Среднеквадратическое отклонение (Mean square deviation)
Среднеквадратическое отклонение — статистическая характеристика распределения случайной величины, показывающая среднюю степень разброса значений величины относительно математического ожидания. Обозначается греческой σ (сигма) или буквой S .
Среднеквадратическое отклонение измеряется в единицах самой случайной величины и используется при расчёте стандартной ошибки среднего арифметического, при построении доверительных интервалов, при статистической проверке гипотез, при измерении линейной взаимосвязи между случайными величинами.
Определяется как квадратный корень из дисперсии случайной величины. Стандартное отклонение на основании смещённой оценки дисперсии (иногда называемой просто выборочной дисперсией):
S = √ 1 n n ∑ i = 1 ( x i − ¯ x ) 2 .
Стандартное отклонение на основании несмещённой оценки дисперсии:
S 0 = √ n n − 1 S 2 = √ 1 n − 1 n ∑ i = 1 ( x i − ¯ x ) 2 ,
где S 2 — выборочная дисперсия; x i — i-й элемент выборки; n — объём выборки; ¯ x — среднее арифметическое выборки (выборочное среднее):
¯ x = 1 n n ∑ i = 1 x i = 1 n ( x 1 + … + x n ) .
Большее значение среднеквадратического отклонения показывает больший разброс наблюдаемых значений признака относительно среднего; меньшее значение, соответственно, показывает, что величины в множестве сгруппированы вокруг среднего.
Наряду с дисперсией среднеквадратическое отклонение является одним из параметров нормального распределения. Чем оно выше, тем длиннее «хвосты» распределения.
В анализе данных среднеквадратическое отклонение может использоваться в качестве меры изменчивости значений признаков, степени отклонения желаемых показателей от наблюдаемых, а также для обнаружения выбросов и аномальных значений в данных c помощью правила трёх сигм.
Как найти среднеквадратическое отклонение
В данной статье я расскажу о том, как найти среднеквадратическое отклонение. Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом 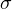 (греческая буква «сигма»).
(греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
- Определите среднее (простое среднее арифметическое ряда значений).
- Затем от каждого из значений отнимите среднее и возведите полученную разность в квадрат (получили квадрат разности).
- Следующим шагом будет вычисление среднего арифметического полученных квадратов разностей (Почему именно квадратов вы сможете узнать ниже).
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
| Порода собаки | Рост в миллиметрах |
| Ротвейлер | 600 |
| Бульдог | 470 |
| Такса | 170 |
| Пудель | 430 |
| Мопс | 300 |
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение. Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее 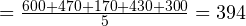 мм.
мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего:
![[ begin{array}{l} 1: 600-394 = 206 \ 2: 470-394 = 76 \ 3: 170-394 = -224\ 4: 430-394 = 36\ 5: 300-394 = -94 end{array} ]](https://yourtutor.info/wp-content/ql-cache/quicklatex.com-3916a3ccd97d909589dfe1dabb970af0_l3.png)
Наконец, чтобы вычислить дисперсию, каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
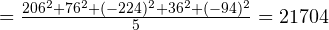
Дисперсия мм 2 .
Таким образом, дисперсия составляет 21704 мм 2 .
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
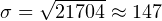 мм (округлено до ближайшего целого значения в мм).
мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть 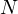 значений, то:
значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки = 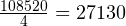 мм 2 .
мм 2 .
При этом стандартное отклонение по выборке равно 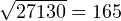 мм (округлено до ближайшего целого значения).
мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
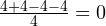 .
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
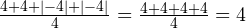 .
.
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
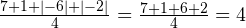 .
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
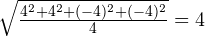 .
.
Для второго примера получится:
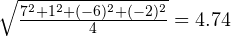 .
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал репетитор по математике в Москве, Сергей Валерьевич
Что такое «сигма»?
Сигмой (σ) в статистическом анализе обозначают стандартное отклонение. Опуская тонкости, которые будут обсуждены ниже, можно сказать, что стандартное отклонение — это та погрешность, то «± сколько-то», которым обязательно сопровождают измерение величины. Если вы измерили массу предмета и получили результат 100 ± 5 грамм, то величина «110 грамм» отличается от измеренного результата на два стандартных отклонения (то есть на 2 сигмы), величина «50 грамм» отличается на 10 стандартных отклонений (на 10 сигм).
Зачем всё это нужно: сигмы и вероятности
При обсуждении погрешностей мы уже говорили, что фраза «измеренная масса равна 100 ± 5 грамм» вовсе не означает, что истинная масса гарантированно лежит в интервале от 95 до 105 грамм. Она может оказаться и за пределами этого интервала «± 1σ», но, как правило, недалеко. В небольшом проценте случаев может даже случиться, что она выходит за пределы интервала «± 2σ», и уж совсем редко она оказывается за пределами «± 3σ». В общем, тенденция ясна: количество сигм связано с вероятностью того, что истинное значение будет настолько отличаться от измеренного.
Вероятность того, что истинное значение попадет в определенный интервал около измеренного среднего значения при нормальном распределении ошибок. Изображение с сайта en.wikipedia.org
Пропустим все математические подробности и покажем результат для самого простого и распространенного случая, который называется «нормальное распределение» (см. рисунок). Вероятность попасть в интервал ± 1σ — примерно 68%, в интервал ± 2σ — примерно 95%, в интервал ± 3σ — примерно 99,8%, и т. д. Итак, можно сформулировать некую договоренность:
Использовать эту договоренность можно разными способами. Если вы просто сообщаете результат измерения (100 ± 5 грамм) и уверены в том, что нормальное распределение применимо, то вы можете сказать, что истинное значение массы с вероятностью 68% лежит в этом интервале, с вероятностью 95% лежит в интервале от 90 до 110 грамм, и т. д.
- Если отличие составляет меньше 1σ, то вероятность того, что два числа согласуются друг с другом, больше 32%. В таком случае просто говорят, что два результата совпадают в пределах погрешностей.
- Если отличие составляет меньше 3σ, то вероятность того, что два числа согласуются друг с другом, больше 0,2%. В физике элементарных частиц такой вероятности недостаточно для каких-либо серьезных выводов, и принято говорить: различие между двумя результатами не является статистически значимым.
- Если отличие от 3σ до 5σ, то это повод подозревать что-то серьезное. Впрочем, даже в этом случае физики говорят осторожно: данные указывают на существование различия между двумя результатами.
- И только если два результата отличаются на 5σ или больше, физики четко заявляют: два результата отличаются друг от друга.
Эти выражения особенно стандартны, когда речь идет о поиске новой частицы. Вы сравниваете экспериментальные данные с теоретическим предсказанием, сделанным без новой частицы, и, если видите отличие от 3 до 5 сигм, вы говорите: получено указание на существование новой частицы (по-английски, evidence). Если же отличие превышает 5 сигм, вы говорите: мы открыли новую частицу (discovery).
Пример 1
Предположим, что вы изучаете какой-то редкий распад мезона и сравниваете его с теоретическим предсказанием в рамках Стандартной модели. Для удобства записи вы выразили результат измерения в виде такой величины:
μ = (измеренная вероятность распада) / (теоретически предсказанная вероятность распада)
и получили ответ: μ = 1,25 ± 0,25. Что вы можете сказать про этот результат?
Во-первых, он отличается от нуля на пять сигм. Значит, он уже классифицируется как открытие, и поэтому вы можете смело заявлять: мы открыли искомый распад мезона (если, конечно, это уже не сделал кто-то до вас; тогда вам придется довольствоваться скромным «подтверждением открытия»). Во-вторых, он отличается от единицы на одну сигму. Такое отклонение «неинтересно», оно не позволяет вам сказать, что вы обнаружили какое-то статистически значимое отличие от теоретических расчетов. Поэтому вы добавляете: измеренное значение согласуется с предсказаниями Стандартной модели.
Предположим далее, что вы набрали в 25 раз больше статистики, перемеряли эту вероятность и получили уточненное значение: μ = 1,20 ± 0,05. Отличие от нуля составляет уже 24 сигмы, так что сомнений в реальности эффекта больше не остается. Отличие от единицы составляет теперь 4 сигмы. Этого еще недостаточно для того, чтобы заявить, что вы открыли Новую физику. Но вы можете четко сказать, что ваши данные расходятся с теоретическими предсказаниями на уровне 4 сигм и указывают на существование эффекта вне Стандартной модели.
Пример 2
Вы изучаете рождение мюонов и антимюонов в каком-то процессе и хотите узнать, можно ли сделать вывод о том, что они рождаются с разной вероятностью. Для мюонов (μ – ) вы получили вероятность рождения x– = 0,18 ± 0,03, а для антимюонов (μ + ) – x+ = 0,30 ± 0,04. Разница получается 0,12, но насколько значимым является это различие?
Если для обеих погрешностей справедливы нормальные распределения, а также если эти погрешности полностью независимы (между ними нет корреляций), то общая погрешность величины x+ – x– вычисляется по формуле суммирования квадратов. Поэтому результат измерения x+ – x– = 0,12 ± 0,05. Отличие составляет 2,4 сигмы, и этого еще недостаточно для каких-либо серьезных выводов.
«Уверенность» против «статистической значимости»
Заметьте, что в приведенных выше примерах нас интересовали вопросы, на которые можно ответить «да» или «нет». Проступает ли в полученных данных какая-то новая частица? Согласуется ли распределение по импульсу с теоретическими расчетами? Зависит ли сечение процесса от энергии столкновений? Совпадает ли масса у частицы и ее античастицы? Попытка ответить на эти вопросы с помощью данных называется на научном языке проверкой гипотез. Вопросы, которые требуют развернутого ответа (подсчитать что-то, объяснить что-то и т. п.), гипотезами не называются.
В простейшем приближении результат экспериментальной проверки гипотезы выглядит так: ответ «да» с вероятностью p и ответ «нет» с вероятностью 1 – p. Эти вероятности очень важны для сообщения результата; физики обычно избегают абсолютных утверждений («мы открыли» или «мы опровергли») без указания вероятностей.
Но тут сразу же надо сделать важное уточнение. Если его четко осознать, то станет понятным, почему такие стандартные для научно-популярных новостей фразы, как «Ученые на 99% уверены, что открыли что-то новое», — обманчивы.
Точная формулировка, которую обычно используют ученые, такова:
При проверке гипотезы получен ответ «да» на уровне статистической значимости p.
При этом величина p часто выражается в виде количества сигм. В англоязычной литературе используется словосочетание confidence level, CL (доверительный уровень). В русскоязычной еще иногда говорят «статистическая достоверность», но такое выражение может привести к путанице в понимании.
Отличие «популярной» фразы от истинного утверждения вот в чём. Во всяком измерении есть не только статистические, но и систематические погрешности. Описанные выше правила связи вероятностей и количества сигм работают только для статистических погрешностей — и то если к ним применимо нормальное распределение. Если статистические погрешности всегда можно обсчитать аккуратно, то систематические погрешности — это немножко искусство. Более того, из многолетнего опыта известно, что сильные систематические отклонения уж точно не описываются нормальным распределением, и потому для них эти правила пересчета не справедливы. Так что даже если экспериментаторы всё перепроверили много раз и указали систематическую погрешность, всегда остается риск, что они что-то упустили из виду. Корректно оценить этот риск невозможно, поэтому вы на самом деле не знаете, с какой истинной вероятностью ваш ответ верен.
Конечно, по умолчанию систематическим погрешностям стоит доверять, особенно если они исходят от опытных экспериментальных групп. Но вековой опыт изучения элементарных частиц показывает, что несмотря на все предосторожности регулярно случаются проколы. Бывает, что коллаборация получает результат, сильно противоречащий какой-то гипотезе, перепроверяет анализ много раз и никаких ошибок у себя не находит. Однако этот результат затем не подтверждается другими — порой намного более точными! — экспериментами. Почему первый эксперимент дал такой странный результат, что в нём было не то, где там ошибка или неучтенная погрешность — всё это зачастую так и остается непонятым (впрочем, иногда источник ошибки быстро вскрывается, как это случилось со «сверхсветовыми» нейтрино в эксперименте OPERA).
Физики к таким оборотам событий уже привыкли, поэтому каждый экспериментальный результат, сильно отличающийся от всей сложившейся к тому времени картины, вызывает оправданный скепсис. Физики так консервативны в своем отношении вовсе не потому, что они ретрограды и намертво уверовали в какую-то одну теорию, как это хотят представить опровергатели физики. Они просто научены всем предыдущим опытом в физике частиц и знают, чем это обычно кончается. Поэтому без независимого подтверждения другими экспериментами подобные сенсации они не поддерживают.
ФЭЧ в сравнении с другими науками
Надо сказать, что сформулированные выше жесткие критерии статистической достоверности характерны именно для физики элементарных частиц и некоторых смежных разделов. Во многих других разделах физики, а тем более в других дисциплинах (в особенности, в биомедицинских науках) критерии намного слабее.
Предположим, вы измерили некие данные и хотите узнать, какова вероятность того, что они «вписываются в норму». Вы проводите статистический тест, который дает вам вероятность того, что «нормальная ситуация» без какого-либо реального отклонения только за счет статистической флуктуации даст вот такое или еще более сильное отклонение. Эта вероятность называется p-значение. В биологии пороговое p-значение, ниже которого уже уверенно говорят про реальное отличие, составляет один или даже несколько процентов. В физике элементарных частиц такое отличие вообще не считают значимым, тут нет даже «указания на существование» какого-то отличия! Ответственное заявление об отличии звучит в ФЭЧ только для p-значений меньше одной двухмиллионной (то есть отклонение больше 5σ). Такой жесткий подход к достоверности утверждений выработался в ФЭЧ примерно полвека назад, в эпоху, когда экспериментаторы видели много отклонений со значимостью в районе 3σ и смело заявляли об открытии новых частиц, хотя потом эти «открытия» не подтверждались. Подробный рассказ об истоках этого критерия см. в постах Tommaso Dorigo (часть 1, часть 2).
В данной статье я расскажу о том, как найти среднеквадратическое отклонение. Этот материал крайне важен для полноценного понимания математики, поэтому репетитор по математике должен посвятить его изучению отдельный урок или даже несколько. В этой статье вы найдёте ссылку на подробный и понятный видеоурок, в котором рассказано о том, что такое среднеквадратическое отклонение и как его найти.
Среднеквадратическое отклонение дает возможность оценить разброс значений, полученных в результате измерения какого-то параметра. Обозначается символом (греческая буква «сигма»).
Формула для расчета довольно проста. Чтобы найти среднеквадратическое отклонение, нужно взять квадратный корень из дисперсии. Так что теперь вы должны спросить: “А что же такое дисперсия?”
Что такое дисперсия
Определение дисперсии звучит так. Дисперсия — это среднее арифметическое от квадратов отклонений значений от среднего.
Чтобы найти дисперсию последовательно проведите следующие вычисления:
- Определите среднее (простое среднее арифметическое ряда значений).
- Затем от каждого из значений отнимите среднее и возведите полученную разность в квадрат (получили квадрат разности).
- Следующим шагом будет вычисление среднего арифметического полученных квадратов разностей (Почему именно квадратов вы сможете узнать ниже).
Рассмотрим на примере. Допустим, вы с друзьями решили измерить рост ваших собак (в миллиметрах). В результате измерений вы получили следующие данные измерений роста (в холке): 600 мм, 470 мм, 170 мм, 430 мм и 300 мм.
| Порода собаки | Рост в миллиметрах |
| Ротвейлер | 600 |
| Бульдог | 470 |
| Такса | 170 |
| Пудель | 430 |
| Мопс | 300 |
Вычислим среднее значение, дисперсию и среднеквадратическое отклонение.
Сперва найдём среднее значение. Как вы уже знаете, для этого нужно сложить все измеренные значения и поделить на количество измерений. Ход вычислений:
Среднее мм.
Итак, среднее (среднеарифметическое) составляет 394 мм.
Теперь нужно определить отклонение роста каждой из собак от среднего:
Наконец, чтобы вычислить дисперсию, каждую из полученных разностей возводим в квадрат, а затем находим среднее арифметическое от полученных результатов:
Дисперсия мм2.
Таким образом, дисперсия составляет 21704 мм2.
Как найти среднеквадратическое отклонение
Так как же теперь вычислить среднеквадратическое отклонение, зная дисперсию? Как мы помним, взять из нее квадратный корень. То есть среднеквадратическое отклонение равно:
мм (округлено до ближайшего целого значения в мм).
Применив данный метод, мы выяснили, что некоторые собаки (например, ротвейлеры) – очень большие собаки. Но есть и очень маленькие собаки (например, таксы, только говорить им этого не стоит).
Самое интересное, что среднеквадратическое отклонение несет в себе полезную информацию. Теперь мы можем показать, какие из полученных результатов измерения роста находятся в пределах интервала, который мы получим, если отложим от среднего (в обе стороны от него) среднеквадратическое отклонение.
То есть с помощью среднеквадратического отклонения мы получаем “стандартный” метод, который позволяет узнать, какое из значений является нормальным (среднестатистическим), а какое экстраординарно большим или, наоборот, малым.
Что такое стандартное отклонение
Но… все будет немного иначе, если мы будем анализировать выборку данных. В нашем примере мы рассматривали генеральную совокупность. То есть наши 5 собак были единственными в мире собаками, которые нас интересовали.
Но если данные являются выборкой (значениями, которые выбрали из большой генеральной совокупности), тогда вычисления нужно вести иначе.
Если есть значений, то:
Все остальные расчеты производятся аналогично, в том числе и определение среднего.
Например, если наших пять собак – только выборка из генеральной совокупности собак (всех собак на планете), мы должны делить на 4, а не на 5, а именно:
Дисперсия выборки = мм2.
При этом стандартное отклонение по выборке равно мм (округлено до ближайшего целого значения).
Можно сказать, что мы произвели некоторую “коррекцию” в случае, когда наши значения являются всего лишь небольшой выборкой.
Примечание. Почему именно квадраты разностей?
Но почему при вычислении дисперсии мы берём именно квадраты разностей? Допустим при измерении какого-то параметра, вы получили следующий набор значений: 4; 4; -4; -4. Если мы просто сложим абсолютные отклонения от среднего (разности) между собой … отрицательные значения взаимно уничтожатся с положительными:
.
Получается, этот вариант бесполезен. Тогда, может, стоит попробовать абсолютные значения отклонений (то есть модули этих значений)?
.
На первый взгляд получается неплохо (полученная величина, кстати, называется средним абсолютным отклонением), но не во всех случаях. Попробуем другой пример. Пусть в результате измерения получился следующий набор значений: 7; 1; -6; -2. Тогда среднее абсолютное отклонение равно:
.
Вот это да! Снова получили результат 4, хотя разности имеют гораздо больший разброс.
А теперь посмотрим, что получится, если возвести разности в квадрат (и взять потом квадратный корень из их суммы).
Для первого примера получится:
.
Для второго примера получится:
.
Теперь – совсем другое дело! Среднеквадратическое отклонение получается тем большим, чем больший разброс имеют разности … к чему мы и стремились.
Фактически в данном методе использована та же идея, что и при вычислении расстояния между точками, только примененная иным способом.
И с математической точки зрения использование квадратов и квадратных корней дает больше пользы, чем мы могли бы получить на основании абсолютных значений отклонений, благодаря чему среднеквадратическое отклонение применимо и для других математических задач.
О том, как найти среднеквадратическое отклонение, вам рассказал репетитор по математике в Москве, Сергей Валерьевич
Стандартное отклонение (англ. Standard Deviation) — простыми словами это мера того, насколько разбросан набор данных.
Вычисляя его, можно узнать, являются ли числа близкими к среднему значению или далеки от него. Если точки данных находятся далеко от среднего значения, то в наборе данных имеется большое отклонение; таким образом, чем больше разброс данных, тем выше стандартное отклонение.
Стандартное отклонение обозначается буквой σ (греческая буква сигма).
Стандартное отклонение также называется:
- среднеквадратическое отклонение,
- среднее квадратическое отклонение,
- среднеквадратичное отклонение,
- квадратичное отклонение,
- стандартный разброс.
Использование и интерпретация величины среднеквадратического отклонения
Стандартное отклонение используется:
- в финансах в качестве меры волатильности,
- в социологии в опросах общественного мнения — оно помогает в расчёте погрешности.
Пример:
Рассмотрим два малых предприятия, у нас есть данные о запасе какого-то товара на их складах.
| День 1 | День 2 | День 3 | День 4 | |
|---|---|---|---|---|
| Пред.А | 19 | 21 | 19 | 21 |
| Пред.Б | 15 | 26 | 15 | 24 |
В обеих компаниях среднее количество товара составляет 20 единиц:
- А -> (19 + 21 + 19+ 21) / 4 = 20
- Б -> (15 + 26 + 15+ 24) / 4 = 20
Однако, глядя на цифры, можно заметить:
- в компании A количество товара всех четырёх дней очень близко находится к этому среднему значению 20 (колеблется лишь между 19 ед. и 21 ед.),
- в компании Б существует большая разница со средним количеством товара (колеблется между 15 ед. и 26 ед.).
Если рассчитать стандартное отклонение каждой компании, оно покажет, что
- стандартное отклонение компании A = 1,
- стандартное отклонение компании Б ≈ 5.
Стандартное отклонение показывает эту волатильность данных — то, с каким размахом они меняются; т.е. как сильно этот запас товара на складах компаний колеблется (поднимается и опускается).
Расчет среднеквадратичного (стандартного) отклонения
Формулы вычисления стандартного отклонения

σ — стандартное отклонение,
xi — величина отдельного значения выборки,
μ — среднее арифметическое выборки,
n — размер выборки.
Эта формула применяется, когда анализируются все значения выборки.

S — стандартное отклонение,
n — размер выборки,
xi — величина отдельного значения выборки,
xср — среднее арифметическое выборки.
Эта формула применяется, когда присутствует очень большой размер выборки, поэтому на анализ обычно берётся только её часть.
Единственная разница с предыдущей формулой: “n — 1” вместо “n”, и обозначение «xср» вместо «μ».
Разница между формулами S и σ («n» и «n–1»)
Состоит в том, что мы анализируем — всю выборку или только её часть:
- только её часть – используется формула S (с «n–1»),
- полностью все данные – используется формула σ (с «n»).
Как рассчитать стандартное отклонение?
Пример 1 (с σ)
Рассмотрим данные о запасе какого-то товара на складах Предприятия Б.
| День 1 | День 2 | День 3 | День 4 | |
| Пред.Б | 15 | 26 | 15 | 24 |
Если значений выборки немного (небольшое n, здесь он равен 4) и анализируются все значения, то применяется эта формула:

Применяем эти шаги:
1. Найти среднее арифметическое выборки:
μ = (15 + 26 + 15+ 24) / 4 = 20
2. От каждого значения выборки отнять среднее арифметическое:
x1 — μ = 15 — 20 = -5
x2 — μ = 26 — 20 = 6
x3 — μ = 15 — 20 = -5
x4 — μ = 24 — 20 = 4
3. Каждую полученную разницу возвести в квадрат:
(x1 — μ)² = (-5)² = 25
(x2 — μ)² = 6² = 36
(x3 — μ)² = (-5)² = 25
(x4 — μ)² = 4² = 16
4. Сделать сумму полученных значений:
Σ (xi — μ)² = 25 + 36+ 25+ 16 = 102
5. Поделить на размер выборки (т.е. на n):
(Σ (xi — μ)²)/n = 102 / 4 = 25,5
6. Найти квадратный корень:
√((Σ (xi — μ)²)/n) = √ 25,5 ≈ 5,0498
Пример 2 (с S)
Задача усложняется, когда существуют сотни, тысячи или даже миллионы данных. В этом случае берётся только часть этих данных и анализируется методом выборки.
У Андрея 20 яблонь, но он посчитал яблоки только на 6 из них.
Популяция — это все 20 яблонь, а выборка — 6 яблонь, это деревья, которые Андрей посчитал.
| Яблоня 1 | Яблоня 2 | Яблоня 3 | Яблоня 4 | Яблоня 5 | Яблоня 6 |
| 9 | 2 | 5 | 4 | 12 | 7 |
Так как мы используем только выборку в качестве оценки всей популяции, то нужно применить эту формулу:

Математически она отличается от предыдущей формулы только тем, что от n нужно будет вычесть 1. Формально нужно будет также вместо μ (среднее арифметическое) написать X ср.
Применяем практически те же шаги:
1. Найти среднее арифметическое выборки:
Xср = (9 + 2 + 5 + 4 + 12 + 7) / 6 = 39 / 6 = 6,5
2. От каждого значения выборки отнять среднее арифметическое:
X1 – Xср = 9 – 6,5 = 2,5
X2 – Xср = 2 – 6,5 = –4,5
X3 – Xср = 5 – 6,5 = –1,5
X4 – Xср = 4 – 6,5 = –2,5
X5 – Xср = 12 – 6,5 = 5,5
X6 – Xср = 7 – 6,5 = 0,5
3. Каждую полученную разницу возвести в квадрат:
(X1 – Xср)² = (2,5)² = 6,25
(X2 – Xср)² = (–4,5)² = 20,25
(X3 – Xср)² = (–1,5)² = 2,25
(X4 – Xср)² = (–2,5)² = 6,25
(X5 – Xср)² = 5,5² = 30,25
(X6 – Xср)² = 0,5² = 0,25
4. Сделать сумму полученных значений:
Σ (Xi – Xср)² = 6,25 + 20,25+ 2,25+ 6,25 + 30,25 + 0,25 = 65,5
5. Поделить на размер выборки, вычитав перед этим 1 (т.е. на n–1):
(Σ (Xi – Xср)²)/(n-1) = 65,5 / (6 – 1) = 13,1
6. Найти квадратный корень:
S = √((Σ (Xi – Xср)²)/(n–1)) = √ 13,1 ≈ 3,6193
Дисперсия и стандартное отклонение
Стандартное отклонение равно квадратному корню из дисперсии (S = √D). То есть, если у вас уже есть стандартное отклонение и нужно рассчитать дисперсию, нужно лишь возвести стандартное отклонение в квадрат (S² = D).
Дисперсия — в статистике это «среднее квадратов отклонений от среднего». Чтобы её вычислить нужно:
- Вычесть среднее значение из каждого числа
- Возвести каждый результат в квадрат (так получатся квадраты разностей)
- Найти среднее значение квадратов разностей.
Ещё расчёт дисперсии можно сделать по этой формуле:

S² — выборочная дисперсия,
Xi — величина отдельного значения выборки,
Xср (может появляться как X̅) — среднее арифметическое выборки,
n — размер выборки.
Правило трёх сигм
Это правило гласит: вероятность того, что случайная величина отклонится от своего математического ожидания более чем на три стандартных отклонения (на три сигмы), почти равна нулю.

Глядя на рисунок нормального распределения случайной величины, можно понять, что в пределах:
- одного среднеквадратического отклонения заключаются 68,26% значений (Xср ± 1σ или μ ± 1σ),
- двух стандартных отклонений — 95,44% (Xср ± 2σ или μ ± 2σ),
- трёх стандартных отклонений — 99,72% (Xср ± 3σ или μ ± 3σ).
Это означает, что за пределами остаются лишь 0,28% — это вероятность того, что случайная величина примет значение, которое отклоняется от среднего более чем на 3 сигмы.
Стандартное отклонение в excel
Вычисление стандартного отклонения с «n – 1» в знаменателе (случай выборки из генеральной совокупности):
1. Занесите все данные в документ Excel.

2. Выберите поле, в котором вы хотите отобразить результат.
3. Введите в этом поле «=СТАНДОТКЛОНА(«
4. Выделите поля, где находятся данные, потом закройте скобки.

5. Нажмите Ввод (Enter).

В случае если данные представляют всю генеральную совокупность (n в знаменателе), то нужно использовать функцию СТАНДОТКЛОНПА.


Коэффициент вариации
Коэффициент вариации — отношение стандартного отклонения к среднему значению, т.е. Cv = (S/μ) × 100% или V = (σ/X̅) × 100%.
Стандартное отклонение делится на среднее и умножается на 100%.
Можно классифицировать вариабельность выборки по коэффициенту вариации:
- при <10% выборка слабо вариабельна,
- при 10% – 20 % — средне вариабельна,
- при >20 % — выборка сильно вариабельна.
Узнайте также про:
- Корреляции,
- Метод Крамера,
- Метод наименьших квадратов,
- Теорию вероятностей
- Интегралы.
Среднее квадратичное отклонение двух, трех, четырех и более чисел. Оно же стандартное отклонение, среднеквадратическое отклонение, среднеквадратичное отклонение, средняя квадратическая, стандартный разброс — показатель рассеивания значений случайной величины относительно её математического ожидания в теории вероятностей и статистике.
Как правило перечисленные термины равны квадратному корню дисперсии.
Пример вычисления стандартного отклонения по следующим формулам:
Вычислим среднюю оценку ученика: 2; 4; 5; 6; 8.
Cредняя оценка будет равна:

Вычисляем квадраты отклонений оценок от их средней оценки:

Вычислим среднее арифметическое (дисперсию) этих значений:

Стандартное отклонение равно квадратному корню дисперсии:

Эта формула справедлива только если эти пять значений и являются генеральной совокупностью. Если бы эти данные были случайной выборкой из какой-то большой совокупности (например, оценки пяти случайно выбранных учеников большого города), то в знаменателе формулы для вычисления дисперсии вместо n = 5 нужно было бы поставить n − 1 = 4:

Тогда стандартное отклонение будет равняться:

Этот результат называется стандартным отклонением на основании несмещённой оценки дисперсии. Деление на n − 1 вместо n даёт неискажённую оценку дисперсии для больших генеральных совокупностей.
×
Пожалуйста напишите с чем связна такая низкая оценка:
×
Для установки калькулятора на iPhone — просто добавьте страницу
«На главный экран»

Для установки калькулятора на Android — просто добавьте страницу
«На главный экран»

Смотрите также
![]()
Загрузить PDF
![]()
Загрузить PDF
Вычислив среднеквадратическое отклонение, вы найдете разброс значений в выборке данных.[1]
Но сначала вам придется вычислить некоторые величины: среднее значение и дисперсию выборки. Дисперсия – мера разброса данных вокруг среднего значения.[2]
Среднеквадратическое отклонение равно квадратному корню из дисперсии выборки. Эта статья расскажет вам, как найти среднее значение, дисперсию и среднеквадратическое отклонение.
-

1
Возьмите наборе данных. Среднее значение – это важная величина в статистических расчетах.[3]
- Определите количество чисел в наборе данных.
- Числа в наборе сильно отличаются друг от друга или они очень близки (отличаются на дробные доли)?
- Что представляют числа в наборе данных? Тестовые оценки, показания пульса, роста, веса и так далее.
- Например, набор тестовых оценок: 10, 8, 10, 8, 8, 4.
-
2
Для вычисления среднего значения понадобятся все числа данного набора данных.[4]
- Среднее значение – это усредненное значение всех чисел в наборе данных.
- Для вычисления среднего значения сложите все числа вашего набора данных и разделите полученное значение на общее количество чисел в наборе (n).
- В нашем примере (10, 8, 10, 8, 8, 4) n = 6.
-
3
Сложите все числа вашего набора данных.[5]
- В нашем примере даны числа: 10, 8, 10, 8, 8 и 4.
- 10 + 8 + 10 + 8 + 8 + 4 = 48. Это сумма всех чисел в наборе данных.
- Сложите числа еще раз, чтобы проверить ответ.
-
4
Разделите сумму чисел на количество чисел (n) в выборке. Вы найдете среднее значение.[6]
- В нашем примере (10, 8, 10, 8, 8 и 4) n = 6.
- В нашем примере сумма чисел равна 48. Таким образом, разделите 48 на n.
- 48/6 = 8
- Среднее значение данной выборки равно 8.
Реклама




-
1
Вычислите дисперсию. Это мера разброса данных вокруг среднего значения.[7]
- Эта величина даст вам представление о том, как разбросаны данные выборки.
- Выборка с малой дисперсией включает данные, которые ненамного отличаются от среднего значения.
- Выборка с высокой дисперсией включает данные, которые сильно отличаются от среднего значения.
- Дисперсию часто используют для того, чтобы сравнить распределение двух наборов данных.
-
2
Вычтите среднее значение из каждого числа в наборе данных. Вы узнаете, насколько каждая величина в наборе данных отличается от среднего значения.[8]
- В нашем примере (10, 8, 10, 8, 8, 4) среднее значение равно 8.
- 10 — 8 = 2; 8 — 8 = 0, 10 — 2 = 8, 8 — 8 = 0, 8 — 8 = 0, и 4 — 8 = -4.
- Проделайте вычитания еще раз, чтобы проверить каждый ответ. Это очень важно, так как полученные значения понадобятся при вычислениях других величин.
-
3
Возведите в квадрат каждое значение, полученное вами в предыдущем шаге.[9]
- При вычитании среднего значения (8) из каждого числа данной выборки (10, 8, 10, 8, 8 и 4) вы получили следующие значения: 2, 0, 2, 0, 0 и -4.
- Возведите эти значения в квадрат: 22, 02, 22, 02, 02, и (-4)2 = 4, 0, 4, 0, 0, и 16.
- Проверьте ответы, прежде чем приступить к следующему шагу.
-
4
Сложите квадраты значений, то есть найдите сумму квадратов.[10]
- В нашем примере квадраты значений: 4, 0, 4, 0, 0 и 16.
- Напомним, что значения получены путем вычитания среднего значения из каждого числа выборки: (10-8)^2 + (8-8)^2 + (10-2)^2 + (8-8)^2 + (8-8)^2 + (4-8)^2
- 4 + 0 + 4 + 0 + 0 + 16 = 24.
- Сумма квадратов равна 24.
-
5
Разделите сумму квадратов на (n-1). Помните, что n – это количество данных (чисел) в вашей выборке. Таким образом, вы получите дисперсию.[11]
- В нашем примере (10, 8, 10, 8, 8, 4) n = 6.
- n-1 = 5.
- В нашем примере сумма квадратов равна 24.
- 24/5 = 4,8
- Дисперсия данной выборки равна 4,8.
Реклама





-
1
Найдите дисперсию, чтобы вычислить среднеквадратическое отклонение.[12]
- Помните, что дисперсия – это мера разброса данных вокруг среднего значения.
- Среднеквадратическое отклонение – это аналогичная величина, описывающая характер распределения данных в выборке.
- В нашем примере дисперсия равна 4,8.
-
2
Извлеките квадратный корень из дисперсии, чтобы найти среднеквадратическое отклонение.[13]
- Как правило, 68% всех данных расположены в пределах одного среднеквадратического отклонения от среднего значения.
- В нашем примере дисперсия равна 4,8.
- √4,8 = 2,19. Среднеквадратическое отклонение данной выборки равно 2,19.
- 5 из 6 чисел (83%) данной выборки (10, 8, 10, 8, 8, 4) находится в пределах одного среднеквадратического отклонения (2,19) от среднего значения (8).
-
3
Проверьте правильность вычисления среднего значения, дисперсии и среднеквадратического отклонения. Это позволит вам проверить ваш ответ.[14]
- Обязательно записывайте вычисления.
- Если в процессе проверки вычислений вы получили другое значение, проверьте все вычисления с самого начала.
- Если вы не можете найти, где сделали ошибку, проделайте вычисления с самого начала.
Реклама



Об этой статье
Эту страницу просматривали 65 043 раза.