Как спарсить любой сайт?
Время на прочтение
6 мин
Количество просмотров 127K

Меня зовут Даниил Охлопков, и я расскажу про свой подход к написанию скриптов, извлекающих данные из интернета: с чего начать, куда смотреть и что использовать.
Написав тонну парсеров, я придумал алгоритм действий, который не только минимизирует затраченное время на разработку, но и увеличивает их живучесть, робастность, масштабируемость.
TL;DR
Чтобы спарсить данные с вебсайта, пробуйте подходы именно в таком порядке:
-
Найдите официальное API,
-
Найдите XHR запросы в консоли разработчика вашего браузера,
-
Найдите сырые JSON в html странице,
-
Отрендерите код страницы через автоматизацию браузера,
-
Если ничего не подошло — пишите парсеры HTML кода.
Совет профессионалов: не начинайте с BS4/Scrapy
BeautifulSoup4 и Scrapy — популярные инструменты парсинга HTML страниц (и не только!) для Python.
Крутые вебсайты с крутыми продактами делают тонну A/B тестов, чтобы повышать конверсии, вовлеченности и другие бизнес-метрики. Для нас это значит одно: элементы на вебстранице будут меняться и переставляться. В идеальном мире, наш написанный парсер не должен требовать доработки каждую неделю из-за изменений на сайте.
Приходим к выводу, что не надо извлекать данные из HTML тегов раньше времени: разметка страницы может сильно поменяться, а CSS-селекторы и XPath могут не помочь. Используйте другие методы, о которых ниже. ⬇️
Используйте официальный API
👀 Ого? Это не очевидно 🤔? Конечно, очевидно! Но сколько раз было: сидите пилите парсер сайта, а потом БАЦ — нашли поддержку древней RSS-ленты, обширный sitemap.xml или другие интерфейсы для разработчиков. Становится обидно, что поленились и потратили время не туда. Даже если API платный, иногда дешевле договориться с владельцами сайта, чем тратить время на разработку и поддержку.
Sitemap.xml — список страниц сайта, которые точно нужно проиндексировать гуглу. Полезно, если нужно найти все объекты на сайте. Пример: http://techcrunch.com/sitemap.xml
RSS-лента — API, который выдает вам последние посты или новости с сайта. Было раньше популярно, сейчас все реже, но где-то еще есть! Пример: https://habr.com/ru/rss/hubs/all/
Поищите XHR запросы в консоли разработчика

Все современные вебсайты (но не в дарк вебе, лол) используют Javascript, чтобы догружать данные с бекенда. Это позволяет сайтам открываться плавно и скачивать контент постепенно после получения структуры страницы (HTML, скелетон страницы).

Обычно, эти данные запрашиваются джаваскриптом через простые GET/POST запросы. А значит, можно подсмотреть эти запросы, их параметры и заголовки — а потом повторить их у себя в коде! Это делается через консоль разработчика вашего браузера (developer tools).
В итоге, даже не имея официального API, можно воспользоваться красивым и удобным закрытым API. ☺️Даже если фронт поменяется полностью, этот API с большой вероятностью будет работать. Да, добавятся новые поля, да, возможно, некоторые данные уберут из выдачи. Но структура ответа останется, а значит, ваш парсер почти не изменится.
Алгорим действий такой:
-
Открывайте вебстраницу, которую хотите спарсить
-
Правой кнопкой -> Inspect (или открыть dev tools как на скрине выше)
-
Открывайте вкладку Network и кликайте на фильтр XHR запросов
-
Обновляйте страницу, чтобы в логах стали появляться запросы
-
Найдите запрос, который запрашивает данные, которые вам нужны
-
Копируйте запрос как cURL и переносите его в свой язык программирования для дальнейшей автоматизации.

Вы заметите, что иногда эти XHR запросы включают в себя огромные строки — токены, куки, сессии, которые генерируются фронтендом или бекендом. Не тратьте время на ревёрс фронта, чтобы научить свой парсер генерировать их тоже.
Вместо этого попробуйте просто скопипастить и захардкодить их в своем парсере: очень часто эти строчки валидны 7-30 дней, что может быть окей для ваших задач, а иногда и вообще несколько лет. Или поищите другие XHR запросы, в ответе которых бекенд присылает эти строчки на фронт (обычно это происходит в момент логина на сайт). Если не получилось и без куки/сессий никак, — советую переходить на автоматизацию браузера (Selenium, Puppeteer, Splash — Headless browsers) — об этом ниже.
Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. 🤗 Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? 🙅♀️ Нет! 🙅♂️
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен! 😱😱😱
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):

 Linkedin!")
Алгоритм действий такой:
-
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
-
Внизу ищите длинную длинную строчку с данными.
-
Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто
requests.get. -
Вырезаете JSON из HTML любыми костылямии (я использую
html.find("={")).
Отрендерите JS через Headless Browsers
Если XHR запросы требуют актуальных tokens, sessions, cookies. Если вы нарываетесь на защиту Cloudflare. Если вам обязательно нужно логиниться на сайте. Если вы просто решили рендерить все, что движется загружается, чтобы минимизировать вероятность бана. Во всех случаях — добро пожаловать в мир автоматизации браузеров!
Если коротко, то есть инструменты, которые позволяют управлять браузером: открывать страницы, вводить текст, скроллить, кликать. Конечно же, это все было сделано для того, чтобы автоматизировать тесты веб интерфейса. I’m something of a web QA myself.
После того, как вы открыли страницу, чуть подождали (пока JS сделает все свои 100500 запросов), можно смотреть на HTML страницу опять и поискать там тот заветный JSON со всеми данными.
driver.get(url_to_open)
html = driver.page_sourceSelenoid — open-source remote Selenium cluster
Для масштабируемости и простоты, я советую использовать удалённые браузерные кластеры (remote Selenium grid).
Недавно я нашел офигенный опенсорсный микросервис Selenoid, который по факту позволяет вам запускать браузеры не у себя на компе, а на удаленном сервере, подключаясь к нему по API. Несмотря на то, что Support team у них состоит из токсичных разработчиков, их микросервис довольно просто развернуть (советую это делать под VPN, так как по умолчанию никакой authentication в сервис не встроено). Я запускаю их сервис через DigitalOcean 1-Click apps: 1 клик — и у вас уже создался сервер, на котором настроен и запущен кластер Headless браузеров, готовых запускать джаваскрипт!
Вот так я подключаюсь к Selenoid из своего кода: по факту нужно просто указать адрес запущенного Selenoid, но я еще зачем-то передаю кучу параметров бразеру, вдруг вы тоже захотите. На выходе этой функции у меня обычный Selenium driver, который я использую также, как если бы я запускал браузер локально (через файлик chromedriver).
def get_selenoid_driver(
enable_vnc=False, browser_name="firefox"
):
capabilities = {
"browserName": browser_name,
"version": "",
"enableVNC": enable_vnc,
"enableVideo": False,
"screenResolution": "1280x1024x24",
"sessionTimeout": "3m",
# Someone used these params too, let's have them as well
"goog:chromeOptions": {"excludeSwitches": ["enable-automation"]},
"prefs": {
"credentials_enable_service": False,
"profile.password_manager_enabled": False
},
}
driver = webdriver.Remote(
command_executor=SELENOID_URL,
desired_capabilities=capabilities,
)
driver.implicitly_wait(10) # wait for the page load no matter what
if enable_vnc:
print(f"You can view VNC here: {SELENOID_WEB_URL}")
return driverЗаметьте фложок enableVNC. Верно, вы сможете смотреть видосик с тем, что происходит на удалённом браузере. Всегда приятно наблюдать, как ваш скрипт самостоятельно логинится в Linkedin: он такой молодой, но уже хочет познакомиться с крутыми разработчиками.
Парсите HTML теги
Если случилось чудо и у сайта нет ни официального API, ни вкусных XHR запросов, ни жирного JSON внизу HTML, если рендеринг браузерами вам тоже не помог, то остается последний, самый нудный и неблагодарный метод. Да, это взять и начать парсить HTML разметку страницы. То есть, например, из <a href="https://okhlopkov.com">Cool website</a> достать ссылку. Это можно делать как простыми регулярными выражениями, так и через более умные инструменты (в питоне это BeautifulSoup4 и Scrapy) и фильтры (XPath, CSS-selectors).
Мой единственный совет: постараться минимизировать число фильтров и условий, чтобы меньше переобучаться на текущей структуре HTML страницы, которая может измениться в следующем A/B тесте.
Надеюсь, что-то из этого было полезно! Я считаю, что в парсинге важно, с чего ты начинаешь. С чего начать — я рассказал, а дальше ваш ход 😉
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером системы Promopult. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
Что такое парсинг и зачем он нужен
ПО для парсинга
Пример 1. Как спарсить цену
Пример 2. Как спарсить фотографии
Пример 3. Как спарсить характеристики товаров
Пример 4. Как парсить отзывы (с рендерингом)
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Пример 6. Как парсить структуру сайта на примере DNS-Shop
Возможности парсинга на основе XPath
Ограничения при парсинге
Что такое парсинг и зачем он нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию. Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.

ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться услуги от компаний, которые создадут парсер под ваши задачи. Стоят такие услуги относительно дорого. В результате программисты под заказ напишут некую программу либо на Python, либо на каком-то еще языке, которая будет собирать информацию с нужного вам сайта. Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ вы уже пользуетесь, но просто не знаете, что в ней есть такой функционал. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
- Screaming Frog SEO Spider (есть только годовая лицензия).
- Netpeak Spider (есть триал на 14 дней, лицензии на месяц и более).
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, коды, теги и все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Профессиональные инструменты PromoPult: быстрее, чем руками, дешевле, чем у других, бесплатные опции.
Съем позиций, кластеризация запросов, парсер Wordstat, сбор поисковых подсказок, сбор фраз ассоциаций, парсер мета-тегов и заголовков, анализ индексации страниц, чек-лист оптимизации видео, генератор из YML, парсер ИКС Яндекса, нормализатор и комбинатор фраз, парсер сообществ и пользователей ВКонтакте.
Давайте смотреть на реальных примерах.
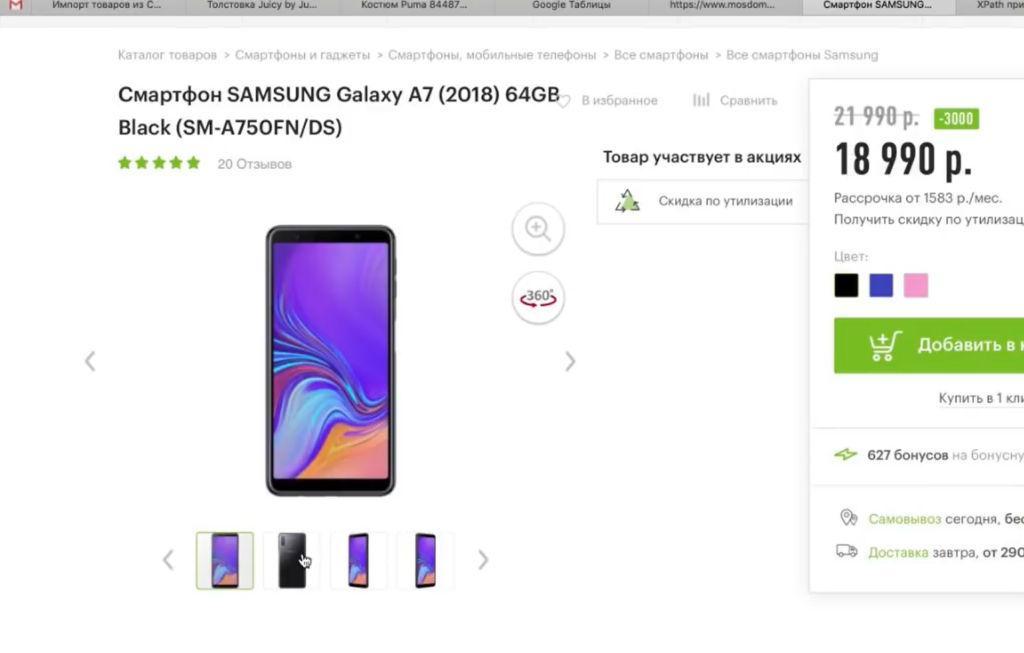
Пример 1. Как спарсить цену
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать, сколько у него стоят товары.
Возьмем для примера сайт mosdommebel.ru.
У нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?
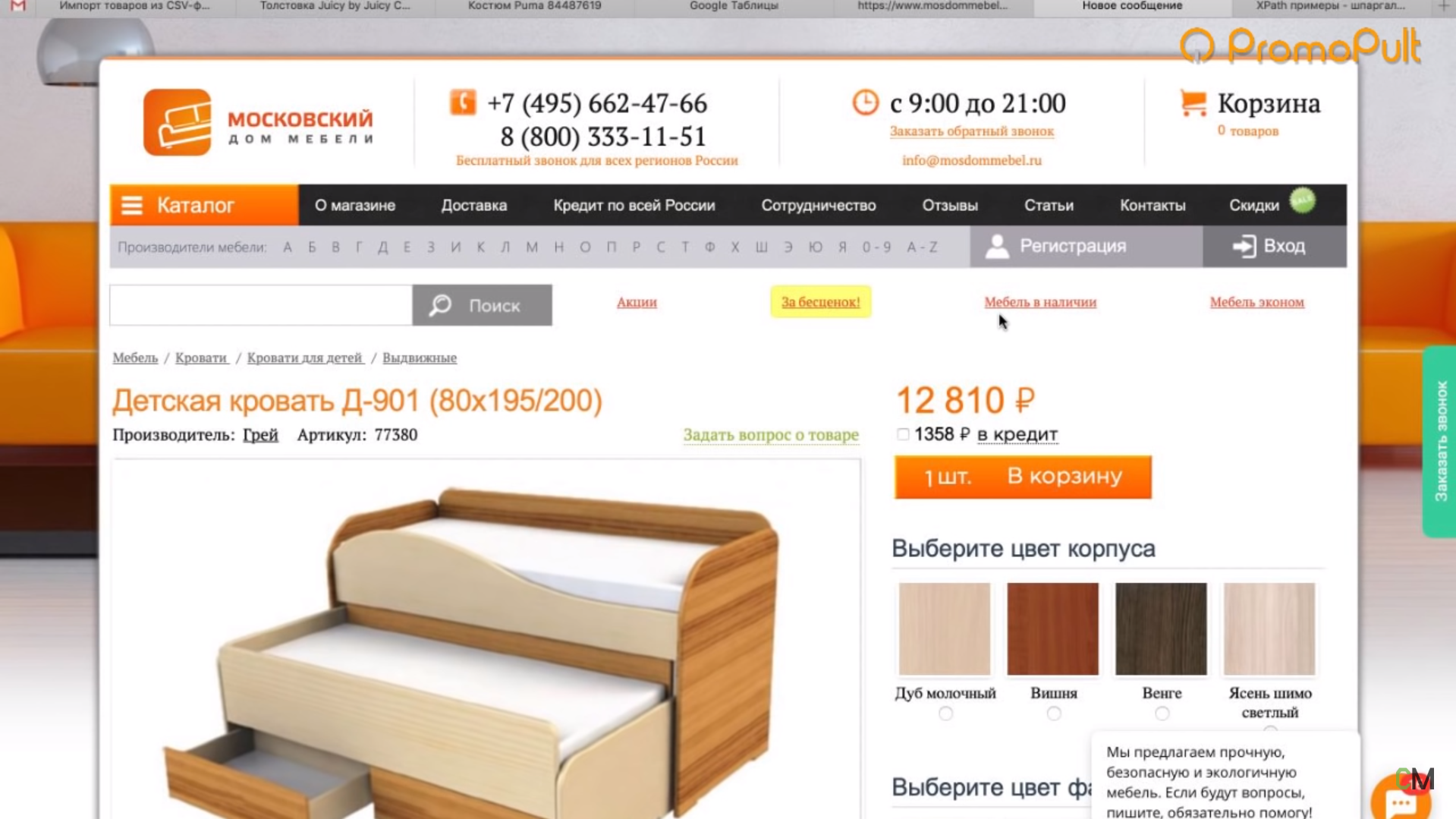
Мы видим, что цена отображается вверху справа, напротив заголовка h1. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
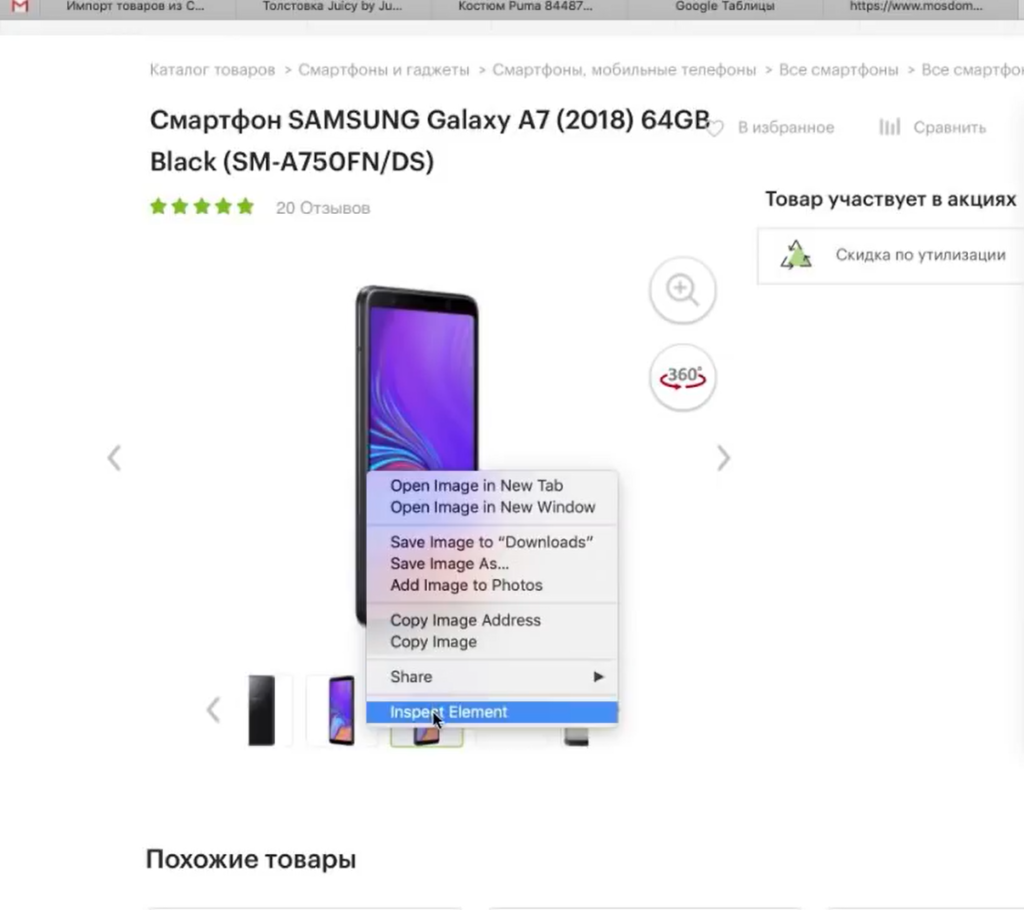
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).
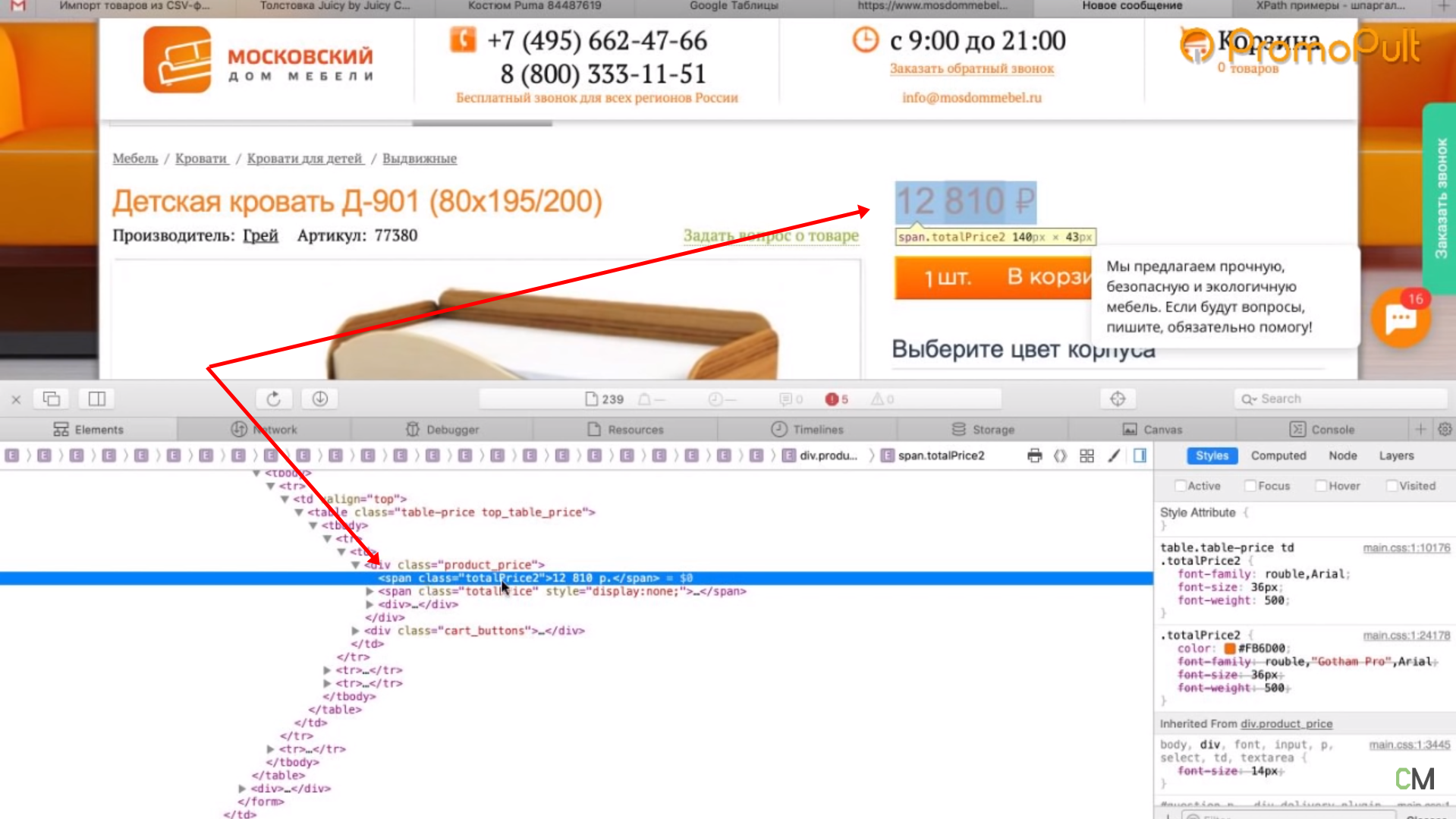
Мы видим, что цена у нас помещается в тег с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке.
Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег <span> и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.
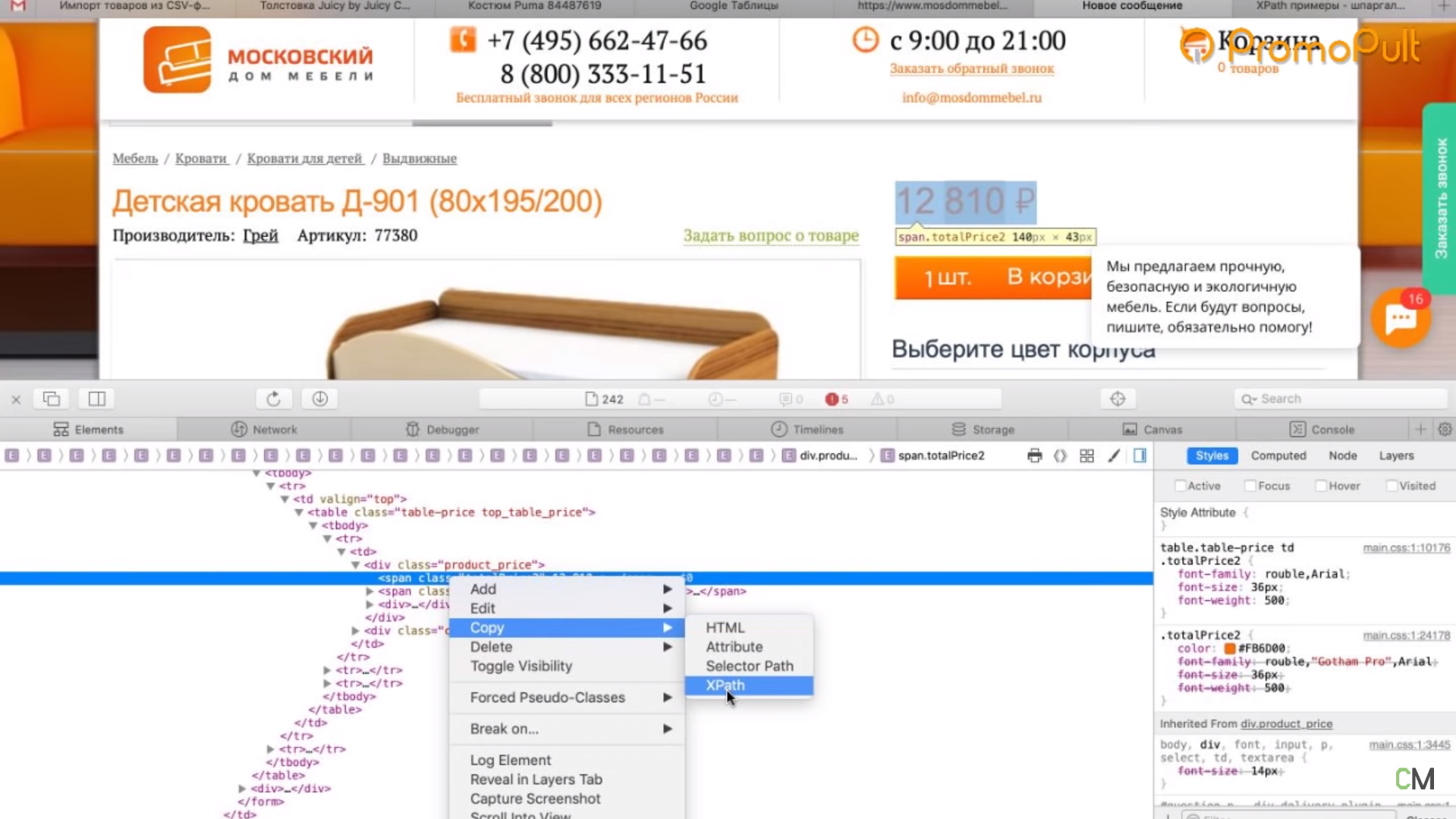
Выглядит она так:
/html/body/div[1]/div[2]/div[4]/table/tbody/tr/td/div[1]/div/table[2]/tbody/tr/td[2]/form/table/tbody/tr[1]/td/table/tbody/tr[1]/td/div[1]/span[1]Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
Например, такая справка:
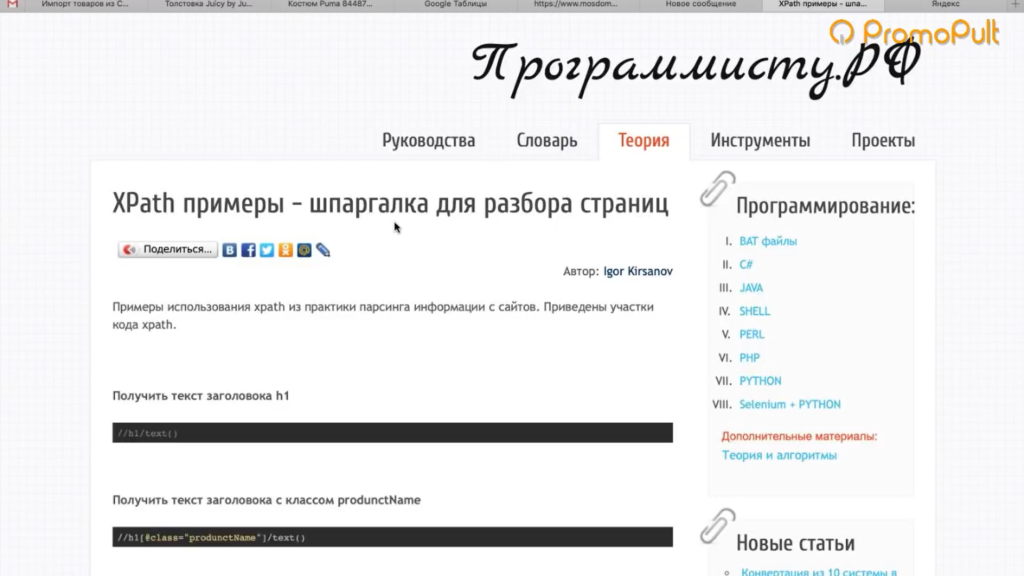
Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h1, нам нужно написать вот так:
//h1/text()Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
//h1[@class="productName"]/text()То есть поставить «//» как обращение к некому элементу на странице, написать тег h1 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос
Мы идем в один из парсеров. В данном случае — Screaming Frog Seo Spider.
Эта программа бесплатна для анализа небольшого сайта — до 500 страниц.
 Интерфейс Screaming Frog Seo Spider
Интерфейс Screaming Frog Seo Spider
Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега h1, незаполненных метатегов или каких-нибудь битых ссылок.
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
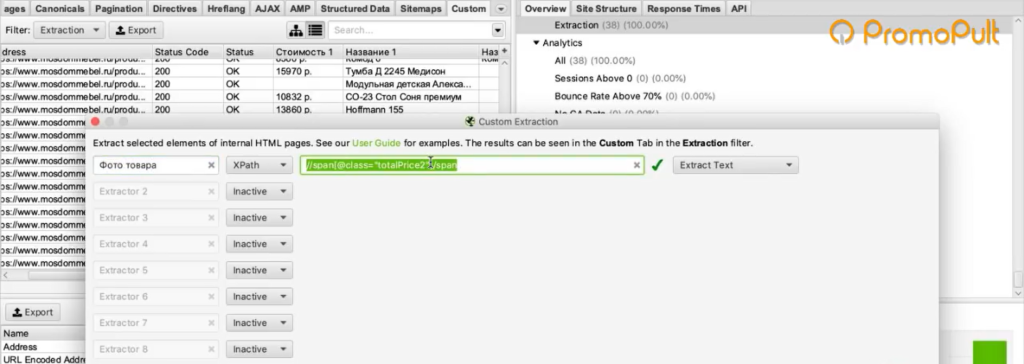
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
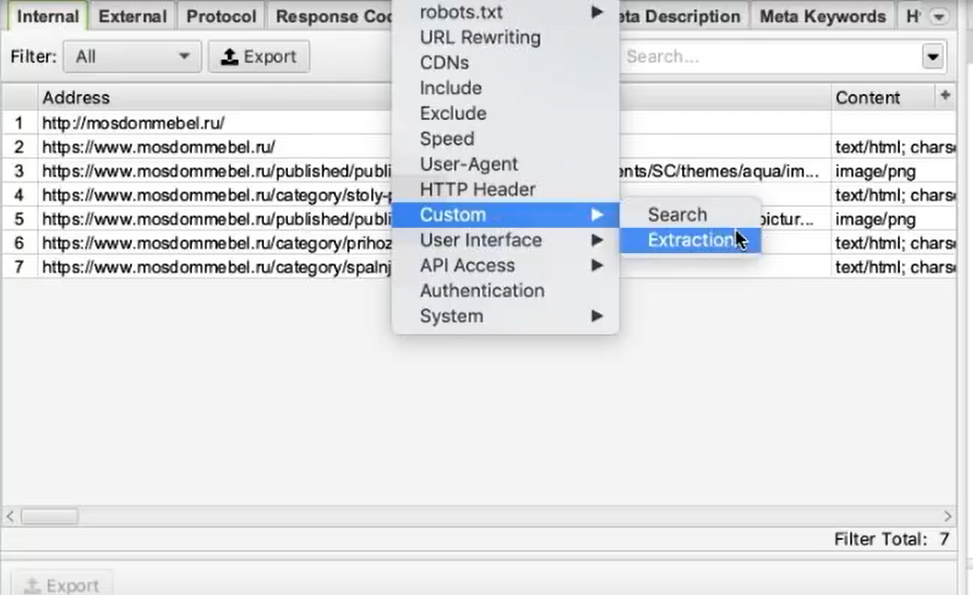
Заходим в Extraction. Нам нужно с сайта Московского дома мебели собрать цены товаров.
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом <span> с классом totalPrice2. Формируем вот такой XPath запрос:
//span[@class="totalPrice2"]/spanИ указываем его в разделе Configuration > Custom > Extractions. Для удобства можем назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:
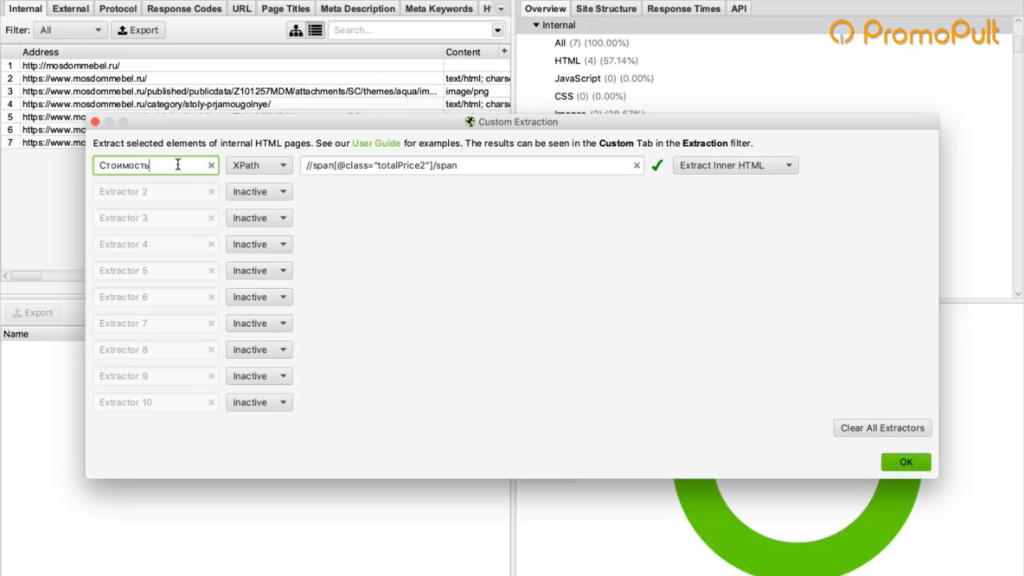
Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.
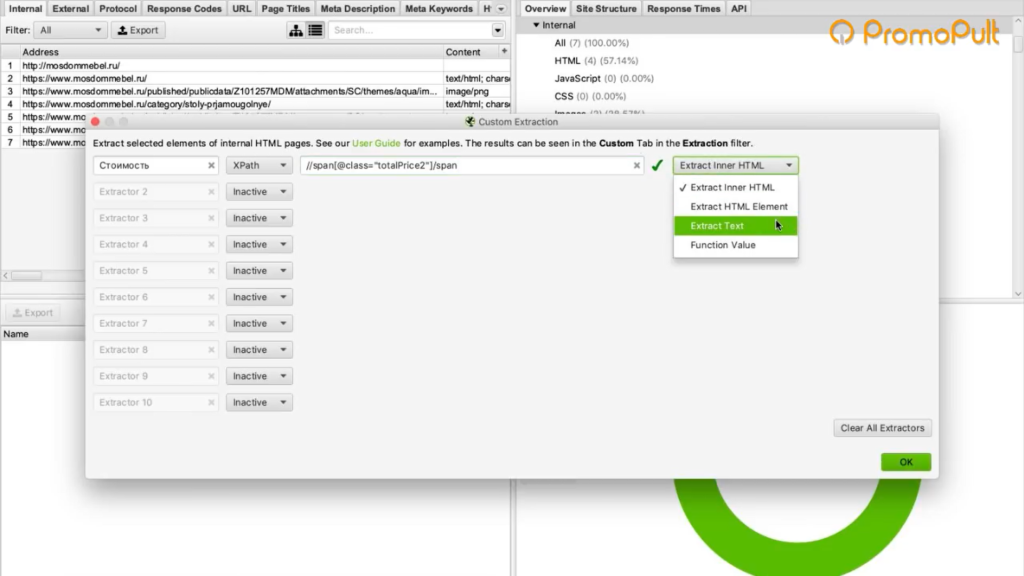
Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.
Откуда их взять? Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес:
https://www.mosdommebel.ru/sitemap.xml.Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта.
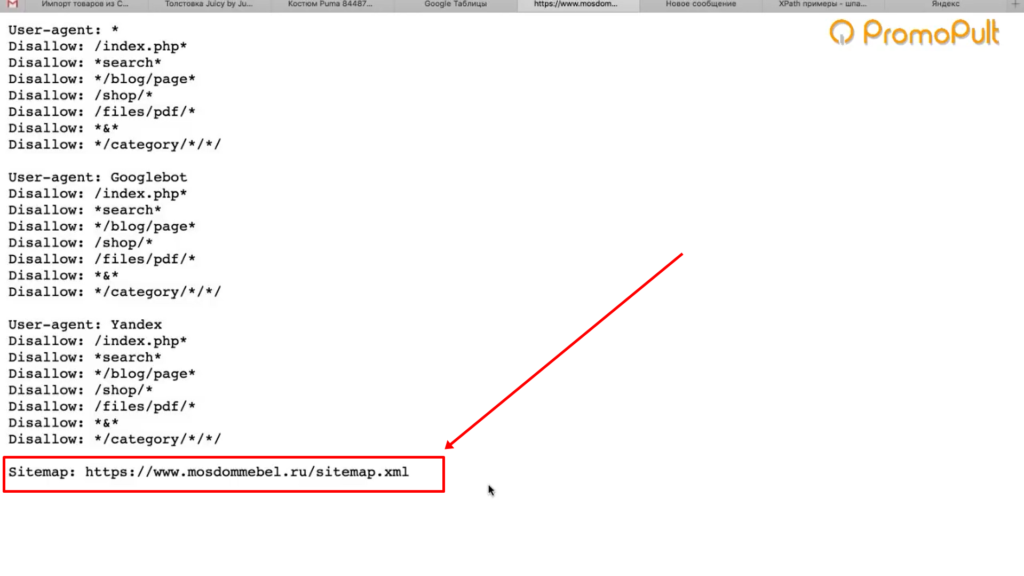 Ссылка на карту сайта в файле robots.txt
Ссылка на карту сайта в файле robots.txt
Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара. Тогда придется запускать стандартный режим в парсере — он будет ходить по всем разделам сайта. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
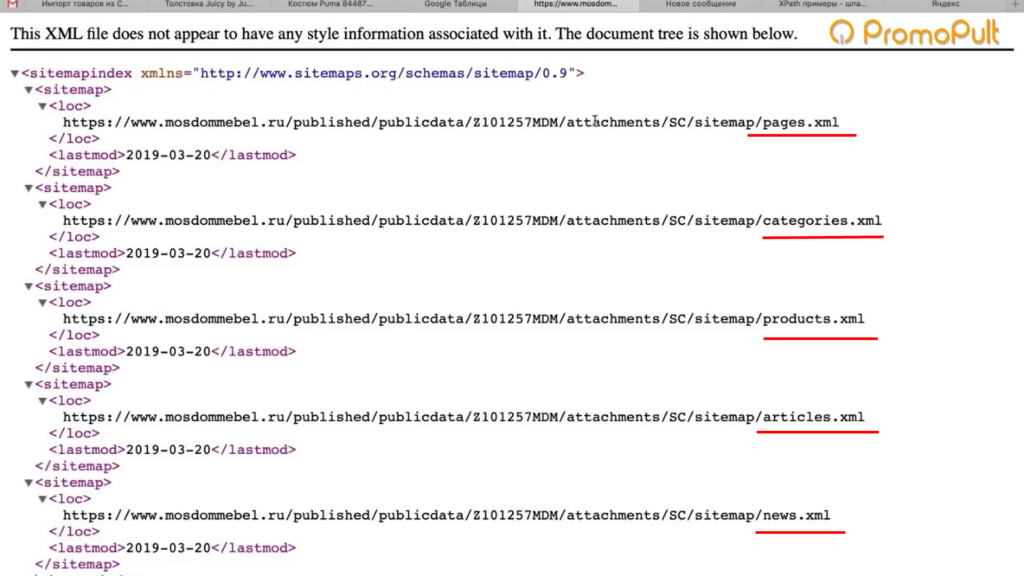 Ссылки на отдельные sitemap-файлы под все типы страниц
Ссылки на отдельные sitemap-файлы под все типы страниц
Нас интересует карта продуктов, то есть карточек товаров.
 Ссылка на sitemap-файл для карточек товара
Ссылка на sitemap-файл для карточек товара
Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все страницы. Нам нужно его запустить в режиме List.
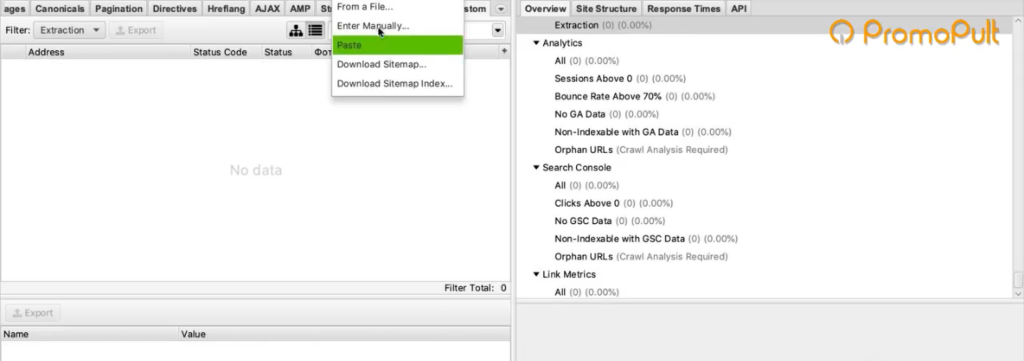
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.

Жмем кнопку Upload и кликаем по Download Sitemap.

Указываем ссылку на Sitemap карточек товара, нажимаем ОК.
Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:
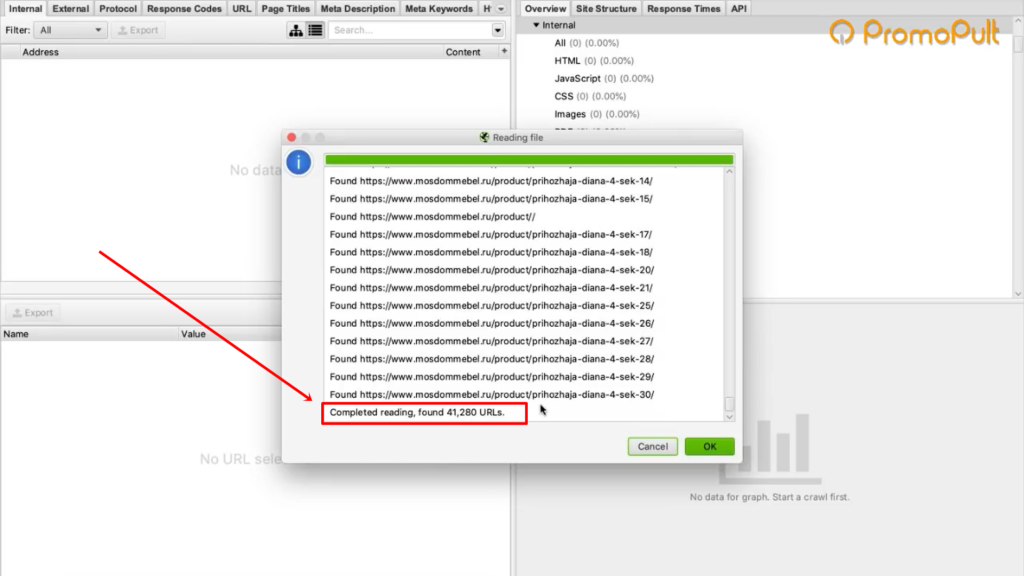
Нажимаем ОК, и у нас начинается парсинг сайта.
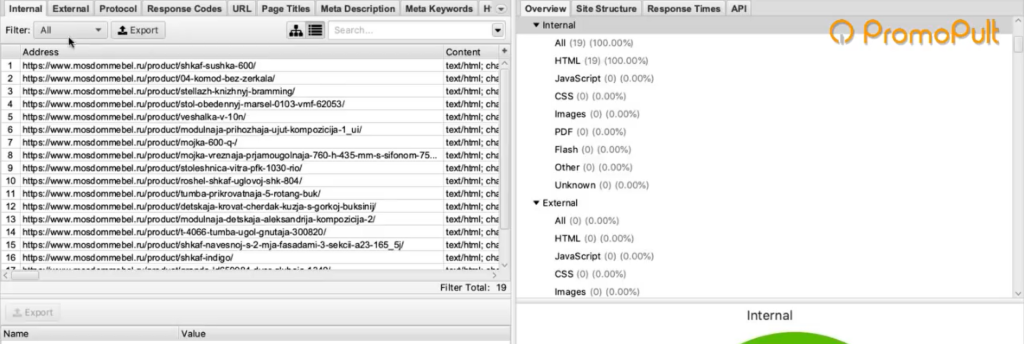
После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.
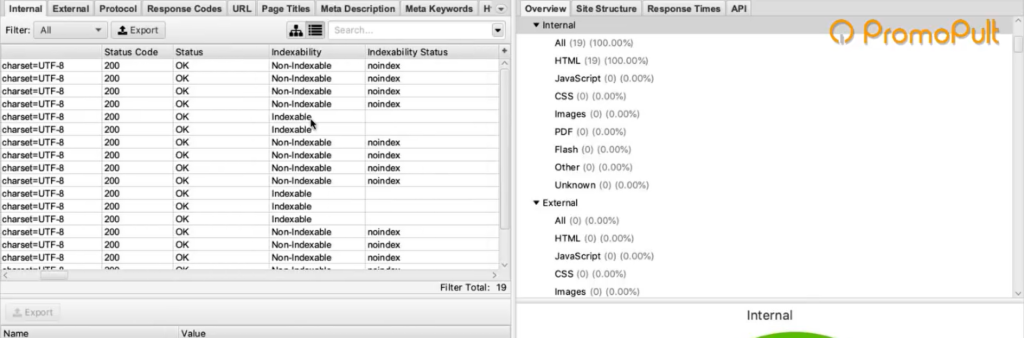
Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.
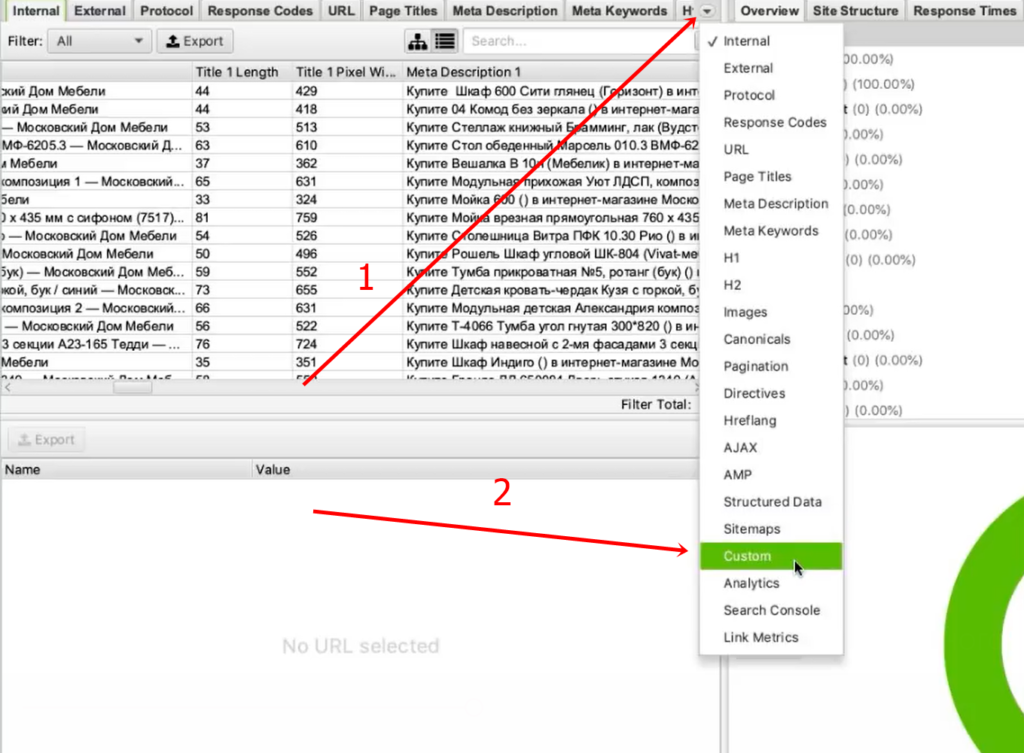
И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.
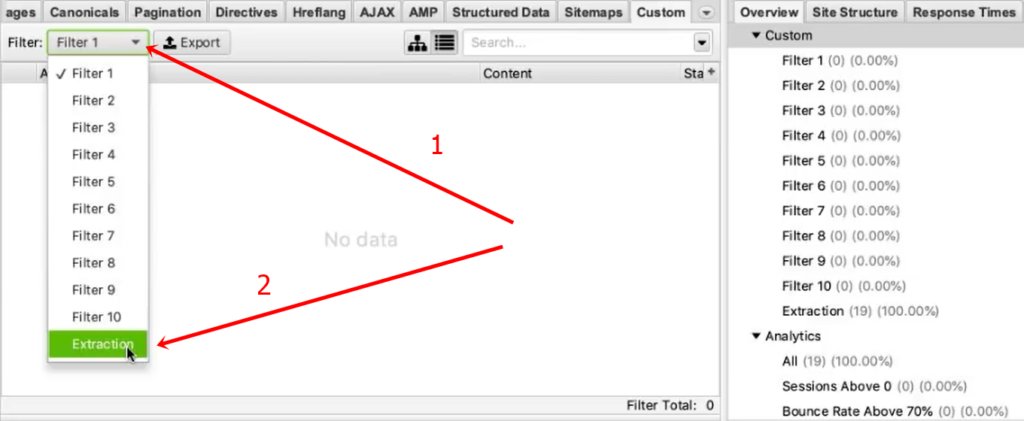
Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.
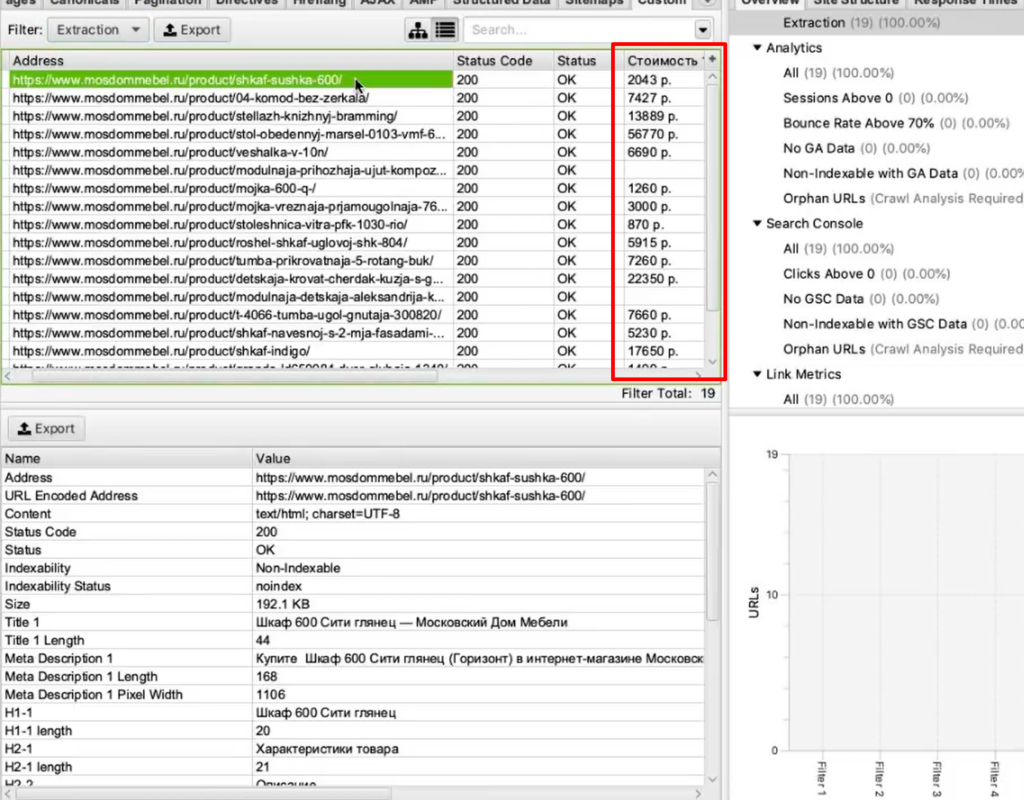
Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.
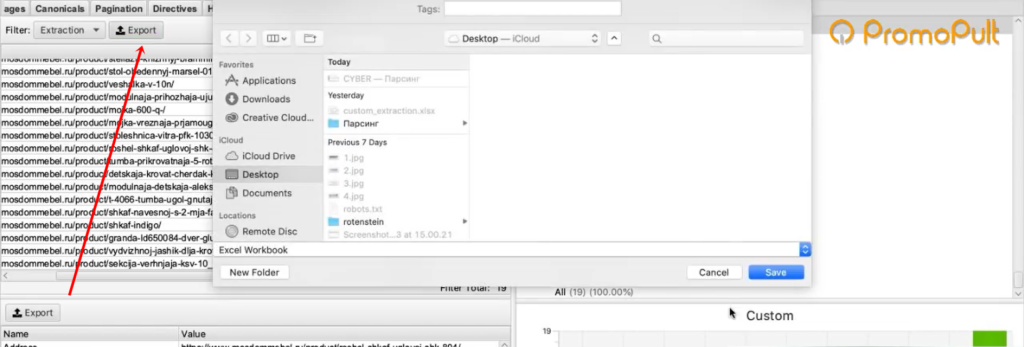
После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
Если бы мы хотели получить что-нибудь еще, например, дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction. И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h1>.
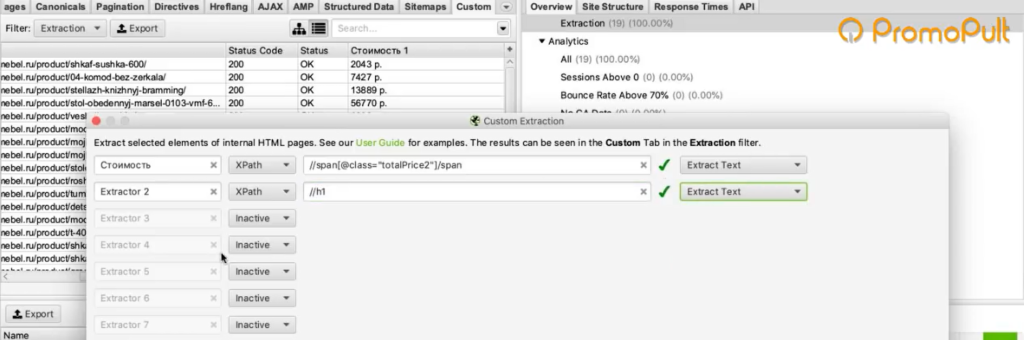
Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.
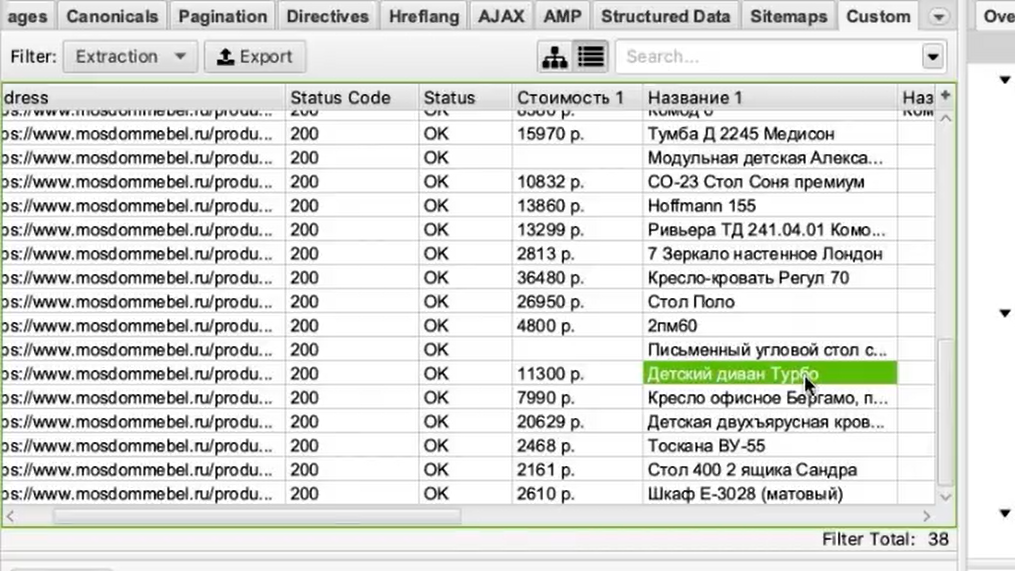
В результате получаем такую связку: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе.
Важный момент: h1 собрать легко. Это стандартный элемент html-кода и для его парсинга можно использовать стандартный XPath-запрос (посмотрите в справке). В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.
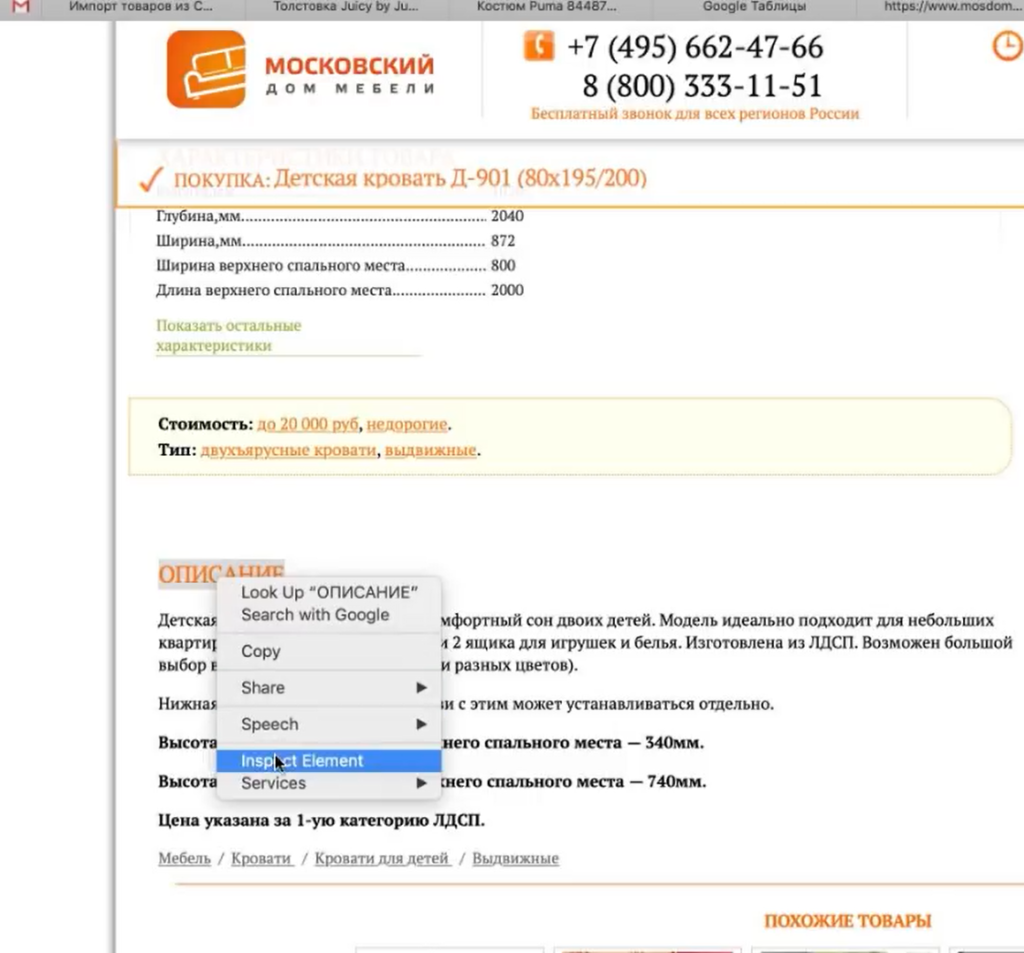
Оказывается, все описание товара лежит в теге <table> с классом product_description. Если мы его соберем, то у нас в таблицу выгрузится полное описание.
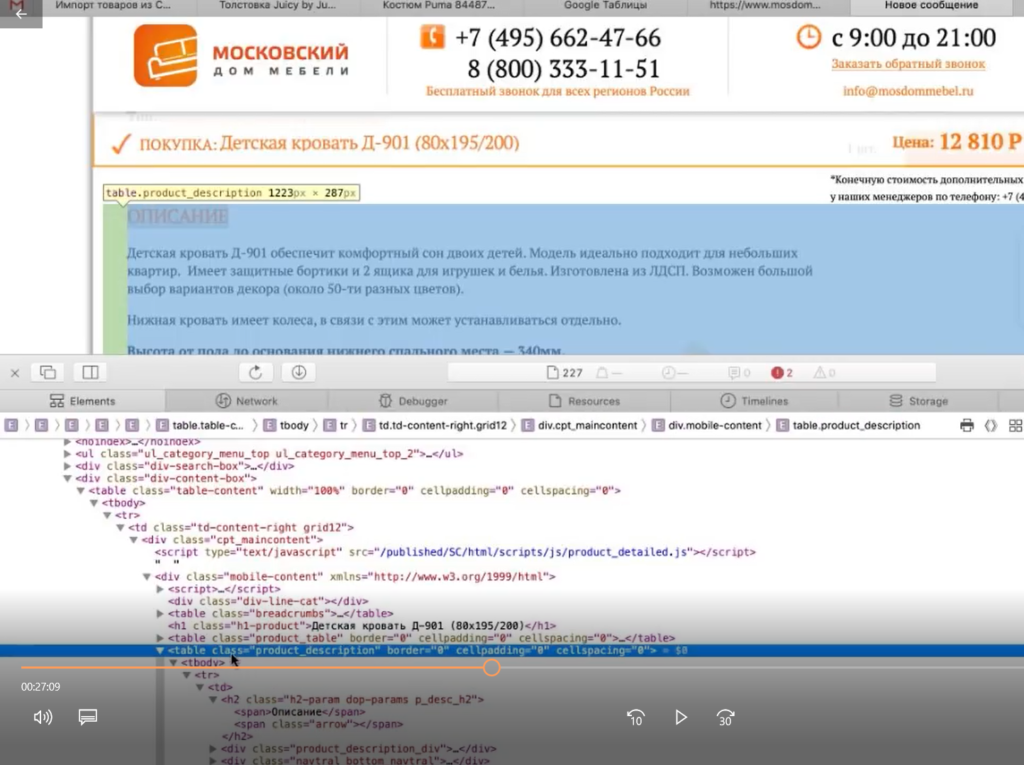
Здесь есть нюанс. Текст описания на странице сайта сделан с разметкой. Например, здесь есть переносы на новую строчку, что-то выделяется жирным.

Если вам нужно спарсить текст описания с уже готовой разметкой, то в настройках Extraction в парсере мы можем выбрать парсинг с html-кодом.
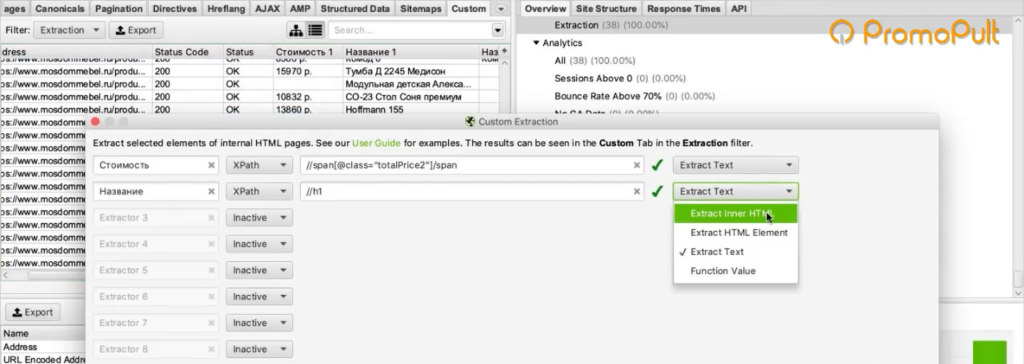
Если вы не хотите собирать весь html-код (потому что он может содержать какие-то классы, которые к вашему сайту никакого отношения не имеют), а нужен текст в чистом виде, выбираем только текст. Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Собрав все необходимые элементы и прогнав по ним парсинг, вы получите таблицу с исчерпывающей информацией по товарам у конкурента.
Такой парсинг можно запускать регулярно (например, раз в неделю) для отслеживания цен конкурентов. И сравнивать, у кого что стоит дороже/дешевле.
Пример 2. Как спарсить фотографии
Рассмотрим вариант решения другой прикладной задачи — парсинга фотографий.
На сайте Эльдорадо у каждого товара есть довольно-таки немало фотографий. Предположим, вы их хотите взять — это универсальные фото от производителя, которые можно использовать для демонстрации на своем сайте.
Задача: собрать в Excel адреса всех картинок, которые есть у разных карточек товара. Не в виде файлов, а в виде ссылок. Потом по ссылкам вы сможете их скачать либо напрямую загрузить на свой сайт. Большинство движков интернет-магазинов, таких как Битрикс и Shop-Script, поддерживают загрузку фотографий по ссылке. Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти фотографии.
Ищем свойства картинок
Для начала нам нужно понять, где в коде указаны свойства, адрес фотографии на каждой карточке товара.
Нажимаем правой клавишей на фотографию, выбираем Inspect Element, начинаем исследовать.
Смотрим, в каком элементе и с каким классом у нас находится данное изображение, что оно из себя представляет, какая у него ссылка и т.д.

Изображения лежат в элементе <span>, у которого id — firstFotoForma. Чтобы спарсить нужные нам картинки, понадобится вот такой XPath-запрос:
//*[@id="firstFotoForma"]/*/img/@srcУ нас здесь обращение к элементам с идентификатором firstFotoForma, дальше есть какие-то вложенные элементы (поэтому прописана звездочка), дальше тег img, из которого нужно получить содержимое атрибута src. То есть строку, в которой и прописан URL-адрес фотографии. Попробуем это сделать.
Берем XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction, вставляем и жмем ОК.
Для начала попробуем спарсить одну карточку. Нужно скопировать ее адрес и добавить в Screaming Frog таким образом: Upload > Paste
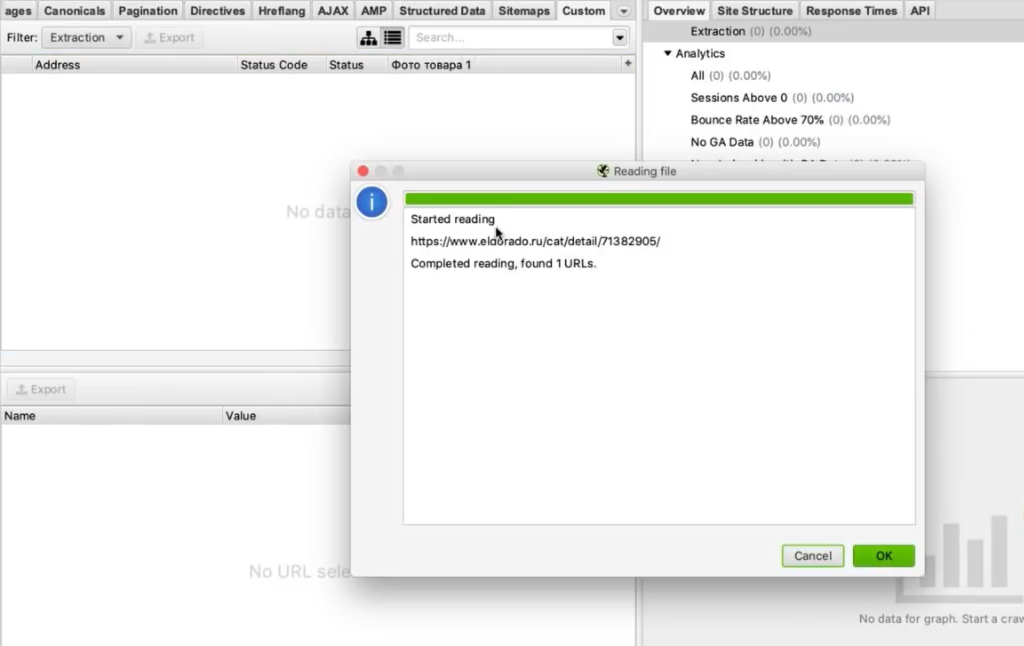
Нажимаем ОК. У нас начинается парсинг.
Screaming Frog спарсил одну карточку товара и у нас получилась такая табличка. Рассмотрим ее подробнее.
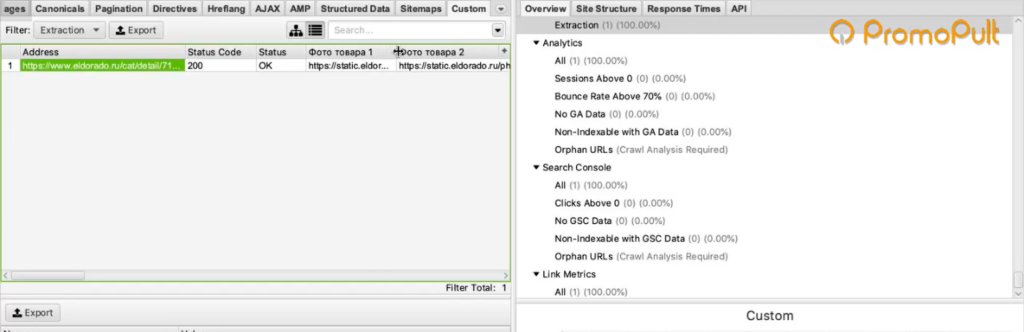
Мы загрузили один URL на входе, и у нас автоматически появилось сразу много столбцов «фото товара». Мы видим, что по этому товару собралось 9 фотографий.
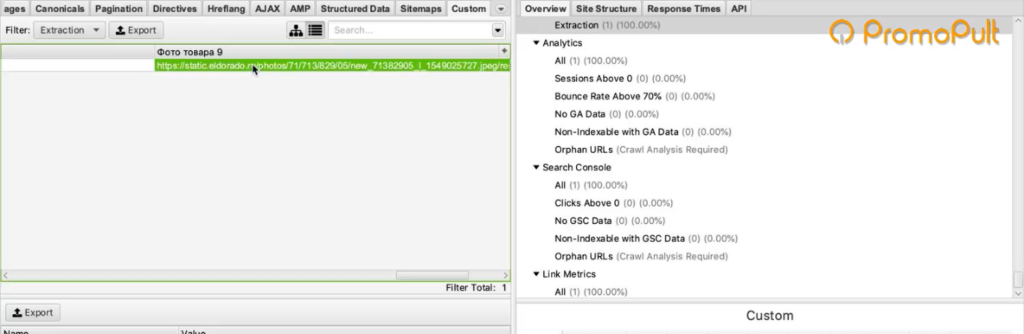
Для проверки попробуем открыть одну из фотографий. Копируем адрес фотографии и вставляем в адресной строке браузера.

Фотография открылась, значит парсер сработал корректно и вытянул нужную нам информацию.
Теперь пройдемся по всему сайту в режиме Spider (для переключения в этот режим нужно нажать Mode > Spider). Укажем адрес https://www.eldorado.ru, нажимаем старт и запускаем парсинг.
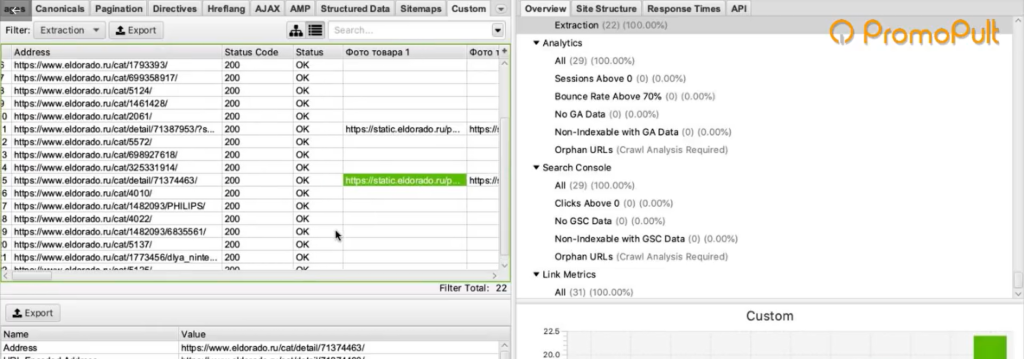
Так как программа парсит весь сайт, то по страницам, которые не являются карточками товара, ничего не находится.
А с карточек товаров собираются ссылки на все фотографии.
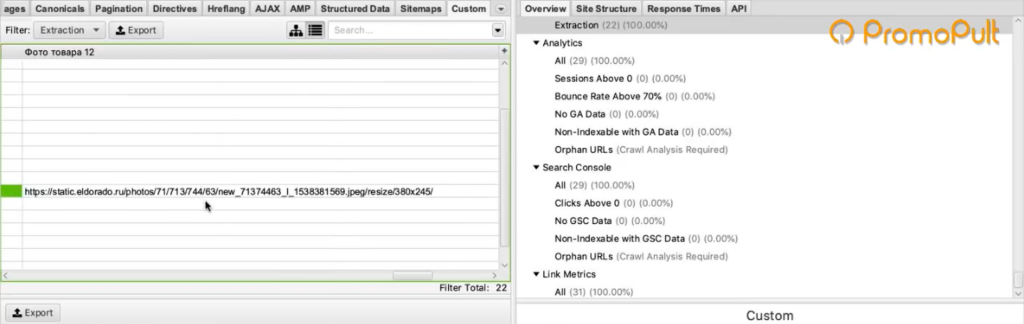
Таким образом мы сможем собрать их и положить в Excel-таблицу, где будут указаны ссылки на все фотографии для каждого товара.
Если бы мы собирали артикулы, то еще раз зашли бы в Configuration > Custom > Extraction и добавили бы еще два XPath-запроса: для парсинга артикулов, а также тегов h1, чтобы собрать еще названия. Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Пример 3. Как спарсить характеристики товаров
Следующий пример — ситуация, когда нам нужно насытить карточки товаров характеристиками. Представьте, что вы продаете книжки. Для каждой книги у вас указано мало характеристик — всего лишь год выпуска и автор. А у Озона (сильный конкурент, сильный сайт) — характеристик много.
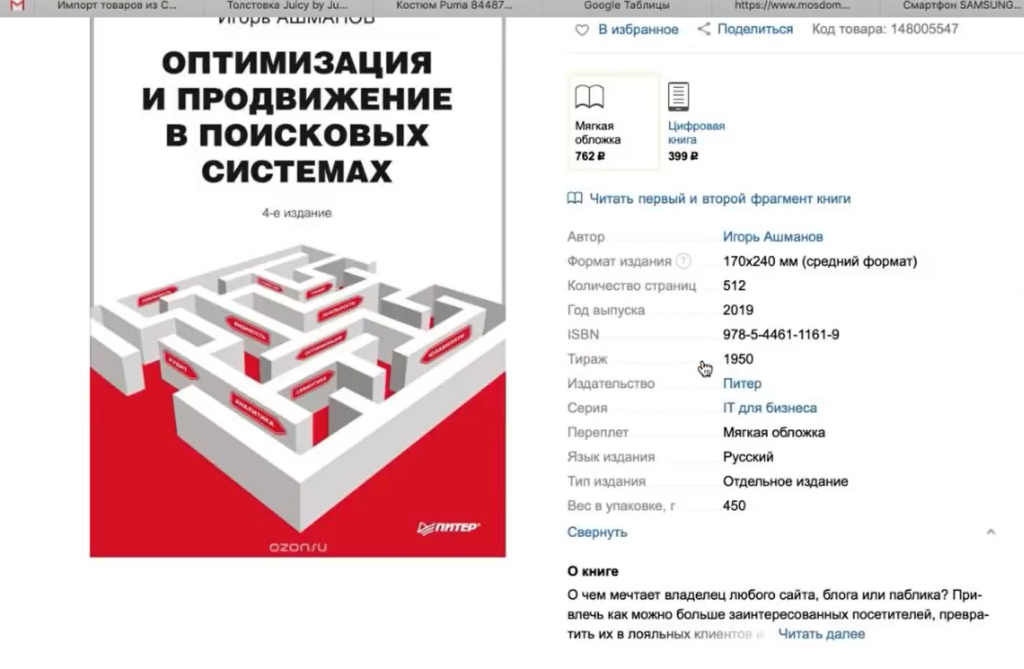
Вы хотите собрать в Excel все эти данные с Озона и использовать их для своего сайта. Это техническая информация, вопросов с авторским правом нет.
Изучаем характеристики
Нажимаете правой кнопкой по характеристике, выбираете Inspect Element и смотрите, как называется элемент, который содержит каждую характеристику.
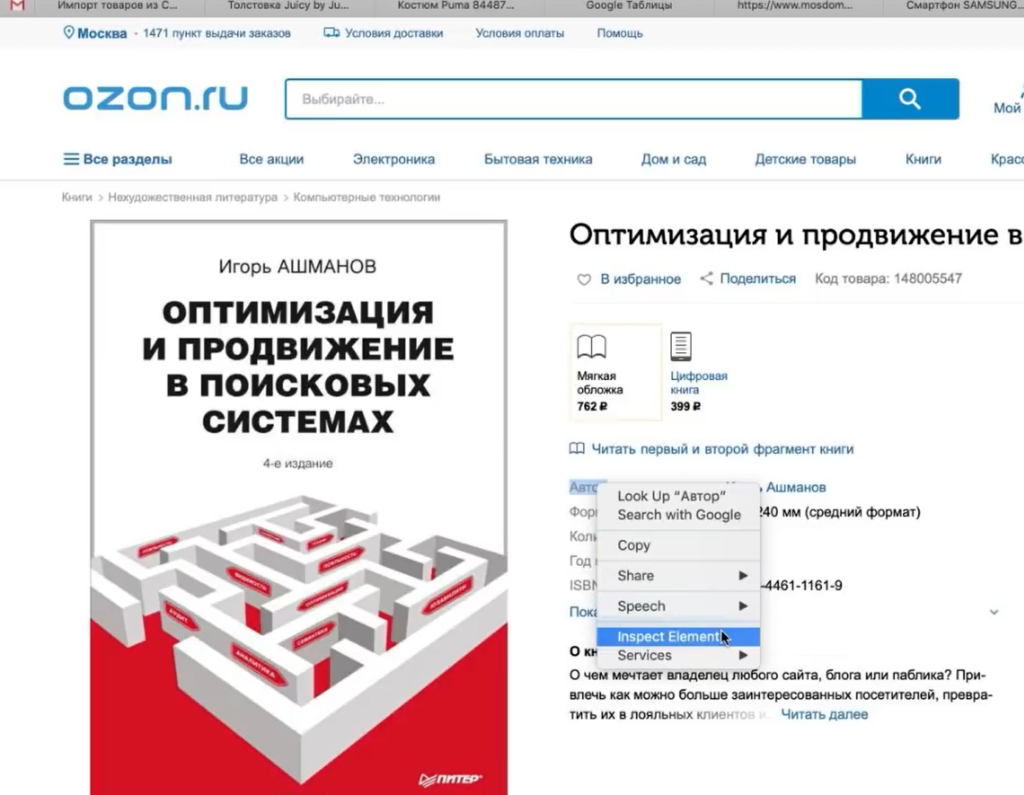
У нас это элемент <div>, у которого в качестве класса указана строка eItemProperties_Line.
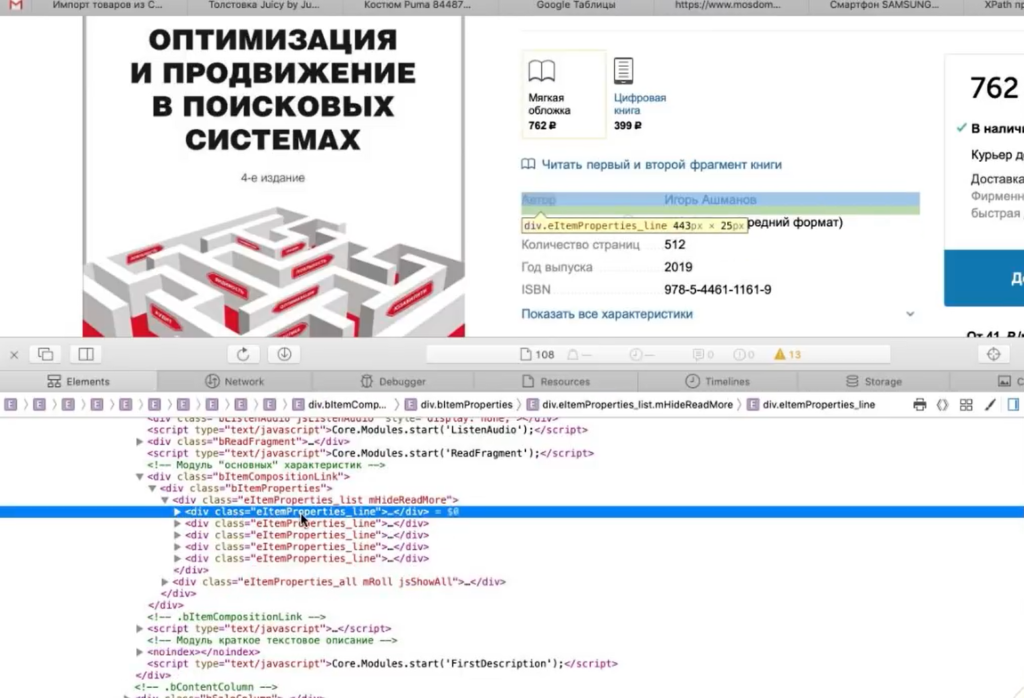
И дальше внутри каждого такого элемента <div> содержится название характеристики и ее значение.

Значит нам нужно собирать элементы <div> с классом eItemProperties_Line.
Для парсинга нам понадобится вот такой XPath-запрос:
//*[@class="eItemProperties_line"]Идем в Screaming Frog, Configuration > Custom > Extraction. Вставляем XPath-запрос, выбираем Extract Text (так как нам нужен только текст в чистом виде, без разметки), нажимаем ОК.

Переключаемся в режим Mode > List. Нажимаем Upload, указываем адрес страницы, с которой будем собирать характеристики, нажимаем ОК.
После завершения парсинга переключаемся на вкладку Custom, в списке фильтров выбираем Extraction.
И видим — парсер собрал нам все характеристики. В каждой ячейке находится название характеристики (например, «Автор») и ее значение («Игорь Ашманов»).
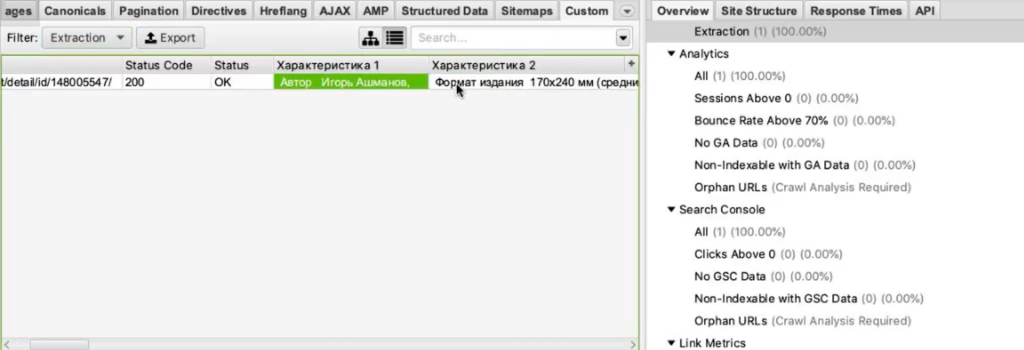
Пример 4. Как парсить отзывы (с рендерингом)
Следующий пример немного нестандартен — на грани «серого» SEO. Это парсинг отзывов с того же Озона. Допустим, мы хотим собрать и перенести на свой сайт тексты отзывов ко всем книгам.
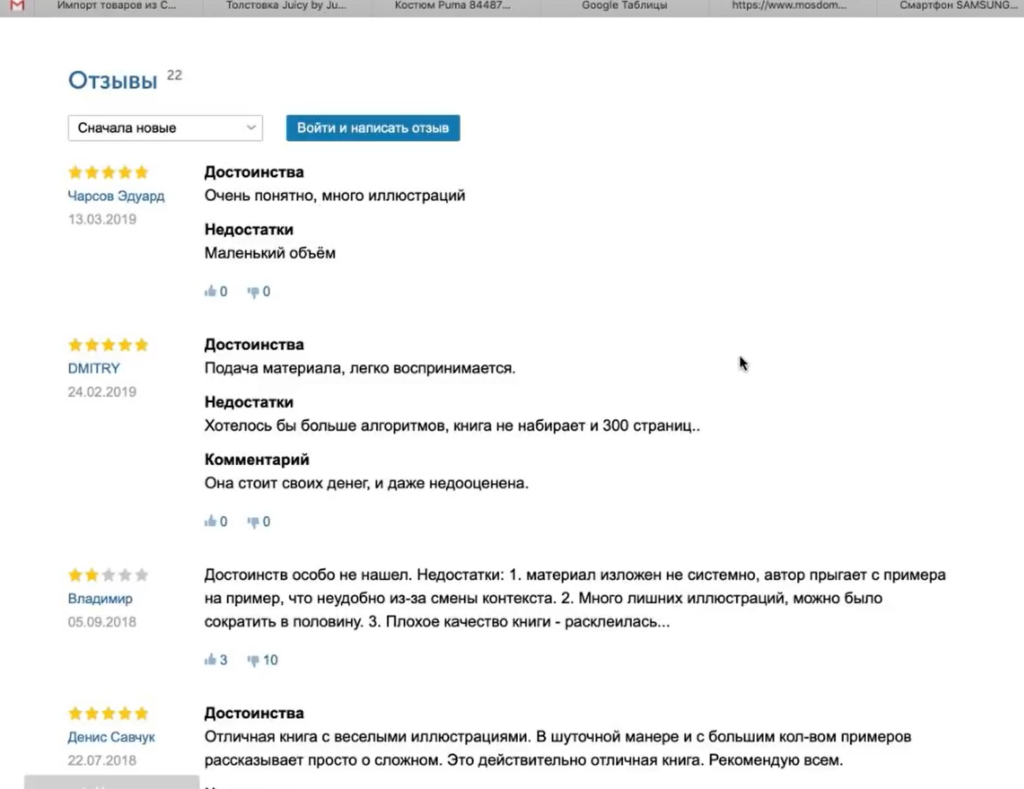
Покажем процесс на примере одного URL. Начнем с того, что посмотрим, где отзывы лежат в коде.

Они находятся в элементе <div> с классом jsCommentContent:
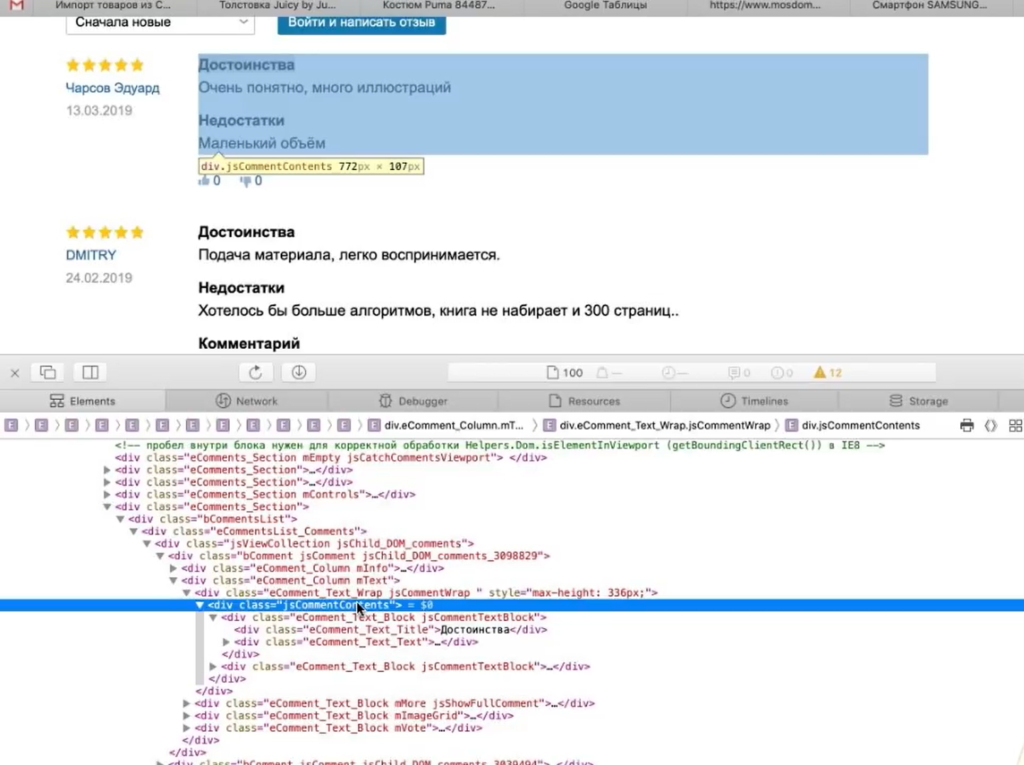
Следовательно, нам нужен такой XPath-запрос:
//*[@class="jsCommentContents"]Добавляем его в Screaming Frog. Теперь копируем адрес страницы, которую будем анализировать, и загружаем в парсер.
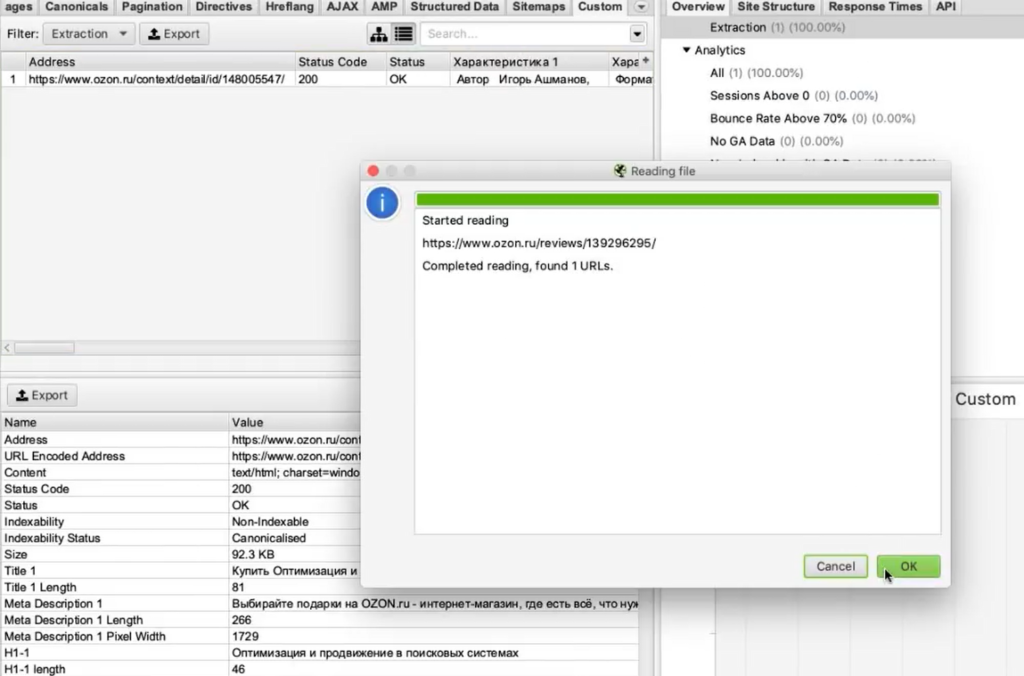
Жмем ОК и видим, что никакие отзывы у нас не загрузились:
Почему так? Разработчики Озона сделали так, что текст отзывов грузится в момент, когда вы докручиваете до места, где отзывы появляются (чтобы не перегружать страницу). То есть они изначально в коде нигде не видны.
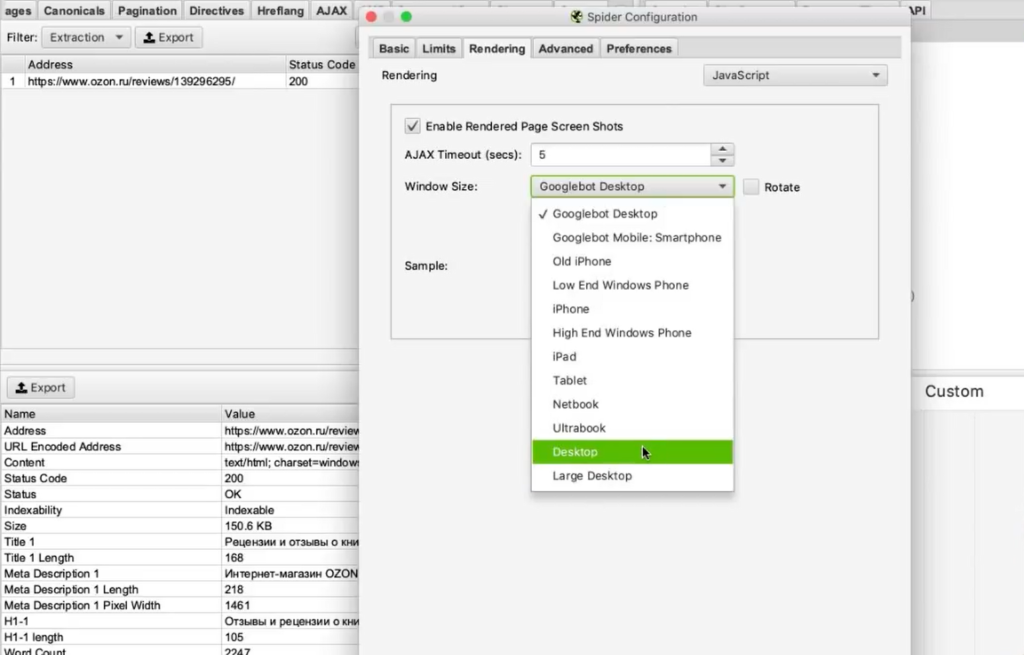
Чтобы с этим справиться, нам нужно зайти в Configuration > Spider, переключиться на вкладку Rendering и выбрать JavaScript. Так при обходе страниц парсером будет срабатывать JavaScript и страница будет отрисовываться полностью — так, как пользователь увидел бы ее в браузере. Screaming Frog также будет делать скриншот отрисованной страницы.

Мы выбираем устройство, с которого мы якобы заходим на сайт (десктоп). Настраиваем время задержки перед тем, как будет делаться скриншот, — одну секунду.
Нажимаем ОК. Введем вручную адрес страницы, включая #comments (якорная ссылка на раздел страницы, где отображаются отзывы).
Для этого жмем Upload > Enter Manually и вводим адрес:
Обратите внимание! При рендеринге (особенно, если страниц много) парсер может работать очень долго.
Итак, парсер собрал 20 отзывов. Внизу они показываются в качестве отрисованной страницы. А вверху в табличном варианте мы видим текст этих отзывов.
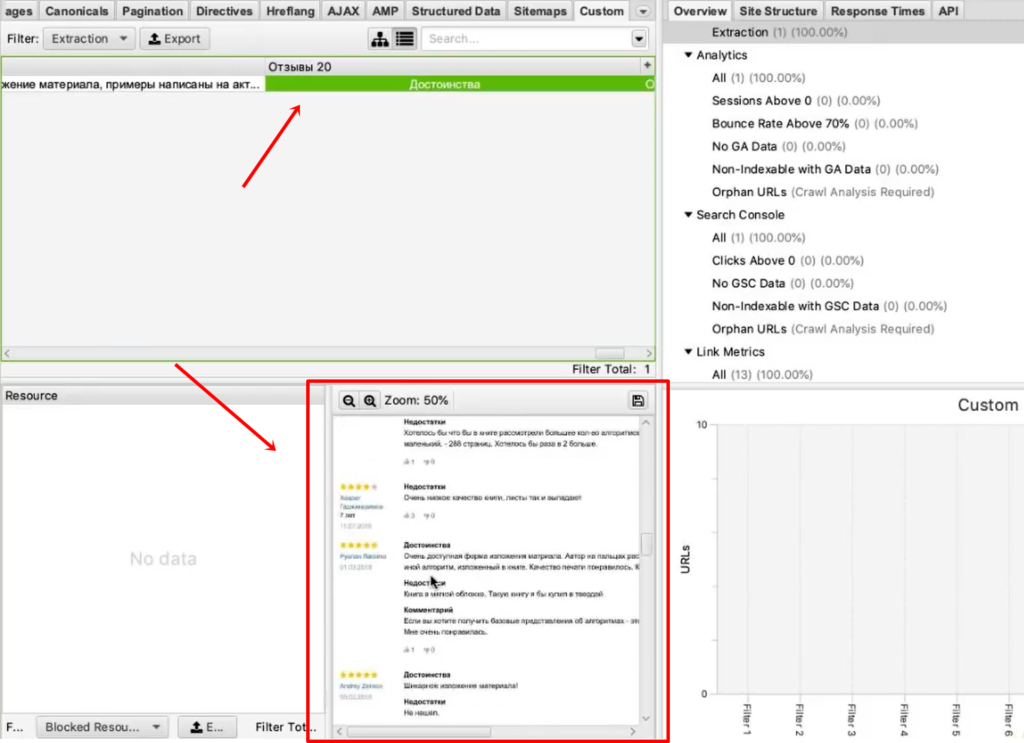
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
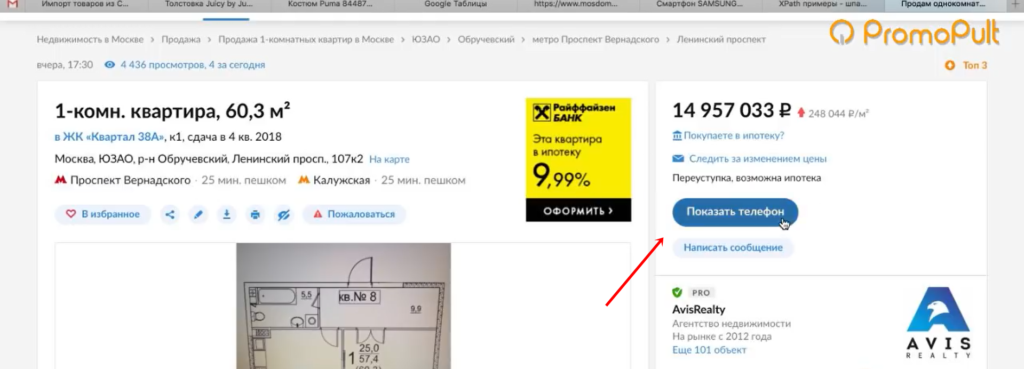
Следующий пример — сбор телефонов с сайта cian.ru. Здесь есть предложения о продаже квартир. Допустим, стоит задача собрать телефоны с каких-то предложений или вообще со всех.
У этой задачи есть особенности. На странице объявления телефон скрыт кнопкой «Показать телефон».
После клика он виден. А до этого в коде видна только сама кнопка.
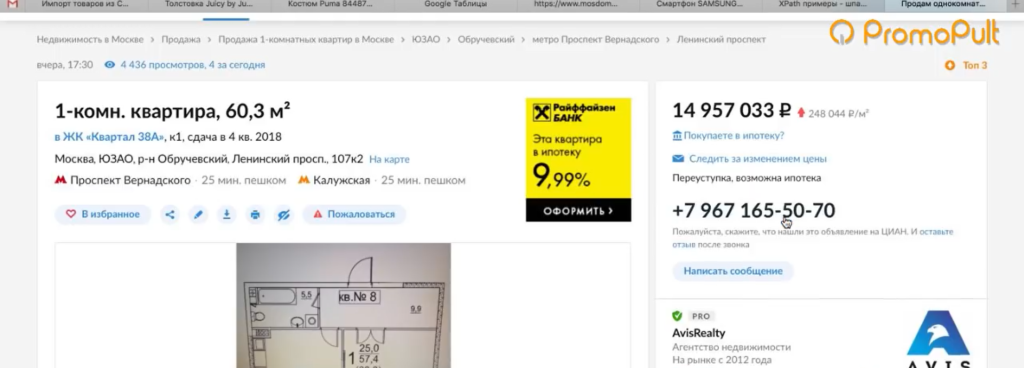
Но на сайте есть недоработка, которой мы воспользуемся. После нажатия на кнопку «Показать телефон» мы видим, что она начинается «+7 967…». Теперь обновим страницу, как будто мы не нажимали кнопку, посмотрим исходный код страницы и поищем в нем «967».
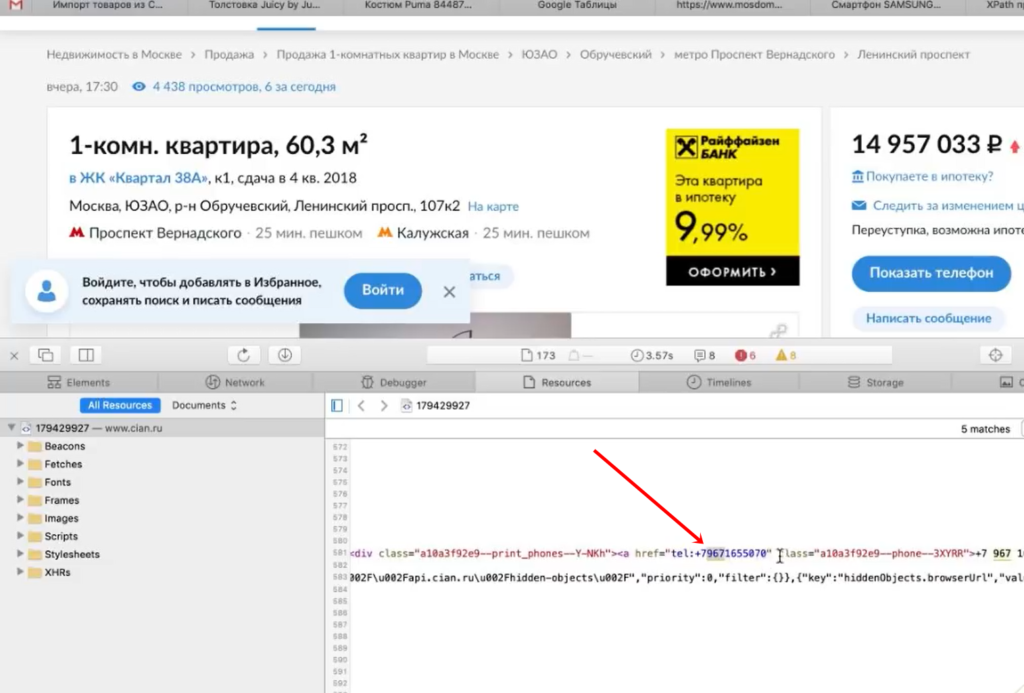
И вот, мы видим, что этот телефон уже есть в коде. Он находится у ссылки, с классом a10a3f92e9—phone—3XYRR. Чтобы собрать все телефоны, нам нужно спарсить содержимое всех элементов с таким классом.
Используем этот класс в XPath-запросе:
//*[@class="a10a3f92e9--phone--3XYRR"]Идем в Screaming Frog, Custom > Extraction. Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:
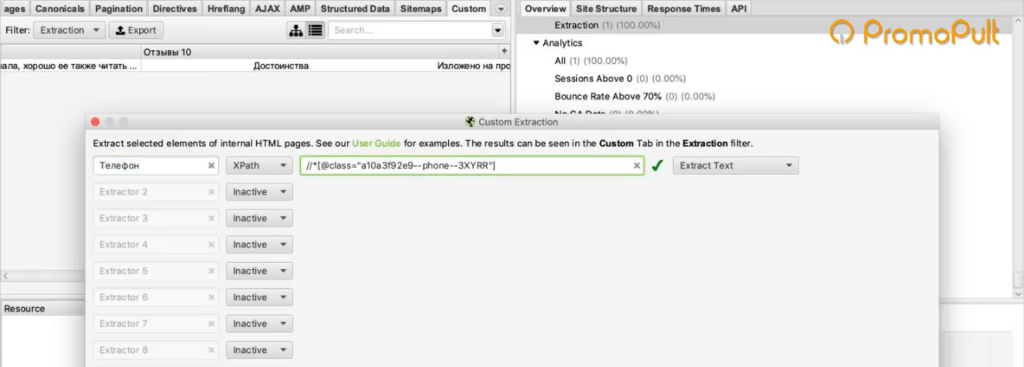
Берем список ссылок (для примера я отобрал несколько ссылок на страницы объявлений) и добавляем их в парсер.
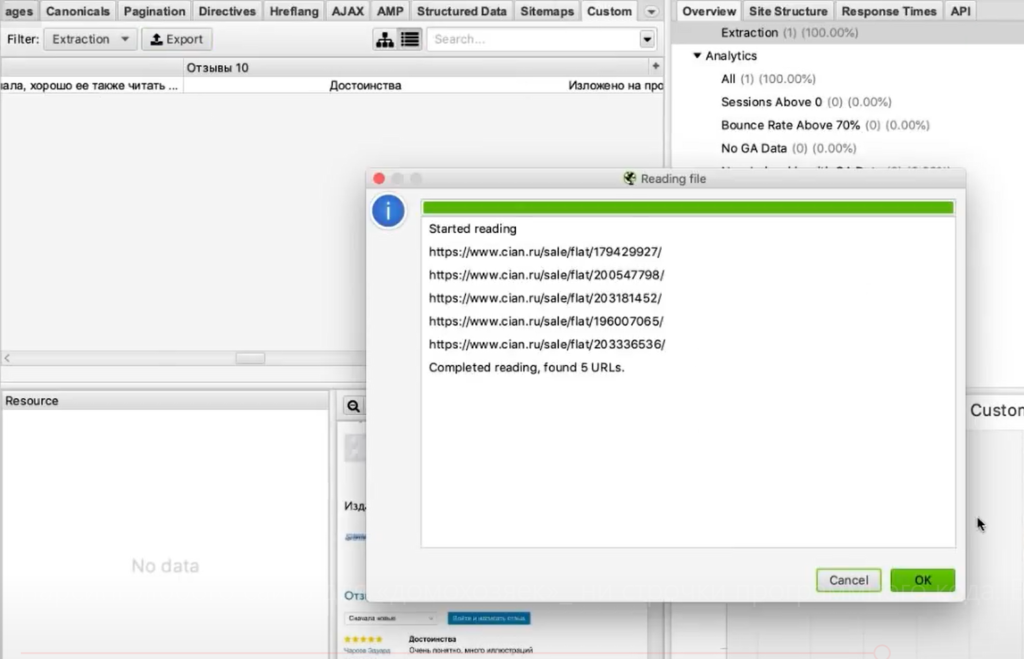
В итоге мы видим связку: адрес страницы — номер телефона.
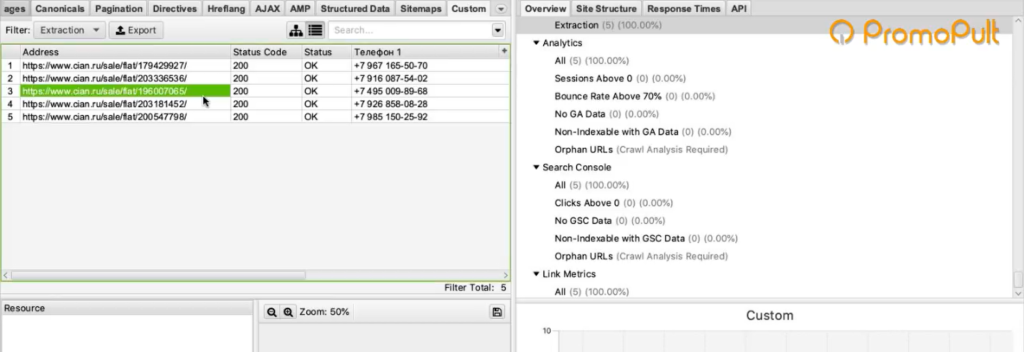
Также мы можем собрать в дополнение к телефонам еще что-то. Например, этаж.
Алгоритм такой же:
- Кликаем по этажу, Inspect Element.
- Смотрим, где в коде расположена информация об этажах и как обозначается.
- Используем класс или идентификатор этого элемента в XPath-запросе.
- Добавляем запрос и список страниц, запускаем парсер и собираем информацию.
Пример 6. Как парсить структуру сайта на примере DNS-Shop
И последний пример — сбор структуры сайта. С помощью парсинга можно собрать структуру какого-то большого каталога или интернет-магазина.
Рассмотрим, как собрать структуру dns-shop.ru. Для этого нам нужно понять, как строятся хлебные крошки.
Нажимаем на любую ссылку в хлебных крошках, выбираем Inspect Element.
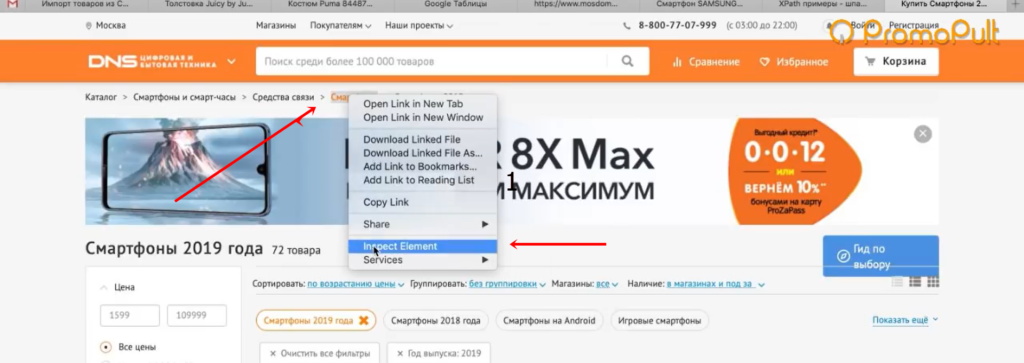
Эта ссылка в коде находится в элементе <span>, у которого атрибут itemprop (атрибут микроразметки) использует значение «name».
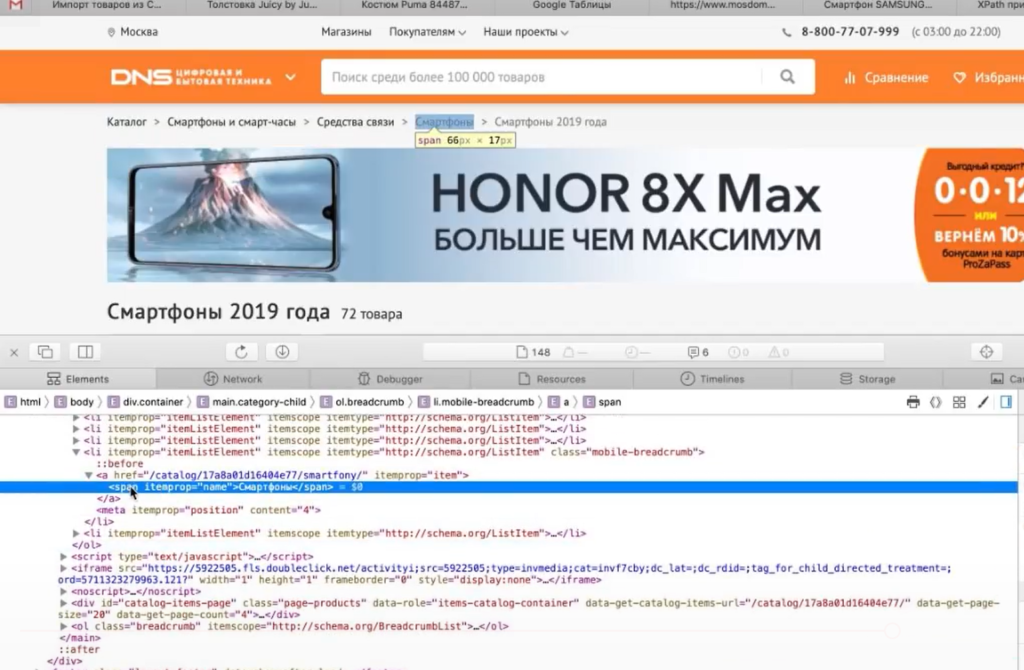
Используем элемент span со значением микроразметки в XPath-запросе:
//span[@itemprop="name"]Указываем XPath-запрос в парсере:
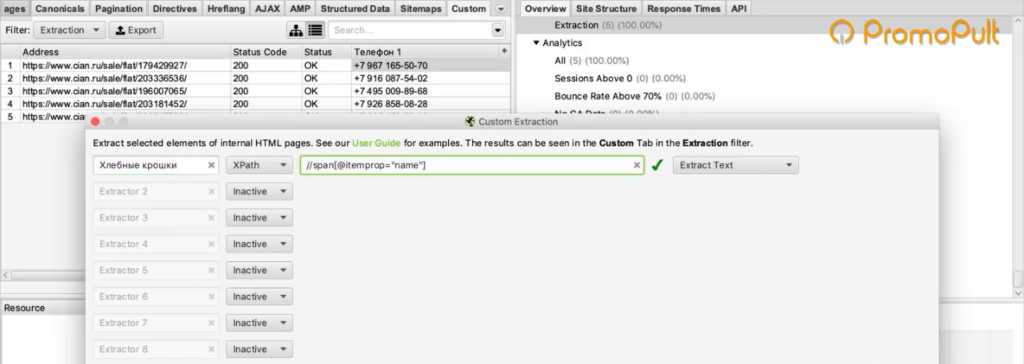
Пробуем спарсить одну страницу и получаем результат:
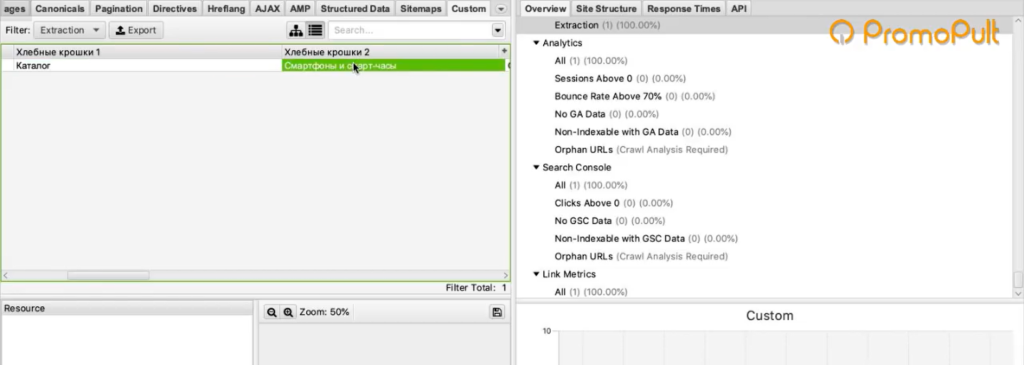
Таким образом мы можем пройтись по всем страницам сайта и собрать полную структуру.
Возможности парсинга на основе XPath
Что можно спарсить:
1. Любую информацию с почти любого сайта.
Нужно понимать, что есть сайты с защитой от парсинга. Например, если вы захотите спарсить любой проект Яндекса — у вас ничего не получится. Авито — тоже довольно-таки сложно. Но большинство сайтов можно спарсить.
2. Цены, наличие товаров, любые характеристики, фото, 3D-фото.
3. Описание, отзывы, структуру сайта.
4. Контакты, неочевидные свойства и т.д.
Любой элемент на странице, который есть в коде, вы можете вытянуть в Excel.
Ограничения при парсинге
- Бан по user-agent. При обращении к сайту парсер отсылает запрос user-agent, в котором сообщает сайту информацию о себе. Некоторые сайты сразу блокируют доступ парсеров, которые в user-agent представляются как приложения. Это ограничение можно легко обойти. В Screaming Frog нужно зайти в Configuration > User-Agent и выбрать YandexBot или Googlebot.
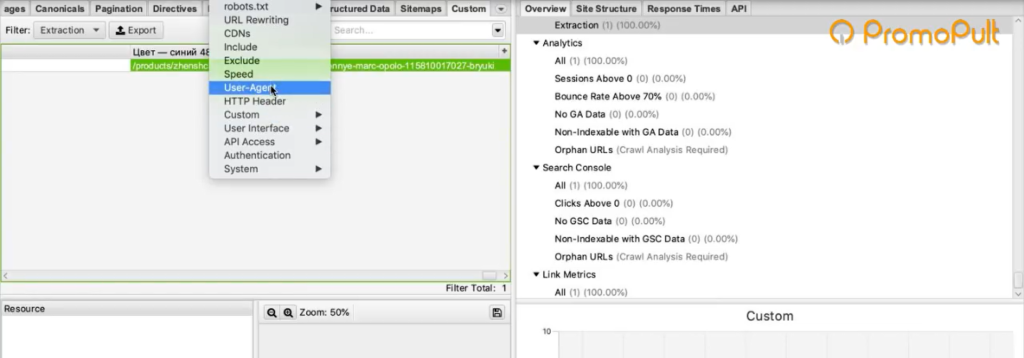
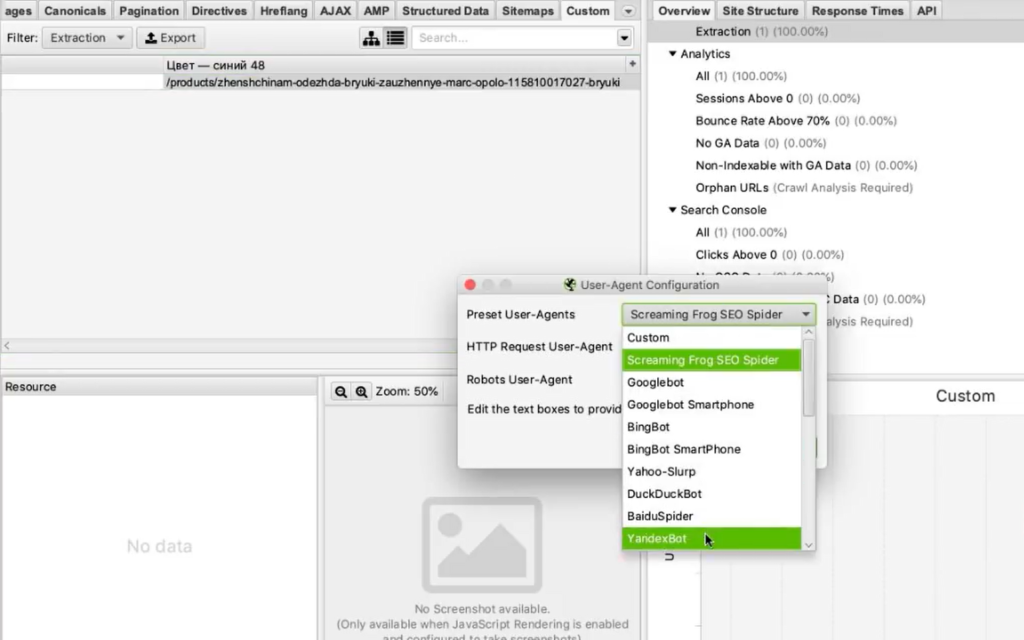
Подмена юзер-агента вполне себе решает данное ограничение. К большинству сайтов мы получим доступ таким образом.
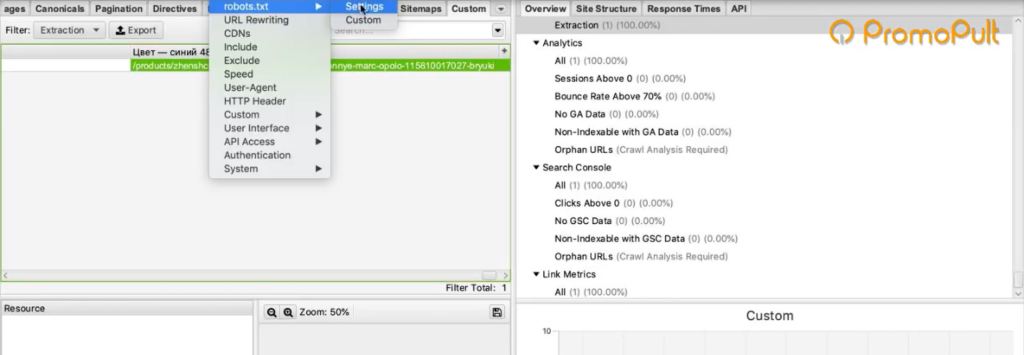
- Запрет в robots.txt. Например, в robots.txt может быть прописан запрет индексирования каких-то разделов для Google-бота. Если мы user-agent настроили как Googlebot, то спарсить информацию с этого раздела не сможем.
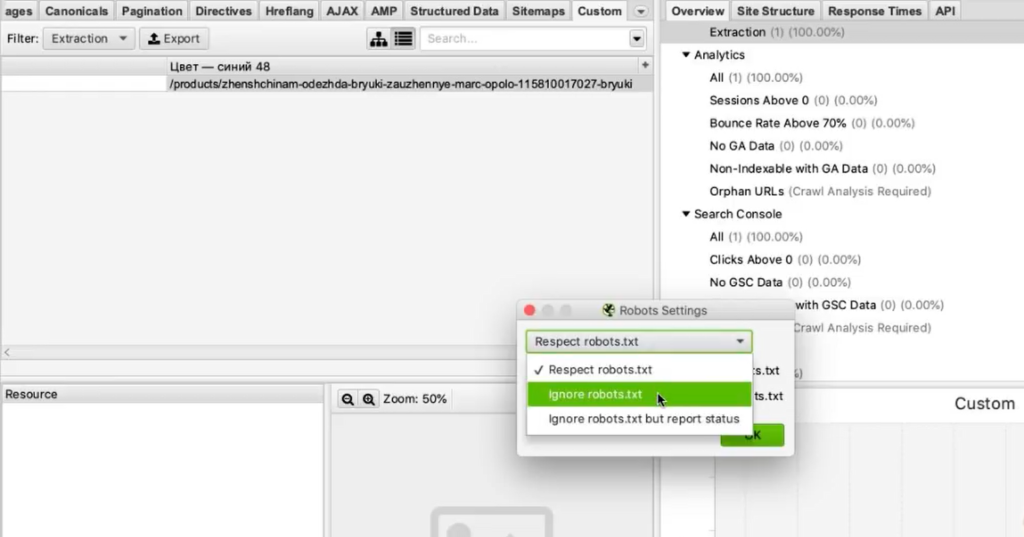
Чтобы обойти ограничение, заходим в Screaming Frog в Configuration > Robots.txt > Settings
И выбираем игнорировать robots.txt
- Бан по IP. Если вы долгое время парсите какой-то сайт, то вас могут заблокировать на определенное или неопределенное время. Здесь два варианта решения: использовать VPN или в настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
- Анализатор активности / капча. Некоторые сайты защищаются от парсинга с помощью умного анализатора активности. Если ваши действия похожи на роботизированные (когда обращаетесь к странице, у вас нет курсора, который двигается, или браузер не похож на стандартный), то анализатор показывает капчу, которую парсер не может обойти. Такое ограничение можно обойти, но это долго и дорого.
Теперь вы знаете, как собрать любую нужную информацию с сайтов конкурентов. Пользуйтесь приведенными примерами и помните — почти все можно спарсить. А если нельзя — то, возможно, вы просто не знаете как.
#статьи
- 13 май 2022
-

0
Не надо тыкать мне в лицо своим питоном: простой парсинг сайтов на Node.js для тех, кто ничего об этом не знает.
Иллюстрация: Node.js / Colowgee для Skillbox Media

Парсинг, также известный как веб-скрейпинг, — это автоматизированный сбор данных по Сети. И у него тысячи возможных способов применения в профессиях, связанных с постоянной работой с информацией. На примере парсинга статей с двух сайтов с помощью JavaScript и фреймворка Node.js я покажу, как он может помочь современному журналисту, пиарщику и маркетологу — тем, кто, казалось бы, далёк от программирования.
Предположим, у нас есть сайт-источник и мы хотим прочитать все статьи на нём, чтобы разобраться в определённой теме или сделать подборку новостей. Страниц на сайте много, и листать ленту очень долго. Что делать? Было бы удобно сначала получить список публикаций, а потом отфильтровать нужные.
Вкратце процедуру сбора данных с сайта можно описать следующим образом:
- Определяем сайт-источник и желаемые данные.
- Выясняем способ пагинации (перехода по страницам) и структуру кода сайта.
- Любым из множества возможных способов делаем последовательные сетевые запросы по каждой странице. Если у сайта есть API — используем API, если нет — другие инструменты.
- Переводим полученные данные в удобный формат.
- Записываем итоговые данные в файл.
Успех зависит от правильного анализа сайта. Нам нужно будет выяснить:
- Как происходит переход на следующую страницу. Это нужно, чтобы парсер делал всё автоматически, — в противном случае сбор завершится на первой же странице. Обычно это происходит при нажатии кнопки типа «Далее» или «Следующая страница» — а парсер имитирует нажатие.
- Правильное и точное место, где в HTML-разметке сайта содержатся нужные материалы. Для этого придётся определить местонахождение (вложенность) блоков, а также их селекторы.
Запросы нужно делать «вежливо», то есть с некоторой задержкой, чтобы не навредить сайту-источнику (например, не очень хорошо запускать цикл из сотни мгновенных запросов сразу ко всем страницам архива).
И категорически запрещено нарушать авторские права. Перед разработкой парсера стоит ознакомиться с пользовательским соглашением, которое может прямо запрещать автоматический сбор данных.
Для примера парсинга я взял два сайта, пагинация которых устроена по-разному: в первом случае это клик по кнопке «Следующая страница», а во втором — бесконечная подгрузка.
Наш парсер будет работать на языке JavaScript и в среде выполнения Node.js с использованием дополнительных модулей axios и jsdom:
- С помощью языка JavaScript мы будем объявлять переменные и константы, а также запускать функции и циклы.
- Фреймворк Node.js позволит выполнять всё это не в браузере, а через командную строку Windows.
- Встроенный в Node.js модуль fs (сокращение от file system) позволит работать с файловой системой компьютера, чтобы создавать файлы с результатом.
- Дополнительно скачиваемый модуль axios позволит в удобном виде делать HTTP-запросы по ссылкам.
- Дополнительно скачиваемый модуль jsdom позволит разбирать получаемый результат в виде DOM‑дерева, как если бы это делалось в браузере.
Перейдём к установке. Для этого нужно скачать и установить любым из способов Node.js с официального сайта. После этого с JavaScript-кодом можно будет работать из командной строки, в том числе запускать JS-файлы и отдельные команды.
Вместе с Node.js устанавливается так называемый менеджер пакетов npm, он позволит установить модули axios и jsdom. Открываем командную строку и вводим по очереди команды npm install axios и npm install jsdom — после каждой нужно дождаться завершения установки пакета. Можно установить модули в папку по умолчанию или в папку со своим проектом, это на ваше усмотрение.
Обратите внимание, что в качестве дополнительных модулей мы выбрали одни из наиболее популярных решений — об этом говорит статистика их скачиваний за неделю в каталоге npm. Логика такая: если их так часто используют, значит, они проверены и работают более или менее надёжно.
В классическом случае каждая страница с материалами сайта — отдельная, переход инициируется пользователем по клику. Для парсинга нужно по очереди перебрать все страницы, делая остановки на каждой и записывая необходимые данные, а затем переходить к следующей, пока доступные страницы не закончатся.
Посмотрим, как такой вид перехода реализован на сайте профессионального журнала «Журналист», и попробуем его спарсить. Этот сайт был выбран в качестве объекта для парсинга по следующим причинам:
- Во-первых, мы с редактором Skillbox Media «Код» согласились, что это классный журнал
- Во-вторых, структура пагинации журнала позволяет использовать его для демонстрации технологии.
- В-третьих, редакция «Журналиста» любезно согласилась нам помочь.

На сайте содержатся материалы примерно за шесть лет: больше 160 страниц, на каждой примерно пара десятков статей — итого почти 3000 материалов. Что получим на выходе: HTML-файл со списком названий статей и ссылками.
Выясняем способ перехода между страницами. Здесь переход по страницам происходит по нажатию кнопки «Читать ещё» под статьями, которая отправляет на сервер запрос вида «https://jrnlst.ru/node?page=2" и таким образом подгружает на ту же страницу дополнительные материалы, относящиеся к следующей странице.
Но мы воспользуемся вторым способом, который есть на сайте: ссылками вида «https://jrnlst.ru/?page=[номер страницы]», которые загружают именно отдельные страницы со статьями. Нумерация идёт с нулевой страницы (главной), хотя это прямо и не указывается.
Находим последнюю страницу, на которой нужно завершить сбор. Экспериментально я установил, что на момент написания статьи последней была страница под номером 162: на ней под статьями вместо кнопки перехода находится лаконичная надпись «Пока что это всё».
Нашёл я её просто: переходил по ссылкам с произвольными номерами страниц, начав с «page=200» (выбрал как предположение) и постепенно сокращая цифры, — здесь всё зависит от сайта, времени его существования и предположительной частоты обновления. Получается, у нас 163 страницы, так как мы должны учесть и нулевую (главную).
Показываем парсеру, где в HTML-коде находится нужная информация. С помощью встроенных в браузер инструментов веб-разработки изучаем структуру кода и выясняем — нужные нам заголовки в HTML‑иерархии находятся вот по какому пути: элемент с классом «block-views-articles-latest-on-front-block» → первый элемент с классом «view-content» → все элементы с классом «flex-teaser-square» (по очереди) → в каждом из них первый элемент с классом «views-field views-field-title» → в каждом из них первый элемент с тегом ‘a’ (то есть гиперссылка с названием статьи).
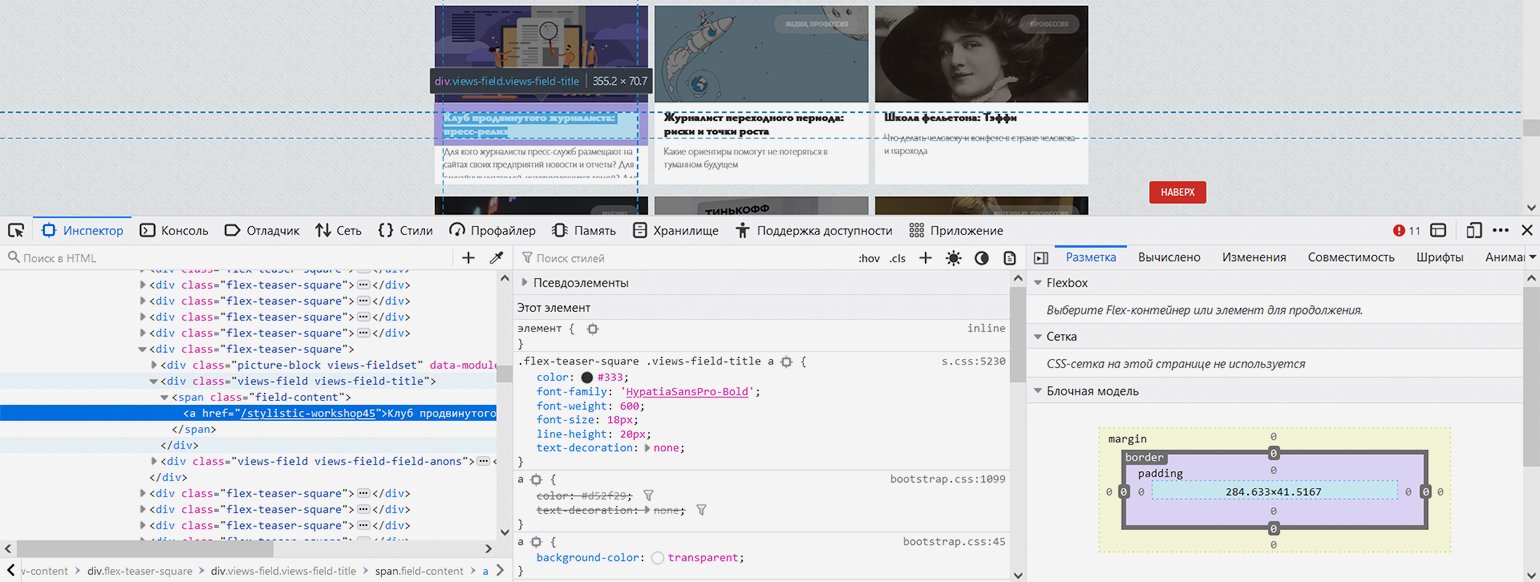
Скриншот: Евгений Колесников для Skillbox Media
Теперь, когда у нас есть все необходимые данные для парсера, давайте автоматизируем процесс сборки материалов.
Наш парсер будет состоять из двух файлов — JS-файл с собственно кодом и bat-файл для запуска по клику:
- Создадим файл с именем «JJ Articles Parser.js» (JJ — удобное сокращение от «журнал „Журналист“» — никакой магии). В этом файле будет практически весь наш исполняемый код.
- Создадим файл start.bat и пропишем в нём следующие команды:
cd "D:ваш_путьJJ Articles Parser" node JJ_articles_parser.js pause
Здесь всё просто:
- Первая строка — командой cd переходим в нужные диск и папку.
- Вторая строка запускает интерпретатор Node.js и тут же передаёт ему в обработку наш JS-файл.
- Команда pause делает так, чтобы командная строка не выключалась после выполнения кода.
Теперь займёмся кодом самого парсера:
/* Парсер статей журнала «Журналист» (https://jrnlst.ru) */ // Записывает заголовки и ссылки на статьи в HTML-файл // Написан на Node.js с использованием модулей axios и jsdom const axios = require('axios'); // Подключение модуля axios для скачивания страницы const fs = require('fs'); // Подключение встроенного в Node.js модуля fs для работы с файловой системой const jsdom = require("jsdom"); // Подключение модуля jsdom для работы с DOM-деревом (1) const { JSDOM } = jsdom; // Подключение модуля jsdom для работы с DOM-деревом (2) const pagesNumber = 162; // Количество страниц со статьями на сайте журнала на текущий день. На каждой странице до 18 статей const baseLink = 'https://jrnlst.ru/?page='; // Типовая ссылка на страницу со статьями (без номера в конце) var page = 0; // Номер первой страницы для старта перехода по страницам с помощью пагинатора var parsingTimeout = 0; // Стартовое значение задержки следующего запроса (увеличивается с каждым запросом, чтобы не отправлять их слишком часто) function paginator() { function getArticles() { var link = baseLink + page; // Конструктор ссылки на страницу со статьями для запроса по ней console.log('Запрос статей по ссылке: ' + link); // Уведомление о получившейся ссылке // Запрос к странице сайта axios.get(link) .then(response => { var currentPage = response.data; // Запись полученного результата const dom = new JSDOM(currentPage); // Инициализация библиотеки jsdom для разбора полученных HTML-данных, как в браузере // Определение количества ссылок на странице, потому что оно у них не всегда фиксированное. Это значение понадобится в цикле ниже var linksLength = dom.window.document.getElementById('block-views-articles-latest-on-front-block').getElementsByClassName('view-content')[0].getElementsByClassName('flex-teaser-square').length; // Перебор и запись всех статей на выбранной странице for (i = 0; i < linksLength; i++) { // Получение относительных ссылок на статьи (так в оригинале) var relLink = dom.window.document.getElementById('block-views-articles-latest-on-front-block').getElementsByClassName('view-content')[0].getElementsByClassName('flex-teaser-square')[i].getElementsByClassName('views-field views-field-title')[0].getElementsByTagName('a')[0].outerHTML; // Превращение ссылок в абсолютные var article = relLink.replace('/', 'https://jrnlst.ru/') + '<br>' + 'n'; // Уведомление о найденных статьях console.log('На странице ' + 'найдена статья: ' + article); // Запись результата в файл fs.appendFileSync('ПУТЬ/articles.html', article, (err) => { if (err) throw err; }); }; if (page > pagesNumber) { console.log('Парсинг завершён.')}; // Уведомление об окончании работы парсера }); page++; // Увеличение номера страницы для сбора данных, чтобы следующий запрос был на более старую страницу }; for (var i = page; i <= pagesNumber; i++) { var getTimer = setTimeout(getArticles, parsingTimeout); // Запуск сбора статей на конкретной странице с задержкой parsingTimeout += 10000; // Определение времени, через которое начнётся повторный запрос (к следующей по счёту странице) }; return; // Завершение работы функции }; paginator(); // Запуск перехода по страницам и сбора статей
Посмотреть код на Pastebin
На всё ровно 50 строк с учётом детальных комментариев для читающего и уведомлений в консоль о ходе выполнения программы.
Концептуально этот парсер работает так:
- Подключаем нужные модули.
- Определяем константы: количество страниц сайта, основную часть ссылки (кроме номера страницы, который как раз меняется).
- Определяем стартовые значения основных переменных: начало прохода с нулевой страницы и нулевую задержку запросов, которая будет постоянно увеличиваться.
- Определяем основную функцию парсера под названием paginator(), в которой находится почти весь код.
- Последней строкой запускаем эту функцию.
Отдельно скажем об устройстве функции paginator().
Внутри неё есть ещё одна функция — getArticles(), которая конструирует ссылку на последующую страницу из постоянной «базовой части» и номера, делает GET-запрос с помощью команды модулю axios, разбирает результат как DOM-дерево с помощью модуля jsdom, вынимает все ссылки на странице, превращает их из относительных в абсолютные, записывает результат в файл и увеличивает переменную с номером страницы для использования в следующем запросе.
Цикл for, который запускает внутреннюю функцию getArticles() — по расписанию и со всё увеличивающейся задержкой. Установлена задержка в 10 секунд, потому что это не будет сильно нагружать сайт, а общее время выполнения не окажется слишком долгим — плюс разработчики сайта сами рекомендовали такое время в директиве crawl-delay в файле robots.txt (хотя так делают разработчики далеко не всех сайтов, потому что эта директива считается устаревшей). Каждый последующий запуск функции инициирует запрос к более старой странице, поскольку каждый предыдущий запуск увеличивает переменную с номером страницы на 1.
Функция getArticles() запускается, пока переменная с номером следующей страницы не превысит константу с общим количеством страниц. Тогда выполнение всего кода завершается с уведомлением в консоль. В противном случае парсер пытался бы стучаться в двери сайта бесконечно, в чём нет никакого смысла.
Скриншот: Евгений Колесников для Skillbox Media
Когда код написан и настроен, остаётся только запустить его кликом по батнику (start.bat) и наблюдать в реальном времени за выполнением. Примерно через полчаса мы получим HTML-файл со списком всех 2920 статей ссылками, как и планировалось.
Напомним, второй способ — это загрузка дополнительных статей на ту же страницу. Обычно в таких случаях простых способов перейти на какую-то дату или в конец просто нет. Страницы со статьями, конечно же, существуют, но только для сервера, обрабатывающего запрос на подгрузку, а не для пользователя.
Для демонстрации этого способа пагинации по предложению редактора Тимура спарсим рубрику «Код» Skillbox Media (без новостей, только статьи). Как тут, спрашивается, применить описанные выше принципы сбора, если видимой нумерации страниц нет? Пойдём по тем же шагам, что и в прошлом примере.
В этом случае наши действия будут иными: нужно открыть в браузере инструменты веб-разработки на вкладке «Сеть», чтобы пошпионить за выполняемыми сайтом запросами, а после этого нажать на странице рубрики на кнопку «Показать ещё», подгружающую дополнительные материалы.

Скриншот: Евгений Колесников для Skillbox Media
В списке запросов можно увидеть POST-запрос к сайту skillbox.ru на выполнение PHP-файла с говорящим названием getArticlesIndex.php, ответ возвращается в часто используемом формате разметки данных JSON. URL запроса: https://skillbox.ru/local/ajax/getArticlesIndex.php — при этом на вкладке «Запрос» можно увидеть, что он передаётся с такими параметрами:
{
"params[SECTION_ID]": "10",
"params[CODE_EXCLUDE]": "news",
"params[FIRST_IS_FULL]": "Y",
"params[COUNT]": "7",
"params[PAGE_NUM]": "2",
"params[FIELDS][]": "PROPERTY_FAKE_COUNTER",
"params[CACHE_TYPE]": "A",
"params[COMPONENT_TEMPLATE]": "articles"
}
Параметр «PAGE_NUM», равный в данном случае 2, соответствует как раз номеру страницы, «SECTION_ID», равный 10, соответствует рубрике «Код», которую мы собрались парсить, а «COUNT», равный 7, — количеству выводимых на странице материалов.
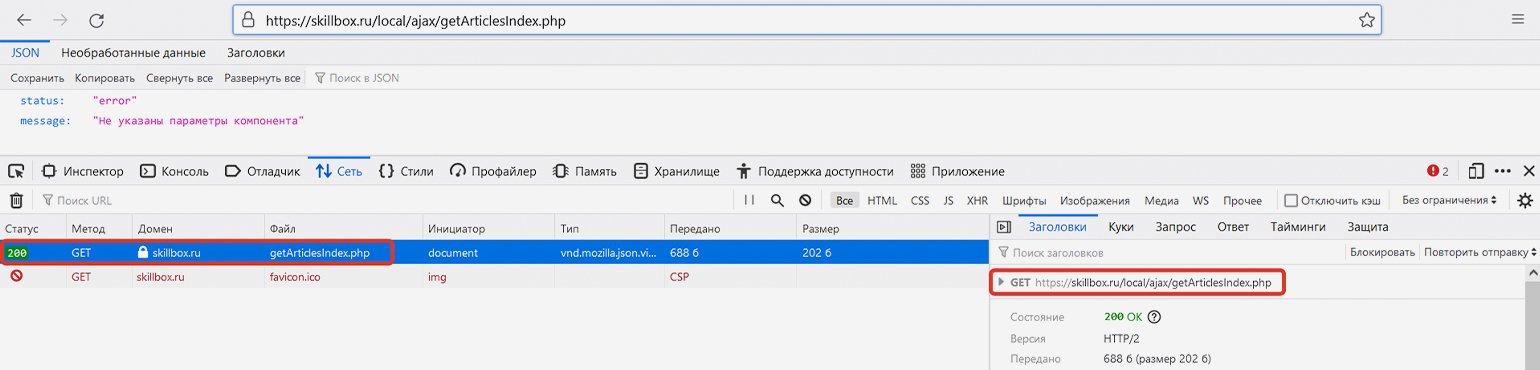
Обратите внимание, что загрузка дополнительных статей в данном случае оформлена как POST-запрос, а не GET- (обычно GET-запрос используется для получения данных с сервера, а POST-запрос — для отправки). Почему это так — отдельный вопрос, выходящий за рамки статьи. При разработке парсера мы должны подстроиться под логику разработчиков сайта, однако ради любопытства попробуем провести небольшой эксперимент.
Если мы скопируем указанную выше ссылку и перейдём по ней без указания параметров, то сайт выдаст ошибку («status: error») — он просто не будет знать, какую информацию мы у него просим. Здесь браузер передаст именно GET-запрос, а не POST-, однако сайт всё равно нам отвечает (сообщение об ошибке — тоже сообщение).
Скриншот: Евгений Колесников для Skillbox Media
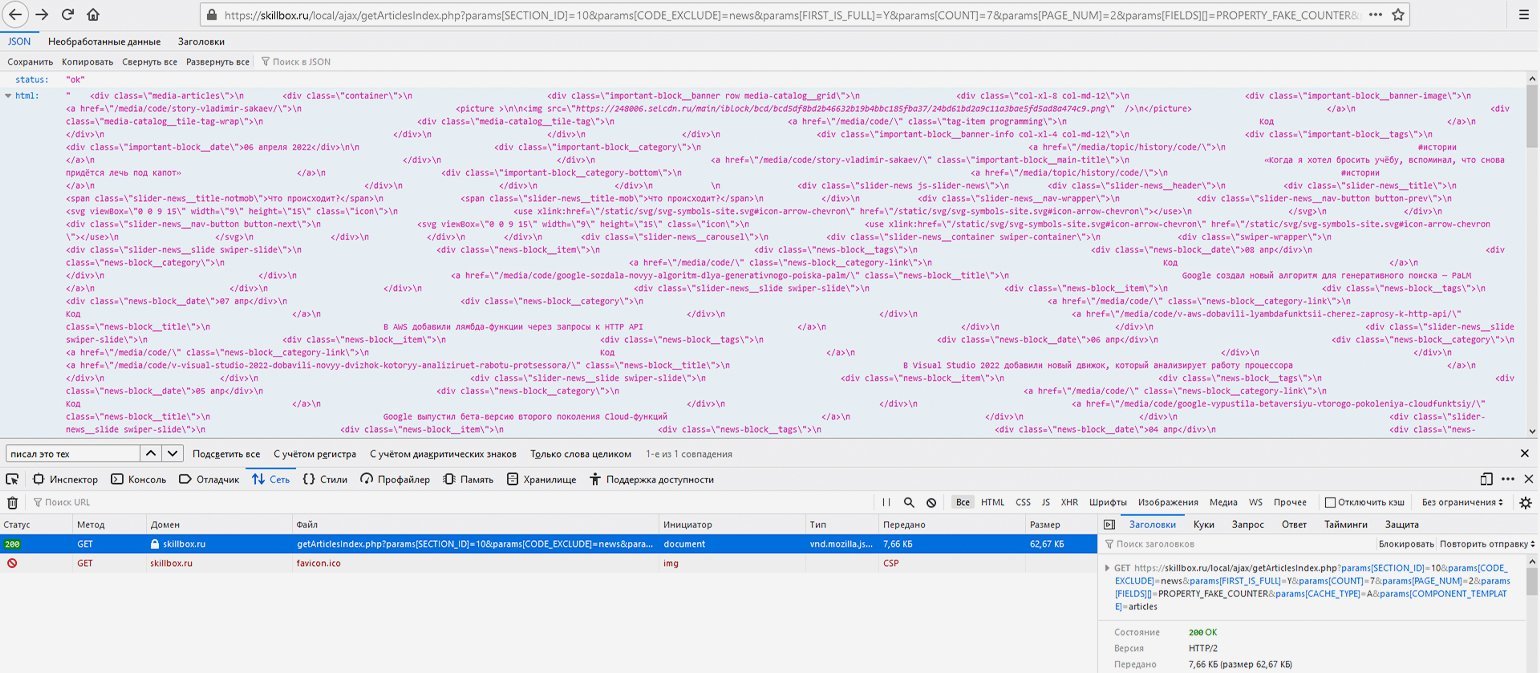
Если попробовать сделать прямой запрос по той же ссылке и с указанием правильных параметров, то опять же в результате GET-запроса получим JSON-ответ с HTML-кодом дополнительных статей и статусом «ok».
Например, соединим базовую ссылку и указанные выше параметры в единую строку — https://skillbox.ru/local/ajax/getArticlesIndex.php?params[SECTION_ID]=10& params[CODE_EXCLUDE]=news& params[FIRST_IS_FULL]=Y& params[COUNT]=7& params[PAGE_NUM]=2& params[FIELDS][]=PROPERTY_FAKE_COUNTER& params[CACHE_TYPE]=A& params[COMPONENT_TEMPLATE]=articles — и сделаем GET-запрос, перейдя по конечной ссылке. В ответ сайт отдаст данные в JSON-формате — это будет разметка списка статей на второй странице, в чём легко убедиться, найдя в этой мешанине через поиск доступные на сайте названия статей.
Скриншот: Евгений Колесников для Skillbox Media
Теперь, когда мы примерно поняли структуру пагинации, нужно определиться, где же парсеру надо остановиться — где заканчиваются статьи.
Загуглив фразу «Skillbox запустил медиа», находим материал «Подборка статей Skillbox в честь запуска медиа» от 8 июля 2018 года в блоге Skillbox на Medium. Это уже что-то — теперь можно догадаться, что статьи на сайте появились примерно в первой половине 2018 года.
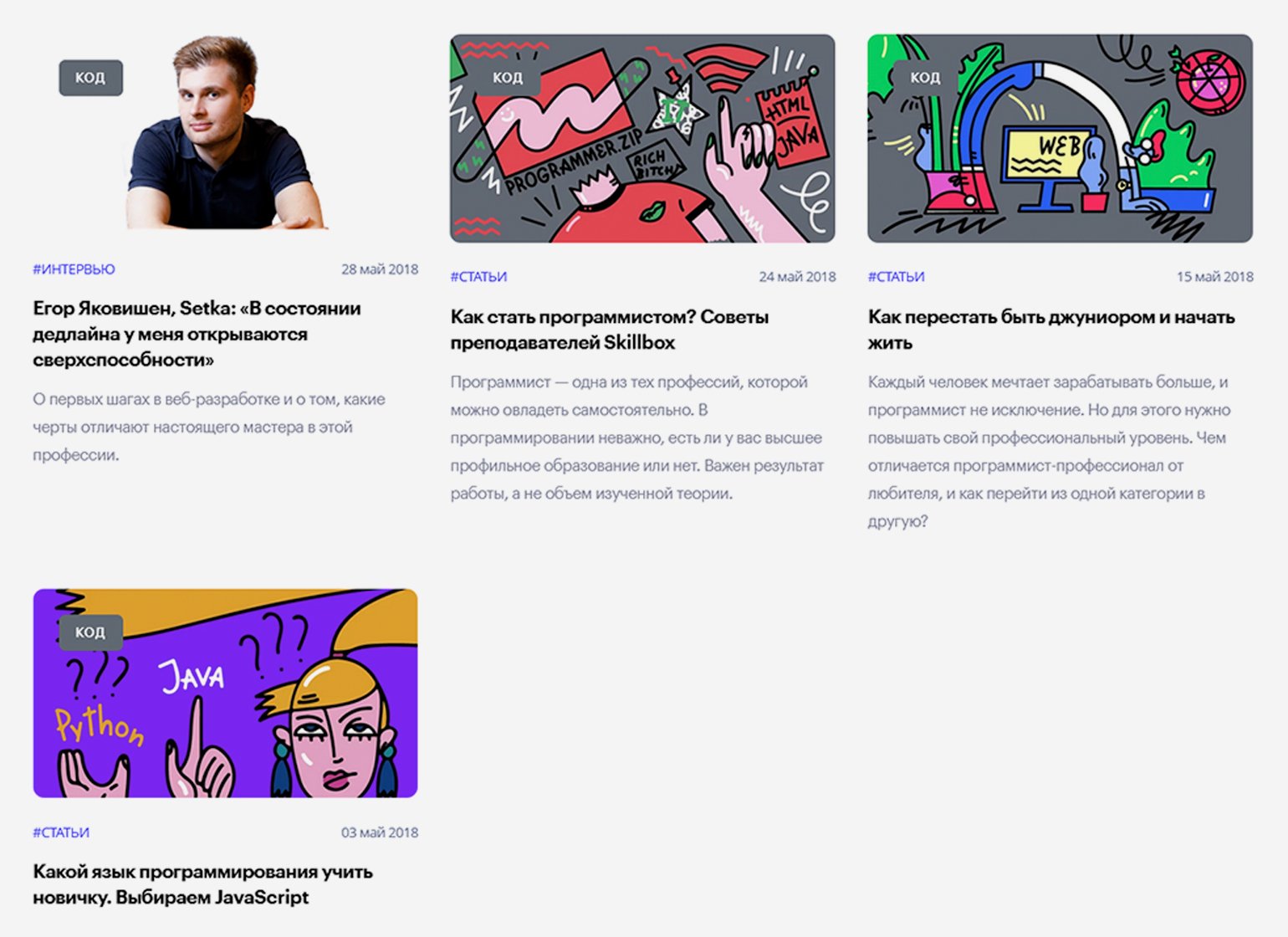
Как и в предыдущем примере, начинаем искать номер последней страницы перебором параметра «[PAGE_NUM]». Если введённого номера страницы нет, сайт отдаёт первую страницу — в таком случае номер нужно уменьшить.
На момент написания статьи последняя страница была под номером 101, на каждой — по семь материалов: исходя из этого было сделано предположение, что всего в рубрике «Код» должно быть примерно 707 статей (в реальности их оказалось 705, потому что на последней странице было только пять публикаций). В данном случае автор мог сверить подсчёты с редактором раздела, который подтвердил их правильность, — однако так везёт далеко не всегда. Судя по выданному сайтом результату, первая статья раздела — «Какой язык программирования учить новичку. Выбираем JavaScript» от 3 мая 2018 года.
Скриншот: Евгений Колесников для Skillbox Media
Вернёмся к первой странице рубрики и попробуем с помощью инструментов веб-разработчика найти местонахождение ссылок на статьи, чтобы указать его парсеру.
Скриншот: Евгений Колесников для Skillbox Media
Со статьёй в закрепе проблем нет — она такая одна, это элемент с классом «important-block__main-title».
Скриншот: Евгений Колесников для Skillbox Media
С остальными посложнее: блочный элемент <div> с классом «media-catalog__tile-title» вложен в ссылку — элемент <a>, что довольно необычно. <div> содержит только текст заголовка, а у ссылки <a> не указан класс — но всё это мы решим с помощью правильной навигации.
Создаём два файла — skbx_code_articles_parser.js с кодом и start.bat для его запуска. Батник копируем почти без изменений — отличаться будут только путь и имя запускаемого скрипта. В JS-файл вставляем следующий код:
/* Парсер статей рубрики «Код» портала Skillbox Media (https://skillbox.ru/media/code/) */ // Записывает заголовки и ссылки на статьи в HTML-файл // Написан на Node.js с использованием модулей axios и jsdom const axios = require('axios'); // Подключаем к Node.js модуль axios для скачивания страницы const fs = require('fs'); // Подключение встроенного в Node.js модуля fs для работы с файловой системой const jsdom = require("jsdom"); // Подключение модуля jsdom для работы с DOM-деревом (1) const { JSDOM } = jsdom; // Подключение модуля jsdom для работы с DOM-деревом (2) const pagesNumber = 101; // Количество страниц со статьями на сайте журнала на текущий день. На каждой странице по семь статей var page = 1; // Номер первой страницы для старта перехода по страницам с помощью пагинатора var parsingTimeout = 0; // Стартовое значение задержки следующего запроса (увеличивается с каждым запросом, чтобы не отправлять их слишком часто) // Определяем стартовые параметры запроса (меняться будет только номер страницы) var params = new URLSearchParams(); params.append('params[SECTION_ID]', '10'); params.append('params[CODE_EXCLUDE]', 'news'); params.append('params[FIRST_IS_FULL]', 'Y'); params.append('params[COUNT]', '7'); params.append('params[PAGE_NUM]', '1'); params.append('params[FIELDS][]', 'PROPERTY_FAKE_COUNTER'); params.append('params[CACHE_TYPE]', 'A'); params.append('params[COMPONENT_TEMPLATE]', 'articles'); function paginator() { function getArticles() { console.log('Запрос статей со страницы ' + params.get('params[PAGE_NUM]')); // Уведомление о номере текущей страницы // Запрос к странице сайта axios.post('https://skillbox.ru/local/ajax/getArticlesIndex.php?', params) .then(response => { var currentPage = response.data; // Запись полученного результата var jsonToHtml = currentPage.html; // Получаем из JSON-ответа только HTML-код const dom = new JSDOM(jsonToHtml); // Инициализация библиотеки jsdom для разбора полученных HTML-данных, как в браузере // Парсинг закреплённой статьи var pinnedHeaderSpaces = dom.window.document.getElementsByClassName('important-block__main-title')[0].innerHTML; // Получение заголовка закреплённой статьи с лишними пробелами var pinnedHeader = pinnedHeaderSpaces.trim(); // Заголовок закреплённой статьи с удалёнными лишними пробелами var pinnedLink = dom.window.document.getElementsByClassName('important-block__main-title')[0].getAttribute('href'); // Получение относительной ссылки на закреплённую статью var pinnedArticle = '<a href="https://skillbox.ru' + pinnedLink + '">' + pinnedHeader + '</a><br>'+ 'n'; // Итоговая ссылка с заголовком закреплённой статьи console.log('На странице найдена закреплённая статья: ' + pinnedArticle); // Запись закреплённой статьи в файл fs.appendFileSync('ПУТЬ/articles.html', pinnedArticle, (err) => { if (err) throw err; }); // Парсинг остальных шести статей на странице var articlesNumber = dom.window.document.getElementsByClassName('media-catalog__tile-title').length; // Определение количества ссылок на странице, потому что на последней странице их меньше. Эта цифра понадобится в цикле ниже for (var art = 0; art < articlesNumber; art++) { var articleHeaderSpaces = dom.window.document.getElementsByClassName('media-catalog__tile-title')[art].innerHTML; // Получение заголовка статьи с лишними пробелами var articleHeader = articleHeaderSpaces.trim(); // Заголовок статьи с удалёнными лишними пробелами var articleLink = dom.window.document.getElementsByClassName('media-catalog__tile')[art].getElementsByClassName('media-catalog__tile-title')[0].parentElement.getAttribute('href'); // Получение относительной ссылки на статью var article = '<a href="https://skillbox.ru' + articleLink + '">' + articleHeader + '</a><br>'+ 'n'; // Итоговая ссылка с заголовком статьи console.log('На странице найдена статья: ' + article); // Запись статьи в файл fs.appendFileSync('ПУТЬ/articles.html', article, (err) => { if (err) throw err; }); }; if (page > pagesNumber) { console.log('Парсинг завершён.'); // Уведомление об окончании работы парсера }; }); page++; // Увеличение номера страницы для сбора данных, чтобы следующий запрос был на более старую страницу params.set('params[PAGE_NUM]', page); return; }; for (var i = page; i <= pagesNumber; i++) { var getTimer = setTimeout(getArticles, parsingTimeout); // Запуск сбора статей на конкретной странице с задержкой parsingTimeout += 10000; // Определение времени, через которое начнётся повторный запрос (к следующей по счёту странице) }; return; }; paginator(); // Запуск перехода по страницам и сбора статей
Посмотреть код на Pastebin
Наш код изменился, но всё ещё похож на прошлый. Обратите внимание на ряд нюансов:
- Делаем не GET-, а POST-запрос, поэтому вместо метода axios.get() будем использовать axios.post() (строка 29).
- Используем интерфейс URLSearchParams для передачи и чтения найденных выше параметров сетевого запроса в особом формате (строки 14–23, 27 и 62–63).
- Немного затрагиваем получение данных из JSON-формата, но только в одной строчке (строки 32–33).
- На каждой странице сначала отдельно парсим закреплённую статью, а потом шесть обычных, следуя логике вёрстки сайта.
Скриншот: Евгений Колесников для Skillbox Media
Как и в прошлом примере, запускаем парсер кликом на файл start.bat и примерно 17 минут ждём результата — HTML-файла со списком из 705 статей.
И ваш парсер тоже. Вы можете читать этот материал через день или через год после выхода. На момент подготовки статьи сайт Skillbox Media выводил по семь статей на странице: одну в закрепе и шесть снизу. Впоследствии разработчики неожиданно удвоили выдачу — теперь уже выводится по 14 статей в следующем порядке: одна в закрепе, шесть снизу, снова одна в закрепе и ещё шесть снизу.
Мы решили оставить этот факт как часть урока о парсерах: сайт, который вы собираете, может в любой момент поменять дизайн и структуру материалов, поэтому не следует ожидать, что ваш сборщик будет работать вечно даже на одном и том же ресурсе.
В ходе теста выяснилось, что с выдачей 14 материалов вместо семи указанный выше код также справляется, поскольку параметры с номером страницы и количеством статей на ней взаимосвязаны и ответ сервера адаптируется под ваш запрос (даже если он построен по старому принципу).
Однако, если, как и раньше, подстраиваться под логику разработчиков, будет разумно поменять навигацию: указать в константе в два раза меньшее число страниц и поменять порядок перебора расположенных на них элементов — имея в два раза больше статей на каждой, для сохранения правильного порядка мы должны задать проход по алгоритму «первый закреп, обычные статьи с первой по шестую, второй закреп, обычные статьи с седьмой по 12-ю». Вы можете сделать это самостоятельно в качестве упражнения.
Мы рассмотрели два рабочих способа автоматического сбора материалов на сайтах СМИ. Есть и другие варианты: парсить список материалов в Excel-таблицу, в файл закладок для импорта в браузер, сделать красивый дизайн, автоматически отправлять результат в Telegram-чат через бота, сортировать, проводить контент-анализ (рубрики, ключевые слова, частота публикации), вставлять галочки для отметки прочитанного и так далее — насколько хватит фантазии.
Вероятно, приведённый выше код не идеален, ведь он написан не профессиональным программистом, а журналистом, применяющим программирование в работе. Это важный момент: он показывает, что сейчас программирование нужно всем и доступно всем, если выйти за пределы привычных методов работы и изучить что-то новое.
Исходные данные – это фундамент для успешной работы в области анализа и обработки данных. Существует множество источников данных, и веб-сайты являются одним из них. Часто они могут быть вторичным источником информации, например: сайты агрегации данных (Worldometers), новостные сайты (CNBC), социальные сети (Twitter), платформы электронной коммерции (Shopee) и так далее. Эти веб-сайты предоставляют информацию, необходимую для проектов по анализу и обработке данных.
Но как нужно собирать данные? Мы не можем копировать и вставлять их вручную, не так ли? В такой ситуации решением проблемы будет парсинг сайтов на Python. Этот язык программирования имеет мощную библиотеку BeautifulSoup, а также инструмент для автоматизации Selenium. Они оба часто используются специалистами для сбора данных разных форматов. В этом разделе мы сначала познакомимся с BeautifulSoup.
ШАГ 1. УСТАНОВКА БИБЛИОТЕК
Прежде всего, нам нужно установить нужные библиотеки, а именно:
- BeautifulSoup4
- Requests
- pandas
- lxml
Для установки библиотеки вы можете использовать pip install [имя библиотеки] или conda install [имя библиотеки], если у вас Anaconda Prompt.
«Requests» — это наша следующая библиотека для установки. Ее задача — запрос разрешения у сервера, если мы хотим получить данные с его веб-сайта. Затем нужно установить pandas для создания фрейма данных и lxml, чтобы изменить HTML на формат, удобный для Python.
ШАГ 2. ИМПОРТИРОВАНИЕ БИБЛИОТЕК
После установки библиотек давайте откроем вашу любимую среду разработки. Мы предлагаем использовать Spyder 4.2.5. Позже на некоторых этапах работы мы столкнемся с большими объемами выводимых данных и тогда Spyder будет удобнее в использовании чем Jupyter Notebook.
Итак, Spyder открыт и мы можем импортировать необходимую библиотеку:
# Import library
from bs4 import BeautifulSoup
import requests
ШАГ 3. ВЫБОР СТРАНИЦЫ
В этом проекте мы будем использовать webscraper.io. Поскольку данный веб-сайт создан на HTML, код легче и понятнее даже новичкам. Мы выбрали эту страницу для парсинга данных:
Она является прототипом веб-сайта онлайн магазина. Мы будем парсить данные о компьютерах и ноутбуках, такие как название продукта, цена, описание и отзывы.
ШАГ 4. ЗАПРОС НА РАЗРЕШЕНИЕ
После выбора страницы мы копируем ее URL-адрес и используем request, чтобы запросить разрешение у сервера на получение данных с их сайта.
# Define URL
url = ‘https://webscraper.io/test-sites/e-commerce/allinone/computers/laptops'#
Ask hosting server to fetch url
requests.get(url)
Результат <Response [200]> означает, что сервер позволяет нам собирать данные с их веб-сайта. Для проверки мы можем использовать функцию request.get.
pages = requests.get(url)
pages.text
Когда вы выполните этот код, то на выходе получите беспорядочный текст, который не подходит для Python. Нам нужно использовать парсер, чтобы сделать его более читабельным.
# parser-lxml = Change html to Python friendly format
soup = BeautifulSoup(pages.text, ‘lxml’)
soup

ШАГ 5. ПРОСМОТР КОДА ЭЛЕМЕНТА
Для парсинга сайтов на Python мы рекомендуем использовать Google Chrome, он очень удобен и прост в использовании. Давайте узнаем, как с помощью Chrome просмотреть код веб-страницы. Сначала нужно щелкнуть правой кнопкой мыши страницу, которую вы хотите проверить, далее нажать Просмотреть код и вы увидите это:
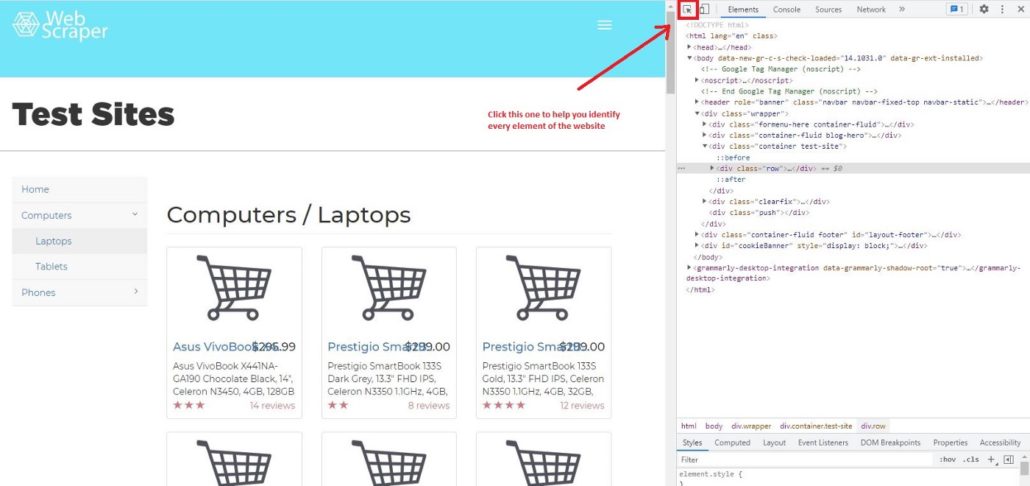
Затем щелкните Выбрать элемент на странице для проверки и вы заметите, что при перемещении курсора к каждому элементу страницы, меню элементов показывает его код.
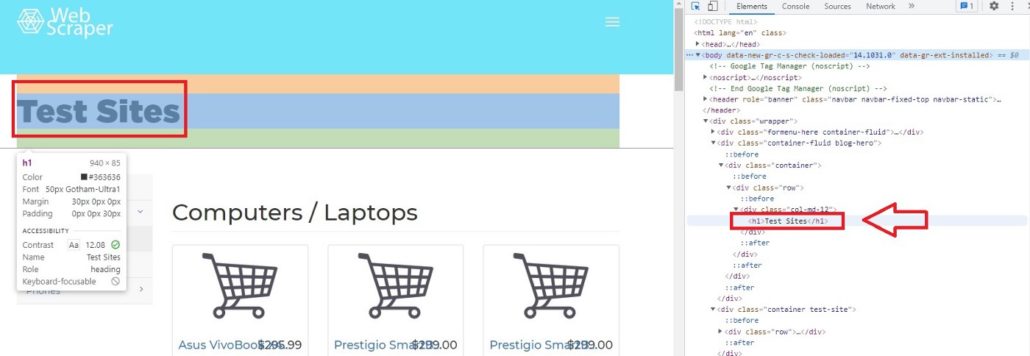
Например, если мы переместим курсор на Test Sites, элемент покажет, что Test Sites находится в теге h1. В Python, если вы хотите просмотреть код элементов сайта, можно вызывать теги. Характерной чертой тегов является то, что они всегда имеют < в качестве префикса и часто имеют фиолетовый цвет.
Как выбрать решение для парсинга сайтов: классификация и большой обзор программ, сервисов и фреймворков
ШАГ 6. ДОСТУП К ТЕГАМ
Если мы, к примеру, хотим получить доступ к элементу h1 с помощью Python, мы можем просто ввести:
# Access h1 tag
soup.h1
Результат будет:
soup.h1
Out[11]: <h1>Test Sites</h1>
Вы можете получить доступ не только к однострочным тегам, но и к тегам класса, например:
# Access header tagsoup.header#Access div tag soup.div
Не забудьте перед этим определить soup, поскольку важно преобразовать HTML в удобный для Python формат.
Вы можете получить доступ к определенному из вложенных тегов. Вложенные теги означают теги внутри тегов. Например, тег <p> находится внутри другого тега <header>. Но когда вы получаете доступ к определенному тегу из <header>, Python всегда покажет результаты из первого индекса. Позже мы узнаем, как получить доступ к нескольким тегам из вложенных.
# Access string from nested tags
soup.header.p
Результат:
soup.header.p
Out[10]: <p>Web Scraper</p>
Вы также можете получить доступ к строке вложенных тегов. Нужно просто добавить в код string.
# Access string from nested tags
soup.header.p
soup.header.p.string
Результат:
soup.header.p
soup.header.p.string
Out[12]: ‘Web Scraper’
Следующий этап парсинга сайтов на Python — это получение доступа к атрибутам тегов. Для этого мы можем использовать функциональную возможность BeautifulSoup attrs. Как результат применения attrs мы получим словарь.
# Access ‘a’ tag in <header>
a_start = soup.header.a
a_start#
Access only the attributes using attrs
a_start.attrs
Результат:
Out[16]:{‘data-toggle’: ‘collapse-side’,
‘data-target’: ‘.side-collapse’,
‘data-target-2’: ‘.side-collapse-container’}
Мы можем получить доступ к определенному атрибуту. Учтите, что Python рассматривает атрибут как словарь, поэтому data-toggle, data-target и data-target-2 являются ключом. Вот пример получение доступа к ‘data-target:
a_start[‘data-target’]
Результат:
a_start[‘data-target’]
Out[17]: ‘.side-collapse’
Мы также можем добавить новый атрибут. Имейте в виду, что изменения влияют только на веб-сайт локально, а не на веб-сайт в мировом масштабе.
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Результат:
a_start[‘new-attribute’] = ‘This is the new attribute’
a_start.attrs
a_start
Out[18]:
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</a>
Парсинг таблицы с сайта на Python: Пошаговое руководство
ШАГ 7. ДОСТУП К КОНКРЕТНЫМ АТРИБУТАМ ТЕГОВ
Мы узнали, что в теге может быть больше чем один вложенный тег. Например, если мы запустим soup.header.div, <div> будет иметь много вложенных тегов. Учтите, что мы вызываем только <div> внутри <header >, поэтому другой тег внутри <header> не будет показан.
Результат:
soup.header.div
Out[26]:
<div class=”container”><div class=”navbar-header”>
<a data-target=”.side-collapse” data-target-2=”.side-collapse-container” data-toggle=”collapse-side” new-attribute=”This is the new attribute”>
<button aria-controls=”navbar” aria-expanded=”false” class=”navbar-toggle pull-right collapsed” data-target=”#navbar” data-target-2=”.side-collapse-container” data-target-3=”.side-collapse” data-toggle=”collapse” type=”button”>
...
</div>
Как мы видим, в одном теге находится много атрибутов и вопрос заключается в том, как получить доступ только к тому атрибуту, который нам нужен. В BeautifulSoup есть функция ‘find’ и ‘find_all’. Чтобы было понятнее, мы покажем вам, как использовать обе функции и чем они отличаются друг от друга. В качестве примера найдем цену каждого товара. Чтобы увидеть код элемента цены, просто наведите курсор на индикатор цены.
После перемещения курсора мы можем определить, что цена находится в теге h4, значение класса pull-right price.
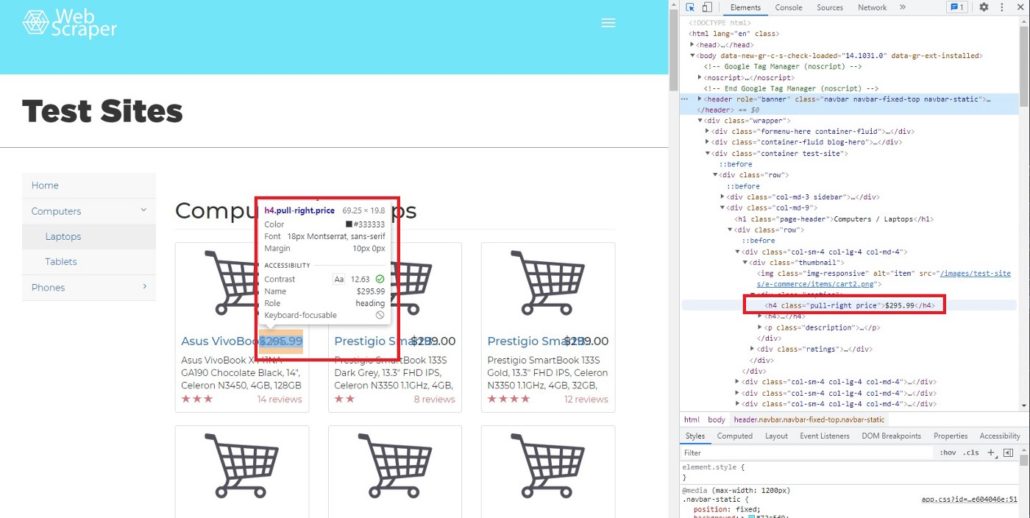
Далее мы хотим найти строку элемента h4, используя функцию find:
# Searching specific attributes of tags
soup.find(‘h4’, class_= ‘pull-right price’)
Результат:
Out[28]: <h4 class=”pull-right price”>$295.99</h4>
Как видно, $295,99 — это атрибут (строка) h4. Но что будет, если мы используем find_all.
# Using find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)
Результат:
Out[29]:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>,
<h4 class=”pull-right price”>$356.49</h4>,
....
</h4>]
Вы заметили разницу между find и find_all?
Да, все верно, find нужно использовать для поиска определенных атрибутов, потому что он возвращает только один результат. Для парсинга больших объемов данных (например, цена, название продукта, описание и т. д.), используйте find_all.
Кроме того, можем получить часть результата функции find_all. В данном случае мы хотим видеть только индексы с 3-го до 5-го.
# Slicing the results of find_all
soup.find_all(‘h4’, class_= ‘pull-right price’)[2:5]
Результат:
Out[32]:[<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$306.99</h4>,
<h4 class=”pull-right price”>$321.94</h4>]
[!] Не забывайте, что в Python индекс первого элемента в списке — 0, а последний не учитывается.
ШАГ 8. ИСПОЛЬЗОВАНИЕ ФИЛЬТРА
При необходимости мы можем найти несколько тегов:
# Using filter to find multiple tagssoup.find_all(['h4', 'a', 'p'])soup.find_all(['header', 'div'])
soup.find_all(id = True) # class and id are special attribute so it can be written like this
soup.find_all(class_= True)
Поскольку class и id являются специальными атрибутами, поэтому можно писать class_ и id вместо ‘class’ или ‘id’.
Использование фильтра поможет нам получить необходимые данные с веб-сайта. В нашем случае это название, цена, отзывы и описания. Итак, сначала определим переменные.
# Filter by name name = soup.find_all(‘a’, class_=’title’) # Filter by priceprice = soup.find_all(‘h4’, class_ = ‘pull-right price’)# Filter by reviews reviews = soup.find_all(‘p’, class_ = ‘pull-right’)# Filter by description description = soup.find_all(‘p’, class_ =’description’)
Фильтр по названию:
[<a class=”title” href=”/test-sites/e-commerce/allinone/product/545" title=”Asus VivoBook X441NA-GA190">Asus VivoBook X4…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/546" title=”Prestigio SmartBook 133S Dark Grey”>Prestigio SmartB…</a>,
<a class=”title” href=”/test-sites/e-commerce/allinone/product/547" title=”Prestigio SmartBook 133S Gold”>Prestigio SmartB…</a>,
...
</a>]
Фильтр по цене:
[<h4 class=”pull-right price”>$295.99</h4>,
<h4 class=”pull-right price”>$299.00</h4>,
<h4 class=”pull-right price”>$299.00</h4>,<h4 class=”pull-right price”>$306.99</h4>,
...
</h4>]
Фильтр по отзывам:
[<p class=”pull-right”>14 reviews</p>,<p class=”pull-right”>8 reviews</p>,
<p class=”pull-right”>12 reviews</p>,<p class=”pull-right”>2 reviews</p>,
...
</p>]
Фильтр по описанию:
[<p class=”description”>Asus VivoBook X441NA-GA190 Chocolate Black, 14", Celeron N3450, 4GB, 128GB SSD, Endless OS, ENG kbd</p>,
<p class=”description”>Prestigio SmartBook 133S Dark Grey, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
<p class=”description”>Prestigio SmartBook 133S Gold, 13.3" FHD IPS, Celeron N3350 1.1GHz, 4GB, 32GB, Windows 10 Pro + Office 365 1 gadam</p>,
...
</p>]
ШАГ 9. ОЧИСТКА ДАННЫХ
Очевидно, результаты все еще в формате HTML, поэтому нам нужно очистить их и получить только строку элемента. Используем для этого функцию text.
Text может служить для сортировки строк HTML кода, однако нужно определить новую переменную, например:
# Try to call priceprice1 = soup.find(‘h4’, class_ = ‘pull-right price’)
price1.text
Результат:
Out[55]: ‘$295.99’
На выходе получается только строка из кода, но этого недостаточно. На следующем этапе мы узнаем, как парсить все строки и сделать из них список.
ШАГ 10. ИСПОЛЬЗОВАНИЕ ЦИКЛА FOR ДЛЯ СОЗДАНИЯ СПИСКА СТРОК
Чтобы сделать список из всех строк, необходимо создать цикл for.
# Create for loop to make string from find_all list
product_name_list = []
for i in name:
name = i.text
product_name_list.append(name)price_list = []
for i in price:
price = i.text
price_list.append(price)
review_list = []
for i in reviews:
rev = i.text
review_list.append(rev)
description_list = []
for i in description:
desc = i.text
description_list.append(desc)ШАГ 11. СОЗДАНИЕ ФРЕЙМА ДАННЫХ
После того, как мы создали цикл for и все строки были добавлены в списки, остается заключительный этап парсинга сайтов на Python — построить фрейм данных. Для этой цели нам нужно импортировать библиотеку pandas.
# Create dataframe# Import library import pandas as pdtabel = pd.DataFrame({‘Product Name’:product_name_list, ‘Price’: price_list, ‘Reviews’:review_list, ‘Description’:description_list})
Теперь эти данные можно использовать для работы в проектах по анализу и обработке данных, в машинном обучении, для получения другой ценной информации.

Надеюсь, это руководство будет вам полезно, особенно для тех, кто изучает парсинг сайтов на Python. До новых встреч в следующем проекте.
Если у вас возникнут сложности с парсингом сайтов на Python или с парсингом приложений, обращайтесь в компанию iDatica — напишите письмо или заполните заявку указав все детали задачи по парсингу.
Парсинг (web scraping) — это автоматизированный сбор открытой информации в интернете по заданным условиям. Парсить можно данные с сайтов, поисковой выдачи, форумов и социальных сетей, порталов и агрегаторов. В этой статье разбираемся с парсерами сайтов.
Часто требуется получить и проанализировать большой массив технической и коммерческой информации, размещенной на своих проектах или сайтах конкурентов. Для сбора таких данных незаменимы парсеры — программы или сервисы, которые «вытаскивают» нужную информацию и представляют ее в структурированном виде.
Парсинг — это законно?
Сбор открытой информации в интернете не запрещен законодательством РФ. Более того, в п.4 статьи 29 Конституции закреплено «право свободно искать, получать, передавать, производить и распространять информацию любым законным способом». Парсинг данных часто сравнивают с фотографированием ценников в магазинах: если информация есть в открытом доступе, не защищена авторским правом или другими ограничениями, значит, ее можно копировать и распространять.
Применительно к данным в интернете это значит, что законным является сбор сведений, для получения которых не требуется авторизация. А вот персональные данные пользователей защищены отдельным законом и парсить их с целью таргетирования рекламы или email-рассылок нельзя.
Кому и зачем нужны парсеры сайтов
Парсеры экономят время на сбор большого объема данных и группировку их в нужный вид. Такими сервисами пользуются интернет-маркетологи, вебмастера, SEO-специалисты, сотрудники отделов продаж.
Парсеры могут выполнять следующие задачи:
- Сбор цен и ассортимента. Это полезно для интернет-магазинов. При помощи парсера можно мониторить цены конкурентов и наполнять каталог на своем ресурсе в автоматическом режиме.
- Парсинг метаданных сайта (title, description, заголовков H1) пригодится SEO-специалистам.
- Анализ технической оптимизации ресурса (битые ссылки, ошибки 404, неработающие редиректы и др.) потребуется сеошникам и вебмастерам.
- Программы для скачивания сайтов целиком или парсеры контента (текстов, картинок, ссылок) находятся в «серой» зоне. С их помощью недобросовестные вебмастера клонируют сайты для последующей продажи с них ссылок. Сюда же отнесем парсинг данных с агрегаторов и картографических сервисов: Авито, Яндекс.Карт, 2gis и других. Собранные базы используются для спамных обзвонов и рассылок.
Кому и для каких целей требуются парсеры, разобрались. Если вам нужен этот инструмент, есть несколько способов его заполучить.
- При наличии программистов в штате проще всего поставить им задачу сделать парсер под нужные цели. Так вы получите гибкие настройки и оперативную техподдержку. Самые популярные языки для создания парсеров — PHP и Python.
- Воспользоваться бесплатным или платным облачным сервисом.
- Установить подходящую по функционалу программу.
- Обратиться в компанию, которая разработает инструмент под ваши нужды (ожидаемо самый дорогой вариант).
С первым и последним вариантом все понятно. Но выбор из готовых решений может занять немало времени. Мы упростили эту задачу и сделали обзор инструментов.
Классификация парсеров
Парсеры можно классифицировать по различным признакам.
- По способу доступа к интерфейсу: облачные решения и программы, которые требуют установки на компьютер.
- По технологии: парсеры на основе языков программирования (Python, PHP), расширения для браузеров, надстройки в Excel, формулы в Google таблицах.
- По назначению: мониторинг конкурентов, сбор данных в определенной нише рынка, парсинг товаров и цен для наполнения каталога интернет-магазина, парсеры данных соцсетей (сообществ и пользователей), проверка оптимизации своего ресурса.
Разберем парсеры по разным признакам, подробнее остановимся на парсерах по назначению.
Парсеры сайтов по способу доступа к интерфейсу
Облачные парсеры
Облачные сервисы не требуют установки на ПК. Все данные хранятся на серверах разработчиков, вы скачиваете только результат парсинга. Доступ к программному обеспечению осуществляется через веб-интерфейс или по API.
Примеры облачных парсеров с англоязычным интерфейсом:
- http://import.io/,
- Mozenda (есть также ПО для установки на компьютер),
- Octoparce,
- ParseHub.
Примеры облачных парсеров с русскоязычным интерфейсом:
- Xmldatafeed,
- Диггернаут,
- Catalogloader.
У всех сервисов есть бесплатная версия, которая ограничена или периодом использования, или количеством страниц для сканирования.
Программы-парсеры
ПO для парсинга устанавливается на компьютер. В подавляющем большинстве случаев такие парсеры совместимы с ОС Windows. Обладателям mac OS можно запускать их с виртуальных машин. Некоторые программы могут работать со съемных носителей.
Примеры парсеров-программ:
- ParserOK,
- Datacol,
- SEO-парсеры — Screaming Frog, ComparseR, Netpeak Spider и другие.
Парсеры сайтов в зависимости от используемой технологии
Парсеры на основе Python и PHP
Такие парсеры создают программисты. Без специальных знаний сделать парсер самостоятельно не получится. На сегодня самый популярный язык для создания таких программ Python. Разработчикам, которые им владеют, могут быть полезны:
- библиотека Beautiful Soup;
- фреймворки с открытым исходным кодом Scrapy, Grab и другие.
Заказывать разработку парсера с нуля стоит только для нестандартных задач. Для большинства целей можно подобрать готовые решения.
Парсеры-расширения для браузеров
Парсить данные с сайтов могут бесплатные расширения для браузеров. Они извлекают данные из html-кода страниц при помощи языка запросов Xpath и выгружают их в удобные для дальнейшей работы форматы — XLSX, CSV, XML, JSON, Google Таблицы и другие. Так можно собрать цены, описания товаров, новости, отзывы и другие типы данных.
Примеры расширений для Chrome: Parsers, Scraper, Data Scraper, kimono.
Парсеры сайтов на основе Excel
В таких программах парсинг с последующей выгрузкой данных в форматы XLS* и CSV реализован при помощи макросов — специальных команд для автоматизации действий в MS Excel. Пример такой программы — ParserOK. Бесплатная пробная версия ограничена периодом в 10 дней.
Парсинг при помощи Google Таблиц
В Google Таблицах парсить данные можно при помощи двух функций — importxml и importhtml.
- Функция IMPORTXML импортирует данные из источников формата XML, HTML, CSV, TSV, RSS, ATOM XML в ячейки таблицы при помощи запросов Xpath. Синтаксис функции:
IMPORTXML("https://site.com/catalog"; "//a/@href")
IMPORTXML(A2; B2)
Расшифруем: в первой строке содержится заключенный в кавычки url (обязательно с указанием протокола) и запрос Xpath.
Знание языка запросов Xpath для использования функции не обязательно, можно воспользоваться опцией браузера «копировать Xpath»:
Вторая строка указывает ячейки, куда будут импортированы данные.
IMPORTXML можно использовать для сбора метатегов и заголовков, количества внешних ссылок со страницы, количества товаров на странице категории и других данных.
- У IMPORTHTML более узкий функционал — она импортирует данные из таблиц и списков, размещенных на странице сайта. Синтаксис функции:
IMPORTHTML("https://https://site.com/catalog/sweets"; "table"; 4)
IMPORTHTML(A2; B2; C2)
Расшифруем: в первой строке, как и в предыдущем случае, содержится заключенный в кавычки URL (обязательно с указанием протокола), затем параметр «table», если хотите получить данные из таблицы, или «list», если из списка. Числовое значение (индекс) означает порядковый номер таблицы или списка в html-коде страницы.
Парсеры сайтов в зависимости от решаемых задач
Чтобы не ошибиться с выбором ПО или облачного сервиса для парсинга, нужно понимать спектр задач, которые они решают. Мы разделили парсеры по сферам применения.
Парсеры для организаторов совместных покупок (СП)
Отдельная категория парсеров предназначена для тех, кто занимается организацией совместных покупок в соцсетях ВКонтакте и Одноклассники. Владельцы групп СП закупают партии товара мелким оптом по цене дешевле, чем в розницу. Для этого нужно постоянно мониторить ассортимент и цены на сайтах поставщиков. Чтобы сократить трудозатраты, можно использовать специализированные парсеры.
У таких парсеров простой, интуитивно понятный интерфейс панели управления, в котором можно указать необходимые настройки — страницы для парсинга, расписание, группы в соцсетях для выгрузки и другие.
Примеры сервисов:
- SPparser.ru,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser,
- Облачный парсер.
Что умеют парсеры для СП:
- парсить товары из интернет-магазинов и групп в соцсетях;
- выгружать товары с фото и ценами в альбомы соцсетей — Одноклассники и ВКонтакте;
- выгружать данные в формате CSV и XLS(X);
- обновлять информацию в автоматическом режиме — подгружать новые товары и удалять те, которых нет в наличии.
Сервисы мониторинга конкурентов
Эта группа парсеров позволяет ценам в интернет-магазине оставаться на уровне рынка. Сервисы мониторят заданные ресурсы, сопоставляют товары и цены на них с вашим каталогом и предоставляет возможность скорректировать цену на более привлекательную. Такие парсеры мониторят сайты конкурентов, обновляемые прайсы в форматах XLS(X), CSV и других, маркетплейсы (Яндекс.Маркет, e-katalog и другие прайс-агрегаторы).
Примеры парсеров цен конкурентов:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Сбор данных и автонаполнение контентом
Такие парсеры облегчают работу контент-менеджерам интернет-магазинов тем, что заменяют ручной мониторинг сайтов поставщиков, сравнение и изменение ассортимента, описаний, цен. Парсер собирает данные с сайтов-доноров (названия и описания товаров, цены, изображения и др.), выгружает их в файл или сразу на сайт. В настройках есть возможность сделать наценку, объединить данные с нескольких сайтов, запускать сбор данных в автоматическом режиме по расписанию или вручную.
Примеры парсеров для наполнения интернет-магазинов:
- Catalogloader,
- Xmldatafeed,
- Диггернаут
Многофункциональные парсеры
Такие инструменты способны собирать данные под разные задачи — наполнение интернет-магазинов, мониторинг цен конкурентов, парсинг агрегаторов данных, сбор SEO-параметров и прочее. К этой группе относятся все браузерные расширения с функцией парсинга.
Другие примеры многофункциональных парсеров:
- Import.io, Mozenda — комплексы инструментов для извлечения и визуализации данных. Подходят для среднего и крупного бизнеса с большим объемом задач.
- Octoparce — инструмент для мониторинга цен и сбора данных с любого сайта. Данные выгружаются в форматы CSV или Excel. Есть доступ по API.
- ParseHub — облачный парсер для сбора цен, контактов, маркетинговых данных, скачивания файлов, мониторинга конкурентов. Работает со всеми типами сайтов, в том числе, агрегаторами и маркетплейсами. Данные доступны в форматах CSV, Excel, Google Sheets, предоставляется доступ по API.
- Datacol. Извлекает данные с сайтов, агрегаторов, соцсетей, Яндекс.Карт и других источников. Базовые функции можно расширить при помощи плагинов. Программа платная, но есть демо-версия для тестирования.
- ParserOK. С помощью программы можно парсить данные из интернет-магазинов, контактов, загружать файлы различных форматов в облачное хранилище.
SEO-парсеры
Парсеры используются SEO-специалистами для комплексного анализа сайта: внутренней, технической и внешней оптимизации. У одних может быть узкий функционал, другие представляют собой мощные SEO-комбайны из различных профессиональных инструментов.
Задачи, которые могут выполнять SEO-парсеры:
- указывать на корректность настройки главного зеркала;
- анализировать содержание robots.txt и sitemap.xml;
- указывать наличие, длину и содержание метатегов title и description, количество и содержание заголовков h1 — h6;
- определять коды ответа страниц;
- генерировать XML-карту сайта;
- определять уровень вложенности страниц и визуализировать структуру сайта;
- указывать наличие/отсутствие атрибутов alt у картинок;
- определять битые ссылки;
- определять наличие атрибута rel=»canonical»;
- предоставлять данные по внутренней перелинковке и внешней ссылочной массе;
- отображать сведения о технической оптимизации: скорости загрузки, валидности кода, оптимизации под мобильные устройства и др.
Кратко охарактеризуем функционал популярных SEO-парсеров:
- Screaming Frog SEO Spider
- Netpeak Spider
- ComparseR
- SiteAnalyzer от Majento
- SE Ranking
- A-Parser
- PR-CY
- Xenu’s Link Sleuth
Screaming Frog SEO Spider
Пожалуй, самый популярный SEO-анализатор от британских разработчиков. С его помощью можно быстро и наглядно выяснить:
- содержимое, код ответа, статус индексации каждой страницы;
- длину и содержимое title и description;
- наличие и содержимое заголовков h1 и h2;
- информацию об изображениях на сайте — формат, размер, статус индексации;
- информацию по настройке канонических ссылок и пагинации;
- другие важные данные.
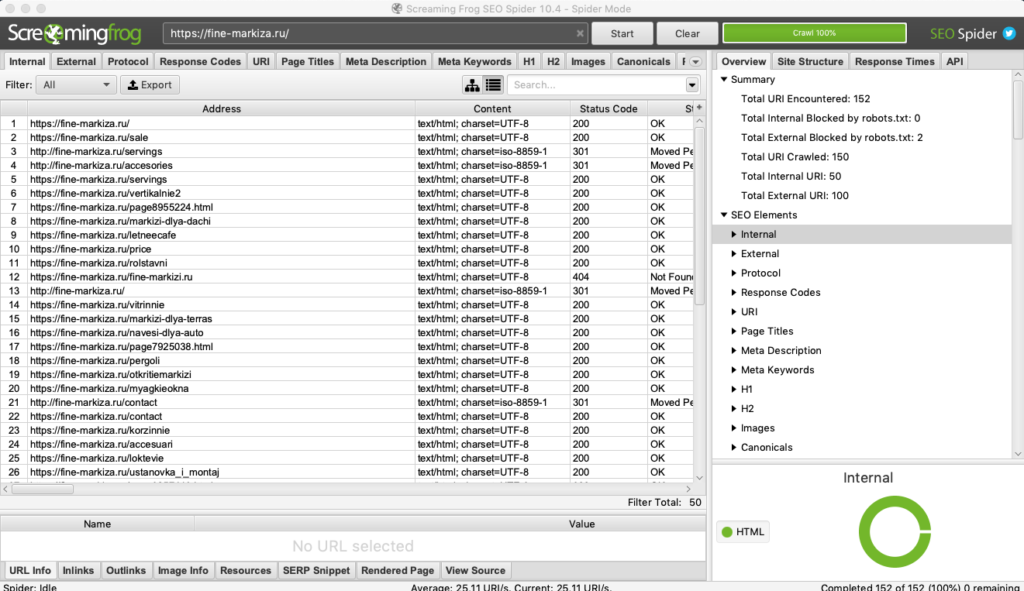
Бесплатная версия ограничена 500-ми url. В платной (лицензию можно купить на год) количество страниц для парсинга не ограничено, и она имеет гораздо больше возможностей. Среди них — парсинг цен, названий и описаний товаров с любого сайта. Как это сделать, мы подробно описали в гайде.
Netpeak Spider
Популярный инструмент для комплексного анализа сайта. Проверяет ресурс на ошибки внутренней оптимизации, анализирует важные для SEO параметры: битые ссылки, дубли страниц и метатегов, коды ответа, редиректы и другие. Можно импортировать данные из Google Search Console и систем веб-аналитики. Для агентств есть возможность сформировать брендированный отчет.
Инструмент платный, базовые функции доступны доступны во всех тарифах. Бесплатный пробный период — 14 дней.
ComparseR
Это программа, которая анализирует ресурс на предмет технических ошибок. Особенность парсера в том, что он также показывает все страницы сайта в индексе Яндекс и Google. Эта функция полезна, чтобы выяснить, какие url не попали в индекс, а какие находятся в поиске (и те ли это страницы, которые нужны оптимизатору).
Программу можно купить и установить на один компьютер. Для того, чтобы ознакомиться с принципом работы, скачайте демо-версию.
SiteAnalyzer от Majento
Бесплатная программа для сканирования всех страниц, скриптов, документов и изображений сайта. Используется для проведения технического SEO-аудита. Требует установки на ПК (ОС Windows), но может работать и со съемного носителя. «Вытаскивает» следующие данные: коды ответа сервера, наличие и содержимое метатегов и заголовков, определение атрибута rel=»canonical», внешние и внутренние ссылки для каждой страницы, дубли страниц и другие.
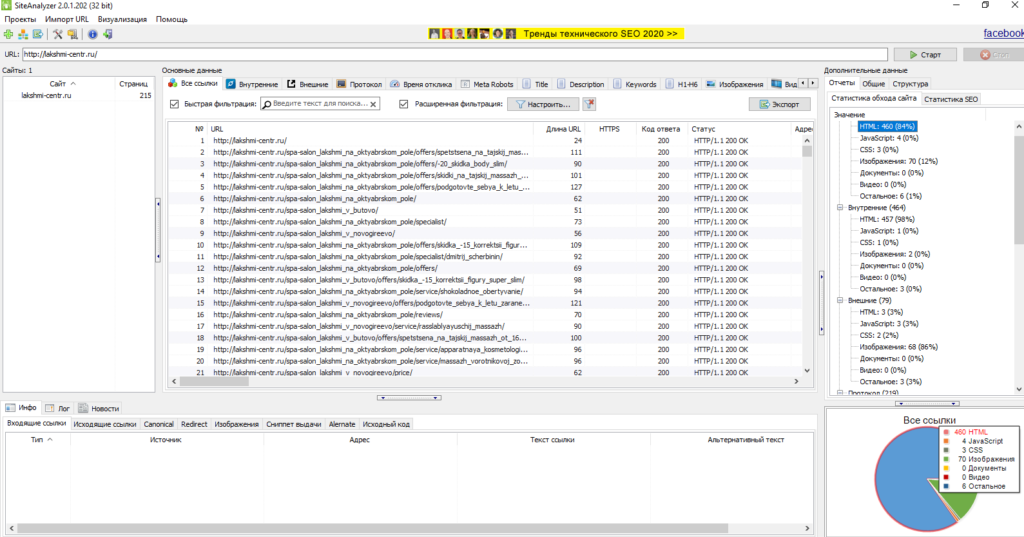
Отчет можно экспортировать в форматы CSV, XLS и PDF.
Анализ сайта от SE Ranking
Инструмент анализирует ключевые параметры оптимизации сайта: наличие robots.txt и sitemap.xml, настройка главного зеркала, дубли страниц, коды ответа, метатеги и заголовки, технические ошибки, скорость загрузки, внутренние ссылки. По итогам сканирования сайту выставляется оценка по 100-балльной шкале. Есть опция создания XML-карты сайта. Полезная возможность для агентств — формирование брендированного отчета, который можно скачать в удобном формате или отправить на email. Отчеты запускаются вручную или по расписанию.
Возможны две модели оплаты — за проверки позиций и ежемесячная подписка. Бесплатный пробный период — 2 недели.
A-Parser
Этот сервис объединяет более 70 парсеров под разные цели: парсинг выдачи популярных поисковых систем, ключевых слов, приложений, социальных сетей, Яндекс и Google карт, крупнейших интернет-магазинов, контента и другие. Кроме использования готовых инструментов есть возможности для программирования собственных парсеров на основе регулярных выражений, XPath, JavaScript. Разработчики также предоставляют доступ по API.
Тарифы зависят от количества опций и срока бесплатных обновлений. Возможности парсера можно оценить в демо-версии, которая будет доступна в течение шести часов после регистрации.
Анализ сайта от PR-CY
Онлайн-инструмент для анализа сайтов более чем по 70 пунктам. Указывает на ошибки оптимизации, предлагает варианты их решения, формирует SEO-чеклист и рекомендации по улучшению ресурса. По итогам сканирования сайту выставляется оценка в процентах.
Бесплатно можно получить лишь общую информацию по количеству страниц в индексе, наличию/отсутствию вирусов и фильтров поисковых систем, ссылочному профилю и некоторые другие данные. Более детальный анализ платный. Тариф зависит от количества сайтов, страниц в них и проверок на аккаунте. Есть возможность для ежедневного мониторинга, сравнения с показателями конкурентов и выгрузки брендированных отчетов. Бесплатный пробный период — 7 дней.
Упомянем также о парсерах, которые решают узконаправленные задачи и могут быть полезны владельцам сайтов, вебмастерам и SEO-специалистам.
Xenu’s Link Sleuth
Бесплатная программа для парсинга всех url сайта: внешних и внутренних ссылок, ссылок на картинки и скрипты и т.д. Можно использовать для разных задач, в том числе, для поиска битых ссылок на сайте. Программу нужно скачать и установить на компьютер (ОС Windows).
По каждой ссылке будет показан ее статус, тип (например, text/plain или text/html), размер, анкор и ошибка.
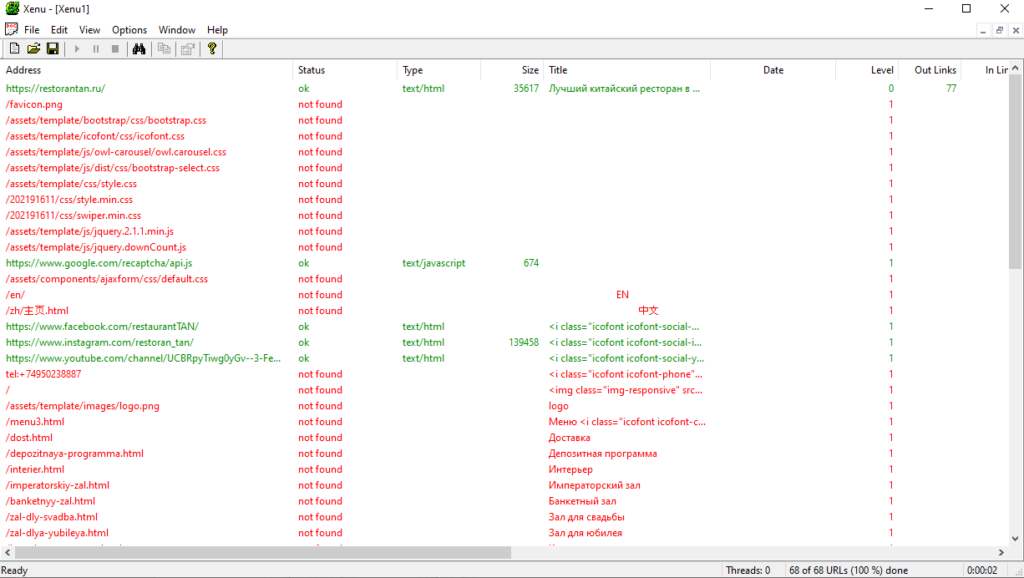
Парсер метатегов и заголовков PromoPult
Это инструмент, который парсит метатеги title, description, keywords и заголовки h1-h6. Можно воспользоваться им для анализа своего проекта или сайтов-конкурентов. В первом случае легко выявить незаполненные, неинформативные, слишком длинные или короткие метатеги, дубли метаданных, во втором — выяснить, какие ключевые запросы используют конкуренты, определить структуру и логику формирования метатегов.
Добавить список url можно вручную, XLSX-файлом или ссылкой на XML-карту сайта. Отчеты выгружаются в форматах HTML и XLSX. Первые 500 запросов — бесплатно. Все нюансы работы с инструментом мы описали в гайде.
Как выбрать парсер
- Определитесь с целью парсинга: мониторинг конкурентов, наполнение каталога, проверка SEO-параметров, совмещение нескольких задач.
- Выясните, какие данные в каком объеме и в каком виде вам нужно получить на выходе.
- Подумайте о том, насколько регулярно вам нужно собирать и обрабатывать данные: разово, ежемесячно, ежедневно?
- Если у вас большой ресурс со сложным функционалом, имеет смысл заказать создание парсера с гибкими настройками под ваши цели. Для стандартных проектов на рынке достаточно готовых решений.
- Выберите несколько инструментов и изучите отзывы. Особое внимание обратите на качество технической поддержки.
- Соотнесите уровень подготовки (свой или ответственного за работу с данными лица) со сложностью инструмента.
- На основе перечисленных выше параметров выберите подходящий инструмент и тариф. Возможно, под ваши задачи хватит бесплатного функционала или пробного периода.