21.11.2021 | Категория Информационная безопасность
Дисклеймер: Мы не несем ответственность за Ваши действия и не призываем Вас к каким-либо действиям! Все материалы взяты с открытых источников, опубликованы для образовательных целей.
Оглавление
- Широковещательный шторм в состоянии петли
- Методы предотвращения
- Создание широковещательного шторма (петли)
- LLMNR
- Анализ последствий
1. Широковещательный шторм в состоянии петли
Петля (или кольцо) в локальной сети — это ситуация, при которой часть информации от коммутатора не рассылается по компьютерам, а кочует по двум параллельным маршрутам, как бы замыкающимся в кольцо.
Данные при этом бесконечно кружатся по этому кольцу, постепенно увеличиваясь в размерах и забивая весь канал. Петля является крайне неприятным явлением для локальной сети или её отдельного участка и требует немедленного решения.
Для большего понимания простейшая схема петли представлена ниже.
Компьютер ПК-1 отправляет кадр (frame) по сети через коммутатор компьютеру ПК-N. Коммутатор получает кадр и в таблицу коммутации заносит адрес компьютера ПК-1 с портом. Коммутатор не знает где расположен порт получателя кадра, кроме порта, из которого этот кадр был получен.
Соответственно, кадр получает ПК-N и получает виртуальный коммутатор GNS3 (далее будет подробно показано, как реализовать виртуальную сеть с помощью GNS3). Виртуальный коммутатор GNS3, который расположен в ПК-N, производит аналогичные действия.
Компьютеры расположенные в локальной сети получают несколько кадров — один от коммутатора локальной сети, другой от виртуального коммутатора. Одновременно с этим, копию кадра от коммутатора локальной сети получает виртуальный коммутатор GNS3.
Так как для виртуального коммутатора копия является “новым” кадром, то он производит стандартный процесс коммутации кадра. Тем самым происходит бесконечное циркулирование кадра между сегментами сети.
2. Методы предотвращения
Единственной возможностью прекратить циркулирование фрейма между сегментами сети является выключение одного из каналов связи между ними. Данную функцию реализует протокол STP, который оставляет между сегментами только один возможный канал связи между сегментами сети.
3. Создание широковещательного шторма (петли)
Рассмотрим проблему создания петли в сетевом программном эмуляторе GNS3. GNS3 позволяет комбинировать виртуальные и реальные устройства, используемые для моделирования сложных сетей.
Он использует программное обеспечение эмуляции Dynamips для имитации Cisco IOS. Для создания петли воспользуемся одним из способов подключения GNS3 к реальной физической сети.
Этот способ возможен, если компьютер подключен к коммутатору (к локальной сети). Схема изображена на рисунке 3.

- Рис. 3 Схема соединения 2 хостов и 1 коммутатора
- У хостов в качестве интерфейса указываем “nio_gen_eth:Ethernet N”.

Перед этим проведем анализ трафика в сети с помощью ПО Wireshark (рис. 3).

Рис.4 Анализ трафика в сети с помощью Wireshark
В среднем в сети проходит 5-10 пакетов в секунду. Основной пакет — это LLMNR, который в последствии будет являться причиной нарушения работоспособности коммутатора. Сначала стоит разобрать сам протокол LLMNR.
4. LLMNR
LLMNR, англ. Link-Local Multicast Name Resolution — протокол стека TCP/IP, основанный на формате пакета данных DNS, который позволяет компьютерам выполнять разрешение имен хостов в локальной сети.
Для LLMNR выделены порты 5355/UDP и 5355/TCP, в IPv4 выделен широковещательный адрес 224.0.0.
252 и MAC-адрес 01-00-5E-00-00-FC, в IPv6 — FF02:0:0:0:0:0:1:3 (сокращённая запись — FF02::1:3) и MAC-адрес 33-33-00-01-00-03.
![]()
Рис. 5 Структура заголовка пакета LLMNR
Служба LLMNR (Link-Local Multicast Name Resolution) позволяет организовать одноранговое разрешение имен в пределах одной подсети для IPv4, IPv6 или обоих видов адресов сразу без обращения к серверам, на что не способны ни DNS, ни WINS. WINS предоставляет как клиент-серверную, так и одноранговую службу разрешения имен, но не поддерживает адреса IPv6.
DNS, с другой стороны, поддерживает оба тина адресов, но требует наличия серверов. Разрешение имен LLMNR, работает для адресов IPv6 и IPv4 в тех случаях, когда другие службы разрешения имен недоступны, например, в домашних сетях, в небольших предприятиях, во временных сетях или корпоративных сетях, где по каким-то причинам недоступны DNS-службы.
Поскольку трафик LLMNR не проходит через маршрутизаторы, вы не рискуете случайно заполнить им сеть.Как и WINS, LLMNR позволяет преобразовать имя хоста в IP-адрес. По умолчанию LLMNR включен на всех компьютерах под управлением Windows. Эти компьютеры прибегают к LLMNR, если попытки узнать имя хоста через DNS окончились неудачей.
В результате, разрешение имен в Windows работает следующим образом:
- Хост посылает запрос на первичный DNS-сервер. Если он не получает ответа или получает сообщение об ошибке, он по очереди посылает запросы на все вторичные DNS-серверы. Если и это не помогло, разрешение имени передается LLMNR.
- Хост посылает многоадресный UDP-запрос, запрашивая IP-адрес для нужного имени компьютера. Этот запрос идет только по локальной подсети.
- Каждый компьютер локальной подсети, поддерживающий LLMNR и сконфигурированный для ответа на поступающие запросы, сравнивает имя со своим хост-именем. Если они не совпадают, компьютер отбрасывает запрос. Если имена совпадают, компьютер пересылает исходному хосту одноадресное сообщение с ІР-адресом.
5. Анализ последствий
Компьютеры с LLMNR должны проверять уникальность своих имен в подсети.
В большинстве случаев это происходит при запуске, восстановлении из спящего режима или при смене параметров сетевого интерфейса.
Если компьютер еще не проверил уникальность своего имени, он должен указывать это в ответе на запрос. После создания петли в GNS3 (рис. 3), увидим некоторые особенности в Wireshark (рис. 6).

После создании петли сразу же в сети наблюдается рост количества пакетов к экспоненциальному росту их числа и парализует работу сети. Это состояние в сети называется широковещательный шторм. Широковещательный шторм — лавина широковещательных пакетов (на втором уровне модели OSI — кадров).
Считается нормальным, если широковещательные пакеты составляют не более 10 % от общего числа пакетов в сети.Довольно часто к широковещательному шторму приводят петли в сети при неправильной настройке канального протокола Spanning Tree. Spanning Tree Protocol (STP) — канальный протокол.
Основной задачей STP является устранение петель в топологии произвольной сети Ethernet, в которой есть один или более сетевых мостов, связанных избыточными соединениями.
STP решает эту задачу, автоматически блокируя соединения, которые в данный момент для полной связности коммутаторов являются избыточными.
Рассмотрим, создадим и заюзаем аппаратную петлю на порте коммутатора
Если взять кусок патч-корда и воткнуть оба хвоста в один коммутатор, то получится петля. И в целом петля на порте коммутатора или сетевой карты — зло. Но если постараться, то и этому явлению можно найти полезное применение, например сделать сигнализацию с тревожной кнопкой.
INFO
- Rx и Tx — обозначения Receive и Transmit на схемах (приём и передача).
- Loop — англ. петля, контур, шлейф, виток, спираль.
Типичная сеть состоит из узлов, соединенных средой передачи данных и специализированным сетевым оборудованием, таким как маршрутизаторы, концентраторы или коммутаторы.
Все эти компоненты сети, работая вместе, позволяют пользователям пересылать данные с одного компьютера на другой, возможно в другую часть света.
Коммутаторы являются основными компонентами большинства проводных сетей. Управляемые коммутаторы делят сеть на отдельные логические подсети, ограничивают доступ из одной подсети в другую и устраняют ошибки в сети (коллизии).
Петли, штормы и порты — это не только морские термины. Петлей называют ситуацию, когда устройство получает тот же самый сигнал, который отправляет.
Представь, что устройство «кричит» себе в порт: «Я здесь!» — слушает и получает в ответ: «Я здесь!».
Оно по-детски наивно радуется: есть соседи! Потом оно кричит: «Привет! Лови пакет данных!» — «Поймал?» — «Поймал!» — «И ты лови пакет данных! Поймал?» — «Конечно, дружище!»
Вот такой сумасшедший разговор с самим собой может начаться из-за петли на порте коммутатора.
Такого быть не должно, но на практике петли по ошибке или недосмотру возникают сплошь и рядом, особенно при построении крупных сетей.
Кто-нибудь неверно прописал марштуры и хосты на соседних коммутаторах, и вот уже пакет вернулся обратно и зациклил устройство. Все коммутаторы в сети, через которые летают пакеты данных, начинает штормить.
Такое явление называется широковещательным штормом (broadcast storm).
Меня удивил случай, когда установщик цифрового телевидения вот так подсоединил патч-корд (рис. 1). «Куда-то же он должен быть воткнут…» — беспомощно лепетал он.
 Рис. 1. Синий свитч с петлей на борту
Рис. 1. Синий свитч с петлей на борту
Другие статьи в выпуске: 
- Содержание выпуска
- Подписка на «Хакер»-60%
Однако не всё так страшно. Почти в каждом приличном коммутаторе есть функция loop_detection, которая защищает устройство и его порт от перегрузок в случае возникновения петли.
Настраиваем коммутаторы
Перед тем как начинать настройку, необходимо установить физическое соединение между коммутатором и рабочей станцией.
Существует два типа кабельных соединений для управления коммутатором: соединение через консольный порт (если он имеется у устройства) и через порт Ethernet (по протоколу Telnet или через web-интерфейс).
Консольный порт используется для первоначального конфигурирования коммутатора и обычно не требует настройки.
Для того чтобы получить доступ к коммутатору через порт Ethernet, устройству необходимо назначить IP-адрес.
Web-интерфейс является альтернативой командной строке и отображает в режиме реального времени подробную информацию о состоянии портов, модулей, их типе и т. д. Как правило, web-интерфейс живет на 80 HTTP-порте IP-коммутатора.
Настройка DLink DES-3200
Для того чтобы подключиться к НТТР-серверу, необходимо выполнить перечисленные ниже действия с использованием интерфейса командной строки.
- Назначить коммутатору IP-адрес из диапазона адресов твоей сети с помощью следующей команды:
DES-3200# config ipif System
ipaddress xxx.xxx.xxx.xxx/yyy.yyy.yyy.yyy.Здесь xxx.xxx.xxx.xxx — IP-адрес, yyy.yyy.yyy.yyy. — маска подсети.
- Проверить, правильно ли задан IP-адрес коммутатора, с помощью следующей команды:
DES-3200# show ipif - Запустить на рабочей станции web-браузер и ввести в его командной строке IP- адрес коммутатора.
Управляемые коммутаторы D-Link имеют консольный порт, который с помощью кабеля RS-232, входящего в комплект поставки, подключается к последовательному порту компьютера. Подключение по консоли иногда называют подключением Out-of-Band. Его можно использовать для установки коммутатора и управления им, даже если нет подключения к сети.
После подключения к консольному порту следует запустить эмулятор терминала (например, программу HyperTerminal в Windows). В программе необходимо задать следующие параметры:
Baud rate: 9,600
Data width: 8 bits
Parity: none
Stop bits: 1
Flow Control: none
При соединении коммутатора с консолью появится окно командной строки. Если оно не появилось, нажми Ctrl+r , чтобы обновить окно.
Коммутатор предложит ввести пароль. Первоначально имя пользователя и пароль не заданы, поэтому смело жми клавишу Enter два раза. После этого в командной строке появится приглашение, например DES-3200#. Теперь можно вводить команды.
Команды бывают сложными, многоуровневыми, с множеством параметров, и простыми, для которых требуется всего один параметр.Введи «?» в командной строке, чтобы вывести на экран список всех команд данного уровня или узнать параметры команды.
Например, если надо узнать синтаксис команды config, введи в командной строке:
DES-3200#config + пробел
Далее можно ввести «?» или нажать кнопку Enter. На экране появится список всех возможных способов завершения команды. Лично я для вывода этого списка на экран пользуюсь клавишей TAB.
 Loopback-тест
Loopback-тест
Базовая конфигурация коммутатора
При создании конфигурации коммутатора прежде всего необходимо обеспечить защиту от доступа к нему неавторизованных пользователей.
Самый простой способ обеспечения безопасности — создание учетных записей для пользователей с соответствующими правами. Для учетной записи пользователя можно задать один из двух уровней привилегий: Admin или User.
Учетная запись Admin имеет наивысший уровень привилегий. Создать учетную запись пользователя можно с помощью следующих команд CLI:
DES-3200# create account admin/user
(знак «/» означает ввод одного из двух параметров)
После этого на экране появится приглашение для ввода пароля и его подтверждения: «Enter a case-sensitive new password». Максимальная длина имени пользователя и пароля составляет 15 символов. После успешного создания учетной записи на экране появится слово Success. Ниже приведен пример создания учетной записи с уровнем привилегий Admin:
Username «dlink»:
DES-3200#create account admin dlink
Command: create account admin dlink
Enter a case-sensitive new password:****
Enter the new password again for confirmation:****
Success.
DES-3200#
Изменить пароль для существующей учетной записи пользователя можно с помощью следующей команды: DES-3200# config account Ниже приведен пример установки нового пароля для учетной записи dlink:
DES-3200#config account dlink
Command: config account dlink
Enter a old password:****
Enter a case-sensitive new password:****
Enter the new password again for confirmation:****
Success.
Проверка созданной учетной записи выполняется с помощью следующей команды: DES-3200# show account. Для удаления учетной записи используется команда delete account .
Шаг второй. Чтобы коммутатором можно было удаленно управлять через web-интерфейс или Telnet, коммутатору необходимо назначить IP-адрес из адресного пространства сети, в которой планируется использовать устройство. IP-адрес задается автоматически с помощью протоколов DHCP или BOOTP или статически с помощью следующих команд CLI:
DES-3200# config ipif System dhcp,
DES-3200# config ipif System ipaddress
xxx.xxx.xxx.xxx/yyy.yyy.yyy.yyy.
Здесь xxx.xxx.xxx.xxx — IP-адрес, yyy.yyy.yyy.yyy. — маска подсети, System — имя управляющего интерфейса коммутатора.
Шаг третий. Теперь нужно настроить параметры портов коммутатора. По умолчанию порты всех коммутаторов D-Link поддерживают автоматическое определение скорости и режима работы (дуплекса). Но иногда автоопределение производится некорректно, в результате чего требуется устанавливать скорость и режим вручную.
Для установки параметров портов на коммутаторе D-Link служит команда config ports. Ниже я привел пример, в котором показано, как установить скорость 10 Мбит/с, дуплексный режим работы и состояние для портов коммутатора 1–3 и перевести их в режим обучения.
DES-3200#config ports 1-3 speed 10_full learning
enable state enable
Command: config ports 1-3 speed 10_full learning
enable state enable
Success
Команда show ports выводит на экран информацию о настройках портов коммутатора.
Шаг четвертый. Сохранение текущей конфигурации коммутатора в энергонезависимой памяти NVRAM. Для этого необходимо выполнить команду save:
DES-3200#save
Command: save
Saving all settings to NV-RAM… 100%
done.
DES-3200#
Шаг пятый. Перезагрузка коммутатора с помощью команды reboot:
DES-3200#reboot
Command: reboot
Будь внимателен! Восстановление заводских настроек коммутатора выполняется с помощью команды reset.
DES-3200#reset config
А то я знал одного горе-админа, который перезагружал коммутаторы командой reset, тем самым стирая все настройки.
loop_detection для коммутаторов Alcatel
interface range ethernet e(1-24)
loopback-detection enable
exit
loopback-detection enable
loop_detection для коммутаторов Dlink
enable loopdetect
config loopdetect recover_timer 1800
config loopdetect interval 1
config loopdetect mode port-based
config loopdetect trap none
config loopdetect ports 1-24 state enabled
config loopdetect ports 25-26 state disabled
Грамотный админ обязательно установит на каждом порте соответствующую защиту.
Но сегодня мы хотим применить loopback во благо. У такого включения есть замечательное свойство. Если на порте коммутатора имеется петля, устройство считает, что к нему что-то подключено, и переходит в UP-состояние, или, как еще говорят, «порт поднимается». Вот эта-то фишка нам с тобой и нужна.
Loopback
Loop — это аппаратный или программный метод, который позволяет направлять полученный сигнал или данные обратно отправителю. На этом методе основан тест, который называется loopback-тест.
Для его выполнения необходимо соединить выход устройства с его же входом. Смотри фото «loopback-тест».
Если устройство получает свой собственный сигнал обратно, это означает, что цепь функционирует, то есть приемник, передатчик и линия связи исправны.
Устраиваем аппаратную петлю
Устроить обратную связь очень просто: соединяется канал приема и передачи, вход с выходом (Rx и Tx).
 Таблица 1. Распиновка RJ45
Таблица 1. Распиновка RJ45
Обожми один конец кабеля стандартно, а при обжиме второго замкни жилы 2 и 6, а также 1 и 3. Если жилы имеют стандартную расцветку, надо замкнуть оранжевую с зеленой, а бело-оранжевую с бело-зеленой. Смотри рис. 3.
 Нумерация контактов RJ-45
Нумерация контактов RJ-45
Теперь, если воткнешь такой «хвостик» в порт коммутатора или в свою же сетевую карту, загорится зелёненький сигнал link. Ура! Порт определил наше «устройство»!
Красная кнопка, или Hello world
Ну куда же без Hello world? Каждый должен хоть раз в жизни вывести эти слова на экран монитора! Сейчас мы с тобой напишем простейший обработчик событий, который будет срабатывать при замыкании красной кнопки. Для этого нам понадобятся только кнопка с двумя парами контактов, работающих на замыкание, витая пара и коннектор. На всякий случай приведу схему красной кнопки (рис. 4).
 Схема красной кнопки
Схема красной кнопки
Паяльник в руках держать умеешь? Соединяем так, чтобы одна пара контактов замыкала оранжевую жилу с зеленой, а другая — бело-оранжевую с бело-зеленой. На всяких случай прозвони соединение мультиметром.
Все, теперь можно тестировать. Вставь обжатую часть в порт сетевой карты или в порт коммутатора. Ничего не произошло? Хорошо. Нажми кнопку. Линк поднялся? Замечательно!
 Сама красная кнопка
Сама красная кнопка
Вот листинг простейшего обработчика Hello World на Cshell:
Скрипт на Cshell, генерящий Hello word
#!/bin/csh
# ver. 1.0
# Проверяем, запущен ли процесс в памяти
if ( ‘ps | grep ‘redbut’ | grep -v ‘grep’ | wc -l’
Реально ли найти петлю в локальной сети из неуправляемых коммутаторов?
Локальные сети, построенные в конце 90-х уже, конечно, изжили себя. Однако, их модернизация или полное обновление в некоторых ситуациях просто физически невозможно или финансово нецелесообразно — не позволяет планировка здания, реже — топология сети.
Часто проблемой с «петлей» страдают именно такие сети, которые еще можно встретить с студенческих общежитиях. Так как цены на ремонт или перепланировку общежития на голову выше цены ремонт квартиры. Речь идет не о косметическом ремонте, от которого толку, в общем-то, будет мало.
А капитальный ремонт в текущих реалиях непостижимая цель для наших МОУ.
Для начала разберемся, что же такое петля.
Петля — это правильно не завершенная передача пакета (сигнала), т.е. получатель, которому был адресован пакет его не получает. Так продолжается бесконечно, т.к. пакет маршрутизируется «по кругу» возвращаясь опять в коммутатор, с которого был отправлен. Таким образом эфир засоряется таким безадресным трафиком, который, в свою очередь, мешает прохождению
Cisco тоже делает неуправляемые коммутаторы

Хорошо, если ядро сети построено на хорошем управляемом коммутаторе, вроде Mikrotik, который сообщит (в логах) на каком интерфейсе появилась петля. Есть две основные причины появления петли — сбойный свитч, либо неверно настроенное абонентское устройство, подключенное в общую сеть (например, DHCP-сервер на роутере, использующий широковещательные пакеты). А теперь плохие новости:
В сети, построенной на неуправляемых свитчах, определить местонахождение петли ни аппаратными, ни программными средствами, нельзя!
Знаменитый MikroTik RB951G-2HnD

Единственное, что может помочь — визуальный осмотр всех свитчей в сети. Зачастую проблемное устройство выдает беспорядочная, взбесившаяся индикация на всех портах, но далеко не факт, что это не полезный трафик. «Защиты от дураков» без костылей, в общем-то нет, даже если вы привяжете мак-адрес сетевых карт к IP-адресу, который выставите вручную — это не спасёт от широковещательного запроса.
Решение проблемы простое — стоит обратить свой взор на управляемые свитчи, на которых можно резать ненужный трафик.
Коммутаторы Маршрутизация
Петля в локальной сети: что такое и как найти
Петля (или кольцо) в локальной сети это ситуация, при которой часть информации от коммутатора не рассылается по компьютерам, а кочует по двум параллельным маршрутам, как бы замыкающимся в кольцо. Данные при этом бесконечно кружатся по этому кольцу, постепенно увеличиваясь в размерах и забивая весь канал.
Петля является крайне неприятным явлением для локальной сети или её отдельного участка и требует немедленного решения. Для большего понимания простейшая схема петли представлена ниже.
 Пример петли в локальной сети
Пример петли в локальной сети
С петлей мне пришлось столкнуться в одной средней размеров конторе по долгу службы. Офис там располагался в видавшем виде здании, по-моему, даже частично или полностью деревянном. Сетевое оборудование было соответствующее, поэтому, когда в один не слишком добрый понедельник мне заявили о медленном Интернете, я, поначалу, не придал этому особого значения. Затем отвалились и Интернет, и 1С.
Поняв, что проблема, скорее всего, в неисправности коммутатора или кольце, я отправился в коммутационную. Там меня ждали три неуправляемых D-Link’а (это не оскорбление, а вполне себе термин для коммутатора).
Поначалу я всё же думал на неисправность коммутатора (тем более, что есть у меня субъективное недоверие к D-link). Количество портов трех 24-портовых коммутаторов для небольшого офиса на 10-15 машин было излишним, и оставалось еще от старых-добрых времен, когда компов в сетке было больше.
Для вычисления виновника я по очереди выключал коммутаторы, и смотрел как на это отреагирует сеть. После нахождения нужного мне свича, все пользователи были переведены на оставшиеся два коммутатора, а я стал думать как вычислить нужный мне порт, ведь неисправен мог быть не весь коммутатор.
Тогда ко мне и закралась мысль о кольце.
Первым делом я стал проверять, не может ли быть так, что один и тот же патч-корд воткнут обоими концами в один свич. Мне повезло, и такой кабель действительно был. Это вполне могло быть «подарком» предыдущего админа, чем-то не сошедшегося с руководством. Во всяком случае, вряд ли бы кто-то полез к свичам случайно.
Если бы кольцо не было таким явным, мне пришлось бы помучиться. Дело в том, что я выключил коммутатор, и повторного появления кольца нужно было бы подождать. Потом пришлось бы доставать из портов патч-корды и смотреть на реакцию сети. В целом, всё равно всё свелось бы к схеме, нарисованной выше, с её сетевыми розетками и патч-панелями.
Итак, несколько советов как вычислить петлю в локальной сети:
- Локализуйте проблему. Падает вся сеть или отдельный участок? Если у одного отдела сеть есть, а у другого нет, то проверяйте коммутатор, раздающий сеть на тот отдел.
- Какой тип коммутатора(-ов) используется? Это может быть управляемый коммутатор или неуправляемый. В проблемном участке может быть и смесь из обоих вариантов. В случае с неуправляемым коммутатором придется вычислять проблемный порт методом научного тыка. В управляемом коммутаторе порты можно закрыть через веб-интерфейс.
- Проверьте кабели. Скорее всего, дело всё-таки в физическом закольцевании сети. Но может «сдуреть» отдельно взятый порт в коммутаторе или сетевой плате компьютера. Редко, но может встретиться ситуация с дублированием функций DHCP-сервера, когда устройство (роутер, коммутатор или компьютер), которое этого делать не должно, раздаёт остальным некорректные настройки сети. В таком случае выключите DHCP-сервер и попробуйте получить адрес с какого-либо компьютера в проблемном участке сети. Если опасения подтвердились — проверяйте устройства на предмет включения функции DHCP-сервера. В первую очередь, конечно, роутеры и коммутаторы.
На этом, пожалуй, всё, что нужно знать о тактике борьбы с петлями в локальных сетях. Напоследок еще можно дать совет — пользуйтесь управляемым оборудованием. Это существенно облегчает труд системного администратора и позволяет решать ряд проблем, вообще не вставая из-за стола.
Как найти петлю в локальной сети и как её оперативно устранить
Сетевая петля — на самом деле, опасная штука. Очень часто ее появление связано с неправильным подсоединением линков маршрутизаторов или коммутаторов. Реже она случается из-за неверных настроек маршрутного адреса.
Как найти такую петлю, мы разберем чуть ниже. Но в целом предугадывать возникновение таких петель не получается. Ее наличие становится видимым, уже когда проявляются признаки зацикливания или когда уже полностью «ложится» вся наша сеть.
Как образуется сетевая петля
Если посмотреть на принцип «сетевой петли», то для большего понимания скажем, что это когда пакет каких-либо данных долго блуждает по одному и тому же маршрутному кругу от коммутатора к коммутатору и никак не может достичь своего конечного получателя.
От этого случается перегрузка сети и она «ложится», так как становится просто перегруженной IP-пакетами, которые не перестают множиться из-за коммуникации между сетевыми устройствами.
Но пакеты не покидают маршрутную сеть, а блуждают внутри сетевой петли, так и образуется сетевой шторм.
Плюс, так как внутри локальной сети присутствует большое количество зациклившихся пакетов, то достаточно сильно снижается пропускающая способность всего канала связи. Но это тоже еще не все. Если у вас довольно большая сеть, то могут случиться проблемы и на других участках. Одна немного приятная новость, что возникшее зацикливание не вечно, жизнь самих сетевых пакетов ограничена по времени.
Как определить сетевую петлю по ее признакам
Чтобы найти сетевую петлю, нужно определить ее сначала по ее признакам. Благо, они четко определяемые и заметные. Для начала нужно закрепить 2 определения:
- TTL — это временное ограничение жизни сетевого пакета;
- IP ID — это и так понятно.
Любой сетевой пакет, пройдя через коммутатор в своем поле TTL, заполучает значение на одну единицу меньше. Так вот, очень уменьшенное значение TTL — это явный признак зацикленной локальной сети.
Потому что низкий TTL объясняется тем, что пакет проходил много раз через маршрутизатор, с каждым разом уменьшаясь. Его нормальное значение обычно не превышает 30.
Уменьшаясь до единицы в сетевой петле, он потом «погибает».
Сетевой широковещательный шторм — это еще один признак того, как найти петлю в локальной сети. По сути это наличие внутри сети большого количества сетевых пакетов с идентичным значениями IP ID. Иногда их количество может переваливать за тысячу.
Как найти сетевую петлю в локальной сети
Чтобы найти петлю в сети, можно воспользоваться анализатором сетевого трафика — сниффером. Его плюс, что он показывает не только имеющуюся петлю, но и все устройства, которые ее создали. Чтобы воспользоваться сниффером, нужно следовать определенным шагам:
- Первое, что нужно сделать, — это определить локальный участок, где происходит зацикливание. Определить нетрудно — там возникают проблемы с Интернетом.
- Подберите любой сниффер и можете его запускать для определения зацикленных устройств.
- Определите сетевые пакеты, создающие шторм, и отфильтруйте их. Найти их будет несложно — их огромное количество и у многих схожий ID IP.
Отдельным видом сетевой петли является физическое зацикливание сети. Простым языком — это когда в порты коммутатора подсоединяют два конца одного провода. В маленьких локальных сетях это, конечно, вряд ли может произойти, если проводов всего несколько, но в больших корпоративных сетях — легко.
Это может быть как ошибка монтажников, так и в процессе эксплуатации сети, кто-то из работяг-неспециалистов начудил.
И это может быть необязательно в самом коммутаторе, куда доступ ограничен, а просто, к примеру, один из офисных работников конец одного подключенного линка случайно или нет включил в другую интернет-розетку и вуаля — сетевая петля.
Как найти такую сетевую петлю в локальной сети, наверное, понятно. Нужно визуально осматривать все подключения. После того, конечно, как удастся локализовать проблемный участок.
Discovering Network Loops (Layer 2) with Wireshark
A network loop occurs when there is more than one path exists between the source and destination. Consider the figure below, in which two switches are connected to each other with multiple path. Imagine that Layer 2 loop prevention mechanism is not enabled or is broken on the switches somehow.
The broadcast or multicast frames created by any end point in the network will be received by the switches and flooded out of every port except the port that the frame was received on, creating a layer 2 loop between two switches.
Even if you disconnect every end point from the network, there will still be an infinite broadcast and multicast storm between both switches.
What is broadcast, multicast, unicast and how does it work?
In packet switching network, there are 3 types of frames; broadcast, multicast and unicast.
1. Broadcast Frame
Broadcast is the term used to describe communication where a frame is sent from one end point to all other end points at the same time. In this type of communication, there is only one sender that sends data frames to all connected receivers.
2. Multicast Frame
Multicast is the term used to describe communication where a frame is sent from one end point to one or multiple end points at the same time. In this type of communication, there is only one sender that sends data frame to one or multiple connected receivers.
3. Unicast Frame
Unicast is the term used to describe communication where a frame is sent from one end point to the only one end point. In this type of communication, there is only one sender that sends data frame to one connected receiver.
How does a switch know if a frame is broadcast, multicast or unicast?
It is all about how mac address format is designed. MAC address is 48 bits (6 bytes) unique identifier. Each byte is called an “octet”. See more details below.
source: https://en.wikipedia.org
The first 24 bits (3 bytes) of mac address is called organisationally Unique Identifier (OUI), which identifies a vendor, manufacturer, or other organization. See some OUI below.
- 00:12:1e: represents Juniper Networks.
- 00:19:06: represents Cisco Systems, Inc.
- 00:1d:60: represents ASUSTek COMPUTER INC.
- 52:54:00: represents Realtek.
- 08:00:27: represent PCS Systemtechnik GmbH.
ALSO READ: Configure and Test FreeRADIUS PAP & CHAP Authentication
Individual/Group (IG) bit is used to differentiate unicast frames from multicast frames. When the bit is set to zero (0), it means it is a unicast frame. When it is set to one (1), it means the frame is a multicast.
The bit is located in the most significant byte of mac address. In the figure above, “b0” is the IG bit.
When it comes to broadcast frames, a special mac address (FF-FF-FF-FF-FF-FF) is used to distinguish broadcast frames from the other traffics.
What are the reasons behind a network loop?
Network loops occur due to many reasons. The most common causes are below.
- Human error in cabling.
- Unidirectional link failure in a fiber cable.
- Buggy spanning tree.
- Buggy network devices (IP Phones).
As a network administrator, I mostly experience the first and last one.
For learning and testing purpose, the easiest way to create a loop is just disabling spanning tree on the switch and plugging network cable from one port to the other one. But it is a rare case in a network to have that kind of loop.
It happens only with hubs and dummy switches that do not run a spanning tree. A second method to easily create a loop is using buggy IP phones. Here is a list from Cisco: https://quickview.cloudapps.cisco.com/quickview/bug/CSCvd03371
ALSO READ: Analyze TLS and mTLS Authentication with Wireshark
If you have one of the phones in the list, you can create a loop. (I am sure there are some other models that have the bug but not listed there)
When you accidentally plug both PC Port cable and Network Port cable of the phone into the network switch, it’ll cause a network loop that brings down the network.
The reason is that the STP packet sent by the switch through the Network Port gets filtered by the phone.
Since the switch does not get the STP packet back through the PC Port, it will not block that port, leaving the network prone to a broadcast or multicast storm. In a short time, a loop occurs and the network goes down.
How to protect your network from loop?
It actually depends on what kind of equipment you have and what sort of loop prevention mechanisms it has. Protection method commonly used are below.
- Enabling Storm control
- Enabling Spanning Tree Protocol (STP, RSTP, MSTP, etc)
- Enabling the other proprietary loop prevention mechanism
Find a loop with Wireshark
Use “unicast / (broadcast +multicast)” formula which gives you a great idea. Let’s test it on my packets I captured during the loop. We will create a filter (eth.dst.lg == 0) that shows the packets contain IG bit of zero (0), which displays unicast packets. See the details below.
ALSO READ: 100% proven ways to find hidden endpoints [Tutorial]
Number of unicast packets is 510. The number of total packets is 1870829.
Broadcasts + multicast = total packets – unicasts = 1870829-510 = 1870319
As you see both in the screenshot and calculation, unicast packet ratio is pretty low which indicate that a loop has occurred. The number of broadcast and multicast packets can be found with this filter: (eth.dst.lg == 1 ) or (eth.addr == ff:ff:ff:ff:ff:ff)
Header Checksum or Identification fields in IP header can be used to check if a loop has happened.
Since every time both fields change for each packet, when you see multiple the same Header Checksum or Identification field in other packets, you can easily say there has been a loop. Remember that Header Checksum and Identification are 2 bytes fields.
Even if it is low, there is always a chance there would be a collision of the fields. Collision simply means that the same identifier or calculation to be assigned to the different packets.
- 1) Select a broadcast or multicast packet and go to IP header section.
- 2) Right click on the “Header Checksum” and a menu appears.
- 3) Click on “Apply as Colum”
4) Do the same steps for “Identification” filed too.
«Идеальный шторм» и как это лечится
Время на прочтение
7 мин
Количество просмотров 122K
Привет, Хабр!
Broadcast storm (широковещательный шторм) – это такой ночной кошмар сетевиков, когда в считанные секунды парализуется передача полезного трафика во всей сети ЦОД. Как это происходит и о чем надо было раньше думать – в нашем сегодняшнем посте.


Откуда есть пошла
Вначале была Ethernet, и не было в ней маршрутизации, и сейчас тоже нету, а посему приходится коммутатору отправлять пакеты данных во все порты – ну, чтобы наверняка. От адресата приходит ответ на определенный порт, коммутатор запоминает соответствие [порт — адресат] и следующая “посылка” отправляется уже не абы куда, а по памятным, так сказать, местам.
Если же ответа нет, а в момент отправки unknown unicast пара-тройка коммутаторов оказываются замкнуты в кольцо, посылка возвращается “отправителю”, который, понятно, снова забрасывает ее во все порты, поскольку ну а что ему еще делать. «Бесхозный» пакет данных опять возвращается и опять улетает. Каждый следующий виток “закольцованного” broadcast flood сопровождается экспоненциальным ростом количества пакетов в сегменте сети. Очень скоро эта лавина «забивает» полосу пропускания портов, на заднем плане красиво «вскипают» перегруженные процессоры коммутаторов – и ваша сеть превращается в памятник самой себе.
Причиной шторма может стать как хакерская атака, так и осечка вашего же инженера при настройке оборудования – или вовсе сбой протоколов. Иными словами, никто не застрахован.
Был такой случай
В 2009 году в сети одного из наших клиентов случился бродкастовый шторм, который мгновенно перекинулся к нам, парализовав работу всей сети передачи данных компании. Отвалились почта, телефония и интернет, система мониторинга «сошла с ума» – и стало невозможно даже локализовать «первоисточник». Полная перезагрузка коммутатора не помогла. Нам ничего не оставалось, кроме как последовательно отключать ВСЕ порты, клиентские и свои собственные… Такой вот «черный понедельник».
Как позже выяснилось, один из сотрудников клиента перепутал порты оборудования – и закольцевал свою топологию на уровне бродкастового домена. Бывает.
Понятно, что в группе риска здесь, в первую очередь, коммерческие ЦОДы: резервированное подключение для каждого клиента само по себе уже означает избыточность соединений между коммутаторами. Однако сетевикам корпоративных дата-центров я бы также не рекомендовал расслабляться: замкнуть по рассеянности пару коммутаторов друг на друга можно и в серверной.
Хорошая новость заключается в том, что при грамотной подготовке вы можете отделаться легким испугом там, где в противном случае получили бы простой сервиса.
С чего начать
Начните с сегментирования сети посредством VLAN: когда сеть разбита на мелкие изолированные сегменты (fault domain), шторм, “накрывший” один из участков, этим участком и ограничивается. Ну, в идеале. В действительности мощный шторм, увы, способен “вбрасывать” пакеты и в так называемые независимые виртуальные сети тоже.
По-хорошему здесь нужно отказаться от “закольцованных” VLAN как внутри собственной инфраструктуры, так и при подключении клиентов к сети (если речь о коммерческом ЦОД). Например, использовать протоколы FHRP и U-образную топологию на уровне доступа.

U-образная топология позволяет избежать закольцованности
В ряде случаев, впрочем, от «закольцованности» при всем желании никуда не деться. Скажем, необходимо развернуть отказоустойчивую (2N) инфраструктуру для заказчика с подключением к нашему облаку. Клиентские VLAN’ы здесь приходится «пробрасывать» внутри облачной инфраструктуры между всеми ESXi хостами кластера виртуализации, – то есть само решение подразумевает полное дублирование всех сетевых элементов.
Смотрим в картинку – видим кольцо.

Кольцевая топология возникает при полном резервировании каналов связи и инфраструктуры заказчика
Что делать, если вы – «властелин колец»
Делать можно разное, и у каждого варианта, как водится, — свои преимущества и издержки.
Вот, например, протокол RSTP (модификация SpanningTreeProtocol) умеет быстро – в пределах 6 секунд – находить и «разбивать» бродкастовые петли. Находит он их посредством обмена BPDU (Bridge Protocol Data Unit) сообщениями между коммутаторами, а “разбивает” блокировкой резервных линков. В случае проблем с основным каналом RTSP перестраивает топологию, используя резервный порт.
Хорошая в целом штука, но есть нюанс. Под каждый VLAN выделяется один RSTP-процесс, при этом количество процессов, в отличие от VLAN, сильно ограничено, и при резком росте числа VLAN’ов в рамках одной сетки процессов RSTP может банально не хватить. То есть для корпоративного дата-центра пойдет, а для коммерческого – с постоянно растущим числом клиентов (VLAN) – уже не очень.
На этот случай имеется MSTP – улучшенное и дополненное издание RSTP. Умеет объединять несколько VLAN в один STP процесс (instance), что в хорошем смысле слова сказывается на масштабируемости сети: “потолок” здесь составляет 4096 клиентов (максимальное число VLAN). MSTP также позволяет управлять трафиком, распределяя MST процессы между основным линком и резервным, и дает возможность при необходимости разгружать “загнавшиеся” коммутаторы. Однако с MST нужно уметь работать, то есть это плюс как минимум один недешевый умник в штат (что доступно не всем).

Протоколы RSTP и MST «разрывают» петлю, блокируя трафик по одному из каналов
Из проверенных альтернатив MSTP можем посоветовать FlexLinks от Cisco, который мы используем, когда на стороне клиента находится один коммутатор или стек под единым управлением. FlexLinks умеет резервировать линки коммутатора без применения STP, “назначая” в каждой паре портов основной и резервный. Используется на уровне доступа (access) при подключении оборудования разных компаний по принципу Looped Triangle в коммерческом ЦОД. Очень простой в плане настройки инструмент, что и само по себе приятно, и позволяет рассчитывать на бОльшую стабильность сервиса (по сравнению, например, с STP). Вы полюбите FlexLinks за мгновенное переключение на резервные линки и балансировку нагрузки по VLAN – а потом, возможно, разлюбите за возможность применять его исключительно в топологии Looped Triangle.

В топологии Looped Triangle можно добиться мгновенного переключения трафика между каналами в случае сбоя
Теперь отвлечемся от техники. Любите ли вы экономическую эффективность так же, как люблю ее я? Тогда вам будет интересно узнать, что и MST RSTP, и FlexLinks, блокируя резервные линки, фактически исключают половину портов из круговорота трафика в природе.
А вот решения, которые так не делают: Cisco VSS (Virtual Switch System), Nexus vPC (virtual port-channel), Juniper virtual router и другие mLAG-подобные (multichassis link aggregation) технологии. Хороши тем, что задействует все доступные линки, объединяя их в один логический канал EtherChannel. Получается своего рода коммутирующий кластер, в котором модуль управления одного из коммутаторов (Control-plane) “рулит” всеми линками кластера (Data-Plane). В случае выхода текущего Control-plane из строя его полномочия автоматически передаются “оставшемуся в живых”. Мы используем Cisco Nexus vPC для балансировки нагрузки между линками клиентов, у которых по одному коммутатору или стеку. Если же на стороне клиента два отдельных коммутатора, связанных общим VLAN, добавляем в схему STP.

Объединение линков в один логический канал решает проблему со штормами и не сказывается на производительности
Если у вас облака
Виртуализация, катастрофоустойчивые облачные сервисы, распределенные между дата-центрами, и прочие кластерные решения – все это требует несколько иного подхода к организации Layer 2 сети. Убираем STP на антресоли – достаем TRILL.
TRILL использует механизм маршрутизации на Ethernet-уровне и сама строит свободный от петель путь для бродкастового трафика, тем самым предотвращая возникновение штормов. Ну не чудо ли?:) Еще TRILL позволяет равномерно распределять нагрузку между линками (до 16 линков), объединять распределенные дата-центры в единую L2-сеть и гибко управлять трафиком. TRILL – общепринятый стандарт, у которого быстро появились вендорские варианты: FabricPath от Cisco (который используем мы) и VCS от Brocade. Juniper разработал собственную технологию Qfabric, позволяющую создавать единую Ethernet фабрику.
Контрольный выстрел
Какой протокол даст вам 100% защиту от шторма? Правильно, никакой. Поэтому, возможно, вас заинтересуют следующие два инструмента:
• Storm-control
Позволяет установить посекундную “квоту” на количество бродкастовых пакетов, проходящих через один порт. Все, что сверх «квоты», – отбрасывается, и таким образом контролируется нагрузка. Некоторый нюанс заключается в том, что Storm-control не отличает полезный трафик от мусора.
• Control—plane policing (CoPP)
Этакий storm-control для процессора коммутатора. При бродкастовом шторме, помимо прочего, резко возрастает количество ARP-запросов. Когда это количество зашкаливает, процессор загружается на 100% – и сеть, понятно, говорит вам “до свиданья”. CoPP умеет “дозировать” количество ARP-запросов и таким образом управлять нагрузкой на процессор. Неплохо справляется и с броадкастовыми штормами со стороны точек обмена трафиком, и с различными DDoS-атаками — проверено.
Как построить death proof сеть
Итак, какие из возможных вариантов мы проверили на себе и используем в зависимости от вводных:
1. U, V и П-образные топологии + RSTP (MST) + storm control + CoPP.
Базовый набор, в первую очередь, для коммерческого ЦОД, в котором приходится подключать к собственной сети большое количество внешних (неконтролируемых) сетей – и потому крайне желательно не допускать возникновения «петель» вообще.
Если U, V и П-образные топологии не ваш случай, «сокращенный» вариант RSTP (MST) + storm control + CoPP тоже подойдет.
2. Если есть задача максимально использовать возможности оборудования и каналов, присмотритесь к варианту mLAG (VSS, vPC) + storm control + CoPP.
3. Если у вас уже имеется оборудование Cisco или Juniper и нет противопоказаний по топологии, попробуйте комбинацию Flex Links/RTG + storm control + CoPP.
4. Если у вас сложносочиненный случай с распределенными площадками и прочими изысками виртуализации и отказоустойчивости, ваш вариант TRILL + storm control + CoPP.
5. Если вы не знаете, какой у вас случай, – мы можем поговорить об этом:).
Главное – начать делать хоть что-то уже сейчас, даже если вам искренне кажется, что бродкастовый шторм это то, что бывает с другими. В реальности штормы «накрывают» сети самых разных масштабов, а нелепые ошибки совершают даже люди, которые, что называется, двадцать лет в искусстве. «И пусть это вдохновит вас на подвиг» (с).
Дисклеймер: Мы не несем ответственность за Ваши действия и не призываем Вас к каким-либо действиям! Все материалы взяты с открытых источников, опубликованы для образовательных целей.
Оглавление
- Широковещательный шторм в состоянии петли
- Методы предотвращения
- Создание широковещательного шторма (петли)
- LLMNR
- Анализ последствий
1. Широковещательный шторм в состоянии петли
Петля (или кольцо) в локальной сети — это ситуация, при которой часть информации от коммутатора не рассылается по компьютерам, а кочует по двум параллельным маршрутам, как бы замыкающимся в кольцо. Данные при этом бесконечно кружатся по этому кольцу, постепенно увеличиваясь в размерах и забивая весь канал. Петля является крайне неприятным явлением для локальной сети или её отдельного участка и требует немедленного решения. Для большего понимания простейшая схема петли представлена ниже.
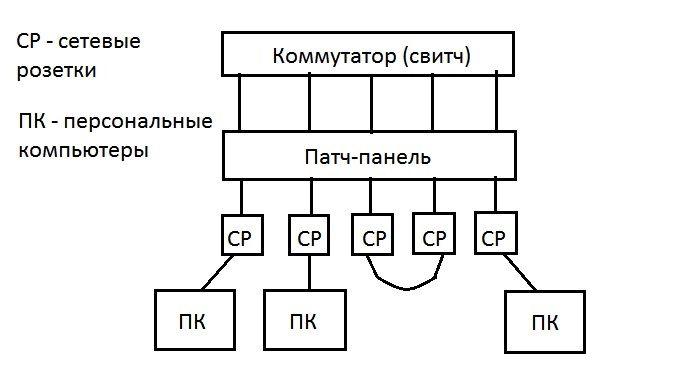
Рис.1 Пример петли в локальной сети
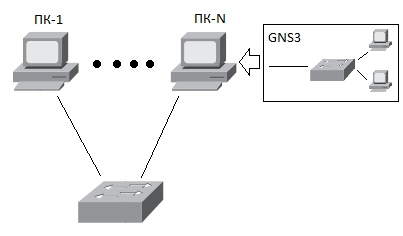
Рис. 2 Пример топологии сети
Пример топологии, рассматриваемой сети, изображен на рисунке 2.
Компьютер ПК-1 отправляет кадр (frame) по сети через коммутатор компьютеру ПК-N. Коммутатор получает кадр и в таблицу коммутации заносит адрес компьютера ПК-1 с портом. Коммутатор не знает где расположен порт получателя кадра, кроме порта, из которого этот кадр был получен. Соответственно, кадр получает ПК-N и получает виртуальный коммутатор GNS3 (далее будет подробно показано, как реализовать виртуальную сеть с помощью GNS3). Виртуальный коммутатор GNS3, который расположен в ПК-N, производит аналогичные действия. Компьютеры расположенные в локальной сети получают несколько кадров — один от коммутатора локальной сети, другой от виртуального коммутатора. Одновременно с этим, копию кадра от коммутатора локальной сети получает виртуальный коммутатор GNS3. Так как для виртуального коммутатора копия является “новым” кадром, то он производит стандартный процесс коммутации кадра. Тем самым происходит бесконечное циркулирование кадра между сегментами сети.
2. Методы предотвращения
Единственной возможностью прекратить циркулирование фрейма между сегментами сети является выключение одного из каналов связи между ними. Данную функцию реализует протокол STP, который оставляет между сегментами только один возможный канал связи между сегментами сети.
3. Создание широковещательного шторма (петли)
Рассмотрим проблему создания петли в сетевом программном эмуляторе GNS3. GNS3 позволяет комбинировать виртуальные и реальные устройства, используемые для моделирования сложных сетей. Он использует программное обеспечение эмуляции Dynamips для имитации Cisco IOS. Для создания петли воспользуемся одним из способов подключения GNS3 к реальной физической сети. Этот способ возможен, если компьютер подключен к коммутатору (к локальной сети). Схема изображена на рисунке 3.
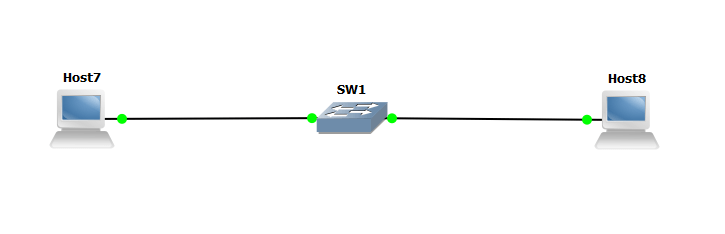
Рис. 3 Схема соединения 2 хостов и 1 коммутатора
У хостов в качестве интерфейса указываем “nio_gen_eth:Ethernet N”.
Перед этим проведем анализ трафика в сети с помощью ПО Wireshark (рис. 3).
Рис.4 Анализ трафика в сети с помощью Wireshark
В среднем в сети проходит 5-10 пакетов в секунду. Основной пакет — это LLMNR, который в последствии будет являться причиной нарушения работоспособности коммутатора. Сначала стоит разобрать сам протокол LLMNR.
4. LLMNR
LLMNR, англ. Link-Local Multicast Name Resolution — протокол стека TCP/IP, основанный на формате пакета данных DNS, который позволяет компьютерам выполнять разрешение имен хостов в локальной сети. Для LLMNR выделены порты 5355/UDP и 5355/TCP, в IPv4 выделен широковещательный адрес 224.0.0.252 и MAC-адрес 01-00-5E-00-00-FC, в IPv6 — FF02:0:0:0:0:0:1:3 (сокращённая запись — FF02::1:3) и MAC-адрес 33-33-00-01-00-03.
.png)
Рис. 5 Структура заголовка пакета LLMNR
Служба LLMNR (Link-Local Multicast Name Resolution) позволяет организовать одноранговое разрешение имен в пределах одной подсети для IPv4, IPv6 или обоих видов адресов сразу без обращения к серверам, на что не способны ни DNS, ни WINS. WINS предоставляет как клиент-серверную, так и одноранговую службу разрешения имен, но не поддерживает адреса IPv6. DNS, с другой стороны, поддерживает оба тина адресов, но требует наличия серверов. Разрешение имен LLMNR, работает для адресов IPv6 и IPv4 в тех случаях, когда другие службы разрешения имен недоступны, например, в домашних сетях, в небольших предприятиях, во временных сетях или корпоративных сетях, где по каким-то причинам недоступны DNS-службы. Поскольку трафик LLMNR не проходит через маршрутизаторы, вы не рискуете случайно заполнить им сеть.Как и WINS, LLMNR позволяет преобразовать имя хоста в IP-адрес. По умолчанию LLMNR включен на всех компьютерах под управлением Windows. Эти компьютеры прибегают к LLMNR, если попытки узнать имя хоста через DNS окончились неудачей. В результате, разрешение имен в Windows работает следующим образом:
- Хост посылает запрос на первичный DNS-сервер. Если он не получает ответа или получает сообщение об ошибке, он по очереди посылает запросы на все вторичные DNS—серверы. Если и это не помогло, разрешение имени передается LLMNR.
- Хост посылает многоадресный UDP-запрос, запрашивая IP-адрес для нужного имени компьютера. Этот запрос идет только по локальной подсети.
- Каждый компьютер локальной подсети, поддерживающий LLMNR и сконфигурированный для ответа на поступающие запросы, сравнивает имя со своим хост-именем. Если они не совпадают, компьютер отбрасывает запрос. Если имена совпадают, компьютер пересылает исходному хосту одноадресное сообщение с ІР-адресом.
5. Анализ последствий
Компьютеры с LLMNR должны проверять уникальность своих имен в подсети. В большинстве случаев это происходит при запуске, восстановлении из спящего режима или при смене параметров сетевого интерфейса. Если компьютер еще не проверил уникальность своего имени, он должен указывать это в ответе на запрос. После создания петли в GNS3 (рис. 3), увидим некоторые особенности в Wireshark (рис. 6).
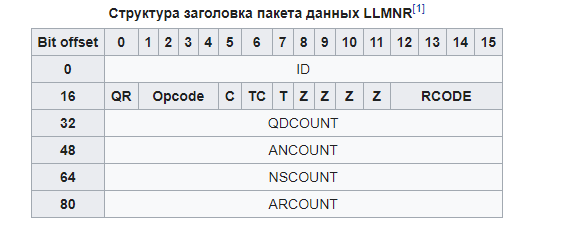
Рис. 6 Количество пакетов в сети

Рис. 7 Загруженность пропускной способности канала передачи
Рис. 8 Отключение сетевых дисков №1 и №2
.png)
Рис. 9 Анализ трафика с помощью Wireshark после создания петли
После создании петли сразу же в сети наблюдается рост количества пакетов к экспоненциальному росту их числа и парализует работу сети. Это состояние в сети называется широковещательный шторм. Широковещательный шторм — лавина широковещательных пакетов (на втором уровне модели OSI — кадров). Считается нормальным, если широковещательные пакеты составляют не более 10 % от общего числа пакетов в сети.Довольно часто к широковещательному шторму приводят петли в сети при неправильной настройке канального протокола Spanning Tree. Spanning Tree Protocol (STP) — канальный протокол. Основной задачей STP является устранение петель в топологии произвольной сети Ethernet, в которой есть один или более сетевых мостов, связанных избыточными соединениями. STP решает эту задачу, автоматически блокируя соединения, которые в данный момент для полной связности коммутаторов являются избыточными.
Сетевая петля — на самом деле, опасная штука. Очень часто ее появление связано с неправильным подсоединением линков маршрутизаторов или коммутаторов. Реже она случается из-за неверных настроек маршрутного адреса.
Как найти такую петлю, мы разберем чуть ниже. Но в целом предугадывать возникновение таких петель не получается. Ее наличие становится видимым, уже когда проявляются признаки зацикливания или когда уже полностью «ложится» вся наша сеть.
Как образуется сетевая петля
Если посмотреть на принцип «сетевой петли», то для большего понимания скажем, что это когда пакет каких-либо данных долго блуждает по одному и тому же маршрутному кругу от коммутатора к коммутатору и никак не может достичь своего конечного получателя. От этого случается перегрузка сети и она «ложится», так как становится просто перегруженной IP-пакетами, которые не перестают множиться из-за коммуникации между сетевыми устройствами. Но пакеты не покидают маршрутную сеть, а блуждают внутри сетевой петли, так и образуется сетевой шторм.
Плюс, так как внутри локальной сети присутствует большое количество зациклившихся пакетов, то достаточно сильно снижается пропускающая способность всего канала связи. Но это тоже еще не все. Если у вас довольно большая сеть, то могут случиться проблемы и на других участках. Одна немного приятная новость, что возникшее зацикливание не вечно, жизнь самих сетевых пакетов ограничена по времени.
Как определить сетевую петлю по ее признакам
Чтобы найти сетевую петлю, нужно определить ее сначала по ее признакам. Благо, они четко определяемые и заметные. Для начала нужно закрепить 2 определения:
- TTL — это временное ограничение жизни сетевого пакета;
- IP ID — это и так понятно.
Любой сетевой пакет, пройдя через коммутатор в своем поле TTL, заполучает значение на одну единицу меньше. Так вот, очень уменьшенное значение TTL — это явный признак зацикленной локальной сети. Потому что низкий TTL объясняется тем, что пакет проходил много раз через маршрутизатор, с каждым разом уменьшаясь. Его нормальное значение обычно не превышает 30. Уменьшаясь до единицы в сетевой петле, он потом «погибает».
Сетевой широковещательный шторм — это еще один признак того, как найти петлю в локальной сети. По сути это наличие внутри сети большого количества сетевых пакетов с идентичным значениями IP ID. Иногда их количество может переваливать за тысячу.
Как найти сетевую петлю в локальной сети
Чтобы найти петлю в сети, можно воспользоваться анализатором сетевого трафика — сниффером. Его плюс, что он показывает не только имеющуюся петлю, но и все устройства, которые ее создали. Чтобы воспользоваться сниффером, нужно следовать определенным шагам:
- Первое, что нужно сделать, — это определить локальный участок, где происходит зацикливание. Определить нетрудно — там возникают проблемы с Интернетом.
- Подберите любой сниффер и можете его запускать для определения зацикленных устройств.
- Определите сетевые пакеты, создающие шторм, и отфильтруйте их. Найти их будет несложно — их огромное количество и у многих схожий ID IP.
Отдельным видом сетевой петли является физическое зацикливание сети. Простым языком — это когда в порты коммутатора подсоединяют два конца одного провода. В маленьких локальных сетях это, конечно, вряд ли может произойти, если проводов всего несколько, но в больших корпоративных сетях — легко. Это может быть как ошибка монтажников, так и в процессе эксплуатации сети, кто-то из работяг-неспециалистов начудил. И это может быть необязательно в самом коммутаторе, куда доступ ограничен, а просто, к примеру, один из офисных работников конец одного подключенного линка случайно или нет включил в другую интернет-розетку и вуаля — сетевая петля.
Как найти такую сетевую петлю в локальной сети, наверное, понятно. Нужно визуально осматривать все подключения. После того, конечно, как удастся локализовать проблемный участок.

3 ноября 2012, 17:06

19

594963

80



I think that I shall never see
A graph more lovely than a tree.
A tree whose crucial propertеу
Is loop-free connectivity.
A tree that must be sure to span
So packets can reach every LAN.
First, the root must be selected.
By ID, it is elected.
Least-cost paths from root are traced.
In the tree, these paths are placed.
A mesh is made by folks like me,
Then bridges find a spanning tree.
— Radia Joy Perlman
В прошлом выпуске мы остановились на статической маршрутизации. Теперь надо сделать шаг в сторону и обсудить вопрос стабильности нашей сети.
Дело в том, что однажды, когда вы — единственный сетевой админ фирмы “Лифт ми Ап” — отпросились на полдня раньше, вдруг упала связь с серверами, и директора не получили несколько важных писем. После короткой, но ощутимой взбучки вы идёте разбираться, в чём дело, а оказалось, по чьей-то неосторожности выпал из разъёма кабель, ведущий к коммутатору в серверной. Небольшая проблема, которую вы могли исправить за две минуты, и даже вообще избежать, существенно сказалась на вашем доходе в этом месяце и возможностях роста.
Итак, сегодня обсуждаем: проблему широковещательного шторма ,работу и настройку протокола STP и его модификаций (RSTP, MSTP, PVST, PVST+) ,технологию агрегации интерфейсов и перераспределения нагрузки между ними ,некоторые вопросы стабильности и безопасности, как изменить схему существующей сети, чтобы всем было хорошо.
Содержание выпуска
- Широковещательный шторм
- STP
- Роли портов
- Состояния портов
- Виды STP
- RSTP
- MSTP
- Практика
- L2 security
- Port security
- DHCP Snooping
- IP Source Guard
- Dynamic ARP Inspection
- EtherChannel/EtherTrunk/LAG
- Материалы выпуска
Оборудование, работающее на втором уровне модели OSI (коммутатор), должно выполнять 3 функции: запоминание адресов, перенаправление (коммутация) пакетов, защита от петель в сети. Разберем по пунктам каждую функцию.
Запоминание адресов и перенаправление пакетов: Как мы уже говорили ранее, у каждого свича есть таблица сопоставления MAC-адресов и портов (aka CAM-table — Content Addressable Memory Table). Когда устройство, подключенное к свичу, посылает кадр в сеть, свич смотрит MAC-адрес отправителя и порт, откуда получен кадр, и добавляет эту информацию в свою таблицу. Далее он должен передать кадр получателю, адрес которого указан в кадре.
По идее, информацию о порте, куда нужно отправить кадр, он берёт из этой же CAM-таблицы. Но, предположим, что свич только что включили (таблица пуста), и он понятия не имеет, в какой из его портов подключен получатель. В этом случае он отправляет полученный кадр во все свои порты, кроме того, откуда он был принят. Все конечные устройства, получив этот кадр, смотрят MAC-адрес получателя, и, если он адресован не им, отбрасывают его. Устройство-получатель отвечает отправителю, а в поле отправителя ставит свой адрес, и вот свич уже знает, что такой-то адрес находится на таком-то порту (вносит запись в таблицу), и в следующий раз уже будет переправлять кадры, адресованные этому устройству, только в этот порт.
Чтобы посмотреть содержимое CAM-таблицы, используется команда show mac address-table. Однажды попав в таблицу, информация не остаётся там пожизненно, содержимое постоянно обновляется и если к определенному mac-адресу не обращались 300 секунд (по умолчанию), запись о нем удаляется.
Тут всё должно быть понятно. Но зачем защита от петель? И что это вообще такое?
Широковещательный шторм
Часто, для обеспечения стабильности работы сети в случае проблем со связью между свичами (выход порта из строя, обрыв провода), используют избыточные линки (redundant links) — дополнительные соединения. Идея простая — если между свичами по какой-то причине не работает один линк, используем запасной. Вроде все правильно, но представим себе такую ситуацию: два свича соединены двумя проводами (пусть будет, что у них соединены fa0/1 и fa0/24).

Одной из их подопечных — рабочих станций (например, ПК1) вдруг приспичило послать широковещательный кадр (например, ARP-запрос). Раз широковещательный, шлем во все порты, кроме того, с которого получили.

Второй свич получает кадр в два порта, видит, что он широковещательный, и тоже шлет во все порты, но уже, получается, и обратно в те, с которых получил (кадр из fa0/24 шлет в fa0/1, и наоборот).

Первый свич поступает точно также, и в итоге мы получаем широковещательный шторм (broadcast storm), который намертво блокирует работу сети, ведь свичи теперь только и занимаются тем, что шлют друг другу один и тот же кадр.

Как можно избежать этого? Ведь мы, с одной стороны, не хотим штормов в сети, а с другой, хотим повысить ее отказоустойчивость с помощью избыточных соединений? Тут на помощь нам приходит STP (Spanning Tree Protocol)
STP
Основная задача STP — предотвратить появление петель на втором уровне. Как это сделать? Да просто отрубить все избыточные линки, пока они нам не понадобятся. Тут уже сразу возникает много вопросов: какой линк из двух (или трех-четырех) отрубить? Как определить, что основной линк упал, и пора включать запасной? Как понять, что в сети образовалась петля? Чтобы ответить на эти вопросы, нужно разобраться, как работает STP.
STP использует алгоритм STA (Spanning Tree Algorithm), результатом работы которого является граф в виде дерева (связный и без простых циклов)
Для обмена информацией между собой свичи используют специальные пакеты, так называемые BPDU (Bridge Protocol Data Units). BPDU бывают двух видов: конфигурационные (Configuration BPDU) и панические “ААА, топология поменялась!” TCN (Topology Change Notification BPDU). Первые регулярно рассылаются корневым свичом (и ретранслируются остальными) и используются для построения топологии, вторые, как понятно из названия, отсылаются в случае изменения топологии сети (проще говоря, подключенииотключении свича). Конфигурационные BPDU содержат несколько полей, остановимся на самых важных:
- Идентификатор отправителя (Bridge ID)
- Идентификатор корневого свича (Root Bridge ID)
- Идентификатор порта, из которого отправлен данный пакет (Port ID)
- Стоимость маршрута до корневого свича (Root Path Cost)
Что все это такое и зачем оно нужно, объясню чуть ниже. Так как устройства не знают и не хотят знать своих соседей, никаких отношений (смежности/соседства) они друг с другом не устанавливают. Они шлют BPDU из всех работающих портов на мультикастовый ethernet-адрес 01-80-c2-00-00-00 (по умолчанию каждые 2 секунды), который прослушивают все свичи с включенным STP.
Итак, как же формируется топология без петель?
Сначала выбирается так называемый корневой мост/свич (root bridge). Это устройство, которое STP считает точкой отсчета, центром сети; все дерево STP сходится к нему. Выбор базируется на таком понятии, как идентификатор свича (Bridge ID). Bridge ID это число длиной 8 байт, которое состоит из Bridge Priority (приоритет, от 0 до 65535, по умолчанию 32768+номер vlan или инстанс MSTP, в зависимости от реализации протокола), и MAC-адреса устройства. В начале выборов каждый коммутатор считает себя корневым, о чем и заявляет всем остальным с помощью BPDU, в котором представляет свой идентификатор как ID корневого свича. При этом, если он получает BPDU с меньшим Bridge ID, он перестает хвастаться своим и покорно начинает анонсировать полученный Bridge ID в качестве корневого. В итоге, корневым оказывается тот свич, чей Bridge ID меньше всех.
Такой подход таит в себе довольно серьезную проблему.
Дело в том, что, при равных значениях Priority (а они равные, если не менять ничего) корневым выбирается самый старый свич, так как мак адреса прописываются на производстве последовательно, соответственно, чем мак меньше, тем устройство старше (естественно, если у нас все оборудование одного вендора).
Понятное дело, это ведет к падению производительности сети, так как старое устройство, как правило, имеет худшие характеристики. Подобное поведение протокола следует пресекать, выставляя значение приоритета на желаемом корневом свиче вручную, об этом в практической части.
Роли портов
После того, как коммутаторы померились айдями и выбрали root bridge, каждый из остальных свичей должен найти один, и только один порт, который будет вести к корневому свичу. Такой порт называется корневым портом (Root port). Чтобы понять, какой порт лучше использовать, каждый некорневой свич определяет стоимость маршрута от каждого своего порта до корневого свича. Эта стоимость определяется суммой стоимостей всех линков, которые нужно пройти кадру, чтобы дойти до корневого свича. В свою очередь, стоимость линка определяется просто- по его скорости (чем выше скорость, тем меньше стоимость). Процесс определения стоимости маршрута связан с полем BPDU “Root Path Cost” и происходит так:
- Корневой свич посылает BPDU с полем Root Path Cost, равным нулю
- Ближайший свич смотрит на скорость своего порта, куда BPDU пришел, и добавляет стоимость согласно таблице
Скорость порта Стоимость STP (802.1d) 10 Mbps 100 100 Mbps 19 1 Gbps 4 10 Gbps 2 - Далее этот второй свич посылает этот BPDU нижестоящим коммутаторам, но уже с новым значением Root Path Cost, и далее по цепочке вниз
Если имеют место одинаковые стоимости (как в нашем примере с двумя свичами и двумя проводами между ними — у каждого пути будет стоимость 19) — корневым выбирается меньший порт.
Далее выбираются назначенные (Designated) порты. Из каждого конкретного сегмента сети должен существовать только один путь по направлению к корневому свичу, иначе это петля. В данном случае имеем в виду физический сегмент, в современных сетях без хабов это, грубо говоря, просто провод. Назначенным портом выбирается тот, который имеет лучшую стоимость в данном сегменте. У корневого свича все порты — назначенные.
И вот уже после того, как выбраны корневые и назначенные порты, оставшиеся блокируются, таким образом разрывая петлю.  *На картинке маршрутизаторы выступают в качестве коммутаторов. В реальной жизни это можно сделать с помощью дополнительной свитчёвой платы.
*На картинке маршрутизаторы выступают в качестве коммутаторов. В реальной жизни это можно сделать с помощью дополнительной свитчёвой платы.
Состояния портов
Чуть раньше мы упомянули состояние блокировки порта, теперь поговорим о том, что это значит, и о других возможных состояниях порта в STP. Итак, в обычном (802.1D) STP существует 5 различных состояний:
- Блокировка (blocking): блокированный порт не шлет ничего. Это состояние предназначено, как говорилось выше, для предотвращения петель в сети. Блокированный порт, тем не менее, слушает BPDU (чтобы быть в курсе событий, это позволяет ему, когда надо, разблокироваться и начать работать)
- Прослушивание (listening): порт слушает и начинает сам отправлять BPDU, кадры с данными не отправляет.
- Обучение (learning): порт слушает и отправляет BPDU, а также вносит изменения в CAM- таблицу, но данные не перенаправляет.
- Пересылка (forwarding): этот может все: и посылаетпринимает BPDU, и с данными оперирует, и участвует в поддержании таблицы mac-адресов. То есть это обычное состояние рабочего порта.
- Отключен (disabled): состояние administratively down, отключен командой shutdown. Понятное дело, ничего делать не может вообще, пока вручную не включат.
Порядок перечисления состояний не случаен: при включении (а также при втыкании нового провода), все порты на устройстве с STP проходят вышеприведенные состояния именно в таком порядке (за исключением disabled-портов).
Возникает закономерный вопрос: а зачем такие сложности? А просто STP осторожничает. Ведь на другом конце провода, который только что воткнули в порт, может быть свич, а это потенциальная петля. Вот поэтому порт сначала 15 секунд (по умолчанию) пребывает в состоянии прослушивания — он смотрит BPDU, попадающие в него, выясняет свое положение в сети — как бы чего не вышло, потом переходит к обучению еще на 15 секунд — пытается выяснить, какие mac-адреса “в ходу” на линке, и потом, убедившись, что ничего он не поломает, начинает уже свою работу.
Итого, мы имеем целых 30 секунд простоя, прежде чем подключенное устройство сможет обмениваться информацией со своими соседями.
Современные компы грузятся быстрее, чем за 30 секунд. Вот комп загрузился, уже рвется в сеть, истерит на тему “DHCP-сервер, сволочь, ты будешь айпишник выдавать, или нет?”, и, не получив искомого, обижается и уходит в себя, извлекая из своих недр айпишник автонастройки. Естественно, после таких экзерсисов, в сети его слушать никто не будет, ибо “не местный” со своим 169.254.x.x. Понятно, что все это не дело, но как этого избежать?
Portfast
Для таких случаев используется особый режим порта — portfast. При подключении устройства к такому порту, он, минуя промежуточные стадии, сразу переходит к forwarding-состоянию. Само собой, portfast следует включать только на интерфейсах, ведущих к конечным устройствам (рабочим станциям, серверам, телефонам и т.д.), но не к другим свичам.
Есть очень удобная команда режима конфигурации интерфейса для включения нужных фич на порту, в который будут включаться конечные устройства: switchport host. Эта команда разом включает PortFast, переводит порт в режим access (аналогично switchport mode access), и отключает протокол PAgP (об этом протоколе подробнее в разделе агрегация каналов).
Виды STP
STP довольно старый протокол, он создавался для работы в одном LAN-сегменте. А что делать, если мы хотим внедрить его в нашей сети, которая имеет несколько VLANов?
Стандарт 802.1Q, о котором мы упоминали в статье о коммутации, определяет, каким образом вланы передаются внутри транка. Кроме того, он определяет один процесс STP для всех вланов. BPDU по транкам передаются нетегированными (в native VLAN). Этот вариант STP известен как CST (Common Spanning Tree). Наличие только одного процесса для всех вланов очень облегчает работу по настройке и разгружает процессор свича, но, с другой стороны, CST имеет недостатки: избыточные линки между свичами блокируются во всех вланах, что не всегда приемлемо и не дает возможности использовать их для балансировки нагрузки.
Cisco имеет свой взгляд на STP, и свою проприетарную реализацию протокола — PVST (Per-VLAN Spanning Tree) — которая предназначена для работы в сети с несколькими VLAN. В PVST для каждого влана существует свой процесс STP, что позволяет независимую и гибкую настройку под потребности каждого влана, но самое главное, позволяет использовать балансировку нагрузки за счет того, что конкретный физический линк может быть заблокирован в одном влане, но работать в другом. Минусом этой реализации является, конечно, проприетарность: для функционирования PVST требуется проприетарный же ISL транк между свичами.
Также существует вторая версия этой реализации — PVST+, которая позволяет наладить связь между свичами с CST и PVST, и работает как с ISL- транком, так и с 802.1q. PVST+ это протокол по умолчанию на коммутаторах Cisco.
RSTP
Все, о чем мы говорили ранее в этой статье, относится к первой реализация протокола STP, которая была разработана в 1985 году Радией Перлман (ее стихотворение использовано в качестве эпиграфа). В 1990 году эта реализации была включена в стандарт IEEE 802.1D. Тогда время текло медленнее, и перестройка топологии STP, занимающая 30-50 секунд (!!!), всех устраивала. Но времена меняются, и через десять лет, в 2001 году, IEEE представляет новый стандарт RSTP (он же 802.1w, он же Rapid Spanning Tree Protocol, он же Быстрый STP). Чтобы структурировать предыдущий материал и посмотреть различия между обычным STP (802.1d) и RSTP (802.1w), соберем таблицу с основными фактами:
| STP (802.1d) | RSTP (802.1w) |
| В уже сложившейся топологии только корневой свич шлет BPDU, остальные ретранслируют | Все свичи шлют BPDU в соответствии с hello-таймером (2 секунды по умолчанию) |
| Состояния портов | |
| — блокировка (blocking) — прослушивание (listening) — обучение (learning) — перенаправлениепересылка (forwarding) — отключен (disabled) | — отбрасывание (discarding), заменяет disabled, blocking и listening — learning — forwarding |
| Роли портов | |
| — корневой (root), участвует в пересылке данных, ведет к корневому свичу — назначенный (designated), тоже работает, ведет от корневого свича — неназначенный (non-designated), не участвует в пересылке данных | — корневой (root), участвует в пересылке данных — назначенный (designated), тоже работает — дополнительный (alternate), не участвует в пересылке данных — резервный (backup), тоже не участвует |
| Механизмы работы | |
| Использует таймеры: Hello (2 секунды) Max Age (20 секунд) Forward delay timer (15 секунд) | Использует процесс proposal and agreement (предложение и соглашение) |
| Свич, обнаруживший изменение топологии, извещает корневой свич, который, в свою очередь, требует от всех остальных очистить их записи о текущей топологии в течение forward delay timer | Обнаружение изменений в топологии влечет немедленную очистку записей |
| Если не-корневой свич не получает hello- пакеты от корневого в течение Max Age, он начинает новые выборы | Начинает действовать, если не получает BPDU в течение 3 hello-интервалов |
| Последовательное прохождение порта через состояния Blocking (20 сек) — Listening (15 сек) — Learning (15 сек) — Forwarding | Быстрый переход к Forwarding для p2p и Edge-портов |
Как мы видим, в RSTP остались такие роли портов, как корневой и назначенный, а роль заблокированного разделили на две новых роли: Alternate и Backup. Alternate — это резервный корневой порт, а backup — резервный назначенный порт. Как раз в этой концепции резервных портов и кроется одна из причин быстрого переключения в случае отказа. Это меняет поведение системы в целом: вместо реактивной (которая начинает искать решение проблемы только после того, как она случилась) система становится проактивной, заранее просчитывающей “пути отхода” еще до появления проблемы. Смысл простой: для того, чтобы в случае отказа основного переключится на резервный линк, RSTP не нужно заново просчитывать топологию, он просто переключится на запасной, заранее просчитанный.
Ранее, для того, чтобы убедиться, что порт может участвовать в передаче данных, требовались таймеры, т.е. свич пассивно ждал в течение означенного времени, слушая BPDU. Ключевой фичей RSTP стало введение концепции типов портов, основанных на режиме работы линка- full duplex или half duplex (типы портов p2p или shared, соответственно), а также понятия пограничный порт (тип edge p2p), для конечных устройств. Пограничные порты назначаются, как и раньше, командой spanning-tree portfast, и с ними все понятно — при включении провода сразу переходим к forwarding-состоянию и работаем. Shared-порты работают по старой схеме с прохождением через состояния BLK — LIS — LRN — FWD. А вот на p2p-портах RSTP использует процесс предложения и соглашения (proposal and agreement).
Не вдаваясь в подробности, его можно описать так: свич справедливо считает, что если линк работает в режиме полного дуплекса, и он не обозначен, как пограничный, значит, на нем только два устройства — он и другой свич. Вместо того, чтобы ждать входящих BPDU, он сам пытается связаться со свичом на том конце провода с помощью специальных proposal BPDU, в которых, конечно, есть информация о стоимости маршрута к корневому свичу. Второй свич сравнивает полученную информацию со своей текущей, и принимает решение, о чем извещает первый свич посредством agreement BPDU. Так как весь этот процесс теперь не привязан к таймерам, происходит он очень быстро — только подключили новый свич — и он практически сразу вписался в общую топологию и приступил к работе (можете сами оценить скорость переключения в сравнении с обычным STP на видео).
В Cisco-мире RSTP называется PVRST (Per-Vlan Rapid Spanning Tree).
MSTP
Чуть выше, мы упоминали о PVST, в котором для каждого влана существует свой процесс STP. Вланы довольно удобный инструмент для многих целей, и поэтому, их может быть достаточно много даже в некрупной организации. И в случае PVST, для каждого будет рассчитываться своя топология, тратиться процессорное время и память свичей.
А нужно ли нам рассчитывать STP для всех 500 вланов, когда единственное место, где он нам нужен- это резервный линк между двумя свичами?
Тут нас выручает MSTP. В нем каждый влан не обязан иметь собственный процесс STP, их можно объединять. Вот у нас есть, например, 500 вланов, и мы хотим балансировать нагрузку так, чтобы половина из них работала по одному линку (второй при этом блокируется и стоит в резерве), а вторая- по другому. Это можно сделать с помощью обычного STP, назначив один корневой свич в диапазоне вланов 1-250, а другой- в диапазоне 250-500. Но процессы будут работать для каждого из пятисот вланов по отдельности (хотя действовать будут совершенно одинаково для каждой половины). Логично, что тут хватит и двух процессов.
MSTP позволяет создавать столько процесов STP, сколько у нас логических топологий (в данном примере — 2), и распределять по ним вланы.
Думаем, нет особого смысла углубляться в теорию и практику MSTP в рамках этой статьи (ибо теории там ого-го), интересующиеся могут пройти по ссылке.
Агрегация каналов
Но какой бы вариант STP мы не использовали, у нас все равно существует так или иначе неработающий линк. А возможно ли задействовать параллельные линки по полной и при этом избежать петель? Да, отвечаем мы вместе с циской, начиная рассказ о EtherChannel.
Иначе это называется link aggregation, link bundling, NIC teaming, port trunkinkg
Технологии агрегации (объединения) каналов выполняют 2 функции: с одной стороны, это объединение пропускной способности нескольких физических линков, а с другой — обеспечение отказоустойчивости соединения (в случае падения одного линка нагрузка переносится на оставшиеся). Объединение линков можно выполнить как вручную (статическое агрегирование), так и с помощью специальных протоколов: LACP (Link Aggregation Control Protocol) и PAgP (Port Aggregation Protocol). LACP, опеределяемый стандартом IEEE 802.3ad, является открытым стандартом, то есть от вендора оборудования не зависит. Соответственно, PAgP — проприетарная цисковская разработка.
В один такой канал можно объединить до восьми портов. Алгоритм балансировки нагрузки основан на таких параметрах, как IP/MAC-адреса получателей и отправителей и порты. Поэтому в случае возникновения вопроса: “Хей, а чего так плохо балансируется?” в первую очередь смотрите на алгоритм балансировки.
Практика
Наверное, большинство ошибок в Packet Tracer допущено в части кода, отвечающего за симуляцию STP, будте готовы. В случае сомнения сохранитесь, закройте PT и откройте заново
Итак, переходим к практике.
Для начала внесем некоторые изменения в топологию — добавим избыточные линки. Учитывая сказанное в самом начале, вполне логично было бы сделать это в московском офисе в районе серверов — там у нас свич msk-arbat-asw2 доступен только через asw1, что не есть гуд. Мы отбираем (пока, позже возместим эту потерю) гигабитный линк, который идет от msk-arbat-dsw1 к msk-arbat-asw3, и подключаем через него asw2. Asw3 пока подключаем в порт Fa0/2 dsw1. Перенастраиваем транки:
msk-arbat-dsw1(config)#interface gi1/2
msk-arbat-dsw1(config-if)#description msk-arbat-asw2
msk-arbat-dsw1(config-if)#switchport trunk allowed vlan 2,3
msk-arbat-dsw1(config-if)#int fa0/2
msk-arbat-dsw1(config-if)#description msk-arbat-asw3
msk-arbat-dsw1(config-if)#switchport mode trunk
msk-arbat-dsw1(config-if)#switchport trunk allowed vlan 2,101-104
msk-arbat-asw2(config)#int gi1/2
msk-arbat-asw2(config-if)#description msk-arbat-dsw1
msk-arbat-asw2(config-if)#switchport mode trunk
msk-arbat-asw2(config-if)#switchport trunk allowed vlan 2,3
msk-arbat-asw2(config-if)#no shutdown
Не забываем вносить все изменения в документацию! Скачать актуальную версию документа.
Скачать актуальную версию документа.
Теперь посмотрим, как в данный момент у нас самонастроился STP. Нас интересует только VLAN0003, где у нас, судя по схеме, петля.
msk-arbat-dsw1>en
msk-arbat-dsw1#show spanning-tree vlan 3
Разбираем по полочкам вывод команды  Итак, какую информацию мы можем получить? Так как по умолчанию на современных цисках работает PVST+ (т.е. для каждого влана свой процесс STP), и у нас есть более одного влана, выводится информация по каждому влану в отдельности, каждая запись предваряется номером влана. Затем идет вид STP: ieee значит PVST, rstp — Rapid PVST, mstp то и значит. Затем идет секция с информацией о корневом свиче: установленный на нем приоритет, его mac-адрес, стоимость пути от текущего свича до корневого, порт, который был выбран в качестве корневого (имеет лучшую стоимость), а также настройки таймеров STP. Далее- секция с той же информацией о текущем свиче (с которого выполняли команду). Затем- таблица состояния портов, которая состоит из следующих колонок (слева направо):
Итак, какую информацию мы можем получить? Так как по умолчанию на современных цисках работает PVST+ (т.е. для каждого влана свой процесс STP), и у нас есть более одного влана, выводится информация по каждому влану в отдельности, каждая запись предваряется номером влана. Затем идет вид STP: ieee значит PVST, rstp — Rapid PVST, mstp то и значит. Затем идет секция с информацией о корневом свиче: установленный на нем приоритет, его mac-адрес, стоимость пути от текущего свича до корневого, порт, который был выбран в качестве корневого (имеет лучшую стоимость), а также настройки таймеров STP. Далее- секция с той же информацией о текущем свиче (с которого выполняли команду). Затем- таблица состояния портов, которая состоит из следующих колонок (слева направо):
- Собственно, порт
- Его роль (Root- корневой порт, Desg- назначенный порт, Altn- дополнительный, Back- резервный)
- Его статус (FWD- работает, BLK- заблокирован, LIS- прослушивание, LRN- обучение)
- Стоимость маршрута до корневого свича
- Port ID в формате: приоритет порта.номер порта
- Тип соединения
Итак, мы видим, что Gi1/1 корневой порт, это дает некоторую вероятность того, что на другом конце линка корневой свич. Смотрим по схеме, куда ведет линк: ага, некий msk-arbat-asw1.
msk-arbat-asw1#show spanning-tree vlan 3
И что же мы видим?
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 32771
Address 0007.ECC4.09E2
This bridge is the root
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Вот он, наш корневой свич для VLAN0003.
А теперь посмотрим на схему.
Ранее, мы увидели в состоянии портов, что dsw1 блокирует порт Gi1/2, разрывая таким образом петлю. Но является ли это оптимальным решением? Нет, конечно. Сейчас наша новая сеть работает точь-в-точь как старая — трафик от asw2 идет только через asw1. Выбор корневого маршрутизатора никогда не нужно оставлять на совесть глупого STP.
Исходя из схемы, наиболее оптимальным будет выбор в качестве корневого свича dsw1 — таким образом, STP заблокирует линк между asw1 и asw2. Теперь это все надо объяснить недалекому протоколу. А для него главное что? Bridge ID. И он неслучайно складывается из двух чисел. Приоритет — это как раз то слагаемое, которое отдано на откуп сетевому инженеру, чтобы он мог повлиять на результат выбора корневого свича.
Итак, наша задача сводится к тому, чтобы уменьшить (меньше-лучше, думает STP) приоритет нужного свича, чтобы он стал Root Bridge. Есть два пути:
- Вручную установить приоритет, заведомо меньший, чем текущий:
msk-arbat-dsw1>enable msk-arbat-dsw1#configure terminal msk-arbat-dsw1(config)#spanning-tree vlan 3 priority ? <0-61440> bridge priority in increments of 4096 msk-arbat-dsw1(config)#spanning-tree vlan 3 priority 4096Теперь он стал корневым для влана 3, так как имеет меньший Bridge ID:
msk-arbat-dsw1#show spanning-tree vlan 3 VLAN0003 Spanning tree enabled protocol ieee Root ID Priority 4099 Address 000B.BE2E.392C This bridge is the root Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec - Дать умной железке решить все за тебя:
msk-arbat-dsw1(config)#spanning-tree vlan 3 root primaryПроверяем:
msk-arbat-dsw1#show spanning-tree vlan 3 VLAN0003 Spanning tree enabled protocol ieee Root ID Priority 24579 Address 000B.BE2E.392C This bridge is the root Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Мы видим, что железка поставила какой-то странный приоритет.
Откуда взялась эта круглая цифра, спросите вы? А все просто — STP смотрит минимальный приоритет (т.е. тот, который у корневого свича), и уменьшает его на два шага инкремента (который составляет 4096, т.е. в итоге 8192). Почему на два? А чтобы была возможность на другом свиче дать команду spanning-tree vlan n root secondary (назначает приоритет = приоритет корневого — 4096), что позволит нам быть уверенными, что, если с текущим корневым свичом что-то произойдет, его функции перейдут к этому, “запасному”.
Вероятно, вы уже видите на схеме, как лампочка на линке между asw2 и asw1 пожелтела? Это STP разорвал петлю. Причем именно в том месте, в котором мы хотели. Sweet! Зайдем проверим: лампочка — это лампочка, а конфиг — это факт.
msk-arbat-asw2#show spanning-tree vlan 3
VLAN0003
Spanning tree enabled protocol ieee
Root ID Priority 24579
Address 000B.BE2E.392C
Cost 4
Port 26(GigabitEthernet1/2)
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Bridge ID Priority 32771 (priority 32768 sys-id-ext 3)
Address 000A.F385.D799
Hello Time 2 sec Max Age 20 sec Forward Delay 15 sec
Aging Time 20
Interface Role Sts Cost Prio.Nbr Type
---------------- ---- --- --------- -------- --------------------------------
Fa0/1 Desg FWD 19 128.1 P2p
Gi1/1 Altn BLK 4 128.25 P2p
Gi1/2 Root FWD 4 128.26 P2p
Теперь полюбуемся, как работает STP: заходим в командную строку на ноутбуке PTO1 и начинаем бесконечно пинговать наш почтовый сервер (172.16.0.4). Пинг сейчас идет по маршруту ноутбук-asw3-dsw1-gw1-dsw1(ну тут понятно, зачем он крюк делает — они из разных вланов)-asw2-сервер. А теперь поработаем Годзиллой из SimСity: нарушим связь между dsw1 и asw2, вырвав провод из порта (замечаем время, нужное для пересчета дерева).
Пинги пропадают, STP берется за дело, и за каких-то 30 секунд коннект восстанавливается. Годзиллу прогнали, пожары потушили, связь починили, втыкаем провод обратно. Пинги опять пропадают на 30 секунд! Мда-а-а, как-то не очень быстро, особенно если представить, что это происходит, например, в процессинговом центре какого-нибудь банка.
Но у нас есть ответ медленному PVST+! И ответ этот — Быстрый PVST+ (так и называется, это не шутка: Rapid-PVST). Посмотрим, что он нам дает. Меняем тип STP на всех свичах в москве командой конфигурационного режима: spanning-tree mode rapid-pvst
Снова запускаем пинг, вызываем Годзиллу… Эй, где пропавшие пинги? Их нет, это же Rapid-PVST. Как вы, наверное, помните из теоретической части, эта реализация STP, так сказать, “подстилает соломку” на случай падения основного линка, и переключается на дополнительный (alternate) порт очень быстро, что мы и наблюдали. Ладно, втыкаем провод обратно. Один потерянный пинг. Неплохо по сравнению с 6-8, да?
L2 security
Port security
Теперь расскажем вкратце, как обеспечить безопасность сети на втором уровне OSI. В этой части статьи теория и практическая конфигурация совмещены. Увы, Packet Tracer не умеет ничего из упомянутых в этом разделе команд, поэтому все без иллюстраций и проверок.
Для начала, следует упомянуть команду конфигурации интерфейса switchport port-security, включающую защиту на определенном порту свича. Затем, с помощью switchport port-security maximum 1 мы можем ограничить количество mac-адресов, связанных с данным портом (т.е., в нашем примере, на данном порту может работать только один mac-адрес). Теперь указываем, какой именно адрес разрешен: его можно задать вручную switchport port-security mac-address адрес, или использовать волшебную команду switchport port-security mac-address sticky, закрепляющую за портом тот адрес, который в данный момент работает на порту. Далее, задаем поведение в случае нарушения правила switchport port-security violation {shutdown | restrict | protect}: порт либо отключается, и потом его нужно поднимать вручную (shutdown), либо отбрасывает пакеты с незарегистрированного мака и пишет об этом в консоль (restrict), либо просто отбрасывает пакеты (protect).
Помимо очевидной цели — ограничение числа устройств за портом — у этой команды есть другая, возможно, более важная: предотвращать атаки. Одна из возможных — истощение CAM-таблицы. С компьютера злодея рассылается огромное число кадров, возможно, широковещательных, с различными значениями в поле MAC-адрес отправителя. Первый же коммутатор на пути начинает их запоминать. Одну тысячу он запомнит, две, но память-то оперативная не резиновая, и среднее ограничение в 16000 записей будет довольно быстро достигнуто. При этом дальнейшее поведение коммутатора может быть различным. И самое опасное из них с точки зрения безопасности: коммутатор может начать все кадры, приходящие на него, рассылать, как широковещательные, потому что MAC-адрес получателя не известен (или уже забыт), а запомнить его уже просто некуда. В этом случае сетевая карта злодея будет получать все кадры, летающие в вашей сети.
DHCP Snooping
Другая возможная атака нацелена на DHCP сервер. Как мы знаем, DHCP обеспечивает клиентские устройства всей нужной информацией для работы в сети: ip-адресом, маской подсети, адресом шюза по умолчанию, DNS-сервера и прочим. Атакующий может поднять собственный DHCP, который в ответ на запрос клиентского устройства будет отдавать в качестве шлюза по умолчанию (а также, например, DNS-сервера) адрес подконтрольной атакующему машины. Соответственно, весь трафик, направленный за пределы подсети обманутыми устройствами, будет доступен для изучения атакующему — типичная man-in-the-middle атака. Либо такой вариант: подлый мошенник генерируют кучу DHCP-запросов с поддельными MAC-адресами и DHCP-сервер на каждый такой запрос выдаёт IP-адрес до тех пор, пока не истощится пул.
Для того, чтобы защититься от подобного вида атак, используется фича под названием DHCP snooping. Идея совсем простая: указать свичу, на каком порту подключен настоящий DHCP-сервер, и разрешить DHCP-ответы только с этого порта, запретив для остальных. Включаем глобально командой ip dhcp snooping, потом говорим, в каких вланах должно работать ip dhcp snooping vlan номер(а). Затем на конкретном порту говорим, что он может пренаправлять DHCP-ответы (такой порт называется доверенным): ip dhcp snooping trust.
IP Source Guard
После включения DHCP Snooping’а, он начинает вести у себя базу соответствия MAC и IP-адресов устройств, которую обновляет и пополняет за счет прослушивания DHCP запросов и ответов. Эта база позволяет нам противостоять еще одному виду атак — подмене IP-адреса (IP Spoofing). При включенном IP Source Guard, каждый приходящий пакет может проверяться на:
- соответствие IP-адреса источника адресу, полученному из базы DHCP Snooping (иными словами, айпишник закрепляется за портом свича)
- соответствие MAC-адреса источника адресу, полученному из базы DHCP Snooping
Включается IP Source Guard командой ip verify source на нужном интерфейсе. В таком виде проверяется только привязка IP-адреса, чтобы добавить проверку MAC, используем ip verify source port-security. Само собой, для работы IP Source Guard требуется включенный DHCP snooping, а для контроля MAC-адресов должен быть включен port security.
Dynamic ARP Inspection
Как мы уже знаем, для того, чтобы узнать MAC-адрес устройства по его IP-адресу, используется протокол ARP: посылается широковещательный запрос вида “у кого ip-адрес 172.16.1.15, ответьте 172.16.1.1”, устройство с айпишником 172.16.1.15 отвечает.
Подобная схема уязвима для атаки, называемой ARP-poisoning aka ARP-spoofing: вместо настоящего хоста с адресом 172.16.1.15 отвечает хост злоумышленника, заставляя таким образом трафик, предназначенный для 172.16.1.15, следовать через него.
Для предотвращения такого типа атак используется фича под названием Dynamic ARP Inspection. Схема работы похожа на схему DHCP-Snooping’а: порты делятся на доверенные и недоверенные, на недоверенных каждый ARP-ответ подвергаются анализу: сверяется информация, содержащаяся в этом пакете, с той, которой свич доверяет (либо статически заданные соответствия MAC-IP, либо информация из базы DHCP Snooping). Если не сходится, пакет отбрасывается и генерируется сообщение в syslog. Включаем в нужном влане (вланах): ip arp inspection vlan номер(а). По умолчанию все порты недоверенные, для доверенных портов используем ip arp inspection trust.
EtherChannel/EtherTrunk/LAG
Помните, мы отобрали у офисных работников их гигабитный линк и отдали его в пользу серверов? Сейчас они, бедняжки, сидят, на каких-то ста мегабитах, прошлый век! Попробуем расширить канал, и на помощь призовем EtherChannel.
В данный момент у нас соединение идет от fa0/2 dsw1 на Gi1/1 asw3, отключаем провод. Смотрим, какие порты можем использовать на asw3: ага, fa0/20-24 свободны, кажется. Вот их и возьмем.
Со стороны dsw1 пусть будут fa0/19-23. Соединяем порты для EtherChannel между собой. На asw3 у нас на интерфейсах что-то настроено, обычно в таких случаях используется команда конфигурационного режима default interface range fa0/20-24, сбрасывающая настройки порта (или портов, как в нашем случае) в дефолтные. Packet tracer, увы, не знает такой хорошей команды, поэтому в ручном режиме убираем каждую настройку, и тушим порты (лучше это сделать, во избежание проблем)
msk-arbat-asw3(config)#interface range fa0/20-24
msk-arbat-asw3(config-if-range)#no description
msk-arbat-asw3(config-if-range)#no switchport access vlan
msk-arbat-asw3(config-if-range)#no switchport mode
msk-arbat-asw3(config-if-range)#shutdown
ну а теперь волшебная команда
msk-arbat-asw3(config-if-range)#channel-group 1 mode on
то же самое на dsw1:
msk-arbat-dsw1(config)#interface range fa0/19-23
msk-arbat-dsw1(config-if-range)#channel-group 1 mode on
поднимаем интерфейсы asw3, и вуаля: вот он, наш EtherChannel, раскинулся аж на 5 физических линков. В конфиге он будет отражен как interface Port-channel 1. Настраиваем транк (повторить для dsw1):
msk-arbat-asw3(config)#int port-channel 1
msk-arbat-asw3(config-if)#switchport mode trunk
msk-arbat-asw3(config-if)#switchport trunk allowed vlan 2,101-104
Как и с STP, есть некая трудность при работе с etherchannel в Packet Tracer’e. Настроить-то мы, в принципе, можем по вышеописанному сценарию, но вот проверка работоспособности под большим вопросом: после отключения одного из портов в группе, трафик перетекает на следующий, но как только вы вырубаете второй порт — связь теряется и не восстанавливается даже после включения портов.
Отчасти в силу только что озвученной причины, отчасти из-за ограниченности ресурсов мы не сможем раскрыть в полной мере эти вопросы и посему оставляем бОльшую часть на самоизучение.
Материалы выпуска
- Новый план коммутации
- Файл PT с лабораторной.
- Конфигурация устройств
- STP или STP
- Безопасность канального уровня
- Агрегация каналов
Авторы
- eucariot — Марат Сибгатулин (inst, tg, in)
- Макс Gluck
Оставайтесь на связи
Пишите нам: info@linkmeup.ru
Канал в телеграме: t.me/linkmeup_podcast
Канал на youtube: youtube.com/c/linkmeup-podcast
Подкаст доступен в iTunes, Google Подкастах, Яндекс Музыке, Castbox
Сообщество в вк: vk.com/linkmeup
Группа в фб: www.facebook.com/linkmeup.sdsm
Добавить RSS в подкаст-плеер.
Пообщаться в общем чате в тг: https://t.me/linkmeup_chatПоддержите проект:





19

594963

80
80 коментариев
Ещё статьи

Анонс подкаста. Выпуск 51. Сетевики скоро будут не нужны ///UPD: Эфир закончен
Когда: 14.05.2017 в 15:00 (МСК) Кто: Алексей Учакин. Сетевой инженер, автор блога nixman.info.Наташа Самойленко. Автор курса “Python для сетевых инженеров”Дмитрий Фиголь. Инженер ТП вендора. Главный апологет автоматизацииАлександр Клиппер. AmazonПро что: …
282
12482
7
30 апреля 2017
IP телефония в Cisco
Видео подготовлено нашим постоянным читателем — Вадимом Семёновым. ==================== Коллеги, здравствуйте. Позвольте представить вашему вниманию видеообзор IP телефонии Cisco для начинающих инженеров. Возможно, кто-то еще не сталкивался с этим, но …
Итоги года или день рождения СДСМ
22 декабря 2011 года началась дивная история выдуманной компании ЛифтМиАп, а вместе с ней увидел свет нулевой выпуск из цикла Сети Для Самых Маленьких. Прошёл ровно год, пора подвести количественные …
0
6694
21
22 декабря 2012