К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL: http://webcache.googleusercontent.com/search?q=cache:lifehacker.ru. Замените lifehacker.ru на адрес нужной страницы и нажмите Enter.
Сайт Google →
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()
Читайте также 💻🔎🕸
- 3 специальных браузера для анонимного сёрфинга
- Что делать, если тормозит браузер
- Как включить режим инкогнито в разных браузерах
- 6 лучших браузеров для компьютера
- Как установить расширения в мобильный «Яндекс.Браузер» для Android
Работа с сохраненной копией страницы
Содержание:
- Зачем нужна сохраненная копия страницы и как её посмотреть
- Как посмотреть сохраненную копию в Google
- Как посмотреть сохраненную копию веб-страницы в Яндекс
- Почему сохраненной страницы может не быть
- Специализированные веб-архивы
- Wayback Machine
- Archive.Today
- Расширения для браузеров
- Cached Page
- Выводы
Чтобы пользователь нашел документ в поисковой выдаче, недостаточно добавления его на сервер. Контент должен быть проиндексирован (добавлен поисковыми роботами в индекс) поисковыми системами Яндекс и Google. Поэтому, наличие сохраненной копии — показатель что поисковый бот был на странице. Рассмотрим, что можно посмотреть и какие ошибки обнаружить с помощью сохраненной копии веб-страницы.
Роботы Яндекса и Google добавляют копии найденных веб-страниц в специальное место в облаке — кеш. При этом новая копия страницы перезаписывает старую. Поэтому в кеше отображаются свежие версии веб-страниц.
Сохраненная копия — это версия веб-страницы, которая сохранена в кэше поисковой системы. Условно это бесплатная резервная копия от поисковых систем.
На самом деле веб-страницы сохраняют:
- Поисковые системы. В них находится находится последняя проиндексированная версия страницы. Такие «снимки» используют SEO-специалисты, чтобы увидеть какие данные обнаружил на странице поисковый бот;
- Специализированные сервисы. Занимаются сохранением содержимого веб-страницы. Основная задача таких сервисов сохранить страницы в конкретный момент времени. С помощью них вы можете узнать как выглядел сайт или страница несколько лет назад.
Зачем нужна сохраненная копия страницы и как её посмотреть
На сайтах регулярно происходит добавление нового и редактирование существующего контента. Периодически изменяется его дизайн, добавляются и/или удаляются графические элементы. Это трудоемкая работа в процессе, которой могут возникнуть ошибки: потеряться контент, «съехать дизайн», удалиться блок или перестать индексироваться часть материала. Выявить, как выглядела страницы до определенного момента, поможет сохраненная копия.
Пример из практики:
Есть у нас технически сложный проект, который при заполнении объема памяти перестает, корректно работать. Если по простому, то вместо работающего сайта, мы видим ошибку базы данных.
Время от времени сайт отваливается по ночам, а утром разработчики все исправляют. И тут важный момент, сохраненные копии, позволяют понять успели ли поисковые системы проиндексировать сломанный сайт или нет. А также позволяют выявить, какие именно страницы успел переобойти бот.
Как посмотреть сохраненную копию в Google
Рассмотрим на примере страницы https://discript.ru/prodvizhenie-sajtov/kolomna/. Перед url адресом пропишите оператор «site:». В сниппете (блок информации о странице веб-сайта) результата, нажмите на иконку в виде треугольника, выберите соответствующий пункт.
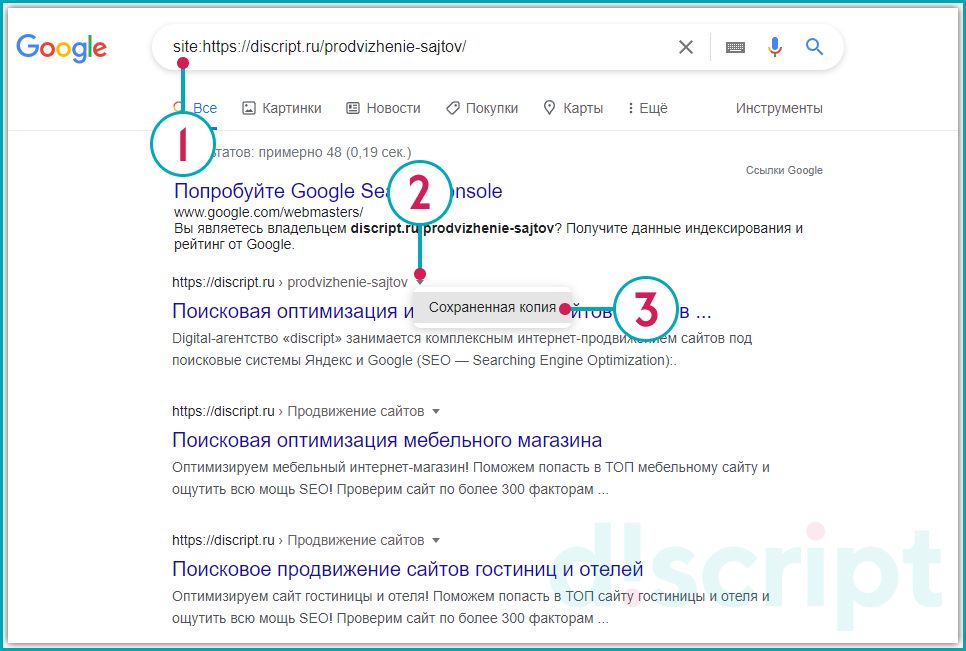
Сохраненная копия в Google
Откроется сохраненная копия веб-страницы. Google выведет окно с сообщением, что открылся «снимок» страницы.
Разберем представленную информацию:
- Дату фиксации. В данном параметре указано, когда был сделан слепок страницы. Поэтому сопоставив указанную дату с датой внесения правок, можно предположить успел ли поисковый бот обойти страницу или еще нет (Важно! данный метод не гарантирует 100% верную информацию, т.к. данные хранятся в кеше и могут отличаться в зависимости от вашего место нахождения) ;
- Полная версия. Отображается версия страница, как должен был ее увидеть пользователь.
- Текстовая версия. Позволяет просмотреть контент веб-страницы без применения стилей. Такой формат позволяет увидеть скрытые от пользователя элементы, но доступные для поисковых роботов Яндекса и Google;
- Исходный код. Выводит исходный код HTML-страницы. Это требуется для изучения тега Title и мета тегов, таких как Description. Данное представление позволяет изучить, как сверстана веб-страница, и нет ли на ней критических ошибок.
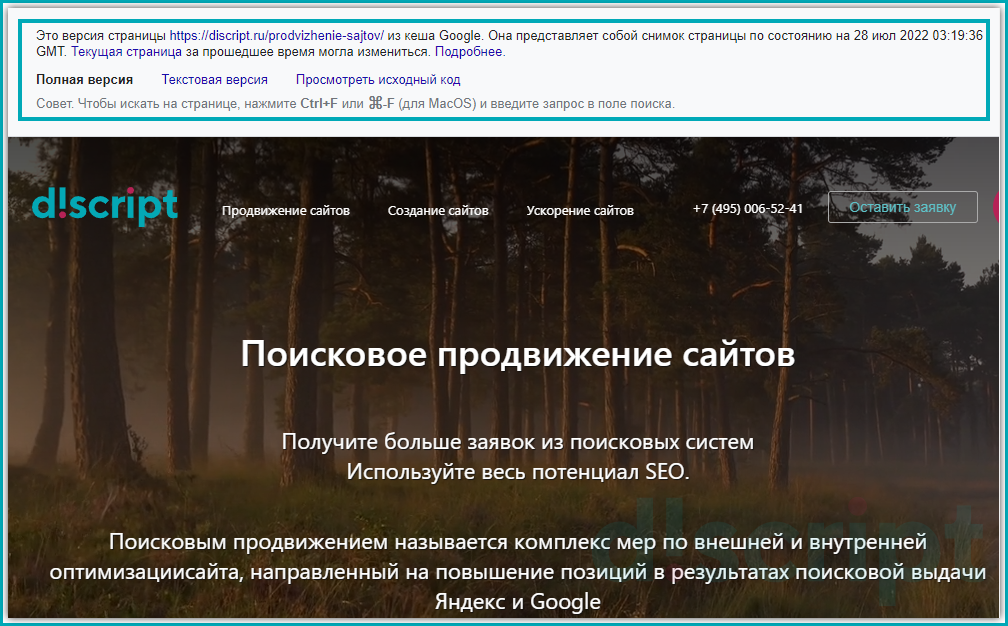
Просмотр версии страницы из кеша Google
Как посмотреть сохраненную копию веб-страницы в Яндекс
Рассмотрим на примере страницы https://discript.ru/site-development/. В строку поиска обязательно пропишите оператор «url:» перед url-адресом. нажмите на значок в виде трех горизонтальных точек, выберите «Сохраненная копия».
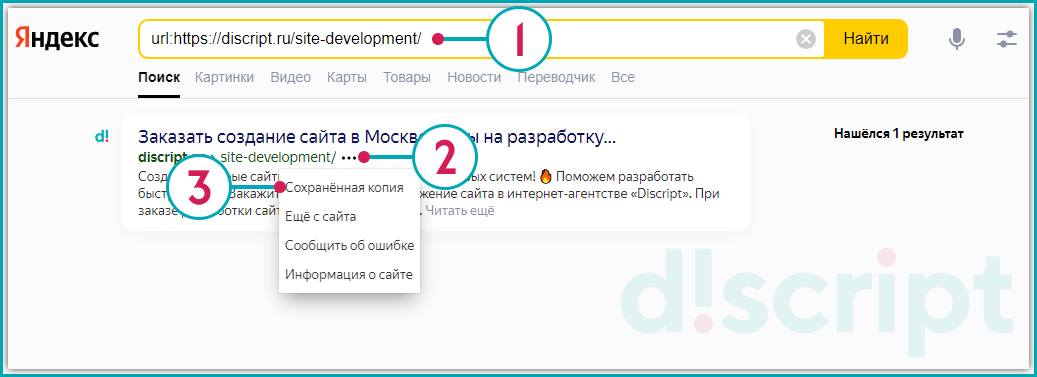
Пример поиска сохраненной страницы в Яндексе
Далее Яндекс предоставит следующие данные:
- Дата индексации. Данное значение информирует в какой момент выполнен слепок страницы.
- Полная версия страницы. Отображение страницы со всеми стилями.
- Текстовая версия страницы. Текстовая версия, аналогично позволяет изучить страницу без стилей и получить всю скрытую информацию. Часто именно при проверке текстовой копии обнаруживаются сквозные блоки текста на страницах. Т.к. при использовании стилей они скрыты.
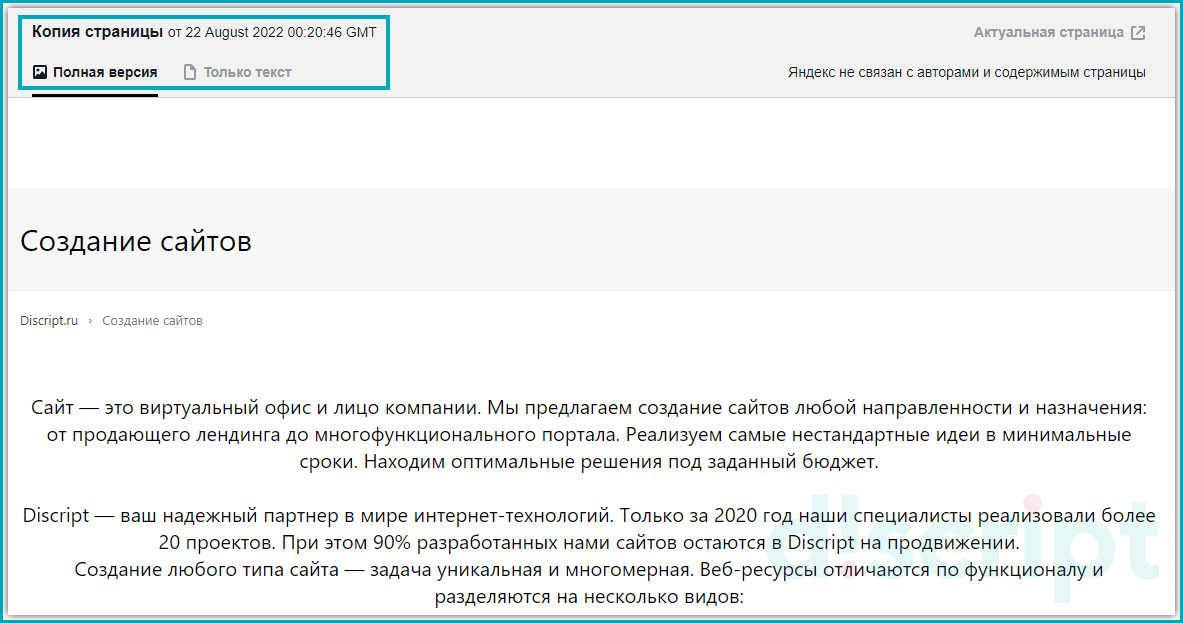
Предоставление данных о копии страницы в Яндексе
Почему сохраненной страницы может не быть
Это происходит в результате:
- Сбой работы поисковых систем. Разработчики Яндекса даже говорят, что нет стопроцентной гарантии, что страница сохранится. Конкретная причина не указывается.
- HTML-код содержит мета тег мета-тег «robots» со значением «noarchive», что означает запрет на кэширование (локальное сохранение данных для получения быстрого доступа к странице при следующих запросах).
Что предпринять если в ПС нет сохраненной копии, а посмотреть содержимое нужно? Попробуйте изучить специализированные площадки и расширения.
Рассмотренными выше способами можно посмотреть:
- Мобильную версию веб-сайта. Пропишите url мобильной версии в Яндексе или Google. Из выдачи перейдите на нее далее, как в примере рассмотренном выше.
- Адаптивную версию. Перейдя в сохраненную копию (так же как в примере выше). Открываем инструменты разработчика. Клавиша F12 в обозревателе. Или нажать ПКМ на пустом месте страницы, выбрать «Посмотреть код». Переходим в раздел мобильное отображение и перезагружаем веб-страницу.
Специализированные веб-архивы
Выше мы обсуждали, что существуют сервисы, задачи которых сохранять в истории страницы сайтов. Сейчас рассмотрим их подробнее и расскажем, как с ними работать.
И начнем с самого популярного и известно.
Wayback Machine
Сервис Wayback Machine — бесплатным онлайн-архивом, задача которого является сохранить и архивировать информацию размещенную в открытых интернет‑ресурсах. Wayback Machine является частью некоммерческого проекта Интернет Архива. На его серверах хранятся копии веб-сайтов, книг, аудио, фото, видео.
Чтобы открыть копию страницы перейдите на https://archive.org/, далее откроется поисковая форма, куда пропишите URL страницы. Нажмите кнопку «GO».

Онлайн-архив Wayback Machine
Сервис отобразит имеющиеся в архиве снимки.
Далее выберите в календаре нужную дату и откройте страницы. Результатом вывода будет открытие страницы, которую зафиксировали роботы за выбранную дату.
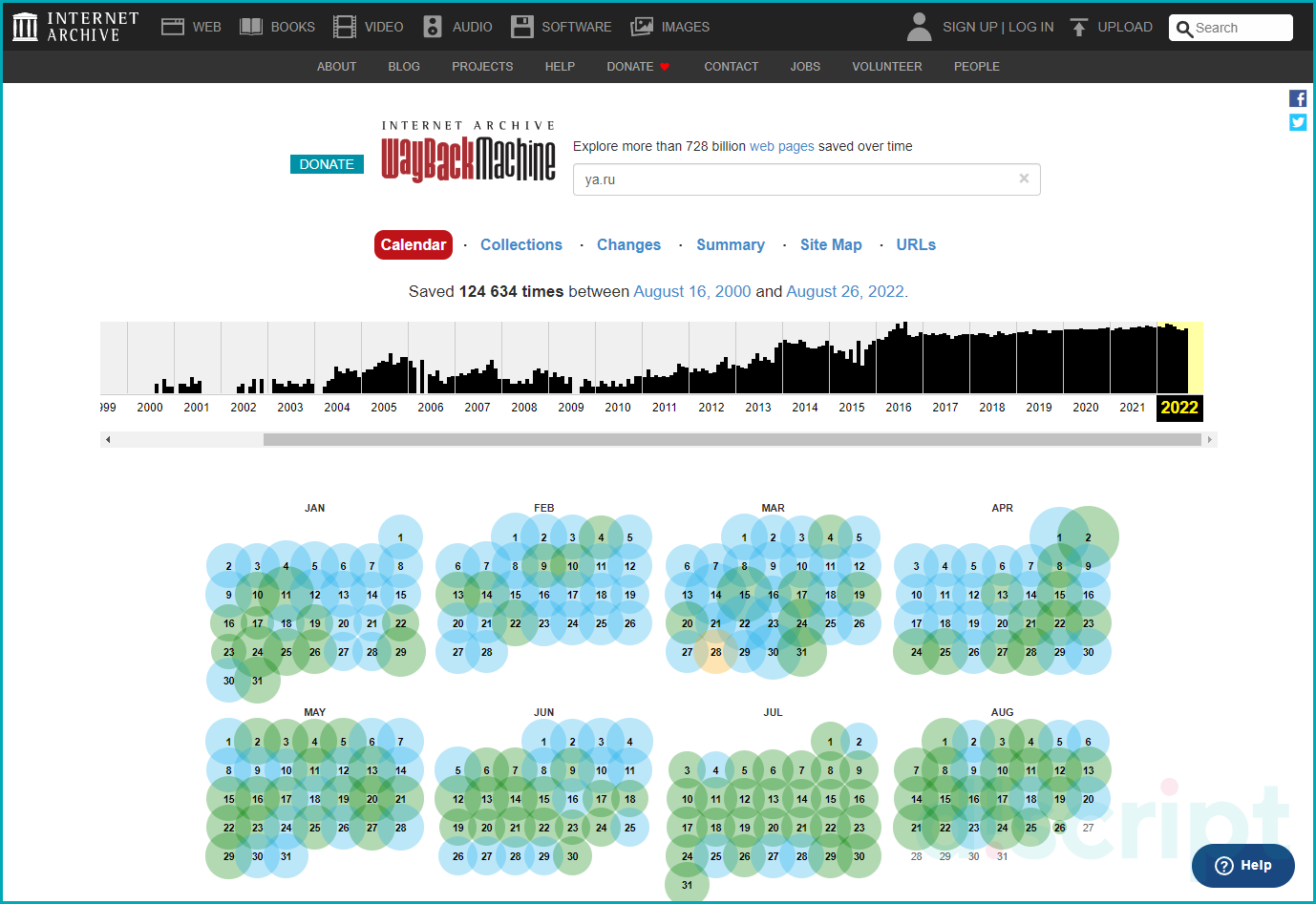
Календарь Wayback Machine
Кроме просмотра снимков страниц, сервис поможет:
- Проанализировать robots.txt. Сервис будет сканировать веб-сайты вне зависимости от настроек robots.txt;
- Узнать данные о домене. Актуально перед покупкой. Уточните какая информация размещалась на нем. Если вы купите «заспамленный» или домен под «санкциями» (например была размещена информация для взрослых) новый контент будет плохо ранжироваться. Если же ранее на нем размещалась информация, которая подходит по тематике и качеству для вашего будущего ресурса, тогда вы сможете использовать ее на этом же домене.
- Найти в архивных копиях пропавшую информацию.
- Если, например, на веб-сайте наблюдается спад трафика, откройте сохраненную версия сайта до момента уменьшения посещаемости. Проанализируйте, какие были сделаны изменения, чтобы разобраться в причине падения посещаемости.
Archive.Today
Archive.Today — бесплатный некоммерческий севрис сохраняющий веб-страницы в оналйн режиме. Особенность — сохраняет не только статические страницы, но и генерируемые Веб 2.0-проектами страницы. Например, карты Google.
Основное отличие от Wayback Machine, что Archive.Today сохраняет веб-страницы только по запросу пользователей. При этом сервер полностью сохраняет:
- HTML-страницы,
- CSS файлы,
- JS файлы,
- PDF,
- аудио файлы,
- пр.
Важно, помнить, что Archive.Today игнорирует файл robots.txt поэтому в нем можно сохранить страницы недоступные для Wayback Machine.
Обратите внимание, общий в Размер заархивированной страницы со всеми изображениями не должен превышать 50 МБ.
У Archive.Today есть собственное приложение для браузера Mozilla Firefox. Ссылка на ПО https://addons.mozilla.org/en-US/firefox/addon/archive-page/
Для начала работы с Archive.Today перейдите по адресу: https://archive.md/. Чтобы получить результат укажите в форму интересующий URL-адрес.
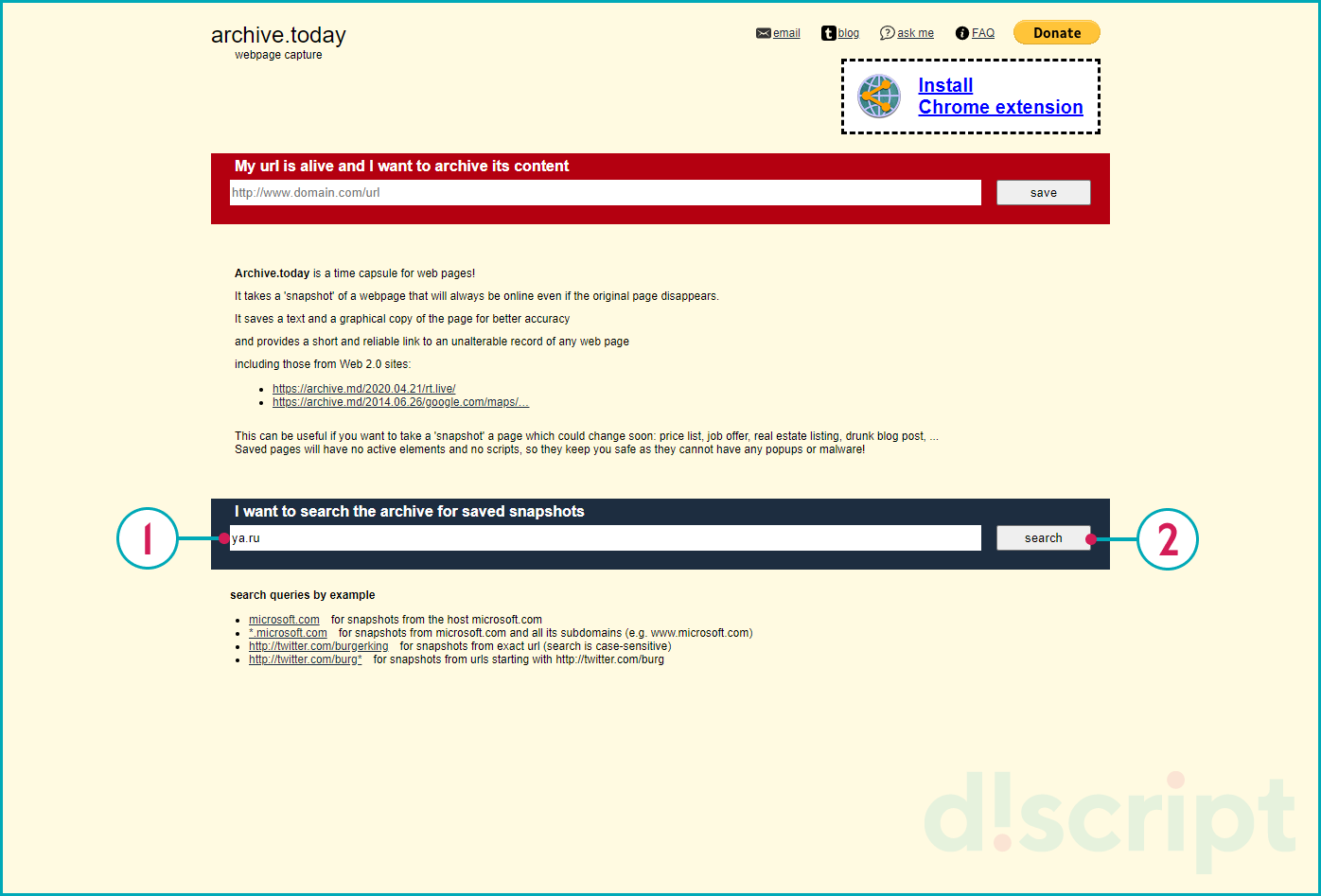
Сервис Archive.Today
Откроется страница с сохраненными снимками и информацией о дате создания копии.
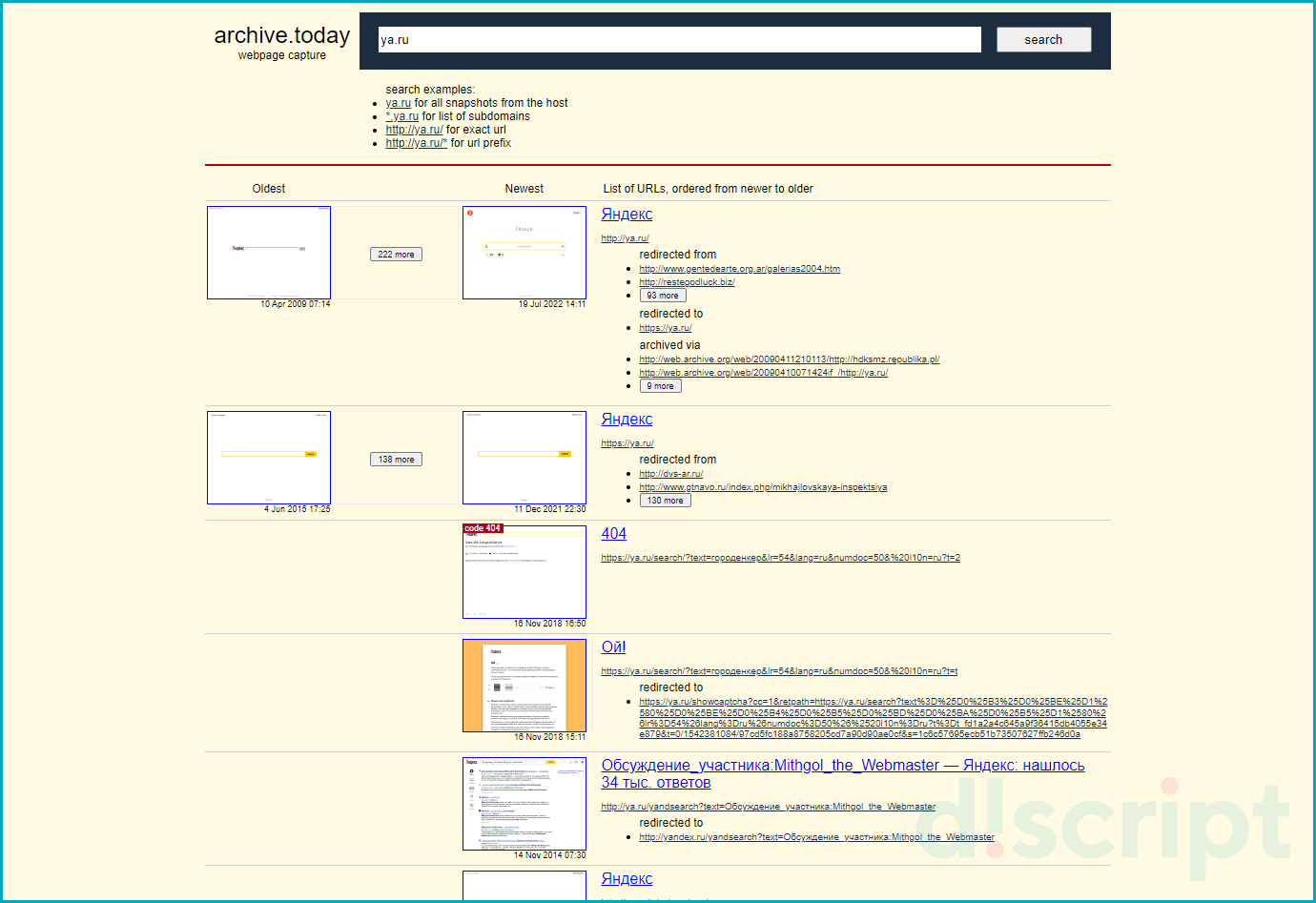
Страница с сохраненными снимками в сервисе Archive.Today
Вы можете скачать сохраненную копию виде архива. И восстановить версию страницы у себе на сервере.
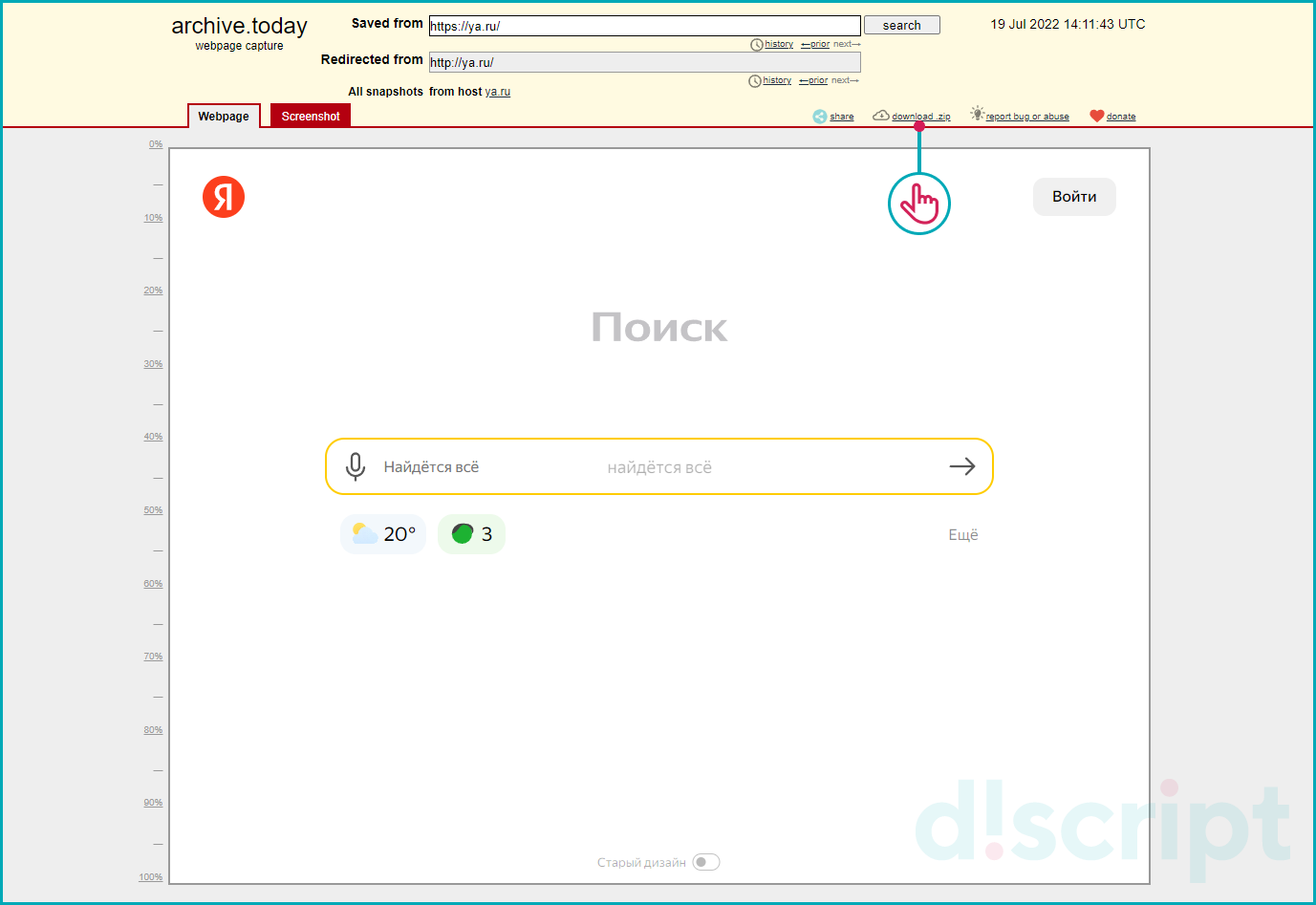
Сохранение страницы в сервисе Archive.Today
Расширения для браузеров
Существуют, плагины для браузеров, позволяющие создавать и просматривать сохраненные версии страниц.
Например, расширение Web Cache Viewer позволяет:
- Загружать веб-страницу из локального кэша на компьютере;
- Автоматически находить страницу при помощи сервиса Wayback Machine.
Перейдя по ссылке, рассмотренной, выше, нажмите кнопку «Установить».
Сервис Web Cache Viewer
После инсталляции расширения в браузере, нажмите правой кнопкой мыши пустом месте страницы для просмотра версии из Google или Wayback Machine.
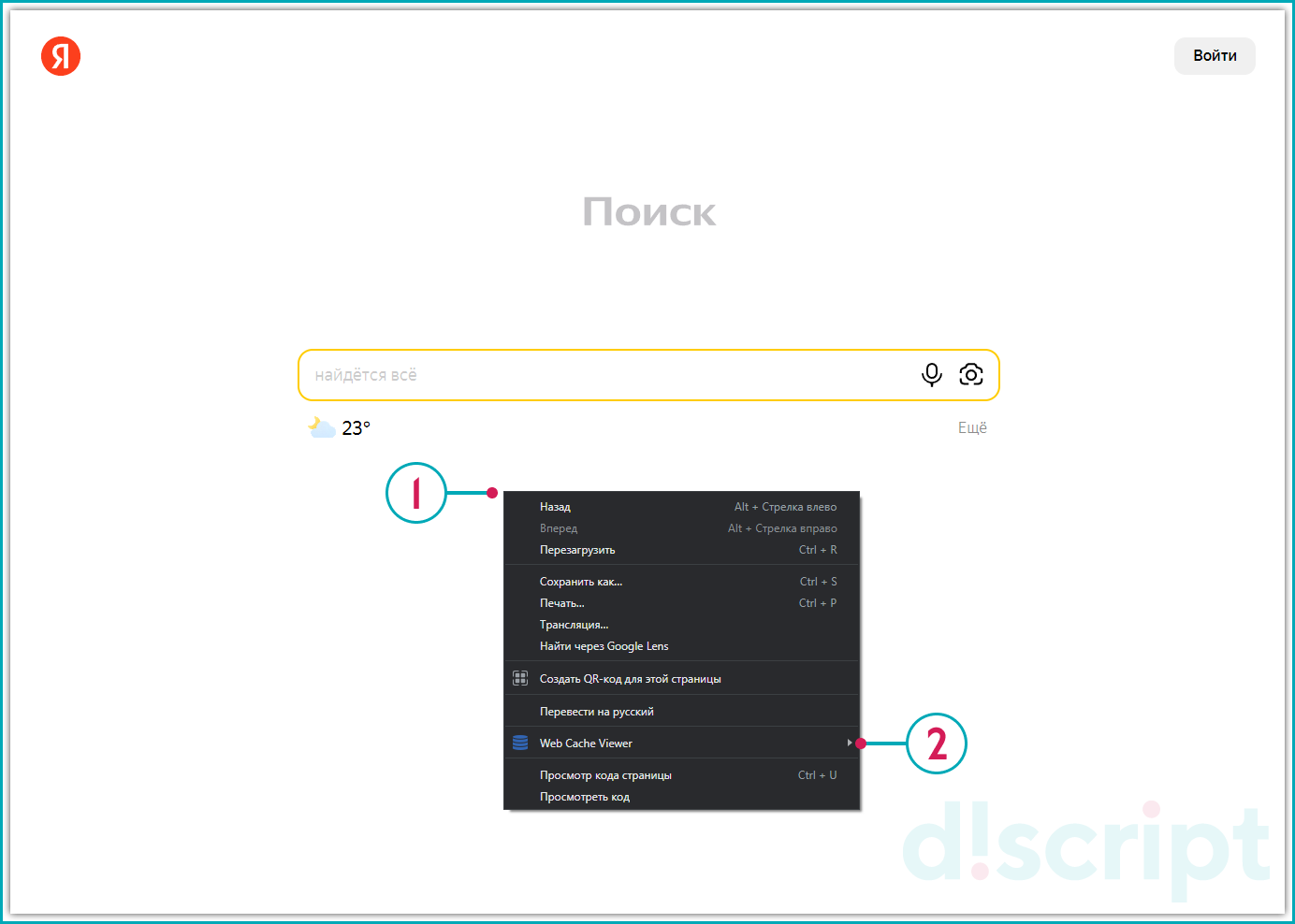
Просмотр версии из Google или Wayback Machine
Для пользователей Firefox существует аналогичное дополнение со схожим функционалом Web Archives.
Cached Page
Веб-сайт Cached Page ищет копии веб-страниц в поиске Google, Интернет Архиве, WebSite. Используйте площадку, если описанные выше способы не помогли найти сохраненную копию веб-сайта.
Пропишите название сайта в специальную форму. Для поиска нажмите одну из трех кнопок. Сервис предложит произвести поиск веб-страницы в:
- Веб-кэш Google;
- Интернет Архив;
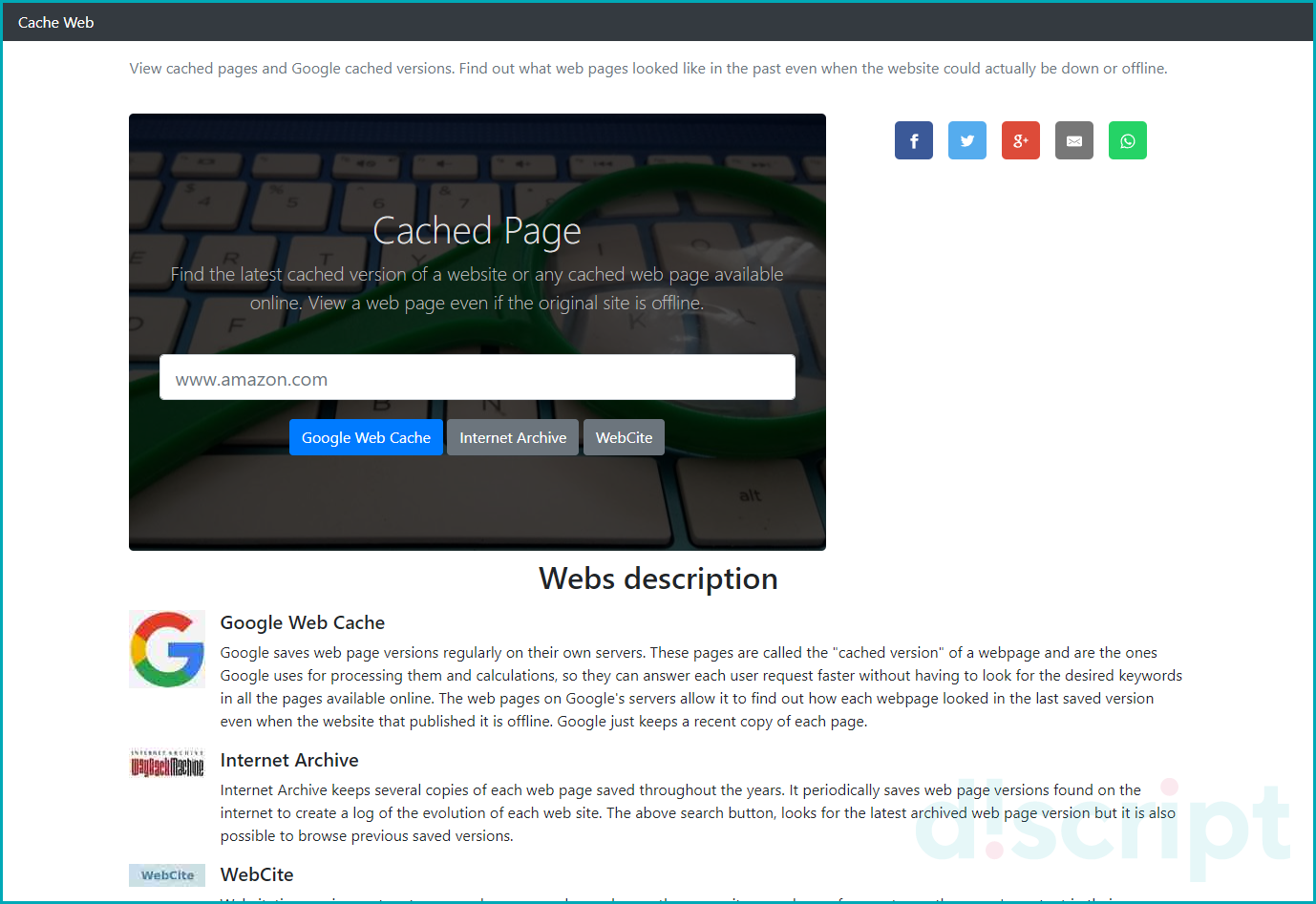
Поиск в сервисе Cached Page
Например, прописав в форму адрес https://discript.ru/prodvizhenie-sajtov/lyubercy/, и нажав кнопку «Архив Интернета», произойдет переход на страницу сервиса Wayback Machine. Если страница сохранена в БД сервиса, она отобразится на странице.
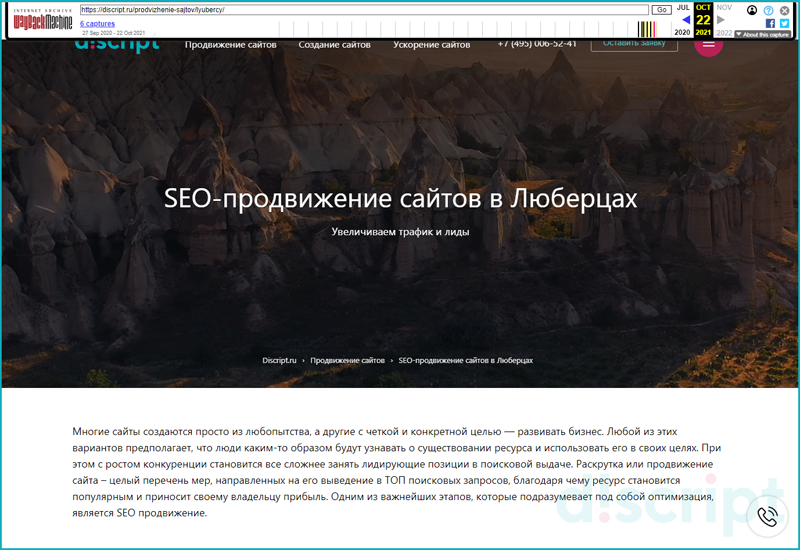
Отображение страницы в сервисе Wayback Machine
Выводы
Работая с сохраненными копиями страниц, можно выявить достаточного много полезных нюансов.
Сохраненные копии позволяют:
- Узнать, поисковый бот успел ли обойти вашу страницу после внесенных правок.
- Как бот воспринимает информацию со страницы. Все ли учитывает или остались места, которые ПС не видят.
- Выявить, какие элементы пропали и когда.
- Выявить, какие страницы успел обойти поисковый бот, после того, как сайт перестал быть доступным.
- Создать копии страниц.
- Восстановить копию сайта, когда забыли оплатить домен.
Сохраненная копия веб-страницы поможет определить, какая версия документа проиндексирована поисковыми роботами и участвует в ранжировании. Поэтому наличие «снимка» страницы в Яндексе и Google говорит об успешной проведенной индексации.
Другие статьи
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
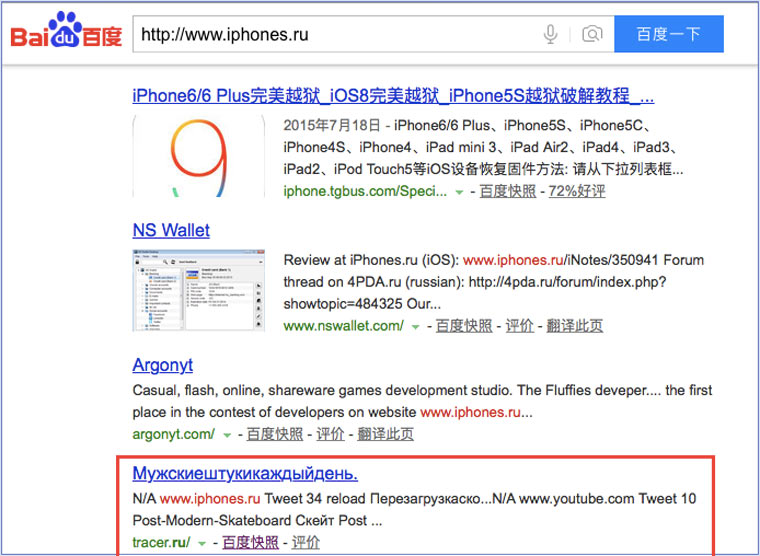
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
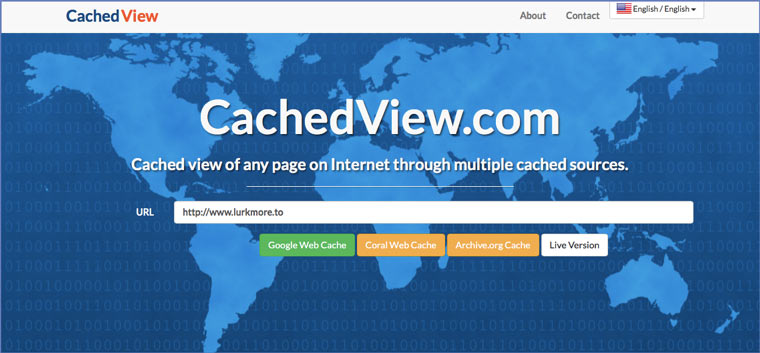
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
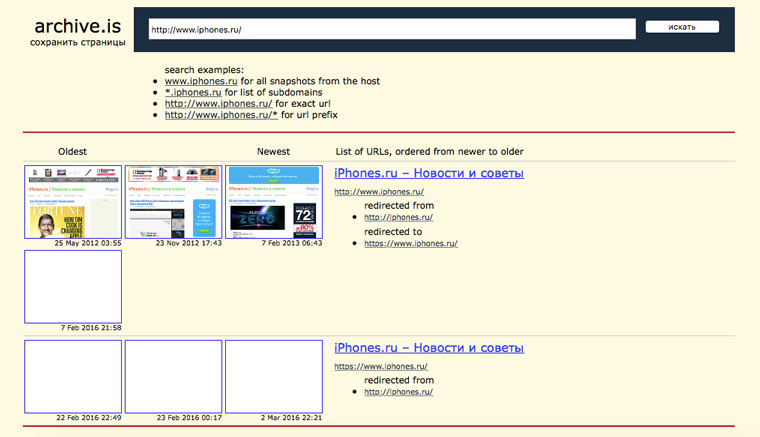
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
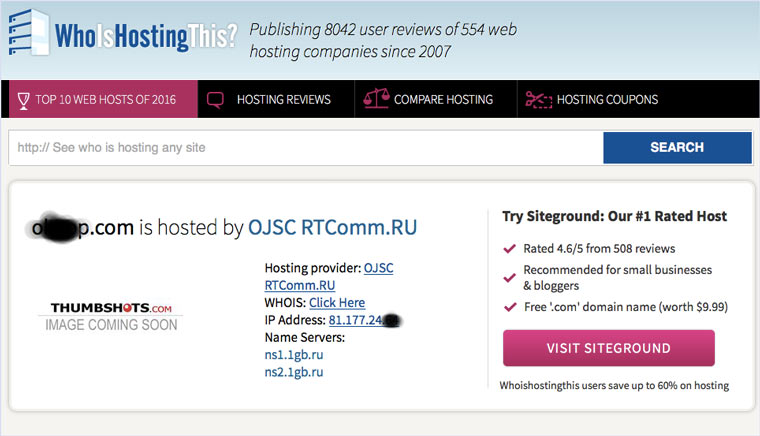
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()
Содержание
- Как очень удобно сохранять нужные и важные для вас ссылки из интернета, на полезные и интересные сайты.
- Где в компьютере хранятся ссылки на сайты, добавленные в закладки и (см.)?
- Бесплатный сервис хранения ссылок
- Предисловие
- Вступление
- Описание сервиса
- Иконки
- Группы
- Подгруппы
- Backup всех ссылок
- Разделы сайта
- Короткие ссылки
- Друзья
- Боксы ссылок
- Публичные ссылки
- Лента
- Темы, языки
- Как сохранить ссылку на рабочем столе
- Сохранение ссылки на компьютер
- Способ 1: Создание URL-ярлыка сайта на рабочем столе
- Способ 2: Ссылки на панели задач
- Заключение
- Помогла ли вам эта статья?
- Поделиться статьей в социальных сетях:
- Еще статьи по данной теме:
- Где Яндекс Браузер хранит на компьютере файл с закладками?
- Просмотр закладок в интерфейсе браузера
- Где Яндекс Браузер хранит закладки. Файл «Bookmarks»
Как очень удобно сохранять нужные и важные для вас ссылки из интернета, на полезные и интересные сайты.

Если мне нужна новая категория, то я справа нажимаю «добавить еще одну колонку» и вписываю название.
А если же у меня появиться потребность добавить новую понравившуюся мне ссылку, то я в нужной категории, внизу, жму «Добавить еще одну карточку». Далее вписываю название этой карточки и кликаю «Добавить». В итоге карточка создана, но пока без превью — картинки.



Открываю. В описание закидываю ссылку. Во вложениях креплю картинку. Все


В результате я имею вот такую привлекательную карточку. Тыкнув по ней, она откроется и мне останется только нажать по ссылке. В общем, очень удобно. Не страшен крах жесткого диска, все под рукой (можно закрепить вкладку в браузере) и очень симпатично выглядит.
А так же, если остались вопросы, советуем посмотреть видео урок на эту тему, расположенный ниже. Всем спасибо за внимание и до встречи.
Источник
Где в компьютере хранятся ссылки на сайты, добавленные в закладки и (см.)?
Ссылки на часто посещаемые сайты обычно сохраняют в закладках браузера.
А где в памяти компьютере хранятся эти ссылки,
можно ли их как-то посмотреть, не открывая браузера,
и вообще, какой объем памяти занимают закладки и одна отдельная ссылка?
![]()
D:Users AppDataLocalGoogleChromeUser DataDefault
В этой папке надо найти файл Bookmarks (он без расширения). При просмотре этого файла блокнотом, то можно найти все ссылки из Избранного с описаниями. Формат файла JSON, и все русские буквы будут в виде escape-unicode, но сами ссылки вполне понятны и обозримы.
![]()
Закладки хранятся либо в специальной папке с некоторой структурой файлов, либо в специальном структурированном файле. Для каждого браузера и для каждой операционной системы это место меняется. Для Internet Explorer есть папка Favorites в недрах папки с данными пользователя. Для других браузеров так же есть свои папки и файлы Favorites или Bookmarks, размещенные в подпапках с данными этих программ. Просто задайте поиск файлов с этими масками и найдете требуемое для каждого установленного браузера и пользователя в системе.
![]()
Сделать это Вы можете как в ручную, так и при помощи различных сервисов (правда это уже как правило стоит денег).
![]()
Если вы имеете ввиду от поисковиков, то так
![]()
Ссылка вот такого вида называется «гиперссылка» и не имеет ничего общего со сноской.
Чтобы из какого-то текста, например, «читать далее», сделать гиперссылку, надо выделить этот текст и нажать комбинацию Ctrl+K. Открочется меню ввода адреса гиперссылки такого вида:

![]()
Что бы пользоваться гуглом как я понимаю нужно зарегистрироваться в системе,тогда я думаю у вас не будет никаких проблем.
![]()
Хочу Вас огорчить, но их практически нет. Я пыталась даже ненароком разместить ссылки в интернет- магазинах, притом не самых популярных.
Однако, никто не отменял социальные сети, в которых можно размещать записи на своем форуме, своей стене.
Можно найти в соцсетях тематические группы, оставлять там комментарии к постам со ссылкам на Ваши отзывы. Лучше комментарии оставлять в виде ответа кому- либо, так это будет не очень смахивать на откровенную рекламу. Если не хотите со своей странички, можете зарегистрировать себе запасную, рекламную так сказать.
Источник
Бесплатный сервис хранения ссылок

Предисловие
Знаю, что “хабра-народ” сейчас очень негодует, что стало очень мало технических статей, Хабр “не торт” и т.п. поэтому напишу сразу – это не техническая статья.
Цель статьи – поделиться удобным бесплатным сервисом хранения ссылок.
Конечно, можно было бы написать подробное техническое повествование. Например, целая история с изменением регулярного выражения для проверки корректности ссылки, сколько бы его не настраивали – всегда находилась ссылка, которая не вписывалась бы в правила. Но тогда бы получилась целая серия статей, которые наверняка никому и не интересны. Да и некоторые NDA надо учитывать.
Вступление
Этот раздел описывает причину, почему появился такой сервис, и если вы ревностно относитесь к своему времени, смело пропускайте его.
Был проект. Построенный на IIS + ASP.NET + MVC. Время шло. Появлялись новые версии MVC. Проект переезжал с версии на версию. Проект использовал достаточно специфическую внутреннюю архитектуру, поэтому MVC обрастал всё новыми костылями.
Шло время и в MVC подвезли новый промежуточный веб сервер Kestrel. Возможно, этот факт послужил последней песчинкой заставившей перевесить чашу весов, было принято решение написать свой web-стек. Превратить все костыли в архитектурную особенность. Чтобы код помогал программисту, а не вызывал отвращение.
Честно сказать – по прошествии времени можно сделать вывод.
Чёткое понимание, что сейчас за такую работу вряд ли бы взялись. Но т.к. путь проделан и результат есть – дальнейшая разработка вызывает только моральное удовольствие. Конечно “удовольствие” измеритель достаточно эфемерный, но проявляется это в том, что новые архитектурные изменения не ложатся костылями, а гармонично вписывается в текущую структуру. Не разрушая её, а дополняя. Разработка ведётся быстрее. Новые фичи не ломают старые. Все довольны.
Так вот. По мере написание своего web-стека встал вопрос о тестировании.
И этот сервисом оказался – сервис хранения ссылок. Более того этот сайт оказался отличным тестовым полигоном для отработки различных web идей. И по мере своего существования обрастал всё новым функционалом. Который тестировался, уходил в другие проекты, но и оставался в сервисе.
Было решено написать документацию к нему. Нуднейшее дело я вам скажу. Ну и поделится с другими.
Описание сервиса
Сервис предназначен для хранения ваших ссылок. И по мере наполнения ссылками – должен становится личным удобным каталогом. Весь функционал сервиса построен на идее – минимальное количество действий для получения результата – сохранения ссылки. При этом все возможные лишние действия – автоматизированы.
Главный интерфейс изображён в шапке этой статьи. В общей структуре он одинаков для разных разделов сервиса, таких как например “Шифрованные ссылки” или “Публичные ссылки”. Для добавления ссылки в каталог, её копируем в поле, которое расположено в верхней части сайта. Нажимаете кнопку “Добавить” – собственно это все действия.
Далее ссылка передаётся на сервер. Там подвергается проверке работоспособности. Проверяется доступ по протоколам http/https. Проверяется редирект ссылки. При необходимости производится промежуточное сохранение и отправка cookies. После всех проверок сохраняется конечный вариант.
Далее сервис загружает вашу ссылку и производит поиск заглавия. При этом производится автоматическое определение правильной кодировки – многие сайты возвращают неправильную кодировку. Для некоторых популярных сайтов поиск названия производится в заранее определённых местах. При поиске названия автоматически определяется тип ссылки. Сервис может, например, отличать PDF от html.
В конце всей процедуры сохраняется правильная ссылка и её заглавие. Это информация и заносится в каталог.
У каждой добавленной ссылки есть меню настройки. Для вызова меню для ссылки надо нажать на иконку в виде квадрата слева от ссылки. При нажатии появляется меню управления ссылкой. Меню состоит из 5 кнопок
Перемещение ссылки в другую группу подгруппу
Редактирование заголовка ссылки
Редактирование URL ссылки
Иконки
Для часто используемых сайтов можно сделать иконку быстрого доступа. Иконки подобны ярлыкам программ в Windows. Располагаются в поле иконок – область сразу после меню групп. Размер поля иконок можно изменять. Положение и размер иконки так же можно менять.
Положение заглавия иконки. Верх, середина, низ, нету заглавия.
Редактировать заглавие иконки
Меню настройки картинки иконки. Можно загрузить картинку из интернета или с компьютера.
Фиксировать иконку. Запретить перетягивание.
Группы
Все добавленные ссылки делятся по группам. Группы – это страницы каталога ссылок. Выбор группы происходит путём нажатия на кнопку с именем группы. Меню групп закреплено и не прокручивается вместе с прокруткой.
Кнопки групп можно двигать. Слева каждой кнопки есть полоса для перетягивания. Самая первая кнопка меню – это кнопка открытия вашего каталога ссылок в виде оглавления.
Это список всех групп/подгрупп с активными линками. Щелчок мыши – быстрый переход в нужную категорию.
Для управления группами ест отдельная страница. Вход – кнопка в виде креста в правой части меню групп.
Подгруппы
Группы делятся на подгруппы. Внутри подгруппы можно установить способ сортировки ссылок.
Сортировка ссылок по названию. Сверху-вниз.
Сортировка ссылок по названию. Снизу-вверх.
Сортировка по дате добавления ссылки. Сверху-вниз.
Сортировка по дате добавления ссылки. Снизу-вверх.
Подгруппы можно перемещать между группами. Последовательность подгрупп меняется. Щелчок по заглавию подгруппы выделяет её. Новая добавленная ссылка будет добавлена в эту подгруппу.
Backup всех ссылок
Если вы боитесь потери ваших ссылок – вы можете в любой момент сохранить все их на ваш компьютер. Для этого есть четыре кнопки в верхней левой части экрана. При нажатии на кнопку будет предложено сохранить файл со всеми вашими ссылками. Файл будет в том формате кнопку которого вы нажали.
Файл будет содержать ссылки только того раздела, из которого вы нажали сохранение. Например, ссылки для раздела “Ваши ссылки” или “Шифрованные ссылки”. Шифрованные ссылки расшифровываются на стороне браузера и формируется файл – который вам предлагается для скачки. Который будет содержать уже расшифрованные ссылки.
Загрузка всех ссылок в текстовом формате
Загрузка всех ссылок в виде html страницы. Можно либо сохранить файл, либо сразу открыть в браузере.
Загрузка всех ссылок в виде JSON кодировки. Предназначен для автоматизированных систем.
Загрузка всех ссылок в виде XML кодировки. Предназначен для автоматизированных систем.
Разделы сайта
Ваши ссылки.
Это первый и основной раздел сайта. Это собственно основной формируемый каталог ссылок. Каталог имеет широчайшие возможности по настройке отображения и управления добавленными ссылками.
Шифрованные ссылки.
Если вы хотите чтобы ваши ссылки не были видны администраторам сайта. А так же пользователям, которые по тем или иным причинам зашли на сайт под вашим логином – но которые не знаю специальный пароль, то этот раздел для вас.
Раздел по предоставляемым функциям аналогичен разделу “Ваши ссылки”. Но ссылки хранятся на сервере в зашифрованном виде.
Короткие ссылки
Если вам нужно превратить длинную ссылку в короткую, то этот раздел для вас. Раздел по функциональности аналогичен разделу “Ваши ссылки”. Для удобного пользования ссылки также добавляются в группы/подгруппы. Все операции со ссылками такие же, как в разделе “Ваши ссылки”.
Друзья
Раздел друзья предоставляет 2 функции:
Кинуть ссылку другу. Получить ссылку от друга
Открыть другу для просмотра любую группу из раздела “Ваши ссылки”
Т.е. этот раздел по функциям напоминает почту. Но только для ссылок. Последовательность действий следующая.
Вы отправляете запрос на добавление в друзья. Ваш запрос принимают. И в списке друзей у вас появляется новый друг. У каждого друга есть входящая папка и исходящая. Вы можете кидать ссылки друг другу. При этом ссылки распределяются на просмотренные или нет. Ссылку можно «лайкнуть».
Так же другу можно открыть для просмотра любую группу из раздела «Ваши ссылки».
Боксы ссылок
Боксы с ссылками это страница с группой ссылок и имеющая общедоступный из интернета адрес. Например вам нужно оставить на форуме, блоге или в youtubе – список ссылок. Но при этом вы ходите редактировать этот список впоследствии. А также хотите знать, сколько пользователей интересовалось ссылками. Тогда инструмент “Бокс ссылок” – то что вам надо.
Интерфейс аналогичен остальным разделам. Каждая группа в разделе “Бокс ссылок” – это отдельная страница который имеет самостоятельный адрес.
Каждый бокс имеет текстовый блок, в котором вы можете разместить текстовую информацию. Информация также будет доступна по адресу бокса.
Справа адреса бокса расположен счётчик переходов по этому адресу, а также кнопки управления счётчиком. Также счётчик переходов имеет каждая ссылка в отдельности. Ссылки в бокс добавляются также как и в других разделах.
В бокс также можно добавить подгруппы – если ссылок много и вы хотите их систематизировать для удобства просмотра.
Публичные ссылки
Раздел по функционалу аналогичен разделу “Ваши ссылки”, но все добавленные ссылки становятся публичными. Это значит, что на вас могут подписаться другие пользователи, в разделе “Лента” и просматривать ваши публичные ссылки.
Лента
Это раздел для просмотра публичных ссылок других пользователей. Раздел состоит из 3 подразделов.
Лента новых публичных ссылок пользователей, на которых вы подписаны
Лента представляет собой непрерывный список ссылок пользователей, на которых вы подписаны. Ссылки добавляются от новых к старым. Лента отображается с автоподгрузкой данных.
Просмотр всех публичных ссылок конкретного пользователя
Раздел предоставляет список всех публичных пользователей, на которых вы подписаны. Список располагается в левом всплывающем окне
Поиск публичных пользователей
Раздел отображает в виде списка всех публичных пользователей, на которых вы можете подписаться. Если раздел пуст – публичных пользователей нет. Пользователи, на которых вы подписаны, так же не отображаются в разделе.
Темы, языки
Сайт доступен в 2 языках en/ru и в 2 темах тёменая/светлая.
Источник
Как сохранить ссылку на рабочем столе

Сохранить ссылку на рабочий стол или прикрепить её на панели вкладок в интернет-обозревателе очень просто и производится это буквально несколькими щелчками мыши. В этой статье будет показан способ решения данной задачи на примере браузера Google Chrome. Приступим!
Сохранение ссылки на компьютер
Чтобы сохранить нужную вам веб-страницу, потребуется произвести всего несколько действий. В этой статье будет описано два способа, которые помогут сохранить ссылку на веб-ресурс из интернета при помощи браузера Гугл Хром. Если вы пользуетесь другим интернет-обозревателем, не стоит беспокоиться — во всех популярных браузерах этот процесс происходит одинаково, поэтому представленную ниже инструкцию можно считать универсальной. Исключением является разве что Microsoft Edge — к сожалению, в нём нельзя воспользоваться первым способом.
Способ 1: Создание URL-ярлыка сайта на рабочем столе
Этот способ требует буквально двух нажатий мыши и позволяет перенести ссылку, ведущую на сайт, в любое удобное для пользователя место на компьютере — к примеру, на рабочий стол.
Уменьшаем окно интернет-обозревателя так, чтобы было видно рабочий стол. Можно нажать на сочетание клавиш «Win + правая или левая стрелочка», чтобы интерфейс программы мгновенно переместился в левый или правый, в зависимости от выбранного направления, край монитора.

Выделяем URL-адрес сайта и переносим его на свободное пространство рабочего стола. Должна появиться маленькая строчка текста, где будет написано название сайта и маленькое изображение, которое можно увидеть на открытой с ним вкладке в браузере.

Способ 2: Ссылки на панели задач
В Windows 10 появилась возможность создавать свои или пользоваться предустановленными вариантами папок на панели задач. Они называются панелями и одна из таких может содержать в себе ссылки на веб-страницы, которые будут открываться посредством установленного по умолчанию браузера.
Важно: Если вы используете Internet Explorer, то в панель «Ссылки» будут автоматически добавляться вкладки, которые находятся в категории «Избранных» в данном веб-обозревателе.

Заключение
В этом материале были рассмотрены два способа сохранения ссылки на веб-страницу. Они позволяют в любое время получить быстрый доступ к избранным вкладкам, что поможет сохранить время и быть более продуктивным.
Помимо этой статьи, на сайте еще 12336 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Помогла ли вам эта статья?
Поделиться статьей в социальных сетях:
Еще статьи по данной теме:
Спасибо огромное.Наконец-то нашла ясное и понятное разъяснение о сохранении ссылок.Пока не потеряла нить мысли,ответьте пожалуйста,как скопировать ссылочку из моей папки на рабочем столе в комментарий.Миллион раз пробовала- не получается.Я новичок.
Здравствуйте, Нелли. Все просто — кликните правой кнопкой мышки по ярлыку на рабочем столе и выберите в контекстном меню пункт «Свойства». В появившемся окошке будет открыта вкладка «Веб-документ» (если нет — перейдите в нее), а в строке «URL-адрес» будет указана ссылка. Скопируйте ее клавишами CTRL+C или через правый клик — «Копировать».
ЗДРАВСТВУЙТЕ! ОЧЕНЬ ВАМ БЛАГОДАРНА ЗА ЭТОТ УРОК, ДЛЯ МЕНЯ В ПРОЦЕССЕ УЧЁБЫ ОЧЕНЬ ВАЖНЫ ССЫЛКИ, К КОТОРЫМ ПРИХОДИТСЯ ВОЗВРАЩАТЬСЯ И НЕ РАЗ….. НО ВОТ ПОЯВИЛИСЬ ВОПРОСЫ ЕЩЁ. 1) НА НИЖНЕЙ ПАНЕЛИ НЕ УДАЛЯЕТСЯ НАЗВАНИЕ ССЫЛКИ И ОНО, ЕСТЕСТВЕННО ЗАНИМАЕТ МНОГО МЕСТА., И 2) ВОПРОС— КАК СОЗДАТЬ ПАПКУ С ЭТИМИ ССЫЛКАМИ, ЧТО НА СТОЛЕ, ЧТО НА ПАНЕЛИ, ЧТОБЫ МОЖНО БЫЛО ПРОСМАТРИВАТЬ И ВЫБИРАТЬ НУЖНУЮ ССЫЛКУ…? СПАСИБО ВАМ И ОЧЕНЬ ХОТЕЛОСЬ БЫ ПОЛУЧИТЬ ОТВЕТ ОТ ВАС.
Здравствуйте, Roza. Извините за столь поздний ответ и спасибо за положительный отзыв. А теперь о Ваших вопросах:
2) Ссылки на рабочем столе можно просто поместить в папку, любую, и она даже может находиться в каком-угодно месте на диске. То есть Вы просто нажимаете в любом удобном месте (пустом месте папки или рабочего стола) правой кнопкой мышки, выбираете пункты «Создать» — «Папку», называете ее так, как посчитаете нужным, и перемещаете туда все ссылки. Работать и открываться они будут так же, как и ранее.
1) и вторая половина Вашего вопроса под номером 2) — Говоря об аналогичном решении на панели задач — при настройках по умолчанию панель «Ссылки» и так является папкой. И если у Вас это не так, вероятно, причина того, что все отображаются полностью, заключается в том, что и значки, которые рядом с этой панелью (правая часть панели задач), тоже все отображаются, а не сворачиваются в трее. О том, как их свернуть (и в таком случае ссылки будут помещены в папку), рассказывается в отдельных статьях на нашем сайте, с ними и рекомендую ознакомиться.
Источник
Где Яндекс Браузер хранит на компьютере файл с закладками?
Закладки в Яндекс браузере, как и любом другом – это сохраненная пользователем ссылка на статью, включающая в себя:
Для удобства, доступ к закладкам осуществляется из интерфейса браузера. Сам обозреватель хранит всю пользовательскую информацию на компьютере (включая сохраненные логины и пароли) в специальной папке с профилем. Непосредственно закладки, хранятся в файле «Bookmarks».
Все браузеры (включая Chrome, FifeFox и Opera) используют следующую систему – непосредственный доступ к закладкам, осуществляется из интерфейса обозревателя, а файл «Bookmarks» используется для их переноса в другой обозреватель или в случаях его переустановки.
 Все браузеры (включая Chrome, FifeFox и Opera) используют следующую систему – непосредственный доступ к закладкам, осуществляется из интерфейса обозревателя, а файл «Bookmarks» используется для их переноса в другой обозреватель или в случаях его переустановки.
Все браузеры (включая Chrome, FifeFox и Opera) используют следующую систему – непосредственный доступ к закладкам, осуществляется из интерфейса обозревателя, а файл «Bookmarks» используется для их переноса в другой обозреватель или в случаях его переустановки.Просмотр закладок в интерфейсе браузера
Посмотреть закладки в Яндекс Браузере, удобнее всего через интерфейс браузера. Там же вы сможете их: открыть, изменить, вывести на панель и даже экспортировать в html формате, для последующего переноса на другой ПК.
1. Откройте обозреватель и перейдите в меню.

2. Найдите пункт «Закладки» — «Диспетчер закладок». Или воспользуйтесь горячими клавишами – по умолчанию «Ctrl + Shift + O».

3. Вы попали на страницу со списком всех ранее сохраненных страниц.

Помимо выше озвученных функций, вы можете их удобно отсортировать по папкам или упорядочить по заголовкам.
Где Яндекс Браузер хранит закладки. Файл «Bookmarks»
Доступ к файлу закладок может осуществляться двумя путями: через ярлык программы или напрямую, через проводник. Сначала рассмотрим быстрый способ найти их – используя ярлык.
1. Нажмите правой кнопкой мыши на ярлыке Яндекс Браузера, на рабочем столе. В контекстном меню выберите расположение файла.

2. Вы попали в директорию с исполняемым файлом обозревателя. Вернитесь на шаг назад, в папку «YandexBrowser» и перейдите в «User Data».

3. В папке «Default», найдите документ с названием «Bookmarks» — это и есть ваши сохраненные закладки.

Вы можете скопировать его или просто перенести на другой носитель. Во втором случае, он заново создаться, но будет пустым.
Если указанных документов — нет, откройте окно проводника, выберите вкладку «Вид» и отметьте флажком пункт «Скрытые элементы».

А затем просто вставьте путь к необходимой папке – «C:UsersИмя_пользователяAppDataLocalYandexYandexBrowserUser DataDefault», где «С» — буква диска, на которую установлена OS, а «Имя_пользователя» — никнейм указанный при входе в Windows.

Я указал все возможные способы, как найти закладки в Яндекс Браузере. Рекомендую так же ознакомиться со статьей о том, как перенести закладки в другой браузер или наоборот в Яндекс.
Возникают вопросы или нашли неточность – обязательно напишите в комментариях, разберемся :).
Источник
Угадать, когда удалят страницу с интересующей информацией, — невозможно. В любой момент ресурс может быть заблокирован или приведен на новый домен. Из-за этого найти контент, который пользователь просматривал ранее, — сложно. Приходится снова изучать результаты раздачи в Google и Яндекс. При этом нет никакой гарантии, что владелец компьютера найдет то, что искал.
Поиск Google

Просмотр сохранённых в кэше Google страниц начинается так же, как и любой другой поиск Google. Когда вы ввели поисковый запрос и видите результаты, нажмите на стрелку рядом с URL-адресом и выберите опцию «Сохранённая копия» для просмотра последних сохранённых в Google версий страниц.
Когда сайт загрузился, Google уведомляет, что это устаревшая версия, и указывает дату её создания. Также есть опция просмотра только текстового варианта страница и исходного кода. Вы не сможете переходить на другие страницы и при этом оставаться в кэш-версии. Если вы попытаетесь перейти по ссылке, откроется действующая версия сайта.
Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Wayback Machine

Существуют организации, которые пытаются сохранить историю интернета. Самой известной такой организацией является некоммерческая Internet Archive, где хранятся веб-сайты, текст, видео, аудиозаписи, программное обеспечение и изображения, которые трудно найти где-то ещё. Старые версии веб-сайта вы можете посмотреть также на Wayback Machine.
Введите URL-адрес и движок архивного поиска покажет календарь, где отображается, когда Wayback Machine сохранила эту страницу. Нажмите на дату в календаре для просмотра того, как сайт выглядел в этот день. Wayback Machine и является отличным способом изучения истории интернета.
Вариант 2: Просмотр файлов кеша
Браузер сохраняет весь свой кеш на жесткий диск. Этим можно воспользоваться для просмотра файлов в определенных целях, но только при помощи дополнительного софта. Мы будем использовать бесплатное приложение ChromeCacheView.
- Попав на страницу программы, вы можете ознакомиться с основной информацией касательно нее. Ссылка на скачивание расположена в нижней части страницы и называется «Download ChromeCacheView».
- Запускается она прямо из сжатой папки, выполнять распаковку и установку не требуется.
- Изначально, если на компьютере установлен Google Chrome, откроется его кеш. Смените папку на ту, что использует Yandex. Для этого кликните по кнопке в виде папки с документом.
- Щелкните по «Yandex Cache Folder», если уверены, что кеш располагается именно там. Те, кто переносил его, к примеру, на другой диск, должны нажать на кнопку с тремя точками и указать путь самостоятельно.
- После того, как папка изменилась на нужную, нажмите «ОК».
- Вы увидите список всех кешированных объектов. Они представлены в виде ссылок, но далеко не все из них работают. Ориентироваться в них помогают дополнительные колонки приложения, а также домены ссылок.
- Дважды нажав по конкретному результату, вы откроете его свойства. Возможно, там располагается необходимая вам информация.
- Часто пользователи ищут через кеш какой-то медиаконтент, например, видео или картинки. Упорядочьте отображение записей, щелкнув по колонке «Content Type», найдите нужный формат и просматривайте результаты.
- Ссылки на них обычно кликабельны — выделите строчку и нажмите на кнопку с земным шаром. Ссылка откроется в новой вкладке браузера по умолчанию.
- Если вам требуются другие действия с кешем, узнайте больше о возможностях программы для их реализации. В этом также поможет страница программы, где представлены разного рода инструкции и пояснения.









Мы рады, что смогли помочь Вам в решении проблемы. Помимо этой статьи, на сайте еще 12384 инструкций. Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам. Отблагодарите автора, поделитесь статьей в социальных сетях.
Опишите, что у вас не получилось. Наши специалисты постараются ответить максимально быстро.
Archive.Today

Сайт архивирования Archive.Today позволяет пользователям сохранять текущие веб-страницы и искать ранее сохранённые. Введите URL-адрес для сохранения или для просмотра сохранённых страниц, которые также можно скачивать на компьютер.
Если вы хотите посмотреть архивные версии веб-сайта, введите его адрес в поисковую панель и появятся результаты с домашней страницей и связанными отдельными страницами. Если есть больше одной версии одной страницы, они будут показываться все вместе для упрощения просмотра.
Как посмотреть кэш страницы сайта?
Все основные поисковики охотно предоставляют возможность просмотреть кэш веб-документов в их индексе. Сделать это можно вручную или по-быстрому.
По-быстрому — проще всего при помощи специальных сервисов и дополнений для браузеров, почитайте эти статьи (там всё просто):
- RDS bar в Хроме.
- Page Promoter в Firefox.
Но и вручную уметь это делать также полезно, потому как плагины иногда глючат, сервисы недоступны и т.п.
Да, и увидеть кэш документа не получится, если он вообще не проиндексирован. Про то, как проверить индексацию в Яндексе, Гугле, Mail.ru и Bing.com — здесь.
Расширения для браузеров

Существуют расширения для браузеров на все случаи жизни, в том числе и для доступа к кэшированной версии сайта.
Добавьте в Chrome расширение Web Cache Viewer и нажмите правой кнопкой мыши на любой странице для просмотра версии из Google или Wayback Machine. Расширение под названием View Page Archive & Cache для Chrome или Firefox идёт ещё дальше и позволяет смотреть кэшированные версии веб-страниц из многочисленных поисковых движков, таких как Bing, Baidu, Yandex.
Как найти архивные копии сайтов интернета или машина времени для сайтов
Существует настоящая, реальная машина времени, в которой можно ненадолго вернуться в прошлое и увидеть, например, как выглядел тот или иной сайт несколько лет назад. Думаете, никому не нужны копии сайтов многолетней давности? Ошибаетесь! Для очень многих людей сервис по архивированию информации весьма полезен.

Во-первых, это просто интересно! Из чистого любопытства и от избытка свободного времени можно посмотреть, как выглядел любимый, популярный ресурс на заре его рождения.
Во-вторых, далеко не все владельцы сайтов ведут свои архивы. Знать место, где можно найти информацию, которая была на сайте в какой-то момент, а потом пропала, не просто полезно, а очень важно.
В-третьих, само по себе сравнение является важнейшим методом анализа, который позволяет оценить ход и результаты нашей деятельности. Кстати, при проведении анализа веб-ресурса очень эффективно использовать ряд методов сравнения.
Поэтому наличие уникальнейшего архива веб-страниц интернета позволяет нам получить доступ к огромному количеству аудио-, видео- и текстовых материалов. По утверждению разработчиков, «интернет-архив» хранит больше материалов, чем любая библиотека мира. Мы попали в правильное место!
Что нужно, чтобы найти копии сайтов интернета
Для того, чтобы отправиться в прошлое, нужно перейти на сайт archive.org и воспользоваться поисковой строкой.

Простой поиск в архиве сохраненных сайтов выдает нам ссылки на все сохраненные копии запрашиваемой страницы.

Из этого скриншота видно, что сайт kopilkasovetov.com был создан в 2012 году (Кстати, важно отметить, с помощью практически идеального хостинга Спринтхост — рекомендую!). Переключаясь на нужный нам год, можно увидеть даты, выделенные кружочками, это и есть даты сохранения копии сайта. Например, в 2015 году, пока можно будет увидеть только одну копию от 7 февраля.
Зачем нужен web archive и как его можно использовать
Веб-архивирование нужно для того, чтобы можно было восстановить важную утерянную информацию с сайта, которая может не сохраниться из-за технических проблем или повреждения вирусом.

Например, владелец сайта создал его и наполнил описанием продукции, полезными статьями и изображениями по тематике. Через время веб-ресурс был обновлен и тексты заменены на новые. А еще через время понадобились именно старые тексты. В таких случаях и нужен открытый интернет-архив, в котором можно найти десятки сохраненных версий сайта на разные даты.
Предназначение веб-архивов:
- Возможность восстановления собственного контента в случае повреждения или удаления старых текстов и изображений.
- Просмотр старых файлов на других работающих веб-сайтах.
- Анализ изменений наполнения онлайн-ресурсов (собственных и конкурентных).

Сохранение авторского контента — это важная функция. Намного проще корректировать уже имеющиеся тексты, чем писать новые с нуля. Можно сделать рерайт (переписывание текста другим словами с сохранением смысла и структуры). Особенности использования резервных копий приведены в Табл. 1.
Табл. 1. Для каких целей можно использовать более ранний контент
| Цели | Особенности применения |
| Восстановление сайта | Бывают случаи непоправимого повреждения онлайн-ресурса — из-за вирусов, хакерских атак. Если не было проведено резервное копирование на своем хостинге, то можно будет найти свои тексты в веб-архиве |
| Наполнение сайта по похожей тематике | Старый экспертный текст по своей тематике может понадобиться при создании лэндинга, вспомогательного онлайн-ресурса. Если тексты неуникальны, их нужно рерайтить |
| Ведение блога | Для привлечения трафика на профильный сайт нужно вести блог с текстами узкой тематики. Это могут быть советы по выбору товаров, использованию продукции и другой контент. Для написания таких текстов может потребоваться информация со старых копий веб-ресурса |
| Публикации на странице в социальных сетях | Бизнес-аккаунт в соцсетях помогает поднять узнаваемость бренда и компании, привлечь новых покупателей, расширить рынки сбыта. Для постов в социальных сетях можно использовать тексты, которые ранее были опубликованы на сайте (если они не дублируются с новыми) |

Что такое бэкап сайта и зачем он нужен
Бэкап — это резервная копия данных. Она нужна на случай, если с оригиналом что-то случится. Кнопка «Удалить» попадёт под горячую руку, сгорит компьютер или наступит армагеддон — не страшно. Если есть копия, потерянные данные можно быстро восстановить.
Любой ценной информации нужны бэкапы: семейным фото, почтовой переписке, рабочим документам. Но особенно — сайтам. И на это есть три причины.
- Ненадёжный хостинг. Сайт — это набор файлов, который хранится на сервере. Серверы, как и любые компьютеры, ломаются. Сотрудники, которые следят за их работой, ошибаются. Программное обеспечение даёт сбой. Любая из этих проблем может стоить вам сайта.
- Злоумышленники. Истории про конкурентов, которые проникли на сайт и на главной странице написали «Васька дурак» или просто всё удалили, конечно, редкость. Гораздо чаще сайтам вредят вирусы. И один из способов от них избавиться — восстановить чистую резервную копию.
- Наше несовершенство. Больше, чем ненадёжный хостинг и злоумышленники, сайтам угрожают их владельцы. «Случайно удалил», «нажал не туда», «переделал, а теперь хочу всё вернуть» — люди несовершенны, всем нам свойственно ошибаться. Сайт без бэкапа не прощает ошибок.
Не страшно потерять сайт, собранный на коленке за пять минут. Обиднее, когда заплатил за разработку, фотографии и тексты; привлек посетителей через рекламу; всё настроил. Еще больнее потерять площадку, куда регулярно заходят за покупками тысячи посетителей. Поэтому если сайт вам дорог — делайте бэкапы.
Что если сохраненной страницы нет?
Иногда в выдаче при нажатии на зеленую стрелку отсутствует пункт «Сохраненная копия». Этому может быть несколько причин:
- Иногда некоторые браузеры, в которых установлены плагины для блокировки рекламы, могут не отображать эту ссылку. Стоит попробовать приостановить плагин или удалить его и просмотреть сайт снова;
- Яндекс вообще не гарантирует попадание страницы сайта в сохраненные копии. То есть если ресурса нет, значит по какой-то причине поисковик решил не делать резервной копии. Ничего страшного, стоит проверить, не сохранила ли страницы сайта другая поисковая система — например, Google;
- Сайт отказал поисковым роботам в индексации своих страниц. Файл robots.txt, который может лежать в корне сайта, содержит инструкции для поисковых роботов, каким образом они должны сканировать его. Например, он может содержать требование не сканировать сайт совсем или сканировать только отдельные его страницы;
- Схожая с предыдущим пунктом причина. В html коде веб-ресурса может быть указан мета-тег Robots с атрибутом noarchive. Эта директива запрещает поисковому роботу делать копию сохраненной страницы.

Уникальный контент из веб-архива
Многие коммерческие сайты через некоторое время существования закрываются. Если на них был опубликован полезный контент (экспертные статьи, аналитические обзоры и другая важная информация), то после закрытия первоисточника они могут быть востребованными. То есть, сайт уже не работает и ранее написанные статьи могут использоваться на информационных порталах (если они уникальны).
Веб-архив является очень полезным сервисом, который может пригодиться в различных ситуациях. Быстрое восстановление потерянных данных может значительно сэкономить время и финансы, если сайт подвергнется хакерской атаке или же перестанет работать из-за серьезной технической проблемы. Веб-архив дает возможность не только просматривать старые версии своего сайта, но и анализировать контент конкурентов, сохраненный в разные периоды времени.
Общая информация о резервном копировании на хостинге
На услуге хостинга REG.RU резервные копии создаются автоматически. На VPS автоматическое резервное копированиe не предусмотрено. Вы можете самостоятельно настроить резервное копирование через панель управления или заказать дополнительную услугу резервного копирования VPS.
Если вам необходимо восстановить сайт (отдельные файлы или базы данных), используйте систему резервного копирования. Резервные копии данных собираются ежедневно и создаются в ночное время. Сформированные копии отображаются только во второй половине дня.
Обратите внимание
- Каждый бэкап хранится в течение 30 суток
, после чего автоматически удаляется. - Бэкапы создаются с 00.00 (МСК) и доступны для скачивания после 14.00 следующего дня.
В резервную копию включаются базы данных и файлы, размер которых не превышает 300 Мб.
В бэкап НЕ включаются:
- содержимое папки ~/tmp;
- почта;
- cron-задания;
- настройки, созданные в панели управления хостингом.
Как открыть систему резервного копирования
Скачать или восстановить резервные копии можно двумя способами:
через Личный кабинет
- 1. Авторизуйтесь на сайте REG.RU и перейдите в раздел Домены и услуги.
- 2.
Кликните по названию нужной услуги хостинга:
- 3.
На открывшейся странице в разделе Управлениенажмите на раздел
Резервные копии
.

Если вы являетесь партнёром REG.RU, откройте систему резервного копирования следующим способом:
через панель управления хостингом
Открыть систему резервного копирования можно через панели хостинга:
ISPmanager
cPanel
Plesk
Обратите внимание!
Если внешний вид вашей панели управления отличается от представленного в инструкции, кликните в левом нижнем углу «Старый интерфейс»
Перейдите в раздел Инструменты
—
Управление резервными копиями
и нажмите
ОК
:

В разделе Файлы
выберите пункт
Менеджер резервных копий
:

В открывшемся окне кликните по ссылке Система автоматической выдачи резервных копий
:

Обратите внимание!
Если внешний вид вашей панели управления отличается от представленного в инструкции, перейдите в раздел «Сайты и домены» и в правом верхнем углу измените вид на «Активный».
В разделе Сайты и домены
в панели настроек справа выберите пункт
Резервные копии
:

На открывшейся странице перейдите по ссылке Система автоматической выдачи резервных копий
:
