратегией является стратегия
.
Программная реализация критерия Байеса:
class BayesCriteria(gameMatrix: ProbabilityGameMatrix) : ICriteria {
val gameMatrix: ProbabilityGameMatrix
init {
this.gameMatrix = gameMatrix
}
fun ProbabilityGameMatrix.bayesProbability(): List<Pair<GameVector, Double?>> {
var am: MutableList<Pair<GameVector, Double>> = mutableListOf()
for (a in this.alternatives) {
var alprob: Double = 0.0
for (i in 0..a.values.lastIndex) {
alprob += a.values[i] * this.probabilities[i]
}
am.add(Pair(a, alprob))
}
return am.toList();
}
override fun optimum(): List<GameVector> {
val risk = gameMatrix.bayesProbability()
val maxBayes = risk.maxWith(Comparator { o1, o2 -> o1.second!!.compareTo(o2.second!!) })
return risk
.filter { r -> r.second == maxBayes!!.second }
.map { m -> m.first }
}
}Критерий Лапласа
Критерий Лапласа представляет упрощенную максимизацию математического ожидания полезности, когда справедливо предположение о равной вероятности уровней спроса, что избавляет от необходимости сбора реальной статистики.
В общем случае при использовании критерия Лапласа матрица ожидаемых полезностей и оптимальный критерий определяются следующим образом:
![$u_{opt} = max[overline{U}]\ overline{U}= begin{bmatrix} overline{u}_{1} \ overline{u}_{2}\ ...\ overline{u}_{n} end{bmatrix}, overline{u}_{i} = frac{1}{n}sum_{j=1}^nu_{i,j}$](https://habrastorage.org/getpro/habr/formulas/44c/d12/4f4/44cd124f40214082b663947b8713c311.svg)
Рассмотрим пример принятия решений по критерию Лапласа. Рассчитаем среднеарифметическое для каждой стратегии:

Таким образом, выигрышной стратегией является стратегия
.
Программная реализация критерия Лапласа:
class LaplaceCriteria(gameMatrix: GameMatrix) : ICriteria {
val gameMatrix: GameMatrix
init {
this.gameMatrix = gameMatrix
}
fun GameMatrix.arithemicMean(): List<Pair<GameVector, Double>> {
return this.alternatives.map { m -> Pair(m, m.values.average()) }
}
override fun optimum(): List<GameVector> {
val risk = gameMatrix.arithemicMean()
val maxBayes = risk.maxWith(Comparator { o1, o2 -> o1.second.compareTo(o2.second) })
return risk
.filter { r -> r.second == maxBayes!!.second }
.map { m -> m.first }
}
}Смешанные стратегии. Аналитический метод
Аналитический метод позволяет решить игру в смешанных стратегиях. Для того, чтобы сформулировать алгоритм нахождения решения игры аналитическим методом, рассмотрим некоторые дополнительные понятия.
Стратегия
 доминирует стратегию
доминирует стратегию
 , если все
, если все
 . Иными словами, если в некоторой строке платёжной матрицы все элементы больше или равны соответствующим элементам другой строки, то первая строка доминирует вторую и называется доминант-строкой. А также если в некотором столбце платёжной матрицы все элементы меньше или равны соответствующим элементам другого столбца, то первый столбец доминирует второй и называется доминант-столбцом.
. Иными словами, если в некоторой строке платёжной матрицы все элементы больше или равны соответствующим элементам другой строки, то первая строка доминирует вторую и называется доминант-строкой. А также если в некотором столбце платёжной матрицы все элементы меньше или равны соответствующим элементам другого столбца, то первый столбец доминирует второй и называется доминант-столбцом.
Нижней ценой игры называется
 .
.
Верхней ценой игры называется
 .
.
Теперь можно сформулировать алгоритм решения игры аналитическим методом:
- Вычислить нижнюю
 и верхнюю цены игры. Если , то записать ответ в чистых стратегиях, если нет — продолжаем решение дальше
и верхнюю цены игры. Если , то записать ответ в чистых стратегиях, если нет — продолжаем решение дальше - Удалить доминирующие строки доминирующие столбцы. Их может быть несколько. На их место в оптимальной стратегии соответствующие компоненты будут равны 0
- Решить матричную игру методом линейного программирования.
 и верхнюю
и верхнюю  цены игры. Если
цены игры. Если  , то записать ответ в чистых стратегиях, если нет — продолжаем решение дальше
, то записать ответ в чистых стратегиях, если нет — продолжаем решение дальшеДля того, чтобы привести пример необходимо привести класс, описывающий решение
Solve
class Solve(gamePriceObr: Double, solutions: List<Double>, names: List<String>) {
val gamePrice: Double
val gamePriceObr: Double
val solutions: List<Double>
val names: List<String>
private val formatter: NumberFormat = DecimalFormat("#0.00")
init{
this.gamePrice = 1 / gamePriceObr
this.gamePriceObr = gamePriceObr;
this.solutions = solutions
this.names = names
}
override fun toString(): String{
var s = "Цена игры: " + formatter.format(gamePrice) + "n"
for (i in 0..solutions.lastIndex){
s += "$i) " + names[i] + " = " + formatter.format(solutions[i] / gamePriceObr) + "n"
}
return s
}
fun itersect(matrix: GameMatrix): String{
var s = "Цена игры: " + formatter.format(gamePrice) + "n"
for (j in 0..matrix.alternativeNames.lastIndex) {
var f = false
val a = matrix.alternativeNames[j]
for (i in 0..solutions.lastIndex) {
if (a.equals(names[i])) {
s += "$j) " + names[i] + " = " + formatter.format(solutions[i] / gamePriceObr) + "n"
f = true
break
}
}
if (!f){
s += "$j) " + a + " = 0n"
}
}
return s
}
}И класс, выполняющий решение симплекс-методом. Поскольку в математике я не разбираюсь, то воспользовался готовой реализацией из Apache Commons Math
Solver
open class Solver (gameMatrix: GameMatrix) {
val gameMatrix: GameMatrix
init{
this.gameMatrix = gameMatrix
}
fun solve(): Solve{
val goalf: List<Double> = gameMatrix.alternatives.map { a -> 1.0 }
val f = LinearObjectiveFunction(goalf.toDoubleArray(), 0.0)
val constraints = ArrayList<LinearConstraint>()
for (alt in gameMatrix.alternatives){
constraints.add(LinearConstraint(alt.values.toDoubleArray(), Relationship.LEQ, 1.0))
}
val solution = SimplexSolver().optimize(f, LinearConstraintSet(constraints), GoalType.MAXIMIZE,
NonNegativeConstraint(true))
val sl: List<Double> = solution.getPoint().toList()
val solve = Solve(solution.getValue(), sl, gameMatrix.alternativeNames)
return solve
}
}
Теперь выполним решение аналитическим методом. Для наглядности возьмем другую игровую матрицу:

В этой матрице есть доминирующее множество:
begin{pmatrix} 2& 4\ 6& 2end{pmatrix}
Решение
val alternativeNames: List<String> = listOf("Культура 1", "Культура 2", "Культура 3")
val natureStateNames: List<String> =
listOf("Прохладное и дождливое", "Нормальное", "Жаркое и сухое", "Ветреное")
val matrix: List<List<Double>> = listOf(
listOf(2.0, 4.0, 8.0, 5.0),
listOf(6.0, 2.0, 4.0, 6.0),
listOf(3.0, 2.0, 5.0, 4.0)
)
val gm = GameMatrix(matrix, alternativeNames, natureStateNames)
val (dgm, list) = gm.dominateMatrix()
println(dgm.toString())
println(list.reduce({s1, s2 -> s1 + "n" + s2}))
println()
val s: Solver = Solver(dgm)
val solve = s.solve()
println(solve)
Решение игры
 при цене игры равной 3,33
при цене игры равной 3,33
Вместо заключения
Надеюсь, эта статья будет полезна тем, кому необходимо в первом приближении с решением игр с природой. Вместо выводов ссылка на GitHub.
Буду благодарен за конструктивную обратную связь!