Рассмотрим, зачем нужен файл robots.txt для WordPress, где он находится на хостинге и как настроить правильный robots.txt для WordPress.
Для чего нужен файл robots.txt?
Для того чтобы сайт начал отображаться в Яндекс, Google, Yahoo и других поисковых системах (ПС), они должны внести его страницы в свои каталоги. Этот процесс называется индексацией.
Чтобы проиндексировать тот или иной веб-ресурс, поисковые системы посылают на сайты поисковых роботов (иногда их называют ботами). Они методично сканируют и обрабатывают содержимое каждой страницы сайта. После окончания индексации начинается «социальная жизнь» ресурса: его контент попадается пользователям в результатах поиска по запросам.
Многие сайты создаются на готовых движках и CMS (системах управления контентом) WordPress, Joomla, Drupal и других. Как правило, такие системы содержат страницы, которые не должны попадать в поисковую выдачу:
- временные файлы (tmp);
- личные данные посетителей (private);
- служебные страницы (admin);
- результаты поиска по сайту и т. д.
Чтобы внутренняя информация не попала в результаты поиска, ее нужно закрыть от индексации. В этом помогает файл robots.txt. Он служит для того, чтобы сообщить поисковым роботам, какие страницы сайта нужно индексировать, а какие — нет. Иными словами, robots.txt — это файл, состоящий из текстовых команд (правил), которыми поисковые роботы руководствуются при индексации сайта.
Наличие robots.txt значительно ускоряет процесс индексации. Благодаря нему в поисковую выдачу не попадают лишние страницы, а нужные индексируются быстрее.
Где находится robots.txt WordPress?
Файл robots.txt находится в корневой папке сайта. Если сайт создавался на WordPress, скорее всего, robots.txt присутствует в нем по умолчанию. Чтобы найти robots.txt на WordPress, введите в адресной строке браузера:
https://www.домен-вашего-сайта/robots.txt- Если файл присутствует, откроется страница с перечнем правил индексации. Однако чтобы редактировать их, вам потребуется найти и открыть robots.txt на хостинге. Как правило, он находится в корневой папке сайта:
- Если же файл robots.txt по какой-то причине отсутствует, вы можете создать его вручную на своем компьютере и загрузить на хостинг или воспользоваться готовыми решениями (плагинами WordPress).
Как создать файл robots.txt для WordPress?
Есть два способа создания robots.txt:
-
Вручную на компьютере.
-
С помощью плагинов в WordPress.
Первый способ прост лишь на первый взгляд. После создания пустого документа и загрузки его на сайт, вы должны будете наполнить его содержанием (директивами). Ниже мы расскажем об основных правилах, однако стоит учитывать, что тонкая настройка требует специальных знаний SEO-оптимизации.
Создание robots.txt вручную
-
1.
Откройте программу «Блокнот».
-
2.
Нажмите Файл → Сохранить как… (или комбинацию клавиш Ctrl + Shift + S):
-
3.
Введите название robots.txt и нажмите Сохранить.
-
4.
Откройте корневую папку сайта и загрузите в нее созданный файл по инструкции.
Готово, вы разместили пустой файл и после этого сможете редактировать его прямо в панели управления хостингом.
Создание robots.txt с помощью плагина
-
1.
Откройте административную панель WordPress по инструкции.
-
2.
Перейдите в раздел «Плагины» и нажмите Добавить новый:
-
3.
Введите в строке поиска справа название Yoast SEO и нажмите Enter.
-
4.
Нажмите Установить → Активировать:
-
5.
Перейдите к настройкам плагина, выбрав в меню SEO → Инструменты. Затем нажмите Редактор файлов:
-
6.
Нажмите Создать файл robots.txt:
-
7.
Нажмите Сохранить изменения в robots.txt:
Готово, файл с минимальным количеством директив будет создан автоматически.
Настройка robots.txt WordPress
После создания файла вам предстоит настроить robots.txt для своего сайта. Рассмотрим основы синтаксиса (структуры) этого файла:
- Файл может состоять из одной и более групп директив (правил).
- В каждой группе должно указываться, для какого поискового робота предназначены правила, к каким разделам/файлам у него нет доступа, а к какому — есть.
- Правила читаются поисковыми роботами по порядку, сверху вниз.
- Файл чувствителен к регистру, поэтому если название раздела или файла задано капслоком (например, FILE.PDF), именно так стоит писать и в robots.txt.
- Все правила одной группы должны следовать без пропуска строк.
- Чтобы оставить комментарий, нужно прописать шарп (#) в начале строки.
Все правила в файле задаются через двоеточие. Например:
Где User-agent — команда (директива), а Googlebot — значение.
Основные директивы и их значения
User-agent — эта директива указывает, на каких поисковых роботов распространяются остальные правила в документе. Она может принимать следующие значения:
- User-agent: * — общее правило для всех поисковых систем;
- User-agent: Googlebot — робот Google;
- User-agent: Yandex — робот Яндекс;
- User-agent: Mai.ru — робот Mail.ru;
- User-agent: Yahoo Slurp — робот Yahoo и др.
У крупнейших поисковых систем Яндекс и Google есть десятки роботов, предназначенных для индексации конкретных разделов и элементов сайтов. Например:
- YandexBot — для органической выдачи;
- YandexDirect — для контекстной рекламы;
- YandexNews — для новостных сайтов и т. п.
Для решения некоторых специфических задач веб-разработчики могут обращаться к конкретным поисковым роботам и настраивать правила исключительно для них.
Disallow — это директива, которая указывает, какие разделы или страницы нельзя посещать поисковым роботам. Все значения задаются в виде относительных ссылок (то есть без указания домена). Основные правила запрета:
- Disallow: /wp-admin — закрывает админку сайта;
- Disallow: /cgi-bin — запрет индексации директории, в которой хранятся CGI-скрипты;
- Disallow: /*? или Disallow: /search — закрывает от индексации поиск на сайте;
- Disallow: *utm* — закрывает все страницы с UTM-метками;
- Disallow: */xmlrpc.php — закрывает файл с API WordPress и т. д.
Вариантов того, какие файлы нужно закрывать от индексации, очень много. Вносите значения аккуратно, чтобы по ошибке не указать контентные страницы, что повредит поисковой позиции сайта.
Allow — это директива, которая указывает, какие разделы и страницы должны проиндексировать поисковые роботы. Как и с директивой Disallow, в значении нужно указывать относительные ссылки:
- Allow: /*.css или Allow: *.css — индексировать все css-файлы;
- Allow: /*.js — обходить js-файлы;
- Allow: /wp-admin/admin-ajax.php — разрешает индексацию асинхронных JS-скриптов, которые используются в некоторых темах.
В директиве Allow не нужно указывать все разделы и файлы сайта. Проиндексируется всё, что не было запрещено директивой Disallow. Поэтому задавайте только исключения из правила Disallow.
Sitemap — это необязательная директива, которая указывает, где находится карта сайта Sitemap. Единственная директива, которая поддерживает абсолютные ссылки (то есть местоположение файла должно указываться целиком): Sitemap: https://site.ru/sitemap.xml , где site.ru — имя домена.
Также есть некоторые директивы, которые считаются уже устаревшими. Их можно удалить из кода, чтобы не «засорять» файл:
- Crawl-delay. Задает паузу в индексации для поисковых роботов. Например, если задать для Crawl-Delay параметр 2 секунды, то каждый новый раздел/файл будет индексироваться через 2 секунды после предыдущего. Это правило раньше указывали, чтобы не создавать дополнительную нагрузку на хостинг. Но сейчас мощности современных процессоров достаточно для любой нагрузки.
- Host. Указывает основное зеркало сайта. Например, если все страницы сайта доступны с www и без этого префикса, один из вариантов будет считаться зеркалом. Главное — чтобы на них совпадал контент. Раньше зеркало нужно было задавать в robots.txt, но сейчас поисковые системы определяют этот параметр автоматически.
- Clean-param. Директива, которая использовалась, чтобы ограничить индексацию совпадающего динамического контента. Считается неэффективной.
Пример robots.txt
Рассмотрим стандартный файл robots.txt, который можно скопировать и использовать для блога, заменив название домена в директиве Sitemap и убрав комментарии (текст справа, включая #):
User-agent: * # общие правила для всех поисковых роботов
Disallow: /wp-admin/ # запретить индексацию папки wp-admin (все служебные папки)
Disallow: /readme.html # закрыть доступ к стандартному файлу о программном обеспечении
Disallow: /*? # запретить индексацию результатов поиска по сайту
Disallow: /?s= # запретить все URL поиска по сайту
Allow: /wp-admin/admin-ajax.php # индексировать асинхронные JS-файлы темы
Allow: /*.css # индексировать CSS-файлы
Allow: /*.js # индексировать JS-скрипты
Sitemap: https://site.ru/sitemap.xml # указать местоположение карты сайтаКак редактировать robots.txt на WordPress?
Чтобы внести изменения в файл robots.txt, откройте его в панели управления хостингом. Используйте плагин Yoast SEO (или аналогичное решение в WordPress) для редактирования файлов:
Проверка работы файла robots.txt
Чтобы убедиться в корректности составленного файла, используйте стандартный инструмент Яндекс.Вебмастер:
- 1.
-
2.
Перейдите в раздел Инструменты → Анализ robots.txt.
-
3.
Содержимое robots.txt обновится автоматически. Нажмите Проверить:
Если в синтаксисе файла будут ошибки, Яндекс укажет, в каких строчках проблема и даст рекомендации по исправлению.
Огромную роль в продвижении играет файл robots в WordPress, да и на любом сайте. Одной строчкой можно полностью выкинуть ресурс из индекса, либо грамотно управлять поведением поискового робота, чтобы сократить время на индексацию и показать только необходимый контент.
Не путайте с meta name=”robots” в той же пагинации, который прописывается в коде и в основном управляет атрибутами noindex и nofollow.
Содержание
- Правильный общий файл robots txt для WordPress
- Где лежит robots txt
- Как создать robots
- Проверка работы в валидаторе Yandex
- Создать и отредактировать robots в плагине Yoast
- Clearfy PRO – автоматический и правильный robots
- Идеальный robots для WooCommerce в WordPress
Правильный общий файл robots txt для WordPress
Покажу какой использовать лучший, универсальный и правильный пример robots txt для всех сайтов WordPress, он сделает базовые настройки, остальные директивы вы должны вносить сами на блог.
User-agent: *
Disallow: /wp-
Disallow: /tag/
Disallow: */trackback
Disallow: */page
Disallow: /author/*
Disallow: /template.html
Disallow: /readme.html
Disallow: *?replytocom
Allow: */uploads
Allow: *.js
Allow: *.css
Allow: *.png
Allow: *.gif
Allow: *.jpg
Sitemap: https://site.ru/sitemap.xmlВ примере вместо site вставляем домен своего сайта. Далее разберемся как оперировать командами. Все просто:
- Disallow запрещает роботам сканировать и выкачивать данные из указанных директорий.
- Allow разрешает проверять составляющие ресурса, в основном тут открывают только картинки и остальные медиафайлы.
- Sitemap путь до карты в формате xml, чтобы роботу не искать самому, тут указывается ее точный адрес.
Набора данных стандартных команд хватит для 99% задач в WordPress. Например, есть папка с файлами, которые не должны попасть в индекс, просто проставляете с помощью относительного адреса путь до нее с командой disallow. Далее можете составить свои команды, но будьте осторожны не закройте доступ к важной информации.
Существую устаревшие директивы: Host – указывает на главное зеркало, сейчас это определяется автоматически по редиректу, Crawl-delay и Clean-param – показывает сколько времени можно находится роботу на странице и разрешение на выкачку дубликатов. Их не нужно использовать, лучший исход ничего не произойдет, худший возможны проблемы с другими ПС отличными от Яндекса и Google.
Где лежит robots txt
Независимо от CMS, разработки и вида, robots txt должен лежать в корне сайта, то есть в папке откуда загружается главная. В WordPress это папка, где находятся каталоги wp-admin, wp-content и wp-includes.
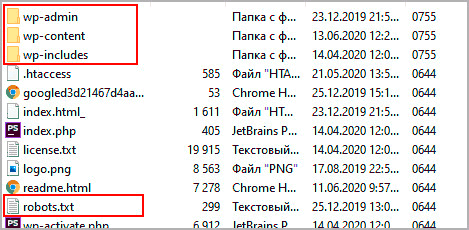
Часто бывает, что пользователи не могут найти, почти в 100 процентах случаев это виртуальные файлы. То есть при запросе url в адресной строке браузера он создается автоматически, скорее всего в каком-то плагине, физически на хостинге его не увидеть.
Как создать robots
Чтобы создать robots советую применять простой блокнот. Для начала создадим новый документ.
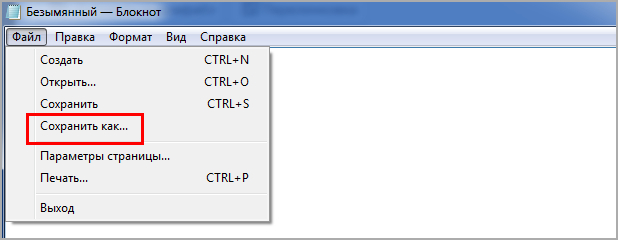
Далее помещаем содержимое, можете скопировать из поля выше, каждое правило с новой строчки, это важно, возможно при копировании все будет в одну строку.
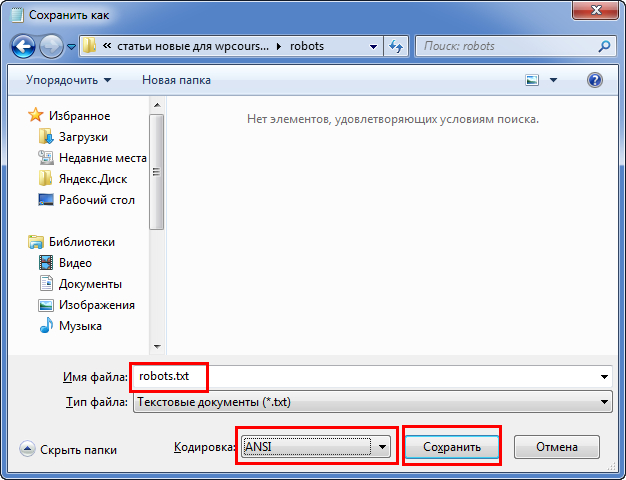
Чтобы установить tuj на сервере, придется создать FTP соединение. Скриншот был выше, показывал где он должен располагаться.
Проверка работы в валидаторе Yandex
Если сайт зарегистрирован в сервисе для вебмастеров от Яндекса, то доступен инструмент проверки работы. В панели переходим Инструменты – Анализ robots txt. Вводим страницы для проверки, в первые две я ввел каталоги, которые начинаются с wp- (напомню, они запрещены к индексации), а другие две это просто статьи.
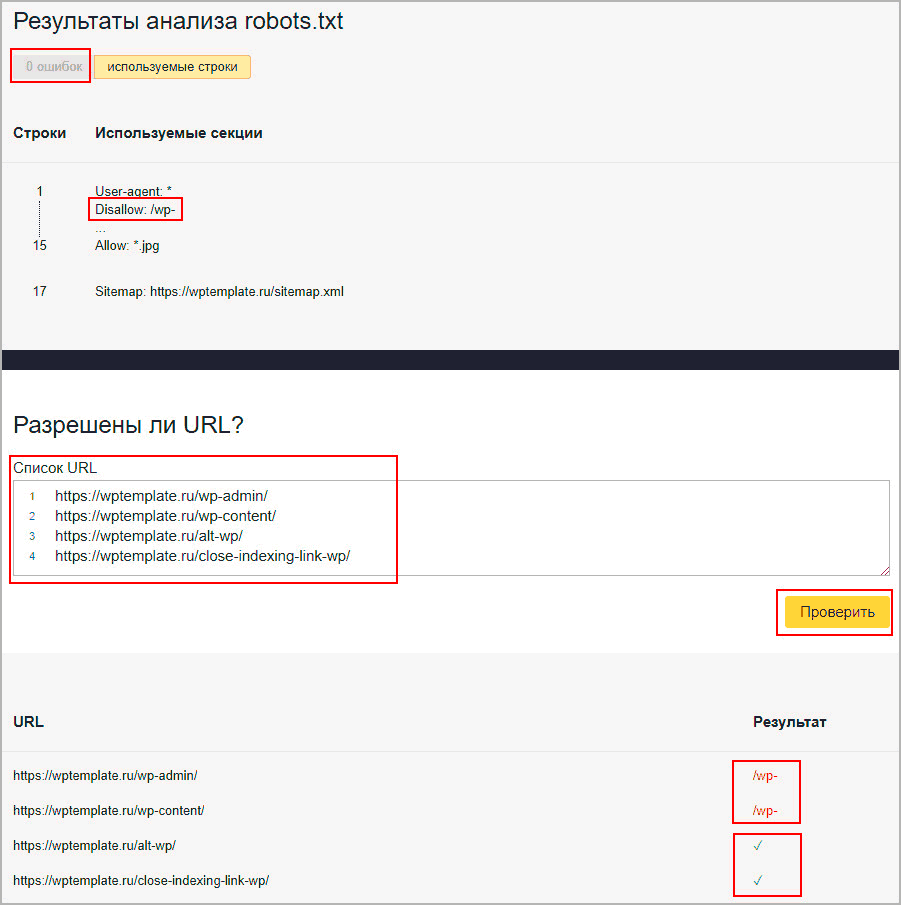
- Смотрим, чтобы ошибок не было.
- Вспоминаем что у нас есть
Disallow: /wp-. - Вводим url для проверки.
- Видим, что первые две запрещены к сканированию, потому что начинаются с wp-.
- Вторые две разрешены и стоят зеленые галочки.
Создать и отредактировать robots в плагине Yoast
В Yoast есть отличный инструмент формирующий robots txt, причем он создает файл физически, роботс появится на вашем хостинге, если бы вы его создавали самостоятельно. Причем после деактивации Yoast файл не стирается с хостинга, это крутое дополнение, потому что остальные плагины SEO в WordPress, делают виртуальные копии.
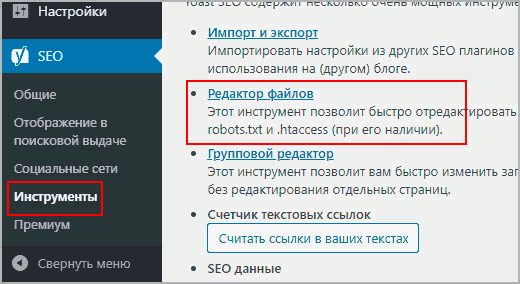
На следующей странице в вордпресс будет предложение создать robots, если нет, или отредактировать при его наличии. Копируйте код представленный выше. Так вам не придется скачивать и разбираться с удаленным соединением, а просто изменить из админки.
Не советую применять функции создания в плагине All in SEO Pack (AIOSP), других дополнениях и онлайн сервисами, потому что интерфейс формирования, очень не удобный, и создается именно виртуальный элемент, то есть после деактивации роботс пропадет.
Clearfy PRO – автоматический и правильный robots
В одной из настроек Clearfy является создание robots txt, причем он абсолютно идентичен, представленному в статье, с возможностью изменить команды.
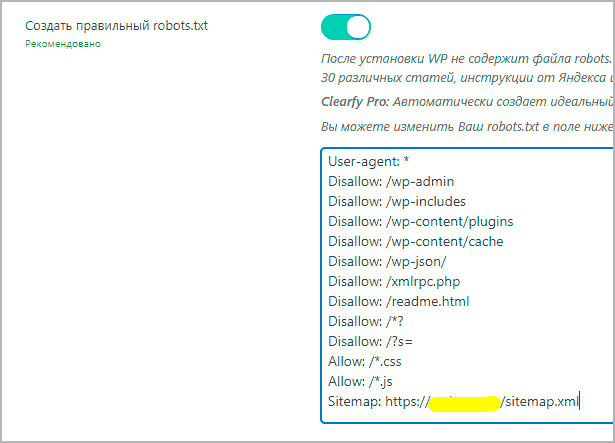
Отмечу что создание правильного роботс, это только одна из 50 разнообразных фишек, по улучшению WordPress, например, расстановка ALT у изображений.
Идеальный robots для WooCommerce в WordPress
Если используете плагин интернет магазина WooCommerce, то советую внести несколько дополнительных строк в robots txt, чтобы адреса оформления заказов, корзины и остальные технические документы не попадали в индекс поисковых систем, и тогда получим идеальную инструкцию для поведения роботов в магазине под управлением WordPress.
Disallow: /cart/
Disallow: /checkout/
Disallow: /*add-to-cart=*
Disallow: /my-account/На этом закончим урок, мы разобрались где хранится, как добавить и читать, что написано в robots txt для движка WordPress.
Чтобы помочь поисковым системам правильно индексировать ваш блог, нужно сделать правильный файл Robots txt для WordPress. Посмотрим как его создать и чем наполнить.
Он нужен для поисковых систем, для правильной индексации ими веб-ресурса. Содержимое файла «говорит» поисковому роботу, какие страницы нужно показывать в поиске, а какие скрыть. Это позволяет управлять контентом в поисковой выдаче.
Например, при запросе в Гугле “купить холодильник” конечному покупателю незачем попадать на страницу администрирования магазина. Ему важно перейти сразу в раздел “Холодильники”.
Наполнять robots.txt нужно уже на этапе разработки сайта. Его изменения вступают в силу не сразу. Может пройти неделя или несколько месяцев.
Где находится Robots?
Этот обычный тестовый файл лежит в корневом каталоге сайта. Его можно получить по адресу
https://site.ru/robots.txt
Движок изначально Роботс не создает. Это нужно делать вручную или пользоваться инструментами, которые создают его автоматически.
Не могу найти этот файл
Если по указанному адресу содержимое файл отображается, но на сервере его нет, то значит он создан виртуально. Поисковику все равно. Главное, чтобы он был доступен.
Из чего состоит
Из 4 основных директив:
- User-agent — правила поисковым роботам.
- Disalow — запрещает доступ.
- Allow — разрешает.
- Sitemap — полный URL-адрес карты XML.
Правильный robots.txt для ВордПресс
Вариантов много. Инструкции на каждом сайте отличаются.
Вот пример корректного robots.txt, в котором учтены все разделы сайта. Коротко разберем директивы.
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-content/cache
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /xmlrpc.php
Disallow: /license.txt
Disallow: /readme.html
Disallow: /trackback/
Disallow: /comments/feed/
Disallow: /*?replytocom
Disallow: */feed
Disallow: */rss
Disallow: /author/
Disallow: /?
Disallow: /*?
Disallow: /?s=
Disallow: *&s=
Disallow: /search
Disallow: *?attachment_id=
Allow: /*.css
Allow: /*.js
Allow: /wp-content/uploads/
Allow: /wp-content/themes/
Allow: /wp-content/plugins/
Sitemap: https://site.ru/sitemap_index.xml
В первой строке указывается, что ресурс доступен для всех поисковых роботов (краулеров).
Allow разрешают добавлять в индекс скрипты, стили, файлы загрузок, тем и плагинов.
Последняя — это адрес XML-карты.
Как создать robots.txt для сайта
Рассмотрим несколько методов: вручную и с помощью WordPress-плагинов.
Вручную
Это можно сделать например, в Блокноте (если локальный сервер) или через FTP-клиент (на хостинге).
Вручную добавить robots.txt на сайт проще всего по FTP. Для этого необходимо создать сам файл в текстовом формате. Затем, воспользовавшись одним из FTP-клиентов (например, FileZilla), загрузить robots.txt в корневую папку сайта (рядом с файлами wp-config.php, wp-settings.php).
После успешной загрузки robots.txt, перейдите по адресу https://ваш_сайт.ru/robots.txt, чтобы посмотреть актуальное состояние файла.
С помощью плагинов
Для облегчения создания robots.txt в WordPress существуют специальные плагины. Некоторые из них: WordPress Robots.txt File, DL Robots.txt, Yoast SEO, All in One SEO Pack.
Clearfy Pro
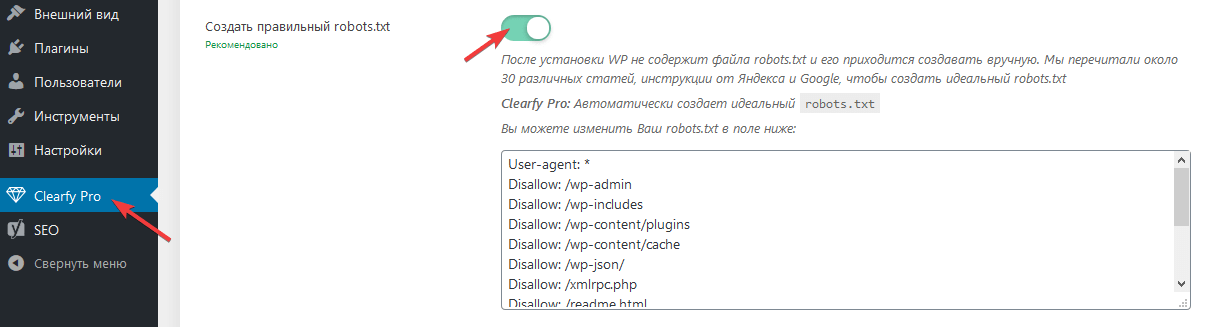
Clearfy Pro создает виртуальный файл. Для этого:
- Перейдите в админ-меню Clearfy Pro.
- На вкладке SEO задействуйте опцию Создать правильный robots.txt.
- Он создастся автоматически. При желании отредактируйте в поле здесь же.
- Сохраните изменения.
Всегда можно отредактировать содержимое Robots. Просто измените/дополните его нужным содержимым и сохраните изменения.
Активировать промокод на 15%
Yoast SEO
Рассмотрим создание файла robots.txt на примере одного из самых мощных SEO-плагинов Yoast SEO.
Этот мощный СЕО-модуль для WP также решит задачу.
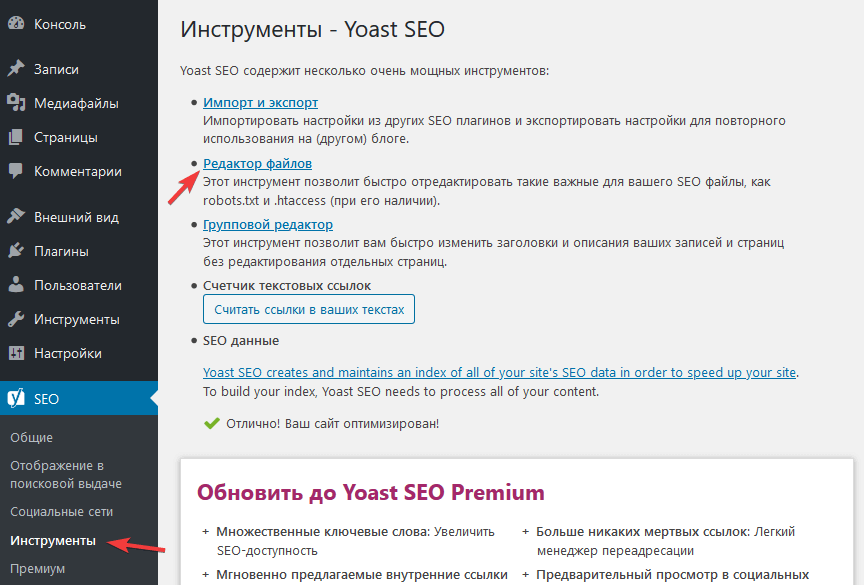
- Перейдите SEO > Инструменты.
- Нажмите Редактор файлов.

- Если в корневом каталоге этого файла нет, кликните Создать файл robots.txt. В редакторе вставьте вышеописанный код и нажмите Сохранить изменения в robots.txt.

Если есть, то откроется редактор для внесения изменений.
- Нажмите Сохранить изменения в robots.txt.


All in One SEO Pack
Это решение тоже «умеет» работать с Robots. Для этого:
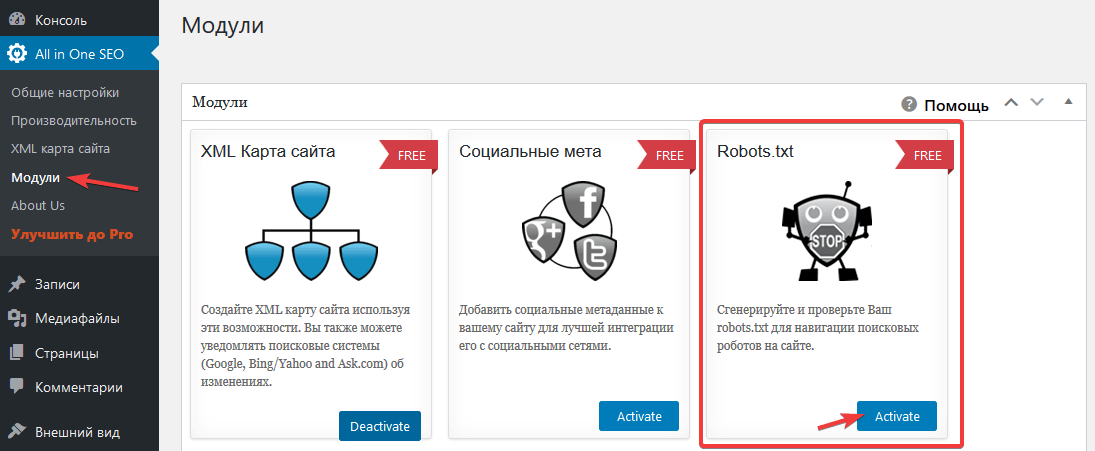
- Откройте All in One SEO > Модули.
- Выберите одноименное название модуля и нажмите Activate.

- Перейдите All in One SEO > Robots.txt.
- В полях добавьте директивы.


Настройка для интернет-магазинов (WooCommerce)
Для WordPress-ресурсов с использованием этого расширения просто добавьте эти правила:
Disallow: /cart/
Disallow: /checkout/
Disallow: /*add-to-cart=*
Disallow: /my-account/Нажмите, пожалуйста, на одну из кнопок, чтобы узнать понравилась статья или нет.
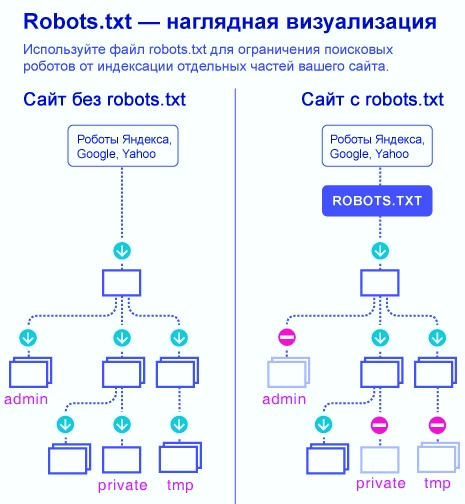
Файл robots.txt необходим роботам поисковых систем, чтобы они могли понять, какие страницы и разделы сайта следует посещать и включать в индекс, а какие – не нужно. Запрещенные для посещения поисковыми ботами страницы не будут индексироваться и появляться в выдаче Яндекса, Google и прочих поисковиков.
Вот наглядный пример того, в чем разница между веб-ресурсом, у которого настроен файл robots, и сайтом без него:
В данной статье я расскажу о нескольких способах правильной настройки robots.txt для популярного движка WordPress.
Оптимальный код файла для WordPress
User-agent: *
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /? # все параметры запроса с ?
Disallow: /*? # поиск
Disallow: /& # поиск
Disallow: /*& # поиск
Disallow: /author/ # архив автора
Disallow: /embed # все встраивания
Disallow: /page/ # все виды пагинации
Disallow: /trackback # уведомление о ссылках-трекбэках
Allow: /uploads # открываем uploads
Allow: /*.js # внутри /wp- (/*/ - для приоритета)
Allow: /*.css # внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.svg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.pdf # файлы в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php
Sitemap: https://domain.ru/sitemap.xmlСкачать .zip
Важно! Не забудьте поменять “https://domain.ru/sitemap.xml” на свой пусть к файлу sitemap.
Теперь разберем, какие директивы в коде что означают:
1. Директива User-agent: * означает, что все правила, описанные ниже нее, касаются всех роботов поисковых систем. Если вы хотите прописать правила для одного определенного бота, вместо * нужно ввести его имя. Например:
- User-agent: Googlebot – для главного робота Гугла.
- User-agent: Yandex – для главного бота Яндекса.
Подробнее о директиве User-agent
2. Строка Allow: /uploads указывается, чтобы разрешить ботам вносить в индекс страницы, где присутствует /uploads. Нужно обязательно указать данное правило, потому что выше запрещены к индексированию страницы, которые начинаются с /wp-, а проблема в том, что /uploads присутствует в /wp-content/uploads.
Команда Allow: /uploads нужна для перебивания правила Disallow: /wp-, так как по ссылкам типа /wp-content/uploads/ могут располагаться изображения, важные для индексации. Помимо картинок есть вероятность присутствия прочих файлов, которые нет нужды запрещать включать в поиск. Строчку Allow допускается прописывать и до, и после Disallow.
Подробнее о директиве Allow
3. Директивы Disallow:
запрещают ботам переходить по ссылкам, начинающимся с:
- Disallow: /trackback — закрывает уведомления
- Disallow: /s или Disallow: /*? — закрывает страницы поиска
- Disallow: /page/ — закрывает все виды пагинации
Подробнее о директиве Dissalow
4. Строчка Sitemap: http://domain.ru/sitemap.xml сообщает поисковому боту о XML файле с картой сайта. Если на вашем ресурсе присутствует данный файл, укажите к нему полный путь. Если их несколько, нужно прописать путь отдельно к каждому из них.
Рекомендуется не закрывать от индексации фиды: Disallow: /feed.
Это связано с тем, что доступ к фидам нужен, к примеру, для подключения сайта к каналу Яндекс Дзен, Турбо страниц. Могут быть еще некоторые случаи, где нужны открытые фиды. Через feed передается контент в формате .rss. Если вы не знаете что это такое, то читайте более подробную статью — что такое RSS.
У фидов собственный формат в заголовках ответа, что позволяет поисковым системам понять, что это фид, а не HTML документ, и обрабатывать его по-другому.
А если вы не хотите передавать RSS, чтобы например у вас не воровали через него контент, то тогда надежнее отключить его с помощью специальных плагинов, например Disable Feeds.
Сортировка правил перед обработкой
Google и Яндекс обрабатывают правила Disallow и Allow без соблюдения порядка, в котором они прописаны в robots.txt. Поисковики сортируют директивы от коротких к длинным, после чего обрабатывают последнюю подходящую директиву.
Например, данная инструкция:
User-agent: *
Allow: /uploads
Disallow: /wp-Поисковые системы обработают следующим образом:
User-agent: *
Disallow: /wp-
Allow: /uploadsВ случае проверки ссылки типа /wp-content/uploads/file.jpg, директива Disallow сначала
запретит ссылку с /wp-,
а затем Allow разрешит ее индексировать, поэтому ссылка будет доступна для
роботов.
На заметку.
Запомните главное при сортировке правил: чем директива в файле robots.txt длиннее, тем
она приоритетнее. Когда директивы одинаковой длины, приоритетной становится Allow.
Стандартный файл robots для WordPress
Хотя первый метод является более современным и логичным, но я все же пользуюсь вторым файлом robots.txt. Потому что мне так спокойнее, что с помощью директивы Dissalow: /wp- я не запрещу что то нужное, поэтому я прописываю каждую папку отдельно.
Исходя из вышеперечисленных правок, у меня получается вот такой robots.txt:
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-json/
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /embed
Disallow: /trackback
Disallow: /page/
Disallow: /search
Disallow: /&
Disallow: /?
Disallow: /*?
Allow: /wp-admin/admin-ajax.php
Sitemap: http://domain.ru/sitemap.xmlСкачать .zip
Важно! Не забудьте поменять “https://domain.ru/sitemap.xml” на свой пусть к файлу sitemap.
Доработка файла под свои цели
Если потребуется заблокировать еще какие-то страницы или разделы веб-ресурса, добавьте директиву Disallow. К примеру, желая скрыть от роботов все публикации в рубрике News, пропишите правило:
Disallow: /newsТак вы запретите ботам переходить по ссылкам типа http://domain.ru/news и закроете от индексации такие страницы:
- http://domain.ru/news;
- http://domain.ru/my/news/nazvanie/;
- http://domain.ru/category/newsletter-nazvanie.html.
Постоянно проверяйте, какие страницы проиндексированы поисковыми системами и находятся в выдаче. Сделать это можно с помощью оператора site:domain.ru.
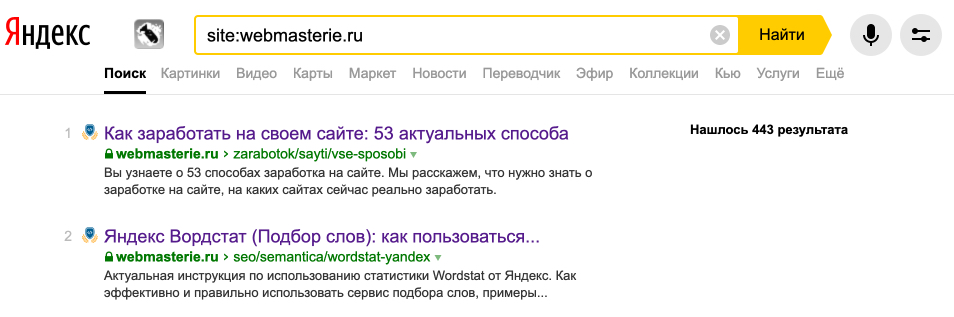
И если заметили мусорные, ненужные страницы, то блокируйте их в robots.txt.
Проверка файла и документация
Проверить корректность директив, прописанных в robots.txt, вы можете по ссылкам:
- Google Search Console https://www.google.com/webmasters/tools/dashboard?pli=1. Необходимо зарегистрировать сайт в панели вебмастера, если вы этого еще не сделали.
- Яндекс: http://webmaster.yandex.ru/robots.xml.
- Сервис для создания и проверки файла robots: https://seolib.ru/tools/generate/robots/.
- Сервис для создания robots.txt: http://pr-cy.ru/robots/.
- Документация Яндекса: https://yandex.ru/support/webmaster/controlling-robot/robots-txt.html.
- Документация Google: https://developers.google.com/search/reference/robots_txt.
Подробнее о проверке файла robots.txt
Динамический robots.txt
В CMS Вордпресс обработка запроса на файл robots производится
отдельно. Вебмастеру нет нужды самостоятельно создавать в корневом каталоге
сайта файл robots. Это
не то что можно не делать, но и нужно, иначе плагины не смогут изменять
созданный вебмастером файл, когда в этом появится необходимость.
Для изменения содержания динамического robots налету,
через хук do_robotstxt, добавьте данный код
в файл funtcions.php:
add_action( 'do_robotstxt', 'my_robotstxt' );
function my_robotstxt(){
$lines = [
'User-agent: *',
'Disallow: /wp-admin/',
'Disallow: /wp-includes/',
'',
];
echo implode( "rn", $lines );
die; // обрываем работу PHP
}При переходе по ссылке http://example.com/robots.txt вы
увидите следующий код:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/Заключение
Обязательно следите за актуальностью своего robots.txt. Проверяйте страницы на индексацию, чтобы там не было мусорных, не нужных страниц. Если такие заметили, то блокируйте их. При внесении изменений в файл robots.txt для уже рабочего веб-сайта результат будет видно не раньше, чем через 2-3 месяца.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Если вы посетили эту страницу тогда вас интересует где находится файл robots.txt в WordPress. С данной проблемой обычно сталкиваются чайники в WordPress. После прочтения короткой статьи вы выясните все что вам нужно знать.
По большому счету я могу написать просто “Файл расположен в корневой директории сайта”. Увы этот ответ удовлетворит лишь часть посетителей, не все знают о “корнях” и тому подобном. По этому давайте все разберем, как в первый раз.
Как проверить существует ли файл robots.txt
Сперва проверим есть ли нужный файл вообще, для этого вписываем в строке браузера адрес-сайта.ru/robots.txt, если документ откроется, и вы увидите текст на английском, примерно такого рода:

Значит все в порядке, файл существует, в противном случае, скорее всего, отсутствует, или находиться не там где нужно, его потребуется создать.
Давайте для начала определимся как вам удобно работать с файлами сайта. Для этого существует несколько способов. Первый не очень удобный, но зато более привычен для любителей Windows — это программа на вашем хостинге, с помощью которой вы создаете и удаляете файлы и папки своего сайта. Выглядеть это все дело должно примерно так:

В папке WWW/ВАШ-САЙТ должны быть папки wp-includes, wp-content, wp-admin ниже них расположен нужный вам файл роботс. Один способ разобрали, можно идти к следующему.
Если вы умеете пользоваться FTP, тогда заходим в соответствующую программу на вашем компьютере и переходим на ваш сайт, проходим тот же путь по папкам что в примере выше и находим необходимый документ.
Файл robots.txt в WordPress должен лежать именно в той же папке, что и wp-includes, wp-content, wp-admin. Не ищите его в других местах, его либо там нет либо он там валяется без толку, роботы его не найдут.
Создать правильное руководство для поисковых систем поможет эта статья.