К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Как найти сайт, на который уже заходил
Ссылка на сайт, располагающаяся в избранном, помогает в любое время снова вернуться на нужный ресурс. Но что делать, если вы не успели занести адрес посещенного сайта в закладки, а именно сейчас возникла необходимость повторного визита на этот ресурс? Любой браузер автоматически записывает историю просмотров, которая хранит отметки о всех посещенных веб-страницах.

Вам понадобится
- — компьютер, с которого вы в последний раз заходили на нужный сайт.
Инструкция
Если вы пользуетесь браузером Google Chrome, то для просмотра записей о посещенных сайтах сначала нажмите на изображение гаечного ключа в правом верхнем углу экрана. В открывшемся списке выберите пункт «История».
Для того, чтобы ускорить поиск нужного вам ресурса, воспользуйтесь поисковой строкой в верхней части страницы. Введите одно или несколько слов из названия или описания веб-страницы.
Если вы хотите получить доступ к посещенным веб-страницам в Internet Explorer, щелкните по звездочке, которая находится в правом верхнем углу экрана между изображениями домика и шестеренки. В появившемся окне выберите вкладку «Журнал».
Для поиска веб-страницы, просмотренной в определенный день, выберите из списка со стрелочкой, находящегося в верхней части модуля с историей, строчку «Просмотр по дате». После чего нажмите на нужную дату и в списке посещенных сайтов найдите интересующий вас ресурс.
Чтобы узнать адрес раздела определенного сайта или перечень поисковых запросов в поисковой системе, предпочтите в том же выпадающем списке пункт «Просмотр по узлу». Затем найдите нужный адрес в перечне посещенных сайтов и, просмотрев все просмотренные страницы этого веб-узла, перейдите на ту из них, которая вам необходима.
При необходимости вернуться на страницу, которую вы просматривали совсем недавно, раскройте список способов расположении истории поиска, щелкните по записи «Просмотр по порядку посещения». Просмотрите записи и зайдите на понадобившийся вам ресурс.
Если вы помните одно или несколько слов из названия или описания забытого сайта, то выберите из списка со стрелочкой запись «Поиск в журнале». В специальное после введите слово или словосочетание на том языке, на котором они используются на веб-странице, и нажмите кнопку «Начать поиск». По окончании процесса обнаружения совпадений в списке посещенных адресов щелкните по нужной вам записи.
Для поиска посещенного адреса в браузере Mozilla Firefox сначала нажмите на оранжевый прямоугольник со стрелочкой, где располагается надпись Firefox. Затем наведите курсор на пункт «Журнал», располагающийся в открывшемся списке, и выберите запись «Показать весь журнал».
После чего в появившемся окне щелкните по нужной дате из представленного перечня и выберите интересующий сайт. Чтобы разыскать сайт по его названию или описанию, введите соответствующее слово или словосочетание в форму поиска, находящуюся в правой верхней части модуля, и перейдите на найденный ресурс.
Видео по теме
Источники:
- где находится список посещенных сайтов
Войти на сайт
или
Забыли пароль?
Еще не зарегистрированы?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
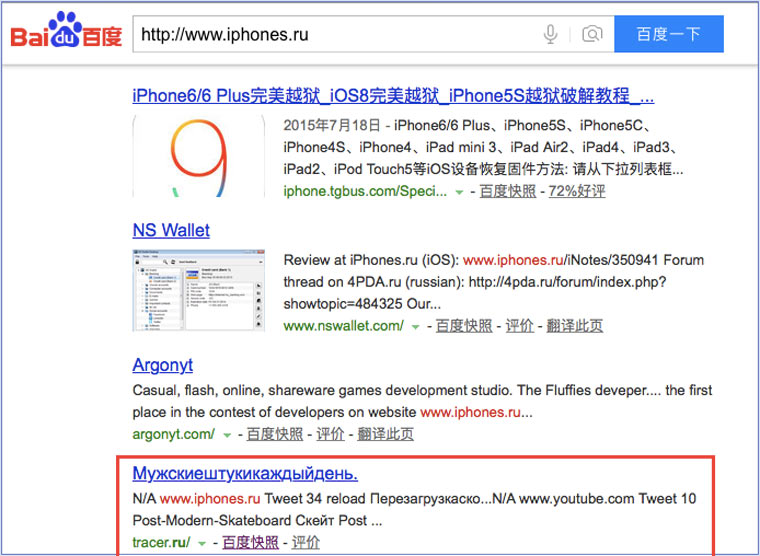
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
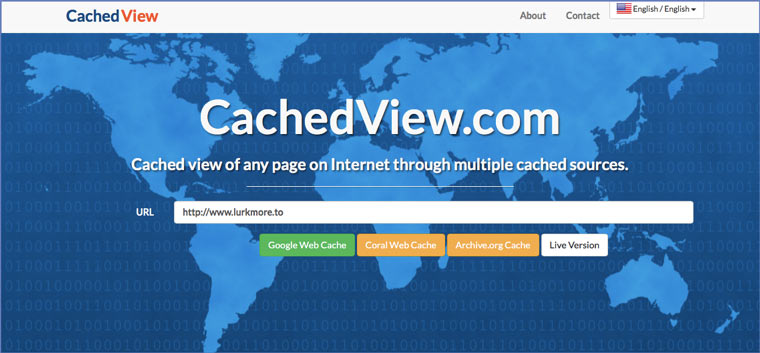
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
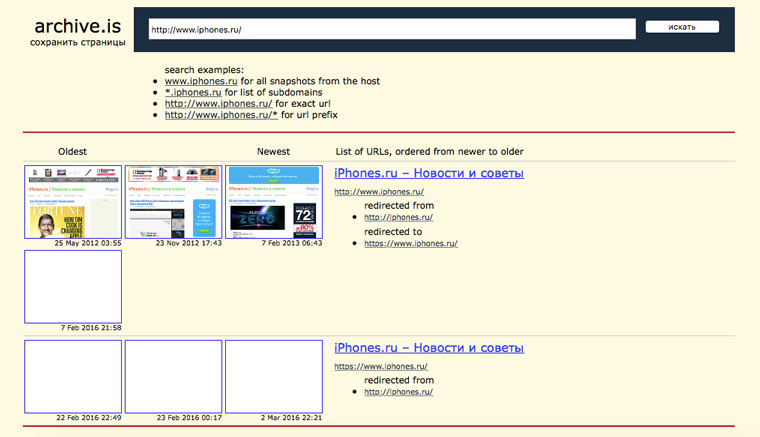
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
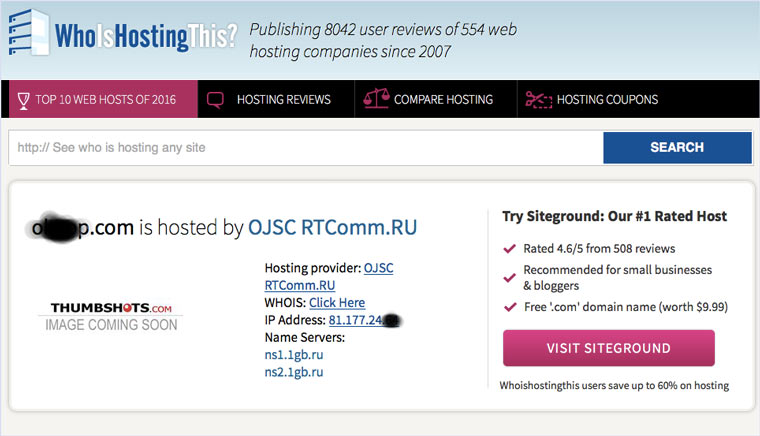
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
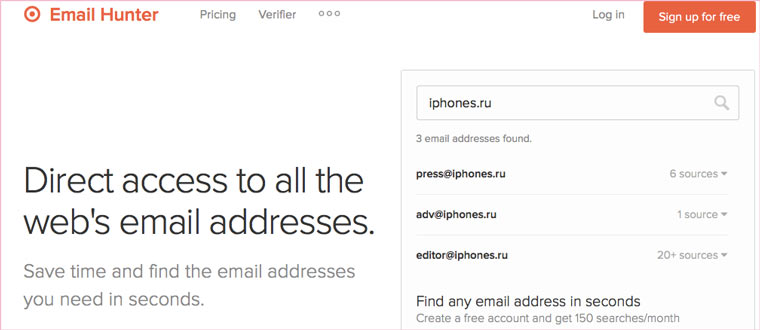
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()

Не стоит отчаиваться, если вы очистили историю браузера, а вам по каким-то причинам нужно ее восстановить. Сегодня мы подробно рассмотрим, как вернуть утерянные ссылки в Яндекс.Браузере.
Способ 1. Программа Handy Recovery
Данные о посещенных сайтах обычно находятся в памяти вашего компьютера, в корневой папке Yandex. Если вы удалили историю по каким-то причинам, то ее можно попытаться восстановить.
Handy Recovery позволит вернуть утерянные файлы прямо в папке яндекса.

Чтобы восстановить историю, скачайте программу Handy Recovery и откройте ее. Затем в левой части окна перейдите в «AppData» и найдите там папку «YandexBrowser». После этого нажмите кнопку «Восстановить» в верхней части программы.
Не забудьте закрыть Яндекс.Браузер на время восстановления, чтобы не создавать конфликтов с программой. После завершения процесса откройте браузер, и проверьте наличие истории.
Способ 2. Отыскать посещенный сайт через кэш
Если вы очистили исключительно данные посещения ресурсов, но не затронули кэш, то с его помощью можно попытаться найти нужную ссылку.
1. Перейдите по нижеуказанной ссылке:
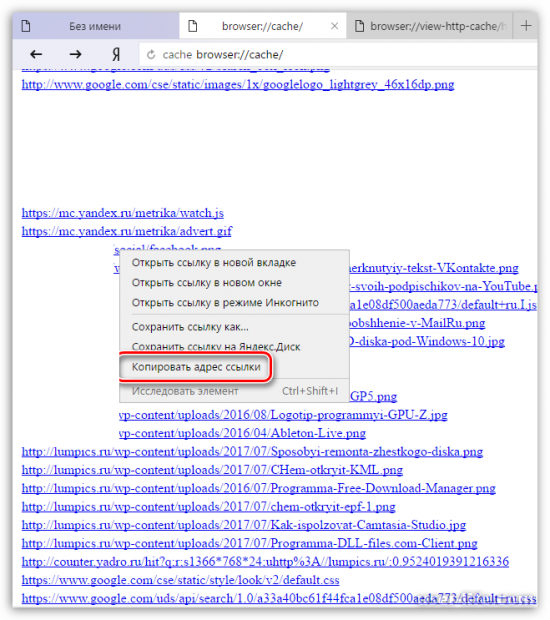
browser://cache
2. Перед вами появится страница со ссылками. Найдите в списке сайтов нужный и кликните по ссылке правой кнопкой мыши, затем выберите пункт «Копировать адрес ссылки».
Ссылка должна выглядеть примерно так.
Способ 3. Восстановление системы
На крайний случай вы сможете воспользоваться самым радикальным способом. В операционной системе Windows есть встроенная функция восстановления системы, которая позволяет вернуть состояние устройства к тому моменту, когда история браузера была доступна.
Нужно выбрать такую точку восстановления, чтобы в указанный момент времени память о посещенных страницах все еще хранилась в вашем браузере.
Система вернет состояние компьютера в указанный период, но оставит пользовательские файлы нетронутыми.
Восстановление программой Piriform Recuva
История Яндекс Браузера хранится в специальном файле под названием History. Во время очистки через штатные опции он удаляется с диска стандартным способом. Но его можно вернуть при помощи специальных восстанавливающих утилит. Ниже приводится метод восстановления посредством бесплатной программы Piriform Recuva, но вы можете применить другое аналогичное по функциям ПО.
2. Щёлкните кнопку «Download Free Version».
3. После перемещения по странице в первом блоке снова кликните «Free Download».
4. На новой вкладке, в блоке «Recuva Free», под надписью «Download from:», щёлкните ссылку «FileHippo.com».
5. Клацните в правой части загрузившейся странички «… Latest Version».
6. По завершении загрузки запустите инсталлятор.
7. Вверху справа кликом мыши откройте ниспадающее меню со списком языков и выберите «Russian».
8. Нажмите «Install».
9. Когда появится сообщение «…. Setup Completed», нажмите «Run Recuva».
10. В панели установщика клацните «Далее».
11. Чтобы найти все удалённые файлы в профиле Яндекса, выберите настройку «Показ всех файлов». Снова щёлкните «Далее».
12. В списке «Размещение … » кликните «В указанном месте». В строке задайте путь к профилю браузера Яндекс:
C:UsersИМЯAppDataLocalYandexYandexBrowserUser DataDefault
Вместо «ИМЯ» вставьте название вашей учётной записи в системе. (Оно отображается в панели «Пуск» вверху правого блока под иконкой.) Либо воспользуйтесь кнопкой «Обзор» и укажите директорию профиля вручную через системное окно.
13. После установки пути нажмите «Далее».
14. Щелчком мышки установите «птичку» в настройке «Включить углублённый анализ».
15. Клацните кнопку «Начать».
16. Дождитесь окончания процедуры восстановления (прогресс выполнения будет отображаться в дополнительной панели).
17. Программа отобразит список найденных удалённых файлов в указанной директории, которые можно вернуть. Найдите в нём файл «History» и кликните возле него окошко, чтобы появилась «галочка».
18. Щёлкните «Восстановить». Укажите путь к папке профиля для размещения восстановленного файла с историей. Либо выберите альтернативную директорию и затем самостоятельно переместите history.
19. Запустите браузер и откройте журнал посещённых веб-страниц.
Создание бэкапа
Резервирование истории исключает всевозможные неприятности, связанные со случайным удалением журнала (по ошибке, в результате вирусной атаки или программного сбоя). Но, разумеется, о создании копии нужно побеспокоиться заранее. Создать бэкап и выполнить восстановление при помощи него можно различными методами.
Способ №1: копирование файла
1. Откройте профиль в директории браузера:
C: → Users → → AppData → Local → Yandex → YandexBrowser → User Data → Default
2. Кликните правой кнопкой по файлу History. В списке клацните «Копировать».
3. Вставьте файл в другую папку. Желательно, чтобы она находилась в другом разделе диска (не системном!).
4. Это и будет ваш бэкап. При необходимости вы можете его снова вставить в профиль Яндекса — заменить текущий файл History.
Резервирование утилитой hc.Historian
hc.Historian — достойная альтернатива штатному инструменту браузеров для просмотра журнала посещений. В автоматическом режиме она создаёт отдельный бэкап истории, который в любой момент можно просмотреть и использовать для восстановления. Даже в случае полного удаления браузера.
В интерфейсе утилиты можно задавать настройки резервирования (указывать директорию, архиватор для компрессии копии, а также браузер, данные которого нужно обрабатывать).
Синхронизация
Синхронизация подразумевает сохранение всех настроек пользовательского профиля с возможностью последующего его восстановления (загрузки) в браузере не только на компьютере, но и на мобильных устройствах (например, на Андроиде).
Примечание.Чтобы воспользоваться этим способом, вам понадобится учётная запись в системе Yandex.
1. Кликните «Меню». В списке нажмите «Синхронизация».
2. Введите логин и пароль для входа в аккаунт.
3. Клацните «Включить синхронизацию».
4. Теперь, когда вам нужно будет восстановить историю и другие пользовательские данные, снова откройте раздел «Синхронизация» и выполните авторизацию в профиле.
Существуют два способа сохранить свои личные данные от чужих глаз в мобильной версии Яндекс Браузера.
Первый способ — это функция смартфона, а не самого мобильного браузера. Так, необходимо зайти на любую страницу через браузер, в котором должна быть удалена история и нажать функциональную клавишу смартфона, вызвав настройки. Следует выбрать пункт “История” (в некоторых моделях “Личные настройки”) и кликнуть на строчку “Очистить историю”. Удалится вся история поиска.
Второй вариант, как удалить историю в Яндексе на телефоне — воспользоваться возможностями самого Яндекс Браузера. Необходимо выбрать значок “Настройки” в открытом окне браузера от популярной поисковой системы, нажать “Конфиденциальность”, а затем — “Очистить данные” или “Удаление данных о просмотренных страницах”. Таким способом можно не только но и удалить кеш, очистить журнал только за определенные промежутки времени или удалить некоторые (не все) разделы. Достаточно лишь поставить “галочки” в соответствующих полях и сохранить изменения кнопкой “Очистить историю”.
Восстановление удаленных данных
Что делать, если вопрос “Как удалить историю на телефоне в Яндексе?” успешно решен (и соответственно, журнал посещений очищен), но через время потребовалось вернуться к определенной веб-странице, посещаемой неделю или месяц назад. Даже в сохраненной истории найти конкретный ресурс, как правило, довольно сложно, как обстоит ситуация с удаленным журналом?
Теоретически восстановить эти данные возможно, но на практике процедура выполнима только для продвинутых пользователей. Да и то, часто восстановление удаленной истории браузера не стоит усилий — проще попытаться найти пропавшую веб-страницу, набрав тот же запрос в строке поиска. Если необходимость восстановить историю все же существует, то лучше обратиться к специалисту, но не стоит самостоятельно устанавливать из интернета программы, которые обещают восстановить поврежденные файлы.
Такое программное обеспечение, во-первых, может содержать вирусы, а во-вторых, вряд ли поможет с историей браузера. Если восстановить временные и автосохраненные файлы подобным программам и под силу, то удаленный журнал поиска уж точно не в их компетенции.
Как очистить кэш в других мобильных браузерах?
В любом другом мобильном браузере удалить историю просмотров удобнее всего программными средствами самого смартфона. Как это сделать было описано выше — первый способ удаления истории. Кроме того, можно воспользоваться и функциями конкретного браузера, как правило, опция очистки журнала посещений находится в разделе личных настроек или настроек конфиденциальности пользователя.
Будьте осторожны при восстановлении системы, не стоит делать этого без крайней необходимости. Первая два способа являются полностью безопасными. Надеемся, вам помогла наша статья.

История браузера — это список посещённых сайтов, от которого периодически необходимо избавляться для ускорения работы компьютера. Если вместе с бесполезным для системы «мусором» пользователь случайно удалил важные для него ссылки, их всегда можно восстановить. Это несложно сделать, к примеру, в «Яндекс.Браузере».
Возможно ли восстановить удалённую историю в «Яндекс.Браузере»
Прежде всего нужно понимать, что все временные данные обозревателя, в том числе история, — это файлы, которые записаны в специальной директории на системном диске. При удалении истории эти файлы уничтожаются, но их можно вернуть с помощью:
- синхронизации. По умолчанию история синхронизируется с аккаунтом, т. е. сервер «Яндекс» хранит данные о посещениях пользователя;
- cookies. Они позволяют увидеть историю и время посещений сайтов и найти необходимую ссылку;
- программ для восстановления файлов и возврата удалённых данных;
- отката системы до момента очистки истории.
Как восстановить данные с помощью синхронизации профиля
Синхронизация данных профиля — это уникальная возможность для сохранения всех личных данных, включая закладки, пароли и историю просмотров. Если у вас есть аккаунт в «Яндекс.Браузере» и включена синхронизация, восстановить историю будет очень просто:
- Открываем меню «Яндекс.Браузера» (значок трёх линий на верхней панели) и выбираем «Настройки».
Открываем меню «Яндекс.Браузера» и выбираем «Настройки»
В настройке «Синхронизация» щёлкаем «Отключить»
В установках обозревателя нажимаем «Настроить синхронизацию»
Нажимаем кнопку «Включить синхронизацию»
Способ, что описан выше, очень простой и удобный в исполнении, но однажды он меня подвёл. Мне необходимо было восстановить закладки браузера после неудачного импорта из другого обозревателя. Дважды возникала аналогичная ситуация и всё получалось, однако на третий раз синхронизация данных упорно не происходила, даже после повторного запроса. Исправил проблему следующим образом: удалил браузер через среду деинсталляции вместе с настройками, затем инсталлировал последнюю версию. После запустил синхронизацию и получил обратно все данные за несколько секунд.
При деинсталляции обозревателя необходимо удалять все данные программы
Как найти утраченную ссылку во временных файлах
Посмотреть временные файлы двумя способами можно было до версии 16.0 «Яндекс.Браузера». Позднее разработчики убрали возможность просматривать страницу с кэшем и оставили только интерфейс для cookies. К сожалению, этот способ не сможет вывести на прямую ссылку из истории посещений, но файл cookie подскажет сайту, куда нужно вас направить:
-
В адресную строку «Яндекс.Браузера» вставляем строчку browser://settings/cookies и нажимаем Enter.
В адресную строку прописываем browser://settings/cookies и нажимаем Enter
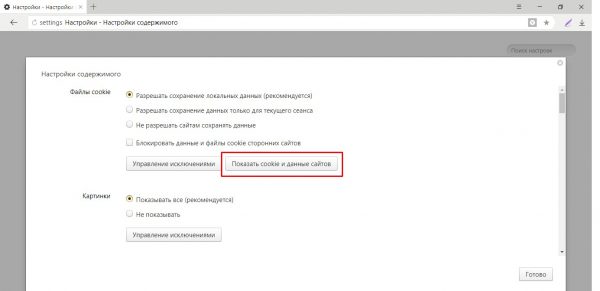
Нажимаем кнопку «Показать cookie и данные сайтов»
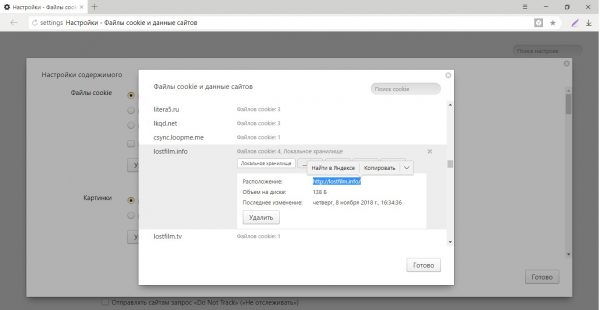
Файлы cookie содержат информацию о том, когда был вход и на какой сайт
Как восстановить историю с помощью программ для восстановления файлов
Физическое восстановление файлов на поверхности жёсткого диска — довольно сложный процесс. Однако существует несколько программ, которые с успехом справляются с этой задачей.
Одной из них является Handy Recovery. Эта утилита восстанавливает удалённые файлы с сохранением директорий. Это помогает не запутаться при копировании данных. Кроме того, программа имеет очень простой и понятный интерфейс на русском языке и подходит даже новичкам.
- Скачиваем из интернета, устанавливаем и запускаем программу.
- При первом же запросе на анализ диска выбираем корневую папку C.
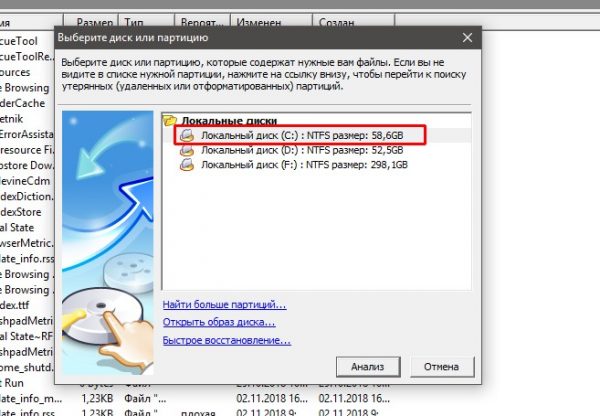
При запуске программы выбираем раздел диска для сканирования
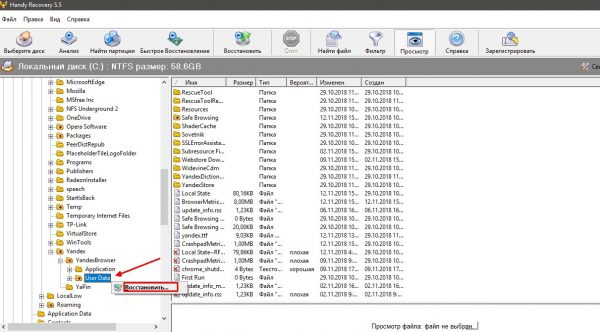
Находим нужную папку, щёлкаем по ней правой кнопкой и нажимаем «Восстановить»
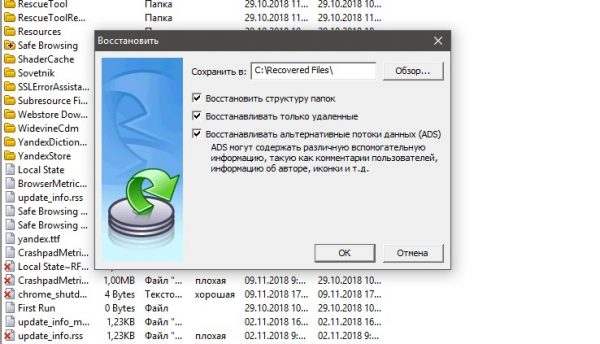
Выбираем директорию для восстановления файлов
Как восстановить историю через откат системы Windows
Откат системы — это универсальный инструмент восстановления Windows, который используется для того, чтобы вернуть ОС работоспособность. Например, в случае установки недоброкачественного ПО, драйверов, игр и так далее решить проблемы с вирусами и повреждениями системных файлов поможет откат к точке восстановления.
Процесс проходит в несколько этапов:
- Открываем папку «Служебные» в меню «Пуск».
- Щёлкаем ПКМ по «Командной строке», наводим курсор на пункт «Дополнительно» и выбираем «Запуск от имени администратора».
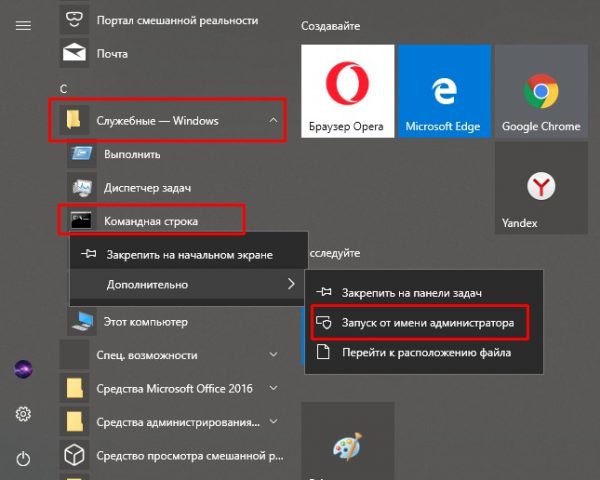
Через меню «Пуск» открываем терминал «Командной строки»
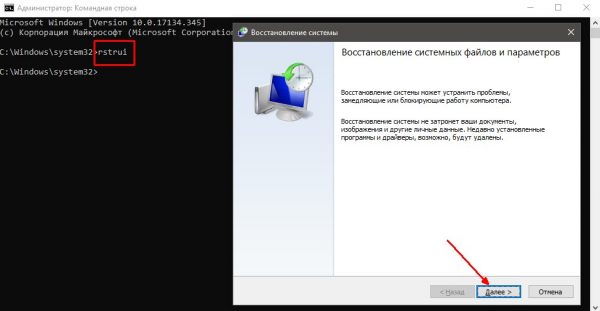
В «Командой строке» вводим команду rstrui и нажимаем Enter
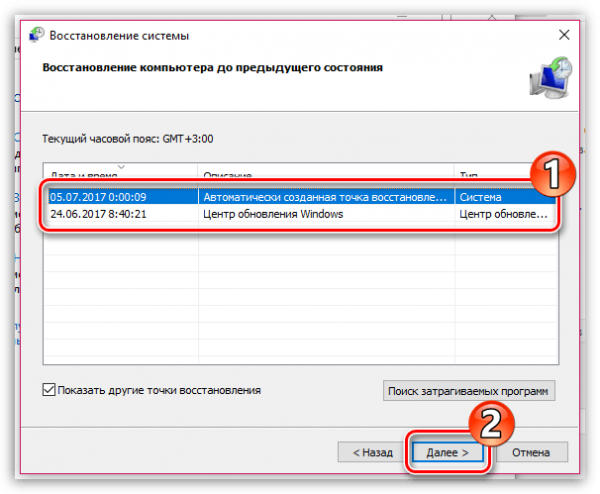
Выбираем точку восстановления и нажимаем «Далее»
Видео: как сделать откат системы Windows через точку восстановления
Восстановить историю «Яндекс.Браузера» довольно просто. Нужно лишь воспользоваться одним из вышеприведённых примеров и вся удалённая информация вернётся к свободному доступу.

Как бы хороша память пользователя ни была, а всё ж таки историю посещённых страниц в Яндекс Браузере запомнить он не всегда может. Особенно, в тех случаях, когда прогулка по Глобальной сети затянулась на несколько часов, и было просмотрено добрых два-три десятка сайтов, да и ещё многие из них незнакомые, увиденные, так сказать, впервые.
Как их взять на заметку? Опытные товарищи сразу же подскажут: «Делов-то! Открой журнал браузера, пройди по ссылке и добавь её в закладки.» Да, всё верно. А вот если этой самой истории уже нет, если все записи в ней стёрты по завершении онлайн-сессии. Как тогда?
Конечно, когда все ссылки удаленные, ситуация не из простых. Однако вернуть их можно. Эта статья расскажет вам, как посмотреть удалённую историю в Яндекс Браузере, а также как создать её резервную копию и выполнить при необходимости восстановление.
Как вернуть удалённую историю
Восстановить историю в Яндекс Браузере можно различными способами. Рассмотрим пошагово их реализацию на ПК.
Способ №1: откат системы
Восстановить историю в браузере после удаления можно посредством возвращения настроек системы к сохранённой точке восстановления. Но помните, что установленное ПО, ваши личные настройки, данные, созданные после создания резерва операционной системы, удаляются. То есть цифровой «слепок» отображает состояние ОС, которое было на момент его сохранения.
Есть и другой существенный нюанс: постарайтесь вспомнить, очищали ли вы журнал веб-обозревателя до резервирования ОС, и когда выполнялось последнее резервирование. Если очистка проводилась или резервной точке больше месяца, выполнять восстановление не целесообразно. Есть большая вероятность того, что историю вернуть не удастся.
1. Зажмите вместе клавиши — «Ctrl» + «Break».
2. В меню появившегося окна кликните «Дополнительные параметры… ».
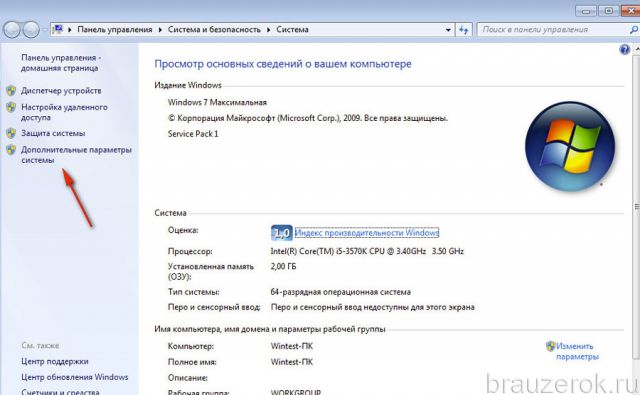
3. В панели «Свойства» клацните вкладку «Защита системы».
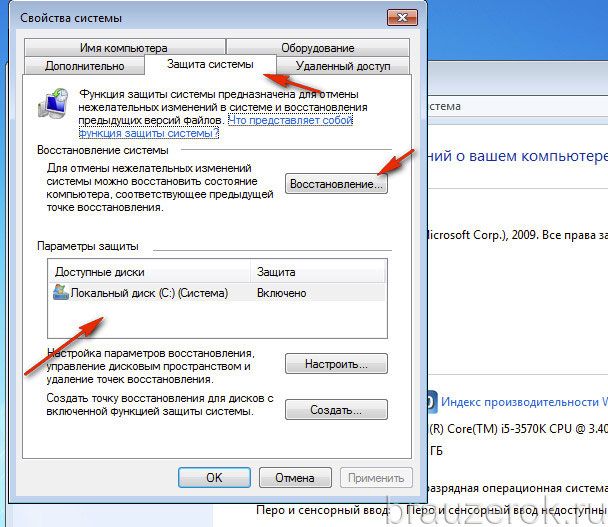
4. В блоке «Параметры», в списке «Доступные диски», выделите кликом мышки «Диск C».
5. Нажмите кнопку «Восстановление».
6. Установите флажок в окошке «Показать другие… ». Выберите последнюю точку восстановления.
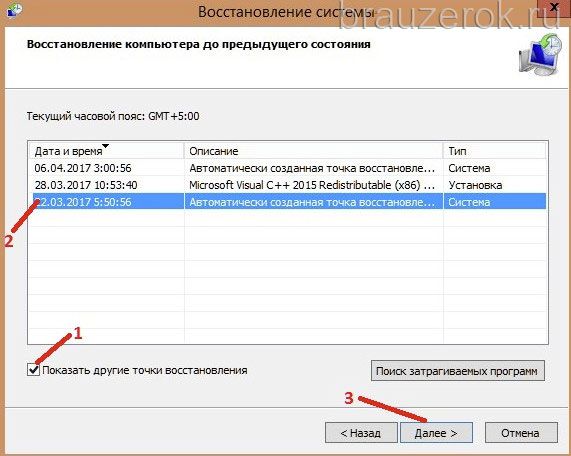
7. Клацните «Далее».
8. Следуйте инструкции системы, чтобы завершить откат настроек.
Способ №2: восстановление программой Piriform Recuva
История Яндекс Браузера хранится в специальном файле под названием History. Во время очистки через штатные опции он удаляется с диска стандартным способом. Но его можно вернуть при помощи специальных восстанавливающих утилит. Ниже приводится метод восстановления посредством бесплатной программы Piriform Recuva, но вы можете применить другое аналогичное по функциям ПО.
1. Откройте офсайт приложения — https://www.piriform.com/recuva.
2. Щёлкните кнопку «Download Free Version».
3. После перемещения по странице в первом блоке снова кликните «Free Download».
4. На новой вкладке, в блоке «Recuva Free», под надписью «Download from:», щёлкните ссылку «FileHippo.com».
5. Клацните в правой части загрузившейся странички «… Latest Version».
6. По завершении загрузки запустите инсталлятор.
7. Вверху справа кликом мыши откройте ниспадающее меню со списком языков и выберите «Russian».
8. Нажмите «Install».
9. Когда появится сообщение «…. Setup Completed», нажмите «Run Recuva».
10. В панели установщика клацните «Далее».
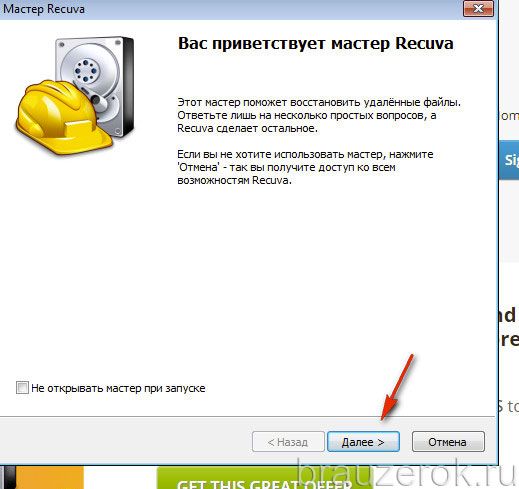
11. Чтобы найти все удалённые файлы в профиле Яндекса, выберите настройку «Показ всех файлов». Снова щёлкните «Далее».
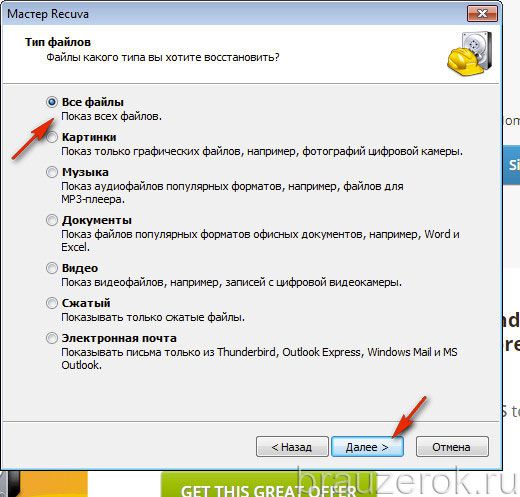
12. В списке «Размещение … » кликните «В указанном месте». В строке задайте путь к профилю браузера Яндекс:
C:UsersИМЯAppDataLocalYandexYandexBrowserUser DataDefault
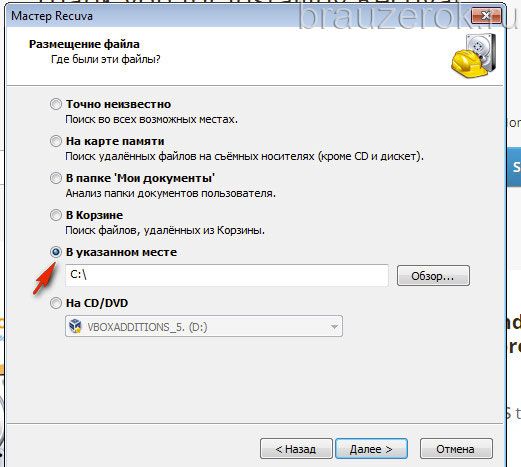
Вместо «ИМЯ» вставьте название вашей учётной записи в системе. (Оно отображается в панели «Пуск» вверху правого блока под иконкой.) Либо воспользуйтесь кнопкой «Обзор» и укажите директорию профиля вручную через системное окно.
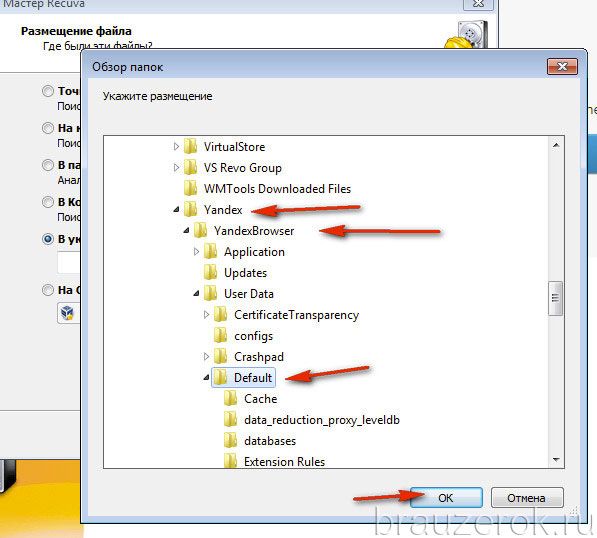
13. После установки пути нажмите «Далее».
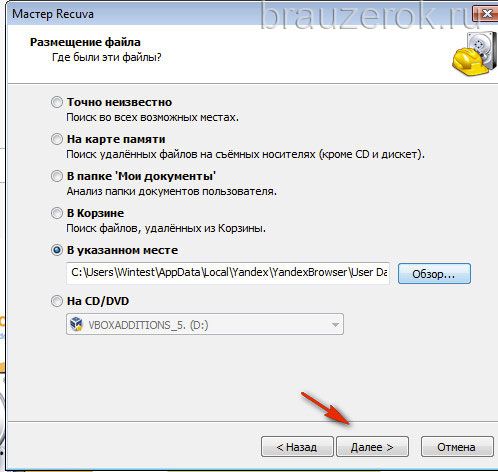
14. Щелчком мышки установите «птичку» в настройке «Включить углублённый анализ».
15. Клацните кнопку «Начать».
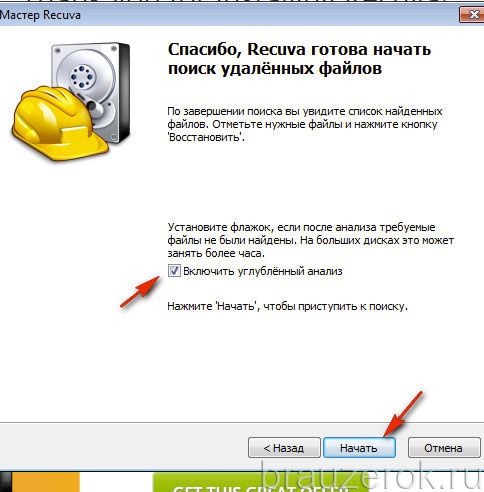
16. Дождитесь окончания процедуры восстановления (прогресс выполнения будет отображаться в дополнительной панели).
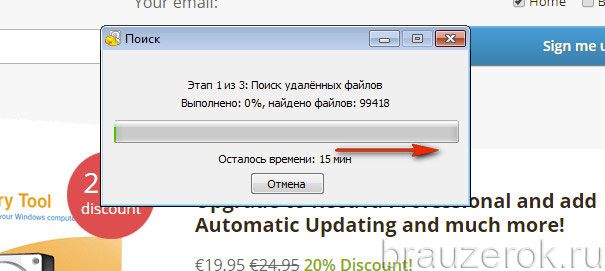
17. Программа отобразит список найденных удалённых файлов в указанной директории, которые можно вернуть. Найдите в нём файл «History» и кликните возле него окошко, чтобы появилась «галочка».
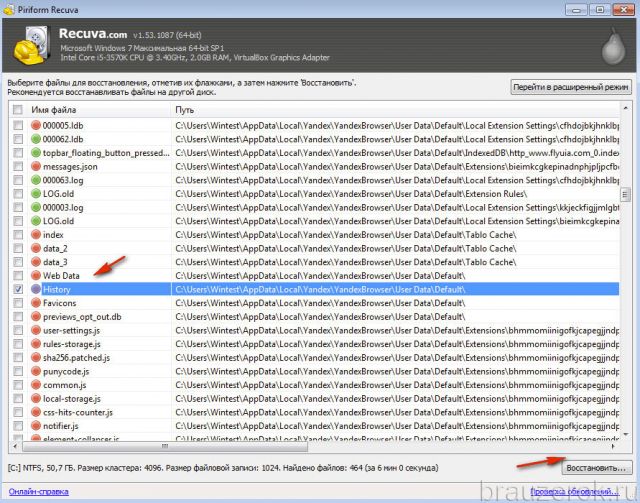
18. Щёлкните «Восстановить». Укажите путь к папке профиля для размещения восстановленного файла с историей. Либо выберите альтернативную директорию и затем самостоятельно переместите history.
19. Запустите браузер и откройте журнал посещённых веб-страниц.
Способ №3: просмотр кэша и куки
Этот способ «спасёт» вас, если в браузере проводилась лишь выборочная очистка, в результате которой кэш и все сохранённые куки остались «нетронутыми». В этих данных можно довольно легко найти ссылки на веб-ресурсы, загруженные в процессе веб-сёрфинга.
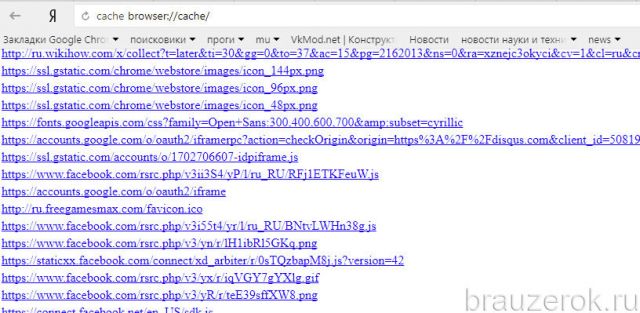
Итак, чтобы найти URL в кэше, сделайте так:
1. В адресной строке Яндекса наберите — browser://cache.
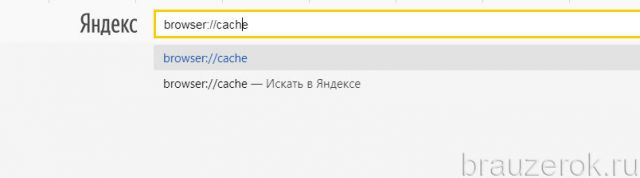
2. Просмотрите список, кликните интересующие ссылки и добавьте их в закладки.
1. Нажмите кнопку «Меню» (иконка «три линии» вверху справа).
2. Откройте раздел «Настройки».
3. Внизу страницы нажмите «Показать дополнительные… ».
4. В блоке «Личные данные» щёлкните «Настройки содержимого».
5. В подразделе «Файлы cookie» клацните кнопку «Показать cookie… ».
6. В списке отображаются имена сайтов, куки которых были сохранены в браузере. Перенесите все необходимые ссылки в закладки и закройте панель.
Создание бэкапа
Резервирование истории исключает всевозможные неприятности, связанные со случайным удалением журнала (по ошибке, в результате вирусной атаки или программного сбоя). Но, разумеется, о создании копии нужно побеспокоиться заранее. Создать бэкап и выполнить восстановление при помощи него можно различными методами.
Способ №1: копирование файла
1. Откройте профиль в директории браузера:
C: → Users → → AppData → Local → Yandex → YandexBrowser → User Data → Default
2. Кликните правой кнопкой по файлу History. В списке клацните «Копировать».
3. Вставьте файл в другую папку. Желательно, чтобы она находилась в другом разделе диска (не системном!).
4. Это и будет ваш бэкап. При необходимости вы можете его снова вставить в профиль Яндекса — заменить текущий файл History.
Способ №2: резервирование утилитой hc.Historian
hc.Historian — достойная альтернатива штатному инструменту браузеров для просмотра журнала посещений. В автоматическом режиме она создаёт отдельный бэкап истории, который в любой момент можно просмотреть и использовать для восстановления. Даже в случае полного удаления браузера.
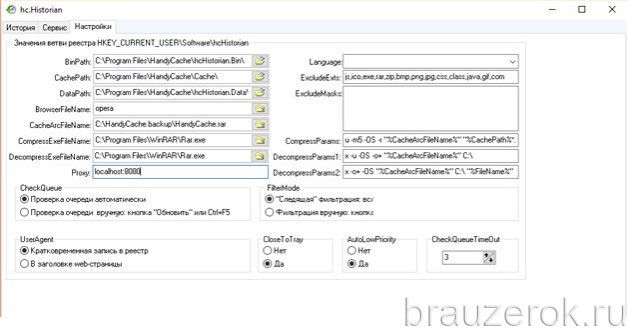
В интерфейсе утилиты можно задавать настройки резервирования (указывать директорию, архиватор для компрессии копии, а также браузер, данные которого нужно обрабатывать).
Способ №3: синхронизация
Синхронизация подразумевает сохранение всех настроек пользовательского профиля с возможностью последующего его восстановления (загрузки) в браузере не только на компьютере, но и на мобильных устройствах (например, на Андроиде).
1. Кликните «Меню». В списке нажмите «Синхронизация».
2. Введите логин и пароль для входа в аккаунт.
3. Клацните «Включить синхронизацию».
4. Теперь, когда вам нужно будет восстановить историю и другие пользовательские данные, снова откройте раздел «Синхронизация» и выполните авторизацию в профиле.
Выберите наиболее действенный способ восстановления конкретно для вашего случая. Восстановление файла утилитой Recuva, безусловно, выполнить проще и безопасней. Но если она не смогла обнаружить ранее удалённый журнал, можно выполнить откат настроек системы. Не забывайте периодически создавать бэкапы истории, если в ней хранятся важные, ценные для вас ссылки.
Работа с сохраненной копией страницы
Содержание:
- Зачем нужна сохраненная копия страницы и как её посмотреть
- Как посмотреть сохраненную копию в Google
- Как посмотреть сохраненную копию веб-страницы в Яндекс
- Почему сохраненной страницы может не быть
- Специализированные веб-архивы
- Wayback Machine
- Archive.Today
- Расширения для браузеров
- Cached Page
- Выводы
Чтобы пользователь нашел документ в поисковой выдаче, недостаточно добавления его на сервер. Контент должен быть проиндексирован (добавлен поисковыми роботами в индекс) поисковыми системами Яндекс и Google. Поэтому, наличие сохраненной копии — показатель что поисковый бот был на странице. Рассмотрим, что можно посмотреть и какие ошибки обнаружить с помощью сохраненной копии веб-страницы.
Роботы Яндекса и Google добавляют копии найденных веб-страниц в специальное место в облаке — кеш. При этом новая копия страницы перезаписывает старую. Поэтому в кеше отображаются свежие версии веб-страниц.
Сохраненная копия — это версия веб-страницы, которая сохранена в кэше поисковой системы. Условно это бесплатная резервная копия от поисковых систем.
На самом деле веб-страницы сохраняют:
- Поисковые системы. В них находится находится последняя проиндексированная версия страницы. Такие «снимки» используют SEO-специалисты, чтобы увидеть какие данные обнаружил на странице поисковый бот;
- Специализированные сервисы. Занимаются сохранением содержимого веб-страницы. Основная задача таких сервисов сохранить страницы в конкретный момент времени. С помощью них вы можете узнать как выглядел сайт или страница несколько лет назад.
Зачем нужна сохраненная копия страницы и как её посмотреть
На сайтах регулярно происходит добавление нового и редактирование существующего контента. Периодически изменяется его дизайн, добавляются и/или удаляются графические элементы. Это трудоемкая работа в процессе, которой могут возникнуть ошибки: потеряться контент, «съехать дизайн», удалиться блок или перестать индексироваться часть материала. Выявить, как выглядела страницы до определенного момента, поможет сохраненная копия.
Пример из практики:
Есть у нас технически сложный проект, который при заполнении объема памяти перестает, корректно работать. Если по простому, то вместо работающего сайта, мы видим ошибку базы данных.
Время от времени сайт отваливается по ночам, а утром разработчики все исправляют. И тут важный момент, сохраненные копии, позволяют понять успели ли поисковые системы проиндексировать сломанный сайт или нет. А также позволяют выявить, какие именно страницы успел переобойти бот.
Как посмотреть сохраненную копию в Google
Рассмотрим на примере страницы https://discript.ru/prodvizhenie-sajtov/kolomna/. Перед url адресом пропишите оператор «site:». В сниппете (блок информации о странице веб-сайта) результата, нажмите на иконку в виде треугольника, выберите соответствующий пункт.
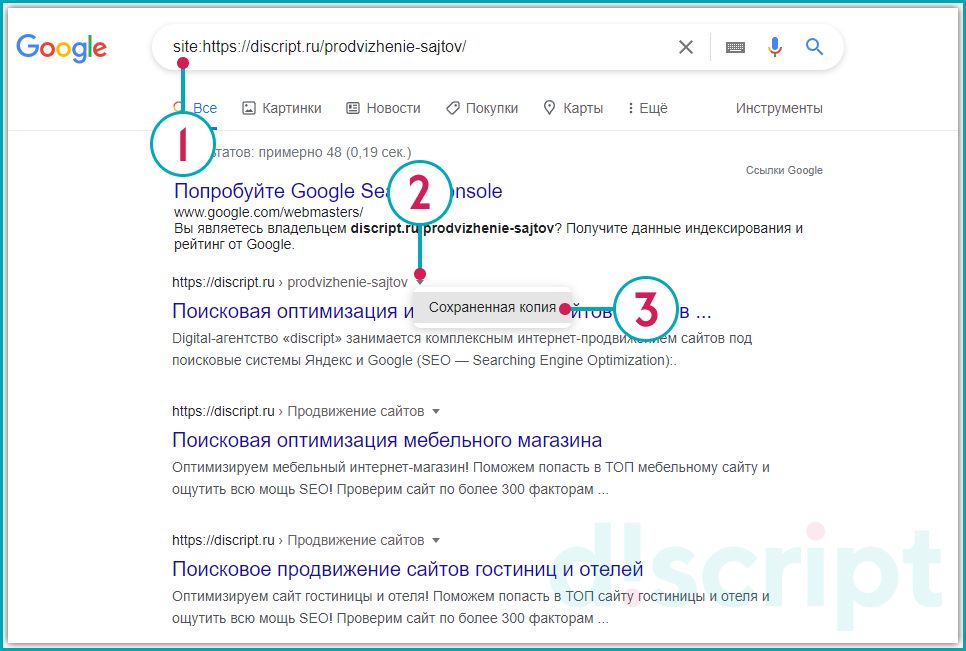
Сохраненная копия в Google
Откроется сохраненная копия веб-страницы. Google выведет окно с сообщением, что открылся «снимок» страницы.
Разберем представленную информацию:
- Дату фиксации. В данном параметре указано, когда был сделан слепок страницы. Поэтому сопоставив указанную дату с датой внесения правок, можно предположить успел ли поисковый бот обойти страницу или еще нет (Важно! данный метод не гарантирует 100% верную информацию, т.к. данные хранятся в кеше и могут отличаться в зависимости от вашего место нахождения) ;
- Полная версия. Отображается версия страница, как должен был ее увидеть пользователь.
- Текстовая версия. Позволяет просмотреть контент веб-страницы без применения стилей. Такой формат позволяет увидеть скрытые от пользователя элементы, но доступные для поисковых роботов Яндекса и Google;
- Исходный код. Выводит исходный код HTML-страницы. Это требуется для изучения тега Title и мета тегов, таких как Description. Данное представление позволяет изучить, как сверстана веб-страница, и нет ли на ней критических ошибок.
Просмотр версии страницы из кеша Google
Как посмотреть сохраненную копию веб-страницы в Яндекс
Рассмотрим на примере страницы https://discript.ru/site-development/. В строку поиска обязательно пропишите оператор «url:» перед url-адресом. нажмите на значок в виде трех горизонтальных точек, выберите «Сохраненная копия».
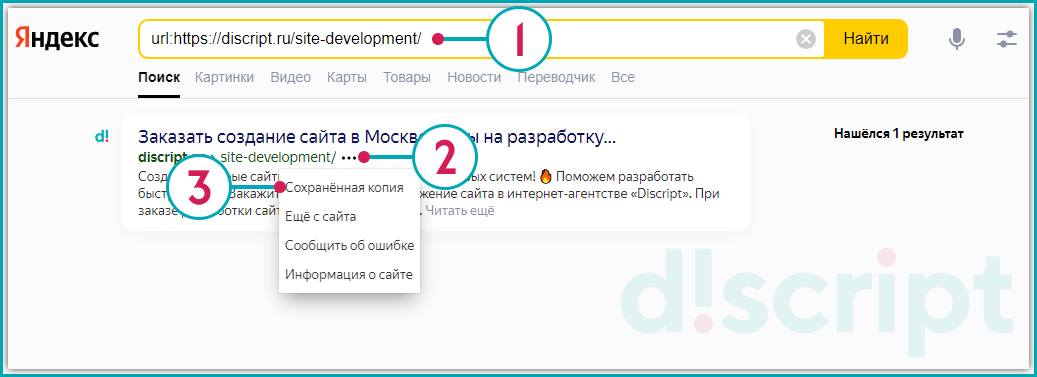
Пример поиска сохраненной страницы в Яндексе
Далее Яндекс предоставит следующие данные:
- Дата индексации. Данное значение информирует в какой момент выполнен слепок страницы.
- Полная версия страницы. Отображение страницы со всеми стилями.
- Текстовая версия страницы. Текстовая версия, аналогично позволяет изучить страницу без стилей и получить всю скрытую информацию. Часто именно при проверке текстовой копии обнаруживаются сквозные блоки текста на страницах. Т.к. при использовании стилей они скрыты.
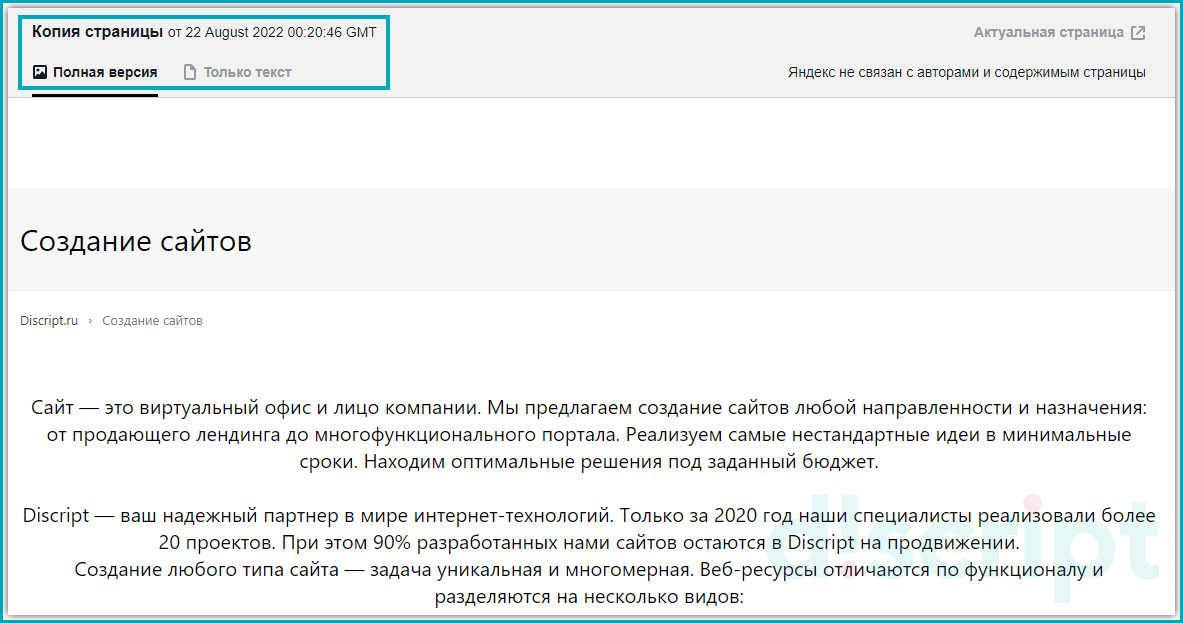
Предоставление данных о копии страницы в Яндексе
Почему сохраненной страницы может не быть
Это происходит в результате:
- Сбой работы поисковых систем. Разработчики Яндекса даже говорят, что нет стопроцентной гарантии, что страница сохранится. Конкретная причина не указывается.
- HTML-код содержит мета тег мета-тег «robots» со значением «noarchive», что означает запрет на кэширование (локальное сохранение данных для получения быстрого доступа к странице при следующих запросах).
Что предпринять если в ПС нет сохраненной копии, а посмотреть содержимое нужно? Попробуйте изучить специализированные площадки и расширения.
Рассмотренными выше способами можно посмотреть:
- Мобильную версию веб-сайта. Пропишите url мобильной версии в Яндексе или Google. Из выдачи перейдите на нее далее, как в примере рассмотренном выше.
- Адаптивную версию. Перейдя в сохраненную копию (так же как в примере выше). Открываем инструменты разработчика. Клавиша F12 в обозревателе. Или нажать ПКМ на пустом месте страницы, выбрать «Посмотреть код». Переходим в раздел мобильное отображение и перезагружаем веб-страницу.
Специализированные веб-архивы
Выше мы обсуждали, что существуют сервисы, задачи которых сохранять в истории страницы сайтов. Сейчас рассмотрим их подробнее и расскажем, как с ними работать.
И начнем с самого популярного и известно.
Wayback Machine
Сервис Wayback Machine — бесплатным онлайн-архивом, задача которого является сохранить и архивировать информацию размещенную в открытых интернет‑ресурсах. Wayback Machine является частью некоммерческого проекта Интернет Архива. На его серверах хранятся копии веб-сайтов, книг, аудио, фото, видео.
Чтобы открыть копию страницы перейдите на https://archive.org/, далее откроется поисковая форма, куда пропишите URL страницы. Нажмите кнопку «GO».

Онлайн-архив Wayback Machine
Сервис отобразит имеющиеся в архиве снимки.
Далее выберите в календаре нужную дату и откройте страницы. Результатом вывода будет открытие страницы, которую зафиксировали роботы за выбранную дату.
Календарь Wayback Machine
Кроме просмотра снимков страниц, сервис поможет:
- Проанализировать robots.txt. Сервис будет сканировать веб-сайты вне зависимости от настроек robots.txt;
- Узнать данные о домене. Актуально перед покупкой. Уточните какая информация размещалась на нем. Если вы купите «заспамленный» или домен под «санкциями» (например была размещена информация для взрослых) новый контент будет плохо ранжироваться. Если же ранее на нем размещалась информация, которая подходит по тематике и качеству для вашего будущего ресурса, тогда вы сможете использовать ее на этом же домене.
- Найти в архивных копиях пропавшую информацию.
- Если, например, на веб-сайте наблюдается спад трафика, откройте сохраненную версия сайта до момента уменьшения посещаемости. Проанализируйте, какие были сделаны изменения, чтобы разобраться в причине падения посещаемости.
Archive.Today
Archive.Today — бесплатный некоммерческий севрис сохраняющий веб-страницы в оналйн режиме. Особенность — сохраняет не только статические страницы, но и генерируемые Веб 2.0-проектами страницы. Например, карты Google.
Основное отличие от Wayback Machine, что Archive.Today сохраняет веб-страницы только по запросу пользователей. При этом сервер полностью сохраняет:
- HTML-страницы,
- CSS файлы,
- JS файлы,
- PDF,
- аудио файлы,
- пр.
Важно, помнить, что Archive.Today игнорирует файл robots.txt поэтому в нем можно сохранить страницы недоступные для Wayback Machine.
Обратите внимание, общий в Размер заархивированной страницы со всеми изображениями не должен превышать 50 МБ.
У Archive.Today есть собственное приложение для браузера Mozilla Firefox. Ссылка на ПО https://addons.mozilla.org/en-US/firefox/addon/archive-page/
Для начала работы с Archive.Today перейдите по адресу: https://archive.md/. Чтобы получить результат укажите в форму интересующий URL-адрес.
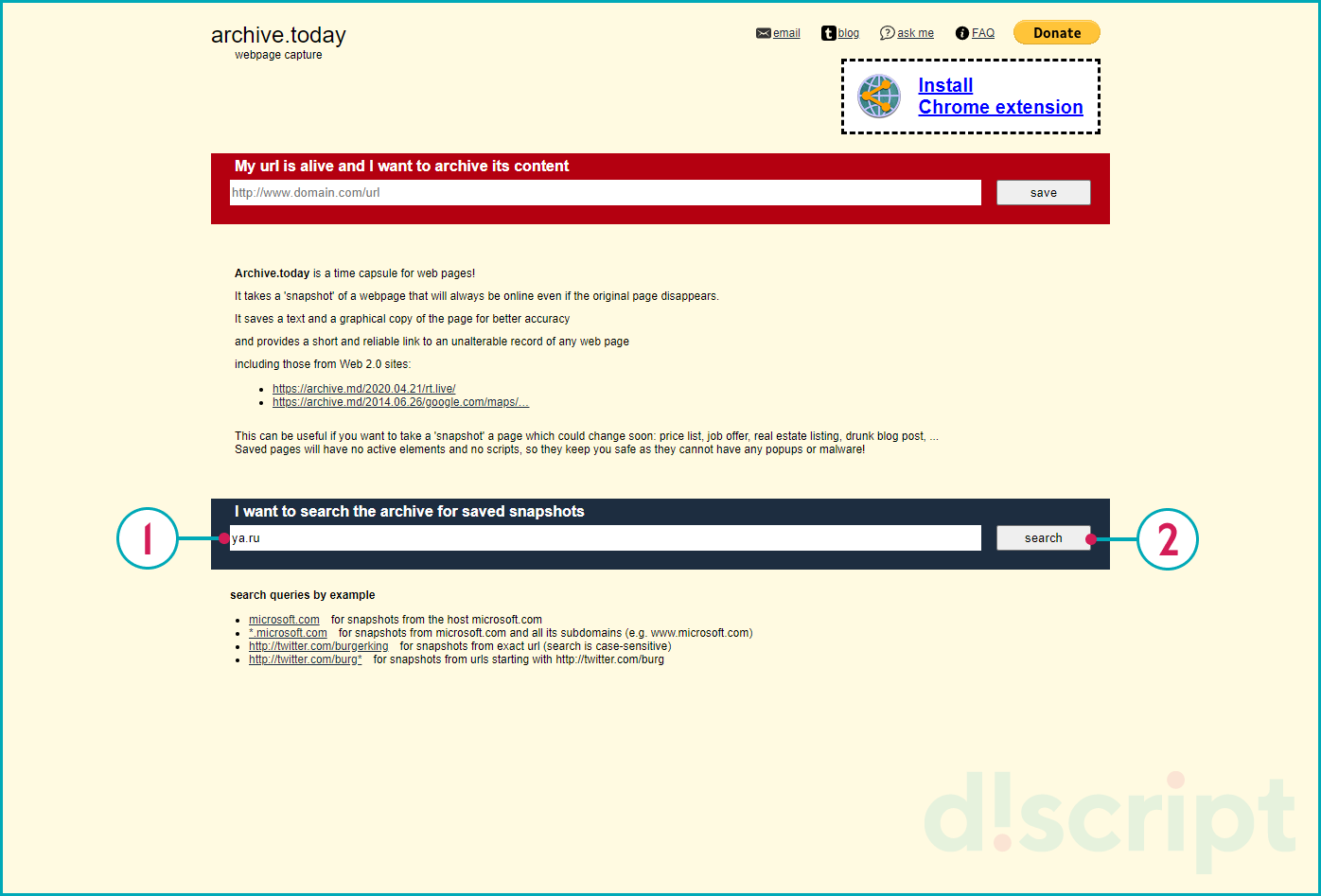
Сервис Archive.Today
Откроется страница с сохраненными снимками и информацией о дате создания копии.
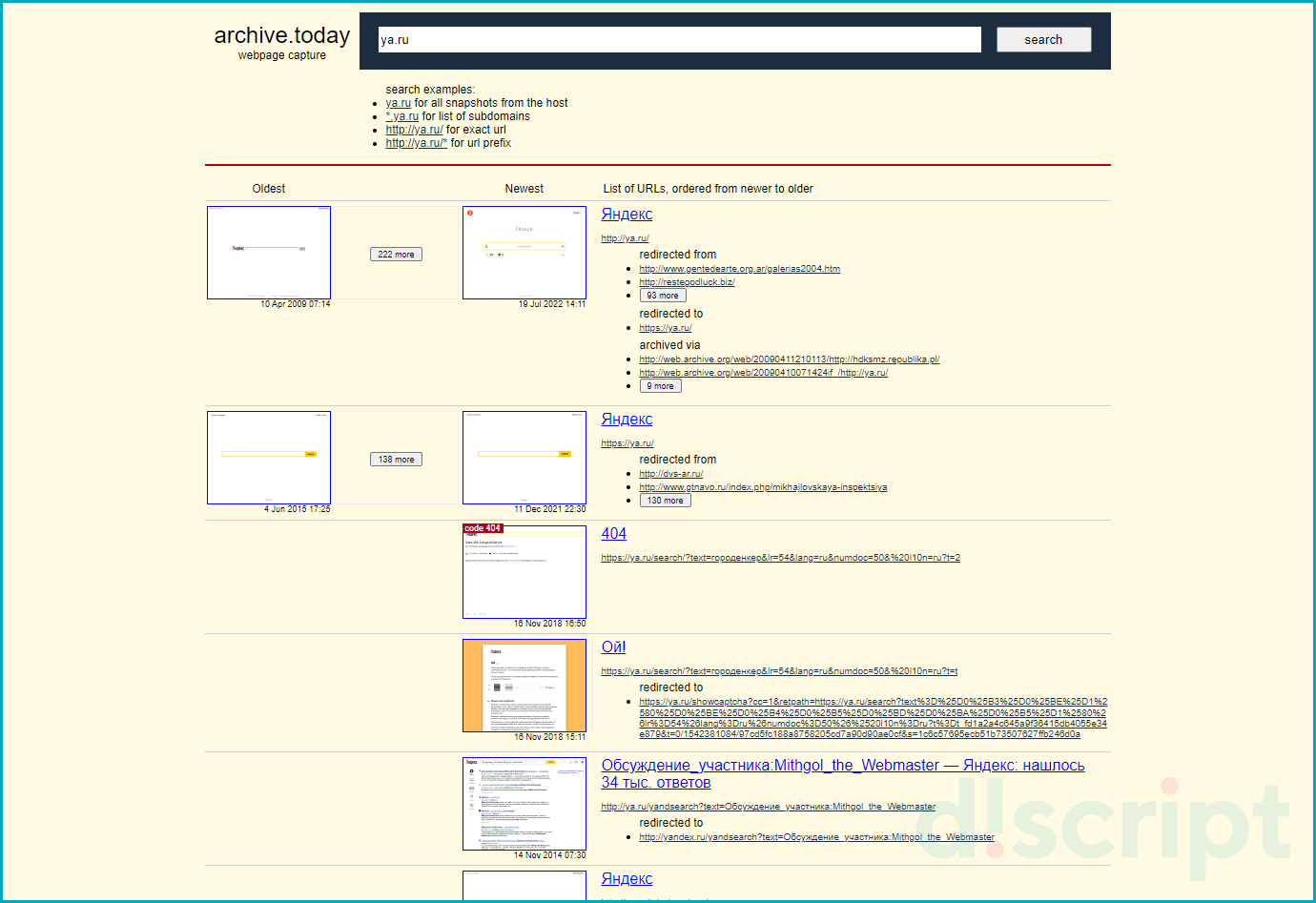
Страница с сохраненными снимками в сервисе Archive.Today
Вы можете скачать сохраненную копию виде архива. И восстановить версию страницы у себе на сервере.
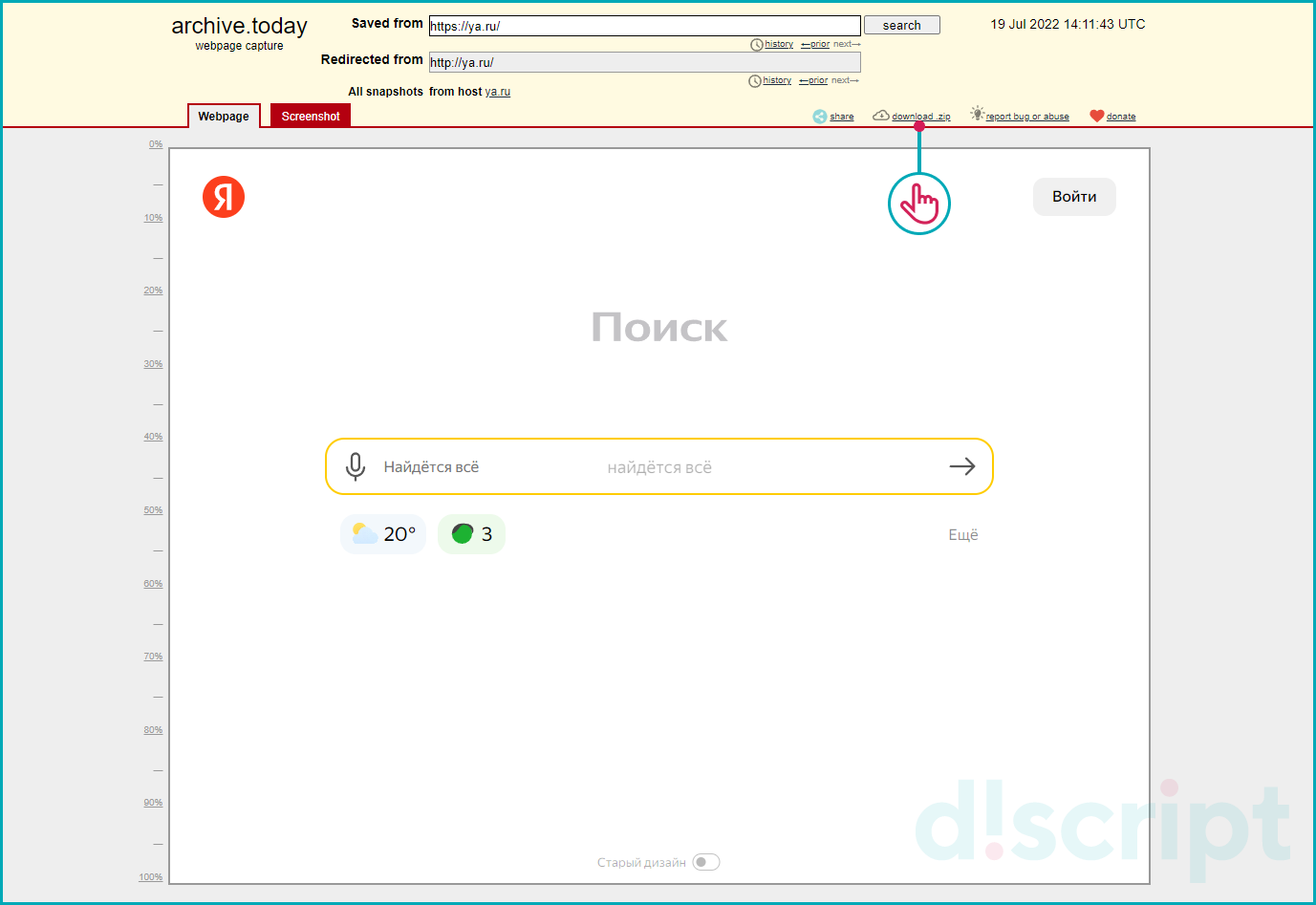
Сохранение страницы в сервисе Archive.Today
Расширения для браузеров
Существуют, плагины для браузеров, позволяющие создавать и просматривать сохраненные версии страниц.
Например, расширение Web Cache Viewer позволяет:
- Загружать веб-страницу из локального кэша на компьютере;
- Автоматически находить страницу при помощи сервиса Wayback Machine.
Перейдя по ссылке, рассмотренной, выше, нажмите кнопку «Установить».
Сервис Web Cache Viewer
После инсталляции расширения в браузере, нажмите правой кнопкой мыши пустом месте страницы для просмотра версии из Google или Wayback Machine.
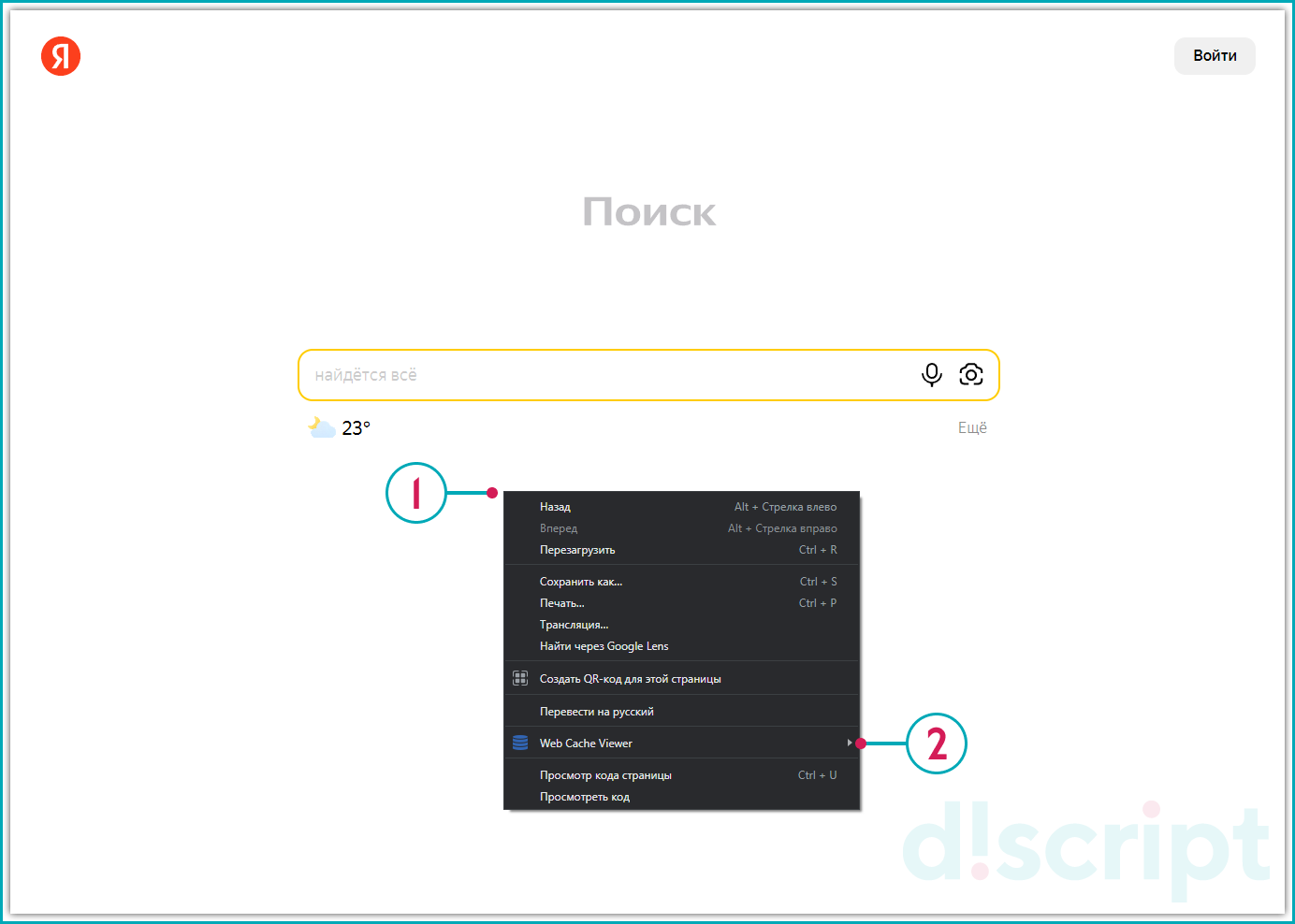
Просмотр версии из Google или Wayback Machine
Для пользователей Firefox существует аналогичное дополнение со схожим функционалом Web Archives.
Cached Page
Веб-сайт Cached Page ищет копии веб-страниц в поиске Google, Интернет Архиве, WebSite. Используйте площадку, если описанные выше способы не помогли найти сохраненную копию веб-сайта.
Пропишите название сайта в специальную форму. Для поиска нажмите одну из трех кнопок. Сервис предложит произвести поиск веб-страницы в:
- Веб-кэш Google;
- Интернет Архив;
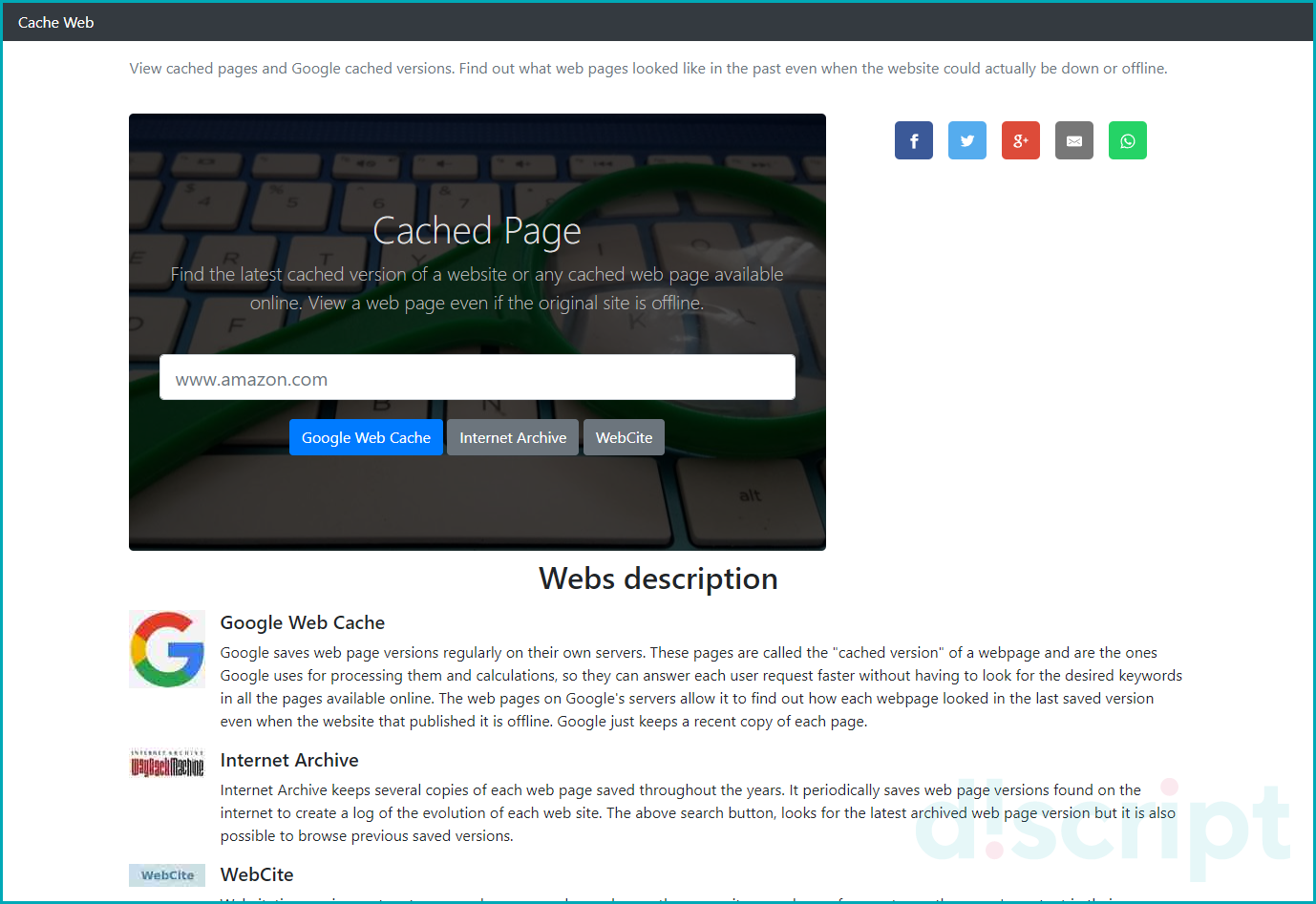
Поиск в сервисе Cached Page
Например, прописав в форму адрес https://discript.ru/prodvizhenie-sajtov/lyubercy/, и нажав кнопку «Архив Интернета», произойдет переход на страницу сервиса Wayback Machine. Если страница сохранена в БД сервиса, она отобразится на странице.
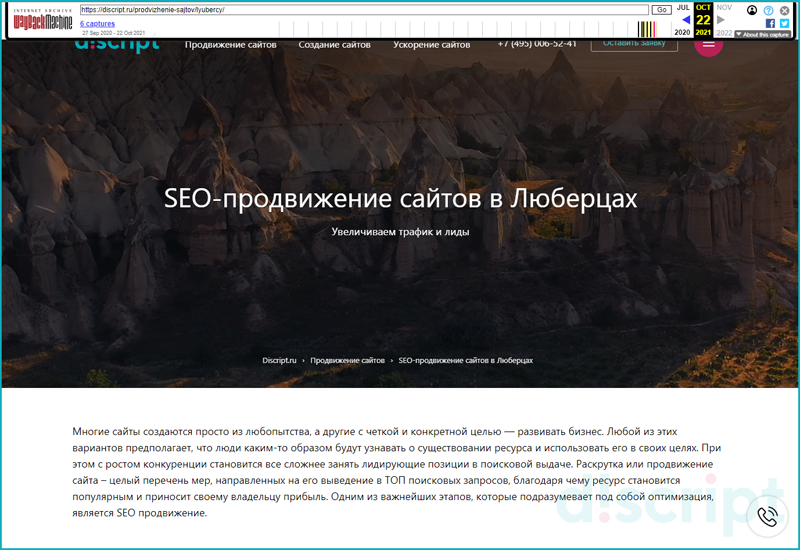
Отображение страницы в сервисе Wayback Machine
Выводы
Работая с сохраненными копиями страниц, можно выявить достаточного много полезных нюансов.
Сохраненные копии позволяют:
- Узнать, поисковый бот успел ли обойти вашу страницу после внесенных правок.
- Как бот воспринимает информацию со страницы. Все ли учитывает или остались места, которые ПС не видят.
- Выявить, какие элементы пропали и когда.
- Выявить, какие страницы успел обойти поисковый бот, после того, как сайт перестал быть доступным.
- Создать копии страниц.
- Восстановить копию сайта, когда забыли оплатить домен.
Сохраненная копия веб-страницы поможет определить, какая версия документа проиндексирована поисковыми роботами и участвует в ранжировании. Поэтому наличие «снимка» страницы в Яндексе и Google говорит об успешной проведенной индексации.