SEARCH
Функция возвращает положение строки текста в пределах другой строки.
Синтаксис функции:
| =SEARCH(findtext; texttosearch; startposition) |
|---|
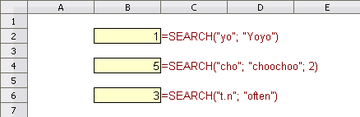
![]()
Рис. 1. Пример функции.
где:
- findtext — искомая текстовая строка;
- texttosearch — текст, в котором осуществляется поиск;
- startposition — (необязательный) позиция, с которой начинается поиск.
Функция SEARCH возвращает положение символа из первого появления findtext в пределах texttosearch, начиная с символьной позиции startposition. По умолчанию startposition — 1, если опущен. Поиск не учитывает регистр.
Поиск будет использовать регулярные выражения, если они разрешены (меню Сервис → Параметры → InfraOffice.pro Calc → Вычисления).
Если найти строку findtext не удалось, возвращается ошибка #VALUE!.
Установка параметра Условия поиска = и <> должны распространяться на всю ячейку в диалоговом окне Сервис → Параметры → InfraOffice.pro Calc → Вычисления, не оказывает на поиск никакого эффекта.
На рис. 1:
- в ячейке B2 возвращается 1. Поиск выполняется без учёта регистра.;
- в ячейке B6 возвращается 3, если регулярные выражения разрешены. “.” означает любой одиночный символ в регулярном выражении, таким образом “t.n” соответствует “ten”.
![]()
BASE
Преобразует положительное целое число
с заданным основанием в текст, выражающий
число в определенной системе
счисления. Используются цифры 0-9 и
буквы A-Z.
Синтаксис:
BASE(Число; Основание; [Минимальная
длина])
Число: положительное целое число
для преобразования.
Основание: основание системы
счисления. Это может быть любое
положительное целое число от 2 до 36.
Минимальная_длина (необязательный
параметр): минимальная длина созданной
последовательности символов. Если текст
короче указанной минимальной длины, в
начало строки добавляются нули.
Пример:
=BASE(17;10;4) возвращает
значение 0017 в десятичной системе
счисления.
=BASE(17;2) возвращает
значение 10001 в двоичной системе счисления.
=BASE(255;16;4) возвращает число 00FF в
шестнадцатеричной системе счисления.
CHAR
Служит для преобразования числа в
символ в соответствии с текущей кодовой
таблицей. Число может быть целым
двухзначным или трехзначным числом.
Коды больше 127 могут зависеть
от системной кодировки (например,
iso-8859-1, iso-8859-2, Windows 1252, Windows 1250) и поэтому
быть непереносимыми.
Синтаксис:
CHAR(Число)
Число: число от 1 до 255, определяющее
кодовое значение символа.
Пример:
=CHAR(100) возвращает символ «d».
=»abc» & CHAR(10) & «def» обеспечивает
вставку символа разрыва строки.
CLEAN
Служит для удаления всех непечатаемых
символов из строки.
Синтаксис:
CLEAN(«Текст»)
Текст: текст, из которого требуется
удалить все непечатаемые символы.
CODE
Возвращает числовой код первого
символа в текстовой строке.
Синтаксис:
CODE(«Текст»)
Текст: текст, для которого требуется
определить код первого символа.
Коды больше 127 могут зависеть
от системной кодировки (например,
iso-8859-1, iso-8859-2, Windows 1252, Windows 1250) и поэтому
быть непереносимыми.
Пример:
=CODE(«Hieronymus») возвращает значение
72, =CODE(«hieroglyphic») возвращает значение
104.
CONCATENATE
Объединяет несколько текстовых
элементов в одну строку.
Синтаксис:
CONCATENATE(«Текст1»; …; «Текст30»)
Текст 1; текст 2; …: до 30 текстовых
элементов, которые требуется объединить
в одну строку.
Пример:
=CONCATENATE(«Доброе «;»утро «;»миссис
«;»Доу») возвращает значение
«Доброе утро, миссис Доу».
DECIMAL
Преобразует текст с символами,
представленными в определеннойсистеме
счисления, в положительное целое
число с заданным основанием. Основа
должна входить в диапазон от 2 до 36.
Пробелы и символы табуляции игнорируются.
В поле Текст регистр символов не
учитывается.
Если основание равно 16, первая x, X, 0x
или 0X, а также добавочная h или H не
учитываются. Если основание равно 2,
добавочная b или B не учитывается. При
использовании символов, которые не
принадлежат к указанной системе
счисления, выдается ошибка.
Синтаксис:
DECIMAL(«Текст»; Основание)
Текст: текст для преобразования.
Для определения различия между числом
шестнадцатеричном формате A1 и ссылки
на ячейку A1 число следует заключить в
кавычки, например «A1» или «FACE».
Основание: основание системы
счисления. Это может быть любое
положительное целое число от 2 до 36.
Пример:
=DECIMAL(«17»;10) возвращает значение
17.
=DECIMAL(«FACE»;16) возвращает значение
64206.
=DECIMAL(«0101»;2) возвращает значение
5.
EXACT
Служит для сравнения двух текстовых
строк и возвращает значение TRUE, если
они совпадают. Данная функция учитывает
регистр символов.
Синтаксис:
EXACT(«Текст1»; «Текст2»)
Текст1: первый текст для сравнения.
Текст2: второй текст для сравнения.
Пример:
=EXACT(» microsystems»;» Microsystems»)
возвращает значение FALSE.
FIND
Служит для поиска текстовой строки в
другой строке. Можно также определить
начальную позицию поиска. Искомый
фрагмент может быть числом или любой
строкой символов. Регистр учитывается.
Синтаксис:
FIND(«Искомый текст»; «Текст»;
Позиция)
Искомый_текст: текст для поиска.
Текст: текст, в котором выполняется
поиск.
Позиция (необязательный параметр):
позиция в тексте, с которой начинается
поиск.
Пример:
=FIND(76;998877665544) возвращает значение 6.
LEFT
Возвращает первый символ или символы
текста.
Синтаксис:
LEFT(«Текст»; Число)
Текст: текст, для которого требуется
определить аббревиатуру из начальных
букв.
Число (необязательный параметр):
количество символов в начальном тексте.
Если этот параметр не определен,
возвращается один символ.
Пример:
=LEFT(«вывод»;3) возвращает значение
“out”.
LEN
Возвращает длину строки, включая
пробелы.
Синтаксис:
LEN(«Текст»)
Текст: текст, длину которого
требуется определить.
Пример:
=LEN(«Добрый день») возвращает
значение 14.
=LEN(12345.67) возвращает значение 8.
LOWER
Служит для преобразования заглавных
букв в текстовой строке в строчные.
Синтаксис:
LOWER(«Текст»)
Текст: текст для преобразования.
Пример:
=LOWER(«Солнце») возвращает значение
«солнце».
PROPER
Делает первые буквы всех слов в
текстовой строке прописными.
Синтаксис:
PROPER(«Текст»)
Текст: текст для преобразования.
Пример:
=PROPER(«open office») возвращает значение
Open Office.
REPLACE
Заменяет отрезок текстовой строки
другой текстовой строкой. Эту функцию
можно использовать для замены символов
и чисел (они автоматически преобразуются
в текст). Результат функции всегда
отображается в виде текста. Если число,
преобразованное в текст, требуется
использовать в дальнейших расчетах,
его необходимо преобразовать в число
с помощью функции VALUE.
Текст, содержащий числа, следует
заключать в кавычки, чтобы он не был
распознан как число и автоматически
преобразован в текст.
Синтаксис:
REPLACE(«Текст»; Позиция;
Длина; «Новый текст»)
Текст: текст, часть которого
требуется заменить.
Позиция: начальная позиция для
замены текста.
Длина: количество символов в тексте
для замены.
Новый_текст: текст для замены
исходного текста.
Пример:
=REPLACE(«1234567″;1;1;»444»)
возвращает значение «444234567». Один
символ в позиции 1 заменяется на Новый
текст.
REPT
Служит для повторения строки символов
указанное количество раз.
Синтаксис:
REPT(«Текст»; Число)
Текст: текст для повторения.
Число: количество повторений.
Максимальное количество символов в
результате — 255.
Пример:
=REPT(«Доброе утро»;2) возвращает
значение «Доброе утроДоброе утро».
RIGHT
Возвращает последний символ или
символы текста.
Синтаксис:
RIGHT(«Текст»;Количество)
Текст: текст, из которого требуется
извлечь правую часть.
Число (необязательный параметр):
количество символов в правой части
текста.
Пример:
=RIGHT(«Sun»;2) возвращает значение
«un».
ROMAN
Преобразует числа в римские цифры.
Диапазон значений должен включать числа
от 0 до 3999; режимы обозначаются целым
числом от 0 до 4.
Синтаксис:
ROMAN(Число; Режим)
Число: число для преобразования
в римскую цифру.
Режим (необязательный параметр):
степень упрощения. Чем выше это значение,
тем выше степень упрощения римского
числа.
Пример:
=ROMAN(999) возвращает значение CMXCIX.
=ROMAN(999;0) возвращает значение CMXCIX.
=ROMAN (999;1) возвращает значение LMVLIV.
=ROMAN(999;2) возвращает значение XMIX.
=ROMAN(999;3) возвращает значение VMIV.
=ROMAN(999;4) возвращает значение IM.
SEARCH
Возвращает позицию текстового сегмента
в строке символов. В качестве параметра
можно указать начальную позицию поиска.
Искомый текст может быть числом или
любой последовательностью символов.
Регистр не учитывается.
Поиск поддерживает
регулярные
выражения. Например, можно ввести
«all.*», чтобы найти первое вхождение
«all», за которым следует любое
количество символов. Чтобы выполнить
поиск текста, который также является
регулярным выражением, необходимо
ввести символы перед каждым символом.
Чтобы включить или отключить автоматическую
оценку регулярных выражений, используйте
команду Сервис — Параметры — LibreOffice
Calc — Вычислить.
Синтаксис:
SEARCH(«Искомый текст»;
«Текст»; Позиция)
Искомый_текст: текст для поиска.
Текст: текст, в котором будет
выполняться поиск.
Позиция (необязательный параметр):
позиция в тексте, с которой начинается
поиск.
Пример:
=SEARCH(54;998877665544) возвращает значение 10.
UPPER
Служит для преобразования букв строки
в поле текст в прописные.
Синтаксис
UPPER(«Текст»)
Текст: строчные буквы, которые
требуется преобразовать в прописные.
Пример
=UPPER(«Доброе утро») возвращает
значение ДОБРОЕ УТРО.
Note to readers: LibreOffice added wildcards and regular expressions, generally compatible with other spreadsheet applications like Excel, around version 5. At the time of this question, I was using the latest version of LO in the Debian repository, which pre-dated that. If you are reading this now, the accepted answer is the best solution. I can think of only one case where you might want to use this answer as an alternative: if you’re stuck with an ancient version of LO Calc (which sometimes happens with some featherweight distros that use custom packages). I’ll leave this answer in place just in case.
Here’s a workaround that uses a helper column (it can be used without a helper column if your version of LO Calc supports SUMPRODUCT, which I’ll show at the end).

You can hide column B. Cell B1 contains:
=ISNUMBER(SEARCH("a",A1))*ROW()
Copy that down the column as needed. This provides the row number if the cell contains «a», otherwise zero. The cell address that you want is in D1:
=ADDRESS(SUM(B1:B3),1)
The sum of the matching row and a bunch of zeros gives you the row, and the column is known. You could use these values directly inside a formula rather than creating a text representation of the address.
You can eliminate the helper column with SUMPRODUCT, in which case the formula in D1 would be:
=ADDRESS(SUMPRODUCT(ISNUMBER(SEARCH("a",A1:A3))*ROW(A1:A3)),1)
SUMPRODUCT treats the range as an array and does what the helper column does in one step.
конца абзаца. Например, условие поиска «п.ск» возвращает и «пуск», и
«писк».
абзаца. Особые объекты, например, пустые поля или привязанные к символу
врезки, в начале абзаца игнорируются. Пример: «^Петр».
абзаца. Особые объекты, например, пустые поля или привязанные к символу
врезки, в конце абзаца игнорируются. Пример: «Петр$».
$ сам по себе означает конец абзаца. С его помощью возможно искать и заменять разрывы абзацев.
поиске «Аб*в» будут найдены «Ав», «Абв», «Аббв», «Абббв» и т. д.
Всегда будет найдена самая длинная возможная строка, соответствующая
данному искомому элементу в абзаце. Если в абзаце содержится строка «AX 4
AX4», выделяется весь фрагмент.
поиске термина «Тексты?» будут найдены «Текст» и «Тексты», а при поиске
«x(ab|c)?y» будут найдены «xy», «xaby» или «xcy».
символы, а не как регулярное выражение (за исключением сочетаний n, t,
> и <). Например, «текст.» находит «текст.», а не «тексты» или
«тексту».
клавиш SHIFT+ВВОД. Чтобы изменить разрыв строки на разрыв абзаца,
введите n в поля Найти и Заменить на и выполните поиск и замену.
n в текстовом поле Поиск означает разрыв строки, вставленный с помощью комбинации клавиш Shift+Enter.
n в текстовом поле Заменить означает разрыв абзаца, который можно ввести с помощью клавиши Enter или Return.
not «checkbook» whereas «bookb» finds «checkbook» but not «bookmark».
The discrete word «book» is found by both search terms.
Например, если ввести «авто» в поле Найти и «&трасса» в поле Заменить на, слово «авто» будет заменено словом «автотрасса».
Также можно ввести «&» в поле Заменить на, чтобы изменить Атрибуты или Формат строки, найденной в соответствии с условиями поиска.
Символы упорядочены по кодовым значениям.
UXXXXXXXX
For obscure characters there is a separate variant with capital U and eight hexadecimal digits (XXXXXXXX).
For certain symbol fonts the code for special characters may depend on the used font. You can view the codes by choosing Insert — Special Character.
открывающей скобкой. Например, результатом поиска «сине{2}» также будет
«синева».
вхождений данного символа перед открывающей скобкой. Например,
результатом поиска «сине{1,2}» также будет «синее» и «синева».
встречаться символ перед открывающей скобкой. Например, при поиске
«сине{2,}» будет найдено «синее», «синеее» и «синеееее».
Этот параметр определяет символы внутри скобок как ссылку. После
этого можно ссылаться на первую ссылку в текущем выражении с помощью
«1», на вторую — с помощью «2» и т. д.
Например, если текст содержит число 13487889, то при осуществлении
поиска с использованием регулярного выражения (8)711 будет найдено
«8788».
Также можно использовать скобки () для группировки элементов, например, при поиске «а(бв)?г» будет найдено «аг» или «абвг».
В поле Заменить на:
Для замены ссылок используется знак «$» (доллар) вместо «» (обратная
косая черта). Обозначение «$0» используется для замены всей найденной
строки.
e([:digit:])? — finds ‘e’ followed by zero or one digit. Note that
currently all named character classes like [:digit:] must be enclosed in
parentheses.
^([:digit:])$ — finds lines or cells with exactly one digit.
Для комплексного поиска можно объединить условия поиска.
^[:digit:]{3}$
^ означает поиск совпадения с начала абзаца.
[:digit:] совпадение с любым десятичным знаком.
{3} означает поиск только 3-х цифр.
$ означает окончание поиска совпадения в конце абзаца.
Есть ли в LO Calc функция, которая найдет ячейку с заданным текстом?
Появляются функции поиска и поиска, чтобы указать местоположение в строке. То есть, если я ищу текст «a» в двух ячейках, одна из которых содержит «xxxa», а другая содержит «bbb», ответ будет 4.
Это не то, что мне нужно. Мне нужно найти, в какой ячейке находится рассматриваемый текст.
Просто используйте функцию MATCH() . Поскольку он поддерживает регулярные выражения, вы можете использовать MATCH() для поиска частичных строк.
Вот пример:

Массив поиска — A1:A4 , критерий поиска — .*a.* (Это регулярное выражение, синтаксис см. Ссылку выше). Результат формулы =MATCH(".*a.*";A1:A4;0) равен 2 , поскольку вторая ячейка в массиве поиска — это первая ячейка, которая соответствует шаблону поиска.
РЕДАКТИРОВАТЬ:
Относительно регулярного выражения: вот список символов регулярного выражения. Выражение .*a.* Состоит из:
- буквальным
aсоответствующий единый символ; aсопоставляя любой символ;- звездочка
., квантификатор, означающий «ноль или более» относительно предыдущего символа.
Таким образом, шаблон регулярного выражения соответствует каждому содержимому ячейки, содержащему a , перед которым следует любое количество других символов. Чтобы ознакомиться с регулярными выражениями, проверьте RegExr или онлайн-тестер регулярных выражений.
Вот обходной путь, который использует вспомогательный столбец.
Вы можете скрыть столбец B. Ячейка B1 содержит:
=ISNUMBER(SEARCH("a",A1))*ROW()
Скопируйте это вниз по столбцу по мере необходимости. Это обеспечивает номер строки, если ячейка содержит «а», иначе ноль. Адрес ячейки, который вы хотите, находится в D1:
=ADDRESS(SUM(B1:B3),1)
Сумма совпадающей строки и группы нулей дает вам строку, и столбец известен. Вы можете использовать эти значения непосредственно внутри формулы, а не создавать текстовое представление адреса.