Why would you use a list comprehension? A list comprehension only knows about any one member of a list at a time, so that would be an odd approach. Instead:
def findMiddle(input_list):
middle = float(len(input_list))/2
if middle % 2 != 0:
return input_list[int(middle - .5)]
else:
return (input_list[int(middle)], input_list[int(middle-1)])
This one should return the middle item in the list if it’s an odd number list, or a tuple containing the middle two items if it’s an even numbered list.
Edit:
Thinking some more about how one could do this with a list comprehension, just for fun. Came up with this:
[lis[i] for i in
range((len(lis)/2) - (1 if float(len(lis)) % 2 == 0 else 0), len(lis)/2+1)]
read as:
«Return an array containing the ith digit(s) of array lis, where i is/are the members of a range, which starts at the length of lis, divided by 2, from which we then subtract either 1 if the length of the list is even, or 0 if it is odd, and which ends at the length of lis, divided by 2, to which we add 1.»
The start/end of range correspond to the index(es) we want to extract from lis, keeping in mind which arguments are inclusive/exclusive from the range() function in python.
If you know it’s going to be an odd length list every time, you can tack on a [0] to the end there to get the actual single value (instead of an array containing a single value), but if it can or will be an even length list, and you want to return an array containing the two middle values OR an array of the single value, leave as is. 
Почему вы используете понимание списка? Понимание списка знает только об одном члене списка за раз, так что это будет странный подход. Вместо:
def findMiddle(input_list):
middle = float(len(input_list))/2
if middle % 2 != 0:
return input_list[int(middle - .5)]
else:
return (input_list[int(middle)], input_list[int(middle-1)])
Это должно возвращать средний элемент в списке, если он представляет собой список нечетных номеров, или кортеж, содержащий два элемента, если он является четным списком.
Редактировать:
Еще раз подумав о том, как можно сделать это с пониманием списка, просто для удовольствия. Пришел к следующему:
[lis[i] for i in
range((len(lis)/2) - (1 if float(len(lis)) % 2 == 0 else 0), len(lis)/2+1)]
читать как:
«Возвращает массив, содержащий i й разряд массива lis, где я — члены диапазона, начинающийся the length of lis, divided by 2, from which we then subtract either 1 if the length of the list is even, or 0 if it is odd и заканчивается the length of lis, divided by 2, to which we add 1 «
Начало/конец диапазона соответствуют индексу (es), который мы хотим извлечь из lis, имея в виду, какие аргументы включены/исключены из функции range() в python.
Если вы знаете, что каждый раз он будет списком нечетной длины, вы можете сделать ставку на [0] до конца, чтобы получить фактическое одиночное значение (вместо массива, содержащего одно значение), но если оно может или будет список длины, и вы хотите вернуть массив, содержащий два средних значения или массив из одного значения, оставить как есть.
Массивы
Массивы – одна из самых фундаментальных структур данных в информатике. Они встроены во все языки программирования, даже такие низкоуровневые, как C или Assembler. Массивы представляют собой группу элементов одного типа, которые расположены на непрерывном участке памяти компьютера. Например, [5, 8, -1] или ['a', 'b', 'c'].
Поскольку элементы массива стоят рядом друг с другом, мы можем получить доступ к любому их индексу. Например, к первому, третьему или последнему элементу за время O(1).
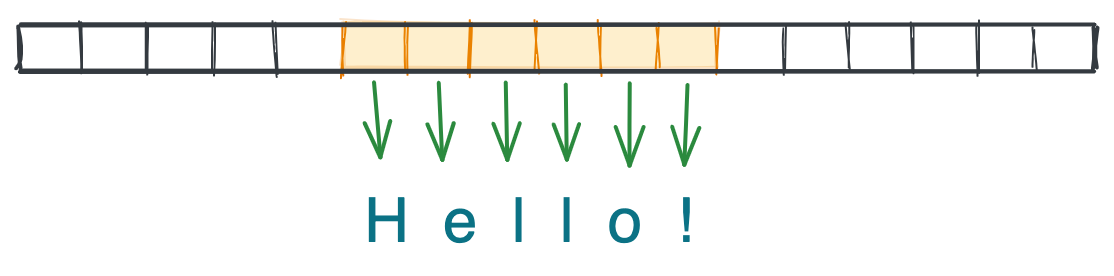
В таких языках, как C и Java, требуется заранее указывать размер массива и тип данных. Структура списка в Python позволяет обойти эти требования, сохраняя данные в виде указателей на местоположение элементов в памяти, автоматически изменяя размер массива, когда место заканчивается. Элементам памяти не обязательно находиться рядом друг с другом.
Реализация
Основные ограничения, с которыми мы сталкиваемся при создании массивов на языке Python:
- После выделения места для массива мы не можем получить больше, не создав новый массив.
- Все значения в массиве должны быть одного типа.
Мы можем реализовать в Python очень простой класс Array, который имитирует основную функциональность массивов в языках более низкого уровня.
from typing import Any
class Array:
def __init__(self, n: int, dtype: Any):
self.vals = [None] * n
self.dtype = dtype
def get(self, i: int) -> Any:
"""
Возвращает значение как индекс i
"""
return self.vals[i]
def put(self, i: int, val: Any) -> None:
"""
Обновляем массив как индекс i с val. Val должно быть одного типа с self.dtype
"""
if not isinstance(val, self.dtype):
raise ValueError(f"val явл {type(val)}; должно быть {self.dtype}")
self.vals[i] = val
Давайте рассмотрим, какие способы реализации класса Array мы можем использовать. Создадим экземпляр. Подтвердим, что первый индекс пустой. Заполним слот символом char, а затем вернем его. Наши предыдущие действия подтвердили, что массив отвергает non-char (несимвольные) значения. Код не самый лучший, но рабочий:
arr = Array(10, str)
arr.get(0) # None
arr.put(0, 'a') # None
arr.get(0) # 'a'
arr.put(1, 5)
# ValueError: val is <class 'int'>; must be <class 'str'>
Пример
В процессе работы с массивами вы, скорее всего, захотите использовать встроенный список Python, или массив NumPy, а не созданный нами класс Array. Однако, в целях использования массива, который не меняет размер, необходимо разобраться с Leetcode LC 1089: Duplicate Zeros (Дублирование нулей). Цель данных действий – продублировать все нули в массиве, изменяя его на месте таким образом, чтобы элементы двигались вниз и исчезали, а не увеличивали размер массива или создавали новый.
def duplicate_zeros(arr: list) -> None:
"""
Дублируем все нули в массиве, оставляя его первоначальную длину. Например, [1, 0, 2, 3] -> [1, 0, 0, 2]
"""
i = 0
while i < len(arr):
if arr[i] == 0:
arr.insert(i, 0) # Вставляем 0 как индекс i
arr.pop() # Убираем последний элемент
i += 1
i += 1
В итоге мы итеративно перемещаемся по списку, пока не найдем ноль. Затем вставляем еще один ноль и исключаем последний элемент для сохранения размера массива.
Обратите внимание: в данном случае важно использовать цикла while, а не for, так как мы изменяем массив по мере его прохождения. Тщательный контроль над индексом i позволяет нам пропустить вставленный ноль, чтобы избежать двойного счета.
Связанные списки
Связанные списки – еще одна ключевая структура данных в информатике. Как и массивы, связный список – это группа значений. Однако, в отличие от массивов, значения в связанном списке не обязательно должны быть одного типа, и нам не нужно заранее определять размер списка.
Основным элементом связанного списка является узел, который содержит некоторые данные и указатель на любое место в памяти.
Ниже представлен связанный список со значениями [1, 'a', 0.3]. Обратите внимание на различие размеров элементов. Мы видим четыре байта для целых и плавающих чисел, один байт для символов. Каждый узел имеет четырехбайтовый указатель, расстояние между узлами различно, последний из них содержит нулевой указатель, который указывает в пространство.
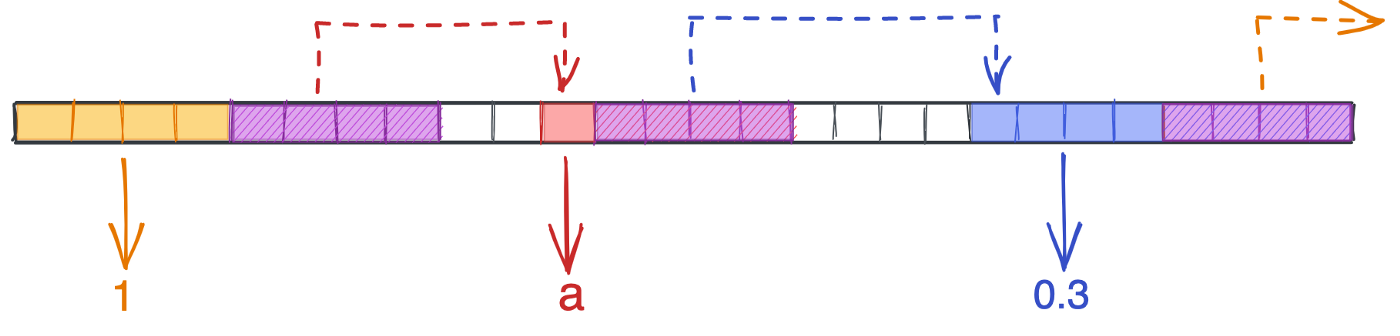
Отсутствие ограничений на типы данных и длину делает связанные списки привлекательными. Однако эта гибкость создает некоторые проблемы. Программе доступен только верх списка, а это значит, что для поиска любого другого узла нам придется пройти весь список. Другими словами, мы лишаемся O(1) поиска для любого элемента, кроме первого узла. Если вы запрашиваете 100-й элемент, то для его получения потребуется 100 шагов: схема O(n).
Можно сделать связанные списки более универсальными. Для этого необходимо добавить указатели на предыдущие узлы и раскрыть конец списка, или сделать его кольцевым. В целом, выбор связанных списков вместо массивов является платой за удобство.
Реализация
Чтобы создать связанный список в Python, начнем с определения узла. Необходимы только две части: данные, которые хранит узел и указатель на следующий узел в списке. Добавим метод __repr__ для того, чтобы было легче увидеть содержание узла.
class ListNode:
def __init__(self, val=None, next=None):
self.val = val
self.next = next
def __repr__(self):
return f"ListNode со значением {self.val}"
Далее попробуем использовать класс ListNode. Важно отметить, что вершина списка – это наша переменная head. Необходимо итеративно добавлять .next для доступа к более глубоким узлам, поскольку мы не можем ввести индекс типа [1] или [2], чтобы добраться до них.
head = ListNode(5)
head.next = ListNode('abc')
head.next.next = ListNode(4.815162342)
print(head) # ListNode со значением 5
print(head.next) # ListNode со значением abc
print(head.next.next) # ListNode со значением 4.815162342
Для того чтобы было легче добавить узел как в конец, так и в начало списка, напишем функции:
def add_to_end(head: ListNode, val: Any) -> None:
ptr = head
while ptr.next:
ptr = ptr.next
ptr.next = ListNode(val)
def add_to_front(head: ListNode, val: Any) -> ListNode:
node = ListNode(val)
node.next = head
return node
В add_to_end создаем переменную ptr (указатель). Она начинается с head и обходит список, пока не достигнет последнего узла, атрибутом .next которого является нулевой указатель. Далее, устанавливаем значение .next этого узла в новый ListNode. Внутри функции не нужно ничего возвращать, чтобы изменение вступило в силу.
В add_to_front мы создаем новый head, устанавливаем указатель .next в вершину существующего связанного списка. Вручную обновляем head вне данной функции с помощью нового узла. В противном случае, head по-прежнему будет указывать на старый head.
# Создает и расширяет список
head = ListNode(5)
add_to_end(head, 'abc')
add_to_end(head, 4.815162342)
# Вывод
print(head) # ListNode со значением 5
print(head.next) # ListNode со значением abc
print(head.next.next) # ListNode со значением 4.815162342
# Пытаемся обновить head
add_to_front(head, 0)
print(head) # ListNode со значением 5
# Корректное обновление head
head = add_to_front(head, 0)
print(head) # ListNode со значением 0
Пример
Один из частых вопросов, который возникает во время работы со связными списками – возврат среднего узла. Так как обычно существует только начало списка, нет возможности заранее узнать его длину. Исходя из этого, может показаться, что нам придется обойти список дважды: один раз, чтобы узнать его длину, а второй, чтобы пройти половину пути.
Ранее мы использовали указатель, чтобы обойти список по одному узлу за раз, пока не дойдем конца.
На самом деле существует способ найти середину списка за один проход.
Что если у нас будет два указателя? Первый из них будет перемещаться по одному узлу за подход, а второй – по два. В тот момент, когда быстрый указатель достигнет конца списка, наш первоначальный указатель окажется только в середине.
Исходя из написанного выше, мы ответим на LC 876: Середина связанного списка (Middle of the Linked List) следующим образом:
def find_middle(head: ListNode) -> ListNode:
"""
Return middle node of linked list. If even number of nodes,
returns the second middle node.
"""
# Смотрим на медленную и быструю точки
slow = head
fast = head.next
# Прогоняем список через цикл
while fast and fast.next:
slow = slow.next
fast = fast.next.next
return slow
В данном случае при работе с Leetcode, мы убеждаемся, что head.next – правильный вариант.
# Список: A -> B -> C -> D -> E
# Середина: C
# Начало с head: неправильно
# Slow: A -> B -> C -> D ==> Середина: D
# Fast: A -> C -> E -> null
# Начало с head.next: правильно
# Slow: A -> B -> C ==> Середина: C
# Fast: B -> D -> null
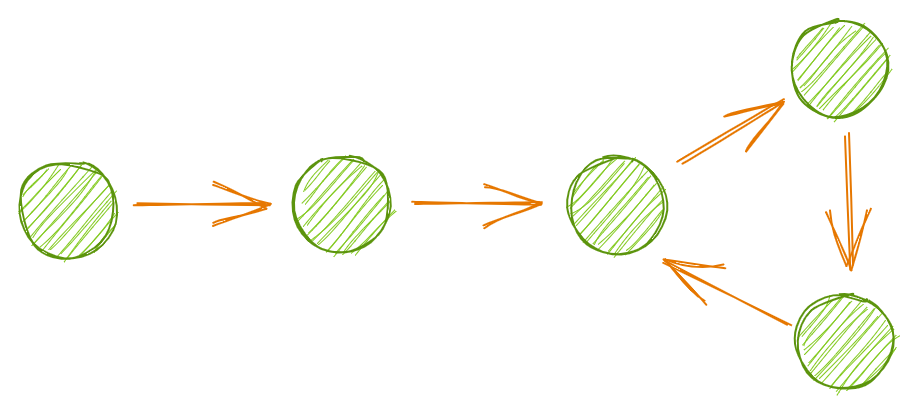
LC 141. Linked List Cycle: Цикл связанного списка – пример использования медленных и быстрых указателей. Наша цель определить, есть ли в списке цикл, который возникает, когда следующий указатель узла показывает на более ранний узел в списке.
Проблема в том, что проход списка через цикл будет бесконечным.
Один из вариантов решения заключается в том, что нам нужно установить ограничение на продолжительность выполнения обхода, или решить проблему повторяющихся паттернов за некоторый период времени.
Более простой подход заключается в использовании двух указателей.
В данном случае невозможно использование while fast и fast.next, так как эти методы имеют значение False только при достижении конца списка. Вместо этого, подставим slow и fast на первый и второй узлы. Будем перемещать их по списку с разной скоростью, пока они не совпадут. В конце списка вернем False. Если два указателя будут показывать на один и тот же узел, вернем True.
def has_cycle(head: ListNode) -> bool:
"""
Определяем где связанный список имеет цикл
"""
slow = head
fast = head.next
while slow != fast:
# Находим конец списка
if not (fast or fast.next):
return False
slow = slow.next
fast = fast.next.next
return True
***
Мы узнали, что такое массивы и связанные списки. Это важная составляющая структур данных, которая используется во всех языках программирования.
В следующей части материала приступим к изучению деревьев и графов.
Материалы по теме
- 📈 Big O нотация: что это такое и почему ее обязательно нужно знать каждому программисту
- Какие алгоритмы нужно знать, чтобы стать хорошим программистом?
- Изучаем алгоритмы: полезные книги, веб-сайты, онлайн-курсы и видеоматериалы
Зачем вам использовать понимание списка? Понимание списка знает только о любом члене списка за раз, так что это был бы странный подход. Вместо:
def findMiddle(input_list):
middle = float(len(input_list))/2
if middle % 2 != 0:
return input_list[int(middle - .5)]
else:
return (input_list[int(middle)], input_list[int(middle-1)])
Этот должен возвращать средний элемент в списке, если это список нечетных чисел, или кортеж, содержащий два средних элемента, если это список с четным номером.
Редактировать:
Подумайте еще о том, как можно сделать это с помощью понимания списка, просто для удовольствия. Придумали это:
[lis[i] for i in
range((len(lis)/2) - (1 if float(len(lis)) % 2 == 0 else 0), len(lis)/2+1)]
читать как:
«Вернуть массив, содержащий ith цифра (ы) массива lisгде я есть / являются членами диапазона, который начинается в the length of lis, divided by 2, from which we then subtract either 1 if the length of the list is even, or 0 if it is oddи который заканчивается в the length of lis, divided by 2, to which we add 1«.
Начало / конец диапазона соответствуют индексу (ам), из которых мы хотим извлечь lisучитывая, какие аргументы являются включающими / исключающими из range() функция в питоне.
Если вы знаете, что каждый раз это будет нечетный список длины, вы можете [0] до конца, чтобы получить фактическое единственное значение (вместо массива, содержащего единственное значение), но если это может или будет список четной длины, и вы хотите вернуть массив, содержащий два средних значения ИЛИ массив из одно значение, оставить как есть.:)
Список
Назад в начало
Список — это непрерывная динамическая коллекция элементов. Каждому элементу списка присваивается порядковый номер — его индекс. Первый индекс равен нулю, второй — единице и так далее. Основные операции для работы со списками — это индексирование, срезы, добавление и удаление элементов, а также проверка на наличие элемента в последовательности.
Создание пустого списка выглядит так:
empty_list = []
Создадим список, состоящий из нескольких чисел:
numbers = [40, 20, 90, 11, 5]
Настало время строковых переменных:
fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
Не будем забывать и о дробях:
fractions = [3.14, 2.72, 1.41, 1.73, 17.9]
Мы можем создать список, состоящий из различных типов данных:
values = [3.14, 10, ‘Hello world!’, False, ‘Python is the best’]
И такое возможно (⊙_⊙)
list_of_lists = [[2, 4, 0], [11, 2, 10], [0, 19, 27]]
Индексирование
Что же такое индексирование? Это загадочное слово обозначает операцию обращения к элементу по его порядковому номеру ( ( ・ω・)ア напоминаю, что нумерация начинается с нуля). Проиллюстрируем это на примере:
fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
print(fruits[0])
print(fruits[1])
print(fruits[4])
>>> Apple
>>> Grape
>>> Orange
Списки в Python являются изменяемым типом данных. Мы можем изменять содержимое каждой из ячеек:
fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
fruits[0] = ‘Watermelon’
fruits[3] = ‘Lemon’
print(fruits)
>>> [‘Watermelon’, ‘Grape’, ‘Peach’, ‘Lemon’, ‘Orange’]
Индексирование работает и в обратную сторону. Как такое возможно? Всё просто, мы обращаемся к элементу списка по отрицательному индексу. Индекс с номером -1 дает нам доступ к последнему элементу, -2 к предпоследнему и так далее.
fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
print(fruits[-1])
print(fruits[-2])
print(fruits[-3])
print(fruits[-4])
>>> Orange
>>> Banan
>>> Peach
>>> Grape
Создание списка с помощью list()
Переходим к способам создания списка. Самый простой из них был приведен выше. Еще раз для закрепления:
smiles = [‘(ಠ_ಠ)’, ‘( ̄﹃ ̄)’, ‘( ͡° ͜ʖ ͡°)’, ‘(╮°-°)╮’]
А есть еще способы? Да, есть. Один из них — создание списка с помощью функции list() В неё мы можем передать любой итерируемый объект (да-да, тот самый по которому можно запустить цикл (• ᵕ •) )
Рассмотрим несколько примеров:
letters = list(‘abcdef’)
numbers = list(range(10))
even_numbers = list(range(0, 10, 2))
print(letters)
print(numbers)
print(even_numbers)
>>> [‘a’, ‘b’, ‘c’, ‘d’, ‘e’, ‘f’
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> [0, 2, 4, 6, 8]
Длина списка
С созданием списка вроде разобрались. Следующий вопрос: как узнать длину списка? Можно, конечно, просто посчитать количество элементов… (⊙_⊙) Но есть способ получше! Функция len() возвращает длину любой итерируемой переменной, переменной, по которой можно запустить цикл. Рассмотрим пример:
fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
print(len(fruits))
>>> 5
numbers = [40, 20, 90]
print(len(numbers))
>>> 3
«…любой итерируемой», а это значит:
string = ‘Hello world’
print(len(string))
# 11
>>> 11
print(len(range(10))
>>> 10
Срезы
В начале статьи что-то говорилось о «срезах». Давайте разберем подробнее, что это такое. Срезом называется некоторая подпоследовательность. Принцип действия срезов очень прост: мы «отрезаем» кусок от исходной последовательности элемента, не меняя её при этом. Я сказал «последовательность», а не «список», потому что срезы работают и с другими итерируемыми типами данных, например, со строками.
fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
part_of_fruits = fruits[0:3]
print(part_of_fruits)
>>> [‘Apple’, ‘Grape’, ‘Peach’]
Детально рассмотрим синтаксис срезов:
итерируемая_переменная[начальный_индекс:конечный_индекс — 1:длина_шага]
Обращаю ваше внимание, что мы делаем срез от начального индекса до конечного индекса — 1. То есть i = начальный_индекс и i < конечный индекс
Больше примеров!
fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
print(fruits[0:1])
# Если начальный индекс равен 0, то его можно опустить
print(fruits[:2])
print(fruits[:3])
print(fruits[:4])
print(fruits[:5])
# Если конечный индекс равен длине списка, то его тоже можно опустить
print(fruits[:len(fruits)])
print(fruits[::])
>>> [‘Apple’]
>>> [‘Apple’, ‘Grape’]
>>> [‘Apple’, ‘Grape’, ‘Peach’]
>>> [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’]
>>> [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
>>> [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
>>> [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
Самое время понять, что делает третий параметр среза — длина шага!
fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
print(fruits[::2])
print(fruits[::3])
# Длина шага тоже может быть отрицательной!
print(fruits[::-1])
print(fruits[4:2:-1])
print(fruits[3:1:-1])
>>> [‘Apple’, ‘Peach’, ‘Orange’]
>>> [‘Apple’, ‘Banan’]
>>> [‘Orange’, ‘Banan’, ‘Peach’, ‘Grape’, ‘Apple’]
>>> [‘Orange’, ‘Banan’]
>>> [‘Banan’, ‘Peach’]
А теперь вспоминаем всё, что мы знаем о циклах. В Python их целых два! Цикл for и цикл while Нас интересует цикл for, с его помощью мы можем перебирать значения и индексы наших последовательностей. Начнем с перебора значений:
fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
for fruit in fruits:
print(fruit, end=‘ ‘)
>>> Apple Grape Peach Banan Orange
Выглядит несложно, правда? В переменную fruit объявленную в цикле по очереди записываются значения всех элементов списка fruits
А что там с перебором индексов?
for index in range(len(fruits)):
print(fruits[index], end=‘ ‘)
Этот пример гораздо интереснее предыдущего! Что же здесь происходит? Для начала разберемся, что делает функция range(len(fruits))
Мы с вами знаем, что функция len() возвращает длину списка, а range() генерирует диапазон целых чисел от 0 до len()-1.
Сложив 2+2, мы получим, что переменная index принимает значения в диапазоне от 0 до len()-1. Идем дальше, fruits[index] — это обращение по индексу к элементу с индексом index списка fruits. А так как переменная index принимает значения всех индексов списка fruits, то в цикле мы переберем значения всех элементов нашего списка!
Операция in
С помощью in мы можем проверить наличие элемента в списке, строке и любой другой итерируемой переменной.
fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
if ‘Apple’ in fruits:
print(‘В списке есть элемент Apple’)
>>> В списке есть элемент Apple
fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
if ‘Lemon’ in fruits:
print(‘В списке есть элемент Lemon’)
else:’
print(‘В списке НЕТ элемента Lemon’)
>>> В списке НЕТ элемента Lemon
Приведу более сложный пример:
all_fruits = [‘Apple’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Orange’]
my_favorite_fruits = [‘Apple’, ‘Banan’, ‘Orange’]
for item in all_fruits:
if item in my_favorite_fruits:
print(item + ‘ is my favorite fruit’)
else:
print(‘I do not like ‘ + item)
>>> Apple is my favorite fruit
>>> I do not like Grape
>>> I do not like Peach
>>> Banan is my favorite fruit
>>> Orange is my favorite fruit
Методы для работы со списками
Начнем с метода append(), который добавляет элемент в конец списка:
# Создаем список, состоящий из четных чисел от 0 до 8 включительно
numbers = list(range(0,10,2))
# Добавляем число 200 в конец списка
numbers.append(200)
numbers.append(1)
numbers.append(2)
numbers.append(3)
print(numbers)
>>> [0, 2, 4, 6, 8, 200, 1, 2, 3]
Мы можем передавать методу append() абсолютно любые значения:
all_types = [10, 3.14, ‘Python’, [‘I’, ‘am’, ‘list’]]
all_types.append(1024)
all_types.append(‘Hello world!’)
all_types.append([1, 2, 3])
print(all_types)
>>> [10, 3.14, ‘Python’, [‘I’, ‘am’, ‘list’], 1024, ‘Hello world!’, [1, 2, 3]]
Метод append() отлично выполняет свою функцию. Но, что делать, если нам нужно добавить элемент в середину списка? Это умеет метод insert(). Он добавляет элемент в список на произвольную позицию. insert() принимает в качестве первого аргумента позицию, на которую нужно вставить элемент, а вторым — сам элемент.
# Создадим список чисел от 0 до 9
numbers = list(range(10))
# Добавление элемента 999 на позицию с индексом 0
numbers.insert(0, 999)
print(numbers) # первый print
numbers.insert(2, 1024)
print(numbers) # второй print
numbers.insert(5, ‘Засланная строка-шпион’)
print(numbers) # третий print
>>> [999, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # первый print
>>> [999, 0, 1024, 1, 2, 3, 4, 5, 6, 7, 8, 9] # второй print
>>> [999, 0, 1024, 1, 2, ‘Засланная строка-шпион’, 3, 4, 5, 6, 7, 8, 9] # третий print
Отлично! Добавлять элементы в список мы научились, осталось понять, как их из него удалять. Метод pop() удаляет элемент из списка по его индексу:
numbers = list(range(10))
print(numbers) # 1
# Удаляем первый элемент
numbers.pop(0)
print(numbers) # 2
numbers.pop(0)
print(numbers) # 3
numbers.pop(2)
print(numbers) # 4
# Чтобы удалить последний элемент, вызовем метод pop без аргументов
numbers.pop()
print(numbers) # 5
numbers.pop()
print(numbers) # 6
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 1
>>> [1, 2, 3, 4, 5, 6, 7, 8, 9] # 2
>>> [2, 3, 4, 5, 6, 7, 8, 9] # 3
>>> [2, 3, 5, 6, 7, 8, 9] # 4
>>> [2, 3, 5, 6, 7, 8] # 5
>>> [2, 3, 5, 6, 7] # 6
Теперь мы знаем, как удалять элемент из списка по его индексу. Но что, если мы не знаем индекса элемента, но знаем его значение? Для такого случая у нас есть метод remove(), который удаляет первый найденный по значению элемент в списке.
all_types = [10, ‘Python’, 10, 3.14, ‘Python’, [‘I’, ‘am’, ‘list’]]
all_types.remove(3.14)
print(all_types) # 1
all_types.remove(10)
print(all_types) # 2
all_types.remove(‘Python’)
print(all_types) # 3
>>> [10, ‘Python’, 10, ‘Python’, [‘I’, ‘am’, ‘list’]] # 1
>>> [‘Python’, 10, ‘Python’, [‘I’, ‘am’, ‘list’]] # 2
>>> [10, ‘Python’, [‘I’, ‘am’, ‘list’]] # 3
А сейчас немного посчитаем, посчитаем элементы списка с помощью метода count()
numbers = [100, 100, 100, 200, 200, 500, 500, 500, 500, 500, 999]
print(numbers.count(100)) # 1
print(numbers.count(200)) # 2
print(numbers.count(500)) # 3
print(numbers.count(999)) # 4
>>> 3 # 1
>>> 2 # 2
>>> 5 # 3
>>> 1 # 4
В программировании, как и в жизни, проще работать с упорядоченными данными, в них легче ориентироваться и что-либо искать. Метод sort() сортирует список по возрастанию значений его элементов.
numbers = [100, 2, 11, 9, 3, 1024, 567, 78]
numbers.sort()
print(numbers) # 1
fruits = [‘Orange’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Apple’]
fruits.sort()
print(fruits) # 2
>>> [2, 3, 9, 11, 78, 100, 567, 1024] # 1
>>> [‘Apple’, ‘Banan’, ‘Grape’, ‘Orange’, ‘Peach’] # 2
Мы можем изменять порядок сортировки с помощью параметра reverse. По умолчанию этот параметр равен False
fruits = [‘Orange’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Apple’]
fruits.sort()
print(fruits) # 1
fruits.sort(reverse=True)
print(fruits) # 2
>>> [‘Apple’, ‘Banan’, ‘Grape’, ‘Orange’, ‘Peach’] # 1
>>> [‘Peach’, ‘Orange’, ‘Grape’, ‘Banan’, ‘Apple’] # 2
Иногда нам нужно перевернуть список, не спрашивайте меня зачем… Для этого в самом лучшем языке программирования на этой планете JavaScr..Python есть метод reverse():
numbers = [100, 2, 11, 9, 3, 1024, 567, 78]
numbers.reverse()
print(numbers) # 1
fruits = [‘Orange’, ‘Grape’, ‘Peach’, ‘Banan’, ‘Apple’]
fruits.reverse()
print(fruits) # 2
>>> [78, 567, 1024, 3, 9, 11, 2, 100] # 1
>>> [‘Apple’, ‘Banan’, ‘Peach’, ‘Grape’, ‘Orange’] # 2
Допустим, у нас есть два списка и нам нужно их объединить. Программисты на C++ cразу же кинулись писать циклы for, но мы пишем на python, а в python у списков есть полезный метод extend(). Этот метод вызывается для одного списка, а в качестве аргумента ему передается другой список, extend() записывает в конец первого из них начало второго:
fruits = [‘Banana’, ‘Apple’, ‘Grape’]
vegetables = [‘Tomato’, ‘Cucumber’, ‘Potato’, ‘Carrot’]
fruits.extend(vegetables)
print(fruits)
>>> [‘Banana’, ‘Apple’, ‘Grape’, ‘Tomato’, ‘Cucumber’, ‘Potato’, ‘Carrot’]
В природе существует специальный метод для очистки списка — clear()
fruits = [‘Banana’, ‘Apple’, ‘Grape’]
vegetables = [‘Tomato’, ‘Cucumber’, ‘Potato’, ‘Carrot’]
fruits.clear()
vegetables.clear()
print(fruits)
print(vegetables)
>>> []
>>> []
Осталось совсем чуть-чуть всего лишь пара методов, так что делаем последний рывок! Метод index() возвращает индекс элемента. Работает это так: вы передаете в качестве аргумента в index() значение элемента, а метод возвращает его индекс:
fruits = [‘Banana’, ‘Apple’, ‘Grape’]
print(fruits.index(‘Apple’))
print(fruits.index(‘Banana’))
print(fruits.index(‘Grape’))
>>> 1
>>> 0
>>> 2
Финишная прямая! Метод copy(), только не падайте, копирует список и возвращает его брата-близнеца. Вообще, копирование списков — это тема достаточно интересная, давайте рассмотрим её по-подробнее.
Во-первых, если мы просто присвоим уже существующий список новой переменной, то на первый взгляд всё выглядит неплохо:
fruits = [‘Banana’, ‘Apple’, ‘Grape’]
new_fruits = fruits
print(fruits)
print(new_fruits)
>>> [‘Banana’, ‘Apple’, ‘Grape’]
>>> [‘Banana’, ‘Apple’, ‘Grape’]
Но есть одно маленькое «НО»:
fruits = [‘Banana’, ‘Apple’, ‘Grape’]
new_fruits = fruits
fruits.pop()
print(fruits)
print(new_fruits)
# Внезапно, из списка new_fruits исчез последний элемент
>>> [‘Banana’, ‘Apple’]
>>> [‘Banana’, ‘Apple’]
При прямом присваивании списков копирования не происходит. Обе переменные начинают ссылаться на один и тот же список! То есть если мы изменим один из них, то изменится и другой. Что же тогда делать? Пользоваться методом copy(), конечно:
fruits = [‘Banana’, ‘Apple’, ‘Grape’]
new_fruits = fruits.copy()
fruits.pop()
print(fruits)
print(new_fruits)
>>> [‘Banana’, ‘Apple’]
>>> [‘Banana’, ‘Apple’, ‘Grape’]
Отлично! Но что если у нас список в списке? Скопируется ли внутренний список с помощью метода copy() — нет:
fruits = [‘Banana’, ‘Apple’, ‘Grape’, [‘Orange’,‘Peach’]]
new_fruits = fruits.copy()
fruits[-1].pop()
print(fruits) # 1
print(new_fruits) # 2
>>> [‘Banana’, ‘Apple’, ‘Grape’, [‘Orange’]] # 1
>>> [‘Banana’, ‘Apple’, ‘Grape’, [‘Orange’]] # 2
Решение задач
1. Создайте список из 10 четных чисел и выведите его с помощью цикла for
2. Создайте список из 5 элементов. Сделайте срез от второго индекса до четвертого
3. Создайте пустой список и добавьте в него 10 случайных чисел и выведите их. В данной задаче нужно использовать функцию randint.
from random import randint
n = randint(1, 10) # Случайное число от 1 до 10
4. Удалите все элементы из списка, созданного в задании 3
5. Создайте список из введенной пользователем строки и удалите из него символы ‘a’, ‘e’, ‘o’
6. Даны два списка, удалите все элементы первого списка из второго
a = [1, 3, 4, 5]
b = [4, 5, 6, 7]
# Вывод
>>> [6, 7]
7. Создайте список из случайных чисел и найдите наибольший элемент в нем.
8. Найдите наименьший элемент в списке из задания 7
9. Найдите сумму элементов списка из задания 7
10.Найдите среднее арифметическое элементов списка из задания 7
Сложные задачи
1. Создайте список из случайных чисел. Найдите номер его последнего локального максимума (локальный максимум — это элемент, который больше любого из своих соседей).
2. Создайте список из случайных чисел. Найдите максимальное количество его одинаковых элементов.
3. Создайте список из случайных чисел. Найдите второй максимум.
a = [1, 2, 3] # Первый максимум == 3, второй == 2
4. Создайте список из случайных чисел. Найдите количество различных элементов в нем.