Смотря как и чем » спрятанный»
для ламеров, юзеров и прочих начинающих халявщиков есть несколько (по степени трудоёмкости) вариантов
1 — синтаксис/операторы запроса в поисковой системе
в поисковой строке набрать по следующему шаблону » [содержимое][пробел]site:[адрес домена/сайта]
*пример поиска слова «скидка» по сайту(корневому домену) site.ru — «скидка site:site.ru» данный синтаксис просканирует доступные страницы для просмотра и покажет все страницы в которых присутствует слово «скидка»
*пример поиска файлов с любым названием но только с расширением pdf — «.pdf site:site.ru» как вариант *.pdf всё зависит от конкретной поисковой системы. Как следствие можно играться — «название.» Соответственно будет искать файл с любым расширением но с названием название. так же есть синтаксис который позволяет искать как в названии так и в расширении файла часть этого названия/расширения.
2 — Специализированные программы закачки сайта полностью
так как я понятия не имею о вашей платформе искать вам нужно такими запросами — «site download», «site sucker» site как вариант заменить web
3 — Ну и как тут уже писали ранее, зайти в исходный код страницы, что зависит как от платформы/ОС так и от конкретного браузера.
В принципе если файл вообще существует а не редирект этого файла на каком то ресурсе, файл достать всегда можно. Однако на всякую хитрожо..ую хитрость найдутся методы защиты. Делайте собственный уникальный контент, ибо за кражу, плагиат и копипаст, по рукам будут давать всё чаще и чаще, и просто жалобой уже не отделаетесь.
RTFM… кибер сопляки. RTFM
Халява переоценённый и насквозь утопичный фактор. Так или иначе платить придётся.
Для особо ограниченных и альтернативно-одарённых
А) Синтаксис нужно вводить непосредственно поисковую строку конкретно поисковика (а не через сквозные панели ввода поиска)
Б) site.ru не существует это пример который нужно заменить адресом(доменом) который вы хотите проверить на содержимое нужное вам
В) кавычки в синтаксисе запроса не пишутся — они показывают границы начала и конца синтаксиса (который требуется ввести.
Никогда не бывает лишним просканировать веб-сайт на наличие скрытых каталогов и файлов (скрытых – имеются ввиду каталоги и файлы, на которые не ведут ссылки, и о которых знает только веб-мастер). Как минимум, можно узнать что-то новое о сайте, а бывает просто выпадает супер-приз — архив сайта или базы данных, бэкап чувствительных файлов и т.д.
— это сканер веб-контента. Он ищет существующие (возможно, скрытые) веб-объекты. В основе его работы лежит поиск по словарю, он формирует запросы к веб-серверу и анализирует ответ.
DIRB поставляется с набором настроенных на атаку словарей для простого использования, но вы можете использовать и ваш собственный список слов. Также иногда DIRB можно использовать как классический CGI сканер, но помните, что в первую очередь это сканер содержимого, а не сканер уязвимостей.
Главная цель DIRB — это помочь профессионалам в аудите веб-приложений. Особенно в тестах ориентированных на безопасность. Она покрывает некоторые дыры, не охваченные классическими сканерами веб-уязвимостей. DIRB ищет специфические веб-объекты, которые другие сканеры CGI не ищут. Она не ищет уязвимости и не ищет веб-содержимое, которое может быть уязвимым.
Может быть, эта программа станет последней попыткой для невезучих аналитиков по безопасности…
Примечания
<базовый_адрес> : Основной URL для сканирования. (Используйте -resume для возобновления сессии)
<список(и)_файлов> : Список словарей. (словарь1, словарь2, словарь3…)
| Название файла | Полный путь до файла | Количество записей в файле | Описание содержимого |
|---|---|---|---|
| big.txt | /usr/share/wordlists/dirb/big.txt | 20469 | |
| catala.txt | /usr/share/wordlists/dirb/catala.txt | 161 | |
| common.txt | /usr/share/wordlists/dirb/common.txt | 4614 | |
| euskera.txt | /usr/share/wordlists/dirb/euskera.txt | 197 | |
| extensions_common.txt | /usr/share/wordlists/dirb/extensions_common.txt | 29 | Расширения файлов |
| indexes.txt | /usr/share/wordlists/dirb/indexes.txt | 10 | |
| mutations_common.txt | /usr/share/wordlists/dirb/mutations_common.txt | 49 | |
| best1050.txt | /usr/share/wordlists/dirb/others/best1050.txt | 1049 | Лучшая выборка из 1050 пунктов |
| best110.txt | /usr/share/wordlists/dirb/others/best110.txt | 110 | Лучшая выборка из 110 пунктов |
| best15.txt | /usr/share/wordlists/dirb/others/best15.txt | 15 | Лучшая выборка из 15 пунктов |
| names.txt | /usr/share/wordlists/dirb/others/names.txt | 8607 | |
| small.txt | /usr/share/wordlists/dirb/small.txt | 959 | |
| spanish.txt | /usr/share/wordlists/dirb/spanish.txt | 449 | Испанские слова в каталогах |
| alphanum_case_extra.txt | /usr/share/wordlists/dirb/stress/alphanum_case_extra.txt | 95 | |
| alphanum_case.txt | /usr/share/wordlists/dirb/stress/alphanum_case.txt | 62 | |
| char.txt | /usr/share/wordlists/dirb/stress/char.txt | 26 | |
| doble_uri_hex.txt | /usr/share/wordlists/dirb/stress/doble_uri_hex.txt | 256 | |
| test_ext.txt | /usr/share/wordlists/dirb/stress/test_ext.txt | 17576 | |
| unicode.txt | /usr/share/wordlists/dirb/stress/unicode.txt | 65536 | |
| uri_hex.txt | /usr/share/wordlists/dirb/stress/uri_hex.txt | 256 | |
| apache.txt | /usr/share/wordlists/dirb/vulns/apache.txt | 30 | Apache |
| axis.txt | /usr/share/wordlists/dirb/vulns/axis.txt | 17 | |
| cgis.txt | /usr/share/wordlists/dirb/vulns/cgis.txt | 3494 | |
| coldfusion.txt | /usr/share/wordlists/dirb/vulns/coldfusion.txt | 21 | |
| domino.txt | /usr/share/wordlists/dirb/vulns/domino.txt | 291 | |
| fatwire_pagenames.txt | /usr/share/wordlists/dirb/vulns/fatwire_pagenames.txt | 2711 | |
| fatwire.txt | /usr/share/wordlists/dirb/vulns/fatwire.txt | 101 | |
| frontpage.txt | /usr/share/wordlists/dirb/vulns/frontpage.txt | 43 | |
| hpsmh.txt | /usr/share/wordlists/dirb/vulns/hpsmh.txt | 238 | |
| hyperion.txt | /usr/share/wordlists/dirb/vulns/hyperion.txt | 579 | |
| iis.txt | /usr/share/wordlists/dirb/vulns/iis.txt | 59 | IIS |
| iplanet.txt | /usr/share/wordlists/dirb/vulns/iplanet.txt | 36 | |
| jboss.txt | /usr/share/wordlists/dirb/vulns/jboss.txt | 19 | |
| jersey.txt | /usr/share/wordlists/dirb/vulns/jersey.txt | 129 | |
| jrun.txt | /usr/share/wordlists/dirb/vulns/jrun.txt | 13 | |
| netware.txt | /usr/share/wordlists/dirb/vulns/netware.txt | 60 | |
| oracle.txt | /usr/share/wordlists/dirb/vulns/oracle.txt | 1075 | Oracle |
| ror.txt | /usr/share/wordlists/dirb/vulns/ror.txt | 121 | |
| sap.txt | /usr/share/wordlists/dirb/vulns/sap.txt | 1111 | |
| sharepoint.txt | /usr/share/wordlists/dirb/vulns/sharepoint.txt | 1708 | |
| sunas.txt | /usr/share/wordlists/dirb/vulns/sunas.txt | 52 | |
| tests.txt | /usr/share/wordlists/dirb/vulns/tests.txt | 34 | |
| tomcat.txt | /usr/share/wordlists/dirb/vulns/tomcat.txt | 87 | Tomcat |
| vignette.txt | /usr/share/wordlists/dirb/vulns/vignette.txt | 74 | |
| weblogic.txt | /usr/share/wordlists/dirb/vulns/weblogic.txt | 361 | |
| websphere.txt | /usr/share/wordlists/dirb/vulns/websphere.txt | 560 | |
| apache-user-enum-1.0.txt | /usr/share/wordlists/dirbuster/apache-user-enum-1.0.txt | 8930 | Перечисление пользователей Apache 1.0 |
| apache-user-enum-2.0.txt | /usr/share/wordlists/dirbuster/apache-user-enum-2.0.txt | 10355 | Перечисление пользователей Apache 2.0 |
| directories.jbrofuzz | /usr/share/wordlists/dirbuster/directories.jbrofuzz | 58688 | |
| directory-list-1.0.txt | /usr/share/wordlists/dirbuster/directory-list-1.0.txt | 141708 | Список директорий |
| directory-list-2.3-medium.txt | /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt | 220560 | Список директорий среднего размера |
| directory-list-2.3-small.txt | /usr/share/wordlists/dirbuster/directory-list-2.3-small.txt | 87664 | Список директорий малого размера |
| directory-list-lowercase-2.3-medium.txt | /usr/share/wordlists/dirbuster/directory-list-lowercase-2.3-medium.txt | 207643 | Список директорий среднего размера, имена приведены к нижнему регистру |
| directory-list-lowercase-2.3-small.txt | /usr/share/wordlists/dirbuster/directory-list-lowercase-2.3-small.txt | 81643 | Список директорий малого размера, имена приведены к нижнему регистру |

Каждый современный сайт содержит файлы и папки, на которые не ведут никакие ссылки. Среди них могут попадаться весьма интересные, например, забытые резервные копии базы данных или сайта, phpMyAdmin, входы в административные панели и другие страницы, не предназначенные для всеобщего доступа.
Ниже мы расскажем, как пользоваться программой lulzbuster для поиска файлов и папок. Поехали.
Очень быстрый и умный инструмент для перебора веб директорий и файлов написан на C. Используется для поиска скрытых папок и файлов, на которые отсутствуют ссылки.
С одной стороны, lulzbuster очень прост в использовании, но при этом имеет много настроек и дополнительных возможностей.
Домашняя страница: https://nullsecurity.net/tools/scanner.html
Справка по lulzbuster
Использование:
lulzbuster -s <АРГУМЕНТ> [ОПЦИИ] | <ПРОЧЕЕ>
Опции:
опции указания цели
-s <url> - начальный url с которого начнётся сканирование
опции http
-h <тип> - тип http запроса (по умолчанию: GET) - ? для вывода списка типов
-x <код> - исключить их показа коды статуса http (по умолчанию: 400,404,500,501,502,503
несколько кодов разделяются ',')
-f - следовать http перенаправлениям. Подсказка: лучше попробуйте добавить '/'
с опцией '-A' вместо использование '-f'
-F <число> - число уровней следования http редиректам (по умолчанию: 0)
-u <строка> - строка user-agent (по умолчанию: встроенные windows firefox)
-U - использовать случайный user-agents из встроенных
-c <строка> - передать указанный заголовок или несколько заголовков (например, 'Cookie: foo=bar; lol=lulz')
-a <creds> - учётные данные http аутентификации (формат: <пользователь>:<пароль>)
-r - включить автоматическое обновление реферера
-j <число> - указать версию http (по умолчанию: дефолтная версия curl default) - ? для вывода всех
опции таймаута
-D <число> - количество секунд для задержки между запросами (по умолчанию: 0)
-C <число> - количество секунд для таймаута соединения (по умолчанию: 10)
-R <число> - количество секунд для таймаута запроса (по умолчанию: 30)
-T <число> - количество секунд перед признанием поражения и полного выхода из lulzbuster
(по умолчанию: нет)
опции тонкой подстройки
-t <число> - число потоков для одновременного сканирования (по умолчанию: 30)
-g <число> - размер кэша подключений для curl (по умолчанию: 30)
Примечание: это значение всегда должно быть равным значению, указанному с опцией -t
другие опции
-w <файл> - файл словаря
(по умолчанию: /usr/share/lulzbuster/lists/medium.txt)
-A <строка> - добавить любые слова, разделённые запятой (например, '/,.php,~bak)
-p <адрес> - адрес прокси (формат: <схема>://<хост>:<порт>) - ? для
вывода списка всех поддерживаемых схем
-P <creds> - учётные данные проверки подлинности на прокси (формат: <пользователь>:<пароль>)
-i - небезопасный режим (пропустить проверку сертификата ssl/tls)
-S - умный режим aka пропуск ложных срабатываний, больше информации,
и т.д. (используйте это если скорость не является вашим первым приоритетом!)
-n <строка> - сервера имён (по умолчанию: '1.1.1.1,8.8.8.8,208.67.222.222'
если несколько, то разделяются запятыми '.')
-l <файл> - сохранить найденные пути и действительные url в файл журнала
прочее
-X - вывести список встроенных user-agents
-V - вывести версию lulzbuster и выйти
-H - вывести справку и выйти
Примеры запуска lulzbuster
Поиск на сайте (-s https://failsame.ru/) скрытых файлов и папок с использованием большого словаря (-w /usr/share/lulzbuster/lists/big.txt):
lulzbuster -s https://failsame.ru/ -w /usr/share/lulzbuster/lists/big.txt
Установка lulzbuster
Установка в Kali Linux
sudo apt install libcurl4 libcurl4-openssl-dev git clone https://github.com/noptrix/lulzbuster cd lulzbuster make lulzbuster sudo make install
Установка в BlackArch
Программа предустановлена в BlackArch.
sudo pacman -S lulzbuster
Скриншоты lulzbuster
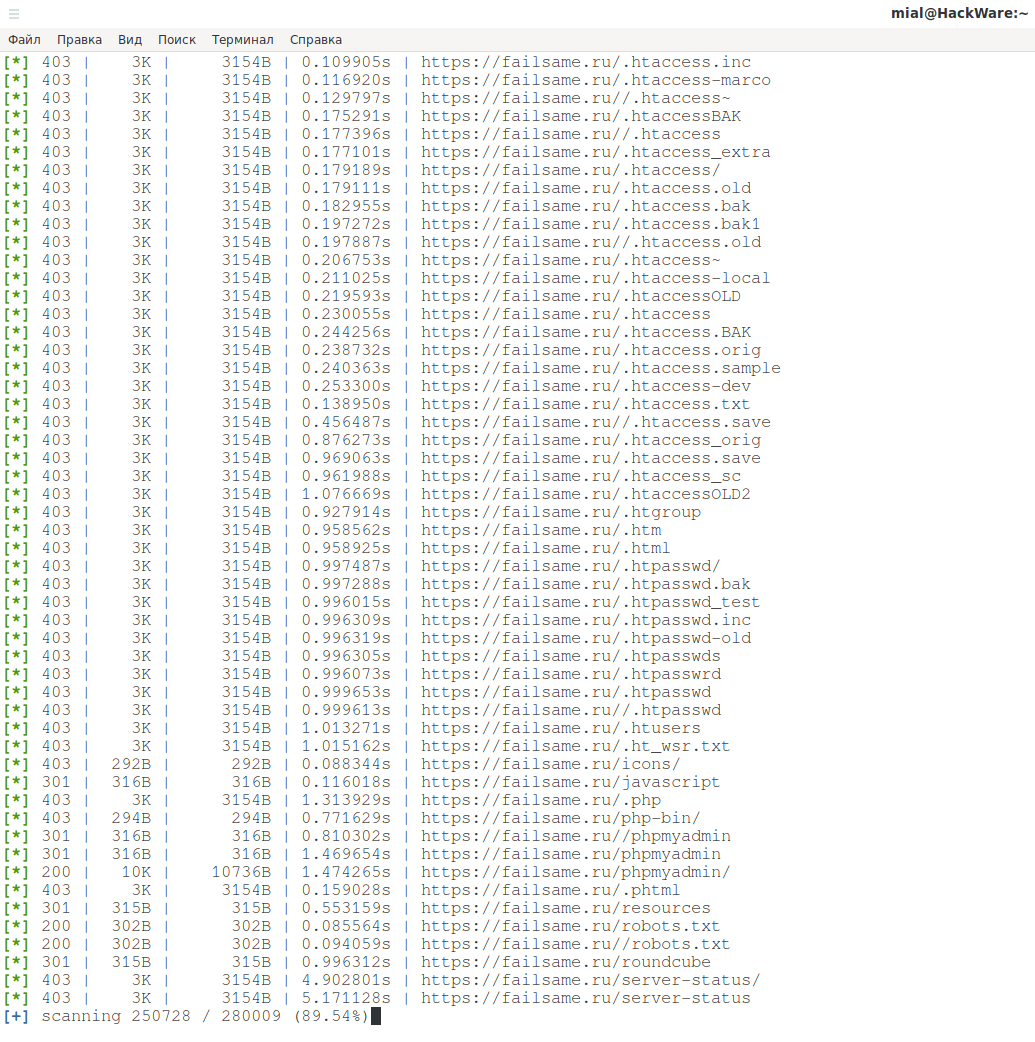
Как запустить поиск скрытых файлов в lulzbuster
Обратите внимание: программа делает много запросов к сайту и может стать причиной сбоя в его работе (как это происходит при DoS атаке), поэтому чужие сайты сканируйте только с разрешения их владельца! Вас предупредили!!!
У программы только одна обязательная опция -s после которой нужно указать целевой сайт:
lulzbuster -s https://SITE.RU/
Причём сайт нужно указывать с протоколом, например:
lulzbuster -s https://file-mix.com/
Программа начнёт с вывода своих настроек — многие значения установлены по умолчанию, но их можно изменить опциями:
Затем программа начнёт выводить данные со следующими столбцами:
- code (HTTP код статуса ответа)
- size (размер полученных данных)
- real size (реальный размер)
- resp time (время ответа)
- url (адрес найденной страницы)
По умолчанию используется словарь среднего размера, а всего с программой поставляется три словаря:
- big.txt (большой)
- medium.txt (средний)
- small.txt (маленький)
В Kali Linux эти словари размещены в следующих файлах:
- /usr/local/share/lulzbuster/lists/big.txt
- /usr/local/share/lulzbuster/lists/medium.txt
- /usr/local/share/lulzbuster/lists/small.txt
Для выбора любого из этих словарей, либо своего собственного, используйте опцию -w, например:
lulzbuster -s https://file-mix.com/ -w /usr/local/share/lulzbuster/listsbig.txt
Как исключить ответы с определёнными кодами статуса
По умолчанию не показываются ссылки, которые вернули следующие HTTP коды ответа: 400,404,500,501,502,503. Вы можете изменить этот список, добавив или удалив любые коды. Для этого используется опция -x, сами коды ответа нужно перечислять через запятую:
lulzbuster -s https://SITE.com/ -x 400,404,500,501,502,503,403,405
Как сохранить результаты lulzbuster в файл
По умолчанию lulzbuster выводит информацию в стандартный вывод ошибок (stderr). Вы можете указать файл для сохранения результатов опцией -l:
lulzbuster -s https://file-mix.com/ -w /usr/local/share/lulzbuster/lists/small.txt -l ~/file-mix.com-url.txt
Обратите внимание, что лучше указывать абсолютный путь до файла, т. к. в противном случае файл будет сохранён относительно рабочей директории lulzbuster.
Как добавить расширение для сканируемых файлов
С помощью опции -A <СТРОКА> можно добавить любые слова, разделённые запятой (например, /,.php,~bak).
Как сканировать с lulzbuster через Tor
Если это ещё не сделано, установите и запустите службу Tor:
sudo apt install tor
sudo systemctl start tor
Теперь к вашей команде lulzbuster добавьте опцию -p socks5://localhost:9050, например:
lulzbuster -s https://file-mix.com/ -p socks5://localhost:9050
Помните, что некоторые сайты вовсе не принимают подключения с IP адресов сети Tor.
Как сканировать с lulzbuster через прокси
Поддерживается несколько видов прокси, чтобы увидеть доступные варианты выполните команду:
lulzbuster -p ?
Пример вывода:
[+] available proxy schemes
> http
> https
> socks4
> socks4a
> socks5
> socks5h
Для прокси используйте следующие опции:
-p <адрес> - адрес прокси (формат: <схема>://<хост>:<порт>)
-P <creds> - учётные данные проверки подлинности на прокси (формат: <пользователь>:<пароль>)
Как сканировать в lulzbuster если недействительный сертификат
Бывает, что сертификат просрочен, либо сканируется IP адрес, в этом случае веб-браузеры показывают предупреждение, а lulzbuster останавливает сканирование с ошибкой:
[-] could not connect to:
Чтобы выполнить сканирование даже несмотря на неверный сертификат, используйте опцию -i:
lulzbuster -s https://koronavirus.info/ -i
Умный режим lulzbuster
Умный режим, который заключается в пропуске ложных срабатываний, показывает больше информации и т. д., включается опцией -S:
lulzbuster -s https://file-mix.com/ -S
Используйте умный режим только если скорость не является вашим важным приоритетом!
Изменение User Agent в lulzbuster
В lulzbuster уже встроен большой список пользовательских агентов, чтобы вывести их список выполните команду:
lulzbuster -X
Вы можете указать любое значение User Agent с помощью опции -u <СТРОКА>.
Также вы можете использовать случайные User Agent из встроенных, для этого укажите опцию -U.
lulzbuster с http аутентификацией и передачей заголовков
Возможно выполнять сканирования с lulzbuster с HTTP аутентификацией или передачей HTTP заголовков (например, кукиз). Это можно сделать следующими
-c <строка> - передать указанный заголовок или несколько заголовков (например, 'Cookie: foo=bar; lol=lulz')
-a <creds> - учётные данные http аутентификации (формат: <пользователь>:<пароль>)
Скорость сканирования и таймаут lulzbuster
С помощью опции -t <ЧИСЛО> можно указать количество потоков, которыми будет выполняться сканирование.
Также доступны следующие опции таймаута:
-D <число> - количество секунд для задержки между запросами (по умолчанию: 0)
-C <число> - количество секунд для таймаута соединения (по умолчанию: 10)
-R <число> - количество секунд для таймаута запроса (по умолчанию: 30)
-T <число> - количество секунд перед признанием поражения и полного выхода из lulzbuster
(по умолчанию: нет)
Сканирование методами POST, HEAD, PUT, DELETE и другими
По умолчанию сканирование выполняется методом GET, но можно выбрать другой метод HTTP запросов.
Чтобы вывести список всех доступных методов выполните команду:
lulzbuster -h ?
Пример вывода:
[+] available HTTP requests types
> HEAD
> GET
> POST
> PUT
> DELETE
> OPTIONS
Желаемый тип HTTP запросов указывается опцией -h <ТИП>.
Как сканировать разными версиями HTTP
У протокола HTTP имеется несколько версий и можно выбрать ту, которую вы хотите использовать. Для этого задействуйте опцию -j <ЧИСЛО>.
Чтобы увидеть доступные версии HTTP выполните команду:
lulzbuster -j ?
Пример вывода:
[+] available http versions
> 1.0
> 1.1
> 2.0
> 3.0
Как и зачем искать скрытый контент на сайте
Опубликовано: 15.12.2018. Обновлено: 19.09.2019 1 354 3
Ответ на вопрос, зачем искать скрытый контент на сайте, даёт раздел помощи для Вебмастеров Яндекса:

Следующие два метода поиска скрытого контента подразумевают ручную работу с каждой страницей, поэтому на практике возможно выборочно проверять по одному примеру страниц, сделанных по разным шаблонам. Внешне они отличаются оформлением, содержанием, и расположением составляющих блоков (главная страница, страница категории, карточка товара, новостная страница).
Метод 1. Веб Девелопер
Веб Девелопер — популярный плагин для вебмастеров. Есть версия для Google Chrome, Mozilla FireFox и других браузеров.
Открываем страницы и поочерёдно выключаем в плагине все скрипты:

Изменения после выключения можно увидеть после обновления страницы.
Стили:

Метод 2. Проверка кода страницы в Яндекс.Вебмастере
В Яндекс.Вебмастере проверяем ответ сервера и внизу раскрываем содержимое страницы:

Таким образом мы видим код страницы, как его «видит» бот поисковой системы.
Результат может отличаться от того, что можно увидеть при просмотре кода в браузере.
Например, как выглядит код страницы при обычном просмотре в браузере:

Между открывающим тегом боди и следующим дивом ничего нет.
Но если посмотреть через Вебмастер, видны спамные ссылки:

В общем-то не нужно образование программиста, чтобы найти эти ссылки. Но программист нужен, чтобы найти вредоносный код, разместивший ссылки, и поставить защиту на сайт, чтобы избежать подобных проблем в будущем.
При использовании обоих методов ищем:
- Подозрительные фрагменты.
- Повторы контента, не отображаемые на сайте.
- Подозрительные ссылки на внешние источники.
Метод 3. Поиск кода display:none
Стиль display:none позволяет скрывать от пользователя контент на странице.
При помощи ComparseR ищем фрагмент на сайте в двух вариантах:
- display:none
- display: none (с пробелом).
Однако, метод не поможет, если стиль вынесен в отдельный файл стилей. Кроме того, свойство может использоваться для вполне «белых» задач, как, например, скрытие части контента для адаптивной версии сайта. Поэтому метод имеет ограниченное применение, но позволяет осуществить поиск сразу по всем страницам сайта.
А что с обычными текстами, без злого умысла скрытыми в табах, всплывающих окнах и т.д.?
Содержимое, скрытое скриптами, в значительной степени (или полностью) игнорируется Гуглом при расчёте текстовой релевантности страниц. Поэтому значимый полезный контент должен быть открыт. Допустимо скрывать только если объём контента незначителен или неважен для оптимизации данной страницы.
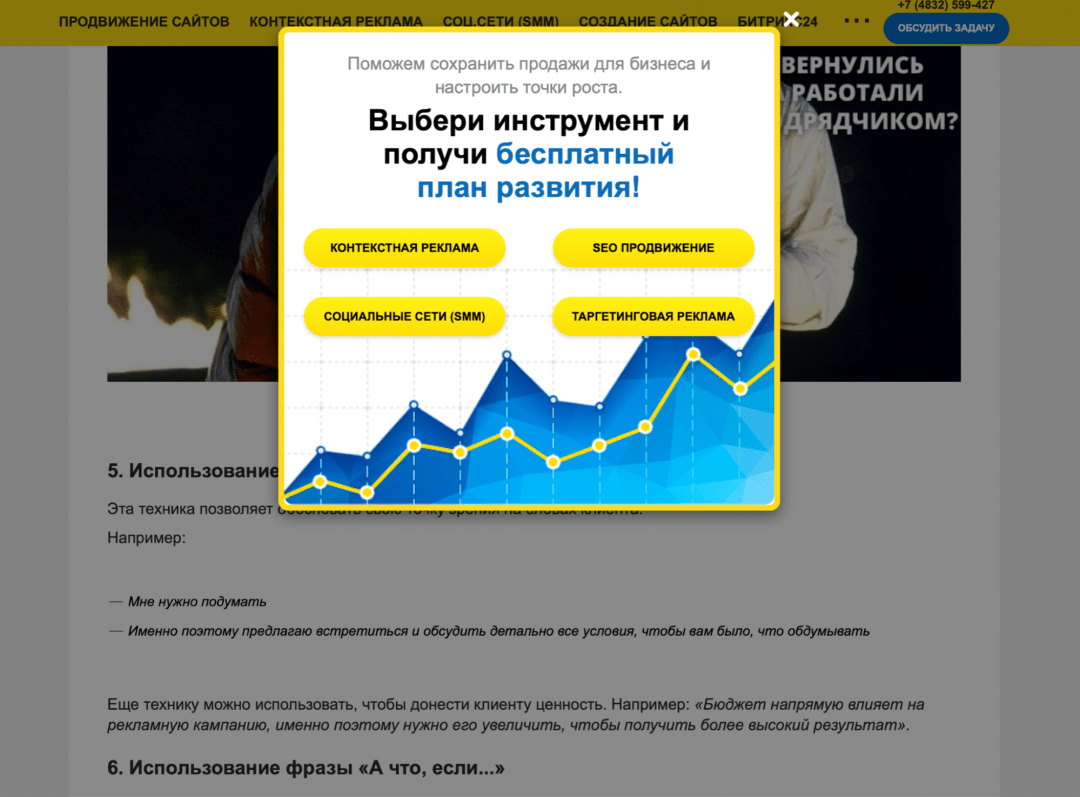
Как убрать что угодно на любом сайте
Итак, очередной сайт решил перегородить вам обзор своей никчемной нападайкой. Она должна провисеть на экране 10 секунд и только потом отключиться. Но зачем тратить 10 секунд жизни, если можно отключить нападайку самостоятельно за 8?
Как работают всплывающие нападайки и поп-апы с рекламой
Такие всплывающие окна делаются очень просто:
- Хозяева сайта создают на своей странице объект, который лежит сверху всего, как целлофан на обложке журнала.
- Этому объекту задают ширину во весь экран и высоту во весь экран, чтобы нельзя было дальше кликать и переходить по сайту.
- Затем этому объекту устанавливают затемнённый фон. Так появляется затемнение всего экрана. Именно эта штука с затемнением и мешает нормально пользоваться страницей.
- Внутрь объекта с затемнением кладут ещё один объект — рекламу, баннер, призыв подписаться, предложение оставить свой номер телефона.
- И всё это висит поперёк страницы
Наша задача — отключить оба объекта, чтобы они пропали с глаз долой.
Всё дело — в CSS
Чтобы компьютер понимал, какие элементы есть на странице, используют язык HTML, который говорит: «Тут заголовок, тут ссылка, тут обычный текст, тут картинка». А чтобы было ясно, как эти элементы должны выглядеть и работать, используют специальные правила — их называют стилями. Стили задают цвет и внешний вид всего, что есть на странице, а ещё управляют размером и поведением каждого элемента.
Стили хранятся в таблицах, таблицы называют каскадными, всё вместе называется CSS — cascading style sheets.
Вот больше примеров и практики по CSS:
Именно возможности CSS позволяют рисовать такие нападайки, которые занимают весь экран и мешают читать. Но мы используем свойства CSS против подобных сайтов и перепишем всё под себя. Для этого нам нужно будет найти код элемента, который отвечает за нападайку.
Как найти код нужного элемента
Чтобы увидеть, какой именно кусок кода отвечает за всплывающее окно, будем пользоваться средствами самого браузера — Инспектором. В Хроме он вызывается нажатием клавиш Ctrl+Shift+i, а в Сафари — Cmd+Option+i.
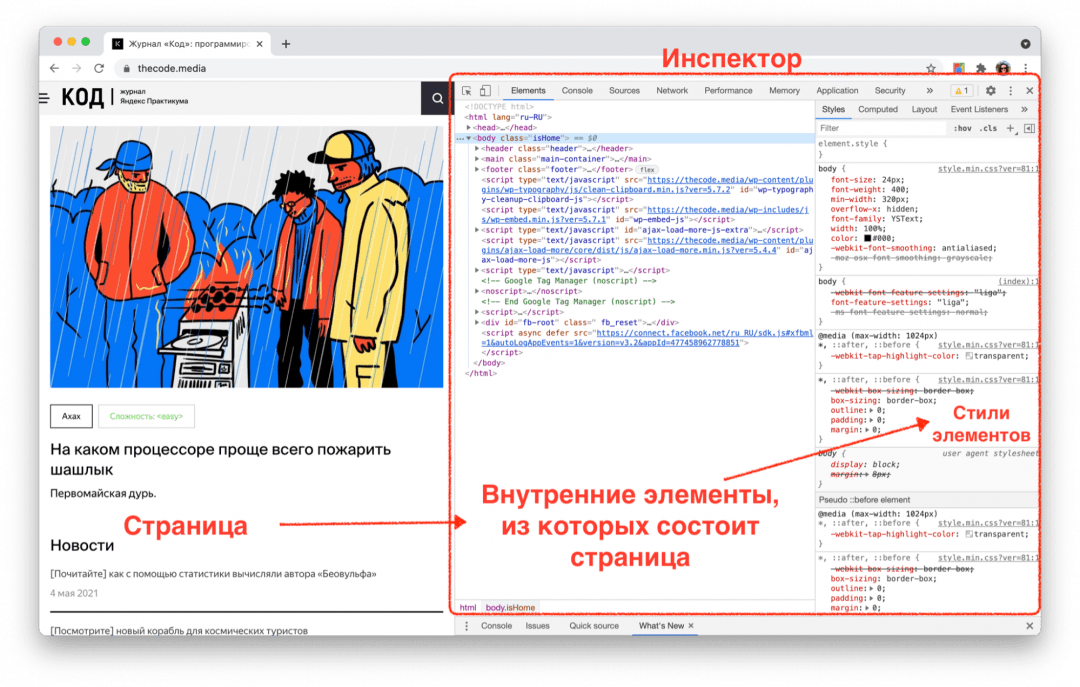
Но есть ещё один способ, который сейчас нам подходит больше:
- Открываем страницу и дожидаемся, пока появится реклама.
- Затем правой кнопкой мыши щёлкаем на картинке в центре, которая мешает просмотру, и выбираем «Просмотреть код» (Inspect Element).
- Инспектор сразу подсветит нужную нам строчку.
Мы нашли участок кода, который отвечает за назойливую рекламу. Теперь пусть браузер сам закроет окно. Для этого используем свойство display — оно решает, показывать этот элемент или нет.
Скрываем элемент со страницы
Чтобы окно не показывалось, нужно написать свойство display:none . Но бывает так, что CSS игнорирует такие команды, если это же свойство задаётся чуть позже в другом месте. Если нужно, чтобы команда выполнилась несмотря ни на что, после команды пишут слово !important — именно так, с восклицательным знаком в начале. Это говорит о том, что у команды приоритет над всеми остальными и её нужно исполнять:
Осталось вставить эту команду в нужное место. Оставляем синюю линию Инспектора на той же строке и переходим на вкладку Styles:
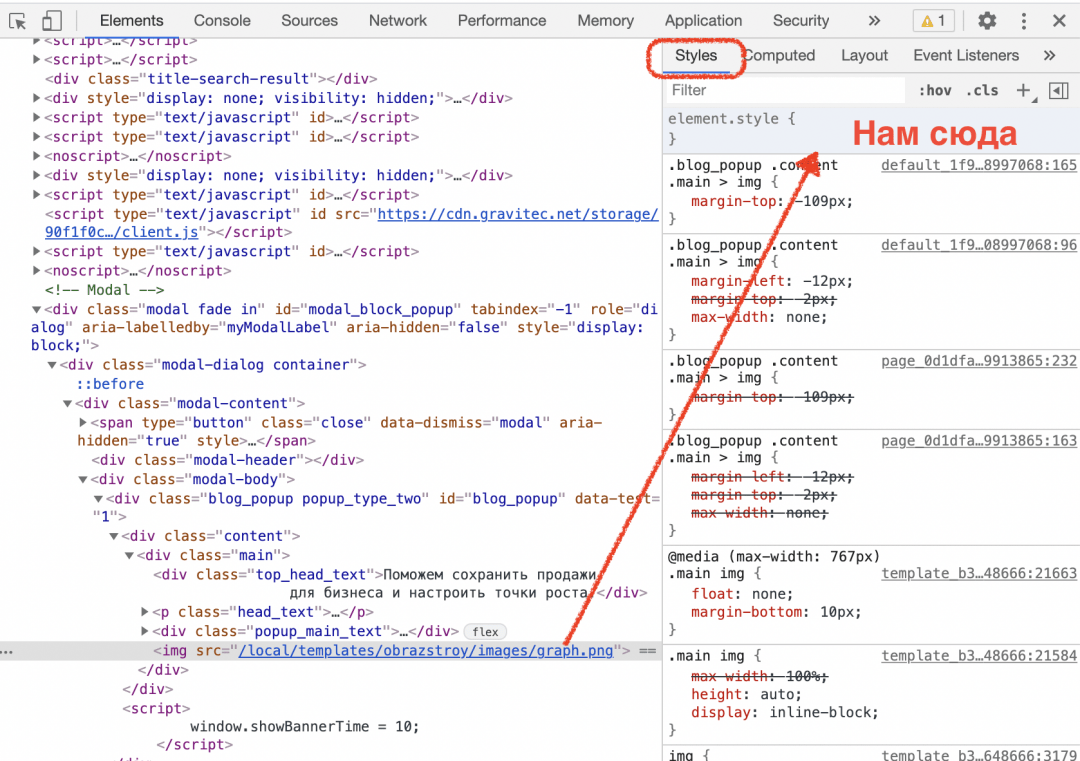
Там как раз прописаны все CSS-стили, которые отвечают за свойства и поведение этого элемента. Находим в самом верху блок element.style , щёлкаем в нём на свободном месте и вставляем нашу команду display:none !important :
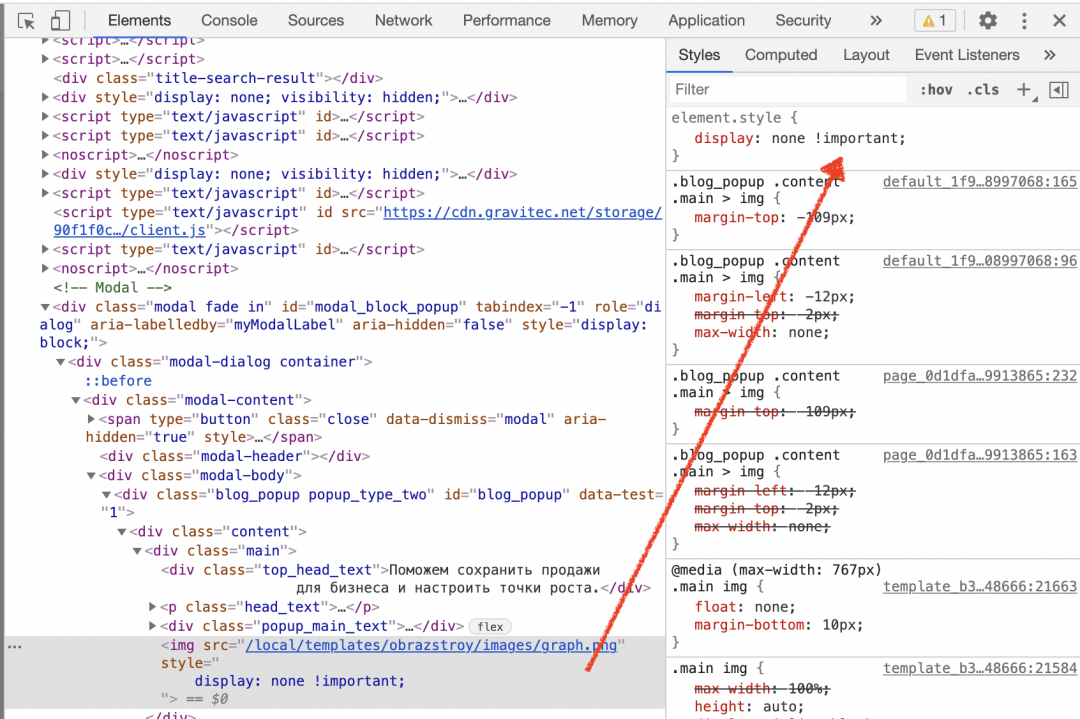
Картинка исчезла, но осталось затемнение, которое всё равно мешает читать. Разберёмся и с этим: щёлкаем правой кнопкой мыши в любом месте затемнения, выбираем «Посмотреть код», вставляем в element.style нашу команду — готово.
Это работает только с нападайками?
Этим способом можно скрыть что угодно, поскольку свойство display есть у всего на странице: у новостей ВКонтакте, постов в Facebook или картинок в Instagram.
❗️ Важный момент: всё, что мы делаем таким образом, происходит только внутри нашего браузера и не влияет на отображение сайта у других людей. Если перезагрузить страницу сайта, то сайт может напасть на вас рекламой снова.
Как найти и удалить скрытые ссылки в шаблонах cms-систем
Найти скрытые ссылки — это первоочередная задача любого проекта для которого используются сторонние шаблоны cms-систем и любые другие html-шаблоны.
С точки зрения поисковой оптимизации, наличие внешних не только скрытых ссылок в шаблоне сайта, отрицательно сказываются на развитии вашего проекта, но благоприятно влияют на сайт который указан в этих ссылках.

Через сторонние ссылки, которые у вас будут указаны в шаблоне, поисковые системы могут существенно понизить ваш сайт в поисковой выдаче. И с большей долей вероятности такие сайты, на которых обнаруживаются скрытые ссылки, попадают под санкции поисковых систем.
Чем больше внешних ссылок на сайт, тем лучше для определения ранжирования сайта в поисковых системах. Это одна из основных причин размещения скрытых ссылок в шаблонах популярных cms-систем.
В этом видео я расскажу не только о том как найти скрытые ссылки, но и как сделать скрытую ссылку, как посмотреть скрытую ссылку с помощью сервиса и приложения, а так же как удалить скрытую ссылку.
Теперь по порядку.
Как найти скрытые ссылки
Для поиска воспользуемся одним из популярных сервисов validator.org. Отличная возможность без всяких регистраций, в режиме реального времени, быстро проверить скрытые ссылки в шаблоне.
https://validator.w3.org/checklink.
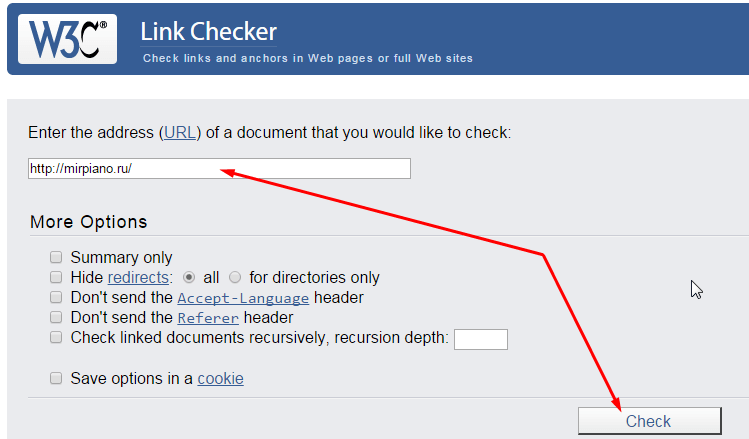
Данный валидатор поможет найти все видимые и невидимые ссылки. Работает просто, добавляем адрес сайта в поле address и нажимаем кнопку Check. Время проверки зависит от объема информации. Пока нет необходимости разбираться со всеми возможностями сервиса, а нас главным образом интересует информация в конце страницы в поле List of redirects.
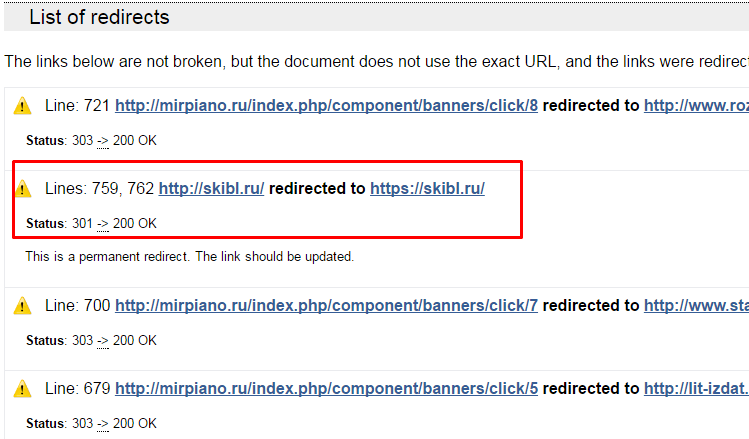
Для любого автора проекта такая ссылка сразу бросится в глаза и в случае, когда нет опыта определить, всегда можно понять по внешнему адресу, перейдя по нему, либо по длине самой ссылке. На скриншоте видно такую ссылку, она отличается от всех остальных.
Как удалить видимые и скрытые ссылки
В большинстве случаев главным местом для размещения скрытых ссылок является индексный файл (index.html и index.php) шаблона joomla, wordpress, либо других cms-систем. Хорошо если мы видим стороннюю ссылку, в этом случае у нас есть возможность сократить время на принятие мер.
Найти нужный блок в шаблоне можно с помощью приложения firebug для браузера mozilla firefox и в нем же можно понять как формируется сам блок или отдельно взятая ссылка. Прежде чем редактировать шаблон, необходимо сделать резервную копию сайта или отдельно взятого шаблона.
Все дело в том, что некоторые ссылки нельзя взять просто так и удалить, можно повредить работоспособность всего сайта, или только индексную страницу шаблона. Существует не мало возможностей по «закреплению» ссылок или целых блоков, с помощью web-программирования для того, чтобы нельзя было их удалить.
В первом случае все достаточно просто. Находим блок по идентификатору или классу в шаблоне и удаляем. Но что делать если ссылку удалить нельзя? Можно скрыть ссылку в css-стилях.
В этом случае, с помощью того же приложения firebug, необходимо найти стили видимой или скрытой ссылки, или блока в котором она находится и прописать дополнительное свойство (visibility: hidden;). Данный параметр просто спрячет видимую ссылку.
Можно найти скрытые ссылки и с помощью разных программ и расширений которых достаточно много. В одном из своих видео уроков, ошибка протокола https в wordpress, я рассказывал об одной такой программе Screaming Frog SEO Spider.
Удалить скрытые ссылки я все же советую вручную, без использования программ. Если скрытые ссылки добавлены без возможности удаления, т.есть, намертво, программа может все удалить и потом трудно будет разобраться где и как формировались скрытые ссылки.
В случае обнаружения скрытой ссылки в шаблоне и при невозможности удаления ее, лучше не используйте такие шаблоны, а авторов или адрес ресурсов заносите в черный список.
Как сделать скрытую ссылку
Одним из способов сделать скрытую ссылку на сайте-это добавить в css-стили или непосредственно в стили самой ссылки следующее свойство (z-index:-999px;). Отрицательное значение может быть любым, главное чтобы ссылка находилась за пределами границ самого шаблона, как бы в стороне или за ним.
Вот здесь конечно, никто ее не увидит, но поисковые роботы ее индексируют и воспринимают как внешнюю ссылку ведущую например на сайт производителя шаблона (в лучшем случае), а в худшем-на варезный или порно-сайт с кишащими там вирусами.
Ну а после посещения таких сайтов обычно можно увидеть на весь экран своего компьютера огромную «мартышку» или еще чего.
Видео урок найти скрытые ссылки
Если статья и видео оказались полезными для вас, оставляйте комментарии или отзывы.