From Wikipedia, the free encyclopedia
In statistics, the explained sum of squares (ESS), alternatively known as the model sum of squares or sum of squares due to regression (SSR – not to be confused with the residual sum of squares (RSS) or sum of squares of errors), is a quantity used in describing how well a model, often a regression model, represents the data being modelled. In particular, the explained sum of squares measures how much variation there is in the modelled values and this is compared to the total sum of squares (TSS), which measures how much variation there is in the observed data, and to the residual sum of squares, which measures the variation in the error between the observed data and modelled values.
Definition[edit]
The explained sum of squares (ESS) is the sum of the squares of the deviations of the predicted values from the mean value of a response variable, in a standard regression model — for example, yi = a + b1x1i + b2x2i + … + εi, where yi is the i th observation of the response variable, xji is the i th observation of the j th explanatory variable, a and bj are coefficients, i indexes the observations from 1 to n, and εi is the i th value of the error term. In general, the greater the ESS, the better the estimated model performs.
If  and
and  are the estimated coefficients, then
are the estimated coefficients, then

is the i th predicted value of the response variable. The ESS is then:

- where the value estimated by the regression line .[1]


In some cases (see below): total sum of squares (TSS) = explained sum of squares (ESS) + residual sum of squares (RSS).
Partitioning in simple linear regression[edit]
The following equality, stating that the total sum of squares (TSS) equals the residual sum of squares (=SSE : the sum of squared errors of prediction) plus the explained sum of squares (SSR :the sum of squares due to regression or explained sum of squares), is generally true in simple linear regression:

Simple derivation[edit]

Square both sides and sum over all i:

Here is how the last term above is zero from simple linear regression[2]



So,


Therefore,
![{displaystyle {begin{aligned}&sum _{i=1}^{n}2({hat {y}}_{i}-{bar {y}})(y_{i}-{hat {y}}_{i})=2{hat {b}}sum _{i=1}^{n}(x_{i}-{bar {x}})(y_{i}-{hat {y}}_{i})\[4pt]={}&2{hat {b}}sum _{i=1}^{n}(x_{i}-{bar {x}})((y_{i}-{bar {y}})-{hat {b}}(x_{i}-{bar {x}}))\[4pt]={}&2{hat {b}}left(sum _{i=1}^{n}(x_{i}-{bar {x}})(y_{i}-{bar {y}})-sum _{i=1}^{n}(x_{i}-{bar {x}})^{2}{frac {sum _{j=1}^{n}(x_{j}-{bar {x}})(y_{j}-{bar {y}})}{sum _{j=1}^{n}(x_{j}-{bar {x}})^{2}}}right)\[4pt]={}&2{hat {b}}(0)=0end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0df16697d14368c46e7270b6e4e5ee0d1b819d29)
Partitioning in the general ordinary least squares model[edit]
The general regression model with n observations and k explanators, the first of which is a constant unit vector whose coefficient is the regression intercept, is

where y is an n × 1 vector of dependent variable observations, each column of the n × k matrix X is a vector of observations on one of the k explanators,  is a k × 1 vector of true coefficients, and e is an n × 1 vector of the true underlying errors. The ordinary least squares estimator for is
is a k × 1 vector of true coefficients, and e is an n × 1 vector of the true underlying errors. The ordinary least squares estimator for is

The residual vector  is
is  , so the residual sum of squares
, so the residual sum of squares  is, after simplification,
is, after simplification,

Denote as  the constant vector all of whose elements are the sample mean
the constant vector all of whose elements are the sample mean  of the dependent variable values in the vector y. Then the total sum of squares is
of the dependent variable values in the vector y. Then the total sum of squares is

The explained sum of squares, defined as the sum of squared deviations of the predicted values from the observed mean of y, is

Using  in this, and simplifying to obtain
in this, and simplifying to obtain  , gives the result that TSS = ESS + RSS if and only if
, gives the result that TSS = ESS + RSS if and only if  . The left side of this is times the sum of the elements of y, and the right side is times the sum of the elements of
. The left side of this is times the sum of the elements of y, and the right side is times the sum of the elements of  , so the condition is that the sum of the elements of y equals the sum of the elements of , or equivalently that the sum of the prediction errors (residuals)
, so the condition is that the sum of the elements of y equals the sum of the elements of , or equivalently that the sum of the prediction errors (residuals)  is zero. This can be seen to be true by noting the well-known OLS property that the k × 1 vector
is zero. This can be seen to be true by noting the well-known OLS property that the k × 1 vector ![X^{T}{hat e}=X^{T}[I-X(X^{T}X)^{{-1}}X^{T}]y=0](https://wikimedia.org/api/rest_v1/media/math/render/svg/48b919724d6469ec94125e22146b93be8608cd05) : since the first column of X is a vector of ones, the first element of this vector
: since the first column of X is a vector of ones, the first element of this vector  is the sum of the residuals and is equal to zero. This proves that the condition holds for the result that TSS = ESS + RSS.
is the sum of the residuals and is equal to zero. This proves that the condition holds for the result that TSS = ESS + RSS.
In linear algebra terms, we have  ,
,  ,
,  .
.
The proof can be simplified by noting that  . The proof is as follows:
. The proof is as follows:

Thus,

which again gives the result that TSS = ESS + RSS, since  .
.
See also[edit]
- Sum of squares (statistics)
- Lack-of-fit sum of squares
- Fraction of variance unexplained
Notes[edit]
- ^ «Sum of Squares — Definition, Formulas, Regression Analysis». Corporate Finance Institute. Retrieved 2020-06-11.
- ^ Mendenhall, William (2009). Introduction to Probability and Statistics (13th ed.). Belmont, CA: Brooks/Cole. p. 507. ISBN 9780495389538.
References[edit]
- S. E. Maxwell and H. D. Delaney (1990), «Designing experiments and analyzing data: A model comparison perspective». Wadsworth. pp. 289–290.
- G. A. Milliken and D. E. Johnson (1984), «Analysis of messy data», Vol. I: Designed experiments. Van Nostrand Reinhold. pp. 146–151.
- B. G. Tabachnick and L. S. Fidell (2007), «Experimental design using ANOVA». Duxbury. p. 220.
- B. G. Tabachnick and L. S. Fidell (2007), «Using multivariate statistics», 5th ed. Pearson Education. pp. 217–218.
What Is the Residual Sum of Squares (RSS)?
The residual sum of squares (RSS) is a statistical technique used to measure the amount of variance in a data set that is not explained by a regression model itself. Instead, it estimates the variance in the residuals, or error term.
Linear regression is a measurement that helps determine the strength of the relationship between a dependent variable and one or more other factors, known as independent or explanatory variables.
Key Takeaways
- The residual sum of squares (RSS) measures the level of variance in the error term, or residuals, of a regression model.
- The smaller the residual sum of squares, the better your model fits your data; the greater the residual sum of squares, the poorer your model fits your data.
- A value of zero means your model is a perfect fit.
- Statistical models are used by investors and portfolio managers to track an investment’s price and use that data to predict future movements.
- The RSS is used by financial analysts in order to estimate the validity of their econometric models.
Understanding the Residual Sum of Squares
In general terms, the sum of squares is a statistical technique used in regression analysis to determine the dispersion of data points. In a regression analysis, the goal is to determine how well a data series can be fitted to a function that might help to explain how the data series was generated. The sum of squares is used as a mathematical way to find the function that best fits (varies least) from the data.
The RSS measures the amount of error remaining between the regression function and the data set after the model has been run. A smaller RSS figure represents a regression function that is well-fit to the data.
The RSS, also known as the sum of squared residuals, essentially determines how well a regression model explains or represents the data in the model.
How to Calculate the Residual Sum of Squares
RSS = ∑ni=1 (yi — f(xi))2
Where:
yi = the ith value of the variable to be predicted
f(xi) = predicted value of yi
n = upper limit of summation
Residual Sum of Squares (RSS) vs. Residual Standard Error (RSE)
The residual standard error (RSE) is another statistical term used to describe the difference in standard deviations of observed values versus predicted values as shown by points in a regression analysis. It is a goodness-of-fit measure that can be used to analyze how well a set of data points fit with the actual model.
RSE is computed by dividing the RSS by the number of observations in the sample less 2, and then taking the square root: RSE = [RSS/(n-2)]1/2
Special Considerations
Financial markets have increasingly become more quantitatively driven; as such, in search of an edge, many investors are using advanced statistical techniques to aid in their decisions. Big data, machine learning, and artificial intelligence applications further necessitate the use of statistical properties to guide contemporary investment strategies. The residual sum of squares—or RSS statistics—is one of many statistical properties enjoying a renaissance.
Statistical models are used by investors and portfolio managers to track an investment’s price and use that data to predict future movements. The study—called regression analysis—might involve analyzing the relationship in price movements between a commodity and the stocks of companies engaged in producing the commodity.
Finding the residual sum of squares (RSS) by hand can be difficult and time-consuming. Because it involves a lot of subtracting, squaring, and summing, the calculations can be prone to errors. For this reason, you may decide to use software, such as Excel, to do the calculations.
Any model might have variances between the predicted values and actual results. Although the variances might be explained by the regression analysis, the RSS represents the variances or errors that are not explained.
Since a sufficiently complex regression function can be made to closely fit virtually any data set, further study is necessary to determine whether the regression function is, in fact, useful in explaining the variance of the dataset.
Typically, however, a smaller or lower value for the RSS is ideal in any model since it means there’s less variation in the data set. In other words, the lower the sum of squared residuals, the better the regression model is at explaining the data.
Example of the Residual Sum of Squares
For a simple (but lengthy) demonstration of the RSS calculation, consider the well-known correlation between a country’s consumer spending and its GDP. The following chart reflects the published values of consumer spending and Gross Domestic Product for the 27 states of the European Union, as of 2020.
| Consumer Spending vs. GDP for EU Member States | ||
|---|---|---|
| Country | Consumer Spending (Millions) |
GDP (Millions) |
| Austria | 309,018.88 | 433,258.47 |
| Belgium | 388,436.00 | 521,861.29 |
| Bulgaria | 54,647.31 | 69,889.35 |
| Croatia | 47,392.86 | 57,203.78 |
| Cyprus | 20,592.74 | 24,612.65 |
| Czech Republic | 164,933.47 | 245,349.49 |
| Denmark | 251,478.47 | 356,084.87 |
| Estonia | 21,776.00 | 30,650.29 |
| Finland | 203,731.24 | 269,751.31 |
| France | 2,057,126.03 | 2,630,317.73 |
| Germany | 2,812,718.45 | 3,846,413.93 |
| Greece | 174,893.21 | 188,835.20 |
| Hungary | 110,323.35 | 155,808.44 |
| Ireland | 160,561.07 | 425,888.95 |
| Italy | 1,486,910.44 | 1,888,709.44 |
| Latvia | 25,776.74 | 33,707.32 |
| Lithuania | 43,679.20 | 56,546.96 |
| Luxembourg | 35,953.29 | 73,353.13 |
| Malta | 9,808.76 | 14,647.38 |
| Netherlands | 620,050.30 | 913,865.40 |
| Poland | 453,186.14 | 596,624.36 |
| Portugal | 190,509.98 | 228,539.25 |
| Romania | 198,867.77 | 248,715.55 |
| Slovak Republic | 83,845.27 | 105,172.56 |
| Slovenia | 37,929.24 | 53,589.61 |
| Spain | 997,452.45 | 1,281,484.64 |
| Sweden | 382,240.92 | 541,220.06 |
Consumer spending and GDP have a strong positive correlation, and it is possible to predict a country’s GDP based on consumer spending (CS). Using the formula for a best fit line, this relationship can be approximated as:
GDP = 1.3232 x CS + 10447
The units for both GDP and Consumer Spending are in millions of U.S. dollars.
This formula is highly accurate for most purposes, but it is not perfect, due to the individual variations in each country’s economy. The following chart compares the projected GDP of each country, based on the formula above, and the actual GDP as recorded by the World Bank.
| Projected and Actual GDP Figures for EU Member States, and Residual Squares | ||||
|---|---|---|---|---|
| Country | Consumer Spending Most Recent Value (Millions) | GDP Most Recent Value (Millions) | Projected GDP (Based on Trendline) | Residual Square (Projected — Real)^2 |
| Austria | 309,018.88 | 433,258.47 | 419,340.782016 | 193,702,038.819978 |
| Belgium | 388,436.00 | 521,861.29 | 524,425.52 | 6,575,250.87631504 |
| Bulgaria | 54,647.31 | 69,889.35 | 82,756.320592 | 165,558,932.215393 |
| Croatia | 47,392.86 | 57,203.78 | 73,157.232352 | 254,512,641.947534 |
| Cyprus | 20,592.74 | 24,612.65 | 37,695.313568 | 171,156,086.033474 |
| Czech Republic | 164,933.47 | 245,349.49 | 228,686.967504 | 277,639,655.929706 |
| Denmark | 251,478.47 | 356,084.87 | 343,203.311504 | 165,934,549.28587 |
| Estonia | 21,776.00 | 30,650.29 | 39,261.00 | 74,144,381.8126542 |
| Finland | 203,731.24 | 269,751.31 | 280,024.176768 | 105,531,791.633079 |
| France | 2,057,126.03 | 2,630,317.73 | 2,732,436.162896 | 10,428,174,337.1349 |
| Germany | 2,812,718.45 | 3,846,413.93 | 3,732,236.05304 | 13,036,587,587.0929 |
| Greece | 174,893.21 | 188,835.20 | 241,865.695472 | 2,812,233,450.00581 |
| Hungary | 110,323.35 | 155,808.44 | 156,426.85672 | 382,439.239575558 |
| Ireland | 160,561.07 | 425,888.95 | 222,901.407824 | 41,203,942,278.6534 |
| Italy | 1,486,910.44 | 1,888,709.44 | 1,977,926.894208 | 7,959,754,135.35658 |
| Latvia | 25,776.74 | 33,707.32 | 44,554.782368 | 117,667,439.825176 |
| Lithuania | 43,679.20 | 56,546.96 | 68,243.32 | 136,804,777.364243 |
| Luxembourg | 35,953.29 | 73,353.13 | 58,020.393328 | 235,092,813.852894 |
| Malta | 9,808.76 | 14,647.38 | 23,425.951232 | 77,063,312.875298 |
| Netherlands | 620,050.30 | 913,865.40 | 830,897.56 | 6,883,662,978.71 |
| Poland | 453,186.14 | 596,624.36 | 610,102.900448 | 181,671,052.608372 |
| Portugal | 190,509.98 | 228,539.25 | 262,529.805536 | 1,155,357,865.6459 |
| Romania | 198,867.77 | 248,715.55 | 273,588.833264 | 618,680,220.331183 |
| Slovak Republic | 83,845.27 | 105,172.56 | 121,391.061264 | 263,039,783.25037 |
| Slovenia | 37,929.24 | 53,589.61 | 60,634.970368 | 49,637,102.7149851 |
| Spain | 997,452.45 | 1,281,484.64 | 1,330,276.08184 | 2,380,604,796.8261 |
| Sweden | 382,240.92 | 541,220.06 | 516,228.185344 | 624,593,798.821215 |
The column on the right indicates the residual squares–the squared difference between each projected value and its actual value. The numbers appear large, but their sum is actually lower than the RSS for any other possible trendline. If a different line had a lower RSS for these data points, that line would be the best fit line.
Is the Residual Sum of Squares the Same as R-Squared?
The residual sum of squares (RSS) is the absolute amount of explained variation, whereas R-squared is the absolute amount of variation as a proportion of total variation.
Is RSS the Same as the Sum of Squared Estimate of Errors (SSE)?
The residual sum of squares (RSS) is also known as the sum of squared estimate of errors (SSE).
What Is the Difference Between the Residual Sum of Squares and Total Sum of Squares?
The total sum of squares (TSS) measures how much variation there is in the observed data, while the residual sum of squares measures the variation in the error between the observed data and modeled values. In statistics, the values for the residual sum of squares and the total sum of squares (TSS) are oftentimes compared to each other.
Can a Residual Sum of Squares Be Zero?
The residual sum of squares can be zero. The smaller the residual sum of squares, the better your model fits your data; the greater the residual sum of squares, the poorer your model fits your data. A value of zero means your model is a perfect fit.
++++++++++++++++++++++
Обратитесь к многим статьям
++++++++++++++++++++++
Во-первых: гипотеза
Бросать монету
- Гипотеза H0 [Гипотеза]: Монеты являются справедливыми [появляется в положительных и скоростях реакции]
- HA Гипотеза [Осмотр]: Монеты проблематичны
Весь процесс тестирования гипотезы заключается в том, чтобы проверить по гипотезам H0, и если вывод противоречивой получен, то предположения H0 будут отклонены.
Так называемое противоречие, результаты теста, вероятность, которая появляется в условиях гипотезы H0. 】
Р значение: в гипотезе первоначальной гипотезы (H0) правильно,Вероятность появления статуса или хуже.
1.1 H0 Предположения, мы знаем, что монеты бросают, а количество положительных, в соответствии с бинарным распределением.
А, мы бросаем 10 монет.
Результат появился 8 фронт.
B, запрашивать два таблица распределения,Одностороннее значение p【8,9,10】
p(8/9/10)=0.05
Как этот результат этого?
В H0 гипотезе [ярмарка монет], бросить 8 передних и более экстремальных случаевОдностороннее значение p0,05, если существует значительный уровень 0,05, то мы отказываемся изменить предположения H0 и думать, что монета проблематичная.
1.2 Так как фронт брошен 8 раз, почему также добавляют 9 спереди, 10 фронт, эти еще две экстремальные вероятности?
- Во-первых, определение значения p есть.
- Во-вторых, вообще распределенные, нездоровые к единственной вероятности, вероятность поиска области очень проста, то есть область.

1.3 Значительный уровень 0,05
Фактически, значительный уровень — это субъективное определенное значение.
Например, мы определяем значительный уровень 0,01.
Затем вышеупомянутое тестовое значение p = 0,05, меньше, чем значительный уровень 0,01, то это означает, что мы не можем отклонить гипотезу H0, нужно больше тестов, а то как менее, чем этот уровень 0,01, мы можем отказаться от предположений H0.
Второй: T тест
2.1, две поля пшеницы, A и B, MirafaDian традиционный процесс, процесс улучшения полей Эмиана.
Известно, что выход выхода μ0 = 100, стандартное отклонение от пробы σ [стандартное отклонение неизвестно];
B Образец n, выхода выходов деформации образца X = 120, стандарт образца плохой S,Формула Xi — это единый выход растений [может рассматривать каждый отдельных штамма B], среднее значение X — это среднее значение A, поскольку в целом a, но потому, что мы предполагаем, что он является частью одного из одного общего Все отдельные растения единого растительного производства с одним заводом B.

2.2, гипотеза
- H0 Гипотеза [Гипотеза]: B не улучшается, Jiajia находится под распределением
- HA Гипотеза: в гипотезе H0, небесное значение x = 120, может ли образец стандартной дифы не может произойти?
Известно, что нормальное распределение, N (μ0, σ ^ 2) от μ0 = 100, стандартное отклонение σ.

2.3, происхождение значения T
T статистика формулы:

А, молекула = x — μ0, согласно главной карте Taizu, промежуток является стандартным отклонением σ, чтобы исключить влияние пролета, мы разделяем молекулы в стандартном отклонении, (x — μ0) / σ, Но потому что σ неизвестный, заменен B, Final (x — μ0) / s
【Из-за стандартной разницы σ a a, мы предполагаем, что часть из того же распределения, поэтому стандартная разница между B составляет приблизительно。】
****************************************************************************************************************************
Мы всеСредство двух образцов, стандартного отклонения и стандартного отклонения их соответствующих матерей.
****************************************************************************************************************************
b、Сплит S / √n означает: стандартная ошибка выводится образец.
Объяснение: Я с различными этимиками, если мы очень, тогда мы будем подчиняться, B. x = 120, подробное объяснение B улучшить производство.
Чтобы отразить влияние N количества образцов в формулу, мы позволяем Splitter S, которое делится на корневом номере N, тем самым уменьшая родительское значение, в конечном итоге увеличивая значение T, чтобы отразить эффект образца N.
2.4, T распределение
Мы находим значение T, так как вы знаете значение P, соответствующую значение T?
A, Функция плотности вероятности

B, карта распределения

Согласно Freedom V = N-1, таблица проверяется, чтобы найти соответствующее значение P, и если он может отказаться от первоначальной гипотезы H0 под соответствующим значительным уровнем.
В-третьих: наименьший квадрат
****************************************************************************************************************************
1, стандартное отклонение »[отражает флуктуацию точек данных]: указывает на индикатор варианта личности, отражающий степень дискретной к среднему образцу образца, является индикатором измерения точности данных.
2, Стандартная ошибка) [Светоотражающая волновая волна ситуации]: относится к испытанию отбора проб (или повторных и других прецизионных измерений)Стандартная разница в среднем образцаОтражает степень изменчивости образца среднего размера в среднем средне, отражая размер ошибки выборки, является индикатором измерения метрики.
Объяснение: в качестве количества образцов (или количество измерений) n увеличивается, стандартное отклонение имеет тенденцию к устойчивому значению, тем ближе стандарт образца, тем ближе к общему стандартному отклонению, а стандартная ошибка последовала за количеством образцов ( Или количество измерений) n увеличение постепенно уменьшается, тем больше средних средств образцов ближе к общей среднему среднему μ;
3, интервал доверия: даВерныйНекоторые из образцовИнтервальная оценка общих параметров,Настоящее значение этого параметра имеет определенную вероятность падения по результатам измерения.
4, Формула
А, стандартная формула отклонения:

B, стандартная ошибка формулы:
Ошибка настройки n измеренийE1、E2……EnЗатем стандартная ошибка σ этого набора измерений равна:

среди них,E = Xi − TГде: e- ошибка;Xi— Определите значение; T-Tright Value.
Из-за измеренногоПравда неизвестнаОшибки каждой оценки измерения не знают, поэтому его нельзя получить в формуле.
Арифметический средний может быть получен при измерении, он ближе всего к истинному значению (N), и это легко рассчитатьРазница между измерением и арифметическим средним, называется остаточным(Помните в V). Теоретический анализ показывает, что остаточный V используется для представления ограниченного времени (N раз) наблюденияРезультаты измеренийСтандартная ошибка σ, его формула расчета:

Для набора одинаковых точности измерений (N раз) измерения данных средних арифметических, его ошибка должна быть меньше. Теоретический анализ показывает, что его арифметическая средняя стандартная ошибка. В некоторых книгах или в калькуляторе используйте символы S):

c、Стандартная ошибка 1 /
D, доверительный интервал
95% доверительный интервал β1 = [β1-2SE(β1),β1+2SE(β1)】
****************************************************************************************************************************
Минимальный множитель: самая маленькая, подтвердила значение элементов коэффициентов и перехвата через RSS.
На практике мы можем получить порцию данных наблюдений, рассчитать параметры наименьших квадратов линии, но общая регрессия не наблюдается.
У нас есть группа наблюдения [y, x], есть n значений
Среди них, Y-переменные: Y1, Y2, Y3, ,,,,,,,,,,,, Ю.Н.
X-переменная соответствует x1, x2, x3 ,,,,,,,,,,,,,,,,
а, образец средней оценки общего среднего
Итак, как наш единственный набор Y переменной средней х0, насколько точна оценка генерал- Y истинного среднего ц? Насколько это далеко?
Общее уравнение регрессии: стандартное отклонение SE (μ0) = σ / √n
Вариация: var (μ0) = σ ^ 2 / n
Среди них: молекулярное σ,Общее наблюдениеYi значитСтандартное отклонение,Оценка ошибки остаточных стандартов RSEЗнаменатель — корневое значение номера образца N.
Стандартное отклонение SE (μ0) говорит нам о том, что выборочное среднее μ0 оценивается отклонение от общего среднего реального среднего мкм.
Стандартная формула отклонения, сообщите мне, что количество образцов n, тем меньше отклонение.
B. Исследуйте наименьшие квадраты β0, β1, с общем истинным β0, β1 подход
SE(β0)
SE(β1)
С. Оценка стандартного отклонения SE (х0) является остаточным стандартной ошибкой РГП / √N [имеется в виде модели является правильным, и β0, β1 реальным значением, но все же отклонение].
Общее наблюдение за стандартным отклонением Yi означаетДисперсия σ ^ 2,отRSSПо оценкам.
В-четвертых: линейная регрессия существительное
1, остаточная площадь и RSS (остаточная сумма квадратов) [Не называйте SSE (сумма квадратов для ошибки)
RSS = Σi=1n (yi — yi^)2

2, остаточная стандартная ошибка RSE (остаточная стандартная ошибка)
RSE = √(RSS/(n-2))
3, вернитесь на квадрат иSSR(Сумма квадратов для регрессии)SSM(Sum of Squares for Model)】
【ПрозвищеESS(explained sum of squares) 】
SSR = Σi=1n (yi^ — y)2
4, общая площадь и SST (сумма квадратов общего)
SST = Σi=1n (yi — y)2
5, в целом: общая площадь и = квадрат возврата и + остаточные квадраты
SST=SSR + RSS
доказывать:Доказательство Вики
Объяснение: Общая площадь и представление SST, общая разность данных, мы знаем, что общая разница, две части, можно интерпретировать + unplanable.
ССР регрессионный площадь и представление, данные могут быть интерпретированы [то есть, разница в уравнении регрессии может объяснить]
Остаточная фракция RSS и указывает на то, что разница не объяснена. [Уравнение регрессии не может объяснить]
6, Свобода [Количество р регрессионного фактора]
RSS остаточный квадрат и свобода DFR = N -P -1
SSR регрессионный квадрат и свобода DFM = P
Общая площадь и свобода DFT = N -1
dft = dfr + drm
============================================================================
В статистике, степень свободы относится к числу переменных, которые не ограничены при расчете определенной статистики. Обычно DF = N-K. Там, где п является содержанием образца, к этому число ограниченных условий или переменным, или числа других независимых статистических данных при вычислении статистики. По оценкам, общая дисперсия оценивается, разведенный квадрат и. До тех пор пока N-1 число расщепленных квадратов определяется, дисперсия определяется, так как значение числа N-1 известен после того, как среднее значение определяется, величина п-1 определяется. Здесь, средний эквивалентен условие рестрикции, и так как это условие ограничения добавляется, степень свободы от общей дисперсии является N-1.
============================================================================
7、Остаточная сумма квадратов [незапланированная дисперсия]
MSR(Mean of Squares for residual) = RSS / DFR
Возвращение с площади и означающее [Развращение объяснения]
MSM( Mean of Squares for Model) = SSR /DFM
Пятый: линейная регрессия и анализ отклонений
1. Анализ переменных в дисперсионном анализе фактически являются переменными в линейной регрессии, а переменный пакет в дисперсионном анализе являются независимым переменными в линейной регрессии.
Анализ линейной регрессии и дисперсии одинаковы из-за переменных, являются непрерывной информацией,
Аргумент отличается, и дисперсия представляет собой классифицированную переменную, а линейная регрессия представляет собой непрерывные данные.
2, разностное сравнение[Исследование три препарата в ABC, влияя на объем легочной емкости, разделенный на три группы, каждую группу из 5 тестов лиц, целью которых является естественным, чтобы увидеть, если есть разница между этими тремя препаратами, то есть ли разница между Переменные значительны]
А, анализ дисперсии

б, изменение в линейную регрессию

3, объяснение
Как, эта форма почти форма линейной регрессии?
Y связано с переменными, X является собственной переменной. Единственное место с линейной регрессией:X и Y в линейной регрессии соответствуют одному。
————————————————————————————————————————————————————————-
[Раннее обнаружение дифференциального [различные образцы, по существу равны], линейная регрессия, потому что мы не можем сделать данные [X1, Y1], потому что X1 может только соответствовать одному Y1, но реальный общий, один X1 Значение может соответствовать Значение бесчисленного y1, но в целом никто не знает. На практике мы должны увидеть карту остаточной распределения, если она случайно распределяется, то мы считаем, что детектирование частичного разности удовлетворено. 】
————————————————————————————————————————————————————————-
X и Y дисперсионного анализа — один ко многим, а именно один х, соответствующий нескольким значениям Y, но это не влияет на анализ.
Фактически, даже в линейной регрессии, иногда будет пару явлений. Например, эффект веса на грузоподъемность легких, если есть несколько человек с той же весом тела, есть пара явлений. Это больше похоже на анализ дисперсии.
Наконец, добавьте некоторые резюме, теоретические вещи, общие линейные модели могут быть примерно так:
y=α+βx+ε,
На самом деле, каждый должен быть очень знакомым, что, как правило, имеет эту формулу в главе линейной регрессии в учебнике статистики. Y — это потому, что переменная — это переменная, но необходимо обратить внимание на классификационную переменную. Когда X — это форма переменных, когда X представляет собой непрерывную переменную, она становится линейной. Форма регрессии в форме.
Шестое: T Осмотр линейной регрессии
Тестовый объект: является ли параметр коэффициента одного регрессии значительно 0.
Принцип строительства: это фактор обнаружения достаточно близко? Послушное распределение — это T распределение.
Предварительные условия: простота обнаружения различий [разные образцы по существу равномерно], линейная регрессия, поскольку мы не можем сделать данные [x1, y1], потому что x1 — это только один y1, но это правда, значение x1 может соответствовать бесчисленным Y1, но в целом никто не знает. На практике мы должны увидеть карту остаточной распределения, если она случайно распределяется, то мы считаем, что детектирование частичного разности удовлетворено.
Если распределение остатков регулярно, то мы должны делать трансформацию, такие как трансформация журнала, соответствующие ядерные функции и т. Д.
Линейная регрессия: y = β1 * x + β0 + e
y = 8*x + 6 + e
- H0 Гипотеза [Гипотеза]: β1 = 0
- HA Гипотеза [Осмотр]: Если вы найдете значение β1, очень мало под Beta1 = 0?
T Испытание оригинальной формулы:

Линейная регрессионная тестовая формула:
t=(β1 — 0)/ SE(β1 )
Где: Se (β1) относится к стандартному отклонению β1 коэффициента регрессии.
Седьмое: линейная регрессия F осмотр
============================================================================
Определение: F Test также называют дисперсией дисперсии, в основном путем сравнения дисперсии S ^ 2 из двух наборов данных, чтобы определить, имеет ли их распределение значительную разницу. Что касается того, существует ли системная ошибка между двумя наборами данных, тест T выполняется после выполнения FET F и определяется, что их распределение не имеет существенных различий.
Другие объяснения: Одним из них является то, что остаточная дисперсия недостаточно снижается по сравнению с дисперсией образца, указывающая на то, что большинство примеров информации уже включена в основную модель.
============================================================================
Структурный принцип: от формулы фракционного квадрата и разложения, интерпретация линейной зависимости переменной интерпретации значительна к интерпретации переменных из квадрата мокроты и формулы разложения.
Тестовый объект: все коэффициенты регрессии всего уравнения все обнаружены до 0.
Линейная регрессия: y = β0 + β1 * x + β2 * x ,, βp * x + e
- H0 Гипотеза [Гипотеза]: β1 = β2 = βp = 0
- HA Гипотеза [Осмотр]: по крайней мере один β не 0,H0 Гипотеза [Гипотеза] Условия, F Тестовые презентационные карты Распределение карты。
F Test Formula = MSM / MSR
=(SSR/p) / (RSS/n-p-1)
= Я могу объяснить / неизвестно вызывает [остаточный ущерб]
F Результаты обнаружения, проверьте значение таблицы P, см. Если он может отказаться от первоначальной гипотезы.
При отклонении, то есть как минимум один β не 0.
Также: линейная регрессия, f = t ^ 2.Ссылка ссылки: документ Baidu
Регрессия – это статистический метод, который помогает квалифицировать отношения между взаимосвязанными экономическими переменными. Первый шаг включает в себя оценку коэффициента независимой переменной, а затем измерение достоверности оцененного коэффициента. Это требует формулирования гипотезы, и на основе гипотезы мы можем создать функцию.
Если менеджер хочет определить взаимосвязь между рекламными расходами фирмы и доходами от продаж, он подвергнется проверке гипотезы. Предполагая, что более высокие расходы на рекламу приводят к увеличению продаж для фирмы. Менеджер собирает данные о расходах на рекламу и о выручке от продаж за определенный период времени. Эта гипотеза может быть переведена в математическую функцию, где она приводит к –
Y = A + Bx
Где Y – продажи, x – расходы на рекламу, A и B – постоянные.
После перевода гипотезы в функцию основание для этого должно найти связь между зависимой и независимой переменными. Значение зависимой переменной имеет наибольшее значение для исследователей и зависит от значения других переменных. Независимая переменная используется для объяснения изменения зависимой переменной. Это может быть классифицировано в два типа –
-
Простая регрессия – одна независимая переменная
-
Множественная регрессия – несколько независимых переменных
Простая регрессия – одна независимая переменная
Множественная регрессия – несколько независимых переменных
Простая регрессия
Ниже приведены шаги для построения регрессионного анализа –
- Укажите модель регрессии
- Получить данные о переменных
- Оценить количественные отношения
- Проверьте статистическую значимость результатов
- Использование результатов в принятии решений
Формула для простой регрессии –
Y = a + bX + u
Y = зависимая переменная
X = независимая переменная
а = перехват
б = уклон
и = случайный фактор
Данные поперечного сечения предоставляют информацию о группе объектов в данный момент времени, тогда как данные временных рядов предоставляют информацию об одном объекте с течением времени. Когда мы оцениваем уравнение регрессии, оно включает в себя процесс определения наилучшей линейной зависимости между зависимой и независимой переменными.
Метод обыкновенных наименьших квадратов (OLS)
Обычный метод наименьших квадратов предназначен для подгонки линии через разброс точек таким образом, чтобы сумма квадратов отклонений точек от линии сводилась к минимуму. Это статистический метод. Обычно программные пакеты выполняют оценку OLS.
Y = a + bX
Коэффициент определения (R 2 )
Коэффициент детерминации – это мера, которая показывает процент изменения зависимой переменной из-за изменений в независимых переменных. R 2 является показателем качества модели соответствия. Ниже приведены методы –
Общая сумма квадратов (TSS)
Сумма квадратов отклонений значений выборки Y от среднего значения Y.
TSS = SUM (Y i – Y) 2
Y i = зависимые переменные
Y = среднее значение зависимых переменных
я = количество наблюдений
Регрессия Сумма квадратов (RSS)
Сумма квадратов отклонений расчетных значений Y от среднего значения Y.
RSS = СУММА (Ỷ i – uY) 2
Ỷ i = оценочное значение Y
Y = среднее значение зависимых переменных
я = количество вариантов
Ошибка суммы квадратов (ESS)
Сумма квадратов отклонений выборочных значений Y от расчетных значений Y.
ESS = СУММА (Y i – Ỷ i ) 2
Ỷ i = оценочное значение Y
Y i = зависимые переменные
я = количество наблюдений
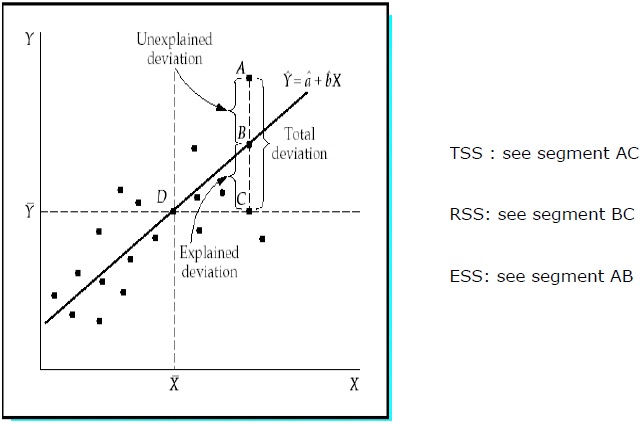
R2 =
RSS / TSS
= 1 –
ESS / TSS
R 2 измеряет долю общего отклонения Y от его среднего значения, что объясняется регрессионной моделью. Чем ближе R 2 к единице, тем больше объясняющая сила уравнения регрессии. Значение R 2, близкое к 0, указывает на то, что уравнение регрессии будет иметь очень мало объяснительной силы.
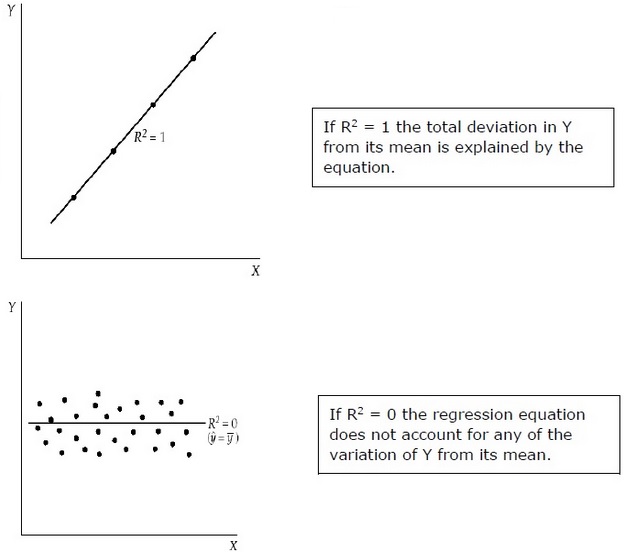
Для оценки коэффициентов регрессии используется выборка из совокупности, а не всей совокупности. Важно делать предположения о населении на основе выборки и делать выводы о том, насколько хороши эти предположения.
Оценка коэффициентов регрессии
Каждая выборка из населения генерирует свой собственный перехват. Для расчета статистической разницы можно использовать следующие методы:
Двуххвостый тест –
Нулевая гипотеза: H 0 : b = 0
Альтернативная гипотеза: H a : b ≠ 0
Один хвостатый тест –
Нулевая гипотеза: H 0 : b> 0 (или b <0)
Альтернативная гипотеза: H a : b <0 (или b> 0)
Статистический тест –
б = расчетный коэффициент
E (b) = b = 0 (нулевая гипотеза)
SE b = стандартная ошибка коэффициента
,
Значение t зависит от степени свободы, одного или двух неудачных испытаний и уровня значимости. Для определения критического значения t можно использовать t-таблицу. Затем идет сравнение t-значения с критическим значением. Нужно отклонить нулевую гипотезу, если абсолютное значение статистического теста больше или равно критическому t-значению. Не отвергайте нулевую гипотезу, если абсолютное значение статистического теста меньше критического t-значения.
Множественный регрессионный анализ
В отличие от простой регрессии в множественном регрессионном анализе, коэффициенты указывают на изменение зависимых переменных, предполагая, что значения других переменных постоянны.
Тест статистической значимости называется F-тестом . F-тест полезен, поскольку он измеряет статистическую значимость всего уравнения регрессии, а не только для отдельного человека. Здесь В нулевой гипотезе нет никакой связи между зависимой переменной и независимыми переменными совокупности.
Формула – H 0 : b1 = b2 = b3 =…. = bk = 0
Не существует никакой связи между зависимой переменной и k независимыми переменными для совокупности.
F-тест статический –
F= frac left( fracR2K right) frac(1−R2)(nk−1)
Критическое значение F зависит от числителя и знаменателя, степени свободы и уровня значимости. F-таблица может быть использована для определения критического значения F. По сравнению с F – значением с критическим значением (F *) –
Если F> F *, нам нужно отвергнуть нулевую гипотезу.
Если F <F *, не отклоняйте нулевую гипотезу, так как нет существенной связи между зависимой переменной и всеми независимыми переменными.