Для поиска различной информации в интернете нужны поисковые системы. Поисковая система dark web является одним из лучших способов поиска информации, скрытой от общественности. Существует много различных dark web поисковых систем с соответствующей специализацией.
Для понимания работы поисковиков и определения их сильных сторон, нужно немного знать о темной сети?. Даркнет является сетью Onion-сайтов и сервисов, доступных только через Tor-браузер. Наиболее распространенным способом использования Даркнета является поиск скрытой информации о хакерстве, наркотиках, утечке данных и других незаконных действиях.
Существует много различных типов Dark Web поисковых систем, и у каждого есть своя специализация. Например, некоторые из них обладают лучшими возможностями поиска. Некоторые специализируются на поиске инструментов слежки или рекомендаций для журналистов по борьбе с правительственной слежкой и цензурой. Другие поисковые системы находят сайты с незаконным контентом . Также есть поисковики для более обобщенного поиска в темном интернете.
Ahmia.fi
Надежный поисковик Ahmia.fi придерживается политики в отношении любых «материалов, содержащих насилие» и отличается от многих других dark web поисковых систем, индексирующих сайты с материалами о сексуальном насилии над детьми. Ahmia.fi также доступен в surface web и поддерживает поиск в сети i2p.
The Hidden Wiki
Поиск в Даркнете очень трудоемкий из-за появления в результатах поиска 20 спам-ссылок и всего 1 настоящей. The Hidden Wiki решит эту проблему, предоставив каталог сайтов и ссылок на них. Также доступна surface-версия Wiki .
Haystak
Haystak проиндексировал более 1,5 миллиарда страниц и более 260 000 сайтов. Есть платная версия поисковика с дополнительными функциями поиска с использованием регулярных выражений, просмотра несуществующих сайтов onion и доступа к их API. Одна из функций позволяет получить доступ к базе данных различной украденной информации.
Torch
Torch существует с 1996 года и обладает плохой системой поиска. При поиске URL-адреса любой соцсети поисковик показывает все, кроме необходимого сайта. Такое действие показывает способность поисковой системы искать информацию даже в очень далеких уголках Даркнета.
DuckDuckGo
DuckDuckGo обязательно окажется почти в каждом списке dark web поисковых систем. Поисковик предоставляет анонимность и показывает результаты поверхностного поиска в большем количестве, чем результаты из Даркнета. Поисковик не нашел 1 результат поиска в темной сети по нескольким случайным запросам. DuckDuckGo достоин упоминания в этом списке из-за своей ориентированности на конфиденциальность, а не на бизнес.
Насколько безопасны поисковые системы темной паутины?
Несмотря на свои возможности поиска скрытой информации, поисковики могут быть опасны. Не стоит использовать dark web поисковые системы со своего личного компьютера. Пользователь может подвергнуть риску свои пароли, криптофонды и другую личную информацию.
Кроме того, некоторые сайты в Даркнете могут содержать вредоносные программы, способные заразить компьютер посетителя и украсть информацию. Многие результаты поиска могут привести к очень откровенному и шокирующему контенту, такому как жестокое обращение с детьми, кровь, пытки, насилие, угрозы, терроризм или другие виды незаконного контента.
Пользователям нужно выполнять поиски законного контента и избегать использования прокси-серверов, поскольку злоумышленник может легко заразить устройство вредоносным ПО или использовать прокси-сервер для кражи криптовалюты пользователя.
Самым безопасным способом доступа к Даркнету является анонимный браузер Tor , способный защитить личные данные пользователя во время просмотра темной паутины. Также рекомендуется использование VPN вместе с браузером.
Помимо Tor существует несколько альтернативных Onion-браузеров с анонимным поиском:
-
12P
-
Whonix
-
Globus
-
Freepto
-
Disconnect
Как использовать Dark Web поисковые системы?
Поисковые системы Даркнета используют сложное ПО для поиска в скрытой сети и индексирования всей найденной информации. После индексации поисковые системы позволяют находить информацию через интерфейс системы.
Для увеличения возможностей поиска важно понимать какую информацию поисковая система находит лучше всех. Например, поисковая система Grams известна поиском наркотиков, а The Hidden Wiki лучше подходит для поиска электронных книг и статей о конфиденциальности. В независимости от поисковой системы в Даркнете пользователь найдет сайты, скрытые от широкой публики и полезные для поиска определенной информации.
Чтобы оставаться в безопасности, нужно избегать нелегальных сайтов в темном интернете. Пользователь должен всегда использовать надежный VPN и регулярно обновлять Tor-браузер для избежания взлома.
Дарквеб (dark web, «темная паутина», «темная сеть») – это часть всемирной паутины (World Wide Web), которая находится в даркнетах, и доступ к которой можно получить только при помощи специального программного обеспечения (такого как Tor). Дарквеб относится к глубокой сети, то есть является частью сети, недоступной для обычных поисковиков.
Даркнет (англ. darknet) — оверлейная сеть (overlay network, т.е. сеть, построенная поверх другой сети, в данном случае «поверх» Интернета), которая не может быть обнаружена обычными методами и доступ к которой предоставляется через специальное ПО, например, с помощью Tor.
Видимая сеть — это часть Всемирной паутины, находящаяся в открытом лёгком доступе для широкой публики и индексируемая поисковыми системами.
![]()
Download Article
![]()
Download Article
The internet has changed immensely over the years. For some, it can be hard to imagine what older websites even looked like. And yet, it is still possible to find old websites that no longer exist! Whether you are simply curious, or want to revisit a specific webpage from long ago, this wikiHow article will teach you how to use a variety of tools for surfing the internet of old.
-

1
Go to https://web.archive.org/ on your web browser. The Wayback Machine is a popular tool for archiving old websites, but anyone can search its archives as well. Head to the site’s URL to get started.
-
2
Conduct a search in the Machine’s search bar. The search bar is centered towards the top of the page. You can either type in a specific URL, or a few keywords relating to a site you are looking for.
- The Wayback Machine doesn’t quite support keyword searches the way Google or Bing do. In other words, you should only search for specific sites on the Wayback Machine’s search engine.
- To conduct a broader search of the Wayback Machine, try doing a Google search using site:https://web.archive.org/.
Advertisement
-
3
Choose a site. Depending on your search, the Wayback Machine will yield different sites to choose from. Pick one to continue.
-
4
Select a year on the bar graph. There should be a bar graph atop your screen, indicating the history of the website. Scrub along the bar graph with your cursor to see the different dates, and click one to discover what that site looked like in the past.




Advertisement
-
1
Run a standard Google search. To begin your journey into the internet’s past, search for something on Google as you usually would.
- If you are looking for an old page or article on a specific site, you might want to use site: followed by the URL to yield the proper results. (ex. site:wikihow.com). [1]
- If you are looking for an old page or article on a specific site, you might want to use site: followed by the URL to yield the proper results. (ex. site:wikihow.com). [1]
-
2
Click Tools. It should be located atop your results page, just under the right-hand side of the search bar.
-
3
Click Any time. Once you click Tools, Google will provide two options along the left-hand side of your screen: Any time and All results. Use the former to look into the internet’s past.
-
4
Click Custom range. Google offers several different filters for the timeframe of your search. If you need something fairly recent, the preset options are likely sufficient. But if you truly want to dip into the internet’s past, select Custom range to reach back even further.
-
5
Adjust the search’s date range. Your custom date range can be as wide or as narrow as you would like. Add a From and a To date to see what Google has to offer!
-
6
Click Go. Once you have chosen your date range, click the Go button to modify your search.
- Keep in mind that some sites may have been published a long time ago, but will automatically redirect to their most current version. Still, a wide variety of sites, including web forums and message boards, will offer a peek into their past.
- Sometimes, Google stores a «Cached» version of a webpage, although it may not be particularly old. Click the three dots next to a search result, then click «Cached» (if available) to see it. This could be helpful when looking for a recent edit or deletion.
- Also keep in mind Google’s results are for websites that do still exist, but may be hidden deep in Google’s search results due to their age.






Advertisement
-
1
Run a standard Bing search. Bing may not be as popular as Google, but it is likely to yield its own unique results.
-
2
Click Date. It is located atop the page, similar to where Google’s «Tools» icon is located. It will lead to a drop-down menu.
-
3
Create a Custom range. The drop-down menu offers a few different filters for specifying your search. To look really far back, create a Custom range of dates.
-
4
Click Apply. Your Bing search will automatically update to reflect your custom date range, and offer a glimpse into the internet’s past!
- Keep in mind Bing’s results are for websites that do still exist, but may be hidden deep in Bing’s search results due to their age.




Advertisement
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
About This Article
Article SummaryX
1. Go to web.archive.org.
2. Search for a website.
3. Select a website.
4. Select a date.
Did this summary help you?
Thanks to all authors for creating a page that has been read 69,478 times.
Is this article up to date?
![]()
Загрузить PDF
![]()
Загрузить PDF
Поисковые системы, такие как Google, индексируют более триллиона страниц Всемирной паутины, но в интернете существует информация, до которой невозможно добраться через обычные поисковики. В большинстве случаев такую информацию следует искать непосредственно на сайтах. Глубокая паутина (невидимая сеть) также включает информацию о скрытных сообществах, которые хотят избежать огласки и интереса к себе со стороны властей.
-
1
Найдите базу данных при помощи обычной поисковой системы; введите ключевую фразу, аналогичную следующим: «база данных дикой природы», «база данных хип-хопа» (без кавычек) и тому подобное. Получить доступ к таким базам данных можно только введя определенный поисковый запрос, поэтому большинство поисковиков не могут найти информацию в таких базах данных, что автоматически помещает ее в невидимую сеть. Поисковик может найти базу данных, но для поиска определенной информации вам необходимо воспользоваться строкой поиска на найденном сайте.
- Примеры бесплатных или частично бесплатных баз данных (сайтов): Science.gov, FreeLunch для экономических данных.
-
2
Используйте специализированные сайты для поиска баз данных. На таких сайтах, как Публичная библиотека интернета, DirectSearch, Infomine можно найти списки ссылок на базы данных и другие высококачественные источники информации. Также можно воспользоваться сервисом searchengineguide.com, чтобы найти специализированный поисковик для поиска конкретной информации в базах данных.
-
3
Ищите информацию при помощи компьютеров в академических библиотеках. Библиотеки институтов и университетов зачастую имеют доступ к платным базам данных, включающих информацию, которую нельзя найти при помощи обычного поисковика. Спросите библиотекаря, к каким базам данных имеет доступ библиотека. Также вы можете получить доступ к таким базам данных при помощи вашего читательского билета, но это зависит от конкретной библиотеки и определенной базы данных.
-
4
Ищите данные в проекте The Internet Archive, который аккумулирует и хранит цифровую информацию. В этом проекте можно найти архивы сайтов, которые уже не существуют, видео и аудио записи, а также копии самых первых игр.
Реклама




-
1
Разберитесь, что такое сеть Tor. Сеть Tor – эта область невидимой сети, которую иногда называют «Dark net» (Теневая паутина), используемая для торговли, общения и хранения информации, доступ к которой нужно ограничить.[1]
Для получения доступа к сети Tor необходимо использовать специальное программное обеспечение (браузер Tor; так вы сможете просматривать веб-сайты домена .onion). Большая часть активности в Tor сети является незаконной (или полулегальной), но эту сеть используют журналисты для общения с анонимными источниками информации, а также люди, которые хотят обеспечить максимальный уровень защиты их информации.- Доступ к сети Tor является легальным, но ваша активность в ней может не быть таковой.
-
2
Скачайте браузер Tor. Это бесплатная программа, при помощи которой вы можете просматривать веб-страницы анонимно; браузер Tor сильно усложняет работу тех, кто отслеживает интернет-активность пользователей. Многие сообщества в невидимой сети доступны только через браузер Tor, так как они предпочитают анонимность, конфиденциальность и секретность. Скачайте браузер Tor с этого сайта, чтобы получить доступ к невидимой сети.
- Веб-страницы в сети Tor, как правило, ненадежны, то есть могут быть недоступны несколько часов или дней, или исчезнуть навсегда. Также они медленно грузятся, так как сеть Tor основана на подключении к ней через компьютеры других пользователей (для защиты вашей анонимности).
- Tor браузер поддерживает Android и iOS, но в этих системах Tor браузер не гарантирует вашу анонимность, а потому ими не рекомендуется пользоваться.[2]
Более того, расширения Tor для других браузеров не являются надежными и, как правило, не поддерживается организацией Tor.
-
3
Обеспечьте вашу анонимность. Доступ к невидимой сети является законным, но многие люди используют анонимность, чтобы участвовать в нелегальной деятельности. Принимая следующие меры предосторожности, избегайте вредоносных атак и отслеживания вашей активности правоохранительными органами:
- Щелкните по «S» (слева от адресной строки браузера Tor) и нажмите «Запретить скрипты в глобальном масштабе».[3]
- Включите брандмауэр (в Windows или Mac OS).
- Заклейте объектив веб-камеры (или встроенной камеры ноутбука) непрозрачной лентой (лучше такой, которая не оставляет следов).[4]
- Никогда не скачивайте файлы с веб-страниц в сети Tor, даже документы .pdf или .doc. Особенно небезопасен обмен файлами через торрент-трекеры.
- Щелкните по «S» (слева от адресной строки браузера Tor) и нажмите «Запретить скрипты в глобальном масштабе».[3]
-
4
Начните работу с введения в невидимую сеть. Одним из самых популярных сайтов в глубокой паутине является Hidden Wiki, который включает ссылки на полезные сайты в невидимой сети. Если вы не можете получить доступ к этому сайту в браузере Tor, попробуйте открыть этот или этот альтернативный сайт. Вы также можете попросить совета у пользователей невидимой сети на сайтах /r/deepweb, /r/onions, /r/Tor.
- Доступ к большинству сайтов в невидимой сети можно получить только через браузер Tor, а не обычный браузер.
-
5
Используйте специализированный поисковик. В глубокой паутине использование обычных поисковиков не очень эффективно. Для поиска информации в глубокой паутине используйте специализированные поисковики, например, Torch, TorSearch, Ahmia.
- Если вы ищете очень известный сайт из невидимой сети, то его найдет и обычный поисковик, например, Google.[5]
- Если вы ищете очень известный сайт из невидимой сети, то его найдет и обычный поисковик, например, Google.[5]
-
6
-
7
Общайтесь с пользователями глубокой паутины. Эта область интернета проигрывает крупным веб-сайтам, отчасти из-за пресечения незаконной деятельности, а отчасти потому, что многие веб-сайты создаются и поддерживаются без какой-либо серьезной финансовой поддержки. Чтобы узнать последние новости невидимой сети, общайтесь с ее пользователями на сайте OnionChat.
Реклама







Советы
- Вертикальный поиск также доступен для определенной информации. Например, http://www.findthatfile.com – это специфический поисковик для поиска двоичных файлов.
Реклама
Об этой статье
Эту страницу просматривали 490 936 раз.
Была ли эта статья полезной?
Здравствуйте, дорогие читатели! Сегодня я, мистер Whoer, расскажу Вам о таком феномене Интернета, как «Глубокая паутина» или «Глубокий Интернет» .
Системы поиска, например, Yandex или Google, за время своего существования проиндексировали свыше триллиона страниц в Мировой паутине. Но наряду с огромным количеством открытых (проиндексированных) данных существует информация, к которой сложно подобраться через стандартные системы поиска. Зачастую такая информация располагается только на веб-хостингах. «Глубокий Интернет» (по-английски – «deep web») содержит данные о скрытых сайтах, которые предпочитают быть «в тени» и не вызывать к себе интереса. Это могут быть ресурсы, доступ к которым осуществляется только по инвайтам, или пиратские сайты. Также не индексируются странички, поиск которых запретил непосредственно владелец, и сайты, доступные только для зарегистрированных пользователей, например, почти все социальные сети.
Важно понять, что перечисленные ресурсы не являются анонимными или зашифрованными – к ним можно получить доступ, но это возможно лишь зная прямую ссылку на них, потому что поисковики не индексируют веб-страницы, на которые нет гиперссылок, размещенных на других ресурсах Интернета.
Как попасть в глубокий интернет? Сайты глубокого интернета.
Итак, как найти, как зайти и как попасть в глубокий Интернет? Для нахождения «глубинных» ресурсов нужно использовать специализированные технологии поиска баз данных «Deep web».
В качестве примера бесплатных или частично платных сайтов (баз данных) приведем следующие: Science.gov (для научных данных), FreeLunch (для экономических), и даже Википедия есть в глубоком интернете!
TOR поисковики
Более простым методом поиска onion сайтов является использование специальных поисковых систем. Наиболее известным примером является поисковик Grams.

Даже по логотипу понятно, что поисковик тщательно имитирует Google, и надо отметить, неплохо с этим справляется. Поисковая выдача достаточно обширна, ссылки выдаются как на onion сайты, так и на обычные странички в Интернете.
Использовать поисковик очень просто – вводите в поисковую строку запрос, ставите галочку “show only onion sites” и кликаете на значок «лупы».
Алгоритмы ранжирования полученной выдачи, как кажется, полностью повторяют гугловские, за тем лишь исключением, что на данном ресурсе вы никогда не увидите рекламных блоков. Так что смело можно сказать, что найти нужную информацию в «глубоком» интернете с этим поисковиком довольно просто.
На втором месте топ сайтов onion поисковиков находится Fess. В отличие от Grams этот сайт onion использует tor-движок в своей основе, что позволяет ему более гибко индексировать именно TOR-сайты.
Если вы на сайте в первый раз, то рекомендуем сначала узнать, что такое Tor, прочитав статью на эту тему.
Тем не менее, следует отметить, что ни одна из перечисленных и опробованных нами поисковых систем не идут ни в какое сравнение с Google или Yandex. О ранжировании сайтов в выдаче по различным критериям поведения, обратным ссылкам и прочим факторам можно забыть – сайты показываются так, как решили программисты. Правда почти везде присутствует ручная фильтрация — например, Fess просит присылать на e-mail найденные пользователями списки onion сайтов.
Как ещё открыть onion сайты?
Осуществлять поиск баз данных можно и при использовании специализированных сайтов. Такого рода ресурсы «глубокого интернета», как, например, Публичная библиотека интернета, Infomine, DirectSearch, как правило, содержат перечни ссылок на скрытые источники информации. Для того, чтобы найти список поисковиков глубокого Интернета, рекомендуем воспользоваться сервисом «searchengineguide.com».
Также существует вариант получения недоступной через обычный поисковик информации с помощью ресурсов в академических библиотеках. Библиотеки высших учебных заведений, как правило, имеют оплаченный доступ к уникальным базам данных, содержащих информацию, которую невозможно отыскать с помощью простой поисковой системы. Можно поинтересоваться у работника библиотеки, к какой информации открыт доступ, или, (если Вы студент) используя читательский билет, получить доступ к университетским базам данных.
Прекрасной возможностью найти редкие данные являются сайты, хранящие архивные копии Интернета. Например, выполняя поиск данных в проекте TheInternetArchive, который собирает, накапливает и хранит цифровую информацию, Вы сможете отыскать массу интересного – архивы веб-сайтов, которые прекратили свое существование, копии выпущенных игр, а также аудио и видео записи и ссылки на глубокий интернет.
Частью «глубокого Интернета», иногда нарекаемой «Darknet» (Темная паутина), является глубокая сеть Тор, которая используется для общения, торговли и хранения информации, доступность которой должна быть строго ограничена. Чтобы получить доступ к такой сети, нужно воспользоваться специальным программным обеспечением (браузер Tor, с помощью которого можно просматривать веб-сайты в зоне .onion).
Активность в сети Tor по большей части является полулегальной (то есть не совсем законной). Этой сетью пользуются люди, которые предпочитают максимальный уровень защиты своих данных, а также журналисты, при общении с анонимными источниками. Доступ к сети Tor является легальным, но активность пользователя в ней не считается таковой.
Браузер Tor значительно усложняет задачу отслеживания интернет-активности пользователя, и у Вас появляется возможность посещать веб-страницы анонимно. «Глубокий интернет» содержит есть множество сообществ, которые предпочитают конфиденциальность, поэтому они доступны только посредством браузера Tor.
Некоторые особенности onion-сети:
– интернет-страницы в сети Tor зачастую бывают вне зоны доступа в течение нескольких минут, иногда недель или вообще могут исчезнуть навсегда, что обуславливает их ненадежность. Также страницы достаточно медленно загружаются по причине подключения к сети Tor путем использования компьютеров других пользователей с целью обеспечения вашей анонимности.
– Tor-браузер не гарантирует Вам анонимность в поддерживаемых им операционных системах iOS и Android, и, следовательно, их использование не рекомендуется. Для других интернет-браузеров возможности Tor являются ненадежными и, как правило, не поддерживаются структурой Tor.
Отметим, что большинство людей пользуются «глубокой паутиной» с целью незаконной деятельности. Чтобы избежать отслеживания вашей активности, а также вредоносных атак на ваш компьютер, следует принять следующие меры предосторожности:
— В левой стороне адресной строки браузера Tor кликнуть «S», далее выбрать «Запретить скрипты в глобальном масштабе»;
— в операционной системе Windows или Mac OS активировать брандмауэр;
— замаскировать объектив веб-камеры, например, заклеив его лентой или скотчем, во избежание несанкционированного включения камеры без ведома пользователя;
— ни в коем случае не закачивать файлы с интернет-страниц в сети Tor, даже простые документы doc или excel, и не обмениваться через торрент-трекеры файлами, что весьма и весьма небезопасно.
Использование обычных поисковиков в «глубокой паутине» не будет эффективным и не принесет желаемых результатов. Хотя, если Вы ищите очень популярный сайт из глубокой паутины, то обычный поисковик (типа yandex или google) вполне может справиться с такой задачей.
Тем не менее, множество ссылок на сайты глубокого интернета, которые могут быть полезны в «глубокой паутине», Вы найдете на популярнейшем её сайте – HiddenWiki – и без помощи поисковика. В «глубокой паутине» также существуют как легальные сервисы, которые во многом похожи на сервисы обычной сети, (к примеру, сервис обмена изображениями) так и более специфичные, (например, сайты по разоблачению противоправных действий или коллекции книг по антиправительственной тематике).
Используем TOR + VPN
Чтобы войти в глубокий интернет абсолютно анонимно, помимо TOR следует использовать VPN, который будет шифровать переданные пакеты не только в браузере, но и через все другие программы, и скрывать использование анонимных серверов. VPN от Whoer.net имеет множество других положительных качеств, таких как отсутствие рекламы и записи логов.
Заключение
Важно запомнить, что использование обычных поисковиков в «глубокой паутине» не будет эффективным и не принесет желаемых результатов. Хотя, если Вы ищите очень популярный сайт из глубокой паутины, то обычный поисковик (типа yandex или google) вполне может справиться с такой задачей.
Тем не менее, множество ссылок на сайты глубокого интернета, которые могут быть полезны в «глубокой паутине», можно найти только на популярнейшем её сайте – HiddenWiki. Помните, что в «глубокой паутине» также существуют как легальные сервисы, которые во многом похожи на сервисы обычной сети, (к примеру, сервис обмена изображениями) так и более специфичные, (например, сайты по разоблачению противоправных действий или коллекции книг по антиправительственной тематике).
Предлагаем перейти в комментарии и поделиться известными вам ссылками на onion сайты. До встречи на страницах нашего блога … или в «глубоком интернете» 
Предлагаем просмотреть наше видео, где мы также рассказываем что такое «глубокой интернет» и как туда попасть:
Вряд ли стал писать на эту простую тему, если бы не статья, которая начинается так:
Узнать, сколько страниц было проиндексировано Google, можно с помощью Search Console. Но как отыскать те URL, которые отсутствуют в индексе поисковой системы? Справиться с этой задачей поможет специальный скрипт на Python.
цитата из перевода на searchengines.ru
Вот это да, подумал я. Автор предлагает:
- Установить на компьютер Phyton 3.
- Установить библиотеку BeautifulSoup.
- Установить Tor в качестве прокси-сервера.
- Установить Polipo для преобразования socks-прокси в http-прокси.
- Провести настройки в консоли (не Search Conosole! в терминале операционной системы!).
- Увидеть предупреждение в конце статьи “Если скрипт не работает, то Google, возможно, блокирует Tor. В этом случае используйте свой собственный прокси-сервер”.
- Побиться головой о стену (ой, тут все-таки прорвался мой сарказм).
Как проверять индексацию без лишних мучений?
Автор опирается на верный в основе способ – запросы к выдаче с оператором info:. Это самый надежный метод, но у него есть огромный минус. Один запрос проверяет один url. А что если у нас их 10 000? Или больше?
Очевидно, что нужен более экономный путь. И он есть. Рассказываю.
Во-первых, получаем полный список страниц сайта. Если вы следуете стандартам веб-разработки и минимально заботитесь об индексации, то он должен содержаться в sitemap.xml.
Для удобства работы выгружаем url в виде простого списка. Это можно сделать, открыв xml-файл в Excel:
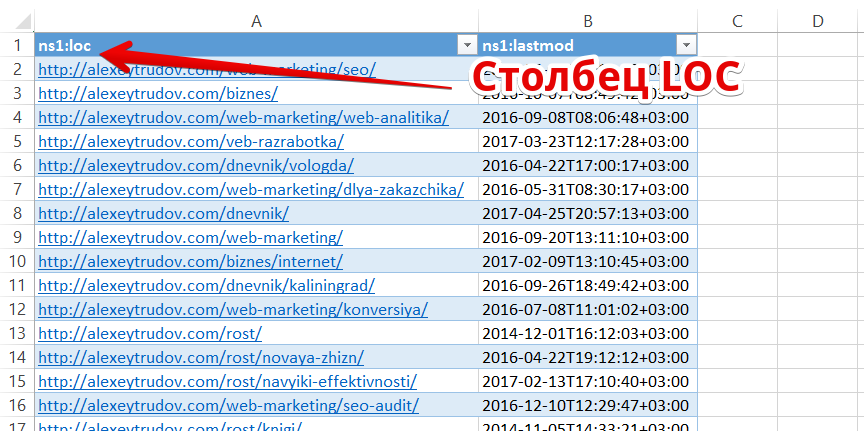
Вся дальнейшая работа сводится к тому, чтобы удалить из списка те страницы, которые есть в индексе.
В посте Как проверить индексацию сайта или раздела в Google? Ответ не так уж прост! я писал о том, что традиционно используемые для пробивки индекса операторы “site:” и “inurl:” не дают точных результатов. Если страница не обнаруживается поиском с оператором, это не значит, что ее нет в базе Googe.
Но! Если уж страница нашлась – это значит, что она в индексе. Понимаете разницу? Оператор находит не все, но уж что находит – то в индексе. Этим и воспользуемся.
Смотрим основные разделы и типичные паттерны в url, формируем список запросов для проверки индекса в них.
Например, для этого блога:
- site:alexeytrudov.com/dnevnik/
- site:alexeytrudov.com/web-marketing/
- site:alexeytrudov.com/veb-razrabotka/
Как быть, если в url нет ЧПУ и явной структуры? Можно придумать много способов. Например, помимо site: указывать фразу, которая есть только в шаблоне определенного раздела. Или наоборот – добавить слово со знаком минус, чтобы найти url, где оно не содержится.
Суть в том, чтобы а) покрыть разные части сайта и б) использовать достаточно сложный запрос, на который Гугл выдаст много результатов (см. предыдущую статью).
Каждый из запросов способен принести нам до 1000 новых url. Нужно выгрузить результаты по ним для сравнения со списком из карты сайта.
Как парсить выдачу?
Способов миллион. Два примера.
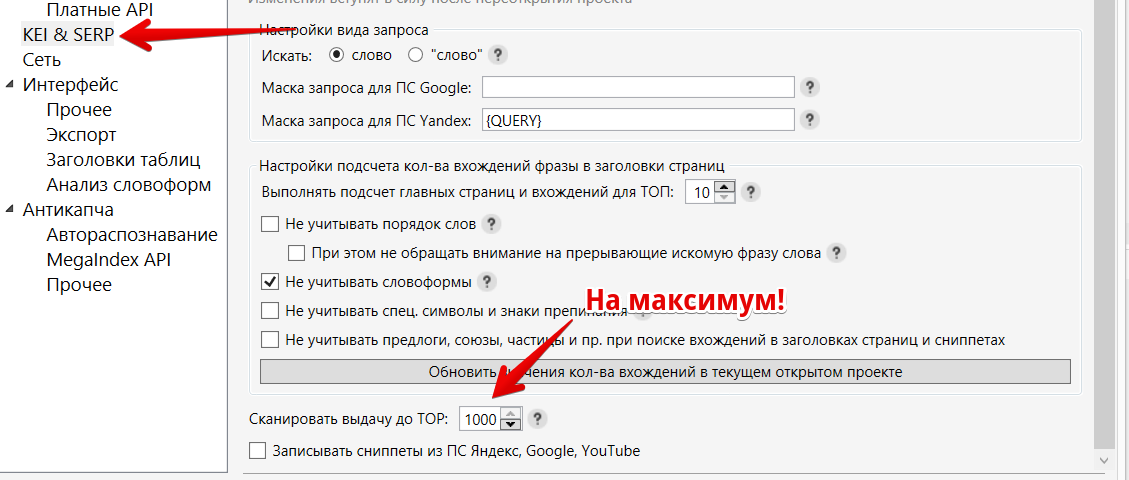
Можно воспользоваться Key Collector (куплен у каждого оптимизатора еще в прошлой жизни). Добавляем как фразы запросы с операторами:

Перед запуском настроим максимальное количество результатов в выдаче:
Теперь сам сбор данных:
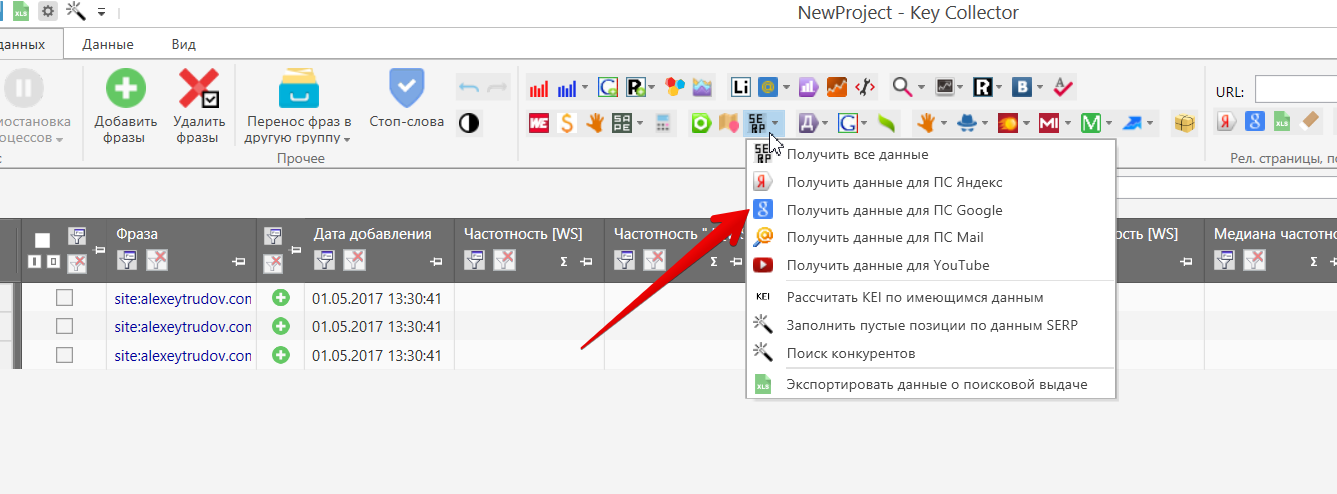
Дожидаемся сбора и выгружаем список url (то же меню, “Экспортировать данные о поисковой выдаче”). Получаем csv-файл со множеством ссылок (у меня на 3 запроса – 136 url, половина сайта, добавив ключи по остальным рубрикам наверняка нашел бы почти все).
Можно ли справиться без Key Collector и вообще без платных программ? Конечно!
- Устанавливаете расширение gInfinity в Chrome (https://chrome.google.com/webstore/detail/ginfinity/dgomfdmdnjbnfhodggijhpbmkgfabcmn).
- Устанавливаете расширение Web Developer (http://chrispederick.com/work/web-developer/) – оно крайне полезно и для других нужд.
Первый плагин нам позволяет загружать в выдаче Google больше 100 результатов простой прокруткой.

Для формирования перечня ссылок нажимаем на значок Web Developer:
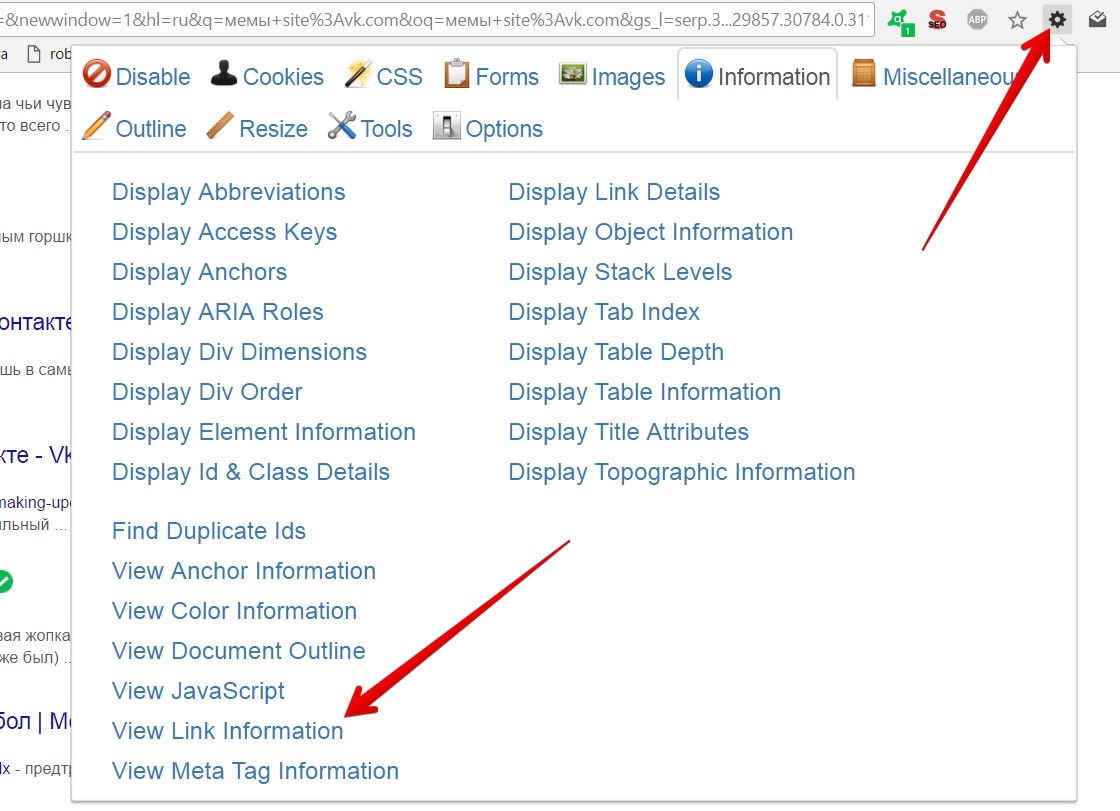
Запрос – зажатая кнопка PageDown – выгрузка.
Теперь нам остается только сравнить списки и вычленить url, которые есть в карте, но отсутствуют в выгрузках из выдачи.
Для сравнения можно использовать бесплатный онлайн-сервис: https://bez-bubna.com/free/compare.php (ну или Excel). Заодно, кстати, не помешает найти страницы, которые есть в выдаче и отсутствуют в карте сайта. Это признак либо неполной карты, либо генерации “мусорных” документов и неправильных настроек индексации.
Если вы корректно подобрали запросы, то наверняка нашли 90% проиндексированных url и сильно сократили объем работы. С оставшимися можно разобраться с помощью оператора info. Разумеется, не стоит это делать руками – можно использовать Rush Analytics. Анализ 100 ссылок будет стоить 5 рублей. Благодаря предыдущим операциям мы существенно экономим. Или можно собрать выдачу тем же Кейколлектором (тут уже правда уже может потребоваться антикапча).
Если хотите еще сократить список кандидатов на платную проверку, то можете также определить список страниц, приносивших трафик за последнюю неделю-две (уж они-то почти наверняка в индексе!) и отсеять найденные. О том, как выгружать url точек входа см. в статье об анализе страниц, потерявших трафик.
Как видите, с задачей поиска непроиндексированных страниц у небольших и средних (где-нибудь до 50 тысяч страниц) вполне можно справиться без возни с консолью, прокси, phyton-библиотеками и так далее. Достаточно иметь под рукой популярные инструменты, пригодные для множества других задач.
UPD: Виталий Шаповал резонно заметил, что:
Наверняка, есть публичный индекс и его непубличная часть, поэтому “непроиндексированные Google страницы” является терминологией вводящей в заблуждение. Корректно говорить об отсутствии в индексе, что меняет постановку вопроса почему такие страницы отсутствуют.
Согласен с этим уточнением; использовал термин из исходной статьи по инерции. Впрочем для практики разница небольшая – так или иначе результирующий список url требуется проработать, рассмотрев разные причины отсутствия (не было визита робота/запрещена индексация/неподходящий контент).