В прошлой статье мы уже разобрали, что такое временной ряд и функцию тренда. Теперь подробнее разберемся с терминологией и остановимся на одной из моделей временного ряда.
Из чего состоит временной ряд
Уровни временного ряда (Yt) представляют из себя сумму двух компонент:
- Регулярную составляющую
- Случайную составляющую
В свою очередь регулярная составляющая состоит из:
- Тренда
- Сезонности
- Циклической составляющей
Однако, в модели необязательно наличие всех этих компонент сразу.
Случайная компонента отражает влияние случайных возмущений на модель, которые по отдельности имеют незначительное воздействие, но суммарно их влияние ощущается.
То есть, в общем случае временной ряд представляет из себя наличие четырех составляющих:
- Тренд (Tt)
- Сезонность (St)
- Цикличность (Ct)
- Случайные возмущения (Et)
Циклическая компонента, по сравнению с сезонностью, имеет более длительный эффект и меняется от цикла к циклу. Поэтому, ее обычно объединяют с трендом.
Виды моделей временного ряда
Обычно, выделяют две модели временного ряда и третью — смешанную.
- Аддитивная модель

-
Мультипликативная модель

-
Смешанная модель

При выборе необходимой модели временного ряда смотрят на амплитуду колебаний сезонной составляющей. Если ее колебания относительно постоянны, то выбирают аддитивную модель. То есть, амплитуда колебаний примерно одинакова:

Если амплитуда сезонных колебаний возрастает или уменьшается, строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
Построение этих моделей сводится к расчету тренда (Tt), сезонности (St) и случайных возмущений (Et) для каждого уровня ряда (Yt).
Алгоритм построения модели
- Выравниваем ряд с помощью скользящей средней, то есть сглаживаем ряд и отфильтровываем высокочастотные колебания.
- Рассчитываем значение сезонной компоненты St.
- Рассчитываем значения Tt с использованием полученного уравнения тренда.
- Используя полученные значения St и Tt, находим прогнозные значения уровней временного ряда.
- Оцениваем качество модели.
Реализация на практике
Итак, мы имеем на руках данные о продажах за 2016 и 2017 год и хотим спрогнозировать продажи на 2018 год.


Шаг 1
Следуя нашему алгоритму, мы должны сгладить временной ряд. Воспользуемся методом скользящей средней. Видим, что в каждом году есть большие пики (май-июнь 2016 и апрель 2017), поэтому возьмем период сглаживания пошире, например, месячную динамику, т.е. 12 месяцев.
Удобнее брать период сглаживания в виде нечетного числа, тогда формула для расчета уровней сглаженного ряда:

yi — фактическое значение i-го уровня ряда,
yt — значение скользящей средней в момент времени t,
2p+1 — длина интервала сглаживания.
Но так как мы решили использовать месячную динамику в виде четного числа 12, то данная формула нам не подойдет и мы воспользуемся этой:
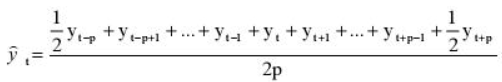
Иными словами, мы учитываем половины от крайних уровней ряда в диапазоне, в остальном формула не претерпела больше никаких изменений. Вот ее точный вид для нашей задачи:
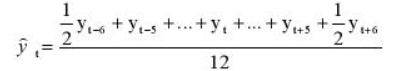
Сглаживаем наши уровни ряда и растягиваем формулу вниз:

Сразу можем построить график из известных значений уровня продаж и их сглаженной. Выведем ее уравнение и значение коэффициента детерминации R^2:

В качестве сглаженной я выбрала полином третьей степени, так как он лучше всего описывал уровни временного ряда и имел наибольший R^2.

Шаг 2
Так как мы рассматриваем аддитивную модель вида: 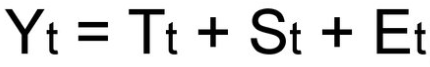
Найдем оценки сезонной компоненты как разность между фактическими уровнями ряда и значениями скользящей средней St+Et = Yt-Tt, так как Yt и Tt мы уже знаем.

Используем оценки сезонной компоненты (St+Et) для расчета значений сезонной компоненты St. Для этого найдем средние за каждый интервал (по всем годам) оценки сезонной компоненты St.

Средняя оценка сезонной компоненты находится как сумма по столбцу, деленная на количество заполненных строк в этом столбце. В нашем случае оценки сезонной составляющей расположились в строках без пересечений, поэтому сумма по столбцам состоит из одиночных значений, следовательно и среднее будет таким же. Если бы мы располагали периодом побольше, например с 2015, у нас бы добавилась еще одна строка и мы смогли бы полноценно найти среднее, поделив сумму на 2.
В моделях с сезонной компонентой обычно предполагается, что сезонные воздействия за период взаимопогашаются. В аддитивной модели это выражается в том, что сумма значений сезонной компоненты по всем интервалам должна быть равна нулю. Поэтому найдя значение случайной составляющей, поделив сумму средних оценок сезонной составляющей на 12, мы вычитаем ее значение из каждой средней оценки и получаем скорректированную сезонную компоненту, St.
Далее, заполняем нашу таблицу значениями сезонной составляющей дублируя ряд каждые 12 месяцев, то есть три раза:

Шаг 3
Теперь рассчитываем значения уровня тренда T(t) по тому уравнению, которое мы получили при построении сглаженного тренда на первом шаге.
T(t) = -23294+34114*t-1593*t^2+26,3*t^3
Вместо t используем значения из столбца Период из соответствующей строки.

Шаг 4
Имея рассчитанные значения S(t) и T(t) мы можем рассчитать прогнозные значения уровней ряда Y(t). Для этого накладываем уровни сезонности на тренд.

Теперь построим график известных значений Y(t) и спрогнозированных за 2018 год.

Вот мы и нашли спрогнозированные значения уровней продаж на 2018 год. Значения отражают возрастающую тенденцию и сезонные пики. Конечно, эти данные не дают 100% точности, ведь существует множество внешних воздействий, которые могут изменить направление тренда, поэтому к прогнозным значениям обычно строят доверительный интервал, это такой коридор, внутри которого могут колебаться прогнозные значения с заданной вероятностью (чаще всего выбирают 95%). Но об этом я расскажу в следующей статье.
Шаг 5
Осталось оценить точность модели. Для этого будем использовать среднюю ошибку аппроксимации, которая поможет рассчитать ошибку в относительном выражении. Иными словами, это среднее отклонение расчетных значений от фактических, которое вычисляется по формуле:

yi — спрогнозированные уровни ряда,
yi* — фактические уровни ряда,
n — количество складываемых элементов.
Модель может считаться адекватной, если:

Итак, рассчитываем ошибку аппроксимации для нашего случая. Так как в основе нашего тренда лежит полином третьей степени, прогнозные значения начинают хорошо повторять фактические значения к концу 2016 года, думаю, я думаю, поэтому корректнее было бы рассчитать ошибку аппроксимации для значений 2017 года.

Сложив весь столбец с ошибками аппроксимации и поделив на 12, получаем среднюю ошибку аппроксимации 4,13%. Это значение меньше 15% и можем сделать вывод об адекватности модели.
Не забывайте, что прогнозы не бывают точными на 100%. Любые неожиданные внешние воздействия могут развернуть значения уровней ряда в неизвестном направлении 🙂
Полезные ссылки:
- Ссылка на пример Google Sheets
- Построение функции тренда в Excel. Быстрый прогноз без учета сезонности
- Бывшев В.А. Эконометрика
- Об авторе
- Свежие записи

Сезонная составляющая (сезонная компонента) и её оценка.
Известны данные по ВВП в России за 2008-2012 г.
|
год |
квартал |
объём ВВП, млрд.руб |
|
2008 |
1 |
8878 |
|
2 |
10238 |
|
|
3 |
11542 |
|
|
4 |
10619 |
|
|
2009 |
1 |
8335 |
|
2 |
9245 |
|
|
3 |
10411 |
|
|
4 |
10816 |
|
|
2010 |
1 |
9617 |
|
2 |
10693 |
|
|
3 |
11843 |
|
|
4 |
13019 |
|
|
2011 |
1 |
11680 |
|
2 |
13038 |
|
|
3 |
14406 |
|
|
4 |
15462 |
Построить аддитивную модель временного ряда, выделив сезонную и трендовую составляющие
Найдём коэффициенты автокорреляции
| r1 |
0,777705 |
| r2 |
0,475503 |
| r3 |
0,513819 |
| r4 |
0,781028 |
Построим коррелограмму

По высоким значениям коэффициентов автокорреляции 1 и 4 порядка выдвигаем гипотезу о наличии тренда и сезонной составляющей .
Для оценки сезонной компоненты аддитивной модели составим таблицу
Для этого:
- Просуммируем уровни ряда последовательно за 4 квартала со сдвигом на один сезон (итого за 4 квартала)
- Найдем скользящие средние, делением каждой суммы на 4.
- Приведем скользящие средние с помощью центрирования, найдя средние значения из двух последовательных скользящих средних.
- Найдем оценки сезонной компоненты как разность между фактическим y и центрированной скользящей средней
|
t |
y |
Итого за 4 кв. |
Скользящая средняя за 4 кв. |
Центрированная скользящая средняя |
Оценка сезонной компоненты |
|
1 |
8878 |
— |
— |
— |
— |
|
2 |
10238 |
41277 |
10319,3 |
— |
— |
|
3 |
11542 |
40734 |
10183,5 |
10251,38 |
1290,63 |
|
4 |
10619 |
39741 |
9935,3 |
10059,38 |
559,63 |
|
5 |
8335 |
38610 |
9652,5 |
9793,88 |
-1458,88 |
|
6 |
9245 |
38807 |
9701,8 |
9677,13 |
-432,13 |
|
7 |
10411 |
40089 |
10022,3 |
9862,00 |
549,00 |
|
8 |
10816 |
41537 |
10384,3 |
10203,25 |
612,75 |
|
9 |
9617 |
42969 |
10742,3 |
10563,25 |
-946,25 |
|
10 |
10693 |
45172 |
11293,0 |
11017,63 |
-324,63 |
|
11 |
11843 |
47235 |
11808,8 |
11550,88 |
292,13 |
|
12 |
13019 |
49580 |
12395,0 |
12101,88 |
917,13 |
|
13 |
11680 |
52143 |
13035,8 |
12715,38 |
-1035,38 |
|
14 |
13038 |
54586 |
13646,5 |
13341,13 |
-303,13 |
|
15 |
14406 |
— |
— |
— |
— |
|
16 |
15462 |
— |
— |
— |
— |
Рассчитаем значения сезонной компоненты
|
Показатели |
Год |
Квартал |
|||
|
1 кв. |
2 кв. |
3 кв. |
4 кв. |
||
|
1 |
1290,63 |
559,63 |
|||
|
2 |
-1458,88 |
-432,13 |
549,00 |
612,75 |
|
|
3 |
-946,25 |
-324,63 |
292,13 |
917,13 |
|
|
4 |
-1035,38 |
-303,13 |
|||
| Итого за сезон |
-3440,50 |
-1059,88 |
2131,75 |
2089,50 |
|
| Средняя оценка сезонной компоненты, |
-1146,83 |
-353,29 |
710,58 |
696,50 |
|
| Скорректированная сезонная компонента, |
-1123,57 |
-330,03 |
733,84 |
719,76 |
Все значения для расчетов возьмем из колонки «Оценка сезонной компоненты», последовательно внося их в таблицу
Сумма «Скорректированной сезонной компоненты» равна нулю.
Для расчета скорректированной сезонной компоненты определим корректирующий коэффициент.
Составим таблицу, где T + ε колонка с возможным трендом (за вычетом сезонности)
|
t |
y |
Si (скорректированная S) |
y – S = T + ε |
|
1 |
2301 |
-373,48 |
2674,48 |
|
2 |
2567 |
-139,52 |
2706,52 |
|
3 |
3050 |
266,48 |
2783,52 |
|
4 |
3064 |
246,52 |
2817,48 |
|
5 |
2891 |
-373,48 |
3264,48 |
|
6 |
3149 |
-139,52 |
3288,52 |
|
7 |
3671 |
266,48 |
3404,52 |
|
8 |
3696 |
246,52 |
3449,48 |
|
9 |
3522 |
-373,48 |
3895,48 |
|
10 |
3984 |
-139,52 |
4123,52 |
|
11 |
4645 |
266,48 |
4378,52 |
|
12 |
4979 |
246,52 |
4732,48 |
|
13 |
4441 |
-373,48 |
4814,48 |
|
14 |
5070 |
-139,52 |
5209,52 |
|
15 |
5897 |
266,48 |
5630,52 |
|
16 |
6354 |
246,52 |
6107,48 |
Строим график модели за вычетом сезонной компоненты
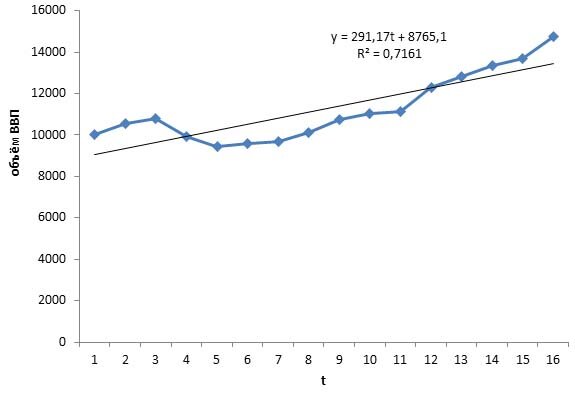
Коэффициенту детерминации очень высок (близок к 1), таким образом, полученная линейная модель может использоваться для прогнозирования
Оценим качество такой модели с помощью инструмента регрессия
| ВЫВОД ИТОГОВ | ||||
|
Регрессионная статистика |
||||
| Множественный R |
0,846 |
|||
| R-квадрат |
0,716 |
|||
| Нормированный R-квадрат |
0,696 |
|||
| Стандартная ошибка |
903,55 |
|||
| Наблюдения |
16 |
|||
| Дисперсионный анализ | ||||
|
df |
SS |
MS |
F |
|
| Регрессия |
1 |
28826034 |
28826034 |
35,30883 |
| Остаток |
14 |
11429564 |
816397,4 |
|
| Итого |
15 |
40255598 |
||
|
Коэффи-циенты |
Стандартная ошибка |
t-статистика |
P-Значение |
|
| Y-пересечение |
8765,144 |
473,824 |
18,499 |
3,09E-11 |
| t |
291,174 |
49,002 |
5,942 |
3,6E-05 |
Модель y = 291,174t + 8765,144 высокого качества, поскольку коэффициент корреляции очень высок и модель значима в целом и по параметрам при уровне значимости 95%, т.к. уровни значимости критерия Фишера и Стьюдента намного меньше 5% (0,05) – см. колонки Значимость F и P-Значение.
Материалы сайта
Обращаем Ваше внимание на то, что все материалы опубликованы для образовательных целей.
Каким
бы видом экономической деятельности
Вы не занимались, всегда приходится
планировать Вашу деятельность на будущий
период. Например, ожидаемые объемы
продаж, издержки, ставки процента и т.д.
Мы всегда используем опыт, накопленный
в прошлом, для прогнозировании
(предсказания) будущих (ожидаемых)
значений какого-либо экономического
показателя. При изучении регрессионных
моделей мы вариацию зависимой переменной
объясняли на основе изучения значений
независимых переменных. Можно использовать
тот же подход, когда в качестве независимой
переменной будет выступать переменная
времени. К примеру, мы хотим объяснить
колебания объемов продаж только через
изменение значений этого показателя
во времени, без учета каких-либо других
факторов. Если удается выявить определенную
тенденцию изменения фактических
значений, то её можно использовать для
прогнозирования будущих значений
данного показателя.
Множество
данных, в которых время является
независимой переменной, называется
временным рядом.
Значения
некоторого показателя (например, объемы
продаж) изменяются под воздействием
целого ряда факторов. Например, если
компания предлагает на рынке новый вид
продукции высокого качества, то с
течением времени объем продаж этой
продукции возрастает (Рис.13). По устаревшей
продукции объем продаж убывает (Рис.14)
О бъем
бъем
продаж

 Время
Время
Рис.
13. Объемы продаж новой продукции
пользующейся спросом.
Объем продаж


 Время
Время
Рис. 14. Объемы
продаж устаревшей продукции.
Общее
изменение значений переменной во времени
называется трендом и обозначается через
Т.
Рассмотрим
следующий пример 4.1. В таблице 4.11
представлено количество продукции,
проданной компанией FORA LTD в течение
последних 13 кварталов.
Таблица 4.11.
Количество продукции, проданной в
течение последних 13 кварталов
|
ДАТА |
Количество
Проданной |
|
Январь – март |
239 |
|
Апрель – июнь |
201 |
|
Июль – сентябрь |
182 |
|
Октябрь – декабрь |
297 |
|
Январь – март |
324 |
|
Апрель – июнь |
278 |
|
Июль – сентябрь |
257 |
|
Октябрь – декабрь |
384 |
|
Январь – март |
401 |
|
Апрель – июнь |
360 |
|
Июль – сентябрь |
335 |
|
Октябрь – декабрь |
462 |
|
Январь – март |
481 |
Построим
по данным таблицы график, на оси абсцисс
которого отметим временные промежутки,
а оси ординат – объемы продаж. Этот
график указывает на то, что значения
переменных характеризуют не только
тренд, они подвержены также и циклическим
колебаниям. Если колебания временного
ряда повторяются через небольшие
промежутки времени, то они называются
сезонными колебаниями. График указывает
на возможность возрастающего линейного
тренда, а так же наличие сезонных
колебаний (летом объемы продаж падают,
зимой возрастают).
Под
сезонной вариацией понимают любую
систематическую вариацию, повторяющуюся
через относительно небольшие промежутки
времени. Например, при изучении недельного
товарооборота под “сезоном” понимается
один день. Кроме того, графики временных
рядов могут содержать еще и циклическую
вариацию, связанную, например, с
периодичностью кризисов, космических
циклов и др. Эту компоненту находят по
данным за длительные промежутки времени
в 10, 15 или 20 лет. Задача прогнозирования
состоит в том, чтобы выделить компоненты
временного ряда, характеризующие
собственно тренд, сезонную компоненту
и циклическую компоненту.
Тренд
на рисунке 15 показывает, что в целом
объем продаж возрос в среднем примерно
с 230 тыс. шт. и 1996 году до 390 тыс. шт. в 1998
году. Из графика так же видно, что сезонная
компонента практически не изменилась
за три года.

Объем
продаж
Рис.15
Мы
рассмотрим методы прогнозирования
только с учетом сезонной компоненты.
Для этого используются модели с аддитивной
компонентой и модели с мультипликативной
компонентой. Если сезонная вариация
постоянна в различных временных периодах,
то для анализа временного ряда подходит
модель с аддитивной компонентой. Если
сезонная вариация не является константой,
например, увеличивается с возрастанием
значений тренда, то для анализа лучше
подходит модель с мультипликативной
компонентой, в которой значения сезонной
компоненты представляют собой определенную
долю трендового значения. Каждой из
этих моделей соответствуют различные
методы расчета компоненты тренда,
использующие сочетание методов
скользящего среднего и линейной
регрессии.
Следует
помнить, что поскольку сезонные колебания
характеризуются относительно небольшими
временными интервалами, то прогнозирование
по моделям с сезонной компонентой –
также краткосрочное.
-
Анализ модели
с аддитивной компонентой:
A = T + S + E
Моделью
с аддитивной компонентой называется
такая модель, в которой вариация значений
переменной во времени наилучшим образом
описывается через сложение отдельных
компонент. Предположив, что циклическая
вариация не учитывается, модель
фактических значений переменной А можно
представить следующим образом:
Фактическое
значение = Трендовое значение + Сезонная
вариация + Ошибка,
то есть
A = T + S + E
В
моделях как с аддитивной, так и с
мультипликативной компонентой общая
процедура анализа примерно одинакова:
Шаг 1. Расчет
значений сезонной компоненты.
Шаг 2. Вычитание
сезонной компоненты из фактических
значений. Этот шаг называется
десезонализацией данных. Расчет тренда
на основе полученных десезонализированных
данных.
Шаг
3. Расчет ошибок как разности между
фактическими и трендовыми значениями.
Шаг
4. Расчет среднего линейного отклонения
или среднеквадратической ошибки для
обоснования соответствия модели исходным
данным или для выбора из множества
моделей наилучшей.
-
Расчет сезонной
компоненты в аддитивных моделях
Стабильность
сезонной компоненты в примере (таблица
4.1) указывает на то, что модель с аддитивной
компонентой подходит для анализа этого
временного ряда. То есть фактические
объемы продаж можно выразить следующим
образом:
A = T + S + E
Для
того чтобы элиминировать влияние
сезонной компоненты воспользуемся
методом скользящей средней, которую
рассчитаем с интервалом в три месяца.
Этот расчет и все последующие проведем
в таблице 4.12.
Таблица 4.12 . Расчет
по 4 точкам центрированных скользящих
средних значений тренда для модели A –
T = S + E
|
ДАТА |
Объем продаж, |
Итого за 4 квартала |
Скользящая |
Центрированная |
Оценка A-T=S+E |
|
Январь — март |
239 |
||||
|
Апрель – июнь |
201 |
||||
|
919 |
229,75 |
||||
|
Июль – сентябрь |
182 |
240,4 |
-58,4 |
||
|
1004 |
251 |
||||
|
Октябрь – декабрь |
297 |
260,6 |
+36,4 |
||
|
1081 |
270,25 |
||||
|
Январь — март |
324 |
279,6 |
+44,4 |
||
|
1156 |
289 |
||||
|
Апрель – июнь |
278 |
299,9 |
-21,9 |
||
|
1243 |
310,75 |
||||
|
Июль – сентябрь |
257 |
320,4 |
-63,4 |
||
|
1320 |
330 |
||||
|
Октябрь – декабрь |
384 |
340,3 |
+43,8 |
||
|
1402 |
350,5 |
||||
|
Январь — март |
401 |
360,2 |
+40,8 |
||
|
1480 |
370 |
||||
|
Апрель – июнь |
360 |
379,8 |
-19,8 |
||
|
1558 |
389,5 |
||||
|
Июль – сентябрь |
335 |
399,5 |
-64,5 |
||
|
1638 |
409,5 |
||||
|
Октябрь – декабрь |
462 |
||||
|
Январь — март |
481 |
Просуммировав
первые 4 значения, получим общий объем
продаж в 1996 году. Поделив эту сумму на
4, найдем средний объем продаж в каждом
квартале 1996 года:
(239 + 201 + 182 + 297)/4 =
299,75
Полученное
значение уже не содержит сезонной
компоненты, так как представляет собой
среднюю величину за год. У нас появилась
оценка значения тренда для середины
года, то есть для точки, лежащей в середине
между кварталами II и III. Последовательно
продвигаясь вперед с шагом в один
квартал, рассчитаем средние квартальные
значения для промежутков: апрель 1996 –
март 1997 (251), июль 1996 – июнь 1997 (270,25) и т.д.
Данная процедура позволяет генерировать
скользящие средние по 4 точкам исходного
множества данных. Получаемое таким
образом множество скользящих средних
представляет наилучшую оценку искомого
тренда.
Теперь
полученные значения тренда можно
использовать для нахождения оценок
сезонной компоненты. Мы рассчитываем:
A – T = S + E.
К
сожалению, оценки значений тренда,
получаемые в результате расчета
скользящих средних по 4 точкам, относятся
к несколько иным моментам времени, чем
фактические данные. Первая оценка,
равная 229,75, представляет собой точку,
совпадающую с серединой 1996 года, то есть
лежит в центре промежутка фактических
объемов продаж во II и III кварталах. Вторая
оценка, равная 251, лежит между фактическими
значениями в III и IV кварталах. Нам же
необходимы десезонализированные средние
значения, соответствующие тем же
интервалам времени, что и фактические
значения за квартал. Положение
десезонализированных средних во времени
сдвигается путем дальнейшего расчета
средних для каждой пары значений. Найдем
среднюю из первой и второй оценок,
центрируя их июнь-сентябрь 1996 года, т.е.
(229,75 + 251)/2 = 240,4
Это
и есть десезонализированная средняя
за июль-сентябрь 1996 г. Эту десезонализированную
величину, которая называется центрированной
скользящей средней, можно непосредственно
сравнивать с фактическим значением за
июль-сентябрь 1996 года, равным 182. Отметим,
что это означает отсутствие оценок
тренда за первые два или последние два
квартала временного ряда.
После
расчетов в таблице 4.12. мы имеем оценки
сезонной компоненты, которые включают
в себя ошибку или остаток. Прежде чем
мы сможем использовать сезонную
компоненту, нужно пройти два следующих
этапа. Вновь перейдем к расчетам с
использованием таблицы 4.13. Найдем
средние значения сезонных оценок для
каждого сезона года
Таблица 4.13. Расчет
средних значений сезонной компоненты
|
Номер квартала |
||||||
|
ГОД |
1 |
2 |
3 |
4 |
||
|
1996 1997 1998 |
— +44,4 +40,8 |
— -21,9 -19,8 |
-58,4 -63,4 -64,5 |
+36,4 +43,8 — |
||
|
Итого |
+85,2 |
-41,7 |
-186,3 |
+80,2 |
||
|
Среднее |
85,2 |
-41,7 |
-186,3 |
80,2 |
||
|
Оценка Компоненты |
+42,6 |
-20,8 |
-62,1 |
+40,1 |
Сумма=- 0,2 |
|
|
Скорректированная |
+42,6 |
-20,7 |
-62,0 |
+40,1 |
Сумма = 0 |
Эта
процедура позволяет уменьшить некоторые
значения ошибок. Наконец, скорректируем
средние значения, увеличивая или уменьшая
их на одно и то же число таким образом,
чтобы их общая сумма была равна нулю.
Это необходимо, чтобы усреднить значения
сезонной компоненты в целом за год.
Обычно корректирующий фактор рассчитывается
путем деления суммы оценок сезонных
компонент на число сезонов. В нашем же
примере мы оценки второго и третьего
кварталов округлили до ближайшего
большего числа.
Значения
скорректированной сезонной компоненты
подтверждают наши выводы, сделанные на
основе диаграммы. Объемы продаж за два
зимних месяца превышают среднее трендовое
значение приблизительно на 40 тыс. шт.,
а объемы продаж за два летних месяца
ниже средних на 21 и 62 тыс. шт. соответственно.
Аналогичная
процедура применима при определении
сезонной вариации за любой промежуток
времени. Если, например, в качестве
сезона выступают дни недели, для
элиминирования влияния ежедневной
“сезонной компоненты” также рассчитывают
скользящую среднюю, но уже не по четырем,
а по семи точкам. Эта скользящая средняя
представляет собой значение тренда в
середине недели, то есть в четверг, таким
образом, необходимость в центрировании
отпадает.
-
Десезонализация
данных при расчете тренда
Шаг
2 состоит в десезонализации исходных
данных. Она заключается в вычитании
соответствующих значений сезонной
компоненты из фактических значений
данных за каждый квартал, то есть A – S
= T + E, что показано в таблице 4.14.
Таблица 4.14. Расчет
десезонализированных данных
|
ДАТА |
Номер |
Объем продаж, |
Сезонная компонента |
Десезонализированный A |
|
Январь – март |
1 |
239 |
+42,6 |
196,4 |
|
Апрель – июнь |
2 |
201 |
-20,7 |
221,7 |
|
Июль – сентябрь |
3 |
182 |
-62,0 |
244,0 |
|
Октябрь – декабрь |
4 |
297 |
+40,1 |
256,9 |
|
Январь — март |
5 |
324 |
+42,6 |
281,4 |
|
Апрель – июнь |
6 |
278 |
-20,7 |
298,7 |
|
Июль – сентябрь |
7 |
257 |
-62,0 |
319,0 |
|
Октябрь – декабрь |
8 |
384 |
+40,1 |
343,9 |
|
Январь — март |
9 |
401 |
+42,6 |
358,6 |
|
Апрель – июнь |
10 |
360 |
-20,7 |
380,7 |
|
Июль – сентябрь |
11 |
335 |
-62,0 |
397,1 |
|
Октябрь – декабрь |
12 |
462 |
+40,1 |
421,9 |
|
Январь — март |
13 |
481 |
+42,6 |
438,4 |
Новые
оценки тренда, которые все еще содержат
ошибку, можно использовать для построения
модели основного тренда. Если нанести
эти значения на исходную диаграмму, то
можно сделать вывод о существовании
явного линейного тренда (См. рис. 16).

Объем
продаж
Рис.16
Уравнение линии
тренда имеет вид:
![]() ,
,
где х – порядковый
номер квартала,
а и b – параметры
уравнения парной регрессии.
Поскольку
мы нашли, что тренд имеет линейный
характер, то значения параметров линии,
аппроксимирующей тренд, найдем методом
наименьших квадратов.
где y = T + E,
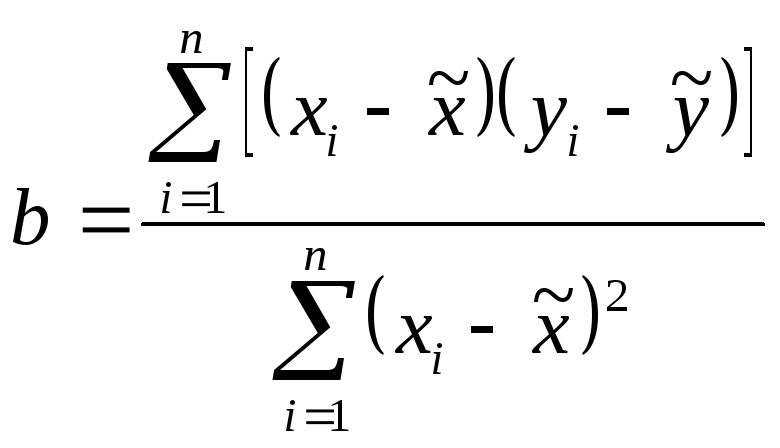 ,
,
![]() .
.
Подставив
значения из последних колонок таблицы
4.14 в соответствующие формулы, получим:
![]() ,
,
![]() .
.
Следовательно,
уравнение модели тренда имеет следующий
вид (с округлением значений коэффициентов
регрессии до ближайших целых значений):
Трендовое
значение объема продаж, тыс. шт. = 180,0 +
20,0 * номер квартала
-
Расчет ошибок
Шаг 3 нашего
алгоритма, предшествующий составлению
прогноза состоит в расчете ошибок или
остатка. Наша модель имеет следующий
вид:
A = T + S + E.
Значение
S было найдено в таблице 4.12, а значение
T в таблице 4.13. Вычитая каждое значение
из фактических объемов продаж, получим
значения ошибок.
Таблица 4.15. Расчет
ошибок для модели с аддитивной компонентой
|
Дата |
Номер |
Объем продаж, |
Сезонная |
Трендовое |
Ошибка, тыс. шт. |
|
Январь |
1 |
239 |
+42,6 |
200 |
-3,6 |
|
Апрель |
2 |
201 |
-20,7 |
220 |
+1,7 |
|
Июль |
3 |
182 |
-62,0 |
240 |
+4,0 |
|
Октябрь |
4 |
297 |
+40,1 |
260 |
-3,1 |
|
Январь |
5 |
324 |
+42,6 |
280 |
+1,4 |
|
Апрель |
6 |
278 |
-20,7 |
300 |
-1,3 |
|
Июль |
7 |
257 |
-62,0 |
320 |
-1,0 |
|
Октябрь |
8 |
384 |
+40,1 |
340 |
+3,9 |
|
Январь |
9 |
401 |
+42,6 |
360 |
-1,6 |
|
Апрель |
10 |
360 |
-20,7 |
380 |
+0,7 |
|
Июль |
11 |
335 |
-62,0 |
400 |
-3,0 |
|
Октябрь |
12 |
462 |
+40,1 |
420 |
+1,9 |
|
Январь |
13 |
481 |
+42,6 |
440 |
-1,6 |
Как
и в случае линейной регрессии для того,
чтобы найти меру соответствия модели
исходным данным, необходимо вычислить
значения ошибок (остатков) модели, то
есть той части значения наблюдения,
которую невозможно объяснить с помощью
построенной модели. Для этого применяют
среднее абсолютное отклонение (mean
absolute deviation MAD) и среднеквадратическую
ошибку (mean square error MCE).
![]()
![]()
Целесообразно
использовать обе меры, так как последняя
из этих мер резко возрастает при наличии
высоких ошибок.
Мы
можем использовать в шаге 4 последний
столбец таблицы 4.15 для расчета MAD и MSE.
![]()
![]()
В нашем случае
ошибки достаточно малы и составляют от
1 до 2%. Тенденция, выявленная по фактическим
данным, достаточно устойчива и позволяет
получить хорошие краткосрочные прогнозы.
-
Прогнозирование
по аддитивной модели
Прогнозные
значения по модели с аддитивной
компонентой рассчитывают как:
F=T+S (тыс. шт. за
квартал),
где
трендовое значение Т=180+20номер
квартала, а сезонная компонента S
составляет +42,6 в январе-марте, -20,7 в
апреле-июне, 62,0 в июле-сентябре и +40,1 в
октябре-декабре.
Порядковый номер
квартала, охватывающего ближайшие три
месяца с апреля по июль 1999 г., равен 14,
таким образом, прогнозное трендовое
значение составит:
Т14=180+2014=460
(тыс. шт. за квартал).
Соответствующая
сезонная компонента равна –20,7 тыс. шт.
Следовательно, прогноз на этот квартал
определяется как:
F (апрель-июнь
1999г.)=460-20,7=439,3 тыс. шт.
Не
следует забывать: чем более отдаленным
является период упреждения, тем меньшей
оказывается обоснованность прогноза.
В данном случае мы предполагаем, что
тенденция, обнаруженная по ретроспективным
данным, распространяется и на будущий
период. Для сравнительно небольших
периодов упреждения такая предпосылка
может действительно иметь место, однако
ее выполнение становится менее вероятным
по мере сопоставления прогнозов на
более отдаленную перспективу.
-
Анализ
модели с мультипликативной компонентной:
А=T SE
SE
В некоторых
временных рядах значение сезонной
компоненты не является константой, а
представляет собой определенную долю
трендового значения. Таким образом,
значения сезонной компоненты увеличиваются
с возрастанием значений тренда.
Пример
4.2. Компания
LORA
Ltd
осуществляет реализацию нескольких
видов продукции. Объемы продаж одного
из продуктов за последние 13 кварталов
представлены в таблице 4.16.
Таблица
4.16. Квартальные объемы продаж компании
LORA
Ltd
|
Дата |
Номер |
Количество |
|
Январь-март |
1 |
70 |
|
Апрель-июнь |
2 |
66 |
|
Июль-сентябрь |
3 |
65 |
|
Октябрь-декабрь |
4 |
71 |
|
Январь-март |
5 |
79 |
|
Апрель-июнь |
6 |
66 |
|
Июль-сентябрь |
7 |
67 |
|
Октябрь-декабрь |
8 |
82 |
|
Январь-март |
9 |
84 |
|
Апрель-июнь |
10 |
69 |
|
Июль-сентябрь |
11 |
72 |
|
Октябрь-декабрь |
12 |
87 |
|
Январь-март |
13 |
94 |
Построим по этим
данным диаграмму (Рис.17)

Рис.17
Объем продаж этого
продукта так же, как и в предыдущем
примере 4.1, подвержен сезонным колебаниям,
и значения его в зимний период выше, чем
в летний. Однако размах вариации
фактических значений относительно
линии тренда постоянно возрастает. К
таким данным следует применять модель
с мультипликативной компонентной:
Фактическое
значение = Трендовое значение
![]() Сезонная
Сезонная
вариация![]() Ошибка,
Ошибка,
т.е.
А
= T
![]() S
S
![]() E
E
В
нашем примере 4.2 есть все основания
предположить существование линейного
тренда, но чтобы полностью в этом
убедиться, проведем процедуру сглаживания
временного ряда.
-
Расчет значений
сезонной компоненты
В
сущности, эта процедура ничем не
отличается от той, которая применялась
для аддитивной модели. Так же вычисляются
центрированные скользящие средние для
трендовых значений, однако оценки
сезонной компоненты представляют собой
коэффициенты, полученные по формуле
А/Т= S
![]() E.
E.
Результаты расчетов приведены в таблице
4.17.
Таблица
4.17. Расчет значений сезонной компоненты
для LORA
Ltd
|
Дата |
Номер |
Объем |
Скользящая |
Центриро-ванная |
Коэффициент А/Т= |
|
1 |
2 |
3 |
4 |
5 |
6 |
|
Январь-март |
1 |
70 |
|||
|
Апрель-июнь |
2 |
66 |
68 |
||
|
Июль-сентябрь |
3 |
65 |
70,25 |
69,13 |
0,940 |
|
Октябрь-декабрь |
4 |
71 |
70.25 |
70,25 |
1,011 |
|
Январь-март |
5 |
79 |
70,75 |
70,50 |
1,121 |
|
Апрель-июнь |
6 |
66 |
73,50 |
72,13 |
0,915 |
|
Июль-сентябрь |
7 |
67 |
74,75 |
74,13 |
0,904 |
|
Октябрь-декабрь |
8 |
82 |
75,50 |
75,13 |
1,092 |
|
Январь-март |
9 |
84 |
76,75 |
76,13 |
1,103 |
|
Апрель-июнь |
10 |
69 |
78 |
77,38 |
0,892 |
|
Июль-сентябрь |
11 |
72 |
80,50 |
79,25 |
0,909 |
|
Октябрь-декабрь |
12 |
87 |
— |
— |
|
|
Январь-март |
13 |
94 |
— |
— |
Значения сезонных
коэффициентов получены на основе
квартальных оценок по аналогии с
алгоритмом, который применялся для
аддитивной модели. Так как значения
сезонной компоненты — это доли, а число
сезонов равно четырем, необходимо, чтобы
их сумма была равна четырем, а не нулю,
как в предыдущем случае. (Если бы в
исходных данных предполагалось семь
сезонов в течение недели по одному дню
каждый, то общая сумма значений сезонной
компоненты должна была бы равняться
семи). Если эта сумма не равна четырем,
производится корректировка значений
сезонной компоненты точно таким же
образом, как это уже делалось ранее. В
таблице оценки, рассчитанные в последнем
столбце предшествующей табл. 4.18,
расположены под соответствующим номером
квартала.
Таблица
4.18. Расчет значений сезонной компоненты
для LORA
Ltd
|
Год |
Номер |
|||||
|
1 |
2 |
3 |
4 |
|||
|
1996 |
— |
— |
0,940 |
1,011 |
||
|
1997 |
1,121 |
0,915 |
0,904 |
1,092 |
||
|
1998 |
1,103 |
0,892 |
0,909 |
— |
||
|
Итого |
2,224 |
1,807 |
2,77753 |
2,103 |
||
|
Среднее |
2,224 |
1,807 |
2,753 |
2,103 |
||
|
Оценка |
1,112 |
0,903 |
0,918 |
1,051 |
Сумма=3,984 |
|
|
Скорректи-рованная |
1,116 |
0,907 |
0,922 |
1,055 |
Сумма=0 |
Как
показывают оценки, в результате
воздействий объемы продаж в январе-марте
увеличиваются на 11,6 % соответствующего
значения тренда (1,116). Аналогично сезонные
воздействия в октябре-декабре приводят
к увеличению объема продаж на 5,5 % от
соответствующего значения тренда. В
двух других кварталах сезонные воздействия
состоят в снижении объемов продаж,
которое составляет 90,7 и 92,2 % от
соответствующих трендовых значений.
-
Десезонализация
данных и расчет уравнения тренда
После
того, как оценки сезонной компоненты
определены, можем приступить к процедуре
десезонализации по формуле А/S=
T
![]() E.
E.
Результаты расчетов этих оценок значений
тренда приведены в таблице 4.19.
Таблица
4.19. Расчет уравнения тренда для компании
LORA
Ltd
|
Дата |
Номер |
Объем |
Коэффициент |
Десезонализированный |
|
Январь-март |
1 |
70 |
1,116 |
62,7 |
|
Апрель-июнь |
2 |
66 |
0,907 |
72,8 |
|
Июль-сентябрь |
3 |
65 |
0,922 |
70,6 |
|
Октябрь-декабрь |
4 |
71 |
1,055 |
67,3 |
|
Январь-март |
5 |
79 |
1,116 |
70,8 |
|
Апрель-июнь |
6 |
66 |
0,907 |
72,8 |
|
Июль-сентябрь |
7 |
67 |
0,922 |
72,7 |
|
Октябрь-декабрь |
8 |
82 |
1,055 |
77,7 |
|
Январь-март |
9 |
84 |
1,116 |
75,2 |
|
Апрель-июнь |
10 |
69 |
0,907 |
76,1 |
|
Июль-сентябрь |
11 |
72 |
0,922 |
78,2 |
|
Октябрь-декабрь |
12 |
87 |
1,055 |
82,4 |
|
Январь-март |
13 |
94 |
1,116 |
84,2 |
Полученные
трендовые значения наносятся на исходную
точечную диаграмму (Рис.18).
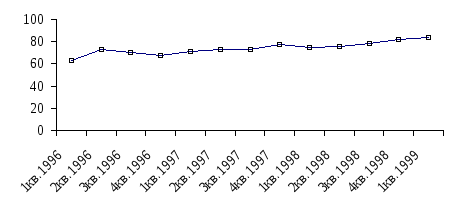
Рис 18.
Точки,
образующие представленный на графике
тренд, достаточно сильно разбросаны.
Объемы продаж в данном случае не образуют
такой строгой последовательности, как
в предыдущем примере с компанией FORA
Ltd.
Скорее всего, пример с LORA
Ltd
более близок к реальной действительности.
Теперь
нужно принять решение о том, какой вид
будет иметь уравнение тренда. Очевидно,
что линия тренда — не кривая, наоборот,
она несколько больше напоминает прямую,
хотя отдельные точки, особенно значения
за 1996 г, расположены хаотически.
Предположим для простоты, что тренд
линейный, и для расчета параметров
прямой, наилучшим образом его
аппроксимирующей, будем применять метод
наименьших квадратов, который дает
следующий результат:
Т
= 64,6 + 1,36
![]() номер квартала (тыс. шт. в квартал).
номер квартала (тыс. шт. в квартал).
Это
уравнение будем использовать в дальнейшем
для расчета оценок трендовых объемов
продаж на каждый момент времени.
-
Расчет
ошибок: А/(Т
S)
= Е или А — (Т
S)
= Е
Итак,
мы нашли значения тренда и сезонной
компоненты. Теперь мы можем использовать
их для того, чтобы рассчитать ошибки в
прогнозируемых по модели объемах продаж
Т![]() S
S
по сравнению
с фактическими значениями А.
В таблице 4.20. эти ошибки рассчитаны как
отношение Е
= А/(Т
![]() S).
S).
Для каждого года
ошибки достаточно велики, что видно из
графика десезонализированных значений.
Однако, начиная и первого квартала 1997
г., величина ошибки составляет в среднем
2-3 % от фактического значения, и можно
сделать вывод о соответствии построенной
модели фактическим данным.
Таблица
4.20. Расчет ошибок для компоненты LORA
Ltd.
|
Дата |
№ |
Объем |
Сезонная S |
Трендовое |
Ошибка |
||
|
Т |
А/(Т |
А-(Т |
|||||
|
Январь-март |
1 |
70 |
1,116 |
66,0 |
73,7 |
0,95 |
-3,7 |
|
Апрель-июнь |
2 |
66 |
0,907 |
67,3 |
61,0 |
1,08 |
+5,0 |
|
Июль-сентябрь |
3 |
65 |
0,922 |
68,7 |
63,3 |
1,03 |
+1,7 |
|
Октябрь-декабрь |
4 |
71 |
1,055 |
70,0 |
73,9 |
0,96 |
-2,9 |
|
Январь-март |
5 |
79 |
1,116 |
71,4 |
79,7 |
0,99 |
-0,7 |
|
Апрель-июнь |
6 |
66 |
0,907 |
72,8 |
66,0 |
1,00 |
0 |
|
Июль-сентябрь |
7 |
67 |
0,922 |
74,1 |
68,3 |
0,98 |
-1,3 |
|
Октябрь-декабрь |
8 |
82 |
1,055 |
755,5 |
79,7 |
1,03 |
+2,3 |
|
Январь-март |
9 |
84 |
1,116 |
76,8 |
85,7 |
0,98 |
-1,7 |
|
Апрель-июнь |
10 |
69 |
0,907 |
78,8 |
70,9 |
0,97 |
-1,9 |
|
Июль-сентябрь |
11 |
72 |
0,922 |
79,6 |
73,3 |
0,98 |
-1,3 |
|
Октябрь-декабрь |
12 |
87 |
1,055 |
80,9 |
85,4 |
1,02 |
+1,6 |
|
Январь-март |
13 |
94 |
1,116 |
82,3 |
91,9 |
1,02 |
+2,1 |
-
Прогнозирование
по модели с мультипликативной
компонентой.
При
составлении прогнозов по любой модели
предполагается, что можно найти уравнение,
удовлетворительно описывающее значение
тренда. В обоих изложенных выше примерах
эти предпосылка была успешно выполнена.
Тренда, который нами рассматривался,
был очевидно линейный. Если бы исследуемый
тренд представлял собой кривую, мы были
бы вынуждены моделировать эту связь с
помощью одного из методов формализации
нелинейных взаимосвязей, рассмотренных
в предыдущей главе. После того, как
параметры уравнения тренда определены,
процедура составления прогнозов
становится совершенно очевидной.
Прогнозные значения определяются по
формуле:
F=
Т![]() S,
S,
где
Т=64,6+1,36![]() номер
номер
квартала (тыс. шт. за квартал),
а
сезонные компоненты составляют 1,116 в
первом квартале, 1,097 — во втором, 0,922 — в
третьем и 1,055 в четвертом квартале.
Ближайший следующий квартал — это второй
квартал 1999., охватывающий период с апреля
по июнь и имеющий во временном ряду
порядковый номер 14. Прогноз объема
продаж в этом квартале составляет:
F=
Т
![]() S
S
= (64 + 1,36
![]() 14)
14)![]() 0,907 = 83,64
0,907 = 83,64![]() 0,907 = 75,9 (тыс. шт. за квартал).
0,907 = 75,9 (тыс. шт. за квартал).
С
учетом величины ошибки прогноза мы
можем сделать вывод, что данная оценка
будет отклоняться от фактического
значения не более, чем на 2 — 3 %. Аналогично,
прогноз на октябрь-декабрь 1999 г.,
рассчитывается для квартала с порядковым
номером 16 с использованием значения
сезонной компоненты для IV
квартала года:
F
= Т
![]() S
S
= (64 + 1,36
![]() 16)
16)![]() 1,055 = 83,36
1,055 = 83,36![]() 1,055 = 91,1(тыс. шт. за квартал).
1,055 = 91,1(тыс. шт. за квартал).
Разумно предположить,
что величина ошибки данного прогноза
будет несколько выше, чем предыдущего,
поскольку этот прогноз рассчитан на
более длительную перспективу.
Резюме
Под
временным рядом понимается любое
множество данных, относящихся к
определенным моментам времени. Это
могут быть, скажем, годы, кварталы, месяцы
или недели. В моделях временного ряда
ретроспективная тенденция используется
для прогнозирования поведения переменной
в будущем. Краткосрочные прогнозы
являются более точными, чем долгосрочные.
Если прогноз составлялся на более
длительный период времени при условии,
что существующая тенденция сохранится
в будущем, то тем больше величина ошибки.
Для
моделирования временных рядов используются
два типа моделей — аддитивная и
мультипликативная. В обоих случаях
предполагается, что значение переменной
и включает в себя ряд компонент. Временной
ряд может состоять из собственно тренда
— общей тенденции изменения значений
переменной; сезонной вариации —
краткосрочных периодических колебаний
значений переменной; циклической
вариации — долгосрочных периодических
колебаний значений переменной; ошибки
или остатка. В данном учебном пособии
не рассматривались массивы данных за
длительные промежутки времени, содержащие
циклическую вариацию.
Рассмотренные
нами модели имеют следующий вид:
Аддитивная
А = Т + S
+ Е
Мультипликативная
А = Т
![]() S
S
![]() Е.
Е.
В
обоих видах моделей для десезонализации
данных применяется метод скользящего
среднего. Затем десезонализированные
данные используются при построении
модели тренда. По этой модели составляют
прогнозы будущих значений тренда. В
случае линейной модели для нахождения
параметров прямой, наилучшим образом
аппроксимирующей фактические значения,
используется метод наложения квадратов.
Процесс построения нелинейных моделей
гораздо более сложен.
В
отличие от линейных регрессионных
моделей для оценки обоснованности или
точности прогнозных моделей статистические
методы, как правило, не используются.
Наилучшую среди нескольких моделей
выбирает специалист, составляющий
прогноз. Чтобы определить, насколько
точно рассматриваемая модель аппроксимирует
прошлые данные, применяются два
показателя:
Среднее
абсолютное отклонение (МАD)=![]() .
.
Среднеквадратическая
ошибка (МSE)=![]() .
.

А. Сначала немного теории
1. Что такое временной ряд?
Временные ряды — это последовательность наблюдений, записываемых через определенные промежутки времени.
В зависимости от частоты наблюдений временной ряд обычно может быть ежечасным, дневным, недельным, ежемесячным, квартальным и годовым. Иногда у вас могут быть секундные и минутные временные ряды, например, количество кликов и посещений пользователей каждую минуту и т. Д.
В большинстве задач используются данные временных рядов. Все, что наблюдается последовательно во времени, является временным рядом.
Примеры данных временных рядов включают:
- Ежедневные цены на акции
- Температура моря по месяцам
- Ежеквартальные продажи для компании
- Годовая прибыль компании
Анализ временных рядов включает понимание различных аспектов внутренней природы ряда, чтобы вы были лучше информированы для создания значимых и точных прогнозов.
Анализ временных рядов — это подготовительный этап перед разработкой прогноза ряда. Чем больше вы узнаете о данных, тем точнее прогноз.
2. Основные шаги в задаче прогнозирования
- Определение проблемы. Часто это самая сложная часть прогнозирования. Тщательное определение проблемы требует понимания того, как будут использоваться прогнозы, кому они нужны, и как функция прогнозирования вписывается в организацию, требующую прогнозов. Прогнозисту необходимо потратить время на общение со всеми, кто будет участвовать в сборе данных, ведении баз данных и использовании прогнозов для будущего планирования.
- Сбор информации. Всегда требуется как минимум два вида информации: (а) статистические данные и (б) накопленный опыт людей, которые собирают данные и используют прогнозы. Часто бывает трудно получить достаточно исторических данных, чтобы соответствовать хорошей статистической модели. Иногда старые данные будут менее полезными из-за структурных изменений в прогнозируемой системе; тогда мы можем использовать только самые свежие данные. Однако помните, что хорошая статистическая модель будет учитывать эволюционные изменения в системе; не выбрасывайте хорошие данные без надобности.
- Исследовательский анализ. Всегда начинайте с графического представления данных. Есть ли закономерности? Есть ли значимая тенденция? Важна ли сезонность? Есть ли доказательства наличия бизнес-циклов? Есть ли какие-либо выбросы в данных, которые должны быть объяснены специалистами? Насколько сильны взаимосвязи между переменными, доступными для анализа? Для помощи в этом анализе были разработаны различные инструменты.
- Выбор и подгонка моделей. Выбор наилучшей модели зависит от наличия исторических данных, силы взаимосвязи между переменной прогноза и любыми независимыми переменными, а также от способа использования прогнозов. Обычно сравнивают две или три потенциальных модели. Каждая модель сама по себе является искусственной конструкцией, которая основана на наборе предположений (явных и неявных) и обычно включает один или несколько параметров, которые должны быть оценены с использованием известных исторических данных.
- Использование и оценка модели прогнозирования. После выбора модели и оценки ее параметров модель используется для составления прогнозов. Эффективность модели можно правильно оценить только после того, как станут доступны данные за прогнозный период. Был разработан ряд методов, помогающих оценить точность прогнозов. Существуют также организационные вопросы использования прогнозов и действий на их основе.
3. Графика временных рядов
Первое, что нужно сделать, — это импортировать данные. Обычно они имеют формат .csv. У них может быть столбец с датой и несколько столбцов для измеренных значений. При наличии нескольких выборок в наборе данных может быть столбец sample_id, и для каждого уникального идентификатора даты будут повторяться. Этот формат называется панельные данные.
Следующее, что нужно сделать в любой задаче анализа данных, — это построить график данных. Графики позволяют визуализировать многие особенности данных, включая закономерности, необычные наблюдения, изменения во времени и отношения между переменными. Затем особенности, которые видны на графиках данных, должны быть включены в максимально возможной степени в используемые методы прогнозирования. Так же, как тип данных определяет, какой метод прогнозирования использовать, он также определяет, какие графики подходят.
На графиках мы можем наблюдать несколько моделей временных рядов:
- Тенденция. Тенденция существует, когда наблюдается долгосрочное увеличение или уменьшение данных. Он не обязательно должен быть линейным. Иногда тенденцию называют «изменением направления», когда она может перейти от повышающейся тенденции к понижающейся.
- Сезонный. Сезонный характер возникает, когда на временной ряд влияют сезонные факторы, такие как время года или день недели. Сезонность всегда фиксированная и известная частота.
- Циклический. Цикл возникает, когда данные показывают рост и падение, которые не имеют фиксированной частоты. Если шаблоны не имеют фиксированных календарных частот, то они циклические. Потому что, в отличие от сезонности, на циклические эффекты обычно влияют бизнес и другие социально-экономические факторы.

- Ежемесячные продажи жилья (вверху слева) демонстрируют сильную сезонность в течение каждого года, а также сильную цикличность с периодом около 6–10 лет. В данных за этот период нет явной тенденции.
- Контракты казначейских векселей США (вверху справа) показывают результаты рынка Чикаго за 100 торговых дней подряд в 1981 году. Здесь нет сезонности, но есть очевидная тенденция к снижению. Возможно, если бы у нас был гораздо более длинный ряд, мы бы увидели, что этот нисходящий тренд на самом деле является частью длинного цикла, но если рассматривать его всего за 100 дней, он кажется трендом.
- Квартальное производство электроэнергии в Австралии (внизу слева) демонстрирует сильную тенденцию к увеличению с сильной сезонностью. Здесь нет никаких свидетельств какого-либо циклического поведения.
- Ежедневное изменение цены акций Google на момент закрытия (внизу справа) не имеет тенденции, сезонности или цикличности. Есть случайные колебания, которые не кажутся очень предсказуемыми, и нет сильных закономерностей, которые помогли бы разработать модель прогнозирования.
Б. Давайте кодировать, строить и учиться
Импорт библиотек
Импорт данных

Данные ежемесячные и есть две переменные. Один для температуры поверхности моря и один для солености морской поверхности.
1. График времени
Для данных временных рядов очевидный график, с которого следует начать, — это временной график. То есть наблюдения отображаются в зависимости от времени наблюдения, а последовательные наблюдения соединяются прямыми линиями.
На этих графиках мы видим:
- Странные значения, например выбросы и значения, которые необходимо объяснить, поскольку они отличаются от сезонности или тенденции.
- Периоды отсутствующих наблюдений.
- Колебания данных. Например, соленость колеблется в 2008 году.
- тренд, сезонность и цикличность. Например, температура имела сильную сезонность и не имела тенденций или цикличности.
В случае отсутствия наблюдений мы можем заполнить их различными способами, например:
- Обратная заливка
- Линейная интерполяция
- Квадратичная интерполяция
- Среднее значение ближайших соседей
- Среднее значение сезонных аналогов

Ежемесячные данные показывают некоторую сезонность в пределах каждого года. Нет ни циклического поведения, ни тренда.
2. Сезонные графики
Сезонный график аналогичен временному графику, за исключением того, что данные отображаются в зависимости от отдельных «сезонов», в которых наблюдались данные. Данные для каждого сезона перекрываются.

На сезонном графике мы сразу видим:
- Более отчетливо сезонный образец, если он существует.
- Определите годы, в которые картина меняется.
- Определите большие прыжки или падения.
На графиках тренда и сезонности мы видим:
- Более четко тренд и сезонность. Например, хотя мы могли бы сказать, что соленость имела сезонность из предыдущих графиков, теперь это более очевидно.
- Годы или месяцы с выбросами.
- Проще сравнивать годы или месяцы.
3. График сезонных подсерий
На альтернативном графике, подчеркивающем сезонные закономерности, данные для каждого сезона собираются вместе на отдельных мини-графиках.

Он выполняет группировку, чтобы более четко видеть месяцы сезонности.
4. Компоненты временных рядов
Данные временных рядов могут отображать множество шаблонов, и часто бывает полезно разделить временной ряд на несколько компонентов, каждый из которых представляет основную категорию шаблонов. Когда мы разбиваем временной ряд на компоненты, мы обычно объединяем тренд и цикл в один компонент тренд-цикл (иногда для простоты называемый трендом). Таким образом, мы думаем о временном ряду, состоящем из трех компонентов: компонента цикла тренда, сезонного компонента и компонента остатка (содержащего все остальное во временном ряду).
Если мы предполагаем аддитивное разложение, то мы можем написать

, где yₜ — данные, Sₜ — сезонная составляющая, Tₜ — составляющая цикла тренда, а Rₜ — составляющая остатка, все в периоде t. В качестве альтернативы мультипликативное разложение можно было бы записать как

Аддитивная декомпозиция является наиболее подходящей, если величина сезонных колебаний или вариация вокруг цикла тренда не меняется в зависимости от уровня временного ряда. Другими словами, мы применяем аддитивную модель, когда кажется, что тренд более линейный, а сезонность и компоненты тренда кажутся постоянными во времени. Когда вариация в сезонном паттерне или вариация вокруг цикла тренда оказывается пропорциональной уровню временного ряда, тогда более подходящим является мультипликативное разложение. Другими словами, мультипликативная модель более уместна, когда мы увеличиваем (или убываем) с нелинейной скоростью. Мультипликативное разложение является обычным для экономических временных рядов. Это разложение называется разложением ETS (ошибка / тренд / сезонность).

Построение всех этих цифр вместе дает мгновенное представление о данных.
Я надеюсь, что эта статья помогла вам в начале (или нет) вашего путешествия во времени и сериалах.
Перейдите к Части 2, чтобы узнать о стационарности, автокорреляции, графике разброса запаздывания, простом скользящем среднем, экспоненциально взвешенном скользящем среднем, двойном и тройном экспоненциальном сглаживании.
Справка: Большое спасибо замечательному udemy course за введение в Анализ временных рядов!
Тренд, сезонность и цикл
Основными составляющими временного ряда являются тренд и сезонная компонента. Составляющие этих рядов могут представлять собой либо тренд, либо сезонную компоненту.
Тренд является систематической компонентой временного ряда, которая может изменяться во времени.
Трендом называют неслучайную функцию, которая формируется под действием общих или долговременных тенденций, влияющих на временной ряд.
Примером тенденции может выступать, например, фактор роста исследуемого рынка.
Автоматического способа обнаружения трендов во временных рядах не существует. Но если временной ряд включает монотонный тренд (т.е. отмечено его устойчивое возрастание или устойчивое убывание), анализировать временной ряд в большинстве случаев нетрудно.
Существует большое разнообразие постановок задач прогнозирования, которое можно подразделить на две группы [24]: прогнозирование односерийных рядов и прогнозирование мультисерийных, или взаимовлияющих, рядов.
Группа прогнозирования односерийных рядов включает задачи построения прогноза одной переменной по ретроспективным данным только этой переменной, без учета влияния других переменных и факторов.
Группа прогнозирования мультисерийных, или взаимовлияющих, рядов включает задачи анализа, где необходимо учитывать взаимовлияющие факторы на одну или несколько переменных.
Кроме деления на классы по односерийности и многосерийности, ряды также бывают сезонными и несезонными.
Последнее деление подразумевает наличие или отсутствие у временного ряда такой составляющей как сезонность, т.е. включение сезонной компоненты.
Сезонная составляющая временного ряда является периодически повторяющейся компонентой временного ряда.
Свойство сезонности означает, что через примерно равные промежутки времени форма кривой, которая описывает поведение зависимой переменной, повторяет свои характерные очертания.
Свойство сезонности важно при определении количества ретроспективных данных, которые будут использоваться для прогнозирования.
Рассмотрим простой пример. На рис. 6.2. приведен фрагмент ряда, который иллюстрирует поведение переменной «объемы продажи товара Х» за период, составляющий один месяц. При изучении кривой, приведенной на рисунке, аналитик не может сделать предположений относительно повторяемости формы кривой через равные промежутки времени.

Рис.
6.2.
Фрагмент временного ряда за сезонный период
Однако при рассмотрении более продолжительного ряда (за 12 месяцев), изображенного на рис. 6.3, можно увидеть явное наличие сезонной компоненты. Следовательно, о сезонности продаж можно говорить только, когда рассматриваются данные за несколько месяцев.

Рис.
6.3.
Фрагмент временного ряда из 12-ти сезонных периодов
Таким образом, в процессе подготовки данных для прогнозирования аналитику следует определить, обладает ли ряд, который он анализирует, свойством сезонности.
Определение наличия компоненты сезонности необходимо для того, чтобы входная информация обладала свойством репрезентативности.
Ряд можно считать несезонным, если при рассмотрении его внешнего вида нельзя сделать предположений о повторяемости формы кривой через равные промежутки времени.
Иногда по внешнему виду кривой ряда нельзя определить, является он сезонным или нет.
Существует понятие сезонного мультиряда. В нем каждый ряд описывает поведение факторов, которые влияют на зависимую (целевую) переменную.
Пример такого ряда — ряды продаж нескольких товаров, подверженных сезонным колебаниям.
При сборе данных и выборе факторов для решения задачи по прогнозированию в таких случаях следует учитывать, что влияние объемов продаж товаров друг на друга здесь намного меньше, чем воздействие фактора сезонности.
Важно не путать понятия сезонной компоненты ряда и сезонов природы. Несмотря на близость их звучания, эти понятия разнятся. Так, например, объемы продаж мороженого летом намного больше, чем в другие сезоны, однако это является тенденцией спроса на данный товар.
Очень часто тренд и сезонность присутствуют во временном ряде одновременно.
Пример. Прибыль фирмы растет на протяжении нескольких лет (т.е. во временном ряде присутствует тренд ); ряд также содержит сезонную компоненту.
Отличия циклической компоненты от сезонной:
- Продолжительность цикла, как правило, больше, чем один сезонный период;
- Циклы, в отличие от сезонных периодов, не имеют определенной продолжительности.
При выполнении каких-либо преобразований понять природу временного ряда значительно проще, такими преобразованиями могут быть, например, удаление тренда и сглаживание ряда.
Перед началом прогнозирования необходимо ответить на следующие вопросы:
- Что нужно прогнозировать?
- В каких временных элементах (параметрах)?
- С какой точностью прогноза?
При ответе на первый вопрос, мы определяем переменные, которые будут прогнозироваться. Это может быть, например, уровень производства конкретного вида продукции в следующем квартале, прогноз суммы продажи этой продукции и т.д.
При выборе переменных следует учитывать доступность ретроспективных данных, предпочтения лиц, принимающих решения, окончательную стоимость Data Mining.
Часто при решении задач прогнозирования возникает необходимость предсказания не самой переменной, а изменений ее значений.
Второй вопрос при решении задачи прогнозирования — определение следующих параметров:
- периода прогнозирования ;
- горизонта прогнозирования ;
- интервала прогнозирования.
Период прогнозирования — основная единица времени, на которую делается прогноз.
Например, мы хотим узнать доход компании через месяц. Период прогнозирования для этой задачи — месяц.
Горизонт прогнозирования — это число периодов в будущем, которые покрывает прогноз.
Если мы хотим узнать прогноз на 12 месяцев вперед с данными по каждому месяцу, то период прогнозирования в этой задаче — месяц, горизонт прогнозирования — 12 месяцев.
Интервал прогнозирования — частота, с которой делается новый прогноз.
Интервал прогнозирования может совпадать с периодом прогнозирования.
Рекомендации по выбору параметров прогнозирования.
При выборе параметров необходимо учитывать, что горизонт прогнозирования должен быть не меньше, чем время, которое необходимо для реализации решения, принятого на основе этого прогноза. Только в этом случае прогнозирование будет иметь смысл.
С увеличением горизонта прогнозирования точность прогноза, как правило, снижается, а с уменьшением горизонта — повышается.
Мы можем улучшить качество прогнозирования, уменьшая время, необходимое на реализацию решения, для которого реализуется прогноз, и, следовательно, уменьшив при этом горизонт и ошибку прогнозирования.
При выборе интервала прогнозирования следует выбирать между двумя рисками: вовремя не определить изменения в анализируемом процессе и высокой стоимостью прогноза. При длительном интервале прогнозирования возникает риск не идентифицировать изменения, произошедшие в процессе, при коротком — возрастают издержки на прогнозирование.
При выборе интервала необходимо также учитывать стабильность анализируемого процесса и стоимость проведения прогноза.