Время на прочтение
6 мин
Количество просмотров 305K
Вступление
Что Вы знаете о обработке строк в Java? Как много этих знаний и насколько они углублены и актуальны? Давайте попробуем вместе со мной разобрать все вопросы, связанные с этой важной, фундаментальной и часто используемой частью языка. Наш маленький гайд будет разбит на две публикации:
- String, StringBuffer, StringBuilder (реализация строк)
- Pattern, Matcher (регулярные выражения)
Сегодня поговорим о регулярных выражениях в Java, рассмотрим их механизм и подход к обработке. Также рассмотрим функциональные возможности пакета java.util.regex.
Регулярные выражения
Регулярные выражения (regular expressions, далее РВ) — мощное и эффективное средство для обработки текста. Они впервые были использованы в текстовых редакторах операционной системы UNIX (ed и QED) и сделали прорыв в электронной обработке текстов конца XX века. В 1987 году более сложные РВ возникли в первой версии языка Perl и были основаны на пакете Henry Spencer (1986), написанном на языке С. А в 1997 году, Philip Hazel разработал Perl Compatible Regular Expressions (PCRE) — библиотеку, что точно наследует функциональность РВ в Perl. Сейчас PCRE используется многими современными инструментами, например Apache HTTP Server.
Большинство современных языков программирования поддерживают РВ, Java не является исключением.
Механизм
Существует две базовые технологии, на основе которых строятся механизмы РВ:
- Недетерминированный конечный автомат (НКА) — «механизм, управляемый регулярным выражением»
- Детерминированный конечный автомат (ДКА) — «механизм, управляемый текстом»
НКА — механизм, в котором управление внутри РВ передается от компонента к компоненту. НКА просматривает РВ по одному компоненту и проверяет, совпадает ли компонент с текстом. Если совпадает — проверятся следующий компонент. Процедура повторяется до тех пор, пока не будет найдено совпадение для всех компонентов РВ (пока не получим общее совпадение).
ДКА — механизм, который анализирует строку и следит за всеми «возможными совпадениями». Его работа зависит от каждого просканированного символа текста (то есть ДКА «управляется текстом»). Даний механизм сканирует символ текста, обновляет «потенциальное совпадение» и резервирует его. Если следующий символ аннулирует «потенциальное совпадение», то ДКА возвращается к резерву. Нет резерва — нет совпадений.
Логично, что ДКА должен работать быстрее чем НКА (ДКА проверяет каждый символ текста не более одного раза, НКА — сколько угодно раз пока не закончит разбор РВ). Но НКА предоставляет возможность определять ход дальнейших событий. Мы можем в значительной степени управлять процессом за счет правильного написания РВ.
Регулярные выражения в Java используют механизм НКА.
Эти виды конечных автоматов более детально рассмотрены в статье «Регулярные выражения изнутри».
Подход к обработке
В языках программирования существует три подхода к обработке РВ:
- интегрированный
- процедурный
- объектно-ориентированный
Интегрированный подход — встраивание РВ в низкоуровневый синтаксис языка. Этот подход скрывает всю механику, настройку и, как следствие, упрощает работу программиста.
Функциональность РВ при процедурном и объектно-ориентированном подходе обеспечивают функции и методы соответственно. Вместо специальных конструкций языка, функции и методы принимают в качестве параметров строки и интерпретируют их как РВ.
Для обработки регулярных выражений в Java используют объектно-ориентированный подход.
Реализация
Для работы с регулярными выражениями в Java представлен пакет java.util.regex. Пакет был добавлен в версии 1.4 и уже тогда содержал мощный и современный прикладной интерфейс для работы с регулярными выражениями. Обеспечивает хорошую гибкость из-за использования объектов, реализующих интерефейс CharSequence.
Все функциональные возможности представлены двумя классами, интерфейсом и исключением:
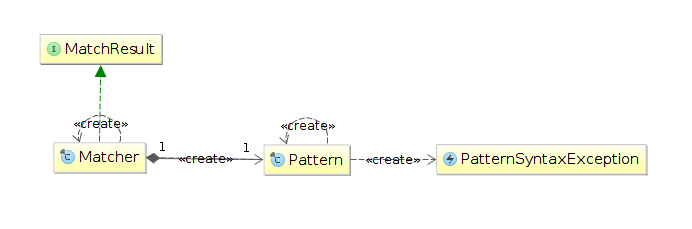
Pattern
Класс Pattern представляет собой скомпилированное представление РВ. Класс не имеет публичных конструкторов, поэтому для создания объекта данного класса необходимо вызвать статический метод compile и передать в качестве первого аргумента строку с РВ:
// XML тэг в формате <xxx></xxx>
Pattern pattern = Pattern.compile("^<([a-z]+)([^>]+)*(?:>(.*)<\/\1>|\s+\/>)$");
Также в качестве второго параметра в метод compile можно передать флаг в виде статической константы класса Pattern, например:
// email адрес в формате xxx@xxx.xxx (регистр букв игнорируется)
Pattern pattern = Pattern.compile("^([a-z0-9_\.-]+)@([a-z0-9_\.-]+)\.([a-z\.]{2,6})$", Pattern.CASE_INSENSITIVE);
Таблица всех доступных констант и эквивалентных им флагов:
| № | Constant | Equivalent Embedded Flag Expression |
|---|---|---|
| 1 | Pattern.CANON_EQ | — |
| 2 | Pattern.CASE_INSENSITIVE | (?i) |
| 3 | Pattern.COMMENTS | (?x) |
| 4 | Pattern.MULTILINE | (?m) |
| 5 | Pattern.DOTALL | (?s) |
| 6 | Pattern.LITERAL | — |
| 7 | Pattern.UNICODE_CASE | (?u) |
| 8 | Pattern.UNIX_LINES | (?d) |
Иногда нам необходимо просто проверить есть ли в строке подстрока, что удовлетворяет заданному РВ. Для этого используют статический метод matches, например:
// это hex код цвета?
if (Pattern.matches("^#?([a-f0-9]{6}|[a-f0-9]{3})$", "#8b2323")) { // вернет true
// делаем что-то
}
Также иногда возникает необходимость разбить строку на массив подстрок используя РВ. В этом нам поможет метод split:
Pattern pattern = Pattern.compile(":|;");
String[] animals = pattern.split("cat:dog;bird:cow");
Arrays.asList(animals).forEach(animal -> System.out.print(animal + " "));
// cat dog bird cow
Matcher и MatchResult
Matcher — класс, который представляет строку, реализует механизм согласования (matching) с РВ и хранит результаты этого согласования (используя реализацию методов интерфейса MatchResult). Не имеет публичных конструкторов, поэтому для создания объекта этого класса нужно использовать метод matcher класса Pattern:
// будем искать URL
String regexp = "^(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)*\/?$";
String url = "http://habrahabr.ru/post/260767/";
Pattern pattern = Pattern.compile(regexp);
Matcher matcher = pattern.matcher(url);
Но результатов у нас еще нет. Чтобы их получить нужно воспользоваться методом find. Можно использовать matches — этот метод вернет true только тогда, когда вся строка соответствует заданному РВ, в отличии от find, который пытается найти подстроку, которая удовлетворяет РВ. Для более детальной информации о результатах согласования можно использовать реализацию методов интерфейса MatchResult, например:
// IP адрес
String regexp = "(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)";
// для сравнения работы find() и matches()
String goodIp = "192.168.0.3";
String badIp = "192.168.0.3g";
Pattern pattern = Pattern.compile(regexp);
Matcher matcher = pattern.matcher(goodIp);
// matches() - true, find() - true
matcher = pattern.matcher(badIp);
// matches() - false, find() - true
// а теперь получим дополнительную информацию
System.out.println(matcher.find() ?
"I found '"+matcher.group()+"' starting at index "+matcher.start()+" and ending at index "+matcher.end()+"." :
"I found nothing!");
// I found the text '192.168.0.3' starting at index 0 and ending at index 11.
Также можно начинать поиск с нужной позиции используя find(int start). Стоит отметить что существует еще один способ поиска — метод lookingAt. Он начинает проверку совпадений РВ с начала строки, но не требует полного соответствия, в отличии от matches.
Класс предоставляет методы для замены текста в указанной строке:
| appendReplacement(StringBuffer sb, String replacement) | Реализует механизм «добавление-и-замена» (append-and-replace). Формирует обьект StringBuffer (получен как параметр) добавляя replacement в нужные места. Устанавливает позицию, которая соответствует end() последнего результата поиска. После этой позиции ничего не добавляет. |
| appendTail(StringBuffer sb) | Используется после одного или нескольких вызовов appendReplacement и служит для добавления оставшейся части строки в объект класса StringBuffer, полученного как параметр. |
| replaceFirst(String replacement) | Заменяет первую последовательность, которая соответствует РВ, на replacement. Использует вызовы методов appendReplacement и appendTail. |
| replaceAll(String replacement) | Заменяет каждую последовательность, которая соответствует РВ, на replacement. Также использует методы appendReplacement и appendTail. |
| quoteReplacement(String s) | Возвращает строку, в которой коса черта (‘ ‘) и знак доллара (‘ $ ‘) будут лишены особого смысла. |
Pattern pattern = Pattern.compile("a*b");
Matcher matcher = pattern.matcher("aabtextaabtextabtextb the end");
StringBuffer buffer = new StringBuffer();
while (matcher.find()) {
matcher.appendReplacement(buffer, "-");
// buffer = "-" -> "-text-" -> "-text-text-" -> "-text-text-text-"
}
matcher.appendTail(buffer);
// buffer = "-text-text-text- the end"
PatternSyntaxException
Неконтролируемое (unchecked) исключение, возникает при синтаксической ошибке в регулярном выражении. В таблице ниже приведены все методы и их описание.
| getDescription() | Возвращает описание ошибки. |
| getIndex() | Возвращает индекс строки, где была найдена ошибка в РВ |
| getPattern() | Возвращает ошибочное РВ. |
| getMessage() | getDescription() + getIndex() + getPattern() |
Спасибо за внимание. Все дополнения, уточнения и критика приветствуются.
Регулярные выражения
Последнее обновление: 25.06.2018

Регулярные выражения представляют мощный инструмент для обработки строк. Регулярные выражения позволяют задать шаблон,
которому должна соответствовать строка или подстрока.
Некоторые методы класса String принимают регулярные выражения и используют их для выполнения операций над строками.
split
Для разделения строки на подстроки применяется метод split(). В качестве параметра он может принимать регулярное выражение,
которое представляет критерий разделения строки.
Например, разделим предложение на слова:
String text = "FIFA will never regret it";
String[] words = text.split("\s*(\s|,|!|\.)\s*");
for(String word : words){
System.out.println(word);
}
Для разделения применяется регулярное выражение «\s*(\s|,|!|\.)\s*». Подвыражние «\s» по сути представляет пробел. Звездочка указывает, что символ может присутствовать от 0 до бесконечного количества раз.
То есть добавляем звездочку и мы получаем неопределенное количество идущих подряд пробелов — «\s*» (то есть неважно, сколько пробелов между словами). Причем пробелы может вообще не быть.
В скобках указывает группа выражений, которая может идти после неопределенного количества пробелов. Группа позволяет нам определить набо значений через вертикальную черту,
и подстрока должна соответствовать одному из этих значений. То есть в группе «\s|,|!|\.» подстрока может соответствовать пробелу,
запятой, восклицательному знаку или точке. Причем поскольку точка представляет специальную последовательность, то, чтобы указать, что мы имеем в виду имеено знак точки, а не специальную последовательность,
перед точкой ставим слеши.
Соответствие строки. matches
Еще один метод класса String — matches() принимает регулярное выражение и возвращает true, если строка соответствует
этому выражению. Иначе возвращает false.
Например, проверим, соответствует ли строка номеру телефона:
String input = "+12343454556";
boolean result = input.matches("(\+*)\d{11}");
if(result){
System.out.println("It is a phone number");
}
else{
System.out.println("It is not a phone number!");
}
В данном случае в регулярном выражение сначала определяется группа «(\+*)». То есть вначале может идти знак плюса, но также он может отсутствовать.
Далее смотрим, соответствуют ли последующие 11 символов цифрам. Выражение «\d» представляет цифровой символ, а число в фигурных скобках — {11} — сколько раз данный тип символов должен повторяться.
То есть мы ищем строку, где вначале может идти знак плюс (или он может отсутствовать), а потом идет 11 цифровых символов.
Класс Pattern
Большая часть функциональности по работе с регулярными выражениями в Java сосредоточена в пакете java.util.regex.
Само регулярное выражение представляет шаблон для поиска совпадений в строке. Для задания подобного шаблона и поиска подстрок в строке, которые удовлетворяют
данному шаблону, в Java определены классы Pattern и Matcher.
Для простого поиска соответствий в классе Pattern определен статический метод boolean matches(String pattern, CharSequence input).
Данный метод возвращает true, если последовательность символов input полностью соответствует шаблону строки pattern:
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello";
boolean found = Pattern.matches("Hello", input);
if(found)
System.out.println("Найдено");
else
System.out.println("Не найдено");
}
}
Но, как правило, для поиска соответствий применяется другой способ — использование класса Matcher.
Класс Matcher
Рассмотрим основные методы класса Matcher:
-
boolean matches(): возвращает true, если вся строка совпадает с шаблоном
-
boolean find(): возвращает true, если в строке есть подстрока, которая совпадает с шаблоном, и переходит к этой подстроке
-
String group(): возвращает подстроку, которая совпала с шаблоном в результате вызова метода find.
Если совпадение отсутствует, то метод генерирует исключениеIllegalStateException. -
int start(): возвращает индекс текущего совпадения
-
int end(): возвращает индекс следующего совпадения после текущего
-
String replaceAll(String str): заменяет все найденные совпадения подстрокой str и возвращает измененную строку с учетом замен
Используем класс Matcher. Для этого вначале надо создать объект Pattern с помощью статического метода compile(), который позволяет установить шаблон:
Pattern pattern = Pattern.compile("Hello");
В качестве шаблона выступает строка «Hello». Метод compile() возвращает объект Pattern, который мы затем можем использовать в программе.
В классе Pattern также определен метод matcher(String input), который в качестве параметра принимает строку, где надо проводить поиск, и возвращает
объект Matcher:
String input = "Hello world! Hello Java!";
Pattern pattern = Pattern.compile("hello");
Matcher matcher = pattern.matcher(input);
Затем у объекта Matcher вызывается метод matches() для поиска соответствий шаблону в тексте:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello";
Pattern pattern = Pattern.compile("Hello");
Matcher matcher = pattern.matcher(input);
boolean found = matcher.matches();
if(found)
System.out.println("Найдено");
else
System.out.println("Не найдено");
}
}
Рассмотрим более функциональный пример с нахождением не полного соответствия, а отдельных совпадений в строке:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
Pattern pattern = Pattern.compile("Java(\w*)");
Matcher matcher = pattern.matcher(input);
while(matcher.find())
System.out.println(matcher.group());
}
}
Допустим, мы хотим найти в строке все вхождения слова Java. В исходной строке это три слова: «Java», «JavaScript» и «JavaSE». Для этого
применим шаблон «Java(\w*)». Данный шаблон использует синтаксис регулярных выражений. Слово «Java» в начале говорит о том, что все совпадения в строке
должны начинаться на Java. Выражение (\w*) означает, что после «Java» в совпадении может находиться любое количество алфавитно-цифровых символов.
Выражение w означает алфавитно-цифровой символ, а звездочка после выражения указывает на неопределенное их количество — их может быть один, два, три или вообще не быть.
И чтобы java не рассматривала w как эскейп-последовательность, как n, то выражение экранируется еще одним слешем.
Далее применяется метод find() класса Matcher, который позволяет переходить к следующему совпадению в строке. То есть первый вызов
этого метода найдет первое совпадение в строке, второй вызов найдет второе совпадение и т.д. То есть с помощью цикла while(matcher.find())
мы можем пройтись по всем совпадениям. Каждое совпадение мы можем получить с помощью метода matcher.group(). В итоге
программа выдаст следующий результат:
Замена в строке
Теперь сделаем замену всех совпадений с помощью метода replaceAll():
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
Pattern pattern = Pattern.compile("Java(\w*)");
Matcher matcher = pattern.matcher(input);
String newStr = matcher.replaceAll("HTML");
System.out.println(newStr); // Hello HTML! Hello HTML! HTML 8.
Также надо отметить, что в классе String также имеется метод replaceAll() с подобным действием:
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
String myStr =input.replaceAll("Java(\w*)", "HTML");
System.out.println(myStr); // Hello HTML! Hello HTML! HTML 8.
Разделение строки на лексемы
С помощью метода String[] split(CharSequence input) класса Pattern можно разделить строку на массив подстрок по
определенному разделителю. Например, мы хотим выделить из строки отдельные слова:
import java.util.regex.Pattern;
public class StringsApp {
public static void main(String[] args) {
String input = "Hello Java! Hello JavaScript! JavaSE 8.";
Pattern pattern = Pattern.compile("[ ,.!?]");
String[] words = pattern.split(input);
for(String word:words)
System.out.println(word);
}
}
И консоль выведет набор слов:
Hello Java Hello JavaScript JavaSE 8
При этом все символы-разделители удаляются. Однако, данный способ разбивки не идеален: у нас остаются некоторые пробелы, которые расцениваются как лексемы, а не как разделители. Для более точной и изощренной разбивки нам следует применять элементы регулярных выражений.
Так, заменим шаблон на следующий:
Pattern pattern = Pattern.compile("\s*(\s|,|!|\.)\s*");
Теперь у нас останутся только слова:
Hello Java Hello JavaScript JavaSE 8
Далее мы подробнее рассмотрим синтаксис регулярных выражений и из каких элементов мы можем создавать шаблоны.
Consider the following code snippet:
String input = "Print this";
System.out.println(input.matches("\bthis\b"));
Output
false
What could be possibly wrong with this approach? If it is wrong, then what is the right solution to find the exact word match?
PS: I have found a variety of similar questions here but none of them provide the solution I am looking for.
Thanks in advance.
asked Feb 27, 2012 at 11:28
![]()
A Null PointerA Null Pointer
2,2413 gold badges26 silver badges28 bronze badges
When you use the matches() method, it is trying to match the entire input. In your example, the input «Print this» doesn’t match the pattern because the word «Print» isn’t matched.
So you need to add something to the regex to match the initial part of the string, e.g.
.*\bthis\b
And if you want to allow extra text at the end of the line too:
.*\bthis\b.*
Alternatively, use a Matcher object and use Matcher.find() to find matches within the input string:
Pattern p = Pattern.compile("\bthis\b");
Matcher m = p.matcher("Print this");
m.find();
System.out.println(m.group());
Output:
this
If you want to find multiple matches in a line, you can call find() and group() repeatedly to extract them all.
answered Feb 27, 2012 at 11:32
![]()
DNADNA
41.9k12 gold badges106 silver badges143 bronze badges
Full example method for matcher:
public static String REGEX_FIND_WORD="(?i).*?\b%s\b.*?";
public static boolean containsWord(String text, String word) {
String regex=String.format(REGEX_FIND_WORD, Pattern.quote(word));
return text.matches(regex);
}
Explain:
- (?i) — ignorecase
- .*? — allow (optionally) any characters before
- b — word boundary
- %s — variable to be changed by String.format (quoted to avoid regex
errors) - b — word boundary
- .*? — allow (optionally) any characters after
![]()
Enlico
22.3k6 gold badges44 silver badges97 bronze badges
answered Sep 20, 2014 at 8:27
![]()
surfealokeseasurfealokesea
4,9424 gold badges27 silver badges38 bronze badges
1
For a good explanation, see: http://www.regular-expressions.info/java.html
myString.matches(«regex») returns true or false depending whether the
string can be matched entirely by the regular expression. It is
important to remember that String.matches() only returns true if the
entire string can be matched. In other words: «regex» is applied as if
you had written «^regex$» with start and end of string anchors. This
is different from most other regex libraries, where the «quick match
test» method returns true if the regex can be matched anywhere in the
string. If myString is abc then myString.matches(«bc») returns false.
bc matches abc, but ^bc$ (which is really being used here) does not.
This writes «true»:
String input = "Print this";
System.out.println(input.matches(".*\bthis\b"));
answered Feb 27, 2012 at 11:33
![]()
Paolo FalabellaPaolo Falabella
24.7k3 gold badges72 silver badges85 bronze badges
0
You may use groups to find the exact word. Regex API specifies groups by parentheses. For example:
A(B(C))D
This statement consists of three groups, which are indexed from 0.
- 0th group — ABCD
- 1st group — BC
- 2nd group — C
So if you need to find some specific word, you may use two methods in Matcher class such as: find() to find statement specified by regex, and then get a String object specified by its group number:
String statement = "Hello, my beautiful world";
Pattern pattern = Pattern.compile("Hello, my (\w+).*");
Matcher m = pattern.matcher(statement);
m.find();
System.out.println(m.group(1));
The above code result will be «beautiful»
![]()
Alan Moore
73.6k12 gold badges100 silver badges156 bronze badges
answered Feb 27, 2012 at 11:43
![]()
teoREtikteoREtik
7,88614 gold badges46 silver badges65 bronze badges
1
System.out.println(input.matches(«.*\bthis$»));
Also works. Here the .* matches anything before the space and then this is matched to be word in the end.
answered Aug 7, 2015 at 5:10
![]()

Проверка на наличие подстрок в строке — довольно распространенная задача в программировании. Например, иногда мы хотим разбить строку, если она содержит разделитель в точке. В других случаях мы хотим изменить поток, если строка содержит (или не имеет) определенную подстроку, которая может быть командой.
Есть несколько способов сделать это в Java, и большинство из них — то, что вы ожидаете увидеть и в других языках программирования. Однако один из подходов, уникальных для Java, — это использование класса Pattern, о котором мы расскажем позже в этой статье.
В качестве альтернативы вы можете использовать Apache Commons и вспомогательный класс StringUtils, который предлагает множество производных методов из основных методов для этой цели.
Основные способы Java
String.contains()
Первый и главный способ проверить наличие подстроки — это метод .contains(). Это обеспечивается самим классом String и очень эффективно.
Метод принимает CharSequence и возвращает true, если последовательность присутствует в строке, для которой мы вызываем метод:
String string = "Java";
String substring = "va";
System.out.println(string.contains(substring));
Запуск этого даст:
Примечание: метод .contains() чувствителен к регистру. Если бы мы попытались искать "Va" в нашем string, результат будет false.
Часто, чтобы избежать этой проблемы, так как мы не хотим быть чувствительны к регистру, вы должны сопоставить регистр обеих строк перед проверкой:
System.out.println(string.toLowerCase().contains(substring.toLowerCase()));
// OR
System.out.println(string.toUpperCase().contains(substring.toUpperCase()));
String.indexOf()
Метод .indexOf() возвращает индекс первого вхождения подстроки в строке и предлагает несколько конструкторов на выбор:
indexOf(int ch)
indexOf(int ch, int fromIndex)
indexOf(String str)
indexOf(String str, int fromIndex)
Мы можем либо искать один символ со смещением или без него, либо искать строку со смещением или без него.
Метод вернет индекс первого вхождения, если присутствует, и -1 если нет:
String string = "Lorem ipsum dolor sit amet.";
// You can also use unicode for characters
System.out.println(string.indexOf('i'));
System.out.println(string.indexOf('i', 8));
System.out.println(string.indexOf("dolor"));
System.out.println(string.indexOf("Lorem", 10));
Запуск этого кода даст:
- Первое вхождение
iв словеipsum, имеет индекс 6 от начала последовательности символов. - Первое вхождение
iсо смещением8находится в словеsit, имеет индекс 19 от начала. - Первое вхождение String
dolor— имеет индекс 12 с начала. - И, наконец, слова
Loremнет при смещении10.
В конечном счете, метод .contains() внутри себя вызывает метод .indexOf(). Это делает .indexOf() даже более эффективным, чем аналог (хотя и очень небольшой), хотя у него есть несколько иной вариант использования.
String.lastIndexOf()
В отличие от метода .indexOf(), который возвращает первое вхождение, метод .lastIndexOf() возвращает индекс последнего вхождения символа или строки со смещением или без него:
String string = "Lorem ipsum dolor sit amet.";
// You can also use unicode for characters
System.out.println(string.lastIndexOf('i'));
System.out.println(string.lastIndexOf('i', 8));
System.out.println(string.lastIndexOf("dolor"));
System.out.println(string.lastIndexOf("Lorem", 10));
Запуск этого кода даст:
Некоторые могут быть немного удивлены результатами и скажут:
lastIndexOf('i', 8) должен был вернуть 19, так как это последнее вхождение символа после 8-го символа в строке
Стоит отметить, что при запуске метода .lastIndexOf() последовательность символов меняется на противоположную. Отсчет начинается с последнего символа и идет к первому.
Это, как говорится — ожидаемый результат — 6 последнее появление символа после пропуска 8 элементов из конца последовательности.
Шаблон с регулярным выражением и Matcher
Класс Pattern существенно скомпилированное представление регулярного выражения. Он используется вместе с классом Matcher для сопоставления последовательностей символов.
Этот класс в первую очередь работает путем компиляции шаблона. Затем мы присваиваем другой шаблон экземпляру Matcher, который использует метод .find() для сравнения назначенных и скомпилированных шаблонов.
Если они совпадают, метод .find() приводит к true. Если шаблоны не совпадают, метод приводит к false.
Pattern pattern = Pattern.compile(".*" + "some" + ".*");
Matcher matcher = pattern.matcher("Here is some pattern!");
System.out.println(matcher.find());
Это даст:
Apache Commons
Из-за его полезности и распространенности в Java, во многих проектах Apache Commons включен в classpath. Это отличная библиотека со многими полезными функциями, часто используемыми в производстве, и проверка подстрок не является исключением.
Apache Commons предлагает класс StringUtils со многими вспомогательными методами для манипуляций со строками, нуль-проверка и т.д. Для решения этой задачи, мы можем использовать любого из методов .contains(), .indexOf(), .lastIndexOf() или .containsIgnoreCase().
Если нет, то это так же просто, как добавить зависимость к вашему файлу pom.xml, если вы используете Maven:
org.apache.commons
commons-lang3
{version}
Или добавив его через Gradle:
compile group: 'org.apache.commons', name: 'commons-lang3', version: '{version}'
StringUtils.contains()
Метод .contains() довольно прост и очень похож на основной Java подход.
Единственное отличие состоит в том, что мы не вызываем метод для проверяемой строки (поскольку он не наследует этот метод), а вместо этого передаем искомую строку вместе со строкой, которую мы ищем:
String string = "Checking for substrings within a String is a fairly common task in programming.";
System.out.println(StringUtils.contains(string, "common task"));
Запуск этого кода даст:
Примечание: этот метод чувствителен к регистру.
StringUtils.indexOf()
Естественно, метод .indexOf() также работает очень похоже на основной подход Java:
String string = "Checking for substrings within a String is a fairly common task in programming.";
// Search for first occurrence of 'f'
System.out.println(StringUtils.indexOf(string, 'f'));
// Search for first occurrence of 'f', skipping the first 12 elements
System.out.println(StringUtils.indexOf(string, 'f', 12));
// Search for the first occurrence of the "String" string
System.out.println(StringUtils.indexOf(string, "String"));
Запуск этого кода даст:
StringUtils.indexOfAny()
Метод .indexOfAny() принимает список символов, а не один, что позволяет нам искать первое вхождение любого из переданных символов:
String string = "Checking for substrings within a String is a fairly common task in programming.";
// Search for first occurrence of 'f' or 'n', whichever comes first
System.out.println(StringUtils.indexOfAny(string, 'f', 'n'));
// Search for the first occurrence of "String" or "for", whichever comes first
System.out.println(StringUtils.indexOfAny(string, "String", "for"));
Запуск этого кода даст:
StringUtils.indexOfAnyBut()
Метод .indexOfAnyBut() ищет первое вхождение любого символа, что это не в предоставленном комплекте:
String string = "Checking for substrings within a String is a fairly common task in programming.";
// Search for first character outside of the provided set 'C' and 'h'
System.out.println(StringUtils.indexOfAny(string, 'C', 'h'));
// Search for first character outside of the provided set 'C' and 'h'
System.out.println(StringUtils.indexOfAny(string, "Checking", "for"));
Запуск этого кода даст:
StringUtils.indexOfDifference()
Метод .indexOfDifference() сравнивает два массива символов, и возвращает индекс первого символа, отличающийся:
String s1 = "Hello World!"
String s2 = "Hello world!"
System.out.println(StringUtils.indexOfDifference(s1, s2));Запуск этого кода даст:
StringUtils.indexOfIgnoreCase()
Метод .indexOfIgnoreCase() возвращает индекс первого вхождения символа в последовательности символов, игнорируя случай:
String string = "Checking for substrings within a String is a fairly common task in programming."
System.out.println(StringUtils.indexOf(string, 'c'));
System.out.println(StringUtils.indexOfIgnoreCase(string, 'c'));
Запуск этого кода даст:
StringUtils.lastIndexOf()
И, наконец, метод .lastIndexOf() работает почти так же, как обычный Java-метод:
String string = "Lorem ipsum dolor sit amet.";
// You can also use unicode for characters
System.out.println(StringUtils.lastIndexOf(string, 'i'));
System.out.println(StringUtils.lastIndexOf(string, 'i', 8));
System.out.println(StringUtils.lastIndexOf(string, "dolor"));
System.out.println(StringUtils.lastIndexOf(string, "Lorem", 10));
Запуск этого кода даст:
StringUtils.containsIgnoreCase()
В методе .containsIgnoreCase(), проверяет содержит строка подстроку, не обращая внимания на случай:
String string = "Checking for substrings within a String is a fairly common task in programming.";
System.out.println(StringUtils.containsIgnoreCase(string, "cOmMOn tAsK"));
Запуск этого кода даст:
StringUtils.containsOnly()
Метод .containsOnly() проверяет, если последовательность символов содержит только указанные значения.
Это может вводить в заблуждение, поэтому можно сказать, что это еще один способ — он проверяет, состоит ли последовательность символов только из указанных символов. Он принимает либо строку, либо последовательность символов:
String string = "Hello World!"
System.out.println(StringUtils.containsOnly(string, 'HleWord!'));
System.out.println(StringUtils.containsOnly(string, "wrld"));
Запуск этого даст:
Строка "Hello World!" действительно построена только из символов в последовательности 'HleWord!'.
Примечание: не все символы из последовательности необходимо использовать в методе string для возврата true. Важно то, что в нем нет символа, которого нет в последовательности символов.
StringUtils.containsNone()
Метод .containsNone(), содержит ли строка какой — либо из «запрещенных» символов из набора:
String string = "Hello World!"
System.out.println(StringUtils.containsNone(string, 'xmt'));
System.out.println(StringUtils.containsNone(string, "wrld"));
Запуск этого кода дает:
StringUtils.containsAny()
И наконец, метод .containsAny() возвращает true, если последовательность символов содержит какой-либо из переданных параметров в форме последовательности символов или строки:
String string = "Hello World!"
System.out.println(StringUtils.containsAny(string, 'h', 'm'));
System.out.println(StringUtils.containsAny(string, "hell"));
Этот код даст:
Список из 25 регулярных выражений в Java, без которых не обойтись ни новичку, ни профессиональному разработчику. С примерами.

Что такое Regex
Глупо спрашивать об очевидном, но вдруг вы новичок в сфере разработки? 
Регулярное выражение – это строка, последовательность символов. Данную строку также принято называть шаблоном, по которому происходит поиск соответствий в других последовательностях символов. Но не каждая строка компилируется в регулярное выражение, а только та, что соответствует их синтаксису.

Что за зверь «Pattern»?
Класс Java Pattern (java.util.regex.Pattern) является основной точкой доступа к API Java регулярных выражений. Всякий раз, когда требуется подключить Regex в работу, все начинается с Java-класса Pattern.
Java Pattern можно использовать двумя способами. Метод Pattern.matches() нужен для быстрой проверки соответствия текста заданному регулярному выражению. Так же можно скомпилировать экземпляр Pattern, используя Pattern.compile(). Его можно использовать несколько раз для сопоставления регулярного выражения с несколькими текстами.
Что за зверь «Matcher»?
Класс Java Matcher (java.util.regex.Matcher) создан для поиска некоторого множества вхождений регулярного выражения в одном тексте и поиска по одному шаблону в разных текстах. Класс Java Matcher имеет много полезных методов.
Например:
boolean matches(): вернет значениеtrueпри совпадении строки с шаблоном.boolean find(): вернет значениеtrueпри обнаружении подстроки, совпадающей с шаблоном, и перейдет к ней.int start(): вернет значение индекса соответствия.int end(): вернет значение индекса последующего соответствия.String replaceAll(String str): вернет значение измененной строки подстрокойstr.
Другие методы Matcher можно найти в официальной документации.
Рассмотрите простой пример работы с Pattern и Matcher.
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main (String[] args) {
Pattern pattern1 = Pattern.compile ("[x-z]+");//Поиск будет происходить от x до z включительно.
//Поиск будет происходить только по символам нижнего регистра.
//Чтобы отключить чувствительность к регистру, можно использовать Pattern.CASE_INSENSITIVE.
Matcher matcher1 = pattern1.matcher ("x y z 1 2 3 4 ");
System.out.println (matcher1.find()); //Поиск любого совпадения с шаблоном.
//Выводится значение true, так как в строке есть символы шаблона.
Matcher matcher2 = pattern1.matcher ("X Y Z 1 2 3 4");
System.out.println (matcher2.find()); //Выводится значение false.
//Так как в строке нет символов, подходящих по шаблону.
Pattern pattern2 = Pattern.compile ("[a-zA-Z0-9]");
//Добавляется поиск по символам нижнего и верхнего регистра, а также цифр.
Matcher matcher3 = pattern2.matcher ("A B C D X Y Z a b c d x y z 1 2 3 4");
System.out.println (matcher3.find()); //Выводится значение true
| . | Соответствие одиночному символу |
| ^regex | Поиск регулярного выражения с совпадением в начале строки |
| regex$ | Поиск регулярного выражения с совпадением в конце строки |
| [abc] | Поиск любого символа, заключенного в квадратные скобки |
| [abc][vz] | Находит значение символа a, b или c, за которыми следуют v или z |
| [^ xyz] | Когда символ располагается перед остальными символами в квадратных скобках, он «отрицает» шаблон. Данный шаблон соответствует любому символу, кроме x, y или z. |
| [a-d1-7] | Диапазоны: соответствует букве между a и d и цифрами от 1 до 7, но не d-1. |
| X|Z | Находит X или Z |
| $ | Конец строки |
| ^ | Начало строки |
| (re) | Создает группу из регулярных выражений, запоминая текст для сравнивания |
| (?: re) | Действует как (re), но не запоминает текст |
Следующие метасимволы имеют предопределенное значение и упрощают использование некоторых общих шаблонов, например, d вместо [0..9].
| Regex | Значение |
| d | Любая цифра (эквивалентно [0-9]) |
| D | Любой символ, кроме цифр |
| s | Символ пробела, сокращение от [t n x0b r f] |
| S | Любой символ, кроме пробела. |
| w | Символы, соответствующие словам, сокращение от [a-zA-Z_0-9] |
| W | Символы, не образующие слов, сокращение [w] |
| b | Соответствует границе слова, где символом слова является [a-zA-Z0-9_] |
| B | Соответствует границам символов, не являющихся словами |
| G | Точка предыдущего соответствия |
Квантификаторы
Квантификатор определяет частоту появления элемента. Символы ?, *, + и {} определяют количество регулярных выражений:
| Regex | Значение | Использование |
| * | Происходит ноль или более раз, сокращенно {0,} | X* не находит ни одной или нескольких букв X, <sbr/>.* Находит любую последовательность символов. |
| + | Происходит один или несколько раз, сокращенно {1,} | X+ Находит одну или несколько букв X |
| ? | Не происходит или происходт один раз,? является сокращением для {0,1}. | X? не находит ни одной буквы X или только одну. |
| {X} | Происходит X раз | d{3} ищет три цифры. |
| {X,Y} | Происходит не менее X, но не более Y раз | d{1,4} означает, что d должно встречаться как минимум один раз и максимум четыре |
| *? | ? после квантификатора делает его ленивым квантификатором. Он пытается найти наименьшее совпадение. Это останавливает регулярное выражение при первом совпадении. |
Квантификаторы имеют три режима, которые называют сверхжадным, жадным и ленивым.
Жадный режим
“A.+a”// Ищет максимальное по длине совпадение в строке.
//Пример жадного квантификатора
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main
{
public static void main(String[] args)
{
Pattern p = Pattern.compile("a+");
Matcher m = p.matcher("aaa");
while (m.find())
System.out.println("Pattern found from " + m.start() +
" to " + (m.end()-1));
}
}
Output:
Pattern found from 0 to 2
Сверхжадный режим
«А.++а»?// Работает также как и жадный режим, но не производит реверсивный поиск при захвате строки.
// Пример сверхжадного квантификатора
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main
{
public static void main(String[] args)
{
Pattern p = Pattern.compile("a++");
Matcher m = p.matcher("aaa");
while (m.find())
System.out.println("Pattern found from " + m.start() +
" to " + (m.end()-1));
}
}
Output:
Pattern found from 0 to 2
Ленивый режим
“A.+?a”// Ищет самое короткое совпадение.
//Пример ленивого квантификатора
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main
{
public static void main(String[] args)
{
Pattern p = Pattern.compile("g+?");
Matcher m = p.matcher("ggg");
while (m.find())
System.out.println("Pattern found from " + m.start() +
" to " + (m.end()-1));
}
}
Output:
Pattern found from 0 to 0 Pattern found from 1 to 1 Pattern found from 2 to 2
Профессиональные разработчики все время работают с регулярными выражениями. Перенимайте их практику: при частом использовании регулярки запомнятся быстро и существенно сэкономят время.
У вас случалось, что вы не можете вспомнить, что сами написали ранее?  Следите, чтобы регулярные выражения комментировались в коде. Особенно это касается новых для вас регулярок. А если всё-таки запутаетесь, помогут сервисы для тестирования и отладки.
Следите, чтобы регулярные выражения комментировались в коде. Особенно это касается новых для вас регулярок. А если всё-таки запутаетесь, помогут сервисы для тестирования и отладки.
Хотите расширить диапазон нашего must-have списка? Пишите в комментариях, что бы вы добавили в наш ТОП.
Полезные материалы по теме:
- ТОП-10 лучших книг по Java для программистов
- ТОП-25 трюков, советов и лучших практик программирования на Java
- Большая подборка книг, видео и статей для Java Junior
- Изучаем Java: дайджест для новичков в программировании